Пишем правильно: онлайн-сервисы для проверки орфографии
Иногда при составлении текстов мы просто не замечаем опечаток или ошибок, хотя они обязательно найдутся. Для исправления этого недоразумения существуют онлайн-сервисы проверки орфографии. Советуем пользоваться ими, особенно когда цена ошибки текста слишком велика: важный документ, большой тираж полиграфии и так далее.Конечно, даже умный компьютер не идеален. Бывает сервис подчеркивают специфические термины, которые не знает и не указывает на смысловое содержание предложения. Но и это можно решить, если пользоваться сразу несколькими сайтами, так можно добиться максимального результата. Орфографические ошибки можно проверить Орфограммкой, Яндекс.Спеллером или Languagetool, подкорректировать оформление – Типографом, а об устранении стилистических ошибок позаботится Главред.
Главред (glvrd.ru)
Один из самых популярных сервисов. Его функционал разработан для усовершенствования рекламных, информационных, новостных материалов, писем, коммерческих предложений, пресс-релизов. Нормальным текстом считается значение от 7 баллов и выше. Советы Главреда помогают очистить текст от словесного мусора, необъективной оценки, клише или фраз, которыми пользуются только провинциальные журналисты. Примерно то же самое умеет созданная автором Главреда программа test-the-text, а автор – небезызвестный Максим Ильяхов.
Его функционал разработан для усовершенствования рекламных, информационных, новостных материалов, писем, коммерческих предложений, пресс-релизов. Нормальным текстом считается значение от 7 баллов и выше. Советы Главреда помогают очистить текст от словесного мусора, необъективной оценки, клише или фраз, которыми пользуются только провинциальные журналисты. Примерно то же самое умеет созданная автором Главреда программа test-the-text, а автор – небезызвестный Максим Ильяхов.
На сайте можно провести онлайн работу над ошибками и узнать, насколько в лучшую (или худшую) сторону изменился текст. Пользуйтесь без фанатизма и без погони за максимальной оценкой. Опытные копирайтеры говорят, что после проверки и правок текст становится более информативным и понятным.
Орфограммка (orfogrammka.ru)
Платный сервис, который выявляет орфографические, грамматические, пунктуационные, стилистические, речевые и смысловые ошибки.
Languagetool (languagetool.org)
Расширение устанавливается в браузер для проверки орфографии и грамматики. Умеет работать с документами в MS Word, LibreOffice, Google Docs, браузерами Firefox и Chrome.
Этот инструмент, предназначенный для выявления орфографических, грамматических, стилистических и других ошибок, удобен своей простотой, а также многоязычностью. Он поддерживает более 20 языков.
Яндекс.Спеллер (tech.yandex.ru/speller/)
Яндекс.Спеллер находит и выделяет орфографические ошибки в текстах на русском, украинском и английском языках. Система узнает слова с несколькими ошибками, а при анализе правильности написания слов учитывает контекст.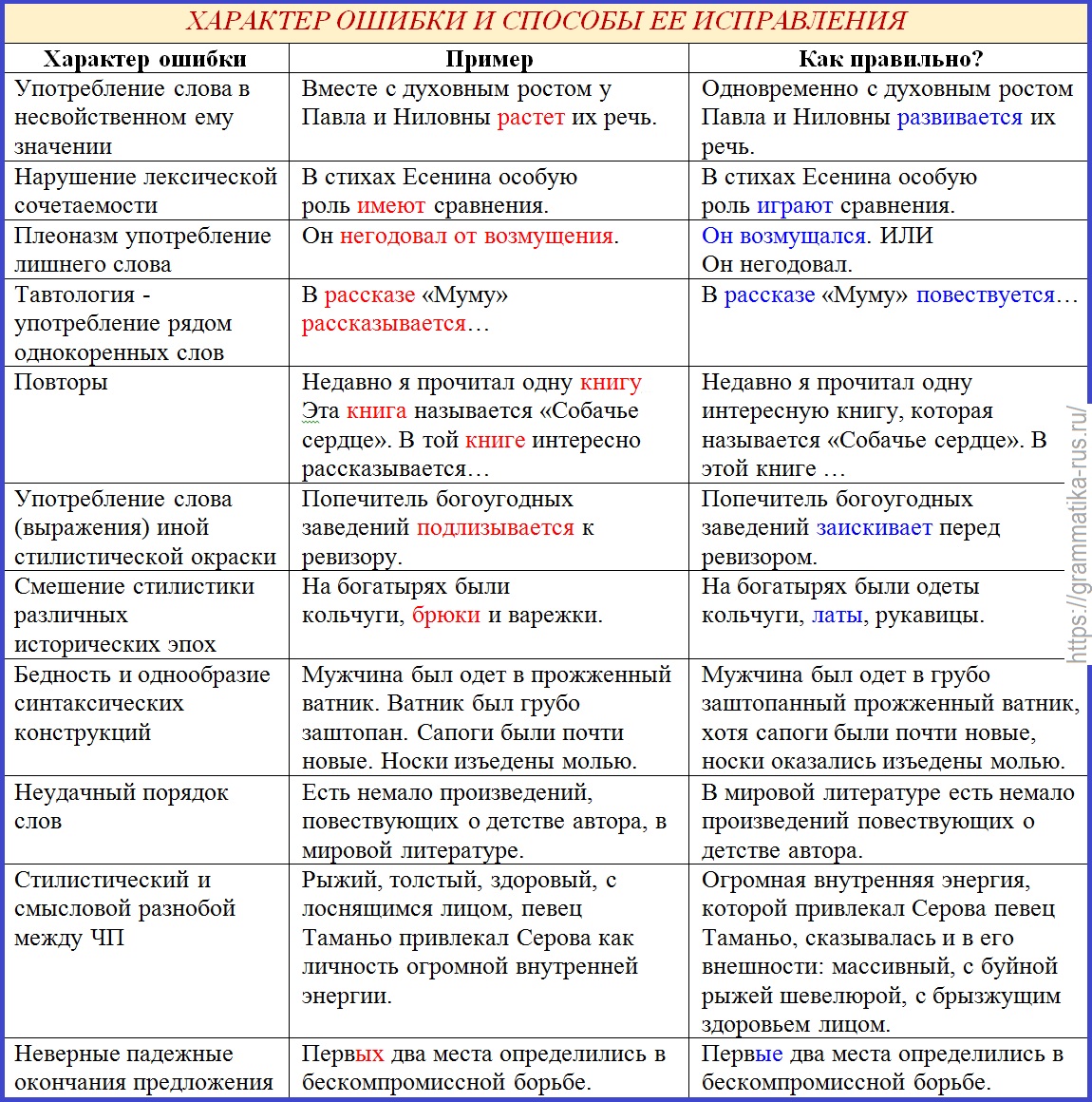
Орфограф (artlebedev.ru/orfograf/)
Созданный студией Артемия Лебедева «Орфограф» проверяет правильность текстов, написанных на русском и английском языках. Не включенные в словарь приложения слова выделяются цветом, который можно выбрать самостоятельно. Проверяются отдельные тексты или целые веб-страницы. Артемий плохого не посоветует.
Meta.ua (translate.meta.ua/ru/orthography/)
Сервис от meta.ua бесплатно проверяет русские, украинские и английские тексты на правописание и предлагает варианты замены неизвестных ему слов. Простая и удобная программка.
Типограф (typograf.ru)
Типограф помогает готовить тексты к размещению на сайтах: исправляет кавычки, неразрывные пробелы, спецсимволы, корректирует опечатки, проверяет правильность слов. Авторы заверяют, что программа способна автоматически исправлять около 95–99% неточностей. Бесплатным сервисом можно пользоваться до 1 июня, потом он станет платным.
Авторы заверяют, что программа способна автоматически исправлять около 95–99% неточностей. Бесплатным сервисом можно пользоваться до 1 июня, потом он станет платным.
И бонусом для проверки уникальности советуем Контент-Вотч, Текст.ру.
Правила русского языка, которые мы не можем запомнить: как решить эту проблему?
Типичные грамматические ошибки
Ирина Кривенкова (кандидат филологических наук, репетитор по русскому языку).
Сегодня я предлагаю разобрать грамматические ошибки.
Ранее я уже рассказывала о речевых ошибках. Если вы еще не смотрели это видео или хотите систематизировать свои знания по этой теме, то вам стоит посмотреть ролик под названием «Типичные речевые ошибки». (Ссылка)
Выясним, чем грамматические ошибки отличаются от речевых.
Грамматические ошибки – это нарушение какой-либо грамматической нормы: словообразовательной, морфологической или синтаксической.
Речевые ошибки – это нарушение лексических норм.
Чтобы выявить грамматическую ошибку, контекст не нужен. Для выявления речевой ошибки контекст обязателен.
Никогда не путайте грамматические ошибки с орфографическими. Орфографические ошибки связаны с правописанием слов.
Чтобы избавиться от речевых ошибок, нужно выполнять задания под номерами 5 и 6. Они проверяют знания лексических норм.
Чтобы избавиться от грамматических ошибок, вы должны тренироваться в выполнении заданий под номерами 7 и 8. Они проверяют знания грамматических норм.
Еще хотела бы обратить ваше внимание на критерии оценивания сочинения. Критерию К9 соответствует соблюдение грамматических норм. При отсутствии грамматических ошибок по этому критерию вы получаете 2 балла, если допускаете 1-2 ошибки – 1 балл, если 3 ошибки и более – 0 баллов. Критерию К10 соответствует соблюдение речевых норм.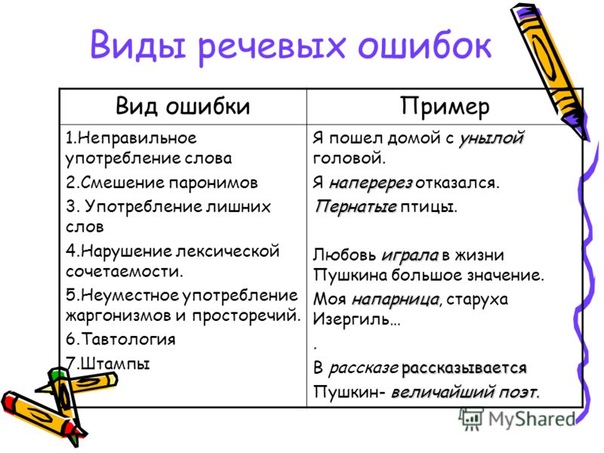 Если вы не допустили ни одной ошибки или сделали одну речевую ошибку, вы получаете 2 балла, за 2-3 ошибки – 1 балл, за 4 и более ошибок ставится 0 баллов.
Если вы не допустили ни одной ошибки или сделали одну речевую ошибку, вы получаете 2 балла, за 2-3 ошибки – 1 балл, за 4 и более ошибок ставится 0 баллов.
Давайте посмотрим, за какие грамматические ошибки могут снизить баллы по критерию К9. Сейчас мы сделаем обзор часто встречающихся грамматических ошибок:
1. Запомните, производные предлоги «благодаря», «согласно», «вопреки», «подобно» употребляются с существительными в дательном падеже. Например, «согласно (чему?) документу». Ошибка заключается в том, что школьники сочетают эти предлоги с родительным падежом, «согласно (чего?) документа» является ошибочным употреблением.
2. Предлог «по» сочетается с существительным в предложном падеже. Ошибкой является то, что ученики употребляют с этим предлогом существительные в дательном падеже. Правильно писать «по окончании», «по завершении», «по прибытии».
3. Обратите внимание на сочетание предлога «по» с существительными «приезд» и «прилет». Грамотно произносить «по приезде» и «по прилете».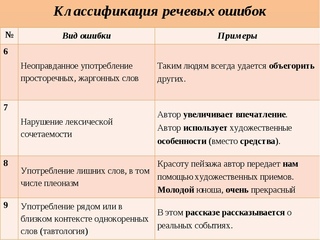
4. Обратим внимание на определенные нормы управления. Наиболее употребительные словосочетания:
— оплатить (что?) проезд;
— заплатить (за что?) за проезд;
— основанный (на чем?) на фактах;
— обоснованный (чем?) фактами;
— директор (чего?) театра;
— заведующий (чем?) библиотекой;
— характерный (для кого? чего?) для Севера климат;
— свойственный (кому? чему?) молодости.
5. Затруднение вызывает образование форм числительных. Во избежание ошибки потренируйтесь в склонении имен числительных. Путаница возникает с числительными «пятьсот», «шестьсот», «семьсот», «восемьсот» и «девятьсот» в родительном падеже. Ошибочным является употребление «нет пятиста» или «нет шестиста». Такой формы не существует. Правильная форма «нет пятисот», «шестисот», «семисот», «восьмисот», «девятисот».
6. Следите за образованием форм степеней сравнения имен прилагательных и наречий. Нельзя смешивать простую и составную формы степеней сравнения. Грубой ошибкой будет сказать «более красивее» или «самый интереснейший». Правильными будут формы «более красивый» или просто «красивее», «самый интересный» или просто превосходная степень «интереснейший».
Грубой ошибкой будет сказать «более красивее» или «самый интереснейший». Правильными будут формы «более красивый» или просто «красивее», «самый интересный» или просто превосходная степень «интереснейший».
7. Когда вы пишете сочинение или другие творческие работы, обращайте внимание на согласование подлежащего со сказуемым. Перед нами сложноподчиненное предложение «Все, кто мог прийти, собрались в зале». В каждой части этого сложного предложения своя грамматическая основа: «все» – подлежащие, «собрались» – сказуемое, они согласуются в числе, в данном случае, в множественном. В придаточной части «кто» – подлежащие, «мог прийти» – сказуемое, они согласуются в единственном числе. Ошибки могут выглядеть следующим образом: «все собрался», что является неверным. Или в придаточной части «кто» в единственном числе, а сказуемое «могли прийти» стоит во множественном числе, что является неверным.
8. Особого внимания заслуживает предложения, в составе которых есть деепричастный оборот. Деепричастие обозначает добавочные действия к основному.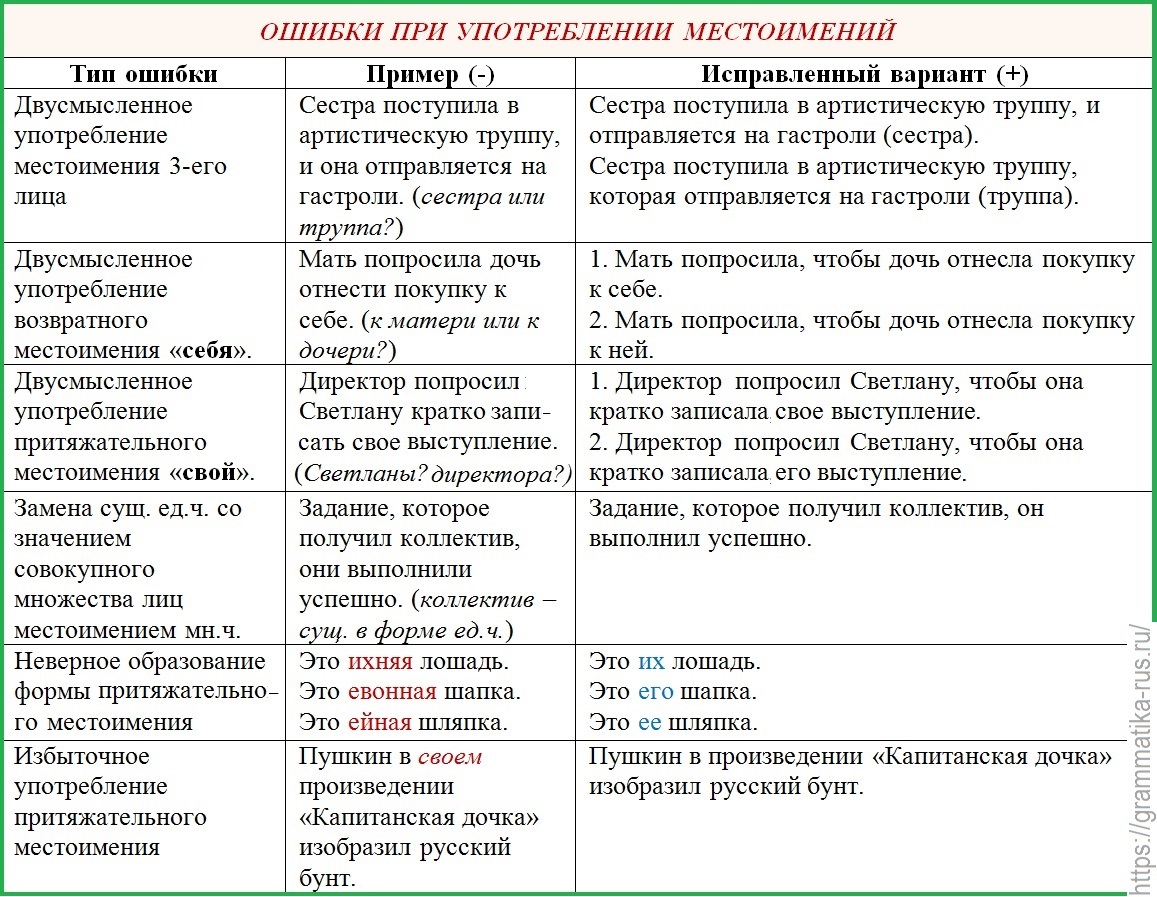
И маленькое напутствие в конце этого видео: вы избавитесь от грамматических ошибок в своих работах и будете получать максимальный балл по критерию К9, если добросовестно подойдете к изучению грамматических норм и будете выполнять задания 7 и 8 теста.
Мы сделали с вами обзор часто встречающихся грамматических ошибок. Если вы хотите продолжить эту тему, пишите в комментариях свои пожелания.
До новых встреч! До свидания!
Благодарим за то, что пользуйтесь нашими материалами. Информация на странице «Типичные грамматические ошибки» подготовлена нашими редакторами специально, чтобы помочь вам в освоении предмета и подготовке к экзаменам. Чтобы успешно сдать нужные и поступить в высшее учебное заведение или техникум нужно использовать все инструменты: учеба, контрольные, олимпиады, онлайн-лекции, видеоуроки, сборники заданий. Также вы можете воспользоваться другими статьями из разделов нашего сайта.
Публикация обновлена: 07.05.2023
FastCorrect: модель быстрой коррекции ошибок для распознавания речи
Исправление ошибок — это важный метод постобработки в распознавании речи, который направлен на обнаружение и исправление ошибок в результатах распознавания речи, тем самым повышая точность распознавания речи. Многие модели исправления ошибок используют авторегрессионные модели с высокой задержкой, но службы распознавания речи предъявляют строгие требования к задержке моделей. В сценариях распознавания речи в реальном времени авторегрессионные модели исправления ошибок нельзя использовать для онлайн-развертывания.
Многие модели исправления ошибок используют авторегрессионные модели с высокой задержкой, но службы распознавания речи предъявляют строгие требования к задержке моделей. В сценариях распознавания речи в реальном времени авторегрессионные модели исправления ошибок нельзя использовать для онлайн-развертывания.
Чтобы ускорить модель исправления ошибок при распознавании речи, исследователи Microsoft Research Asia и Microsoft Azure Speech предложили FastCorrect, неавторегрессионную модель исправления ошибок, основанную на Edit Alignment, которая может ускорить авторегрессионную модель в шесть-девять раз. при сохранении сопоставимой способности исправления ошибок. Поскольку модели распознавания речи часто могут предоставлять несколько альтернативных результатов распознавания, исследователи также предложили FastCorrect 2, в котором несколько результатов используются для подтверждения друг друга и повышения производительности. Исследовательские работы по FastCorrect 1 и 2 были приняты NeurIPS 2021 и EMNLP 2021 соответственно.
FastCorrect
Редактирование выравнивания
FastCorrect использует неавторегрессионную генерацию с редактированием выравнивания для ускорения вывода модели авторегрессионной коррекции. В FastCorrect исследователи сначала вычисляют расстояние редактирования между распознанным текстом (исходным предложением) и текстом, достоверным (целевым предложением). Поскольку исходные и целевые токены выравниваются монотонно в автоматическом распознавании речи (ASR) (в отличие от ошибки перетасовки в нейронном машинном переводе), путем анализа операций вставки, удаления и замены на расстоянии редактирования количество целевых токенов, соответствующих каждому источнику токен после редактирования (т. е. 0 означает удаление, 1 означает неизменность или замену и ≥2 означает вставку), как показано на рисунке 1. В некоторых случаях может быть несколько возможных выравниваний пары исходное-целевое предложение, и будет выбрано окончательное выравнивание на основе оценки соответствия пути (количество совпадающих токенов в выравнивании) и оценки частоты (отражающей достоверность выравнивания в языковой модели).
Архитектура модели
FastCorrect использует неавторегрессивную структуру кодер-декодер с предсказателем длины для преодоления несоответствия длины между кодером (исходное предложение) и декодером (целевое предложение). Как показано на рис. 2, кодировщик принимает исходное предложение в качестве входных данных и выводит скрытую последовательность, которая: 1) подается в предиктор длины для предсказания количества целевых токенов, соответствующих каждому исходному токену (т. е. выравнивание редактирования, полученное в предыдущий подраздел), и 2) используется декодером посредством внимания кодера-декодера. Метка предиктора длины получается в результате выравнивания редактирования, а подробная архитектура предиктора длины показана на правом подрисунке рисунка 2.
Рисунок 2: Архитектура модели FastCorrect.Экспериментальные результаты
Исследователи сообщили о точности и задержке различных моделей коррекции ошибок на AISHELL-1 и на внутреннем наборе данных, как показано в таблице 1. Мы сделали несколько наблюдений: 1) Модель авторегрессионной (AR) коррекции может уменьшить слово коэффициент ошибок (WER) (измеряемый снижением частоты ошибок в словах (WERR)) модели ASR на 15,53% и 8,50% соответственно на тестовом наборе AISHELL-1 и внутреннем наборе данных. 2) LevT, типичная неавторегрессионная модель от NMT, достигает незначительного WERR на AISHELL-1 и даже приводит к увеличению WER на внутреннем наборе данных. Между тем, LevT может ускорить вывод модели AR только в два-три раза на GPU/CPU. 3) FELIX достигает только 4,14% WERR на AISHELL-1 и 0,27% WERR на внутреннем наборе данных, что значительно хуже, чем у FastCorrect, хотя ускорение вывода аналогично. 4) Модель FastCorrect ускоряет вывод модели AR в шесть-девять раз на двух наборах данных на GPU/CPU и достигает 8-14% WERR, что почти сравнимо с моделью коррекции AR по точности.
Мы сделали несколько наблюдений: 1) Модель авторегрессионной (AR) коррекции может уменьшить слово коэффициент ошибок (WER) (измеряемый снижением частоты ошибок в словах (WERR)) модели ASR на 15,53% и 8,50% соответственно на тестовом наборе AISHELL-1 и внутреннем наборе данных. 2) LevT, типичная неавторегрессионная модель от NMT, достигает незначительного WERR на AISHELL-1 и даже приводит к увеличению WER на внутреннем наборе данных. Между тем, LevT может ускорить вывод модели AR только в два-три раза на GPU/CPU. 3) FELIX достигает только 4,14% WERR на AISHELL-1 и 0,27% WERR на внутреннем наборе данных, что значительно хуже, чем у FastCorrect, хотя ускорение вывода аналогично. 4) Модель FastCorrect ускоряет вывод модели AR в шесть-девять раз на двух наборах данных на GPU/CPU и достигает 8-14% WERR, что почти сравнимо с моделью коррекции AR по точности.

FastCorrect 2
Ключевой задачей исправления ошибок ASR является обнаружение и исправление маркеров ошибок. Поскольку поиск луча обычно используется в ASR, обычно генерируются несколько кандидатов, которые доступны для исправления ошибок. Мы утверждаем, что несколько кандидатов могут выполнять эффект голосования, а это означает, что токены из нескольких предложений могут проводить проверку друг друга.
Например, если кандидатами на поиск луча являются три предложения «У меня есть кошка», «У меня есть шляпа» и «У меня есть летучая мышь», то первые две лексемы трех предложений, скорее всего, будут правильными, поскольку они то же самое среди всех кандидатов в лучи. Несоответствие в последнем токене показывает, что: 1) этот токен может нуждаться в исправлении, и 2) произношение наземного токена может заканчиваться на «æt». Эффект голосования можно использовать для повышения коррекции ASR, помогая модели обнаруживать маркер ошибки и давая подсказки о произношении маркера истинности.
Чтобы лучше использовать эффект голосования, исследователи предложили специальные конструкции алгоритма выравнивания и архитектуры модели.
Выравнивание на основе произношения
Поскольку длины нескольких кандидатов обычно различаются, а токены из разных предложений не выровнены по положению, нетривиально выровнять этих кандидатов по токенам, чтобы использовать эффект голосования. Если мы просто используем левое или правое заполнение, чтобы обеспечить одинаковую длину для выравнивания, информация о каждой позиции в разных кандидатах не выравнивается, и поэтому эффект голосования нежизнеспособен. Чтобы воспользоваться эффектом голосования, исследователи предложили новый алгоритм выравнивания, основанный на оценке совпадения токенов и оценке схожести произношения, который может обеспечить максимально возможное совпадение токенов в одной и той же позиции или произношение токенов в одной и той же позиции. насколько это возможно, если токены не совпадают.
Как показано на рисунке 3, по сравнению с простым методом выравнивания (заполнение справа) новый метод выравнивания может: 1) выравнивать одни и те же токены («B», «D» и «F») в одной и той же позиции, 2) изолировать дополнительную лексему, встречающуюся только в одном кандидате («C»), и 3) поддерживать как можно более высокое сходство произношения лексем в одной и той же позиции.
Предсказатель-кандидат для выбора кандидата для декодера
Кандидатов может быть несколько (такое же, как количество исходных предложений), но декодер может принять только одно скорректированное исходное предложение в качестве входных данных. (Поскольку прогнозируемая продолжительность может быть разной для разных кандидатов во время вывода, нецелесообразно подавать в декодер все скорректированные варианты с разной длиной.) Таким образом, необходимо выбрать подходящее исходное предложение для настройки и принять его в качестве входных данных для декодера. . Поэтому исследователи разработали предиктор-кандидат, чтобы выбрать наиболее подходящее исходное предложение. В частности, исследователи хотят выбрать кандидата, который может привести к наименьшим потерям (то есть кандидата, которого легче всего исправить) в модели коррекции.
Как показано на рис. 4, результаты поиска выровненного луча объединяются вдоль каждой позиции, преобразуются линейным слоем, а затем передаются в кодировщик. Выходные данные кодировщика объединяются с исходным внедрением токена и передаются в предиктор для прогнозирования продолжительности каждого исходного токена (с помощью предсказателя длительности) и потери кандидатов (с помощью предсказателя-кандидата). Исходный токен корректируется в соответствии с предсказателем длительности и затем подается в декодер. Наконец, потеря декодера используется как метка кандидата-предсказателя.
4, результаты поиска выровненного луча объединяются вдоль каждой позиции, преобразуются линейным слоем, а затем передаются в кодировщик. Выходные данные кодировщика объединяются с исходным внедрением токена и передаются в предиктор для прогнозирования продолжительности каждого исходного токена (с помощью предсказателя длительности) и потери кандидатов (с помощью предсказателя-кандидата). Исходный токен корректируется в соответствии с предсказателем длительности и затем подается в декодер. Наконец, потеря декодера используется как метка кандидата-предсказателя.
Экспериментальные результаты
В таблице 2 показаны точность коррекции и задержка вывода для различных моделей коррекции, на основании которых мы сделали следующие наблюдения:
По сравнению с базовой линией FastCorrect, FastCorrect 2 может повысить точность коррекции на 2,55 % и 3,22 % с точки зрения снижения WER для AISHELL-1 и внутреннего набора данных соответственно, что показывает эффективность использования информации о нескольких кандидатах. Более того, FastCorrect 2 в пять раз быстрее авторегрессионной модели, что свидетельствует об эффективности логического вывода.
Более того, FastCorrect 2 в пять раз быстрее авторегрессионной модели, что свидетельствует об эффективности логического вывода.
И FastCorrect, и FastCorrect 2 находятся в открытом доступе здесь: https://github.com/microsoft/NeuralSpeech. Исследователи разрабатывают FastCorrect 3 для повышения точности коррекции при высокой скорости логического вывода.
Paper Link:
FastCorrect: быстрое исправление ошибок с редактированием выравнивания для автоматического распознавания речи
https://arxiv.org/abs/2105.03842
FastCorrect 2:Быстрое исправление ошибок для нескольких кандидатов для автоматического распознавания речи
https://arxiv.org/abs/2109.14420
сравнение ошибок ухода за больными заметки, созданные с помощью технологии распознавания речи онлайн и оффлайн и написанные от руки: интервенционное исследование
1. Мэн Ф., Тайра Р.К., Буй А.А., Кангарлоо Х., Черчилль Б.М. Автоматическое создание повторяющейся информации о пациенте для адаптации клинических заметок. Int J Med Inform. 2005; 74 (7–8): 663–673. doi: 10.1016/j.ijmedinf.2005.03.008. [PubMed] [CrossRef] [Академия Google]
Мэн Ф., Тайра Р.К., Буй А.А., Кангарлоо Х., Черчилль Б.М. Автоматическое создание повторяющейся информации о пациенте для адаптации клинических заметок. Int J Med Inform. 2005; 74 (7–8): 663–673. doi: 10.1016/j.ijmedinf.2005.03.008. [PubMed] [CrossRef] [Академия Google]
2. Pollard SE, Neri PM, Wilcox AR, Volk LA, Williams DH, Schiff GD, et al. Как врачи документируют записи амбулаторных посещений в электронной медицинской карте. Int J Med Inform. 2013;82(1):39–46. doi: 10.1016/j.ijmedinf.2012.04.002. [PubMed] [CrossRef] [Google Scholar]
3. El-Kareh R, Gandhi TK, Poon EG, Newmark LP, Ungar J, Lipsitz S, et al. Тенденции в восприятии врачами первичного звена новой электронной медицинской карты. J Gen Intern Med. 2009;24(4):464–468. doi: 10.1007/s11606-009-0906-з. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
4. Джонсон К.Б., Равич В.Дж., Коуэн Дж.А., мл. Мозговой штурм по компьютерной документации следующего поколения: опрос клинической рабочей группы AMIA. Int J Med Inform. 2004;73(9–10):665–674. doi: 10.1016/j.ijmedinf.2004.05.009. [PubMed] [CrossRef] [Google Scholar]
Int J Med Inform. 2004;73(9–10):665–674. doi: 10.1016/j.ijmedinf.2004.05.009. [PubMed] [CrossRef] [Google Scholar]
5. Миллер Р. Х., Сим И. Использование врачами электронных медицинских карт: барьеры и решения. Здоровье Афф. 2004;23(2):116–126. doi: 10.1377/hlthaff.23.2.116. [PubMed] [CrossRef] [Академия Google]
6. Sittig D, Singh H. Электронные медицинские карты и национальные цели безопасности пациентов. N Engl J Med. 2012;367(19):1854–1860. doi: 10.1056/NEJMsb1205420. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
7. Soto CM, Kleinman KP, Simon SR. Качество и корреляты медицинской документации в условиях амбулаторного лечения. BMC Health Serv Res. 2002;2(1):22. doi: 10.1186/1472-6963-2-22. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
8. Hofer TP, Asch SM, Hayward RA, Rubenstein LV, Hogan MM, Adams J, et al. Профилирование качества медицинской помощи: есть ли роль экспертной оценки? BMC Health Serv Res. 2004;4(1):9. дои: 10. 1186/1472-6963-4-9. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
1186/1472-6963-4-9. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
9. Milchak JL, Shanahan RL, Kerzee JA. Внедрение процесса экспертной оценки для повышения согласованности документации по показателям процесса оказания помощи в EMR в учреждениях первичной помощи. J Manag Care Фарм. 2012;18(1):46–53. doi: 10.18553/jmcp.2012.18.1.46. [PubMed] [CrossRef] [Google Scholar]
10. Rosenbloom ST, Denny JC, Xu H, Lorenzi N, Stead WW, Johnson KB. Данные из клинических заметок: взгляд на противоречие между структурой и гибкой документацией. J Am Med Inform Assoc. 2011;18(2):181–186. doi: 10.1136/jamia.2010.007237. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
11. Rosenbloom ST, Stead WW, Denny JC, Giuse D, Lorenzi NM, Brown SH, et al. Создание клинических заметок для электронных систем медицинских карт. Appl Clin Inform. 2010;1(3):232. doi: 10.4338/ACI-2010-03-RA-0019. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
12. Silfen E. Документирование и кодирование обращений пациентов с ЭД: оценка точности электронной медицинской карты. Am J Emerg Med. 2006;24(6):664–678. doi: 10.1016/j.ajem.2006.02.005. [PubMed] [CrossRef] [Академия Google]
Документирование и кодирование обращений пациентов с ЭД: оценка точности электронной медицинской карты. Am J Emerg Med. 2006;24(6):664–678. doi: 10.1016/j.ajem.2006.02.005. [PubMed] [CrossRef] [Академия Google]
13. Эмби П.Дж., Якель Т.Р., Логан Д.Р., Боуэн Д.Л., Куни Т.Г., Горман П.Н. Воздействие компьютеризированной медицинской документации в клинической больнице: восприятие преподавателей и врачей-резидентов. J Am Med Inform Assoc. 2004;11(4):300–309. doi: 10.1197/jamia.M1525. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
14. Руф Э., Чамли Х.С., Добби А.Э. Электронные медицинские карты в поликлиниках: перспективы студентов третьего курса медицинского вуза. BMC Med Educ. 2008;8(1):13. дои: 10.1186/1472-6920-8-13. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
15. Шоу Н. Медицинское образование и информатика в области здравоохранения: пора присоединиться к 21 веку? Stud Health Technol Inform. 2010; 160 (часть 1): 567–571. [PubMed] [Google Scholar]
16. Кабир А., Хэнсон Р., Меллис С. Улучшается ли документирование астмы за счет ввода данных с помощью компьютера? J Qual Clin Pract. 1998;18(3):187–193. [PubMed] [Google Scholar]
Кабир А., Хэнсон Р., Меллис С. Улучшается ли документирование астмы за счет ввода данных с помощью компьютера? J Qual Clin Pract. 1998;18(3):187–193. [PubMed] [Google Scholar]
17. Lee BH, Lehmann CU, Jackson EV, Kost-Byerly S, Rothman S, Kozlowski L, et al. Оценка ошибок назначения контролируемых веществ в педиатрической клинической больнице: анализ безопасности практики назначения анальгетиков при переходе из больницы в дом. Джей Пейн. 2009 г.;10(2):160–166. doi: 10.1016/j.jpain.2008.08.004. [PubMed] [CrossRef] [Google Scholar]
18. Rathish D, Bahini S, Sivakumar T, Thiranagama T, Abarajithan T, Wijerathne B, et al. Употребление наркотиков, ошибки в рецептах и потенциальные лекарственные взаимодействия: опыт сельских районов Шри-Ланки. БМС Фармакол Токсикол. 2016;17(1):27. doi: 10.1186/s40360-016-0071-z. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
19. Эстес Л., Джонсон Дж., Харрахилл М. Использование электронной медицинской карты для реанимации при травмах: возможно ли это. Дж. Эмерг Нурс. 2010;36(4):381–384. doi: 10.1016/j.jen.2010.03.015. [PubMed] [CrossRef] [Академия Google]
Дж. Эмерг Нурс. 2010;36(4):381–384. doi: 10.1016/j.jen.2010.03.015. [PubMed] [CrossRef] [Академия Google]
20. Coffey C, Wurster LA, Groner J, Hoffman J, Hendren V, Nuss K, et al. Сравнение бумажной документации с электронной документацией по реанимации при травмах в педиатрическом травматологическом центре I уровня. Дж. Эмерг Нурс. 2015;41(1):52–56. doi: 10.1016/j.jen.2014.04.010. [PubMed] [CrossRef] [Google Scholar]
21. Shea S, Hripcsak G. Ускорение использования электронных медицинских карт в практике врачей. N Engl J Med. 2010;362(3):192–195. doi: 10.1056/NEJMp0910140. [PubMed] [CrossRef] [Академия Google]
22. Urquhart C, Currell R, Grant MJ, Hardiker NR. Системы сестринского дела: влияние на сестринскую практику и результаты лечения. Cochrane Database Syst Rev. 2009 doi: 10.1002/14651858.CD002099.pub2. [PubMed] [CrossRef] [Google Scholar]
23. Fadahunsi KP, Akinlua JT, O’Connor S, Wark PA, Gallagher J, Carroll C, et al. Протокол для систематического обзора и качественного синтеза рамок качества информации в электронном здравоохранении. Открытый БМЖ. 2019;9(3):e024722. doi: 10.1136/bmjopen-2018-024722. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
Открытый БМЖ. 2019;9(3):e024722. doi: 10.1136/bmjopen-2018-024722. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
24. Хаммана И., Лепанто Л., Подер Т., Беллемаре С., Ли М.С. Распознавание речи в отделении радиологии: систематический обзор. Здоровье Inf Manag. 2015;44(2):4–10. [PubMed] [Google Scholar]
25. Björvell C, Thorell-Ekstrand I, Wredling R. Разработка инструмента аудита планов сестринского ухода в истории болезни. BMJ Квал Саф. 2000;9(1):6–13. [Бесплатная статья PMC] [PubMed] [Google Scholar]
26. Ammenwerth E, Rauchegger F, Ehlers F, Hirsch B, Schaubmayr C. Влияние информационной системы сестринского дела на качество обработки информации в сестринском деле: оценочное исследование с использованием HIS-монитор. Int J Med Inform. 2011;80(1):25–38. doi: 10.1016/j.ijmedinf.2010.10.010. [PubMed] [CrossRef] [Академия Google]
27. Маккартни PR. Распознавание речи для медицинской документации. Am J Matern Child Nursing. 2013;38(5):320. doi: 10. 1097/NMC.0b013e31829c0ae0. [PubMed] [CrossRef] [Google Scholar]
1097/NMC.0b013e31829c0ae0. [PubMed] [CrossRef] [Google Scholar]
28. Weed LL. Медицинские записи, медицинское образование и уход за пациентами: проблемно-ориентированная запись как основной инструмент. Кливленд: Издательство Университета Кейс Вестерн Резерв; 1969. [Google Scholar]
29. Karbasi Z, Bahaadinbeigy K, Ahmadian L, Khajouei R, Mirzaee M. Точность медицинского заключения системы распознавания речи и опыт врачей в больницах. Фронт Здоровье Информ. 2019;8(1):19. doi: 10.30699/fhi.v8i1.199. [CrossRef] [Google Scholar]
30. Басма С., Лорд Б., Джекс Л.М., Ризк М., Скаранело А.М. Частота ошибок в отчетах о визуализации молочной железы: сравнение автоматического распознавания речи и транскрипции под диктовку. Am J Рентгенол. 2011;197(4):923–927. doi: 10.2214/AJR.11.6691. [PubMed] [CrossRef] [Google Scholar]
31. Pezzullo JA, Tung GA, Rogg JM, Davis LM, Brody JM, Mayo-Smith WW. Диктант по распознаванию голоса: рентгенолог в роли транскрипциониста. J цифровое изображение. 2008;21(4):384–389.. doi: 10.1007/s10278-007-9039-2. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
2008;21(4):384–389.. doi: 10.1007/s10278-007-9039-2. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
32. Zhou L, Blackley SV, Kowalski L, Doan R, Acker WW, Landman AB, et al. Анализ ошибок в продиктованных клинических документах с помощью программного обеспечения для распознавания речи и профессиональных транскрипционистов. JAMA Сеть открыта. 2018;1(3):e180530-e. doi: 10.1001/jamanetworkopen.2018.0530. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
33. Коуэн Дж. Клиническое управление и клиническая документация: еще долгий путь? Clin Выполните качественное медицинское обслуживание. 2000;8(3):179–182. doi: 10.1108/10630270020800822. [PubMed] [CrossRef] [Google Scholar]
34. Дэвидсон С.Дж., Цвемер Ф.Л., младший, Натансон Л.А., Соболь К.Н., Хан А.Н. Где мясо? Обещание и реальность клинической документации. Acad Emerg Med Off J Soc Acad Emerg Med. 2004;11(11):1127–1134. doi: 10.1197/j.aem.2004.08.004. [PubMed] [CrossRef] [Google Scholar]
35. Motamedi SM, Posadas-Calleja J, Straus S, Bates DW, Lorenzetti DL, Baylis B, et al. Эффективность компьютерных коммуникационных вмешательств при выписке: систематический обзор. BMJ Квал Саф. 2011;20(5):403–415. doi: 10.1136/bmjqs.2009.034587. [PubMed] [CrossRef] [Google Scholar]
Motamedi SM, Posadas-Calleja J, Straus S, Bates DW, Lorenzetti DL, Baylis B, et al. Эффективность компьютерных коммуникационных вмешательств при выписке: систематический обзор. BMJ Квал Саф. 2011;20(5):403–415. doi: 10.1136/bmjqs.2009.034587. [PubMed] [CrossRef] [Google Scholar]
36. Schiff GD, Bates DW. Может ли электронная клиническая документация помочь предотвратить диагностические ошибки? N Engl J Med. 2010;362(12):1066–1069. doi: 10.1056/NEJMp0911734. [PubMed] [CrossRef] [Google Scholar]
37. Kang HP, Sirintrapun SJ, Nestler RJ, Parwani AV. Опыт работы с распознаванием голоса в хирургической патологии в крупном академическом многопрофильном центре. Ам Джей Клин Патол. 2010;133(1):156–159. doi: 10.1309/AJCPOI5F1LPSLZKP. [PubMed] [CrossRef] [Академия Google]
38. Джонсон М., Лапкин С., Лонг В., Санчес П., Суоминен Х., Басилакис Дж. и соавт. Систематический обзор технологии распознавания речи в здравоохранении. БМС Мед Информ Децис Мак. 2014;14(1):94. дои: 10. 1186/1472-6947-14-94. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
1186/1472-6947-14-94. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
39. Devine EG, Gaehde SA, Curtis AC. Сравнительная оценка трех программ непрерывного распознавания речи при создании медицинских отчетов. J Am Med Inform Assoc JAMIA. 2000;7(5):462–468. doi: 10.1136/jamia.2000.0070462. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
40. Zafar A, Overhage JM, McDonald CJ. Непрерывное распознавание речи для врачей. J Am Med Inform Assoc JAMIA. 1999;6(3):195–204. doi: 10.1136/jamia.1999.0060195. [Бесплатная статья PMC] [PubMed] [CrossRef] [Google Scholar]
41. Dietz U, Rupprecht HJ, Espinola-Klein C, Meyer J. Автоматическое документирование отчетов в кардиологии с использованием системы распознавания речи. З Кардиол. 1996;85(9):684–688. [PubMed] [Google Scholar]
42. Ramaswamy MR, Chaljub G, Esch O, Fanning DD, VanSonnenberg E. Непрерывное распознавание речи в отчетах о МРТ: преимущества, недостатки и влияние. Am J Рентгенол. 2000;174(3):617–622.