Бесплатный онлайн инструмент OCR (Распознавание текста) — Convertio
Преобразование отсканированных документов и изображений в редактируемые форматы Word, Pdf, Excel и Txt (простой текст)
Доступно страниц: 10 (Вы уже использовали 0 страниц)
Если вам нужно распознать больше страниц, пожалуйста, зарегистрируйтесь
Загрузите файлы для распознавания или перетащите их на эту страницу
Выберите файлы
Поддерживаемые форматы файлов:
pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp
Выберите все языки, используемые в документе
Выберите основной язык…РусскийАнглийский—————-АфрикаансАлбанскийАрабский (Саудовская Аравия)Армянский (восточный)Армянский (западный)Азербайджанский (Кириллица)Азербайджанский (Латиница)БаскскийБелорусскийБолгарскийКаталанскийСебуанскийКитайский упрощенныйКитайский традиционныйХорватскийЧешскийДатскийНидерландскийНидерландский (Бельгия)ЭсперантоЭстонскийФиджиФинскийФранцузскийГалисийскийНемецкийГреческийГавайскийИвритВенгерскийИсландскийИндонезийскийИрландскийИтальянскийЯпонскийКазахскийКиргизскийКонгоКорейскийКурдскийЛатинскийЛатышскийЛитовскийМакедонскийМалайский (Малайзия)МальтийскийНорвежский (Букмол)ПольскийПортугальскийПортугальский (Бразилия)РумынскийШотландскийСербский (Кириллица)Сербский (Латиница)СловацкийСловенскийСомалиИспанскийСуахилиШведскийТагальскийТаитиТаджикскийТатарскийТайскийТурецкийТуркменскийУйгурский (Кириллица)Уйгурский (Латиница)УкраинскийУзбекский (Кириллица)Узбекский (Латиница)ВьетнамскийВаллийский
Выберите дополнительные языки. ..РусскийАнглийский—————-АфрикаансАлбанскийАрабский (Саудовская Аравия)Армянский (восточный)Армянский (западный)Азербайджанский (Кириллица)Азербайджанский (Латиница)БаскскийБелорусскийБолгарскийКаталанскийСебуанскийКитайский упрощенныйКитайский традиционныйХорватскийЧешскийДатскийНидерландскийНидерландский (Бельгия)ЭсперантоЭстонскийФиджиФинскийФранцузскийГалисийскийНемецкийГреческийГавайскийИвритВенгерскийИсландскийИндонезийскийИрландскийИтальянскийЯпонскийКазахскийКиргизскийКонгоКорейскийКурдскийЛатинскийЛатышскийЛитовскийМакедонскийМалайский (Малайзия)МальтийскийНорвежский (Букмол)ПольскийПортугальскийПортугальский (Бразилия)РумынскийШотландскийСербский (Кириллица)Сербский (Латиница)СловацкийСловенскийСомалиИспанскийСуахилиШведскийТагальскийТаитиТаджикскийТатарскийТайскийТурецкийТуркменскийУйгурский (Кириллица)Уйгурский (Латиница)УкраинскийУзбекский (Кириллица)Узбекский (Латиница)ВьетнамскийВаллийский
..РусскийАнглийский—————-АфрикаансАлбанскийАрабский (Саудовская Аравия)Армянский (восточный)Армянский (западный)Азербайджанский (Кириллица)Азербайджанский (Латиница)БаскскийБелорусскийБолгарскийКаталанскийСебуанскийКитайский упрощенныйКитайский традиционныйХорватскийЧешскийДатскийНидерландскийНидерландский (Бельгия)ЭсперантоЭстонскийФиджиФинскийФранцузскийГалисийскийНемецкийГреческийГавайскийИвритВенгерскийИсландскийИндонезийскийИрландскийИтальянскийЯпонскийКазахскийКиргизскийКонгоКорейскийКурдскийЛатинскийЛатышскийЛитовскийМакедонскийМалайский (Малайзия)МальтийскийНорвежский (Букмол)ПольскийПортугальскийПортугальский (Бразилия)РумынскийШотландскийСербский (Кириллица)Сербский (Латиница)СловацкийСловенскийСомалиИспанскийСуахилиШведскийТагальскийТаитиТаджикскийТатарскийТайскийТурецкийТуркменскийУйгурский (Кириллица)Уйгурский (Латиница)УкраинскийУзбекский (Кириллица)Узбекский (Латиница)ВьетнамскийВаллийский
Формат и настройки выбора
Документ Microsoft Word (.docx)Microsoft Excel Workbook (. xlsx)Microsoft Excel 97-2003 Workbook (.xls)Microsoft PowerPoint Presentation (.pptx)Searchable PDF Document (.pdf)Text Document (.txt)RTF Document (.rtf)CSV Document (.csv)Electornic Publication (.epub)Xml формат хранения книг (.fb2)DjVu Document (.djvu)
xlsx)Microsoft Excel 97-2003 Workbook (.xls)Microsoft PowerPoint Presentation (.pptx)Searchable PDF Document (.pdf)Text Document (.txt)RTF Document (.rtf)CSV Document (.csv)Electornic Publication (.epub)Xml формат хранения книг (.fb2)DjVu Document (.djvu)
Все страницы
Номера страниц
Как распознать текст с изображения?
Шаг 1
Загрузите изображения или PDF-файлы
Выберите файлы с компьютера, Google Диска, Dropbox, по ссылке или перетащив их на страницу
Шаг 2
Язык и формат
Выберите все языки, используемые в документе. Кроме того, выберите .doc или любой другой формат, который вам нужен в результате (поддерживается больше 10 текстовых форматов)
Шаг 3
Конвертируйте и скачивайте
Нажмите «Распознать», и вы можете сразу загрузить распознанный текстовый файл
Система распознавания шрифта Брайля. Читаем написанное белым по белому / Хабр
В 2018 году мы взяли из детдома в семью слепую девочку Анжелу. Тогда я думал, что это чисто семейное обстоятельство, никак не связанное с моей профессией разработчика систем компьютерного зрения. Но благодаря дочери через два года появилась программа и интернет-сервис для распознавания текстов, написанных шрифтом Брайля — Angelina Braille Reader.
Но благодаря дочери через два года появилась программа и интернет-сервис для распознавания текстов, написанных шрифтом Брайля — Angelina Braille Reader.
Сейчас этот сервис используют сотни людей и в России, и за ее пределами. Тема оказалась хайповой, сюжет о программе даже показали в федеральных новостях на ТВ. Но что важнее — за свою многолетнюю карьеру в ИТ ни в одном проекте я не получал столько искренних благодарностей от пользователей.
Ниже расскажу о том, как делалась эта разработка и с какими трудностями пришлось столкнуться. Более развернутое описание приведено в публикациях [1,2].
Возможно, кто-то захочет внести в проект свой вклад.
Лень — двигатель прогресса
Вы все видели брайлевские символы в лифте и в поликлинике. Каждая буква задана выпуклыми точками. Брайль разработал свою азбуку в 1824 году, и ничего лучше для чтения и письма с тех пор не придумали.
Сейчас слепые активно используют компьютеры и смартфоны с голосовым помощником, свободно перемещаются по всему миру без сопровождения, устраиваются на работу, требующую высокой квалификации.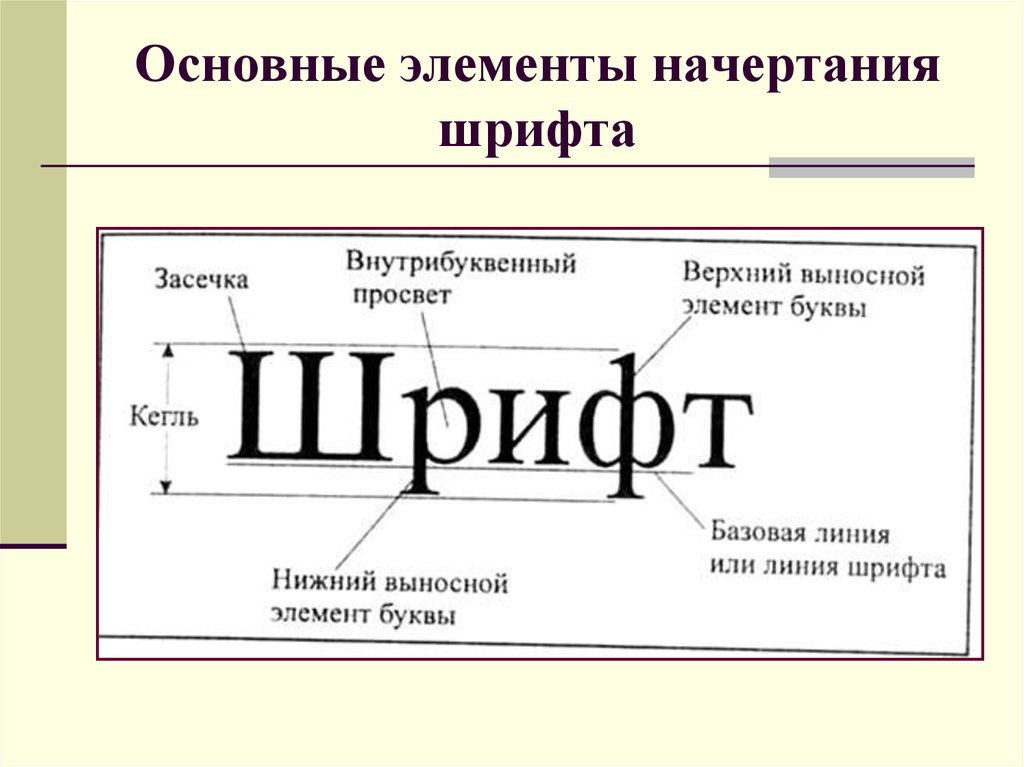 Представление о том, что слепые сидят дома и плетут на заказ авоськи, давно устарело.
Представление о том, что слепые сидят дома и плетут на заказ авоськи, давно устарело.
Но слепые школьники до сих пор читают и пишут на Брайле. Все как у обычных людей. Когда вы последний раз писали страницу текста от руки? А школьники делают это ежедневно, и пропустить этот этап нельзя.
Когда мы отдавали дочь в первый класс, то думали, что будет непросто выучить шрифт Брайля. Но это оказалось ерундовой задачей, не труднее, чем выучить любой незнакомый язык в объеме «алфавит в совершенстве».
А вот дальше сложнее. Дело в том, что брайлевские книги — это выдавленные на белой бумаге пупырышки («точки»), никак не выделенные цветом. Слепые тратят год начальной школы на то, чтобы научиться их нащупывать. У нас такая чувствительность пальцев не развивается за ненадобностью, поэтому 99% брайлевских педагогов и родителей читают это глазами.
Более того! Как и обычная книга, брайлевская книга обычно двусторонняя. Вместе с выступающими точками, которые надо читать, на той же странице есть точки, выдавленные в обратную сторону. Пальцы слепого эти впуклости не замечают, а глаза зрячего видят, и все это вместе превращается в абсолютную кашу. Вообразите, что вы читаете текст на неродном языке, напечатанный светло-серым на прозрачной пленке с двух сторон.
Пальцы слепого эти впуклости не замечают, а глаза зрячего видят, и все это вместе превращается в абсолютную кашу. Вообразите, что вы читаете текст на неродном языке, напечатанный светло-серым на прозрачной пленке с двух сторон.
Рукописный брайлевский текст обычно односторонний, читать его несколько легче, но все равно непросто. В Союзе педагоги приспособились тереть работы школьников копиркой, чтобы сделать точки заметнее, но это решает проблему только отчасти.
Вставка для любопытных: как пишут брайлевским шрифтом вручнуюДля письма брайлевским шрифтом вручную используется специальный прибор: планшет, состоящий из 2 металлических пластин, между которыми закладывается лист бумаги. В верхней пластине сделаны прямоугольные прорези, одна ячейка — одна буква. Металлическим грифелем (шилом) продавливают бумагу в углах прорези или в середине боковой стороны, всего 6 мест под точки. В этих местах в нижней пластине сделаны углубления, таким образом получаются выдавленные брайлевские точки. Пишут справа налево в зеркальном отражении. А чтобы прочитать текст, бумагу надо вынуть из прибора и перевернуть.
Металлическим грифелем (шилом) продавливают бумагу в углах прорези или в середине боковой стороны, всего 6 мест под точки. В этих местах в нижней пластине сделаны углубления, таким образом получаются выдавленные брайлевские точки. Пишут справа налево в зеркальном отражении. А чтобы прочитать текст, бумагу надо вынуть из прибора и перевернуть.
За время обучения дочки в первом классе мы, оба родителя, так замучились таким чтением, что стали весьма мотивированы что-то с этим делать. Мы решили, что приспособить к чтению Брайля компьютер — намного более полезное занятие для папы в свободное время, чем решать конкурсы на Каггле. Потом оказалось, что это нужно не только моей семье, а буквально всем, кто работает со слепыми.
Хочешь сделать хорошо — сделай сам
Разумеется, я был не первым человеком, который занялся компьютерным распознаванием шрифта Брайля на изображении. Есть даже устойчивый термин: OBR (Optical Braille Recognition). Поэтому для начала я попытался найти готовое решение. Напрасно! В открытом доступе имеются только экспериментальные поделки, непригодные для практического применения. Из коммерческих разработок существует специализированный аппаратно-программный комплекс компании ЭлекЖест размером со стол. Это явно не то решение, о котором я мечтал, цену я даже не уточнял.
Напрасно! В открытом доступе имеются только экспериментальные поделки, непригодные для практического применения. Из коммерческих разработок существует специализированный аппаратно-программный комплекс компании ЭлекЖест размером со стол. Это явно не то решение, о котором я мечтал, цену я даже не уточнял.
Попадались программы для распознавания, но они требовали отсканировать лист, причем со специальным светофильтром. Не слишком удобно, тем более что в стандартный сканер А4 брайлевский учебник не помещается. Но хуже то, что даже со сканером и светофильтром у меня не получилось получить приемлемый результат.
После фиаско с поиском готового решения пришлось переключиться на изучение литературы. Статей по оптическому распознаванию Брайля написано много. Во всех статьях процесс распознавания разбивался на этапы, обусловленные ключевым отличием шрифта Брайля от обычных алфавитов в разных языках.
В обычном письме буквы представлены связанными линиями, а в письме по Брайлю — комбинацией от 1 до 6 точек, расположенных в узлах воображаемой сетки. Группировка точек в буквы определяется привязкой к этой сетке.
Группировка точек в буквы определяется привязкой к этой сетке.
Вне привязки к сетке, образуемой всеми брайлевскими буквами в целом, точки не имеют смысла. Так, если мы видим на пустом листе бумаги букву А, то мы легко понимаем, что это буква А. Если мы видим одинокую брайлевскую точку, нельзя определить, что это такое: буква А, запятая (она обозначается единственной точкой, но в другом узле сетки) или просто дефект бумаги.
Вследствие этого, для описанных в литературе алгоритмов OBR практически стандартом оказывается следующий набор шагов (см. обзоры [3,4]):
Найти брайлевские точки.
Восстановить воображаемую сетку.
Сопоставить найденные точки с узлами сетки.
Распознать брайлевские символы.
Конвертировать последовательность брайлевских символов в обычный текст.
Разные авторы используют разные методы нахождения точек и, главное, отделения точек лицевой и обратной стороны: динамический порог, детектор окружностей на основе преобразования Хафа, HOG, LBP, SVM, признаки Хаара и алгоритм Виолы-Джонса, — в общем, практически весь джентльменский набор методов классического компьютерного зрения. В более поздних работах нейросетки тоже применяют.
В более поздних работах нейросетки тоже применяют.
После этого для восстановления сетки используют линейную регрессию, преобразования Хафа, изменения гистограмму распределения координат точек при пошаговом повороте листа…
Не буду приводить подробный обзор литературы (его можно найти в [1,3,4]). Важно, что при таком подходе требуется единая на весь лист воображаемая сетка, к которой привязаны брайлевские точки. Именно поэтому страница должна быть не просто сфотографирована, а отсканирована. Только в этом случае на всем листе точки расположены на параллельных линиях сетки. На случай, если страница при сканировании покосилась, описаны методы нахождения необходимого поворота страницы в исходное положение.
Я не нашел никаких методов для компенсации перспективных искажений (а без них фотографию не сделаешь). Еще сложнее, если сфотографирован не одиночный лист, а страница раскрытой книги. Брайлевские книги толстые и плотные, полностью расправить страницу невозможно. Линии сетки превращаются в дуги. Так что по всему выходило, что для применения опубликованных методов нужен сканер, причем специальный — обычный бытовой мал.
Так что по всему выходило, что для применения опубликованных методов нужен сканер, причем специальный — обычный бытовой мал.
А хотелось сделать так, чтобы достаточно было сделать фото на смартфон и — вжух! — получить расшифрованный текст. Пришлось делать самому.
У нее внутре нейронка
Когда я начинал эту работу (2019г), нейронные сети уже вовсю покоряли задачи компьютерного зрения. В литературе по распознаванию Брайля тоже говорилось об их использовании. Но весьма ограниченном, не выходя за пределы описанного выше шаблона: или для поиска точек, или для разделения точек лицевой и обратной стороны, или для распознавания отдельного символа после того, как будет восстановлена сетка и точки поделены на символы.
И это при том, что уже несколько лет как были опубликованы one step детекторы типа YOLO[5] и SSD[6], которые решали задачу поиска объектов на изображении за один шаг, совмещая одновременно несколько функций — детекции, классификации, регрессии ограничивающего прямоугольника. Можно было ожидать, что нейросеть справится одновременно с задачей поиска точек, восстановления брайлевской сетки в окрестности каждого символа и распознавания символа за один проход. Это позволяло отойти от требования наличия единой сетки для всего листа и, соответственно, обрабатывать изображения искривленных листов и изображения с небольшими перспективными искажениями.
Можно было ожидать, что нейросеть справится одновременно с задачей поиска точек, восстановления брайлевской сетки в окрестности каждого символа и распознавания символа за один проход. Это позволяло отойти от требования наличия единой сетки для всего листа и, соответственно, обрабатывать изображения искривленных листов и изображения с небольшими перспективными искажениями.
За основу я взял RetinaNet[7] с некоторыми изменениями по сравнению с исходными настройками: с учетом того, что мы ищем символы примерно известного размера и пропорций, был изменен набор «якорей» и другие параметры.
В конце концов этот подход дал результат, который я считаю весьма успешным. Но его применение упиралось в серьезную проблему.
Где взять данные, или Мойдодыр спешит на помощь.
Как хорошо известно, для решения обучения нейросети требуется много обучающих данных. И если при решении частных задач вроде поиска и классификации точек или даже отдельных символов каждая страница текста порождает множество обучающих примеров, то для обучения object detection сети необходимы достаточно большие фрагменты текста. Поэтому требуется множество размеченных изображений брайлевских страниц.
Поэтому требуется множество размеченных изображений брайлевских страниц.
Сделать фотографии сотни-другой страниц в разных условиях — несложно. А вот разметка… Как выглядят эти страницы, было показано на рисунке выше, трудоемкость разметки можете себе представить. Идея разметить прямоугольниками каждую букву на сотнях таких страниц совсем не вызывала энтузиазма.
В сети удалось найти единственный публично доступный подходящий датасет: DSBI, опубликованный китайскими товарищами. Он включает 114 размеченных страниц брайлевских текстов. Тексты там на китайском, но это как раз неважно (сами по себе брайлевские символы одинаковы во всех языках). Хуже то, что изображения получены с помощью сканера с идеально плоского листа (это позволило авторам упростить процедуру разметки) и очень мало отличаются друг от друга. Поэтому качественно обучить на нем нейросеть для решения поставленной задачи было невозможно. RetinaNet, обученная на этих данных, выдала на реальных фотографиях брайлевских книг более чем скромный результат — от четверти до половины правильно распознанных символов.
Лучшего я и не ждал. Однако надо же было с чего-то начать! А дальше на помощь пришел подход Active Learning[8].
Идея традиционного Active Learning состоит в том, что мы обучаем нейросеть на имеющихся данных, применяем ее к неразмеченным данным, оцениваем результат (вручную или автоматически с помощью какого-либо критерия), отбираем неразмеченные примеры, которые распознались хуже всех, размечаем их вручную и повторяем обучение на расширенной выборке. И так несколько раз. Тем самым экономятся трудозатраты на разметку тех примеров, с которыми нейросеть и так справляется. Однако в этой задаче я применил полностью противоположный подход. Дело в том, что разметить страницу, состоящую сплошь из ошибок, гораздо сложнее, чем исправить несколько ошибок там, где существенная часть текста внятно распознана.
Особенностью задачи было то, что для многих неразмеченных страниц можно было найти напечатанный там текст в привычном нам виде. Текст, написанный прозой, сопоставить с изображением брайлевской страницы сложно, а вот со стихами все намного проще. Разбивка текста на строки известна, и если в распознанном тексте распознана хотя бы часть символов, которая позволяет идентифицировать строки, то недостающие и ошибочные символы можно восстановить, используя оригинальный текст. Причем лучше использовать даже не стихи, а детские стишки: написанные короткими строками, чтобы не возникало неожиданных переносов строки.
Разбивка текста на строки известна, и если в распознанном тексте распознана хотя бы часть символов, которая позволяет идентифицировать строки, то недостающие и ошибочные символы можно восстановить, используя оригинальный текст. Причем лучше использовать даже не стихи, а детские стишки: написанные короткими строками, чтобы не возникало неожиданных переносов строки.
Поэтому первыми русскими текстами, на которых обучалась нейронная сеть, оказались сказки про Мойдодыра, Телефон, Чудо-дерево. Мысль, что иногда автор относится к своему проекту как к собственному ребенку, заиграла новыми красками.
Когда после нескольких итераций активного обучения качество распознавания достаточно повысилось, можно было включить в обучающий набор прозаические тексты. Сопоставлять их с оригинальным текстом так же, как стихи, было уже слишком сложно, но результаты распознавания можно было преобразовать в плоский текст и проверить спелл-чекером. Большая часть ошибок распознавания при этом подсвечивается, так что разметка радикально облегчается.
Описанный подход привел к идее сделать дальнейший процесс полностью автоматическим. Есть известный метод дообучения нейросети на неразмеченных данных — pseudo labeling[9]. Основная идея метода состоит в том, что результаты распознавания тех неразмеченных данных, где нейросеть показала высокую степень уверенности, включают в обучающий набор в дополнение к исходным размеченным данным, и обучение повторяется.
В описываемой работе в этот цикл я включил этап, на котором учитывается, что найденные нейросетью символы существуют не сами по себе, а должны подчиняться определенным правилам. В первую очередь, можно скорректировать положения символов так, чтобы символы образовывали ровные строки, а также проверить получившиеся слова спелл-чекером и исключить те результаты, которые такую проверку не проходят. Такой подход я предложил назвать «семантически усиленной псевдо-разметкой». В общем случае это — включение в процедуру псевдо-разметки этапа, когда автоматически полученная разметка оценивается и корректируются, используя внешние соображения о допустимости полученных результатов.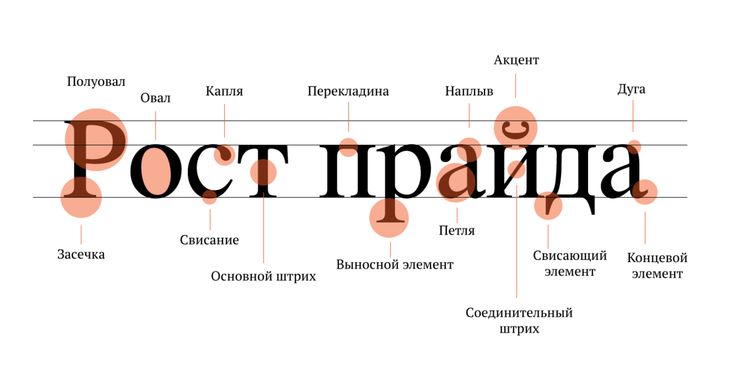 Это дает существенное улучшение результатов по сравнению с обычной псевдо-разметкой (см. [2]). Возможность вытаскивать самого себя за волосы, обучая нейросеть на ее собственных результатах, заканчивается достаточно быстро и ограничена примерами из того же домена, что и исходные размеченные данные. При семантически усиленной псевдо-разметке в процесс обучения включается дополнительная объективная информация. Это не только позволяет использовать больший объем неразмеченных данных, но и дообучить сеть на неразмеченных данных из домена, отличного от того, к которому относятся исходная размеченная обучающая выборка [2].
Это дает существенное улучшение результатов по сравнению с обычной псевдо-разметкой (см. [2]). Возможность вытаскивать самого себя за волосы, обучая нейросеть на ее собственных результатах, заканчивается достаточно быстро и ограничена примерами из того же домена, что и исходные размеченные данные. При семантически усиленной псевдо-разметке в процесс обучения включается дополнительная объективная информация. Это не только позволяет использовать больший объем неразмеченных данных, но и дообучить сеть на неразмеченных данных из домена, отличного от того, к которому относятся исходная размеченная обучающая выборка [2].
В результате применения описанных подходов получалось программное решение, дающее менее 0.5% ошибочных символов при использовании достаточно качественных изображений (хорошая камера, правильное освещение). Я написал простенький сервис на Flask и развернул на домашнем компьютере сервис, которым стал пользоваться я сам и некоторые наши знакомые по сообществу родителей слепых детей.
Кроме того, в результате этой работы получился «наш ответ Китаю»: датасет Angelina Braille Dataset из 240 размеченных фотографий брайлевских текстов. Существенно более сложный и разнообразный по сравнению датасетом DSBI, опубликованным китайскими разработчиками.
Искусство — в массы
Итак, первое время сервис работал на моем домашнем компьютере и количество пользователей прибывало методом сарафанного радио.
В 2021 описываемый сервис стал одним из победителей конкурса World AI & Data Challenge, который проводит Агентство Стратегических Инициатив. В конкурсе участвуют решения самых разных социльных проблем, построенные с помощью AI и Data science. То, что мой проект занял 2-е место в этом конкурсе, привело к двум важным практическим результатам.
Во-первых, АСИ обеспечило информационную поддержку: в специализированные школы по обучению слепых было направлено официальное письмо с поручением ознакомиться с сервисом и дать отзыв. Организовало несколько zoom-конференций с преподавателями-тифлопедагогами. В результате я получил множество очень мотивирующих отзывов. Самый короткий и емкий прозвучал на одной из видеовстреч: «мы ждали эту программу всю жизнь». Но, самое важное — потенциальные пользователи узнали о программе, преодолели «порог вхождения». Только сарафанным радио достичь такого результата было бы невозможно.
В результате я получил множество очень мотивирующих отзывов. Самый короткий и емкий прозвучал на одной из видеовстреч: «мы ждали эту программу всю жизнь». Но, самое важное — потенциальные пользователи узнали о программе, преодолели «порог вхождения». Только сарафанным радио достичь такого результата было бы невозможно.
Во-вторых, компания Яндекс выделила победителям конкурса грант на использование вычислительных мощностей Яндекс-облака. Я мог больше не держать сервис на своем домашнем компьютере, а разместить его на выделенной машине Яндекса.
Подробное описание опыта работы с облачной структурой Яндекса заслуживает отдельной статьи. Приведу основной вывод, к которому я пришел. Облачная структура Яндекса очень хороша для масштабных вычислений. Возможность запустить сразу несколько серверов с Tesla V100 — это прекрасно. Однако пока там нет возможности развернуть бюджетный слабонагруженный сервис, если для работы требуется GPU. Выделенная машина с Tesla V100 для данной задачи — сильный «оверкилл за оверпрайс». Надеюсь, что со временем и для этой ниши будет предложено подходящее решение.
Надеюсь, что со временем и для этой ниши будет предложено подходящее решение.
Решить проблему помог грант Фонда Президенских Грантов, предоставленный АНО «Ангелина» (для эксплуатации сервиса была создана некоммерческая организация). Такие гранты выделяются на различные социальные проекты. В данном случае грант был выдан на приобретение выделенного сервера и размещение его в дата-центре. Пока это оказывается более доступным способом развертывания малонагруженного интернет-сервиса, требующего GPU, чем облачная структура.
Так что, проблема решена?
До сих пор я говорил о проблеме оптического распознавания письма на Брайле. И за кадром осталась задача преобразования шрифра Брайля в обычный текст.
Дело в том, что в брайлевской азбуке всего 63 символа. Нет привычных зрячим людям подчеркиваний, курсива, верхних и нижних индексов и т.п. Буквы разных языков, цифры, математические знаки кодируются одними и теми же символами. Например, символы б, Б, b, β, 2 — это один и тот же брайлевский символ ⠃. Значение зависит от контекста. Например, перед числом ставится специальный числовой знак ⠼. Т.е. ⠼⠃⠃ — это «22». Другие правила сложнее. А полное описание использования шрифта Брайля, включая математические уравнения, дроби, использование различных языков, символов №, %, $, синтаксический и грамматический разбор предложения и т.п. занимает десятки страниц и очень напоминает Драконий Покер Р.Асприна. Кроме того, в английском языке существует система сокращений, когда длинные распространенные слова заменяются более короткими (вместо immediate пишут imm, а вместо friend — fr и т.д.).
Значение зависит от контекста. Например, перед числом ставится специальный числовой знак ⠼. Т.е. ⠼⠃⠃ — это «22». Другие правила сложнее. А полное описание использования шрифта Брайля, включая математические уравнения, дроби, использование различных языков, символов №, %, $, синтаксический и грамматический разбор предложения и т.п. занимает десятки страниц и очень напоминает Драконий Покер Р.Асприна. Кроме того, в английском языке существует система сокращений, когда длинные распространенные слова заменяются более короткими (вместо immediate пишут imm, а вместо friend — fr и т.д.).
Сейчас в сервисе эти правила реализованы в минимальном объеме, достаточно прямолинейно: в виде проверки различных условий и переключения в зависимости от них на на различные словари трансляции. Вряд ли разумно дальше развивать этот подход. И не только потому, что исходный код станет совсем нечитаемым. Многие соглашения используются неформально, предполагают контекст. Так, есть специальный символ, обозначающий переход с русского языка на английский. Но иногда он может применяться к отдельному слову, иногда ко всему следующему тексту, пока не встретится знак перехода на русский. Иногда его не ставят вовсе, если фразы вроде «O, yes, — только и смог сказать сыщик» читают интуитивно.
Но иногда он может применяться к отдельному слову, иногда ко всему следующему тексту, пока не встретится знак перехода на русский. Иногда его не ставят вовсе, если фразы вроде «O, yes, — только и смог сказать сыщик» читают интуитивно.
Существует open source библиотека Liblouis для конвертации между Брайлем и обычным плоским письмом, но в основном она применяется для преобразования плоского письма в Брайль, эта задача намного проще. Обратный перевод там реализован плохо, особенно для русского языка.
Думаю, для решения задачи перевода брайлевского текста в обычный нужно применять подходы, основанные на машинном обучении. Но тут снова мы упираемся в вопрос, где взять обучающую выборку.
Так что проблем еще хватает. Описанная — главная, но не единственная. Есть что улучшить и в оптическом распознавании, и в веб-интерфейсе. Проект открытый, буду рад сотрудничеству. Репозитории на GitHub:
Собственно система распознавания Angelina Braille Reader
Angelina Braille Dataset
Веб-интерфейс
Литература
1. Ovodov I. G. Optical Braille Recognition Using Object Detection Neural Network //Proceedings of the IEEE/CVF International Conference on Computer Vision. – 2021. – С. 1741-1748.
Ovodov I. G. Optical Braille Recognition Using Object Detection Neural Network //Proceedings of the IEEE/CVF International Conference on Computer Vision. – 2021. – С. 1741-1748.
2. Ovodov I. G. Semantic-based annotation enhancement algorithm for semi-supervised machine learning efficiency improvement applied to optical Braille recognition //2021 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus). – IEEE, 2021. – С. 2190-2194.
3. A review on software algorithms for optical recognition of embossed braille characters / V. Udayashankara [и др.] // International Journal of computer applications. — 2013. — Т. 81, № 3. — С. 25—35.
4. Isayed, S. A review of optical Braille recognition / S. Isayed, R. Tahboub //2015 2nd World Symposium on Web Applications and Networking (WSWAN). — IEEE. 2015. — С. 1—6.
5. Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016
6. Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In European conference on computer vision, pages 21–37. Springer, 2016
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In European conference on computer vision, pages 21–37. Springer, 2016
7. Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. In ´ Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
8. Settles B. Active learning literature survey. University of Wisconsin //Computer Science Department. – 2010.
9. Lee D. H. et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks //Workshop on challenges in representation learning, ICML. – 2013. – Т. 3. – №. 2. – С. 896.
Шрифт как объект авторского права в России и США
Шрифт как объект авторского права в России и США
Киселёва А.
2015
За последние сто лет мир вокруг нас сильно изменился. Скорость и масштаб изменений поражают. Начиная с открытия космического пространства и заканчивая интернет-технологиями и робототехникой, новые объекты изучения и новые сферы деятельности появляются со скоростью, нарастающей в геометрической прогрессии. Все эти инновации так или иначе связаны с интеллектуальной деятельностью человека. В последнее время в связи с подъёмом и усложнением общественных отношений появилось много объектов интеллектуальной собственности, которые существовали ранее или не считались таковыми.
Начиная с открытия космического пространства и заканчивая интернет-технологиями и робототехникой, новые объекты изучения и новые сферы деятельности появляются со скоростью, нарастающей в геометрической прогрессии. Все эти инновации так или иначе связаны с интеллектуальной деятельностью человека. В последнее время в связи с подъёмом и усложнением общественных отношений появилось много объектов интеллектуальной собственности, которые существовали ранее или не считались таковыми.
Стандарты, регулирующие интеллектуальную собственность, возникли и существуют для достижения баланса интересов между правообладателями и обществом. С одной стороны, интеллектуальный труд автора должен поощряться, иначе не будет достаточного стимула для культурного и экономического развития. С другой стороны, сообщество рано или поздно должно получить доступ к объектам культурной ценности и произведениям искусства. Кроме того, скорость развития отрасли часто зависит от доступности работ для других авторов (что хорошо видно на примере открытых лицензий на программное обеспечение), что позволяет новым авторам улучшать работы, ранее созданные другими. Если рассматривать этот вопрос в рамках экономического анализа права, то можно сказать, что тот или иной вид деятельности становится объектом авторского права, когда государству экономически невыгодно оставлять такой объект вне правового поля.
Если рассматривать этот вопрос в рамках экономического анализа права, то можно сказать, что тот или иной вид деятельности становится объектом авторского права, когда государству экономически невыгодно оставлять такой объект вне правового поля.
С развитием Интернета и компьютерных технологий шрифты стали именно таким предметом (существует множество концепций шрифтов и гарнитур, используемых в разные эпохи в разных ситуациях. Для целей данной статьи под шрифтом понимается набор символов, созданный художником, который представляет буквы языка, как компьютерный файл, содержащий шрифт, и/или как набор металлических шрифтов, используемых в типографской печати.Если иное не указано или не требуется контекстом, шрифт должен понимать как набор символов, созданных художником, которые представляют собой буквы языка). Однако так было не всегда. С момента изобретения печатного станка Иоганном Гутенбергом в 15 веке и до изобретения пишущей машинки в начале 19 века.го века процесс создания шрифтов был очень трудоемким и дорогим. Что еще более важно, копирование шрифта отнимало столько же времени и денег, сколько и его создание.
Что еще более важно, копирование шрифта отнимало столько же времени и денег, сколько и его создание.
Как отмечает Блейк Фрай в своей статье «Почему шрифты распространяются без защиты авторских прав», создание единого шрифта одного стиля и веса в семействе шрифтов (например, Times New Roman 14 в семействе шрифтов Times New Roman) потребовало бы перфорации. , имевший уникальный набор навыков (наполовину металлург, наполовину скульптор, наполовину кузнец), 800 часов работы на полную ставку. Акцент здесь был сделан не столько на дизайн шрифта и художественную работу, сколько на уникальные навыки специалиста, а также деньги, затраченные на создание шрифта. Копировать шрифт было вообще экономически нецелесообразно, потому что это потребовало бы затрат такого же количества ресурсов и привлечения такого же уникального специалиста. Соответственно, правительства совершенно не были заинтересованы в предоставлении правовой охраны шрифтам. Не появился такой интерес и с изобретением пишущей машинки, поскольку процесс копирования был еще слишком дорог. Однако информационные технологии полностью изменили индустрию шрифтов. Теперь создание шрифта требует уникальных творческих способностей, а не практических навыков и большого количества времени. Если раньше шрифты создавались в основном крупными корпорациями, располагавшими достаточными ресурсами, то теперь шрифты может разрабатывать практически любой пользователь компьютерных программ, предназначенных для этой цели (например, Font Creator, FontForge). Такие цифровые шрифты могут быть скопированы неограниченным количеством людей из-за их полной доступности и простоты копирования. Кроме того, теперь можно незаконно использовать шрифт анонимно. Если раньше рынок купели был узким (все участники рынка знали друг друга), то в случае нарушения можно было обратиться к негосударственным регуляторам рынка (например, прекратить сотрудничество с таким участником, распространить информацию о нарушении, тем самым порча его репутации), теперь анонимное использование делает невозможным обращение к механизмам внеправового регулирования.
Однако информационные технологии полностью изменили индустрию шрифтов. Теперь создание шрифта требует уникальных творческих способностей, а не практических навыков и большого количества времени. Если раньше шрифты создавались в основном крупными корпорациями, располагавшими достаточными ресурсами, то теперь шрифты может разрабатывать практически любой пользователь компьютерных программ, предназначенных для этой цели (например, Font Creator, FontForge). Такие цифровые шрифты могут быть скопированы неограниченным количеством людей из-за их полной доступности и простоты копирования. Кроме того, теперь можно незаконно использовать шрифт анонимно. Если раньше рынок купели был узким (все участники рынка знали друг друга), то в случае нарушения можно было обратиться к негосударственным регуляторам рынка (например, прекратить сотрудничество с таким участником, распространить информацию о нарушении, тем самым порча его репутации), теперь анонимное использование делает невозможным обращение к механизмам внеправового регулирования.
Стоит отметить, что шрифты в настоящее время приобретают все большую и большую независимую ценность. Шрифты используются в рекламе, веб-дизайне, книгах, журналах, городской навигации и многих других отраслях. Например, в контексте рекламы важно подобрать подходящий шрифт, соответствующий своему назначению (яркий, но не резкий цвет), способный создать необходимые эмоции и вызвать у потребителя соответствующие ассоциации (реклама для духи и, например, цирковые представления требуют совсем других шрифтов). Различные шрифты подбираются для создания интерфейса сайта и создания самого веб-продукта. Например, всем известен текст в логотипах Яндекса и Google. Эти поисковые системы привлекают внимание и стали популярными отчасти благодаря шрифтам, используемым в их логотипах. Создатель шрифта для Яндекса, например, дает следующее описание фирменного шрифта: «Фирменный шрифт Яндекса — узкий, гротескный, отличается открытой формой знаков и малым радиусом округлых форм. Динамическое распределение толщины в знаках круглого шрифта прекрасно сочетается со статичностью знаков прямого шрифта <…> Набор хорошо подходит для логотипов услуг, слоганов и пояснительных текстов» (А. Лебедев. Фирменный шрифт Яндекса). Вышеизложенное свидетельствует о том, что каждый шрифт имеет свои особые элементы, разработан и предназначен для использования в определенных ситуациях и что пригодность разрабатываемого шрифта зависит от творческих способностей его дизайнера.
Лебедев. Фирменный шрифт Яндекса). Вышеизложенное свидетельствует о том, что каждый шрифт имеет свои особые элементы, разработан и предназначен для использования в определенных ситуациях и что пригодность разрабатываемого шрифта зависит от творческих способностей его дизайнера.
Государственные и муниципальные органы уделяют особое внимание городской навигации и метрополитену и разрабатывают единые стандарты оформления пояснительных текстов, где особое значение имеет используемый шрифт. Даже обычные пользователи не ограничивают себя стандартным набором шрифтов, предоставляемым операционными системами, ведь сфера творческой деятельности любого пользователя Интернета безгранична. Все это поддерживает идею о том, что шрифт как произведение искусства следует рассматривать как самостоятельный объект авторского права.
В большинстве стран мира, в том числе и в России, шрифты находятся под правовой охраной как произведение авторского права. Например, в 1981 году правительство Германии признало, что шрифты могут быть защищены законами и правилами об авторском праве; английское правительство сделало то же самое в 1989 году (Эрик Шульц. Закон о шрифтах и гарнитурах). На международном уровне шрифты регулируются Венским соглашением об охране шрифтов и их международном депонировании, принятым 12 июня 1973 г. (Венское соглашение об охране шрифтов и их международном депонировании). К сожалению, Соглашение не вступило в силу, так как его признала и ратифицировала только одна страна. Большинство штатов не считают шрифты объектом авторского права напрямую, а не исключают их из общего неполного списка. Соединенные Штаты Америки занимают отдельную позицию в отношении охраняемых авторским правом шрифтов, как заключило Бюро регистрации авторских прав США в 1976, что образцы шрифтов не должны рассматриваться как объекты авторского права (Жаклин Д. Липтон. На © или не на ©? Авторское право и инновации в индустрии цифровых шрифтов). Это решение было дополнительно подкреплено судебной практикой (Eltra Corp. vs Ringer, 579 F.2d 294 (4th Cir. 1978). Такая ситуация вызывает недоумение у специалистов по шрифтовому дизайну, а также у представителей юридической профессии.
Закон о шрифтах и гарнитурах). На международном уровне шрифты регулируются Венским соглашением об охране шрифтов и их международном депонировании, принятым 12 июня 1973 г. (Венское соглашение об охране шрифтов и их международном депонировании). К сожалению, Соглашение не вступило в силу, так как его признала и ратифицировала только одна страна. Большинство штатов не считают шрифты объектом авторского права напрямую, а не исключают их из общего неполного списка. Соединенные Штаты Америки занимают отдельную позицию в отношении охраняемых авторским правом шрифтов, как заключило Бюро регистрации авторских прав США в 1976, что образцы шрифтов не должны рассматриваться как объекты авторского права (Жаклин Д. Липтон. На © или не на ©? Авторское право и инновации в индустрии цифровых шрифтов). Это решение было дополнительно подкреплено судебной практикой (Eltra Corp. vs Ringer, 579 F.2d 294 (4th Cir. 1978). Такая ситуация вызывает недоумение у специалистов по шрифтовому дизайну, а также у представителей юридической профессии. Конечно, это не означает, что шрифты в США вообще не охраняются законом. Таким образом, компьютерная программа, которая позволяет пользователям отображать и воспроизводить шрифт на экране, считается произведением, защищенным авторским правом. Это было принято Бюро авторских прав в 1992 и закреплено в решении по делу Adobe Systems, Inc. против Southern Software, Inc., вынесенном 30 января 1998 г., на которое ссылается Жаклин Д. Липтон в своей работе по защите шрифтов. © или не ©? Авторское право и инновации в индустрии цифровых шрифтов). Суд вынес решение в пользу истца, создав тем самым прецедент защиты воспроизведения шрифта с помощью компьютерной программы. Однако совершенно очевидно, что такое средство защиты недостаточно эффективно. Общеизвестно, что законом об авторском праве охраняется описание программы, а не идея, стоящая за ней. То есть, изменив описание, можно добиться сопоставимого результата: такого же или похожего шрифта. Кроме того, не всегда требуется компьютерная программа для использования шрифта (например, если шрифт используется на нарисованном от руки рекламном плакате), можно скопировать сам шрифт, не затрагивая программу.
Конечно, это не означает, что шрифты в США вообще не охраняются законом. Таким образом, компьютерная программа, которая позволяет пользователям отображать и воспроизводить шрифт на экране, считается произведением, защищенным авторским правом. Это было принято Бюро авторских прав в 1992 и закреплено в решении по делу Adobe Systems, Inc. против Southern Software, Inc., вынесенном 30 января 1998 г., на которое ссылается Жаклин Д. Липтон в своей работе по защите шрифтов. © или не ©? Авторское право и инновации в индустрии цифровых шрифтов). Суд вынес решение в пользу истца, создав тем самым прецедент защиты воспроизведения шрифта с помощью компьютерной программы. Однако совершенно очевидно, что такое средство защиты недостаточно эффективно. Общеизвестно, что законом об авторском праве охраняется описание программы, а не идея, стоящая за ней. То есть, изменив описание, можно добиться сопоставимого результата: такого же или похожего шрифта. Кроме того, не всегда требуется компьютерная программа для использования шрифта (например, если шрифт используется на нарисованном от руки рекламном плакате), можно скопировать сам шрифт, не затрагивая программу. Учитывая изложенное, вопрос предоставления правовой охраны шрифтам в США остается открытым. Так почему же одна из самых прогрессивных правовых систем остается столь консервативной в этой области? Удивительно для системы прецедентного права, именно законодательство США устанавливает такое ограничение. Закон США об авторском праве от 1976 предусматривает, что произведения, защищенные авторским правом, должны также включать изобразительные, графические и скульптурные произведения: «двухмерные и трехмерные произведения изобразительного, графического и скульптурного искусства… К таким произведениям относятся произведения художественного мастерства в отношении их формы, но не их механического или затрагиваются утилитарные аспекты; дизайн полезного предмета, как он определен в этом разделе, должен считаться изобразительным, графическим или скульптурным произведением только в том случае и только в той мере, в какой такой дизайн включает изобразительные, графические или скульптурные элементы, которые могут быть идентифицированы отдельно от , и способны существовать независимо от утилитарных аспектов статьи».
Учитывая изложенное, вопрос предоставления правовой охраны шрифтам в США остается открытым. Так почему же одна из самых прогрессивных правовых систем остается столь консервативной в этой области? Удивительно для системы прецедентного права, именно законодательство США устанавливает такое ограничение. Закон США об авторском праве от 1976 предусматривает, что произведения, защищенные авторским правом, должны также включать изобразительные, графические и скульптурные произведения: «двухмерные и трехмерные произведения изобразительного, графического и скульптурного искусства… К таким произведениям относятся произведения художественного мастерства в отношении их формы, но не их механического или затрагиваются утилитарные аспекты; дизайн полезного предмета, как он определен в этом разделе, должен считаться изобразительным, графическим или скульптурным произведением только в том случае и только в той мере, в какой такой дизайн включает изобразительные, графические или скульптурные элементы, которые могут быть идентифицированы отдельно от , и способны существовать независимо от утилитарных аспектов статьи».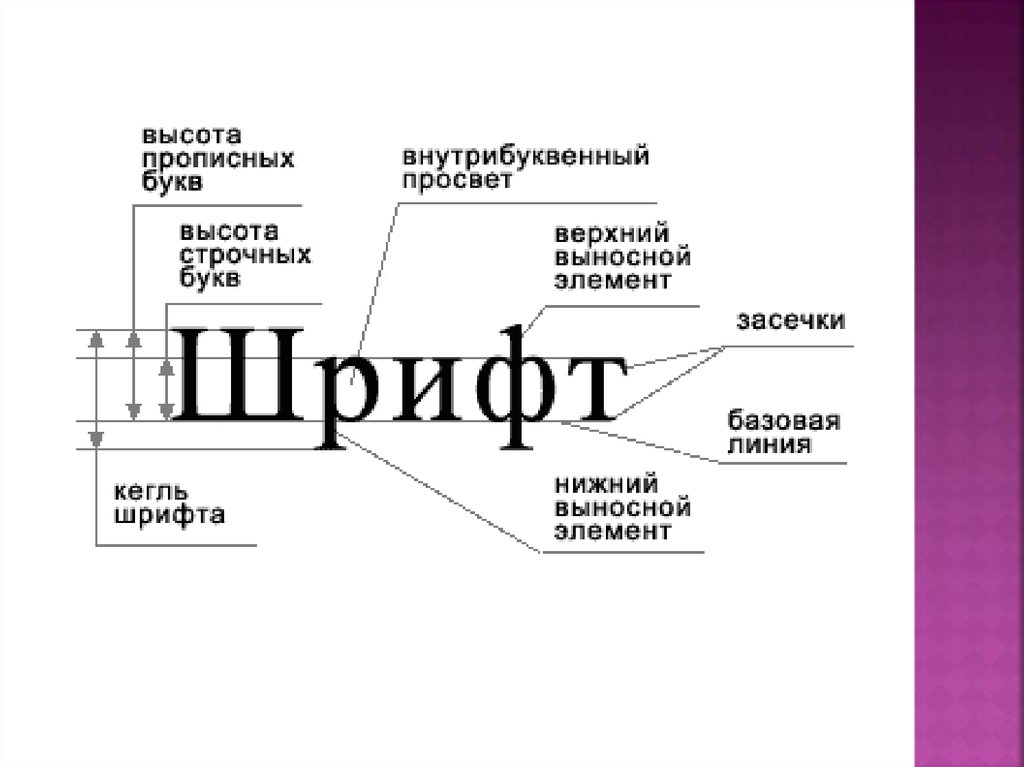 (Закон США об авторском праве).
(Закон США об авторском праве).
Любой шрифт будет полезен и утилитарен, так как это прежде всего набор символов, используемых для общения. Если он не выполняет свое назначение, он перестает быть шрифтом. Однако такой набор символов может иметь оригинальные характеристики помимо формы букв, такие как толщина, яркость, насыщенность, межбуквенный интервал, размер; он может быть округлым, цветочным, прямым или графическим. Но все вышеперечисленное не может существовать отдельно от формы символов шрифта. В какой-то момент Бюро регистрации авторских прав США установило, что художественные элементы полезного и практически утилитарного предмета охраняются авторским правом только в том случае, если такие элементы могут быть физически отделены от самого предмета (Жаклин Д. Липтон. На © или не на ©? Авторское право и Инновации в индустрии цифровых шрифтов). Вот почему шрифты в США не защищены законом об авторском праве. Главный аргумент законодателя и правоохранительных органов в данном случае — якобы сложность и дороговизна использования пользователями в случае признания шрифтов объектами авторского права. Это справедливо, поскольку в таком случае обычный пользователь, интересующийся только утилитарной стороной шрифта, а не его художественной составляющей, нарушил бы исключительные права. Но есть и некоторые контраргументы. В настоящее время существует множество открытых шрифтов, распространяемых свободно и бесплатно, и все они предоставляют широкий выбор для нужд пользователя. Если конкретному пользователю этого недостаточно, то его интересует не утилитарная сторона, а художественная составляющая. Именно такими пользователями являются создатели шрифтов, рекламные и дизайнерские агентства (короче говоря, предприниматели, использующие шрифты в коммерческих целях). Это может квалифицироваться как использование шрифта в качестве объекта авторского права. Кроме того, в Соединенных Штатах действует доктрина «добросовестного использования», которая также может использоваться пользователями для использования шрифтов в некоммерческих целях, если список типов добросовестного использования, указанный в статье 107 Закона США об авторском праве, будет расширен.
Это справедливо, поскольку в таком случае обычный пользователь, интересующийся только утилитарной стороной шрифта, а не его художественной составляющей, нарушил бы исключительные права. Но есть и некоторые контраргументы. В настоящее время существует множество открытых шрифтов, распространяемых свободно и бесплатно, и все они предоставляют широкий выбор для нужд пользователя. Если конкретному пользователю этого недостаточно, то его интересует не утилитарная сторона, а художественная составляющая. Именно такими пользователями являются создатели шрифтов, рекламные и дизайнерские агентства (короче говоря, предприниматели, использующие шрифты в коммерческих целях). Это может квалифицироваться как использование шрифта в качестве объекта авторского права. Кроме того, в Соединенных Штатах действует доктрина «добросовестного использования», которая также может использоваться пользователями для использования шрифтов в некоммерческих целях, если список типов добросовестного использования, указанный в статье 107 Закона США об авторском праве, будет расширен. или должна быть установлена соответствующая прецедентная практика.
или должна быть установлена соответствующая прецедентная практика.
Таким образом, на данный момент шрифты в США как таковые юридически не охраняются в связи с тем, что утилитарные характеристики шрифта физически неотделимы от его художественных элементов. Объектом авторского права признается только программа для ЭВМ, отображающая шрифт на экране компьютера.
Обратимся теперь к российскому опыту правового регулирования шрифтовой отрасли. В Гражданском кодексе Российской Федерации прямо не указано, что шрифты охраняются законом. Однако статья 1259ГК РФ приводится неисчерпывающий перечень объектов авторского права, который позволяет включать в него шрифты, если они носят объективную форму, творческий характер и не выражают идей, понятий, принципов, методов, процессов, системы, методики, а если они не являются решениями технических, организационных и иных задач, или языками программирования (ч. 4 ГК РФ. ст. 1259(5)). Кроме того, к объектам авторского права, перечисленным в статье 1259 Гражданского кодекса, относятся произведения графики и дизайна, в число которых могут входить и шрифты. Как Р.Н. Юрьев справедливо отмечает: «Безусловно, шрифт есть графическое произведение, как по отношению к отдельному шрифтовому знаку, так и по отношению к набору шрифтовых знаков вообще. Поскольку в законодательстве не дается разъяснения понятия «дизайн», его языковое значение еще не установлено и под словом «дизайн» может пониматься как расстановка мебели в помещении, так и внешний вид чего-либо, шрифт может также признаваться «произведением дизайна…» (Юрьев Р.Н. Шрифт как объект авторского права). Таким образом, российское законодательство никоим образом не ограничивает охрану шрифтов законами и подзаконными актами об авторском праве.
Как Р.Н. Юрьев справедливо отмечает: «Безусловно, шрифт есть графическое произведение, как по отношению к отдельному шрифтовому знаку, так и по отношению к набору шрифтовых знаков вообще. Поскольку в законодательстве не дается разъяснения понятия «дизайн», его языковое значение еще не установлено и под словом «дизайн» может пониматься как расстановка мебели в помещении, так и внешний вид чего-либо, шрифт может также признаваться «произведением дизайна…» (Юрьев Р.Н. Шрифт как объект авторского права). Таким образом, российское законодательство никоим образом не ограничивает охрану шрифтов законами и подзаконными актами об авторском праве.
Не менее важно изучить соответствующее внутреннее прецедентное право. В настоящее время существует немало решений о признании шрифтов авторскими произведениями. Важнейшим органом в части предоставления охраны шрифту как отдельному объекту авторского права является Постановление Суда по интеллектуальным правам от 12.12.2014 № С01–1268/2014 (по делу № А40–20099/2014). При этом научно-исследовательская компания ООО «ПараТайп» обратилась в суд с иском к ответчику о запрете использования последним шрифта Родченко, в том числе при издании книг, распространении экземпляров книг-нарушителей, а также о взыскании компенсация за нарушение исключительных прав на произведение. Суд первой инстанции удовлетворил иск частично, запретив использование шрифта и распространение книг-нарушителей, а также присудил частичную компенсацию. Апелляционный суд оставил решение в силе. Суды высшей инстанции, в том числе Суд по интеллектуальным правам (далее именуемый «СИП»), также поддержали это решение. Особый интерес представляет обоснование постановлений судов апелляционной и кассационной инстанций. IPC не рассматривал вопрос о защищенности шрифта авторским правом как объект авторского права, а сослался только на положения закона, в которых перечислены объекты авторского права, и по умолчанию рассматривал шрифт как объект авторского права. Большой интерес представляет решение суда апелляционной инстанции.
При этом научно-исследовательская компания ООО «ПараТайп» обратилась в суд с иском к ответчику о запрете использования последним шрифта Родченко, в том числе при издании книг, распространении экземпляров книг-нарушителей, а также о взыскании компенсация за нарушение исключительных прав на произведение. Суд первой инстанции удовлетворил иск частично, запретив использование шрифта и распространение книг-нарушителей, а также присудил частичную компенсацию. Апелляционный суд оставил решение в силе. Суды высшей инстанции, в том числе Суд по интеллектуальным правам (далее именуемый «СИП»), также поддержали это решение. Особый интерес представляет обоснование постановлений судов апелляционной и кассационной инстанций. IPC не рассматривал вопрос о защищенности шрифта авторским правом как объект авторского права, а сослался только на положения закона, в которых перечислены объекты авторского права, и по умолчанию рассматривал шрифт как объект авторского права. Большой интерес представляет решение суда апелляционной инстанции.
«В апреле 2002 года Т.И. Сафаев, выступая в качестве работника по вышеуказанному трудовому договору, разработал и передал истцу (его работодателю) купель под названием Родченко. Таким образом, вышеуказанный шрифт представляет собой набор стилистически единых изображений всех знаков латинского и кириллического алфавитов (в нескольких вариантах). Процесс создания шрифта требовал индивидуальной мыслительной деятельности, направленной на выражение эстетических представлений о внешнем виде знаков и других символов; это оригинальная работа ее автора, Т.И. Сафаева, и является именно графическим произведением. Таким образом, указанный шрифт является объектом авторского права в соответствии со статьями 6 и 7 Закона Российской Федерации «Об авторском праве и смежных правах» и статьей 1259ГК РФ (постановление Девятого арбитражного апелляционного суда от 8 сентября 2014 г. № 09АП-32019/2014-ГК). Таким образом, суд апелляционной инстанции признал шрифт графическим произведением (объектом авторского права) в понимании Гражданского кодекса Российской Федерации. Не доказав, что шрифт не является объектом авторского права, ответчик в суде кассационной инстанции обжаловал решение суда апелляционной инстанции по иным основаниям: ответчик настаивал на том, что «он использовал не произведение (шрифт) в целом, а только отдельные элементы (персонажи), которые представляли незначительную часть произведения, не защищенного законом об авторском праве. В кассационной жалобе ответчик утверждал, что шрифт может быть объектом интеллектуальной собственности только в том случае, если он представляет собой полный набор всех шрифтовых знаков и символов в одном стиле. <…> Следовательно, как полагал ответчик, использование отдельных знаков на обложке книги не может считаться нарушением исключительных прав на произведение (в данном конкретном случае на шрифт) в целом» (решение № С01– Постановление Суда по интеллектуальным правам от 12 декабря 2014 г. N 1268/2014 по делу № А40–20099/2014). МПК не согласился с этими доводами и постановил, что: «…авторское право распространяется и на часть произведения, если она по своему характеру может быть признана самостоятельным результатом творческой деятельности автора и выражена в объективной форме <… > судам следует иметь в виду, что, пока не доказано обратное, результаты интеллектуальной деятельности признаются творческим трудом.
Не доказав, что шрифт не является объектом авторского права, ответчик в суде кассационной инстанции обжаловал решение суда апелляционной инстанции по иным основаниям: ответчик настаивал на том, что «он использовал не произведение (шрифт) в целом, а только отдельные элементы (персонажи), которые представляли незначительную часть произведения, не защищенного законом об авторском праве. В кассационной жалобе ответчик утверждал, что шрифт может быть объектом интеллектуальной собственности только в том случае, если он представляет собой полный набор всех шрифтовых знаков и символов в одном стиле. <…> Следовательно, как полагал ответчик, использование отдельных знаков на обложке книги не может считаться нарушением исключительных прав на произведение (в данном конкретном случае на шрифт) в целом» (решение № С01– Постановление Суда по интеллектуальным правам от 12 декабря 2014 г. N 1268/2014 по делу № А40–20099/2014). МПК не согласился с этими доводами и постановил, что: «…авторское право распространяется и на часть произведения, если она по своему характеру может быть признана самостоятельным результатом творческой деятельности автора и выражена в объективной форме <… > судам следует иметь в виду, что, пока не доказано обратное, результаты интеллектуальной деятельности признаются творческим трудом. Ответчик, утверждая, что часть шрифта не может рассматриваться как имеющая творческий характер, не обосновал этот довод. Незаконное использование части произведения (шрифта), являющейся самостоятельным объектом гражданско-правовых сделок, влечет нарушение исключительного права на само произведение, поскольку использование части произведения фактически является способом использование произведения в целом» (постановление № С01–1268/2014, вынесенное Судом по интеллектуальным правам 12 декабря 2014 г. по делу № А40–20099/2014).
Ответчик, утверждая, что часть шрифта не может рассматриваться как имеющая творческий характер, не обосновал этот довод. Незаконное использование части произведения (шрифта), являющейся самостоятельным объектом гражданско-правовых сделок, влечет нарушение исключительного права на само произведение, поскольку использование части произведения фактически является способом использование произведения в целом» (постановление № С01–1268/2014, вынесенное Судом по интеллектуальным правам 12 декабря 2014 г. по делу № А40–20099/2014).
Кроме того, Суд по интеллектуальным правам постановил: «Утверждение заявителя в кассационной жалобе о том, что отдельные элементы шрифта не отражают творческого характера деятельности при их создании в силу своей простоты и неотличимости от элементов других шрифтов, является противоречивого характера, поскольку именно творческий характер, по мнению суда, обусловил использование ответчиком шрифта при оформлении обложки спорной книги». (Постановление № С01–1268/2014, вынесенное Судом по интеллектуальным правам от 12 декабря 2014 г. по делу № А40–20099/2014). Таким образом, в данном случае рассматривались два важных вопроса: является ли шрифт объектом авторского права в Российской Федерации и считается ли использование части набора знаков шрифта нарушением исключительных прав (т. признается ли часть символов шрифта отдельным объектом авторского права). На оба вопроса можно ответить утвердительно.
по делу № А40–20099/2014). Таким образом, в данном случае рассматривались два важных вопроса: является ли шрифт объектом авторского права в Российской Федерации и считается ли использование части набора знаков шрифта нарушением исключительных прав (т. признается ли часть символов шрифта отдельным объектом авторского права). На оба вопроса можно ответить утвердительно.
Подводя итог, можно сказать, что мировое сообщество признает шрифты, за некоторыми исключениями, объектами авторского права. Это вызвано, в том числе, тем, что в эпоху Интернета копирование и нелегальное использование шрифтов стало проще, дешевле и безопаснее (из-за анонимного использования). Все это требует создания регуляторных механизмов защиты прав создателей шрифтов, а также признания этих механизмов в судебной практике. Российское законодательство идет в ногу со временем, признавая шрифты объектами авторского права. Законодательство США, являясь наиболее прогрессивным и гибким, в этом вопросе уступает большинству современных законов и правил, поскольку признает объектом авторского права только компьютерные программы, воспроизводящие шрифт. При этом в США производится наибольшее количество самых популярных шрифтов. Поэтому остается надежда, что создателям шрифтов в США будет предоставлен тот же объем прав, что и создателям шрифтов в остальном мире.
При этом в США производится наибольшее количество самых популярных шрифтов. Поэтому остается надежда, что создателям шрифтов в США будет предоставлен тот же объем прав, что и создателям шрифтов в остальном мире.
Обратная связь:
Азиатский текст, кириллица и текст с письмом справа налево в PDF-файлах, Acrobat
Руководство пользователя Отмена
Поиск
Последнее обновление: 12 января 2022 г., 08:42:46 по Гринвичу | Также относится к Adobe Acrobat 2017, Adobe Acrobat 2020
- Руководство пользователя Acrobat
- Знакомство с Acrobat
- Доступ к Acrobat с настольного компьютера, мобильного устройства или Интернета
- Что нового в Acrobat
- Сочетания клавиш
- Системные требования
- Рабочее пространство
- Основы рабочего пространства
- Открытие и просмотр PDF-файлов
- Открытие PDF-файлов
- Навигация по страницам PDF
- Просмотр настроек PDF
- Настройка просмотра PDF
- Включить предварительный просмотр эскизов PDF-файлов
- Отображение PDF в браузере
- Работа с учетными записями онлайн-хранилища
- Доступ к файлам из ящика
- Доступ к файлам из Dropbox
- Доступ к файлам из OneDrive
- Доступ к файлам из SharePoint
- Доступ к файлам с Google Диска
- Acrobat и macOS
- Уведомления Acrobat
- Сетки, направляющие и измерения в PDF-файлах
- Азиатский текст, кириллица и текст с письмом справа налево в PDF-файлах
- Основы рабочего пространства
- Создание PDF-файлов
- Обзор создания PDF-файлов
- Создание PDF-файлов с помощью Acrobat
- Создание PDF-файлов с помощью PDFMaker
- Использование принтера Adobe PDF
- Преобразование веб-страниц в PDF
- Создание PDF-файлов с помощью Acrobat Distiller
- Настройки преобразования Adobe PDF
- PDF-шрифты
- Редактирование PDF-файлов
- Редактирование текста в PDF-файлах
- Редактирование изображений или объектов в PDF
- Поворот, перемещение, удаление и перенумерация страниц PDF
- Редактировать отсканированные файлы PDF
- Улучшение фотографий документов, снятых с помощью мобильной камеры
- Оптимизация PDF-файлов
- Свойства PDF и метаданные
- Ссылки и вложения в PDF-файлах
- слоев PDF
- Миниатюры страниц и закладки в PDF-файлах
- Мастер действий (Acrobat Pro)
- PDF-файлы, преобразованные в веб-страницы
- Настройка PDF для презентации
- Статьи в формате PDF
- Геопространственные файлы PDF
- Применение действий и сценариев к файлам PDF
- Изменить шрифт по умолчанию для добавления текста
- Удалить страницы из PDF
- Сканирование и распознавание символов
- Сканирование документов в PDF
- Улучшение фотографий документов
- Устранение неполадок сканера при сканировании с помощью Acrobat
- Формы
- Основы форм PDF
- Создание формы с нуля в Acrobat
- Создание и распространение PDF-форм
- Заполнение PDF-форм
- Свойства поля формы PDF
- Заполнение и подписание PDF-форм
- Настройка кнопок действий в формах PDF
- Публикация интерактивных веб-форм PDF
- Основные сведения о полях формы PDF
- Поля формы штрих-кода PDF
- Сбор данных форм PDF и управление ими
- О трекере форм
- Справка по PDF-формам
- Отправка PDF-форм получателям по электронной почте или на внутренний сервер
- Объединение файлов
- Объединение или объединение файлов в один PDF-файл
- Поворот, перемещение, удаление и перенумерация страниц PDF
- Добавление верхних и нижних колонтитулов и нумерации Бейтса в PDF-файлы
- Обрезка страниц PDF
- Добавление водяных знаков в PDF-файлы
- Добавление фона в PDF-файлы
- Работа с файлами компонентов в портфолио PDF
- Публикация и совместное использование портфолио PDF
- Обзор портфолио PDF
- Создание и настройка портфолио PDF
- Публикация, рецензирование и комментирование
- Публикация и отслеживание PDF-файлов в Интернете
- Разметка текста с правками
- Подготовка к просмотру PDF
- Запуск обзора PDF
- Размещение общих обзоров на сайтах SharePoint или Office 365
- Участие в проверке PDF
- Добавление комментариев к PDF-файлам
- Добавление штампа в PDF
- Рабочие процессы утверждения
- Управление комментариями | посмотреть, ответить, распечатать
- Импорт и экспорт комментариев
- Отслеживание обзоров PDF и управление ими
- Сохранение и экспорт PDF-файлов
- Сохранение PDF-файлов
- Преобразование PDF в Word
- Преобразование PDF в JPG
- Преобразование или экспорт PDF-файлов в файлы других форматов
- Параметры формата файла для экспорта PDF
- Повторное использование содержимого PDF
- Безопасность
- Расширенный параметр безопасности для PDF-файлов
- Защита PDF-файлов с помощью паролей
- Управление цифровыми идентификаторами
- Защита PDF-файлов с помощью сертификатов
- Открытие защищенных PDF-файлов
- Удаление конфиденциального содержимого из PDF-файлов
- Настройка политик безопасности для PDF-файлов
- Выбор метода защиты для PDF-файлов
- Предупреждения системы безопасности при открытии PDF-файла
- Защита PDF-файлов с помощью Adobe Experience Manager
- Функция защищенного просмотра для PDF-файлов
- Обзор безопасности в Acrobat и PDF-файлах
- JavaScripts в PDF-файлах как угроза безопасности
- Вложения как угроза безопасности
- Разрешить или заблокировать ссылки в PDF-файлах
- Электронные подписи
- Подписание PDF-документов
- Сохраните свою подпись на мобильном телефоне и используйте ее везде
- Отправка документов на электронные подписи
- Создать веб-форму
- Массовый запрос электронной подписи
- Прием онлайн-платежей
- Бренд вашей учетной записи
- О подписях сертификатов
- Подписи на основе сертификата
- Проверка цифровых подписей
- Утвержденный список доверия Adobe
- Управление доверенными удостоверениями
- Печать
- Основные задачи печати PDF
- Печатные буклеты и портфолио в формате PDF
- Дополнительные параметры печати PDF
- Печать в PDF
- Печать цветных PDF-файлов (Acrobat Pro)
- Печать PDF-файлов нестандартных размеров
- Специальные возможности, теги и переформатирование
- Создание и проверка доступности PDF
- Специальные возможности в PDF-файлах
- Инструмент порядка чтения для PDF-файлов
- Чтение PDF-файлов с функциями перекомпоновки и специальных возможностей
- Редактирование структуры документа с помощью панелей «Содержимое» и «Теги»
- Создание доступных PDF-файлов
- Поиск и индексирование
- Создание указателей PDF
- Поиск PDF-файлов
- Мультимедийные и 3D-модели
- Добавление аудио-, видео- и интерактивных объектов в PDF-файлы
- Добавление 3D-моделей в файлы PDF (Acrobat Pro)
- Отображение 3D-моделей в PDF-файлах
- Взаимодействие с 3D-моделями
- Измерение 3D-объектов в PDF-файлах
- Настройка 3D-представлений в PDF-файлах
- Включить 3D-контент в PDF
- Добавление мультимедиа в PDF-файлы
- Комментирование 3D-проектов в PDF-файлах
- Воспроизведение видео, аудио и мультимедийных форматов в PDF-файлах
- Добавлять комментарии к видео
- Инструменты для печати (Acrobat Pro)
- Обзор инструментов для печати
- Следы от принтера и линии роста волос
- Предварительный просмотр вывода
- Сведение прозрачности
- Преобразование цвета и управление чернилами
- Цвет захвата
- Предпечатная проверка (Acrobat Pro)
- Файлы, совместимые с PDF/X, PDF/A и PDF/E
- Предполетные профили
- Расширенные предполетные проверки
- Предполетные отчеты
- Просмотр результатов предварительной проверки, объектов и ресурсов
- Цели вывода в PDF-файлах
- Исправление проблемных областей с помощью инструмента Preflight
- Автоматизация анализа документов с помощью дроплетов или предпечатных действий
- Анализ документов с помощью инструмента Preflight
- Дополнительные проверки в инструменте предварительной проверки
- Предполетные библиотеки
- Переменные предварительной проверки
- Управление цветом
- Поддержание согласованности цветов
- Настройки цвета
- Документы с управлением цветом
- Работа с цветовыми профилями
- Понимание управления цветом
PDF-файлы на азиатском языке
Вы
может использовать Acrobat для просмотра, поиска и
печатать PDF-документы, содержащие азиатский текст (традиционный и упрощенный
китайский, японский и корейский). Вы также можете использовать эти языки
при заполнении форм, добавлении комментариев и применении цифровых подписей.
Вы также можете использовать эти языки
при заполнении форм, добавлении комментариев и применении цифровых подписей.
Почти все функции Acrobat поддерживаются для традиционный и упрощенный китайский, японский, и корейский текст, если вы устанавливаете соответствующий шрифт азиатского языка пакеты.
В Acrobat в Windows необходимо установить поддержку азиатского языка файлы, используя выборочную установку и выбрав азиатский язык Варианты поддержки в разделе «Создать Adobe PDF» и Просмотр Adobe PDF.
PDFMaker и Adobe PDF-принтер автоматически встраивает большинство азиатских шрифтов в ваш файл при создании файлов PDF. Вы можете контролировать, будут ли азиатские встроены шрифты.
В Windows вы можете просматривать и
печатать файлы, содержащие азиатские языки, не имея необходимых
В вашей системе установлена поддержка азиатских языков. Если вы попытаетесь открыть
файл PDF, для которого требуется языковая поддержка, вы автоматически
предложил установить необходимые шрифты.
Кириллица, среднеевропейская и PDF-файлы на восточноевропейских языках
Вы можете работать с файлами Adobe PDF которые содержат кириллический текст (в том числе болгарский и русский), центральные Европейский текст и восточноевропейский текст (включая чешский, венгерский и польский), если шрифты встроены в файлах PDF. Если шрифты встроены, вы можете просмотреть и распечатать файлы в любой системе. Шрифты не нужно встраивать для использования функция поиска.
При открытии файла PDF, в котором поля формы или текстовые поля содержат эти языки, но шрифты не встроены и не установлен в вашей системе, выбрав «Справка» > «Проверить наличие обновлений сейчас». автоматически предлагает загрузить и установить необходимые шрифты.
Иврит, арабский, тайский и вьетнамский язык PDF
Acrobat поддерживает
ввод и отображение тайского и вьетнамского текста. Только в Windows,
Также поддерживаются арабский и иврит. По умолчанию язык с письмом справа налево
Параметры включены в региональных настройках арабского языка и иврита (в Windows).