python — поиск в строке которая задана переменной
Вопрос задан
Изменён 1 год 5 месяцев назад
Просмотрен 142 раза
задача: из строки которая задана переменной извлечь символы с 15 по 25 (символы в будущем для других строк будут меняться), ищу способом find (), полный код программы прилагается
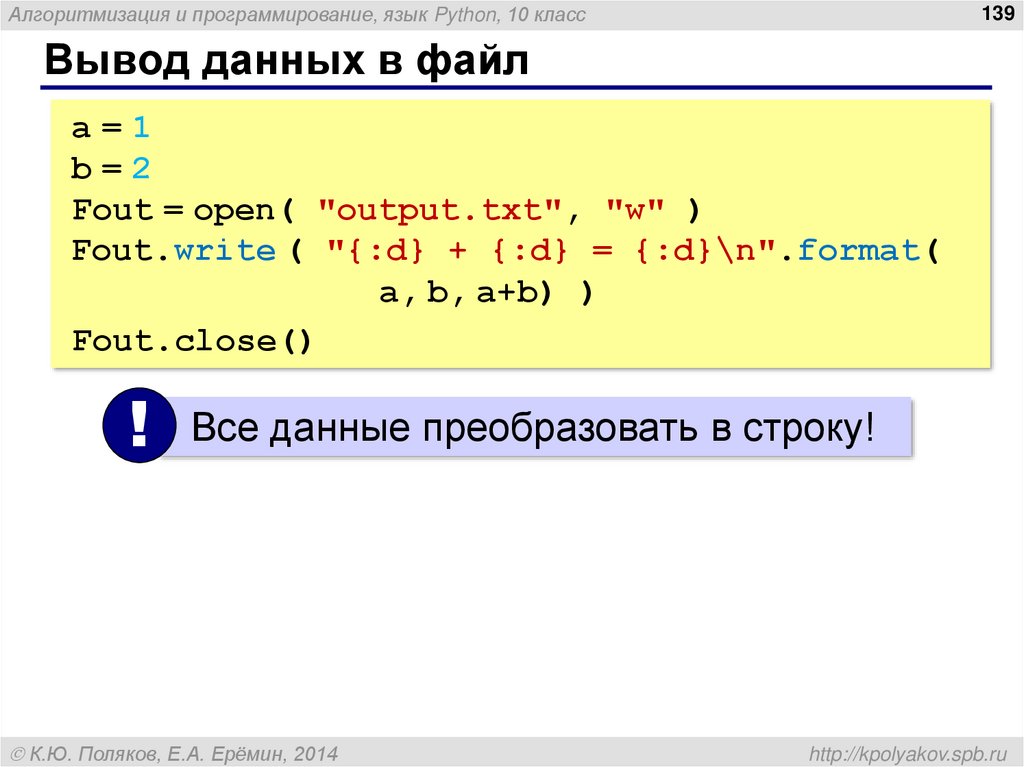
# -*- coding: utf-8 -*-
import setuptools
name: str = input ("Введите имя входящего файла: ")
f = open (name, "r") # открываем файл
lines = f.readlines () # читаем его построчно
t1 = lines [6]
t2 = lines [-5]
t3 = lines [-6]
# -------- поиск в строке
t1.find ('t1', [1], [2]) #----проблема возникает тут!!!!
a=t1.find
# --------
for line in lines:
if line.find ('НА НР') != -1: # то что ищем
t4 = line [7:40] # определяет глубину
print (t4) # выводим на экран проверяем
break
name1: str = input ("Введите имя исходящего файла: ")
f = open (name1, "w+")
# f.
write(str(t1 + "\n" + t2))
f.write ('реквизит верхний// ' + str (a))
f.write ('реквизит нижний// ' + str (t2))
f.write ('дата// ' + str (t3))
f.write ('\nнанр// ' + str (t4))
f.close ()

помогите разобраться с тем как искать подстроку в строке и перекладывать результат в переменную, изначально как видно программа просто вынимала из документа строку и печатал её в новый документ, теперь хочется печатать с конкретного символа до следующего конкретного символа.
- python
- python-3.x
- строки
- парсер
- методы
8
короткий ответ:
s = "Hello world!"
# Срез строки s[индекс_начала_среза:индекс_конца_среза]
# Срез делается по конечный индекс то есть не включительно
print(s[1:4])
# сохранение в переменную
sub_string = s[0:6]
print(sub_string)
# поиск подстроки
start_index = s.find('Hello')
print(start_index)
# .find() возвращает индекс где начинается искомая подстрока
# если вернул -1 значит подстрока не найдена
# то есть если start_index != -1 то подстрока найдена.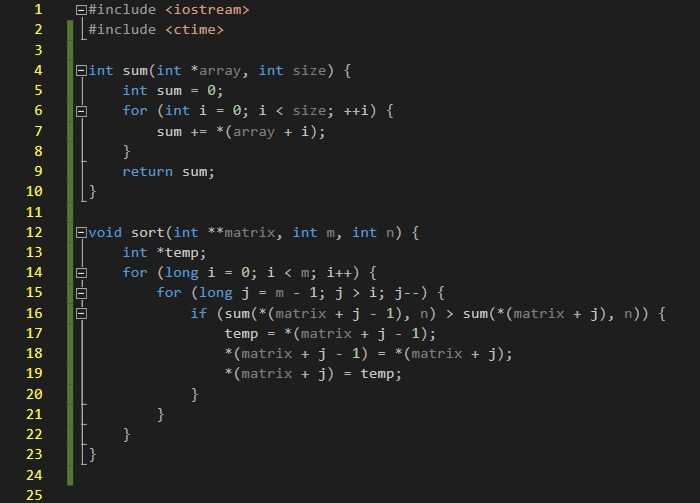
Но я на вашем месте изучил бы статью по ссылке. Там все очень доходчиво объяснено про то как работать со строками.
https://pythonworld.ru/tipy-dannyx-v-python/stroki-funkcii-i-metody-strok.html
Так же, как немного углубитесь, внимательно изучите вот это https://pythonworld.ru/osnovy/vstroennye-funkcii.html и настоятельно рекомендую позапускать каждую команду из списка приведенного по этой ссылке. Это то что вы будете использовать и/или видеть очень часто. Понимать как это работает просто необходимо.
Зарегистрируйтесь или войдите
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
поиск строк в файле по ключевым словам — NTA на vc.
 ru Устали фильтровать данные в excel?
ru Устали фильтровать данные в excel?Есть решение, как с помощью Python осуществить поиск строк в файле по ключевым словам в столбцах.
5378 просмотров
Несомненно, многие из нас в своей работе не раз сталкивались с необходимостью фильтрации данных в файле excel, обычно мы делаем это через встроенный в программу фильтр, но бывают ситуации, когда нужно осуществить отбор строк по большому количеству условий (в нашем случае – по ключевым словам) сразу по нескольким столбцам.
Рассмотрим задачу более подробно. Например, у нас есть файл excel с обращениями клиентов в банк (тысячи строк), который содержит следующие колонки: «ИНН клиента», «Дата обращения», «Обращение», «Решение». В столбце «Обращение» содержится текст обращения клиента, в столбце «Решение» — ответ банка на обращение. Суть обращений может быть абсолютно любой (кредитование, страхование, эквайринг и т.д).
Требуется с помощью поиска ключевых слов/сочетаний слов (например, «КАСКО», «ОСАГО», «автострахов», «залог…авто» и т.
Конечно, можно начать фильтровать данные колонки в excel, но это будет долго и трудоёмко, особенно, если слов для поиска подходящих обращений много (или столбцов, в которых необходимо найти ключевые слова). Поэтому для решения нашей задачи требуется более удобный инструмент – Python.
Ниже представлен код, с помощью которого мы отберем необходимые обращения клиентов:
# Импорт библиотек.
import pandas as pd
import numpy as np
import re
#Чтение исходного файла с данными.
df = pd.read_excel(r’ПУТЬ К ФАЙЛУ\Название исходного файла с данными.xlsx’, dtype=’str’)
# Регулярные выражения.
# Шаблон (слова/сочетания слов, которые необходимо найти в столбцах).
r = r'(каско)|(осаго)|(страх.*?транспорт)|(транспорт.*?страх)|(страх.*?авто)|(авто.*?страх)|(залог.*?транспорт)|(транспорт.*?залог)|(залог.
Подробно с информацией о модуле re, функциями и синтаксисом регулярных выражений в Python можно ознакомиться по следующим ссылкам: https://docs-python.ru/standart-library/modul-re-python/, https://docs-python.ru/standart-library/modul-re-python/sintaksis-reguljarnogo-vyrazhenija/.
Поясним, что «.*?» в выражении (страх.*?транспорт) ищет между «страх» и «транспорт» любое количество символов, вопросительный знак отключает жадность алгоритма поиска (поиск заканчивается как только находится первый «транспорт»).
#Для каждой строки ищем шаблон в столбце «Обращение».
obr = df[‘Обращение’].apply(lambda x: re.search(r, str(x).lower())) #другой вариант: obr = df[‘ Обращение ‘].str.lower().str.contains(r)
#Для каждой строки ищем шаблон в столбце «Решение».
otvet = df[‘Решение’].apply(lambda x: re.search(r, str(x).lower())) #другой вариант: otvet = df[‘Решение’].str.lower().str.contains(r)
#Для каждой строки проверяем наличие шаблона хотя бы в одном из столбцов «Обращение» и «Решение» (результат — True/False).
В результате получаем новый файл excel, в который полностью скопированы нужные нам обращения клиентов:
— в обращении клиента с ИНН 1111111111 в столбцах «Обращение» и «Решение» содержится слово «КАСКО»;
— в обращении клиента с ИНН 333333333333 в столбце «Решение» содержатся сочетания слов «залог…транспорт», «транспорт…страх», «залог…авто», «страх…авто»;
— в обращении клиента с ИНН 444444444444 в столбце «Обращение» содержатся сочетания слов «страх…транспорт»; «транспорт…залог».
Количество столбцов, в которых можно производить поиск ключевых слов, не ограничен – в приведенном примере их два, но у вас может быть больше.
При необходимости для каждого столбца можно задать свой шаблон для поиска слов:
#Шаблон 1 для столбца «Обращение».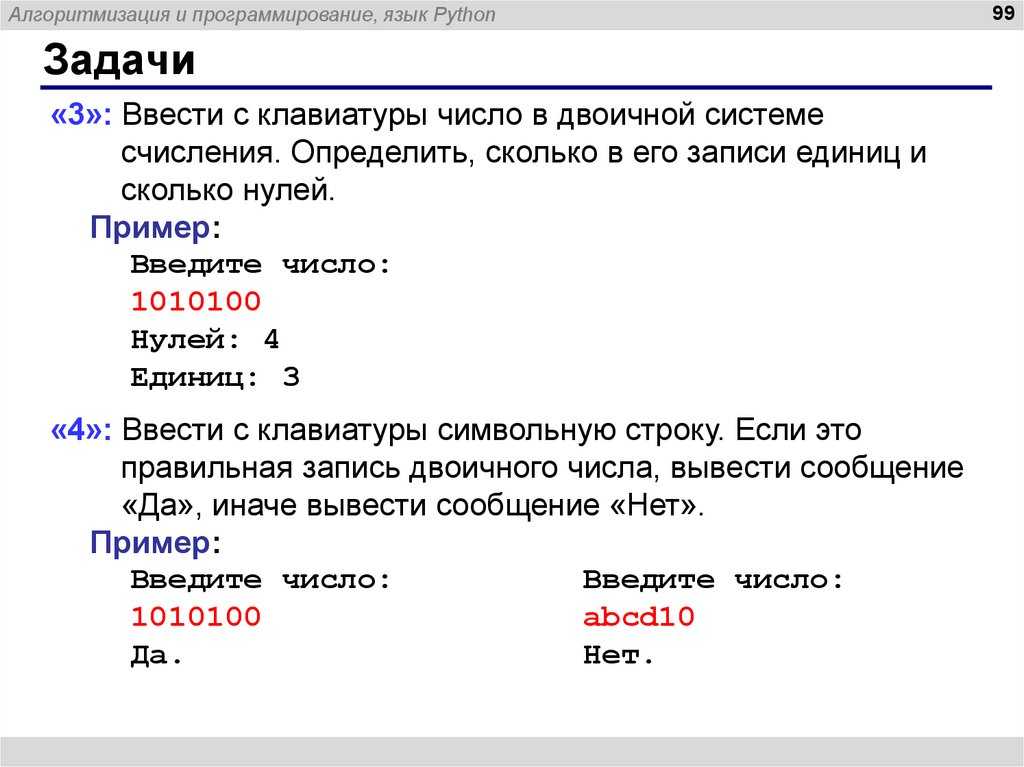 r1= r'(каско)|(осаго)|(страх.*?транспорт)|(транспорт.*?страх)|(страх.*?авто)|(авто.*?страх)’
#Шаблон 2 для столбца «Решение».
r2= r'(залог.*?транспорт)|(транспорт.*?залог)|(залог.*?авто)|(авто.*?залог)|(автострахов)’
#Поиск шаблонов 1 и 2 в столбцах «Обращение» и «Решение» соответственно.
obr = df[‘Обращение’].apply(lambda x: re.search(r1, str(x).lower()))
otvet = df[‘Решение’].apply(lambda x: re.search(r2, str(x).lower()))
r1= r'(каско)|(осаго)|(страх.*?транспорт)|(транспорт.*?страх)|(страх.*?авто)|(авто.*?страх)’
#Шаблон 2 для столбца «Решение».
r2= r'(залог.*?транспорт)|(транспорт.*?залог)|(залог.*?авто)|(авто.*?залог)|(автострахов)’
#Поиск шаблонов 1 и 2 в столбцах «Обращение» и «Решение» соответственно.
obr = df[‘Обращение’].apply(lambda x: re.search(r1, str(x).lower()))
otvet = df[‘Решение’].apply(lambda x: re.search(r2, str(x).lower()))
Если требуется выбрать строки, в которых ключевые слова содержатся и в том, и в другом столбце, то нужно заменить функцию any() на all():
itog = np.all(np.array([~obr.isnull(), ~otvet.isnull()]), axis=0)
Теперь рассмотрим ситуацию, когда у нас имеется несколько файлов excel с обращениями клиентов (с аналогичной структурой столбцов), и необходимо в каждом выбрать подходящие обращения.
Тогда код, с помощью которого мы отберем нужные строки, будет выглядеть так:
#Импорт библиотек.
import pandas as pd
import numpy as np
import os
import re
import warnings
#Игнорирование всех предупреждений. warnings.filterwarnings(‘ignore’)
#Путь к папке с исходными файлами.
path = r’ПУТЬ К ПАПКЕ С ФАЙЛАМИ ‘
#Регулярные выражения.
#Шаблон (слова/сочетания слов, которые необходимо найти в столбцах).
r= r'(каско)|(осаго)|(страх.*?транспорт)|(транспорт.*?страх)|(страх.*?авто)|(авто.*?страх)|(залог.*?транспорт)|(транспорт.*?залог)|(залог.*?авто)|(авто.*?залог)|(автострахов)’
#Создание папки, в которую будут сохраняться файлы с нужными обращениями.
os.makedirs(‘Нужные обращения’, exist_ok=True)
#Получение списка полных имён для всех файлов xlsx в папке с исходными файлами.
docs = []
for root, _, files in os.walk(path):
for file in files:
if file.split(‘.’)[-1] == ‘xlsx’:
docs.append(os.path.join(root, file))
print(f’В директории {path} \nобнаружено {len(docs)} файлов’)
#Для каждого файла из списка производим его чтение, поиск шаблона в столбцах «Обращение» и «Решение», проверяем наличие шаблона хотя бы в одном из данных столбцов, оставляем только те строки в таблице, по которым получен результат True, записываем результат в excel в папку «Нужные обращения».
warnings.filterwarnings(‘ignore’)
#Путь к папке с исходными файлами.
path = r’ПУТЬ К ПАПКЕ С ФАЙЛАМИ ‘
#Регулярные выражения.
#Шаблон (слова/сочетания слов, которые необходимо найти в столбцах).
r= r'(каско)|(осаго)|(страх.*?транспорт)|(транспорт.*?страх)|(страх.*?авто)|(авто.*?страх)|(залог.*?транспорт)|(транспорт.*?залог)|(залог.*?авто)|(авто.*?залог)|(автострахов)’
#Создание папки, в которую будут сохраняться файлы с нужными обращениями.
os.makedirs(‘Нужные обращения’, exist_ok=True)
#Получение списка полных имён для всех файлов xlsx в папке с исходными файлами.
docs = []
for root, _, files in os.walk(path):
for file in files:
if file.split(‘.’)[-1] == ‘xlsx’:
docs.append(os.path.join(root, file))
print(f’В директории {path} \nобнаружено {len(docs)} файлов’)
#Для каждого файла из списка производим его чтение, поиск шаблона в столбцах «Обращение» и «Решение», проверяем наличие шаблона хотя бы в одном из данных столбцов, оставляем только те строки в таблице, по которым получен результат True, записываем результат в excel в папку «Нужные обращения».
В результате создается папка «Нужные обращения», в которой содержатся новые файлы excel с полностью скопированными нужными обращениями клиентов. По количеству и названию данные файлы соответствуют исходным.
Таким образом, благодаря Python поиск строк в файлах по ключевым словам в столбцах становится быстрым и несложным делом. Приведенный код значительно ускоряет и упрощает работу аналитика в части фильтрации строк по большому количеству условий по нескольким столбцам.
Метод Python String find()
Сохранить статью
- Уровень сложности: Базовый
- Последнее обновление: 18 авг, 2022
Улучшить статью
Сохранить статью
Метод Python String find() возвращает наименьший индекс или первое вхождение подстроки, если она найдена в данной строке. Если он не найден, то возвращается -1.
Если он не найден, то возвращается -1.
Синтаксис: str_obj.find(sub, start, end)
Параметры:
- sub: Подстрока, которую необходимо найти в заданной строке.
- начало (необязательно): Начальная позиция, в которой необходимо проверить подстроку в строке.
- конец (необязательно): Конечная позиция — это индекс последнего значения для указанного диапазона. Исключается при проверке.
Возврат: Возвращает наименьший индекс подстроки, если она найдена в заданной строке. Если он не найден, он возвращает -1.
Python String find() method Example
Python3
|
 find(
find( Вывод:
6
Примечание:
- Если начальный и конечный индексы не указаны, то по умолчанию в качестве начального и конечного индексов используются 0 и длина-1, где конечные индексы не включены в наш поиск.
- Метод find() аналогичен index(). Единственное отличие заключается в том, что find() возвращает -1, если искомая строка не найдена, и index() в этом случае выдает исключение.
Пример 1: find() без начального и конечного аргумента
Python3
|
 find (
find (Вывод:
Подстрока 'geeks' найдена в индексе: 0 Подстрока for найдена по индексу: 6 Не содержит заданной подстроки
Пример 2: find() С начальным и конечным аргументами
В этом примере мы указали начальный и конечный аргументы метода Python String find(). Так что данная подстрока ищется в указанной части исходной строки.
Так что данная подстрока ищется в указанной части исходной строки.
Python3
|
Output:
10 -1 -1 6
Объяснение:
- В первом операторе выход равен 10, поскольку задано начальное значение, равное 2, поэтому подстрока проверяется по второму индексу, который называется «eks for geeks».

- Во втором операторе начальное значение задано как 2, а подстрока задана как «выродки», поэтому индексная позиция «выродки» равна 10, но из-за того, что последнее значение исключается, будет найдено только «выродок», который не совпадает с исходной строкой, поэтому вывод равен -1.
- В третьем операторе начальное значение = 4, конечное значение = 10 и задана подстрока = 'g', позиция индекса из 4 будет проверена для данной подстроки, которая находится в позиции 10, которая исключается, поскольку она является конечным индексом.
- В четвертом операторе задано начальное значение = 4, конечное значение = 11 и подстрока = 'for', позиция индекса с 4 по 11 будет проверена для данной подстроки, и указанная подстрока присутствует в индексе 6, так получается вывод.
Статьи по теме
Метод Python String find() с примерами
Что такое Python String find()?
Python String find() — это функция, доступная в библиотеке Python, для поиска индекса первого вхождения подстроки в заданной строке. Строковая функция find() вернет -1 вместо того, чтобы генерировать исключение, если указанная подстрока отсутствует в данной строке.
Строковая функция find() вернет -1 вместо того, чтобы генерировать исключение, если указанная подстрока отсутствует в данной строке.
В этом учебнике по методу Python string find() вы узнаете:
- Что такое Python String find()?
- Синтаксис строки Python find()
- Пример метода find() со значениями по умолчанию
- Пример find() с использованием начального аргумента
- Пример find() с использованием начального и конечного аргументов
- Пример метода find() Чтобы найти позицию заданной подстроки в строке
- Строка Python rfind()
- Индекс строки Python()
- Чтобы найти общее количество вхождений подстроки
Синтаксис строки Python find()
Базовый синтаксис функции find() Python следующий:
string.find(substring,start,end)
Параметры для метода find()
Вот три параметра функции String find() в Python:
- substring : Подстрока, которую вы хотите найти в заданной строке.
- start : (необязательно) Начальное значение, с которого начнется поиск подстроки. По умолчанию это 0,
- end : (необязательно) Конечное значение, на котором заканчивается поиск подстроки. По умолчанию значением является длина строки.
Пример метода find() со значениями по умолчанию
Параметры, передаваемые методу Python find(), представляют собой подстроку, т. е. строку, которую вы хотите найти, начало и конец. Начальное значение по умолчанию равно 0, а конечное значение — длина строки.
В этом примере мы будем использовать метод find() в Python со значениями по умолчанию.
Метод find() выполнит поиск подстроки и выдаст позицию самого первого вхождения подстроки. Теперь, если подстрока присутствует в заданной строке несколько раз, она все равно вернет вам индекс или позицию первой.
Пример:
mystring = "Знакомьтесь, сайт учебных пособий Guru99. Лучший сайт для учебных пособий по Python!"
print("Учебники находятся по адресу:", mystring. find("Учебники"))
find("Учебники"))
Вывод:
Позиция Учебников: 12
Пример find() с использованием начального аргумента
Вы можете искать подстроку в заданной строке и указать начальную позицию, с которой начнется поиск. Параметр запуска может использоваться для того же самого.
В примере начальная позиция будет указана как 15, а метод find() в Python начнет поиск с позиции 15. Здесь конечной позицией будет длина строки, и поиск будет выполняться до конца строки с 15 позиций и далее.
Пример:
mystring = "Знакомьтесь, сайт учебных пособий Guru99. Лучший сайт для учебных пособий по Python!"
print("Учебники находятся в:", mystring.find("Учебники", 20))
Выход:
Позиция Учебников на 48
Пример find() с использованием начального и конечного аргументов
Используя начальный и конечный параметры, мы попытаемся ограничить поиск вместо поиска всей строки.
Пример:
mystring = "Знакомьтесь, сайт учебных пособий Guru99.Лучший сайт для учебных пособий по Python!" print("Учебники находятся по адресу:", mystring.find("Учебники", 5, 30))
Вывод:
Позиция Учебников на 12
Пример метода find() Чтобы найти позицию данной подстроки в строке
Мы знаем, что find() помогает нам найти индекс первого вхождения подстроки. Возвращает -1, если подстрока отсутствует в заданной строке. В приведенном ниже примере показан индекс, когда строка присутствует, и -1, когда мы не находим искомую подстроку.
Пример:
mystring = "Знакомьтесь, Гуру99 Сайт учебных пособий. Лучший сайт для учебных пособий по Python!»
print("Позиция лучшего сайта:", mystring.find("Лучший сайт", 5, 40))
print("Позиция Guru99:", mystring.find("Guru99", 20))
Вывод:
Позиция Лучшего сайта: 27 Позиция Guru99: -1
Строка Python rfind()
Функция Python rfind() аналогична функции find() с той лишь разницей, что rfind() дает наивысший индекс для заданной подстроки, а find() дает наименьший, т. е. самый первый индекс. И rfind(), и find() вернут -1, если подстрока отсутствует.
е. самый первый индекс. И rfind(), и find() вернут -1, если подстрока отсутствует.
В приведенном ниже примере у нас есть строка «Познакомьтесь с учебным сайтом Guru99. Лучший сайт для учебников по Python!» и попытается найти позицию подстроки Tutorials, используя find() и rfind(). Вхождение Tutorials в строку дважды.
Вот пример, где используются и find(), и rfind().
mystring = "Знакомьтесь, сайт учебных пособий Guru99. Лучший сайт для учебных пособий по Python!"
print("Позиция Tutorials используя find() : ", mystring.find("Tutorials"))
print("Позиция туториалов с помощью rfind() : ", mystring.rfind("туториалы"))
Вывод:
Позиция учебников с использованием find() : 12 Позиция учебников с использованием rfind(): 48
Вывод показывает, что find() возвращает индекс самой первой подстроки Tutorials, которую он получает, а rfind() дает последний индекс подстроки Tutorials.
Python string index()
Python string index() — это функция, которая дает вам позицию заданной подстроки точно так же, как find(). Единственная разница между ними заключается в том, что index() выдаст исключение, если подстрока отсутствует в строке, а find() вернет -1.
Единственная разница между ними заключается в том, что index() выдаст исключение, если подстрока отсутствует в строке, а find() вернет -1.
Вот рабочий пример, демонстрирующий поведение функций index() и find().
mystring = "Знакомьтесь, сайт учебных пособий Guru99. Лучший сайт для учебных пособий по Python!"
print("Позиция Tutorials используя find() : ", mystring.find("Tutorials"))
print("Позиция туториалов с помощью index() : ", mystring.index("туториалы"))
Вывод:
Позиция учебников с использованием find() : 12 Позиция учебников с использованием index(): 12
Мы получаем одинаковое положение как для find(), так и для index(). Давайте рассмотрим пример, когда заданная подстрока отсутствует в строке.
mystring = "Знакомьтесь, сайт учебных пособий Guru99. Лучший сайт для учебных пособий по Python!"
print("Позиция учебников с использованием find() : ", mystring.find("test"))
print("Позиция учебников с использованием index() : ", mystring. index("test"))
index("test"))
Вывод:
Позиция учебников с использованием find() : -1 Traceback (последний последний вызов): Файл «task1.py», строка 3, вprint("Позиция учебников с использованием index() : ", mystring.index("test")) ValueError: подстрока не найдена
В приведенном выше примере мы пытаемся найти позицию подстроки «тест». Подстрока отсутствует в заданной строке, и, следовательно, с помощью find() мы получаем позицию как -1, но для index() она выдает ошибку, как показано выше.
Чтобы найти общее количество вхождений подстроки
Чтобы найти общее количество раз, когда подстрока встречается в данной строке, мы будем использовать функцию find() в Python. Будет перебирать строку, используя цикл for от 0 до конца строки. Будет использовать параметр startIndex для find().
Переменные startIndex и count будут инициализированы до 0. Внутри цикла for проверит, присутствует ли подстрока внутри строки, заданной с помощью find() и startIndex как 0.
Значение, возвращаемое из find(), если не -1, обновит startIndex до индекса, в котором найдена строка, а также увеличит значение счетчика.
Вот рабочий пример:
my_string = "тест тестовой строки, тестирование тестовой строки, тестовая строка тестовой строки"
начальный индекс = 0
количество = 0
для i в диапазоне (len (my_string)):
k = my_string.find('test', startIndex)
если (к != -1):
начальный индекс = k+1
количество += 1
к = 0
print("Общее количество тестов подстроки: ", count )
Вывод:
Общее количество тестов подстроки: 6
Резюме
- Метод Python string find() помогает найти индекс первого вхождения подстроки в заданную строку. Он вернет -1, если подстрока отсутствует.
- Параметры, переданные методу поиска подстроки Python, являются подстрокой, т. е. строкой, которую вы хотите найти, начать и закончить. Начальное значение по умолчанию равно 0, а конечное значение — длина строки.