Декодирование текста . Мастерство учителя [Проверенные методики выдающихся преподавателей] [litres]
Декодирование – это процесс расшифровки письменного текста с целью идентификации представленных в нем устных слов. На первый взгляд декодирование может казаться простым делом, относительно низкого порядка, однако овладение им абсолютно необходимо для понимания любого текста и, следовательно, для изучения подавляющего большинства дисциплин. Это основа основ. Надо сказать, недостаточно развитый навык декодирования текста встречается отнюдь не только у учеников младших классов и негативно сказывается на достижениях даже в остальном весьма неплохо подготовленных детей. Если третьекласснику трудно прочесть два-три слова из предложения и ему приходится концентрировать всю энергию на соединении букв в слоги и слова, у него, скорее всего, остается слишком мало сил и ресурсов памяти, чтобы понять смысл всего предложения или даже чтобы помнить начало читаемой фразы к ее концу. Если ученик средней школы на уроке истории читает о причинах Гражданской войны, игнорируя при этом окончания слов, синтаксис предложений нарушается.
Учитывая несомненную важность декодирования текста на любом уровне, учитель должен стараться всегда, в любой ситуации, исправлять ошибки при применении данного навыка – какой бы предмет и в каком классе он ни преподавал. Поскольку эти ошибки часто указывают на более масштабный пробел в знаниях и навыках, можно воспользоваться двумя «антидотами»: во-первых, заучивать с детьми общие правила и, во-вторых, как можно чаще практиковать их в декодировании текстов.
Но какой же прием даст нужные результаты? Если на уроке английского языка ребенок не может прочесть, например, слово  Ну-ка, еще раз – как мы читаем might?» Данный подход обеспечивает сразу два преимущества: требует от ученика принять во внимание новую информацию, а затем правильно декодировать исходное слово и закрепляет в памяти ребенка правило, которое он сможет использовать при декодировании других похожих слов. Теперь, исправляя аналогичную ошибку в следующий раз, учитель может просто спросить: «-i-g-h-t читается?..» – и тем самым заставит ученика вспомнить и применить нужное правило. В большинстве случаев учителю следует позволять ученикам самостоятельно исправлять свои ошибки посредством применения соответствующих правил или новой информации. Данный прием направлен на исходные причины ошибки, а не просто на ее симптомы и в долгосрочной перспективе обычно дает отличные результаты.
Ну-ка, еще раз – как мы читаем might?» Данный подход обеспечивает сразу два преимущества: требует от ученика принять во внимание новую информацию, а затем правильно декодировать исходное слово и закрепляет в памяти ребенка правило, которое он сможет использовать при декодировании других похожих слов. Теперь, исправляя аналогичную ошибку в следующий раз, учитель может просто спросить: «-i-g-h-t читается?..» – и тем самым заставит ученика вспомнить и применить нужное правило. В большинстве случаев учителю следует позволять ученикам самостоятельно исправлять свои ошибки посредством применения соответствующих правил или новой информации. Данный прием направлен на исходные причины ошибки, а не просто на ее симптомы и в долгосрочной перспективе обычно дает отличные результаты.
Впрочем, если говорить об английском языке, то исключения тут – правила, и это, по сути, главная отличительная характеристика данного языка. Многие слова декодировать невозможно, или это очень уж неблагодарное дело. Слова вроде might обычно просто заучиваются, так как общие правила на них не распространяются. В ситуациях, когда самокоррекция невозможна, задача учителя заключается в том, чтобы распознать такой случай, а не тратить на эти слова ценное время, лишь усугубляя путаницу в головах учащихся.
Слова вроде might обычно просто заучиваются, так как общие правила на них не распространяются. В ситуациях, когда самокоррекция невозможна, задача учителя заключается в том, чтобы распознать такой случай, а не тратить на эти слова ценное время, лишь усугубляя путаницу в головах учащихся.
Электронный научный архив УрФУ: Декодирование аллюзий в переводах текстов публичных выступлений (на материале речей Си Цзиньпина) : магистерская диссертация
http://hdl.handle.net/10995/114741| Title: | Декодирование аллюзий в переводах текстов публичных выступлений (на материале речей Си Цзиньпина) : магистерская диссертация |
| Other Titles: | Decoding Allusions in Translations of the Texts of Public Speaking (based on the material of Xi Jinping’s Speeches) |
| Authors: | Сапко, Е. Д. Д.Sapko, E. D. |
| metadata.dc.contributor.advisor: | Зубакина, Т. Н. Zubakina, T. N. |
| Issue Date: | 2022 |
| Publisher: | б. и. |
| Citation: | Сапко Е. Д. Декодирование аллюзий в переводах текстов публичных выступлений (на материале речей Си Цзиньпина) : магистерская диссертация / Е. Д. Сапко ; Уральский федеральный университет имени первого Президента России Б. Н. Ельцина, Уральский гуманитарный институт, Кафедра лингвистики и профессиональной коммуникации на иностранных языках. — Екатеринбург, 2022. — 110 с. — Библиогр.: с. 76-88 (117 назв.). |
| Abstract: | Работа посвящена изучению особенностей декодирования культурно-кодового значения, которое заложено в аллюзивный контекст риторики оратора, на примере речей Си Цзиньпина и их переводов на английский и русский языки. Исследование основывается на положении, что аллюзия, являясь когнитивной категорией, имеет культурно-кодовое значение, которое отражается не только в словарном понятийном содержании, но и в системе экстралингвистических знаний, ассоциаций и образов, обретающих смысл, закрепленный в культуре языковой общности, что обусловливает многоаспектный характер декодирования этого значения.  Логика построения и описания системы аллюзивных языковых единиц учитывает полиаспектность изучения процесса декодирования аллюзии в текстах публичных выступлений и их переводах. Подчеркивается, что аллюзии в выступлениях Си Цзиньпина и их смысловые соответствия в текстах переводов обращены как к внутреннему (носителю китайского языка), так и к внешнему (иноязычной аудитории) адресатам. В результате, сопоставление переводов аллюзивных единиц с оригиналом позволяет сделать вывод, что в двуязычных переводах фрагментов речи оратора представлено неискаженное восприятие оригинального текста: авторская мысль передается без утраты исходного смысла, заложенного в аллюзии, и сохраняется образная нагрузка источника прецедентных языковых единиц. Результаты исследования могут быть использованы в практике преподавания лингвистических дисциплин, а также курсов, связанных с теорией перевода, теорией межкультурной коммуникации, стилистикой текста и лингвокультурологией. Логика построения и описания системы аллюзивных языковых единиц учитывает полиаспектность изучения процесса декодирования аллюзии в текстах публичных выступлений и их переводах. Подчеркивается, что аллюзии в выступлениях Си Цзиньпина и их смысловые соответствия в текстах переводов обращены как к внутреннему (носителю китайского языка), так и к внешнему (иноязычной аудитории) адресатам. В результате, сопоставление переводов аллюзивных единиц с оригиналом позволяет сделать вывод, что в двуязычных переводах фрагментов речи оратора представлено неискаженное восприятие оригинального текста: авторская мысль передается без утраты исходного смысла, заложенного в аллюзии, и сохраняется образная нагрузка источника прецедентных языковых единиц. Результаты исследования могут быть использованы в практике преподавания лингвистических дисциплин, а также курсов, связанных с теорией перевода, теорией межкультурной коммуникации, стилистикой текста и лингвокультурологией. The study is based on the statement that the allusion, being a cognitive category, has a cultural-code meaning, which is reflected not only in the vocabulary conceptual content, but also in the system of extralinguistic knowledge, associations and images that acquire meaning, enshrined in the culture of linguistic community, that determines the multidimensional nature of the decoding this meaning. The interpretation of allusive language units is carried out in accordance with three aspects: pragmatic, philosophical and figurative. 93 text fragments contained allusive contexts are analyzed in the study. In the first chapter, theoretical and methodological issues are considered, based on the scientific works of I. V. Arnold, M. M. Bakhtin, Yu. N. Karaulov, Yu. Kristeva, Yu. M. Lotman, A. P. Chudinov, U. Eco and etc., which reveal the interaction aspects of the concepts «language», «culture», «cultural code» and describe the phenomena «intertextuality» and «precedent text» as linguoculturological phenomena. The study is based on the statement that the allusion, being a cognitive category, has a cultural-code meaning, which is reflected not only in the vocabulary conceptual content, but also in the system of extralinguistic knowledge, associations and images that acquire meaning, enshrined in the culture of linguistic community, that determines the multidimensional nature of the decoding this meaning. The interpretation of allusive language units is carried out in accordance with three aspects: pragmatic, philosophical and figurative. 93 text fragments contained allusive contexts are analyzed in the study. In the first chapter, theoretical and methodological issues are considered, based on the scientific works of I. V. Arnold, M. M. Bakhtin, Yu. N. Karaulov, Yu. Kristeva, Yu. M. Lotman, A. P. Chudinov, U. Eco and etc., which reveal the interaction aspects of the concepts «language», «culture», «cultural code» and describe the phenomena «intertextuality» and «precedent text» as linguoculturological phenomena. Particular attention is given to the functioning of allusions in the text of public speaking and to the features of their decoding in translation, the concept of cultural-code meaning is also introduced. The main statements of P. Ricoeur’s «interpretation theory», which implies a great number of text interpretations, are represented in the chapter. In the second chapter of the study, the algorithm is proposed for the interpretative analysis of figurative units in the speech of Xi Jinping by comparing their representations in three languages. The compilation and description of the allusive language units system reflects the multidimensional aspect of decoding allusion process in the texts of public speaking and their translations. It is underlined that the allusions in the speech of the Chinese leader and their semantic correspondences in the translation texts are addressed both to the internal (native Chinese speaker) and to the external (foreign-language audience) addressees. As a result, comparing translations of allusive units with the original ones, we conclude that bilingual fragment translations of the speaker’s speech present an undistorted perception of the original text: the author’s thought is transmitted without the loss of the original meaning of an allusion, and the figurative component of the source of precedent language units is preserved. Particular attention is given to the functioning of allusions in the text of public speaking and to the features of their decoding in translation, the concept of cultural-code meaning is also introduced. The main statements of P. Ricoeur’s «interpretation theory», which implies a great number of text interpretations, are represented in the chapter. In the second chapter of the study, the algorithm is proposed for the interpretative analysis of figurative units in the speech of Xi Jinping by comparing their representations in three languages. The compilation and description of the allusive language units system reflects the multidimensional aspect of decoding allusion process in the texts of public speaking and their translations. It is underlined that the allusions in the speech of the Chinese leader and their semantic correspondences in the translation texts are addressed both to the internal (native Chinese speaker) and to the external (foreign-language audience) addressees. As a result, comparing translations of allusive units with the original ones, we conclude that bilingual fragment translations of the speaker’s speech present an undistorted perception of the original text: the author’s thought is transmitted without the loss of the original meaning of an allusion, and the figurative component of the source of precedent language units is preserved. |
| Keywords: | МАГИСТЕРСКАЯ ДИССЕРТАЦИЯ MASTER’S THESIS АЛЛЮЗИЯ КУЛЬТУРНЫЙ КОД КУЛЬТУРНО-КОДОВОЕ ЗНАЧЕНИЕ ИНТЕРТЕКСТУАЛЬНОСТЬ ИНТЕРПРЕТАЦИЯ ПУБЛИЧНОЕ ВЫСТУПЛЕНИЕ ALLUSION CULTURAL CODE ICULTURAL CODE MEANING NTERTEXTUALITY INTERPRETATION PUBLIC SPEAKING |
| URI: | http://hdl.handle.net/10995/114741 |
| Access: | Предоставлено автором на условиях простой неисключительной лицензии |
| License text: | http://hdl.handle.net/10995/31613 |
| Appears in Collections: | Магистерские диссертации |
Show full item record Google Scholar
Items in DSpace are protected by copyright, with all rights reserved, unless otherwise indicated.
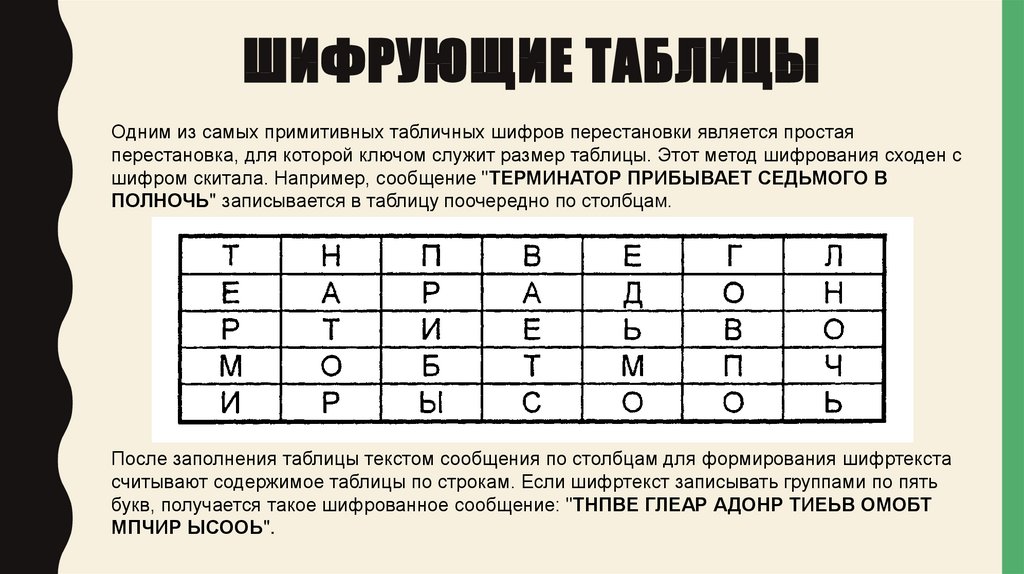
Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст
Чао Чжао, Мэрилин Уокер, Snigdha Chaturvedi
Abstract
Генерация последовательных описаний на естественном языке из структурированных графом данных (например, графа знаний) является сложной задачей, отчасти из-за структурных различий между входным графом и выходным текстом. Следовательно, популярные модели последовательностей, требующие сериализованного ввода, не подходят для этой задачи естественным образом. Графовые нейронные сети, с другой стороны, могут лучше кодировать входной граф, но расширяют структурный разрыв между кодировщиком и декодером, затрудняя точное генерирование. Чтобы сократить этот разрыв, мы предлагаем DualEnc, модель двойного кодирования, которая может не только включать структуру графа, но и обеспечивать линейную структуру выходного текста. Эмпирические сравнения с надежными базовыми показателями одиночного кодировщика показывают, что двойное кодирование может значительно улучшить качество генерируемого текста.
- Идентификатор антологии:
- 2020.ACL-MAIN.224
- Том:
- Материалы 58-й ежегодной встречи Ассоциации для вычислительной лингвистики
- Месяц:
- июля
- Год:
- 2010
- июля
- Год:
- 2010
- . Аддри
- Год:
- 202013
- . Адрес. :
- онлайн
- Место проведения:
- ACL
- SIG:
- Издатель:
- Ассоциация для вычислительной лингвистики
- Примечание:
- Страницы:
- 2481–2491
- Language:
- URL:
- https://aclanthology.org/2020.acl-main.224
- DOI:
- 10.18653/v1/2020.acl-main.224
- Bibkey:
- Процитируйте (ACL):
- Чао Чжао, Мэрилин Уокер и Снигдха Чатурведи. 2020. Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст. В материалах 58-го ежегодного собрания Ассоциации компьютерной лингвистики , , страницы 2481–2491, онлайн.
 Ассоциация компьютерной лингвистики.
Ассоциация компьютерной лингвистики. - Процитируйте (неофициально):
- Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст (Zhao et al., ACL 2020)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2020.acl-main.224.pdf
- Видео:
- http://slideslive.com/38929169
PDF Процитировать Поиск Видео
- BibTeX
- MODS XML
- Сноска
- Предварительно отформатированный
@inproceedings{zhao-etal-2020-bridging,
title = "Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст",
автор = "Чжао, Чао и
Уокер, Мэрилин и
Чатурведи, Снигдха",
booktitle = "Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики",
месяц = июль,
год = "2020",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology. org/2020.acl-main.224",
doi = "10.18653/v1/2020.acl-main.224",
страницы = "2481--2491",
abstract = "Генерация последовательных описаний на естественном языке из структурированных графом данных (например, графа знаний) является сложной задачей, отчасти из-за структурных различий между входным графом и выходным текстом. Следовательно, популярные модели последовательностей, которые требуют сериализованных ввод, не подходят для этой задачи естественным образом. С другой стороны, графовые нейронные сети могут лучше кодировать входной граф, но расширяют структурный разрыв между кодировщиком и декодером, затрудняя точное генерирование. Чтобы сократить этот разрыв, мы предлагаем DualEnc , модель двойного кодирования, которая может не только включать структуру графа, но также может учитывать линейную структуру выходного текста. Эмпирические сравнения с сильными базовыми показателями одиночного кодировщика показывают, что двойное кодирование может значительно улучшить качество генерируемого текста».
org/2020.acl-main.224",
doi = "10.18653/v1/2020.acl-main.224",
страницы = "2481--2491",
abstract = "Генерация последовательных описаний на естественном языке из структурированных графом данных (например, графа знаний) является сложной задачей, отчасти из-за структурных различий между входным графом и выходным текстом. Следовательно, популярные модели последовательностей, которые требуют сериализованных ввод, не подходят для этой задачи естественным образом. С другой стороны, графовые нейронные сети могут лучше кодировать входной граф, но расширяют структурный разрыв между кодировщиком и декодером, затрудняя точное генерирование. Чтобы сократить этот разрыв, мы предлагаем DualEnc , модель двойного кодирования, которая может не только включать структуру графа, но также может учитывать линейную структуру выходного текста. Эмпирические сравнения с сильными базовыми показателями одиночного кодировщика показывают, что двойное кодирование может значительно улучшить качество генерируемого текста». ,
}
,
}
<моды> <информация о заголовке> Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст <название типа="личное">Чао Чжао <роль>автор <название типа="личное">Мэрилин Уокер <роль>автор <название типа="личное">Снигдха Чатурведи <роль>автор <информация о происхождении>2020-07 текст <информация о заголовке> Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики <информация о происхождении>Ассоциация компьютерной лингвистики <место>Онлайн публикация конференции Создание последовательных описаний на естественном языке из графически структурированных данных (например, графа знаний) является сложной задачей, отчасти из-за структурных различий между входным графом и выходным текстом. Следовательно, популярные модели последовательностей, требующие сериализованного ввода, не подходят для этой задачи естественным образом. Графовые нейронные сети, с другой стороны, могут лучше кодировать входной граф, но расширяют структурный разрыв между кодировщиком и декодером, затрудняя точное генерирование. Чтобы сократить этот разрыв, мы предлагаем DualEnc, модель двойного кодирования, которая может не только включать структуру графа, но и обеспечивать линейную структуру выходного текста. Эмпирические сравнения с надежными базовыми показателями одиночного кодировщика показывают, что двойное кодирование может значительно улучшить качество генерируемого текста.
zhao-etal-2020-bridge 10.18653/v1/2020.acl-main.224 <местоположение> https://aclanthology.org/2020.acl-main.224 <часть> <дата>2020-07 <единица экстента="страница">2481 <конец>2491
%0 Материалы конференции %T Преодоление структурного разрыва между кодированием и декодированием для генерации данных в текст %А Чжао, Чао %A Уокер, Мэрилин % А Чатурведи, Снигдха %S Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики %D 2020 %8 июля %I Ассоциация компьютерной лингвистики %С онлайн %F zhao-etal-2020-мост %X Генерация последовательных описаний на естественном языке из графически структурированных данных (например, графа знаний) является сложной задачей, отчасти из-за структурных различий между входным графом и выходным текстом.Следовательно, популярные модели последовательностей, требующие сериализованного ввода, не подходят для этой задачи естественным образом. Графовые нейронные сети, с другой стороны, могут лучше кодировать входной граф, но расширяют структурный разрыв между кодировщиком и декодером, затрудняя точное генерирование. Чтобы сократить этот разрыв, мы предлагаем DualEnc, модель двойного кодирования, которая может не только включать структуру графа, но и обеспечивать линейную структуру выходного текста. Эмпирические сравнения с надежными базовыми показателями одиночного кодировщика показывают, что двойное кодирование может значительно улучшить качество генерируемого текста. %R 10.18653/v1/2020.acl-main.224 %U https://aclanthology.org/2020.acl-main.224 %U https://doi.org/10.18653/v1/2020.acl-main.224 %Р 2481-2491
Markdown (неофициальный)
[Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст] (https://aclanthology.org/2020.acl-main.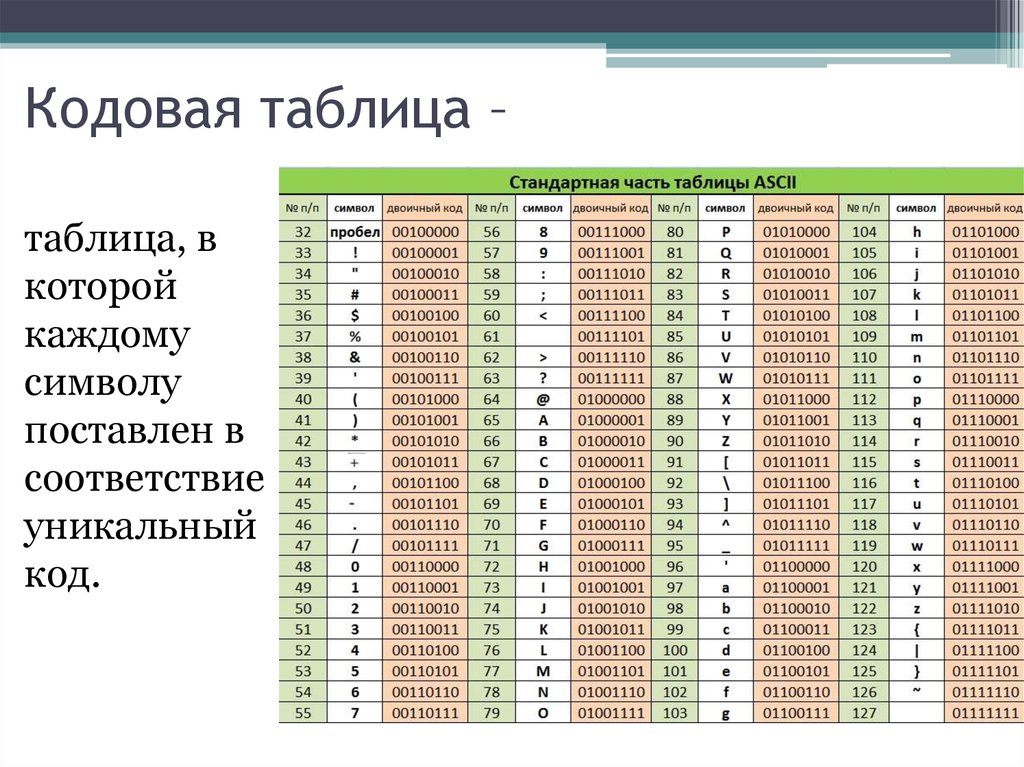 224) (Zhao et al., ACL 2020) )
224) (Zhao et al., ACL 2020) )
- Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст (Чжао и др., ACL 2020)
ACL
- Чао Чжао, Мэрилин Уокер и Снигдха Чатурведи. 2020. Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст. В Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики , страницы 2481–2491, Интернет. Ассоциация компьютерной лингвистики.
Метод декодирования строк Python ()
Сохранить статью
- Уровень сложности: Easy
- Последнее обновление: 16 Дек, 2022
Улучшить статью
Сохранить статью
decode() — это метод, указанный в Strings в Python 2. Этот метод используется для преобразования из одной схемы кодирования, в которой строка аргумента кодируется в желаемую схему кодирования. Это работает противоположно кодированию. Он принимает кодировку строки кодирования для ее декодирования и возвращает исходную строку .
Он принимает кодировку строки кодирования для ее декодирования и возвращает исходную строку .
Синтаксис:
декодирование(кодирование, ошибка) Параметры:
кодирование: Указывает кодировку, на основе которой должно выполняться декодирование.
ошибка : Решает, как обрабатывать ошибки, если они возникают, например, «строгий» вызывает ошибку Unicode в случае исключения, а «игнорировать» игнорирует возникшие ошибки.
Возвраты: Возвращает исходную строку из закодированной строки.
Code #1 : Code to decode the string
Python3
99 »0180 is |
 encode(encoding
encode(encoding  decode(
decode( Output:
Закодированная строка в формате base64: Z2Vla3Nmb3JnZWVrcw== Расшифрованная строка: geeksforgeeks
Приложение: Кодирование и декодирование вместе могут использоваться в простых приложениях для хранения паролей в серверной части и во многих других приложениях, таких как криптография, которые имеют дело с конфиденциальностью информации. Небольшая демонстрация приложения пароля изображена ниже.
Code #2 : Code to demonstrate application of encode-decode
Python3
|
 encode (
encode (