Примеры кода модуля random в Python
В данной статье мы рассмотрим процесс генерации случайных данных и чисел в Python. Для этого будет использован модуль random и некоторые другие доступные модули. В Python модуль random реализует генератор псевдослучайных чисел для различных распределений, включая целые и вещественные числа с плавающей запятой.
Содержание
Список методов модуля random в Python:
| Метод | Описание |
|---|---|
| seed() | Инициализация генератора случайных чисел |
| getstate() | Возвращает текущее внутренне состояние (state) генератора случайных чисел |
| setstate() | Восстанавливает внутреннее состояние (state) генератора случайных чисел |
| getrandbits() | Возвращает число, которое представляет собой случайные биты |
| randrange() | Возвращает случайное число в пределах заданного промежутка |
| randint() | Возвращает случайное число в пределах заданного промежутка |
| choice() | Возвращает случайный элемент заданной последовательности |
| choices() | Возвращает список со случайной выборкой из заданной последовательности |
| shuffle() | Берет последовательность и возвращает ее в перемешанном состоянии |
| sample() | Возвращает заданную выборку последовательности |
| random() | Возвращает случайное вещественное число в промежутке от 0 до 1 |
| uniform() | Возвращает случайное вещественное число в указанном промежутке |
| triangular() | Возвращает случайное вещественное число в промежутке между двумя заданными параметрами. Также можно использовать параметр Также можно использовать параметр mode для уточнения середины между указанными параметрами |
| betavariate() | Возвращает случайное вещественное число в промежутке между 0 и 1, основываясь на Бета-распределении, которое используется в статистике |
| expovariate() | Возвращает случайное вещественное число в промежутке между 0 и 1, или же между 0 и -1, когда параметр отрицательный. За основу берется Экспоненциальное распределение, которое используется в статистике |
| gammavariate() | Возвращает случайное вещественное число в промежутке между 0 и 1, основываясь на Гамма-распределении, которое используется в статистике |
| gauss() | Возвращает случайное вещественное число в промежутке между 0 и 1, основываясь на Гауссовом распределении, которое используется в теории вероятности |
| lognormvariate() | Возвращает случайное вещественное число в промежутке между 0 и 1, основываясь на Логнормальном распределении |
| normalvariate() | Возвращает случайное вещественное число в промежутке между 0 и 1, основываясь на Нормальном распределении, которое используется в теории вероятности |
| vonmisesvariate() | Возвращает случайное вещественное число в промежутке между 0 и 1, основываясь на распределении фон Мизеса, которое используется в направленной статистике |
| paretovariate() | Возвращает случайное вещественное число в промежутке между 0 и 1, основываясь на распределении Парето, которое используется в теории вероятности |
| weibullvariate() | Возвращает случайное вещественное число в промежутке между 0 и 1, основываясь на распределении Вейбулла, которое используется в статистике |
Цели данной статьи
Далее представлен список основных операций, которые будут описаны в руководстве:
- Генерация случайных чисел для различных распределений, которые включают целые и вещественные числа с плавающей запятой;
- Случайная выборка нескольких элементов последовательности
population; - Функции модуля random;
- Перемешивание элементов последовательности.
 Seed в генераторе случайных данных;
Seed в генераторе случайных данных; - Генерация случайных строки и паролей;
- Криптографическое обеспечение безопасности генератора случайных данных при помощи использования модуля secrets. Обеспечение безопасности токенов, ключей безопасности и URL;
- Способ настройки работы генератора случайных данных;
- Использование
numpy.randomдля генерации случайных массивов; - Использование модуля
UUIDдля генерации уникальных ID.
В статье также даются ссылки на некоторые другие тексты сайта, связанные с рассматриваемой темой.
Как использовать модуль random в Python
Для достижения перечисленных выше задач модуль random будет использовать разнообразные функции. Способы использования данных функций будут описаны в следующих разделах статьи.
Совет от администрации: Как не потратить каникулы в пустую?
Не качайте курсы которые были слиты в интернете, в них смысла нет и тем более пользы. Лучше инвестируйте в свои знания, выйдите из зимних каникул с новой профессией.
Лучше инвестируйте в свои знания, выйдите из зимних каникул с новой профессией.
Отвечаем сразу всем кто пишет нам в Telegram «С чего начать изучение Python?». Вот курс, пройдите его!
Получите сертификат!
И вы будете на голову выше остальных кандидатов!
В самом начале работы необходимо импортировать модуль random в программу. Только после этого его можно будет полноценно использовать. Оператор для импорта модуля random выглядит следующим образом:
Теперь рассмотрим использование самого модуля random на простом примере:
import random print(«Вывод случайного числа при помощи использования random.random()») print(random.random())
import random
print(«Вывод случайного числа при помощи использования random.random()») print(random. |
 random())
random())Вывод:
Вывод случайного числа при помощи использования random.random() 0.9461613475266107
Вывод случайного числа при помощи использования random.random() 0.9461613475266107 |
Как видите, в результате мы получили 0.9461613475266107. У вас, конечно, выйдет другое случайно число.
random()является базовой функцией модуляrandom;- Почти все функции модуля
randomзависят от базовой функцииrandom(); random()возвращает следующее случайное число с плавающей запятой в промежутке[0.0, 1.0].
Перед разбором функций модуля random давайте рассмотрим основные сферы их применения.
Генерация случайных чисел в Python
Давайте рассмотрим самый популярный случай использования модуля random — генерацию случайного числа. Для получения случайного целого числа в Python используется функция
Для получения случайного целого числа в Python используется функция randint()
Для генерации случайных целых чисел можно использовать следующие две функции:
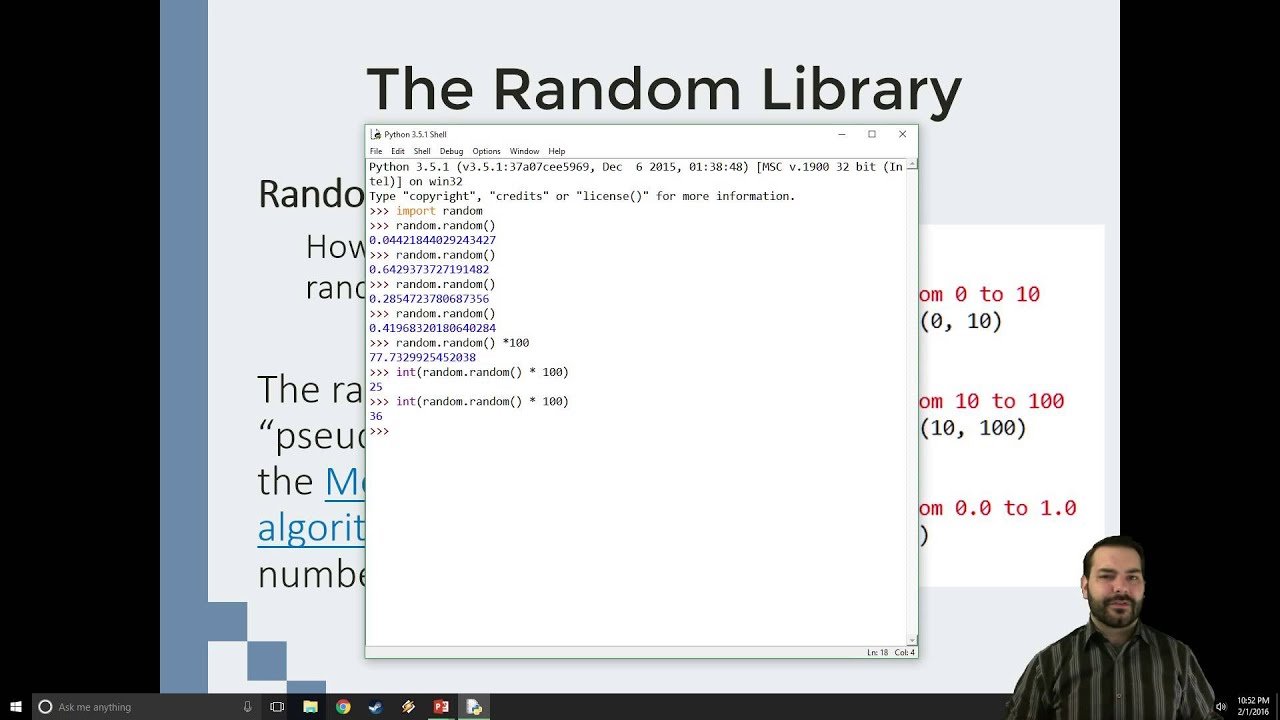
В следующем примере показано, как получить случайно сгенерированное число в промежутке между 0 и 9.
from random import randint print(«Вывод случайного целого числа «, randint(0, 9)) print(«Вывод случайного целого числа «, randrange(0, 10, 2))
from random import randint
print(«Вывод случайного целого числа «, randint(0, 9)) print(«Вывод случайного целого числа «, randrange(0, 10, 2)) |
Вывод:
Вывод случайного целого числа 5 Вывод случайного целого числа 2
Вывод случайного целого числа 5 Вывод случайного целого числа 2 |
Выбор случайного элемента из списка Python
Предположим, вам дан python список городов, и вы хотите вывести на экран случайно выбранный элемент из списка городов. Посмотрим, как это можно сделать:
import random city_list = [‘New York’, ‘Los Angeles’, ‘Chicago’, ‘Houston’, ‘Philadelphia’] print(«Выбор случайного города из списка — «, random.choice(city_list))
import random
city_list = [‘New York’, ‘Los Angeles’, ‘Chicago’, ‘Houston’, ‘Philadelphia’] print(«Выбор случайного города из списка — «, random.choice(city_list)) |
Вывод:
Выбор случайного города из списка — Houston
Выбор случайного города из списка — Houston |
Python функции модуля random
Рассмотрим разнообразные функции, доступные в модуле random.
Случайное целое число — randint(a, b) модуль random
- Возвращает случайное целое число
Number, такое чтоa <= Number <= b; randint(a,b)работает только с целыми числами;- Функция
randint(a,b)принимает только два параметра, оба обязательны; - Полученное в результате случайно число больше или равно
a, а также меньше или равноb.
Пример использования random.randint() в Python:
import random print(«Использование random.randint() для генерации случайного целого числа») print(random.randint(0, 5)) print(random.randint(0, 5))
import random
print(«Использование random.randint() для генерации случайного целого числа») print(random.randint(0, 5)) print(random.randint(0, 5)) |
Вывод:
Использование random.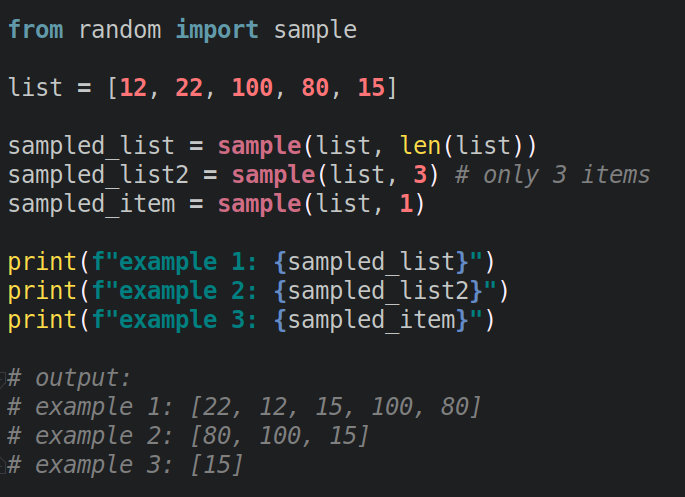 randint() для генерации случайного целого числа
4
2
randint() для генерации случайного целого числа
4
2
Использование random.randint() для генерации случайного целого числа 4 2 |
Генерация случайного целого числа — randrange() модуль random
Метод random.randrange() используется для генерации случайного целого числа в пределах заданного промежутка. Скажем, для получения любого числа в диапазоне между 10 и 50.
Шаг показывает разницу между каждым числом заданной последовательности. Шаг по умолчанию равен 1, однако его значение можно изменить.
Пример использования random.randrange() в Python:
import random print(«Генерация случайного числа в пределах заданного промежутка») print(random.randrange(10, 50, 5)) print(random.randrange(10, 50, 5))
import random
print(«Генерация случайного числа в пределах заданного промежутка») print(random. print(random.randrange(10, 50, 5)) |
 randrange(10, 50, 5))
randrange(10, 50, 5))Вывод:
Генерация случайного числа в пределах заданного промежутка 10 15
Генерация случайного числа в пределах заданного промежутка 10 15 |
Выбор случайного элемента из списка choice() модуль random
Метод random.choice() используется для выбора случайного элемента из списка. Набор может быть представлен в виде списка или python строки. Метод возвращает один случайный элемент последовательности.
Пример использования random.choice() в Python:
import random list = [55, 66, 77, 88, 99] print(«random.choice используется для выбора случайного элемента из списка — «, random.choice(list))
import random
list = [55, 66, 77, 88, 99] print(«random. |
 choice используется для выбора случайного элемента из списка — «, random.choice(list))
choice используется для выбора случайного элемента из списка — «, random.choice(list))Вывод:
random.choice используется для выбора случайного элемента из списка — 55
random.choice используется для выбора случайного элемента из списка — 55 |
Метод sample(population, k) из модуля random
Метод random.sample() используется, когда требуется выбрать несколько элементов из заданной последовательности population.
- Метод
sample()возвращает список уникальных элементов, которые были выбраны из последовательностиpopulation. Итоговое количество элементов зависит от значенияk; - Значение в
populationможет быть представлено в виде списка или любой другой последовательности.
Пример использования random. в Python: sample()
sample()
import random list = [2, 5, 8, 9, 12] print («random.sample() «, random.sample(list,3))
import random
list = [2, 5, 8, 9, 12] print («random.sample() «, random.sample(list,3)) |
Вывод:
random.sample() [5, 12, 2]
random.sample() [5, 12, 2] |
Случайные элементы из списка — choices() модуль random
random.choices(population, weights=None, *, cum_weights=None, k=1)- Метод
random.choices()используется, когда требуется выбрать несколько случайных элементов из заданной последовательности. - Метод
choices()был введен в версии Python 3. 6. Он также позволяет повторять несколько раз один и тот же элемент.
6. Он также позволяет повторять несколько раз один и тот же элемент.
Пример использования random.choices() в Python:
import random # Выборка с заменой list = [20, 30, 40, 50 ,60, 70, 80, 90] sampling = random.choices(list, k=5) print(«Выборка с методом choices «, sampling)
import random
# Выборка с заменой list = [20, 30, 40, 50 ,60, 70, 80, 90] sampling = random.choices(list, k=5)
print(«Выборка с методом choices «, sampling) |
Вывод:
Выборка с методом choices [30, 20, 40, 50, 40]
Выборка с методом choices [30, 20, 40, 50, 40] |
Генератор псевдослучайных чисел — seed() модуль random
- Метод
seed()используется для инициализации генератора псевдослучайных чисел в Python; - Модуль
randomиспользует значение изseed, или отправной точки как основу для генерации случайного числа. Если значения
Если значения seedнет в наличии, тогда система будет отталкиваться от текущего времени.
Пример использования random.seed() в Python:
import random random.seed(6) print(«Случайное число с семенем «,random.random()) print(«Случайное число с семенем «,random.random())
import random
random.seed(6) print(«Случайное число с семенем «,random.random())
print(«Случайное число с семенем «,random.random()) |
Вывод:
Random number with seed 0.793340083761663 Random number with seed 0.793340083761663
Random number with seed 0.793340083761663 Random number with seed 0.793340083761663 |
Перемешивание данных — shuffle() из модуля random
Метод random. используется для перемешивания данных списка или другой последовательности. Метод  shuffle()
shuffle()shuffle() смешивает элементы списка на месте. Самый показательный пример использования — тасование карт.
Пример использования random.shuffle() в Python:
list = [2, 5, 8, 9, 12] random.shuffle(list) print («Вывод перемешанного списка «, list)
list = [2, 5, 8, 9, 12]
random.shuffle(list) print («Вывод перемешанного списка «, list) |
Вывод:
Вывод перемешанного списка [8, 9, 2, 12, 5]
Вывод перемешанного списка [8, 9, 2, 12, 5] |
Генерации числа с плавающей запятой — uniform() модуль random
random.используется для генерации числа с плавающей запятой в пределах заданного промежутка uniform()
uniform()- Значение конечной точки может включаться в диапазон, но это не обязательно. Все зависит от округления значения числа с плавающей запятой;
- Метод может, например, сгенерировать случайно вещественное число в промежутке между 10.5 и 25.5.
Пример использования random.uniform() в Python:
import random print(«Число с плавающей точкой в пределах заданного промежутка») print(random.uniform(10.5, 25.5))
import random
print(«Число с плавающей точкой в пределах заданного промежутка») print(random.uniform(10.5, 25.5)) |
Вывод:
Число с плавающей точкой в пределах заданного промежутка 22.095283175159786
Число с плавающей точкой в пределах заданного промежутка 22. |
 095283175159786
095283175159786triangular(low, high, mode) из модуля random
Функция random.triangular() возвращает случайное вещественное число N с плавающей запятой, которое соответствует условию lower <= N <= upper, а также уточняющему значению mode.
Значение нижнего предела по умолчанию равно нулю, в верхнего — единице. Кроме того, пик аргумента по умолчанию установлен на середине границ, что обеспечивает симметричное распределение.
Функция random.triangular() используется в генерации случайных чисел для треугольного распределения с целью использования полученных значений в симуляции. Это значит, что в при генерации значения применяется треугольное распределение вероятности.
Пример использования random.triangular() в Python:
import random
print(«Число с плавающей точкой через triangular»)
print(random. triangular(10.5, 25.5, 5.5))
triangular(10.5, 25.5, 5.5))
import random
print(«Число с плавающей точкой через triangular») print(random.triangular(10.5, 25.5, 5.5)) |
Вывод:
Число с плавающей точкой через triangular 16.7421565549115
Число с плавающей точкой через triangular 16.7421565549115 |
Генератор случайной строки в Python
В данном разделе будет подробно расписано, как сгенерировать случайную строку фиксированной длины в Python.
Основные аспекты раздела:
- Генерация случайной строки фиксированной длины;
- Получение случайной алфавитно-цифровой строки, среди элементов которой будут как буквы, так и числа;
- Генерация случайного пароля, который будет содержать буквы, цифры и специальный символы.

Криптографическая зашита генератора случайных данных в Python
Случайно сгенерированные числа и данные, полученные при помощи модуля random в Python, лишены криптографической защиты. Следовательно, возникает вопрос — как добиться надежной генерации случайных чисел?
Криптографически надежный генератор псевдослучайных чисел представляет собой генератор чисел, который обладает особенностями, что делают его подходящим для использования в криптографических приложениях, где безопасность данных имеет первостепенное значение.
- Все функции криптографически надежного генератора возвращают полученные случайным образом байты;
- Значение случайных байтов, полученных в результате использования функции, зависит от источников ОС.
- Качество генерации также зависит от случайных источников ОС.
Для обеспечения криптографической надежности генерации случайных чисел можно использовать следующие подходы:
- Применение модуля secrets для защиты случайных данных;
- Использование из модуля os
os.; urandom()
urandom() - Использование класса
random.SystemRandom.
Пример криптографически надежной генерации данных в Python:
import random import secrets number = random.SystemRandom().random() print(«Надежное число «, number) print(«Надежный токен байтов», secrets.token_bytes(16))
import random import secrets
number = random.SystemRandom().random() print(«Надежное число «, number)
print(«Надежный токен байтов», secrets.token_bytes(16)) |
Вывод:
Надежное число 0.11139538267693572 Надежный токен байтов b’\xae\xa0\x91*.\xb6\xa1\x05=\xf7+>\r;Y\xc3′
Надежное число 0.11139538267693572
Надежный токен байтов b’\xae\xa0\x91*. |
 \xb6\xa1\x05=\xf7+>\r;Y\xc3′
\xb6\xa1\x05=\xf7+>\r;Y\xc3′getstate() и setstate() в генераторе случайных данных Python
Функции getstate() и setstate() модуля random позволяют зафиксировать текущее внутреннее состояние генератора.
Используя данные функции, можно сгенерировать одинаковое количество чисел или последовательностей данных.
Состояние генератора getstate() модуль random
Функция getstate() возвращает определенный объект, зафиксировав текущее внутреннее состояние генератора случайных данных. Данное состояние передается методу setstate() для восстановления полученного состояния в качестве текущего.
На заметку: Изменив значение текущего состояния на значение предыдущего, мы можем получить случайные данные вновь. Например, если вы хотите получить аналогичную выборку вновь, можно использовать данные функции.
Восстанавливает внутреннее состояние генератора — setstate() модуль random
Функция setstate() восстанавливает внутреннее состояние генератора и передает его состоянию объекта. Это значит, что вновь будет использован тот же параметр состояния
Это значит, что вновь будет использован тот же параметр состояния state. Объект state может быть получен при помощи вызова функции getstate().
Зачем нужны функции getstate() и setstate() ?
Если вы получили предыдущее состояние и восстановили его, тогда вы сможете оперировать одними и теми же случайными данными раз за разом. Помните, что использовать другую функцию random в данном случае нельзя. Также нельзя изменить значения заданных параметров. Сделав это, вы измените значение состояния state.
Для закрепления понимания принципов работы getstate() и setstate() в генераторе случайных данных Python рассмотрим следующий пример:
import random
number_list = [3, 6, 9, 12, 15, 18, 21, 24, 27, 30]
print(«Первая выборка «, random.sample(number_list,k=5))
# хранит текущее состояние в объекте state
state = random. getstate()
print(«Вторая выборка «, random.sample(number_list,k=5))
# Восстанавливает состояние state, используя setstate
random.setstate(state)
#Теперь будет выведен тот же список второй выборки
print(«Третья выборка «, random.sample(number_list,k=5))
# Восстанавливает текущее состояние state
random.setstate(state)
# Вновь будет выведен тот же список второй выборки
print(«Четвертая выборка «, random.sample(number_list,k=5))
getstate()
print(«Вторая выборка «, random.sample(number_list,k=5))
# Восстанавливает состояние state, используя setstate
random.setstate(state)
#Теперь будет выведен тот же список второй выборки
print(«Третья выборка «, random.sample(number_list,k=5))
# Восстанавливает текущее состояние state
random.setstate(state)
# Вновь будет выведен тот же список второй выборки
print(«Четвертая выборка «, random.sample(number_list,k=5))
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import random
number_list = [3, 6, 9, 12, 15, 18, 21, 24, 27, 30]
print(«Первая выборка «, random.sample(number_list,k=5))
# хранит текущее состояние в объекте state state = random.getstate()
print(«Вторая выборка «, random.sample(number_list,k=5))
# Восстанавливает состояние state, используя setstate random.setstate(state)
#Теперь будет выведен тот же список второй выборки print(«Третья выборка «, random.sample(number_list,k=5))
# Восстанавливает текущее состояние state random.setstate(state)
# Вновь будет выведен тот же список второй выборки print(«Четвертая выборка «, random.sample(number_list,k=5)) |
Вывод:
Первая выборка [18, 15, 30, 9, 6] Вторая выборка [27, 15, 12, 9, 6] Третья выборка [27, 15, 12, 9, 6] Четвертая выборка [27, 15, 12, 9, 6]
Первая выборка [18, 15, 30, 9, 6] Вторая выборка [27, 15, 12, 9, 6] Третья выборка [27, 15, 12, 9, 6] Четвертая выборка [27, 15, 12, 9, 6] |
Как можно заметить в результате вывода — мы получили одинаковые наборы данных. Это произошло из-за сброса генератора случайных данных.
Numpy.random — Генератор псевдослучайных чисел
PRNG является англоязычным акронимом, который расшифровывается как «pseudorandom number generator» — генератор псевдослучайных чисел. Известно, что в Python модуль random можно использовать для генерации случайных скалярных числовых значений и данных.
- Для генерации массива случайных чисел необходимо использовать
numpy.random(); - В модуле numpy есть пакет
numpy.random, который содержит обширный набор функций для генерации случайных n-мерных массивов для различных распределений.
Рассмотрим несколько примеров использования numpy.random в Python.
Генерация случайного n-мерного массива вещественных чисел
- Использование
numpy.random.rand()для генерации n-мерного массива случайных вещественных чисел в пределах[0.0, 1.0) - Использование
numpy.random.uniform()для генерации n-мерного массива случайных вещественных чисел в пределах[low, high)
import numpy random_float_array = numpy.random.rand(2, 2) print(«2 X 2 массив случайных вещественных чисел в [0.0, 1.0] \n», random_float_array,»\n») random_float_array = numpy.random.uniform(25.5, 99.5, size=(3, 2)) print(«3 X 2 массив случайных вещественных чисел в [25.5, 99.5] \n», random_float_array,»\n»)
import numpy
random_float_array = numpy.random.rand(2, 2) print(«2 X 2 массив случайных вещественных чисел в [0.0, 1.0] \n», random_float_array,»\n»)
random_float_array = numpy.random.uniform(25.5, 99.5, size=(3, 2)) print(«3 X 2 массив случайных вещественных чисел в [25.5, 99.5] \n», random_float_array,»\n») |
Вывод:
2 X 2 массив случайных вещественных чисел в [0.0, 1.0] [[0.08938593 0.89085866] [0.47307169 0.41401363]] 3 X 2 массив случайных вещественных чисел в [25.5, 99.5] [[55.4057854 65.60206715] [91.62185404 84.16144062] [44.348252 27.28381058]]
2 X 2 массив случайных вещественных чисел в [0.0, 1.0] [[0.08938593 0.89085866] [0.47307169 0.41401363]]
3 X 2 массив случайных вещественных чисел в [25.5, 99.5] [[55.4057854 65.60206715] [91.62185404 84.16144062] [44.348252 27.28381058]] |
Генерация случайного n-мерного массива целых чисел
Для генерации случайного n-мерного массива целых чисел используется numpy.random.random_integers():
import numpy random_integer_array = numpy.random.random_integers(1, 10, 5) print(«1-мерный массив случайных целых чисел \n», random_integer_array,»\n») random_integer_array = numpy.random.random_integers(1, 10, size=(3, 2)) print(«2-мерный массив случайных целых чисел \n», random_integer_array)
import numpy
random_integer_array = numpy.random.random_integers(1, 10, 5) print(«1-мерный массив случайных целых чисел \n», random_integer_array,»\n»)
random_integer_array = numpy.random.random_integers(1, 10, size=(3, 2)) print(«2-мерный массив случайных целых чисел \n», random_integer_array) |
Вывод:
1-мерный массив случайных целых чисел [10 1 4 2 1] 2-мерный массив случайных целых чисел [[ 2 6] [ 9 10] [ 3 6]]
1-мерный массив случайных целых чисел [10 1 4 2 1]
2-мерный массив случайных целых чисел [[ 2 6] [ 9 10] [ 3 6]] |
Выбор случайного элемента из массива чисел или последовательности
- Использование
numpy.random.choice()для генерации случайной выборки; - Использование данного метода для получения одного или нескольких случайных чисел из n-мерного массива с заменой или без нее.
Рассмотрим следующий пример:
import numpy array =[10, 20, 30, 40, 50, 20, 40] single_random_choice = numpy.random.choice(array, size=1) print(«один случайный выбор из массива 1-D», single_random_choice) multiple_random_choice = numpy.random.choice(array, size=3, replace=False) print(«несколько случайных выборов из массива 1-D без замены», multiple_random_choice) multiple_random_choice = numpy.random.choice(array, size=3, replace=True) print(«несколько случайных выборов из массива 1-D с заменой», multiple_random_choice)
import numpy
array =[10, 20, 30, 40, 50, 20, 40] single_random_choice = numpy.random.choice(array, size=1) print(«один случайный выбор из массива 1-D», single_random_choice)
multiple_random_choice = numpy.random.choice(array, size=3, replace=False) print(«несколько случайных выборов из массива 1-D без замены», multiple_random_choice)
multiple_random_choice = numpy.random.choice(array, size=3, replace=True) print(«несколько случайных выборов из массива 1-D с заменой», multiple_random_choice) |
Вывод:
один случайный выбор из массива 1-D [40] несколько случайных выборов из массива 1-D без замены [10 40 50] несколько случайных выборов из массива 1-D с заменой [20 20 10]
один случайный выбор из массива 1-D [40] несколько случайных выборов из массива 1-D без замены [10 40 50] несколько случайных выборов из массива 1-D с заменой [20 20 10] |
В будущих статьях будут описаны другие функции пакета random из nympy и способы их использования.
Генерация случайных универсально уникальных ID
Модуль Python UUID предоставляет неизменяемые UUID объекты. UUID является универсально уникальным идентификатором.
У модуля есть функции для генерации всех версий UUID. Используя функцию uuid.uuid4(), можно получить случайно сгенерированное уникальное ID длиной в 128 битов, которое к тому же является криптографически надежным.
Полученные уникальные ID используются для идентификации документов, пользователей, ресурсов и любой другой информации на компьютерных системах.
Пример использования uuid.uuid4() в Python:
import uuid # получить уникальный UUID safeId = uuid.uuid4() print(«безопасный уникальный id «, safeId)
import uuid
# получить уникальный UUID safeId = uuid.uuid4() print(«безопасный уникальный id «, safeId) |
Вывод:
безопасный уникальный id fb62463a-cd93-4f54-91ab-72a2e2697aff
безопасный уникальный id fb62463a-cd93-4f54-91ab-72a2e2697aff |
Игра в кости с использованием модуля random в Python
Далее представлен код простой игры в кости, которая поможет понять принцип работы функций модуля random. В игре два участника и два кубика.
- Участники по очереди бросают кубики, предварительно встряхнув их;
- Алгоритм высчитывает сумму значений кубиков каждого участника и добавляет полученный результат на доску с результатами;
- Участник, у которого в результате большее количество очков, выигрывает.
Код программы для игры в кости Python:
import random PlayerOne = «Анна» PlayerTwo = «Алекс» AnnaScore = 0 AlexScore = 0 # У каждого кубика шесть возможных значений diceOne = [1, 2, 3, 4, 5, 6] diceTwo = [1, 2, 3, 4, 5, 6] def playDiceGame(): «»»Оба участника, Анна и Алекс, бросают кубик, используя метод shuffle»»» for i in range(5): #оба кубика встряхиваются 5 раз random.shuffle(diceOne) random.shuffle(diceTwo) firstNumber = random.choice(diceOne) # использование метода choice для выбора случайного значения SecondNumber = random.choice(diceTwo) return firstNumber + SecondNumber print(«Игра в кости использует модуль random\n») #Давайте сыграем в кости три раза for i in range(3): # определим, кто будет бросать кости первым AlexTossNumber = random.randint(1, 100) # генерация случайного числа от 1 до 100, включая 100 AnnaTossNumber = random.randrange(1, 101, 1) # генерация случайного числа от 1 до 100, не включая 101 if( AlexTossNumber > AnnaTossNumber): print(«Алекс выиграл жеребьевку.») AlexScore = playDiceGame() AnnaScore = playDiceGame() else: print(«Анна выиграла жеребьевку.») AnnaScore = playDiceGame() AlexScore = playDiceGame() if(AlexScore > AnnaScore): print («Алекс выиграл игру в кости. Финальный счет Алекса:», AlexScore, «Финальный счет Анны:», AnnaScore, «\n») else: print(«Анна выиграла игру в кости. Финальный счет Анны:», AnnaScore, «Финальный счет Алекса:», AlexScore, «\n»)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
Генерация случайных данных в Python (Руководство)
Насколько случайны случайности? Это странный вопрос, но желательно его задать, если речь идет об информационной безопасности. Когда вы генерируете случайные данные, числа или строки в Python, неплохо иметь хотя бы приблизительное представление о том, как именно генерируются эти данные.
Содержание:
Здесь мы рассмотрим несколько различных способов генерации данных в Python и перейдем к их сравнению в таких категориях, как безопасность, универсальность, предназначение и скорость.
Мы обещаем, что данное руководство не будет похоже на урок математики, или криптографии: математики здесь будет ровно столько, сколько необходимо!
Насколько случайны случайности?
Во первых, нужно сделать небольшое заявление. Большая часть случайных данных, сгенерированных в Python — не совсем “случайная” в научном понимании слова. Скорее, это псевдослучайность, сгенерированная генератором псевдослучайных чисел (PRNG), который по сути, является любым алгоритмом для генерации на первый взгляд случайных, но все еще воспроизводимых данных.
Совет от администрации: Как не потратить каникулы в пустую?
Не качайте курсы которые были слиты в интернете, в них смысла нет и тем более пользы. Лучше инвестируйте в свои знания, выйдите из зимних каникул с новой профессией.
Отвечаем сразу всем кто пишет нам в Telegram «С чего начать изучение Python?». Вот курс, пройдите его!
Получите сертификат!
И вы будете на голову выше остальных кандидатов!
“Настоящие” случайные числа могут быть сгенерированы при помощи (как вы, скорее всего, можете догадаться), настоящим генератором случайных чисел (true random number generator, TRNG). Пример: регулярно поднимать игральный кубик с пола, подбрасывать его в воздух и дать ему приземлиться.
Представим, что вы совершаете бросок произвольно и понятия не имеете, какое число выпадет на кубике. Бросок кубика — это грубая форма использования аппаратного обеспечения для генерации числа, которое не является детерминированным. TRNG выходит за рамки этой статьи, однако это стоит упомянуть в любом случае, хотя бы для сравнения.
PRNG, выполняемые обычно программным, а не аппаратным обеспечением, немного отличаются. Вот краткое описание:
Они начинают со случайного числа, также известного как зерно и затем используют алгоритм для генерации псевдослучайной последовательности битов, основанных на нём.
В какой-то момент вам могут посоветовать почитать документацию. И эти люди не то, что ошибутся. Вот интересный сниппет из документации модуля random, который вам не стоит упускать:
Внимание: псевдослучайные генераторы этого модуля не должны быть использованы в целях безопасности (источник).
Возможно, вы уже сталкивались с random.seed(999), random.seed(1234), или им подобным. Этот вызов функции проходит через генератор случайных чисел, который используется модулем random Python. Это то, что делает последующие вызовы генератора случайных чисел детерминированными: вход А производит выход Б. Это чудо может стать проклятием, если используется неправильно.
Возможно термины “случайный” и “детерминированный” выглядят так, будто не могут упоминаться в одном контексте. Чтобы прояснить этот момент, вот супер упрощенная версия random(), которая итеративно создает “случайное” число, используя x = (x * 3) % 19.
“Х” изначально определен как значение сид (cлучайное начальное значение), после чего превращается в детерминированную последовательность чисел, основанных на этом семени:
class NotSoRandom(object): def seed(self, a=3): «»»Самый загадочный генератор случайных чисел в мире.»»» self.seedval = a def random(self): «»»Смотрите, случайные числа!»»» self.seedval = (self.seedval * 3) % 19 return self.seedval _inst = NotSoRandom() seed = _inst.seed random = _inst.random
class NotSoRandom(object): def seed(self, a=3): «»»Самый загадочный генератор случайных чисел в мире.»»» self.seedval = a def random(self): «»»Смотрите, случайные числа!»»» self.seedval = (self.seedval * 3) % 19 return self.seedval
_inst = NotSoRandom() seed = _inst.seed random = _inst.random |
Не стоит воспринимать этот пример слишком буквально, так как он служит чисто для отображения концепции. Если вы используете значение сид 1234, дальнейшая последовательность вызовов random() всегда должна быть идентичной:
>>> seed(1234) >>> [random() for _ in range(10)] [16, 10, 11, 14, 4, 12, 17, 13, 1, 3] >>> seed(1234) >>> [random() for _ in range(10)] [16, 10, 11, 14, 4, 12, 17, 13, 1, 3]
>>> seed(1234) >>> [random() for _ in range(10)] [16, 10, 11, 14, 4, 12, 17, 13, 1, 3]
>>> seed(1234) >>> [random() for _ in range(10)] [16, 10, 11, 14, 4, 12, 17, 13, 1, 3] |
Мы рассмотрим более серьезную иллюстрацию данного примера в дальнейшем.
Что значит “криптографически безопасно”?
Если вам казалось, что в статье мало акронимов типа “RNG” — то добавим сюда еще один: CSPRNG — криптографически безопасный PRNG. CSPRNG подходят для генерации конфиденциальных данных, таких как пароли, аутентификаторы и токены. Благодаря заданной случайно строке, условный злодей не сможет определить, какая строка шла за или перед этой строкой в последовательности случайных строк.
Еще один термин, с которым вы можете столкнуться — энтропия. В двух словах, она ссылается на количество случайностей, желаемых или введенных. Например, один модуль Python, который мы рассмотрим в данной статье, определяет DEFAULT_ENTROPY = 32, количество возвращаемых байтов по умолчанию. Разработчики считают это количество байтов “достаточным”.
Обратите внимание: В данной статье я предполагаю, что байт ссылается на 8 битов, как в далеких 60-х, а не к какой-либо другой единице хранения. Можете называть его октетом, если хотите.
Главная суть CSPRNG — это то, что они все еще псевдослучайные. Они сконструированы таким образом, что являются внутренне детерминированными, но добавляют некие другие переменные, или имеют определенную собственность, которая делает их “достаточно случайными”, чтобы запретить поддержку любой функции, которая выполняет детерменизм.
Что вы из этого почерпнете?
Практически, это значит, что вам нужно использовать PRNG для статистического моделирования, симуляции и сделать случайные данные воспроизводимыми. PRNG также значительно быстрее, чем CSPRNG, что вы и увидите в дальнейшем. Используйте CSPRNG для безопасности и в криптографических приложениях, где конфиденциальные данные являются обязательным условием.
В дополнение к расширению использования вышеупомянутых примеров в этой статье, вы познакомитесь с инструментами Python для работы как с PRNG, так и с CSPRNG:
- Опции PRNG включают в себя модуль random из стандартной библиотеки Python, а также основанную на массивах копию NumPy, под названием numpy.random
- Модули Python, такие как os, secrets, и uuid содержат функции для генерации криптографически безопасных объектов.
Мы рассмотрим все вышеперечисленное и подытожим детальным сравнением.
PRNG в Python
Модуль random
Возможно самый известный инструмент для генерации случайных данных в Python — это модуль random, который использует алгоритм PRNG под названием Mersenne Twister в качестве корневого генератора.
Ранее, мы затронули random.seed(), и теперь настало подходящее время, чтобы узнать, как он работает. Сначала, давайте создадим случайные данные без сидинга. Функция random.random() возвращает случайное десятичное число с интервалом [0.0, 1.0). В результате всегда будет меньше, чем правая конечная точка (1.0). Это также известно, как полуоткрытый диапазон:
>>> # Пока не вызываем random.seed() >>> import random >>> random.random() 0.35553263284394376 >>> random.random() 0.6101992345575074
>>> # Пока не вызываем random.seed() >>> import random >>> random.random() 0.35553263284394376
>>> random.random() 0.6101992345575074 |
Если вы запустите этот код лично, весьма вероятно, что полученные числа на вашем компьютере будут другими. По умолчанию, когда вы не используете сид генератор, вы используете текущее системное время, или “источник случайности” вашей операционной системы, если это доступно.
С random.seed() вы можете сделать результаты воспроизводимыми, и цепочка вызова, после random.seed(), будет генерировать один и тот же след данных:
>>> random.seed(444) >>> random.random() 0.3088946587429545 >>> random.random() 0.01323751590501987 >>> random.seed(444) # Re-seed >>> random.random() 0.3088946587429545 >>> random.random() 0.01323751590501987
>>> random.seed(444) >>> random.random() 0.3088946587429545 >>> random.random() 0.01323751590501987
>>> random.seed(444) # Re-seed >>> random.random() 0.3088946587429545
>>> random.random() 0.01323751590501987 |
Обратите внимание на повторение “случайных” чисел. Последовательность случайных чисел становится детерменированной, или полностью определенной значением сида, 444.
Давайте рассмотрим основы того, как функционирует модуль random. Ранее мы создали случайное десятичное число. Вы можете сгенерировать случайное целое число между двумя отметками в Python при помощи функции random.randint(). Таким образом охватывается целый интервал [x, y] и обе конечные точки могут быть включены:
>>> random.randint(0, 10) 7 >>> random.randint(500, 50000) 18601
>>> random.randint(0, 10) 7
>>> random.randint(500, 50000) 18601 |
С random.randrange(), вы можете исключить правую часть интервала, то есть сгенерированное число всегда остается внутри [x, y) и всегда будет меньше правой части:
>>> random.randrange(1, 10) 5
>>> random.randrange(1, 10) 5 |
Если вы хотите сгенерировать случайные десятичные числа, которые находятся в определенном интервале [x, y], вы можете использовать random.uniform(), который вырывается из непрерывного равномерного распределения:
>>> random.uniform(20, 30) 27.42639687016509 >>> random.uniform(30, 40) 36.33865802745107
>>> random.uniform(20, 30) 27.42639687016509
>>> random.uniform(30, 40) 36.33865802745107 |
Чтобы взять случайный элемент из последовательности, не являющейся пустой (такой как список или кортеж), вы можете использовать random.choice(). Также есть random.choices() для выборки нескольких элементов из последовательности с заменой (дубликаты возможны):
>>> items = [‘one’, ‘two’, ‘three’, ‘four’, ‘five’] >>> random.choice(items) ‘four’ >>> random.choices(items, k=2) [‘three’, ‘three’] >>> random.choices(items, k=3) [‘three’, ‘five’, ‘four’]
>>> items = [‘one’, ‘two’, ‘three’, ‘four’, ‘five’] >>> random.choice(items) ‘four’
>>> random.choices(items, k=2) [‘three’, ‘three’] >>> random.choices(items, k=3) [‘three’, ‘five’, ‘four’] |
Вы можете сделать последовательность случайной прямо на месте, при помощи random.shuffle(). Таким образом удастся обновить объект последовательности и сделать порядок элементов случайным:
>>> random.sample(items, 4) [‘one’, ‘five’, ‘four’, ‘three’]
>>> random.sample(items, 4) [‘one’, ‘five’, ‘four’, ‘three’] |
Если вы не хотите делать это с изначальным списком, сначала вам может понадобиться сделать копию, а потом уже перемешать её. Вы можете создавать копии списков Python при помощи модуля copy, или просто x[:], или x.copy(), где x является списком.
Перед тем, как перейти к генерированию случайных данных в NumPy, давайте рассмотрим еще одно приложение, которое частично включено в процесс: генерация последовательности уникальных случайных строк с одинаковой длиной.
В первую очередь, это может разобраться с устройством функции. Вам нужно выбрать из “пула” символов, таких как буквы, числа, и\или знаки препинания, совмести их в одну строку, и затем проверить, является ли эта строка сгенерированной. Python работает отлично для такого типа тестирования:
import string def unique_strings(k: int, ntokens: int, pool: str=string.ascii_letters) -> set: «»»Generate a set of unique string tokens. k: Length of each token ntokens: Number of tokens pool: Iterable of characters to choose from For a highly optimized version: https://stackoverflow.com/a/48421303/7954504 «»» seen = set() while len(seen) < ntokens: token = ».join(random.choices(pool, k=k)) seen.add(token) return seen
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import string
def unique_strings(k: int, ntokens: int, pool: str=string.ascii_letters) -> set: «»»Generate a set of unique string tokens.
k: Length of each token ntokens: Number of tokens pool: Iterable of characters to choose from
For a highly optimized version: https://stackoverflow.com/a/48421303/7954504 «»»
seen = set() while len(seen) < ntokens: token = ».join(random.choices(pool, k=k)) seen.add(token) return seen |
«».join() присоединяет буквы из random.choices() в простую строку, где «k» это длинна строки. Это токен добавлен в набор, который не может иметь дубликатов, и цикл while будет проходить, пока набор не будет содержать количество элементов, которое вы определили.
На заметку: Модуль string содержит ряд полезных констант: cii_lowercase, ascii_uppercase, string.punctuation, ascii_whitespace и еще много других.
Давайте проверим эту функцию:
>>> unique_strings(k=4, ntokens=5) {‘AsMk’, ‘Cvmi’, ‘GIxv’, ‘HGsZ’, ‘eurU’} >>> unique_strings(5, 4, string.printable) {«‘O*1!», ‘9Ien%’, ‘W=m7<‘, ‘mUD|z’}
>>> unique_strings(k=4, ntokens=5) {‘AsMk’, ‘Cvmi’, ‘GIxv’, ‘HGsZ’, ‘eurU’}
>>> unique_strings(5, 4, string.printable) {«‘O*1!», ‘9Ien%’, ‘W=m7<‘, ‘mUD|z’} |
Для хорошо настроенной версии этой функции, этот ответ Stack Overflow использует функции генератора, привязку имени и еще несколько продвинутых хитростей, чтобы создать более быструю, криптографически безопасную версию упомянутой ранее unique_strings().
PRNG для массивов: numpy.random
Одна вещь, которую вы могли заметить, заключается в том, что большинство функций из случайного числа возвращают скалярное значение (один int, float, или другой объект). Если вы хотели сгенерировать последовательность случайных чисел, один из способов достичь этого — охватить список Python:
>>> [random.random() for _ in range(5)] [0.021655420657909374, 0.4031628347066195, 0.6609991871223335, 0.5854998250783767, 0.42886606317322706]
>>> [random.random() for _ in range(5)] [0.021655420657909374, 0.4031628347066195, 0.6609991871223335, 0.5854998250783767, 0.42886606317322706] |
Есть еще один вариант, который был разработан как раз для этого. Вы можете рассматривать пакет numpy.random от NumPy как стандартный модуль random библиотеки Python, но только для массивов NumPy. (Он также имеет возможность рисовать из гораздо большего количество статистических распределений).
Обратите внимание на то, что numpy.random использует собственные PRNG, которые отделены от обычных случайных чисел. Вы не будете создавать детерминестически случайные массивы NumPy с вызовом random.seed():
>>> import numpy as np >>> np.random.seed(444) >>> np.set_printoptions(precision=2) # Выводим десятичное число
>>> import numpy as np >>> np.random.seed(444) >>> np.set_printoptions(precision=2) # Выводим десятичное число |
Без дальнейших церемоний, вот несколько примеров, удовлетворяющих ваш аппетит:
>>> # Возвращение примеров из стандартного нормального распределения >>> np.random.randn(5) array([ 0.36, 0.38, 1.38, 1.18, -0.94]) >>> np.random.randn(3, 4) array([[-1.14, -0.54, -0.55, 0.21], [ 0.21, 1.27, -0.81, -3.3 ], [-0.81, -0.36, -0.88, 0.15]]) >>> # `p` это возможность выбора каждого элемента >>> np.random.choice([0, 1], p=[0.6, 0.4], size=(5, 4)) array([[0, 0, 1, 0], [0, 1, 1, 1], [1, 1, 1, 0], [0, 0, 0, 1], [0, 1, 0, 1]])
>>> # Возвращение примеров из стандартного нормального распределения >>> np.random.randn(5) array([ 0.36, 0.38, 1.38, 1.18, -0.94])
>>> np.random.randn(3, 4) array([[-1.14, -0.54, -0.55, 0.21], [ 0.21, 1.27, -0.81, -3.3 ], [-0.81, -0.36, -0.88, 0.15]])
>>> # `p` это возможность выбора каждого элемента >>> np.random.choice([0, 1], p=[0.6, 0.4], size=(5, 4)) array([[0, 0, 1, 0], [0, 1, 1, 1], [1, 1, 1, 0], [0, 0, 0, 1], [0, 1, 0, 1]]) |
В синтаксе для randn(d0, d1, …, dn), параметры d0, d1, …, dn являются опциональными и указывают форму итогового объекта. Здесь, np.random.randn(3, 4) создает 2d массив с 3 строками и 4 столбцами. В качестве данных будут i.i.d., что означает, что каждая точка данных создается независимо от других.
Еще одна простая операция — это создание последовательности случайных логических значений: True или False. Один из способов сделать это — использовать np.random.choice([True, False]). Однако, будет практически в 4 раза быстрее выбрать (0, 1), а затем отобразить эти целые числа в соответствующие булевские значения:
КОД # randint является [inclusive, exclusive), в отличие отrandom.randint()
КОД
>>> # NumPy’s `randint` is [inclusive, exclusive), unlike `random.randint()` >>> np.random.randint(0, 2, size=25, dtype=np.uint8).view(bool) array([ True, False, True, True, False, True, False, False, False, False, False, True, True, False, False, False, True, False, True, False, True, True, True, False, True])
>>> # NumPy’s `randint` is [inclusive, exclusive), unlike `random.randint()` >>> np.random.randint(0, 2, size=25, dtype=np.uint8).view(bool) array([ True, False, True, True, False, True, False, False, False, False, False, True, True, False, False, False, True, False, True, False, True, True, True, False, True]) |
Что на счет генерации коррелированных данных? Скажем, вы хотите симулировать два корелированных временных ряда. Один из способов сделать — это использовать функцию multivariate_normal() нашего NumPy, которая учитывает матрицу ковариации. Другими словами, чтобы списать из одной нормальной распределенной случайной переменной, вам нужно определить ее среднее значение и дисперсию (или стандартное отклонение).
Для выборки из многомерного нормального распределения, вы определяете матрицу ковариации и средние значения, в итоге вы получите несколько взаимосвязанных рядов данных, которые разделены приблизительно нормально.
Однако, в отличие от ковариации, корреляция — это более знакомая для большинства мера, к тому же более интуитивная. Это ковариация, нормализованная продуктом стандартных отклонений, так что вы можете определить ковариацию с точки зрения корреляции и стандартного отклонения:
Итак, можете ли вы списать случайные выборки из многомерного нормального распределения, определив матрицу корреляции и стандартные отклонения? Да, но вам нужно будет получить приведенную выше формулу матрицы. Здесь, S — это вектор стандартных отклонений, P — это их корреляционная матрица, и С — это результирующая (квадратная) ковариационная матрица:
Это может быть выражено в NumPy следующим образом:
def corr2cov(p: np.ndarray, s: np.ndarray) -> np.ndarray: «»»Ковариационная матрица от корреляции и стандартных отклонений»»» d = np.diag(s) return d @ p @ d
def corr2cov(p: np.ndarray, s: np.ndarray) -> np.ndarray: «»»Ковариационная матрица от корреляции и стандартных отклонений»»» d = np.diag(s) return d @ p @ d |
Теперь, вы можете сгенерировать два временных ряда, которые коррелируют, но все еще являются случайными:
>>> # Начало с корреляционной матрицы и стандартных отклонений >>> # -0.40 это корреляция между А и B, а корреляция >>> # самой переменной равна 1.0 >>> corr = np.array([[1., -0.40], … [-0.40, 1.]]) >>> # Стандартные отклонения\средние арифметические А и B, соответственно >>> stdev = np.array([6., 1.]) >>> mean = np.array([2., 0.5]) >>> cov = corr2cov(corr, stdev) >>> # `size` это длина временных рядов для 2д данных >>> # (500 месяцев, дней, и так далее). >>> data = np.random.multivariate_normal(mean=mean, cov=cov, size=500) >>> data[:10] array([[ 0.58, 1.87], [-7.31, 0.74], [-6.24, 0.33], [-0.77, 1.19], [ 1.71, 0.7 ], [-3.33, 1.57], [-1.13, 1.23], [-6.58, 1.81], [-0.82, -0.34], [-2.32, 1.1 ]]) >>> data.shape (500, 2)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
>>> # Начало с корреляционной матрицы и стандартных отклонений >>> # -0.40 это корреляция между А и B, а корреляция >>> # самой переменной равна 1.0 >>> corr = np.array([[1., -0.40], … [-0.40, 1.]])
>>> # Стандартные отклонения\средние арифметические А и B, соответственно >>> stdev = np.array([6., 1.]) >>> mean = np.array([2., 0.5]) >>> cov = corr2cov(corr, stdev)
>>> # `size` это длина временных рядов для 2д данных >>> # (500 месяцев, дней, и так далее). >>> data = np.random.multivariate_normal(mean=mean, cov=cov, size=500) >>> data[:10] array([[ 0.58, 1.87], [-7.31, 0.74], [-6.24, 0.33], [-0.77, 1.19], [ 1.71, 0.7 ], [-3.33, 1.57], [-1.13, 1.23], [-6.58, 1.81], [-0.82, -0.34], [-2.32, 1.1 ]]) >>> data.shape (500, 2) |
Вы можете рассматривать данные как 500 пар обратно-коррелированных точек данных. Вот проверка правильности, так что вы можете вернуться к изначальному вводу, который приблизительно соответствует corr, stdev, и mean из примера выше:
>>> np.corrcoef(data, rowvar=False) array([[ 1. , -0.39], [-0.39, 1. ]]) >>> data.std(axis=0) array([5.96, 1.01]) >>> data.mean(axis=0) array([2.13, 0.49])
>>> np.corrcoef(data, rowvar=False) array([[ 1. , -0.39], [-0.39, 1. ]])
>>> data.std(axis=0) array([5.96, 1.01])
>>> data.mean(axis=0) array([2.13, 0.49]) |
Перед тем как мы перейдем к CSPRNG, может быть полезно обобщить некоторые случайные функции и копии numpy.random:
| Модуль random | Аналог NumPy | Использование |
| random() | rand() | Случайное десятичное [0.0, 1.0) |
| randint(a, b) | random_integers() | Случайное целое число [a, b] |
| randrange(a, b[, step]) | randint() | Случайное целое число [a, b) |
| uniform(a, b) | uniform() | Случайное десятичное [a, b] |
| choice(seq) | choice() | Случайный элемент из seq |
| choices(seq, k=1) | choice() | Случайные k элементы из seq с заменой |
| sample(population, k) | choice() с параметром replace=False | Случайные k элементы из seq без замены |
| shuffle(x[, random]) | shuffle() | Перемешка порядка |
| normalvariate(mu, sigma) или gauss(mu, sigma) | normal() | Пример из нормального распределения со средним значением mu и стандартным отклонением sigma |
Обратите внимание: NumPy специализируется на построении и обработке больших, многомерных массивов. Если вам нужно только одно значение, то random будет достаточно, к тому же, еще и быстрее. Для небольших последовательностей, random может быть еще быстрее, так как NumPy имеет ряд дополнительных расходов.
Мы рассмотрели две фундаментальные опции PRNG, так что теперь мы можем перейти к еще более безопасным адаптациям.
CSPRNG в Python
os.urandom(): настолько случайно, на сколько возможно
Функция Python под названием os.urandom() используется как в secrets, так и в uuid (мы к ним скоро придем). Чтобы не вдаваться в лишние подробности, os.urandom() генерирует зависимые от операционной системы случайные байты, которые спокойно можно назвать криптографически надежными:
- На операционных системах Unix, она считывает случайные байты из специального файла /dev/urandom, который за раз “открывает доступ к окружающим шумам, собранным из драйверов устройств и прочих ресурсов” (спасибо, Википедия). Это искаженная информация: частично о состоянии вашего оборудования и системы в определенный момент времени, и в тоже время, значительно случайные данные;
- Для Windows, используется функция C++ под названием CryptGenRandom(). Эта функция все еще технически псевдослучайная, но работает путем генерации значения сида из переменных, таких как ID процесса, состояние памяти, и так далее;
С os.urandom() нет такого понятия, как ручной сидинг. Хотя эта функция технически является псевдослучайной, она лучше подходит под наше понимание случайности. Единственный аргумент — это количество байтов в выдаче:
>>> os.urandom(3) b’\xa2\xe8\x02’ >>> x = os.urandom(6) >>> x b’\xce\x11\xe7″!\x84’ >>> type(x), len(x) (bytes, 6)
>>> os.urandom(3) b’\xa2\xe8\x02′
>>> x = os.urandom(6) >>> x b’\xce\x11\xe7″!\x84′
>>> type(x), len(x) (bytes, 6) |
Перед тем как мы пойдем дальше, сейчас подходящее время для мини-урока о кодировке символов. Многие люди, как и я, имеют своего рода аллергическую реакцию, когда они видят объекты байтов и длинный ряд символов \x. Однако, будет полезным знать, как последовательности, такие как упомянутый x в итоге становятся строками и числами.
os.urandom() возвращает последовательность одиночных байтов:
>>> x b’\xce\x11\xe7″!\x84′
>>> x b’\xce\x11\xe7″!\x84′ |
Но как это в итоге превращается в строку или последовательность чисел?
Сначала нужно обратиться к фундаментальным основам вычисления, которые заключаются в том, что байт состоит из 8 битов. Вы можете воспринимать бит как одинарную цифру, которая равна либо 1, либо 0.
Байт эффективно выбирает между 0 и 1 восемь раз, так что и 01101100, и 1111000 могут представлять байты. Попробуйте следующее, чтобы увидеть, как F-строки Python представлены в вашем интерпретаторе Python 3.6:
>>> binary = [f'{i:0>8b}’ for i in range(256)] >>> binary[:16] [‘00000000’, ‘00000001’, ‘00000010’, ‘00000011’, ‘00000100’, ‘00000101’, ‘00000110’, ‘00000111’, ‘00001000’, ‘00001001’, ‘00001010’, ‘00001011’, ‘00001100’, ‘00001101’, ‘00001110’, ‘00001111’]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
>>> binary = [f'{i:0>8b}’ for i in range(256)] >>> binary[:16] [‘00000000’, ‘00000001’, ‘00000010’, ‘00000011’, ‘00000100’, ‘00000101’, ‘00000110’, ‘00000111’, ‘00001000’, ‘00001001’, ‘00001010’, ‘00001011’, ‘00001100’, ‘00001101’, ‘00001110’, ‘00001111’] |
Это эквивалент [bin(i) for i in range(256)] с определенным форматированием. bin() конвертирует целое число в его бинарное представление в качестве строки.
Что это нам дает? Использование диапазона (256) выше — это не случайный выбор. Учитывая, что мы можем использовать только 8 битов, каждый из которых имеет 2 варианта, значит мы имеем 2*8=256 возможных “комбинаций”.
Это значит, что каждый байт отображает целое число от 0 до 255. Другими словами, нам понадобится больше, чем 8 битов, чтобы выразить целое число 256. Вы можете подтвердить это, проверив, что len(f'{256:0>8b}’) теперь 9, а не 8.
Хорошо, теперь вернемся к типу данных байтов, которые мы видели выше, построив последовательность битов, соответствующую числам от 0 до 255:
bites = bytes(range(256))
bites = bytes(range(256)) |
Если вы вызовите list(bites), вы вернетесь к списку Python, который работает от 0 до 255._`abcdefghijklmnopqrstuvwxyz{|}~\x7f\x80\x81\x82\x83\x84\x85\x86′
‘\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b’
# …
Эти бекслешы являются выходными последовательностями, а \xhh отображает символ с шестнадцатеричным значением hh. Некоторые элементы битов отображены буквально (печатные символы, такие как буквы, числа и знаки препинания). Большая части выражена проблеами. \x08 представляет клавишу backspace на клавиатуре, в то время как \x13 — возврат каретки (часть новой строки в системах Windows).
Если вы хотите переосмыслить шестнадцатеричный код, вот полезный комментарий Чарльза Петцольда: “Скрытый язык” — отличное место для этого. Hex — это основанная на нумерации из 16 чисел система, которая, вместо того, чтобы использовать от 0 до 9, использует от 0 до 9 и от «а» до «f» в качестве основных цифр.
Наконец, давайте вернемся к тому, где мы начинали, с последовательностью случайных байтов x. Надеюсь, так теперь будет понятнее. Вызов .hex() в байтовом объекте дает строку шестнадцатеричных чисел, каждое из которых соответствует десятичному числу от 0 до 255:
>>> x b’\xce\x11\xe7″!\x84’ >>> list(x) [206, 17, 231, 34, 33, 132] >>> x.hex() ‘ce11e7222184’ >>> len(x.hex()) 12
>>> x b’\xce\x11\xe7″!\x84′
>>> list(x) [206, 17, 231, 34, 33, 132]
>>> x.hex() ‘ce11e7222184’
>>> len(x.hex()) 12 |
Последний вопрос: каким образом b.hex() длиной 12 символов, если «х» длиной всего 6 байтов? Это связано с тем, что два шестнадцатеричных числа соответствуют одному байту. Str версия байтов всегда будет в два раза длиннее ожидаемого.
Даже если байт (такой, как \x01) не нуждается в полном наборе из 8 битов для отображения, b.hex() всегда будет использовать два числа на байт, так что номер 1 будет отображен как 01, а не просто 1. При этом математически, оба варианта получаются одинакового размера.
Техническая информация: то, что мы в основном рассмотрели здесь — это то, как объекты байтов становятся строками. Еще одна особенность заключается в том, как байты, создаваемые os.urandom(), конвертируются в десятичное число с интервалом [0.0, 1.0), как и в криптографически безопасной версии random.random(). Если вам интересно углубиться в данный вопрос, этот сниппет кода показывает, как int.from_bytes() делает начальное преобразование в целое число, используя систему с нумерацией 256.
Имея это ввиду, давайте рассмотрим предоставленный недавно модуль secrets, который делает генерацию токенов безопасности намного более удобным для пользователя.
Python умеет хранить секреты
Предоставленный одним из самых ярких PEP в Python 3.6, модуль secrets де-факто выполняет роль модуля для генерации криптографически безопасных случайных байтов и строк.
Вы можете проверить исходный код модуля, который является аккуратным и лаконичным примером 25 строк. Модуль secrets — это, по сути, обертка вокруг os.urandom(). Он экспортирует множество функций для генерации случайных чисел, байтов и строк. Большая часть этих примеров прекрасно рассказывают о себе сами:
>>> n = 16 >>> # Создание безопасных токенов >>> secrets.token_bytes(n) b’A\x8cz\xe1o\xf9!;\x8b\xf2\x80pJ\x8b\xd4\xd3’ >>> secrets.token_hex(n) ‘9cb190491e01230ec4239cae643f286f’ >>> secrets.token_urlsafe(n) ‘MJoi7CknFu3YN41m88SEgQ’ >>> # Безопасная версия для `random.choice()` >>> secrets.choice(‘rain’) ‘a’
>>> n = 16
>>> # Создание безопасных токенов >>> secrets.token_bytes(n) b’A\x8cz\xe1o\xf9!;\x8b\xf2\x80pJ\x8b\xd4\xd3′
>>> secrets.token_hex(n) ‘9cb190491e01230ec4239cae643f286f’
>>> secrets.token_urlsafe(n) ‘MJoi7CknFu3YN41m88SEgQ’
>>> # Безопасная версия для `random.choice()` >>> secrets.choice(‘rain’) ‘a’ |
Что на счет конкретного примера? Вы (скорее всего) пользовались сервисами сокращения URL, такими как tinyurl или bit.ly, которые превращают длинный URL в что-нибудь вроде этого: https://bit.ly/2LwO8SH. Большинство сервисов сокращения не делают никакого сложного хеширования от ввода до вывода. Они просто генерируют случайную строку, и проверяют, чтобы она не была сгенерирована ранее, и связывают её с входящим URL-ом.
Предположим, что взглянув на Root Zone Database, вы зарегистрировали сайт short.ly. Вот функция, которая поможет начать работу с вашим сервисом:
from secrets import token_urlsafe DATABASE = {} def shorten(url: str, nbytes: int=5) -> str: ext = token_urlsafe(nbytes=nbytes) if ext in DATABASE: return shorten(url, nbytes=nbytes) else: DATABASE.update({ext: url}) return f’short.ly/{ext}
from secrets import token_urlsafe
DATABASE = {}
def shorten(url: str, nbytes: int=5) -> str: ext = token_urlsafe(nbytes=nbytes) if ext in DATABASE: return shorten(url, nbytes=nbytes) else: DATABASE.update({ext: url} |
Генераторы Python. Их создание и использование.
Приходилось ли вам когда-либо работать с настолько большим набором данных, что он переполнял память вашего компьютера? Или быть может у вас была сложная функция, для которой нужно было бы сохранять внутреннее состояние при вызове? А если при этом функция была слишком маленькой, чтобы оправдать создание собственного класса? Во всех этих случаях вам придут на помощь генераторы Python и ключевое слово yield.
Прочитав эту статью вы узнаете:
- Что собой представляют генераторы Python и как их использовать
- Как задавать функции и выражения создающие генераторы
- Как работает в Python ключевое слово yield
Если вы являетесь Питонистом начального или среднего уровня и вы заинтересованы в том, чтобы научиться работать с большими наборами данных в питоновском стиле, то скорее всего это руководство для вас.
По ссылке ниже вы можете скачать копию файла с данными, используемыми в этом руководстве.
Скачать табличные данные, используемые в данном руководстве.
Использование Генераторов
Функции генераторов (их описание можно почитать в PEP 255) представляют собой особый вид функций, которые возвращают «ленивый итератор». И хотя содержимое этих объектов вы можете перебирать также как и списки, но при этом, в отличие от списков, ленивые итераторы не хранят свое содержимое в памяти. Чтобы составить общее представление об итераторах в Python взгляните на статью Python “for” Loops (Definite Iteration).
Теперь, когда вы имеете примерное представление о том, чем является генератор, у вас наверняка появилось желание увидеть как он работает. Давайте рассмотри два примера. В первом вы увидите общий принцип работы генераторов. В последующих у вас будет возможность изучить работу генераторов более подробно.
Пример 1: Чтение больших файлов
Списки Python
Работа с потоками данных и большими файлами, такими например как CSV, являются наиболее распространенными вариантами использования генераторов. Давайте возьмем CSV файл (CSV является стандартным форматом для обмена данными, колонки в нем разделяются при помощи запятых). Предположим, что вы хотите посчитать количество имеющихся в нем рядов. Код ниже предлагает один из путей для, того, чтобы осуществить это:
csv_gen = csv_reader("some_csv.txt")
row_count = 0
for row in csv_gen:
row_count += 1
print(f"Row count is {row_count}")Глядя на этот пример, вы можете предположить что csv_gen является списком. Для того чтобы заполнить этот список, csv_reader() открывает файл и загружает его содержимое в csv_gen. Затем программа перебирает список, увеличивая значение row_count для каждого следующего ряда.
Это вполне приемлемое решение, но будет ли этот подход работать, если файл окажется слишком большим? А что если файл окажется больше чем вся доступная память, которая есть в нашем распоряжении? Для того чтобы ответить на этот вопрос, давайте предположим, что csv_reder() будет открывать файл и считывать его в массив.
def csv_reader(file_name):
file = open(file_name)
result = file.read().split("\n")
return resultЭта функция открывает данный файл и использует file.read() вместе со .split() для того, чтобы добавить каждый ряд данных как отдельный элемент списка. Если бы вы использовали эту версию cvs_reader() в блоке кода с подсчетом (вы его увидите далее), тогда бы вы увидели следующее сообщение:
Traceback (most recent call last):
File "ex1_naive.py", line 22, in <module>
main()
File "ex1_naive.py", line 13, in main
csv_gen = csv_reader("file.txt")
File "ex1_naive.py", line 6, in csv_reader
result = file.read().split("\n")
MemoryErrorВ этом случае open() возвращает объект генератора, который вы можете «лениво» (не обсчитывая заранее) перебирать ряд за рядом. Тем не менее, file.read().split() загружает все данные в память сразу, вызывая ошибку памяти (MemoryError).
До того как это произойдет, вы можете заметить, что ваш компьютер замедлился. Возможно вам потребуется даже вручную остановить программу. Но что нам делать, если мы хотим этого избежать?
Генераторы Python
Давайте взглянем на новое определение функции csv_reader():
def csv_reader(file_name):
for row in open(file_name, "r"):
yield rowВ этой версии вы открываете файл и проходите его содержимое, возвращая ряд за рядом. Этот код выводит следующий результат без каких-либо ошибок:
Row count is 64186394
Почему так получилось? Да потому что вы по сути превратили функцию csv_reader() в генератор. Эта версия кода открывает файл, проходит по строкам и извлекает для чтения лишь отдельный ряд, вместо того, чтобы возвращать весь файл целиком.
Также вы можете определить выражение создающее генератор, которое очень похоже по синтаксису на выражение создающее список. В таком виде вы можете использовать генератор без вызова функции:
csv_gen = (row for row in open(file_name))
Такой способ создания генератора csv_gen является более лаконичным.
Более подробно о yield мы расскажем позже, а пока запомните основные отличия между использованием ключевых слов yield и return:
- Использование yield приведет к созданию генератора.
- Использование return приведет к возврату только первой строки файла.
Пример 2: Создание бесконечной последовательности
Давайте теперь в качестве другого примера рассмотрим генератор бесконечной последовательности. В Python для того, чтобы получить конечную последовательность мы обычно вызываем функцию range(). Затем мы передаем ее значение как аргумент в функцию list():
a = range(5) list(a) [0, 1, 2, 3, 4]
Создание же бесконечной последовательности стопроцентно потребует от нас использования генератора. Причина проста — ограниченность памяти нашего компьютера.
def infinite_sequence():
num = 0
while True:
yield num
num += 1Этот блок кода не велик и хорошо смотрится. Сперва, мы задаем переменную num и создаем бесконечный цикл. Затем мы немедленно извлекаем num с помощью yield в ее исходном состоянии (это во многом повторяет то, что делает range()). После этого мы увеличиваем num на 1.
Если вы попробуете запустить этот код в теле цикла for, то увидите, что на самом деле он бесконечный:
for i in infinite_sequence(): print(i, end=" ") 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 [...] 6157818 6157819 6157820 6157821 6157822 6157823 6157824 6157825 6157826 6157827 6157828 6157829 6157830 6157831 6157832 6157833 6157834 6157835 6157836 6157837 6157838 6157839 6157840 6157841 6157842 KeyboardInterrupt Traceback (most recent call last): File "<stdin>", line 2, in <module>
Эта программа будет исполняться, до тех пор, пока вы ее вручную не остановите.
Вместо использования Loop, вы также можете использовать на генераторе функцию next(). Это окажется особенно удобным при тестировании работы генератора в консоли:
gen = infinite_sequence() next(gen) 0 next(gen) 1 next(gen) 2 next(gen) 3
Здесь у нас показан генератор, под названием gen, который мы можем вручную перебирать с помощью вызова функции next(). Это работает как отличная проверка. Она позволяет нам убедиться что генератор выдает результат, который мы от него ожидаем.
Примечание: Когда мы используем next(), Python вызывает метод .__next__(), для функции, которая передается в качестве аргумента. При этом существуют специальные возможности, но разговор о них находится за рамками данной статьи. Если вам интересно, попробуйте поменять аргументы, которые передаются в next() и посмотрите на результат.
Пример 3: Нахождение палиндромов
Вы можете использовать бесконечные последовательности множеством различных способов. Одним из них, который мы отметим особенно, является создание детектора палиндромов. Детектор палиндромов выявляет все последовательности букв и цифр, которые являются палиндромами. Это слова или числа, которые читаются одинаково вперед и назад, как «121» например. Сперва давайте зададим наш числовой детектор палиндромов:
def is_palindrome(num):
# Skip single-digit inputs
if num // 10 == 0:
return False
temp = num
reversed_num = 0
while temp != 0:
reversed_num = (reversed_num * 10) + (temp % 10)
temp = temp // 10
if num == reversed_num:
return num
else:
return FalseНе особо беспокойтесь о понимании вычислений, лежащих в основе данного кода. Просто заметьте, что функция принимает введенное число, переворачивает его, и сравнивает с оригиналом. Теперь вы можете использовать генератор бесконечной последовательности для получения бегущего списка со всеми числовыми палиндромами:
for i in infinite_sequence():
pal = is_palindrome(i)
if pal:
print(pal)
11
22
33
[...]
99799
99899
99999
100001
101101
102201
KeyboardInterrupt
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
File "<stdin>", line 5, in is_palindromeВ консоли выводятся только те номера, которые читаются одинаково и вперед и назад.
Примечание: на практике вам вряд ли придется писать свой собственный бесконечный генератор последовательностей, по той простой причине, что есть уже очень эффективный генератор itertools.count() из модуля itertools.
Теперь, когда вы познакомились с простым примером использования генератора бесконечной последовательности, давайте рассмотрим более детально работу этого генератора.
Понимание работы генератора Python
К этому моменту вы уже познакомились с двумя основными способами создания генераторов: с помощью функции и с помощью выражения. У вас также должно было сформироваться интуитивное представление о том, как работает генератор. Давайте теперь уделим некоторое время тому, чтобы сделать наши знания более четкими.
Функции генераторов выглядят и действуют как обычные функции, но с одной определяющей особенностью. А именно, функция генератора используют ключевое слово yield вместо return. Давайте вспомним функцию генератора, которую мы написали ранее:
def infinite_sequence():
num = 0
while True:
yield num
num += 1Это похоже на типичное определение функции, за исключением yield и кода, который следует за ним. Ключевое слово yield применяется там, где значение нужно отправить обратно вызывающей стороне. Но в отличие от return, выхода из функции в данном случае не происходит. Вместо этого, при возврате состояние функции запоминается. Более того, когда next() вызывается для объекта-генератора (явно или неявно в цикле for), ранее полученная переменная num увеличивается, а затем возвращается снова. Поскольку функции генератора похожи на другие функции и действуют подобным образом, вы можете предположить, что выражения создающие генераторы очень похожи на другие выражениях в Python создающие объекты.
Примечание. Если вы хотите больше узнать о генераторах списков, множеств и словарей в Python, можете прочитать статью Эффективное использование генераторов списков (англ).
Создание генератора с помощью выражения
Как и выражения создающие списки, выражения создающие генераторы позволяют быстро получить объект генератора с помощью всего одной строчки кода. Использоваться они могут в тех же случаях, что и выражения создающие списки, но при этом у них есть одно дополнительное преимущество. Их можно создавать не удерживая весь объект в памяти перед итерацией. Если перефразировать, вы не будете расходовать память при использовании генератора.
Давайте для примера возьмем возведение в квадрат некоторых чисел:
nums_squared_lc = [num**2 for num in range(5)] nums_squared_gc = (num**2 for num in range(5))
И nums_squared_lc, и nums_squared_gc выглядят практически одинаково, но есть одно ключевое отличие. Вы сможете его заметить? Для первого объекта использовались квадратные скобки и это привело к созданию списка. Для второго использовались круглые скобки, и это привело к созданию генератора. Посмотрите, что произойдет, если мы выведем содержание каждого из этих объектов:
nums_squared_lc [0, 1, 4, 9, 16] nums_squared_gc <generator object <genexpr> at 0x107fbbc78>
Это подтверждает тот факт, что с помощью круглых скобок вы создали объект генератора, а также то, что он отличается от списка.
Профилирование эффективности генератора
Ранее мы узнали, что использование генераторов является отличным способом оптимизации памяти. И хотя генератор бесконечной последовательности является наиболее ярким примером этой оптимизации, давайте рассмотрим еще один пример с возведением числа в квадрат и проверим размер полученных объектов.
Вы можете сделать это с помощью вызова функции sys.getsizeof ():
import sys nums_squared_lc = [i * 2 for i in range(10000)] sys.getsizeof(nums_squared_lc) 87624 nums_squared_gc = (i ** 2 for i in range(10000)) print(sys.getsizeof(nums_squared_gc)) 120
В этом случае размер списка, полученного с помощью выражения составляет 87 624 байта, а размер генератора — только 120. То есть, список занимает памяти в 700 раз больше, чем генератор! Однако нужно помнить одну вещь. Если размер списка меньше доступной памяти на работающей машине, тогда обработка его будет занимать меньше времени, чем аналогичная обработка генератора. Чтобы удостовериться в этом, давайте просуммируем результаты приведенных выше выражений. Вы можете использовать для анализа функцию cProfile.run ():
import cProfile
cProfile.run('sum([i * 2 for i in range(10000)])')
5 function calls in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.001 0.001 0.001 0.001 <string>:1(<listcomp>)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1 0.000 0.000 0.001 0.001 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {built-in method builtins.sum}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
cProfile.run('sum((i * 2 for i in range(10000)))')
10005 function calls in 0.003 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
10001 0.002 0.000 0.002 0.000 <string>:1(<genexpr>)
1 0.000 0.000 0.003 0.003 <string>:1(<module>)
1 0.000 0.000 0.003 0.003 {built-in method builtins.exec}
1 0.001 0.001 0.003 0.003 {built-in method builtins.sum}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}Здесь вы можете видеть, что суммирование всех значений, содержащихся в списке заняло около трети времени аналогичного суммирования с помощью генератора. Поэтому если скорость является для вас проблемой, а память — нет, то список, возможно, окажется лучшим инструментом для работы.
Примечание. Эти измерения действительны не только для генераторов, созданных с помощью выражений. Они абсолютно идентичны и для генераторов, созданных с помощью функции. Ведь, как мы уже говорили выше, эти генераторы эквивалентны.
Запомните, что выражения создающие списки возвращают списки, в то время как выражения генераторов возвращают генераторы. Генераторы работают одинаково, независимо от того, построены они на основе функции или выражения. Использование выражения позволяет вам задать простые генераторы одной строкой и также предполагает yield в конце каждой итерации. Ключевое слово yield, безусловно, является основой, на которой основывается вся функциональность генераторов. В следующих статьях мы углубимся в его работу.
Python. Модуль random. Функции для последовательностей
Содержание
Поиск на других ресурсах:
1. Функция random.choice(). Получить случайный элемент в последовательности
Функция random.choice() предназначена для получения случайного элемента из непустой последовательности. Общая форма функции
random.choice(sequence)
где sequence – некоторая непустая последовательность значений, которыми могут быть числа, строки и т.д.
Если задать пустую последовательность, то будет сгенерировано исключение IndexError, которое возникает когда индекс последовательности находится за пределами диапазона.
Пример. В примере формируются две последовательности. Первая последовательность – дни недели. Вторая последовательность – произвольные числа. В обоих случаях будет вызвана функция choice() для выбора случайного значения.
# Функция random.choice()
# подключить модуль random
import random
# 1. Сформировать последовательность строк
days = ('Sun', 'Mon', 'Tue', 'Wed', 'Thi', 'Fri', 'Sat')
# получить случайный элемент из последовательности
rand_day = random.choice(days)
print(rand_day)
# 2. Сформировать последовательность чисел
intNumbers = ( 2, 17, -11, -20, 33)
# получить случайный элемент из последовательности
randIntNumber = random.choice(intNumbers)
print(randIntNumber)Каждый раз после запуска программы на выполнение будет случайно выбираться случайный элемент из последовательности. Один из случаев получения результата выполнения программы
Wed -20
⇑
2. Функция random.choices(). Взять список элементов из популяции
Данная функция введена начиная с версии Python 3.6.
Функция random.choices(population, k) возвращает список элементов из набора population. Размер результирующего списка равен значению k.
Согласно документации Python общая форма функции следующая
random.choices(population, weights=None, *, cum_weights=None, k=1)
где
- population – некоторая популяция (набор) элементов. Если значение population есть пустым, то возникает исключение IndexError;
- k – количество элементов в результирующем списке, который получается из набора population;
- weights – последовательность, которая задает относительные веса при выборе элементов из набора population. Перед выполнения выбора относительные веса weights конвертируются в совокупные веса cum_weights;
- cum_weights – альтернативная последовательность к weights. Если задана последовательность cum_weights, то устанавливаются совокупные (cumulative) веса при выборе элементов из набора population. Например, относительные веса [ 1, 3, -2, 5 ] есть эквивалентные совокупным (cumulative weights) весам [ 1, 4, 2, 7 ].
Пример.
# Функция random.choices()
# подключить модуль random
import random
# сформировать некоторую последовательность (популяцию)
seq1 = [ 'а', 'b', 'с', 'd', 'е', 'f', 'g', 'h' ]
# из популяции seq1 образовать новые последовательности
seq2 = random.choices(seq1, [1, 1, 2, 1, 2, 3, 3, 3], k=6)
print('seq2 = ', seq2)
seq3 = random.choices(seq1, [5, 5, 5, 5, 5, 5, 5, 5], k=3)
print('seq3 = ', seq3)
seq4 = random.choices(seq1, [1, 1, 1, 1, 1, 1, 1, 1], k=3)
print('seq4 = ', seq4)
seq5 = random.choices(seq1, [1, 1, 1, 1, 1, 1, 1, 1], k=10)
print('seq5 = ', seq5)Результат работы программы
seq2 = ['g', 'g', 'c', 'g', 'f', 'g'] seq3 = ['c', 'f', 'c'] seq4 = ['a', 'c', 'e'] seq5 = ['g', 'h', 'h', 'd', 'h', 'h', 'd', 'h', 'f', 'g']
⇑
3. Функция random.shuffle(). Изменить последовательность
Функция random.shuffle() применяется к последовательностям. Функция произвольно изменяет позиции элементов последовательности.
Общая форма вызова функции
random.shuffle(sequence[, random])
где sequence – некоторая последовательность, которая может содержать элементы разных типов.
Пример.
# Функция random.shuffle() # подключить модуль random import random # 1. Сформировать последовательность целых чисел arr = [ 2, 3, 4, 5 ] print(arr) # перемешать последовательность random.shuffle(arr) print(arr) # 2. Сформировать последовательность вещественных чисел arr2 = [ 1.8, -2.8, 3.5, 4.77, -11.2 ] print(arr2) # вывести предыдущий вариант # перемешать последовательность random.shuffle(arr2) print(arr2) # 3. Сформировать последовательность элементов разных типов sequence = [ 'abc', 0.223, 25, True] print(sequence) # перемешать элементы в последовательности random.shuffle(sequence) print(sequence)
Результат выполнения программы
[2, 3, 4, 5] [2, 4, 5, 3] [1.8, -2.8, 3.5, 4.77, -11.2] [1.8, 4.77, -2.8, -11.2, 3.5] ['abc', 0.223, 25, True] [0.223, True, 25, 'abc']
⇑
4. Функция random.sample(). Получить список
Функция random.sample() создает новую последовательность уникальных элементов заданного размера. Последовательность уникальных элементов выбирается из некоторого набора или популяции. Предыдущая последовательность не изменяется
Общая форма функции
random.sample(population, k)
где
- population – некоторая популяция, служащая входными данными для формирования результирующей последовательности;
- k – размер результирующей последовательности.
Пример.
# Функция random.sample()
# подключить модуль random
import random
# 1. Сформировать последовательность элементов
arr = [ 'a2', 3, '4', 5, False, 5, 5, 5 ]
print("arr = ", arr)
sample = random.sample(arr,3) # sample = [5, 'a2', '4']
print('random.sample(arr,3) = ', sample)
sample = random.sample(arr,6) # sample = [5, 5, 'a2', '4', 5, False]
print('random.sample(arr,6) = ', sample)
# 2. Последовательность чисел
numbers = [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 10 чисел
sample = random.sample(numbers,10) # все элементы
print('numbers = ', numbers)
print('random.sample(numbers,10) = ', sample)Результат выполнения программы
arr = ['a2', 3, '4', 5, False, 5, 5, 5] random.sample(arr,3) = [5, 3, 'a2'] random.sample(arr,6) = [5, '4', 'a2', 5, 3, 5] numbers = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] random.sample(numbers,10) = [0, 6, 5, 3, 2, 7, 1, 8, 9, 4]
⇑
Связанные темы
⇑
Случайные числа в Python | Портал информатики для гиков
Python определяет набор функций, которые используются для генерации или управления случайными числами. Этот конкретный тип функций используется во многих играх, лотереях или любых приложениях, требующих генерации случайных чисел.
Операции с номерами Рэндона:
1. choice () : — Эта функция используется для генерации 1 случайного числа из контейнера.
2. randrange (beg, end, step) : — Эта функция также используется для генерации случайного числа, но в пределах диапазона, указанного в его аргументах. Эта функция принимает 3 аргумента: начальный номер (включается в генерацию), последний номер (исключается при генерации) и шаг (чтобы пропустить числа в диапазоне при выборе).
|
Выход:
A random number from list is : 4 A random number from range is : 41
3. random () : — Это число используется для генерации случайного числа с плавающей запятой меньше 1 и больше или равно 0.
4. seed () : — Эта функция отображает конкретное случайное число с указанным аргументом seed . Все случайные числа, вызываемые после сеяного значения, возвращают сопоставленное число.
|
Выход:
A random number between 0 and 1 is : 0.510721762520941 The mapped random number with 5 is : 0.6229016948897019 The mapped random number with 7 is : 0.32383276483316237 The mapped random number with 5 is : 0.6229016948897019 The mapped random number with 7 is : 0.32383276483316237
5. shuffle () : — эта функция используется для перемешивания всего списка, чтобы случайным образом расположить их.
6.iform (a, b) : — эта функция используется для генерации случайного числа с плавающей запятой между числами, указанными в ее аргументах. Он принимает два аргумента: нижний предел (включается в генерацию) и верхний предел (не включается в генерацию).
|
Выход:
The list before shuffling is : 1 4 5 10 2 The list after shuffling is : 2 1 4 5 10 The random floating point number between 5 and 10 is : 5.183697823553464
Эта статья предоставлена Манджитом Сингхом. Если вы как GeeksforGeeks и хотели бы внести свой вклад, вы также можете написать статью с помощью contribute.geeksforgeeks.org или по почте статьи [email protected]. Смотрите свою статью, появляющуюся на главной странице GeeksforGeeks, и помогите другим вундеркиндам.
Пожалуйста, пишите комментарии, если вы обнаружите что-то неправильное или вы хотите поделиться дополнительной информацией по обсуждаемой выше теме.
Рекомендуемые посты:
Случайные числа в Python
0.00 (0%) 0 votes
Вывод нескольких случайных фраз в Python
Вы здесь: Главная — Python — Основы Python — Вывод нескольких случайных фраз в Python
В данном примере скрипта на Python я покажу Вам как можно вывести несколько случайных фраз из файла. Где это может понадобиться? Например, Вам надо сделать генератор вопросов для проведения тестирования по какой-либо теме. Далее показан простой код на Python, который позволяет этого добиться. Код хорошо документирован, но если остались вопросы — задавайте их в комментариях.
# импортируем библиотеку random
import random# читаем файл в список
# file - название файла
def read2list(file):
# открываем файл в режиме чтения utf-8
file = open(file, 'r', encoding='utf-8')
# читаем все строки и удаляем переводы строк
lines = file.readlines()
lines = [line.rstrip('\n') for line in lines]
# закрываем файл
file.close()
# возвращаем список строк из файла
return lines
# возвращает 5 случайных вопросов
def get_questions(numberOfAnswers = 5):
# получаем список строк из файла
answers = read2list('answers_data.txt')
# выбираем 5 случайных строк из списка с помощью встроенной функции choices
items = random.choices(population=answers, k=numberOfAnswers)
# возвращаем список
return items
Как видите код достаточно простой, но со своей задачей справляется. Кроме того, хочу заметить, что если Вы будете вызывать функцию get_questions в цикле, учтите, что она может возвращать одни и те же вопросы время от времени. Для того, чтобы этого избежать, можно из списка answers удалять эти пять строк. Таким образом, Вы сгенерируете уникальные вопросы для каждого теста.
- Создано 02.01.2020 12:01:54
- Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
<a href=»https://myrusakov.ru» target=»_blank»><img src=»https://myrusakov.ru/images/button.gif» alt=»Как создать свой сайт» /></a>Она выглядит вот так:
-
Текстовая ссылка:
<a href=»https://myrusakov.ru» target=»_blank»>Как создать свой сайт</a>Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):
[URL=»https://myrusakov.ru»]Как создать свой сайт[/URL]
Python random — генерация случайных чисел / последовательностей
Эта статья посвящена модулю random в Python, который используется для генерации псевдослучайных чисел для различных вероятностных распределений.
Методы случайного модуля Python
1. семя ()
Инициализирует генератор случайных чисел. Чтобы сгенерировать новую случайную последовательность, необходимо установить начальное число в зависимости от текущего системного времени. random.seed () устанавливает начальное число для генерации случайных чисел.
2. getstate ()
Возвращает объект, содержащий текущее состояние генератора. Чтобы восстановить состояние, передайте объект в setstate () .
3. setstate (state_obj)
Восстанавливает состояние генератора в момент вызова getstate () , передавая объект состояния.
4. getrandbits (k)
Возвращает целое число Python с k случайными битами. Это полезно для таких методов, как randrange () , для обработки произвольных больших диапазонов для генерации случайных чисел.
>>> импорт случайный >>> random.getrandbits (100) # Получить случайное целое число размером 100 бит 802952130840845478288641107953
Вот пример, иллюстрирующий методы getstate () и setstate () .
случайный импорт
random.seed (1)
# Получить состояние генератора
состояние = random.getstate ()
print ('Создание случайной последовательности из 3-х целых чисел ...')
для i в диапазоне (3):
печать (random.randint (1, 1000))
# Восстановить состояние до точки до создания последовательности
случайный.setstate (состояние)
print ('Создание одинаковой идентичной последовательности из 3-х целых чисел ...')
для i в диапазоне (3):
печать (random.randint (1, 1000))
Возможный выход:
Генерация случайной последовательности из 3 целых чисел ... 138 583 868 Создание одинаковой идентичной последовательности из 3-х целых чисел ... 138 583 868
Генерировать случайные целые числа
Модуль random предоставляет несколько специальных методов для генерации случайных целых чисел.
1. randrange (старт, стоп, шаг)
Возвращает случайно выбранное целое число из диапазона (начало, остановка, шаг) .Это вызывает ValueError , если start > stop .
2. randint (а, б)
Возвращает случайное целое число от a до b (оба включительно). Это также вызывает ValueError , если a > b .
Вот пример, иллюстрирующий обе вышеуказанные функции.
случайный импорт
я = 100
j = 20e7
# Генерирует случайное число от i до j
a = random.randrange (i, j)
пытаться:
b = случайный.рандранж (j, i)
кроме ValueError:
print ('ValueError в randrange () с момента запуска> остановки')
c = random.randint (100, 200)
пытаться:
d = random.randint (200, 100)
кроме ValueError:
print ('ValueError в randint () с 200> 100')
print ('я =', я, 'и j =', j)
print ('randrange () сгенерированное число:', a)
print ('randint () сгенерированное число:', c)
Возможный выход
ValueError в randrange () с момента запуска> остановки ValueError в randint () с 200> 100 i = 100 и j = 200000000.0 randrange () сгенерированный номер: 143577043 сгенерированное число randint (): 170
Генерация случайных чисел с плавающей запятой
Подобно генерации целых чисел, существуют функции, которые генерируют случайные последовательности с плавающей запятой.
- случайный. random () -> Возвращает следующее случайное число с плавающей запятой от [0,0 до 1,0)
- random. uniform (a, b) -> Возвращает случайное число с плавающей запятой
N, такое что a <= N <= b , если a <= b, и b <= N <= a , если b- случайный. expovariate (lambda) -> Возвращает число, соответствующее экспоненциальному распределению.
- случайный. gauss (mu, sigma) -> Возвращает число, соответствующее гауссовскому распределению.
Есть аналогичные функции для других распределений, таких как нормальное распределение, гамма-распределение и т. Д.
Пример создания этих чисел с плавающей запятой приведен ниже:
случайный импорт
print ('Случайное число от 0 до 1:', random.случайный ())
print ('Равномерное распределение между [1,5]:', random.uniform (1, 5))
print ('Распределение Гаусса со средним значением = 0 и стандартным отклонением = 1:', random.gauss (0, 1))
print ('Экспоненциальное распределение с лямбда = 0,1:', random.expovariate (0,1))
print ('Нормальное распределение со средним значением = 1 и стандартным отклонением = 2:', random.normalvariate (1, 5))
Возможный выход
Случайное число от 0 до 1: 0,44663645835100585 Равномерное распределение между [1,5]: 3.65657099941547 Распределение Гаусса со средним значением = 0 и стандартным отклонением = 1: -2.271813609629832 Экспоненциальное распределение с лямбда = 0,1: 12,64275539117617 Нормальное распределение со средним значением = 1 и стандартным отклонением = 2: 4,2595111757
Случайные последовательности с использованием модуля случайности
Подобно целым числам и последовательностям с плавающей запятой, универсальная последовательность может быть набором элементов, например List / Tuple. Модуль random предоставляет полезные функции, которые могут вводить состояние случайности в последовательности.
1. случайный.перемешать (x)
Используется для перемешивания последовательности на месте. Последовательность может быть любым списком / кортежем, содержащим элементы.
Пример кода для иллюстрации перетасовки:
случайный импорт
последовательность = [random.randint (0, i) для i в диапазоне (10)]
print ('Перед перемешиванием', последовательность)
random.shuffle (последовательность)
print ('После перемешивания', последовательность)
Возможный выход:
Перед перемешиванием [0, 0, 2, 0, 4, 5, 5, 0, 1, 9] После перемешивания [5, 0, 9, 1, 5, 0, 4, 2, 0, 0]
2.random.choice (seq)
Это широко используемая на практике функция, при которой вы хотите случайным образом выбрать элемент из списка / последовательности.
случайный импорт
a = ['один', 'одиннадцать', 'двенадцать', 'пять', 'шесть', 'десять']
печать (а)
для i в диапазоне (5):
печать (random.choice (a))
Возможный выход
[«один», «одиннадцать», «двенадцать», «пять», «шесть», «десять»] 10 11 шесть двенадцать двенадцать
3. random.sample (совокупность, k)
Возвращает случайную выборку из последовательности длиной k .
случайный импорт
a = ['один', 'одиннадцать', 'двенадцать', 'пять', 'шесть', 'десять']
печать (а)
для i в диапазоне (3):
b = random.sample (a, 2)
print ('случайная выборка:', b)
Возможный выход
[«один», «одиннадцать», «двенадцать», «пять», «шесть», «десять»] случайная выборка: ['пять', 'двенадцать'] случайная выборка: ['десять', 'шесть'] случайная выборка: ['одиннадцать', 'один']
Случайное число
Поскольку псевдослучайная генерация основана на предыдущем числе, мы обычно используем системное время, чтобы убедиться, что программа выдает новый результат каждый раз, когда мы ее запускаем.Таким образом, мы используем семян .
Python предоставляет нам random.seed () , с помощью которого мы можем установить семя для получения начального значения. Это начальное значение определяет вывод генератора случайных чисел, поэтому, если оно остается прежним, вывод также остается прежним.
случайный импорт
random.seed (1)
print ('Генерация случайной последовательности из 4 чисел ...')
print ([random.randint (1, 100) для i в диапазоне (5)])
# Сбросить семя снова на 1
random.seed (1)
# Теперь мы получаем ту же последовательность
печать ([случайный.randint (1, 100) для i в диапазоне (5)])
Возможный выход
Генерация случайной последовательности из 4 чисел ... [18, 73, 98, 9, 33] [18, 73, 98, 9, 33]
Это гарантирует, что мы должны помнить о семени при работе с псевдослучайными последовательностями, поскольку последовательность может повторяться, если семя не изменилось.
Заключение
Мы узнали о различных методах, которые предоставляет нам модуль Python random для работы с целыми числами, числами с плавающей запятой и другими последовательностями, такими как списки и т. Д.Мы также видели, как начальное число влияет на последовательность псевдослучайных чисел.
Список литературы
Случайное число Python — JournalDev
В этом руководстве мы узнаем о случайном числе Python. В нашем предыдущем руководстве мы узнали о математическом модуле Python.
Python Random Number
Для работы со случайным числом Python нам нужно сначала импортировать модуль Python random . Модуль Python random обеспечивает псевдослучайность.
Модуль случайных чисел Python использует Mersenne Twister в качестве основного генератора случайных чисел. Таким образом, этот модуль совершенно не подходит для криптографических целей, поскольку является детерминированным. Тем не менее, мы можем использовать модуль Python random в большинстве случаев, потому что модуль random Python содержит множество хорошо известных случайных распределений.
Python Random Integer
В этом разделе мы обсудим генерацию целых чисел случайным образом. Мы можем использовать функцию randint (a, b) , чтобы получить случайное целое число от a до b .Опять же, мы можем получить число из последовательности, используя функцию randrange (start, stop, step) . Давайте посмотрим на пример получения случайного целого числа Python.
импортировать случайный как rand
а = 10
б = 100
print ('\ na =', a, 'и b =', b)
print ('номер печати [', a, ',', b, '):', rand.randint (a, b))
start = 1
стоп = 12
step = 2
print ('\ nsequence = [1, 3, 5, 7, 9, 11]')
print ('вывод одного числа из последовательности:', rand.randrange (start, stop, step))
Для каждого прогона вывод будет изменяться.Однако здесь приведен пример вывода.
Python Random Float
Существует несколько функций, которые возвращают вещественное число или число с плавающей запятой случайным образом. Например, функция random () возвращает действительное число от 0 до 1 (исключая).
Опять же, uniform (a, b) функций возвращают действительное число от a до b. Кроме того, в модуле Python random также доступны некоторые случайные распределения. Мы также можем получить реальное число из этого распределения.
Мы можем получить случайные числа из экспоненциального распределения, используя экспоненциальную функцию (лямбд) .
импортировать случайный как rand
print ('Случайное число от 0 до 1:', rand.random ())
print ('Равномерное распределение [1,5]:', rand.uniform (1, 5))
print ('Распределение по Гауссу mu = 0, sigma = 1:', rand.gauss (0, 1))
print ('Лямбда экспоненциального распределения = 1/10:', rand.expovariate (1/10))
Выходные значения будут отличаться для каждого выполнения. Вы получите такой результат.
Случайное число от 0 до 1: 0,5311529501408693
Равномерное распределение [1,5]: 3.8716411264052546
Распределение Гаусса mu = 0, sigma = 1: 0.87720056893
Лямбда с экспоненциальным распределением = 1/10: 1,4637113187536595
Python Random seed
Генерация случайных чисел Python основана на предыдущем числе, поэтому использование системного времени — отличный способ гарантировать, что каждый раз, когда наша программа запускается, она генерирует разные числа.
Мы можем использовать функцию python random seed () для установки начального значения. Обратите внимание: если наше начальное значение не изменяется при каждом выполнении, мы получим одинаковую последовательность чисел. Ниже приведен пример программы, подтверждающей эту теорию о ценности семян.
случайный импорт
random.seed (10)
print ('1-е случайное число =', random.random ())
print ('2-е случайное число =', random.random ())
print ('1-й случайный интервал =', random.randint (1, 100))
print ('2-й случайный int =', random.randint (1, 100))
# сбрасываем начальное число на 10, т.е. первое значение
random.seed (10)
print ('3-е случайное число =', random.random ())
print ('4-е случайное число =', random.random ())
print ('3-й случайный интервал =', random.randint (1, 100))
print ('4-й случайный интервал =', random.randint (1, 100))
На изображении ниже показан результат работы программы примера случайного начального числа python.У нас будет одна и та же последовательность случайных чисел для каждого прогона.
Случайный список Python — choice (), shuffle (), sample ()
Есть несколько функций для использования случайности в последовательности. Например, используя функцию choice () , вы можете получить случайный элемент из последовательности.
Опять же, используя функцию shuffle () , вы можете перемешивать элементы в последовательности.
Также, используя функцию sample () , вы можете случайным образом получить количество элементов x из последовательности.Итак, давайте посмотрим на следующий код для примера случайного списка.
импортировать случайный как rand
# инициализировать последовательности
строка = "неудобство"
l = [1, 2, 3, 4, 10, 15]
# получить один элемент случайным образом
print ('Случайно выбранный одиночный символ:', rand.choice (строка))
print ('одно случайно выбранное число:', rand.choice (l))
# получить несколько элементов
print ('Случайно выбранные 4 символа из строки:', rand.sample (string, 4))
print ('Случайно выбранный список длиной 4:', rand.sample (l, 4))
# перемешать список
ранд.перемешать (l)
print ('список перемешан:', l) # распечатать список
Вы можете получить следующий результат.
Случайно выбранный одиночный символ: i
одно случайно выбранное число: 10
Случайно выбранные 4 символа из строки: ['e', 'c', 'n', 'n']
Случайно выбранный список из 4-х длин: [2, 10, 3, 15]
список перемешан: [2, 4, 15, 3, 10, 1]
Итак, это все для случайного числа Python. Чтобы узнать больше, смотрите их официальную документацию.
random — Генераторы псевдослучайных чисел
| Назначение: | Реализует несколько типов генераторов псевдослучайных чисел. |
|---|---|
| Доступен в: | 1,4 и более поздних версиях |
Модуль случайных чисел обеспечивает быстрый генератор псевдослучайных чисел основан на алгоритме Mersenne Twister . Первоначально разработан для производят входные данные для моделирования Монте-Карло, Mersenne Twister генерирует числа с почти равномерным распределением и большим периодом, что делает его подходит для широкого спектра применений.
Генерация случайных чисел
Функция random () возвращает следующее случайное число с плавающей запятой. значение из сгенерированной последовательности.Все возвращаемые значения падают в диапазоне 0 <= n <1.0.
случайный импорт
для i в xrange (5):
напечатать '% 04.3f'% random.random ()
Многократный запуск программы приводит к различным последовательностям числа.
$ python random_random.py 0,182 0,155 0,097 0,175 0,008 $ python random_random.py 0,851 0,607 0,700 0,922 0,496
Чтобы сгенерировать числа в определенном числовом диапазоне, используйте uniform () вместо.
случайный импорт
для i в xrange (5):
напечатать '% 04.3f '% random.uniform (1, 100)
Передайте минимальные и максимальные значения, а uniform () регулирует возвращать значения из random () по формуле min + (max — мин) * случайный ().
$ python random_uniform.py 6,899 14,411 96,792 18,219 63,386
Посев
random () выдает разные значения каждый раз, когда вызывается, и имеет очень большой период перед повторением любых чисел. Это полезно для создания уникальных значений или вариаций, но бывают случаи, когда наличие одного и того же набора данных, доступного для обработки разными способами, полезно.Один из способов — использовать программу для генерации случайных значений. и сохраните их для обработки отдельным шагом. Это не может быть практично для больших объемов данных, поэтому random включает функция seed () для инициализации псевдослучайного генератора так что он производит ожидаемый набор значений.
случайный импорт
random.seed (1)
для i в xrange (5):
напечатать '% 04.3f'% random.random ()
Начальное значение управляет первым значением, полученным по используемой формуле. для получения псевдослучайных чисел, и поскольку формула детерминированный, он также устанавливает полную последовательность, созданную после семени изменено.Аргументом функции seed () может быть любой хешируемый объект. По умолчанию используется зависящий от платформы источник случайности, если доступен. В противном случае используется текущее время.
$ python random_seed.py 0,134 0,847 0,764 0,255 0,495 $ python random_seed.py 0,134 0,847 0,764 0,255 0,495
Состояние сохранения
Другой способ управления числовой последовательностью — это сохранять внутреннее состояние генератора между тестовыми запусками. Восстановление предыдущее состояние перед продолжением снижает вероятность повторяющиеся значения или последовательности значений из более раннего ввода.В Функция getstate () возвращает данные, которые можно использовать для повторно инициализируйте генератор случайных чисел позже с помощью setstate ().
случайный импорт
импорт ОС
импортировать cPickle как рассол
если os.path.exists ('state.dat'):
# Восстановить ранее сохраненное состояние
print 'Найдено state.dat, инициализирует случайный модуль'
с open ('state.dat', 'rb') как f:
состояние = pickle.load (f)
random.setstate (состояние)
еще:
# Используйте известное начальное состояние
print 'No state.dat, seeding'
random.seed (1)
# Произвести случайные значения
для i в xrange (3):
напечатать '% 04.3f '% random.random ()
# Сохранить состояние для следующего раза
с open ('state.dat', 'wb') как f:
pickle.dump (random.getstate (), f)
# Произвести больше случайных значений
print '\ nПосле сохранения состояния:'
для i в xrange (3):
напечатать '% 04.3f'% random.random ()
Данные, возвращаемые getstate (), являются деталью реализации, поэтому в этом примере данные сохраняются в файл с помощью pickle, но в противном случае рассматривает его как черный ящик. Если файл существует при запуске программы, он загружает старое состояние и продолжает работу. Каждый запуск дает несколько чисел до и после сохранения состояния, чтобы показать, что восстановление состояния заставляет генератор снова выдавать те же значения.
$ python random_state.py Нет state.dat, seeding 0,134 0,847 0,764 После сохранения состояния: 0,255 0,495 0,449 $ python random_state.py Найден state.dat, инициализирующий случайный модуль 0,255 0,495 0,449 После сохранения состояния: 0,652 0,789 0,094
Целые случайные числа
random () генерирует числа с плавающей запятой. Возможно преобразовать результаты в целые числа, но используя randint () для генерации целые числа напрямую удобнее.
случайный импорт
print '[1, 100]:'
для i в xrange (3):
печатать случайным образом.рандинт (1, 100)
Распечатать
напечатайте '[-5, 5]:'
для i в xrange (3):
напечатать random.randint (-5, 5)
Аргументы функции randint () являются концами включающего диапазона. для значений. Числа могут быть положительными или отрицательными, но первое значение должно быть меньше второго.
$ python random_randint.py [1, 100]: 3 47 72 [-5, 5]: 4 1 -3
randrange () — это более общая форма выбора значений из спектр.
случайный импорт
для i в xrange (3):
печатать случайным образом.рандом (0, 101, 5)
randrange () поддерживает аргумент step в дополнение к start и стоп-значения, поэтому это полностью эквивалентно выбору случайного значения из диапазона (старт, стоп, шаг). Это более эффективно, потому что диапазон фактически не построен.
$ python random_randrange.py 50 55 45
Выбор случайных предметов
Генераторы случайных чисел часто используют для выбора случайного элемента. из последовательности пронумерованных значений, даже если эти значения не числа.random включает функцию choice () для произвольный выбор из последовательности. Этот пример моделирует подбрасывать монету 10000 раз, чтобы посчитать, сколько раз выпадет орел и сколько раз решка.
случайный импорт
импортировать itertools
results = {'Heads': 0,
'решки': 0,
}
стороны = resultss.keys ()
для i в диапазоне (10000):
результаты [random.choice (стороны)] + = 1
print 'Heads:', results ['головы']
напечатайте 'Tails:', results ['tails']
Допускаются только два результата, поэтому вместо чисел и преобразовать их слова «орла» и «решка» используются с выбор().Результаты заносятся в словарь с помощью имена результатов как ключи.
$ python random_choice.py Голов: 5069 Хвосты: 4931
Перестановки
При моделировании карточной игры необходимо перемешать колоду карт, а затем «Раздайте» их игрокам, не используя одну и ту же карту более чем один раз. Использование choice () может привести к раздаче той же карты дважды, поэтому вместо этого колоду можно перемешать с помощью shuffle () и затем отдельные карты удаляются по мере раздачи.
случайный импорт
импортировать itertools
def new_deck ():
список возврата (itertools.продукт(
itertools.chain (xrange (2, 11), ('J', 'Q', 'K', 'A')),
('H', 'D', 'C', 'S'),
))
def show_deck (колода):
p_deck = колода [:]
а p_deck:
row = p_deck [: 13]
p_deck = p_deck [13:]
для j в строке:
напечатайте '% 2s% s'% j,
Распечатать
# Получите новую колоду, расставив карты по порядку
колода = new_deck ()
print 'Начальная колода:'
show_deck (колода)
# Перетасуйте колоду, чтобы случайный порядок
random.shuffle (колода)
print '\ nТасованная колода:'
show_deck (колода)
# Раздайте 4 руки по 5 карт в каждой
руки = [[], [], [], []]
для i в xrange (5):
для h в руках:
часдобавить (deck.pop ())
# Покажи руки
напечатать '\ nHands:'
для n, h в enumerate (руки):
напечатайте '% d:'% (n + 1),
для c в h:
напечатайте '% 2s% s'% c,
Распечатать
# Показать оставшуюся колоду
print '\ nОставшаяся колода:'
show_deck (колода)
Карты представлены в виде кортежей с номиналом и буквой с указанием костюма. Сданные «руки» создаются путем добавления одной карты. за раз в каждый из четырех списков и удаляя его из колоды, чтобы он не может быть сдан снова.
$ python random_shuffle.ру Начальная колода: 2H 2D 2C 2S 3H 3D 3C 3S 4H 4D 4C 4S 5H 5D 5C 5S 6H 6D 6C 6S 7H 7D 7C 7S 8H 8D 8C 8S 9H 9D 9C 9S 10H 10D 10C 10S JH JD JC JS QH QD QC QS KH KD KC KS AH AD AC AS Перетасованная колода: 4C 3H AD JH 7D 3D 5C 6D 5D 7S 5S KH 8S QC 5H 7C 4D 4S 2H JD KD AH 10S KC 6C 6H 8H 10H QD AC 2S 7H JC 9S AS 8C QH 9D 4H 8D JS 2D 3S 9C 10D 3C 6S 2C QS KS 10C 9H Руки: 1: 9H 2C 9C 8D 8C 2: 10C 6S 3S 4H AS 3: КС 3С 2Д 9Д 9С 4: QS 10D JS QH JC Оставшаяся колода: 4C 3H AD JH 7D 3D 5C 6D 5D 7S 5S KH 8S QC 5H 7C 4D 4S 2H JD KD AH 10S KC 6C 6H 8H 10H QD AC 2S 7H
Для многих симуляций требуются случайные выборки из совокупности входных данных. значения.Функция sample () генерирует образцы без повторяющиеся значения и без изменения входной последовательности. Этот example печатает случайную выборку слов из системного словаря.
случайный импорт
с open ('/ usr / share / dict / words', 'rt') как f:
слова = f.readlines ()
words = [w.rstrip () вместо w в словах]
для w в random.sample (слова, 5):
печать w
Алгоритм получения набора результатов учитывает размеры входных данных и выборки, запрошенные для получения результата в виде максимально эффективно.
$ python random_sample.py удовольствия последовательность послушность Youdendrift Итурейский $ python random_sample.py джигамари читательский мелкая спора панкоподобный фораминифер
Несколько одновременных генераторов
В дополнение к функциям уровня модуля, random включает Случайный класс для управления внутренним состоянием для нескольких случайных генераторы чисел. Доступны все функции, описанные выше. как методы случайных экземпляров, и каждый экземпляр может быть инициализируется и используется отдельно, не влияя на значения возвращено другими экземплярами.
случайный импорт
время импорта
print 'Инициализация по умолчанию: \ n'
r1 = random.Random ()
r2 = random.Random ()
для i в xrange (3):
напечатайте '% 04.3f% 04.3f'% (r1.random (), r2.random ())
print '\ nТо же семя: \ n'
seed = time.time ()
r1 = random.Random (начальное число)
r2 = random.Random (начальное число)
для i в xrange (3):
напечатайте '% 04.3f% 04.3f'% (r1.random (), r2.random ())
В системе с хорошим естественным заполнением случайных значений экземпляры запускаются в уникальных штатах. Однако, если нет хорошей платформы random генератор значений, экземпляры, вероятно, были засеяны текущее время и, следовательно, производят те же значения.
$ python random_random_class.py Инициализация по умолчанию: 0,171 0,711 0,184 0,558 0,818 0,113 То же семя: 0,857 0,857 0,925 0,925 0,040 0,040
Чтобы генераторы производили значения из разных частей случайный период, используйте jumpahead (), чтобы сдвинуть один из них из исходного состояния.
случайный импорт
время импорта
r1 = random.Random ()
r2 = random.Random ()
# Установите r2 в другую часть случайного периода, чем r1.
r2.setstate (r1.getstate ())
r2.jumpahead (1024)
для i в xrange (3):
напечатайте '% 04.3f% 04.3f'% (r1.random (), r2.random ())
Аргумент функции jumpahead () должен быть неотрицательным целым числом. на основе количества значений, необходимых для каждого генератора. внутренний состояние генератора скремблируется на основе входного значения, но не просто увеличивая его на указанное количество шагов.
$ python random_jumpahead.py 0,405 0,159 0,592 0,765 0,501 0,764
SystemRandom
Некоторые операционные системы предоставляют генератор случайных чисел, который доступ к большему количеству источников энтропии, которые можно ввести в генератор.random предоставляет эту функцию через SystemRandom класс, который имеет тот же API, что и Random но использует os.urandom () для генерации значений, которые составляют основу всех остальных алгоритмов.
случайный импорт
время импорта
print 'Инициализация по умолчанию: \ n'
r1 = random.SystemRandom ()
r2 = random.SystemRandom ()
для i в xrange (3):
напечатайте '% 04.3f% 04.3f'% (r1.random (), r2.random ())
print '\ nТо же семя: \ n'
seed = time.time ()
r1 = random.SystemRandom (начальное число)
r2 = random.SystemRandom (начальное число)
для i в xrange (3):
напечатать '% 04.3f% 04.3f '% (r1.random (), r2.random ())
Последовательности, созданные SystemRandom, не воспроизводятся потому что случайность исходит от системы, а не от программного обеспечения state (фактически, seed () и setstate () не действуют на все).
$ python random_system_random.py Инициализация по умолчанию: 0,374 0,932 0,002 0,022 0,692 1 000 То же семя: 0,182 0,939 0,154 0,430 0,649 0,970
Неравномерные распределения
В то время как равномерное распределение значений, производимых random () полезен для многих целей, другие распределения более точно моделируйте конкретные ситуации.Случайный модуль также включает функции для создания значений в этих распределениях. Они перечислены здесь, но не рассматриваются подробно, поскольку их использование имеют тенденцию быть специализированными и требуют более сложных примеров.
Обычный
Нормальное распределение обычно используется для неравномерного непрерывного значения, такие как классы, рост, вес и т. д. Кривая, полученная распределение имеет отличительную форму, которая привела к тому, что по прозвищу «колоколообразная кривая». random включает две функции для генерирование значений с нормальным распределением, normalvariate () и немного более быстрый gauss () (нормальное распределение также называется распределением Гаусса).
Связанная функция lognormvariate () производит псевдослучайное значения, где логарифм значений распределен нормально. Логнормальные распределения полезны для значений, которые являются продуктом несколько случайных величин, которые не взаимодействуют.
Приблизительное значение
Треугольное распределение используется в качестве приблизительного распределения. для небольших выборок. «Кривая» треугольного распределения имеет низкие точки при известных минимальных и максимальных значениях, а высокие точки — и режим, который оценивается на основе «наиболее вероятного» результата (отражается аргументом режима для triangular ()).
Экспоненциальная
expovariate () дает экспоненциальное распределение, полезное для моделирование значений времени прибытия или интервала для однородного Пуассона такие процессы, как скорость радиоактивного распада или поступающие запросы на веб-сервер.
Распределение Парето, или степенной закон, соответствует многим наблюдаемым явлений и популяризирован книгой Криса Андерона, The Long Хвост . Функция paretovariate () полезна для моделирования распределение ресурсов между людьми (богатство людям, спрос на музыканты, внимание к блогам и т. д.).
Угловой
Распределение фон Мизеса, или нормальное по кругу, распределение (произведено vonmisesvariate ()) используется для вычисления вероятностей циклических такие значения, как углы, календарные дни и время.
Размеры
betavariate () генерирует значения с бета-распределением, которое обычно используется в байесовской статистике и таких приложениях, как задача моделирование продолжительности.
Гамма-распределение, полученное функцией gammavariate (), используется для моделирование размеров таких вещей, как время ожидания, количество осадков и вычислительные ошибки.
Распределение Вейбулла, вычисленное с помощью weibullvariate (), используется в анализ отказов, промышленное проектирование и прогнозирование погоды. Это описывает распределение размеров частиц или других дискретных объекты.
См. Также
- случайный
- Стандартная библиотека документации для этого модуля.
- Mersenne Twister: Генератор однородных псевдослучайных чисел с равномерным распределением 623 размерностей
- Статья М. Мацумото и Т. Нисимура из ACM Труды по моделированию и компьютерному моделированию Vol.8, № 1, стр. 3-30 января 1998 г.
- Википедия: Mersenne Twister
- Статья об алгоритме псевдослучайного генератора, используемом Python.
- Википедия: Равномерное распределение
- Статья о непрерывных равномерных распределениях в статистике.
Генератор случайных чисел
Эта версия генератора создает случайное целое число. Он может работать с очень большими целыми числами до нескольких тысяч цифр.
Полная версия
Эта версия генератора может создавать одно или несколько случайных целых или десятичных чисел.Он может работать с очень большими числами с точностью до 999 цифр.
Случайное число — это число, выбранное из пула ограниченных или неограниченных чисел, которое не имеет заметного шаблона для предсказания. Пул чисел почти всегда независим друг от друга. Однако пул номеров может иметь определенное распределение. Например, рост учеников в школе имеет тенденцию к нормальному распределению вокруг среднего роста. Если рост ученика выбирается случайным образом, у выбранного числа больше шансов быть ближе к среднему росту, чем быть классифицированным как очень высокий или очень низкий.Вышеупомянутые генераторы случайных чисел предполагают, что сгенерированные числа не зависят друг от друга и будут равномерно распределены по всему диапазону возможных значений.
Генератор случайных чисел, подобный приведенным выше, — это устройство, которое может генерировать одно или несколько случайных чисел в пределах определенной области. Генераторы случайных чисел могут быть аппаратными или псевдослучайными. Аппаратные генераторы случайных чисел могут включать в себя использование игральных костей, монеты для подбрасывания или многих других устройств.
Генератор псевдослучайных чисел — это алгоритм для генерации последовательности чисел, свойства которой приблизительно соответствуют свойствам последовательностей случайных чисел. Компьютерные генераторы случайных чисел почти всегда являются генераторами псевдослучайных чисел. Тем не менее, числа, генерируемые генераторами псевдослучайных чисел, на самом деле не случайны. Точно так же наши генераторы выше также являются генераторами псевдослучайных чисел.