Как найти песню по звуку онлайн
Здравствуйте дорогие друзья. В этом посте вы узнаете о том, как найти песню по звуку онлайн. Недавно столкнулся с такой проблемой, поэтому я отписываюсь в виде поста. Я рассмотрю пару онлайн-сервисов и специальных утилит для компьютера. А так же рассмотрю парочку программ для смартфонов. Дам им оценку, а вы уже выберите чем пользоваться.
Пожалуй сначала начну с онлайн-сервисов.
Англоязычный сервис. Посмотреть его вы сможете здесь . В базе более миллиона композиций. Ну и если следовать логике, то охват англоязычных песен будет больше, так как сайт на английском. Хотя, английский это международный язык, поэтому, возможно я ошибаюсь. Ну да ладно. Сложностей возникнуть не должно. Все размещено так, чтобы любой смог сообразить, что и куда нажимать.
Поиск осуществляется двумя способами, это:
- Загрузкой файла с вашего компьютера
- При помощи ссылки
Чтобы найти то, что вы ищите, сервису понадобится максимум 30 секунд.
С помощью этого сервиса, вы сможете найти песню по звуку через микрофон. Зайти сможете отсюда . Сайт не требует установки какой-либо программы. Распознание происходит непосредственно на сайте. Начало распознания начинается после нажатия на кнопку «Click and Sing or Hum»:
После этого для распознания вам потребуется лишь разрешить использование микрофона.
После этого можете поднести микрофон к источнику звука. Подержать некоторое время, затем нажать на «Click to Stop». После проделанного, вы увидите результат. Если ничего не нашлось, то возможно, качество восприятия звука было плохим или же в базе данных нет искомой песни.
Это был случай, когда исходящий звук был извне. Если вы услышали хорошую песню в YouTube или еще где-то, то вы также можете воспользоваться данным сервисом.
Для включения микшера нужно зайти в настройки звука. Для каждой системы расписывать не буду, можно воспользоваться универсальным способом. В меню «Пуск» необходимо ввести слово «Звук». Затем открыть настройки звука.
Есть еще несколько способов. Можно зайти через панель управления. Также в трее есть регулировка звука, нажмите правой кнопкой мыши по иконке и зайдите в «Звуки».
Первый способ универсален, остальные способы не везде. В windows 8 на сколько я знаю нельзя зайти через панель управления. Хотя вам пользователям виднее. Я на windows 8 особо не сидел, поэтому извиняйте. Вот как должны выглядеть настройки:
Микрофон как я уже говорил
Tunatic – это программа для компьютера, которая находит песни онлайн.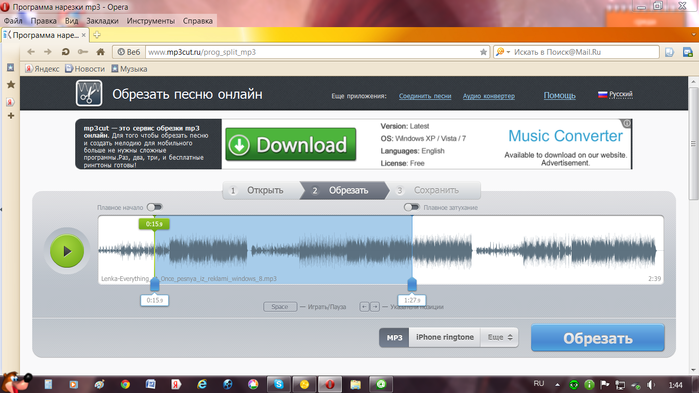 Скачиваем здесь
. Использование очень просто. Есть возможность нахождения песен с микрофона, а также с воспроизводимых звуков на компьютере будь то YouTube или что-то другое. Для того чтобы выбрать чем пользоваться, необходимо зайти в настройки программы. Для этого нажмите правой кнопкой мыши по окну, и выберите «Settings».
Скачиваем здесь
. Использование очень просто. Есть возможность нахождения песен с микрофона, а также с воспроизводимых звуков на компьютере будь то YouTube или что-то другое. Для того чтобы выбрать чем пользоваться, необходимо зайти в настройки программы. Для этого нажмите правой кнопкой мыши по окну, и выберите «Settings».
Затем выберите либо микрофон, либо микшер. Здесь тот же случай, что и с midomi. Микрофон — для распознания песен извне. Микшер — распознание звуков на компьютере.
После всего, можно начинать распознание песни. Нужно нажать на иконку лупы в программе.
MusicBrainz Picard
Данная программа способна распознать альбом по одной композиции, которая в него входит. Думаю она больше подойдет тем, кто хочет купить или скачать какой-то альбом, в котором есть распознаваемая композиция. Скачать ее можно вот здесь .
Для распознания вам необходимо нажать на «Файл», далее «Добавить файл» или «Добавить папку». После нажать на «Сканировать».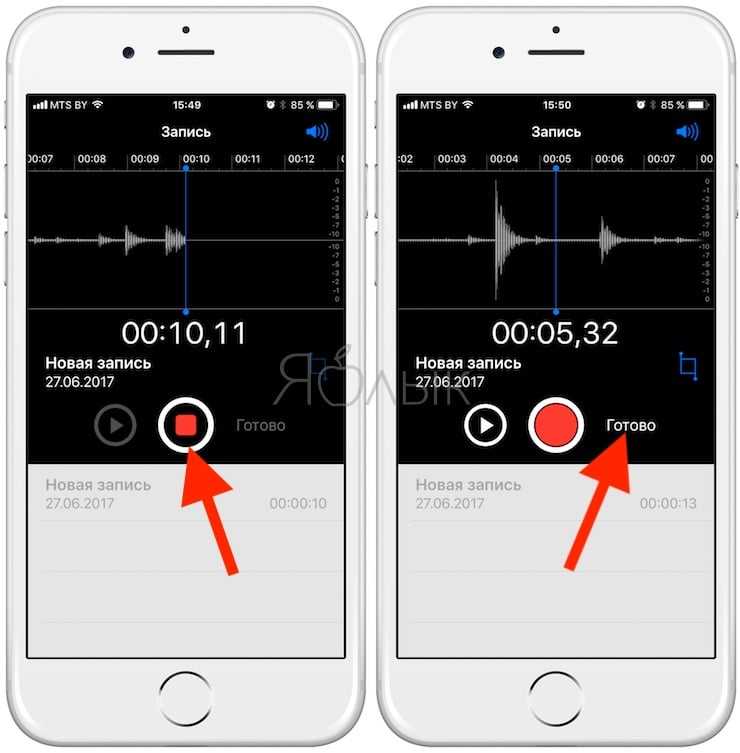 После должны появиться результаты поиска.
После должны появиться результаты поиска.
Данная программа работает на смартфонах с операционной системой Android, Windows Phone, IOS и не только. Распознание происходит через микрофон телефона. Если услышите какую-то интересную песню, то включите программу на телефоне и запустите распознание. Программа найдет название через интернет. Работает отлично, всем советую. Официальный сайт — перейти .
TrackID
Еще одно приложения для смартфонов. Создано исключительно для Android. Разобраться несложно, почти так же как и с предыдущей программой.
По моему мнению, лучше использовать Shazam, чем TrackID. Так или иначе решать вам, чем вы будете пользоваться. Найти программу сможете на Google Play .
Если кто-то знает еще какие-нибудь программки или онлайн-сервисы для распознания звука, то пишите в комментах, буду рад. Ну а на этом все. Подписывайтесь на блог делайте репосты. Пока!
Как Яндекс распознаёт музыку с микрофона / Хабр
Поиск по каталогу музыки — это задача, которую можно решать разными путями, как с точки зрения пользователя, так и технологически. Яндекс уже довольно давно научился искать и по названиям композиций, и по текстам песен. На сказанные голосом запросы про музыку мы тоже умеем отвечать в Яндекс.Поиске под iOS и Android, сегодня же речь пойдёт о поиске по аудиосигналу, а если конкретно — по записанному с микрофона фрагменту музыкального произведения. Именно такая функция встроена в мобильное приложение Яндекс.Музыки:
Яндекс уже довольно давно научился искать и по названиям композиций, и по текстам песен. На сказанные голосом запросы про музыку мы тоже умеем отвечать в Яндекс.Поиске под iOS и Android, сегодня же речь пойдёт о поиске по аудиосигналу, а если конкретно — по записанному с микрофона фрагменту музыкального произведения. Именно такая функция встроена в мобильное приложение Яндекс.Музыки:
В мире есть всего несколько специализированных компаний, которые профессионально занимаются распознаванием музыкальных треков. Насколько нам известно, из поисковых компаний Яндекс стал первым, кто стал помогать российскому пользователю в решении этой задачи. Несмотря на то, что нам предстоит ещё немало сделать, качество распознавания уже сопоставимо с лидерами в этой области. К тому же поиск музыки по аудиофрагменту не самая тривиальная и освещённая в Рунете тема; надеемся, что многим будет любопытно узнать подробности.
О достигнутом уровне качества
Базовым качеством мы называем процент валидных запросов, на которые дали релевантный ответ — сейчас около 80%.
Технически задача формулируется следующим образом: на сервер поступает десятисекундный фрагмент записанного на смартфон аудиосигнала (мы его называем запросом), после чего среди известных нам треков необходимо найти ровно тот один, из которого фрагмент был записан. Если фрагмент не содержится ни в одном известном треке, равно как и если он вообще не является музыкальной записью, нужно ответить «ничего не найдено». Отвечать наиболее похожими по звучанию треками в случае отсутствия точного совпадения не требуется.
База треков
Как и в веб-поиске, чтобы хорошо искать, нужно иметь большую базу документов (в данном случае треков), и они должны быть корректно размечены: для каждого трека необходимо знать название, исполнителя и альбом.
Зачем нам треки из интернета, и что мы с ними делаем
Наша цель как поисковой системы — полнота: на каждый валидный запрос мы должны давать релевантный ответ. В базе Яндекс.Музыки нет некоторых популярных исполнителей, не все правообладатели пока участвуют в этом проекте. С другой стороны, то что у нас нет права давать пользователям слушать какие-то треки с сервиса, вовсе не означает, что мы не можем их распознавать и сообщать имя исполнителя и название композиции.
Раз мы — зеркало интернета, мы собрали ID3-теги и дескрипторы каждого популярного в Сети трека, чтобы опознавать и те произведения, которых нет в базе Яндекс. Музыки. Хранить достаточно только эти метаданные — по ним мы показываем музыкальные видеоклипы, когда нашлись только записи из интернета.
Музыки. Хранить достаточно только эти метаданные — по ним мы показываем музыкальные видеоклипы, когда нашлись только записи из интернета.
Малоперспективные подходы
Как лучше сравнивать фрагмент с треками? Сразу отбросим заведомо неподходящие варианты.
- Побитовое сравнение. Даже если принимать сигнал напрямую с оптического выхода цифрового проигрывателя, неточности возникнут в результате перекодирования. А на протяжении передачи сигнала есть много других источников искажений: громкоговоритель источника звука, акустика помещения, неравномерная АЧХ микрофона, даже оцифровка с микрофона. Всё это делает неприменимым даже нечёткое побитовое сравнение.
- Водяные знаки. Если бы Яндекс сам выпускал музыку или участвовал в производственном цикле выпуска всех записей, проигрываемых на радио, в кафе и на дискотеках — можно было бы встроить в треки звуковой аналог «водяных знаков». Эти метки незаметны человеческому уху, но легко распознаются алгоритмами.
- Нестрогое сравнение спектрограмм. Нам нужен способ нестрогого сравнения. Посмотрим на спектрограммы оригинального трека и записанного фрагмента. Их вполне можно рассматривать как изображения, и искать среди изображений всех треков самую похожую (например, сравнивая как векторы с помощью одной из известных метрик, таких как L²):
Но в применении этого способа «в лоб» есть две сложности:
б) оказывается что одни различия более показательны, чем другие.
В итоге, для каждого трека нам нужно минимальное количество наиболее характерных (т.е. кратко и точно описывающих трек) признаков.
Каким признакам не страшны искажения?
Основные проблемы возникают из-за шума и искажений на пути от источника сигнала до оцифровки с микрофона. Можно для разных треков сопоставлять оригинал с фрагментом, записанным в разных искусственно зашумлённых условиях — и по множеству примеров найти, какие характеристики лучше всего сохраняются. Оказывается, хорошо работают пики спектрограммы, выделенные тем или иным способом — например как точки локального максимума амплитуды. Высота пиков не подходит (АЧХ микрофона их меняет), а вот их местоположение на сетке «частота-время» мало меняется при зашумлении. Это наблюдение, в том или ином виде, используется во многих известных решениях — например, в Echoprint. В среднем на один трек получается порядка 300 тыс. пиков — такой объём данных гораздо более реально сопоставлять с миллионами треков в базе, чем полную спектрограмму запроса.
Можно для разных треков сопоставлять оригинал с фрагментом, записанным в разных искусственно зашумлённых условиях — и по множеству примеров найти, какие характеристики лучше всего сохраняются. Оказывается, хорошо работают пики спектрограммы, выделенные тем или иным способом — например как точки локального максимума амплитуды. Высота пиков не подходит (АЧХ микрофона их меняет), а вот их местоположение на сетке «частота-время» мало меняется при зашумлении. Это наблюдение, в том или ином виде, используется во многих известных решениях — например, в Echoprint. В среднем на один трек получается порядка 300 тыс. пиков — такой объём данных гораздо более реально сопоставлять с миллионами треков в базе, чем полную спектрограмму запроса.
Но даже если брать только местоположения пиков, тождественность множества пиков между запросом и отрезком оригинала — плохой критерий. По большому проценту заведомо известных нам фрагментов он ничего не находит. Причина — в погрешностях при записи запроса. Шум добавляет одни пики, глушит другие; АЧХ всей среды передачи сигнала может даже смещать частоту пиков. Так мы приходим к нестрогому сравнению множества пиков.
Шум добавляет одни пики, глушит другие; АЧХ всей среды передачи сигнала может даже смещать частоту пиков. Так мы приходим к нестрогому сравнению множества пиков.
Нам нужно найти во всей базе отрезок трека, наиболее похожий на наш запрос. То есть:
- сначала в каждом треке найти такое смещение по времени, где бы максимальное число пиков совпало с запросом;
- затем из всех треков выбрать тот, где совпадение оказалось наибольшим.
Для этого строим гистограмму: для каждой частоты пика, которая присутствует и в запросе, и в треке, откладываем +1 по оси Y в том смещении, где нашлось совпадение:
Трек с самой высоким столбцом в гистограмме и есть самый релевантный результат — а высота этого столбца является мерой близости между запросом и документом.
Борьба за точность поиска
Опыт показывает, что если искать по всем пикам равнозначно, мы будем часто находить неверные треки. Но ту же меру близости можно применять не только ко всей совокупности пиков документа, но и к любому подмножеству — например, только к наиболее воспроизводимым (устойчивым к искажениям). Заодно это и удешевит построение каждой гистограммы. Вот как мы выбираем такие пики.
Но ту же меру близости можно применять не только ко всей совокупности пиков документа, но и к любому подмножеству — например, только к наиболее воспроизводимым (устойчивым к искажениям). Заодно это и удешевит построение каждой гистограммы. Вот как мы выбираем такие пики.
Отбор по времени: сначала, внутри одной частоты, по оси времени от начала к концу записи запускаем воображаемое «опускающееся лезвие». При обнаружении каждого пика, который выше текущего положения лезвия, оно срезает «верхушку» — разницу между положением лезвия и высотой свежеобнаруженного пика. Затем лезвие поднимается на первоначальную высоту этого пика. Если же лезвие не «обнаружило» пика, оно немного опускается под собственной тяжестью.
Разнообразие по частотам: чтобы отдавать предпочтение наиболее разнообразным частотам, мы поднимаем лезвие не только в само́й частоте очередного пика, но и (в меньшей степени) в соседних с ней частотах.
Отбор по частотам: затем, внутри одного временно́го интервала, среди всех частот, выбираем самые контрастные пики, т. е. самые большие локальные максимумы среди срезанных «верхушек».
е. самые большие локальные максимумы среди срезанных «верхушек».
При отборе пиков есть несколько параметров: скорость опускания лезвия, число выбираемых пиков в каждом временно́м интервале и окрестность влияния пиков на соседей. И мы подобрали такую их комбинацию, при которой остаётся минимальное число пиков, но почти все они устойчивы к искажениям.
Ускорение поиска
Итак, мы нашли метрику близости, хорошо устойчивую к искажениям. Она обеспечивает хорошую точность поиска, но нужно ещё и добиться, чтобы наш поиск быстро отвечал пользователю. Для начала нужно научиться выбирать очень малое число треков-кандидатов для расчёта метрики, чтобы избежать полного перебора треков при поиске.
Повышение уникальности ключей: Можно было бы построить индекc
Частота пика → (Трек, Местоположение в нём).
Увы, такой «словарь» возможных частот слишком беден (256 «слов» — интервалов, на которые мы разбиваем весь частотный диапазон). Большинство запросов содержит такой набор «слов», который находится в большинстве из наших 6 млн документов. Нужно найти более отличительные (discriminative) ключи — которые с большой вероятностью встречаются в релевантных документах, и с малой в нерелевантных.
Большинство запросов содержит такой набор «слов», который находится в большинстве из наших 6 млн документов. Нужно найти более отличительные (discriminative) ключи — которые с большой вероятностью встречаются в релевантных документах, и с малой в нерелевантных.
Для этого хорошо подходят пары близко расположенных пиков. Каждая пара встречается гораздо реже.
У этого выигрыша есть своя цена — меньшая вероятность воспроизведения в искажённом сигнале. Если для отдельных пиков она в среднем P, то для пар — P2 (т.е. заведомо меньше). Чтобы скомпенсировать это, мы включаем каждый пик сразу в несколько пар. Это немного увеличивает размер индекса, но радикально сокращает число напрасно рассмотренных документов — почти на 3 порядка:
Оценка выигрыша
Например, если включать каждый пик в 8 пар и «упаковать» каждую пару в 20 бит (тогда число уникальных значений пар возрастает до ≈1 млн), то:
- число ключей в запросе растёт в 8 раз
- число документов на ключ уменьшается в ≈4000 раз: ≈1 млн/256
- итого, число напрасно рассмотренных документов уменьшается в ≈500 раз: ≈4000/8
Отобрав с помощью пар малое число документов, можно переходить к их ранжированию. Гистограммы можно с тем же успехом применять к парам пиков, заменив совпадение одной частоты на совпадение обеих частот в паре.
Гистограммы можно с тем же успехом применять к парам пиков, заменив совпадение одной частоты на совпадение обеих частот в паре.
Двухэтапный поиск: для дополнительного уменьшения объёма расчётов мы разбили поиск на два этапа:
- Делаем предварительный отбор (pruning) треков по очень разреженному набору наиболее контрастных пиков. Параметры отбора подбираются так, чтобы максимально сузить круг документов, но сохранить в их числе наиболее релевантный результат
- Выбирается гарантированно наилучший ответ — для отобранных треков считается точная релевантность по более полной выборке пиков, уже по индексу с другой структурой:
Трек→(Пара частот, Местоположение в треке).
Такая двухэтапность ускорила поиск в 10 раз. Интересно, что в 80% случаев результат даже огрублённого ранжирования на первом этапе совпадает с самым релевантным ответом, полученным на втором этапе.
В результате всех описанных оптимизаций вся база, необходимая для поиска, стала в 15 раз меньше, чем сами файлы треков.
Индекс в памяти: И наконец, чтобы не ждать обращения к диску на каждый запрос, весь индекс размещён в оперативной памяти и распределён по множеству серверов, т.к. занимает единицы терабайт.
Ничего не найдено?
Случается, что для запрошенного фрагмента либо нет подходящего трека в нашей базе, либо фрагмент вообще не является записью какого-либо трека. Как принять решение, когда лучше ответить «ничего не найдено», чем показать «наименее неподходящий» трек? Отсекать по какому-нибудь порогу релевантности не удаётся — для разных фрагментов порог различается многократно, и единого значения на все случаи просто не существует. А вот если отсортировать отобранные документы по релевантности, форма кривой её значений даёт хороший критерий. Если мы знаем релевантный ответ, на кривой отчётливо видно резкое падение (перепад) релевантности, и напротив — пологая кривая подсказывает, что подходящих треков не найдено.
Что дальше
Как уже говорилось, мы в начале большого пути. Впереди целый ряд исследований и доработок для повышения качества поиска: например, в случаях искажения темпа и повышенного шума. Мы обязательно попробуем применить машинное обучение, чтобы использовать более разнообразный набор признаков и автоматически выбирать из них наиболее эффективные.
Кроме того, мы планируем инкрементальное распознавание, т.е. давать ответ уже по первым секундам фрагмента.
Другие задачи аудиопоиска по музыке
Область информационного поиска по музыке далеко не исчерпывается задачей с фрагментом с микрофона. Работа с «чистым», незашумлённым сигналом, претерпевшим только пережатие, позволяет находить дублирующиеся треки в обширной коллекции музыки, а также обнаруживать потенциальные нарушения авторского права. А поиск неточных совпадений и разного вида схожести — целое направление, включающее в себя поиск кавер-версий и ремиксов, извлечение музыкальных характеристик (ритм, жанр, композитор) для построения рекомендаций, а также поиск плагиата.
Отдельно выделим задачу поиска по напетому отрывку. Она, в отличие от распознавания по фрагменту музыкальной записи, требует принципиально другого подхода: вместо аудиозаписи, как правило, используется нотное представление произведения, а зачастую и запроса. Точность таких решений получается сильно хуже (как минимум, из-за несопоставимо бо́льшего разброса вариаций запроса), а поэтому хорошо они опознают лишь наиболее популярные произведения.
Что почитать
- Avery Wang: «An Industrial-Strength Audio Search Algorithm», Proc. 2003 ISMIR International Symposium on Music Information Retrieval, Baltimore, MD, Oct. 2003. Эта статья впервые (насколько нам известно) предлагает использовать пики спектрограммы и пары пиков как признаки, устойчивые к типичным искажениям сигнала.
- D. Ellis (2009): «Robust Landmark-Based Audio Fingerprinting». В этой работе даётся конкрентый пример реализации отбора пиков и их пар с помощью «decaying threshold» (в нашем вольном переводе — «опускающегося лезвия»).

- Jaap Haitsma, Ton Kalker (2002): «A Highly Robust Audio Fingerprinting System». В данной статье предложено кодировать последовательные блоки аудио 32 битами, каждый бит описывает изменение энергии в своем диапазоне частот. Описанный подход легко обобщается на случай произвольного кодирования последовательности блоков аудиосигнала.
- Nick Palmer: «Review of audio fingerprinting algorithms and looking into a multi-faceted approach to fingerprint generation». Основной интерес в данной работе представляет обзор существующих подходов к решению описанной задачи. Также описаны этапы возможной реализации.
- Shumeet Baluja, Michele Covell: «Audio Fingerprinting: Combining Computer Vision & Data Stream Processing». Статья, написанная коллегами из Google, описывает подход на основе вейвлетов с использованием методов компьютерного зрения.
- Arunan Ramalingam, Sridhar Krishnan: «Gaussian Mixture Modeling Using Short Time Fourier Transform Features For Audio Fingerprinting» (2005).
 В данной статье предлагается описывать фрагмент аудио с помощью модели Гауссовых смесей поверх различных признаков, таких как энтропия Шеннона, энтропия Реньи, спектрольные центроиды, мэлкепстральные коэффициенты и другие. Приводятся сравнительные значения качества распознавания.
В данной статье предлагается описывать фрагмент аудио с помощью модели Гауссовых смесей поверх различных признаков, таких как энтропия Шеннона, энтропия Реньи, спектрольные центроиды, мэлкепстральные коэффициенты и другие. Приводятся сравнительные значения качества распознавания. - Dalibor Mitrovic, Matthias Zeppelzauer, Christian Breiteneder: «Features for Content-Based Audio Retrieval». Обзорная работа про аудио-признаки: как их выбирать, какими свойствами они должны обладать и какие существуют.
- Natalia Miranda, Fabiana Piccoli: «Using GPU to Speed Up the Process of Audio Identification». В статье предлагается использование GPU для ускорения вычисления сигнатур.
- Shuhei Hamawaki, Shintaro Funasawa, Jiro Katto, Hiromi Ishizaki, Keiichiro Hoashi, Yasuhiro Takishima: «Feature Analysis and Normalization Approach for Robust Content-Based Music Retrieval to Encoded Audio with Different Bit Rates.» MMM 2009: 298-309. В статье акцентируется внимание на повышении робастности представления аудиосигнала на основе мел-кепстральных коэффициентов (MFCC).
 Для этого используется метод нормализации кепстра (CMN).
Для этого используется метод нормализации кепстра (CMN).
BirdNET Sound ID — Самый простой способ идентифицировать птиц по звуку.
Идентификация птиц по звуку. Помощь науке и сохранению.
Как компьютеры могут научиться распознавать птиц по звукам? Центр природоохранной биоакустики К. Лизы Янг в Корнеллской лаборатории орнитологии и кафедра медиа-информатики в Хемницком технологическом университете пытаются найти ответ на этот вопрос. Наши исследования в основном сосредоточены на обнаружении и классификации птичьих звуков с помощью машинного обучения — мы хотим помочь экспертам и гражданским ученым в их работе по мониторингу и защите наших птиц. BirdNET — это исследовательская платформа , целью которой является распознавание птиц по звуку в масштабе. Мы поддерживаем различное оборудование и операционные системы, такие как микроконтроллеры Arduino, Raspberry Pi, смартфоны, веб-браузеры, рабочие станции и даже облачные сервисы. BirdNET — это общественная научная платформа , а также программное обеспечение для анализа очень больших коллекций аудио. BirdNET стремится предоставить инновационных инструментов для защитников природы, биологов и орнитологов.
BirdNET — это общественная научная платформа , а также программное обеспечение для анализа очень больших коллекций аудио. BirdNET стремится предоставить инновационных инструментов для защитников природы, биологов и орнитологов.
На этой странице представлены некоторые из наших публичных демонстраций, в том числе демонстрация прямой трансляции, демонстрация анализа аудиозаписей, приложение для Android и iOS и его визуализация представленных материалов. Все демонстрации основаны на искусственной нейронной сети , которую мы называем BirdNET . Мы постоянно улучшаем функции и производительность наших демоверсий — пожалуйста, регулярно проверяйте нас.
В настоящее время BirdNET может идентифицировать около 3000 наиболее распространенных в мире видов. В ближайшее время мы добавим больше видов.
Хотите использовать BirdNET для анализа большого набора данных? Перейдите в наш репозиторий GitHub, чтобы загрузить BirdNET.
Есть вопросы? Пожалуйста, сообщите нам об этом (мы говорим по-английски и по-немецки): [email protected]
Вы когда-нибудь слышали звук птицы, который не могли определить? Узнайте, как использовать наше приложение для смартфонов BirdNET, чтобы идентифицировать своих загадочных птиц во время путешествия по Сапсакерскому лесу!
Узнайте, как идентифицировать птиц по звуку, с помощью бесплатного мобильного приложения и веб-сайта BirdNET Корнельской лаборатории орнитологии. Достижения в области машинного обучения упрощают идентификацию птиц по их звукам. Вопросы и ответы с разработчиком BirdNET Стефаном Калем.
Демонстрация прямой трансляции обрабатывает живой аудиопоток с микрофона за пределами Корнелльской лаборатории орнитологии, расположенной в заповеднике Сапсакер-Вудс в Итаке, штат Нью-Йорк. В этой демонстрации используется искусственная нейронная сеть, обученная на 180 наиболее распространенных видах в районе Сапсакерского леса. Наша система разбивает аудиопоток на сегменты, преобразует эти сегменты в спектрограммы (визуальные представления аудиосигнала) и передает спектрограммы через сверточную нейронную сеть почти в реальном времени. Веб-страница объединяет вероятности видов за последние пять секунд в одно предсказание. Если вероятность для одного вида достигает 15% или выше, вы можете увидеть маркер, указывающий предполагаемое положение соответствующего звука в прокручиваемой спектрограмме прямой трансляции. Эта демонстрация предназначена для больших экранов.
В этой демонстрации используется искусственная нейронная сеть, обученная на 180 наиболее распространенных видах в районе Сапсакерского леса. Наша система разбивает аудиопоток на сегменты, преобразует эти сегменты в спектрограммы (визуальные представления аудиосигнала) и передает спектрограммы через сверточную нейронную сеть почти в реальном времени. Веб-страница объединяет вероятности видов за последние пять секунд в одно предсказание. Если вероятность для одного вида достигает 15% или выше, вы можете увидеть маркер, указывающий предполагаемое положение соответствующего звука в прокручиваемой спектрограмме прямой трансляции. Эта демонстрация предназначена для больших экранов.
Перейдите по этой ссылке, чтобы просмотреть демонстрацию.
Надежная идентификация видов птиц в записанных аудиофайлах станет революционным инструментом для исследователей, специалистов по охране природы и орнитологов. Эта демонстрация предоставляет веб-интерфейс для загрузки и анализа аудиозаписей. Эта демонстрация, основанная на искусственной нейронной сети, включающей почти 1000 наиболее распространенных видов Северной Америки и Европы, показывает наиболее вероятные виды для каждой секунды записи. Обратите внимание: нам необходимо перенести аудиозаписи на наши серверы для обработки файлов. Эта демонстрация предназначена для больших экранов.
Эта демонстрация, основанная на искусственной нейронной сети, включающей почти 1000 наиболее распространенных видов Северной Америки и Европы, показывает наиболее вероятные виды для каждой секунды записи. Обратите внимание: нам необходимо перенести аудиозаписи на наши серверы для обработки файлов. Эта демонстрация предназначена для больших экранов.
Перейдите по этой ссылке, чтобы просмотреть демонстрацию.
Щелкните здесь, чтобы загрузить демо-запись.
Это приложение позволяет вам записывать файл с помощью встроенного микрофона вашего устройства Android или iOS, а искусственная нейронная сеть сообщит вам о наиболее вероятных видах птиц, присутствующих в вашей записи. Мы используем встроенную функцию звукозаписи смартфонов и планшетов, а также GPS-сервис, чтобы делать прогнозы на основе местоположения и даты. Попробуйте! Обратите внимание: нам необходимо перенести аудиозаписи на наши серверы для обработки файлов. Качество записи может отличаться в зависимости от вашего устройства. Внешние микрофоны, вероятно, повысят качество записи.
Качество записи может отличаться в зависимости от вашего устройства. Внешние микрофоны, вероятно, повысят качество записи.
Перейдите по этой ссылке, чтобы загрузить приложение для Android.
Перейдите по этой ссылке, чтобы загрузить приложение для iOS.
Перейдите по этой ссылке, чтобы просмотреть представленные материалы в реальном времени.
Следите за нашим ботом в Твиттере.
Примечание. Если вы столкнулись с какой-либо нестабильностью или у вас есть какие-либо вопросы относительно функциональности, сообщите нам об этом. В ближайшее время мы добавим новые функции, вы будете получать все обновления автоматически.
Лаборатория орнитологии Корнелла
Лаборатория Корнелла, занимающаяся продвижением понимания и защиты мира природы, объединяет людей из всех слоев общества, чтобы делать новые научные открытия, делиться идеями и стимулировать природоохранную деятельность. Наш Центр птиц и биоразнообразия Джонсона в Итаке, штат Нью-Йорк, является глобальным центром изучения и защиты птиц и биоразнообразия, а также центром миллионов гражданских научных наблюдений со всего мира.
Нажмите на эту ссылку, чтобы посетить наш веб-сайт.
Центр природоохранной биоакустики К. Лизы Янг
Центр природоохранной биоакустики им. К. Лизы Янг, базирующийся в Корнеллской лаборатории орнитологии, собирает и интерпретирует звуки природы, разрабатывая и применяя инновационные технологии природоохраны в различных экологических масштабах, чтобы вдохновлять и информировать сохранение дикой природы и среды обитания. Наша междисциплинарная команда работает с сотрудниками над наземными, водными и морскими биоакустическими исследовательскими проектами, направленными на решение проблем сохранения во всем мире.
Нажмите на эту ссылку, чтобы посетить наш веб-сайт.
Технологический университет Хемница
Технологический университет Хемница является государственным университетом в Хемнице, Германия. Это третий по величине университет в Саксонии, в котором обучается более 11 000 студентов. Он был основан в 1836 году как Königliche Gewerbeschule (Королевский торговый колледж), а в 1963 году был преобразован в Technische Hochschule, технологический университет. TU Chemnitz, в котором работает около 1500 сотрудников в области науки, техники и управления, считается одним из самых важных работодателей в область, край.
TU Chemnitz, в котором работает около 1500 сотрудников в области науки, техники и управления, считается одним из самых важных работодателей в область, край.
Нажмите на эту ссылку, чтобы посетить наш веб-сайт.
Кафедра медиаинформатики
Кафедра медиаинформатики Хемницкого технологического университета занимается контент-анализом больших разнородных наборов данных с 2007 года. Кроме того, кафедра медиаинформатики проводит исследования и преподает в области человеко-компьютерное взаимодействие с особым акцентом на критический и инклюзивный дизайн взаимодействия, а также на новые (мобильные) способы взаимодействия.
Нажмите на эту ссылку, чтобы посетить наш веб-сайт.
Стефан Каль
Я работаю постдоком в Центре природоохранной биоакустики им. К. Лизы Янг в Корнеллской лаборатории орнитологии и Хемницком технологическом университете. Моя работа включает в себя разработку приложений ИИ с использованием сверточных нейронных сетей для биоакустики, мониторинга окружающей среды и дизайна мобильного взаимодействия человека с компьютером. Я главный разработчик BirdNET и наших демонстраторов.
Я главный разработчик BirdNET и наших демонстраторов.
Ашакур Рахаман
Я работаю аналитиком Центра природоохранной биоакустики им. К. Лизы Ян в Лаборатории орнитологии Корнелла и менеджером сообщества приложения BirdNET. Я активно участвую в охране окружающей среды посредством научных исследований и участия общественности. Понимание взаимосвязи между природными звуками и воздействием антропогенных факторов на коммуникативное пространство животных — моя страсть.
Коннор Вуд
Мой основной интерес как постдока в Центре природоохранной биоакустики К. Лизы Янг в Лаборатории орнитологии Корнелла заключается в понимании того, как популяции диких животных и экологические сообщества реагируют на изменения окружающей среды, и, таким образом, способствуя их сохранению. . Я использую аудиоданные, собранные во время крупномасштабных проектов мониторинга, для изучения сообществ птиц Северной Америки.
Кристин Бранк
В качестве постдока в Центре природоохранной биоакустики им. К. Лизы Янг я использую биоакустические данные о птичьих сообществах в калифорнийской Сьерра-Неваде, чтобы смоделировать заселенность нескольких основных видов птиц в ответ на среду обитания и пожары. условия. Эти модели и данные будут использоваться менеджерами для обоснования решений по сохранению в будущем, особенно в условиях неопределенного климата.
К. Лизы Янг я использую биоакустические данные о птичьих сообществах в калифорнийской Сьерра-Неваде, чтобы смоделировать заселенность нескольких основных видов птиц в ответ на среду обитания и пожары. условия. Эти модели и данные будут использоваться менеджерами для обоснования решений по сохранению в будущем, особенно в условиях неопределенного климата.
Амир Дадхах
Я разработчик программного обеспечения и специалист по информатике на кафедре медиаинформатики Хемницкого технологического университета, специализируюсь на прикладной информатике и дизайне, ориентированном на человека. Я ведущий разработчик iOS-версии приложения BirdNET.
Хольгер Клинк
Я Джон У. Фитцпатрик, директор Центра природоохранной биоакустики им. К. Лизы Ян в Лаборатории орнитологии Корнелла, научный сотрудник Центра устойчивого развития Аткинсона в Корнельском университете и адъюнкт доцент Орегонского государственного университета. Мои текущие исследования сосредоточены на разработке и применении аппаратных и программных средств для пассивно-акустического мониторинга наземных и морских экосистем и биоразнообразия.
Пожертвовать
BirdNET — это исследовательский проект, финансируемый извне. Мы хотим разработать новые функции, добавить больше видов, расширить наши услуги и, самое главное, предоставить отличный опыт для орнитологов и тех, кто хочет ими стать.
Своим пожертвованием вы можете помочь нам в достижении этих целей.
Каждая сумма ценна! Это помогает нам покрывать расходы на сервер и продолжать наши исследования.
Сделать пожертвование
Совместная работа
В настоящее время вы изучаете тему, в которой BirdNET может быть полезен, или у вас есть идея для исследовательского проекта? Дайте нам знать! Вы хотели бы поддержать нас в области разработки программного обеспечения и приложений?
Свяжитесь с нами.
Мы открыты для ваших идей и хотели бы поговорить с вами.
Отправьте нам электронное письмо: [email protected]
Вуд, К. М., Кал, С. , Чаон, П., Пири, М. З., и Клинк, Х. (2021). Охват съемки, продолжительность записи и состав сообщества влияют на наблюдаемое видовое богатство при пассивных акустических съемках. Методы экологии и эволюции . [PDF]
, Чаон, П., Пири, М. З., и Клинк, Х. (2021). Охват съемки, продолжительность записи и состав сообщества влияют на наблюдаемое видовое богатство при пассивных акустических съемках. Методы экологии и эволюции . [PDF]
Каль, С. , Вуд, К. М. , Эйбл, М., и Клинк, Х. (2021). BirdNET: решение для глубокого обучения для мониторинга разнообразия птиц. Экологическая информатика , 61 , 101236. [Источник]
Каль, С., Дентон, Т., Клинк, Х. , Глотин, Х., Гоо, Х., Веллинга, В. П., … и Джоли, А. (2021). Обзор BirdCLEF 2021: идентификация криков птиц в записях звукового ландшафта. В CLEF 2021 (Рабочие заметки) . [PDF]
Джоли, А., Гоо, Х., Каль, С. , Пичек, Л., Лориел, Т., Коул, Э., … и Мюллер, Х. (2021). Обзор LifeCLEF 2021: оценка идентификации видов и прогнозирования их распространения на основе машинного обучения. In Международная конференция Форума межъязыковой оценки европейских языков (стр. 371-393). Спрингер, Чам. [PDF]
In Международная конференция Форума межъязыковой оценки европейских языков (стр. 371-393). Спрингер, Чам. [PDF]
Каль, С. , Клапп, М., Хоппинг, В., Гоо, Х., Глотин, Х., Планке, Р., … и Джоли, А. (2020). Обзор BirdCLEF 2020: распознавание звуков птиц в сложных акустических условиях. В CLEF 2020 (Рабочие заметки) . [PDF]
Джоли, А., Гоо, Х., Каль, С. , Денеу, Б., Серважан, М., Коул, Э., … и Лориел, Т. (2020). Обзор LifeCLEF 2020: системно-ориентированная оценка автоматизированной идентификации видов и прогнозирования их распространения. В Международная конференция Форума межъязыковой оценки европейских языков (стр. 342–363). Спрингер, Чам. [PDF]
Каль, С. (2020). Идентификация птиц по звуку: широкомасштабное распознавание акустических событий для мониторинга активности птиц. Диссертация. Хемницкий технологический университет, Хемниц, Германия. [PDF]
Каль, С. , Штётер, Ф. Р., Гоо, Х., Глотин, Х., Планке, Р., Веллинга, В. П., и Джоли, А. (2019). Обзор BirdCLEF 2019: крупномасштабное распознавание птиц в звуковых ландшафтах.
Р., Гоо, Х., Глотин, Х., Планке, Р., Веллинга, В. П., и Джоли, А. (2019). Обзор BirdCLEF 2019: крупномасштабное распознавание птиц в звуковых ландшафтах.
In CLEF 2019 (Рабочие заметки) . [PDF]
Джоли, А., Гоо, Х., Ботелла, К., Каль, С. , Серважан, М., Глотин, Х., … и Мюллер, Х. (2019). Обзор LifeCLEF 2019: идентификация амазонских растений, птиц Южной и Северной Америки и прогнозирование ниши.
In Международная конференция Форума межъязыковой оценки европейских языков (стр. 387-401). Спрингер, Чам. [PDF]
Жоли, А., Гоо, Х., Ботелла, К., Каль, С. , Пупар, М., Серважан, М., … и Шлютер, Дж. (2019). LifeCLEF 2019: Проблемы идентификации и прогнозирования биоразнообразия.
В Европейская конференция по информационному поиску (стр. 275-282). Спрингер, Чам. [PDF]
Каль, С. , Вильгельм-Штайн, Т., Клинк, Х. , Коверко, Д., и Эйбл, М. (2018). Распознавание птиц по звуку — базовая система BirdCLEF 2018 года.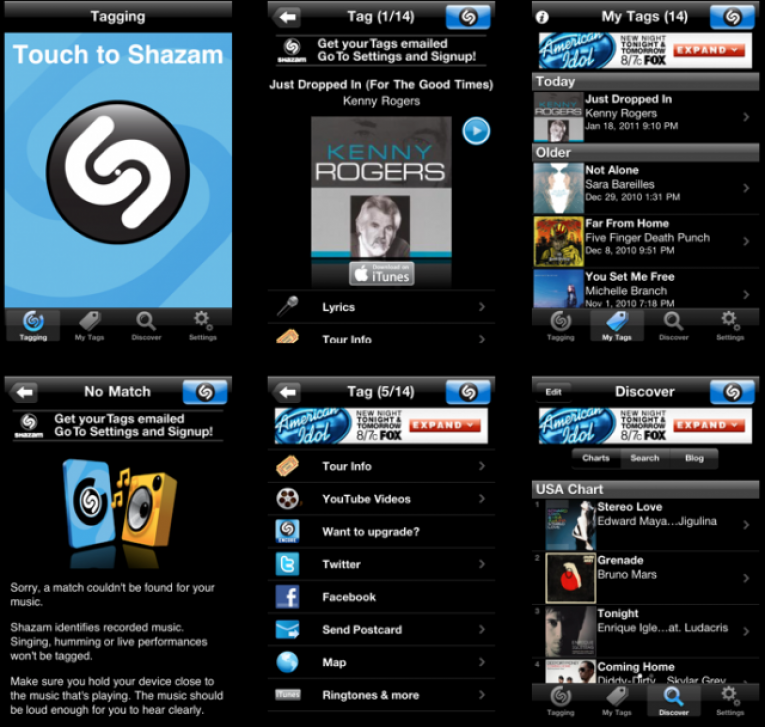
Препринт arXiv arXiv:1804.07177 . [PDF]
Goëau, H., Kahl, S. , Glotin, H., Planqué, R., Vellinga, WP, & Joly, A. (2018). Обзор BirdCLEF 2018: идентификация моновидов и звуковых ландшафтов птиц.
В CLEF 2018 (Рабочие заметки) . [PDF]
Каль, С. , Вильгельм-Штайн, Т., Клинк, Х. , Коверко, Д., и Эйбл, М. (2018). Базовый уровень для крупномасштабной идентификации видов птиц в полевых записях.
В CLEF 2018 (Рабочие заметки) . [PDF]
Каль, С. , Вильгельм-Штайн, Т., Хусейн, Х., Клинк, Х. , Коверко, Д., Риттер, М., и Эйбл, М. (2017). Крупномасштабная классификация звуков птиц с использованием сверточных нейронных сетей.
В CLEF 2018 (Рабочие заметки) . [PDF]
Воспроизведение музыки в прямом эфире Zoom/видеозвонке
Использование настроек аудио и списков воспроизведения для добавления треков в онлайн-мероприятие
Правильная музыка может помочь создать отличное впечатление от онлайн-мероприятия. Достижение правильного баланса между фоновой музыкой и громкостью ваших инструкций имеет решающее значение для обеспечения того, чтобы вас услышали и поняли во время саундтрека.
Достижение правильного баланса между фоновой музыкой и громкостью ваших инструкций имеет решающее значение для обеспечения того, чтобы вас услышали и поняли во время саундтрека.
Многие распространенные проблемы со звуком при вызовах Zoom возникают из-за того, что фоновая музыка улавливается тем же микрофоном, в который вы говорите. Вы можете настроить параметры масштабирования, чтобы этого не произошло.
Другие факторы также могут играть роль, и ниже описано несколько вещей, с помощью которых вы можете попытаться улучшить качество звука.
В этой статье рассматриваются:
Настройки масштабирования
Настройки музыкального проигрывателя
Headphones
Other troubleshooting tips
Alternative music sharing settings
Advantages
Disadvantages
✨ Please note: The Zoom integration is available on the Lite план или выше.
Настройки масштабирования
Лучший способ убедиться, что ваш микрофон не улавливает музыку, которую вы играете, — это настроить параметры вызова Zoom.
Вы должны убедиться, что музыка, которой делятся с вашими посетителями, насколько это возможно, поступает через ваше устройство, а не через микрофон, через который вы говорите.
(Расположение кнопки экрана «Поделиться» может различаться в зависимости от того, как вы получаете доступ к Zoom).
💡 Примечание: Изменение этого параметра не отключит ваш микрофон, но, помимо звука с микрофона, вы также будете делиться любыми звуками (включая музыку), которые воспроизводятся на вашем устройстве.
Настройки музыкального проигрывателя
После настройки параметров масштабирования все, что вам нужно сделать, это начать воспроизводить музыку, которую вы хотите включить в свой класс. Это может быть через службу потоковой передачи (Spotify, Apple Music и т. д.) или непосредственно с компакт-диска или файла, но его необходимо воспроизводить через устройство, которое вы используете для вызова Zoom.
Это может быть через службу потоковой передачи (Spotify, Apple Music и т. д.) или непосредственно с компакт-диска или файла, но его необходимо воспроизводить через устройство, которое вы используете для вызова Zoom.
Вы можете регулировать громкость музыки из любого приложения, в котором вы ее воспроизводите. Если вы не знакомы с настройками, вы всегда можете воспроизвести дорожку, когда представляете свое мероприятие, и проверить, слышат ли ее другие, прежде чем правильно начать работу с мероприятием. Если он слишком громкий, уменьшите его в приложении (не с помощью настроек громкости вашего устройства или любой стереосистемы/динамика, к которой вы можете быть подключены) —
Когда урок закончится, не забудьте остановить музыку через приложение музыкального проигрывателя — простое снятие наушников поможет вам, но не всем остальным участникам звонка!
💡 Примечание: По закону вы должны иметь соответствующую лицензию для воспроизведения музыки в любой общедоступной среде, онлайн или нет. Вы должны убедиться, что у вас есть право демонстрировать музыку, которую вы будете использовать, до вашего мероприятия (см. «Альтернативные методы обмена музыкой» ниже для метода, не требующего лицензии).
Вы должны убедиться, что у вас есть право демонстрировать музыку, которую вы будете использовать, до вашего мероприятия (см. «Альтернативные методы обмена музыкой» ниже для метода, не требующего лицензии).
Наушники
Если вы предоставили общий доступ к звуку вашего устройства через настройки Zoom, как описано выше, ваш микрофон не должен слышать музыку, чтобы ее могли услышать ваши посетители. Качество звука улучшится, если микрофон не улавливает музыку.
Если вы можете подключить наушники к компьютеру (в идеале без проводов через Bluetooth, хотя проводные наушники тоже подойдут, если вы их безопасно используете), то вы можете слушать музыку с их помощью и убедиться, что ваш микрофон только подобрать звук вашего голоса.
Другие советы по устранению неполадок
Используйте внешний микрофон
Внешний микрофон предпочтительнее, если у вас есть к нему доступ. Он должен располагаться как можно ближе к вам, источнику звука.
Он должен располагаться как можно ближе к вам, источнику звука.
Управляйте громкостью микрофона
Вы также должны иметь возможность включить микрофон через настройки устройства, что означает, что ваш голос будет звучать громче в звуковом миксе. Способ сделать это зависит от используемого вами устройства, но быстрый поиск в Google «как увеличить громкость микрофона на вашем устройстве» должен помочь вам найти необходимое руководство.
Улучшите свое окружение
Убедитесь, что в записываемом пространстве как можно меньше окружающего шума и отсутствует эхо. Больше всего отражаются пустые комнаты с твердыми поверхностями; стремитесь к комнате, которая не пуста и содержит мягкие поверхности, такие как ковры и коврики.
Убедитесь, что звук ваших посетителей отключен.
Это особенно важно, если вы не используете наушники, так как любые звуки ваших посетителей могут быть уловлены вашим микрофоном и воспроизведены для всех.
Альтернативные способы обмена музыкой
Еще один способ, которым ваши посетители могут наслаждаться музыкой, — поделиться своим плейлистом перед мероприятием, а затем заставить всех включить воспроизведение одновременно с вами.
Большинство сервисов потоковой передачи музыки предлагают функцию совместного использования с различными способами доставки вашего плейлиста:
(Spotify)
Так что все, что вам нужно сделать, это выбрать лучшие треки и указать вашим посетителям правильное направление. Bookwhen’s Поле сообщения с подтверждением бронирования — идеальное место для размещения ссылки, которая будет передана бронирующим лицам после того, как они забронируют билет.
Преимущества
Недостатки
Синхронизация так, чтобы все находились в одной точке песни, может быть затруднена
Требуется, чтобы каждый участник имел доступ к сервису, для которого вы создаете список воспроизведения.
