Python. Работа с текстом. Строки.
На уроке «Python. Взлом шифров. продолжение-2» я обещал рассказать о работе с текстом. Начнем со строк. Строки в Python-е, как и в PHP и JavaScript, могут заключаться в двойные или одинарные кавычки:
s1="Это строка" s2='Это тоже строка' print (s1) print (s2)
Это позволяет создать строки с кавычками внутри (либо с апострофами внутри):
s1="Внутри кавычек могут быть 'апостофы' ''''" s2='А внутри апостофов "кавычки" """ ' print (s1) print (s2)
Еще есть такая фича, как тройные кавычки. Они позволят задать многострочный стринг:
s="""Это первая строка а это вторая и третья и четвертая""" print (s)
Другой способ задания многострочного текста — это использование символов «\n», хотя первый способ зачастую более наглядный. Вот этот код выполнит тоже самое:
s="Это первая строка\nа это вторая\nи третья\nи четверая" print (s)
Строки можно складывать (конкатенация):
s="Hello "+"word" print (s)
Можно умножить строку на число, в этом случае она дублируется столько раз, на сколько ее умножили:
s="Hello "*3 print (s)
Но при попытке умножить на дробное число выйдет ошибка:
«Traceback (most recent call last):
File «D:/Самообразование/Python работа с тектом/text6. py», line 3, in <module>
py», line 3, in <module>
s=»Hello «*3.1
TypeError: can’t multiply sequence by non-int of type ‘float’»
Аналогично не «прокатит» и умножение строки на строку, так как данная операция не имеет смысла.
Кстати, при умножении строки на число от перестановки множителей произведение не меняется:
s=3*"Hello " print (s)
Такой код выдаст тоже самое, что и предыдущий. А вот со сложением данный номер не пройдет, так как там просто вторая строка с конца присоединяется к перовой.
К символам строки можно обращаться как к элементам массива, счет при этом начинается с нуля. Например, вот такой код вернет запятую:
s="Hello, world! " print (s[5])
Можно использовать срез. Например, вот такая программа вернет «lo,»:
s="Hello, world! " print (s[3:7])
Самый прикол, что можно получить каждый второй, каждый третьи и так далее символ из среза, например, каждый второй:
s="Hello, world! " print (s[1:10:2])
Такая программа вернет строку: «el,wr», а вот такая:
s="Hello, world! " print (s[1:10:3])
Вернет: «eow».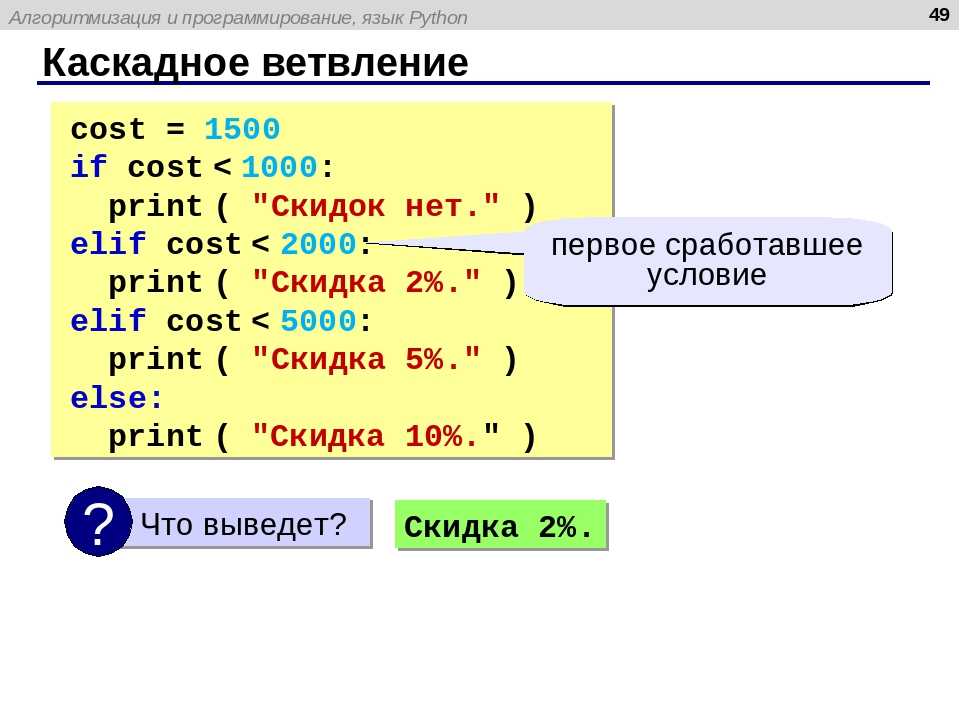
А еще в срезе могут быть отрицательные значения, это значит, что брать надо с конца. Например, если мы хотим получить предпоследний символ, мы можем написать [-2]. А вот если обратиться так: [:-2] то программа вернет все символы, кроме последних двух.
Теперь пара практических задач.
Задача 1.
Решение. Вспомним урок Python. Взлом шифров. Продолжение, где для распарсиваняи строки мы использовали split. Тут поступим точно так же, распарсим строку, превратив ее в список, переберем все элементы списка, используя классический алгоритм поиска максимума:
s="а на к в игра слово параллелепипед велосипед в не у компьютер"
ls=s.split(" ")
max_len=0
word=""
for el in ls:
word_len=len(el)
if word_len>max_len:
max_len=word_len
word=el
print("Слово с максимальной длиной: "+word)
Программа вернет «Слово с максимальной длиной: параллелепипед».
Задача 2. Необходимо анализировать сигнал. Этот сигнал состоит из цифр от 0 до 9 и знака #. Две и более идущие цифры подряд обозначают эту цифру. Если цифра должна повторяться, то это обозначается двумя или более знаками # (предыдущая цифра повторяется). Одинарная цифра или знак # считается помехой и не должен учитывается. Например, сочетание «12233##577766###» обозначает «233766».
Решение. Будем анализировать строку сигнала в цикле, меняя режим цикла, если идут два и более символа подряд. Последний символ и последнюю цифру запоминаем. Символ запоминаем чтобы отследить, что иду два и более подряд, а цифру для того, чтобы знак «#» удвоил ее.
Вот такая получается программа:
source_str="12233##577766###"
last_digit=""
last_simbol=""
dist_str=""
str_len=len(source_str)
i=0
is_wait=True
while i<str_len:
simb=source_str[i]
if simb==last_simbol:
if not is_wait:
if simb=="#":
dist_str=dist_str+last_digit
else:
dist_str=dist_str+simb
last_digit=simb
is_wait=True
else:
is_wait=False
last_simbol=simb
i=i+1
print(dist_str)
кодировки, нормализация, чистка / Хабр
Зачем эта статья?
Об обработке текстов на естественном языке сейчас знают все. Все хоть раз пробовали задавать вопрос Сири или Алисе, пользовались Grammarly (это не реклама), пробовали генераторы стихов, текстов… или просто вводили запрос в Google. Да, вот так просто. На самом деле Google понимает, что вы от него хотите, благодаря штукам, которые умеют обрабатывать и анализировать естественную речь в вашем запросе.
Все хоть раз пробовали задавать вопрос Сири или Алисе, пользовались Grammarly (это не реклама), пробовали генераторы стихов, текстов… или просто вводили запрос в Google. Да, вот так просто. На самом деле Google понимает, что вы от него хотите, благодаря штукам, которые умеют обрабатывать и анализировать естественную речь в вашем запросе.
При анализе текста мы можем столкнуться с ситуациями, когда текст содержит специфические символы, которые необходимо проанализировать наравне с «простым текстом» (взять даже наши горячо любимые вставки на французском из «Война и мир») или формулы, например. В таком случае обработка текста может усложниться.
Вы можете заметить, что если ввести в поисковую строку запрос с символами с ударением (так называемый модифицирующий акут), к примеру «ó», поисковая система может показать результаты, содержащие слова из вашего запроса, символы с ударением уже выглядят как обычные символы.
Обратите внимание на следующий запрос:
Запрос содержит символ с модифицирующим акутом, однако во втором результате мы можем заметить, что выделено найденное слово из запроса, только вот оно не содержит вышеупомянутый символ, просто букву «о».
Конечно, уже есть много готовых инструментов, которые довольно неплохо справляются с обработкой текстов и могут делать разные крутые вещи, но я не об этом хочу вам поведать. Я не буду рассказывать про nltk, стемминг, лемматизацию и т.п. Я хочу опуститься на несколько ступенек ниже и обсудить некоторые тонкости кодировок, байтов, их обработки.
Откуда взялась статья?
Одним из важных составляющих в области ИИ является обработка текстов на естественном языке. В процессе изучения данной тематики я начал задавать себе вопросы, которые в конечном итоге привели меня к изучению кодировок, представлению текстов в памяти, как они преобразуются, приводятся к нормальной форме. Я плохо понимал эту тему в начале, потребовалось немало времени и мозгового ресурса, чтобы понять, принять и запомнить некоторые вещи. Написанием данной статьи я хочу облегчить жизнь людям, которые столкнутся с необходимостью чтения и обработки текстов на Python и самому закрепить изученное. А некоторыми полезными поинтами своего изучения я постараюсь поделиться в данной статье.
Важная ремарка: я не являюсь специалистом в области обработки текстов. Изложенный материал является результатом исключительно любительского изучения.
Проблема чтения файлов
Допустим, у нас есть файл с текстом. Нам нужно этот текст прочитать. Казалось бы, пиши себе такой вот скрипт для чтения из файла да и радуйся:
with open("some_text.txt", "r") as file:
content = file.read()
print(content)В файле содержится вот такое вот изречение:
pitón
что переводится с испанского как питон. Однако консоль OC Windows 10 покажет нам немного другой результат:
C:\my\habr\TextsInPython> python .\script1.py pitón
Сейчас мы разберёмся, что именно пошло не так и по какой причине.
Кодировка
Думаю, это не будет сюрпризом, если я скажу, что любой символ, который заносится в память компьютера, хранится в виде числа, а не в виде литерала. Это число определяется как идентификатор или кодовая позиция
символа.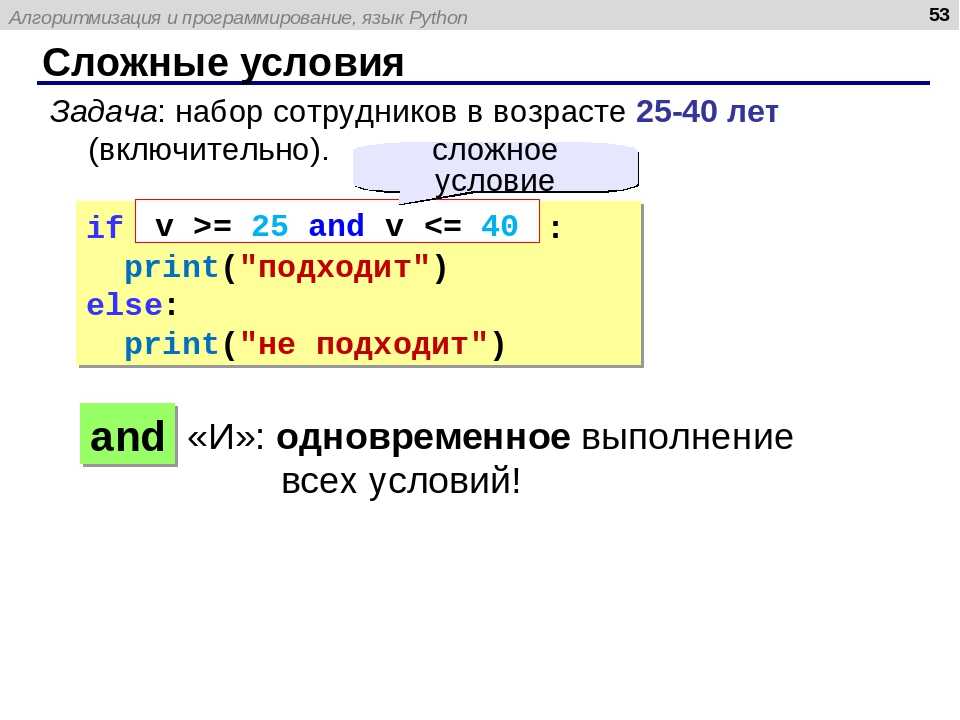 Кодировка определяет, какое именно число будет ассоциировано с символом.
Кодировка определяет, какое именно число будет ассоциировано с символом.Предположим, у нас есть некоторый файл с неизвестным содержимым, и нам нужно его прочитать, однако мы не знаем, какая у файла кодировка. Попробуем декодировать содержимое файла.
with open("simple_text.txt", "r") as file:
text = file.read()
print(text)Посмотрим на результат:
C:\my\habr\TextsInPython> python .\script2.py ÿþ<♦8♦@♦
Очень интересно, ничего непонятно. По умолчанию Python использует кодировку utf-8, но видимо запись в файл происходила не с её помощью. Здесь нам придёт на помощь дополнительный параметр функции open — параметр encoding, который позволяет указать конкретную кодировку, в которой следует прочитать файл (или записывать в него). Попробуем перебрать несколько кодировок и найти подходящую.
codecs = ["cp1252", "cp437", "utf-16be", "utf-16"]
for codec in codecs:
with open("simple_text.txt", "r", encoding=codec) as file:
text = file.
read()
print(codec.rjust(12), "|", text)Результат:
C:\my\habr\TextsInPython> python .\script3.py
cp1252 | ÿþ<8@
cp437 | ■<8@
utf-16be | 㰄㠄䀄
utf-16 | мирРазные кодировки расшифровывают байты из файла по-разному, то есть разным кодовым позициям могут соотвествовать разные символы. Пример примитивный, несложно догадаться, что истинная кодировка файла — это utf-16.
Важный поинт: при записи и чтении из файлов следует указывать конкретную кодировку, это позволит избежать путаницы в дальнейшем.
Ошибки, связанные с кодировками
При возникновении ошибки, связанной с кодировками, интерпретатор выдаст одно из следующих исключений:
UnicodeError. Это общее исключение для ошибок кодировки.UnicodeDecodeError. Данное исключение возбуждается, если встречается кодовая позиция, которая отсутствует в кодировке.UnicodeEncodeError.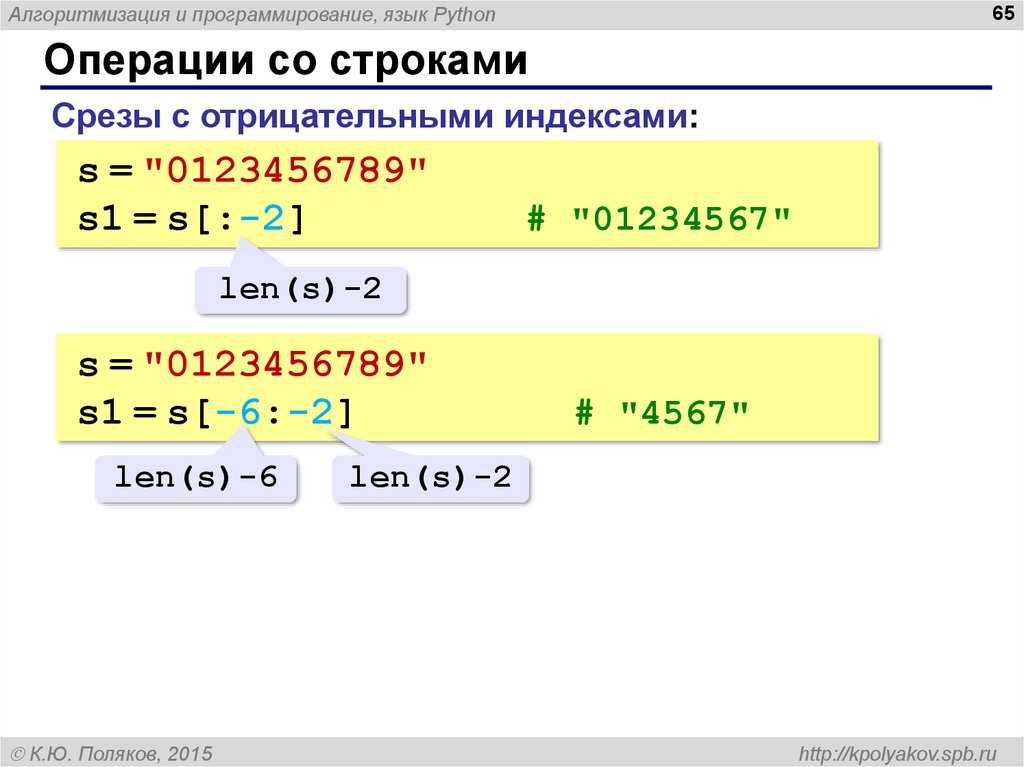 А это исключение возбуждается, когда символ, который необходимо закодировать, незнаком для кодировки.
А это исключение возбуждается, когда символ, который необходимо закодировать, незнаком для кодировки.
Попытка выполнения вот такого кода (в файле всё ещё содержится испанский питон):
with open("some_text.txt", "r", encoding="ascii") as file:
file.read()даст нам следующий результат:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 3: ordinal not in range(128)
Кодировка ASCII не поддерживает никакой алфавит, кроме английского. Поэтому декодирование символа «ó» вызывает у ASCII сложности. Однако Python всемогущ и есть механизм, который позволяет обработать ошибки кодировок. Это дополнительный параметр методов decode — параметр errors. Он может принимать следующие значения:
Для обеих функций:
Обозначение | Суть |
| Значение по умолчанию. |
| Несоответсвующие символы пропускаются без возбуждения исключений. |
 Несоотвествующие кодировке символы возбуждают исключения
Несоотвествующие кодировке символы возбуждают исключения Только для метода encode:
Обозначение | Суть |
|---|---|
| Несоотвествующие символы заменяются на символ ? |
| Несоответствующие символы заменяются на соответсвующие значения XML. |
| Несоответствующие символы заменяются на определённые последовательности с обратным слэшем. |
| Несоответствующие символы заменяются на имена этих символов, которые берутся из базы данных Unicode. |
Также отдельно выделены значения surrogatepass и surrogateescape.
Приведём пример использования таких обработчиков:
>>> text = "pitón"
>>> text.encode("ascii", errors="ignore")
b'pitn'
>>> text.encode("ascii", errors="replace")
b'pit?n'
>>> text.encode("ascii", errors="xmlcharrefreplace")
b'pitón'
>>> text.encode("ascii", errors="backslashreplace")
b'pit\\xf3n'
>>> text.encode("ascii", errors="namereplace")
b'pit\\N{LATIN SMALL LETTER O WITH ACUTE}n'Важный поинт: если в текстах могут встретиться неожиданные для кодировки символы, во избежание возбуждения исключений можно использовать обработчики.
Cворачивание регистра
Сворачивание регистра — это попытка унифицировать текст любого представления к канонической форме. Например, приведение всего текста в нижний регистр. Также над текстом производятся некоторые преобразования (например, немецкая «эсцет» — «ß» — преобразуется в «ss»).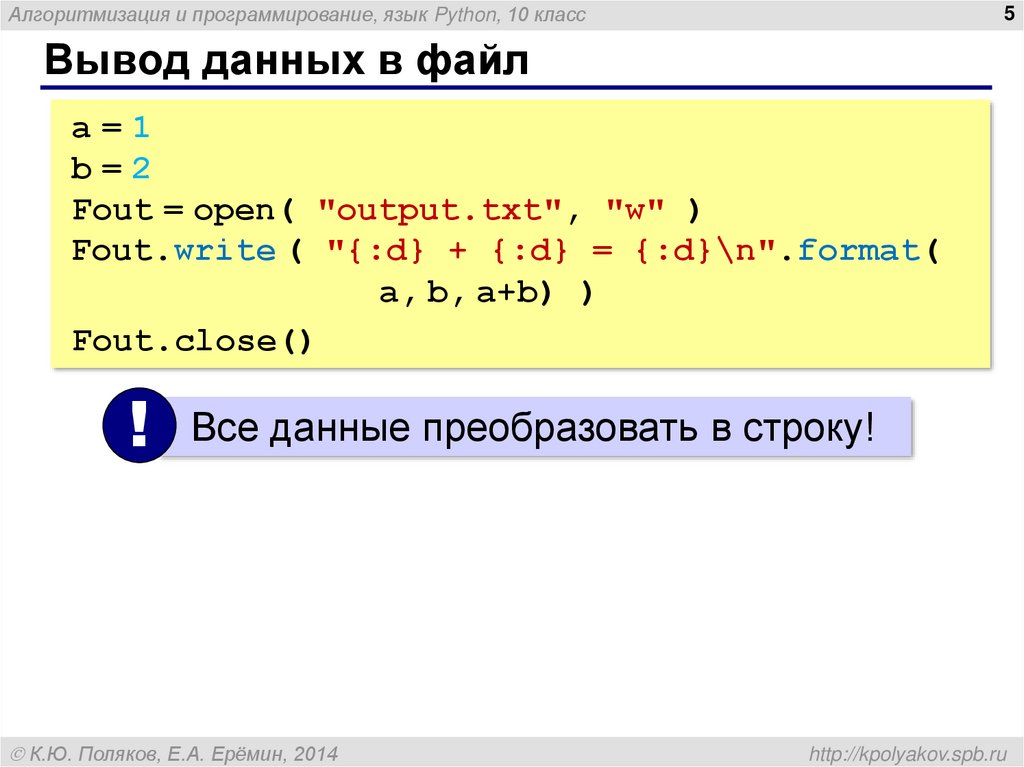 В Python 3.3 появился метод
В Python 3.3 появился метод str.casefold(), который как раз выполняет сворачивание регистра. Если текст содержит только символы кодировки latin1, результат применения этого метода будет аналогичен методу str.lower().
И по классике приведём пример:
>>> text = "Die größte Stadt der Welt liegt in China" >>> text.casefold() 'die grösste stadt der welt liegt in china'
В результате применённый метод не только привёл весь текст к нижнему регистру, но и преобразовал специфический немецкий символ.
Важный поинт: привести текст можно не только методом str.lower(), но и методом str.casefold(), который может выполнить дополнительные преобразования текста.
Нормализация
Нормализация — это полноценное приведение текста к единому представлению.
Чтобы обозначить важность нормализации, приведём простой пример:
letter1 = "µ" letter2 = "μ"
Внешне два этих символа выглядят абсолютно одинаково. Однако если мы попытаемся вывести имена этих символов, как их видит интерпретатор Python’a, результат нас порядком удивит.
Однако если мы попытаемся вывести имена этих символов, как их видит интерпретатор Python’a, результат нас порядком удивит.
В Python есть отличный встроенный модуль, который содержит данные о символах Unicode, их имена, являются ли они цифрамии и т.п. (методы по типу str.isdigit() берут информацию из этих данных). Воспользуемся данным модулем, чтобы вывести имена символов, исходя из информации, которая содержится в базе данных Unicode.
import unicodedata letter1 = "µ" letter2 = "μ" print(unicodedata.name(letter1)) print(unicodedata.name(letter2))
Результат выполнения данного кода:
C:\my\habr\TextsInPython> python .\script7.py MICRO SIGN GREEK SMALL LETTER MU
Итак, интерпретатор Python’a видит эти символы как два разных, но в стандарте Unicode они имеют одинаковое отображение.Такие символы называют каноническими эквивалентами. Приложения будут считать два этих символа одинаковыми, но не интерпретатор.
Посмотрим на ещё один пример:
>>> s1 = 'café'
>>> s2 = 'cafe\u0301'
>>> s1, s2
('café', 'café')
>>> s1 == s2
False
>>> len(s1), len(s2)
(4, 5)
Данные символы также будут являться каноническими эквивалентами.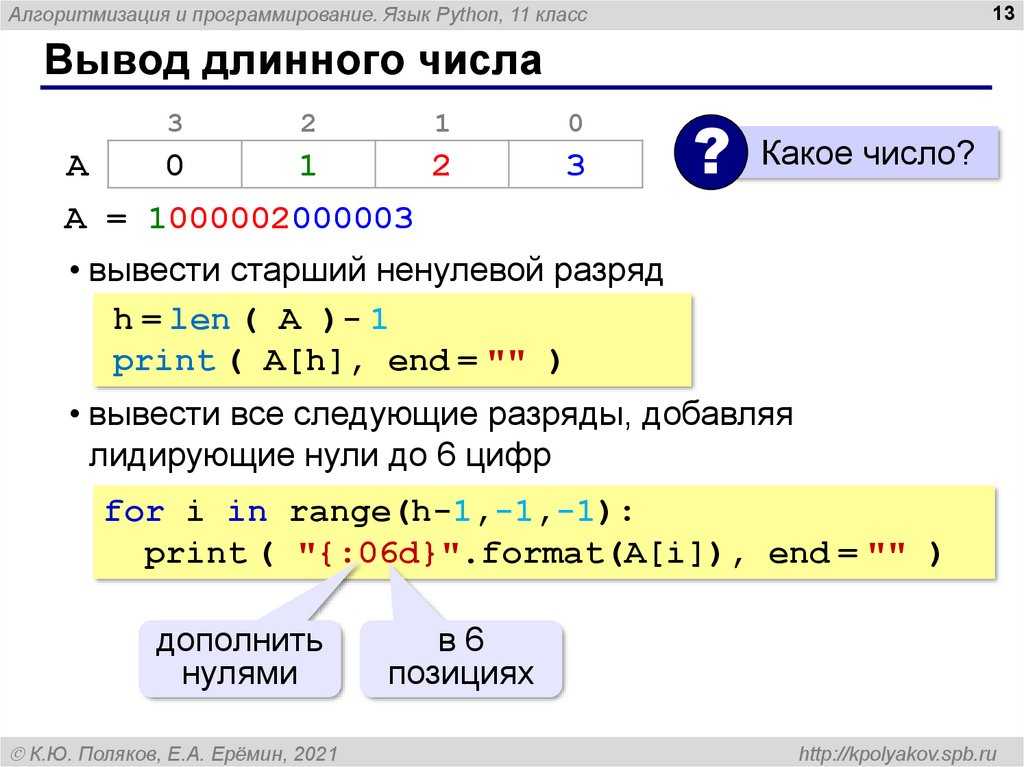 Из примера мы видим, что символ «é» в стандарте Unicodeможет быть представлен двумя способами, которые к тому же имеют разную длину. Символ «é» может быть представлен одним или двумя байтами.
Из примера мы видим, что символ «é» в стандарте Unicodeможет быть представлен двумя способами, которые к тому же имеют разную длину. Символ «é» может быть представлен одним или двумя байтами.
Решением таких конфликтов занимается нормализация. Она реализована в Python в функции unicodedata.normalize.Первым аргумент является так называемая форма нормализации — нормализации строк Unicode, которые позволяют определить, эквивалентны ли какие-либо две строки Unicode друг другу. Всего предлагается четыре формы:
Форма | Описание |
|---|---|
Normalization Form D (NFD) | Canonical Decomposition |
Normalization Form C (NFC) | Canonical Decomposition, следующая за Canonical Composition |
Normalization Form KD (NFKD) | Compatibility Decomposition |
Normalization Form KC (NFKC) | Compatibility Decomposition, следующая за Canonical Composition |
Разберём каждую форму немного подробнее.
NFC
При указании данной формы нормализации происходит каноническая композиция (как, собственно, и гласит название) кодовых позиций с целью получения самой короткой эквивалентной строки.
>>> unicodedata.normalize("NFC", s1), unicodedata.normalize("NFC", s2)
('café', 'café')
>>> len(unicodedata.normalize("NFC", s1)), len(unicodedata.normalize("NFC", s2))
(4, 4)
>>> unicodedata.normalize("NFC", s1) == unicodedata.normalize("NFC", s2)
True
>>> len(unicodedata.normalize("NFC", s1)) == len(unicodedata.normalize("NFC", s2))
TrueИтак, нормализация обеих строк внешне их не изменила, однако длина строки s2 стала равной 4 (т.е. на один байт меньше). Была произведена композиция байтов e\u0301, которые являлись отображением «é». Данная последовательность была заменена на минимальное представление символа, т.е. теперь представление этого символа для интерпретатора выглядит как в строке s1. Как результат, мы видим, что длина нормализованных строк стала равной, и сами строки также стали равны.
Как результат, мы видим, что длина нормализованных строк стала равной, и сами строки также стали равны.
NFD
С этой формой ситуация аналогичная, только происходит декомпозиция байтов, т.е. разложение символа на несколько байт.
>>> unicodedata.normalize("NFD", s1), unicodedata.normalize("NFD", s2)
('café', 'café')
>>> len(unicodedata.normalize("NFD", s1)), len(unicodedata.normalize("NFD", s2))
(5, 5)
>>> unicodedata.normalize("NFD", s1) == unicodedata.normalize("NFD", s2)
True
>>> len(unicodedata.normalize("NFD", s1)) == len(unicodedata.normalize("NFD", s2))
TrueЗдесь мы видим, что длина строки s1 увеличилась на один байт. Думаю, уже несложно догадаться, почему.
На данном этапе настал момент ввести понятие символа совместимости. Символы совместимости (compatibility characters) были введены в Unicode ради совместимости с другими стандартами, в частности, стандарты, которые предшествовали Unicode. Это означает, что некоторые символы могут встречаться в стандарте несколько раз. Мы уже могли наблюдать это явление в начале этого раздела на примере с символом «мю». Он считается символом совместимости.
Это означает, что некоторые символы могут встречаться в стандарте несколько раз. Мы уже могли наблюдать это явление в начале этого раздела на примере с символом «мю». Он считается символом совместимости.
NFKC и NFKD
При данных формах нормализации символы совместимости заменяются на его более предпочтительное представление, что также называется совместимой декомпозицией. Однако при данных формах нормализации может быть потеряно форматирование.
Немного модифицируем наш пример из начала раздела. Выведем кодовые позиции символов до и после нормализации:
import unicodedata
letter1 = "µ"
letter2 = "μ"
print("Before normalizing:", ord(letter1), ord(letter2))
letter1 = unicodedata.normalize("NFKC", letter1)
letter2 = unicodedata.normalize("NFKC", letter2)
print("After normalizing:", ord(letter1), ord(letter2))И результат выполнения кода:
Before normalizing: 181 956 After normalizing: 956 956
Итак, мы видим, что первый символ (который являлся знаком «микро») был заменён на греческую «мю», т. е. более предпочтительное представление символа. Таким образом, если необходимо, например, провести частотный анализ текста, формы нормализации, которые затрагивают символы совместимости, могут помочь с этим, приводя символы совместимости к единому представлению.
е. более предпочтительное представление символа. Таким образом, если необходимо, например, провести частотный анализ текста, формы нормализации, которые затрагивают символы совместимости, могут помочь с этим, приводя символы совместимости к единому представлению.
Важный поинт: нормализация может очень помочь для поиска валидных документов или индексирования текста. Если вы занимаетесь разработкой таких систем, не стоит сбрасывать алгоритмы нормализации со счетов.
Дополнительные материалы: что использовалось в статье и что почитать по теме
«Fluent Python», Лучано Ромальо
В этой книге целая глава посвящена изучению строк, байтов и Unicode (Глава 4. Тексты и байты). Она есть на русском и английском языках, но в русском переводе допущено немало ошибок, так что открывайте русский вариант на свой страх и риск. Материал статьи в большей степени опирается на данную книгу. Некоторые примеры также взяты оттуда.
Документация для Unicode на официальном сайте Python
Куда ж без неё, родимой. Там тоже можно найти немало полезной информации, если вам понадобится работать с текстами и делать больше, чем просто считывание из файла. Хотя в некоторых случаях и на этом можно споткнуться.
Там тоже можно найти немало полезной информации, если вам понадобится работать с текстами и делать больше, чем просто считывание из файла. Хотя в некоторых случаях и на этом можно споткнуться.
Unicode® Standard Annex
Это части стандарта Unicode, которые выложены в открытый доступ в виде отдельных статей. Почитать их можно вот здесь.
Работа с текстовыми файлами в Python
Этот урок является частью серии из 15 уроков — Вы находитесь на уроке 3 | предыдущий урок | следующий урок
Содержание
- Цели урока
- Работа с текстовыми файлами
- Создание и запись в текстовый файл
- Чтение из текстового файла
- Добавление к уже существующему текстовому файлу
- Рекомендуемая литература
Цели урока
В этом уроке вы узнаете, как работать с текстовыми файлами с помощью Python.
Это включает в себя открытие, закрытие, чтение и запись в . файлы с помощью программирования. txt
txt
Следующие несколько уроков этой серии будут включать в себя загрузку веб-страницы с Интернет и реорганизации содержимого в полезные фрагменты Информация. Вы будете выполнять большую часть своей работы, используя код Python. написано и выполнено в Komodo Edit.
Работа с текстовыми файлами
Python упрощает работу с файлами и текстом. Давайте начнем с файлы.
Создание и запись в текстовый файл
Начнем с краткого обсуждения терминологии. На предыдущем уроке (в зависимости от вашей операционной системы: установка Mac, Windows установки или установки Linux), вы видели, как отправить информацию в окно «Command Output» вашего текстового редактора с помощью Команда печати Python.
печать («привет, мир»)
Язык программирования Python — объектно-ориентированный . То есть, что
он построен вокруг объекта особого типа, объекта , который
содержит как данные , так и ряд методов для доступа и изменения
эти данные. После того, как объект создан, он может взаимодействовать с другими
объекты.
После того, как объект создан, он может взаимодействовать с другими
объекты.
В приведенном выше примере мы видим один тип объекта, строку «hello Мир». Строка представляет собой последовательность символов, заключенную в кавычки. Ты может написать строку одним из трех способов:
сообщение1 = 'привет, мир' message2 = "привет, мир" сообщение3 = """привет Привет Привет мир"""
Важно отметить, что в первых двух примерах вы можете используйте одинарные или двойные кавычки/кавычки, но нельзя смешивать два в одной строке.
Например, следующее неверно:
message1 = "hello world" message2 = "привет, мир" message3 = 'Я не могу есть огурцы'
Подсчитать количество одинарных кавычек в сообщении3. Для этого вы работаете пришлось бы escape апостроф:
message3 = 'Я не могу есть соленые огурцы'
Или перепишите фразу как:
message3 = "Я не могу есть соленые огурцы"
В третьем примере тройные кавычки обозначают строку, охватывающую
более одной строки.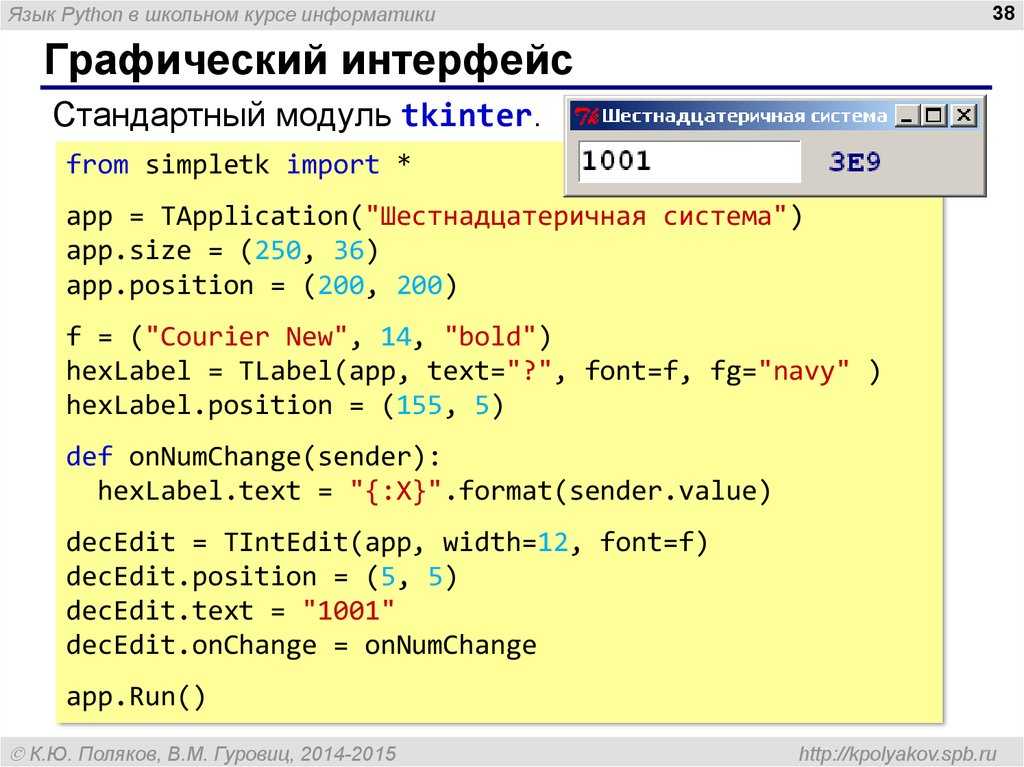
Печать — это команда, которая печатает объекты в текстовом виде. Печать
Команда в сочетании со строкой создает оператор .
Вы будете использовать печать в тех случаях, когда вы хотите создать
информацию, на которую нужно немедленно реагировать. Иногда, однако,
вы будете создавать информацию, которую хотите сохранить, отправить
кем-то другим или использовать в качестве входных данных для дальнейшей обработки другим
программа или набор программ. В этих случаях вы захотите отправить
информацию в файлы на жестком диске, а не в «Командную
Панель «Вывод». Введите следующую программу в текстовый редактор и сохраните
это как файл-выход.py .
# файл-выход.py
f = открыть('helloworld.txt','w')
f.write('привет, мир')
е.закрыть()
В Python любая строка, начинающаяся с решётки (#), называется комментарий и игнорируется интерпретатором Python. Комментарии предназначены
чтобы позволить программистам общаться друг с другом (или напоминать
сами понимают, что делает их код, когда они немного поработают над ним. месяцы спустя). В более широком смысле сами программы обычно
написаны и отформатированы таким образом, чтобы программистам было легче
общаться друг с другом. Код, который ближе к требованиям
машина называется низкоуровневый , тогда как код, который ближе к
естественный язык высокого уровня . Одно из преимуществ использования языка
как Python, заключается в том, что он очень высокого уровня, что облегчает нам
общаться с вами (за счет некоторых затрат с точки зрения вычислительной
эффективность).
месяцы спустя). В более широком смысле сами программы обычно
написаны и отформатированы таким образом, чтобы программистам было легче
общаться друг с другом. Код, который ближе к требованиям
машина называется низкоуровневый , тогда как код, который ближе к
естественный язык высокого уровня . Одно из преимуществ использования языка
как Python, заключается в том, что он очень высокого уровня, что облегчает нам
общаться с вами (за счет некоторых затрат с точки зрения вычислительной
эффективность).
В этой программе f — это файловый объект , а открыть , записать и закрыть — это файл методы . Другими словами, открыть, написать и закрыть сделать что-то с
объект f , который в данном случае определяется как файл .txt . это скорее всего
иное использование термина «метод», чем вы могли бы ожидать, и со временем
со временем вы обнаружите, что слова, используемые в контексте программирования, имеют
несколько (или полностью) иное значение, чем в повседневном
речь. В этом случае вспомните, что методы — это фрагменты кода, выполняющие
действия. Они делают что-то с чем-то другим и возвращают результат. Ты
можно попытаться подумать об этом, используя пример из реального мира, такой как отдача команд
к семейной собаке. Собака (объект) понимает команды (т.
«методы»), такие как «лаять», «сидеть», «притворяться мертвыми» и так далее. Мы будем
обсудить и узнать, как использовать многие другие методы, как мы продвигаемся вперед.
В этом случае вспомните, что методы — это фрагменты кода, выполняющие
действия. Они делают что-то с чем-то другим и возвращают результат. Ты
можно попытаться подумать об этом, используя пример из реального мира, такой как отдача команд
к семейной собаке. Собака (объект) понимает команды (т.
«методы»), такие как «лаять», «сидеть», «притворяться мертвыми» и так далее. Мы будем
обсудить и узнать, как использовать многие другие методы, как мы продвигаемся вперед.
f — выбранное нами имя переменной; Вы могли бы назвать это примерно все, что ты любишь. В Python имена переменных могут быть составлены из верхнего и нижнего регистров. строчные буквы, цифры и символы подчеркивания… но вы не можете использовать имена команд Python в качестве переменных. Если вы попытались назвать свою файловую переменную например, «печатать», ваша программа не будет работать, потому что это зарезервированное слово, которое является частью языка программирования.
Имена переменных Python также чувствительны к регистру , что означает, что
foobar, Foobar и FOOBAR будут разными переменными.
Когда вы запускаете эту программу, метод open сообщит вашему компьютеру, что
создайте новый текстовый файл helloworld.txt в той же папке, что и у вас
сохранил программу file-output.py . Параметр w говорит о том, что вы намерены
для записи содержимого в этот новый файл с помощью Python.
Обратите внимание, что, поскольку и имя файла, и параметр окружены одинарные кавычки, как вы знаете, хранятся как строки; забывая включать кавычки приведет к сбою вашей программы.
На следующей строке ваша программа записывает сообщение «hello world» (другое string) в файл, а затем закрывает его. (Для получения дополнительной информации о эти операторы см. в разделе о файловых объектах в Python. Справочник по библиотеке.)
Дважды щелкните кнопку «Запустить Python» в Komodo Edit, чтобы выполнить
программе (или ее эквиваленте в любом текстовом редакторе, который вы решили
использование: например, нажмите на «#!» и «Выполнить» в TextWrangler). Хотя ничего
будут напечатаны на панели «Вывод команды», вы увидите статус
сообщение, которое говорит что-то вроде
Хотя ничего
будут напечатаны на панели «Вывод команды», вы увидите статус
сообщение, которое говорит что-то вроде
`/usr/bin/python file-output.py` вернул 0.
в Mac или Linux или
'C:\Python27\Python.exe file-output.py' вернул 0.
в Windows.
Это означает, что ваша программа выполнена успешно. Если вы используете Файл -> Открыть -> Файл в Komodo Edit, вы можете открыть файл helloworld.txt . Он должен содержать однострочное сообщение:
Hello World!
Поскольку текстовые файлы содержат минимальное количество информации о форматировании, они, как правило, маленькие, их легко обменивать между разными платформами (т. е. с Windows на Linux или Mac или наоборот) и легко отправить от одной компьютерной программы к другой. Обычно они также могут быть прочитаны люди, использующие текстовый редактор, такой как Komodo Edit.
Чтение из текстового файла
Python также имеет методы, позволяющие получать информацию из файлов. Введите следующую программу в текстовый редактор и сохраните ее как
Введите следующую программу в текстовый редактор и сохраните ее как файл-ввод.py . Когда вы нажмете «Выполнить», чтобы выполнить его, он откроет
текстовый файл, который вы только что создали, прочитайте из него однострочное сообщение и
распечатайте сообщение на панели «Вывод команды».
# файл-input.py
f = открыть('helloworld.txt','r')
сообщение = f.read()
распечатать (сообщение)
е.закрыть()
В этом случае параметр r используется для указания того, что вы открываете
файл на читать из него . Параметры позволяют выбирать среди различных
параметры, которые позволяет конкретный метод. Возвращаясь к примеру с семейной собакой,
собаку можно научить лаять один раз, когда она получает закуску со вкусом говядины.
и дважды, когда он получает со вкусом курицы. Вкус закуски
является параметром. Каждый метод отличается тем, какие параметры он
приму. Вы не можете, например, попросить собаку спеть итальянскую
опера — если только ваша собака не особенно талантлива.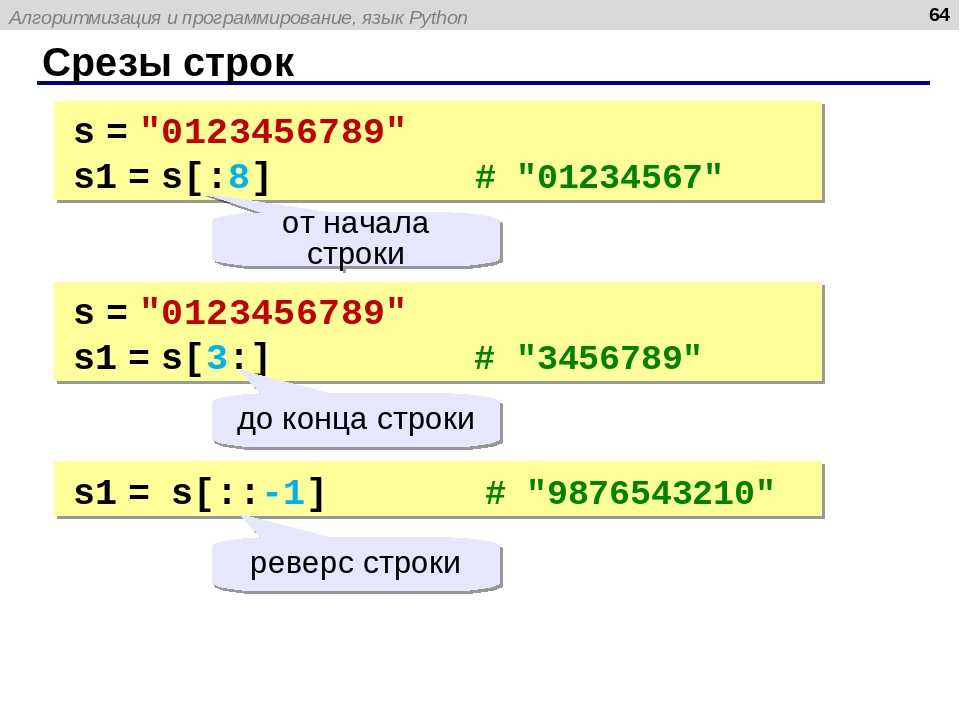 Вы можете посмотреть
возможные параметры для конкретного метода на веб-сайте Python или
часто их можно найти, набрав метод в поисковике вместе
с «Питоном».
Вы можете посмотреть
возможные параметры для конкретного метода на веб-сайте Python или
часто их можно найти, набрав метод в поисковике вместе
с «Питоном».
Чтение — еще один файловый метод. Содержимое файла (однострочный
message) копируются в message , которое мы решили назвать
эту строку, а затем команда print используется для отправки содержимого сообщение на панель «Вывод команды».
Добавление к уже существующему текстовому файлу
Третий вариант — открыть уже существующий файл и добавить к нему дополнительные элементы. Примечание
что если вы откроете файл и используете напишите метод , программа будет
перезаписать все, что могло содержаться в файле . Это не
проблема, когда вы создаете новый файл или когда хотите перезаписать
содержимое существующего файла, но это может быть нежелательно, когда вы
ведут журнал событий или собирают большой набор данных в один
файл. Итак, вместо напишите , вы захотите использовать метод append ,
обозначенный a .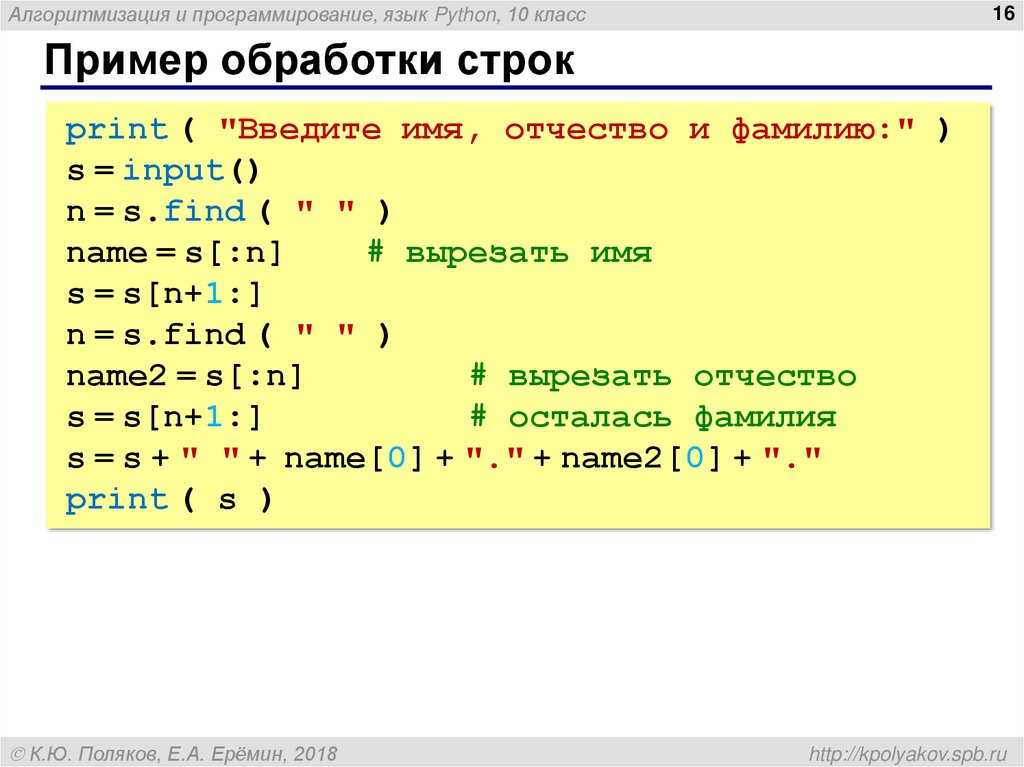
Введите следующую программу в текстовый редактор и сохраните ее как файл-append.py . Когда вы запустите эту программу, она откроет тот же файл helloworld.txt , созданный ранее, и добавьте второй «hello world»
в файл. «\n» означает новую строку.
# файл-append.py
f = открыть('helloworld.txt','а')
f.write('\n' + 'привет, мир')
е.закрыть()
После запуска программы откройте файл helloworld.txt и посмотрите
что случилось. Закройте текстовый файл и перезапустите file-append.py несколько раз.
больше раз. Когда вы открываете helloworld.txt снова вы должны заметить несколько
дополнительные сообщения «привет мир» ждут вас.
В следующем разделе мы обсудим модульность и повторное использование кода.
Рекомендуемая литература
- Учебник для непрограммистов по Python 2.6/Hello, World
Что нужно знать о работе с текстом при разработке Python
# разработка
Разработка программного обеспечения требует работы с текстом и его обработки определенным образом. В рамках своей работы разработчики должны часто проверять наличие слов, объединять фрагменты текста, извлекать подстроку или проверять строку символов с помощью регулярных выражений. На помощь приходит Python, один из языков программирования, который легко и быстро справляется с обработкой текста.
В рамках своей работы разработчики должны часто проверять наличие слов, объединять фрагменты текста, извлекать подстроку или проверять строку символов с помощью регулярных выражений. На помощь приходит Python, один из языков программирования, который легко и быстро справляется с обработкой текста.
серверная часть питон
посмотрим, что мы можем Создайте для тебя
перспективные цифровые продукты
посмотреть наши услуги
# разработка
разработка программного обеспечения
узел. js
серверная часть
js
серверная часть
Джоанна | Специалист по контент-маркетингу
Павел | Старший бэкенд-инженер
# разработка
разработка программного обеспечения
узел.