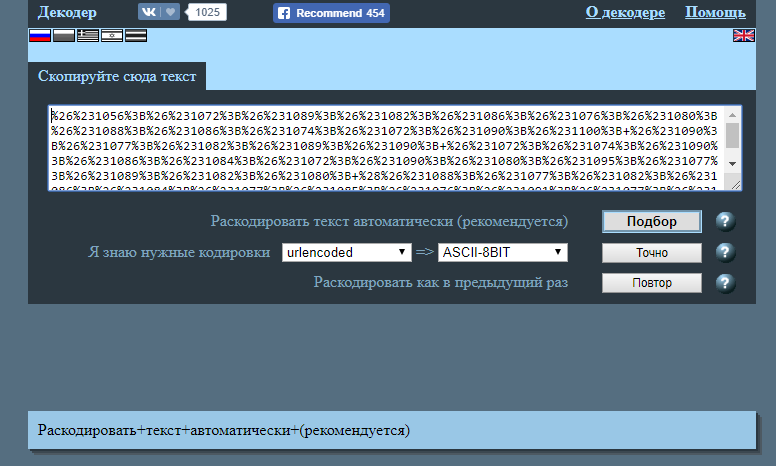
Раскодировать текст онлайн: сервисы для раскодировки
Весь текстовый контент, с которым мы работаем, хранится изначально в числовом виде. Для его преобразования используется кодирование. В различных системах одним и тем же значениям соответствуют различные буквенные, цифровые или просто символьные последовательности. Так иногда можно открыть документ или страничку и увидеть непонятные символы. Получается, что здесь данные были сохранены в другой кодировке. В таком случае можно раскодировать текст онлайн, с помощью специализированных сервисов. Все перечисленные ниже инструменты являются довольно популярными и функциональными.
СОДЕРЖАНИЕ СТАТЬИ:
Универсальный декодер
Сервис отлично справляется с кириллицей. Очень популярен среди юзеров рунета. Если вы выбрали его для работы, то необходимо сделать копию текста, нуждающегося в декодировании и вставить в специальное поле. Следует размещать отрывок так, чтобы уже на первой строчке были непонятные знаки.
Если вы хотите, чтобы ресурс автоматически смог раскодировать, придется отметить это в списке выбора. Но можно выполнять и ручную настройку, указав выбранный тип. Итоги можете найти в разделе «Результат». Вот только тут есть определенные ограничения. К примеру, если в поле вставить отрывок более 100 Кб, софт не обработает его, так что нужно будет выбирать кусочки.
Но можно выполнять и ручную настройку, указав выбранный тип. Итоги можете найти в разделе «Результат». Вот только тут есть определенные ограничения. К примеру, если в поле вставить отрывок более 100 Кб, софт не обработает его, так что нужно будет выбирать кусочки.
Как раскодировать текст онлайн с помощью Fox Tools
Здесь вы можете выбирать итоговый результат. Программа способна функционировать и в режиме «по умолчанию», который используется для неизвестных кодировок, но в таком случае необходимо отмечать самостоятельно вариант текстового объекта, подходящего больше всего. Инструмент простой и доступный, поэтому идеально подойдет даже новичкам.
Декодер Артемия Лебедева
Данный дешифратор способен взаимодействовать со всеми популярными кодировками. Приложение может предложить пользователю сложный и простой рабочий режим. В первом показывается не только исходник, но и преобразование. Еще можно указать кодировку, куда понадобилось перевести текст, из открывающегося списка. В правом блоке вы найдете результат для прочтения.
В правом блоке вы найдете результат для прочтения.
Translit.net
Этот инструмент имеет сложный внешний вид, но по принципу работы он не отличается от остальных. Необходимо ввести текстовый отрывок и в ручном режиме установить настройки.
Программа Штирлиц
Приложение, которым легко раскодировать онлайн, было создано для работы с русскоязычными объектами. Сюда можно текст копировать из буфера обмена, а также из самого текстового файла. Программа, позволяющая раскодировать текст онлайн, проверяет разные схемы. Если схема корректно не отображает все русские слова, используется следующая. Еще здесь можно создавать авторскую кодовую схему и пользоваться ей для работы. Для одновременной обработки нескольких файлов, нужно индивидуально открывать каждый из них.
Пользуемся стандартным Word
Этот редактор очень популярен, именно с ним работает большая часть пользователей. Так что они регулярно сталкиваются с некорректным отображением букв или невозможностью открыть участок с неподходящей кодировкой. Если документ Ворд открылся в режиме ограниченной функциональности, следует ее убрать. Если все еще отображаются непонятные знаки, укажите верную кодировку в программных настройках. Для этого идете по такому пути:
Если документ Ворд открылся в режиме ограниченной функциональности, следует ее убрать. Если все еще отображаются непонятные знаки, укажите верную кодировку в программных настройках. Для этого идете по такому пути:
Файл (Office)/Параметры/Дополнительно.
В разделе «Общие» установите галочку в спецнастройке «Подтверждать преобразование формата». Соглашаетесь с изменениями, закрываете прогу, а потом опять открываете файл. В окошке «Преобразование» выбираете «Кодированный текст». Ищите свой вариант.
Определение кодировки
Есть несколько способов определения:
- В Ворде во время открытия документа: если есть отличия от СР1251, редактор предлагает выбирать одну из самых подходящих кодировок. Оценить, насколько они аналогичны, можно по превью текстового образца;
- В утилите KWrite. Сюда загружаете объект с расширением .txt и используете настройки в меню «Кодирование»;
- Открываете объект в обозревателе Mozilla Firefox. При правильном отображении в разделе «Вид» ищите кодировку.
 Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»;
Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»; - Пользователи Unix могут воспользоваться приложением Enca.
С помощью предложенных инструментов вы можете быстро и легко раскодировать текст онлайн. Если у вас мало знаний, воспользуйтесь утилитами с простым меню и функционалом.
кодировки, нормализация, чистка / Хабр
Зачем эта статья?
Об обработке текстов на естественном языке сейчас знают все. Все хоть раз пробовали задавать вопрос Сири или Алисе, пользовались Grammarly (это не реклама), пробовали генераторы стихов, текстов… или просто вводили запрос в Google. Да, вот так просто. На самом деле Google понимает, что вы от него хотите, благодаря штукам, которые умеют обрабатывать и анализировать естественную речь в вашем запросе.
При анализе текста мы можем столкнуться с ситуациями, когда текст содержит специфические символы, которые необходимо проанализировать наравне с «простым текстом» (взять даже наши горячо любимые вставки на французском из «Война и мир») или формулы, например. В таком случае обработка текста может усложниться.
В таком случае обработка текста может усложниться.
Вы можете заметить, что если ввести в поисковую строку запрос с символами с ударением (так называемый модифицирующий акут), к примеру «ó», поисковая система может показать результаты, содержащие слова из вашего запроса, символы с ударением уже выглядят как обычные символы.
Обратите внимание на следующий запрос:
Запрос содержит символ с модифицирующим акутом, однако во втором результате мы можем заметить, что выделено найденное слово из запроса, только вот оно не содержит вышеупомянутый символ, просто букву «о».
Конечно, уже есть много готовых инструментов, которые довольно неплохо справляются с обработкой текстов и могут делать разные крутые вещи, но я не об этом хочу вам поведать. Я не буду рассказывать про nltk, стемминг, лемматизацию и т.п. Я хочу опуститься на несколько ступенек ниже и обсудить некоторые тонкости кодировок, байтов, их обработки.
Откуда взялась статья?
Одним из важных составляющих в области ИИ является обработка текстов на естественном языке. В процессе изучения данной тематики я начал задавать себе вопросы, которые в конечном итоге привели меня к изучению кодировок, представлению текстов в памяти, как они преобразуются, приводятся к нормальной форме. Я плохо понимал эту тему в начале, потребовалось немало времени и мозгового ресурса, чтобы понять, принять и запомнить некоторые вещи. Написанием данной статьи я хочу облегчить жизнь людям, которые столкнутся с необходимостью чтения и обработки текстов на Python и самому закрепить изученное. А некоторыми полезными поинтами своего изучения я постараюсь поделиться в данной статье.
В процессе изучения данной тематики я начал задавать себе вопросы, которые в конечном итоге привели меня к изучению кодировок, представлению текстов в памяти, как они преобразуются, приводятся к нормальной форме. Я плохо понимал эту тему в начале, потребовалось немало времени и мозгового ресурса, чтобы понять, принять и запомнить некоторые вещи. Написанием данной статьи я хочу облегчить жизнь людям, которые столкнутся с необходимостью чтения и обработки текстов на Python и самому закрепить изученное. А некоторыми полезными поинтами своего изучения я постараюсь поделиться в данной статье.
Важная ремарка: я не являюсь специалистом в области обработки текстов. Изложенный материал является результатом исключительно любительского изучения.
Проблема чтения файлов
with open("some_text.txt", "r") as file:
content = file. read()
print(content)
read()
print(content)В файле содержится вот такое вот изречение:
pitón
что переводится с испанского как питон. Однако консоль OC Windows 10 покажет нам немного другой результат:
C:\my\habr\TextsInPython> python .\script1.py pitón
Сейчас мы разберёмся, что именно пошло не так и по какой причине.
Кодировка
Думаю, это не будет сюрпризом, если я скажу, что любой символ, который заносится в память компьютера, хранится в виде числа, а не в виде литерала. Это число определяется как идентификатор или кодовая позиция символа. Кодировка определяет, какое именно число будет ассоциировано с символом.
Предположим, у нас есть некоторый файл с неизвестным содержимым, и нам нужно его прочитать, однако мы не знаем, какая у файла кодировка. Попробуем декодировать содержимое файла.
with open("simple_text.txt", "r") as file:
text = file.read()
print(text)Посмотрим на результат:
C:\my\habr\TextsInPython> python .\script2.py ÿþ<♦8♦@♦
Очень интересно, ничего непонятно. По умолчанию Python использует кодировку utf-8, но видимо запись в файл происходила не с её помощью. Здесь нам придёт на помощь дополнительный параметр функции open — параметр encoding, который позволяет указать конкретную кодировку, в которой следует прочитать файл (или записывать в него). Попробуем перебрать несколько кодировок и найти подходящую.
codecs = ["cp1252", "cp437", "utf-16be", "utf-16"]
for codec in codecs:
with open("simple_text.txt", "r", encoding=codec) as file:
text = file.read()
print(codec.rjust(12), "|", text)Результат:
C:\my\habr\TextsInPython> python .\script3.py
cp1252 | ÿþ<8@
cp437 | ■<8@
utf-16be | 㰄㠄䀄
utf-16 | мирРазные кодировки расшифровывают байты из файла по-разному, то есть разным кодовым позициям могут соотвествовать разные символы. Пример примитивный, несложно догадаться, что истинная кодировка файла — это utf-16.
Важный поинт: при записи и чтении из файлов следует указывать конкретную кодировку, это позволит избежать путаницы в дальнейшем.
Ошибки, связанные с кодировками
При возникновении ошибки, связанной с кодировками, интерпретатор выдаст одно из следующих исключений:
UnicodeError. Это общее исключение для ошибок кодировки.UnicodeDecodeError. Данное исключение возбуждается, если встречается кодовая позиция, которая отсутствует в кодировке.UnicodeEncodeError. А это исключение возбуждается, когда символ, который необходимо закодировать, незнаком для кодировки.
Попытка выполнения вот такого кода (в файле всё ещё содержится испанский питон):
with open("some_text.txt", "r", encoding="ascii") as file:
file.read()даст нам следующий результат:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 3: ordinal not in range(128)
Кодировка ASCII не поддерживает никакой алфавит, кроме английского. Поэтому декодирование символа «ó» вызывает у ASCII сложности. Однако Python всемогущ и есть механизм, который позволяет обработать ошибки кодировок. Это дополнительный параметр методов
Поэтому декодирование символа «ó» вызывает у ASCII сложности. Однако Python всемогущ и есть механизм, который позволяет обработать ошибки кодировок. Это дополнительный параметр методов encode и decode — параметр errors. Он может принимать следующие значения:
Для обеих функций:
Обозначение | Суть |
| Значение по умолчанию. Несоотвествующие кодировке символы возбуждают исключения |
| Несоответсвующие символы пропускаются без возбуждения исключений. |
Только для метода encode:
Обозначение | Суть |
|---|---|
| Несоотвествующие символы заменяются на символ |
| Несоответствующие символы заменяются на соответсвующие значения XML. |
| Несоответствующие символы заменяются на определённые последовательности с обратным слэшем. |
| Несоответствующие символы заменяются на имена этих символов, которые берутся из базы данных Unicode. |
Также отдельно выделены значения surrogatepass и surrogateescape.
Приведём пример использования таких обработчиков:
>>> text = "pitón"
>>> text.encode("ascii", errors="ignore")
b'pitn'
>>> text.encode("ascii", errors="replace")
b'pit?n'
>>> text.encode("ascii", errors="xmlcharrefreplace")
b'pitón'
>>> text.encode("ascii", errors="backslashreplace")
b'pit\\xf3n'
>>> text.encode("ascii", errors="namereplace")
b'pit\\N{LATIN SMALL LETTER O WITH ACUTE}n'Важный поинт

Cворачивание регистра
Сворачивание регистра — это попытка унифицировать текст любого представления к канонической форме. Например, приведение всего текста в нижний регистр. Также над текстом производятся некоторые преобразования (например, немецкая «эсцет» — «ß» — преобразуется в «ss»). В Python 3.3 появился метод str.casefold(), который как раз выполняет сворачивание регистра. Если текст содержит только символы кодировки latin1, результат применения этого метода будет аналогичен методу str.lower().
И по классике приведём пример:
>>> text = "Die größte Stadt der Welt liegt in China" >>> text.casefold() 'die grösste stadt der welt liegt in china'
В результате применённый метод не только привёл весь текст к нижнему регистру, но и преобразовал специфический немецкий символ.
Важный поинт: привести текст можно не только методом str.lower(), но и методом str., который может выполнить дополнительные преобразования текста.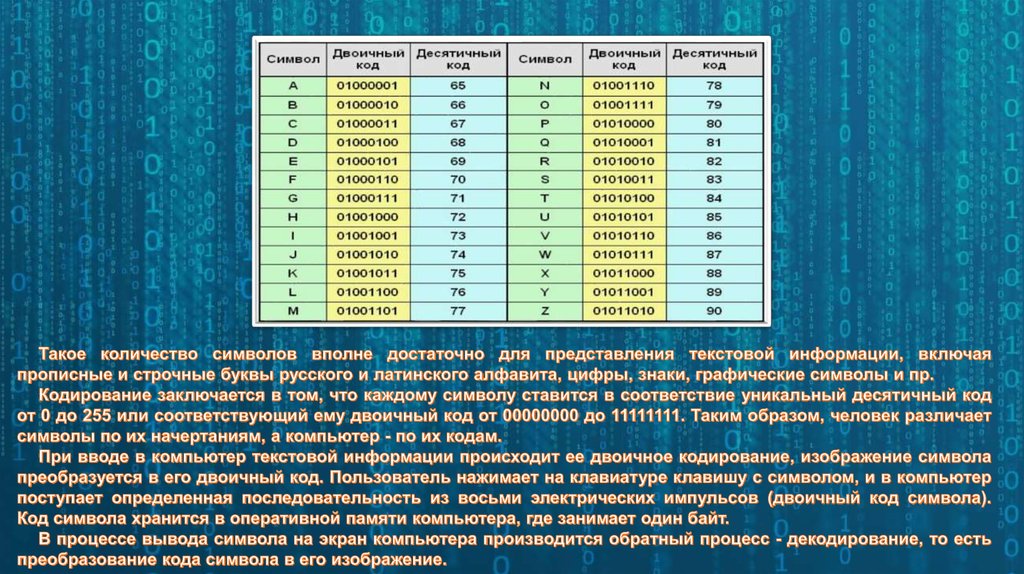 casefold()
casefold()
Нормализация
Нормализация — это полноценное приведение текста к единому представлению.
Чтобы обозначить важность нормализации, приведём простой пример:
letter1 = "µ" letter2 = "μ"
Внешне два этих символа выглядят абсолютно одинаково. Однако если мы попытаемся вывести имена этих символов, как их видит интерпретатор Python’a, результат нас порядком удивит.
В Python есть отличный встроенный модуль, который содержит данные о символах Unicode, их имена, являются ли они цифрамии и т.п. (методы по типу
import unicodedata letter1 = "µ" letter2 = "μ" print(unicodedata.name(letter1)) print(unicodedata.name(letter2))
Результат выполнения данного кода:
C:\my\habr\TextsInPython> python .\script7.py MICRO SIGN GREEK SMALL LETTER MU
Итак, интерпретатор Python’a видит эти символы как два разных, но в стандарте Unicode они имеют одинаковое отображение.Такие символы называют каноническими эквивалентами. Приложения будут считать два этих символа одинаковыми, но не интерпретатор.
Посмотрим на ещё один пример:
>>> s1 = 'café'
>>> s2 = 'cafe\u0301'
>>> s1, s2
('café', 'café')
>>> s1 == s2
False
>>> len(s1), len(s2)
(4, 5)
Данные символы также будут являться каноническими эквивалентами. Из примера мы видим, что символ «é» в стандарте Unicodeможет быть представлен двумя способами, которые к тому же имеют разную длину. Символ «é» может быть представлен одним или двумя байтами.
Решением таких конфликтов занимается нормализация. Она реализована в Python в функции unicodedata.normalize.Первым аргумент является так называемая форма нормализации — нормализации строк Unicode, которые позволяют определить, эквивалентны ли какие-либо две строки Unicode друг другу. Всего предлагается четыре формы:
Всего предлагается четыре формы:
Форма | Описание |
|---|---|
Normalization Form D (NFD) | Canonical Decomposition |
Normalization Form C (NFC) | Canonical Decomposition, следующая за Canonical Composition |
Normalization Form KD (NFKD) | Compatibility Decomposition |
Normalization Form KC (NFKC) | Compatibility Decomposition, следующая за Canonical Composition |
Разберём каждую форму немного подробнее.
NFC
При указании данной формы нормализации происходит каноническая композиция (как, собственно, и гласит название) кодовых позиций с целью получения самой короткой эквивалентной строки.
>>> unicodedata.normalize("NFC", s1), unicodedata.normalize("NFC", s2)
('café', 'café')
>>> len(unicodedata. normalize("NFC", s1)), len(unicodedata.normalize("NFC", s2))
(4, 4)
>>> unicodedata.normalize("NFC", s1) == unicodedata.normalize("NFC", s2)
True
>>> len(unicodedata.normalize("NFC", s1)) == len(unicodedata.normalize("NFC", s2))
True
normalize("NFC", s1)), len(unicodedata.normalize("NFC", s2))
(4, 4)
>>> unicodedata.normalize("NFC", s1) == unicodedata.normalize("NFC", s2)
True
>>> len(unicodedata.normalize("NFC", s1)) == len(unicodedata.normalize("NFC", s2))
TrueИтак, нормализация обеих строк внешне их не изменила, однако длина строки s2 стала равной 4 (т.е. на один байт меньше). Была произведена композиция байтов e\u0301, которые являлись отображением «é». Данная последовательность была заменена на минимальное представление символа, т.е. теперь представление этого символа для интерпретатора выглядит как в строке s1. Как результат, мы видим, что длина нормализованных строк стала равной, и сами строки также стали равны.
NFD
С этой формой ситуация аналогичная, только происходит декомпозиция байтов, т.е. разложение символа на несколько байт.
>>> unicodedata.normalize("NFD", s1), unicodedata.normalize("NFD", s2)
('café', 'café')
>>> len(unicodedata. normalize("NFD", s1)), len(unicodedata.normalize("NFD", s2))
(5, 5)
>>> unicodedata.normalize("NFD", s1) == unicodedata.normalize("NFD", s2)
True
>>> len(unicodedata.normalize("NFD", s1)) == len(unicodedata.normalize("NFD", s2))
True
normalize("NFD", s1)), len(unicodedata.normalize("NFD", s2))
(5, 5)
>>> unicodedata.normalize("NFD", s1) == unicodedata.normalize("NFD", s2)
True
>>> len(unicodedata.normalize("NFD", s1)) == len(unicodedata.normalize("NFD", s2))
TrueЗдесь мы видим, что длина строки s1 увеличилась на один байт. Думаю, уже несложно догадаться, почему.
На данном этапе настал момент ввести понятие символа совместимости. Символы совместимости (compatibility characters) были введены в Unicode ради совместимости с другими стандартами, в частности, стандарты, которые предшествовали Unicode. Это означает, что некоторые символы могут встречаться в стандарте несколько раз. Мы уже могли наблюдать это явление в начале этого раздела на примере с символом «мю». Он считается символом совместимости.
NFKC и NFKD
При данных формах нормализации символы совместимости заменяются на его более предпочтительное представление, что также называется совместимой декомпозицией. Однако при данных формах нормализации может быть потеряно форматирование.
Однако при данных формах нормализации может быть потеряно форматирование.
Немного модифицируем наш пример из начала раздела. Выведем кодовые позиции символов до и после нормализации:
import unicodedata
letter1 = "µ"
letter2 = "μ"
print("Before normalizing:", ord(letter1), ord(letter2))
letter1 = unicodedata.normalize("NFKC", letter1)
letter2 = unicodedata.normalize("NFKC", letter2)
print("After normalizing:", ord(letter1), ord(letter2))И результат выполнения кода:
Before normalizing: 181 956 After normalizing: 956 956
Итак, мы видим, что первый символ (который являлся знаком «микро») был заменён на греческую «мю», т.е. более предпочтительное представление символа. Таким образом, если необходимо, например, провести частотный анализ текста, формы нормализации, которые затрагивают символы совместимости, могут помочь с этим, приводя символы совместимости к единому представлению.
Важный поинт: нормализация может очень помочь для поиска валидных документов или индексирования текста. Если вы занимаетесь разработкой таких систем, не стоит сбрасывать алгоритмы нормализации со счетов.
Если вы занимаетесь разработкой таких систем, не стоит сбрасывать алгоритмы нормализации со счетов.
Дополнительные материалы: что использовалось в статье и что почитать по теме
«Fluent Python», Лучано Ромальо
В этой книге целая глава посвящена изучению строк, байтов и Unicode (Глава 4. Тексты и байты). Она есть на русском и английском языках, но в русском переводе допущено немало ошибок, так что открывайте русский вариант на свой страх и риск. Материал статьи в большей степени опирается на данную книгу. Некоторые примеры также взяты оттуда.
Документация для Unicode на официальном сайте Python
Куда ж без неё, родимой. Там тоже можно найти немало полезной информации, если вам понадобится работать с текстами и делать больше, чем просто считывание из файла. Хотя в некоторых случаях и на этом можно споткнуться.
Unicode® Standard Annex
Это части стандарта Unicode, которые выложены в открытый доступ в виде отдельных статей. Почитать их можно вот здесь.
Почитать их можно вот здесь.
Base64 | Конвертер Base64
Комментариев: 66 | Рейтинг: 4.7/5
«Base64 Decode Online» — это бесплатный декодер для онлайн-декодирования Base64 в текст или двоичный файл. Другими словами, это инструмент, который преобразует Base64 в исходные данные. Этот онлайн-декодер так же умен, как и прост. Его сверхспособность — способность автоматически определять стандарт кодирования. Благодаря ему этот конвертер позволяет «расшифровывать» некоторые строки Base64, даже когда другие онлайн или оффлайн декодеры бессильны и не могут их расшифровать, потому что поддерживают только «основной» стандарт. Если вы ищете обратный процесс, проверьте кодировку Base64.
Base64
*Base64 Standard
Автоматическое определение (работает как шарм, однако иногда может дать сбой для коротких строк) Основной (используется по умолчанию всеми и везде) MIME (вывод делится на фиксированные 76 строк и используется для кодирования содержимого электронной почты, такого как файлы или нелатинские буквы) ASCII Armor (используется OpenPGP, идентичен Base64 для MIME, но добавляет контрольную сумму ввода) Base64URL (в отличие от других стандартов, выходные данные этого стандарта можно безопасно использовать в качестве имени файла или URL-адреса) IMAP (используется протоколом доступа к сообщениям в Интернете в качестве международного соглашения об именах почтовых ящиков) PEM (устаревший стандарт, изначально использовавшийся протоколом Privacy-Enhanced Mail) xsd:NMTOKEN (предоставляет безопасные строки для использования в качестве действительных токенов имен XML) xsd:Name (предоставляет безопасные строки для использования в качестве действительных идентификаторов XML)Строгое декодирование
Нет (игнорировать недопустимые символы и принудительно использовать значение декодирования как Base64). Да (декодируйте значение, если оно содержит только допустимые символы Base64).
Да (декодируйте значение, если оно содержит только допустимые символы Base64).Кодировка символов
Автоопределение (экспериментальная функция, которая может не работать для «экзотических» кодировок) UTF-8 ISO-8859-1, латиница1 Windows-1251, СР1251 Windows-1252, cp1252 SJIS, x-sjis, SHIFT-JIS EUC-CN, CN-GB, x-euc-CN, gb2312 ЭУК-КР, х-эук-кр CP936, ГБК ISO-8859-2, латиница2 EUC-JP, EUC, x-euc-jp ИСО-8859-15 БОЛЬШАЯ 5, CN-БОЛЬШАЯ 5, БОЛЬШАЯ ПЯТЬ ИСО-8859-9, латиница5 Windows-1254, CP1254 ASCII, ANSI_X3.4-1968, iso-ir-6, ANSI_X3.4-1986, ISO_646.irv:1991, US-ASCII, ISO646-US, США, IBM367, cp367, csASCII ISO-8859-7, греческий КОИ8-Р ГБ18030, ГБ-18030-2000 UTF-7 CP932, MS932, Windows-31J, MS_Kanji ISO-8859-8, иврит ISO-8859-4, латиница4 ISO-8859-5, кириллица ISO-8859-6, арабский КОИ8-У ИСО-8859-13 ISO-2022-JP ИСО-8859-16 ISO-8859-10, латиница6 ISO-8859-3, латиница3 ISO-8859-14, латиница8 eucJP-выиграть, eucJP-открыть, eucJP-мс SJIS-win, SJIS-open, SJIS-ms EUC-TW, x-EUC-TW СР950 УВК, СР949 CP866, IBM866 ArmSCII-8 CP850, IBM850Текст
Здесь появится результат декодирования Base64Как декодировать Base64 онлайн с помощью этого инструмента декодера
 org/HowToStep»>
Вставьте свою строку в поле «Base64».
org/HowToStep»>
Вставьте свою строку в поле «Base64».- Выберите стандарт алгоритма (если не знаете, оставьте как есть, т.к. декодер определит его автоматически).
- Включите строгий режим декодирования, если вы хотите убедиться, что ваша строка Base64 содержит только допустимые символы.
- Если вы знаете, в какой кодировке были исходные данные, выберите ее в списке «Кодировка символов».
- Нажмите кнопку «Декодировать Base64».
- Загрузите или скопируйте результат из поля «Текст».
Стандарты, принимаемые онлайн-инструментом декодирования Base64
Чтобы претендовать на звание «лучший декодер Base64», он поддерживает следующие стандарты:
- Основной (используется по умолчанию всеми и везде)
- MIME (результат разбивается на фиксированные 76 строк и используется для кодирования содержимого электронной почты, такого как файлы или нелатинские буквы)
- ASCII Armor (используется OpenPGP, идентичен Base64 для MIME, но добавляет контрольную сумму ввода)
- Base64URL (в отличие от других стандартов, выходные данные этого стандарта можно безопасно использовать в качестве имени файла или URL-адреса)
- IMAP (используется протоколом доступа к сообщениям в Интернете в качестве международного соглашения об именах почтовых ящиков)
- PEM (устаревший стандарт, изначально использовавшийся протоколом Privacy-Enhanced Mail)
- xsd:NMTOKEN (предоставляет безопасные строки для использования в качестве действительных токенов имен XML)
- xsd:Name (предоставляет безопасные строки для использования в качестве действительных идентификаторов XML)
Кодировки символов, поддерживаемые декодером Base64
Кроме того, он может декодировать строки, закодированные с использованием следующих кодировок символов:
UTF-8, UTF-7, ASCII, ANSI_X3. 4-1968, iso-ir-6, ANSI_X3.4-1986, ISO_646.irv:1991, US-ASCII, ISO646-US, США, IBM367, cp367, csASCII , EUC-JP, EUC, x-euc-jp, SJIS, x-sjis, SHIFT-JIS, eucJP-win, eucJP-open, eucJP-ms, SJIS-win, SJIS-open, SJIS-ms, CP932, MS932, Windows-31J, MS_Kanji, ISO-2022-JP, GB18030, gb-18030-2000, Windows-1252, cp1252, Windows-1254, CP1254, ISO-8859-1, latin1, ISO-8859-2, latin2, ISO-8859-3, latin3, ISO-8859-4, latin4, ISO-8859-5, кириллица, ISO-8859-6, арабский, ISO-8859-7, греческий, ISO-8859-8, иврит, ISO-8859-9, latin5, ISO-8859-10, latin6, ISO-8859-13, ISO-8859-14, latin8, ISO-8859-15, ISO-8859-16, EUC-CN, CN-GB, x-euc-cn, gb2312, CP936, GBK, EUC-TW, x-euc-tw, BIG-5, CN-BIG5, BIG-FIVE, CP950, EUC-KR, x-euc-kr, UHC, CP949, Windows-1251, CP1251, CP866, IBM866, KOI8-R, KOI8-U, ArmSCII-8, CP850, IBM850
4-1968, iso-ir-6, ANSI_X3.4-1986, ISO_646.irv:1991, US-ASCII, ISO646-US, США, IBM367, cp367, csASCII , EUC-JP, EUC, x-euc-jp, SJIS, x-sjis, SHIFT-JIS, eucJP-win, eucJP-open, eucJP-ms, SJIS-win, SJIS-open, SJIS-ms, CP932, MS932, Windows-31J, MS_Kanji, ISO-2022-JP, GB18030, gb-18030-2000, Windows-1252, cp1252, Windows-1254, CP1254, ISO-8859-1, latin1, ISO-8859-2, latin2, ISO-8859-3, latin3, ISO-8859-4, latin4, ISO-8859-5, кириллица, ISO-8859-6, арабский, ISO-8859-7, греческий, ISO-8859-8, иврит, ISO-8859-9, latin5, ISO-8859-10, latin6, ISO-8859-13, ISO-8859-14, latin8, ISO-8859-15, ISO-8859-16, EUC-CN, CN-GB, x-euc-cn, gb2312, CP936, GBK, EUC-TW, x-euc-tw, BIG-5, CN-BIG5, BIG-FIVE, CP950, EUC-KR, x-euc-kr, UHC, CP949, Windows-1251, CP1251, CP866, IBM866, KOI8-R, KOI8-U, ArmSCII-8, CP850, IBM850
Почему онлайн-инструмент декодирования Base64 принимает недопустимые символы?
По умолчанию этот онлайн-инструмент декодирования Base64 удаляет символы вне алфавита Base64, что позволяет декодировать строки Base64, даже если они неприемлемы с точки зрения стандарта. Например, это позволяет избежать ошибок, если строка Base64 была скопирована с дополнительными пробелами или знаками препинания. Ю может легко отключить эту функцию, включив опцию «Строгое декодирование».
Например, это позволяет избежать ошибок, если строка Base64 была скопирована с дополнительными пробелами или знаками препинания. Ю может легко отключить эту функцию, включив опцию «Строгое декодирование».
Дополнительные инструменты для декодирования строки Base64
Существуют также некоторые дополнительные декодеры Base64, которые специализируются на декодировании данных определенного типа:
- ASCII-код
- Аудио
- Файл
- Шестнадцатеричный
- Изображение
- ПДФ
- Текст
- Видео
Онлайн калькулятор: Декодер текстовых файлов
Декодер текстовых файлов
С помощью этого калькулятора можно декодировать и читать текстовый файл в какой-либо кодировке.
До того, как Unicode стал популярным, для представления текстов на национальных языках (особенно для языков, не использующих латиницу) использовались различные кодировки символов.
Этот калькулятор может быть полезен для чтения текстового файла в устаревшей кодировке.
Чтобы увидеть содержимое старого текстового файла, загрузите его в калькулятор и выберите кодировку. В результате будет отображаться читаемый текст или набор бессмысленных символов, если кодировка выбрана неправильно.
Просмотр текстового файла
Текстовый файл
- Перетащите файлы сюда (CP869)DOS Иврит (CP862)DOS Исландский (CP861)DOS Latin 1 (CP850)DOS Latin 2 (CP852)DOS Latin US (CP437)DOS Nordic (CP865)DOS Португальский (CP860)DOS Турецкий (CP857)EBCDIC 037 США/ КанадаEBCDIC 1026 ТурецкийEBCDIC 424 ИвритEBCDIC 500 МеждународныйEBCDIC 875 ГреческийGSM 03.38ISO 8-битный урду (IBM CP1006)ISO 8859-5ISO 8859-6ISO 8859-7ISO 8859-8ISO 8859-9ISO-IR-68ISO/IEC 8859-1 (латиница-1)ISO/IEC 8859-10 (латиница-6)ISO/IEC 8859-11ISO/IEC 8859-13 (латиница-7)ISO/IEC 8859-14ISO/IEC 8859-15 (латиница-9)ISO/IEC 8859-16 (латиница-10)ISO/IEC 8859-2 (латиница-2)ISO/IEC 8859-3ISO/ IEC 8859-4 (Latin-4)KOI8-RKOI8-UKPS 9566KZ-1048Mac OS CelticMac OS Central EuropeanMac OS ХорватскийMac OS CyrillicMac OS DingbatsMac OS GaelicMac OS GreekMac OS IcelandicMac OS InuitMac OS RomanMac OS РумынскийMac OS TurkishUTF-8Windows-1250Windows-1251Windows-1252Windows -1253Windows-1254Windows-1255Windows-1256Windows-1257Windows-1258Windows-874Windows-932Windows-936Windows-949Windows-950
Если вы не можете выбрать правильную кодировку, вы можете использовать следующий калькулятор, чтобы определить ее полуавтоматически.
 Калькулятор попытается отобразить текст, используя все доступные кодировки. В результате одна из строк таблицы будет содержать правильно отображаемый фрагмент исходного текста; слева от него будет имя кодировки.
Калькулятор попытается отобразить текст, используя все доступные кодировки. В результате одна из строк таблицы будет содержать правильно отображаемый фрагмент исходного текста; слева от него будет имя кодировки. Поиск кодировки текстового файла
Текстовый файл
Перетащите файлы сюда
КодировкаAtari STCP 856 ИвритDOS Арабский (CP864)DOS Балтийский край (CP775)DOS Кириллица (CP855)DOS Кириллица Русский (CP866)DOS Французский Канада (CP863)DOS Греческий (CP737)DOS Греческий 2 (CP869)DOS Иврит ( CP862)DOS Исландский (CP861)DOS Latin 1 (CP850)DOS Latin 2 (CP852)DOS Latin US (CP437)DOS Nordic (CP865)DOS Португальский (CP860)DOS Турецкий (CP857)EBCDIC 037 США/КанадаEBCDIC 1026 ТурецкийEBCDIC 424 ИвритEBCDIC 500 МеждународныйEBCDIC 875 ГреческийGSM 03.38ISO 8-битный урду (IBM CP1006)ISO 8859-5ISO 8859-6ISO 8859-7ISO 8859-8ISO 8859-9ISO-IR-68ISO/IEC 8859-1 (латиница-1)ISO/IEC 8859-10 (латиница-6)ISO/IEC 8859-11ISO/IEC 8859-13 (латиница-7)ISO/IEC 8859-14ISO/IEC 8859-15 (латиница-9)ISO/IEC 8859-16 (латиница-10)ISO/IEC 8859-2 (латиница-2)ISO/IEC 8859-3ISO/ IEC 8859-4 (Latin-4)KOI8-RKOI8-UKPS 9566KZ-1048Mac OS CelticMac OS Central EuropeanMac OS ХорватскийMac OS CyrillicMac OS DingbatsMac OS GaelicMac OS GreekMac OS IcelandicMac OS InuitMac OS RomanMac OS РумынскийMac OS TurkishUTF-8Windows-1250Windows-1251Windows-1252Windows -1253Windows-1254Windows-1255Windows-1256Windows-1257Windows-1258Windows-874Windows-932Windows-936Windows-949Windows-950
Файл очень большой.