кодировка — python — как раскодировать любую кодировку в utf-8?
Вопрос задан
Изменён 1 год 5 месяцев назад
Просмотрен 415 раз
письма приходят на почту в разных кодировках, мне нужно достать текст из письма, но он бывает в разных кодировках (эта кодировка также задается в параметрах письма). Но у меня не получается раскодировать все текста сообщений, чтобы получить текст. Код получения писем скопировал с сайта http://espressocode.top/python-fetch-your-gmail-emails-from-a-particular-user/:
import email, imaplib user = '[email protected]' password = 'parol' imap_url = 'imap.gmail.com' # Функция для получения части содержимого электронной почты, т.е. его части тела def get_body(msg): if msg.is_multipart(): return get_body(msg.get_payload(0)) else: return msg.get_payload(None, True) # Функция для поиска пары ключ-значение def search(key, value, con): result, data = con.search(None, key, '"{}"'.format(value)) return data # Функция для получения списка электронных писем под этим ярлыком def get_emails(result_bytes): msgs = [] # все данные электронной почты помещаются в массив for num in result_bytes[0].split(): typ, data = con.fetch(num, '(RFC822)') msgs.append(data) return msgs # это сделано для соединения SSL с GMAIL con = imaplib.IMAP4_SSL(imap_url) # вход пользователя в con.login(user, password) # вызов функции для проверки электронной почты под этим ярлыком con.select('Inbox') # получение писем от этого пользователя "tu**h*****[email protected]" msgs = get_emails(search('FROM', '[email protected]', con)) # Поиск необходимого контента в наших сообщениях # Пользователь может вносить пользовательские изменения в этой части # получить необходимый контент, который ему нужен # распечатывать их в порядке их отображения в вашем Gmail for msg in msgs[::-1]: for sent in msg: if type(sent) is tuple: # кодировка установлена как utf-8 content = str(sent[1], 'utf-8') data = str(content) # Обработка ошибок, связанных с unicodenecode try: print(data) except UnicodeEncodeError as e: pass break
 is_multipart():
return get_body(msg.get_payload(0))
else:
return msg.get_payload(None, True)
# Функция для поиска пары ключ-значение
def search(key, value, con):
result, data = con.search(None, key, '"{}"'.format(value))
return data
# Функция для получения списка электронных писем под этим ярлыком
def get_emails(result_bytes):
msgs = [] # все данные электронной почты помещаются в массив
for num in result_bytes[0].split():
typ, data = con.fetch(num, '(RFC822)')
msgs.append(data)
return msgs
# это сделано для соединения SSL с GMAIL
con = imaplib.IMAP4_SSL(imap_url)
# вход пользователя в
con.login(user, password)
# вызов функции для проверки электронной почты под этим ярлыком
con.select('Inbox')
# получение писем от этого пользователя "tu**h*****
is_multipart():
return get_body(msg.get_payload(0))
else:
return msg.get_payload(None, True)
# Функция для поиска пары ключ-значение
def search(key, value, con):
result, data = con.search(None, key, '"{}"'.format(value))
return data
# Функция для получения списка электронных писем под этим ярлыком
def get_emails(result_bytes):
msgs = [] # все данные электронной почты помещаются в массив
for num in result_bytes[0].split():
typ, data = con.fetch(num, '(RFC822)')
msgs.append(data)
return msgs
# это сделано для соединения SSL с GMAIL
con = imaplib.IMAP4_SSL(imap_url)
# вход пользователя в
con.login(user, password)
# вызов функции для проверки электронной почты под этим ярлыком
con.select('Inbox')
# получение писем от этого пользователя "tu**h*****При кодировке 8bit письма перекодируются в нормальную (читабельную) кодировку, но когда приходят другие кодировки, например base64, то перекодирование не срабатывает.
- python
- кодировка
- почта
Зарегистрируйтесь или войдите
Регистрация через GoogleОтправить без регистрации
ПочтаНеобходима, но никому не показывается
Отправить без регистрации
ПочтаНеобходима, но никому не показывается
By clicking “Отправить ответ”, you agree to our terms of service and acknowledge that you have read and understand our privacy policy and code of conduct.
Python Декодирование байтов в UTF-8
Вопрос задан
Изменён 4 года 2 месяца назад
Просмотрен 4k раза
Есть функция, которая читает файл побайтового. Нужно перевести файл в кодировку UTF-8. Пробовал использовать такой код для чтения файла
def readTags(filepath):
with open(filepath, 'rb') as f:
byte = f.read()
print(byte)
while byte:
byte = f.read()
try:
print(byte.decode('utf-8'))
except Exception as e:
continue
Но байты остаются в стандартном виде, т.е.
\xd0\xa1\xd0\xbf\xd0\xb0\xd1\x81\xd0\xb8\xd0\xb1\xd0\xbe \xd0\xb7\xd0\xb0 \xd0\xbf\xd0\xbe\xd0\xbc\xd0\xbe\xd1\x89\xd1\x8c
Как можно перевести данные байты в строку?
- python-3.
byte = f.read()
в данном случае читает весь файл, весь же файл лучше и декодировать.
with open(filepath, 'rb') as f:
bs = f.read()
print(bs.decode('utf-8'))
только тогда лучше воспользоваться сразу текстовым режимом
with open(filepath, 'r', encoding='utf-8') as f:
cs = f.read()
print(cs)
Если же читать нужно именно побайтно, тут нужно понимать — utf-8 мультибайтовая кодировка, каждый символ может занимать как один так и несколько байт. Поэтому все равно получается не строго побайтовое кодирование.
import codecs
decoder = codecs.getincrementaldecoder('utf-8')()
with open('utf.txt', 'rb') as f:
while True:
bt = f.read(1)
if bt == b'':
break
print('byte:', bt, 'chars:', decoder.decode(bt))
decoder.decode(b'', True)
byte: b'\xd0' chars: byte: b'\xa1' chars: С byte: b'\xd0' chars: byte: b'\xbf' chars: п byte: b'\xd0' chars: byte: b'\xb0' chars: а byte: b'\xd1' chars: byte: b'\x81' chars: с byte: b'\xd0' chars: byte: b'\xb8' chars: и byte: b'\xd0' chars: byte: b'\xb1' chars: б byte: b'\xd0' chars: byte: b'\xbe' chars: о
bytes = b'\xd0\xa1\xd0\xbf\xd0\xb0\xd1\x81\xd0\xb8\xd0\xb1\xd0\xbe \xd0\xb7\xd0\xb0 \xd0\xbf\xd0\xbe\xd0\xbc\xd0\xbe\xd1\x89\xd1\x8c' print(bytes.3decode()) Спасибо за помощь
Зарегистрируйтесь или войдите
Регистрация через Google Регистрация через Facebook Регистрация через почтуОтправить без регистрации
ПочтаНеобходима, но никому не показывается
Отправить без регистрации
ПочтаНеобходима, но никому не показывается
By clicking “Отправить ответ”, you agree to our terms of service and acknowledge that you have read and understand our privacy policy and code of conduct.
Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст
Чао Чжао, Мэрилин Уокер, Snigdha Chaturvedi
Abstract
Генерация последовательных описаний на естественном языке из структурированных графом данных (например, графа знаний) является сложной задачей, отчасти из-за структурных различий между входным графом и выходным текстом.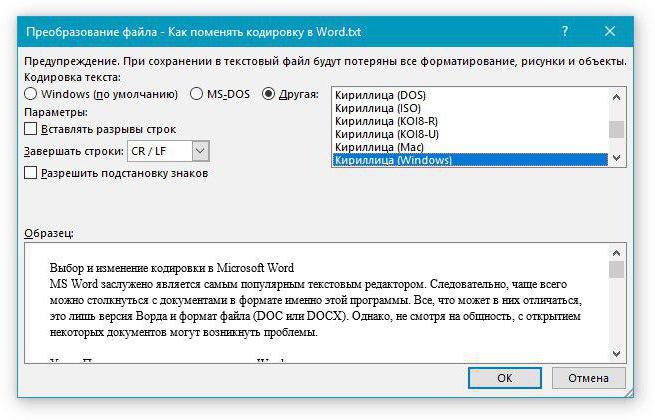 Следовательно, популярные модели последовательностей, которые требуют сериализованного ввода, не подходят для этой задачи естественным образом. Графовые нейронные сети, с другой стороны, могут лучше кодировать входной граф, но расширяют структурный разрыв между кодировщиком и декодером, затрудняя точное генерирование. Чтобы сократить этот разрыв, мы предлагаем DualEnc, модель двойного кодирования, которая может не только включать структуру графа, но и обеспечивать линейную структуру выходного текста. Эмпирические сравнения с надежными базовыми показателями одиночного кодировщика показывают, что двойное кодирование может значительно улучшить качество генерируемого текста.
Следовательно, популярные модели последовательностей, которые требуют сериализованного ввода, не подходят для этой задачи естественным образом. Графовые нейронные сети, с другой стороны, могут лучше кодировать входной граф, но расширяют структурный разрыв между кодировщиком и декодером, затрудняя точное генерирование. Чтобы сократить этот разрыв, мы предлагаем DualEnc, модель двойного кодирования, которая может не только включать структуру графа, но и обеспечивать линейную структуру выходного текста. Эмпирические сравнения с надежными базовыми показателями одиночного кодировщика показывают, что двойное кодирование может значительно улучшить качество генерируемого текста. - Идентификатор антологии:
- 2020.acl-main.224
- Том:
- Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики
- Месяц: 900 12 июля
- Год:
- 2020
- Адрес :
- Online
- Место проведения:
- ACL
- SIG:
- Издатель:
- Примечание:
- Страницы:
- 2481–2491
- Язык:
- URL:
- https://aclanthology.
 org/2020.acl-main.224
org/2020.acl-main.224 - DOI:
- 10.18653/v1/2020.acl-main.2 24
- Биб-ключ:
- Процитируйте (ACL):
- Чао Чжао, Мэрилин Уокер и Снигдха Чатурведи. 2020. Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст. В материалах 58-го ежегодного собрания Ассоциации компьютерной лингвистики , , страницы 2481–2491, онлайн. Ассоциация компьютерной лингвистики.
- Процитируйте (неофициально):
- Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст (Zhao et al., ACL 2020)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2020.acl-main.224.pdf
- Видео:
- http://slideslive.com/38929169
90 083 PDF Процитировать Поиск Видео
- BibTeX
- MODS XML
- Сноска
- Предварительно отформатированный
@inproceedings{zhao-etal-2020-bridging,
title = "Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст",
автор = "Чжао, Чао и
Уокер, Мэрилин и
Чатурведи, Снигдха",
booktitle = "Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики",
месяц = июль,
год = "2020",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology. org/2020.acl-main.224",
doi = "10.18653/v1/2020.acl-main.224",
страницы = "2481--2491",
abstract = "Генерация последовательных описаний на естественном языке из структурированных графом данных (например, графа знаний) является сложной задачей, отчасти из-за структурных различий между входным графом и выходным текстом. Следовательно, популярные модели последовательностей, которые требуют сериализованных ввод, не подходят для этой задачи естественным образом. С другой стороны, графовые нейронные сети могут лучше кодировать входной граф, но расширяют структурный разрыв между кодировщиком и декодером, затрудняя точное генерирование. Чтобы сократить этот разрыв, мы предлагаем DualEnc , модель двойного кодирования, которая может не только включать структуру графа, но также может учитывать линейную структуру выходного текста. Эмпирические сравнения с сильными базовыми показателями одиночного кодировщика показывают, что двойное кодирование может значительно улучшить качество генерируемого текста».
org/2020.acl-main.224",
doi = "10.18653/v1/2020.acl-main.224",
страницы = "2481--2491",
abstract = "Генерация последовательных описаний на естественном языке из структурированных графом данных (например, графа знаний) является сложной задачей, отчасти из-за структурных различий между входным графом и выходным текстом. Следовательно, популярные модели последовательностей, которые требуют сериализованных ввод, не подходят для этой задачи естественным образом. С другой стороны, графовые нейронные сети могут лучше кодировать входной граф, но расширяют структурный разрыв между кодировщиком и декодером, затрудняя точное генерирование. Чтобы сократить этот разрыв, мы предлагаем DualEnc , модель двойного кодирования, которая может не только включать структуру графа, но также может учитывать линейную структуру выходного текста. Эмпирические сравнения с сильными базовыми показателями одиночного кодировщика показывают, что двойное кодирование может значительно улучшить качество генерируемого текста».
,
}
<моды> <информация о заголовке> Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст <название типа="личное">Чао Чжао <роль>автор <название типа="личное">Мэрилин Уокер <роль>автор <название типа="личное">Снигдха Чатурведи <роль>автор <информация о происхождении>2020-07 текст <информация о заголовке> Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики <информация о происхождении>Ассоциация компьютерной лингвистики <место>Онлайн публикация конференции Создание последовательных описаний на естественном языке из графически структурированных данных (например, графа знаний) является сложной задачей, отчасти из-за структурных различий между входным графом и выходным текстом. Следовательно, популярные модели последовательностей, которые требуют сериализованного ввода, не подходят для этой задачи естественным образом. Графовые нейронные сети, с другой стороны, могут лучше кодировать входной граф, но расширяют структурный разрыв между кодировщиком и декодером, затрудняя точное генерирование. Чтобы сократить этот разрыв, мы предлагаем DualEnc, модель двойного кодирования, которая может не только включать структуру графа, но и обеспечивать линейную структуру выходного текста. Эмпирические сравнения с надежными базовыми показателями одиночного кодировщика показывают, что двойное кодирование может значительно улучшить качество генерируемого текста.
zhao-etal-2020-bridge 10.18653/v1/2020.acl-main.224 <местоположение> https://aclanthology.org/2020.acl-main.224 <часть> <дата>2020-07 <единица экстента="страница">2481 <конец>2491
%0 Материалы конференции %T Преодоление структурного разрыва между кодированием и декодированием для генерации данных в текст %А Чжао, Чао %A Уокер, Мэрилин % А Чатурведи, Снигдха %S Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики %D 2020 %8 июля %I Ассоциация компьютерной лингвистики %С онлайн %F zhao-etal-2020-мост %X Генерация последовательных описаний на естественном языке из графически структурированных данных (например, графа знаний) является сложной задачей, отчасти из-за структурных различий между входным графом и выходным текстом.Следовательно, популярные модели последовательностей, которые требуют сериализованного ввода, не подходят для этой задачи естественным образом. Графовые нейронные сети, с другой стороны, могут лучше кодировать входной граф, но расширяют структурный разрыв между кодировщиком и декодером, затрудняя точное генерирование. Чтобы сократить этот разрыв, мы предлагаем DualEnc, модель двойного кодирования, которая может не только включать структуру графа, но и обеспечивать линейную структуру выходного текста. Эмпирические сравнения с надежными базовыми показателями одиночного кодировщика показывают, что двойное кодирование может значительно улучшить качество генерируемого текста. %R 10.18653/v1/2020.acl-main.224 %U https://aclanthology.org/2020.acl-main.224 %U https://doi.org/10.18653/v1/2020.acl-main.224 %Р 2481-2491
Markdown (неофициальный)
[Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст] (https://aclanthology.org/2020. acl-main.224) (Zhao et al., ACL 2020) )
acl-main.224) (Zhao et al., ACL 2020) )
- Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст (Чжао и др., ACL 2020)
ACL
- Чао Чжао, Мэрилин Уокер и Снигдха Чатурведи. 2020. Преодоление структурного разрыва между кодированием и декодированием для преобразования данных в текст. В Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики , страницы 2481–2491, Интернет. Ассоциация компьютерной лингвистики.
с использованием различных методов декодирования для генерации языка с помощью Transformers
Назад к блогуОпубликовано 1 марта 2020 г. Обновление на GitHub
патриквонплатен Патрик фон ПлатенВведение
В последние годы возрос интерес к открытым
генерация языка благодаря появлению крупных трансформеров
языковые модели, обученные на миллионах веб-страниц, таких как знаменитая платформа OpenAI
Модель GPT2. результаты по генерации условного открытого языка впечатляют,
например GPT2 включен
единороги,
XLNet,
Контролируемый язык с
КОНТР.
Помимо улучшенной архитектуры трансформатора и массивного неконтролируемого
тренировочные данные, лучшие методы декодирования также сыграли важную роль
роль.
результаты по генерации условного открытого языка впечатляют,
например GPT2 включен
единороги,
XLNet,
Контролируемый язык с
КОНТР.
Помимо улучшенной архитектуры трансформатора и массивного неконтролируемого
тренировочные данные, лучшие методы декодирования также сыграли важную роль
роль.
В этом сообщении блога дается краткий обзор различных стратегий декодирования.
и, что более важно, показывает, как вы можете реализовать их с очень небольшими затратами
усилия, используя популярную библиотеку трансформаторов !
Все следующие функции могут использоваться для авторегрессии генерация языка (здесь освежитель). Короче говоря, авторегрессивное поколение языка основано в предположении, что распределение вероятностей последовательности слов можно разложить на произведение условного следующего слова раздачи: 9T P(w_{t} | w_{1: t-1}, W_0) \text{ ,с } w_{1:0} = \emptyset, P(w1:T∣W0)=t=1∏T P(wt∣w1:t−1,W0) , где w1:0=∅,
и W0W_0W0 – исходная контекстная последовательность слов. Длина ТТТ
последовательности слов обычно определяется на лету и соответствует
к временному шагу t=Tt=Tt=T токен EOS генерируется из P(wt∣w1:t−1,W0)P(w_{t} | w_{1: t-1}, W_{0})P (вес∣w1:t−1,W0).
Длина ТТТ
последовательности слов обычно определяется на лету и соответствует
к временному шагу t=Tt=Tt=T токен EOS генерируется из P(wt∣w1:t−1,W0)P(w_{t} | w_{1: t-1}, W_{0})P (вес∣w1:t−1,W0).
Генерация авторегрессивного языка теперь доступна для GPT2 , XLNet , OpenAi-GPT , CTRL , TransfoXL , XLM , Bart , T5 в обоих
PyTorch и Tensorflow >= 2.0!
Мы проведем экскурсию по наиболее известным в настоящее время методам декодирования, главным образом Жадный поиск , Лучевой поиск , Выборка Top-K и Top-p выборка .
Давайте быстро установим трансформаторы и загрузим модель. Мы будем использовать GPT2 в Tensorflow 2.1 для демонстрации, но API один к одному одинаков для ПиТорч.
!pip install -q git+https://github.com/huggingface/transformers.git !pip установить -q тензорный поток == 2.1
импортировать тензорный поток как tf из трансформеров импортировать TFGPT2LMHeadModel, GPT2Tokenizer токенизатор = GPT2Tokenizer.from_pretrained("gpt2") # добавить токен EOS в качестве токена PAD, чтобы избежать предупреждений модель = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)
Жадный поиск
Жадный поиск просто выбирает слово с наибольшей вероятностью как его следующее слово: wt=argmaxwP(w∣w1:t−1)w_t = argmax_{w}P(w | w_{1:t-1})wt=argmaxwP(w∣w1:t−1 ) на каждом временном шаге ттт. На следующем скетче показан жадный поиск.
Начиная со слова «The»,\text{«The»},»The», алгоритм жадно выбирает следующее слово с наибольшей вероятностью «хороший»\текст{«хороший»}»хороший» и так далее, так что что окончательная сгенерированная последовательность слов будет («The»,»симпатичная»,»женщина»)(\text{«The»}, \text{«милая»}, \text{«женщина»})(«The», «хорошая женщина») общая вероятность 0,5×0,4=0,20,5 х 0,4 = 0,20,5×0,4=0,2.
Далее мы будем генерировать последовательности слов, используя GPT2 на
контекст («Я»,»наслаждаюсь»,»гуляю»,»с»,»моя»,»милая»,»собака»)(\text{«Мне»}, \text{«наслаждаюсь»}, \text{ «прогулка»}, \text{«с»}, \text{«моя»}, \text{«милая»}, \text{«собака»})(«мне»,»наслаждаюсь»,»прогулка», «с», «мой», «милый», «собака»). Давайте
посмотрите, как можно использовать жадный поиск в
Давайте
посмотрите, как можно использовать жадный поиск в трансформаторы :
# контекст кодирования, на котором основана генерация
input_ids = tokenizer.encode('Мне нравится гулять с моей милой собачкой', return_tensors='tf')
# генерировать текст до тех пор, пока длина вывода (включая длину контекста) не достигнет 50
greedy_output = model.generate (input_ids, max_length = 50)
print("Вывод:\n" + 100 * '-')
печать (tokenizer.decode (greedy_output [0], skip_special_tokens = True))
Выход: -------------------------------------------------- -------------------------------------------------- Мне нравится гулять с моей милой собакой, но я не уверен, что когда-нибудь смогу гулять со своей собакой. Я не уверен, что когда-нибудь смогу гулять со своей собакой. я не уверен, что буду
Хорошо! Мы сгенерировали наш первый короткий текст с помощью GPT2 😊.
сгенерированные слова, следующие за контекстом, разумны, но модель
быстро начинает повторяться! Это очень распространенная проблема в
генерации языка в целом и, кажется, тем более в жадных
и поиск луча — проверьте Vijayakumar et
и др. , 2016 и Шао и др.
al., 2017.
, 2016 и Шао и др.
al., 2017.
Основным недостатком жадного поиска является то, что он пропускает высокие значения. слова вероятности, скрытые за словом низкой вероятности, как это видно на наш эскиз выше:
Слово «имеет»\text{«имеет»}»имеет» с его высокой условной вероятностью 0,90,90,9 скрывается за словом «собака»\text{«собака»}»собака», которое имеет только вторая по величине условная вероятность, так что жадный поиск пропускает последовательность слов «The»,»dog»,»has»\text{«The»}, \text{«dog»}, \text{«has»}»The»,»dog»,»has» .
К счастью, у нас есть поиск по лучу, чтобы решить эту проблему!
Поиск луча
Лучевой поиск снижает риск пропуска скрытого слова высокой вероятности
последовательности, сохраняя наиболее вероятные num_beams гипотез на каждом
временной шаг и, в конечном счете, выбор гипотезы, которая имеет общий
наивысшая вероятность. Давайте проиллюстрируем с помощью num_beams=2 :
На временном шаге 1, помимо наиболее вероятной гипотезы («The»,»nice»)(\text{«The»}, \text{«nice»})(«The «,»хороший»),
поиск луча также отслеживает второй
скорее всего один («The»,»dog»)(\text{«The»}, \text{«dog»})(«The»,»dog»). На временном шаге 2 поиск луча обнаруживает, что последовательность слов («The»,»dog»,»has»)(\text{«The»}, \text{«dog»}, \text{«has»}) («Собака», «имеет»),
имеет с 0.360.360.36
более высокая вероятность, чем («The»,»приятная»,»женщина»)(\text{«The»}, \text{«приятная»}, \text{«женщина»})(«The»,»приятная» ,»женщина»),
который имеет 0.20.20.2 . Отлично, программа нашла наиболее вероятную последовательность слов в
наш игрушечный пример!
На временном шаге 2 поиск луча обнаруживает, что последовательность слов («The»,»dog»,»has»)(\text{«The»}, \text{«dog»}, \text{«has»}) («Собака», «имеет»),
имеет с 0.360.360.36
более высокая вероятность, чем («The»,»приятная»,»женщина»)(\text{«The»}, \text{«приятная»}, \text{«женщина»})(«The»,»приятная» ,»женщина»),
который имеет 0.20.20.2 . Отлично, программа нашла наиболее вероятную последовательность слов в
наш игрушечный пример!
Поиск луча всегда будет находить выходную последовательность с большей вероятностью чем жадный поиск, но не гарантирует нахождения наиболее вероятного выход.
Давайте посмотрим, как можно использовать поиск луча в трансформаторах . Мы устанавливаем num_beams > 1 и Early_stopping=True , так что генерация завершена
когда все гипотезы луча достигли токена EOS.
# активировать поиск луча и раннюю остановку
луч_выход = модель.генерировать (
input_ids,
максимальная_длина=50,
число_лучей=5,
Early_stopping = Истина
)
print("Вывод:\n" + 100 * '-')
печать (tokenizer. decode (beam_output [0], skip_special_tokens = True))
decode (beam_output [0], skip_special_tokens = True))
Выход: -------------------------------------------------- -------------------------------------------------- Мне нравится гулять с моим милым псом, но я не уверен, что когда-нибудь снова смогу гулять с ним. Я не уверена, что смогу когда-нибудь снова ходить с ним. я не уверен, что буду
Хотя результат, возможно, более беглый, вывод по-прежнему включает
повторение одних и тех же последовательностей слов.
Простое решение состоит в том, чтобы ввести n-грамм ( или словесных последовательностей
n слов) штрафы, введенные Paulus et al.
(2017) и Klein et al.
(2017). Самый обычный н-грамм штраф гарантирует, что n-грамм не появится дважды, установив вручную
вероятность следующих слов, которые могли бы создать уже виденную n-грамму на 0.
Давайте попробуем, установив no_repeat_ngram_size=2 так, чтобы не было 2-грамм появляется дважды:
# установите для параметра no_repeat_ngram_size значение 2 луч_выход = модель.генерировать ( input_ids, максимальная_длина=50, число_лучей=5, no_repeat_ngram_size=2, Early_stopping = Истина ) print("Вывод:\n" + 100 * '-') печать (tokenizer.decode (beam_output [0], skip_special_tokens = True))
Выход: -------------------------------------------------- -------------------------------------------------- Мне нравится гулять с моим милым псом, но я не уверен, что когда-нибудь снова смогу гулять с ним. Я думал об этом некоторое время, и я думаю, что мне пора сделать перерыв
Отлично, так намного лучше! Мы видим, что повторения нет. появляться больше. Тем не менее, n-грамм штрафов должны использоваться с Забота. Создана статья о городе Нью-Йорк не следует использовать 2-граммовый штраф или иначе, появится только название города один раз на весь текст!
Другая важная особенность поиска луча заключается в том, что мы можем сравнивать
верхние балки после генерации и выбрать сгенерированную балку, которая соответствует нашей
цель лучше всего.
В преобразователях мы просто устанавливаем параметр num_return_sequences равным
количество наиболее результативных лучей, которые должны быть возвращены. Убеждаться
хотя это num_return_sequences <= num_beams !
# установить return_num_sequences > 1
beam_outputs = model.generate(
input_ids,
максимальная_длина=50,
число_лучей=5,
no_repeat_ngram_size=2,
количество_возвратов_последовательностей=5,
Early_stopping = Истина
)
# теперь у нас есть 3 выходных последовательности
print("Вывод:\n" + 100 * '-')
для i, beam_output в enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))
Выход: -------------------------------------------------- -------------------------------------------------- 0: Мне нравится гулять с моим милым псом, но я не уверен, что когда-нибудь снова смогу с ним гулять. Я думал об этом некоторое время, и я думаю, что мне пора сделать перерыв 1: Мне нравится гулять с моим милым псом, но я не уверен, что когда-нибудь снова смогу с ним гулять.Я думал об этом некоторое время, и я думаю, что мне пора вернуться к 2: Мне нравится гулять с моей милой собакой, но я не уверен, что когда-нибудь снова смогу гулять с ней. Я думал об этом некоторое время, и я думаю, что мне пора сделать перерыв 3: Мне нравится гулять с моей милой собакой, но я не уверен, что когда-нибудь снова смогу гулять с ней. Я думал об этом некоторое время, и я думаю, что мне пора вернуться к 4: Мне нравится гулять с моим милым псом, но я не уверен, что когда-нибудь снова смогу с ним гулять. Я думал об этом некоторое время, и я думаю, что мне пора сделать шаг
Как видно, гипотезы о пяти лучах лишь незначительно отличаются друг к другу - что не должно быть слишком удивительным при использовании только 5 лучи.
В бессрочную генерацию недавно привели пару причин вперед, почему поиск луча может быть не лучшим вариантом:
Поиск луча может очень хорошо работать в задачах, где длина желаемое поколение более или менее предсказуемо, как в машинном перевод или обобщение - см.
 Murray et al.
(2018) и Ян и соавт.
(2018). Но это не так
для открытой генерации, где желаемая длина вывода может варьироваться
сильно, напр. создание диалогов и историй.
Murray et al.
(2018) и Ян и соавт.
(2018). Но это не так
для открытой генерации, где желаемая длина вывода может варьироваться
сильно, напр. создание диалогов и историй.Мы видели, что поиск по лучу сильно страдает от повторяющихся поколение. Это особенно трудно контролировать с помощью n-грамм - или другие штрафы в генерации историй с момента нахождения хорошего компромисса между принудительным «неповторением» и повторяющимися циклами одинаковых n-грамм требует большой тонкой настройки.
Как утверждалось в Ari Holtzman et al. (2019), человек высокого качества язык не следует распределению высокой вероятности следующего слова. Другими словами, как люди, мы хотим, чтобы сгенерированный текст удивлял. нас и не быть скучным/предсказуемым. Авторы прекрасно это показывают построение вероятности, которую модель даст человеческому тексту по сравнению с тем, что поиск луча.
Так что давайте перестанем быть скучными и введем немного рандома 🤪.
Выборка
В своей основной форме выборка означает случайный выбор следующего слова wtw_twt в соответствии с его условным распределением вероятностей:
-1}) wt∼P(w∣w1:t−1)
Взяв пример выше, следующий график визуализирует язык генерации при выборке.
Становится очевидным, что генерация языка с использованием выборки не детерминированный больше. Слово ("car")(\text{"car"})("car") выбирается из условное распределение вероятностей P(w∣"The")P(w | \text{"The"})P(w∣"The"), за которым следует выборкой ("диски")(\text{"диски"})("диски") из P(w∣"The","car")P(w | \text{"The"}, \text{" car"})P(w∣"The","car") .
В трансформаторах мы устанавливаем do_sample=True и деактивируем Top-K выборка (подробнее об этом позже) через top_k=0 . Далее мы будем
исправить random_seed=0 для наглядности. Смело меняйте random_seed для экспериментов с моделью.
# set seed для воспроизведения результатов.Не стесняйтесь менять семя, чтобы получить другие результаты. tf.random.set_seed (0) # активируем семплирование и деактивируем top_k, установив top_k сэмплирование на 0 sample_output = модель.генерировать ( input_ids, do_sample = Верно, максимальная_длина=50, топ_к=0 ) print("Вывод:\n" + 100 * '-') печать (tokenizer.decode (sample_output [0], skip_special_tokens = True))
Выход: -------------------------------------------------- -------------------------------------------------- Мне нравится гулять с моей милой собакой. Он только что дал мне совершенно новое чувство рук». Но кажется, что собаки многому научились, дразня местную упряжь, когда они берутся за внешнюю. "Я беру
Интересно! Текст вроде нормальный, но если приглядеться, то
не очень последователен. 3-граммовые новое ручное управление и местная батарея
жгут очень странные и не похоже, что они были написаны
человек. Это большая проблема при выборке последовательностей слов: модели
часто производят бессвязную тарабарщину, ср. Ари Хольцман и др.
(2019).
Ари Хольцман и др.
(2019).
Хитрость заключается в том, чтобы сделать распределение P(w∣w1:t−1)P(w|w_{1:t-1})P(w∣w1:t−1) более четким
(увеличивая вероятность слов с высокой вероятностью и уменьшая
вероятность маловероятностных слов) за счет снижения так называемого температура софтмакс.
Пример приложения температуры к нашему примеру сверху может выглядеть следующим образом.
Условное распределение следующего слова шага t=1t=1t=1 становится намного четче, почти не оставляя шансов слову ("car")(\text{"car"})("car") выбрано.
Давайте посмотрим, как мы можем охладить дистрибутив в библиотеке с помощью
установка температура = 0,7 :
# установить начальное значение для воспроизведения результатов. Не стесняйтесь менять семя, чтобы получить другие результаты.
tf.random.set_seed (0)
# использовать температуру для снижения чувствительности к кандидатам с низкой вероятностью
sample_output = модель.генерировать (
input_ids,
do_sample = Верно,
максимальная_длина=50,
топ_к=0,
температура=0,7
)
print("Вывод:\n" + 100 * '-')
печать (tokenizer.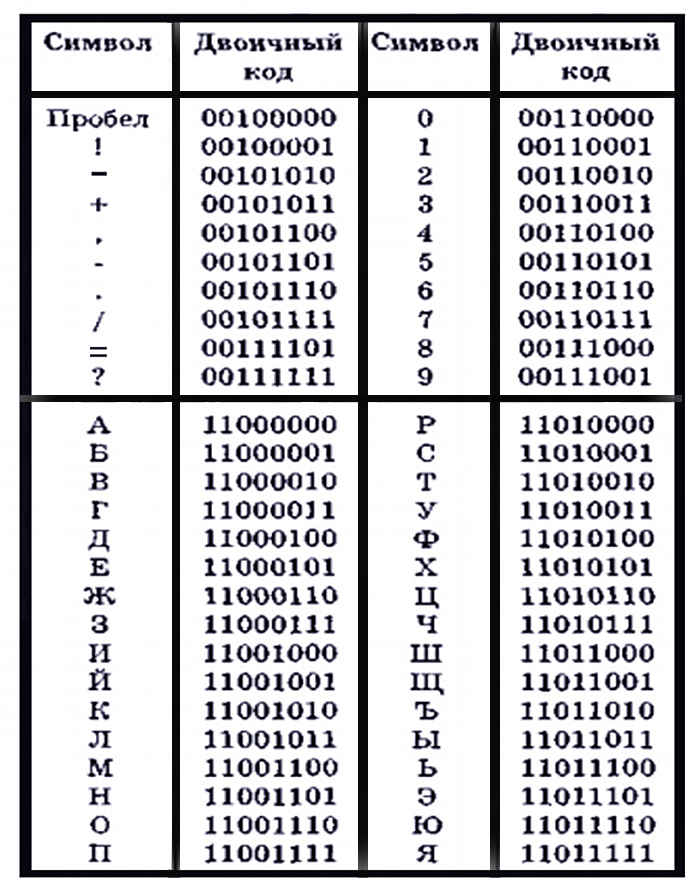 decode (sample_output [0], skip_special_tokens = True))
decode (sample_output [0], skip_special_tokens = True))
Выход: -------------------------------------------------- -------------------------------------------------- Мне нравится гулять с моей милой собакой, но я не слишком люблю быть дома. Я также нахожу это немного странным, когда хожу по магазинам. Я всегда далеко от дома, но у меня есть несколько друзей
ОК. Здесь менее странные n-граммы, а вывод более связный.
сейчас! Хотя применение температуры может сделать распределение менее случайным, в
ее предел, при установке температуры →0\to 0→0, шкала температуры
выборка становится равной жадному декодированию и будет страдать от того же
проблемы как раньше.
Выборка Top-K
Вентилятор эт. al (2018) представил
простая, но очень мощная схема выборки, называемая выборкой Top-K .
При выборке Top-K фильтруются K наиболее вероятных следующих слов, а
вероятностная масса перераспределяется только между теми K следующими словами. GPT2
принял эту схему выборки, что было одной из причин ее
Успех в создании историй.
GPT2
принял эту схему выборки, что было одной из причин ее
Успех в создании историй.
Мы расширяем диапазон слов, используемых для обоих шагов выборки в примере выше с 3 слов до 10 слов, чтобы лучше проиллюстрировать выборку Top-K .
Установив K=6K = 6K=6, на обоих шагах выборки мы ограничиваем нашу выборку до 6 слов. В то время как 6 наиболее вероятных слов, определенных как Vtop-KV _{\ text {top-K}} Vtop-K включает всего ок. две трети всего вероятностная масса на первом шаге, она включает в себя почти все вероятностная масса на втором шаге. Тем не менее мы видим, что это успешно отсеивает довольно странных кандидатов («не», «тот», «маленький», «рассказал»)(\text{``не"}, \text{``самый"}, \text{``маленький"} , \text{``сказал"})("не","тот","маленький","сказал") на втором шаге выборки.
Давайте посмотрим, как Top-K можно использовать в библиотеке, установив top_k=50 :
# set seed для воспроизведения результатов.Не стесняйтесь менять семя, чтобы получить другие результаты. tf.random.set_seed (0) # установить для top_k значение 50 sample_output = модель.генерировать ( input_ids, do_sample = Верно, максимальная_длина=50, топ_к=50 ) print("Вывод:\n" + 100 * '-') печать (tokenizer.decode (sample_output [0], skip_special_tokens = True))
Выход: -------------------------------------------------- -------------------------------------------------- Мне нравится гулять с моей милой собакой. Как хорошо иметь среду, в которой ваша собака может поделиться с вами, и мы позаботимся о вас. Надеемся, вам будет интересна эта история! я из
Совсем неплохо! Этот текст, пожалуй, самый 90 142 звучащий по-человечески 90 143 текст, поэтому
далеко. Одна из проблем, связанных с выборкой Top-K , заключается в том, что она не
динамически адаптировать количество слов, которые отфильтровываются из следующего
распределение вероятностей слов P(w∣w1:t−1)P(w|w_{1:t-1})P(w∣w1:t−1).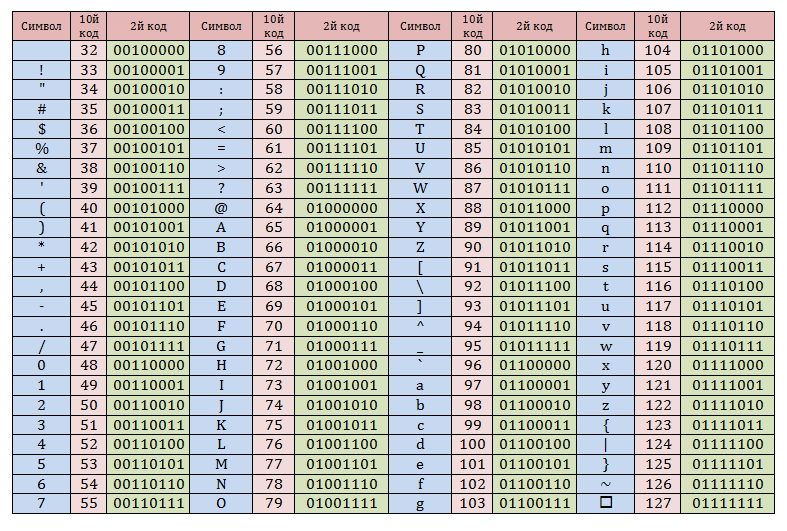 Это может быть
проблематично, так как некоторые слова могут быть взяты из очень резкого
распределения (распределение справа на графике выше), тогда как
другие из гораздо более плоского распределения (распределение слева в
график выше).
Это может быть
проблематично, так как некоторые слова могут быть взяты из очень резкого
распределения (распределение справа на графике выше), тогда как
другие из гораздо более плоского распределения (распределение слева в
график выше).
На шаге t=1t=1t=1, Top-K исключает возможность отбора проб
("люди","большой","дом","кот")(\text{"люди"}, \text{"большой"}, \text{"дом"}, \text{"кот"}) ("люди", "большой", "дом", "кот"), которые кажутся разумными
кандидаты. С другой стороны, на этапе t=2t=2t=2 способ включает
возможно неподходящие слова ("вниз", "а")(\текст{"вниз"}, \текст{"а"})("вниз","а") в выборочном пуле
слова. Таким образом, ограничение выборки фиксированным размером K может поставить под угрозу
модель для создания тарабарщины для резких распределений и ограничения
креативность модели для плоского распределения. Эта интуиция привела Ари
Хольцман и др. (2019) создавать Топ-п - или ядерный -отбор проб.
Выборка Top-p (ядра)
Вместо выборки только из наиболее вероятных К слов, в Топ-р выборка выбирает из наименьшего возможного набора слов, кумулятивная вероятность превышает вероятность p . Вероятностная масса затем перераспределяется среди этого набора слов. Таким образом, размер набор слов ( он же количество слов в наборе) можно динамически увеличиваться и уменьшаться в зависимости от вероятности следующего слова распределение. Хорошо, это было очень многословно, давайте визуализируем.
Установив p=0,92p=0,92p=0,92, выборка Top-p выбирает минимальное число
слов превысить вместе p=92%p=92\%p=92% вероятностной массы, определяемой как
Vtop-pV _{\text{top-p}}Vtop-p. В первом примере это были 9 самых
вероятные слова, в то время как ему нужно выбрать только первые 3 слова во втором
например больше 92%. На самом деле очень просто! Видно, что это
сохраняет широкий диапазон слов, где следующее слово, возможно, меньше
предсказуемый, напр. P(w∣"The")P(w | \text{"The''})P(w∣"The"), и всего несколько слов, когда
следующее слово кажется более предсказуемым, например. P(w∣"The","автомобиль")P(w | \text{"The"}, \text{"автомобиль"})P(w∣"The","автомобиль").
P(w∣"The")P(w | \text{"The''})P(w∣"The"), и всего несколько слов, когда
следующее слово кажется более предсказуемым, например. P(w∣"The","автомобиль")P(w | \text{"The"}, \text{"автомобиль"})P(w∣"The","автомобиль").
Хорошо, пора проверить это в трансформаторах ! Активируем Топ-р выборка по настройке 0 < top_p < 1 :
# установить seed для воспроизведения результатов. Не стесняйтесь менять семя, чтобы получить другие результаты.
tf.random.set_seed (0)
# отключить выборку top_k и выборку только из 92% наиболее вероятных слов
sample_output = модель.генерировать (
input_ids,
do_sample = Верно,
максимальная_длина=50,
топ_р=0,92,
топ_к=0
)
print("Вывод:\n" + 100 * '-')
печать (tokenizer.decode (sample_output [0], skip_special_tokens = True))
Выход: -------------------------------------------------- -------------------------------------------------- Мне нравится гулять с моей милой собакой.Он никогда не будет прежним. Я смотрю, как он играет. Ребята, моей собаке нужно имя. Особенно, если он встречается с крыльями. Что это было? у меня было много о
Отлично, похоже, это мог написать человек. Хорошо, может еще не совсем.
Хотя теоретически Top-p кажется более элегантным, чем Top-K , оба метода хорошо работают на практике. Top-p также можно использовать в сочетании с Top-K , что позволяет избежать слов с очень низким рейтингом, но позволяет динамический отбор.
Наконец, чтобы получить несколько независимых выходных данных, мы можем снова установить параметр num_return_sequences > 1 :
# установить начальное число для воспроизведения результатов. Не стесняйтесь менять семя, чтобы получить другие результаты.
tf.random.set_seed (0)
# установить top_k = 50 и установить top_p = 0,95 и num_return_sequences = 3
sample_outputs = модель.генерировать (
input_ids,
do_sample = Верно,
максимальная_длина=50,
топ_к=50,
топ_р=0,95,
num_return_sequences=3
)
print("Вывод:\n" + 100 * '-')
для i, sample_output в enumerate(sample_outputs):
print("{}: {}". format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
Выход: -------------------------------------------------- -------------------------------------------------- 0: Мне нравится гулять с моей милой собакой. Как хорошо, что есть возможность погулять с собакой. Но у меня есть проблема с собакой, и как она всегда смотрит на нас и всегда пытается заставить меня увидеть, что я могу что-то сделать. 1: Мне нравится гулять с моей милой собакой, она любит путешествовать по разным уголкам планеты, даже по пустыне! Мир не настолько велик, чтобы путешествовать на автобусе с нашим любимым щенком, но именно там я нахожу свою любовь 2: Мне нравится гулять со своей милой собакой и играть с нашими детьми», — сказал Дэвид Дж. Смит, директор Общества защиты животных США. «В результате у меня больше работы в свое время», — сказал он.
Круто, теперь у вас должны быть все инструменты, чтобы ваша модель могла писать свои
истории с трансформерами !
Заключение
В качестве методов декодирования ad-hoc выборка top-p и top-K кажется
производить более беглый текст, чем традиционный жадный - и луч поиск
на генерацию открытого языка. В последнее время стало больше
доказательства того, что очевидные недостатки жадных и луч поиск -
в основном генерирующие повторяющиеся последовательности слов - вызваны моделью
(особенно способ обучения модели), а не декодирование
метод, ср. Веллек и др.
(2019). Также, как показано в
Веллек и др. (2020), это выглядит как
Выборка top-K и top-p также страдает от повторяющихся слов.
последовательности.
В последнее время стало больше
доказательства того, что очевидные недостатки жадных и луч поиск -
в основном генерирующие повторяющиеся последовательности слов - вызваны моделью
(особенно способ обучения модели), а не декодирование
метод, ср. Веллек и др.
(2019). Также, как показано в
Веллек и др. (2020), это выглядит как
Выборка top-K и top-p также страдает от повторяющихся слов.
последовательности.
В Welleck et al. (2019), авторы показывают, что, согласно человеческим оценкам, поиск лучей может генерировать более плавный текст, чем Выборка Top-p , при адаптации цель обучения модели.
Генерация открытых языков — быстро развивающаяся область исследований и, как это часто бывает, здесь нет универсального метода, поэтому нужно посмотреть, что лучше всего работает в конкретном случае использования.
Хорошо, что вы можете опробовать все различные методы декодирования в трансформеры 🤗.
Это было краткое введение в использование различных методов декодирования.
в преобразования и последние тенденции в создании открытых языков.
Отзывы и вопросы очень приветствуются на Github репозиторий.
Чтобы узнать больше о создании увлекательных историй, ознакомьтесь с разделом «Пишем с трансформерами»
Спасибо всем, кто внес свой вклад в запись в блоге: Александру Рашу, Жюльену Шоману, Томасу Вульфу, Виктору Сань, Сэму Шлейферу, Клементу Деланге, Ясин Жернит. , Оливер Астранд и Джон де Вассейдж.
Приложение
Есть пара дополнительных параметров для метода generate которые не были упомянуты выше. Мы объясним их здесь кратко!
min_lengthможно использовать, чтобы заставить модель не создавать EOS токен (= не заканчивать предложение) до достиженияmin_length. Это используется довольно часто при обобщении, но может быть полезно и в вообще, если пользователь хочет иметь более длинные выходные данные.