Java или C++ для базы данных
Мне дана курсовая работа по предмету базы данных, и у меня стоит вопрос: при помощи какого языка реализовать задачу C++ или Java. Я владею основами C++, но в дальнейшем хочу перейти на Java и собственно хочу сейчас начать изучения этого языка и для более лучшего изучения реализовать проект.
Вот в чем суть вопроса, хочу услышать ваше мнение, стоит ли мне писать базу данных на Java и хватит ли мне ~3-х месяцев для реализации этого проекта на незнакомом языке или же эта задача требует неплохого знания Java, и мне стоит перестраховаться и писать на знакомом C++?
И второй вопрос: на чем нынче более актуально и какой язык более подходит для цели написания базы даных Java или C++?
- java
- c++
- sql
Если Вы хотите использовать Java в будущем — пишите на Java. Java — очень мощный язык и позволяет решить практически любую задачу. Если вы переходите на джаву с С++, позволю дать несколько советов (как человек, который сам совершил такой переход несколько лет назад).
- Хотите, чтобы в голове прояснилась философия джавы — прочитайте книжку с одноименным названием авторства Брюса Эккеля. Именно она дала мне фундаментальные знания языка. Сделайте это перед тем, как писать код (потратите неделю, но затем потратите меньше времени на исправление косяков).
- Джава обладает очень мощной стандартной библиотекой. Если вам нужен какой-то велосипед — поищите его вначале в библиотеке, а затем уже в других местах.
- Не верьте никому, что джава обладает плохой производительностью, надежностью и т.д. Так говорят только люди, незнающие ее. Джава — очень мощный язык, позволяющий делать удивительные вещи.
- Программируйте, больше программируйте. 3 месяца программирования по 3 часа в день дадут вам колоссальный опыт, который вы не приобретете на лекциях и читая книги.
@RandomGuest, раз
Написать новую СУБД
тогда, видимо (исходя из ~3 мес.), Вы должны сосредоточиться на «внутренностях», т.е. том, что называют физической организацией и API для основных операций с этим уровнем.
Тут Вы будете должны довольно тесно взаимодействовать с ОС для эффективной работы с файлами.
IMHO в подобной ситуации на первом этапе не стоит стремиться к системонезависимым решениям (но, держать это в уме, разрабатывая иерархию функций, без сомнения, стоит), поэтому с++ (или чистый си) представляется более хорошим выбором.
Не думаю, чтобы целью тривиальной курсовой работы была разработка новой СУБД. 🙂
Скорее всего, речь идет о написании какого-то решения с использованием существующей СУБД для работы с данными в рамках проекта.
- Хотите учить Java — учите её. Проект это хорошая практика, даже если вы его завалите (что вряд ли, хороших студентов часто вытаскивают), у вас будет опыт, который пригодится в реальной жизни.
- За 3 месяца вы Java хорошо не выучите. Впрочем, и C++ тоже. Java учится легче.
- Если вы делаете что-то с прицелом на будущее, возможно вам нужен фреймворк наподобие Hibernate.
 (Найдите и почитайте, готовьтесь к массивам англоязычного текста.) Вообще, Java вся про фреймворки, вам придётся выучить их много.
(Найдите и почитайте, готовьтесь к массивам англоязычного текста.) Вообще, Java вся про фреймворки, вам придётся выучить их много. - Мне кажется, Java больше подходит для баз данных. (Но я могу ошибаться, я не большой специалист в ней.) Но вы должны выбирать не по этому критерию, а по критерию «пригодится или нет в будущем». Если вы хотите изучать Java, а ваша тема курсовой не подходит, поменяйте тему курсовой. Плевать, что вы типа писали её с начала года, практика важнее.
Для написания СУБД преимущественно используются Си и в некоторых моментах могут подключать С++. Даже такие любители Java, как Oracle и IBM, написали свои СУБД на Си + С++. Это обусловлено требованиями, которые предъявлены к СУБД: много I/O операций, большие объемы данных в оперативной памяти и операции с ними, и главное, это все должно быть максимально быстрым.
Но, я думаю, Вы не собираетесь писать СУБД для реального использования с учетом всех особенностей и требований к ним, поэтому язык Вам тут будет совершенно неважен. Можете выбрать как Java, так и C++, особой разницы быть не должно. Какие-то глубокие познания языка тут не нужны, скорее нужно хорошее понимание, как функционирует СУБД и какие компоненты она содержит.
Можете выбрать как Java, так и C++, особой разницы быть не должно. Какие-то глубокие познания языка тут не нужны, скорее нужно хорошее понимание, как функционирует СУБД и какие компоненты она содержит.
И я бы на вашем месте уточнил задачу по вопросу @avp, чтобы обойтись без: «Написать новую СУБД, как я понимаю«.
Мне дана курсовая работа по предмету базы данных, и у меня стоит вопрос: при помощи какого языка реализовать задачу C++ или Java.
Напиши курсовую сначала на С++, а потом на Java — повысишь уровень знания C++ и Java, поймёшь преимущества и недостатки языков, изучишь их работу с базой данных… короче, серьёзно повысишь свой скилл…
1Для СУБД главный показатель — быстрота выполнения запросов. Посмотрите, на чем написаны самые известные SQL и NoSQL СУБД — в основном там будет С, С++, иногда что-то еще более низкоуровневое. Джава, при всех её достоинствах, не самый быстрый язык, и СУБД на джаве не была бы слишком востребована.
Зарегистрируйтесь или войдите
Регистрация через Google Регистрация через Facebook Регистрация через почтуОтправить без регистрации
ПочтаНеобходима, но никому не показывается
Отправить без регистрации
ПочтаНеобходима, но никому не показывается
By clicking “Отправить ответ”, you agree to our terms of service and acknowledge that you have read and understand our privacy policy and code of conduct.
Работа с базами данных
- Подключаемся к базе данных
- Создаем базу данных с помощью isql
- Firebird SQL
Подключаемся к базе данных
В директории examples Вашей
инсталляции Firebird лежит образец базы данных — employee., которую можно использовать «для
пробы пера». fdb
fdb
Имя сервера и путь
Если Вы вдруг решили переместить образец базы данных на другой диск, убедитесь, что он физически подключен к компьютеру. Разделяемые (shared), присоединенные (mapped) диски или (на Unix) смонтированные (mounted) SMB (Samba) файловые системы не будут работать. Это правило касается любых создаваемых Вами баз данных.
При использовании TCP/IP строка подключения состоит из двух частей: имя сервера и путь к файлу. Формат строки имеет следующий вид:
Для Linux-серверов:
имя-сервера:/путь-к-файлу/имя-файла-базы-данных
Пример для Linux или другой Posix-системы с именем
serverxyz:serverxyz:/opt/interbase/examples/employee. fdb
fdbДля Windows-серверов:
имя-сервера:буква-диска:\путь-к-файлу\имя-файла-базы-данных
Пример для Windows:
serverxyz:C:\Program Files\Firebird\examples\employee.fdb
Оператор CONNECT
Для подключения к базе данных Firebird пользователь должен
аутентифицироваться с использованием имени пользователя и правильного
пароля. Кроме того, любому пользователю отличному от SYSDBA, root (Posix — системы), или Administrator (на Windows-системах, если
Firebird запущен от имени этого пользователя) необходимо иметь
разрешения на доступ к объектам внутри самой базы данных (так
называемые объектные привилегии).
masterkey.Используем isql
Существует несколько способов подключения к базе данных с
использованием утилиты isql. Один из них
— это использование isql в интерактивном
режиме. Перейдите в подкаталог bin директории, в которой установлена
Ваша версия Firebird, и в командной строке наберите isql (для Linux: ./isql) [↵
означает «нажать клавишу Enter»]:
C:\Program Files\Firebird\Firebird_1_5\bin>isql↵ Use CONNECT or CREATE DATABASE to specify a database SQL>CONNECT "C:\Program Files\Firebird\Firebird_1_5\examples\employee.fdb"↵ CON>user 'SYSDBA' password 'masterkey';↵
Важно
В isql каждое SQL-выражение должно завершаться точкой с запятой. Если строка не заканчивается точкой с запятой, и Вы нажимаете клавишу Enter, isql будет считать, что выражение будет продолжаться на следующей строке и сменит приглашение с
SQL>наCON>. Это позволяет разбивать длинные выражения на несколько строк. Если Вы нажали клавишу Enter, забыв указать точку с запятой, просто наберите символ после приглашения и нажмите Enter ещё раз.
Если, используя Classic Server под Linux, не указать имя хоста, будет предпринята попытка организовать прямое локальное соединение. Что, в свою очередь, может закончиться неудачей в случае отсутствия у текущей учетной записи Linux необходимых прав доступа к файлу базы данных. В этом случае попробуйте подключиться к
localhost:/<path>. В этом случае файл будет открывать серверный процесс (который в Firebird 1.5 обычно работает от имениfirebird). С другой стороны, попытка сетевого соединения может закончиться неудачно, если пользователь создавал базу данных при локальном подключении и у сервера нет необходимых прав.
В случае использования Classic Server под Windows, Вы должны указывать имя хоста (это может быть
localhost) и полный путь, в противном случае подключиться не получиться.
Замечание
Несмотря на то, что в Firebird «нормальными»
символами разделения строк являются одинарные кавычки, в примере,
при указании пути к базе данных, использовались двойные кавычки.
Это необходимо, так же как и в некоторых других утилитах командной
строки, при указании путей, содержащих пробелы. Одинарные кавычки
будут работать для путей, не содержащих пробелы.
Одинарные кавычки
будут работать для путей, не содержащих пробелы.
Кавычки вокруг «SYSDBA» и «masterkey» необязательны. Также не обязательно заключать в кавычки путь к базе данных, не содержащий пробелов.
Далее isql сообщит о том, что Вы подключились:
DATABASE "C:\Program Files\Firebird\Firebird_1_5\examples\employee.fdb", User: sysdba SQL>
Теперь Вы можете продолжить эксперименты с базой employee.fdb. isql означает interactive SQL [utility] (интерактивный SQL).
Вы можете использовать её для извлечения данных, получения
метаинформации, создания объектов базы данных, запуска скриптов и
многого другого.
Для того, чтобы вернуться в командную строку наберите
SQL>QUIT;↵
За дополнительной информацией об использовании isql обращайтесь к Using Firebird, глава 10: Interactive SQL Utility (isql).
Используем графические утилиты
Обычно, графические средства самостоятельно собирают строку соединения на основании информации, вводимой пользователем в отдельных полях — имя сервера, путь к базе данных, имя пользователя и пароль. Как их использовать должны быть понятно из информации, изложенной в предыдущем разделе.
Замечание
Существуют средства, в которых имя сервера + полный путь ожидаются в виде одной строки
Помните, что на Linux и других Posix-системах имена файлов и названия команд являются чувствительными к регистру
Создаем базу данных с помощью isql
Утилита isql позволяет создавать базы
данных более, чем одним способом. Мы же рассмотрим простой способ
создания базы данных в интерактивном режиме, хотя для серьезного
использования Вам, скорее всего, потребуется научиться создавать и
использовать скрипты. В руководстве Using
Firebird имеется отдельная глава, посвященная этому
вопросу.
Мы же рассмотрим простой способ
создания базы данных в интерактивном режиме, хотя для серьезного
использования Вам, скорее всего, потребуется научиться создавать и
использовать скрипты. В руководстве Using
Firebird имеется отдельная глава, посвященная этому
вопросу.
Запускаем isql
Для создания базы данных с использованием утилиты
isql в интерактивном режиме, в командной
строке перейдите в директорию bin и наберите isql (Windows) или ./isql (Linux):
C:\Program Files\Firebird\Firebird_1_5\bin>isql↵ Use CONNECT or CREATE DATABASE to specify a database
Оператор CREATE DATABASE
Теперь Вы можете создать базу данных. Предположим, что Вы хотите
создать базу данных test. и сохранить её в
папке  fdb
fdbdata на диске D:
SQL>CREATE DATABASE 'D:\data\test.fdb' page_size 8192↵ CON>user 'SYSDBA' password 'masterkey';↵
Важно
В отличии от оператора CONNECT, в операторе CREATE DATABASE кавычки вокруг пути к файлу, имени пользователя и пароля являются обязательными.
Если Вы используете Classic Server под Linux и в пути не указываете имя хоста, будет произведена попытка создать файл базы данных с Вашей учетной записью в Linux в качестве владельца.
 Может быть это именно то, что Вы и хотите, а может и
нет (подумайте о правах доступа, если Вы хотите, чтобы к базе
данных мог подключаться кто-то еще). Если же в пути указать,
например,
Может быть это именно то, что Вы и хотите, а может и
нет (подумайте о правах доступа, если Вы хотите, чтобы к базе
данных мог подключаться кто-то еще). Если же в пути указать,
например, localhost:, тогда создавать и влдаеть файлом будет серверный процесс (который в Firebird 1.5 обычно работает от имениfirebird).В случае использования Classic Server под Windows, Вы должны указывать имя хоста (которое может быть
localhost) плюс полный путь к файлу, в противном случае процесс создания закончится неудачей.
Будет создана база данных и через некоторое время вновь появится приглашение SQL. Теперь Вы подключены к новой базе данных и можете создать какие-нибудь объекты в ней.
Чтобы убедиться, что там действительно база данных, выполните запрос:
SQL>SELECT * FROM RDB$RELATIONS;↵
На экран будет выдано большое количество данных! Этот запрос извлекает все строки из системной таблицы, в которой Firebird хранит метаданные для таблиц. «Пустая» база данных на самом деле не очень-то и пустая – она содержит базу данных, которая будет расти, наполняясь метаданными, по мере создания Вами новых объектов в ней.
Для возвращения в командную строку, наберите
SQL>QUIT;↵
За дополнительной информацией об isql обращайтесь к
главе 10 Using Firebird: Interactive SQL Utility (isql).
Firebird SQL
Каждая систем управления базами данных имеет свои отличительные особенности в реализации SQL. По сравнению с любой другой СУБД, за возможным исключением «близкой родственницы» — InterBase®, Firebird наиболее строгим образом соответствует стандарту SQL. Разработчики, переходящие с других продуктов, соответствующих стандарту в меньшей степени, ошибочно воспринимают Firebird странным, притом, что многие мнимые «странности» на самом деле не являются таковыми.
Деление целых чисел
В соответствии со стандартом SQL, Firebird при вычислении
частного от деления целого числа на целое округляет результат до
ближайшего меньшего целого. В случае если Вы не были готовы, это может
слегка шокировать Вас при получении результатов.
Например, следующее вычисление является корректным с точки зрения SQL:
1 / 3 = 0
Если Вы переходите с СУБД, в которой частное от деления целого на другое целое приводится к нецелому, Вам будет необходимо доработать подобные выражения и заменить тип делимого, делителя или обоих на число с плавающей или фиксированной точкой.
Например, предыдущий пример, для получения результата отличного от нуля, можно изменить следующим образом:
1.000 / 3 = 0.333
Что следует знать о строках
Разделительный символ строк
В Firebird строки отделяются парными символами одинарных
кавычек – 'Замечательная строка' – (ASCII код —
39, не 96). Если Вы использовали предыдущие
версии предшественницы Firebird, InterBase®, Вы можете вспомнить,
что там символы одинарных и двойных кавычек использовались
одновременно как разделители строк. В Firebird двойные кавычки не
могут использоваться в качестве разделителей строк в SQL
выражениях.
Если Вы использовали предыдущие
версии предшественницы Firebird, InterBase®, Вы можете вспомнить,
что там символы одинарных и двойных кавычек использовались
одновременно как разделители строк. В Firebird двойные кавычки не
могут использоваться в качестве разделителей строк в SQL
выражениях.
Апострофы в строках
Если Вам необходимо использовать в строке символ апострофа, Вы можете «экранировать» (escape) его, предварив его другим апострофом.
Например, следующая строка приведет к ошибке:
'Joe's Emporium'
потому, что анализатор проинтерпретирует текст как строку 'Joe', за которой следуют какие-то неизвестные
ключевые слова.
Чтобы сделать строку правильной, необходимо добавить второй апостроф:
'Joe''s Emporium'
Обратите внимание на то, что это ДВА символа одинарной кавычки, а не символ двойных кавычек.
Конкатенация строк
В SQL для конкатенации строк используются два символа
«трубы» (ASCII 124, в паре без пробела между ними). При
этом «+» является символом арифметического сложения,
соответственно, при попытке его использования для объединения строк,
вы получите сообщение об ошибке. Следующее выражение дополняет
значения столбца фразой «Reported by: »:
'Reported by: ' || LastName
Будьте внимательны с конкатенацией и учтите, что Firebird
выдаст сообщение об ошибке при попытке соединения значений двух или
более столбцов типа char или varchar, чья суммарная потенциальная
длина превышает предельный размер для строковых типов (32
Kb).
Кроме этого обратите внимание на нижеизложенный раздел NULL в выражениях относительно конкантенации в выражениях,
содержащих NULL.
Идентификаторы в двойных кавычках
До выхода стандарта SQL-92, не допускалось использовать в качестве имен объектов (идентификаторов) ключевые слова, не учитывался регистр букв и не допускались пробельные символы. Стандарт SQL-92 сделал всё это возможным, определив, что идентификаторы должны определяться в парных двойных кавычках (ASCII код — 34) и при использовании также должны выделяться парными кавычками.
Смысл этого «подарка» заключался в упрощении
процесса миграции метаданных из нестандартных СУБД в совместимые со
стандартом. Обратная сторона медали заключается в том, что если Вы
решаете использовать идентификаторы в двойных кавычках, их
чувствительность к регистру и заключение их в двойные кавычки
становятся обязательными.
Обратная сторона медали заключается в том, что если Вы
решаете использовать идентификаторы в двойных кавычках, их
чувствительность к регистру и заключение их в двойные кавычки
становятся обязательными.
При выполнении ограниченного набора условий, Firebird предлагает определенное послабление. Если идентификатор, определенный в двойных кавычках:
был определен в верхнем регистре,
не совпадает с ключевым словом,
и не содержит пробелов,
…тогда он может использоваться в SQL-выражениях без кавычек
и учета регистра символов. (Однако, если Вы заключаете идентификатор
в кавычки, Вы должны снова учитывать регистр символов!)
(Однако, если Вы заключаете идентификатор
в кавычки, Вы должны снова учитывать регистр символов!)
Внимание
Не перемудрите с этим делом! Например, если у Вас есть таблицы «TESTTABLE» и «TestTable», определенные в двойных кавычках , и Вы выполняете запрос вида:
SQL>select * from TestTable;
…в результате Вы получите записи из таблицы «TESTTABLE», а не «TestTable»!
Обычно, рекомендуется, в случае отсутствия убедительных
причин, избегать использования двойных кавычек при определении
идентификаторов. К счастью, Firebird позволяет одновременно
использовать идентификаторы в кавычках и без них – поэтому не бывает
проблем в случае необходимости использования ключевых слов в
качестве идентификаторов в унаследованных базах данных.
Внимание
Некоторые инструменты администрирования по умолчанию принудительно заключают в двойные кавычки все идентификаторы. Постарайтесь выбрать средство, которое позволяет делать это опционально.
NULL в выраженияхВ SQL, NULL — это не значение. Это условие,
или состояние, элемента данных, в котором его
значение не известно, в связи с этим NULL не
может выступать в качестве значения. Если NULL участвует в арифметических или других выражениях, результат всегда
будет NULL. Это не нуль, не пустота (пробел) или
«пустая строка» и NULL не ведет себя
как одно из этих значений.
Приведем некоторые, возможно «удивительные» для
Вас, примеры вычислений и сравнений с участием NULL:
1 + 2 + 3 +NULL=NULLnot (NULL) =NULL'Home ' || 'sweet ' ||NULL=NULLif (a = b) then MyVariable = 'Equal'; else MyVariable = 'Not equal';
Если и
aиb—NULL— то после выполнения данного кода, значениеMyVariableбудет'Not equal'(не равны). Потому что результат вычисления
выражения
Потому что результат вычисления
выражения 'a = b'будетNULL, если хотя бы один из операндов будетNULL. Соответственно, в контексте этого «if...then»,NULLведет себя какFALSE, блок ‘then‘ пропускается и выполняется блок ‘else‘.if (a <> b) then MyVariable = 'Not equal'; else MyVariable = 'Equal';
В этом примере,
MyVariableбудет иметь значение'Equal'(равны), еслиa—NULL, аb— нет, или наоборот. Объяснение аналогично
предыдущему случаю.
Объяснение аналогично
предыдущему случаю.FirstName || ' ' || LastName
в результате даст
NULL, если хотя быFirstNameилиLastName—NULL.
Подсказка
Воспринимайте NULL как НЕИЗВЕСТНО и ощущения странности результатов
пропадут! Если значение Number не известно, то
результат ‘1 + 2 + 3 + Number‘ так же получается
не известным (и поэтому NULL). Если содержимое MyString не известно, тогда не известен результат
конкатенации ‘MyString || YourString‘
(даже если YourString не-NULL) и т. д.
д.
Подробнее о
NULL.Больше информации об особенностях NULL можно найти в руководстве NULL в
СУБД Firebird, доступном по адресу:
языковой агностик — Внедрение базы данных — С чего начать
Поскольку принятый ответ предлагает только (хорошие) ссылки на другие ресурсы, я решил поделиться своим опытом написания webdb, небольшой экспериментальной базы данных для браузеров. Я также приглашаю вас прочитать исходный код. Он довольно маленький. Вы должны быть в состоянии прочитать его и получить общее представление о том, что он делает за пару часов. Предупреждение : Я ноль в этом, и с тех пор, как я это написал, я узнал об этом намного больше и вижу, что делаю некоторые вещи неправильно. Тем не менее, это может помочь вам начать.
Я начал с адаптации дерева AVL в соответствии со своими потребностями. Дерево AVL — это разновидность самобалансирующегося бинарного дерева поиска. Вы сохраняете ключ K и связанные данные (если есть) в узле, затем все элементы с ключом
Дерево AVL — это разновидность самобалансирующегося бинарного дерева поиска. Вы сохраняете ключ K и связанные данные (если есть) в узле, затем все элементы с ключом < K в узле в левом поддереве и все элементы с ключом > K в правом поддерево. Вы можете использовать массив для хранения элементов данных, если хотите поддерживать неуникальные ключи.
Это дерево даст вам основы: Создать , Обновить , Удалить и способ быстро получить элемент по ключу или все элементы с ключом < x или с ключом между x и y и т. д. Он может служить индексом для нашей таблицы.
В качестве следующего шага я написал код, который позволяет клиентскому коду определять схему. Такие методы, как createTable() и т. д. Схемы обычно связаны с SQL, но даже не-SQL имеет схему; они обычно требуют, чтобы вы отметили поле идентификатора и любые другие поля, по которым вы хотите выполнить поиск. Вы можете сделать свою схему настолько причудливой, насколько хотите, но обычно вы хотите смоделировать, по крайней мере, какие столбцы служат первичным ключом и какие поля будут часто выполняться и нуждаются в индексе.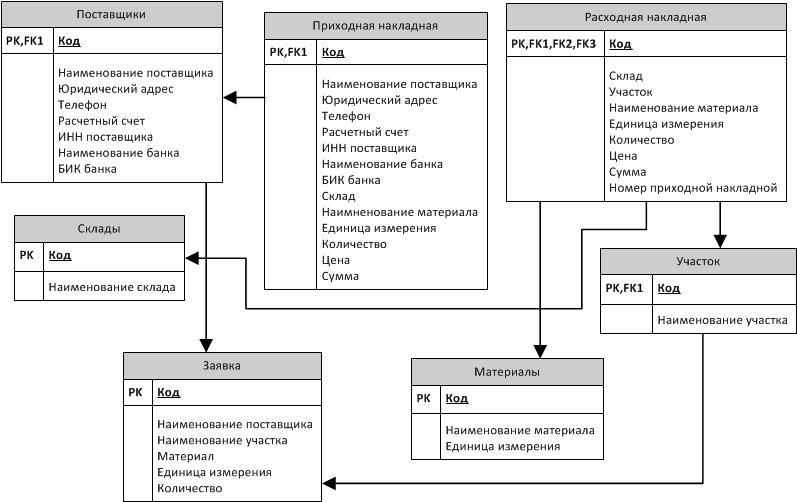
Я решил использовать созданное на первом этапе дерево для хранения своих предметов. Это были простые объекты JS. Определив, какое поле содержит PK, я мог бы просто вставить элемент в дерево, используя значение этого поля в качестве ключа. Это дает мне быстрый поиск по идентификатору (диапазон).
Затем я добавил еще одно дерево для каждого столбца, которому нужен индекс. В этих деревьях я хранил не полную запись, а только ключ. Таким образом, чтобы получить клиента по фамилии, я бы сначала использовал индекс по фамилии, чтобы получить идентификатор, а затем индекс первичного ключа, чтобы получить фактическую запись. Причина, по которой я не просто сохранил (ссылку на) фактический объект, заключается в том, что это немного упрощает операции над множествами (см. следующий шаг)
Теперь, когда у нас есть таблица с индексами для PK и полей поиска, мы можем реализовать запросы. Я не заходил слишком далеко, так как это быстро усложняется, но вы можете получить хорошую функциональность, используя только некоторые основы. WebDB не реализует соединения; все запросы работают только с одной таблицей. Но как только вы это поймете, вы увидите довольно четкий (хотя и длинный и извилистый) путь к выполнению объединений и других сложных вещей.
WebDB не реализует соединения; все запросы работают только с одной таблицей. Но как только вы это поймете, вы увидите довольно четкий (хотя и длинный и извилистый) путь к выполнению объединений и других сложных вещей.
В WebDB, чтобы получить всех клиентов с firstName = 'John' и city = 'Нью-Йорк' (при условии, что это два поля поиска), вы должны написать что-то вроде:
var webDb = ...
var johnsFromNY = webDb.customers.get({
имя: 'Джон',
город: "Нью-Йорк"
})
Чтобы решить эту проблему, мы сначала делаем два поиска: мы получаем набор X всех идентификаторов клиентов с именем «Джон» и мы получаем набор Y всех идентификаторов клиентов из Нью-Йорка. Затем мы выполняем пересечение этих двух наборов, чтобы получить все идентификаторы клиентов с именами «Джон» 9.0004 И из Нью-Йорка. Затем мы проходим через наш набор полученных идентификаторов, получая фактическую запись для каждого из них и добавляя ее в массив результатов.
Используя операторы множества, такие как объединение и пересечение, мы можем выполнять поиск И и ИЛИ . Я реализовал только И .
Выполнение соединений будет (я думаю) включать создание временных таблиц в памяти, затем их заполнение по мере выполнения запроса объединенными результатами, а затем применение критериев запроса к временной таблице. Я так и не попал туда. Затем я попытался использовать некоторую логику синхронизации, но это было слишком амбициозно, и дальше все пошло под откос 🙂
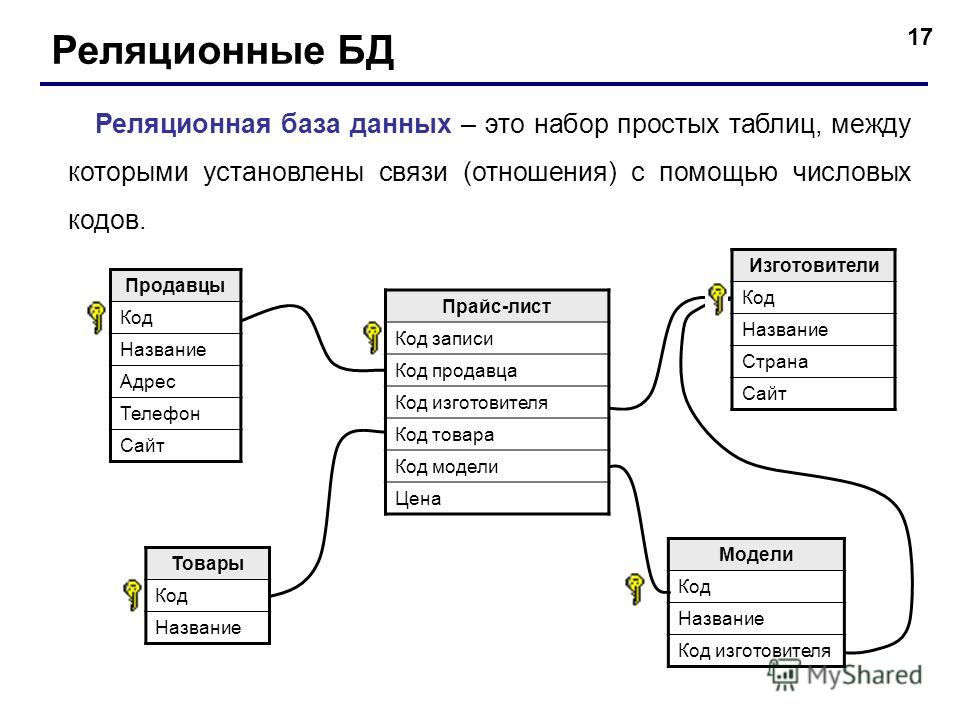
c++ - В какой момент стоит использовать базу данных?
спросил
Изменено 4 года, 4 месяца назад
Просмотрено 4к раз
У меня вопрос по базам данных и в какой момент стоит углубляться в них.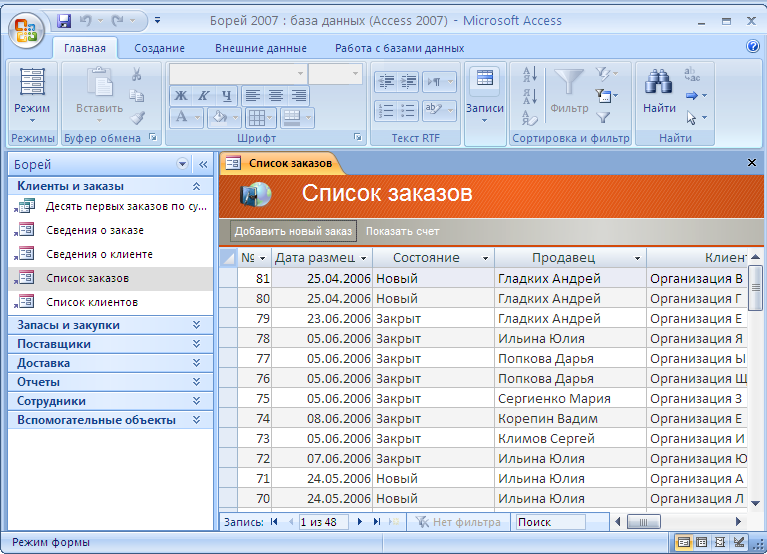 Я прежде всего инженер по встраиваемым системам, но я пишу приложение, использующее Qt для взаимодействия с нашим контроллером.
Я прежде всего инженер по встраиваемым системам, но я пишу приложение, использующее Qt для взаимодействия с нашим контроллером.
Мы находимся в странной точке, когда у нас достаточно данных, чтобы можно было внедрить базу данных (около 700+ элементов и пополняется), чтобы управлять всем, но я не уверен, что сейчас стоит тратить на это время. У меня нет проблем с реализацией графического интерфейса с файлами, сгенерированными из Excel и проанализированными, но это становится утомительным и трудным для отслеживания даже с помощью скриптов VBA. Я экспериментировал с преобразованием наших данных во что-то более управляемое для приложения с помощью Microsoft Access, и, похоже, это работает хорошо. Если это сработает, я всего в одном шаге (или нескольких) от использования базы данных SQL и использования библиотеки Qt для доступа и изменения ее.
У меня нет большого опыта управления данными на этом уровне, и мне любопытно, как лучше всего подойти к этому. Итак, каковы некоторые из реальных преимуществ использования базы данных в этом случае? Я понимаю, что многое из этого может быть очень специфичным для приложения, но некоторые общие идеи и предложения о том, как охватить линию встроенного/прикладного программирования, были бы полезны.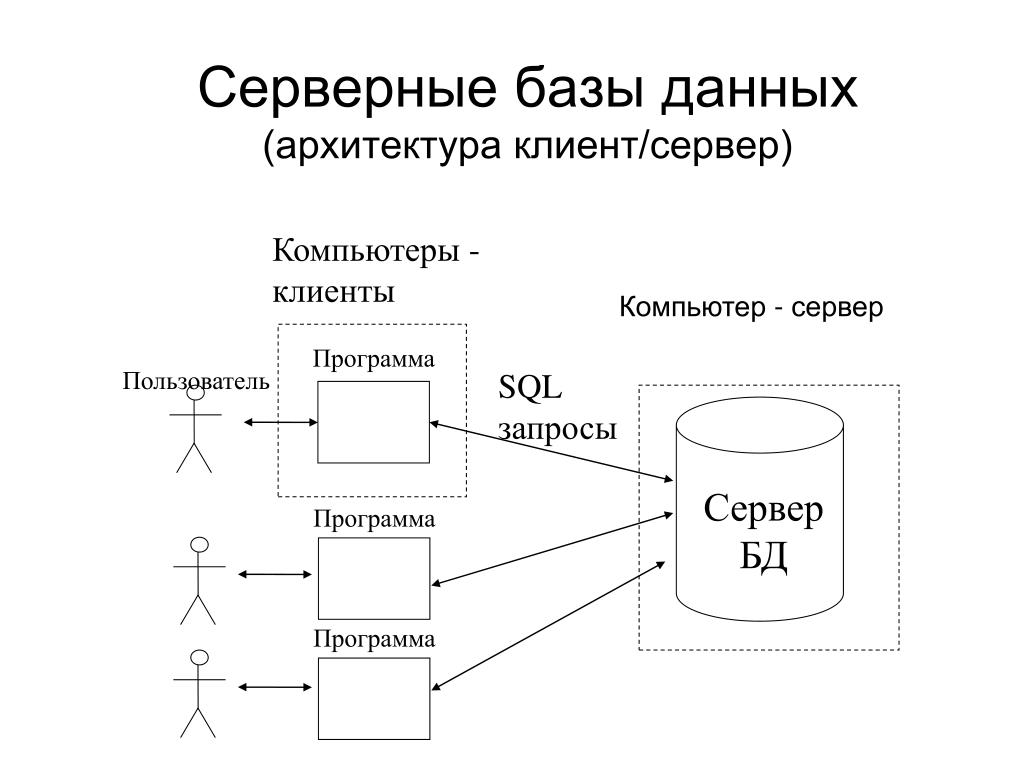
Речь не идет о размещении базы данных во встроенном проекте. Это также не бизнес-приложение, в котором обычно используются большие базы данных. Я разрабатываю графический интерфейс для одного пользователя на рабочем столе для взаимодействия с микроконтроллером для целей мониторинга и настройки.
Я решил использовать SQLite. Вы можете делать очень интересные вещи с данными, которые я не рассматривал при первом запуске этого проекта.
- c++
- sql
- база данных
- qt
- пользовательский интерфейс
База данных имеет смысл, когда:
- Ваше приложение развивается до некоторых форма исполнения, управляемого данными.
- Вы тратите время на проектирование и разработка внешнего хранилища данных структуры.
- Обмен данными между приложениями или организации (в том числе индивидуальные человек)
- Данные больше не являются короткими и
простой.
- Дублирование данных
Эволюция к выполнению, управляемому данными
Когда данные меняются, а выполнение нет, это признак управляемой данными программы или частей программы, управляемых данными. Набор опций конфигурации является признаком функции, управляемой данными, но все приложение может не управляться данными. В любом случае база данных может помочь в управлении данными. (Библиотека базы данных или приложение не обязательно должны быть огромными, как Oracle, но могут быть компактными и средними, как SQLite).
Проектирование и разработка внешних структур данных
Отправка вопросов в Stack Overflow о сериализации или преобразовании деревьев и списков для использования файлов является хорошим признаком того, что ваша программа перешла на использование базы данных. Кроме того, если вы тратите какое-то количество времени на разработку алгоритмов для хранения данных в файле или на разработку данных в файле, самое время изучить использование базы данных.
Совместное использование данных
Независимо от того, обменивается ли ваше приложение данными с другим приложением, другой организацией или другим лицом, база данных может помочь. При использовании базы данных легче достичь согласованности данных. Одна из больших проблем при расследовании проблем заключается в том, что команды используют разные данные. Клиент может использовать один набор данных; группа проверки — другая, а разработка — с использованием другого набора данных. База данных упрощает управление версиями данных и позволяет объектам использовать одни и те же данные.
Комплексные данные
Программы начинаются с использования небольших таблиц жестко запрограммированных данных. Это приводит к использованию динамических данных с картами, деревьями и списками. Иногда данные расширяются от простых двух столбцов до 8 и более. Теория баз данных и базы данных могут упростить организацию данных. Пусть база данных заботится об управлении данными и освобождает ваше приложение и время разработки. В конце концов, способ управления данными не так важен, как качество данных и их доступность.
В конце концов, способ управления данными не так важен, как качество данных и их доступность.
Дублирование данных
Часто, когда объем данных увеличивается, постоянно растет привлекательность дублирующихся данных. Базы данных и теория баз данных могут свести к минимуму дублирование данных. Базы данных можно настроить так, чтобы они предупреждали о дублировании.
При переходе к использованию базы данных необходимо учитывать множество факторов. Некоторые из них включают, но не ограничиваются: сложность данных, дублирование данных (включая части данных), сроки проекта, затраты на разработку и вопросы лицензирования. Если ваша программа может работать более эффективно с базой данных, сделайте это. База данных также может сэкономить время разработки (и деньги). Существуют и другие задачи, которые вы и ваше приложение можете выполнять помимо управления данными. Оставьте управление данными экспертам.
2 То, что вы описываете, не похоже на типичное бизнес-приложение, и многие из ответов, уже опубликованных здесь, предполагают, что это именно то приложение, о котором вы говорите, поэтому позвольте мне предложить другую точку зрения.
Будете ли вы использовать базу данных для 700 элементов, будет сильно зависеть от характера данных.
Я бы сказал, что примерно в 90% случаев при таком масштабе вы будете пользоваться облегченной базой данных, такой как SQLite, при условии, что:
- Данные потенциально могут вырасти значительно больше, чем вы описываете,
- Данные могут использоваться несколькими пользователями,
- Возможно, вам потребуется выполнить запросы к данным (что, я думаю, вы сейчас не делаете), и
- Данные можно легко описать в виде таблицы.
В остальных 10 % случаев ваши данные будут сильно структурированы, иерархичны, основаны на объектах и не вписываются в табличную модель базы данных или таблицы Excel. В этом случае рассмотрите возможность использования XML-файлов.
Я знаю, что разработчики инстинктивно любят использовать базы данных для решения подобных проблем, но если вы в настоящее время используете данные Excel для разработки пользовательских интерфейсов (или отображения параметров конфигурации), а не для отображения записей о клиентах, XML может подойти лучше. XML более выразителен, чем Excel или таблицы базы данных, и им легко манипулировать с помощью простого текстового редактора.
XML более выразителен, чем Excel или таблицы базы данных, и им легко манипулировать с помощью простого текстового редактора.
Синтаксические анализаторы XML и связыватели данных для C++ легко найти.
Я рекомендую вам ввести базу данных в ваше приложение, ваше приложение станет более гибким, его будет легче поддерживать и улучшать с помощью новых функций в будущем.
Я бы начал с облегченной файловой базы данных, такой как Sqlite.
С хорошо спроектированной базой данных вы получите:
- Уменьшенную избыточность данных
- Повышение целостности данных
- Повышенная безопасность данных
И последнее, но не менее важное: использование базы данных избавит вас от ада импорта/обновления/экспорта Excel !
Причины использования базы данных:
- Одновременная запись. Достичь параллелизма в базах данных легко
- Простой запрос. SQL-запросы, как правило, намного короче, чем процедурный код для поиска данных.
 ОБНОВЛЕНИЯ, INSERT INTO также могут делать много вещей с очень небольшим количеством кода
ОБНОВЛЕНИЯ, INSERT INTO также могут делать много вещей с очень небольшим количеством кода - Целостность. Ограничения очень легко определить, и они применяются без написания кода. Если у вас есть ненулевое ограничение, вы можете быть уверены, что значение не будет нулевым, и не нужно никуда писать проверки. Если у вас есть ограничение внешнего ключа, у вас не будет «висячих ссылок».
- Производительность для больших наборов данных. Индексацию очень просто добавить в базу данных SQL
Причины отказа от использования базы данных:
- Это дополнительная зависимость (хотя существуют очень легкие базы данных — например, мне нравится h3 для Java)
- Данные плохо подходят для реляционной схемы. Вещи, которые в основном являются картами ключ/значение. XML (хотя базы данных часто поддерживают XPath и т. д.).
- Иногда файлы удобнее. Их можно сравнивать, объединять, редактировать с помощью обычного текстового редактора и т. д. Иногда электронные таблицы могут быть более практичными (вам не нужно создавать редактор — вы можете использовать программу для работы с электронными таблицами)
- Ваши данные уже где-то
Когда у вас много данных, и вы не знаете, как они будут использоваться в будущем.
Например, вы можете добавить базу данных SQLite во встроенное приложение, которое должно регистрировать статистические данные, которые вы не знаете, как они будут использоваться. Позже вы отправляете полную базу данных для внедрения в более крупную базу данных, работающую на центральном сервере, и эти данные можно легко использовать с помощью запросов.
На самом деле, если целью вашего приложения является "сбор данных", то база данных просто необходима.
1Я вижу довольно много требований, которым хорошо отвечают базы данных:
1). Специальные запросы. Найдите мне все {X}, соответствующие критериям Y
2). Данные со структурой, которая может выиграть от нормализации — выделения общих значений в отдельные «таблицы». Таким образом вы можете сэкономить место и уменьшить вероятность несогласованности. Как только вы это сделаете, эти специальные запросы станут действительно полезными.
3). Большие объемы данных. Профессиональные базы данных очень хорошо используют ресурсы, умную оптимизацию запросов и стратегии пейджинга. Попытка написать этот материал самостоятельно — настоящий вызов.
Профессиональные базы данных очень хорошо используют ресурсы, умную оптимизацию запросов и стратегии пейджинга. Попытка написать этот материал самостоятельно — настоящий вызов.
Последнее тебе явно не нужно, но два других, возможно, тебе подходят.
Не забывайте, что соответствующая база данных может быть совершенно другой в зависимости от ваших требований (и не забывайте, что текстовый файл может использоваться в качестве базы данных, если ваши требования достаточно просты - например, файлы конфигурации просто определенный тип базы данных). Такими параметрами могут быть:
- количество записей
- размер элементов данных
- нужно ли совместно использовать базу данных с другими устройствами? Одновременно?
- насколько сложны отношения между различными фрагментами данных
- база данных доступна только для чтения (например, создается во время сборки и не изменяется)?
- нужно ли одновременно обновлять базу данных несколькими объектами?
- вам нужна поддержка сложных запросов?
Для базы данных с 700 записями вполне может подойти отсортированный в памяти массив, загруженный из текстового файла. Но я также вижу потребность во встроенной базе данных SQL или, возможно, в том, чтобы контроллер запрашивал данные из базы данных по сетевому соединению, в зависимости от различных требований (и ограничений ресурсов).
Но я также вижу потребность во встроенной базе данных SQL или, возможно, в том, чтобы контроллер запрашивал данные из базы данных по сетевому соединению, в зависимости от различных требований (и ограничений ресурсов).
Нет определенной точки, в которой база данных стоит. Вместо этого я обычно задаю следующие вопросы:
- Растет ли объем данных, которые использует/создает приложение?
- Верхний предел роста данных неизвестен (или не ясен)?
- Нужно ли приложению собирать или фильтровать эти данные?
- Могут ли данные использоваться в будущем, которые сейчас не очевидны?
- Важна ли производительность извлечения и/или хранения данных?
- Есть ли (или могут быть) несколько пользователей приложения, которые обмениваются данными?
Если я отвечаю «Да» на большинство этих вопросов, я почти всегда выбираю базу данных (в отличие от других вариантов, таких как XML/ini/CSV/Excel/текстовые файлы или файловая система).
Кроме того, если у приложения будет много пользователей, которые могут одновременно обращаться к данным, я склоняюсь к полному серверу базы данных (MySQL, SQl Server, Oracle и т. д.).
д.).
Но часто в ситуации с одним пользователем (или небольшим параллелизмом) локальная база данных, такая как SQLite, не может быть лучше переносимости и простоты развертывания.
Чтобы добавить минус: не подходит для обработки в реальном времени из-за недетерминированной задержки. Однако этого вполне достаточно для поиска и настройки рабочих параметров, например, во время запуска. Я бы не стал помещать доступ к базе данных в критические временные пути.
Вам не нужна база данных, если у вас есть несколько тысяч строк в одной или двух таблицах для обработки в одном пользовательском приложении (для встроенной точки).
Если это для нескольких пользователей (одновременный доступ, блокировка) или необходимость транзакций, вам определенно следует рассмотреть базу данных. Обработка сложных структур данных в нормализованных таблицах и поддержание целостности или огромный объем данных будут еще одним признаком того, что вам следует использовать базу данных.
Похоже, ваше приложение работает на настольном компьютере и просто обменивается данными со встроенным устройством.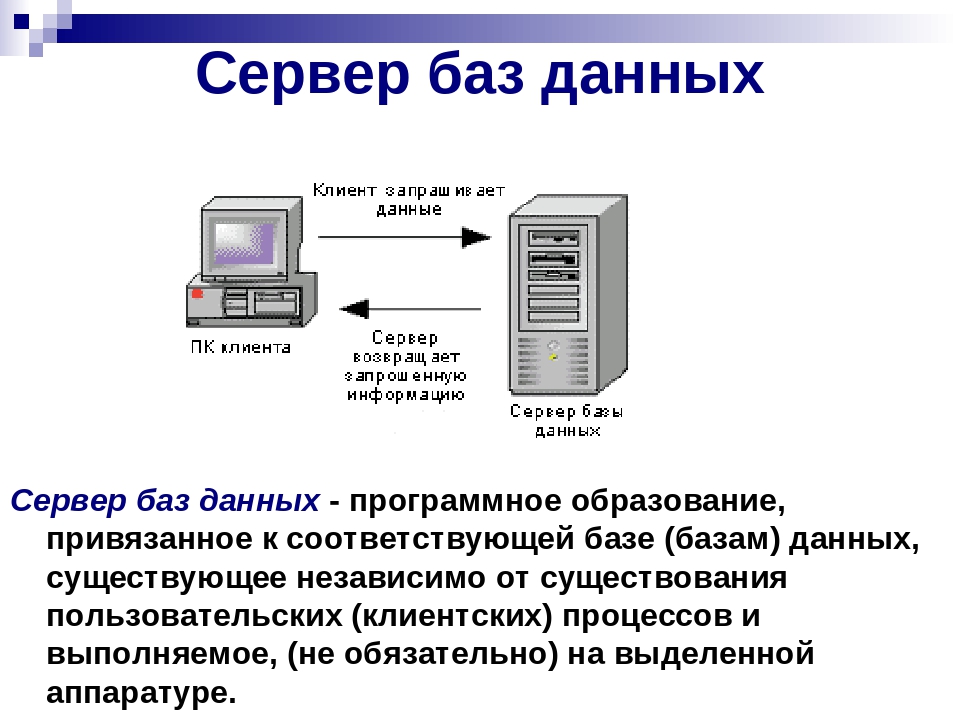
Таким образом, использование базы данных намного удобнее. Использование одного на встроенной платформе — гораздо более сложная проблема.
На настольном ПК я использую базу данных, когда необходимо постоянно хранить новую информацию и извлекать эту информацию реляционным способом. Для чего я не использую базы данных, так это для хранения статической информации, информации, которую я читаю один раз при загрузке, и все. Исключение составляют ситуации, когда у приложения много пользователей и есть необходимость хранить эту информацию для каждого пользователя.
Мне кажется, что вы собираете информацию со своего встроенного устройства, каким-то образом сохраняете ее, а затем используете для отображения через графический интерфейс.
Это хороший вариант для использования базы данных, особенно если вы можете спроектировать систему таким образом, чтобы демон сбора данных управлял непрерывной связью со встроенным устройством. Затем это приложение может просто записывать данные в базу данных. Когда запускается графический интерфейс, он может извлекать данные для отображения.
Когда запускается графический интерфейс, он может извлекать данные для отображения.
Использование базы данных также облегчит разработку вашего графического интерфейса, если вам нужно отобразить различные представления, например, «показать мне все записи между двумя датами». С базой данных вы просто запрашиваете правильные значения для отображения с помощью правильного SQL-запроса, и графический интерфейс отображает все, что возвращается, позволяя вам отделить большую часть кода «бизнес-логики» от графического интерфейса.
У нас тоже похожая ситуация. У нас есть набор данных, поступающих из разных тестовых установок, и в настоящее время они выгружаются в листы Excel, обрабатываются с помощью Perl или VBA.
Мы обнаружили, что этот метод имеет много проблем:
i. Управление данными с помощью таблиц Excel довольно громоздко. Через какое-то время у вас будет много листов Excel, и нет простого способа извлечь из них необходимые данные.
ii. Люди начинают рассылать листы Excel туда и сюда для комментариев и рецензирования по электронной почте. Электронная почта становится основным способом управления комментариями, связанными с данными. Эти комментарии теряются в более поздний момент времени, и нет никакого способа восстановить их обратно.
Электронная почта становится основным способом управления комментариями, связанными с данными. Эти комментарии теряются в более поздний момент времени, и нет никакого способа восстановить их обратно.
III. Создается несколько копий файлов, и изменения в одной копии не отражаются в другой — управление версиями отсутствует.
По тем же причинам мы решили перейти на решение на основе базы данных и в настоящее время работаем над ним. Позвольте мне резюмировать, что мы пытаемся сделать:
i. База данных находится на центральном сервере, доступном для ПК во всех тестовых установках.
ii. Все данные помещаются во временное хранилище (файлы на локальный жесткий диск) сразу после их создания. Из файлов они помещаются в базу данных процессом, работающим в фоновом режиме (поэтому, даже если есть проблема с сетью, данные будут присутствовать в локальной файловой системе).
III. У нас есть веб-приложение, которое позволяет пользователям входить в систему и получать доступ к данным в нужном им формате.