Дополнение текстовых и рабочих объектов типами объектов
Руководство пользователя Отмена
Поиск
Последнее обновление May 25, 2023 02:47:23 AM GMT
- Руководство пользователя Illustrator
- Основы работы с Illustrator
- Введение в Illustrator
- Новые возможности в приложении Illustrator
- Часто задаваемые вопросы
- Системные требования Illustrator
- Illustrator для Apple Silicon
- Рабочая среда
- Основные сведения о рабочей среде
- Ускоренное обучение благодаря панели «Обзор» в Illustrator
- Создание документов
- Панель инструментов
- Комбинации клавиш по умолчанию
- Настройка комбинаций клавиш
- Общие сведения о монтажных областях
- Управление монтажными областями
- Настройка рабочей среды
- Панель свойств
- Установка параметров
- Рабочая среда «Сенсорное управление»
- Поддержка Microsoft Surface Dial в Illustrator
- Отмена изменений и управление историей дизайна
- Повернуть вид
- Линейки, сетки и направляющие
- Специальные возможности в Illustrator
- Безопасный режим
- Просмотр графических объектов
- Работа в Illustrator с использованием Touch Bar
- Файлы и шаблоны
- Инструменты в Illustrator
- Краткий обзор инструментов
- Выбор инструментов
- Выделение
- Частичное выделение
- Групповое выделение
- Волшебная палочка
- Лассо
- Монтажная область
- Выделение
- Инструменты для навигации
- Рука
- Повернуть вид
- Масштаб
- Инструменты рисования
- Градиент
- Сетка
- Создание фигур
- Градиент
- Текстовые инструменты
- Текст
- Текст по контуру
- Текст по вертикали
- Текст
- Инструменты рисования
- Перо
- Добавить опорную точку
- Удалить опорные точки
- Опорная точка
- Кривизна
- Отрезок линии
- Прямоугольник
- Прямоугольник со скругленными углами
- Эллипс
- Многоугольник
- Звезда
- Кисть
- Кисть-клякса
- Карандаш
- Формирователь
- Фрагмент
- Инструменты модификации
- Поворот
- Отражение
- Масштаб
- Искривление
- Ширина
- Свободное трансформирование
- Пипетка
- Смешать
- Ластик
- Ножницы
- Быстрые действия
- Ретротекст
- Светящийся неоновый текст
- Старомодный текст
- Перекрашивание
- Преобразование эскиза в векторный формат
- Введение в Illustrator
- Illustrator на iPad
- Представляем Illustrator на iPad
- Обзор по Illustrator на iPad.

- Ответы на часто задаваемые вопросы по Illustrator на iPad
- Системные требования | Illustrator на iPad
- Что можно и нельзя делать в Illustrator на iPad
- Обзор по Illustrator на iPad.
- Рабочая среда
- Рабочая среда Illustrator на iPad
- Сенсорные ярлыки и жесты
- Комбинации клавиш для Illustrator на iPad
- Управление настройками приложения
- Документы
- Работа с документами в Illustrator на iPad
- Импорт документов Photoshop и Fresco
- Выбор и упорядочение объектов
- Создание повторяющихся объектов
- Объекты с переходами
- Рисование
- Создание и изменение контуров
- Рисование и редактирование фигур
- Текст
- Работа с текстом и шрифтами
- Создание текстовых надписей по контуру
- Добавление собственных шрифтов
- Работа с изображениями
- Векторизация растровых изображений
- Цвет
- Применение цветов и градиентов
- Представляем Illustrator на iPad
- Облачные документы
- Основы работы
- Работа с облачными документами Illustrator
- Общий доступ к облачным документам Illustrator и совместная работа над ними
- Публикация документов для проверки
- Обновление облачного хранилища для Adobe Illustrator
- Облачные документы в Illustrator | Часто задаваемые вопросы
- Устранение неполадок
- Устранение неполадок с созданием или сохранением облачных документов в Illustrator
- Устранение неполадок с облачными документами в Illustrator
- Основы работы
- Добавление и редактирование содержимого
- Рисование
- Основы рисования
- Редактирование контуров
- Рисование графического объекта с точностью на уровне пикселов
- Рисование с помощью инструментов «Перо», «Кривизна» и «Карандаш»
- Рисование простых линий и фигур
- Трассировка изображения
- Упрощение контура
- Определение сеток перспективы
- Инструменты для работы с символами и наборы символов
- Корректировка сегментов контура
- Создание цветка в пять простых шагов
- Рисование перспективы
- Символы
- Рисование контуров, выровненных по пикселам, при создании проектов для Интернета
- 3D-объекты и материалы
- Подробнее о 3D-эффектах в Illustrator
- Создание трехмерной графики
- Проецирование рисунка на трехмерные объекты
- Создание трехмерного текста
- Создание трехмерных объектов
- Подробнее о 3D-эффектах в Illustrator
- Цвет
- О цвете
- Выбор цветов
- Использование и создание цветовых образцов
- Коррекция цвета
- Панель «Темы Adobe Color»
- Цветовые группы (гармонии)
- Панель «Темы Color»
- Перекрашивание графического объекта
- Раскрашивание
- О раскрашивании
- Раскрашивание с помощью заливок и обводок
- Группы с быстрой заливкой
- Градиенты
- Кисти
- Прозрачность и режимы наложения
- Применение обводок к объектам
- Создание и редактирование узоров
- Сетки
- Узоры
- Выбор и упорядочение объектов
- Выделение объектов
- Слои
- Группировка и разбор объектов
- Перемещение, выравнивание и распределение объектов
- Размещение объектов
- Блокировка, скрытие и удаление объектов
- Копирование и дублирование объектов
- Поворот и отражение объектов
- Переплетение объектов
- Перерисовка объектов
- Кадрирование изображений
- Трансформирование объектов
- Объединение объектов
- Вырезание, разделение и обрезка объектов
- Марионеточная деформация
- Масштабирование, наклон и искажение объектов
- Объекты с переходами
- Перерисовка с помощью оболочек
- Перерисовка объектов с эффектами
- Создание фигур с помощью инструментов «Мастер фигур» и «Создание фигур»
- Работа с динамическими углами
- Улучшенные процессы перерисовки с поддержкой сенсорного ввода
- Редактирование обтравочных масок
- Динамические фигуры
- Создание фигур с помощью инструмента «Создание фигур»
- Глобальное изменение
- Текст
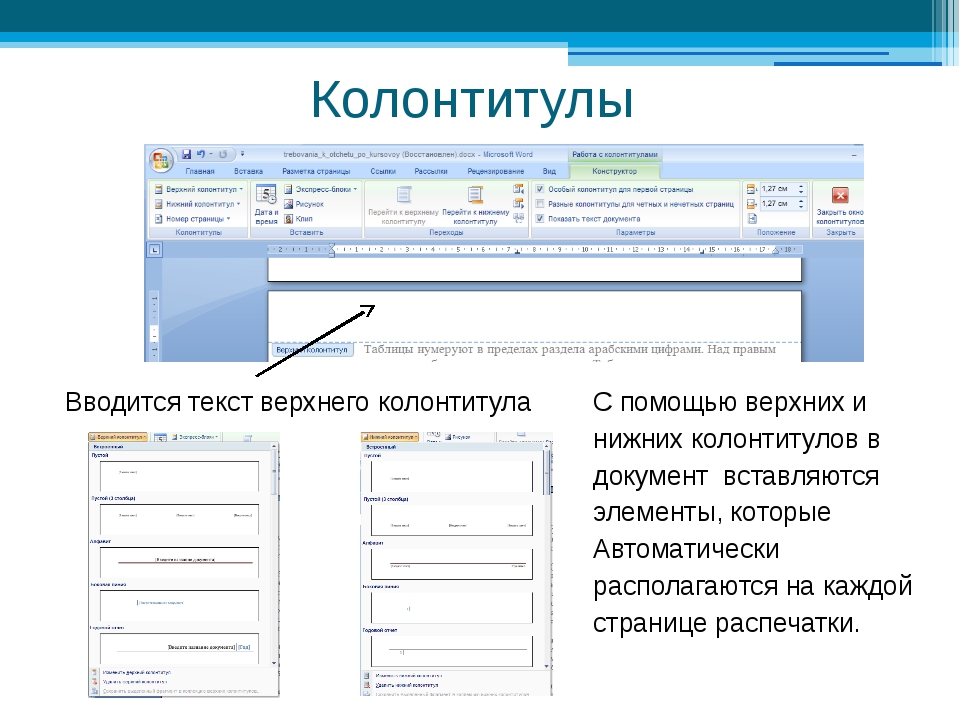
- Дополнение текстовых и рабочих объектов типами объектов
- Создание маркированного и нумерованного списков
- Управление текстовой областью
- Шрифты и оформление
- Определение и использование шрифтов из изображений и обведенного текста
- Форматирование текста
- Импорт и экспорт текста
- Форматирование абзацев
- Специальные символы
- Создание текста по контуру
- Стили символов и абзацев
- Табуляция
- Поиск отсутствующих шрифтов (технологический процесс Typekit)
- Шрифт для арабского языка и иврита
- Шрифты | Часто задаваемые вопросы и советы по устранению проблем
- Создание эффекта 3D-текста
- Творческий подход к оформлению
- Масштабирование и поворот текста
- Интерлиньяж и межбуквенные интервалы
- Расстановка переносов и переходы на новую строку
- Проверка орфографии и языковые словари
- Форматирование азиатских символов
- Компоновщики для азиатской письменности
- Создание текстовых проектов с переходами между объектами
- Создание текстового плаката с помощью трассировки изображения
- Создание специальных эффектов
- Работа с эффектами
- Стили графики
- Атрибуты оформления
- Создание эскизов и мозаики
- Тени, свечения и растушевка
- Обзор эффектов
- Веб-графика
- Лучшие методы создания веб-графики
- Диаграммы
- SVG
- Фрагменты и карты изображений
- Рисование
- Импорт, экспорт и сохранение
- Импорт
- Помещение нескольких файлов в документ
- Управление связанными и встроенными файлами
- Сведения о связях
- Извлечение изображений
- Импорт растровых изображений
- Импорт файлов Adobe PDF
- Импорт файлов EPS, DCS и AutoCAD
- Библиотеки Creative Cloud Libraries в Illustrator
- Библиотеки Creative Cloud Libraries в Illustrator
- Диалоговое окно «Сохранить»
- Сохранение иллюстраций
- Экспорт
- Использование графического объекта Illustrator в Photoshop
- Экспорт иллюстрации
- Сбор ресурсов и их массовый экспорт
- Упаковка файлов
- Создание файлов Adobe PDF
- Извлечение CSS | Illustrator CC
- Параметры Adobe PDF
- Палитра «Информация о документе»
- Импорт
- Печать
- Подготовка к печати
- Настройка документов для печати
- Изменение размера и ориентации страницы
- Задание меток обреза для обрезки и выравнивания
- Начало работы с большим холстом
- Печать
- Наложение
- Печать с управлением цветами
- Печать PostScript
- Стили печати
- Метки и выпуск за обрез
- Печать и сохранение прозрачных графических объектов
- Треппинг
- Печать цветоделенных форм
- Печать градиентов, сеток и наложения цветов
- Наложение белого
- Подготовка к печати
- Автоматизация задач
- Объединение данных с помощью панели «Переменные»
- Автоматизация с использованием сценариев
- Автоматизация с использованием операций
- Устранение неполадок
- Проблемы с аварийным завершением работы
- Восстановление файлов после сбоя
- Проблемы с файлами
- Поддерживаемые форматы файлов
- Проблемы с драйвером ГП
- Проблемы устройств Wacom
- Проблемы с файлами DLL
- Проблемы с памятью
- Проблемы с файлом настроек
- Проблемы со шрифтами
- Проблемы с принтером
- Как поделиться отчетом о сбое с Adobe
- Повышение производительности Illustrator

Узнайте, как дополнить текстовые и рабочие объекты типами объектов, а также выполнить обтекание текстом объектов векторной графики.
Для улучшения дизайна при создании логотипов, брошюр, баннеров или любых иллюстраций можно добавлять текст тремя разными способами. Кроме того, можно удалять пустые текстовые объекты, удалять замещающий текст, добавляемый по умолчанию, заполнять только выделенные текстовые объекты замещающим текстом и выполнять обтекание текстом.
Посмотрите это видео продолжительностью 1 минута 24 секунды, чтобы узнать, как создать логотип с использованием текста в Illustrator.
Хотите создать логотип? Запустите Illustrator.
Начало работы
Добавьте текст в точке, в области или фигуре и по контуру в соответствии с вашими требованиями к дизайну:
Ввод текста в область
Ввод текста в точке
Текст из точки представляет собой горизонтальную или вертикальную строку текста с началом в месте щелчка, которая увеличивается по мере ввода символов. Каждая строка текста является независимой. Текст удлиняется или сокращается при вводе или удалении, но не переходит на следующую строку. Выполните следующие шаги, чтобы ввести текст в точке:
Выполните следующие шаги, чтобы ввести текст в точке:
Добавляйте текст в любой точке.
Выберите инструмент Текст (T) или инструмент Вертикальный текст.
Нажмите в любом месте, чтобы ввести текст. Нажмите клавишу Enter или Return, чтобы начать новую строку в этом же текстовом объекте.
Выберите инструмент Выделение (V), чтобы выделить текстовый объект.
Ввод текста в область
Текст в области (называемый также текстом в абзаце) использует границы объекта, чтобы управлять размещением символов по горизонтали или вертикали. Когда текст достигает границы, он автоматически переносится, чтобы уместиться в заданной области. Выполните следующие действия, чтобы ввести текст в любую область векторного изображения:
Используйте любой из следующих способов для определения ограничительной области:
Перетащите, чтобы определить ограничительную область
Выберите инструмент Прямоугольник (M) и перетащите курсор по диагонали, чтобы создать прямоугольный объект.
Преобразовывайте любую фигуру в ограничительную область
Для создания объекта выберите инструменты «Фигура», например инструмент Эллипс, инструмент Многоугольник или любой другой инструмент для рисования фигур.
Выберите инструмент Текст в области или инструмент Вертикальный текст в области .
Нажмите в любом месте в контуре объекта. Теперь объект заполнен замещающим текстом.
Введите текст.
Ввод текста по контуру
Текст можно вводить по любому контуру или внутрь любой фигуры. Выполните указанные действия, чтобы узнать, как:
Добавлять текст по любому контуру или внутрь фигуры.
Рисовать контур или фигуру.
Выберите инструмент Текст по контуру или Вертикальный текст по контуру.
Щелкните в начале контура или в любой точке границы фигуры.

Контур или граница фигуры теперь заполнены замещающим текстом.
Введите текст.
Удаление пустых текстовых объектов из изображения
Удаление неиспользуемых текстовых объектов уменьшает размер файла и упрощает процесс экспорта или печати. Можно создать пустые текстовые объекты, если, например, случайно щелкнуть инструментом Текст в области изображения, а затем выбрать другой инструмент. Выполните следующие действия, чтобы удалить пустые текстовые объекты:
Выберите команду Объект > Контур > Вычистить.
Выделите Пустые текстовые контуры.
Удалите шаблонный текст
Все новые текстовые объекты в Illustrator заполняются замещающим текстом. Выполните следующие действия, чтобы отключить это поведение Illustrator, выставленное по умолчанию:
Выберите Редактирование > Настройки > Текст.

Снимите выбор с параметра Заполнение только выделенных текстовых объектов замещающим текстом.
Заполнение только выделенных текстовых объектов замещающим текстом
Выполните следующие действия для заполнения выделенных текстовых объектов замещающим текстом:
Создайте или выберите существующий текстовый объект в монтажной области.
Выберите меню Текст > Заполнить шаблонным текстом.
Текст в области может обтекать любой объект, включая текстовые объекты, импортированные изображения и нарисованные объекты.
Для начала убедитесь, что для объекта, вокруг которого вы хотите выполнить обтекание текстом:
- Текст введен в области (в текстовом поле).
- Текст находится в том же слое, что и объект обтекания.
- В иерархии слоя текст расположен прямо под объектом обтекания.

- Если слой содержит несколько текстовых объектов, переместите текстовые объекты, которые не будут участвовать в обтекании, в другие слои или выше объекта обтекания.
Обтекание текстом вокруг объекта
Выберите объект или объекты, вокруг которых будет выполнено обтекание текстом.
Выберите команду Объект > Обтекание текстом > Создать.
Отмена обтекания текстом вокруг объекта
Выберите объект, вокруг которого будет выполнено обтекание текстом.
Выберите команду Объект > Обтекание текстом > Освободить.
Вы можете дополнительно настроить способ обтекания текстом, установив следующие параметры обтекания.
Установка параметров обтекания
Параметры обтекания можно задать до или после обтекания текстом.
Выделите объект обтекания.
Выберите команду Объект > Обтекание текстом > Параметры обтекания текстом и задайте следующие параметры:
- Смещение задает расстояние между текстом и объектом обтекания. Можно ввести положительное или отрицательное значение.
- Обратное обтекание выполняет обтекание текстом вокруг обратной стороны объекта.
- Смещение задает расстояние между текстом и объектом обтекания. Можно ввести положительное или отрицательное значение.
Обновить текст из прежних версий
Текстовые объекты, созданные в Illustrator 10 и более ранних версиях, невозможно редактировать, пока они не обновлены для использования в более поздних версиях. После обновления пользователь получает доступ ко всем функциям обработки текста в Illustrator CS5 и более поздних версий, например к стилям символов и абзацев, оптическому кернингу, а также получает полную поддержку шрифтов OpenType®.
Выберите любой из следующих параметров:
Выберите любой из следующих параметров:
Если при обновлении текста из прежних версий создается его копия, можно использовать следующие команды:
Советы и рекомендации
Теперь, когда вы знаете, как добавить текст к своей иллюстрации, вот несколько советов и рекомендаций по работе с текстом в области:
- Не щелкайте существующий объект при работе с инструментом Текст.
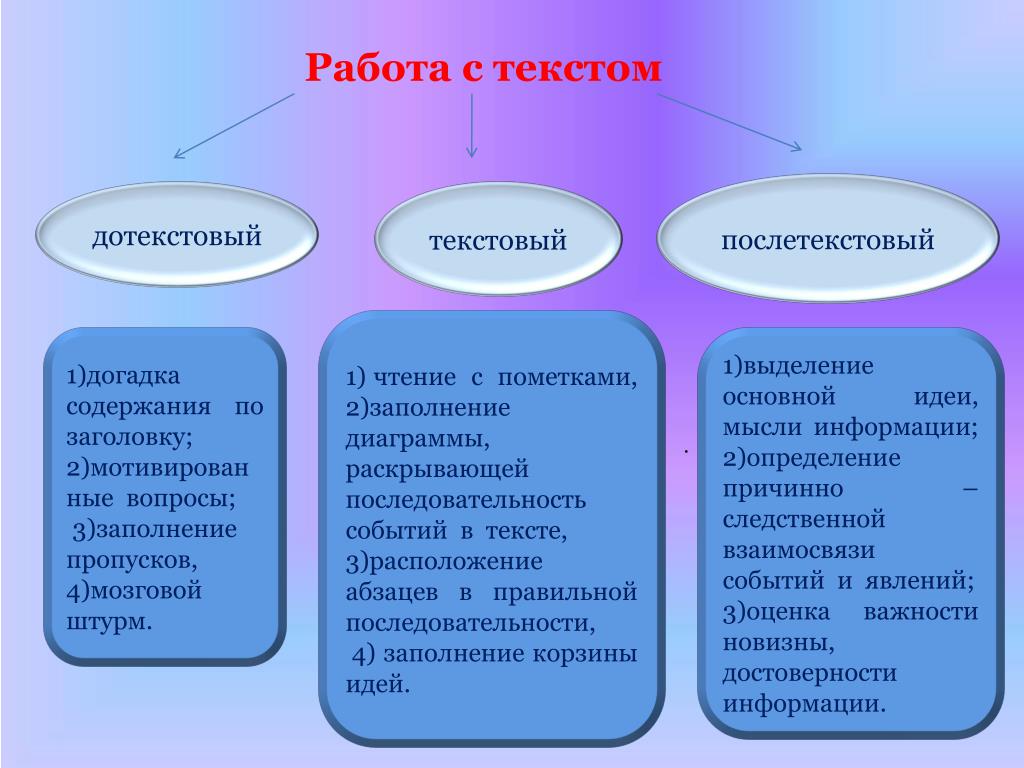 При этом текстовый объект преобразуется в Текст в области, чтобы ввести текст в область, или Текст по контуру, чтобы ввести текст по контуру. Вы можете заблокировать или скрыть объект, чтобы сохранить его «как есть».
При этом текстовый объект преобразуется в Текст в области, чтобы ввести текст в область, или Текст по контуру, чтобы ввести текст по контуру. Вы можете заблокировать или скрыть объект, чтобы сохранить его «как есть». - Настройте ограничительную рамку, установив параметр Показать ограничительную рамку. Если ограничительная рамка не отображается, нажмите Просмотр > Показать ограничительную рамку.
- Если объект представляет собой открытый контур, для определения ограничительной области можно использовать инструмент Текст в области . Для определения границ Illustrator рисует воображаемую линию между конечными точками контура.
- Чтобы преобразовать фигуру в текстовую область, обязательно нажмите на контур, а не внутри контура.
связанные ресурсы
- Управление текстовой областью
- Связь текста
- Создание текста по контуру
Обращайтесь к нам
Мы будем рады узнать ваше мнение. Поделитесь своими мыслями с сообществом Adobe Illustrator.
Поделитесь своими мыслями с сообществом Adobe Illustrator.
Вход в учетную запись
Войти
Управление учетной записью5 лайфхаков в Figma для работы с текстом, картинками и заливкой / Skillbox Media
Дизайн
#Руководства- 0
Рассказываем, как использовать математику в Figma, сделать из картинки заливку и включить пиксельное отображение вектора.
Vkontakte Twitter Telegram Скопировать ссылкуИллюстрация: Meery Mary для Skillbox Media
Вячеслав Лазарев
Редактор. Пишет про дизайн, редактирует книги, шутит шутки, смотрит аниме.
Пишет про дизайн, редактирует книги, шутит шутки, смотрит аниме.
В Figma есть множество скрытых функций и горячих клавиш, которые самостоятельно найти не так просто. Но если их освоить, вы сможете ускорить работу над макетом: быстрее менять все цвета или сбрасывать настройки шрифта.
Рассказываем о пяти простых лайфхаках, которые помогут вам быстрее работать в Figma.
Если вы не смогли сразу настроить интерлиньяж текстовой строки и решили оставить его стандартным, просто удалите своё значение из поля ввода. Figma автоматически вернёт значение по умолчанию, и вам не придётся подбирать его заново.
Самостоятельно сместить какой-либо объект на один пиксель или на 1% — не всегда просто. Чтобы не вычислять значение нужного размера или расположения в уме, сделайте это прямо в полях ввода — например, наберите «144+1%». Графический редактор сам всё посчитает, и свойства объекта тут же изменятся.
Чтобы не вычислять значение нужного размера или расположения в уме, сделайте это прямо в полях ввода — например, наберите «144+1%». Графический редактор сам всё посчитает, и свойства объекта тут же изменятся.
Таким образом можно изменить размер объекта, его расположение и непрозрачность. Математический расчёт работает во всех полях, где нужно вводить числа.
Если в Figma вы рисуете векторное изображение, которое потом хотите использовать как растровое, его внешний вид важно заранее проверить. Чтобы лишний раз не выгружать картинку и не редактировать её наугад, воспользуйтесь пиксельным режимом. В нём Figma будет отображать все объекты в растровом формате, и вы сможете заранее понять, как будут выглядеть мелкие детали вашего изображения.
Чтобы включить пиксельный режим просмотра, нажмите сочетание клавиш Ctrl + Alt + Y (на macOS — Ctrl + Y). Либо нажмите на иконку , затем View и выберите Pixel Preview.
Если вы не использовали стили при проектировании приложения, а клиент попросил поменять оттенок красного, то не нужно сразу бросаться и перекрашивать каждый макет. Просто выделите их, и на панели настроек появится список используемых цветов, которые можно поменять.
Кстати, в этом же меню из любого цвета можно сделать стиль.
Обычно в Figma стили делают из простых цветов либо градиентов. То же самое можно сделать с обычными картинками и использовать их как заливку любых фреймов, фигур или даже текста.
Как добавить изображение в стили
- Добавьте на макет любое изображение и выделите его.
- Перейдите в пункт Fill («Заливка») и нажмите на иконку .
- В появившемся меню нажмите на плюсик.
- Назовите стиль и сохраните.
- Чтобы использовать стиль, в пункте Fill нажмите на иконку из кружков и выберите нужный шаблон. Стиль можно выбрать и для обводки в пункте Stroke — он находится под Fill.

Больше о Figma
Самоучитель по Figma
Самые полные и полезные инструкции, которые помогут вам освоить все функции графического редактора.
Vkontakte Twitter Telegram Скопировать ссылку Научитесь: Figma с нуля до PRO Узнать большеОбъявили победителей премии Workspace Digital Awards-2023 08 июн 2023
NVIDIA и WPP создадут движок на основе ИИ, чтобы генерировать рекламу 08 июн 2023
Облачный провайдер beeline cloud провёл ребрендинг 06 июн 2023
Понравилась статья?
ДаКак работает преобразование изображения в текст (также известное как оптическое распознавание символов)
Извлечение текста из изображений никогда не было проще, чем сегодня, благодаря технологии оптического распознавания символов (OCR).
OCR позволяет нам делать множество полезных вещей, таких как поиск изображений с помощью текстовых запросов, воспроизведение документов без их ввода вручную и даже преобразование рукописного текста в цифровой текст.
Но что такое оптическое распознавание символов? Как это работает на самом деле? Это может показаться вам черной магией, но к концу этой статьи вы будете иметь четкое представление о том, как компьютеры могут распознавать буквы и слова.
Как работает оптическое распознавание символов
Чтобы понять, как текст извлекается из изображения, нам сначала нужно понять, что такое изображения и как они хранятся на компьютерах.
пикселей — это одна точка определенного цвета. Изображение по сути является набором пикселей. Чем больше пикселей в изображении, тем выше его разрешение. Компьютер не знает, что изображение указателя действительно является указателем — он просто знает, что первый пиксель имеет этот цвет, следующий пиксель — этот цвет, и отображает все свои пиксели, чтобы вы могли видеть.
Это означает, что текст и нетекст ничем не отличаются от компьютера, и поэтому оптическое распознавание символов так сложно. Имея это в виду, вот как это работает.
Шаг 1. Предварительная обработка изображения
Перед извлечением текста изображение необходимо определенным образом помассировать, чтобы облегчить извлечение и повысить вероятность успеха. Это называется предварительной обработкой, и разные программные решения используют разные комбинации методов.
Наиболее распространенные методы предварительной обработки включают:
Бинаризация
Каждый пиксель изображения преобразуется в черный или белый. Цель состоит в том, чтобы четко определить, какие пиксели относятся к тексту, а какие — к фону, что ускоряет фактический процесс оптического распознавания символов.
Устранение перекоса
Поскольку документы редко сканируются с идеальным выравниванием, символы могут оказаться наклонными или даже перевернутыми. Цель здесь состоит в том, чтобы определить горизонтальные текстовые строки, а затем повернуть изображение так, чтобы эти строки были на самом деле горизонтальными.
Цель здесь состоит в том, чтобы определить горизонтальные текстовые строки, а затем повернуть изображение так, чтобы эти строки были на самом деле горизонтальными.
Удаление пятен
Независимо от того, было ли изображение бинарным или нет, могут присутствовать шумы, которые могут мешать идентификации символов. Удаление пятен избавляет от этого шума и пытается сгладить изображение.
Удаление строк
Идентифицирует все строки и метки, которые, вероятно, не являются символами, а затем удаляет их, чтобы не запутаться в реальном процессе оптического распознавания символов. Это особенно важно при сканировании документов с таблицами и коробками.
Зонирование
Разделяет изображение на отдельные фрагменты текста, например, для обозначения столбцов в документах с несколькими столбцами.
Изображение предоставлено: WayneRay/WikimediaШаг 2: Обработка изображения
Прежде всего, процесс OCR пытается установить базовую линию для каждой строки текста в изображении (или, если он был зонирован при предварительной обработке, он будет работать через каждую зону по одному). Каждая идентифицированная строка символов обрабатывается одна за другой.
Каждая идентифицированная строка символов обрабатывается одна за другой.
Для каждой строки символов программа OCR определяет расстояние между символами, ища вертикальные линии нетекстовых пикселей (что должно быть очевидно при правильной бинаризации). Каждый фрагмент пикселей между этими нетекстовыми строками помечен как «токен», представляющий один символ. Следовательно, этот шаг называется токенизация .
После того, как все потенциальные символы на изображении размечены, программное обеспечение OCR может использовать два разных метода для определения того, какими символами на самом деле являются эти маркеры:
Распознавание образов
весь набор известных глифов, включая цифры, знаки препинания и другие специальные символы, и выбирается наиболее близкое совпадение. Этот метод также известен как сопоставление матриц.
Здесь есть несколько недостатков. Во-первых, токены и глифы должны быть одинакового размера, иначе ни один из них не будет совпадать. Во-вторых, жетоны должны быть написаны тем же шрифтом, что и глифы, что исключает рукописный ввод. Но если шрифт токена известен, распознавание образов может быть быстрым и точным.
Во-вторых, жетоны должны быть написаны тем же шрифтом, что и глифы, что исключает рукописный ввод. Но если шрифт токена известен, распознавание образов может быть быстрым и точным.
Извлечение признаков
Каждый токен сравнивается с различными правилами, которые описывают, каким символом он может быть. Например, две вертикальные линии одинаковой высоты, соединенные одной горизонтальной линией, скорее всего, будут заглавной буквой H.
Этот метод полезен, поскольку он не ограничен определенными шрифтами или размерами. Он также может быть более тонким при распознавании тонких различий между заглавной I, строчной L и цифрой 1. Недостатки? Программирование правил намного сложнее, чем простое сравнение пикселей токена с пикселями глифа.
Шаг 3: Постобработка изображения
После того, как сопоставление всех токенов завершено, программное обеспечение OCR может просто завершить работу и представить вам результаты. Но обычно требуется немного больше обмана, чтобы убедиться, что вы не закатываете глаза от тарабарских результатов.
Лексическое ограничение
Все слова сравниваются со словарем одобренных слов, и все несоответствующие слова заменяются наиболее подходящим словом. Словарь является одним из примеров лексики. Это может помочь исправить слова с ошибочными символами, например «шип» вместо «th0rn».
Оптимизация для конкретных приложений
Когда OCR используется в определенных условиях, например для медицинских или юридических документов, может использоваться специальный тип OCR, специально разработанный для этих параметров. В этих случаях программное обеспечение OCR может искать математические уравнения, отраслевые термины и т. д.
Естественный язык
Этот продвинутый метод исправляет предложения, используя языковую модель, которая описывает вероятность того, что за одним словом последуют другие слова. Это похоже на технологию, которая предсказывает, какое слово вы хотите ввести следующим на клавиатуре мобильного телефона.
Если все сделано правильно, текст может быть замечательно читаемым.
Теперь, когда вы знаете, как работает OCR, должно быть легко увидеть, что не все инструменты OCR одинаковы. Точность ваших результатов будет сильно зависеть от того, насколько хорошо программное обеспечение реализует различные методы OCR, обсуждаемые в этой статье.
Мы настоятельно рекомендуем OneNote для этого, и это только одна из причин, по которой он превосходит Evernote для ведения заметок. Если вы готовы платить за премиум-решение, обратите внимание на OmniPage. См. наше сравнение OneNote и OmniPage для OCR. Для мобильных документов вам понадобятся эти приложения OCR для устройств Android.
Как вы используете OCR? Есть ли какие-нибудь любимые инструменты OCR, которые мы не упомянули? Дайте нам знать в комментариях ниже!
Поиск текста в изображение и изображения в изображение с использованием CLIP
Введение
Сегодня предприятия имеют дело с постоянно растущими объемами данных. Особенно в розничной торговле, моде и других отраслях, где имидж продукта играет важную роль.
Особенно в розничной торговле, моде и других отраслях, где имидж продукта играет важную роль.
В такой ситуации мы часто можем описать один продукт по-разному, что усложняет выполнение точного и минимально трудоемкого поиска.
Могу ли я воспользоваться современными решениями искусственного интеллекта для решения такой задачи?
Вот где CLIP OpenAI пригодится. Алгоритм глубокого обучения, который упрощает соединение текста и изображений.
После прочтения этого концептуального блога вы поймете: (1) что такое CLIP, (2) как он работает и почему вы должны его внедрить, и, наконец, (3) как реализовать его для собственного варианта использования, используя как локальные и облачные векторные индексы.
Что такое CLIP?
Contrastive Language-Image Pre-training (сокращенно CLIP) — это современная модель, представленная OpenAI в феврале 2021 года [1].
CLIP — это нейронная сеть, обученная примерно на 400 миллионах пар (текст и изображение). В обучении используется контрастный подход к обучению, который направлен на объединение текста и изображений, позволяя выполнять такие задачи, как классификация изображений, со сходством текста и изображения.
В обучении используется контрастный подход к обучению, который направлен на объединение текста и изображений, позволяя выполнять такие задачи, как классификация изображений, со сходством текста и изображения.
Это означает, что CLIP может определить, совпадают ли заданное изображение и текстовое описание без обучения для определенного домена. Расширение возможностей CLIP для готового поиска текста и изображений, которому посвящена эта статья.
Помимо поиска текста и изображений, мы можем применять CLIP для классификации изображений, генерации изображений, поиска сходства изображений, ранжирования изображений, отслеживания объектов, управления робототехникой, создания подписей к изображениям и многого другого.
Почему вы должны использовать модели CLIP?
Ниже приведены некоторые причины, которые способствовали принятию моделей CLIP сообществом ИИ.
Кроме того, внедрение Vision Transformer обеспечило дополнительный трехкратный прирост эффективности вычислений по сравнению со стандартным ResNet.
Эффективность CLIP при нулевой передаче (источник)
Более общая и гибкая
CLIP превосходит существующие модели ImageNet в новых областях благодаря своей способности изучать широкий спектр визуальных представлений непосредственно из естественного языка.
На следующем рисунке показана производительность CLIP с нулевым выстрелом по сравнению с моделями ResNet с производительностью линейного зонда с несколькими выстрелами в задачах мелкозернистого обнаружения объектов, геолокации, распознавания действий и оптического распознавания символов.
Средняя линейная оценка по 27 наборам данных (источник)
Архитектура CLIP
Архитектура CLIP состоит из двух основных компонентов: (1) кодировщик текста и (2) кодировщик изображений. Эти два кодировщика совместно обучены предсказывать правильные пары из набора обучающих примеров (изображение, текст).
- Магистраль кодировщика текста представляет собой модель преобразователя [2], а базовый размер использует 63 миллиона параметров, 12 слоев и модель шириной 512, содержащую 8 головок внимания.

- Кодировщик изображений , с другой стороны, использует как Vision Transformer (ViT), так и ResNet50 в качестве своей основы, ответственной за генерацию представления признаков изображения.
Как работает алгоритм CLIP?
Мы можем ответить на этот вопрос, поняв эти три подхода: (1) контрастное предварительное обучение, (2) создание классификатора набора данных из размеченного текста и, наконец, (3) применение метода нулевого выстрела для классификации.
Давайте объясним каждое из этих трех понятий.
Контрастное предварительное обучение (источник)
1. Контрастное предварительное обучение
На этом этапе пакет из 32 768 пар изображения и текста одновременно проходит через кодировщики текста и изображения для создания векторных представлений текст и связанное с ним изображение соответственно.
Обучение выполняется путем поиска каждого изображения, ближайшего текстового представления во всем пакете, что соответствует максимальному косинусному сходству между фактическими N максимально близкими парами.
Кроме того, фактические изображения отдаляются от всех остальных текстов, сводя к минимуму их косинусное сходство.
Наконец, симметричная потеря кросс-энтропии оптимизируется по ранее вычисленным показателям подобия.
Создание набора данных классификации и предсказание нулевого выстрела (источник)
2. Создание классификатора набора данных из текста метки
В этом разделе второго шага все метки/объекты кодируются в следующем формате контекста: {объект} . Векторное представление каждого контекста генерируется кодировщиком текста.
Если у нас есть собака, автомобиль и самолет в качестве классов набора данных, мы выведем следующие представления контекста:
- фотография собаки
- фотография автомобиля
- фотография плоскость
Изображение, иллюстрирующее представления контекста
3. Использование нулевого предсказания
Мы используем выходные данные раздела 2, чтобы предсказать, какой вектор изображения соответствует какому вектору контекста. Преимущество применения подхода прогнозирования нулевого выстрела заключается в том, что модели CLIP лучше обобщают невидимые данные.
Преимущество применения подхода прогнозирования нулевого выстрела заключается в том, что модели CLIP лучше обобщают невидимые данные.
Реализация CLIP с помощью Python
Теперь, когда мы знаем архитектуру CLIP и то, как она работает, в этом разделе мы рассмотрим все шаги для успешной реализации двух реальных сценариев. Во-первых, вы поймете, как выполнять поиск изображений на естественном языке. Кроме того, вы сможете выполнять поиск изображения к изображению с помощью.
В конце процесса вы поймете преимущества использования векторной базы данных для такого варианта использования.
Общий рабочий процесс варианта использования
(Присоединяйтесь к записной книжке Colab!)
Сквозной процесс описан в приведенном ниже рабочем процессе. Мы начинаем со сбора данных из набора данных Hugging Face, которые затем обрабатываются для дальнейшего создания векторных индексных векторов с помощью кодировщиков изображений и текста. Наконец, клиент Pinecone используется для вставки их в векторный индекс.
После этого пользователь сможет искать изображения на основе текста или другого изображения.
Общий рабочий процесс поиска изображений
Предварительные условия
Для создания реализации необходимы следующие библиотеки.
Установить библиотеки
%%bash # Раскомментируйте это, если используете его в первый раз. -qqq для ОБНУЛЕНИЯ pip3 -qqq установить наборы данных трансформаторов факела # Следующие две библиотеки избегают UnidentifiedImageError pip3 -qqq установить gdcm pip3 -qqq установить pydicom pip -qqq установить faiss-gpu pip -qqq установить pinecone-клиент
Импорт библиотек
Импорт ОС импорт фейс импортный факел импорт запросы на импорт импорт сосновой шишки импортировать numpy как np импортировать панд как pd из изображения импорта PIL из io импортировать BytesIO импортировать IPython.display импортировать matplotlib.pyplot как plt из наборов данных импортировать load_dataset из коллекций импортировать OrderedDict из трансформеров импортировать CLIPProcessor, CLIPModel, CLIPTokenizer
Сбор и исследование данных
Набор данных концептуальных подписей состоит из примерно 3,3 млн изображений с двумя основными столбцами: URL-адрес изображения и его заголовок. Вы можете найти более подробную информацию по соответствующей ссылке Huggingface.
Вы можете найти более подробную информацию по соответствующей ссылке Huggingface.
# Получить набор данных
image_data = load_dataset("conceptual_captions", split="train")
Предварительная обработка данных
Не все URL-адреса в наборе данных действительны. Мы исправим это, протестировав и удалив все ошибочные записи URL.
по определению check_valid_URLs (image_URL):
пытаться:
ответ = запросы.get(image_URL)
Image.open(BytesIO(response.content))
вернуть Истина
кроме:
вернуть ложь
защита get_image (image_URL):
ответ = запросы.get(image_URL)
image = Image.open(BytesIO(response.content)).convert("RGB")
вернуть изображение
Следующее выражение создает новый фрейм данных с новым столбцом «is_valid», который имеет значение True, если URL-адрес действителен, или False в противном случае.
# Преобразование кадра данных image_data_df["is_valid"] = image_data_df["image_url"].apply(check_valid_URLs) # Получить действительные URL-адреса image_data_df = image_data_df[image_data_df["is_valid"]==True] # Получить изображение по URL image_data_df["image"] = image_data_df["image_url"].apply(get_image)
Второй шаг — загрузка изображений по URL-адресам. Это помогает нам избежать постоянных веб-запросов.
Внедрение изображений и текста
Необходимыми условиями для успешного внедрения кодировщиков являются модель, процессор и токенизатор.
Следующая функция удовлетворяет требованиям идентификатора модели и устройства, используемого для вычислений, будь то ЦП или ГП.
по определению get_model_info (model_ID, устройство):
# Сохраняем модель на устройство
модель = CLIPModel.from_pretrained(model_ID).to(устройство)
# Получить процессор
процессор = CLIPProcessor.from_pretrained(model_ID)
# Получить токенизатор
токенизатор = CLIPTokenizer.from_pretrained(model_ID)
# Возвращаем модель, процессор и токенизатор
модель возврата, процессор, токенизатор
# Установить устройство
device = "cuda", если torch. cuda.is_available(), иначе "cpu"
# Определяем идентификатор модели
model_ID = "openai/clip-vit-base-patch42"
# Получить модель, процессор и токенизатор
модель, процессор, токенизатор = get_model_info(model_ID, устройство)
cuda.is_available(), иначе "cpu"
# Определяем идентификатор модели
model_ID = "openai/clip-vit-base-patch42"
# Получить модель, процессор и токенизатор
модель, процессор, токенизатор = get_model_info(model_ID, устройство)
Встраивание текста
Мы начинаем с создания встраивания одного текста перед применением той же функции ко всему набору данных.
определение get_single_text_embedding (текст): входы = токенизатор (текст, return_tensors = "pt") text_embeddings = model.get_text_features (** входные данные) # преобразовать вложения в массив numpy embedding_as_np = text_embeddings.cpu().detach().numpy() вернуть embedding_as_np def get_all_text_embeddings (df, text_col): df["text_embeddings"] = df[str(text_col)].apply(get_single_text_embedding) вернуть дф # Применяем функции к набору данных image_data_df = get_all_text_embeddings (image_data_df, «заголовок»)
Первые пять строк выглядят следующим образом:
Формат векторного указателя, содержащего вложения заголовков/текста
Встраивания изображений
Тот же процесс используется для встраивания изображений, но с другими функциями.
по определению get_single_image_embedding(my_image): изображение = процессор( текст = Нет, изображения = мое_изображение, return_tensors="pt" )["значения_пикселей"].к(устройство) встраивание = model.get_image_features(изображение) # преобразовать вложения в массив numpy embedding_as_np = embedding.cpu().detach().numpy() вернуть embedding_as_np защита get_all_images_embedding (df, img_column): df["img_embeddings"] = df[str(img_column)].apply(get_single_image_embedding) вернуть дф image_data_df = get_all_images_embedding (image_data_df, «изображение»)
Окончательный формат индекса вектора текста и изображения выглядит следующим образом:
Индекс вектора с вложениями изображений и подписей (Изображение автора)
Подход к хранению векторов — Локальный векторный индекс Vs. Облачный векторный индекс
В этом разделе мы рассмотрим два разных подхода к хранению вложений и метаданных для выполнения поиска: первый использует предыдущий фрейм данных, а второй использует Pinecone.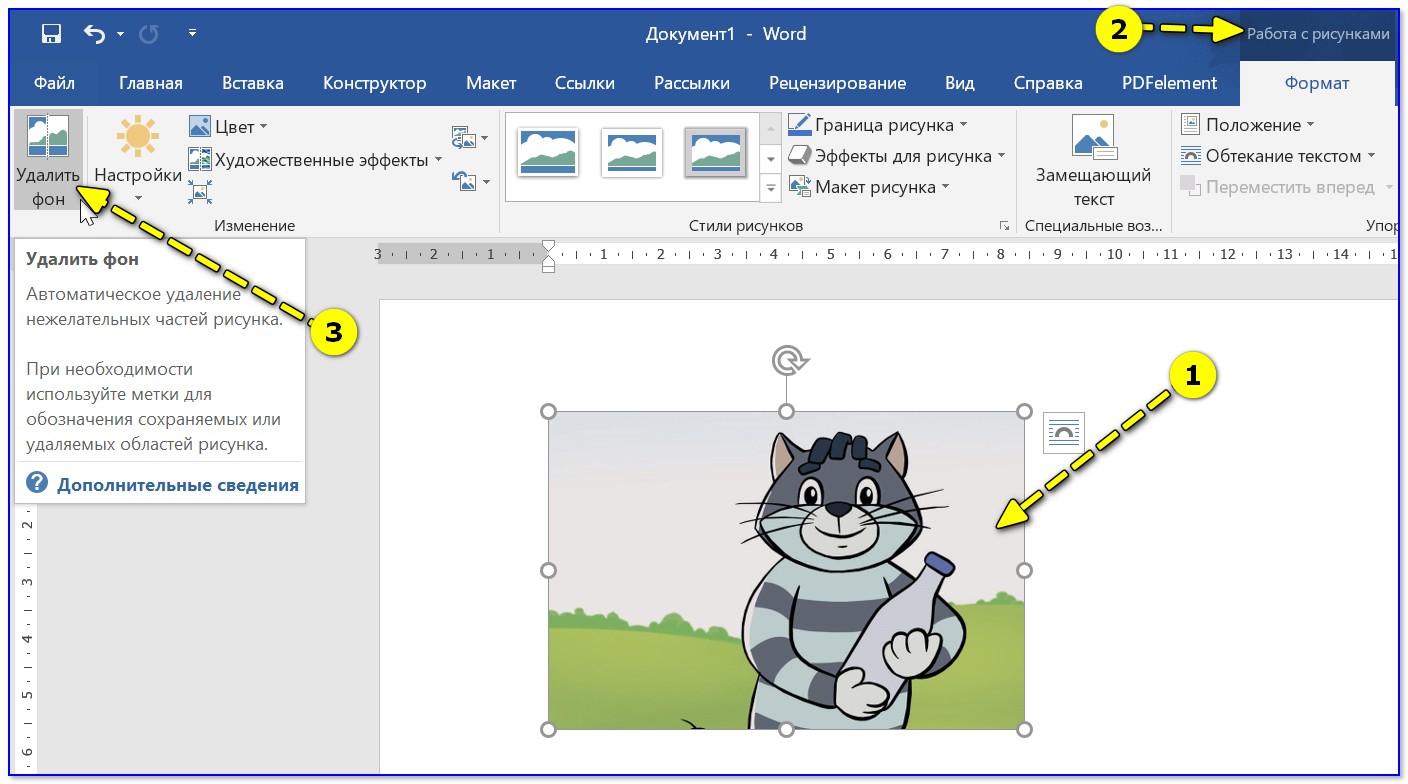 Оба подхода используют метрику косинусного сходства.
Оба подхода используют метрику косинусного сходства.
Использование локального фрейма данных в качестве индекса вектора
Вспомогательная функция get_top_N_images создает похожие изображения для двух сценариев, показанных в приведенном выше рабочем процессе: поиск текста в изображение или поиск изображения в изображение.
из sklearn.metrics.pairwise import cosine_similarity
def get_top_N_images (запрос, данные, top_K = 4, search_criterion = "текст"):
# Текст в изображение Поиск
если(search_criterion.lower() == "текст"):
query_vect = get_single_text_embedding (запрос)
# Поиск изображения к изображению
еще:
query_vect = get_single_image_embedding (запрос)
# Соответствующие столбцы
reevant_cols = ["заголовок", "изображение", "cos_sim"]
# Запустить поиск сходства
data["cos_sim"] = data["img_embeddings"].apply(lambda x: cosine_similarity(query_vect, x))# строка 17
данные["cos_sim"] = данные["cos_sim"]. apply(лямбда x: x[0][0])
"""
Получить top_K (4 — значение по умолчанию) статей, похожих на запрос
"""
most_similar_articles = data.sort_values(by='cos_sim', по возрастанию=False)[1:top_K+1] # строка 24
вернуть большинство_подобных_статей[релевантные_столбцы].reset_index()
apply(лямбда x: x[0][0])
"""
Получить top_K (4 — значение по умолчанию) статей, похожих на запрос
"""
most_similar_articles = data.sort_values(by='cos_sim', по возрастанию=False)[1:top_K+1] # строка 24
вернуть большинство_подобных_статей[релевантные_столбцы].reset_index()
Давайте разберемся, как мы выполняем рекомендацию.
→ Пользователь указывает либо текст, либо изображение в качестве критерия поиска, но модель по умолчанию выполняет поиск текста в изображении.
→ В строке 17 выполняется косинусное сходство между каждым вектором изображения и входным вектором пользователя.
→ Наконец, в строке 24 отсортируйте результат по показателю схожести в порядке убывания, и мы вернем наиболее похожие изображения, исключив первое, соответствующее самому запросу.
Пример поиска
Эта вспомогательная функция упрощает визуализацию рекомендуемых изображений рядом друг с другом. Каждое изображение будет иметь соответствующую подпись и оценку сходства.
по определению plot_images_by_side(top_images):
index_values = список (top_images.index.values)
list_images = [top_images.iloc[idx].image для idx в index_values]
list_captions = [top_images.iloc[idx].caption для idx в index_values]
Similarity_score = [top_images.iloc[idx].cos_sim для idx в index_values]
n_строка = n_столбец = 2
_, axs = plt.subplots (n_row, n_col, figsize = (12, 12))
топор = топор.flatten ()
для img, axe, caption, sim_score в zip (list_images, axs, list_captions, Similarity_score):
ax.imshow (изображение)
sim_score = 100*float("{:.2f}".format(sim_score))
ax.title.set_text(f"Подпись: {caption}\nСходство: {sim_score}%")
plt.show()
Преобразование текста в изображение
→ Сначала пользователь вводит текст, который используется для поиска.
→ Во-вторых, мы запускаем поиск сходства.
→ В-третьих, строим изображения, рекомендованные алгоритмом.
query_caption = image_data_df.iloc[10].caption # Печатаем исходный текст запроса print("Запрос: {}".format(query_caption)) # Запускаем поиск по сходству top_images = get_top_N_images (заголовок запроса, image_data_df) # Нарисуйте рекомендуемые изображения plot_images_by_side (top_images)
Строка 3 генерирует следующий текст:
Запрос: актер прибывает на премьеру фильма
Строка 9 выдает сюжет ниже.
Изображения, соответствующие тексту: «актер прибывает на премьеру фильма»
Изображение в изображение
Применяется тот же процесс. Единственная разница на этот раз в том, что пользователь предоставляет изображение вместо подписи.
# Получить изображение запроса и показать его query_image = image_data_df.iloc[55].image query_image
Исходное изображение поиска (изображение в индексе)
# Запустить поиск подобия и построить результат top_images = get_top_N_images(query_image, image_data_df, search_criterion="image") # Отобразить результат plot_images_by_side (top_images)
Мы запускаем поиск, указав search_criterion, который является «изображением» в строке 2.
Окончательный результат показан ниже.
Изображения, соответствующие поиску между изображениями (Изображение автора)
Мы можем заметить, что некоторые изображения менее похожи, что вносит шум в рекомендацию. Мы можем уменьшить этот шум, указав пороговый уровень подобия. Например, рассмотрим все изображения с не менее чем 60-процентным сходством.
Эффективное использование возможностей управляемого индекса векторов с помощью Pinecone
Pinecone предоставляет полностью управляемую, легко масштабируемую базу данных векторов, которая позволяет легко создавать высокопроизводительные приложения для поиска векторов.
В этом разделе описаны этапы от получения учетных данных API до внедрения поисковой системы.
Получите ваш API Pinecone
Ниже описаны восемь шагов для получения ваших учетных данных API, начиная с веб-сайта Pinecone.
Восемь основных шагов для получения клиентского API Pinecone
Настройка индекса вектора
С помощью API мы можем создать индекс, который позволит нам выполнять все действия по созданию, обновлению, удалению и вставке.
шишка.инит(
api_key = "ВАШ_API_KEY",
environment="YOUR_ENV" # найти рядом с ключом API в консоли
)
my_index_name = "поиск клипа-изображения"
vector_dim = image_data_df.img_embeddings[0].shape[1]
если my_index_name не в pinecone.list_indexes():
# Создаем измерение векторов
pinecone.create_index(name = my_index_name,
измерение=vector_dim,
метрика="косинус", осколки=1,
pod_type='s1.x1')
# Подключиться к индексу
my_index = сосновая шишка.Index(index_name = my_index_name)
- pinecone.init Раздел инициализирует рабочую область pinecone, чтобы разрешить взаимодействие в будущем.
- в строках с 8 по 9 мы указываем имя, которое мы хотим для индекса вектора, а также размерность векторов, которая в нашем сценарии равна 512.
- из строк с 11 по 16 мы создаем индекс, если он еще не существует.
Результат следующей инструкции показывает, что у нас нет данных в индексе.
my_index.describe_index_stats()
Единственная информация, которой мы располагаем, это размерность, равная 512.
{'размерность': 512,
'index_fullness': 0.0,
«пространства имен»: {},
'total_vector_count': 0}
Заполнение базы данных
Теперь, когда мы настроили базу данных Pinecone, следующим шагом будет ее заполнение следующим кодом.
image_data_df["vector_id"] = image_data_df.index
image_data_df["vector_id"] = image_data_df["vector_id"].apply(str)
# Получить все метаданные
final_metadata = []
для индекса в диапазоне (len (image_data_df)):
final_metadata.append({
«ID»: индекс,
'заголовок': image_data_df.iloc[index].caption,
'изображение': image_data_df.iloc[индекс].image_url
})
image_IDs = image_data_df.vector_id.tolist()
image_embeddings = [arr.tolist() для записи в image_data_df.img_embeddings.tolist()]
# Создаем единый список формата словаря для вставки
data_to_upsert = list(zip(image_IDs, image_embeddings, final_metadata))
# Загружаем окончательные данные
my_index. upsert (векторы = data_to_upsert)
# Проверяем размер индекса для каждого пространства имен
my_index.describe_index_stats()
upsert (векторы = data_to_upsert)
# Проверяем размер индекса для каждого пространства имен
my_index.describe_index_stats()
Давайте разбираться, что здесь происходит.
Данные для обновления требуют трех компонентов: уникальные идентификаторы (ID) каждого наблюдения, список сохраняемых вложений и метаданные, содержащие дополнительную информацию о данных для сохранения.
→ В строках с 5 по 12 метаданные создаются путем сохранения «ID», «заголовка» и «URL» каждого наблюдения.
→ В строках 14 и 15 мы генерируем список идентификаторов и конвертируем вложения в список списков.
→ Затем мы создаем список словарей, отображающих идентификаторы, вложения и метаданные.
→ Окончательные данные вставляются в индекс с помощью функции .upsert() .
Аналогично предыдущему сценарию, мы можем проверить, что все векторы были обновлены с помощью my_index.describe_index_stats() .
Запустить запрос
Все, что осталось, — это запросить наш индекс, используя поиски «текст-изображение» и «изображение-изображение». Оба будут использовать следующий синтаксис:
Оба будут использовать следующий синтаксис:
my_index.query(my_query_embedding, top_k=N, include_metadata=True)
→ my_query_embedding — это вложение (в виде списка) запроса (заголовка или изображения), предоставленного пользователем.
→ N соответствует максимальному количеству возвращаемых результатов.
→ include_metadata=True означает, что мы хотим, чтобы результат запроса включал метаданные.
Текст в изображение
# Получить текст запроса text_query = image_data_df.iloc[10].caption # Получить встраивание подписи query_embedding = get_single_text_embedding(text_query).tolist() # Запустить запрос my_index.query(query_embedding, top_k=4, include_metadata=True)
Ниже приведен ответ JSON, возвращенный запросом
результат запроса преобразования текста в изображение (изображение автора)
Из атрибута «matches» мы можем наблюдать четыре наиболее похожих изображения, возвращенных запросом.
Изображение к изображению
Тот же подход применяется к поиску изображения к изображению.
image_query = image_data_df.iloc[43].image
Это изображение, предоставленное пользователем в качестве критерия поиска.
Запрос изображения
# Получить встраивание текста query_embedding = get_single_image_embedding(image_query).tolist() # Запустить запрос my_index.query(query_embedding, top_k=4, include_metadata=True)
Результат запроса изображения к изображению (Изображение автора)
Когда вы закончите, не забудьте удалить свой индекс, чтобы освободить ресурсы:
pinecone.delete_index(my_index)
Каковы преимущества использования сосновой шишки по сравнению с локальным фреймом данных pandas?
Этот подход с использованием шишки имеет несколько преимуществ:
→ Простота : подход с запросами намного проще, чем первый подход, когда пользователь несет полную ответственность за управление векторным индексом.
→ Скорость : Сосновая шишка работает быстрее, что соответствует большинству отраслевых требований.
→ Масштабируемость : векторный индекс, размещенный на Pinecone, масштабируется практически без усилий пользователя. Первый подход будет становиться все более сложным и медленным по мере масштабирования.
→ Меньшая вероятность потери информации : векторный индекс на основе Pinecone размещается в облаке с резервными копиями и высокой информационной безопасностью. Первый подход слишком высок для производственных сценариев использования.
→ Подходит для веб-служб : результат, предоставленный запросом, имеет формат JSON и может использоваться другими приложениями, что делает его более подходящим для веб-приложений.
Заключение
Поздравляем, вы только что узнали, как полностью реализовать приложение для поиска изображений, используя как изображение, так и естественный язык.