Типы данных в C#
Вы здесь: Главная — C# — Основы C# — Типы данных в C#
C# — это статически типизированный язык программирования. Поэтому перед тем как использовать переменную в C# Вы должны определить ее тип. Тип переменной задает ограничение на значение переменной, а также виды операций, которые можно выполнять с ней.
Итак, таблица с типами переменных в C# представлена ниже:
| Тип данных | Размер | Описание |
|---|---|---|
| int | 4 байта | Хранит целые числа в диапазоне от -2,147,483,648 до 2,147,483,647 |
| long | 8 байт | Хранит целые числа в диапазоне от -9,223,372,036,854,775,808 до 9,223,372,036,854,775,807 |
| float | 4 байта | Хранит дробные числа с точностью до 7 знаков после запятой |
| double | 8 байт | Хранит дробные числа с точностью до 15 знаков после запятой |
| bool | 1 бит | Хранит логические значения true или false |
| char | 2 байта | Хранит один символ/букву в одинанрных кавычках |
| string | 2 байта на символ | Хранит последовательность символов, обрамленных в двойные кавычки |
Числа
Числа в C# делятся на две большие группы:
- Целочисленные типы — к ним относятся int и double
- Числа с плавающей запятой — float и double
Как правило в C#
наиболее часто используются тип int и double.
int number1 = 100 // целое число
long number2 = 230000000000L // целое число типа longfloat number3 = 10.12F
double number4 = 1999399.23737D
Как говорилось ранее, типы float и double отличаются друг от друга диапазоном значений и количеством знаков после запятой. Так какой же из типов использовать?
Точность значения с плавающей запятой (float) указывает, сколько цифр это значение может иметь после десятичной точки. Точность float составляет всего шесть или семь десятичных цифр, в то время как double переменные имеют точность около 15 цифр. Поэтому для большинства расчетов безопаснее использовать double.
Логические переменные
Логический тип данных в C# объявляется с ключевым словом bool
bool isTrue = true;
bool isFalse = false;
Символы и строки
char symbol = 'C' // один символ в одинарных кавычках!string str = "как так строка"
Таким образом, C# имеет подобную базовую систему типов, которых будет хватать в большинстве случае. Однако, помимо этого у языка также есть более продвинута система типов, ориентированная на
оптимизации под кокретные задачи.
Однако, помимо этого у языка также есть более продвинута система типов, ориентированная на
оптимизации под кокретные задачи.
- Создано 01.12.2020 12:27:42
- Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
<a href=»https://myrusakov.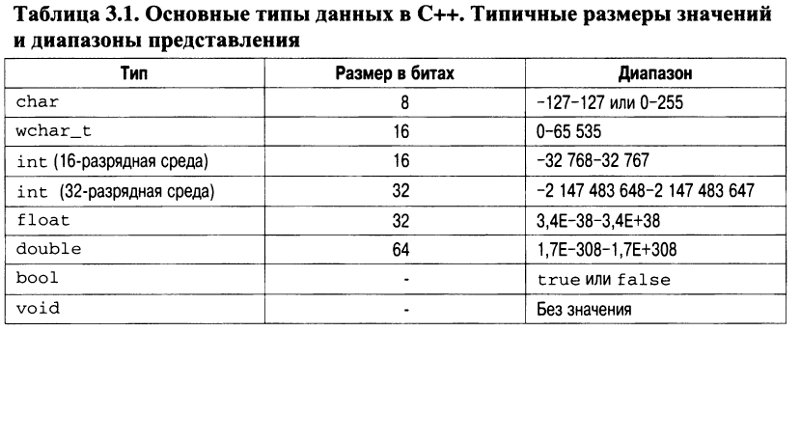 ru» target=»_blank»><img src=»https://myrusakov.ru/images/button.gif» alt=»Как создать свой сайт» /></a>
ru» target=»_blank»><img src=»https://myrusakov.ru/images/button.gif» alt=»Как создать свой сайт» /></a> -
Текстовая ссылка:
<a href=»https://myrusakov.ru» target=»_blank»>Как создать свой сайт</a>Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):
[URL=»https://myrusakov.ru»]Как создать свой сайт[/URL]
Типы данных, определяемые пользователем в C++
В реальных задачах информация, которую требуется обрабатывать, может иметь достаточно сложную структуру. Для ее адекватного представления используются типы данных, построенные на основе простых типов данных, массивов и указателей. Язык C++ позволяет программисту определять свои типы данных и правила работы с ними. Исторически для таких типов сложилось наименование, вынесенные в название статьи, хотя правильнее было бы назвать их типами, определяемыми программистом.
Переименование типов (typedef)
Для того чтобы сделать программу более ясной, можно задать типу новое имя с помощью ключевого слова typedef:
typedef тип новое_имя [ размерность ];
В данном случае квадратные скобки являются элементом синтаксиса. Размерность может отсутствовать. Примеры:
typedef unsigned int UINT;
typedef char Msg[100];
typedef struct{
char f1o[30];
int date, code;
double salary;} Worker;
Введенное таким образом имя можно использовать таким же образом, как и имена стандартных типов:
UINT i, j ; // две переменных типа unsigned int
Msg str[10]; // массив из 10 строк по 100 символов
Worker staff[100]; // массив из 100 структур
Кроме задания типам с длинными описаниями более коротких псевдопимов, typedef используется для облегчения переносимости программ: если машинно-зависимые типы объявить с помощью операторов typedef, при переносе программы потребуется внести изменения только в эти операторы.
Перечисления (enum)
При написании программ часто возникает потребность определить несколько именованных констант, для которых требуется, чтобы все они имели различные значения (при этом конкретные значения могут быть не важны). Для этого удобно воспользоваться перечисляемым типом данных, все возможные значения которого задаются списком целочисленных констант. Формат:
enum [ имя_типа ] { список_констант };
Имя типа задается в том случае, если в программе требуется определять переменные этого типа. Компилятор обеспечивает, чтобы эти переменные принимали значения только из списка констант. Константы должны быть целочисленными и могут инициализироваться обычным образом. При отсутствии инициализатора первая константа обнуляется, а каждой следующей присваивается на единицу большее значение, чем предыдущей:
enum Err {ERR__READ, ERR__WRITE, ERR_CONVERT};
Err error;
switch (error){
case ERR_READ: /* операторы */ break;
case ERR_WRITE: /* операторы */ break;
case ERR_CONVERT: /* операторы */ break;
}
Константам ERR_READ, ERR_WRITE, ERR_CONVERT присваиваются значения 0, 1 и 2 соответственно.
Другой пример:
enum {two = 2, three, four, ten = 10, eleven, fifty = ten + 40};
Константам three и four присваиваются значения 3 и 4, константе eleven — 11.
Имена перечисляемых констант должны быть уникальными, а значения могут совпадать. Преимущество применения перечисления перед описанием именованных констант и директивой #define состоит в том, что связанные константы нагляднее; кроме того, компилятор при инициализации констант может выполнять проверку типов.
При выполнении арифметических операций перечисления преобразуются в целые. Поскольку перечисления являются типами, определяемыми пользователем, для них можно вводить собственные операции.
ПримечаниеДиапазон значений перечислепия определяется количеством бит, необходимым для представления всех его значений. Любое значение целочисленного типа можно явно привести к типу перечислепия, по при выходе за пределы его диапазона результат не определен.
Структуры (struct)
В отличие от массива, все элементы которого однотипны, структура может содержать элементы разных типов. В языке C++ структура является видом класса и обладает всеми его свойствами, но во многих случаях достаточно использовать структуры так, как они определены в языке С:
В языке C++ структура является видом класса и обладает всеми его свойствами, но во многих случаях достаточно использовать структуры так, как они определены в языке С:
struct [ имя_типа ] {
тип_1 элемент_1:
тип_2 элемент_2;
тип_n элемент_n;
} [ список_описателей ];
Элементы структуры называются полями структуры и могут иметь любой тип, кроме типа этой же структуры, но могут быть указателями на него. Если отсутствует имя типа, должен быть указан список описателей переменных, указателей или массивов. В этом случае описание структуры служит определением элементов этого списка:
// Определение массива структур и указателя на структуру:
struct {
char f1o[30];
int date, code;
double salary;
}staff[100], *ps;
Если список отсутствует, описание структуры определяет новый тип, имя которого можно использовать в дальнейшем наряду со стандартными типами, например:
struct Worker{ // описание нового типа Worker
char f1o[30];
int date, code;
double salary;
}; // описание заканчивается точкой с запятой
// определение массива типа Worker и указателя на тип Worker:
Worker staff[100], *ps;[/ccie_cpp]
Имя структуры можно использовать сразу после его объявления (определение можно дать позднее) в тех случаях, когда компилятору не требуется знать размер структуры, например:
struct List;. // объявление структуры List
// объявление структуры List
struct Link{
List *p; // указатель на структуру List
Link *prev, *succ; // указатели на структуру Link
};
struct List { / * определение структуры List * / };
Это позволяет создавать связные списки структур.
Для инициализации структуры значения ее элементов перечисляют в фигурных скобках в порядке их описания:
struct{
char fio[30];
int date, code;
double salary;
}worker = {"Страусенке". 31. 215. 3400.55};
При инициализации массивов структур следует заключать в фигурные скобки каждый элемент массива (учитывая, что многомерный массив — это массив массивов):
struct complex{
float real, im;
} compl [2][3] = {
{{1. 1}. {1. 1}. {1. 1}}. // строка 1. TO есть массив compl[0]
{{2. 2}. {2. 2}. {2. 2}} // строка 2. то есть массив compl[1]
};
Для переменных одного и того же структурного типа определена операция присваивания, при этом происходит поэлементное копирование. Структуру можно передавать в функцию и возвращать в качестве значения функции. Другие операции со структурами могут быть определены пользователем. Размер структуры не обязательно равен сумме размеров ее
Структуру можно передавать в функцию и возвращать в качестве значения функции. Другие операции со структурами могут быть определены пользователем. Размер структуры не обязательно равен сумме размеров ее
элементов, поскольку они могут быть выровнены по границам слова.
Доступ к полям структуры выполняется с помощью операций выбора . (точка) при обращении к полю через имя структуры и -> при обращении через указатель, например:
Worker worker, staff[100], *ps;
worker.fio = "Страусенке";
staff[8].code = 215;
ps->salary = 0.12;
Если элементом структуры является другая структура, то доступ к ее элементам выполняется через две операции выбора:
struct А {int а; double х;};
struct В {А а; double х;} х[2];
х[0].а.а = 1;
х[1].х = 0.1;
Как видно из примера, поля разных структур могут иметь одинаковые имена, поскольку у них разная область видимости. Более того, можно объявлять в одной области видимости структуру и другой объект (например, переменную или массив) с одинаковыми именами, если при определении структурной переменной использовать слово struct, но не советую это делать — запутать компилятор труднее, чем себя.
Битовые поля
Битовые поля — это особый вид полей структуры. Они используются для плотной упаковки данных, например, флажков типа «да/нет». Минимальная адресуемая ячейка памяти — 1 байт, а для хранения флажка достаточно одного бита. При описании битового поля после имени через двоеточие указывается длина поля в битах (целая положительная константа):
struct Options{
bool centerX:1;
bool centerY:1;
unsigned int shadow:2;
unsigned int palette:4;
};
Битовые поля могут быть любого целого типа. Имя поля может отсутствовать, такие поля служат для выравнивания на аппаратную границу. Доступ к полю осуществляется обычным способом — по имени. Адрес поля получить нельзя, однако в остальном битовые поля можно использовать точно так же, как обычные поля структуры. Следует учитывать, что операции с отдельными битами реализуются гораздо менее эффективно, чем с байтами и словами, так как компилятор должен генерировать специальные коды, и экономия памяти под переменные оборачивается увеличением объема кода программы.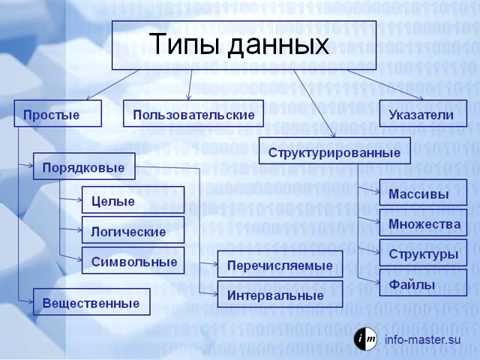 Размещение битовых полей в памяти зависит от компилятора и аппаратуры.
Размещение битовых полей в памяти зависит от компилятора и аппаратуры.
Объединения (union)
Объединение (union) представляет собой частный случай структуры, все поля которой располагаются по одному и тому же адресу. Формат описания такой же, как у структуры, только вместо ключевого слова struct используется слово union. Длина объединения равна наибольшей из длин его полей, В каждый момент времени в переменной типа объединение хранится только одно значение, и ответственность за его правильное использование лежит на программисте.
Объединения применяют для экономии памяти в тех случаях, когда известно, что больше одного поля одновременно не требуется:
#include
int niain(){
enum paytype {CARD, CHECK};
paytype ptype;
union payment{
char card[25];
long check;
} info;
/* присваивание значений info и ptype */
switch (ptype){
case CARD: cout << "Оплата no карте: " << info. card; break;
card; break;
case CHECK: cout << "Оплата чеком: " << info.check; break;
}
return 0;
}Объединение часто используют в качестве поля структуры, при этом в структуру удобно включить дополнительное поле, определяющее, какой именно элемент объединения используется в каждый момент. Имя объединения можно не указывать, что позволяет обращаться к его полям непосредственно:
#include
int niain(){
enum paytype {CARD, CHECK};
struct{
paytype ptype;
union payment{
char card[25];
long check;
}
} info;
/* присваивание значений info и ptype */
switch (ptype){
case CARD: cout << "Оплата no карте: " << info.card; break;
case CHECK: cout << "Оплата чеком: " << info.check; break;
}
return 0;
}Объединения применяются также для разной интерпретации одного и того же битового представления (но, как правило, в этом случае лучше использовать явные операции преобразования типов).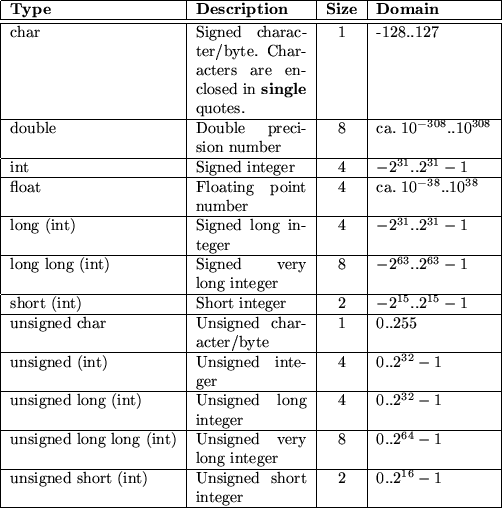 В качестве примера рассмотрим работу со структурой, содержащей битовые поля:
В качестве примера рассмотрим работу со структурой, содержащей битовые поля:
struct Options{
bool centerX:1;
bool centerY:1;
unsigned int shadow:2;
unsigned int palette:4;
}
union{
unsigned char ch;
Options bit;
}option = {0xC4};
cout << option.bit.palette;
option.ch &= 0xF0; // наложение маски
По сравнению со структурами на объединения налагаются некоторые ограничения. Смысл некоторых из них станет понятен позже:
- объединение может инициализироваться только значением его первого элемента;
- объединение не может содержать битовые поля;
- объединение не может содержать виртуальные методы, конструкторы, деструкторы и операцию присваивания;
- объединение не может входить в иерархию классов.
По материалам книги Т.А. Павловской «C\C++. Программирование на языке высокого уровня».
Типы данных
Все типы данных в языка C# являются производными базового класса Object, и, таким образом, наследуют все его члены. Описание класса Object содержится в пространстве имен System. Класс Object обладает статическими методами:
Описание класса Object содержится в пространстве имен System. Класс Object обладает статическими методами:- Equals(Object, Object) проверяет равенство двух указанных экземпляров объектов, возвращает логическое значение.
- ReferenceEquals(Object, Object) проверяет, являются ли переданные объекты одним и тем же объектом, возвращает логическое значение.
К нестатическим методам класса Object относятся
- Equals(Object) – вызывается для конкретного экземпляра и проверяет равенство этого экземпляра объекту, переданному в качестве аргумента, возвращает логическое значение.
- Finalize() – пытается освободить ресурсы памяти, занимаемые объектом.
- GetHashCode() – генерирует хэш-код для объекта.
- GetType() – возвращает тип текущего объекта.
- MemberwiseClone() – создает еще один объект того же типа и копирует в него все данные нестатических полей текущего объекта.
- ToString() – преобразует объект к строковому представлению.
Все типы данных C#, унаследованные от класса Object, можно разделить на:
- Простые данные – для использования данных таких типов достаточно указать только имя переменной или величину константы. К ним относятся логические значения, целые и вещественные числа, а также символьные значения.
- Агрегирующие данные – данные, содержащие внутри себя несколько значений полей. К ним относятся массивы, перечисления, структуры, классы.
Другое деление типов данных на
- Базовые, или встроенные – это типы данных, которые содержатся в стандарте языка. К ним относятся простые базовые типы, а также строковый тип string.
- Библиотечные – это типы, которые содержатся в библиотеках, обычно .NET Framework. Чтобы использовать библиотечные типы данных необходимо знать их поля и методы, а также пространство имен, в котором они описаны.
- Пользовательские – определенные программистом.

В таблице перечислены встроенные типы языка C#, их размер и диапазон представления.
| Тип данных | Псевдоним .NET Framework | Размер, байт | Диапазон |
|---|---|---|---|
| byte | System.Byte | 1 | -128…127 |
| sbyte | System.SByte | 1 | 0…255 |
| short | System.Int16 | 2 | -32768…32767 |
| ushort | System.UInt16 | 2 | 0…65535 |
| int | System.Int32 | 4 | 2 147 483 648 … 2 147 483 647 |
| uint | System.UInt32 | 4 | 0 … 4 294 967 295 |
| long | System.Int64 | 8 | -9 223 372 036 854 775 808 … 9 223 372 036 854 775 807 |
| ulong | System.UInt64 | 8 | 0 . .. 18 446 744 073 709 551 615 .. 18 446 744 073 709 551 615 |
| bool | System.Boolean | 1 | True, False |
| float | System.Single | 4 | ±1,5×10−45 … ±3,4 × 1038 |
| double | System.Double | 8 | ±1,5×10−45 … ±3,4 × 1038 |
| decimal | System.Decimal | 16 | ±1,0×10−28 … ±7,9 × 1028 |
| char | System.Char | 2 | Символ Юникода |
| string | System.String | Строка символов Юникода | |
Поскольку C# является языком со строгой типизацией данных, любая переменная перед ее использованием должна быть объявлена. Причем область видимости переменной ограничивается пространством имен, в котором она объявлена.
Для объявления переменных используется следующий синтаксис. Без инициализации
С инициализацией
Если необходимо объявить несколько переменных одного типа, то они могут быть записаны после названия типа через запятую.
Если переменная объявлена без инициализации, ей присваивается значение по умолчанию, равное 0.
Целочисленные данные
Встроенные типы данных языка C# включают 1-байтное, 2-байтное, 4-байтное и 8-байтное представление целочисленных данных в знаковой и беззнаковой форме.
Для знаковой формы представления старший разряд числа отводится под хранение его знака, поэтому диапазон представления значащей части чисел со знаком в 2 раза меньше, чем для беззнаковых.
Для инициализации целочисленных данных чаще всего используются целочисленные константы, записанные с помощью цифр десятичной или шестнадцатеричной системы счисления. Шестнадцатеричная константа начинается с символов 0x или 0X. Для отрицательных констант используется предшествующий символ −ю
Пример объявления целочисленных переменных:
Все целочисленные данные имеют константные поля MaxValue и MinValue, содержание максимальное и минимальное значения, которые могут быть представлены данными соответствующего типа.
Логические данные
Логические данные представлены логическим типом bool. Несмотря на то, что данные логического типа могут принимать только одно из двух значений True или False, объем памяти, отводимый для хранения логических переменных составляет 1 байт.
Вещественные данные
Представление вещественных данных представляет собой диапазон, симметричный относительно нуля. При выполнении операций с плавающей точкой не создаются исключения, а в исключительных ситуациях возвращается 0 (в случае слишком маленького значения), бесконечность PositiveInfinity (в случае большого положительного значения) или NegativeInfinity (в случае большого по величине отрицательного значения) или нечисловое значение (NaN) если операция с плавающей точкой является недопустимой.
Для инициализации вещественных чисел могут использоваться константы. Вещественное число состоит из знака, целой части, дробной части и порядка числа. В качестве разделителя целой и дробной части в тексте программы используется точка.
 Порядок числа представляет собой степень 10, на которую следует умножить значащую часть вещественного числа.
Порядок числа представляет собой степень 10, на которую следует умножить значащую часть вещественного числа. Примеры объявления вещественных констант Представление вещественного числа со знаком включает в себя целую часть, дробную часть и порядок числа.
По умолчанию все вещественные константы имеют тип double. Если последним символом константы указан суффикс f или F, константа имеет тип float. Если последним символом константы указан суффикс m или M, константа имеет тип decimal.
В силу особенностей представления вещественных чисел в разрядной сетке вычислительной машины, при работе с вещественными числами могут возникнуть проблемы, связанные с точностью их представления. Наименьшее целое вещественное число, которое может быть представлено в разрядной сетке float или double определяется константным полем Epsilon этих типов.
Тип decimal обладает более точным и узким диапазоном по сравнению с типами float и double, и поэтому больше подходит для использования в финансовых расчетах.

Символьные данные
Символьная переменная представляет собой 2-байтное значение типа char, являющееся символом таблицы Юникод. Для инициализации символьных данных могут использоваться константы следующих типов Все символьные представления констант заключаются в апострофы ».
Строковые данные
Несмотря на то, что строковый тип данных не является простым, он является встроенным типом языка C#. Строковый тип данных string позволяет создавать строки любой длины, для инициализации которых используется последовательность символов, заключенная в кавычки «…». Тип данных string также содержит ряд методов для обработки строковых данных.
Закрепить использование базовых типов данных Вы можете в разделе Типы данных курса Алгоритмика
Автор: Вставская Елена Владимировна
Написать комментарий:
C++ — Типы данных
При написании программы на любом языке вам нужно использовать различные переменные для хранения различной информации. Переменные — это не что иное, как зарезервированные ячейки памяти для хранения значений. Это означает, что при создании переменной вы сохраняете некоторое пространство в памяти.
Переменные — это не что иное, как зарезервированные ячейки памяти для хранения значений. Это означает, что при создании переменной вы сохраняете некоторое пространство в памяти.
Вы можете хранить информацию различных типов данных, таких как символ, широкий символ, целое число, плавающая точка, двойная плавающая точка, логическое значение и т. Д. На основе типа данных переменной операционная система выделяет память и решает, что можно сохранить в зарезервированная память.
Примитивные встроенные типы
C ++ предлагает программисту богатый набор встроенных, а также пользовательских типов данных. В следующих таблицах перечислены семь основных типов данных C ++:
| Type | Keyword |
|---|---|
| Boolean | bool |
| Character | char |
| Integer | int |
| Floating point | float |
| Double floating point | double |
| Valueless | void |
| Wide character | wchar_t |
Некоторые из основных типов могут быть изменены с использованием одного или нескольких модификаторов этого типа:
- signed
- unsigned
- short
- long
В следующей таблице показан тип переменной, объем памяти, который требуется для хранения значения в памяти, и то, что является максимальным и минимальным значением, которое может быть сохранено в таких переменных.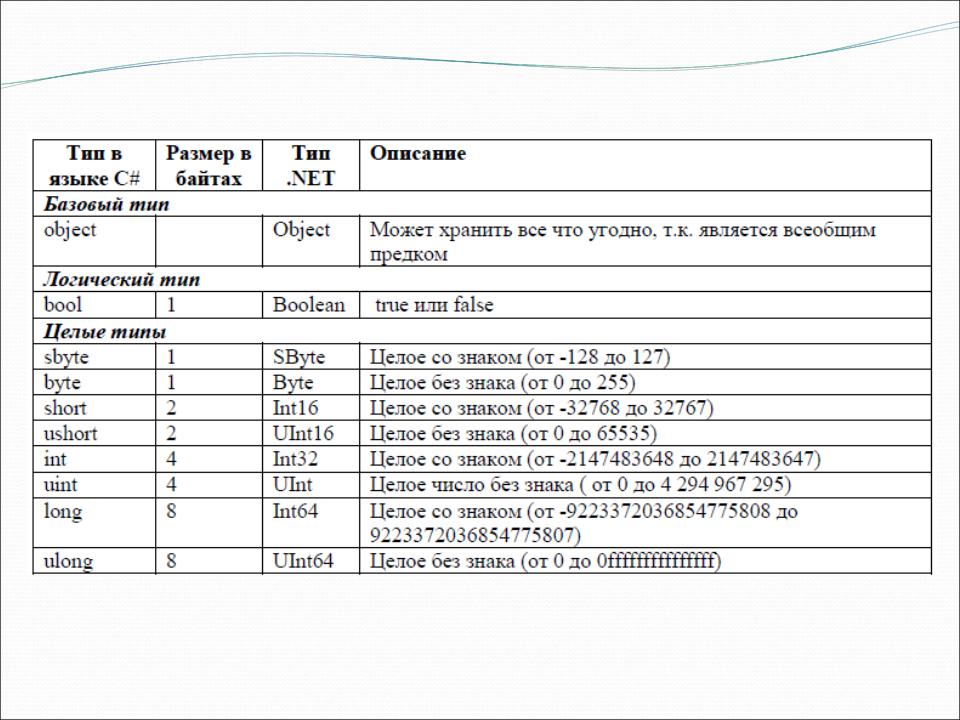
| Type | Typical Bit Width | Typical Range |
|---|---|---|
| char | 1byte | -127 to 127 or 0 to 255 |
| unsigned char | 1byte | 0 to 255 |
| signed char | 1byte | -127 to 127 |
| int | 4bytes | -2147483648 to 2147483647 |
| unsigned int | 4bytes | 0 to 4294967295 |
| signed int | 4bytes | -2147483648 to 2147483647 |
| short int | 2bytes | -32768 to 32767 |
| unsigned short int | Range | 0 to 65,535 |
| signed short int | Range | -32768 to 32767 |
| long int | 4bytes | -2,147,483,648 to 2,147,483,647 |
| signed long int | 4bytes | same as long int |
| unsigned long int | 4bytes | 0 to 4,294,967,295 |
| float | 4bytes | +/- 3. 4e +/- 38 (~7 digits) 4e +/- 38 (~7 digits) |
| double | 8bytes | +/- 1.7e +/- 308 (~15 digits) |
| long double | 8bytes | +/- 1.7e +/- 308 (~15 digits) |
| wchar_t | 2 or 4 bytes | 1 wide character |
Размер переменных может отличаться от размера, указанного в приведенной выше таблице, в зависимости от компилятора и компьютера, который вы используете. Ниже приведен пример, который даст правильный размер различных типов данных на вашем компьютере.
#include <iostream>
using namespace std;
int main() {
cout << "Size of char : " << sizeof(char) << endl;
cout << "Size of int : " << sizeof(int) << endl;
cout << "Size of short int : " << sizeof(short int) << endl;
cout << "Size of long int : " << sizeof(long int) << endl;
cout << "Size of float : " << sizeof(float) << endl;
cout << "Size of double : " << sizeof(double) << endl;
cout << "Size of wchar_t : " << sizeof(wchar_t) << endl;
return 0;
}В этом примере используется endl , который вводит символ новой строки после каждой строки, а оператор << используется для передачи нескольких значений на экран. Мы также используем оператор sizeof () для получения размера различных типов данных.
Мы также используем оператор sizeof () для получения размера различных типов данных.
Когда приведенный выше код компилируется и выполняется, он производит следующий результат, который может варьироваться от машины к машине:
Size of char : 1
Size of int : 4
Size of short int : 2
Size of long int : 4
Size of float : 4
Size of double : 8
Size of wchar_t : 4Декларации typedef
Вы можете создать новое имя для существующего типа с помощью typedef. Ниже приведен простой синтаксис для определения нового типа с использованием typedef:
typedef type newname; Например, следующее говорит компилятору, что ногами является другое имя для int:
typedef int feet;Теперь следующая декларация совершенно легальна и создает целочисленную переменную, называемую расстоянием:
feet distance;Перечисленные типы
Перечислимый тип объявляет необязательное имя типа и набор из нуля или более идентификаторов, которые могут использоваться как значения типа. Каждый перечислитель является константой, тип которой является перечислением. Для создания перечисления требуется использование ключевого слова enum . Общий вид типа перечисления:
Каждый перечислитель является константой, тип которой является перечислением. Для создания перечисления требуется использование ключевого слова enum . Общий вид типа перечисления:
enum enum-name { list of names } var-list; Здесь enum-name — это имя типа перечисления. Список имен разделяется запятой. Например, следующий код определяет перечисление цветов, называемых цветами, и переменной c цвета типа. Наконец, c присваивается значение «blue».
enum color { red, green, blue } c;
c = blue;По умолчанию значение первого имени равно 0, второе имя имеет значение 1, а третье — значение 2 и т. Д. Но вы можете указать имя, определенное значение, добавив инициализатор. Например, в следующем перечислении зеленый будет иметь значение 5.
enum color { red, green = 5, blue };Здесь blue будет иметь значение 6, потому что каждое имя будет больше, чем предыдущее.
C Урок 4.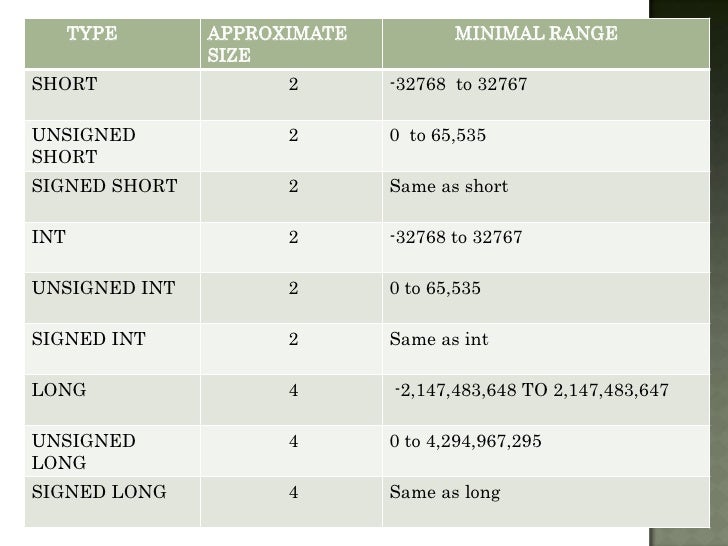 Переменные и типы данных. Часть 1 |
Переменные и типы данных. Часть 1 |
 
 
 
Продолжаем освоение языка C.
И теперь пришло время познакомиться с типами данных, а также способами их представления, одним из которых являются переменные. Также есть ещё константы, но с ними мы будем знакомиться немного позже.
С типами данных мы уже частично познакомились, когда выводили данные различного типа напрямую в консоль посредством функции printf, не задавая их заранее и никак не преобразовывая. Конечно же, можно делать и так, но какой прок от программы, которая просто выводит данные, никак их не обрабатывая и ничего с ними не делая, это не совсем хорошо. Ведь на то он и процессор, чтобы заниматься какой-то автообработкой, а наша программа должна как-то его на это натолкнуть.
В данном уроке мы также не будем данные никак обрабатывать и преобразовывать, но он станет ещё одной ступенькой к данной теме – различным арифметическим и логическим преобразованиям данных, так как без переменных в данном случае не обойтись. Вообще, конечно, можно и обойтись, работая непосредственно с памятью, но это было бы весьма неудобно и ни о какой наглядности и читабельности не было бы и речи.
Вообще, конечно, можно и обойтись, работая непосредственно с памятью, но это было бы весьма неудобно и ни о какой наглядности и читабельности не было бы и речи.
Прежде чем приступить к переменным, мы познакомимся с типами данных, являющимися самой главной основой переменных, так как переменная всегда несёт в себе и представляет какой-то определённый тип.
Данные различного типа – это величины, которые располагаются в каком-то месте памяти и могут занимать в ней различное количество пространства.
Типы данных можно разделить условно на три группы:
- целые – данные целого типа,
- вещественные – данные, которые могут иметь дробную часть,
- символы – данные типа char, которые представляют собой какой-то символ и занимают в памяти всего один байт.
Рассмотрим первый тип. Данные целого типа могут быть различной величины, следовательно будут иметь разный возможный диапазон значений, а также занимать различное количество байт в памяти. Также данные этого типа могут быть знаковыми (возможно отрицательное значение) или беззнаковыми (не меньше нуля).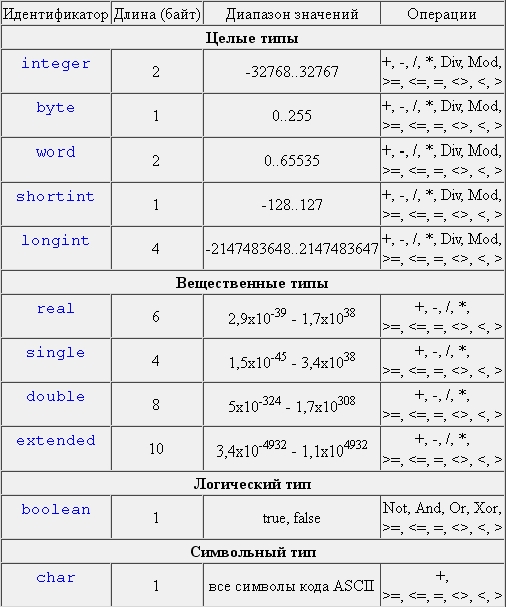
Рассмотрим, какие бывают данные целого типа (в принципе char тоже можно считать целым типом малой величины, так как зачастую его используют в этом качестве, когда хотят оперировать малыми значениями, чтобы сэкономить память, так как они занимают в ней всего один байт).
Данная таблица, думаю, всё это расскажет:
| Тип | Количество бит | Допустимый диапазон |
| char | 8 | -128 … 127 |
| unsigned char | 8 | 0 … 255 |
| short | 16 | -32 768 … 32767 |
| unsigned short | 16 | 0 … 65535 |
| int | 32 | -2 147 483 648 … 2 147 483 647 |
| unsigned int | 32 | 0 … 4 294 967 295 |
| long | 32 | -2 147 483 648 … 2 147 483 647 |
| unsigned long | 32 | 0 … 4 294 967 295 |
| long long | 64 | -9 223 372 036 854 775 808 … 9 223 372 036 854 775 807 |
| unsigned long long | 64 | 0 … 18 446 744 073 709 551 615 |
Аналогичным образом ведёт себя и вещественный тип. Только представители данного типа могут иметь ещё некоторые свойства. Кроме того, что они тоже занимают в памяти каждый определенное количество байт и имеют диапазоны, они могут быть представлены ещё в нормированной форме – в виде числа, умноженного на 10 в определённой степени. Также данный вид представления называют экспоненциальной записью числа.
Только представители данного типа могут иметь ещё некоторые свойства. Кроме того, что они тоже занимают в памяти каждый определенное количество байт и имеют диапазоны, они могут быть представлены ещё в нормированной форме – в виде числа, умноженного на 10 в определённой степени. Также данный вид представления называют экспоненциальной записью числа.
Например, число 135.543 можно представить как 1,35543 . 102.
А, например, число 0.00001245 – как 1.245 . 10-5.
Первый множитель – это мантисса или значащее число, а степень десятки – это экспонент или показатель, но чаще всего употребляется слово порядок, так как степень у нас именно десяти.
В коде мы так написать не можем, в исходном коде первое число будет выглядеть как 1.35543E2, а второе 1. 245E-5.
245E-5.
Мы не будем сейчас вдаваться в подробности, как именно хранится вещественное число в ячейке памяти. Вообще, тема интересная, но в принципе, сейчас она нам особой пользы не принесёт.
Также посмотрим таблицу диапазонов и размера занимаемой памяти определённых вещественных типов
| Тип | Количество бит | Допустимый диапазон |
| float | 32 | -2 147 483 648.0 … 2 147 483 647.0 |
| double | 64 | -9 223 372 036 854 775 808 .0 … 9 223 372 036 854 775 807.0 |
| long double | 64 | -9 223 372 036 854 775 808 .0 … 9 223 372 036 854 775 807.0 |
В некоторой документации пишут, что последний тип занимает 80 бит в памяти. Пока не знаю, где правда, возможно это зависит от операционных систем, либо от каких-то стандартов, либо от компилятора. С этим, думаю, разберёмся позже, когда будем писать исходные коды, отлаживать их и смотреть результаты в дизассемблированном виде.
Про символьный тип говорить особо нечего, так как он в группе только один. Занимает он один байт в памяти.
Ещё существует тип данных bool. Это целочисленный тип данных, так как диапазон допустимых значений — целые числа от 0 до 255. Данный тип используется как логический тип данных исключительно для хранения результатов логических выражений. У логического выражения может быть один из двух результатов – true или false. true — если логическое выражение истинно, false — если логическое выражение ложно. Данный тип может отсутствовать в некоторых компиляторах вообще, тогда мы используем вместо него char либо unsigned char.
Думаю, что для первоначального знакомства с типами данных пока нам достаточно. С остальными тонкостями будем разбираться в процессе дальнейшего изучения языка по мере поступления вопросов.
Теперь о переменных.
Переменные существуют для хранения значений и величин определённых типов данных в памяти.
Для того, чтобы к этим значениям было удобно обращаться, у переменной существует имя. Это наподобие как и у людей, когда они для идентификации друг друга обращаются также по именам.
Самое основное требование для объявления переменной: переменная должна быть объявлена раньше, чем она будет использоваться.
Самый простой способ объявления переменной в коде следующий:
char symbol1;
Сначала мы указываем тип данных, который будет в себе нести наша переменная, а далее мы указываем имя нашей переменной.
Имя переменной должно быть уникальным, то есть недопустимо объявлять две переменных с одним и тем же именем.
Имя переменной для удобства должно отражать суть и назначение нашей переменной, она должна показывать нам, для чего мы её используем, то есть имя должно быть говорящим. Конечно, это не обязательно и никакие стандарты этого не предусматривают и делать это мы должны только для своего удобства, чтобы наш код легче потом читался. Так как язык C – язык для программиста, а ассемблер – это язык для процессора.
Тем не менее существует и стандарт для имени переменной. Не всякие символы можно использовать в имени переменной. можно использовать буквы только латинского алфавита, как верхнего так и нижнего регистра, причём язык C является языком регистрозависимым и, например, переменные с именами Symbol1 и symbol1 – это будут разные переменные.
Также разрешается использовать арабские цифры в именах переменных (от 0 до 9), только с одним ограничением – имя переменной не должно начинаться с цифры, например имя переменной 4symbol использовать запрещено, а s4ymbol – разрешено.
В именах переменных запрещено использовать пробелы, поэтому, например, имя переменной first var запрещено. Но чтобы нам как-то можно было больше рассказать о назначении переменных и всё же использовать там несколько слов, то вместо пробелов разрешено использовать подчёркивания – ‘_‘. Поэтому мы сможем нашу переменную назвать как first_var. Также со знака подчёркивания допустимо начинать имя переменной, но злоупотреблять этим нежелательно, так как во многих библиотеках, в т.ч. стандартных, переменные, имя которых начинается со знака подчёркивания, очень часто используется. Тем самым мы избежим повторения имён, которое недопустимо.
Запрещено также в качестве имён использовать ключевые слова – такие, к примеру, как if, else, int, float. Данные слова зарезервированы и не могут быть использованы.
Также не допускается использование в именах операторов (+, -, = и т.д.), кавычек, скобок и т.д.
Тем не менее, не смотря на все ограничения, переменные – это очень удобный и необходимый механизм для хранения и модификации различных значений и величин.
Несколько переменных мы можем объявить как в разных строках
char symbol1;
int cnt;
float adc_val;
так и в одной
char symbol1; int cnt; float adc_val;
Если переменные объявляются одного типа, то мы можем их объединить в одно объявление. В этом случае имена данных переменных между собой мы разделяем запятыми
char symbol1, symbol2, symbol3;
В случае всех вышеперечисленных операций под переменные, которые мы объявили резервируется место в памяти в таком размере, какой предусматривает тип переменной, которую мы объявляем. В этом случае содержимое резервируемых ячеек памяти как правило не изменяется и значение переменной приобретёт случайную величину. Некоторые компиляторы автоматически присваивают значение 0 объявляемым переменным.
Чтобы переменная приобрела определённое значение, её следует либо инициализировать, либо присвоить ей результат какой-то операции.
Так как с различными операциями мы будем знакомиться не в данном уроке, то познакомимся пока с первым типом придания определённого значения переменной – это её инициализация.
Инициализируются переменные различными способами.
Мы можем сначала наши переменные объявить, а затем инициализировать
char symbol1, symbol2, symbol3;
int cnt;
float adc_val;
symbol1 = 'c';
symbol2 = 'f';
symbol3= 'h';
cnt = 589;
adc_val = 124.54f;
Таким образом мы присвоили нашим переменным определённые значения. Теперь мы с нашими переменными в дальнейшем можем осуществлять какие-то действия – арифметические, логические, также использовать их в параметрах вызываемых функций, например, с помощью функции printf вывести их значения в консоль.
Также мы можем проделать инициализацию наших переменных сразу – на этапе объявления
char symbol1 = 'c', symbol2 = 'f', symbol3= 'h';
int cnt = 589;
float adc_val = 124.54f;
Оператор ‘=‘ (равно) – это оператор присвоения. Используется для присвоения переменной, имя которой находится слева от оператора, значения либо результата выражения, находящегося справа от оператора.
Существует ещё несколько операторов, с которыми мы будем знакомиться в следующих уроках.
В следующей части занятия мы напишем исходный код, в котором объявим, инициализируем и выведем в консоль переменные различного типа и проверим работу кода на практике.
Предыдущий урок Программирование на C Следующая часть
Исходный код
Смотреть ВИДЕОУРОК (нажмите на картинку)
Post Views: 6 095
Вся правда о целочисленных типах в C / Хабр
Для начала несколько вопросов:- Тип
charпо умолчанию знаковый или нет? Аint? - Законно ли неявное приведение
(signed char *)к(char *)? А то же дляint? - Сколько бит в
unsigned char? - Какое максимальное число гарантированно можно поместить в
int? А минимальное? - Тип
longопределённо больше, чемchar, не так ли?
Разумеется, экспериментально искать ответы на эти вопросы с помощью вашего любимого компилятора в вашей любимой системе на вашем любимом компьютере1) — не лучшая идея. Мы говорим о стандарте языка (С99 и новее).
Если вы уверенно сможете правильно ответить на эти вопросы, тогда эта статья не для вас. В противном случае десять минут, потраченные на её чтение, будут весьма полезны.
Предположу, что вы ответили- Знаковые оба.
- Законны оба.
- 8.
- 2147483647. -2147483648.
- Конечно, Кэп.
А правильные ответы такие
char— не регламентируется,int— знаковый.- Для
int— законно, а дляchar— нет. - Не менее 8.
- 32767. -32767
- Вообще говоря, нет.
Про signed и unsigned
Все целочисленные типы кроме
char, по умолчанию знаковые (signed).С char ситуация сложнее. Стандарт устанавливает три различных типа: char, signed char, unsigned char. В частности, указатель типа (signed char *) не может быть неявно приведён к типу (char *).
Хотя формально это три разных типа, но фактически char эквивалентен либо signed char, либо unsigned char — на выбор компилятора (стандарт ничего конкретного не требует).
Подробнее про char я написал в комментариях.
О размере unsigned char
Тип
unsigned char является абстракцией машинного байта. Важность этого типа проявляется в том, что С может адресовать память только с точностью до байта. На большинстве архитектур размер байта равен 8 бит, но бывают и исключения. Например, процессоры с 36-битной архитектурой как правило имеют 9-битный байт, а в некоторых DSP от Texas Instruments байты состоят из 16 или 32 бит. Древние архитектуры могут иметь короткие байты из 4, 5 или 7 бит.Стандарт С вынужден отказаться от допотопных архитектур и требует, чтобы байты были как минимум 8-битные. Конкретное значение (CHAR_BIT2)) для данной платформы записано в заголовочном файле limits.h.
Размеры целочисленных типов в С
C переносимый, поэтому в нём базовые целочисленные типы (
char, short, int и др.) не имеют строго установленного размера, а зависят от платформы. Однако эти типы не были бы переносимы, если бы их размеры были совершенно произвольные: стандарт устанавливает минимальные диапазоны принимаемых значений для всех базовых целочисленные типов. А именно,
signed char:-127…127 (не -128…127; аналогично другие типы)unsigned char: 0…255 (= 28−1)signed short: -32767…32767unsigned short: 0…65535 (= 216−1)signed int: -32767…32767unsigned int: 0…65535 (= 216−1)signed long: -2147483647…2147483647unsigned long: 0…4294967295 (= 232−1)signed long long: -9223372036854775807…9223372036854775807unsigned long long: 0…18446744073709551615 (= 264−1)
Стандарт требует, чтобы максимальное значение
unsigned char было 2CHAR_BIT−1 (см. предыдущий пункт).Стандарт требует sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long). Таким образом, вполне законны ситуации типа sizeof(char)=sizeof(long)=32. Для некоторых DSP от Texas Instruments так и есть.
Конкретные значения этих диапазонов для данной платформы указаны заголовочном файле limits.h.
Новые типы в С99
После того, как C99 добавил тип
long long, целочисленных типов и путаницы стало ещё больше. Чтобы навести порядок, стандарт ввёл заголовочный файл stdint.h, где определяются типы вроде int16_t (равно 16 бит), int_least16_t (минимальный тип, способный вместить 16 бит), int_fast16_t (по крайней мере 16 бит, работа с этим типом наиболее быстрая на данной платформе) и т. п.least- и fast-типы фактически являются заменой рассмотренных выше типов int, short, long и т. п. только вдобавок дают программисту возможность выбора между скоростью и размером.
От типов вроде int16_t, со строгим указанием размера, страдает переносимость: скажем, на архитектуре с 9-битным байтом может просто не найтись 16-битного регистра. Поэтому стандарт тут явно говорит, что эти типы опциональны. Но учитывая, что какой бы код вы ни писали, чуть менее чем во всех случаях целевая архитектура фиксирована даже в худшем случае с точностью до семейства (скажем, x86 или AVR), внутри которого, размер байта не может вдруг поменяться, то переносимость фактически сохраняется. Более того, типы вроде int16_t оказались даже более популярными, чем int_least16_t и int_fast16_t, а при низкоуровневом программировании (микроконтроллеры, драйверы устройств) и подавно, ибо там зачастую неопределённость размера переменной просто непозволительна.
1) Для удобства тройку архитектура+ОС+компилятор далее будем называть просто платформой.
2) Этот макрос правильнее было бы назвать
UCHAR_BIT, но по причинам совместимости он называется так, как называется.Типы данных в C #
- Подписывайтесь на нас
- Питон
- ASP.NET Core
- MVC
- IoC
- Веб-API
- C #
- TypeScript
- Node.js
- Больше
✕
. Учебники .NET
- ASP.NET Core
- ASP.NET MVC
- IoC
- веб-API
- C #
- LINQ
Учебники по скриптам
- TypeScript
- AngularJS 1
- Узел.js
- D3.js
- jQuery
- JavaScript
Другие учебные пособия
- Python
- Sass
- Https
Тесты навыков
- ASP.NET Core
- ASP.NET MVC
- LINQ
- C #
- веб-API
- IoC
- TypeScript
- AngularJS
- Node.js
- jQuery
- JavaScript
Типы данных C # с примерами
В языке программирования C # типы данных используются для определения типа данных, которые может содержать переменная, таких как целое число, число с плавающей запятой, строка и т. Д.в нашем приложении.
C # — это язык программирования Strongly Typed , поэтому перед выполнением каких-либо операций с переменными необходимо определить переменную с требуемым типом данных, чтобы указать, какой тип данных эта переменная может содержать в нашем приложении.
Синтаксис определения типов данных C #
Ниже приводится синтаксис определения типов данных на языке программирования C #.
[Тип данных] [Имя переменной];
[Тип данных] [Имя переменной] = [Значение];
Если вы заметили приведенный выше синтаксис, мы добавили требуемый тип данных перед именем переменной, чтобы сообщить компилятору, какой тип данных может содержать переменная или к какому типу данных принадлежит эта переменная.
[Тип данных] — это тип данных, которые может содержать переменная, например целые, строковые, десятичные и т. Д.
[Имя переменной] — Это имя переменной для хранения значений в нашем приложении.
[Значение] — присвоение переменной требуемого значения.
Теперь мы посмотрим, как использовать типы данных в наших приложениях на C # на примерах.
Пример типов данных C #
Ниже приводится пример использования типов данных в языке программирования C #.
пространство имен Tutlane
{
класс Программа
{
static void Main (string [] args)
{
int number = 10;
string name = «Суреш Дасари»;
двойной процент = 10,23;
символьный пол = ‘M’;
bool isVerified = true;
}
}
}
Если вы видели выше пример типов данных C #, мы определили несколько переменных с разными типами данных на основе наших требований.
Различные типы данных в C #
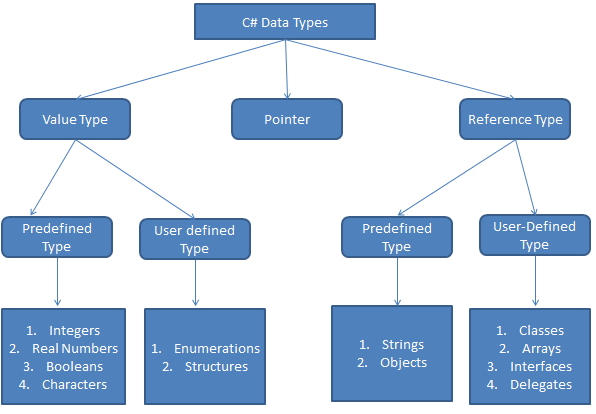
В языке программирования C # у нас есть 3 разных типа данных, это
| Тип | Типы данных |
|---|---|
| Значение Тип данных | int, bool, char, double, float и т. Д. |
| Тип справочных данных | строка, класс, объект, интерфейс, делегат и т. Д. |
| Тип данных указателя | Указатели. |
Следующая диаграмма более подробно иллюстрирует различные типы данных в языке программирования C #.
Типы данных значений C #
В C # типы данных значения напрямую сохраняют значение переменной в памяти. В C # типы данных значения принимают как подписанные, так и беззнаковые литералы.
В следующей таблице перечислены типы данных значений на языке программирования C # с размером памяти и диапазоном значений.
| Тип данных | .NET Тип | Размер | Диапазон |
|---|---|---|---|
| байт | Байт | 8 бит | от 0 до 255 |
| сбайт | SByte | 8 бит | -128 до 127 |
| внутр | Int32 | 32 бита | -2 147 483 648 до 2 147 483 647 |
| uint | UInt32 | 32 бита | 0 до 4294967295 |
| короткий | Int16 | 16 бит | -32 768 до 32 767 |
| ushort | UInt16 | 16 бит | 0 до 65 535 |
| длинный | Int64 | 64 бита | -9,223,372,036,854,775,808 до 9,223,372,036,854,775,807 |
| улонг | UInt64 | 64 бита | 0 до 18 446 744 073 709 551 615 |
| поплавок | Одноместный | 32 бита | -3.402823e38 до 3.402823e38 |
| двойной | Двойной | 64 бита | -1.79769313486232e308 до 1.79769313486232e308 |
| булев | логический | 8 бит | Верно или неверно |
| десятичный | Десятичный | 128 бит | (+ или -) от 1,0 x 10e-28 до 7,9 x 10e28 |
| DateTime | DateTime | – | 0:00:00 01.01.01 до 23:59:59 31.12.9999 |
Типы справочных данных C #
В C # ссылочные типы данных будут содержать адрес в памяти значения переменной, поскольку ссылочные типы не сохраняют значение переменной непосредственно в памяти.
В следующей таблице перечислены ссылочные типы данных на языке программирования C # с размером памяти и диапазоном значений.
| Тип данных | .NET Тип | Размер | Диапазон |
|---|---|---|---|
| строка | Строка | переменной длины | от 0 до 2 миллиардов символов Unicode |
| объект | Объект | – | – |
Типы данных указателя C #
В C # типы данных указателя будут содержать адрес памяти значения переменной.Для получения сведений об указателе у нас есть два символа — амперсанд (&) и звездочка (*) на языке С #.
Ниже приводится синтаксис объявления типа указателя в языке программирования C #.
Ниже приведен пример определения типа указателя в языке программирования C #.
В следующей таблице приведены подробные сведения о различных символах указателя типа, доступных в языке программирования C #.
| Символ | Название | Описание |
|---|---|---|
| и | Оператор адреса | Полезно определить адрес переменной. |
| * | Оператор косвенного обращения | Полезно получить доступ к значению адреса. |
Вот как мы можем использовать типы данных в приложениях C # в соответствии с нашими требованиями.
Использование типов данных
- Введение в программирование
- 1. Элементы программирования
- 1.1 Ваша первая программа
- 1.2 Встроенные типы данных
- 1.3 Условные выражения и циклы
- 1,4 Массивы
- 1.5 Вход и выход
- 1.6 Пример использования: PageRank
- 2. Функции
- 2.1 Статические методы
- 2.2 Библиотеки и клиенты
- 2.3 Рекурсия
- 2.4 Пример: просачивание
- 3. ООП
- 3.1 Использование типов данных
- 3.2 Создание типов данных
- 3.3 Проектирование типов данных
- 3.4 Пример использования: N-Body
- 4. Структуры данных
- 4.1 Производительность
- 4.2 Сортировка и поиск
- 4.3 Стеки и очереди
- 4.4 Таблицы символов
- 4.5 Пример: маленький мир
- 1. Элементы программирования
- Компьютерные науки
- 5.Теория вычислений
- 5.1 Формальные языки
- 5.2 Машины Тьюринга
- 5,3 Универсальность
- 5.4 Вычислимость
- 5.5 Тяжелая трудоспособность
- 9.9 Криптография
- 6. Вычислительная машина
- 6.1 Представление информации
- 6.2 ИГРУШЕЧНАЯ машина
- 6.3 ИГРУШЕЧНОЕ программирование
- 6.4 ИГРУШЕЧНАЯ Виртуальная машина
- 7. Сборка компьютера
- 7.1 Логическая логика
- 7.2 Базовая модель схемы
- 7.3 Комбинационные схемы
- 7.4 Последовательные схемы
- 7.5 Цифровые устройства
- 5.Теория вычислений
- За пределами
- 8. Системы
- 8.1 Программирование библиотеки
- 8.2 компилятора
- 8.3 Операционные системы
- 8.4 Сеть
- 8.5 Приложения Системы
- 9. Научные вычисления
- 9.1 с плавающей точкой
- 9.2 Символьные методы
- 9.3 Численное интегрирование
- 9.4 Дифференциальные уравнения
- 9,5 Линейная алгебра
- 9.6 Оптимизация
- 9.7 Анализ данных
- 9,8 Моделирование
- 8. Системы
- Сайты по теме
- Интернет-ресурсы
- FAQ
- Данные
- Код
- Исправлений
- Лекции
- Приложения
- A. Приоритет оператора
- B. Написание открытого кода
- С.Глоссарий
- D. TOY Шпаргалка
- Е. Матлаб
- Онлайн-курс
- Шпаргалка по Java
- Назначения программирования
Типы данных в C ++ / CLI
Раскрытие информации рекламодателя- Visual C ++ / C ++ »
- Образец главы
- Безопасность
- C ++ »
- Алгоритмы и формулы »
- Общие
- Алгоритмы контрольной суммы
- Комбинации
- Сжатие / декомпрессия
- Факториалы
- Хеш-таблицы
- Связанные списки
- Математика
- В поисках
- Сортировка
- Строковые алгоритмы
- Проблемы переносимости
- C ++ и MFC »
- Общие
- Обработка массивов
- Двоичные деревья
- Биты и байты
- Операции с буфером и памятью
- Обратный звонок
- Классы и использование классов
- Коллекции
- Сжатие
- Перетаскивание
- События
- Исключения
- Внешние ссылки
- Файловый ввод-вывод
- Вызов функции
- Связанные списки
- Отслеживание памяти
- Объектно-ориентированное программирование (ООП)
- Открыть FAQ
- Разбор
- Узоры
- Указатели
- Переносимость
- RTTI
- Сериализация
- Синглтоны
- Стандартная библиотека шаблонов (STL)
- шаблоны
- Учебники
- Дата и время »
- Общие
- Контроль даты
- Временные программы
- C ++ / CLI »
- .NET Framework классов
- Общий
- ASP / ASP.NET
- Бокс и распаковка
- Компоненты
- Сборка мусора и финализаторы
- Взаимодействие
- Переход из неуправляемого
- Процессы и потоки
- шаблоны
- Visual Studio.NET 2003
- Строковое программирование »
- Общие
- Альтернативы CString
- Расширения CString
- Манипуляции с CString
- Открыть FAQ
- Регулярные выражения
- Строковые массивы
- Преобразования строк
- .NET
- Алгоритмы и формулы »
- COM-технологии »
- Программирование ATL и WTL »
- Общие
- ATL
- Активные сценарии
- Элементы управления ActiveX
- База данных
- Отладка
- Внешние ссылки
- Поддержка графики
- Разное.
- Производительность
- Печать
- Учебники
- Коммунальные услуги
- Библиотека шаблонов Windows (WTL)
- Программирование ActiveX »
- Общие
- Активные сценарии
- Элементы управления ActiveX
- Документы ActiveX
- Квартиры и потоки
- Обработка ошибок
- Внешние ссылки
- Общий COM / DCOM
- Разное.
- Реестр
- Безопасность
- Структурированное хранилище
- Учебники
- Упаковщики
- COM + »
- Общие
- COM-взаимодействие
- Управляемый код /.NET
- SOAP и веб-службы
- Программирование оболочки »
- Общие
- Открыть FAQ
- Ярлыки
- Значки в трее
- Начальник предыдущей секции
- Программирование ATL и WTL »
- Элементы управления »
- Лист свойств »
- Открыть FAQ
- Кнопки окна свойств
- Калибровка
- Мастера
- Кнопочное управление »
- Расширенные кнопки
- Кнопки с растровым изображением
- Плоские кнопки
- Меню
- Непрямоугольные кнопки
- Windows XP
- Поле со списком »
- Палитры цветов
- Выпадающее
- Комбинации шрифтов
- Многоколоночные комбинации
- Специальные эффекты
- Подсказки
- Изменить элемент управления »
- Фон и цвет
- Редакторы
- Клавиатура
- Элементы управления маскированным редактированием
- Пароли и безопасность
- Управление вращением
- прозрачный
- ImageList Control »
- Открыть FAQ
- Элемент управления ListBox »
- Флажки
- Цветные списки
- Перетаскивание
- Светодиоды
- Элемент управления ListView »
- Продвинутый
- Цвет фона и изображение
- Флажки
- Колонны
- Пользовательский чертеж
- Данные
- Удаление
- Перетаскивание
- Редактирование позиций и подпунктов
- FilterBar
- Линии сетки
- Элемент управления заголовком
- Введение
- Разное
- Навигация
- Новый элемент управления ListView (IE 4.0)
- Печать
- Списки Недвижимости
- Отчеты
- Полосы прокрутки
- Выбор
- Сортировка
- Подсказка и подсказка к заголовку
- Использование изображений
- Просмотры
- Меню »
- Альтернативное меню
- Растровые меню
- Закрепляемые меню
- Маршрутизация сообщений и команд
- Разное
- XML
- Меню в стиле XP
- Другие элементы управления »
- Растровые кнопки
- Диаграммы и аналоговые элементы управления
- Элементы управления флажком
- Часы и таймеры
- Система управления Cool
- Элементы управления выбором даты и т. Д.
- Цифровое управление
- Методы расширения / создания подклассов
- Выбор файлов и каталогов
- Управление сетью
- Групповой ящик
- Элементы управления HyperLink
- Интернет и Интернет
- Списки, деревья и комбинации
- Кнопка свертывания
- Контроль выполнения
- Изменение размера
- Полосы прокрутки
- Ползунок управления
- Контроль отжима
- Системный лоток
- Элементы управления вкладками
- Элементы управления всплывающей подсказкой
- Диаграммы и аналоговые элементы управления
- Методы расширения / создания подклассов
- Богатый контроль редактирования »
- Преобразования
- Редакторы и монтаж
- Подсветка синтаксиса
- Без окон
- Статическое управление »
- Фаска
- Элементы управления отображением данных
- Прокрутка текста
- Статус бар »
- Продвинутый
- Системный лоток
- Панель инструментов »
- Настройка панелей инструментов
- Док-станция
- Плоская панель инструментов
- Разное
- Размещение элементов управления на панелях инструментов
- Размещение элементов управления на панелях инструментов
- Элемент управления в виде дерева »
- Классы
- Каталог браузеров
- Перетаскивание
- Редактирование этикеток
- Развернуть — Свернуть
- Разное — Продвинутый
- Мультиэкран
- Новый элемент управления Listview (IE 4.0)
- В поисках
- Обход дерева
- Использование изображений
- Лист свойств »
- Данные »
- База данных »
- ADO
- ADO.NET
- ATL
- DAO
- Динамический доступ к данным
- Microsoft Access
- Microsoft Excel
- Разное.
- Объектно-ориентированный
- ODBC
- OLE DB
- Оракул
- SQL Server
- Хранимые процедуры
- XML
- Разное »
- Информация о файле
- Файлы INI
- Значения
- XML
- База данных »
- Фреймворки »
- Пользовательский интерфейс и основы печати »
- Библиотеки компонентов
- Элементы управления Outlook
- Отчетность и написание отчетов
- Скины
- Отчетность и написание отчетов
- Методы и классы окон
- Пользовательский интерфейс и основы печати »
- Графика и мультимедиа »
- Растровые изображения и палитры »
- Захват
- Сжатие
- Отображение и размер
- Внешние ссылки
- Иконки
- Манипуляции с изображениями
- Объединение
- Другие форматы…
- Палитры и таблицы цветов
- Специальные эффекты
- Использование регионов
- Зрителей
- Просмотры и клиенты MDI
- DirectX »
- DirectDraw
- DirectInput
- DirectShow
- DirectX 8
- GDI »
- Захват изображений
- заполняет
- Обработка и обнаружение шрифтов
- GDI +
- Иконки и курсоры
- Строки
- Мультимедиа »
- Аудио
- Настольные эффекты
- Графика
- Изображения
- Таймеры
- Твен
- Видео
- OpenGL »
- Программирование игр
- Печать
- Наложение текстуры
- Растровые изображения и палитры »
- Интернет и сети »
- Интернет-протоколы »
- ActiveX
- Управление браузером
- Чат-программы
- DHTML
- Набор номера
- DNS
- Электронная почта
- Передача файлов
- FTP
- Общий Интернет
- HTML
- HTTP
- Обмен мгновенными сообщениями
- Интернет-протокол (IP)
- Сеть
- Уровень защищенных сокетов (SSL)
- Безопасность
- Потоковое мультимедиа
- Веб-службы
- XML
- Программирование IE »
- Отображение информации
- Безопасность
- Голос
- ISAPI »
- Файлы cookie
- Данные / Базы данных
- Расширения
- Фильтры
- Связанные разделы CODEGURU
- Сетевые протоколы »
- Active Directory
- Базовые сетевые операции
- Удаленный доступ к сети
- Игры
- IPX
- Обмен сообщениями
- Именованные каналы
- Сетевая информация
- Удаленное администрирование
- Удаленный вызов
- Последовательная связь
- TCP / IP
- Решения Winsock
- Интернет-протоколы »
- Разное »
- Разное »
- Контроль приложений
- Язык ассемблера
- Разное »
| Значение данных | ЛЮБОЙ | Определяет основные свойства каждого значения данных.Это аннотация type, что означает, что никакое значение не может быть просто значением данных, не принадлежащим к любому конкретному типу. Каждый конкретный вид — это специализация этого общий абстрактный тип DataValue. |
| логический | BL | Тип Boolean обозначает значения двузначной логики.А Логическое значение может быть true или false , или, как любое другое значение, может быть NULL. |
| BooleanNonNull | БН | Тип BooleanNonNull используется там, где логическое значение не может иметь нулевое значение. А Логическое значение может быть true или ложь . |
| Двоичные данные | БИН | Двоичные данные — это необработанный блок битов. Двоичные данные — это защищенные тип, который НЕ ДОЛЖЕН использоваться вне спецификации типа данных. |
| Инкапсулированные данные | ED | Данные, которые в первую очередь предназначены для интерпретации человеком или для дальнейшая машинная обработка выходит за рамки HL7.Это включает в себя неформатированный или отформатированный письменный язык, мультимедийные данные или структурированная информация, как определено другим стандартом (например, XML-подписи.) Вместо самих данных ED может содержать только ссылку (см. ТЕЛ.) Обратите внимание, что тип данных ST — это специализация Тип данных ED, когда ED Тип носителя — текстовый / простой. |
| Строка символов | СТ | Тип данных символьной строки обозначает текстовые данные, в первую очередь предназначен для машинной обработки (например, сортировки, запросов, индексации, и т.д.) Используется для имен, символов и формальных выражений. |
| Кодированное простое значение | CS | Закодированные данные в простейшей форме состоят из кода.Кодовая система и версия системы кода фиксируется контекстом, в котором встречается значение CS. CS используется для закодированных атрибутов, которые имеют один набор значений, определенный HL7. |
| Кодовое значение | CV | Закодированные данные состоят из кода, отображаемого имени, системы кодов и Оригинальный текст.Используется, когда необходимо отправить одно значение кода. |
| Кодированный порядковый номер | CO | Закодированные данные, в которых заказывается домен, из которого поступает кодовый набор. В Тип данных Coded Ordinal добавляет семантику, связанную с упорядочением, так что модели которые используют такие домены, могут вводить элементы модели, которые включают утверждения о порядке использования терминов в домене. |
| Закодировано эквивалентами | CE | Кодированные данные состоят из кодированного значения (CV) и, необязательно, закодированного значение (я) из других систем кодирования, которые идентифицируют то же самое концепция. Используется, когда могут существовать альтернативные коды. |
| Дескриптор концепции | CD | Дескриптор концепции представляет любой вид концепции, обычно дающий код, определенный в кодовой системе.Дескриптор понятия может содержать исходный текст или фразу, послужили основой для кодирования и одного или нескольких переводов на разные системы кодирования. Дескриптор концепции также может содержать квалификаторы для описания, например, понятие «левая ступня» как посткоординированный термин, построенный из первичный код «FOOT» и квалификатор «LEFT».В исключительных случаях дескриптор понятия не обязательно должен содержать код. но только оригинальный текст, описывающий эту концепцию. |
| Концептуальная роль | CR | Код квалификатора концепции с необязательно названной ролью. Оба квалификатора Коды ролей и ценностей должны быть определены системой кодирования.За Например, если SNOMED RT определяет понятие «нога», ролевое отношение «имеет-латеральность» и еще одно понятие «лево», понятие роли отношение позволяет добавить квалификатор has-laterality: left к первичный код «нога» для построения значения «левая нога». |
| Символьная строка с кодом | SC | Символьная строка, которая необязательно может иметь прикрепленный код.Текст должен присутствовать всегда, если код подарок. Код часто представляет собой местный код. |
| Строка уникального идентификатора | UID | Строка уникального идентификатора — это строка символов, которая идентифицирует объект в глобально уникальном и вневременном стиле. Допустимые форматы а значения и процедуры этого типа данных строго контролируются HL7.В настоящее время идентификаторы, назначаемые пользователем, могут иметь определенный символ. представления идентификаторов объектов ISO (OID) и DCE Universally Уникальные идентификаторы (UUID). HL7 также оставляет за собой право назначать другие формы UID, такие как мнемонические идентификаторы для кодовых систем. |
| Идентификатор экземпляра | II | Идентификатор, который однозначно идентифицирует вещь или объект.Примеры — идентификатор объекта для объектов HL7 RIM, номер медицинской карты, идентификатор заказа, идентификатор позиции каталога услуг, идентификационный номер автомобиля (VIN) и т. Д. Идентификаторы экземпляров определяются на основе объекта ISO. идентификаторы. |
| Универсальный указатель ресурсов | URL | Телекоммуникационный адрес, указанный в соответствии со стандартом Интернет. RFC 1738 [http: // www.ietf.org/rfc/rfc1738.txt]. В URL указывает протокол и точку контакта, определяемую этим протокол для ресурса. Известные применения телекоммуникаций Тип данных адреса — для номеров телефона и телефакса, электронной почты адреса, гипертекстовые ссылки, FTP-ссылки и т. д. |
| Телекоммуникационный адрес | ТЕЛ | Номер телефона (голосовой или факсимильный), адрес электронной почты или другой указатель. для ресурса (информации или услуги), опосредованного телекоммуникациями оборудование.Адрес указан как универсальный указатель ресурсов. (URL) с указанием времени и кодами, которые помогают в решение, какой адрес использовать для данного времени и цели. |
| Часть адреса | ADXP | Символьная строка, которая может иметь тег типа, обозначающий ее роль в адрес.Типичными частями каждого адреса являются улица, номер дома или почтовый ящик, почтовый индекс, город, страна, но другие роли может быть определено на региональном, национальном или корпоративном уровне (например, в военных адресах). Адреса обычно разбиваются на строки, которые обозначаются специальными элементами-разделителями с разрывом строки (например, DEL). |
| Почтовый адрес | н.э. | Почтовый и домашний или рабочий адреса.Последовательность адресных частей, например, улица или почтовый ящик, город, почтовый индекс, страна и т. д. |
| Название объекта Часть | ENXP | Токен символьной строки, представляющий часть имени. Может иметь код типа, обозначающий роль части во всем имени объекта, и код квалификатора для получения дополнительных сведений о типе части имени.Типичными частями имени для имен людей являются имена и фамилии, названия и др. |
| Название организации | EN | Имя человека, организации, места или предмета. Последовательность имени части, такие как имя или фамилия, префикс, суффикс и т. д. Примеры значений имени объекта: «Джим Боб Уолтон-младший.»,» Здоровье Level Seven, Inc. »,« Озеро Тахо »и т. Д. Название объекта может быть таким же простым. в виде строки символов или может состоять из нескольких частей имени объекта, такие как «Джим», «Боб», «Уолтон» и «младший», «Уровень здоровья семь» и «Инк», «Лейк» и «Тахо». |
| Имя человека | PN | Имя для человека.Последовательность частей имени, например, имя или фамилия, префикс, суффикс и т. д. PN отличается от EN, поскольку тип квалификатора не может включать LS (юридический статус). |
| Название организации | НА | Название организации. Последовательность частей имени. |
| Тривиальное имя | TN | Ограничение имени объекта, которое фактически является простой строкой. для простого названия вещей и мест. |
| Кол-во | КОЛ-ВО | Тип данных количества является абстрактным обобщением для всех данных. типы (1), набор значений которых имеет отношение порядка (меньше или равно) и (2) где разница определяется во всех типах данных полностью упорядоченные подмножества значений. Абстракция количественного типа необходима в определение некоторых других типов, таких как интервал и вероятность распространение. |
| Целое число | ИНТ | Целые числа (-1,0,1,2, 100, 3398129 и т. Д.) Являются точными числами. это результаты подсчета и перечисления. Целые числа дискретный, множество целых чисел бесконечно, но счетно. Нет произвольного ограничение накладывается на диапазон целых чисел.Два варианта NULL: определен для положительной и отрицательной бесконечности. |
| Реальный номер | НАСТОЯЩИЙ | Дробные числа. Обычно используется при измерении количеств, оценивается или вычисляется из других действительных чисел. Типичный представление десятичное, где количество значащих десятичных цифры известны как точность.Действительные числа необходимы помимо целых, когда количество реальный мир измеряется, оценивается или вычисляется на основе других реальных числа. Термин «Действительное число» в этой спецификации используется для обозначения что дробные значения охватываются, не обязательно подразумевая полный набор математических действительных чисел. |
| Физическая величина | PQ | Измеренная величина, выражающая результат действия измерения. |
| Представление физических величин | PQR | Представление физической величины в единице из любого кода система. Используется для отображения альтернативного представления физического количество. |
| Сумма в денежном выражении | MO | Денежная сумма — это количество, выражающее количество денег в некоторых валюта.Валюты — это единицы измерения денежных сумм. номинированы в разных экономических регионах. Пока денежная сумма представляет собой единый вид количества (денег) обменных курсов между разные единицы изменчивы. В этом принципиальная разница между физическим количеством и денежными суммами, и причина, почему денежные единицы не являются физическими единицами. |
| Передаточное отношение | RTO | Величина, построенная как частное деленного числителя. по знаменателю количества.Общие множители в числителе и знаменатель автоматически не исключается. RTO поддерживает титры (например, «1: 128») и другие количества, произведенные лаборатории, которые действительно представляют коэффициенты. Коэффициенты — это не просто «структурированные числа», в частности измерения артериального давления (например, «120/60») не являются отношениями. Во многих случаях REAL следует использовать вместо RTO. |
| Момент времени | ТС | Величина, определяющая точку на оси естественного времени. Точка во времени чаще всего представляется в виде календарного выражения. |
| Набор | НАБОР | Значение, которое содержит другие различные значения без определенного порядка. |
| Компонент набора | SXCM | Расширение универсального типа, определяемое ITS для базового типа данных набор, представляющий компонент общего набора над дискретным или непрерывная область значений. Его использование в основном для непрерывного ценностные области. Компонентами дискретного (перечислимого) множества являются отдельные элементы базового типа данных. |
| Последовательность | СПИСОК | Значение, которое содержит другие дискретные значения в определенной последовательности. |
| Сгенерированная последовательность | GLIST | Периодическая или монотонная последовательность значений, созданная из нескольких параметры, а не перечисляются.Используется для указания обычного точки отбора биосигналов. |
| Выборочная последовательность | SLIST | Последовательность выборочных значений, масштабированных и переведенных из списка целочисленные значения. Используется для указания выбранных биосигналов. |
| Сумка | СУМКА | Неупорядоченный набор значений, в котором может содержаться каждое значение более одного раза в сумке. |
| Сумка Товар | BXIT | Расширение универсального типа данных, определяемое ITS, которое представляет собой набор определенное количество одинаковых предметов в сумке. |
| Интервал | ИВЛ | Набор последовательных значений упорядоченного базового типа данных. |
| Граница интервала | IVXB | Расширение универсального типа, определяемое ITS, представляющее граничное значение для интервала. |
| История | HIST | Набор значений данных, соответствующих типу элемента истории (HXIT), (я.е., которые имеют свойство действительного времени). Информация об истории не ограничиваясь прошлым; ожидаемые будущие значения также могут появиться. |
| История Позиция | HXIT | Расширение универсального типа данных, которое маркирует временной диапазон для любого значения данных. любого типа данных. Временной диапазон — это время, в которое информация представленное значением является (было) действительным. |
| Неопределенное значение — вероятностный | УВП | Расширение универсального типа данных, используемое для определения вероятности, выражающей уверенность производителя информации в том, что данное значение имеет место. |
| Непараметрическое распределение вероятностей | АЭС | Набор неопределенных значений с вероятностями (также известный как гистограмма.) |
| Периодический интервал времени | PIVL | Периодически повторяющийся интервал времени. Периодические интервалы имеют два свойства, фаза и период. Фаза определяет «интервал прототип », который повторяется каждый период. |
| Интервал времени, связанный с событием | EIVL | Задает периодический интервал времени, в котором повторение основано на повседневная деятельность или другие важные события, которые связанные со временем, но не полностью определяемые временем. |
| Выражение родительского множества | SXPR | Компонент набора, который сам состоит из компонентов набора, которые оценивается как одно значение. |
| Параметрическое распределение вероятностей | PPD | Расширение общего типа данных, определяющее неопределенность количественной данные с использованием функции распределения и ее параметров.Помимо конкретные параметры распределения, среднее (ожидаемое значение) и стандартное отклонение всегда дается для поддержания минимального уровня взаимодействия, если получающие приложения не могут справиться с определенное распределение вероятностей. |
| Общие спецификации синхронизации | GTS | Набор моментов времени с указанием времени событий и действий. и циклические шаблоны валидности, которые могут существовать для определенных видов информация, такая как номера телефонов (вечерние, дневные), адреса (т. называемые «снежными птицами», обитающие зимой ближе к экватору и дальше от экватора летом) и в рабочее время. |
Модификаторы типа данных в C
Предыдущее руководство Следующее руководство
Модификаторы типа данных в C
Модификаторы типа данных в языке c — это ключевые слова, используемые для изменения свойств текущих свойств типа данных. Модификаторы типа данных подразделяются на следующие типы.
- длинный
- короткий
- без знака
- подписано
Модификаторы имеют префикс базовых типов данных для изменения (увеличения или уменьшения) объема памяти, выделенного переменной.
Например, объем памяти для типа данных int составляет 4 байта для 32-разрядного процессора. Мы можем увеличить диапазон, используя long int, равный 8 байтам. Мы можем уменьшить диапазон, используя short int, равное 2 байтам.
длинный:
Это может быть использовано для увеличения размера текущего типа данных еще на 2 байта, что может быть применено к типам данных int или double. Например, int занимает 2 байта памяти, если мы используем long с целочисленной переменной, тогда он занимает 4 байта памяти.
Синтаксис
длинный а; -> по умолчанию, которые представляют собой long int.
короткий
Обычно тип данных int занимает разные области памяти для другой операционной системы; для выделения фиксированного пространства памяти можно использовать короткое ключевое слово.
Синтаксис
короткий int a; -> занимает 2 байта памяти в каждой операционной системе.
без знака
Это ключевое слово можно использовать, чтобы сделать принимаемые значения типа данных положительным типом данных.
Синтаксис
беззнаковый int a = 100; // правильно беззнаковое int a = -100; // неправильно
Подпись
Это ключевое слово принимает как отрицательные, так и положительные значения, и это свойства или модификаторы типа данных по умолчанию для каждого типа данных.
Пример
int a = 10; // правильно int a = -10; // правильно подписанный int a = 10; // правильно подписанный int a = -10; // правильно
Примечание: в реальном времени не нужно явно писать ключевое слово со знаком для любого типа данных.
Предыдущее руководство Следующее руководство