Проверка вхождения одной строки в другую в Python
Как проверить, содержит ли строка Python другую строку?
Проверка, содержит ли строка какую-нибудь другую строку, это одна из самых распространенных операций, осуществляемых разработчиками.
Если вы раньше (до перехода на Python) писали код, скажем, на Java, для подобной проверки вы могли использовать метод contains.
В Python есть два способа достичь той же цели.
1. Использование оператора in
Самый простой способ проверить, содержится ли в строке другая строка, это использовать оператор Python in.
Давайте рассмотрим пример.
>>> str = "Messi is the best soccer player" >>> "soccer" in str True >>> "football" in str False
Как видите, оператор in возвращает True, если указанная подстрока является частью строки.
False.Этот метод очень простой, понятный, читаемый и идиоматичный.
2. Использование метода find
Также для проверки вхождения одной строки в другую можно использовать строковый метод find.
В отличие от оператора, возвращающего булево значение, метод find возвращает целое число.
Это число является по сути индексом начала подстроки, если она есть в указанной строке. Если этой подстроки в строке не содержится, метод возвращает -1.
Давайте посмотрим, как работает метод find.
>>> str = "Messi is the best soccer player"
>>> str.find("soccer")
18
>>> str.find("Ronaldo")
-1
>>> str.find("Messi")
0Что особенно хорошо в применении этого
метода — вы можете при желании ограничить
пределы поиска, указав начальный и
конечный индекс.
Например:
>>> str = "Messi is the best soccer player"
>>> str.find("soccer", 5, 25)
18
>>> str.find("Messi", 5, 25)
-1Обратите внимание, что для подстроки «Messi» метод вернул -1. Это произошло потому, что мы ограничили поиск в строке промежутком символов с индексами от 5-го до 25-го.
Более сложные способы
Представьте на минутку, что в Python нет никаких встроенных функций или методов, позволяющих проверить, входит ли одна строка в другую. Как бы вы написали функцию для этой цели?
Можно использовать брутфорс-подход и на каждой возможной позиции в строке проверять, начинается ли там искомая подстрока. Но для длинных строк этот процесс будет очень медленным.
Есть лучшие алгоритмы поиска строк. Если вы хотите углубиться в эту тему, можем порекомендовать статью «Rabin-Karp and Knuth-Morris-Pratt Algorithms». Также вам может пригодиться статья «Поиск подстроки» в Википедии.
Также вам может пригодиться статья «Поиск подстроки» в Википедии.
Если вы прочитаете указанные статьи, у вас может родиться закономерный вопрос: так какой же алгоритм используется в Python?
Для поиска ответов на подобные вопросы практически всегда нужно углубиться в исходный код. В этом плане вам повезло: Python это технология с открытым кодом. Давайте же в него заглянем.
Как удачно, что разработчики прокомментировали свой код! Теперь нам совершенно ясно, что метод find использует смесь алгоритмов Бойера-Мура и Бойера-Мура-Хорспула.
Заключение
Для проверки, содержится ли указанная строка в другой строке, в Python можно использовать операторin или метод find.Оператор in возвращает True, если указанная подстрока является частью другой строки. В противном случае он возвращает False.
Метод find возвращает индекс начала подстроки в строке, если эта подстрока там есть, или -1 — если подстрока не найдена.
CPython использует для поиска строк комбинацию алгоритмов Бойера-Мура и Бойера-Мура-Хорспула.
Python. Функции, основанные на поиске и замене подстроки в строке
Содержание
- 1. Функция str.count(). Количество вхождений подстроки в заданном диапазоне
- 2. Функция str.find(). Поиск подстроки в строке
- 3. Функция str.index(). Поиск подстроки в строке с генерированием исключения
- 4. Функция str.rfind(). Найти наибольший индекс вхождения подстроки в строку
- 5. Функция str.rindex(). Найти наибольший индекс вхождения подстроки в строку с генерированием исключения ValueError
- 6. Функция str.replace(). Замена подстроки в строке
- Связанные темы
Поиск на других ресурсах:
1. Функция str.count(). Количество вхождений подстроки в заданном диапазоне
Функция str.count() возвращает количество вхождений подстроки в заданном диапазоне. Согласно документации Python общая форма использования функции следующая
n = str.count(substring[, start[, end]])
где
- n – результат, количество вхождений подстроки substring в строке str, которые не перекрываются;
- str – исходная строка;
- substring – подстрока, которая может входить в строку str;
- start, end – соответственно начальная и конечная позиции (индексы) в строке str, определяющие диапазон который принимается ко вниманию (рассматривается). Иными словами значения start, end определяют срез.
Пример.
# Функция str.count() - количество вхождений подстроки в заданном диапазоне
# 1. Вызов функции с указанием диапазона
s1 = 'abcdef' # исходная строка
n = s1.count('bcd', 0, len(s1)) # n = 1, диапазон 0..5
n = 'ab ab babab'.count('ab', 2, 10) # n = 2
n = 'ab ab babab'.count('ab', 0, 6) # n = 2
# 2. Вызов функции без указания диапазона
s1 = 'Hello world!'
n = s1. count('о') # n = 2, количество символов 'о' в строке
s1 = 'abcbcd abcd'
n = s1.count("bc") # n = 3
# 3. Вызов функции с указанием начального значения start
s1 = 'abc abc abcd'
n = s1.count('abc', 3) # n = 2
count('о') # n = 2, количество символов 'о' в строке
s1 = 'abcbcd abcd'
n = s1.count("bc") # n = 3
# 3. Вызов функции с указанием начального значения start
s1 = 'abc abc abcd'
n = s1.count('abc', 3) # n = 2⇑
2. Функция str.find(). Поиск подстроки в строке
Функция find() предназначена для поиска подстроки в строке. В соответствии с документацией Python общая форма вызова функции следующая:
index = s.find(sub [, start[, end]])
где
- index – целочисленное значение, которое есть индексом первого вхождения подстроки sub в строке s. Если подстрока sub не найдена в строке s, то index=-1;
- s – строка, в которой осуществляется поиск подстроки sub;
- start, end – позиции в строке s. Эти позиции определяют границы среза s[start:end], определяющего обрабатываемый диапазон.
 Если не задавать параметры start, end, то поиск осуществляется во всей строке.
Если не задавать параметры start, end, то поиск осуществляется во всей строке.
Пример.
# Функция str.find() - поиск подстроки в строке
# Исходная строка, в которой осуществляется поиск
s = 'abcde fg hijkl mnop'
# 1. Обработка целой строки
index = s.find('hij') # index = 9
index = s.find('+-=') # index = -1
# 2. Обработка среза s[start:end]
# берется ко вниманию часть 'abcde' строки s
index = s.find('hij', 0, 5) # index = -1
index = s.find('cde', 0, 5) # index = 2
index = 'hello world!'.find('wor', 2, len(s)) # index = 6⇑
3. Функция str.index(). Поиск подстроки в строке с генерированием исключения
Функция str.index() осуществляет поиск подстроки в строке. Данная функция работает так же как и функция str.find(), однако, если подстрока не найдена, то вызывается исключение ValueError.
Согласно документации Python общая форма вызова функции следующая:
pos = str.index(substring [, start [, end]])
где
- pos – позиция подстроки substring в строке str в случае, если строка найдена. Если подстрока не найдена, то вызывается исключение ValueError;
- str – строка, в которой осуществляется поиск;
- start, end – соответственно начальная и конечная позиции в строке str, определяющие диапазон поиска.
Пример.
# Функция str.index() - поиск подстроки в строке
# Случай 1. Генерируется исключение ValueError: substring not found
#t = str.index('sdf', 'abcdef def hj') - исключительная ситуация
# Случай 2. Подстрока существует в строке
s = 'abcdef'
t = s.index('bc') # t = 1 - позиция найденной подстроки
# Поиск в заданном диапазоне
s = 'abc def ghi def'
t = s.index('def', 0, len(s)) # t = 4
# Поиск в диапазоне '012'
s = '0123456789'
t = s.index('012', 0, 3) # t = 0 ⇑
4.
 Функция str.rfind(). Найти наибольший индекс вхождения подстроки в строку
Функция str.rfind(). Найти наибольший индекс вхождения подстроки в строкуФункция str.rfind() возвращает наибольшую позицию (индекс) в строке заданной подстроки, если таковая найдена. Общая форма использования функции следующая:
position = str.rfind(subs[, start[, end]])
где
- position – искомая позиция (индекс) вхождения подстроки subs в строке str. Если подстрока subs в строке str не найдена, то position=-1;
- str – строка, в которой осуществляется поиск подстроки subs;
- subs – заданная подстрока;
- start, end – соответственно начальный и конечный индексы, определяющие срез в строке str.
Пример.
# Функция str.rfind()
# 1. Использование без указания диапазона
s1 = 'abc def ab abc'
index = s1.rfind('ab') # index = 11
index = s1.rfind('jkl') # index = -1
# 2.
Использование с указанием начала start
s1 = '012 345 012'
index = s1.rfind('01', 3) # index = 8
# 3. Использование с указанием начала start и конца end
s1 = 'abc def abc def gh'
s2 = 'bc' # подстрока
index = s1.rfind(s2, 0, len(s1)) # index = 9
index = s1.rfind(s2, 0, 1) # index = -1, подстрока не найдена⇑
5. Функция str.rindex(). Найти наибольший индекс вхождения подстроки в строку с генерированием исключения ValueError
Функция str.rindex() работает также как и функция rfind(), то есть возвращает наибольшую позицию подстроки в строке. Разница между rindex() и rfind() состоит в следующем: если подстрока не найдена в строке, то генерируется исключение ValueError.
Общая форма использования функции следующая:
position = str.rindex(subs[, start[, end]])
где
- position – искомая позиция (индекс) вхождения подстроки subs в строке str. Если подстрока subs в строке str не найдена, генерируется исключение ValueError;
- str – строка, в которой осуществляется поиск подстроки subs;
- subs – заданная подстрока;
- start, end – соответственно начальный и конечный индексы, определяющие срез в строке str.

Пример.
# Функция str.index()
# 1. Использование без указания диапазона
s1 = 'abc def ab abc'
index = s1.rindex('ab') # index = 11
index = str.rindex(s1, ' ') # index = 10, символ пробел на 10-й позиции
# 2. Использование с указанием начала start
s1 = '012 345 012'
index = s1.rindex('01', 3) # index = 8
# 3. Использование с указанием начала start и конца end
s1 = 'abc def abc def gh'
s2 = 'bc' # подстрока
index = s1.rindex(s2, 0, len(s1)) # index = 9
# Следующий код сгенерирует исключение
# ValueError: substring not found
index = s1.rindex(s2, 0, 1)⇑
6. Функция str.replace(). Замена подстроки в строке
Функция str.replace() возвращает копию строки, в который все вхождения подстроки old заменены на new.
Общая форма использования функции
s1 = s2.replace(old, new[, count])
где
- s1 – результирующая строка-копия;
- s2 – строка-оригинал, в которой делаются замены подстроки old на подстроку new;
- old – подстрока, которая может быть заменена другой подстрокой new.
 Количество символов в подстроке произвольно. Если подстрока old не найдена в строке s2, тогда функция возвращает строку s2 без изменений;
Количество символов в подстроке произвольно. Если подстрока old не найдена в строке s2, тогда функция возвращает строку s2 без изменений; - new – подстрока, заменяющая подстроку old в строке s2;
- count – количество замен которые могут быть осуществлены. Если count не задано, то замены осуществляются во всех возможных вхождениях подстроки old в строке s2.
Пример.
# Функция str.replace() - замена подстроки в строке
# 1. Вызов без использования параметра count
s1 = 'abcdef'
s2 = s1.replace('bc', '111') # s2 = 'a111def'
s1 = 'abc abc abc'
s2 = s1.replace('bc', '0000') # s2 = 'a0000 a0000 a0000'
# Случай, если подстрока в строке не найдена
s2 = str.replace(s1, 'jkl', '111') # s2 = 'abcdef'
# 2. Вызов с использованием параметра count
s1 = 'abcd abcd abcd'
s2 = s1.replace('bcd', '+++', 3) # s2 = 'a+++ a+++ a+++'
s2 = s1.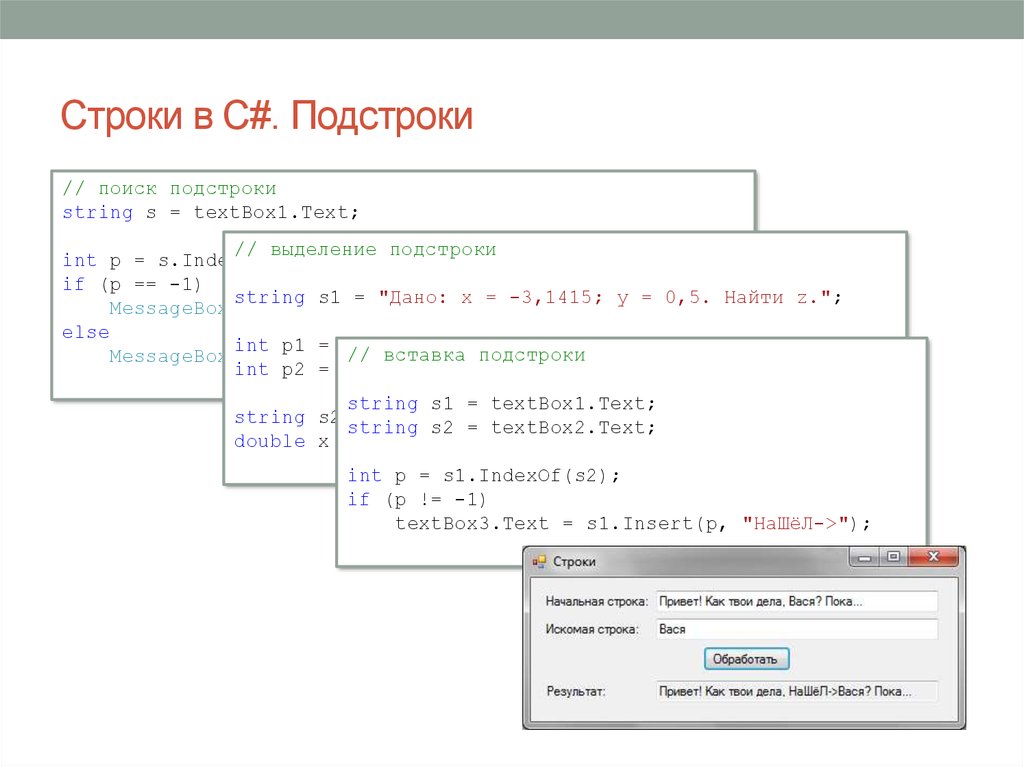 replace('bcd', '++++', 2) # s2 = 'a++++ a++++ abcd'
s2 = s1.replace('ab', '---', 1) # s2 = '---cd abcd abcd'
s2 = s1.replace('abcd', '==', 6) # s2 = '== == =='
replace('bcd', '++++', 2) # s2 = 'a++++ a++++ abcd'
s2 = s1.replace('ab', '---', 1) # s2 = '---cd abcd abcd'
s2 = s1.replace('abcd', '==', 6) # s2 = '== == =='⇑
Связанные темы
- Функции для работы со строками, определяющие особенности строки
- Функции обрабатывающие и определяющие начало и конец строки
- Функции обработки строки в соответствии с форматом или правилом кодирования. Стили форматирования
⇑
Питон | Проверка наличия подстроки в заданной строке
В этой статье мы расскажем, как проверить, содержит ли строка Python другую строку или подстроку в Python. Учитывая две строки, проверьте, есть ли подстрока в данной строке или нет.
Пример 1: Ввод: Подстрока = "выродки"
String="гики для гиков"
Выход: да
Пример 2: Ввод: Подстрока = "выродок"
String="гики для гиков"
Вывод: да Есть ли в Python строка, содержащая метод подстроки
Да, проверка подстроки — одна из наиболее часто используемых задач в Python. Python использует множество методов для проверки строки, содержащей подстроку, например, find(), index(), count() и т. д. Наиболее эффективным и быстрым методом является использование оператора « в «, который используется в качестве оператора сравнения. . Здесь мы рассмотрим различные подходы, такие как:
Python использует множество методов для проверки строки, содержащей подстроку, например, find(), index(), count() и т. д. Наиболее эффективным и быстрым методом является использование оператора « в «, который используется в качестве оператора сравнения. . Здесь мы рассмотрим различные подходы, такие как:
- Использование if… in
- Проверка с использованием метода split()
- Использование метода find()
- Использование метода count()
- Использование метода index()
- Использование магического класса __contains__.
- Using regular expressions
Python3
|
Выход
Да! она присутствует в строкеСпособ 2: Проверка подстроки с помощью метода split()
Проверка наличия или отсутствия подстроки в заданной строке без использования какой-либо встроенной функции. Сначала разбейте данную строку на слова и сохраните их в переменной s, затем, используя условие if, проверьте, присутствует ли подстрока в данной строке или нет.
Сначала разбейте данную строку на слова и сохраните их в переменной s, затем, используя условие if, проверьте, присутствует ли подстрока в данной строке или нет.
Python3
|
Output
yesMethod 3: Check substring using the Метод find()
Мы можем итеративно проверять каждое слово, но Python предоставляет нам встроенную функцию find(), которая проверяет наличие подстроки в строке, что делается в одной строке. Функция find() возвращает -1, если она не найдена, иначе она возвращает первое вхождение, поэтому с помощью этой функции эта проблема может быть решена.
Функция find() возвращает -1, если она не найдена, иначе она возвращает первое вхождение, поэтому с помощью этой функции эта проблема может быть решена.
Python3
|
Вывод
YESМетод 4.
 Проверка подстроки с помощью метода count()
Проверка подстроки с помощью метода count() 7 900 строку, то вы можете использовать метод count() Python. Если подстрока не найдена, то будет напечатано «да», иначе будет напечатано «нет».
Python3
.4040404039. |
Вывод
НЕТМетод 5: Проверка подстроки с помощью метода index()
Метод . index() возвращает начальный индекс подстроки, переданной в качестве параметра. Здесь « подстрока ” is present at index 16.
index() возвращает начальный индекс подстроки, переданной в качестве параметра. Здесь « подстрока ” is present at index 16.
Python3
|
Выход:
16 .0005 Способ 6. Проверка подстроки с помощью магического класса «__contains__». Строка Python __contains__(). Этот метод используется для проверки наличия строки в другой строке или нет. Вывод RegEx можно использовать для проверки наличия в строке указанного шаблона поиска. Выход Output Output Method: Using countof функция Output чтобы проверить, содержит ли строка другую строку в Python. Идентификация таких подстрок пригодится, когда вы работаете с текстовым содержимым из файла или после того, как вы получили пользовательский ввод. Вы можете выполнять различные действия в своей программе в зависимости от того, присутствует подстрока или нет. В этом руководстве вы сосредоточитесь на самом Pythonic способе решения этой задачи, используя оператор членства Наконец, вы также узнаете, как найти подстроки в столбцах pandas . Если вам нужно проверить, содержит ли строка подстроку, используйте оператор принадлежности Python >>> Оператор членства Примечание: Если вы хотите проверить, является ли подстрока , а не в строке, вы можете использовать >>> Поскольку подстрока При использовании Вы можете использовать этот интуитивно понятный синтаксис в условных операторах для принятия решений в вашем коде: >>> В этом фрагменте кода вы используете оператор принадлежности, чтобы проверить, является ли Примечание: Python всегда рассматривает пустые строки как подстроку любой другой строки, поэтому проверка на наличие пустой строки в строке возвращает >>> Это может показаться удивительным, поскольку Python считает строки emtpy ложными, но это крайний случай, о котором полезно помнить. Оператор членства Однако что, если вы хотите узнать больше о подстроке? Если вы прочитаете текст, хранящийся в Какие из этих вхождений нашел Python? Имеет ли значение заглавная буква? Как часто эта подстрока встречается в тексте? И каково расположение этих подстрок? Если вам нужен ответ на любой из этих вопросов, продолжайте читать. Удалить рекламу Строки Python чувствительны к регистру. Если подстрока, которую вы предоставляете, использует заглавные буквы, отличные от того же слова в вашем тексте, то Python не найдет ее. Например, если вы проверяете строчное слово >>> Несмотря на то, что слово секрет появляется несколько раз в тексте заголовка У людей другой подход к языку, чем у компьютеров. Вот почему вы часто хотите игнорировать заглавные буквы, когда проверяете, содержит ли строка подстроку в Python. Вы можете обобщить проверку подстроки, преобразовав весь входной текст в нижний регистр: >>> Преобразование вводимого текста в нижний регистр — распространенный способ объяснить тот факт, что люди думают о словах, различающихся только заглавными буквами, как об одном и том же слове, а компьютеры — нет. Примечание: В следующих примерах вы продолжите работать с Если вы работаете с исходной строкой ( Теперь, когда вы преобразовали строку в нижний регистр, чтобы избежать непреднамеренных проблем, связанных с чувствительностью к регистру, пришло время углубиться и узнать больше о подстроке. Оператор принадлежности Python предоставляет множество дополнительных строковых методов, которые позволяют вам проверять, сколько целевых подстрок содержит строка, искать подстроки в соответствии со сложными условиями или находить индекс подстроки в вашем тексте. В этом разделе вы познакомитесь с некоторыми дополнительными строковыми методами, которые помогут вам больше узнать о подстроке. Примечание: Возможно, вы видели следующие методы, используемые для проверки наличия в строке подстроки. Это возможно, но они не предназначены для этого! Программирование — это творческая деятельность, и всегда можно найти разные способы выполнения одной и той же задачи. Однако для удобочитаемости вашего кода лучше всего использовать методы в том виде, в котором они предназначены для языка, с которым вы работаете. Используя Если вам нужно знать, где в вашей строке встречается подстрока, вы можете использовать >>> Когда вы вызываете Примечание: Если Python не может найти подстроку, то Но что, если вы хотите найти другие вхождения подстроки? Метод >>> Когда вы передаете начальный индекс, который находится за первым вхождением подстроки, поиск Python начинается оттуда. Это означает, что текст содержит подстроку более одного раза. Но как часто он там? Вы можете использовать >>> Вы использовали Вы можете проверить все подстроки, разделив текст по границам слов по умолчанию и распечатав слова на своем терминале, используя >>> В этом примере вы используете Примечание: Вместо того, чтобы печатать подстроки, вы также можете сохранить их в новом списке, например, используя понимание списка с условным выражением: >>> В этом случае вы строите список только из слов, содержащих подстроку, что существенно фильтрует текст. Теперь, когда вы можете проверить все подстроки, которые идентифицирует Python, вы можете заметить, что Python не заботится о том, есть ли какие-либо символы после подстроки 9.0039 "секрет" или нет. Он находит слово независимо от того, следует ли за ним пробел или знак препинания. Это приятно знать, но что делать, если вы хотите установить более строгие условия для проверки подстроки? Удалить рекламу Вы можете сопоставлять только вхождения вашей подстроки, за которыми следует знак препинания, или идентифицировать слова, которые содержат подстроку плюс другие буквы, например В таких случаях, когда требуется более сложное сопоставление строк, вы можете использовать регулярные выражения или регулярные выражения с модулем Python Например, если вы хотите найти все слова, начинающиеся с >>> Функция Затем вы можете получить доступ к этим атрибутам с помощью методов объекта >>> Эти результаты обеспечивают большую гибкость для продолжения работы с совпавшей подстрокой. Например, вы можете искать только те подстроки, за которыми следует запятая ( >>> В вашем тексте есть два возможных совпадения, но вы сопоставили только первый результат, соответствующий вашему запросу. Когда вы используете Чтобы найти все совпадения, используя >>> Используя Когда вы используете группу захвата, вы можете указать, какую часть совпадения вы хотите оставить в своем списке, заключив эту часть в круглые скобки: >>> Заключив секрет в круглые скобки, вы определили единую группу захвата. Функция Примечание: Помните, что в вашем тексте было четыре вхождения подстроки Использование Если вы хотите сохранить эту информацию, то >>> Когда вы используете Вы можете заметить, что в этих результатах появляются знаки препинания, даже если вы все еще используете группу захвата. Это связано с тем, что строковое представление объекта Но объект >>> Вызвав При использовании регулярных выражений вы можете более подробно изучить сопоставление подстрок. Вместо того, чтобы просто проверять, содержит ли строка другую строку, вы можете искать подстроки в соответствии со сложными условиями. Примечание: Если вы хотите узнать больше об использовании групп захвата и составлении более сложных шаблонов регулярных выражений, вы можете глубже изучить регулярные выражения в Python. Использование регулярных выражений с Удалить рекламу Если вы работаете с данными, которые поступают не из простого текстового файла или пользовательского ввода, а из файла CSV или листа Excel, вы можете использовать тот же подход, который обсуждался выше. Однако есть лучший способ определить, какие ячейки в столбце содержат подстроку: вы будете использовать pandas ! В этом примере вы будете работать с CSV-файлом, содержащим поддельные названия компаний и слоганы. Вы можете скачать файл ниже, если хотите работать вместе: Когда вы работаете с табличными данными в Python, обычно лучше сначала загрузить их в pandas >>> В этом блоке кода вы загрузили файл CSV, содержащий тысячу строк поддельных данных компании, в кадр данных pandas и проверили первые пять строк, используя После того, как вы загрузили данные в DataFrame, вы можете быстро запросить весь столбец pandas для фильтрации записей, содержащих подстроку: >>> Вы можете использовать Примечание: Оператор индексирования ( Однако, если вы работаете с производственным кодом, который связан с производительностью, панды рекомендуют использовать оптимизированные методы доступа к данным для индексации и выбора данных. Когда вы работаете с >>> В этом фрагменте кода вы использовали тот же шаблон, что и ранее, для сопоставления только слов, содержащих секрет , но затем продолжите с одним или несколькими символами слова ( Вы можете написать любой сложный шаблон регулярного выражения и передать его Как настойчивый охотник за сокровищами, вы нашли каждый Вы также узнали, как описательно использовать два других строковых метода , которые часто неправильно используются для проверки подстрок: После этого вы узнали, как находить подстроки в соответствии с более сложными условиями с помощью регулярные выражения и несколько функций в модуле Python Наконец, вы также узнали, как можно использовать метод DataFrame 
Python3
a = [ 'Geeks-13' , 'for-56' , 'Geeks-78' , ' xyz-46' ] на i in a: if i.__contains__( "Geeks" ): print (f "Yes! {i } содержит." ) Да! Компьютерщики-13 содержат.
Да! Выродки-78 содержат.
Способ 7. Проверка подстроки с помощью регулярных выражений  В Python есть встроенный пакет re , который можно использовать для работы с регулярными выражениями.
В Python есть встроенный пакет re , который можно использовать для работы с регулярными выражениями. Python3
import re MyString1 = "A geek in need is a geek indeed" MyString2 = "geeks" IF RE.Search (MyString2, MyString1): Печать ( "Да, строка '{0}' присутствует в строке '{1}' 40404040404040404040404. Формат ( MyString2, MyString1)) ELSE : 34. '{1}' " 4. 'not String 9004. 9004. 9004. 9004. 9004. 9004. 9004. (9004.40404040404.  9004. 9004. 9004.
9004. 9004. 9004. . Формат ( MyString2, MyString1)) NO, String 'Geeks' Not In String in String in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in in wort in worpt in out in in in out in wout in worpl
Метод: Использование Постижения списка
Python3
S = "Гики для гисточек" S2 = 39 S2 = 39 " S2 = 39" S2 = " S2 = 39 S2 = " S2 = . 0040
0040 print ([ "yes" if s2 in s else "no" ]) ['yes']
Method: Using lambda function
Python3
s = "geeks for geeks" s2 = "geeks" x = Список ( Фильтр ( Lambda x: (S2 In .). ([ "yes" if x else "no" ]) ['yes']
Python3
import operator as op s = "geeks for geeks" s2 = "geeks" print ([ "yes" if op. 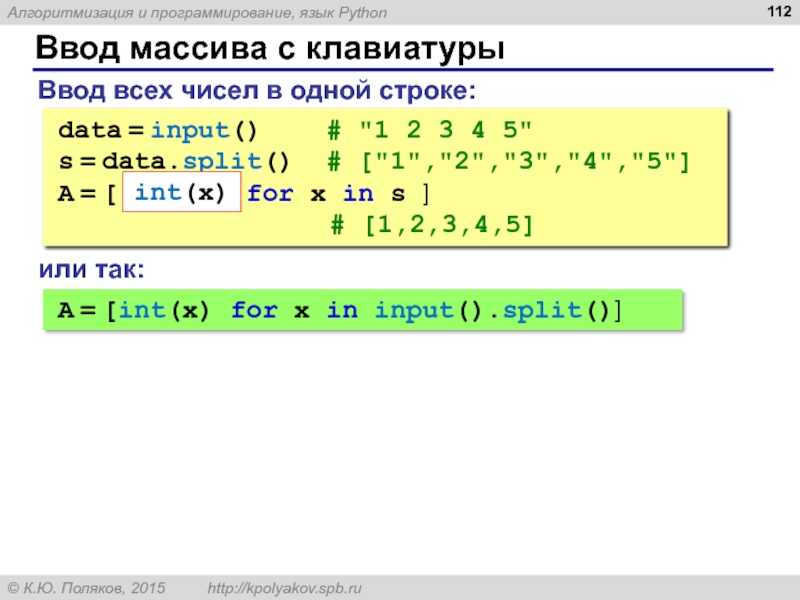 countOf(s.split(),s2)>
countOf(s.split(),s2)> 0 else "no" ]) ['yes']
Как проверить, содержит ли строка Python подстроку — настоящий Python
в . Кроме того, вы узнаете, как идентифицировать правильные строковые методы для связанных, но разных вариантов использования. Это полезно, если вам нужно выполнить поиск данных из CSV-файла. Вы могли бы использовать подход, который вы узнаете в следующем разделе, но если вы работаете с табличные данные , лучше всего загрузить данные в pandas DataFrame и искать подстроки в pandas.
Это полезно, если вам нужно выполнить поиск данных из CSV-файла. Вы могли бы использовать подход, который вы узнаете в следующем разделе, но если вы работаете с табличные данные , лучше всего загрузить данные в pandas DataFrame и искать подстроки в pandas. Как убедиться, что строка Python содержит другую строку
в . В Python это рекомендуемый способ подтверждения наличия подстроки в строке: >>> raw_file_content = """Привет и добро пожаловать.
... Это специальный скрытый файл с СЕКРЕТНЫМ секретом.
... Я не хочу раскрывать тебе Секрет,
... но я хочу по секрету сказать вам, что он у меня есть."""
>>> "секрет" в raw_file_content
Истинный
в дает вам быстрый и удобный способ проверить, присутствует ли подстрока в строке. Вы можете заметить, что строка кода читается почти как английский язык.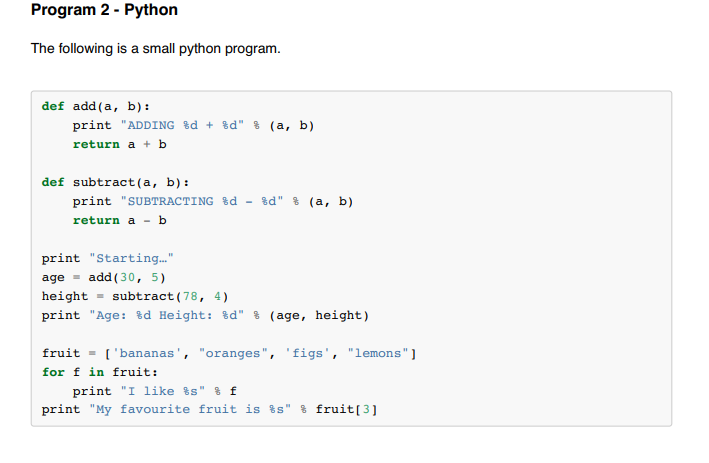
не в : >>> "secret" не в raw_file_content
ЛОЖЬ
"секретная" присутствует в raw_file_content , оператор не в возвращает False . в выражение возвращает логическое значение: Истинно , если Python нашел подстроку Ложь , если Python не нашел подстроку >>> если "секрет" в raw_file_content:
... печать("Найдено!")
...
Найденный!
"secret" подстрокой raw_file_content . Если это так, то вы напечатаете сообщение на терминал. Любой код с отступом будет выполняться только в том случае, если проверяемая вами строка Python содержит предоставленную вами подстроку.
Если это так, то вы напечатаете сообщение на терминал. Любой код с отступом будет выполняться только в том случае, если проверяемая вами строка Python содержит предоставленную вами подстроку. True : >>> "" в "секрет"
Истинный
в — ваш лучший друг, если вам просто нужно проверить, содержит ли строка Python подстроку. raw_file_content , то вы заметите, что подстрока встречается более одного раза и даже в разных вариациях!
Обобщить проверку, удалив чувствительность к регистру
"secret" в заглавной версии исходного текста, проверка оператора принадлежности возвращает False : >>> title_cased_file_content = """Привет и добро пожаловать.
... Это специальный скрытый файл с секретным секретом.
... Я не хочу рассказывать вам секрет,
... Но я хочу по секрету сказать вам, что он у меня есть.
>>> "секрет" в title_cased_file_content
ЛОЖЬ
title_cased_file_content , никогда не появляется во всех строчных буквах. Вот почему проверка, которую вы выполняете с оператором членства, возвращает
Вот почему проверка, которую вы выполняете с оператором членства, возвращает False . Python не может найти строчную строку «секрет» в предоставленном тексте. >>> file_content = title_cased_file_content.lower()
>>> печать (файл_содержимое)
привет и добро пожаловать.
это специальный скрытый файл с секретным секретом.
я не хочу раскрывать тебе тайну,
но я хочу по секрету сказать вам, что у меня есть один.
>>> "секрет" в файле_содержимого
Истинный
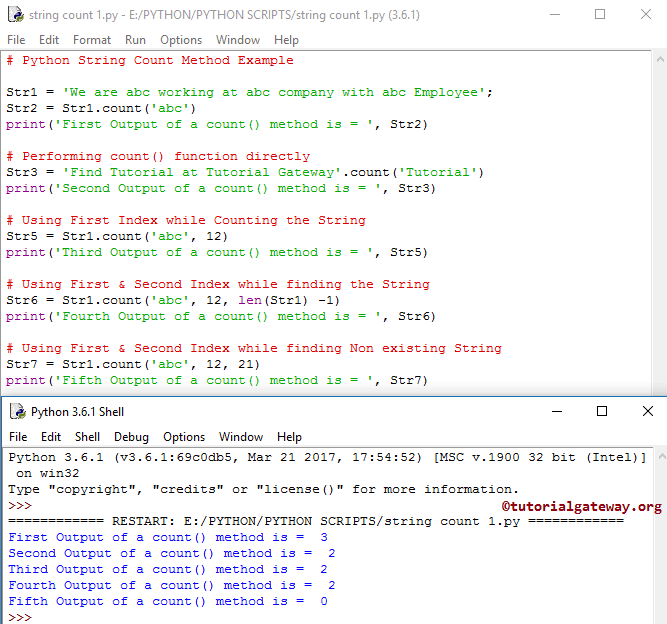
file_content , версией текста в нижнем регистре. raw_file_content ) или с заголовком ( title_cased_file_content ), вы получите разные результаты, потому что они не в нижнем регистре. Не стесняйтесь попробовать это, пока вы работаете с примерами! Узнайте больше о подстроке
к — отличный способ описательно проверить наличие подстроки в строке, но он не дает вам никакой дополнительной информации. Он идеально подходит для условных проверок, но что, если вам нужно больше узнать о подстроках?
в , вы подтверждаете, что строка содержит подстроку. Но вы не получили никакой информации о , где находится подстрока. .index() для строкового объекта: >>> file_content = """привет и добро пожаловать.
 ... это специальный скрытый файл с секретным секретом.
... я не хочу раскрывать тебе секрет,
... но я хочу по секрету сказать вам, что он у меня есть."""
>>> file_content.index("секрет")
59
... это специальный скрытый файл с секретным секретом.
... я не хочу раскрывать тебе секрет,
... но я хочу по секрету сказать вам, что он у меня есть."""
>>> file_content.index("секрет")
59 .index() для строки и передаете ей подстроку в качестве аргумента, вы получаете позицию индекса первого символа первого вхождения подстроки. .index() вызывает исключение ValueError . .index() также принимает второй аргумент, который может определить, с какой позиции индекса начинать поиск. Таким образом, передавая определенные позиции индекса, вы можете пропустить вхождения подстроки, которую вы уже идентифицировали: >>> file_content.index("секрет", 60)
66
 В этом случае вы получите другое совпадение, а не
В этом случае вы получите другое совпадение, а не ValueError . .count() , чтобы быстро получить ответ, используя описательный и идиоматический код Python: >>> file_content.count("секрет")
4
.count() в строчной строке и передали подстроку "secret" в качестве аргумента. Python подсчитал, как часто подстрока появляется в строке, и вернул ответ. Текст содержит подстроку четыре раза. Но как выглядят эти подстроки? для шлейфа : >>> для слова в file_content.split():
... если "секретно" в слове:
... печать (слово)
...
секрет
секрет.
 секрет,
тайно
секрет,
тайно
.split() для разделения текста в пробелах на строки, которые Python упаковывает в список. Затем вы перебираете этот список и используете в для каждой из этих строк, чтобы увидеть, содержит ли она подстроку "secret" . >>> [дословно в file_content.split () если "секрет" в слове]
['секретно', 'секретно.', 'секретно', 'тайно']
 Он даже находит такие слова, как
Он даже находит такие слова, как «тайно» . Найти подстроку с условиями с помощью регулярного выражения
"тайно" . re . «секрет» , но за которыми следует хотя бы одна дополнительная буква, вы можете использовать символ слова регулярного выражения ( \w ), за которым следует квантификатор плюса. ( + ): >>> импорт
>>> file_content = """привет и добро пожаловать.
 ... это специальный скрытый файл с секретным секретом.
... я не хочу раскрывать тебе секрет,
... но я хочу по секрету сказать вам, что он у меня есть."""
>>> re.search(r"secret\w+", file_content)
... это специальный скрытый файл с секретным секретом.
... я не хочу раскрывать тебе секрет,
... но я хочу по секрету сказать вам, что он у меня есть."""
>>> re.search(r"secret\w+", file_content)
re.search() возвращает как подстроку, соответствующую условию, так и ее начальную и конечную позиции индекса, а не просто True ! Match , который обозначается m : >>> m = re.search(r"secret\w+", file_content)
>>> м.группа()
'тайно'
>>> м.промежуток()
(128, 136)
, ) или точка (. ): >>> re.
 search(r"секрет[\.,]", file_content)
search(r"секрет[\.,]", file_content)
re.search() , Python снова находит только первых совпадений . Что делать, если вы хотите все упоминания "секретные" которые соответствуют определенному условию? re , вы можете работать с re.findall() : >>> re.findall(r"секрет[\.,]", file_content)
['секрет.', 'секрет']
re.findall() , вы можете найти все совпадения шаблона в вашем тексте. Python сохраняет для вас все совпадения в виде строк в списке. >>> re.
 findall(r"(секрет)[\.,]", file_content)
['секрет', 'секрет']
findall(r"(секрет)[\.,]", file_content)
['секрет', 'секрет']
findall() возвращает список строк, соответствующих этой захватываемой группе, если в шаблоне имеется ровно одна захватываемая группа. Добавив скобки вокруг secret , вам удалось избавиться от пунктуации! "secret" , и, используя re , вы отфильтровали два конкретных вхождения, которые вы сопоставили в соответствии с особыми условиями. re.findall() с группами соответствия — это мощный способ извлечения подстрок из вашего текста. Но вы получаете только список из строк , что означает, что вы потеряли позиции индекса, к которым у вас был доступ при использовании re.search() . re может дать вам все совпадения в итераторе: >>> для совпадения в re.
 finditer(r"(secret)[\.,]", file_content):
... печать (совпадение)
...
finditer(r"(secret)[\.,]", file_content):
... печать (совпадение)
...
re.finditer() и передаете шаблон поиска и текстовое содержимое в качестве аргументов, вы можете получить доступ к каждому Совпадение с объектом , который содержит подстроку, а также ее начальную и конечную позиции индекса. Match отображает все совпадение, а не только первую группу захвата. Match является мощным контейнером информации, и, как вы уже видели ранее, вы можете выбрать именно ту информацию, которая вам нужна: >>> для совпадения в re.finditer(r"(secret)[\.,]", file_content):
.
 .. печать (соответствие.группа (1))
...
секрет
секрет
.. печать (соответствие.группа (1))
...
секрет
секрет
.group() и указав, что вам нужна первая группа захвата, вы выбрали слово секрет без знаков препинания из каждой совпадающей подстроки. относительно — хороший подход, если вам нужна информация о подстроках или если вам нужно продолжить работу с ними после того, как вы нашли их в тексте. Но что, если вы работаете с табличными данными? Для этого вы обратитесь к пандам. Найти подстроку в столбце pandas DataFrame

DataFrame : >>> импортировать панд как pd
>>> компании = pd.read_csv("companies.csv")
>>> компании.форма
(1000, 2)
>>> компании.голова()
слоган компании
0 Кувалис-Нолан произвели революцию в метриках следующего поколения
1. Дитрих-Шамплин предлагает передовые функциональные возможности
2 ориентированных на пользователя информационных посредника West Inc.
3 ООО «Венер» использует липких информационных посредников
4 Langworth Inc заново изобретает магнитные сети
. . head()
head() >>> компании[companies.slogan.str.contains("секрет")]
слоган компании
7 Maggio LLC нацелена на секретные ниши
117 фирменных секретных методологий Kub and Sons
654 Секретные парадигмы синдиката Косс-Зулауф
656 Бернье-Кин тайно синтезирует внутреннюю полосу пропускания
921 Ward-Shield использует секретную электронную коммерцию
945 Williamson Group выпускает секретные экшн-предметы
.str.contains() в столбце pandas и передать ему подстроку в качестве аргумента для фильтрации строк, содержащих подстроку. [] ) и оператор атрибута ( . ) предлагают интуитивно понятные способы получения отдельного столбца или фрагмента DataFrame.
.str.contains() и вам нужны более сложные сценарии сопоставления, вы также можете использовать регулярные выражения! Вам просто нужно передать шаблон поиска, совместимый с регулярным выражением, в качестве аргумента подстроки: >>> компании[companies.slogan.str.contains(r"secret\w+")]
слоган компании
656 Бернье-Кин тайно синтезирует внутреннюю полосу пропускания
\w+ ). Кажется, только одна из компаний в этом поддельном наборе данных тайно управляет ! ., чтобы вырезать из столбца pandas только те строки, которые вам нужны для анализа. str.contains()
str.contains() Заключение
«секрет» , как бы хорошо он ни был спрятан! В процессе вы узнали, что лучший способ проверить, содержит ли строка подстроку в Python, — это использовать в операторе членства . .count() для подсчета вхождений подстроки в строку .index() , чтобы получить позицию индекса начала подстроки re . .