Реляционная база данных (РБД)
Другие статьи
Реляционные базы данных сокращённо называются РБД, их используют для хранения и предоставления доступа к взаимосвязанным элементам информации. Выстроены на реляционной модели, откуда и пошло название. Это интуитивно понятный табличный способ предоставления сведений.
В таблице РБД каждая строка — это запись с уникальным ключом. У столбцов есть атрибуты данных. И у большинства записей есть значение для каждого атрибута, что позволяет довольно легко устанавливать взаимную связь между элементами.
Структура РБД
Реляционная модель предполагает логическую структуру БД: это таблицы, индексы и представления. Логическую структуру нельзя путать с физической. Это разделение позволяет администраторам управлять физической БД, но при этом сохранять информацию в логической структуре неизменной. Соответственно, изменение имени файла БД не повлияет на то, что именно содержится в его таблицах.
Разделение физического уровня и логического затрагивает также операции, которые являются четко определёнными действиями со структурами и данными БД. Логические операции предоставляют возможность приложениям устанавливать требования к содержанию. А физические операции устанавливают способ доступа к данным, а также к решению задачи.
Логические операции предоставляют возможность приложениям устанавливать требования к содержанию. А физические операции устанавливают способ доступа к данным, а также к решению задачи.
Для обеспечения точности и доступности данных в РБД нужно соблюдать правила целостности. В них можно прописать запрет на использование дубликатов строк в таблицах. Это уменьшить риск того, что неправильная информация попадёт в базу данных.
Реляционная модель
Изначально данные у каждого приложения находились в отдельной структуре, которая была уникальной. При желании разработчика создать приложение, чтобы использовать такие данные, ему надо тщательно разобраться со структурой. Подобный метод организации в прошлом был не особенно эффективен. Плюс на обслуживание уходило много времени. И с оптимизацией также возникали проблемы. Реляционная модель создана, чтобы убрать потребность в применении разных структур базы данных.
РБД обеспечивает стандартный способ представления информации и отправки запросов. Отличительной особенностью является универсальность. То есть такой подход можно применять в каких угодно приложениях. Разработчики выяснили, что таблицы — это ключевое преимущество РБД, поскольку позволяют обеспечить интуитивно понятный способ хранения сведений, адаптивный и эффективный. Плюс он прекрасно подходит для структурирования сведений и для того, чтобы получить к ним доступ.
Отличительной особенностью является универсальность. То есть такой подход можно применять в каких угодно приложениях. Разработчики выяснили, что таблицы — это ключевое преимущество РБД, поскольку позволяют обеспечить интуитивно понятный способ хранения сведений, адаптивный и эффективный. Плюс он прекрасно подходит для структурирования сведений и для того, чтобы получить к ним доступ.
По мере развития разработчики начали применять язык структурированных запросов — SQL. На их основании записывали данные в базу и отправляли запросы. И тогда установили и другую сильную сторону реляционной модель. В частности, уже в течение ряда лет SQL довольно широко применяют как язык запросов в БД. Этот подход построен на алгоритмах реляционной алгебры и достаточно чёткой математической структуре. В итоге работа с какими угодно запросами при обращении к базе данных становится простой и эффективной. Плюс уменьшается количество вероятных ошибок. А если использовать другие подходы, придётся работать с уникальными запросами.
Сильные стороны реляционной базы данных
Реляционная модель — простая и функциональная одновременно. Она подходит для организаций разных размеров и типов. С помощью РБД можно удовлетворять всевозможные информационные потребности. Такие базы данных позволяют контролировать запасы, обрабатывать через Сеть торговые транзакции, управлять данными заказчиков. Последнее становится особенно важным, когда о клиенте нужно знать много информации — реквизиты, контакты и прочее. РБД оптимально подходят для обслуживания разных информационных потребностей при условии, что отдельные элементы системы связаны в общую структуру, а управление происходит на базе правил целостности, причём оно должно быть безопасным и надёжным.
Вообще сами РБД появились ещё в 70-х. Однако сегодня благодаря своим сильным сторонам они стали самыми распространёнными моделями для организации баз данных на планете.
Целостность
Реляционная модель отличается предельной внимательностью к данным в плане целостности. Она поддерживает целостность во всех приложениях и копиях БД. В итоге, когда заказчик кладёт средства на мобильный счёт, то он ждёт, что деньги будут зачислены быстро. И именно РБД гарантируют, что сведения в процессе передачи информации из одной системы в другую не исчезнут.
Она поддерживает целостность во всех приложениях и копиях БД. В итоге, когда заказчик кладёт средства на мобильный счёт, то он ждёт, что деньги будут зачислены быстро. И именно РБД гарантируют, что сведения в процессе передачи информации из одной системы в другую не исчезнут.
Другие базы данных не в состоянии справиться с задачей поддержания целостности. Поэтому они обычно используются для других целей или же в комбинации с РБД.
Фиксация перемен и атомарность
В РБД приняты детальные и довольно строгие бизнес-правила. Это же касается фиксации перемен в БД, то есть в сохранении действий в отношении данных на стабильной основе. Неразрывность имеет большое значение для корректной отчётности, поэтому такое свойство БД очень ценно для правильного бухгалтерского учёта или для учёта, который ведут в целях управления (финансовый учёт). Атомарность гарантирует, что база данных будет вестись согласно правилам, нормативным положением и в соответствии с бизнес-политикой.
Хранимые процедуры и РБД
Доступ к данным на практике означает большое количество действий, которые будут повторяться снова и снова.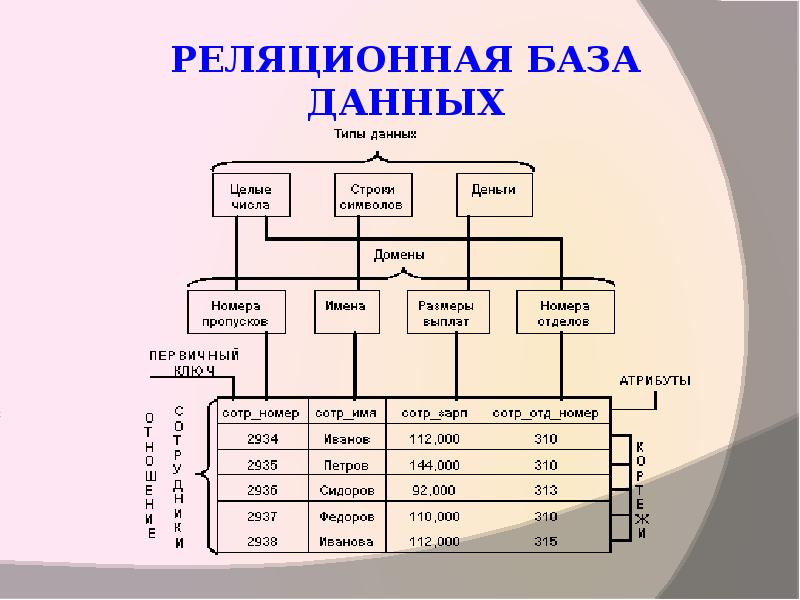 Проще всего прописать их в виде программы. Разработчики не могут в то же время постоянно создавать новые приложения. Это занимает слишком много ресурсов, плюс утяжеляет саму программу.
Проще всего прописать их в виде программы. Разработчики не могут в то же время постоянно создавать новые приложения. Это занимает слишком много ресурсов, плюс утяжеляет саму программу.
Но РБД поддерживают хранимые процедуры. Они представляют собой не полноценные приложения, а блоки кода, и к ним доступ обеспечивается с помощью стандартного вызова, который поступает со стороны кода приложения. То есть по одной и той же хранимой процедуре можно последовательно промаркировать записи для удобства потребителей для самых разных приложений. Хранимые процедуры позволяют разработчикам убедиться, что определённые функции в приложении были правильно реализованы.
РБД и ACID
Транзакции в РБД отличаются 4 важными свойствами:
- атомарность или неразрывность;
- целостность;
- неизменность;
- изолированность.
Эти свойства в комплексе получили название ACID. Неразрывность касается всех частей структуры, которые нужны, чтобы осуществить транзакцию в БД. Целостность или согласованность устанавливает правила сохранения данных после того, как транзакция сделана. Изолированность — это гарантия того, что транзакция не скажется на другие данные до того, как все изменения будут сохранены. А неизменность гарантирует сохранность данных после того, как изменения были уже сохранены в результате транзакции.
Целостность или согласованность устанавливает правила сохранения данных после того, как транзакция сделана. Изолированность — это гарантия того, что транзакция не скажется на другие данные до того, как все изменения будут сохранены. А неизменность гарантирует сохранность данных после того, как изменения были уже сохранены в результате транзакции.
Блокировка БД и параллельный доступ
С данными одновременно могут работать несколько пользователей или приложений. И вполне реалистична ситуация, когда поступит сразу несколько запросов на изменение одной и той же информации. Причём изменения могут быть различного характера. Это вызывает конфликт в БД. В такой ситуации система сохраняет функциональность благодаря функциям «параллельный доступ» и «блокировка».
Блокировка не даёт пользователям или другим приложениям получить какой-либо доступ к данным, пока те обновляются. В отдельных БД блокироваться могут целые таблицы. Это отрицательно сказывается на эффективности такого ПО. Понятно, что работать с ним как с многопользовательским, не выйдет. Однако есть ПО, которые создали реляционные базы, позволяющие выполнять блокировку только на уровне одной единственной записи. В результате все остальные части таблицы будут доступны. Подобный подход положительно влияет на эффективность ПО.
Понятно, что работать с ним как с многопользовательским, не выйдет. Однако есть ПО, которые создали реляционные базы, позволяющие выполнять блокировку только на уровне одной единственной записи. В результате все остальные части таблицы будут доступны. Подобный подход положительно влияет на эффективность ПО.
Что же касается “параллельного доступа”, то обозначенный инструмент применяется, когда нужно обеспечить одновременный доступ. В этом случае работать начинают политики контроля.
СУРБД – система управления реляционными базами данных
Для управления реляционной базой данных нужно специально ПО. Оно позволяет не только управлять, но и контролировать функциональность РБД, сохранять сведения и извлекать их, обрабатывать запросы. Это система управления РБД или СУРБД. Она отвечает за интерфейс между пользователями, приложениями и БД. Кроме того, СУРБД — это ещё и администрирование как таковое.
При выборе конкретного типа БД и продуктов на основе РБД нужно принимать во внимание ряд факторов.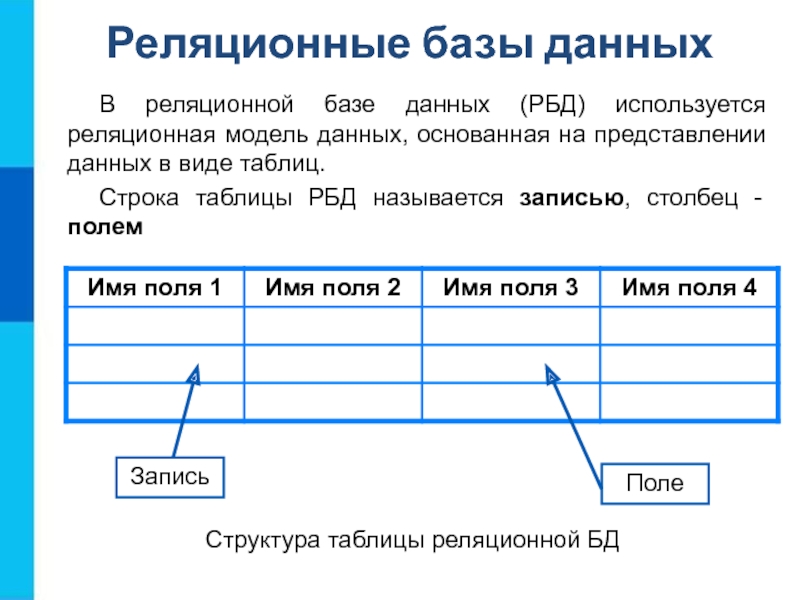 В частности, подбор СУРБД зависит от потребностей компании или предпринимателя. Нужно ответить на ряд вопросов:
В частности, подбор СУРБД зависит от потребностей компании или предпринимателя. Нужно ответить на ряд вопросов:
- Насколько важна точность данных?
- Нужно ли поддерживать многопользовательский режим работы?
- Есть ли разделение по степени точности для конкретных блоков информации?
- Планируется ли применять бизнес-логику для работы с БД?
- Каковы объёмы данных, с которыми будет происходить работа?
- Важна ли масштабируемость?
- Должна ли модель БД поддерживать зеркальные копии?
- Насколько важна целостность применительно к копиям?
- Важно ли наличие параллельного доступа?
- Нужен ли одновременный доступ нескольким приложениям?
- Должно ли ПО поддерживать параллельный доступ без риска для сохранности данных?
- Насколько важна эффективность и надёжность РБД?
- Насколько быстрым должен быть отклик на поступающий запрос?
- Есть ли какая-то специфика в тех данных, с которыми предстоит работать?
- Будет ли пиковая нагрузка на базу данных?
- Планируется ли постепенное наращивание объёма информации, с которой предполагается работа?
- Возможен ли незапланированный простой?
Это стандартные вопросы. Возможно, у вас появятся какие-то свои. Перечень вопросов нужно тщательно продумать. Вам не нужна идеальная СУРБД. Вам необходима система, которая будет оптимально отвечать поставленным задачам.
Возможно, у вас появятся какие-то свои. Перечень вопросов нужно тщательно продумать. Вам не нужна идеальная СУРБД. Вам необходима система, которая будет оптимально отвечать поставленным задачам.
SQL сервер является СУБД, работающей с реляционной базой данной.
Автономность РБД
РБД не стоят на месте, они постоянно развиваются. Они постоянно улучшали надёжность, производительность, безопасность, становились всё проще и проще в обслуживании. Это приводило к усложнению структуры. В итоге администрирование подобной системы стало требовать серьёзных усилий. Как следствие, разработчикам приходится немало времени тратить на оптимизацию таких систем, чтобы избежать чрезмерной громоздкости.
Поэтому было решено найти выход. И им стали автономные технологии. Они позволили нарастить возможности реляционной модели. Так появилась РБД нового типа. Автономная или же самоуправляемая БД — это система, которая сохраняет возможности и преимущества реляционной модели, а также добавляет к ним средства на базе искусственного интеллекта, автоматизации и машинного обучения для оптимизации и мониторинга скорости осуществления запросов и управления.
К примеру, чтобы повысить скорость обработки запросов, такая база проверяет индексы, строит прогнозы. Дальше она сама применяет лучшие результаты. То есть система начинает самосовершенствоваться без участия человека.
В итоге автономная РБД позволяет освободить разработчиков от рутинных задач. В частности, не надо заранее определять требования к инфраструктуре. Для этого есть специальные программные решения. Можно заранее взять в аренду вычислительные мощности или память. Дальше вы будете по мере необходимости получать доступ к тем ресурсам, которые вам объективно нужны и платить только то, что применяете. Таким образом, использование автономных РБД позволяет уменьшить расходы вашей компании и оптимизировать подход к работе с вычислительными мощностями.
Подобные базы данных можно использовать для создания приложений нового уровня. При этом из-за уменьшения влияния человеческого фактора на сам процесс риск ошибки по соответствующим причинам тоже сокращается, что выгодно компаниям и другим пользователям.
Получить помощь в работе с РБД
Подписаться на канал новостей и инструкций 1С
Другие статьи
Структура реляционной базы данных | Основы реляционных баз данных
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
PostgreSQL — это СУБД, созданная для работы с реляционными базами данных. Что такое «реляционная», мы рассмотрим в будущем уроке. А в этом разберем, как устроены такие базы данных.
Структура реляционной базы данных
Данные в реляционных базах данных хранятся в таблицах. Их структура напоминает Microsoft Excel. Каждая строка в таблице — это связанный набор данных, который относится к одному предмету. Например, в таблице можно посмотреть все детали об одном сотруднике — его фамилию, имя, номер, отдел, зарплату, год рождения, адрес и телефон:
Разные таблицы предназначены для хранения информации о различных сущностях, например, пользователи, статьи или заказы в интернет-магазине. В типичных веб-приложениях таблиц десятки и сотни, в больших — тысячи. Например, в Хекслете их несколько сотен.
В типичных веб-приложениях таблиц десятки и сотни, в больших — тысячи. Например, в Хекслете их несколько сотен.
У таблиц в базе данных есть определенная структура. Она включает:
- Название таблицы — уникально в рамках одной базы данных. Имя таблицы и ее структура задаются при создании, но их можно изменить впоследствии
- Столбцы или поля — располагаются в строго определенном порядке, и у каждого поля уникальное имя в рамках одной таблицы
- Тип данных — сопоставляется каждому столбцу. Тип данных ограничивает набор допустимых значений, которые можно присвоить столбцу, и определяет смысловое значение данных для вычислений. Например, в столбец числового типа нельзя записать обычные текстовые строки, но его данные можно использовать в математических вычислениях, и наоборот
- Строки — их число переменно и отражает текущий объем данных. В отличие от таблиц в Exсel, в таблицах реляционных баз данных нет никаких гарантий относительно порядка строк в таблице.
 Он может быть любым, и его можно задать с помощью языка SQL, который рассмотрим позже. Объем данных в разных таблицах сильно отличается — от нескольких штук до миллиардов записей
Он может быть любым, и его можно задать с помощью языка SQL, который рассмотрим позже. Объем данных в разных таблицах сильно отличается — от нескольких штук до миллиардов записей
Пример таблицы с именем users:
Структура
Включает в себя имена полей и их типы. Структура определяет столбцы:
first_name string last_name string email string created_at datetime
Содержание
Включает в себя данные. Содержание определяет строки:
| first_name | last_name | email | created_at | |------------|-----------|-------------------|------------| | Сергей | Петров | [email protected] | 11.10.2005 | | Иван | Сидоров | [email protected] | 03.08.2000 | | Виктор | Курганов | [email protected] | 23.12.2011 |
first_name, last_name, email и created_at — это имена столбцов. Строки содержат данные по каждому столбцу, а в поле created_at установлен тип данных datetime, поэтому туда нельзя записать текст.
В дальнейшем эту структуру можно модифицировать: удалять и добавлять поля, менять типы данных.
Правила именования сущностей базы данных
Именование таблиц и полей в базе не фиксировано и зависит от программиста. Например, в проектах, где используют ORM — название группы фреймворков или библиотек, которые помогают моделировать предметную область и связывать ее с базой данных, — имена определяются соглашениями конкретной экосистемы.
В этом курсе мы используем именование, принятое во фреймворке Rails и его ORM (ActiveRecord). Оно состоит из нескольких правил:
- Все имена в нижнем регистре
- Для имен из нескольких слов используется snake_case — когда слова разделяются подчеркиванием
_без пробелов - Имя таблицы во множественном числе
В отличие от Excel, где ввод данных и отображение визуальные, в СУБД у данных нет никакого представления. Они вводятся и выбираются с помощью команд. При этом существуют специальные клиенты, которые используются, чтобы визуализировать управление базами данных. Они бывают платными и бесплатными. Из бесплатных в мире PostgreSQL наиболее популярен PgAdmin:
Они бывают платными и бесплатными. Из бесплатных в мире PostgreSQL наиболее популярен PgAdmin:
Рекомендуем поставить его и поэкспериментировать внутри.
Управлять структурой базы данных и данными внутри таблиц — две разные задачи. При этом они выполняются одним инструментом — языком SQL.
Язык SQL
SQL (Structured Query Language) — специализированный язык, который разработали, чтобы управлять данными в реляционных СУБД.
-- Пример запроса, который извлекает -- информацию о пользователях из таблицы users SELECT * FROM users;
SQL разрабатывается независимо от баз данных и имеет собственный стандарт, который реализуют конкретные базы данных. Поэтому на базовом уровне все реляционные базы работают примерно одинаково.
Когда вы научитесь работать с одной базой, сможете спокойно переключиться на другую. Базы данных поддерживают основной SQL и дополняют его своими возможностями. На протяжение курса мы будем использовать только стандартные возможности SQL, например, управлять ролями и их правами, создавать базы данных, обновлять данные.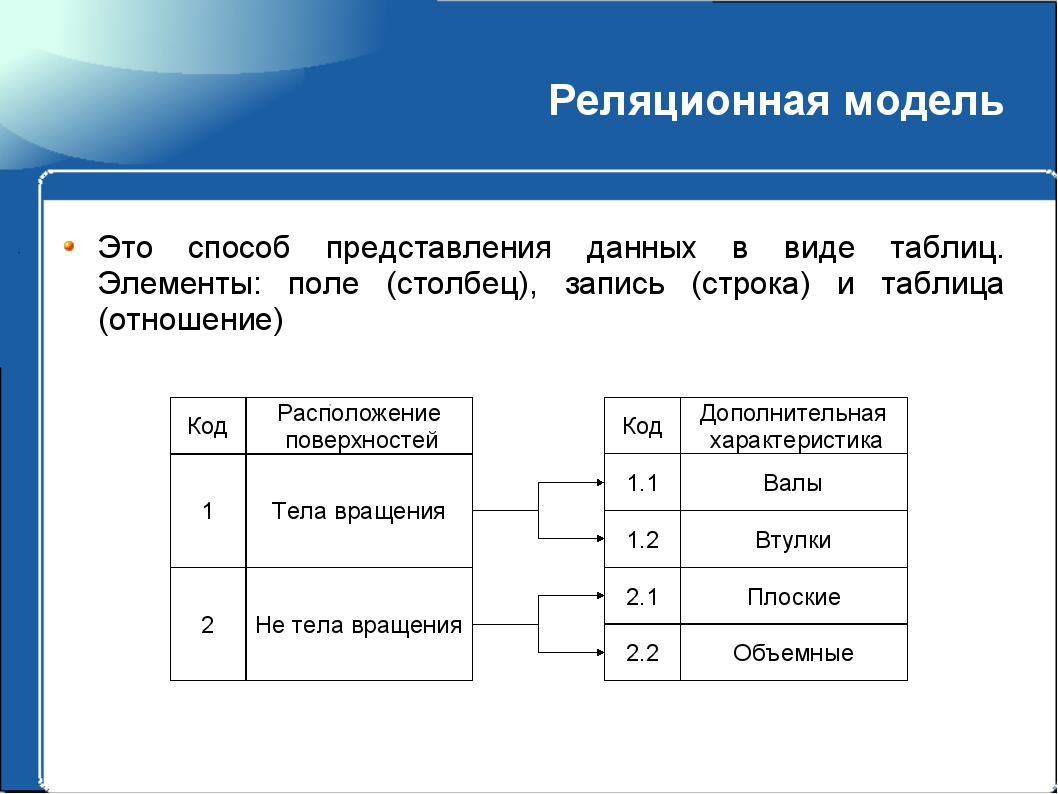 Такие основные возможности должен знать и понимать каждый программист.
Такие основные возможности должен знать и понимать каждый программист.
Выводы
В этом уроке мы рассмотрели структуру реляционных баз данных. Ее основные сущности: название таблицы, столбцы или поля, тип данных и строки. У них есть правила использования и именования, но они будут меняться в зависимости от того, какой фреймворк будет использовать программист.
Чтобы управлять структурой базы данных и данными внутри таблиц, используют язык SQL. Дальше в курсе мы будем на практике применять его стандартные возможности.
Самостоятельная работа
- Установите PgAdmin и подключитесь к СУБД, которую вы установили ранее. Для этого вам придется потратить некоторое время на изучение интерфейса программы. Подробный гайд с картинками
- Изучите интерфейс программы и существующие базы данных
Остались вопросы? Задайте их в разделе «Обсуждение»
Вам ответят команда поддержки Хекслета или другие студенты.
Для полного доступа к курсу нужен базовый план
Базовый план откроет полный доступ ко всем курсам, упражнениям и урокам Хекслета, проектам и пожизненный доступ к теории пройденных уроков. Подписку можно отменить в любой момент.
Подписку можно отменить в любой момент.
Получить доступ
130
курсов
1000
упражнений
2000+
часов теории
3200
тестов
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Электронная почта *
Отправляя форму, вы принимаете «Соглашение об обработке персональных данных» и условия «Оферты», а также соглашаетесь с «Условиями использования»
Наши выпускники работают в компаниях:
Концепции реляционных баз данных
Концепции реляционных баз данных
Глава 2 Термины и концепции баз данных
Система управления реляционными базами данных (RDBMS) хранит и
извлекает данные, представленные в таблицах. Реляционная база данных
состоит из набора таблиц, в которых хранятся взаимосвязанные данные.
Реляционная база данных
состоит из набора таблиц, в которых хранятся взаимосвязанные данные.
В этом разделе представлены некоторые термины и понятия, важны в разговоре о реляционных базах данных.
Таблицы базы данных
В реляционной базе данных все данные хранятся в таблицах , которые состоят из строк и столбцов .
Каждая таблица имеет один или несколько столбцов, и каждому столбцу назначается конкретный тип данных , например, целое число, последовательность символов (для текста) или дата. Каждая строка в таблица имеет значение для каждого столбца.
Типовой фрагмент таблицы с информацией о сотрудниках может выглядеть следующим образом:
emp_ID | emp_lname | emp_fname | emp_phone |
|---|---|---|---|
10057 | Хуонг | Чжан | 1096 |
10693 | Дональдсон | Энн | 7821 |
Таблицы реляционной базы данных имеют некоторые важные характеристики:
- Не имеет значения
порядок столбцов или строк.

- Каждая строка содержит одно и только одно значение для каждого столбец.
- Каждое значение для данного столбца имеет один и тот же тип.
В следующей таблице перечислены некоторые формальные и неформальные реляционные термины базы данных, описывающие таблицы и их содержимое вместе с их эквивалент в других нереляционных базах данных. В этом руководстве используются неофициальные термины.
Формальный относительный термин | Неформальный родственный термин | Эквивалентный нереляционный термин |
|---|---|---|
Связь | Стол | Файл |
Атрибут | Столбец | Поле |
Кортеж | Ряд | Запись |
При разработке базы данных убедитесь, что каждая
таблица в базе данных содержит информацию о конкретной вещи,
таких как сотрудники, продукты или клиенты.
Разрабатывая базу данных таким образом, вы можете настроить структуру что устраняет избыточность и несоответствия. Например, оба отделы продаж и кредиторской задолженности могут искать информацию о клиентах. В реляционной базе данных информация о клиенты вводятся только один раз, в таблицу, которую оба отдела может получить доступ.
Реляционная база данных представляет собой набор связанных таблиц. Ты используешь первичные и внешние ключи для описания отношений между информацией в разных таблицах.
Первичные и внешние ключи
Первичные и внешние ключи определяют реляционную структуру база данных. Эти ключи позволяют каждой строке в таблицах базы данных быть идентифицированы и определять отношения между таблицами.
Таблицы имеют первичный ключ
Все таблицы в реляционной базе данных должны иметь первичный
ключ . Первичный ключ — это столбец или набор столбцов,
что позволяет однозначно идентифицировать каждую строку в таблице.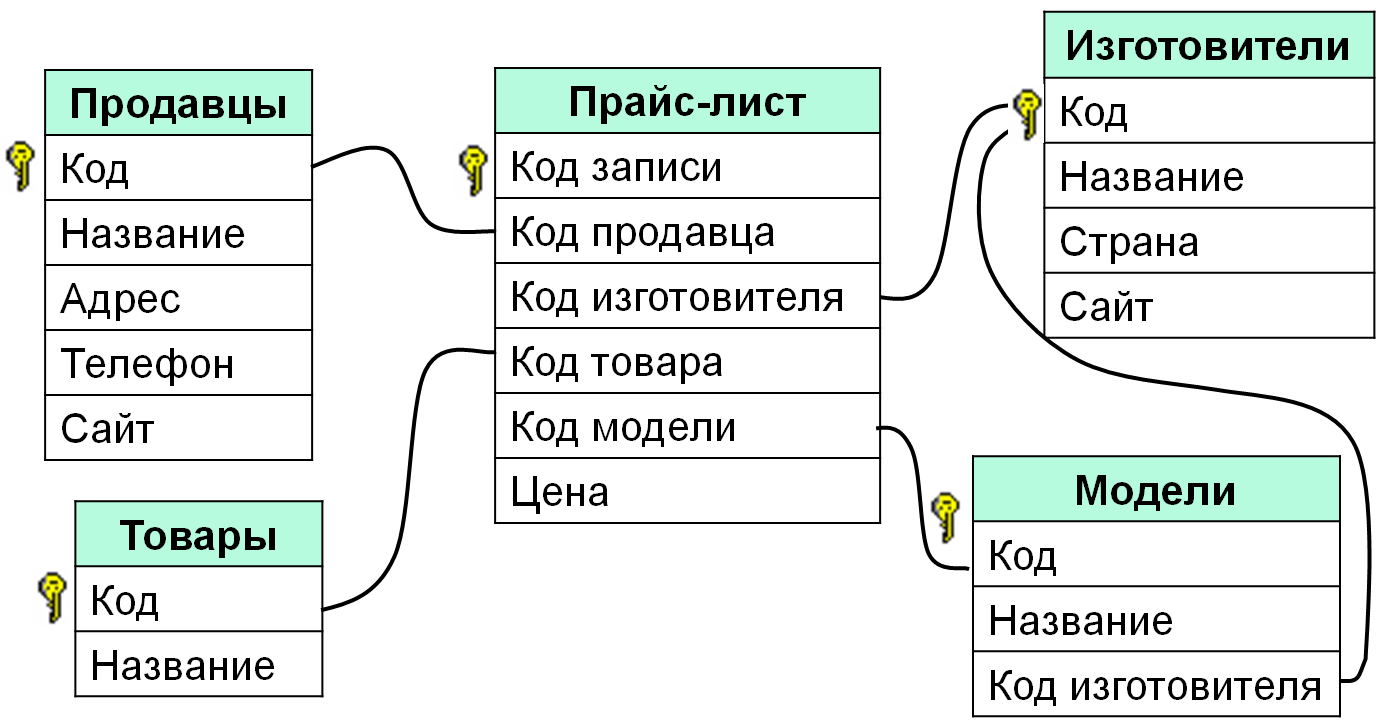 Нет
две строки в таблице с первичным ключом могут иметь один и тот же первичный
ключевое значение.
Нет
две строки в таблице с первичным ключом могут иметь один и тот же первичный
ключевое значение.
Если первичный ключ не назначен, все столбцы вместе становятся первичный ключ. Рекомендуется хранить первичный ключ для каждая таблица максимально компактна.
Примеры
В таблице с информацией о сотрудниках первичный key может быть идентификационным номером, присвоенным каждому сотруднику.
В образце базы данных таблица позиций заказов на продажу следующие столбцы:
- Номер заказа, идентифицирующий заказ, частью которого является товар
- Номер строки, идентифицирующий каждую позицию в любом заказе
- Идентификатор продукта, идентифицирующий заказываемый продукт
- Количество, показывающее, сколько товаров было заказано
- Дата отгрузки, показывающая, когда заказ был отправлен
Чтобы идентифицировать конкретный товар, как номер заказа, так и
требуется номер строки. Первичный ключ состоит из обоих этих
столбцы.
Таблицы связаны внешними ключами
Информация в одной таблице связана с информацией в других таблицах по внешних ключей .
Пример
Образец базы данных содержит одну таблицу с информацией о сотрудниках. и одна таблица с информацией об отделе. Стол отдела имеет следующие столбцы:
- dept_id Идентификационный номер отдела. Это основное ключ от стола.
- dept_name Столбец, содержащий название отдела.
- dept_head_id Идентификатор сотрудника для руководителя отдела.
Чтобы найти название отдела конкретного сотрудника, нет необходимости указывать название отдела сотрудника в таблицу сотрудников. Вместо этого таблица сотрудников содержит столбец, содержащий идентификатор отдела отдела сотрудника. Это называется внешним ключом для отдела стол. Внешний ключ ссылается на конкретную строку в таблице, содержащую соответствующий первичный ключ.
В этом примере таблица сотрудников (которая содержит
ключ в отношении) называется внешней таблицей или , ссылающейся
таблица . Таблица отделов (которая содержит указанный
первичный ключ) называется первичной таблицей или
таблица , на которую ссылается .
Таблица отделов (которая содержит указанный
первичный ключ) называется первичной таблицей или
таблица , на которую ссылается .
Другие объекты базы данных
Реляционная база данных содержит больше, чем набор связанных таблиц. Среди других объектов, составляющих реляционную базу данных:
- Индексы Индексы позволяют быстро находить информацию. Концептуально,
индекс в базе данных подобен индексу в книге. В книге,
индекс связывает каждый проиндексированный термин со страницей или страницами, на которых
появляется слово. В базе данных индекс связывает каждый индексированный столбец
значение физическому местоположению, в котором строка данных, содержащая
индексированное значение сохраняется.
Индексы являются важным элементом дизайна для обеспечения высокой производительности, однако их использование прозрачно для пользователя. - Представления Представления — это вычисляемые или виртуальные таблицы.
 Они
выглядят как таблицы для клиентских приложений, но не содержат данных.
Вместо этого всякий раз, когда к ним обращаются, информация в них
вычисляется из базовых таблиц.
Они
выглядят как таблицы для клиентских приложений, но не содержат данных.
Вместо этого всякий раз, когда к ним обращаются, информация в них
вычисляется из базовых таблиц.
Таблицы, фактически содержащие информацию, иногда назвал базовых таблиц , чтобы отличить их от Просмотры. - Хранимые процедуры и триггеры Это процедуры, содержащиеся в самой базе данных, которые
действовать на основе информации в базе данных.
Вы можете создавать и называть свои собственные хранимые процедуры для выполнения определенные запросы к базе данных и выполнять другие задачи базы данных. Сохранено процедуры могут принимать параметры. Например, вы можете создать хранимая процедура, которая возвращает имена всех клиентов, потрачено больше, чем сумма, которую вы указываете в качестве параметра в вызов на процедуру.Триггер — это специальная хранимая процедура, которая автоматически срабатывает всякий раз, когда пользователь обновляет, удаляет или вставляет данные, в зависимости от о том, как вы определяете триггер.
 Вы связываете триггер с таблицей
или столбцы в таблице. Триггеры полезны для автоматического
поддержание бизнес-правил в базе данных.
Вы связываете триггер с таблицей
или столбцы в таблице. Триггеры полезны для автоматического
поддержание бизнес-правил в базе данных. - Пользователи и группы Каждый пользователь базы данных имеет идентификатор пользователя и пароль. Вы можете установить разрешения для каждого пользователя, чтобы конфиденциальная информация хранится в тайне, и пользователи не могут делать несанкционированные изменения. Пользователей можно объединять в группы, чтобы упростить администрирование. разрешений проще.
- Объекты Java Вы можете установить классы Java в базу данных. Классы Java предоставляют мощный способ встраивания логики в ваш базу данных и специальный класс определяемых пользователем типов данных для хранения информация.
Запросы
Получить данные из базы данных с помощью оператора SELECT.
Основными операциями запроса в реляционной системе являются проекция,
ограничение и присоединиться. Оператор SELECT реализует
все эти операции.
Проекция является подмножеством столбцов в таблице. Ограничение (также называемое выбором ) — это подмножество строк в таблице, основанное на некоторых условиях.
Например, следующий оператор SELECT получает названия и цены всех продуктов, стоимость которых превышает 15 долларов США:
ВЫБЕРИТЕ имя, цена_единицы
ИЗ продукта
ГДЕ цена_единицы > 15
Этот запрос использует как ограничение (WHERE unit_price > 15), и прогноз (SELECT name, unit_price)
СОЕДИНЕНИЕ связывает строки в двух или более таблицах, сравнивая значения в ключевых столбцах и возвращаемые строки с совпадающими значениями. Например, вы можете выбрать идентификационные номера элементов и названия продуктов для всех предметов, для которых более дюжины отправлено:
ВЫБЕРИТЕ sales_order_items.id, product.name
FROM product KEY JOIN sales_order_items
ГДЕ sales_order_items.quantity > 12
Таблица продуктов и sales_order_items
таблицы объединяются на основе отношений внешнего ключа
между ними.
Другие операторы SQL
С помощью SQL можно делать больше, чем просто выполнять запросы. SQL включает операторы которые создают таблицы, представления и другие объекты базы данных. Он также включает операторы, которые изменяют таблицы и команды, которые выполняют многие другие задачи базы данных, обсуждаемые в этом руководстве.
Системные таблицы
Каждая база данных содержит набор из системных таблиц , которые специальные таблицы, которые система использует для управления данными и системой. Эти таблицы иногда называют словарем данных или . системный каталог .
Системные таблицы содержат информацию о базе данных. Ты
никогда не изменяйте системные таблицы напрямую так, как вы можете изменить
другие таблицы. Системные таблицы содержат информацию о таблицах
в базе данных, пользователи базы данных, столбцы в каждой таблице,
и так далее. Эта информация представляет собой данные о данных, или метаданные .
| Copyright © 2000 Sybase, Inc. Все права защищены. | ||
Структурированные данные, SQL и реляционные базы данных
«Чем больше мы можем организовать, найти и управлять информацией, тем эффективнее мы сможем функционировать в нашем современном мире». — Vint Cerf
Мы, люди, ограничены в своей способности запоминать вещи. Наличие инструментов, обеспечивающих немедленный доступ к данным и их анализ, позволяет нам принимать более обоснованные решения.
Сегодня у нас есть системы, которые позволяют врачу просматривать медицинскую карту пациента перед назначением нового лекарства. Ученый-биоинформатик может запросить данные генома, чтобы найти генетическую основу болезни. Бейсбольный скаут, изучая статистику игрока, может оценить его ценность.
Все эти решения можно успешно принять, собирая данные, систематизируя их и затем изучая их, чтобы найти закономерности и смысл. Эти данные должны храниться таким образом, чтобы их можно было изучить. Другими словами, нам нужно его структурировать.
Эти данные должны храниться таким образом, чтобы их можно было изучить. Другими словами, нам нужно его структурировать.
Это видео Ханса Рослинга. Собирая данные о 200 странах за 200 лет, он дает представление о человеческом прогрессе.
Чтобы лучше узнать о структурированных данных, полезно понять проблему, которую они призваны решить: ограничения неструктурированных данных. Неструктурированные данные — это данные, которые содержат информацию без какой-либо структуры, например содержимое электронных писем, книг или изображений.
Хранение данных в неструктурированном виде может работать, если у вас есть только небольшой объем, но как только объем данных начинает расти, он быстро становится громоздким. Например, если вы хотите найти определенную заметку, сделанную вами в блокноте, вам может потребоваться просмотреть всю книгу, чтобы найти ее. На этом этапе вам нужен способ организации или структурирования ваших данных. Одним из способов структурирования данных является их хранение в табличном формате (строки и столбцы), например, в электронных таблицах или списках задач.
Одним из способов структурирования данных является их хранение в табличном формате (строки и столбцы), например, в электронных таблицах или списках задач.
Хранение данных в структурированном виде, например в виде таблицы или электронной таблицы, позволяет нам легко находить данные, а также лучше управлять ими. Данные можно упорядочивать и анализировать различными способами, такими как сортировка по алфавиту или суммирование набора значений.
Распространенным способом структурированного хранения данных является использование реляционной базы данных. Базовое определение базы данных — это просто «структурированный набор данных, хранящихся в компьютере».
Предположим, нам нужно сохранить имя и адрес электронной почты рецензентов популярного веб-сайта. Самый простой подход — открыть электронную таблицу, например, в Google Docs или Microsoft Excel, и ввести несколько имен.
- Джон, [email protected]
- Алиса, [email protected]
Теперь, когда у нас есть электронная таблица, мы решили добавить заголовок, идентифицирующий столбцы и идентификатор для каждого пользователя. Итак, наш рабочий лист выглядит так:
Итак, наш рабочий лист выглядит так:
Далее нам нужно добавить отзывы этих пользователей. Мы не хотим загромождать электронную таблицу, поэтому добавляем новый рабочий лист.
Как вы могли заметить, рабочий лист Users имеет три столбца с именами id , имя пользователя и электронная почта , а рабочий лист «Отзывы» имеет три столбца с именами id , имя пользователя и контент . Большинство электронных таблиц будут использовать несколько рабочих листов для организации данных. Каждый рабочий лист имеет уникальные столбцы, в которых должны храниться данные одного типа (на которые ссылается имя столбца).
Электронную таблицу в целом можно рассматривать как базу данных, а рабочие листы в электронной таблице можно использовать для описания таблиц в базе данных. Таблица содержит строки и столбцы. Каждая строка содержит данные для одного человека. Каждый столбец содержит данные одного определенного вида для всех лиц.
Строки и столбцы рабочего листа аналогичны строкам и столбцам таблицы. Каждая строка представляет собой один набор связанных данных, а столбцы представляют собой стандартизированный способ хранения данных для этого конкретного атрибута.
Эта упрощенная аналогия идеально подходит для концептуального описания базы данных. Помните об этой аналогии, пока мы продвигаемся по книге:
| Электронная таблица | База данных |
| Рабочий лист | Стол |
| Столбец рабочего листа | Столбец таблицы |
| Строка рабочего листа | Запись таблицы |
Теперь предположим, что другие люди в компании заинтересованы в чтении отзывов и добавлении пользователей. Поэтому вы решили поделиться таблицей. Со временем объем информации начинает увеличиваться. Вы начинаете сталкиваться с проблемами с дублированием данных, опечатками, возможно, даже с проблемами форматирования, если несколько человек работают над одним файлом. Простая электронная таблица теперь становится громоздкой, а поиск/сбор информации требует много прокрутки и поиска. В этот момент вам, вероятно, было бы полезно перейти на система управления реляционными базами данных .
Простая электронная таблица теперь становится громоздкой, а поиск/сбор информации требует много прокрутки и поиска. В этот момент вам, вероятно, было бы полезно перейти на система управления реляционными базами данных .
Реляционная база данных — это база данных, организованная в соответствии с реляционной моделью данных. Проще говоря, реляционная модель определяет набор отношений (которые мы можем рассматривать как аналог таблиц) и описывает отношения или соединения между ними, чтобы определить, как могут взаимодействовать данные, хранящиеся в них. Использование реляционной модели поднимает нашу базу данных от данных, представленных в виде простой двумерной таблицы, до такой, в которой мы можем описать данные более сложным и подробным образом. Использование реляционной базы данных помогает нам сократить количество дублирующихся данных и предоставляет нам гораздо более полезную структуру данных для взаимодействия.
Система управления реляционными базами данных , или RDBMS , по сути является программным приложением или системой для управления реляционными базами данных. СУРБД позволяет пользователю или другому приложению взаимодействовать с базой данных, выдавая команды с использованием синтаксиса, который соответствует определенному набору соглашений или стандартов.
СУРБД позволяет пользователю или другому приложению взаимодействовать с базой данных, выдавая команды с использованием синтаксиса, который соответствует определенному набору соглашений или стандартов.
Существует множество систем управления реляционными базами данных, таких как SQLite, MS SQL, PostgreSQL и MySQL. Некоторые из них легковесны, просты в установке и использовании, в то время как другие надежны, масштабируемы, но сложны в установке. Эти различные СУБД могут различаться определенным образом, и некоторые из используемых ими команд могут иметь небольшие синтаксические различия. Однако у них есть одна общая черта — это базовый язык, который они все используют: SQL.
Стоит отметить, что реляционная модель — не единственная модель структурированных данных, используемая программным обеспечением баз данных. Например, такая программа, как MongoDB, использует документно-ориентированную модель хранения данных. Эта и другие системы, использующие нереляционные модели хранения и извлечения данных, часто объединяются под термином «NoSQL». Однако для целей этой книги нас интересует только реляционная модель и то, как можно использовать SQL для взаимодействия с реляционными базами данных.
Однако для целей этой книги нас интересует только реляционная модель и то, как можно использовать SQL для взаимодействия с реляционными базами данных.
SQL , что означает язык структурированных запросов , является языком программирования, используемым для связи с реляционной базой данных.
SQL может произноситься как «Sequel» или как «Ess-Queue-Ell». Люди могут быть весьма педантичны в отношении того, что правильно. Однако лучше просто использовать то, что помогает лучше общаться, перенимая произношение окружающих вас людей.
SQL — это мощный язык, использующий простые английские предложения, которые с помощью нескольких строк позволяют вам Выбрать (найти), Вставить (добавить), Обновить (изменить) и Удалить (удалить) большой объем данных.
Цель этой книги — научить вас SQL, который позволит вам использовать любую из упомянутых выше СУБД и даже другие, не упомянутые. Чтобы научить вас SQL, мы выбрали СУБД PostgreSQL из-за ее широкой применимости и открытого исходного кода. Однако после прочтения этой книги у вас должны быть базовые знания о SQL и реляционных базах данных, а также навыки использования любой реляционной базы данных по вашему выбору.
Однако после прочтения этой книги у вас должны быть базовые знания о SQL и реляционных базах данных, а также навыки использования любой реляционной базы данных по вашему выбору.
SQL немного отличается от других языков программирования, с которыми вы, возможно, сталкивались. SQL — это декларативный язык ; когда вы пишете оператор SQL, вы описываете что нужно сделать, но не точно как это сделать — точные детали того, как выполняется запрос, обрабатываются внутри используемой СУБД.
Краткая история SQL
SQL восходит к 1970-м годам, когда он был задуман Э. Ф. Коддом в его статье «Реляционная модель для больших банков данных» . В документе заложены основы того, что станет реляционными базами данных. Вы можете слышать термин «реляционная алгебра», иногда используемый при работе с базами данных. Математические модели, лежащие в основе реляционных баз данных, выходят за рамки этой книги, но, по сути, это теория, на которой строятся реляционные базы данных.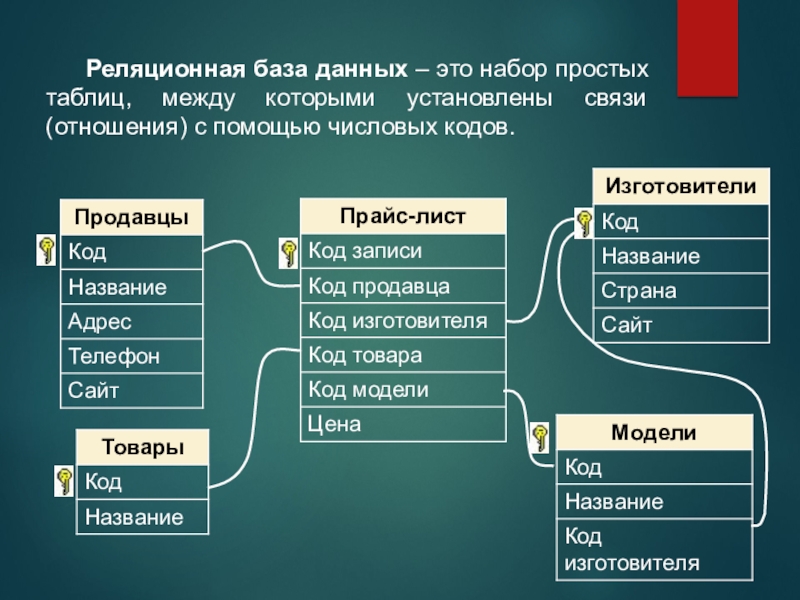 Со временем компании увидели ценность концепций, описанных в статье Кодда, и в 1970-х годах многие из них начали разрабатывать язык SQL и производить продукты, называемые реляционными базами данных.
Со временем компании увидели ценность концепций, описанных в статье Кодда, и в 1970-х годах многие из них начали разрабатывать язык SQL и производить продукты, называемые реляционными базами данных.
Реляционные базы данных получили настолько широкое распространение, что вы, вероятно, используете несколько баз данных в день, даже не подозревая об этом. Меньшие примеры включают Firefox, который использует SQLite для отслеживания истории и данных пользователя, банковские системы, которые могут использовать базу данных Oracle для хранения ежедневных транзакций.
Другой способ, которым вы могли использовать SQL, — это язык программирования, такой как Python или Ruby. Например, если вы когда-либо делали учебник по Ruby on Rails, скорее всего, код, который вы написали, за кулисами сгенерировал для вас SQL. Независимо от того, какой язык вы используете, база данных и ее данные, скорее всего, переживут большую часть кода приложения в вашей программе.
Создание хорошо спроектированной базы данных похоже на закладку фундамента дома, а изучение SQL и концепций реляционных баз данных поможет вам построить приложения на прочном фундаменте.