python — Перенос длинных строк кода с точкой, как правильно по pep8
Задать вопрос
Вопрос задан
Изменён 2 года 6 месяцев назад
Просмотрен 3k раз
Встал вопрос, как правильно и красиво сделать перенос длинной строки кода по PEP8 в месте точки:
result = list(
MyModel.objects
.filter(field1=100)
.exclude(field2='a')
.values_list(field3, flat=True))
Пытаюсь сделать так, вставив отступы в начале каждой строки перед точкой. Но autopep8 переформатирует:
result = list(
MyModel.objects
.filter(field1=100)
.exclude(field2='a')
.values_list(field3, flat=True))
Все бы ничего, но это код, над которым работает команда и она требует единой стилистики.
- python
- code-style
4
Я в подобных случаях считаю самым удобочитаемым вариант при котором первый же кусочек с точкой идёт с новой строки:
result = list(
MyModel
.objects
.filter(field1=100)
.exclude(field2='a')
.values_list(field3, flat=True)
)
Никаких лишних отступов нет и автопроверка стиля не ругается.
2
Зарегистрируйтесь или войдите
Регистрация через GoogleРегистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Разметка кода Python, PEP 8
Рекомендуется придерживаться следующих правил разметки кода
Отступы:
Последующие строки обернутых элементов в скобки должны быть выравнены либо по вертикали, либо с помощью висящего отступа.
При использовании висячего отступа, следует учитывать следующее: в первой строке не должно быть аргументов, и следует использовать дополнительный отступ, чтобы четко отличить себя как строку продолжения.
Правильно:
# Выравнивается с разделителем открытия.
foo = long_function_name(var_one, var_two,
var_three, var_four)
# Добавьте 4 пробела (дополнительный уровень отступа),
# чтобы отличить аргументы.
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
# У висячих строк должны быть отступы.
foo = long_function_name(
var_one, var_two,
var_three, var_four)
Не правильно:
#Аргументы в первой строке запрещены, если не используется вертикальное выравнивание.
foo = long_function_name(var_one, var_two,
var_three, var_four)
# Требуется дополнительное отступы, так как аргументы сливаются с кодом.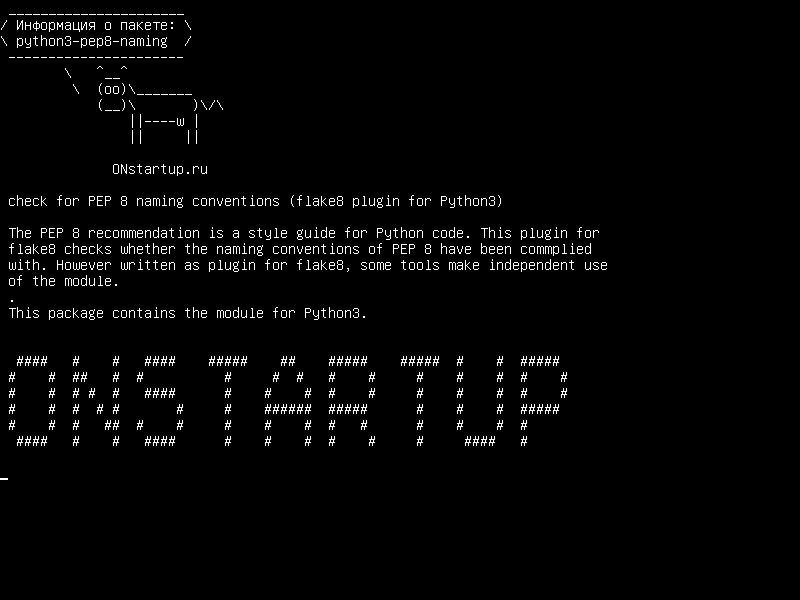 def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
Правило 4 пробелов не является обязательным для строк продолжения.
По желанию:
# Висячие отступы могут иметь отступы, отличные от 4 пробелов. foo = long_function_name ( var_one, var_two, var_three, var_four)
Когда условная часть if достаточно длинная (более 79 символов) и мы должны записать ее в несколько строк, стоит отметить, что сочетание двухсимвольного ключевого слова (например, if. Приемлемые варианты в этой ситуации можно посмотреть в примерах ниже, но не ограничиваться этим:
# Никаких дополнительных отступов, код в конструкции if
# сливается с условием, что затрудняет чтение кода
if (this_is_one_thing and
that_is_another_thing):
do_something()
# Добавить комментарий, который обеспечит некоторое различие # в редакторе при помощи подсветки синтаксиса.if (this_is_one_thing and that_is_another_thing): # Так как .... do_something()
# Добавьте дополнительный отступ в строке условного продолжения.
if (this_is_one_thing
and that_is_another_thing):
do_something()
Закрывающая скобка в многострочных конструкциях может располагаться либо под первым символом последней строки списка:
my_list = [
1, 2, 3,
4, 5, 6,
]
result = some_function_that_takes_arguments (
'a', 'b', 'c',
'd', 'e', 'f',
)
или может быть на уровне первого символа строки, которая начинает многострочную конструкцию:
my_list = [
1, 2, 3,
4, 5, 6,
]
result = some_function_that_takes_arguments (
'a', 'b', 'c',
'd', 'e', 'f',
)
TAB или пробелы?
Пробелы являются предпочтительным методом отступа.
Табуляция должна использоваться исключительно для соответствия с кодом, который уже имеет такие отступы.
Python 3 запрещает смешивать использование табуляции и пробелов для отступа. Код с отступом в виде комбинации символов табуляции и пробелов должен быть преобразован исключительно в пробелы.
Код с отступом в виде комбинации символов табуляции и пробелов должен быть преобразован исключительно в пробелы.
При вызове интерпретатора командной строки Python 2 с параметром -t выдает предупреждения о коде, который смешивает табуляции и пробелы. При использовании -tt эти предупреждения становятся ошибками. Эти варианты настоятельно рекомендуются!
Ограничьте все строки максимум 79 символами.
Для строк документации или комментариев длина строки должна быть ограничена 72 символами.
Ограничение ширины окна редактора позволяет одновременно открывать несколько файлов и хорошо работает при использовании инструментов обзора, которые представляют две версии кода в соседних окнах.
Перенос по умолчанию в большинстве редакторов нарушает визуальную структуру кода, что делает его более трудным для понимания. Данные ограничения приняты для того, чтобы избежать автоматического переноса строк в редакторах с шириной окна, установленной на 80 символов, даже если он помещает маркер курсора в последний столбец. Некоторые IDE могут вообще не иметь авто-переноса строк.
Некоторые IDE могут вообще не иметь авто-переноса строк.
Некоторые команды разработчиков предпочитают более длинные строки при написании кода. Исключительно для поддержания такого кода внутри команды, разрешается увеличить ограничение длины строки до 99 символов, при условии, что комментарии и документация должна быть ограничена 72 символами
Стандартная библиотека Python консервативна и требует ограничения строки до 79 символов (и строки документации/комментариев до 72).
Предпочтительный способ переноса длинных строк — это использование показанного выше переноса кода внутри скобок. Длинные строки можно разбить на несколько строк, заключив выражения в скобки.
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)
Если такое не возможно, например, длинные строковые параметры в аргументах функций, то допустимо использование обратного слеша \.
with open('/path/to/some/file/you/want/to/read') as file_1, \
open('/path/to/some/file/being/written', 'w') as file_2:
file_2.write(file_1.read())
Еще один такой случай возможен с assert утверждениями.
Удостоверьтесь, что сделали отступ в 4 пробела для продолжения строки кода.
Перенос строки до или после двоичного оператора?В течение десятилетий рекомендуется переносить строки после двоичного оператора. Но это может усложнить читабельность. При таком переносе, операторы, как правило, разбросаны по разным столбцам, при этом каждый оператор отошел от своей переменной и перешел на предыдущую строку. Здесь глаз должен сделать дополнительную работу, чтобы увидеть, какие элементы добавляются, а какие вычитаются:
# Неправильно:
# операторы сидят далеко от своих операндов
income = (gross_wages +
taxable_interest +
(dividends - qualified_dividends) -
ira_deduction -
student_loan_interest)
Чтобы решить проблему читаемости, математики следуют противоположному соглашению. Следуя традиции математики, обычно получается более читаемый код:
Следуя традиции математики, обычно получается более читаемый код:
# Правильно:
# легко сопоставлять операторы с операндами
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)
В коде Python допускается перенос до или после двоичного оператора, если есть такое соглашение. Для нового кода предлагается математический стиль.
Пустые строки:Определения функций и классов верхнего уровня должны быть заключены в две пустые строки.
Определения методов внутри класса заключены в одну пустую строку.
Дополнительные пустые строки могут использоваться для разделения групп связанных функций. Пустые строки могут быть пропущены между связкой связанных строк (например, набором фиктивных реализаций).
Используйте пустые строки в функциях, чтобы указать логические разделы.
Python принимает символ перевода формы control-L (т.е. ^ L) в качестве пробела. Многие инструменты обрабатывают эти символы как разделители страниц, поэтому, вы можете использовать их для разделения страниц связанных разделов вашего файла. Обратите внимание, что некоторые редакторы и IDE могут не распознавать
Многие инструменты обрабатывают эти символы как разделители страниц, поэтому, вы можете использовать их для разделения страниц связанных разделов вашего файла. Обратите внимание, что некоторые редакторы и IDE могут не распознавать control-L.
Код в основном дистрибутиве Python всегда должен использовать UTF-8 (или ASCII в Python 2).
Файлы, использующие ASCII (в Python 2) или UTF-8 (в Python 3), не должны иметь декларации кодировки.
В стандартной библиотеке, кодировки, отличные от заданных по умолчанию, следует использовать только для целей тестирования или в тех случаях, когда в комментариях или строке документации необходимо упомянуть имя автора, содержащее символы, отличные от ASCII. В противном случае использование \x , \u , \U или \N escape-файлов является предпочтительным способом включения данных не-ASCII в строковые литералы.
Для Python 3.0 и выше, для стандартной библиотеки предписана следующая политика. Все идентификаторы в стандартной библиотеке Python ДОЛЖНЫ использовать идентификаторы только ASCII и ДОЛЖНЫ использовать английские слова везде, где это возможно (сокращения и технические термины, которые не являются английскими). Кроме того, все строковые литералы и комментарии также должны быть в ASCII.
Все идентификаторы в стандартной библиотеке Python ДОЛЖНЫ использовать идентификаторы только ASCII и ДОЛЖНЫ использовать английские слова везде, где это возможно (сокращения и технические термины, которые не являются английскими). Кроме того, все строковые литералы и комментарии также должны быть в ASCII.
Единственными исключениями являются:
- Контрольные примеры, тестирующие функции, отличные от ASCII,
- Имена авторов. Авторы, чьи имена не основаны на латинском алфавите, ДОЛЖНЫ обеспечить транслитерацию своих имен.
Проектам с открытым исходным кодом с глобальной аудиторией рекомендуется придерживаться аналогичной политики.
Импорт:Импорт обычно должен быть в отдельных строках:
# Правильно: import os import sys # Неправильно: import sys, os
Это нормально, хотя:
from subprocess import Popen, PIPE
Импорт всегда помещается вверху файла, сразу после любых комментариев и строк документации, а также перед глобальными переменными и константами модуля.
Импорт должен быть сгруппирован в следующем порядке:
- Импорт стандартной библиотеки.
- Связанный импорт третьей стороны.
- Локальный импорт приложений или библиотек.
Вы должны поставить пустую строку между каждой группой импорта.
Рекомендуется абсолютный импорт, так как он обычно более читабелен и, как правило, ведет себя лучше (или, по крайней мере, дает лучшие сообщения об ошибках), если система импорта настроена неправильно (например, когда каталог внутри пакета заканчивается в sys.path ):
import mypkg.sibling from mypkg import sibling from mypkg.sibling import example
Однако явный относительный импорт является приемлемой альтернативой абсолютному импорту, особенно когда речь идет о сложном макете в пакете, где использование абсолютного импорта было бы излишне многословным:
from . import sibling from .sibling import example
Код стандартной библиотеки должен избегать сложных макетов пакетов и всегда использовать абсолютный импорт.
Неявный относительный импорт никогда не должен использоваться и был удален в Python 3.
При импорте класса из модуля, обычно можно записать следующее:
from myclass import MyClass from foo.bar.yourclass import YourClass
Если это написание вызывает локальные конфликты имен, то запишите импорт через точку:
import myclass import foo.bar.yourclass
и используйте myclass.MyClass и foo.bar.yourclass.YourClass.
Следует избегать импорта подстановочных знаков ( from <module> import * ), так как из-за этого неясно, какие имена присутствуют в пространстве имен, запутывает как читателей, так и многие автоматизированные инструменты. Существует один оправданный вариант использования для импорта с использованием подстановочного знака, который заключается в повторной публикации внутреннего интерфейса как части общедоступного API.
При повторной публикации имен, все же применяются приведенные ниже рекомендации, касающиеся открытых и внутренних интерфейсов.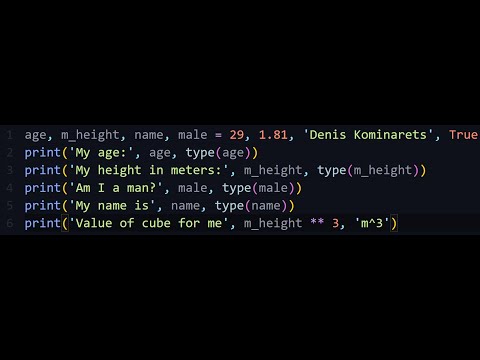
Имена «dunders» (имена с двумя начальными и двумя замыкающими подчеркиваниями), такие как __all__ , __author__ , __version__ и т. ., Должны быть помещены после строки документации модуля, но перед любыми операторами импорта, кроме __future__. Python предписывает, что в __future__ импорт должен стоять перед любым другим кодом, кроме строк документации:
"""This is the example module. This module does stuff. """ from __future__ import barry_as_FLUFL __all__ = ['a', 'b', 'c'] __version__ = '0.1' __author__ = 'Cardinal Biggles' import os import sysКавычки в строках:
В Python одинарные и двойные кавычки функционально одинаковы. PEP не дает рекомендации какие из них предпочтительнее. Выберите правило и придерживайтесь его. Если, например, строка содержит одинарные кавычки, чтобы избежать обратной косой черты в строке, используйте дополнительно двойные кавычки. Это улучшает читаемость.
Это улучшает читаемость.
Для строк с тройными кавычками всегда используйте символы двойной кавычки, чтобы соответствовать соглашению с документированной строкой в PEP 257.
Правильный стиль для разрывов строк при цепочке методов в Python
PEP 8 рекомендует использовать круглые скобки, чтобы вам не нужно было \ , и мягко предлагает разбить перед бинарными операторами, а не после них. Таким образом, предпочтительный способ форматирования вашего кода выглядит следующим образом:
my_var = (что-то вроде этого
.где(мы=делаем_вещи)
.где(мы=доморе)
.где(мы=everdomore))
Два соответствующих отрывка из раздела «Максимальная длина строки»:
Предпочтительным способом переноса длинных строк является использование подразумеваемого Python продолжения строки внутри круглых и фигурных скобок. Длинные строки можно разбивать на несколько строк, заключая выражения в круглые скобки. Их следует использовать вместо использования обратной косой черты для продолжения строки.

… и весь Должен ли разрываться строка до или после бинарного оператора? раздел:
На протяжении десятилетий рекомендуемым стилем было прерывание после бинарных операторов. Но это может повредить удобочитаемости двумя способами: операторы, как правило, получают разбросаны по разным колонкам на экране, и каждый оператор переместился из своего операнда на предыдущую строку. Вот, глаз должен проделать дополнительную работу, чтобы определить, какие элементы добавлены, а какие нет. вычитано:
# Нет: операторы находятся далеко от своих операндов доход = (валовая_заработная плата + налогооблагаемый_процент + (дивиденды - квалифицированные_дивиденды) - ira_deduction - student_loan_interest)Чтобы решить эту проблему удобочитаемости, математики и их издатели следовать противоположному соглашению. Дональд Кнут объясняет традиционное правило в его серии «Компьютеры и набор текста »: «Хотя формулы внутри абзаца всегда разрыв после бинарных операций и отношений, отображаемые формулы всегда прерываются перед бинарными операциями»
Следование традиции математики обычно приводит к более читаемый код:
# Да: легко сопоставить операторы с операндами доход = (валовая_заработная плата + налогооблагаемый_процент + (дивиденды - квалифицированные_дивиденды) - ira_deduction - student_loan_interest)В коде Python допустимо прерывание до или после двоичного файла.
оператора, если соглашение непротиворечиво локально. Для новых предлагается стиль кода Кнута.
Обратите внимание, что, как указано в приведенной выше цитате, PEP 8 использовал , чтобы дать противоположный совет о том, где прерывать работу оператора, приведенный ниже для потомков:
Предпочтительный способ переноса длинных строк — использование подразумеваемой строки Python. продолжение внутри скобок, скобок и фигурных скобок. Длинные очереди могут быть разбивается на несколько строк путем заключения выражений в круглые скобки. Эти следует использовать вместо использования обратной косой черты для продолжения строки. Не забудьте сделать отступ в продолжении строки соответствующим образом. Предпочтительное место разбить бинарный оператор после оператора, а не перед ним. Некоторые примеры:
класс Прямоугольник (Blob): def __init__(я, ширина, высота, цвет='черный', акцент=нет, подсветка=0): если (ширина == 0 и высота == 0 и цвет == «красный» и акцент == «сильный» или выделить> 100): поднять ValueError("извините, вы проиграли") если ширина == 0 и высота == 0 и (цвет == 'красный' или ударение отсутствует): поднять ValueError("Я так не думаю -- значения %s, %s" % (ширина высота)) Blob.__init__(я, ширина, высота, цвет, выделение, выделение)
Rhino — Базовый синтаксис Python
Базовый синтаксис Python
к Дейл Фужье (Последнее обновление: среда, 12 декабря 2018 г.)
Обзор
Многие языки сценариев и программирования, такие как JScript, C# и C++, не пытаются сопоставить выполняемый код с реальными физическими строками, введенными в текстовый редактор. Это связано с тем, что они не распознают конец строки кода, пока не увидят символ завершения (в этих случаях точку с запятой). Таким образом, фактические физические строки типа, занимаемые кодом, не имеют значения.
В отличие от других языков, Python не использует символ конца строки. В большинстве случаев подойдет простой Введите . Тем не менее, Python очень требователен к отступам, пробелам и строкам в некоторых случаях. Этот документ поможет понять форматирование Python.
Этот документ поможет понять форматирование Python.
Важно понимать, как Python интерпретирует:
- Конец оператора
- Имена и заглавные буквы
- Комментарии
- Блочные конструкции
- Вкладки и пробелы
Официальную очень подробную документацию по синтаксису Python см. в Руководстве по стилю для кода Python
Чтобы завершить оператор в Python, вам не нужно вводить точку с запятой или другой специальный символ; вы просто нажимаете Введите . Например, этот код вызовет синтаксическую ошибку: сообщение
. "=" 'Привет, мир!'
Это не будет:
message = 'Hello World!'
В общем, отсутствие обязательного символа завершения оператора упрощает написание скриптов на Python. Однако есть одна сложность: для повышения удобочитаемости рекомендуется ограничить длину любой отдельной строки кода до 79.персонажи. Что произойдет, если у вас есть строка кода, содержащая 100 символов?
Хотя это может показаться очевидным решением, вы не можете разделить оператор на несколько строк, просто введя возврат каретки. Например, следующий фрагмент кода возвращает ошибку времени выполнения в Python, поскольку инструкция была разделена с помощью Введите .
Например, следующий фрагмент кода возвращает ошибку времени выполнения в Python, поскольку инструкция была разделена с помощью Введите .
message= 'Это сообщение вызовет ошибку, потому что он был разделен с помощью кнопки ввода на вашем клавиатура
Вы не можете разделить оператор на несколько строк в Python, нажав Enter . Вместо этого используйте обратную косую черту ( \ ), чтобы указать, что оператор продолжается на следующей строке. В исправленной версии сценария пробел и подчеркивание указывают на то, что оператор, начатый в строке 1, продолжается в строке 2. Чтобы сделать более очевидным, что строка 2 является продолжением строки 1, строка 2 также имеет отступ. четыре пробела. (Это было сделано для удобочитаемости, но вам не нужно делать отступ для продолжающихся строк.)
сообщение\ "=" 'Этот \ обратная косая черта \ действует \ нравиться \ входить' Распечатать\ сообщение
сообщение\ "=" тройной кавычки воля охватывать несколько строк без ошибки''' Распечатать\ сообщение
Продолжение строки происходит автоматически, когда разделение происходит, когда оператор находится внутри круглых скобок ( ( ), квадратных скобок ( [ ) или фигурных скобок ( { ).