Предикаты SQL AND и OR: примеры, синтаксис
Операторы SQL AND и SQL OR — предикаты языка SQL, служащие для создания логических выражений. В SQL предикатами называются операторы, возвращающие значения TRUE или FALSE. Предикат SQL AND — эквивалент логического умножения (конъюнкции), предикат SQL OR — эквивалент логического сложения (дизъюнкции).
Таблица истинности для предикатов следующая:
| first_expression | last_expression | AND | OR |
| TRUE | TRUE | TRUE | TRUE |
| TRUE | FALSE | FALSE | TRUE |
| FALSE | TRUE | FALSE | TRUE |
| FALSE | FALSE | FALSE | FALSE |
Это значит, что, для выполнения условия предиката SQL AND должны быть выполнены оба условия. Для выполнения предиката SQL OR должно быть выполнено хотя бы одно условие.
Предикат SQL AND имеет следующий синтаксис:
boolean_expression AND boolean_expression
Предикат SQL OR имеет следующий синтаксис:
boolean_expression OR boolean_expression
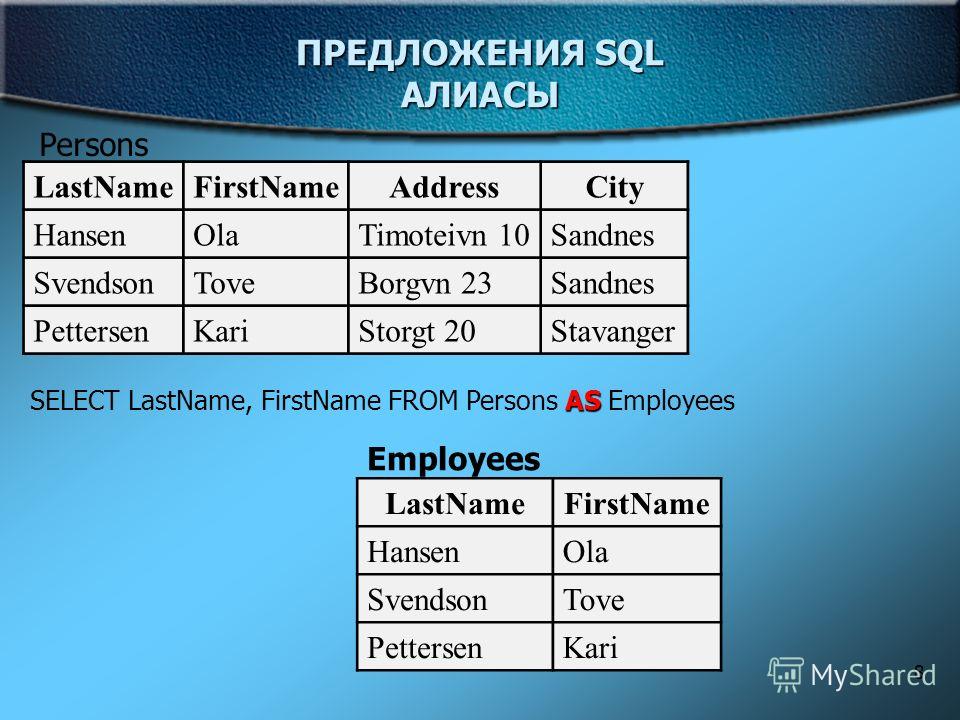
Примеры оператора SQL AND & OR. Имеется следующая таблица Planets:
| ID | PlanetName | Radius | SunSeason | OpeningYear | HavingRings | Opener |
| 1 | Mars | 3396 | 687 | 1659 | No | Christiaan Huygens |
| 2 | Saturn | 60268 | 10759. 22 22 | — | Yes | — |
| 3 | Neptune | 24764 | 60190 | 1846 | Yes | John Couch Adams |
| 4 | Mercury | 2439 | 115.88 | 1631 | No | Nicolaus Copernicus |
| 5 | Venus | 6051 | 243 | 1610 | No | Galileo Galilei |
Пример 1. Используя операторы SQL AND и SQL OR вывести записи планет, у которых радиус планеты меньше 10000 и открытых (OpeningYear) после 1620:
SELECT * FROM Planets WHERE Radius < 10000 AND OpeningYear > 1620
Результат:
| ID | PlanetName | Radius | SunSeason | OpeningYear | HavingRings | Opener |
| 1 | Mars | 3396 | 687 | 1659 | No | Christiaan Huygens |
| 4 | Mercury | 2439 | 115. 88 88 | 1631 | No | Nicolaus Copernicus |
Пример 2. Используя операторы SQL AND и SQL OR вывести записи планет, названия которых начинаются с буквы «N» или заканчиваются на букву «s» и не имеющие колец:
SELECT * FROM Planets WHERE (PlanetName LIKE 'N%' OR PlanetName LIKE '%s') AND HavingRings = 'No'
Результат:
| ID | PlanetName | Radius | SunSeason | OpeningYear | HavingRings | Opener |
| 1 | Mars | 3396 | 687 | 1659 | No | Christiaan Huygens |
| 5 | Venus | 6051 | 243 | 1610 | No | Galileo Galilei |
В этом примере используются как предикат SQL AND так и SQL OR. Конечно же, в запросах их можно использовать сколько угодно раз (так же как и скобки, которые их ограничивают), для задания более точного условия выборки.
Конечно же, в запросах их можно использовать сколько угодно раз (так же как и скобки, которые их ограничивают), для задания более точного условия выборки.
Замечательная функция SQL: количественные предикаты сравнения (ЛЮБОЙ, ВСЕ)
Вы когда-нибудь задумывались о сценарии использования ANY ( также SOME ) и ALL ключевых слов SQL?
Вы, вероятно, еще не сталкивались с этими ключевыми словами в дикой природе. Все же они могут быть чрезвычайно полезными. Но сначала давайте посмотрим, как они определены в стандарте SQL . Легкая часть:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 |
|

Интуитивно понятно, что такой количественный предикат сравнения можно использовать как таковой:
1 2 3 4 5 |
person) |
Давайте продолжим с полезными. Заметьте, что вы, вероятно, написали вышеупомянутые запросы с другим синтаксисом, как таковой:
Заметьте, что вы, вероятно, написали вышеупомянутые запросы с другим синтаксисом, как таковой:
1 2 3 4 5 |
|
Фактически, вы использовали <in predicate> или предикате больше, чем <scalar subquery> и статистическую функцию.
Предикат IN
Это не совпадение, что вы могли использовать <in predicate> же, как вышеупомянутый <quantified comparison predicate> используя ANY . На самом деле, <in predicate> указывается так:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
 4 <
4 < Точно! Разве SQL не красив? Обратите внимание, что неявные последствия 3) приводят к очень специфическому поведению предиката NOT IN отношению к NULL , о котором мало кто знает.
Теперь это становится потрясающим
Пока что в этом <quantified comparison predicate> нет ничего необычного. Все предыдущие примеры можно эмулировать с помощью «более идиоматического» или, скажем, «более повседневного» SQL.
Но истинное удивление <quantified comparison predicate> появляется только при использовании в сочетании с <row value expression> где строки имеют степень / арность более одного:
1 2 3 4 5 6 |
|
Посмотрите вышеупомянутые запросы в действии на PostgreSQL в этом SQLFiddle .
На данный момент стоит упомянуть, что на самом деле немногие базы данных поддерживают…
- выражения значения строки, или …
- количественные предикаты сравнения с выражениями значений строк
Даже если это указано в SQL-92 , похоже, что большинству баз данных все еще не хватает времени для реализации этой функции 22 года спустя.
Эмулируя эти предикаты с помощью jOOQ
Но, к счастью, есть jOOQ, чтобы подражать этим функциям для вас. Даже если вы не используете jOOQ в своем проекте, следующие шаги преобразования SQL могут быть полезны, если вы хотите выразить вышеуказанные предикаты. Давайте посмотрим, как это можно сделать в MySQL:
1 2 3 4 5 6 7 8 |
|
Как насчет другого предиката?
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 |
|
 00) >
00) > Понятно, что предикат EXISTS можно использовать практически во всех базах данных, чтобы имитировать то, что мы видели раньше. Если вам просто нужно это для эмуляции одним выстрелом, приведенных выше примеров будет достаточно. Однако, если вы хотите более формально использовать
Если вам просто нужно это для эмуляции одним выстрелом, приведенных выше примеров будет достаточно. Однако, если вы хотите более формально использовать <row value expression> и <quantified comparison predicate> , вам лучше получить правильное преобразование SQL.
Читайте дальше о преобразовании SQL в этой статье здесь.
T-SQL: дополнительные предикаты в предложении JOINs против предложения WHERE
Есть ли какая-то разница между добавлением дополнительных предикатов в оператор JOIN и добавлением их в качестве дополнительных предложений в оператор WHERE?
Пример 1: предикат в предложении WHERE
select emp.*
from Employee emp
left join Order o on emp.Id = o.EmployeeId
where o.Cancelled = 0
Пример 2: предикат в операторе JOIN
select emp.*
from Employee emp
left join Order o on emp.Id = o.EmployeeId and o. Cancelled = 0
Cancelled = 0
Поделиться Источник Neil Barnwell 07 сентября 2011 в 10:16
4 ответа
- Sql предложении where
У меня есть хранимая процедура, в которой я передаю значение, которое будет использоваться в операторе select в предложении where. Если значение, которое я передаю, равно NULL, я не хочу, чтобы оно было частью той части предложения where, где оно используется. В приведенном ниже примере…
- Использование предложения AND против WHERE в SQL
Я работаю над PHP page , который соединяется с Oracle . Я наткнулся на этот SQL, и я не уверен, что он делает то, что должен, поэтому я решил спросить Здесь. SQL, о котором идет речь, выглядит следующим образом: select tableA.id, tableA.name, tableB.details from tableA left join tableB on…
9
С первым оператором внешнее соединение эффективно превращается во внутреннее соединение из-за условия WHERE, поскольку оно отфильтрует все строки из таблицы employee, где не было найдено заказа (потому что тогда o. Cancelled будет NULL)
Cancelled будет NULL)
Таким образом, эти два утверждения не делают одно и то же.
Поделиться a_horse_with_no_name 07 сентября 2011 в 10:35
4
Я уже получил ответы от некоторых моих коллег, но если они не опубликуют их здесь, я добавлю ответ сам.
Оба этих примера предполагают, что предикат сравнивает столбец таблицы «right» со значением scalar.
Представление
Похоже , что если предикат находится на JOIN, то таблица «right» фильтруется заранее. Если предикат является частью предложения WHERE , то все результаты возвращаются и фильтруются один раз в конце перед возвращением результирующего набора.
Возвращенные Данные
если предикат является частью предложения WHERE , то в ситуации, когда значение «right» равно null (т. е. нет соединяющей строки), вся строка не будет возвращена в конечном результирующем наборе, поскольку предикат будет сравнивать значение с null и, следовательно, возвращать false.
Поделиться Neil Barnwell 07 сентября 2011 в 10:19
3
Просто для того, чтобы рассмотреть случай, когда дополнительный предикат находится в столбце из левой таблицы, это все еще может иметь значение, как показано ниже.
WITH T1(N) AS
(
SELECT 1 UNION ALL
SELECT 2
), T2(N) AS
(
SELECT 1 UNION ALL
SELECT 2
)
SELECT T1.N, T2.N, 'ON' AS Clause
FROM T1
LEFT JOIN T2 ON T1.N = T2.N AND T1.N=1
UNION ALL
SELECT T1.N, T2.N, 'WHERE' AS Clause
FROM T1
LEFT JOIN T2 ON T1.N = T2.N
WHERE T1.N=1
Возвращается
N N Clause
----------- ----------- ------
1 1 ON
2 NULL ON
1 1 WHERE
Поделиться Martin Smith 07 сентября 2011 в 10:56
- используйте логику if-else в предложении where в T-SQL
Есть ли какой-нибудь способ использовать логику if-else в предложении where в T-SQL? или мне нужно реализовать логику с помощью подзапроса?
- If-Else в предложении T-SQL where
Просто интересно, как лучше всего сделать условное предложение WHERE в T-sql sproc? Я не хочу использовать dynamic sql — я бы предпочел использовать параматериализованный sproc.
 Мои параметры не могут быть NULL, но они могут быть пустой строкой. Если они являются пустой строкой,я бы хотел ‘skip’…
Мои параметры не могут быть NULL, но они могут быть пустой строкой. Если они являются пустой строкой,я бы хотел ‘skip’…
0
Вот еще один пример ( четыре случая )
insert into #tmp(1,"A")
insert into #tmp(2,"B")
select "first Query", a.*,b.* from #tmp a LEFT JOIN #tmp b
on a.id =b.id
and a.id =1
union all
select "second Query", a.*,b.* from #tmp a LEFT JOIN #tmp b
on a.id =b.id
where a.id =1
union all
select "Third Query", a.*,b.* from #tmp a LEFT JOIN #tmp b
on a.id =b.id
and b.id =1
union all
select "Fourth Query", a.*,b.* from #tmp a LEFT JOIN #tmp b
on a.id =b.id
where b.id =1
Результаты:
first Query 1 A 1 A
first Query 2 B NULL NULL
second Query 1 A 1 A
Third Query 1 A 1 A
Third Query 2 B NULL NULL
Fourth Query 1 A 1 A
Fourth Query 1 A 1 A
Поделиться Gopal Sanodiya 08 сентября 2011 в 16:24
Похожие вопросы:
Используя псевдоним столбца в предложении where в MS-sql 2000
Я знаю, что вы не можете использовать столбец псевдонима в предложении where для T-SQL; однако предоставила ли Microsoft какой-то обходной путь для этого? Сопутствующие Вопросы : Неизвестный Столбец. ..
..
Случай переключения в T-SQL в предложении where
Здравствуйте, эксперты, у меня есть Sp , который содержит много условий if / else Пожалуйста, помогите мне, как использовать switch Case в T-SQL в предложении where. вот мой запрос if (@Form…
использование CASE в T-SQL в предложении where?
Я пытаюсь использовать случай, чтобы изменить значение им проверки, в предложении where, но я получаю сообщение об ошибке: неправильный синтаксис около ключевого слова ‘CASE’ SQL Server 2005 select…
Sql предложении where
У меня есть хранимая процедура, в которой я передаю значение, которое будет использоваться в операторе select в предложении where. Если значение, которое я передаю, равно NULL, я не хочу, чтобы оно…
Использование предложения AND против WHERE в SQL
Я работаю над PHP page , который соединяется с Oracle . Я наткнулся на этот SQL, и я не уверен, что он делает то, что должен, поэтому я решил спросить Здесь. SQL, о котором идет речь, выглядит…
SQL, о котором идет речь, выглядит…
используйте логику if-else в предложении where в T-SQL
Есть ли какой-нибудь способ использовать логику if-else в предложении where в T-SQL? или мне нужно реализовать логику с помощью подзапроса?
If-Else в предложении T-SQL where
Просто интересно, как лучше всего сделать условное предложение WHERE в T-sql sproc? Я не хочу использовать dynamic sql — я бы предпочел использовать параматериализованный sproc. Мои параметры не…
SQL запрос: разница в условии в предложении On и предложении where
Я пытаюсь получить разницу между нижеприведенными 2 запросами Запрос 1 : В котором я дал условие ‘Orders.OrderID != null’ в предложении on SELECT Customers.CustomerName, Orders.OrderID FROM…
sql переменная предложения where
Я использую VBA и SQL. Мой VBA выглядит так Dim SystemLookup As String Dim SqlString As String If IsNull(Me!SystemLookup) Then Me!SystemLookup = Else SystemLookup = Me!SystemLookup End If SqlString. ..
..
Явные JOINs против неявных соединений?
Мой профессор базы данных сказал нам использовать: SELECT A.a1, B.b1 FROM A, B WHERE A.a2 = B.b2; Скорее, чем: SELECT A.a1, B.b1 FROM A INNER JOIN B ON A.a2 = B.b2; Предположительно Oracle не любит…
Postgres Pro Enterprise : Документация: 9.6: 9.2. Функции и операторы сравнения : Компания Postgres Professional
9.2. Функции и операторы сравнения
Набор операторов сравнения включает обычные операторы, перечисленные в Таблице 9.1.
Таблица 9.1. Операторы сравнения
| Оператор | Описание |
|---|---|
< | меньше |
> | больше |
<= | меньше или равно |
>= | больше или равно |
= | равно |
<> или != | не равно |
Примечание
Оператор != преобразуется в <> на стадии разбора запроса. Как следствие, реализовать операторы
Как следствие, реализовать операторы != и <> по-разному невозможно.
Операторы сравнения определены для всех типов данных, для которых они имеют смысл. Все операторы сравнения представляют собой бинарные операторы, возвращающие значения типа boolean; при этом выражения вида 1 < 2 < 3 недопустимы (так как не существует оператора <, который бы сравнивал булево значение с 3).
Существует также несколько предикатов сравнения; они приведены в Таблице 9.2. Они работают подобно операторам, но имеют особый синтаксис, установленный стандартом SQL.
Таблица 9.2. Предикаты сравнения
| Предикат | Описание |
|---|---|
a BETWEEN x AND y | между |
a NOT BETWEEN x AND y | не между |
a BETWEEN SYMMETRIC x AND y | между, после сортировки сравниваемых значений |
a NOT BETWEEN SYMMETRIC x AND y | не между, после сортировки сравниваемых значений |
a IS DISTINCT FROM b | не равно, при этом NULL воспринимается как обычное значение |
a IS NOT DISTINCT FROM b | равно, при этом NULL воспринимается как обычное значение |
выражение IS NULL | эквивалентно NULL |
выражение IS NOT NULL | не эквивалентно NULL |
выражение ISNULL | эквивалентно NULL (нестандартный синтаксис) |
выражение NOTNULL | не эквивалентно NULL (нестандартный синтаксис) |
логическое_выражение IS TRUE | истина |
логическое_выражение IS NOT TRUE | ложь или неопределённость |
логическое_выражение IS FALSE | ложь |
логическое_выражение IS NOT FALSE | истина или неопределённость |
логическое_выражение IS UNKNOWN | неопределённость |
логическое_выражение IS NOT UNKNOWN | истина или ложь |
Предикат BETWEEN упрощает проверки интервала:
aBETWEENxANDy
равнозначно выражению
a>=xANDa<=y
Заметьте, что BETWEEN считает, что границы интервала также включаются в интервал.
NOT BETWEEN выполняет противоположное сравнение:
aNOT BETWEENxANDy
равнозначно выражению
a<xORa>y
Предикат BETWEEN SYMMETRIC аналогичен BETWEEN, за исключением того, что аргумент слева от AND не обязательно должен быть меньше или равен аргументу справа. Если это не так, аргументы автоматически меняются местами, так что всегда подразумевается непустой интервал.
Обычные операторы сравнения выдают NULL (что означает «неопределённость»), а не true или false, когда любое из сравниваемых значений NULL. Например, 7 = NULL выдаёт NULL, так же, как и 7 <> NULL. Когда это поведение нежелательно, можно использовать предикаты IS [ NOT ] DISTINCT FROM:
aIS DISTINCT FROMbaIS NOT DISTINCT FROMb
Для значений не NULL условие IS DISTINCT FROM работает так же, как оператор <>. Однако, если оба сравниваемых значения NULL, результат будет false, и только если одно из значений NULL, возвращается true. Аналогично, условие
Однако, если оба сравниваемых значения NULL, результат будет false, и только если одно из значений NULL, возвращается true. Аналогично, условие IS NOT DISTINCT FROM равносильно = для значений не NULL, но возвращает true, если оба сравниваемых значения NULL и false в противном случае. Таким образом, эти предикаты по сути работают с NULL, как с обычным значением, а не с «неопределённостью».
Для проверки, содержит ли значение NULL или нет, используются предикаты:
выражениеIS NULLвыражениеIS NOT NULL
или равнозначные (но нестандартные) предикаты:
выражениеISNULLвыражениеNOTNULL
Заметьте, что проверка выражение = NULLNULL считается не «равным» NULL. (Значение NULL представляет неопределённость, и равны ли две неопределённости, тоже не определено. )
)
Подсказка
Некоторые приложения могут ожидать, что выражение = NULLвыражения является NULL. Такие приложения настоятельно рекомендуется исправить и привести в соответствие со стандартом SQL. Однако, в случаях, когда это невозможно, это поведение можно изменить с помощью параметра конфигурации transform_null_equals. Когда этот параметр включён, Postgres Pro преобразует условие x = NULL в x IS NULL.
Если выражение возвращает табличную строку, тогда IS NULL будет истинным, когда само выражение — NULL или все поля строки — NULL, а IS NOT NULL будет истинным, когда само выражение не NULL, и все поля строки так же не NULL. Вследствие такого определения, IS NULL и IS NOT NULL не всегда будут возвращать взаимодополняющие результаты для таких выражений; в частности такие выражения со строками, одни поля которых NULL, а другие не NULL, будут ложными одновременно. В некоторых случаях имеет смысл написать
В некоторых случаях имеет смысл написать строка IS DISTINCT FROM NULL или строка IS NOT DISTINCT FROM NULL, чтобы просто проверить, равно ли NULL всё значение строки, без каких-либо дополнительных проверок полей строки.
Логические значения можно также проверить с помощью предикатов
логическое_выражениеIS TRUEлогическое_выражениеIS NOT TRUEлогическое_выражениеIS FALSEлогическое_выражениеIS NOT FALSEлогическое_выражениеIS UNKNOWNлогическое_выражениеIS NOT UNKNOWN
Они всегда возвращают true или false и никогда NULL, даже если какой-любо операнд — NULL. Они интерпретируют значение NULL как «неопределённость». Заметьте, что IS UNKNOWN и IS NOT UNKNOWN по сути равнозначны IS NULL и IS NOT NULL, соответственно, за исключением того, что выражение может быть только булевого типа.
Также имеется несколько связанных со сравнениями функций; они перечислены в Таблице 9.3.
Таблица 9.3. Функции сравнения
| Функция | Описание | Пример | Результат примера |
|---|---|---|---|
num_nonnulls(VARIADIC "any") | возвращает число аргументов, отличных от NULL | num_nonnulls(1, NULL, 2) | 2 |
num_nulls(VARIADIC "any") | возвращает число аргументов NULL | num_nulls(1, NULL, 2) | 1 |
Команда SELECT Раздел WHERE — Примеры выборки SELECT с разделом WHERE
Раздел WHERE
Если в табличном выражении присутствует раздел WHERE, то следующим вычисляется он.
Условие, следующее за ключевым словом WHERE, может включать предикат условия поиска, булевские операторы AND (и), OR (или) и NOT(нет) и скобки, указывающие требуемый порядок вычислений.
Вычисление раздела WHERE производится по следующим правилам: Пусть R — результат вычисления раздела FROM. Тогда условие поиска применяется ко всем строкам R, и результатом раздела WHERE является таблица SQL, состоящая из тех строк R, для которого результатом вычисления условия поиска является true. Если условие выборки включает подзапросы, то каждый подзапрос вычисляется для каждого кортежа таблицы R (в стандарте используется термин “effectively” в том смысле, что результат должен быть таким, как если бы каждый подзапрос действительно вычислялся заново для каждого кортежа R).
Среди предикатов условия поиска в соответствии со стандартом могут находиться следующие предикаты: предикат сравнения, предикат between, предикат in, предикат like, предикат null, предикат с квантором и предикат exists.
При проверке условия выборки числа сравниваются алгебраически: отрицательные числа считаются меньше, чем положительные, независимо от их абсолютной величины. Строки сравниваются в соответствии с их представлением в коде ANSI. При сравнении двух строк, имеющих разные длины, предварительно более короткая строка дополняется справа пробелами для того, чтобы обе строки имели одинаковую длину.
Предикат сравнения с выражениями или результатами подзапроса. Условие определяется из двух выражений, разделенных одним из знаков операции отношения: =, <>(не равно), >, >=, < и <=.
Арифметические выражения левой и правой частей предиката сравнения строятся по общим правилам построения арифметических выражений и могут включать в общем случае имена столбцов таблиц из раздела FROM и константы. Типы данных арифметических выражений должны быть сравнимыми (например, если тип столбца a таблицы A является типом символьных строк, то предикат “a = 5” недопустим).
Если правый операнд операции сравнения задается подзапросом, то дополнительным ограничением является то, что мощность результата подзапроса должна быть не более единицы. Если хотя бы один из операндов операции сравнения имеет неопределенное значение, или если правый операнд является подзапросом с пустым результатом, то значение предиката сравнения равно unknown.
Для обеспечения переносимости прикладных программ нужно внимательно оценивать специфику работы с неопределенными значениями в конкретной СУБД.
Примеры выборки SELECT с разделом WHERE
Выборка кода и фамилии покупателей, проживающих в Москве.
SELECT CUSTOMERNO, FIRSTNAME, LASTNAME FROM CUSTOMER WHERE CITY = ‘Москва’;
Выборка из таблицы emp данных по служащим отдела с номером 40:
SELECT * FROM emp WHERE deptno = 40;
Извлечение из таблицы записи с полями имя, должность, размер оклада и номер отдела для всех служащих за исключением продавцов из отдела с номером 30:
SELECT ename, job, sal, deptno FROM emp WHERE NOT deptno = 30;
Лекция 3. Предикаты раздела WHERE
3.1. Структура запросов
Лекция 3. Язык SQL. Средства манипулирования данными 3.1. Структура запросов Для того, чтобы можно было более или менее точно рассказать про структуру запросов в стандарте SQL/89, необходимо начать со
ПодробнееБазы данных и Информационные системы
Базы данных и Информационные системы 6/15 Условия отбора данных при запросе к БД Кузиков Б.О. Сумы, СумГУ 2013 Задачи занятия После завершения занятия вы должны уметь и знать следующее: Накладывать ограничения
ПодробнееОглавление. Предисловие…3
Оглавление Предисловие…3 Ч а с т ь I. Базы данных, СУБД и модели данных Глава 1. Назначение технологии баз данных. Функции и основные компоненты систем управления базами данных……………………………………
ПодробнееО языке SQL. Предложение SELECT
О языке SQL Язык SQL предназначен для доступа к информации и управления реляционной базой данных. Управление различными реляционными базами данных осуществляют программы, называемые СУБД — системы управления
ПодробнееI. ПОЯСНИТЕЛЬНАЯ ЗАПИСКА
I. ПОЯСНИТЕЛЬНАЯ ЗАПИСКА Цели: Цель данного курса дать основные понятия теории баз данных и подходы к проектированию реляционных баз данных. Представить современные технологии моделирования информационных
ПодробнееЛабораторная работа 4
OpenOffice.org Base 31 Тема: «Запросы к базе данных» Лабораторная работа 4 Цель работы: ознакомиться со средствами поиска и выборки данных в Open Office.org Base, изучить основные принципы конструирования
ПодробнееЛабораторная работа 17. Предикат exists
Лабораторная работа 17. ТЕМА: «Комбинированные действия с данными» ЦЕЛЬ: Научиться делать комбинированные действия. Порядок выполнения работы: 1. Воспользоваться предикатом Exists; 2. Воспользоваться предикатом
ПодробнееЧАСТЬ I. ОСНОВНЫЕ ПОНЯТИЯ
Содержание Об авторе 17 Посвящение 17 Благодарности 17 Введение 18 Об этой книге 18 Для кого предназначена книга 18 Структура книги 19 Часть I. Основные понятия 19 Часть II. Использование SQL для создания
ПодробнееРеляционная модель данных
Реляционная модель данных Лекция 3 12 правил Кодда 1.Явное представление данных (The Information Rule). 2.Гарантированный доступ к данным (Guaranteed Access Rule). 3.Полная обработка неизвестных значений
ПодробнееОперации и выражения
Глава 5 Операции и выражения В этой главе Выражения в языке VBA Совместимость типов данных Оператор присваивания Арифметические операторы Логические операторы Операторы сравнения Строковые операторы Приоритеты
ПодробнееStructured Query Language
Structured Query Language Курс «Базы данных» Вадим Цесько Санкт-Петербургский государственный политехнический университет 15 марта 2012 г. Вадим Цесько (СПбГПУ) Structured Query Language 15 марта 2012
ПодробнееMS Создание запросов в Microsoft SQL Server 2012
MS-10774 Создание запросов в Microsoft SQL Server 2012 Прод олжит ельн о сть ку рса: 40 академических часов Аттестация: удостоверение о повышении квалификации установленного образца (или сертификат ТПУ)
ПодробнееОСНОВНЫЕ ПОНЯТИЯ БАЗ ДАННЫХ
ОСНОВНЫЕ ПОНЯТИЯ БАЗ ДАННЫХ 1. Выберите правильный порядок действий при проектировании БД а) Решение проблемы передачи данных б) Анализ предметной области, с учетом требования конечных пользователей в)
ПодробнееПодзапросы и предикаты
Подзапросы и предикаты 1 Проблема Требование реляционной модели суперпозиция реляционных операций SELECT обеспечивает ее лиши частично 2 Решение Раннее решение использовать представления CREATE [OR ALTER]
ПодробнееOracle 12c: введение в SQL 1:
Введение в базу данных Oracle 12c Oracle 12c: введение в SQL 1: Обзор основных возможностей БД Oracle 12c Обсуждение основных концепций, а также теоретических и физических аспектов реляционной базы данных
ПодробнееПодзапросы и предикаты
Подзапросы и предикаты 1 Проблема Требование реляционной модели суперпозиция реляционных операций SELECT обеспечивает ее лишь частично 2 Решение Раннее решение использовать представления CREATE [OR ALTER]
ПодробнееЯзык запросов SQL — Structured Query Language
Язык запросов SQL — Structured Query Language Типы запросов данных: SELECT выбрать строки из таблиц; INSERT добавить строки в таблицу; UPDATE изменить строки в таблице; DELETE удалить строки в таблице.
ПодробнееОператоры реляционной алгебры. Лекция 9
Операторы реляционной алгебры Лекция 9 План лекции Значение Основные операторы реляционной алгебры Операции расширения и подведения итогов Операторы обновления Server 2008. Лекция 9 2 Значение реляционной
ПодробнееСоздание запросов к Microsoft SQL Server 2014
Создание запросов к Microsoft SQL Server 2014 20461 ДЕТАЛЬНАЯ ИНФОРМАЦИЯ О КУРСЕ Создание запросов к Microsoft SQL Server 2014 Код курса: 20461 Длительность 40 Формат Разработчик курса Тип Способ обучения
ПодробнееПОИСК В БАЗАХ ДАННЫХ
ПОИСК В БАЗАХ ДАННЫХ Методические указания к лабораторной работе 1. ЦЕЛЬ РАБОТЫ Целью работы является приобретение практических навыков решения задач поиска данных с использования технологии окон данных.
ПодробнееЯзык SQL. Yuriy Shamshin 2/33
Содержание Язык SQL 1. Select базовый оператор языка структурированных запросов 2. Унарные операции на языке структурированных запросов 2.1. Операция выборки 2.2. Операция проекции. 2.3. Операция переименования
ПодробнееЯзык SQL. Инструкция SELECT
Язык SQL Инструкция SELECT Инструкция SELECT Назначение инструкции запрос данных из таблицы, некоторая логическая обработка и возврат результата Логическая обработка запроса абстрактная процедура, которая
ПодробнееМодели данных и СУБД в геоэкологии
Модели данных и СУБД в гео Раздел 2. Реляционные базы данных Современные направления развития баз данных Лекция 2 Преподаватель Воробьёв Д.С. Реляционные базы данных Современные направления развития баз
ПодробнееЯзык SQL. Yuriy Shamshin 2/35
Содержание Язык SQL. 1. Select базовый оператор языка структурированных запросов. 2. Унарные операции на языке структурированных запросов. 2.1. Операция выборки. 2.2. Операция проекции. 2.3. Операция переименования.
ПодробнееАлгоритмы и алгоритмические языки
Алгоритмы и алгоритмические языки Лекции 9 и 10 Регулярные типы (массивы). Некоторые алгоритмы сортировки. (С) Корухова Ю.С., 2012 Язык Паскаль.Типы данных простые целый вещественный логический символьный
ПодробнееПРИМЕНЕНИЕ ЯЗЫКА SQL В MS ACCESS
Московский государственный технический университет имени Н. Э. Баумана Калужский филиал Ю. Е. Гагарин, С. В. Пономарев ПРИМЕНЕНИЕ ЯЗЫКА SQL В MS ACCESS Учебно-методическое пособие УДК 681.3.06 ББК 32.973
ПодробнееРеляционная модель данных
Реляционная модель данных Курс «Базы данных» Вадим Цесько Санкт-Петербургский государственный политехнический университет 18 февраля 2012 г. Вадим Цесько (СПбГПУ) Реляционная модель данных 18 февраля 2012
ПодробнееPredicate Pushdown vs Projection Pushdown в Apache Spark SQL
Продолжая разбирать практические особенности аналитики больших данных с Apache Spark, сегодня рассмотрим возможности оптимизации SQL-запросов в этом Big Data фреймворке с помощью механизмов предикатного и проекционного сжатия. Читайте далее про реализацию Predicate Pushdown и Projection Pushdown в Apache Spark 3, а также их связь с форматами Parquet и AVRO.
Механизмы оптимизации SQL-запросов или что такое Predicate Pushdown и Projection Pushdown
Напомним, при выполнении SQL-запроса, прежде всего происходит его анализ и логическая оптимизация, когда к логическому плану запроса применяются типовые правила. Одним из них является Predicate pushdown – оптимизация, которая применяет условия (предикаты) как можно раньше, предотвращая загрузку ненужных строк.
Этот механизм связан с предикатами, которые являются частью SQL-оператора, фильтрующего данные. Предикаты в математической логике аналогичны логическим условиям (clause) в SQL – утверждениям, которые могут иметь значение ИСТИНА (True) или ЛОЖЬ (False) для разных значений переменных или данных. Применение Predicate pushdown ограничено некоторыми особенностями, например, join-предикаты нельзя поместить после первого join-соединения, на которое они влияют. Но предикаты можно передать через группировку (group by) и оконные функции, если они находятся среди ключей группирования или разделения. Predicate pushdown повышает эффективность работы индексов [1].
В случае обработки больших объемов данных (Big Data) этот механизм может улучшить производительность запросов за счет уменьшения считываний из хранилища и сокращения передаваемого трафика. К примеру, процесс СУБД оценивает предикаты фильтра в запросе по метаданным, хранящимся в файлах хранилища, чтобы считывать только те данные, которые нужны. Для успешного применения этого механизма на практике хранилище данных должно отвечать следующим условия [2]:
- сбалансированность, т.е. размер файлов метаданных меньше фактических файлов данных;
- наличие метаданных и индексов.
Еще одним механизмом оптимизации SQL-запроса является сжатие проекций или исключение столбцов. Projection Pushdown направлено на то, чтобы как можно раньше удалить ненужные столбцы или не извлекать их вообще. При наличии индекса в удаленном столбце база данных может удовлетворить запрос только из индекса (сканирование только по индексу), не извлекая остальные столбцы из самой таблицы. Это может на порядок повысить скорость выполнения запросов [1]. Projection Pushdown хранит данные в столбцах, поэтому, когда проекция ограничивает запрос определенными столбцами, будут возвращены только они [3].
Как устроены Pushdown-механизмы оптимизации в Apache Spark SQL
В Apache Spark Predicate Pushdown позволяет оптимизировать запросы Spark SQL, фильтруя данные в запросе к СУБД и уменьшая количество извлекаемых записей. По умолчанию Spark Dataset API автоматически передает действительные WHERE-условия в базу данных. Поэтому при создании запросов Spark SQL, использующих операторы сравнения, проверка правильности передачи предикатов в базу данных критически важна для получения корректных данных с максимальной производительностью [4].
В частности, при работе с условными операторами WHERE или FILTER сразу после загрузки датасета, Spark SQL будет пытаться передать эти предикаты источнику данных, используя соответствующий запрос SQL с условием предложением WHERE. Таким образом, фильтрация опускается до источника данных. и выполняется на очень низком уровне, а не работает со всем датасетом после его загрузки в память Spark, чтобы избежать проблем с ней. Predicate Pushdown также применяется к SQL-запросам с фильтрами после проекций или фильтрацией по разделам временного окна.
Поскольку Predicate Pushdown работает с WHERE или FILTER, его можно назвать строковым, т.к. эти условия влияют на количество возвращаемых строк. Совмещение предикатного сжатия с сокращением разделов (Partition Pruning) повышает производительность чтения каталогов и файлов из файловой системы, позволяя читать только нужные файлы в указанном разделе. Таким образом, фильтрация данных смещается еще ближе к их источнику, предотвращая сохранение ненужных данных в памяти с целью уменьшения дискового ввода-вывода. К примеру, файлы в столбцовом формате Parquet содержат различные статистические показатели для каждого столбца, включая минимальное и максимальное значения. Predicate Pushdown помогает пропустить нерелевантные данные и работать только с нужными [3].
Predicate Pushdown + Partition PruningВ отличие от сжатия предикатов, сжатие проекций можно назвать столбцовым, поскольку оно ориентировано на сокращение количества передаваемых столбцов, а не строк. Например, если фильтр Predicate Pushdown пропускает только 5% строк, то лишь 5% таблицы будет передано из хранилища в Spark вместо полного набора данных. А если Projection Pushdown выбирает только 3 столбца из 10, то именно они будут переданы из хранилища в Spark. В случае столбцового формата файлов (Parquet, а не AVRO) невыбранные столбцы даже не будут частью фильтра и их не придется читать [5].
Таким образом, Projection Pushdown позволяет свести к минимуму передачу данных между файловой системой или СУБД и движком Spark, удаляя ненужные поля из процесса сканирования таблицы. Это полезно, когда набор данных содержит слишком много столбцов. В свою очередь, Predicate Pushdown повышает производительность за счет уменьшения объема данных, передаваемых между файловой системой или СУБД и механизмом Apache Spark при фильтрации. Pushdown Filtering работает с разделенными столбцами аналогично файлам в формате Parquet. Чтобы это было максимально эффективно, столбцы разделов должны содержать значения меньшего размера с соответствующими данными для разброса нужных файлов по каталогам. Следует избегать слишком большого количества файлов небольшого размера, которые могут снизить эффективность сканирования из-за чрезмерного параллелизма. А малое число файлов большого размера может нарушить параллелизм распределения PySpark-заданий по кластеру, о чем мы рассказывали здесь. О других особенностях оптимизации структурированных запросов в Apache Spark SQL с помощью оптимизатора Catalyst читайте в нашей отдельной статье. В этом материале мы разбираем тонкости соединения двух наборов через SQL-операцию JOIN. А про построение конвейеров машинного обучения в Apache Spark MlLib с использованием структуры данных из SQL, Dataframe, мы поговорим в следующий раз.
Разобраться с особенностями оптимизации SQL-запросов в Apache Spark SQL для эффективной разработки распределенных приложений для аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://modern-sql.com/feature/with/performance
- https://medium.com/microsoftazure/data-at-scale-learn-how-predicate-pushdown-will-save-you-money-7063b80878d7
- https://towardsdatascience.com/predicate-vs-projection-pushdown-in-spark-3-ac24c4d11855
- https://docs.datastax.com/en/dse/6.0/dse-dev/datastax_enterprise/spark/sparkPredicatePushdown.html
- https://stackoverflow.com/questions/58235076/what-is-the-difference-between-predicate-pushdown-and-projection-pushdown
Использование предикатов в запросах
Использование предикатов в запросах
Предикат — это условное выражение, которое в сочетании с логическими операторами И и ИЛИ составляет набор условий в WHERE, Предложение HAVING или ON. В SQL предикат, имеющий значение UNKNOWN, интерпретируется как FALSE.
Предикат, который может использовать индекс для извлечения строк из таблицы, называется sargable .Это название происходит от фразы с аргументом поиска . Предикаты, которые включают сравнения столбца с константами, другими столбцами или выражениями, могут быть саргируемыми.
Предикат в следующем утверждении является sargable. SQL Anywhere может эффективно оценить его, используя первичный индекс таблица Сотрудники.
На плане это выглядит так: Сотрудники <Сотрудники>
Напротив, следующий предикат не подлежит разложению.Хотя столбец EmployeeID индексируется в первичном индексе, с использованием этот индекс не ускоряет вычисление, потому что результат содержит всю или все строки, кроме одной.
На плане это выглядит так: Сотрудники
Точно так же никакой индекс не может помочь в поиске всех сотрудников, чье имя оканчивается на букву k. Опять же, единственное средство Для вычисления этого результата нужно исследовать каждую из строк по отдельности.
Функции
В общем случае предикат, который имеет функцию для имени столбца, не может быть саргирован. Например, индекс не будет использоваться для следующий запрос:
Чтобы избежать использования функции, вы можете переписать запрос, чтобы сделать его доступным для сортировки. Например, вы можете перефразировать приведенный выше запрос:
Запрос, использующий функцию, становится доступным, если вы сохраняете значения функции в вычисляемом столбце и строите индекс на этот столбец.Вычисляемый столбец — это столбец, значения которого получены из других столбцов в таблице. Например, если у вас есть столбец с именем OrderDate который содержит дату заказа, вы можете создать вычисляемый столбец с именем OrderYear, который содержит значения за год, извлеченный из столбца OrderDate.
Затем вы можете добавить индекс в столбец OrderYear обычным способом:
Если вы затем выполните следующую инструкцию, сервер базы данных распознает, что существует индексированный столбец, содержащий этот информации и использует этот индекс для ответа на запрос.
Домен вычисляемого столбца должен быть эквивалентен домену выражения COMPUTE для подстановки столбца
быть произведенным. В приведенном выше примере, если бы YEAR (OrderDate) вернул строку вместо целого числа, оптимизатор не заменил бы вычисляемый столбец для выражения,
и индекс IDX_year не мог использоваться для извлечения требуемых строк.
Для получения дополнительной информации о вычисляемых столбцах см. Работа с вычисляемыми столбцами.
Примеры
В каждом из этих примеров атрибуты x и y являются столбцами одной таблицы. Атрибут z содержится в отдельной таблице. Предположим, что для каждого из этих атрибутов существует индекс.
| Sargable | Не подлежит продаже |
|---|---|
| x = 10 | x <> 10 |
| x НУЛЬ | x НЕ ПУТЬ |
| x > 25 | x = 4 ИЛИ y = 5 |
| x = z | x = y |
| x ДЮЙМ (4, 5, 6) | x НЕ В (4, 5, 6) |
| x КАК ‘pat%’ | x КАК ‘% tern’ |
| x = 20 — 2 | х + 2 = 20 |
Иногда может быть неочевидно, является ли предикат саргируемым.В этих случаях вы можете переписать предикат так что это sargable. Для каждого примера вы можете переписать предикат x LIKE ‘pat%’, используя тот факт, что u является следующей буквой в алфавите после t: x > = ‘pat’ и x <'pau'. В этой форме индекс атрибута x помогает находить значения в ограниченном диапазоне. К счастью, SQL Anywhere выполняет именно это преобразование для вы автоматически.
Предикат sargable, используемый для индексированного поиска по таблице, — это предикат , соответствующий . Предложение WHERE может иметь много совпадающих предикатов. Наиболее подходящий предикат может зависеть от стратегии соединения. Оптимизатор повторно оценивает свой выбор совпадающих предикатов при рассмотрении альтернативных стратегий соединения. См. Обнаружение пригодных для использования условий посредством вывода предикатов.
Работа с предикатами сравнения и сгруппированными запросами
Причина, по которой SQL-92 включает квалификатор ANY и синоним SOME, связана с двусмысленностью слова any.Если я спрошу: «Кто-нибудь из вас знает, как написать оператор SQL SELECT с предложением WHERE?» Я использую любой как экзистенциальный количественный показатель, означающий «хотя бы один» или «несколько». С другой стороны, если я говорю: «Я могу печатать быстрее, чем любой из вас», я использую любой в качестве универсального квантификатора, означающего «все». Таким образом, когда вы пишете WHERE в операторе SELECT, например, если СУБД должна интерпретировать любое значение как экзистенциальный квантификатор, означающий «Показать столбцы в строке из
» если b больше, чем хотя бы одно из значений в «? Или СУБД должна рассматривать любое значение как универсальный квантификатор, означающий» Отображать столбцы в строке из если b больше всех значений в «?ВЫБРАТЬ * ИЗГДЕ b> ЛЮБОЙ
Чтобы прояснить путаницу, разработчики SQL-92 добавили SOME (которое имеет только одно значение — «один или несколько») к стандарту SQL-92 и сохранили экзистенциальное ANY как синоним обратной совместимости.
Понимание УНИКАЛЬНОГО предиката
Предикат UNIQUE в предложении WHERE позволяет выполнять оператор DELETE, INSERT, SELECT или UPDATE в зависимости от того, создает ли подзапрос в предикате UNIQUE таблицу результатов, в которой все строки не дублируются (то есть все строки в таблице результатов уникальны). Если строки таблицы результатов подзапроса уникальны, СУБД выполняет оператор SQL для тестируемой строки.И наоборот, если в таблице результатов есть хотя бы один набор повторяющихся строк, СУБД пропускает выполнение команды SQL и переходит к проверке следующей строки в таблице.
Например, чтобы получить список продавцов, которые либо не продавали, либо совершили только одну продажу в течение сентября 2000 года, вы можете выполнить запрос, подобный:
ВЫБЕРИТЕ emp_ID, first_name, last_name ОТ сотрудников Где УНИКАЛЬНО (ВЫБЕРИТЕ продавца ИЗ счетов-фактур ГДЕ invoice_date> = '01.09.2000' И invoice_date <= '30.09.2000' И счета-фактуры.продавец = сотрудники.emp_ID)
Всегда используется вместе с подзапросом, синтаксис UNIQUE:
[НЕ] УНИКАЛЬНЫЙ
Если таблица результатов, созданная подзапросом в предикате UNIQUE, либо не имеет строк, либо не имеет повторяющихся строк, предикат UNIQUE возвращает TRUE. В текущем примере таблица результатов подзапроса содержит единственный столбец SALESPERSON.Следовательно, если идентификатор продавца появляется не более чем в одной строке в таблице результатов (что означает, что человек совершил не более одной продажи в течение периода), внешний оператор SELECT отобразит идентификатор и имя сотрудника. С другой стороны, если в таблице результатов подзапроса есть один или несколько наборов повторяющихся строк, предикат UNIQUE оценивается как FALSE, и СУБД переходит к проверке следующей строки в таблице EMPLOYEES.
| Примечание | При проверке повторяющихся значений в таблице результатов подзапроса предикат UNIQUE игнорирует любые значения NULL.Таким образом, если подзапрос в предикате UNIQUE дает таблицу результатов Продавец cust_ID sales_total ----------- ------- ----------- 101 ПУСТО 100.00 101 1000 NULL 101 NULL NULL 101 1000 100,00 предикат будет оцениваться как ИСТИНА, потому что никакие две строки не имеют столбцов со всеми одинаковыми значениями, отличными от NULL. |
Некоторые СУБД поддерживают предикат UNIQUE.Поэтому обязательно ознакомьтесь с руководством по системе, прежде чем использовать его в своем коде SQL. Если ваша СУБД не поддерживает предикат, вы всегда можете использовать агрегатную функцию COUNT в предложении WHERE для достижения той же цели. Например, запрос
ВЫБЕРИТЕ emp_ID, first_name, last_name ОТ сотрудников ГДЕ (ВЫБРАТЬ количество (продавец) ИЗ счетов-фактур ГДЕ invoice_date> = '01.09.2000' И invoice_date <= '30.09.2000' И счета-фактуры.продавец = сотрудники.emp_ID) <= 1
выдаст те же результаты, что и предыдущий пример запроса, в котором использовался предикат UNIQUE для вывода списка продавцов с нулевой или одной продажей за сентябрь 2000 года.
Использование предиката OVERLAPS для определения перекрытия одного DATETIME другого
Предикат OVERLAPS использует синтаксис
(,
{|}) ПЕРЕГРУЗКИ
(,
{|})
где
::
{DATE} | {TIME) | {TIMESTAMP}
::
{DATE) | [TIME} | {TIMESTAMP} |
{ИНТЕРВАЛ}
::
'' {ГОД | МЕСЯЦ | ДЕНЬ | ЧАС | МИНУТА | СЕКУНДА}
, чтобы вы могли проверить два хронологических периода времени на совпадение.
Например, предикат OVERLAPS
(ДАТА '01-01-2000 ', ИНТЕРВАЛ' 03 'МЕСЯЦЕВ) ПЕРЕГРУЗКИ (ДАТА '03-15-2000 ', ИНТЕРВАЛ' 10 'ДНЕЙ)
оценивается как ИСТИНА, поскольку часть второго диапазона дат (с 15.03.200 по 25.03.2000) находится в пределах (или перекрывает) часть первого диапазона дат (с 01.01.2000 по 04.01.2000). ). Точно так же предикат OVERLAPS
(ВРЕМЯ '09: 23: 00 ', ВРЕМЯ '13: 45: 00') ПЕРЕЗАГРУЗКИ (ВРЕМЯ '14: 00: 00 ', ВРЕМЯ '14: 25: 00')
оценивается как ЛОЖЬ, потому что никакая часть второго периода времени не лежит в пределах (или перекрывает) часть первого периода времени.
Многие продукты СУБД не поддерживают предикат OVERLAPS. Если у вас есть, вы, скорее всего, будете использовать предикат OVERLAPS в хранимой процедуре, которая принимает даты, время и интервалы в качестве параметров типа данных CHARACTER. Параметры CHARACTER, используемые для хранения дат или временных интервалов, появятся в предикате OVERLAPS вместо буквальных значений, показанных в текущих примерах. Сейчас важно знать, что предикат OVERLAPS возвращает TRUE, если какая-либо часть второго временного интервала попадает в первый, и вы можете указать любой из двух временных интервалов как дату / время начала и дату / время окончания, или дата / время начала и продолжительность (или интервал).
Общие сведения о предложении GROUP BY и сгруппированных запросах
В совете 122 «Понимание того, как агрегатные функции в операторе SELECT создают единую строку результатов», вы узнали, как агрегатные функции SQL (AVG (), COUNT (), MAX () и MIN ()) суммируют данные из одна или несколько таблиц для получения единой строки результатов. Как и агрегатные функции, предложение GROUP BY суммирует данные.Однако вместо создания одной строки итоговых результатов предложение GROUP BY создает несколько промежуточных итогов - по одному для каждой группы строк в таблице.
Например, если вы хотите узнать общую стоимость покупок, сделанных клиентами в течение предыдущего года, вы можете использовать агрегатную функцию SUM () в операторе SELECT, аналогичном
.ВЫБЕРИТЕ СУММ (invoice_total) КАК "Общий объем продаж" ИЗ счетов-фактур ГДЕ invoice_date> = (GETDATE () - 365)
, в результате чего будет получена таблица результатов с единственной (общей) строкой, подобной:
Тотальная распродажа ----------- 47369
С другой стороны, если вы хотите разбить общий объем продаж по клиентам, добавьте предложение GROUP BY, такое как в запросе
ВЫБЕРИТЕ cust_ID, SUM (invoice_total) КАК "Общий объем продаж" ИЗ счетов-фактур ГДЕ invoice_date> = (GETDATE () - 365) ГРУППА ПО cust_ID
, чтобы сообщить СУБД о необходимости создания таблицы результатов с промежуточным итогом объема продаж для каждого клиента, например:
cust_ID Общий объем продаж ------- ----------- 1 7378 5 7378 7 22654 8 1290 9 8669
Запрос, который включает предложение GROUP BY (например, показанный в текущем примере), называется сгруппированным запросом , потому что СУБД группирует (или суммирует) строк, выбранных из исходной таблицы (таблиц), как одну строку значений для каждой группы.Столбцы, названные в предложении GROUP BY (CUST_ID, в текущем примере), известны как столбцы группировки , потому что СУБД использует значения этих столбцов, чтобы решить, какие строки из исходной таблицы принадлежат к каким группам во промежуточной таблице.
После того, как СУБД организует промежуточную таблицу результатов в группы строк, в которых каждая строка в группе имеет одинаковые значения для всех группирующих столбцов, система вычисляет значение агрегатных функций (перечисленных в предложении SELECT) для строк в группа.Наконец, результаты агрегатной функции вместе со значениями других элементов, перечисленных в предложении SELECT, добавляются в окончательную таблицу результатов в виде одной строки для каждой группы.
Общие сведения об ограничениях на сгруппированные запросы
Сгруппированный запрос (определенный как любой оператор SELECT, включающий предложение GROUP BY) подчиняется ограничениям как для столбцов, перечисленных в предложении GROUP BY, так и для выражений выходных значений, перечисленных в предложении SELECT.
Все столбцы группировки (столбцы, перечисленные в предложении GROUP BY) должны быть столбцами из таблиц, перечисленных в предложении FROM. Таким образом, вы не можете группировать строки на основе буквальных значений, результатов агрегатной функции или значения любого другого вычисляемого выражения.
Элементы в списке выбора сгруппированного запроса (ссылки на столбцы, агрегатные функции, литералы и другие выражения в предложении SELECT) должны иметь одно (скалярное) значение для каждой группы строк.Таким образом, каждый элемент в предложении SELECT сгруппированного запроса может быть:
- Столбец группировки
- Литерал (константа)
- Агрегатная функция, которую СУБД применяет к строкам в группе для получения единственного значения, представляющего количество строк (COUNT (), COUNT (*)) или агрегированное значение столбца (MAX (), MIN (), AVG () ) для каждой группы
- Выражение, включающее комбинацию одного или нескольких из других (трех) допустимых элементов предложения SELECT
Поскольку сгруппированные запросы используются для суммирования (или промежуточных итогов) данных в группах (как определено группировкой столбцов, перечисленных в предложении GROUP BY), предложение SELECT сгруппированного запроса (почти) всегда будет включать по крайней мере один из столбцов группировки и одну или несколько агрегатных (столбцовых) функций.В конце концов, сгруппированный запрос, например
ВЫБЕРИТЕ cust_ID ИЗ счетов-фактур ГДЕ inv_date> = (GETDATE () - 365) ГРУППА ПО cust_ID
, который имеет только ссылки на столбцы в своем предложении SELECT, может быть выражен проще как оператор SELECT DISTINCT, например:
ВЫБРАТЬ РАЗЛИЧНЫЙ cust_ID ИЗ СЧЕТОВ ГДЕ inv_date> = (GETDATE () - 365)
И наоборот, если предложение SELECT имеет только агрегатные функции, такие как запрос
ВЫБЕРИТЕ СУММ (invoice_total) КАК "Общий объем продаж", AVG (invoice_total) AS 'Средний счет-фактура' ИЗ счетов-фактур ГДЕ invoice_date> = (GETDATE () - 365) ГРУППА ПО cust_ID
нельзя сказать, какая строка результатов запроса поступила из какой группы.Например, таблица результатов для текущего примера
Общий средний счет за продажу ----------- --------------- 7378 7378.000000 7378 7378.000000 22654 663,5000000 1290 258,000000 8669 4334.500000
дает вам общий объем продаж и средний счет для каждого клиента. Однако после просмотра данных в таблице результатов вы не можете определить, какие общие продажи и средний счет принадлежит какому клиенту.
Использование предложения GROUP BY для группировки строк на основе значения одного столбца
Как вы узнали из совета 88 «Использование оператора SELECT для отображения столбцов из строк в одной или нескольких таблицах», оператор SELECT позволяет отображать все строки в таблице, которые удовлетворяют критериям поиска, указанным в предложении WHERE запроса. (Если нет предложения WHERE, инструкция SELECT отобразит значения данных столбца из всех строк в таблице.) Чтобы разделить строки, возвращаемые оператором SELECT, на группы и отобразить только одну строку значений данных для каждой группы, выполните групповой запрос, добавив предложение GROUP BY к оператору SELECT.
При выполнении группового запроса СУБД выполняет следующие шаги:
- Создает промежуточную таблицу, основанную на декартовом произведении (см. Совет 281, «Понимание декартовых произведений») таблиц, перечисленных в предложении FROM запроса.
- Применяет критерии поиска в предложении WHERE (если есть), удаляя все строки из промежуточной таблицы (созданной на шаге 1), для которых предложение WHERE оценивается как FALSE.
- Распределяет оставшиеся строки в промежуточной таблице в группы так, чтобы значение в столбце группировки (указанном в предложении GROUP BY) было одинаковым для каждой строки в группе.
- Вычисляет значение каждого элемента в предложении SELECT для каждой группы строк и создает одну строку результатов запроса для каждой группы.
- Если запрос включает предложение HAVING, применяет условие поиска к строкам в таблице результатов и удаляет те итоговые строки, для которых предложение HAVING оценивается как FALSE.
- Если оператор SELECT включает предложение DISTINCT (о котором вы узнали из совета 231 «Использование предложения DISTINCT для исключения дубликатов из набора строк»), удаляет все повторяющиеся строки из таблицы результатов.
- Если есть предложение ORDER BY, сортирует строки, оставшиеся в таблице RESULTS, в соответствии со столбцами, перечисленными в предложении ORDER BY. (Вы узнали о предложении ORDER BY в совете 95 «Использование предложения ORDER BY для определения порядка строк, возвращаемых оператором SELECT.")
Например, когда вы выполняете сгруппированный запрос, такой как
Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов' ОТ клиентов ГРУППА ПО состоянию
СУБД создаст таблицу результатов, показывающую количество клиентов, имеющихся у вас в каждом штате. Поскольку предложение FROM имеет только одну таблицу (CUSTOMERS), промежуточная таблица, созданная на шаге 1, состоит из всех строк в таблице CUSTOMERS. Поскольку предложения WHERE нет, СУБД не удаляет строки из промежуточной таблицы.На шаге 3 СУБД сгруппирует строки промежуточной таблицы в группы, в которых значение группирующего столбца (STATE) будет одинаковым для каждой строки в каждой из групп.
Затем СУБД применяет функцию столбца COUNT (*) к каждой группе, чтобы создать строку таблицы результатов, содержащую код состояния и количество клиентов (строк) в группе для каждой группы в таблице. Поскольку нет ни предложения HAVING, ни DISTINCT, СУБД не будет удалять какие-либо строки из таблицы результатов, аналогичные тем, которые показаны в нижней панели окна приложения MS-SQL Server, показанном на рисунке 270.1.
Рисунок 270.1: Запрос анализатора запросов MS-SQL Server и таблица результатов для сгруппированного по одному столбцу запроса
| Примечание | Поскольку предложение ORDER BY отсутствует, расположение строк в таблице результатов в порядке возрастания по столбцу группировки (STATE) является случайным. СУБД отобразит строки в таблице результатов в том порядке, в котором они расположены во временной таблице.Таким образом, не забудьте включить предложение ORDER BY, если вы хотите, чтобы СУБД сортировала строки в таблице результатов в порядке возрастания или убывания в соответствии со значениями в одном или нескольких столбцах. |
Использование предложения GROUP BY для группировки строк на основе нескольких столбцов
В совете 270 «Использование предложения GROUP BY для группировки строк на основе значения одного столбца» вы узнали, как использовать предложение GROUP BY для создания таблицы результатов со сводными (промежуточными) строками на основе группировки строк исходной таблицы на основе по значениям в одном столбце группировки.Оператор SELECT с одним столбцом в предложении GROUP BY является простейшей формой сгруппированного запроса. Если группы строк в таблице зависят от значений в нескольких столбцах, просто перечислите все столбцы, необходимые для определения групп в предложении GROUP BY запроса. Не существует верхнего предела количества столбцов, которые вы можете перечислить в предложении GROUP BY оператора SELECT, и единственное ограничение на группировку столбцов состоит в том, что каждый из них должен быть столбцом в одной из таблиц, перечисленных в предложении FROM запроса.Однако имейте в виду, что независимо от того, сколько столбцов вы перечисляете в предложении GROUP BY, стандартный SQL будет отображать только один уровень групповых промежуточных итогов в таблице результатов запроса.
Например, в совете 270 вы узнали, что можете использовать сгруппированный запрос
.Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов' ОТ клиентов ГРУППА ПО состоянию
, чтобы получить таблицу результатов, показывающую количество клиентов, которые у вас были в каждом штате.Если теперь вы хотите разбить количество клиентов штата по продавцам в каждом штате, вы можете выполнить запрос, аналогичный
.ВЫБЕРИТЕ состояние, продавец, COUNT (*) AS 'Customer Count' ОТ клиентов ГРУППА ПО штатам, продавец
для создания таблицы результатов, например
государственный продавец Количество клиентов ----- ----------- -------------- АЗ 101 1 CA 101 3 LA 101 2 Привет 102 1 LA 102 2 NV 102 2 TX 102 1 АЗ 103 1 LA 103 1 НМ 103 1 TX 103 1
, который группирует клиентов по ПРОДАВЦАМ и в пределах ГОСУДАРСТВА.Обратите внимание, однако, что новый запрос производит только строку промежуточных итогов для каждой пары (СОСТОЯНИЕ, ПРОДАВЕЦ). Стандартный SQL не даст вам и промежуточный итог на основе SALESPERSON и промежуточный итог на основе STATE в той же таблице результатов, даже если вы указали оба столбца в предложении GROUP BY.
| Примечание | Поскольку стандартный SQL дает вам только один уровень промежуточных итогов для каждой уникальной комбинации всех столбцов группировки (столбцы, перечисленные в предложении GROUP BY), вам придется использовать программный SQL для передачи таблицы результатов в прикладную программу, которая может создавайте столько уровней промежуточных итогов, сколько хотите.Другой вариант - изменить порядок строк в таблице результатов с помощью предложения ORDER BY (что вы научитесь делать в совете 272, «Использование предложения ORDER BY для изменения порядка строк в группах, возвращаемых предложением GROUP BY») . Хотя предложение ORDER BY само по себе не создает промежуточных итогов, оно облегчает вам вручную вычисление второго уровня промежуточных итогов, группируя вместе строки с одинаковыми значениями столбцов. Последний способ получить несколько промежуточных итогов непосредственно из одного оператора SQL - использовать предложение MS-SQL Server Transact-SQL COMPUTE (о котором вы узнаете в совете 273 «Использование предложения MS-SQL Transact-SQL COMPUTE для отображения подробностей»). и общее количество строк в той же таблице результатов ").К сожалению, предложение COMPUTE не является частью стандарта SQL-92, и вы сможете использовать его только в СУБД MS-SQL Server. |
Использование предложения ORDER BY для изменения порядка строк в группах, возвращаемых предложением GROUP BY
В совете 95 «Использование предложения ORDER BY для указания порядка строк, возвращаемых оператором SELECT», вы узнали, как использовать предложение ORDER BY для сортировки строк таблицы результатов, возвращаемых несгруппированным запросом.Предложение ORDER BY в сгруппированном запросе работает как предложение ORDERED BY в несгруппированном запросе. Например, чтобы отсортировать таблицу результатов из сгруппированного запроса
Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов' ОТ клиентов ГРУППА ПО состоянию
в порядке убывания количества клиентов в каждом состоянии, перепишите оператор SELECT, включив в него предложение ORDER BY:
Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов' ОТ клиентов ГРУППА ПО состоянию ЗАКАЗАТЬ ПО «Счету клиентов» DESC
Обратите внимание, что вы не ограничены сортировкой результатов запроса на основе любого из столбцов, перечисленных в предложении GROUP BY.Как и во всех запросах, столбцы, перечисленные в предложении ORDER BY, ограничены только столбцами или заголовками, указанными в предложении SELECT запроса. Следовательно, каждое из следующих предложений ORDER BY допустимо для оператора SELECT в текущем примере:
ЗАКАЗАТЬ ПО состоянию ЗАКАЗАТЬ по состоянию «Количество клиентов» ЗАКАЗАТЬ ПО состоянию "Количество клиентов" ЗАКАЗАТЬ ПО «Счету клиентов»
Как упоминалось в совете 271 «Использование предложения GROUP BY для группировки строк на основе нескольких столбцов», вы можете использовать предложение ORDER BY, чтобы упростить ручное вычисление второго (или третьего, или четвертого, или так далее) уровня. промежуточных итогов при просмотре таблицы результатов сгруппированного запроса с несколькими столбцами группировки.Например, расположение строк в таблице результатов из сгруппированного запроса (STATE, SALESPERSON) в совете 271 позволяет легко вручную подсчитать количество клиентов для каждого продавца, даже если запрос предоставляет только промежуточный итог для каждого (STATE, ПРОДАВЕЦ) пара. Просто проведите горизонтальную линию поперек страницы при каждом изменении ПРОДАВЦА и сложите значения CUSTOMER COUNT в блок (группу) строк.
И наоборот, если вы хотите вычислить промежуточные итоги для количества клиентов по штатам, задача усложняется, потому что идентичные аббревиатуры состояний не группируются в таблице результатов.Однако, если вы измените предложение ORDER BY в сгруппированном запросе следующим образом
ВЫБЕРИТЕ состояние, продавец, COUNT (*) AS 'Customer Count' ОТ клиентов ГРУППА ПО штатам, продавец Состояние ORDER BY, «Количество клиентов»
вы можете создать таблицу результатов, аналогичную
государственный продавец Количество клиентов ----- ----------- -------------- АЗ 101 1 АЗ 103 1 CA 101 3 Привет 102 1 LA 101 2 LA 102 2 LA 103 1 НМ 103 1 NV 102 2 TX 102 1 TX 103 1
, который упрощает ручное подведение итогов количества клиентов штата, перечисляя количество клиентов группы для идентичных кодов состояния рядом друг с другом.
Использование предложения MS SQL Transact SQL COMPUTE для отображения подробных и итоговых строк в одной и той же таблице результатов
Предложение MS-SQL Server Transact-SQL COMPUTE позволяет выполнять агрегированные (столбчатые) функции (SUM (), AVG (), MIN (), MAX (), COUNT ()) для строк в таблице результатов. Таким образом, вы можете использовать предложение COMPUTE в операторе SELECT для создания таблицы результатов с как подробной, так и сводной информацией .
Например, предложение COMPUTE в операторе SELECT
ВЫБРАТЬ * ИЗ клиентов ГДЕ состояние В ('CA', 'NV')
ВЫЧИСЛИТЬ СУММ (всего_покупок), СРЕДНЕГО (всего_покупок,
COUNT (cust_ID)
создаст таблицу результатов, аналогичную
.cust_id cust_name государственный продавец total_purchases ------- ------------- ----- ----------- -------------- - 1 Клиент CA 1 CA 101 78252.0000 2 CA Клиент 2 CA 101 45852.0000 6 NV Заказчик 1 NV 102 12589.0000 7 CA Клиент 3 CA 101 75489.0000 12 NV Заказчик 2 NV 102 56789.0000 сумма =============== 268971,0000 в среднем =============== 53794,2000 cnt ========== 5
, который содержит ряды подробной информации о клиентах компании в Калифорнии и Неваде и заканчивается итоговыми строками, показывающими количество клиентов в отчете вместе с общим итоговым итогом и средними продажами для группы в целом.
| Примечание | Строго говоря, оператор SELECT с предложением COMPUTE нарушает основное правило реляционных запросов, поскольку его результат не является таблицей. Поскольку MS-SQL Sever добавляет две строки заголовка и итоговую строку для каждой агрегатной функции в предложении COMPUTE, запрос возвращает комбинацию строк разных типов. |
Хотя это чрезвычайно полезно для подсчета строк и суммирования числовых значений в таблице результатов, использование предложения COMPUTE BY в операторе SELECT ограничивается следующими правилами:
- В предложении COMPUTE можно использовать только столбцы из предложения SELECT.
- Агрегатные функции в предложении COMPUTE нельзя ограничить как DISTINCT.
- Предложение COMPUTE нельзя использовать в инструкции SELECT INTO.
- В предложении COMPUTE можно использовать только имена столбцов (но не заголовки столбцов).
Использование предложений COMPUTE и COMPUTE BY в MS SQL Transact SQL для отображения многоуровневых промежуточных итогов
В совете 271 «Использование предложения GROUP BY для группировки строк на основе нескольких столбцов» вы узнали, как использовать сгруппированный запрос (оператор SELECT с предложением GROUP BY) для группировки данных исходной таблицы и отображения их в таблице результатов. в виде одной итоговой строки для каждой группы.Вы также узнали, что сгруппированный запрос отображает только один уровень промежуточных итогов. Следовательно, вы не можете использовать стандартный сгруппированный запрос для отображения промежуточных итогов групп и общих итогов в одной таблице результатов. Однако, если вы используете COMPUTE BY и предложение COMPUTE в одном несгруппированном запросе , вы можете сгенерировать таблицу результатов, которая содержит как промежуточные, так и общие итоги. (Другими словами, вы можете сгенерировать многоуровневые промежуточные итоги, добавив предложение COMPUTE BY и предложение COMPUTE к оператору SELECT, в котором нет предложения GROUP BY.)
Например, предложения COMPUTE BY и COMPUTE в запросе
ВЫБЕРИТЕ состояние, продавца, всего_покупок ОТ клиентов
ГДЕ состояние IN ('LA', 'CA')
ЗАКАЗАТЬ ПО штату, продавцу
ВЫЧИСЛИТЬ СУММ (total_purchases) ПО штату, продавцу
ВЫЧИСЛИТЬ СУММ (всего_покупок)
отобразит промежуточные и общие итоги в таблице результатов, аналогичной:
государственный продавец total_purchases ----- ----------- --------------- CA 101 78252.0000 CA 101 45852.0000 CA 101 75489.0000 сумма =============== 199593.0000 LA 101 74815.0000 LA 101 15823.0000 сумма ===============.0000 LA 102 96385.0000 LA 102 85247.0000 сумма =============== 181632,0000 LA 103 45612.0000 сумма =============== 45612.0000 сумма =============== 517475.0000
В дополнение к ограничениям предложения COMPUTE (о которых вы узнали из совета 273 «Использование предложения MS-SQL Transact-SQL COMPUTE для отображения подробных и общих строк в одной и той же таблице результатов»), запрос с COMPUTE BY также должен придерживаться следующих правил:
- Чтобы включить предложение COMPUTE BY, оператор SELECT должен иметь предложение ORDER BY.
- Столбцы, перечисленные в предложении COMPUTE BY, должны либо соответствовать, либо быть подмножеством столбцов, перечисленных в предложении ORDER BY. Более того, столбцы в двух предложениях (ORDER BY и COMPUTE BY) должны быть в одном порядке, слева направо, должны начинаться с одного и того же столбца и не должны пропускать какие-либо столбцы.
- Предложение COMPUTE BY не может содержать никаких имен заголовков - только имена столбцов.
Последнее ограничение «без заголовков» может означать, что невозможно выполнить запрос, который использует предложение COMPUTE BY для «суммирования» промежуточных итогов агрегатной функции (ей) в сгруппированном запросе, таком как:
ВЫБЕРИТЕ состояние, продавец, SUM (total_purchases) AS 'Tot_Purchases " ОТ клиентов ГРУППА ПО штатам, продавец ЗАКАЗАТЬ ПО штату, продавцу
В конце концов, TOT_PURCHASES в таблице результатов - это заголовок, а не имя столбца.Таким образом, столбец с промежуточным итогом покупок для каждой пары (STATE, SALESPERSON) не подходит для использования в предложении COMPUTE BY.
Однако, если вы выполните оператор CREATE VIEW, например
СОЗДАТЬ ПРОСМОТР vw_state_emp_tot_purchases AS ВЫБЕРИТЕ состояние, продавец, SUM (total_purchases) AS 'Tot_Purchases)
, который создает виртуальную таблицу , которая использует заголовок агрегатной функции (TOT_PURCHASES в текущем примере) в качестве столбца, вы можете использовать предложение COMPUTE BY для подведения промежуточных итогов агрегированного столбца.В текущем примере TOT_PURCHASES - это столбец в представлении VW_STATE_EMP_TOT_PURCHASES. Следовательно, если вы ссылаетесь на представление как на (виртуальную) таблицу в предложении FROM инструкции SELECT, вы можете использовать предложение COMPUTE BY в запросе, таком как
ВЫБРАТЬ состояние, продавец, tot_purchases ОТ vw_state_emp_tot_purchases ЗАКАЗАТЬ ПО штату, продавцу ВЫЧИСЛИТЬ СУММ (total_purchases) ПО состоянию
, чтобы отображать промежуточный итог продаж для каждого ПРОДАВЦА по СОСТОЯНИЮ (совокупные промежуточные итоги из сгруппированного запроса), а также «общий итог» и отображать продажи по СОСТОЯНИЮ в той же таблице результатов.
Понимание того, как NULL-значения обрабатываются предложением GROUP BY
Проблема, которую создают значения NULL, когда они встречаются в одном (или нескольких) столбцах группировки в сгруппированном запросе, аналогична проблеме, которую эти значения создают для агрегатных функций и критериев поиска. Поскольку группа определяется как набор строк, в которых составное значение столбцов группировки одинаково, какая группа должна включать строку, в которой значение одного или нескольких столбцов, определяющих группу, неизвестно (NULL)?
Если бы СУБД следовала правилу, используемому для критериев поиска в предложении WHERE, то GROUP BY создала бы отдельную группу для каждой строки со значением NULL в любом из столбцов группировки.В конце концов, результат проверки на равенство двух значений NULL в предложении WHERE всегда равен FALSE, потому что NULL не равно NULL в соответствии со стандартом SQL. Следовательно, если строка имеет группирующий столбец со значением NULL, ее нельзя поместить в ту же группу с другой строкой, которая имеет значение NULL в том же столбце группировки, потому что все строки в одной группе должны иметь совпадающие значения группирующего столбца (и NULL <> NULL)
Поскольку они обнаружили, что создание отдельной группы для каждой строки с NULL в столбце группирования сбивает с толку и не имеет полезного значения, разработчики SQL написали стандарт SQL, в котором значения NULL считаются равными для целей предложения GROUP BY.Следовательно, если две строки имеют значения NULL в одних и тех же столбцах группировки и совпадают значения в оставшихся столбцах группировки, отличные от NULL, СУБД сгруппирует строки вместе.
Например, сгруппированный запрос
ВЫБЕРИТЕ состояние, продавец, SUM (amount_purchased) КАК "Всего покупок" ОТ клиентов ГРУППА ПО штатам, продавец ЗАКАЗАТЬ ПО штату, продавцу
отобразит таблицу результатов, аналогичную
.государственный продавец Всего закупок ----- ----------- --------------- НУЛЬ НУЛЬ 61438.0000 NULL 101 196156.0000 AZ NULL 75815.0000 AZ 103 36958.0000 CA 101 78252.0000 LA NULL 181632.0000
для КЛИЕНТОВ, которые содержат следующие строки:
государственный продавец amount_purchased ----- ----------- ---------------- NULL NULL 45612.0000 NULL NULL 15826.0000 ПУСТО 101 45852.0000 ПУСТО 101 74815.0000 ПУСТО 101 75489.0000 АЗ НОЛЬ 75815.0000 AZ 103 36958.0000 CA 101 78252.0000 LA NULL 96385.0000 LA NULL 85247.0000
Использование предложения HAVING для фильтрации строк, включенных в таблицу результатов сгруппированного запроса
Предложение HAVING, как и предложение WHERE, о котором вы узнали в совете 91 «Использование оператора SELECT с предложением WHERE для выбора строк на основе значений столбца», используется для фильтрации строк с атрибутами (значениями столбцов), которые не удовлетворяют критерии поиска пункта.При выполнении запроса СУБД использует критерии поиска в WHERE в качестве фильтра, просматривая таблицу, указанную в предложении FROM запроса (или декартово произведение таблиц, если предложение FROM имеет несколько таблиц) по одной строке за раз. . Система сохраняет для дальнейшей обработки только те строки, значения столбцов которых соответствуют условиям поиска в предложении WHERE. После того, как предложение WHERE (если оно есть) отсеивает ненужные строки, СУБД использует предложение HAVING в качестве фильтра для удаления групп строк (вместоотдельные строки), совокупные или отдельные значения столбцов которых не удовлетворяют условию поиска в предложении HAVING.
Например, предложение WHERE в запросе
ВЫБЕРИТЕ RTRIM (first_name) + '' + last_name AS 'Имя сотрудника', СУММ (amt_purchased) КАК "Общий объем продаж" ОТ клиентов, сотрудников ГДЕ customers.salesperson = employee.emp_ID ГРУППА ПО RTRIM (имя) + '' + фамилия ИМЕЕТ СУММ (amt_purchased)> 250000 ЗАКАЗАТЬ ПО «ОБЩЕМУ ПРОДАЖУ»
сообщает СУБД, что необходимо просмотреть промежуточную таблицу, созданную из декартова произведения таблиц CUSTOMERS и EMPLOYEES, по одной строке за раз и удалить все строки, в которых значение в столбце EMP_ID не равно значению в столбце SALESPERSON.
Затем СУБД группирует оставшиеся строки по имени сотрудника (как указано в предложении GROUP BY). Затем СУБД проверяет каждую группу строк, используя критерии поиска в предложении HAVING. В текущем примере система вычисляет сумму столбца AMT_PURCHASED для каждой группы строк и удаляет строки в любой группе, где агрегатная функция (SUM (AMT_PURCHASED)) возвращает значение, равное или меньшее 250 000.
Хотя критерии поиска в предложении HAVING могут проверять значения отдельных столбцов, а также результаты агрегированных функций, более эффективно помещать тесты значений отдельных столбцов в предложение WHERE запроса (вместоего предложение HAVING). Например, запрос
ВЫБЕРИТЕ emp_ID, RTRIM (first_name) + '' + last_name КАК "Имя сотрудника", СУММ (amt_purchased) КАК "Общий объем продаж" ОТ клиентов, сотрудников ГДЕ customers.salesperson = employee.emp_ID ГРУППА ПО RTRIM (имя) + '' + фамилия ИМЕЕТ (СУММ (amt_purchased) <250000) И (emp_ID> = 102) ЗАКАЗАТЬ ПО «ОБЩЕМУ ПРОДАЖУ»
, который проверяет значение столбца EMP_ID в предложении HAVING для исключения любых сотрудников с общим объемом продаж, равным или превышающим 250 000, которые имеют значение EMP_ID менее 102 из окончательной таблицы результатов, менее эффективен, чем запрос:
ВЫБЕРИТЕ emp_ID, RTRIM (first_name) + '' + last_name КАК "Имя сотрудника", СУММ (amt_purchased) КАК "Общий объем продаж" ОТ клиентов, сотрудников ГДЕ (покупатели.продавец = сотрудники.emp_ID) И (emp_ID> = 102) ГРУППА ПО RTRIM (имя) + '' + фамилия ИМЕЕТ (SUM (amt_purchased) <250000) ЗАКАЗАТЬ ПО «ОБЩЕМУ ПРОДАЖУ»
, который проверяет значение EMP_ID в предложении WHERE (для получения той же таблицы результатов).
В первом запросе (с проверкой столбца EMP_ID в предложении HAVING) СУБД вычислит сумму столбца AMT_PURCHASED для нескольких групп сотрудников (тех, у которых значения столбца EMP_ID в диапазоне 001-101), чтобы исключить только эти строки в этих группах, когда система проверяет значение EMP_ID группы.Второй запрос позволяет избежать объединения строк со значениями столбца EMP_ID менее 102 в группы и вычисления общих продаж для этих групп путем исключения строк из промежуточной таблицы результатов до того, как СУБД объединит строки в группы и применит агрегатную функцию (SUM ()) в HAVING для каждой группы.
Понимание разницы между предложением WHERE и предложением HAVING
СУБД использует критерии поиска в предложениях WHERE и HAVING для фильтрации нежелательных строк из промежуточных таблиц, созданных при выполнении запроса.Однако каждое предложение влияет на другой набор строк. В то время как предложение WHERE фильтрует отдельные строки в декартовом произведении таблиц, перечисленных в предложении FROM оператора SELECT, предложение HAVING экранирует нежелательные группы (строк) из групп, созданных оператором GROUP BY запроса. Таким образом, вы можете использовать предложение WHERE в любом операторе SELECT, в то время как предложение HAVING следует использовать только в сгруппированном запросе (оператор SELECT с предложением GROUP BY).
Если вы используете предложение HAVING без предложения GROUP BY, СУБД рассматривает все строки в исходной таблице как единую группу.Таким образом, агрегатные функции в предложении HAVING применяются к одной и только одной группе (всем строкам во входной таблице), чтобы определить, должны ли строки группы быть включены в результаты запроса или исключены из них.
Например, запрос
ВЫБРАТЬ СУММ (amt_purchased) ОТ клиентов ИМЕЕТ СУММ (amt_purchased) <250000
поместит сумму значений в столбце AMT_PURCHASED в таблицу результатов, только если общая сумма столбца AMT_PURCHASED для всей таблицы CUSTOMERS меньше 250 000.
На практике вы почти никогда не увидите предложение HAVING в операторе SELECT без предложения GROUP BY. В конце концов, какой смысл отображать агрегированное значение для столбца таблицы, только если оно удовлетворяет еще одному критерию поиска? Более того, если вы попытаетесь ограничить агрегирование подмножеством строк во входной таблице, например «покажите мне общие покупки для любого клиента из Калифорнии, Невады или Луизианы, у которого общая сумма покупок составляет менее 250 000 долларов США», изменив запрос в текущий пример на
ВЫБРАТЬ СУММ (amt_purchased) ОТ клиентов
ИМЕЕТ (SUM (amt_purchased) <250000)
И (состояние IN ('CA', 'NV', 'LA'))
Тогда СУБД прервет выполнение запроса и отобразит сообщение об ошибке, подобное:
Сервер: Msg 8119, уровень 16, состояние 1, строка 1 Колонка "клиенты".состояние 'недопустимо в предложении имеющего потому что он не содержится в агрегатной функции и предложения GROUP BY нет.
В результате вы бы переписали оператор SELECT (правильно) как сгруппированный запрос
Состояние ВЫБРАТЬ, СУММ (amt_purchased) ОТ клиентов
ГДЕ СОСТОЯНИЕ В ('CA', 'NV', 'LA')
ГРУППА ПО состоянию
ИМЕЕТ СУММ (amt_purchased) <250000
, в котором предложение HAVING следует сразу за предложением GROUP BY.
Сейчас важно знать, что предложение WHERE полезно как в сгруппированных, так и в несгруппированных запросах, в то время как предложение HAVING должно появляться только сразу после предложения GROUP BY в сгруппированном запросе.
Общие сведения о правилах SQL для использования предложения HAVING в сгруппированном запросе
Как вы узнали из совета 276 «Использование предложения HAVING для фильтрации строк, включенных в таблицу результатов сгруппированного запроса» и совета 277 «Понимание разницы между предложением WHERE и предложением HAVING», вы можете использовать предложение WHERE. или предложение HAVING для исключения строк или включения строк в результаты запроса.Поскольку СУБД использует критерии поиска в предложении WHERE для фильтрации одной строки данных за раз, выражения в предложении WHERE должны быть вычислимыми для отдельных строк. Между тем, выражение (я) в критериях поиска в предложении HAVING должно оцениваться как одно значение для группы строк. Таким образом, условия поиска в предложении WHERE состоят из выражений, в которых используются ссылки на столбцы и литеральные значения (константы). С другой стороны, условия поиска в предложении HAVING обычно состоят из выражений с одной или несколькими агрегатными функциями (столбцами) (такими как COUNT (), COUNT (*), MIN (), MAX (), AVG () или СУММ ()).
При выполнении группового запроса с предложением HAVING СУБД выполняет следующие шаги:
- Создает промежуточную таблицу из декартова произведения таблиц, перечисленных в предложении FROM оператора SELECT. Если в предложении FROM есть только одна таблица, тогда промежуточная таблица будет копией одной исходной таблицы.
- Если есть предложение WHERE, применяет свои условия поиска, чтобы отфильтровать нежелательные строки из промежуточной таблицы.
- Располагает строки промежуточной таблицы в группы строк, в которых все столбцы группировки имеют одинаковые значения.
- Применяет каждое условие поиска в предложении HAVING к каждой группе строк. Если группа строк не удовлетворяет одному или нескольким критериям поиска, удаляет строки группы из промежуточной таблицы.
- Вычисляет значение каждого элемента в предложении SELECT запроса и создает одну (сводную) строку для каждой группы строк. Если элемент предложения SELECT ссылается на столбец, использует значение столбца из любой строки в группе в итоговой строке.Если элемент предложения SELECT является агрегатной функцией, вычисляет значение функции для группы суммируемых строк и добавляет это значение в итоговую строку группы.
- Если запрос включает ключевое слово DISTINCT (как в SELECT DISTINCT), удаляет все повторяющиеся строки из таблицы результатов.
- Если есть предложение ORDER BY, сортирует таблицу результатов по значениям в столбцах, перечисленных в предложении ORDER BY.
Общие сведения о том, как SQL обрабатывает нулевой результат предложения HAVING
Предложение HAVING, как и предложение WHERE, может иметь одно из трех значений: TRUE, FALSE или NULL.Если предложение HAVING оценивается как TRUE для группы строк, СУБД использует значения в строках группы для создания итоговой строки в таблице результатов. И наоборот, если предложение HAVING оценивается как FALSE или NULL для группы строк, СУБД не суммирует строки группы в таблице результатов. Таким образом, СУБД обрабатывает предложение HAVING с NULL-значением так же, как и предложение WHERE с NULL-значением - она пропускает строки, которые привели к значению NULL из таблицы результатов.
Имейте в виду, что значения NULL в столбцах группы не всегда приводят к тому, что условие поиска в предложении HAVING оценивает NULL.Например, запрос
Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов', (COUNT (*) - COUNT (amt_purchased)) КАК 'NULL Sales Count' SUM (amt_purchased) КАК "Продажи" ОТ клиентов ГРУППА ПО состоянию ИМЕЕТ СУММ (amt_purchased) <50000
создаст таблицу результатов, аналогичную той, которая показана на панели результатов в нижней половине окна анализатора запросов MS-SQL Server, показанном на рис. 279.1, даже если три из четырех значений AMT_PURCHASED имеют значение NULL в группе строк клиентов из Калифорнии.
Рисунок 279.1: Запрос анализатора запросов MS-SQL Server и таблица результатов для сгруппированного запроса с предложением HAVING
Как вы узнали из совета 119 «Использование агрегатной функции SUM () для нахождения суммы значений в столбце», агрегатная функция SUM () пропускает NULL при суммировании значений столбца. Следовательно, в текущем примере условие поиска в предложении HAVING оценивается как ИСТИНА для клиентов из Калифорнии, поскольку агрегат SUM () игнорирует три значения NULL AMT_PURCHASED в группе и возвращает агрегированный результат, отличный от NULL (25000).
С другой стороны, если все значений в столбце AMT_PURCHASED равны NULL для группы строк (например, для клиентов из Калифорнии), функция SUM () вернет NULL. В результате предложение HAVING будет оцениваться как NULL, а оператор SELECT не будет суммировать строки группы в своей таблице результатов. В текущем примере, если все строки клиентов из Калифорнии имеют значение NULL в столбце AMT_PURCHASED, оператор SELECT создаст таблицу результатов, аналогичную
.State Customer Count NULL Количество продаж Количество продаж ----- -------------- ---------------- ---------- А2 2 0 33399.0000
, в котором не упоминаются клиенты из Калифорнии.
Однако, если вы измените пример запроса, добавив условие поиска IS NULL, как показано ниже:
Состояние ВЫБРАТЬ, СЧЁТ (*) КАК 'Счетчик клиентов', (COUNT (*) - COUNT (amt_purchased)) КАК 'NULL Sales Count' SUM (amt_purchased) КАК "Продажи" ОТ клиентов ГРУППА ПО состоянию ИМЕЕТ (SUM (amt_purchased) <50000) ИЛИ (СУММ (amt_purchased) НУЛЬ)
предложение HAVING будет иметь значение TRUE для клиентов из Калифорнии (, потому что агрегатная функция SUM () возвращает значение NULL), а оператор SELECT отобразит таблицу результатов, подобную следующей:
State Customer Count NULL Счетчик продаж Продажи ----- -------------- ---------------- ---------- АЗ 2 0 33394.0000 CA 4 4 NULL
Сейчас важно понять, что любая группа строк, для которой предложение HAVING оценивается как NULL (или FALSE), будет исключена из таблицы результатов сгруппированного запроса.
Предикаты универсального сравнения SQL Server с количественной оценкой (ЛЮБОЙ, ВСЕ, НЕКОТОРЫЕ)
SQL-сервер предоставляет нам операторы сравнения для изменения подзапросов.Эта статья начнется с определения универсальной количественной оценки, с краткого ознакомления с логическими примерами из реальной жизни.
Кроме того, я расскажу
- Как ключевое слово SOME становится эквивалентом стандарта ISO для ANY
- Ключевые слова ВСЕ / НЕКОТОРЫЕ / ЛЮБЫЕ
- Типы запросов, в которых полезна универсальная количественная оценка, включая сравнение операторов IN и NOT IN.
Что такое универсальные количественные предикаты
Квантификатор
Квантификатор похож на логический оператор, такой как «И» или «Или». Это представляет собой логическую формулу, определяющую количество, для которого конкретный оператор возвращает ИСТИНА. Это не числовая величина; он связывает переменные в логическом предложении
Универсальная количественная оценка
Универсальная количественная оценка - это логическая константа, которую определяют как «дано любому» или «для всех».Другими словами, он описывается как «любой из набора» или «все в наборе». Это означает, что универсальная количественная оценка может быть удовлетворена каждым членом множества. Короче говоря, его результат зависит от каждого члена группы.
Например…
A. Все (ВСЕ) в классе говорили по-английски.
B. Кто-то (ЛЮБОЙ) в классе говорил по-английски.
Первое утверждение (A) указывает на то, что все люди в классе должны говорить по-английски, чтобы утверждение было истинным.Для большей ясности, утверждение будет ложным, если кто-то не говорит по-английски. Что касается следующего утверждения (B) «Все в классе говорили по-английски», если кто-либо в классе может говорить по-английски, то утверждение должно быть истинным.
Предикаты сравнения и SQL-сервер
SQL распознает кванторы ЛЮБОЙ (или НЕКОТОРЫЕ) и ВСЕ. Квантификатор позволяет сравнивать одно или несколько выражений с одним или несколькими значениями. Чтобы было ясно, он манипулирует операторами сравнения для сравнения значений внешнего запроса со значениями внутреннего запроса.
НЕКОТОРЫЕ
Первоначально синтаксис SQL поддерживал только ВСЕ и ЛЮБОЙ. Но, как мы знаем, ALL и ANY - универсальные кванторы. Однако в английском языке ANY также довольно часто используется в качестве универсального квантификатора. Возьмем пример: «Я могу съесть ЛЮБОЕ количество манго». Это не то же самое, что «Я могу съесть манго». Фактически, это синоним слова «Я могу съесть все манго».
Поскольку ключевое слово ANY может сбивать с толку, ключевое слово SOME было введено вместо ANY и было инициировано в соответствии со стандартом SQL-92.Вот почему сегодня вы можете переключаться между НЕКОТОРЫМ или ЛЮБЫМ.
ЛЮБОЕ / НЕКОТОРЫЕ и ВСЕ
ВСЕ (естественно с «И»)
Цель условия сравнения ALL - сравнить скалярное значение с подзапросом с одним набором столбцов. За подзапросом должен следовать предыдущий оператор, например =,! =,>, <, <=,> =. Он переводится в серию логических выражений, разделенных операторами AND. В иллюстративных целях X <> ALL (A1, A2, A3) преобразуется в X <> A1 AND X <> A2 AND X <> A3.
Синтаксис для ВСЕХ и (ЛЮБЫХ / НЕКОТОРЫХ)
В нашем примере я создал одну таблицу «Сведения о пациенте».
Чтобы использовать эти данные, мы хотим получить подробную информацию о пациентах: кто жив и чей статус АД выше, чем статус АД «мертвого» человека (короче говоря, строки, содержащие «Жив» и bp_status, выше, чем bp_status всех мертвых людей. ).
выберите * из Patient_details , гдеStatus = 'Alive' и BP_status> ALL (выберите BP_status из Patient_details , гдеStatus = 'Dead' ) | 4
В основном разработчик использует EXISTS вместо ALL.
выберите * из Patient_details dtl , гдеStatus = 'Alive' andnotEXISTS (выберите BP_status из пациента_details p_dtl , где dtl.BP_4000 'p_statl , где dtl. ) |
Подробно описано
- «Поле = ВСЕ (подзапрос)»: ЕСЛИ каждое значение, возвращаемое подзапросом, является совпадением, то возвращается истина.
- «Поле> ВСЕ (подзапрос)»: ЕСЛИ каждое значение, возвращаемое подзапросом, больше, чем оно оценивается как ИСТИНА.
- «Поле <ВСЕ (подзапрос)»: ЕСЛИ каждое значение, возвращаемое подзапросом, меньше, тогда оно оценивается как ИСТИНА.
- То же самое с «Поле> = ВСЕ (подзапрос)» и «Поле <= ВСЕ (подзапрос)»
- «Поле! = ВСЕ (подзапрос)»: ЕСЛИ каждое значение, возвращаемое подзапросом, не совпадает, тогда оно оценивается как ИСТИНА.
ЛЮБЫЕ / НЕКОТОРЫЕ (естественно с «ИЛИ»)
Ключевое слово ANY преобразуется в серию предикатов равенства, разделенных оператором OR, например, X ANY (A1, A2, A3) преобразуется в X = A1 OR X = A2 OR X = A3.
Короче говоря, ЛЮБОЙ (или НЕКОТОРЫЕ) позволяет указать желаемое сравнение в каждом предикате, например, X <ЛЮБОЙ (A1, A2, A3) переводится в X Образец Если я хочу получить подробную информацию о пациенте со статусом «Живой» и чей статус АД выше минимального статуса «Мертвый» человек, то мы должны использовать запрос ниже. выберите * из Patient_details whereStatus = 'Alive' and BP_status> any (выберите BP_status из Patient_details whereStatus = 'Dead' ) Использование EXITS вместо ANY выберите * из Patient_details dtl , гдеStatus = 'Alive' andEXISTS (выберите BP_status из пациента_details p_dtl , где dtl.BP_status <= p_dtl. BP_status и Status = 'Dead' ) выберите * из Patient_details dtl whereStatus = 'Alive' and BP_status> (выберите min (BP_status) из пациента_details p_dtl , где dtl. 'Мертвый' ) Чтобы завершить ЛЮБОЕ ключевое слово, Подводя итог, для следующих форм, если вы укажете квантификатор ALL или (ANY / SOME), когда подзапрос может не вернуть ни одной, одной или нескольких строк. Кроме того, при условии, что подзапрос содержит ноль строк на выходе, условие становится ИСТИННЫМ. Возьмем пример BP_status & gt; ВСЕ (выберите BP_status из Patient_details, гдеStatus = 'Healthy' где подзапрос дает ноль строк, что означает, что полная оценка выражения запроса ИСТИНА, поэтому все строки захватываются. Чтобы быть более конкретным, на сервере SQL ANY / SOME и ALL требуют ввода подзапроса. Итак, вместо v <> ANY (b1, b2, b3) вы должны написать v <> ANY (SELECT b1 UNION ALL SELECT b2 UNION ALL SELECT b3). IN Оператор « = ЛЮБОЙ » эквивалентен IN. вы можете использовать IN или = ANY . Для разъяснений: выберите * из Patient_details dtl , где BP_status = any (выберите BP_status из пациента_details p_dtl , где Status = 'Dead' ) Снимок экрана взят из ApexSQL Plan, инструмента для просмотра и анализа планов выполнения запросов SQL Server выберите * из Patient_details dtl , где BP_status IN (выберите BP_status из пациента_details p_dtl , где Status = 'Dead' ) НЕ В Вы можете получить те же результаты с помощью оператора <> ALL, который эквивалентен NOT IN. Для устного перевода: выберите * из Patient_details dtl , где BP_status <> ALL (выберите BP_status из пациента_details p_dtl , где Status = 'Dead' ) выберите * из Patient_details dtl , где BP_status NOTin (выберите BP_status из пациента_details p_dtl , где Status = 'Dead') Приведенный выше план выполнения предназначен для небольшого количества данных, поэтому он выглядит одинаково для обоих случаев.Он может быть изменен соответственно размеру извлекаемых данных. Обратите внимание, что IN допускает в качестве входных данных либо список литералов, либо подзапрос, возвращающий один столбец. Проще говоря, универсальная количественная оценка - это несколько неясная тема, но я надеюсь, что вы нашли эти объяснения и примеры интересными и, возможно, полезными в некоторых случаях. В свободное время он любит проводить время с семьей, особенно с женой.Вдобавок ко всему, он любит гадать и исследовать разные места. Передай привет и поймай его в LinkedIn SQL, также называемые условными выражениями, задают условие строки или группы, имеющее одно из трех возможных состояний: ИСТИНА, ЛОЖЬ, NULL (или неизвестно). Предикаты SQL находятся в конце предложений, функций и выражений SQL внутри существующих операторов запроса Как правило, запрос возвращает то же самое
результат независимо от последовательности, в которой различные предикаты
указано.Однако обратите внимание на следующее: SQL предоставляет следующие логические
предикаты: Оператор сравнения с ЛЮБЫМ квантификатором для выбора идентификатора сотрудника и названия отдела любого сотрудника с идентификаторами 10, 20 и 30. Оператор сравнения с квантификатором ALL для выбора идентификатора сотрудника и названия отдела. Оператор сравнения с квантификатором НЕКОТОРЫЕ для выбора идентификатора сотрудника и названия отдела. Условие поиска в предложении HAVING для выбора из таблицы «Сотрудник» отделов с номерами 10, 20 и 30 и со средней зарплатой не менее 10 000 долларов США, но не более 20 000 долларов США. Оператор CONTAINS используется в предложении WHERE. КАК: [НЕ] СУЩЕСТВУЕТ: Учтите, что у Employee_Master нет записей для EmpID 6-10 [НЕ] ВХОД: ЯВЛЯЕТСЯ [НЕ] NULL: Прочтите блоги DB2: Щелкните здесь Руководство по IBM DB2: Щелкните здесь Часто просто оценить количество строк, соответствующих одному предикату запроса.Когда предикат выполняет простое сравнение между столбцом и скалярным значением, высока вероятность того, что модуль оценки мощности сможет получить оценку хорошего качества из гистограммы статистики. Например, следующий запрос AdventureWorks дает точно правильную оценку для 203 строк (при условии, что с момента построения статистики в данные не было внесено никаких изменений): Глядя на гистограмму статистики для столбца Если мы изменим запрос, чтобы указать дату, которая попадает в сегмент гистограммы, оценщик мощности предполагает, что значения распределены равномерно. При использовании даты Если мы попробуем запрос еще раз с датой Есть много других деталей для оценки количества элементов для простых предикатов, но вышеизложенное послужит напоминанием для наших настоящих целей. Когда запрос содержит более одного предиката столбца, оценка количества элементов становится более сложной. Рассмотрим следующий запрос с двумя простыми предикатами (каждый из которых легко оценить в одиночку): Конкретные диапазоны значений в запросе специально выбраны так, чтобы оба предиката определяли одни и те же строки.Мы могли бы легко изменить значения запроса, чтобы получить любое перекрытие, в том числе полное отсутствие перекрытия. Теперь представьте, что вы оценщик количества элементов: как бы вы получили оценку количества элементов для этого запроса? Проблема сложнее, чем может показаться на первый взгляд. По умолчанию SQL Server автоматически создает статистику в один столбец для обоих столбцов предикатов. Мы также можем создать многоколоночную статистику вручную. Достаточно ли это информации, чтобы дать хорошую оценку для этих конкретных значений? Как насчет более общего случая, когда может быть любая степень перекрытия? Используя два статистических объекта с одним столбцом, мы можем легко получить оценку для каждого предиката, используя метод гистограммы, описанный в предыдущем разделе.Для конкретных значений в запросе выше гистограммы показывают, что диапазон То, что гистограммы не могут сказать нам , - это то, сколько из этих двух наборов строк будет одинаковыми строками . Все, что мы можем сказать, основываясь на информации гистограммы, - это то, что наша оценка должна быть где-то между нулем (для полного отсутствия перекрытия) и 68412.4 ряда (полное перекрытие). Создание статистики с несколькими столбцами не помогает для этого запроса (или для запросов диапазона в целом). Статистика по нескольким столбцам по-прежнему создает гистограмму только для первого именованного столбца, по сути дублируя гистограмму, связанную с одной из автоматически созданных статистических данных. Дополнительная информация о плотности , предоставляемая статистикой по нескольким столбцам, может быть полезна для предоставления информации о среднем случае для запросов, содержащих несколько предикатов равенства, но здесь они нам не помогут. Чтобы произвести оценку с высокой степенью уверенности, нам понадобится SQL Server, чтобы предоставить более точную информацию о распределении данных - что-то вроде многомерной гистограммы статистики . Насколько мне известно, ни один коммерческий механизм баз данных в настоящее время не предлагает подобного средства, хотя по этой теме было опубликовано несколько технических статей (включая исследование Microsoft Research, в котором использовалась внутренняя разработка SQL Server 2000). Не зная ничего о корреляциях и перекрытиях данных для определенных диапазонов значений, неясно, как мы должны действовать, чтобы получить хорошую оценку для нашего запроса.Итак, что здесь делает SQL Server? Средство оценки количества элементов в этих версиях SQL Server обычно предполагает, что значения различных атрибутов в таблице распределяются полностью независимо друг от друга. Это предположение о независимости редко является точным отражением реальных данных, но оно имеет то преимущество, что упрощает вычисления. Используя предположение о независимости, два предиката, связанных между собой Если термин вам незнаком, селективность - это число от 0 до 1, представляющее долю строк в таблице, которые передают предикат.Например, если предикат выбирает 12 строк из таблицы из 100 строк, избирательность будет (12/100) = 0,12. В нашем примере таблица Умножение двух значений селективности (с использованием приведенной выше формулы) дает общую оценку селективности 0,363679 . Умножение этой избирательности на мощность таблицы (113 443) дает окончательную оценку 41256,8 строк: Два предиката, связанных с помощью Интуиция, лежащая в основе формулы, состоит в том, чтобы сложить две селективности, а затем вычесть оценку для их соединения (используя предыдущую формулу).Ясно, что у нас может быть два предиката, каждый из которых имеет избирательность 0,8, но простое сложение их вместе приведет к невозможной комбинированной избирательности 1,6. Несмотря на предположение о независимости, мы должны признать, что два предиката могут перекрываться, поэтому, чтобы избежать двойного счета, оцененная избирательность конъюнкции вычитается. Мы можем легко изменить наш рабочий пример, чтобы использовать Подстановка предикатных избирательностей в формулу Умноженная на количество строк в таблице, эта селективность дает окончательную оценку мощности 95 568,6 : Ни одна из оценок ( 41,257 для запроса Для SQL Server 2008 (R1) по 2012 год включительно Microsoft выпустила исправление, изменяющее способ вычисления селективности только для случая Чтобы активировать измененное поведение, требуется поддерживаемый флаг трассировки 4137. В отдельной статье базы знаний указано, что этот флаг трассировки также поддерживается для каждого запроса, с помощью подсказки Если этот флаг активен, оценка количества элементов использует минимальную избирательность двух предикатов, в результате чего получается оценка 68 412.4 рядов: Это почти идеально подходит для нашего запроса, потому что наши тестовые предикаты точно коррелированы (и оценки, полученные из базовых гистограмм, также очень хороши). Довольно редко предикаты точно коррелируют таким образом с реальными данными, но флаг трассировки, тем не менее, может помочь в некоторых случаях. Обратите внимание, что поведение минимальной избирательности будет применяться ко всем конъюнктивным ( Нет соответствующего флага трассировки для оценки дизъюнктивных ( Вычисление избирательности в SQL Server 2014 ведет себя так же, как и в предыдущих версиях (и флаг трассировки 4137 работает, как и раньше), если уровень совместимости базы данных установлен ниже 120 или если активен флаг трассировки 9481 . Установка уровня совместимости базы данных - это официальный способ использовать оценку мощности до 2014 года в SQL Server 2014.Флаг трассировки 9481 эффективен для выполнения тех же действий, что и на момент написания, а также работает с Если активна новая оценка мощности, SQL Server 2014 использует другую формулу по умолчанию для комбинирования конъюнктивных и дизъюнктивных предикатов. Хотя это и недокументировано, формула избирательности для союзов была обнаружена и задокументирована уже несколько раз.Первое, что я увидел, находится в этом сообщении в португальском блоге, а вторая часть вышла через пару недель. Подводя итог, можно сказать, что подход 2014 года к конъюнктивным предикатам заключается в использовании экспоненциального отката : для таблицы с мощностью C и избирательностью предикатов S 1 , S 2 , S 3 … S n , где S 1 является наиболее избирательным, а S n наименее: Оценка вычисляется как наиболее избирательный предикат, умноженный на мощность таблицы, умноженный на квадратный корень из следующего наиболее избирательного предиката, и так далее, причем каждая новая избирательность получает дополнительный квадратный корень. Напоминая, что избирательность - это число от 0 до 1, ясно, что применение квадратного корня приближает число к 1. Эффект состоит в том, чтобы учесть все предикаты в окончательной оценке, но уменьшить влияние менее избирательных предикаты экспоненциально. Возможно, в этой идее больше логики, чем в предположении независимости , но это все еще фиксированная формула - она не меняется в зависимости от фактической степени корреляции данных. В оценке мощности 2014 г. используется экспоненциальная формула отсрочки для как конъюнктивных, так и дизъюнктивных предикатов , хотя формула, использованная в дизъюнктивном случае ( Флаг трассировки 4137 (для использования минимальной селективности) работает ли , а не в SQL Server 2014, если при компиляции запроса используется новая оценка мощности. Вместо этого есть новый флаг трассировки 9471 . Когда этот флаг активен, минимальная избирательность используется для оценки нескольких конъюнктивных и дизъюнктивных предикатов . Это изменение по сравнению с поведением 4137, которое повлияло только на конъюнктивные предикаты. Точно так же можно указать флаг трассировки 9472 , чтобы предполагать независимость для нескольких предикатов, как это делали предыдущие версии.Этот флаг отличается от 9481 (для использования оценки количества элементов до 2014 г.), потому что в 9472 по-прежнему будет использоваться новая оценка количества элементов, но затронута только формула селективности для нескольких предикатов. Ни 9471, ни 9472 не задокументированы на момент написания (хотя они могут быть в RTM). Удобный способ узнать, какое предположение о селективности используется в SQL Server 2014 (с активным новым средством оценки мощности), - это изучить выходные данные отладки вычисления селективности, полученные, когда активны флаги трассировки 2363 и 3604 .Раздел, который следует искать, относится к калькулятору селективности, который объединяет фильтры, где вы увидите одно из следующего, в зависимости от того, какое предположение используется: Нет реальной перспективы, что 2363 будет задокументирован или поддержан. Нет ничего волшебного в экспоненциальном откате, минимальной селективности или независимости. Каждый подход представляет собой (чрезвычайно) упрощающее предположение, которое может дать или не дать приемлемые оценки для любого конкретного запроса или распределения данных. В некоторых отношениях экспоненциальная отсрочка представляет собой компромисс между двумя крайностями: независимость и минимальная селективность . Тем не менее, важно не возлагать на него необоснованных ожиданий. Пока не будет найден более точный способ оценки избирательности для нескольких предикатов (с приемлемыми характеристиками производительности), по-прежнему важно знать об ограничениях модели и соответственно следить за (потенциальными) ошибками оценки. Различные флаги трассировки обеспечивают некоторый контроль над используемыми предположениями, но ситуация далека от совершенства. Во-первых, самая тонкая степень детализации, при которой может быть применен флаг, - это один запрос - поведение оценки не может быть определено на уровне предиката. Если у вас есть запрос, в котором одни предикаты коррелированы, а другие независимы, флаги трассировки могут вам не сильно помочь без того или иного рефакторинга запроса. Точно так же проблемный запрос может иметь корреляции предикатов, которые плохо моделируются ни одним из доступных вариантов. Специальное использование флагов трассировки требует тех же разрешений, что и Иногда люди говорят на «SQL» и ожидают, что вы знаете всю терминологию.В недавнем разговоре о планах запросов я разглагольствовал о том, как записываются предикаты, когда человек остановил меня и задал очень простой вопрос. Это как загорающаяся лампочка напомнило мне, что не все знают, о чем говорит другой человек, когда терминология упоминается без пояснений. Итак, этот пост ответит на этот очень правильный простой вопрос. Что такое предикат SQL? Предикаты - это выражения, которые оцениваются как ИСТИНА, ЛОЖЬ, НЕИЗВЕСТНО .Существует два типа предикатов: отфильтрованные предикаты и предикаты соединения. отфильтрованных предикатов охватывают ваши WHERE или HAVING clauses в вашем запросе. По сути, это критерии поиска. JOIN Предикаты охватывают ваши предложения FROM в вашем запросе. По сути, это, так сказать, критерии слияния. Они объединяют две или более таблиц на основе критериев сходства соединения. Итак, вот оно.Просто простой блог, чтобы ответить на отличный вопрос. Никогда не бойтесь кого-то остановить и задать вопрос, каким бы простым он ни был. Важно знать терминологию. Я останавливаюсь и прошу людей все время уточнять терминологию во время презентаций или беседы между моими коллегами. Нравится Загрузка ... Список литературы
Нихилеш Патель - профессионал в области баз данных с опытом работы более 7 лет.В основном он занимается проектированием баз данных, разработкой, администрированием, настройкой производительности и оптимизацией (как SQL Server, так и Oracle). Он сотрудничал с SQL Server 2000/2005/2008/2012/2014/2016, базами данных Oracle и PostgreSQL. Он изготовил и разработал базы данных для страхования, телекоммуникаций и связи. Он является администратором базы данных в HighQ solution. Он постоянно развивает свои профессиональные навыки, чтобы не отставать от новых технологий. SQL: используйте в COBOL DB2 Queries
Предикаты
Предикаты SQL могут появиться в следующих предложениях
Правила и приоритет предикатов SQL
Типы логических предикатов SQL
За исключением предиката EXISTS, подзапрос в предикате должен указывать один столбец, если только операнд на другой стороне оператора сравнения не является полным выбором.
Логические операторы, которые работают с предикатами SQL SQL Predicates6
Примеры: Таблица сотрудников
Emp ID Название отдела ID отдела Заработная плата OldEmpID
1 Продажа 10 5000 10
2 Продажи 10 10000 11
3 IT 20 8000 20
4 Маркетинг 30 12000 30
5 IT 20 15000 21
6 часов 40 15000 40
7 КСО ИТ 50 4000 50
8 IT 20 8000 -
9 IT 20 20000 23
10 Маркетинг 30 8000 -
ВЫБРАТЬ EmpID, DeptName
ОТ Сотрудника
ГДЕ DeptID = ANY (10,20,30)
С УР;
ИЛИ ЖЕ
ВЫБЕРИТЕ EmpID, DeptName
ОТ Сотрудника
ГДЕ (DeptID = 10)
ИЛИ (DeptID = 20)
ИЛИ (DeptID = 30)
С УР;
ИЛИ ЖЕ
ВЫБЕРИТЕ EmpID, DeptName
ОТ Сотрудника
ГДЕ DeptID IN (10,20,30)
С УР;
Результат:
Название отдела Emp ID
1 Продажа
2 Продажи
3 IT
4 Маркетинг
5 ИТ
8 ИТ
9 ИТ
10 Marketing ВЫБРАТЬ EmpID, DeptName
ОТ Сотрудника
ГДЕ (Зарплата)> = ВСЕ
(ВЫБЕРИТЕ зарплату от сотрудника
ГДЕ EmpID = 2)
С УР;
ВЫБРАТЬ EmpID, DeptName
ОТ Сотрудника
ГДЕ (Зарплата)> = НЕКОТОРЫЕ
(ВЫБЕРИТЕ зарплату от сотрудника
ГДЕ EmpID = 2)
С УР;
SELECT AVG (Заработная плата)
ОТ Сотрудника
ГДЕ DeptID IN (10,20,30)
ГРУППА ПО DeptID
ИМЕЕТ СРЕДНЮЮ (ЗАРПЛАТУ) МЕЖДУ 10000 И 20000
С УР;
SELECT * FROM employee WHERE DeptID CONTAINS OldEmpID;
Результат:
Emp ID Название отдела ID отдела Заработная плата OldEmpID
1 Продажа 10 5000 10
3 IT 20 8000 20
4 Маркетинг 30 12000 30
6 часов 40 15000 40
7 CSR IT 50 4000 50
ВЫБРАТЬ EmpID, DeptName, DeptID
ОТ Сотрудника
ГДЕ DeptName НРАВИТСЯ "% IT%";
Результат:
Emp ID Название отдела ID отдела
3 IT 20
7 CSR IT 50
SELECT *
ОТ Employee_Master
ГДЕ СУЩЕСТВУЕТ
(ВЫБРАТЬ *
ОТ Сотрудника
ГДЕ Employee_Master.EmpID = Employee.EmpID)
С УР;
Результат:
Emp ID Название отдела ID отдела Заработная плата OldEmpID
1 Продажа 10 5000 10
2 Продажи 10 10000 11
3 IT 20 8000 20
4 Маркетинг 30 12000 30
5 IT 20 15000 21
ВЫБРАТЬ *
ОТ Сотрудника
ГДЕ НЕ СУЩЕСТВУЕТ
(ВЫБРАТЬ *
ОТ Employee_Master
ГДЕ Employee.EmpID = Employee_Master.EmpID)
С УР;
Результат:
Emp ID Название отдела ID отдела Заработная плата OldEmpID
6 часов 40 15000 40
7 КСО ИТ 50 4000 50
8 IT 20 8000 22
9 IT 20 20000 23
10 Маркетинг 30 8000 31
ВЫБРАТЬ *
ОТ Employee_Master
В КОТОРОЙ
(ВЫБРАТЬ *
ОТ Сотрудника
ГДЕ Employee_Master.EmpID = Employee.EmpID)
С УР;
Результат:
Emp ID Название отдела ID отдела Заработная плата OldEmpID
1 Продажа 10 5000 10
2 Продажи 10 10000 11
3 IT 20 8000 20
4 Маркетинг 30 12000 30
5 IT 20 15000 21
ВЫБРАТЬ *
ОТ Employee_Master
ГДЕ НЕ В
(ВЫБРАТЬ *
ОТ Сотрудника
ГДЕ Employee_Master.EmpID = Employee.EmpID)
С УР;
Результат:
Emp ID Название отдела ID отдела Заработная плата OldEmpID
6 часов 40 15000 40
7 КСО ИТ 50 4000 50
8 IT 20 8000 22
9 IT 20 20000 23
10 Маркетинг 30 8000 31
SELECT EmpID
ОТ Сотрудника
ГДЕ OldEmpID НУЛЬ;
Результат:
Emp ID Название отдела ID отдела Заработная плата OldEmpID
8 IT 20 8000 -
10 Маркетинг 30 8000 -
ВЫБРАТЬ EmpID
ОТ Сотрудника
ГДЕ OldEmpID НЕ НУЛЬ;
Результат:
Emp ID Название отдела ID отдела Заработная плата OldEmpID
1 Продажа 10 5000 10
2 Продажи 10 10000 11
3 IT 20 8000 20
4 Маркетинг 30 12000 30
5 IT 20 15000 21
6 часов 40 15000 40
7 КСО ИТ 50 4000 50
9 IT 20 20000 23
Оценка мощности множества предикатов
Одиночные предикаты
ВЫБРАТЬ COUNT_BIG (*)
ИЗ Production.TransactionHistory AS TH
ГДЕ TH.TransactionDate = '20070903';
TransactionDate , становится ясно, откуда взялась эта оценка: DBCC SHOW_STATISTICS (
'Производство.История транзакций',
'Дата сделки')
С ГИСТОГРАММОЙ; 02.09.2007 дает оценку в 227 строк (из записи RANGE_ROWS ). Интересно отметить, что оценка остается на уровне 227 строк независимо от того, какую часть времени мы можем добавить к значению даты (столбец TransactionDate - это тип данных datetime ). 2007-09-05 или 2007-09-06 (оба из которых находятся между 2007-09-04 и 2007-09-07 шагов гистограммы ), оценщик мощности предполагает, что 466 RANGE_ROWS равномерно разделены между двумя значениями, оценивая 233 строки в обоих случаях. Проблемы множественных предикатов
ВЫБРАТЬ
COUNT_BIG (*)
ИЗ Production.TransactionHistory AS TH
ГДЕ
TH.TransactionID МЕЖДУ 100000 И 168412
И TH.TransactionDate МЕЖДУ "20070901" И "20080313"; TransactionID должен соответствовать 68412,4 строк, а диапазон TransactionDate должен соответствовать 68 413 строкам. (Если бы гистограммы были идеальными, эти два числа были бы точно такими же.) SQL Server 7 - 2012
И Избирательность
И (известное как соединение ) с избирательностью S 1 и S 2 , приводят к комбинированной избирательности: (S 1 * S 2 ) TransactionHistory содержит всего 113 443 строки. Предикат для TransactionID оценивается (по гистограмме) для определения 68 412,4 строк, поэтому избирательность составляет (68 412,4 / 113 443) или примерно 0,603055 . Предикат для TransactionDate аналогичным образом оценивается как имеющий избирательность (68 413/113 443) = примерно 0.603061 . OR Селективность
OR (дизъюнкция ) с избирательностями S 1 и S 2 , в результате получается комбинированная избирательность: (S 1 + S 2 ) - (S 1 * S 2 ) OR : ВЫБРАТЬ COUNT_BIG (*)
ИЗ Production.TransactionHistory AS TH
ГДЕ
TH.TransactionID МЕЖДУ 100000 И 168412
ИЛИ TH.TransactionDate МЕЖДУ '20070901' И '20080313'; OR дает комбинированную избирательность: (0.603055 + 0.603061) - (0.603055 * 0.603061) = 0,842437 И ; 95,569 для запроса OR ) не особенно хороша, поскольку обе основаны на предположении моделирования, которое не очень хорошо соответствует распределению данных.Оба запроса фактически возвращают 68 413 строк (поскольку предикаты идентифицируют точно такие же строки). Флаг трассировки 4137 - Минимальная селективность
И (конъюнктивные предикаты). В статье базы знаний по этой ссылке не так много подробностей, но оказывается, что исправление изменяет используемую формулу селективности. Вместо умножения индивидуальных избирательностей оценка мощности для конъюнктивных предикатов теперь использует только самую низкую избирательность. QUERYTRACEON : ВЫБРАТЬ COUNT_BIG (*)
ИЗ Production.TransactionHistory AS TH
ГДЕ
TH.TransactionID МЕЖДУ 100000 И 168412
И TH.TransactionDate МЕЖДУ '20070901' И '20080313'
ОПЦИЯ (QUERYTRACEON 4137); И ) предикатам в запросе; нет способа указать поведение на более детальном уровне. OR ) предикатов с использованием минимальной избирательности. SQL Server 2014
QUERYTRACEON , хотя это не описано в документации. Невозможно узнать, каким будет поведение этого флага в RTM. Оценка = C * S 1 * SQRT (S 2 ) * SQRT (SQRT (S 3 )) * SQRT (SQRT (SQRT (S 4 )))… OR ), еще не была задокументирована (официально или иначе). Флаги трассировки избирательности SQL Server 2014
Последние мысли
DBCC TRACEON , а именно sysadmin . Это, вероятно, подходит для личного тестирования, но для производства лучше использовать руководство по планированию с подсказкой QUERYTRACEON . При использовании руководства по плану для выполнения запроса не требуются дополнительные разрешения (хотя, конечно, для создания руководства по плану требуются повышенные разрешения). предикатов запросов в SQL Server
Нравится:
О Монике Ратбун
Моника Рэтбун живет в Вирджинии, является MVP Microsoft по платформе данных и сертифицированным экспертом по решениям Microsoft.Она имеет почти двадцатилетний опыт работы с широким спектром платформ баз данных, уделяя особое внимание SQL Server и Microsoft Data Platform. Она часто выступает на конференциях ИТ-индустрии по таким темам, как настройка производительности и управление конфигурацией. Она является руководителем группы пользователей Hampton Roads SQL Server. Она увлечена SQL Server и сообществом SQL Server и делает все, что в ее силах, чтобы вернуть их. Монику всегда можно найти в Твиттере (@sqlespresso), где она дает полезные советы.Вы можете найти блог Моники на sqlespresso.comSQL Server - Советы по настройке производительности: в чем разница между предикатом поиска и предикатом?
Чтобы создать этот пример таблицы, похожей на мою (данные случайные, верно .. rs), чтобы иметь возможность следить за статьей и моделировать эти сценарии, вы можете использовать сценарий ниже:
IF (OBJECT_ID ('dbo. Vendas ') НЕ NULL) DROP TABLE dbo.Vendas СОЗДАТЬ ТАБЛИЦУ dbo.Vendas ( Id_Pedido INT ИДЕНТИЧНОСТЬ (1,1), Dt_Pedido DATETIME, [Статус] INT, Quantidade INT, Доблесть ЧИСЛЕННОЕ (18; 2) ) СОЗДАТЬ КЛАСТЕРНЫЙ ИНДЕКС SK01_Pedidos НА dbo.Венды (Id_Pedido) СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС SK02_Pedidos НА dbo.Vendas ([Статус], Dt_Pedido) ВКЛЮЧИТЬ (Quantidade, Valor) ИДТИ ВСТАВИТЬ В dbo.Vendas (Dt_Pedido, [Статус], Quantidade, Valor) ВЫБРАТЬ DATEADD (ВТОРОЙ, (ABS (КОНТРОЛЬНАЯ СУММА (PWDENCRYPT (N ''))) / 2147483647.0) * 199999999, '2015-01-01'), (ABS (КОНТРОЛЬНАЯ СУММА (PWDENCRYPT (N ''))) / 2147483647.0) * 9, (ABS (КОНТРОЛЬНАЯ СУММА (PWDENCRYPT (N ''))) / 2147483647.0) * 10, 0,459485495 * (ABS (КОНТРОЛЬНАЯ СУММА (PWDENCRYPT (N ''))) / 2147483647.0) * 1999 GO 10000 ВСТАВИТЬ В dbo.Венды (Dt_Pedido, [Status], Quantidade, Valor) ВЫБЕРИТЕ Dt_Pedido, [Статус], Quantidade, Valor ИЗ dbo.Vendas GO 9
1 2 3 4 5 6 7 8 9 10 11 12 15 16 17 18 19 20 21 22 23 24 25 26 | IF (OB dJECT.Vendas ') IS NOT NULL) DROP TABLE dbo.Vendas CREATE TABLE dbo.Vendas ( Id_Pedido INT IDENTITY (1,1), Dt_Pedido DATETIME, [Status] INT, Quantid Доблесть NUMERIC (18, 2) ) СОЗДАТЬ КЛАСТЕРИРОВАННЫЙ ИНДЕКС SK01_Pedidos НА dbo.Vendas (Id_Pedido) СОЗДАТЬ НЕЗАКЛЮЧЕННЫЙ ИНДЕКС SK02_Pedidos на dbo.Vendas ([Статус] Dbo.Vendas 9dUDEndas ([Статус]) GO ВСТАВИТЬ В dbo.Vendas (Dt_Pedido, [Status], Quantidade, Valor) SELECT DATEADD (SECOND, (ABS (CHECKSUM (PWDENCRYPT (N ''))) / 2147483647.0) * 199999999, '2015-01-01'), (ABS (КОНТРОЛЬНАЯ СУММА (PWDENCRYPT (N ''))) / 2147483647.0) * 9, (ABS (CHECKSUM (PWDENCRYPT (N ''))) / 2147483647.0) * 10, 0,459485495 * (ABS (CHECKSUM PWDENCRYPT (N ''))) / 2147483647.0) * 1999 GO 10000 INSERT INTO dbo.Vendas (Dt_Pedido, [Status], Quantidade, Valor) SELECT Status [Статус], Quantidade, Valor) SELECT Dt_Pedido Доблесть ОТ dbo.Vendas GO 9 |
Ну, разобравшись в очень простом и кратком объяснении этих двух операций, стало совершенно ясно, что операция Seek для индексов Rowstore почти всегда (не всегда) превосходит Scan. Итак, давайте теперь поговорим о предикате и предикате поиска, которые возникают только тогда, когда таблица имеет индексы, соответствующие определенному запросу.
Предикат поиска Это первый фильтр, который применяется к данным, когда SQL Server выполняет запрос.По этой причине в идеале создаются индексы для определения приоритета предиката поиска для наиболее избирательных столбцов (как можно меньше записей для каждого значения столбца), чтобы первый уровень фильтрации возвращал как можно меньше строк. Работа предиката происходит после предиката поиска. После первого фильтра, выполненного с данными, SQL Server применит оставшиеся фильтры запросов к подмножеству, возвращаемому Seek Predicate, то есть чем больше подмножество на шаге 2 2, тем больше работы оптимизатору запросов, поскольку в Predicate они могут иметь фильтры тяжелые и не очень избирательные.
Ах, но как мне установить различные условия для предиката поиска? Это не ... lol .. Существует очень ограниченное количество операций, которые могут быть выполнены вместе в пределах предиката поиска, таких как, например, операция диапазона (между или> значение и <значение) и другая операция равенства (=) можно использовать вместе в предикате поиска, но две равные операции, будь то диапазон или равенство, нет.
Анализ избирательности столбцов по гистограмме
В приведенном ниже примере с двумя операциями диапазона в одном запросе я продемонстрирую, как определить, насколько избирательны столбцы данного индекса:
SELECT * ОТ dbo.Vendas ГДЕ Dt_Pedido> = '2019-02-06' И Dt_Pedido <'2019-02-09' И [Статус] <5
ВЫБРАТЬ * ИЗ dbo.Vendas ГДЕ Dt_Pedido> = '2019-02-06' И Dt_Pedido <'2019-02-09' И [Статус] <5 |
При поверхностном рассмотрении плана выполнения мы не обнаруживаем ничего, отличного от оптимизированного запроса. Операция поиска, без поиска ключей. Все в порядке.
Но что, если мы посмотрим глубже? Что ж, это не так уж и хорошо. Чтобы вернуть 2,560 строк, мне пришлось прочитать 2,857,984 строки, то есть больше чем в 1000 раз.
Другой способ увидеть, как запрос выполняется в базе данных, - использовать команду SET STATISTICS PROFILE ON:
Возвращение следующего анализа в поле StmtText:
SELECT [Quantidade] * [Valor] FROM [ dbo]. [Vendas] WHERE [Dt_Pedido]> = @ 1 AND [Dt_Pedido] <@ 2 AND [Status] <@ 3
| --Вычислить скаляр (DEFINE: ([Expr1003] = CONVERT_IMPLICIT (numeric (10,0), [dirceuresende].[dbo]. [Vendas]. [Quantidade], 0) * [dirceuresende]. [dbo]. [Vendas]. [Valor]))
| --Параллелизм (сбор потоков)
| --Поиск индекса (ОБЪЕКТ: ([dirceuresende]. [Dbo]. [Vendas]. [SK02_Pedidos]),
ПОИСК: ([dirceuresende]. [Dbo]. [Vendas]. [Status]
SELECT [Quantidade] * [Valor] FROM [dbo]. [Vendas] WHERE [Dt_Pedido]> = @ 1 AND [Dt_Pedido] <@ 2 AND [Status] <@ 3 | --Вычислить скаляр (DEFINE: ([Expr1003] = CONVERT_IMPLICIT (numeric (10,0), [dirceuresende].[dbo]. [Vendas]. [Quantidade], 0) * [dirceuresende]. [dbo]. [Vendas]. [Valor])) | --Parallelism (Gather Streams) | --Index Seek ( ОБЪЕКТ: ([dirceuresende]. [Dbo]. [Vendas]. [SK02_Pedidos]), SEEK: ([dirceuresende]. [Dbo]. [Vendas]. [Status] ГДЕ: ([dirceuresende]. [Dbo]. [Vendas]. [Dt_Pedido]> = CONVERT_IMPLICIT (datetime, [@ 1], 0) AND [dirceuresende]. [Dbo]. [Vendas]. [Dt_Pedido] ОБЪЕКТ: ([dirceuresende].[dbo]. [Vendas]. [SK02_Pedidos]), SEEK: ([dirceuresende]. [dbo]. [Vendas]. [Status] WHERE : ([dirceuresende]. [dbo]. [Vendas]. [Dt_Pedido]> = CONVERT_IMPLICIT (datetime, [@ 1], 0) AND [dirceuresende]. [dbo]. [Vendas]. [dirceuresende]. [dbo] . [Vendas]. [Quantidade], [dirceuresende]. [Dbo]. [Vendas]. [Valor] |
Где SEEK - это предикат поиска, а WHERE - предикат. условия поиска предиката (фильтр состояния) и предиката (фильтр OrderDt).Является ли столбец Status более избирательным, чем столбец OrderDt, тем более в запросе выше? Давайте узнаем, создав статистику для столбца Status и проанализируем гистограмму:
CREATE STATISTICS Vendas_Status ON dbo.Vendas (Status) WITH FULLSCAN ИДТИ DBCC SHOW_STATISTICS ('Vendas', Vendas_Status) GO
СОЗДАТЬ СТАТИСТИКУ Vendas_Status ON dbo.Vendas (Статус) С FULLSCAN GO DBCC SHOW_STATISTICS ('Vendas', Vendas_Status 9007 000 | 0044
СОЗДАТЬ СТАТИСТИКУ Vendas_DtPedido ON dbo.Vendas (Dt_Pedido) WITH FULLSCAN GO DBCC SHOW_STATISTICS ('Vendas', Vendas '9edid4000 9edas_d 9edid4000 000 9edid4000 9edas9Глядя на гистограмму столбца Dt_Request, мы видим, что плотность намного выше, около 29.999 различных значений и в среднем от 20 до 50 тысяч записей для диапазона прямоугольной гистограммы и оценка 512 записей на отдельное значение, что показывает, что это гораздо более избирательный столбец, чем столбец «Состояние». Наблюдение: Будьте осторожны при создании статистики для очень больших таблиц, особенно с предложением FULLSCAN. Если вы не уверены, что используете эту команду для анализа гистограммы, вы можете просто использовать запрос типа SELECT Dt_Order, COUNT (*) FROM Sales GROUP BY Dt_Order, чтобы получить хорошее представление о селективности столбца. Предикат поиска против предикатаТеперь, когда я объяснил основные принципы работы предиката поиска и предиката и как определить избирательность столбца, я продемонстрирую несколько примеров того, как мы можем попытаться идентифицировать и даже контролировать операции предиката поиска и предиката. Вызов индексов нашей таблицы: В этом первом примере я буду использовать запрос с двумя предложениями диапазона (<и / или>), и мы попытаемся управлять предикатом поиска и предикатом для этих запросов: SELECT Quatidade * Valor ОТ dbo.Vendas ГДЕ Dt_Pedido> = '2019-02-06' И Dt_Pedido <'2019-02-09' И [Статус] <5
Результат анализа плана выполнения: Как я объяснил в предыдущем разделе, избирательность столбца OrderDt намного выше, чем столбца Status, и это оправдывает огромное количество прочитанных строк (2.869.003), чтобы вернуть только 2,577 записей на запрос. Хотя операция чтения - это поиск, ее все же можно улучшить, перестроив индекс с использованием более избирательного подхода. Для этого давайте отбросим индекс SK02_Purts и инвертируем столбцы этого индекса, чтобы операция поиска предиката выполнялась в столбце Dt_Purchase вместо столбца Status. DROP INDEX SK02_Pedidos ON dbo.Vendas ИДТИ СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС SK02_Pedidos НА dbo.Vendas (Dt_Pedido, [Status]) ВКЛЮЧИТЬ (Quantidade, Valor) GO
И снова выполним план. : Вау! Какая разница! Обратите внимание, что в дополнение к нашему запросу с использованием CPU 0 мс (ранее 313 мс) и выполнения всего 2 мс (было 71 мс), количество логических чтений упало с 20 900 до 29, а также количество прочитанных строк упало с 2.С 869.003 до 5.657. Все это с простым изменением порядка индексов, которое изменило столбцы, которые являются частью Seek Predicate и Predicate. Пример 2 - Диапазон и равенствоЧто, если бы вместо status <5 было, например, status = 5? Как бы выглядел план выполнения? Новый запрос: SELECT Quantidade * Valor ОТ dbo.Vendas ГДЕ Dt_Pedido> '2019-02-06' И Dt_Pedido <'2019-02-09' AND [Статус] = 5
Анализ плана выполнения с новым запросом: То есть план был очень похож на предыдущий, даже с изменением фильтра статуса. Но теперь возникает вопрос: можно ли еще улучшить этот запрос? DROP INDEX SK02_Pedidos ON dbo.Vendas ИДТИ СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС SK02_Pedidos НА dbo.Vendas ([Статус], Dt_Pedido) ВКЛЮЧИТЬ (Quantidade, Valor) GO
Новый план, созданный при выполнении: А с нашим старым индексом наш запрос стал еще лучше и избирательнее! Поскольку я всегда говорю о производительности, все должно быть проверено и оценено.В этом случае одному из двух запросов будет препятствовать изменение индекса, или вы можете создать два индекса (потребляющих вдвое больше дискового пространства) и добиться наилучшего результата. индекс для каждой ситуации. Очень важно отметить, что создание индексов должно быть очень хорошо продуманным, потому что вы не можете создать индекс для любого запроса банка. Индексы занимают место и замедляют более сложные операции записи для SQL Server, поэтому их следует создавать при необходимости. Оставить комментарий
|