Работа с текстом | Система управления сайтом Business-CMS
В этой статье: интерфейс текстового редактора и его возможности, вставка и набор текста, форматирование текста и графики, вставка различных элементов в текст.
Текстовый редактор позволяет вводить текст статьи, добавлять элементы html-разметки текста, ссылки, таблицы и картинки. Для набора аннотаций используется сокращенная панель инструментов редактора, для ввода текста статьи — полная версия.
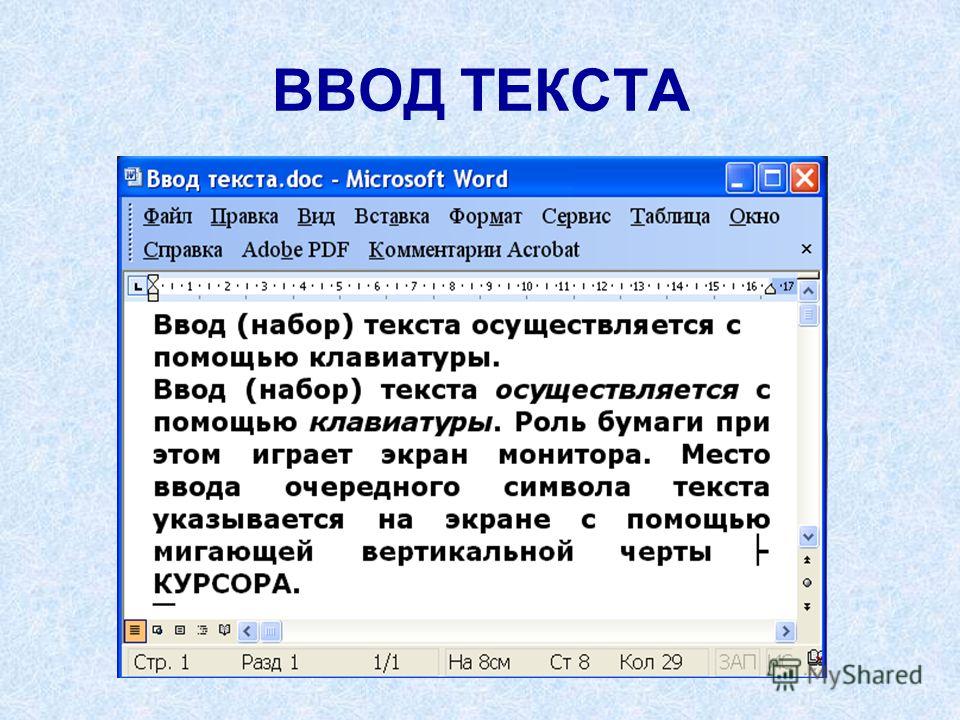
Интерфейс текстового редактора
(1) — меню текстового редактора. На панели под ним кнопками (2) — (11) продублированы самые востребованные команды. Кроме того, при нажатии правой кнопки мыши появляется всплывающее меню для вставки картинки, ссылки или таблицы.
Под полем ввода расположена панель (12), на которой отображаются теги и атрибуты HTML — разметки в соответствии с расположением курсора в тексте.
Кнопки
(2) — отменть и вернуть изменения. Им соответствуют комбинации клавиш Ctrl + Z и Ctrl + Y.
(3) — формат. Это выпадающий список всех стилей для текста, картинок и таблиц сайта. Стили определяются в соответствии с утвержденным дизайном.
(4) — кнопки позволяют сделать выделенный текст жирным, курсивом или подчеркнутым.
(5) — кнопки для выравнивания текста в абзаце: влево, по центру, вправо и по ширине блока.
(6) — по нажатию первой и второй кнопок блока выделенные абзацы примут вид маркированного списка. Вид маркеров — стандартный или в виде цифр. Третья кнопка — отмена форматирования.
На сайте могут использоваться несколько видов списков с различными маркеами. В этом случае, после назначения они допределяются с помощью списка стилей (3).
(7) — кнопка с выпадаюшим меню для вставки и редактирования таблиц.
(8) — вставка ссылок.
(9) — вставки картинок в текст и изменение их размера
(10) — переключение в полноэкранный режим редактирования статьи.
(11) — режим редактирования страницы в виде HTML-разметки.
Перечисленные кнопки дублируют пункты меню (1). Их функции более подробно рассмотрены далее в описании меню.
Набор и вставка текста
Текстовый редактор имеет два режима ввода текста:
- ввод в режиме форматирования
- ввод в виде HTML-разметки.
Кнопка «Исходный код» (11) на панели инструментов редактора осуществляет переключение в режим HTML — разметки.

Основныес действия с текстом сгруппированы в разделе меню «Изменить», им соответствуют «горячие клавиши»:
Выделить все — Ctrl + A
Скопировать — Ctrl + C
Вставить— Ctrl + V
Вырезать— Ctrl + X
а также команды отменть и вернуть изменения — Ctrl + Z / Ctrl + Y. Они дублируются кнопками (2) (см. рисунок выше).
Если вы скопируете текст из MS Word и вставите его в редактируемую статью, то html-код вашей страницы будет перегружен большим количеством служебной информации, добавляемой MS Word, при этом стили текста могут отображаться некорректно. Чтобы очистить код статьи от служебных тегов MS Word, необходимо использовать специальную команду «Изменить/Вставить как текст».
Вставка графики, ссылок и шаблонов
Пункты раздела меню «Вставить » позволяют добавить в верстку страницы:
— видео
— фотографии (9)
— горизонтальные линии для разделения блоков текста.
Установите курсор в место вставки и выберите нужный пункт меню. В появившемся окне заполните поля. (Более подробно о вставке картинок)
Установка ссылок (8) и якорей (ссылка н определенное место веб-страницы) также доступны в этом разделе меню. (Подробнее об установке ссылок)
Если дизайн страницы сайта предполагает сложную верстку, можно использовать шаблоны (заготовки из текстов, таблиц и картинок с HTML-разметкой). Для вставки шаблона выберите пункт меню, в появившемся диалоговом окне укажите нужный шаблон в выпадающем списке.
Вид
Пункты меню позволяют показывать блоки, невидимые символы и контуры, а также переключать редактор в полноэкранный режим (10) (см. рисунок выше). Этот режим удобен для верстки объемных статей. В этом режиме прокрутка текста — с помощью клавиатуры, а панель с кнопками всегда вверху экрана.
Формат
Дизайн сайта предусматривает использование единых стилей оформления для всех страниц сайта. Для корректного отображения информации и картинок необходимо правильно проставить стили текста, таблиц и графики.
Для корректного отображения информации и картинок необходимо правильно проставить стили текста, таблиц и графики.
Форматирование текста
Стили текста включают стиль заголовков, абзаца статьи, маркированных списков. Чтобы правильно оформить текст выбирайте в списке «Формат» любой из утвержденных стилей. Стиль присваивается абзацу.
Иногда требуется выделить несколько слов в статье. С помощью кнопок (4) или команд мею Вы можете присвоить выделенному фрагменту текста различные начертания (жирный, курсив, зачеркнутый, нижний/верхний индекс).
Для абзацев можно изменить выравнивание с помощью кнопок на панели (5) (см. рисунок выше)
Кроме того, можно внести любые изменения в оформление статьи в режиме редактирования текста в виде HTML-разметки.
Очистить формат
Если вы вставляете текст из MS Word или др., то стили текста могут отображаться некорректно. Нужно убрать служебные теги MS Word из кода статьи командой «Очистить формат», а затем продолжить форматирование.
Нужно убрать служебные теги MS Word из кода статьи командой «Очистить формат», а затем продолжить форматирование.
Посмотреть результат форматирования
Зафиксируйте изменения кнопкой «Применить» (если вы еще работаете со статьей ) или «Сохранить и закрыть». После сохранения перейдите на веб-сайт и обновите страницу (Ctrl+R).
Стили для картинок
При обычной вставке растровой графики (без присвоения класса CSS) по умолчанию картинка выравнивается влево и текстом не обтекается. Чтобы присвоить стиль кпртинке, нужно ее выделить и выбрать нужный из списка «Формат».
Таблицы
Вставка таблицы происходит по щелчку в панели, определяющей количество строк и столбцов.
После этого таблице можно присвоить стиль или задать размер ячеек и другие параметры. (Подробнее о работе с таблицами).
Меню по работе с таблицей появляется такде при нажатии правой кнопки мыши или кнопки (7) (см.
ДЛЯ УТОЧНЕНИЯ ДЕТАЛЕЙ
свяжитесь с нами по телефону 8 800 511-06-40
или по электронной почте:
[email protected]
5 лайфхаков в Figma для работы с текстом, картинками и заливкой / Skillbox Media
Дизайн
#Руководства
- 0
Рассказываем, как использовать математику в Figma, сделать из картинки заливку и включить пиксельное отображение вектора.
Vkontakte Twitter Telegram Скопировать ссылкуВячеслав Лазарев
Редактор. Пишет про дизайн, редактирует книги, шутит шутки, смотрит аниме.
Пишет про дизайн, редактирует книги, шутит шутки, смотрит аниме.
В Figma есть множество скрытых функций и горячих клавиш, которые самостоятельно найти не так просто. Но если их освоить, вы сможете ускорить работу над макетом: быстрее менять все цвета или сбрасывать настройки шрифта.
Рассказываем о пяти простых лайфхаках, которые помогут вам быстрее работать в Figma.
Если вы не смогли сразу настроить интерлиньяж текстовой строки и решили оставить его стандартным, просто удалите своё значение из поля ввода. Figma автоматически вернёт значение по умолчанию, и вам не придётся подбирать его заново.
Самостоятельно сместить какой-либо объект на один пиксель или на 1% — не всегда просто.
Таким образом можно изменить размер объекта, его расположение и непрозрачность. Математический расчёт работает во всех полях, где нужно вводить числа.
Если в Figma вы рисуете векторное изображение, которое потом хотите использовать как растровое, его внешний вид важно заранее проверить. Чтобы лишний раз не выгружать картинку и не редактировать её наугад, воспользуйтесь пиксельным режимом. В нём Figma будет отображать все объекты в растровом формате, и вы сможете заранее понять, как будут выглядеть мелкие детали вашего изображения.
Чтобы включить пиксельный режим просмотра, нажмите сочетание клавиш Ctrl + Alt + Y (на macOS — Ctrl + Y). Либо нажмите на иконку , затем View и выберите Pixel Preview.
Если вы не использовали стили при проектировании приложения, а клиент попросил поменять оттенок красного, то не нужно сразу бросаться и перекрашивать каждый макет. Просто выделите их, и на панели настроек появится список используемых цветов, которые можно поменять.
Кстати, в этом же меню из любого цвета можно сделать стиль.
Обычно в Figma стили делают из простых цветов либо градиентов. То же самое можно сделать с обычными картинками и использовать их как заливку любых фреймов, фигур или даже текста.
Как добавить изображение в стили
- Добавьте на макет любое изображение и выделите его.
- Перейдите в пункт Fill («Заливка») и нажмите на иконку .
- В появившемся меню нажмите на плюсик.
- Назовите стиль и сохраните.
- Чтобы использовать стиль, в пункте Fill нажмите на иконку из кружков и выберите нужный шаблон. Стиль можно выбрать и для обводки в пункте Stroke — он находится под Fill.

Больше о Figma
Самоучитель по Figma
Самые полные и полезные инструкции, которые помогут вам освоить все функции графического редактора.
Vkontakte Twitter Telegram Скопировать ссылку
Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать
Научитесь: Figma с нуля до PRO Узнать большеГазировка 7Up обновила айдентику впервые за семь лет 17 фев 2023
Японское искусство оригами вдохновило дизайнеров на создание модульного дивана 16 фев 2023
Турецкий художник точно и выразительно проиллюстрировал трагедию 16 фев 2023
Понравилась статья?
Да
Связывание изображений и текста с помощью OpenAI CLIP | Андре Рибейро
Что такое CLIP и как им пользоваться
Фото Мартен Ньюхолл из Unsplash. Несмотря на то, что глубокое обучение произвело революцию в компьютерном зрении и обработке естественного языка, использование современных современных методов по-прежнему сложно и требует достаточного опыта.
Подходы OpenAI, такие как Contrastive Language-Image Pre-Training (CLIP)¹, направлены на уменьшение этой сложности, что позволяет разработчикам сосредоточиться на практических случаях.
CLIP — это нейронная сеть, обученная на большом наборе (400 М) пар изображений и текста. Как следствие этого многомодального обучения, CLIP можно использовать для поиска фрагмента текста, который лучше всего представляет данное изображение, или наиболее подходящего изображения для заданного текстового запроса.
Это особенно делает CLIP невероятно полезным для стандартного поиска изображений и текста.
CLIP был обучен таким образом, что по изображению он предсказывает, с каким из 32768 случайно выбранных текстовых фрагментов изображение было связано с набором обучающих данных. Идея состоит в том, что для решения задачи модель должна изучить несколько понятий из изображения.
Этот подход значительно отличается от классических задач с изображениями, где модель обычно требуется для идентификации класса из большого набора классов (например, ImageNet).
Таким образом, CLIP совместно обучает кодировщик изображений (например, ResNet50) и кодировщик текста (например, BERT) для прогнозирования правильного сочетания пакета изображений и текста.
Оригинальная иллюстрация обучения CLIP (1) и обучения с нулевым выстрелом (2) (3), доступная в документе Learning Transferable Visual Models From Natural Language Supervision. (1) Фрагменты изображения и текста обрабатываются и кодируются в N-мерный вектор. Модель обучается, минимизируя косинусное расстояние между правильной парой изображение-текст (N реальных пар) и максимизируя косинусное расстояние между неправильными парами (N²-N). (2) Чтобы использовать модель CLIP для нулевого обучения, значения класса кодируются в текстовых фрагментах. (3) Вложения текста для каждого значения класса сравниваются с вложениями изображений и ранжируются по сходству. Подробное описание см. в документе CLIP². Если нужно использовать модель для классификации, кодировщик текста может внедрить классы и сопоставить их с изображением. Этот процесс обычно называют обучением с нулевым выстрелом.
Этот процесс обычно называют обучением с нулевым выстрелом.
В следующих разделах объясняется, как настроить CLIP в Google Colab и как использовать CLIP для поиска изображений и текста.
Установка
Чтобы использовать CLIP, нам сначала нужно установить набор зависимостей. Чтобы облегчить это, мы собираемся установить их через Conda. Кроме того, Google Colab будет использоваться для упрощения репликации.
- Откройте Google Colab
Откройте следующий URL-адрес в браузере: https://research.google.com/colaboratory/
Затем щелкните ссылку NEW PYTHON 3 NOTEBOOK внизу страницы. экран.
Как вы, наверное, заметили, интерфейс ноутбука аналогичен тому, который предоставляет Jupyter. Существует окно кода, в котором вы должны ввести свой код Python.
2. Проверьте Python в Colab
Чтобы установить правильную версию Conda для работы с Colab, нам сначала нужно узнать, какую версию Python использует Colab. Для этого в первой ячейке colab введите
Для этого в первой ячейке colab введите
Это должно вернуть что-то вроде
/usr/local/bin/python
Python 3.7.10
/miniconda/
Затем скопируйте имя версии miniconda, соответствующее основной версии Python, указанной в выводе выше. Версия miniconda должна выглядеть примерно так: Miniconda3-py{VERSION}-Linux-x86_64.sh.
Наконец, введите следующий фрагмент в новую ячейку colab, убедившись, что переменная conda_version задана правильно.
Еще раз подтвердите, что основная версия Python осталась прежней
Это должно вернуть что-то вроде
/usr/local/bin/python
Python 3.7.10
4. Установить CLIP + зависимости
Conda должна быть хорошо настроены сейчас. Следующим шагом является установка зависимостей модели CLIP (pytorch, torchvision и cudatoolkit) с помощью Conda, после чего следует установка самой библиотеки CLIP.
Для этого скопируйте следующий фрагмент в Colab.
Этот шаг может занять некоторое время, так как необходимые библиотеки велики.
5. Добавьте путь conda к sys
Последним шагом перед использованием CLIP является добавление пути conda site-packages к sys. В противном случае установленные пакеты могут быть неправильно определены в среде Colab.
Текст и изображение
Теперь наша среда готова к использованию.
- Импорт модели CLIP
Чтобы использовать CLIP, начните с импорта необходимых библиотек и загрузки модели. Для этого скопируйте следующий фрагмент в Colab.
Это должно показать что-то похожее на показанное ниже, указывающее, что модель была загружена правильно.
100%|█████████████████████████████████████| 354M/354M [00:11<00:00, 30,1МиБ/с]
2. Извлечь вложения изображений
Теперь давайте протестируем модель, используя следующий пример изображения
Изображение Артема Беляйкина из Pexels Для этого, скопируйте следующий фрагмент в Colab. Этот код сначала загрузит изображение с помощью PIL, а затем предварительно обработает его с помощью модели клипа.
Это должно отображать образец изображения, за которым следует обработанный тензор изображения.
Форма тензора:
torch.Size([1, 3, 224, 224])
Функции изображения теперь можно извлечь, вызвав метод encode_image из модели клипа следующим образом
Это должно вернуть функции изображения tensor size
torch.Size([1, 512])
3. Извлеките вложения текста
Создадим набор фрагментов текста, в которые встраиваются разные значения класса следующим образом: #СОРТ#".
Затем мы можем запустить токенизатор клипов для предварительной обработки фрагментов.
Это должно вернуть форму тензора текста
torch.Size([3, 77])
Текстовые функции теперь можно извлечь, вызвав метод 'encode_text' из модели клипа следующим образом
4. Сравните встраивание изображения и встраивание текста
Поскольку теперь у нас есть встраивание изображения и текста, мы можем сравнить каждую комбинацию и ранжировать их в соответствии с их сходством.
Для этого мы можем просто вызвать модель для обоих вложений и вычислить softmax.
Это должно вернуть следующий вывод.
Label probs: [[0.9824866 0.00317319 0.01434022]]
Как и ожидалось, мы можем наблюдать, что фрагмент текста «фотография собаки» имеет наибольшее сходство с образцом изображения.
Теперь вы можете сделать текстовые запросы более контекстными и посмотреть, как они сравниваются. Например, если вы добавите «фото собаки, бегущей по травяному полю», как вы представляете, как теперь будет выглядеть рейтинг?
Полный сценарий
Чтобы получить полный сценарий, перейдите на мою страницу github по этой ссылке:
andreRibeiro1989/medium
clip_getting_started.ipynb.
github.com
Или перейдите непосредственно в блокнот Google Colab, перейдя по этой ссылке:
Google Colaboratory
clip_getting_started.ipynb
colab.research.google.com
чрезвычайно мощный и мощный модель встраивания текста, которую можно использовать для поиска фрагмента текста, который лучше всего представляет данное изображение (например, в классической задаче классификации) или наиболее подходящего изображения для заданного текстового запроса (например, поиск изображения).
CLIP не только мощный, но и исключительно простой в использовании. Эту модель можно легко встроить в API и сделать доступной, например, через лямбда-функцию AWS.
[1] Опенай. « CLIP: соединение текста и изображений »
https://openai.com/blog/clip/#rf36
[2] Алек Рэдфорд, Чон Вук Ким, Крис Халласи и др. « Изучение переносимых визуальных моделей на основе наблюдения за естественным языком »
arXiv: 2103.00020
Лучшее совместное представление изображения и текста
Компьютерное зрение
Два метода, представленные на CVPR, достигают передовых результатов за счет наложения дополнительной структуры на репрезентативное пространство.
Лицюнь Чен
1 июля 2022 г.
В этом году команда Amazon Search приняла две статьи, принятые на конференции по компьютерному зрению и распознаванию образов (CVPR), обе посвящены выравниванию изображений и текста или обучению нейронной сети совместному представлению изображений и связанного с ними текста. Такие представления полезны для ряда задач компьютерного зрения, включая текстовый поиск изображений и текстовый поиск на основе изображений.
Такие представления полезны для ряда задач компьютерного зрения, включая текстовый поиск изображений и текстовый поиск на основе изображений.
Как правило, совместные модели изображения и текста обучаются с использованием контрастного обучения, при котором модели подаются обучающие образцы парами, один положительный и один отрицательный, и она учится объединять положительные примеры в пространстве представления и сталкивать положительные и отрицательные примеры отдельно. Так, например, модель может быть обучена на изображениях с парами связанных текстовых меток, одна правильная метка и одна случайная метка, и научиться связывать изображения с правильными метками в общем мультимодальном репрезентативном пространстве.
Обе наши статьи CVPR основаны на одном и том же наблюдении: простое обеспечение соответствия между различными модальностями с сильным контрастным обучением может привести к вырождению изученных признаков. Чтобы решить эту проблему, в наших статьях исследуются различные способы наложения дополнительной структуры на репрезентативное пространство, чтобы модель обучалась более надежному выравниванию изображения и текста.
Кодовые книги представлений
Нейронная сеть, обученная на мультимодальных данных, будет естественным образом группировать данные одного типа вместе в репрезентативном пространстве. сопутствующие тексты.
Новый подход к выравниванию изображения и текста рассматривает изображение и текст как два «представления» одного и того же объекта и использует кодовую книгу кластерных центров, чтобы охватить совместное пространство кодирования языка и зрения.
Для борьбы с этой тенденцией в разделе «Мультимодальное выравнивание с использованием кодовой книги представлений» мы предлагаем выравнивать изображение и текст на более высоком и стабильном уровне, используя кластерное представление. В частности, мы рассматриваем изображение и текст как два «представления» одного и того же объекта и используем кодовая книга кластерных центров, чтобы охватить совместное пространство кодирования языка и зрения. То есть каждый центр закрепляет группу связанных понятий, независимо от того, выражены ли эти понятия визуально или текстуально.
Во время обучения мы сравниваем положительные и отрицательные образцы с помощью их кластерных назначений, одновременно оптимизируя центры кластеров. Чтобы еще больше сгладить процесс обучения, мы принимаем парадигму дистилляции учитель-ученик, в которой выходные данные модели учителя обеспечивают учебные цели для модели ученика. В частности, мы используем выходные данные модели для одного представления — изображения или текста — чтобы помочь учащимся изучить другое. Мы оценили наш подход на общих эталонных тестах языка зрения и получили новый уровень техники для поиска кросс-модальности с нулевым выстрелом или поиска текста на основе изображений и поиска изображений на основе текста на типах данных, невидимых во время обучения. Наша модель также конкурентоспособна в других задачах передачи.
Обзор подхода репрезентативной кодовой книги. Для простоты показана только одна пара «ученик-учитель» (учитель для изображения, ученик для текста).
Тройное контрастивное обучение
Успех контрастивного обучения в обучении моделей выравнивания изображения и текста объясняется его способностью максимизировать взаимную информацию между парами изображения и текста или степенью, в которой особенности изображения могут быть предсказаны по характеристикам текста и наоборот.
Однако простое выполнение кросс-модального выравнивания (CMA) игнорирует потенциально полезные корреляции внутри каждой модальности. Например, хотя CMA отображает пары изображение-текст близко друг к другу в пространстве встраивания, он не может гарантировать, что аналогичные входные данные из одной и той же модальности останутся близко друг к другу. Эта проблема может усугубиться, если данные предварительной подготовки зашумлены.
В «Предварительном обучении зрительному языку с тройным контрастивным обучением» мы решаем эту проблему, используя тройное контрастивное обучение (TCL) для предварительного обучения зрительному языку. Этот подход использует как кросс-модальные, так и внутримодальные самоконтроль или обучение задачам, устроенным так, что они не требуют помеченных обучающих примеров. Помимо CMA, TCL вводит внутримодальную контрастную цель, чтобы обеспечить дополнительные преимущества в обучении репрезентации.
Слева (A) — архитектура модели с тремя функциями потерь (LMI, IMC и CMA). Справа (B) показана мотивация тройной контрастной потери. Добавление внутримодальных контрастных (IMC) потерь позволяет модели изучить более разумное вложение (синий квадрат) .
Справа (B) показана мотивация тройной контрастной потери. Добавление внутримодальных контрастных (IMC) потерь позволяет модели изучить более разумное вложение (синий квадрат) .
Чтобы воспользоваться преимуществами локализованной и структурной информации из изображения и текста, TCL дополнительно максимизирует среднюю взаимную информацию между локальными областями изображения/текста и их глобальной сводкой. Насколько нам известно, это первая работа, в которой учитывается информация о локальной структуре для обучения мультимодальному представлению. Экспериментальные оценки показывают, что наш подход является конкурентоспособным и достигает нового уровня техники в различных общих последующих задачах языка видения, таких как поиск изображения-текста и визуальные ответы на вопросы.
Об авторе
Лицюнь Чен
Лицюнь Чен — ученый-прикладник из группы Amazon Search.
Senior Data Scientist
Amazon стремится стать самой клиентоориентированной компанией в мире. Цель команды JP Last Mile Technology Team состоит в том, чтобы превзойти ожидания наших клиентов, гарантируя, что их заказы, независимо от того, насколько они велики или малы, будут доставлены максимально быстро, точно и с минимальными затратами. Для достижения этой цели Amazon постоянно стремится вводить новшества и предоставлять лучший в своем классе опыт доставки за счет внедрения новаторских новых продуктов и услуг в сфере доставки «последней мили». Технологическая группа JP Last Mile ищет старшего специалиста по обработке и анализу данных, который будет разрабатывать, пропагандировать и внедрять современные решения для никогда ранее не решаемых проблем, помогая пространству «последней мили» в Токио, Япония. В качестве старшего специалиста по данным вы будете тесно сотрудничать с другими учеными-исследователями, экспертами по машинному обучению и экономистами по всему миру, разрабатывая и проводя эксперименты, исследуя новые алгоритмы и находя новые способы улучшения аналитики последней мили для оптимизации обслуживания клиентов. Вы будете сотрудничать с лидерами в области технологий и продуктов для решения деловых и технологических проблем, используя научные подходы для создания новых услуг, которые удивят и порадуют наших клиентов. Наука в Amazon — это в высшей степени экспериментальная деятельность, хотя теоретический анализ и инновации также приветствуются. Наши ученые тесно сотрудничают с инженерами-программистами, чтобы применить алгоритмы на практике. Они также работают над междисциплинарными усилиями с другими учеными Amazon по всему миру. *Дополнительная информация [Отдел] https://www.amazon.co.jp/b?node=5637343051 [Аналитик данных/Инженер] https://www.amazon.co.jp/b?node=5609906051 [Местоположение] https://www.amazon.co.jp/b?node=5589794051 *Amazon стремится к созданию разнообразной и инклюзивной рабочей среды. Amazon является работодателем с равными возможностями и не допускает дискриминации по признаку расы, национального происхождения, пола, гендерной идентичности, сексуальной ориентации, защищенного статуса ветерана, инвалидности, возраста или другого защищенного законом статуса.
Вы будете сотрудничать с лидерами в области технологий и продуктов для решения деловых и технологических проблем, используя научные подходы для создания новых услуг, которые удивят и порадуют наших клиентов. Наука в Amazon — это в высшей степени экспериментальная деятельность, хотя теоретический анализ и инновации также приветствуются. Наши ученые тесно сотрудничают с инженерами-программистами, чтобы применить алгоритмы на практике. Они также работают над междисциплинарными усилиями с другими учеными Amazon по всему миру. *Дополнительная информация [Отдел] https://www.amazon.co.jp/b?node=5637343051 [Аналитик данных/Инженер] https://www.amazon.co.jp/b?node=5609906051 [Местоположение] https://www.amazon.co.jp/b?node=5589794051 *Amazon стремится к созданию разнообразной и инклюзивной рабочей среды. Amazon является работодателем с равными возможностями и не допускает дискриминации по признаку расы, национального происхождения, пола, гендерной идентичности, сексуальной ориентации, защищенного статуса ветерана, инвалидности, возраста или другого защищенного законом статуса. Для лиц с ограниченными возможностями, которые хотели бы запросить приспособление, посетите веб-сайт https://www.amazon.jobs/disability/jp Основные должностные обязанности Ключевые стратегические цели для этой должности включают: Понимание движущих сил, воздействий и ключевых факторов, влияющих на доставку последней мили динамика. Масштабируйте действия, чтобы предлагать клиентам низкие цены и расширенный выбор, используя научно обоснованные методы и принятие решений. Помощь в создании производственных систем, которые получают данные из нескольких моделей и принимают решения в режиме реального времени. Автоматизация циклов обратной связи для алгоритмов в производстве. Разработайте исходные данные и предположения на основе ранее существовавших моделей для оценки затрат и возможностей экономии, связанных с различными уровнями роста и эксплуатации сети. Использование систем и инструментов Amazon для эффективной работы с терабайтами данных. О команде Команда JP по аналитике выполнения последней мили (LMEA) работает как неотъемлемая часть Amazon Logistics, чтобы гарантировать, что ее бизнес-аналитика, аналитика, инструменты и потребности в планировании удовлетворены.
Для лиц с ограниченными возможностями, которые хотели бы запросить приспособление, посетите веб-сайт https://www.amazon.jobs/disability/jp Основные должностные обязанности Ключевые стратегические цели для этой должности включают: Понимание движущих сил, воздействий и ключевых факторов, влияющих на доставку последней мили динамика. Масштабируйте действия, чтобы предлагать клиентам низкие цены и расширенный выбор, используя научно обоснованные методы и принятие решений. Помощь в создании производственных систем, которые получают данные из нескольких моделей и принимают решения в режиме реального времени. Автоматизация циклов обратной связи для алгоритмов в производстве. Разработайте исходные данные и предположения на основе ранее существовавших моделей для оценки затрат и возможностей экономии, связанных с различными уровнями роста и эксплуатации сети. Использование систем и инструментов Amazon для эффективной работы с терабайтами данных. О команде Команда JP по аналитике выполнения последней мили (LMEA) работает как неотъемлемая часть Amazon Logistics, чтобы гарантировать, что ее бизнес-аналитика, аналитика, инструменты и потребности в планировании удовлетворены. Предоставляя информацию, идеи и поддержку в принятии решений, мы стремимся обеспечить успех всех компонентов Amazon Logistics. Наш набор клиентов включает в себя высшее руководство, операции на станциях, внешних поставщиков, долгосрочное планирование, технологию эксплуатации (голос станции доставки, голос клиента), сетевое планирование и почти все группы бизнес-аналитики и эксплуатации в Amazon Logistics.
Предоставляя информацию, идеи и поддержку в принятии решений, мы стремимся обеспечить успех всех компонентов Amazon Logistics. Наш набор клиентов включает в себя высшее руководство, операции на станциях, внешних поставщиков, долгосрочное планирование, технологию эксплуатации (голос станции доставки, голос клиента), сетевое планирование и почти все группы бизнес-аналитики и эксплуатации в Amazon Logistics.
Специалист по обработке и анализу данных, аналитика выполнения последней мили (LMEA)
Команда Amazon Logistics (AMZL) отвечает за приобретение, проектирование, строительство и управление всеми объектами в сети станций доставки Amazon. AMZL ищет талантливого и увлеченного специалиста по данным, который поможет сформировать свой бизнес «последней мили» с помощью технических стратегий и решений, обрабатывая, анализируя и интерпретируя огромные наборы данных. Вам должно быть удобно справляться с двусмысленностью, решать проблемы и получать удовольствие от работы в динамичной, разнообразной и динамичной среде. Используя аналитическую строгость и статистические методы, вы анализируете данные, чтобы определить возможности для Amazon и наших каналов доставки. И вы сотрудничаете с другими учеными, инженерами, менеджерами по продуктам и программам для развертывания новых продуктов и решений. [Дополнительная информация] Аналитик данных отдела последней мили/инженер бизнес-аналитики Офис в Токио *Amazon стремится к разнообразию и инклюзивности рабочего места. Amazon является работодателем с равными возможностями и не допускает дискриминации по признаку расы, национального происхождения, пола, гендерной идентичности, сексуальной ориентации, защищенного статуса ветерана, инвалидности, возраста или другого защищенного законом статуса. Для лиц с ограниченными возможностями, которые хотели бы запросить приспособление, посетите страницу https://www.amazon.jobs/disability/jp Основные должностные обязанности Создание дорожной карты наиболее сложных бизнес-вопросов и использование данных для формулирования возможного анализа основных причин и решений Управление и выполнение целых проектов или компонентов крупных проектов от начала до конца, включая управление проектами, сбор и обработку данных, синтез и моделирование, решение проблем и передачу идей Партнерство с командами по продуктам, программам и инженерам для разработки и запуска моделей, исследования новых алгоритмов , а также доказать инкрементальность и стимулировать рост.
Используя аналитическую строгость и статистические методы, вы анализируете данные, чтобы определить возможности для Amazon и наших каналов доставки. И вы сотрудничаете с другими учеными, инженерами, менеджерами по продуктам и программам для развертывания новых продуктов и решений. [Дополнительная информация] Аналитик данных отдела последней мили/инженер бизнес-аналитики Офис в Токио *Amazon стремится к разнообразию и инклюзивности рабочего места. Amazon является работодателем с равными возможностями и не допускает дискриминации по признаку расы, национального происхождения, пола, гендерной идентичности, сексуальной ориентации, защищенного статуса ветерана, инвалидности, возраста или другого защищенного законом статуса. Для лиц с ограниченными возможностями, которые хотели бы запросить приспособление, посетите страницу https://www.amazon.jobs/disability/jp Основные должностные обязанности Создание дорожной карты наиболее сложных бизнес-вопросов и использование данных для формулирования возможного анализа основных причин и решений Управление и выполнение целых проектов или компонентов крупных проектов от начала до конца, включая управление проектами, сбор и обработку данных, синтез и моделирование, решение проблем и передачу идей Партнерство с командами по продуктам, программам и инженерам для разработки и запуска моделей, исследования новых алгоритмов , а также доказать инкрементальность и стимулировать рост. Понимание движущих сил, воздействий и ключевых факторов, влияющих на динамику роста продаж. Разработка и масштабирование сквозных моделей и решений машинного обучения. Автоматизация циклов обратной связи для алгоритмов в производстве. Использование систем и инструментов Amazon для эффективной работы с терабайтами данных. О команде Команда Last Mile Execution Analytics (LMEA) компании JP работает как инте важной частью Amazon Logistics, чтобы гарантировать, что ее бизнес-аналитика, аналитика, инструменты и потребности в планировании будут удовлетворены. Предоставляя информацию, понимание и поддержку принятия решений, мы стремимся обеспечить успех всех частей AMZL. Наш набор клиентов включает в себя высшее руководство, операции станции, внешних поставщиков, долгосрочное планирование, технологию эксплуатации (голос станции доставки, голос клиента), планирование сети и почти все команды бизнес-аналитики и эксплуатации. Голос сотрудника [Гармония трудовой и личной жизни] Мы считаем, что важно проводить личное время, например, проводить время с семьей или делать все, что вам нравится, чтобы стимулировать инновации.
Понимание движущих сил, воздействий и ключевых факторов, влияющих на динамику роста продаж. Разработка и масштабирование сквозных моделей и решений машинного обучения. Автоматизация циклов обратной связи для алгоритмов в производстве. Использование систем и инструментов Amazon для эффективной работы с терабайтами данных. О команде Команда Last Mile Execution Analytics (LMEA) компании JP работает как инте важной частью Amazon Logistics, чтобы гарантировать, что ее бизнес-аналитика, аналитика, инструменты и потребности в планировании будут удовлетворены. Предоставляя информацию, понимание и поддержку принятия решений, мы стремимся обеспечить успех всех частей AMZL. Наш набор клиентов включает в себя высшее руководство, операции станции, внешних поставщиков, долгосрочное планирование, технологию эксплуатации (голос станции доставки, голос клиента), планирование сети и почти все команды бизнес-аналитики и эксплуатации. Голос сотрудника [Гармония трудовой и личной жизни] Мы считаем, что важно проводить личное время, например, проводить время с семьей или делать все, что вам нравится, чтобы стимулировать инновации.