Как раньше выглядел яндекс.
2 голосаДоброго дня, уважаемые посетители моего блога. Сегодня я не буду рассказывать о создании сайтов, заработке и других полезных штуках. Я решил немного поразвлечься. Конечно же, это мы будем делать с пользой.
Мы отправимся в прошлое интернета и посмотрим на то, как выглядел дизайн много лет назад. Я научу вас делать это в любое удобное для вас время. С этого момента машина времени будет для вас доступна по первому требованию.
Итак, как посмотреть сайт в прошлом? Сегодня я покажу, а заодно поведаю вам о некоторых интересных фактах из жизни популярных сайтов. Ну что ж, не будем тянуть.
Как смотреть в прошлое
В сожалению, вы не сможете увидеть как выглядел конкретно ваш сайт, но множество популярных ресурсов находится в базе archive.org/web/web.php . По словам самого сервиса, у них сохранилось 500 биллионов страниц.
Просто зайдите на этот портал, введите в поисковую строчку адрес сайта, который хотите увидеть, например Яндекс, и выбирайте Browse History.
Синим цветом на календаре отмечены дни, в которые добавлены скриншоты. Полоса сверху показывает годы. Черные полоски – количество изображений. Чем они выше, тем больше вы можете увидеть. Как вы видите, ближе к нашему времени скриншоты стали добавлять чаще.
Выбираете год, затем дату. Наводите на нее стрелкой, а затем кликаете на время добавления. В данном случае 03:42 или 03:44. Рекомендую последнее действие (с временем) производить через правую кнопку мыши, а в открывшемся меню выбирать «Открыть в новой вкладке». На мой взгляд так удобнее.
И вот перед вами скриншот того, как выглядел Яндекс 12 декабря 1998 года. Эта информация высвечивается в верхнем баре, который можно закрыть при желании. Или, через него же выбирать другую дату. Путешествие во времени осуществляется очень просто. Даже несмотря на то, что «машина» на английском.
Это Яндекс постарше, образец 2000 года.
Так он выглядел в 2005, 11 лет назад.
Ну а так эта поисковая система отображалась в прошлом году.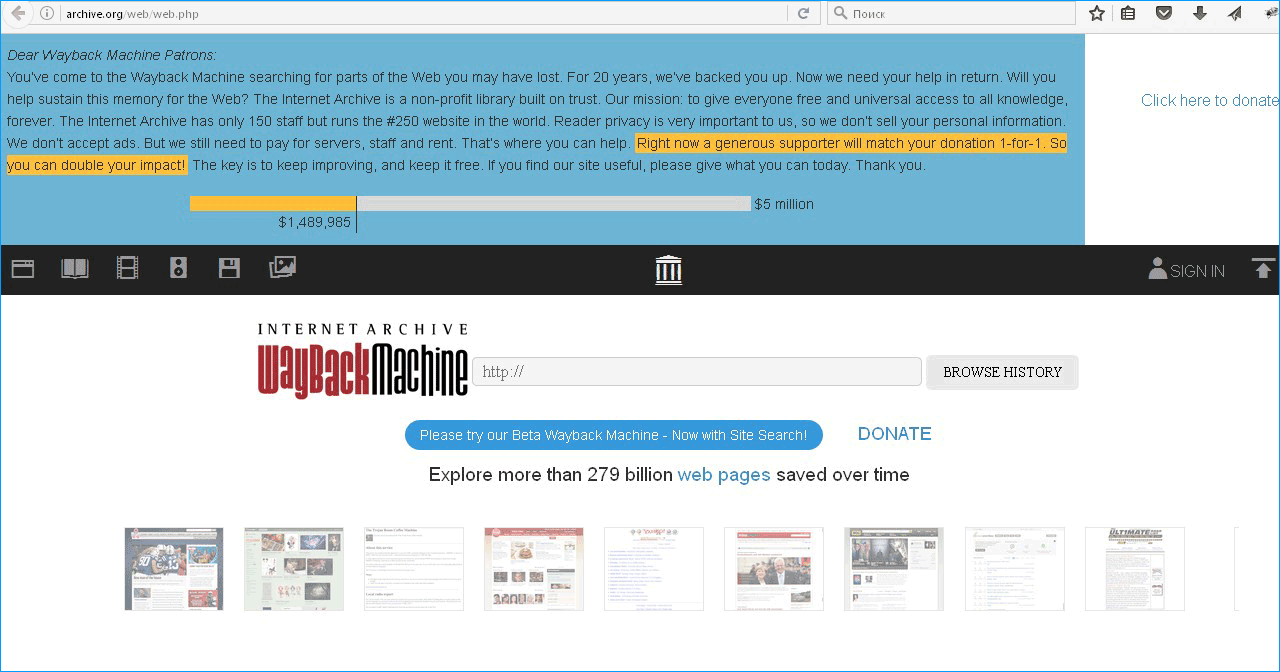 Изменения есть!
Изменения есть!
Ну вот в принципе и все, но не спешите покидать мой блог. Мне бы хотелось показать вам еще несколько популярных проектов и рассказать интересные факты об этих сайтах.
Изначально, популярнейший поисковик Гугл назывался BackRub. И выглядел как-то стрёмно и совершенно непонятно.
Лишь в 1998 он принял более современный внешний вид. Тогда еще, в конце слова Google стоял восклицательный знак. Представляете, это бета версия, то есть тестовая. Тогда еще разработчики исправляли ошибки и проверяли как все работает. Эх, где мои 16 лет.
Уже тогда здесь было две кнопки. Одна со стандартным поиском, а вторая выбирает случайную страницу с информацией. Если бы администраторы убрали кнопку «Мне повезет», которая пользуется бешенной популярностью и по сей день, то смогли бы получать дополнительный доход с рекламы. Он составил бы примерно 100 миллионов долларов в год. Но, они не жадные.
Кстати о деньгах, компания Mozilla ежегодно получает от гугла 300 миллионов за то, что в их браузере по умолчанию стоит поисковая система от Google.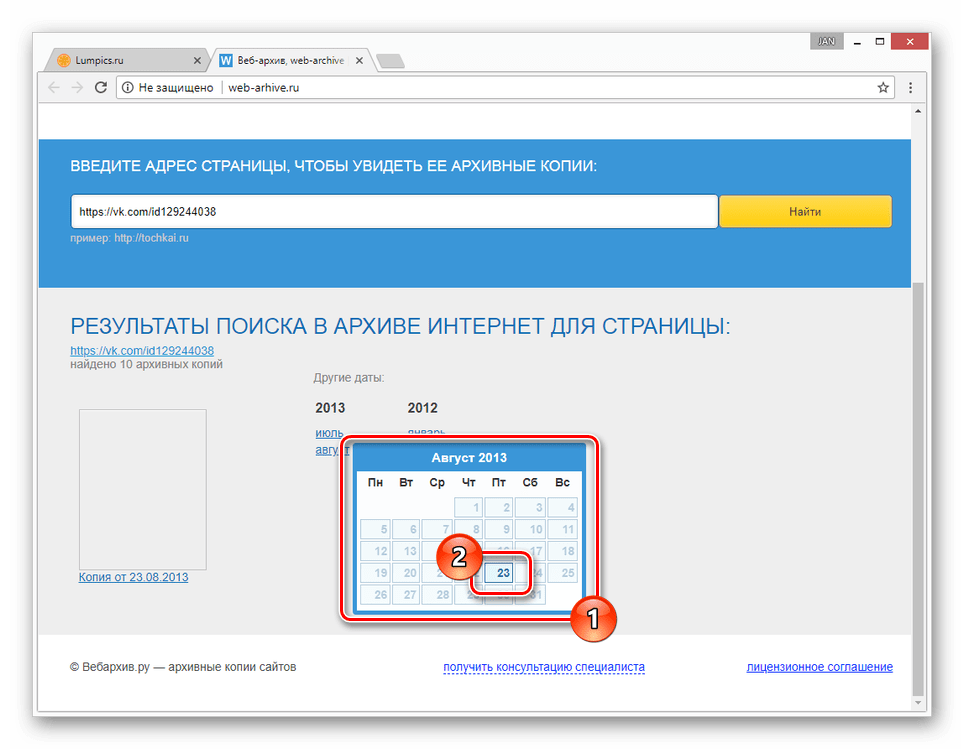
YouTube
Компания YouTube открылась 14 февраля, в день всех влюбленных. В России же его начали использовать лишь в 2007 году, а первым выложенным роликом стала песня Петра Налича «Гитар». С той поры прошло 10 лет.
Если бы ютуб был не видеохостингом, а кинокомпанией, то каждую неделю они смогли бы выпускать по 60 тысяч фильмов. Материала для этого предостаточно.
Кстати, сейчас у ютуба столько же посетителей, сколько было пользователей в интернете в целом в 2000 году. Ежедневно ролики набирают около 2 миллиарда .
YouTube не только стал одной из самых популярных компаний, но еще и делает знаменитыми простых людей. Многим россиянам известны такие люди как Макс Голопогосов (+100500), Рома Желудь, BadComedian, mrFreeman. А вот певица Адель и Джастин Бибер получили всемирную славу благодаря этой социальной сети. Я уже молчу о том, сколько людей благодаря ним .
Вконтакте
Чего только не скрывалось под популярным ныне доменом vk.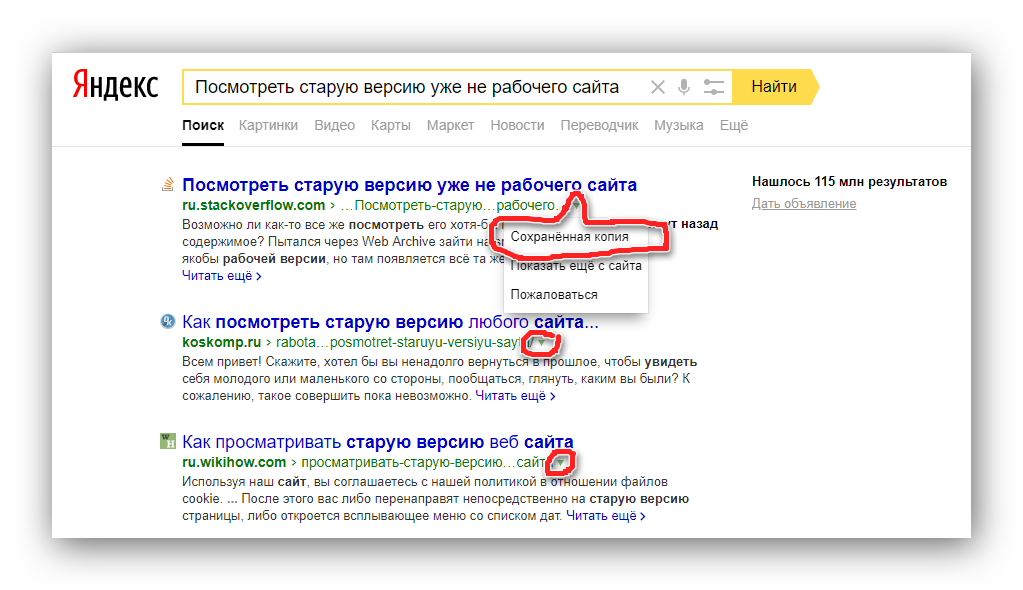 com. Кстати, использовать его стали не сразу, изначально в контакт можно было зайти только по URL: vkontakte.ru, но потом ситуация изменилась и администрация решила облегчить нашу с вами жизнь.
com. Кстати, использовать его стали не сразу, изначально в контакт можно было зайти только по URL: vkontakte.ru, но потом ситуация изменилась и администрация решила облегчить нашу с вами жизнь.
Изначально проект был создан как закрытый справочник студентов и выпускников. Об этом свидетельствует надпись на главной странице того периода.
Мог ли тогда представить Павел Дуров, насколько популярным станет его проект? Сейчас даже смешно смотреть на горделивую надпись: «Нас уже 350 000». Сейчас численность проекта насчитывает миллионы.
Интересных историй о этой социальной сети предостаточно, но на мой взгляд самая впечатляющая заключается в том, что вплоть до 2014 года через Одноклассники нельзя было послать ссылку на информацию, находящуюся Вконтакте. Система не блокировала их, а просто заменяла буквы в словах.
Еще один интересный факт, о котором многие пользователи помнят. В какой-то момент администрация сайта решила поменять дизайн личных страниц.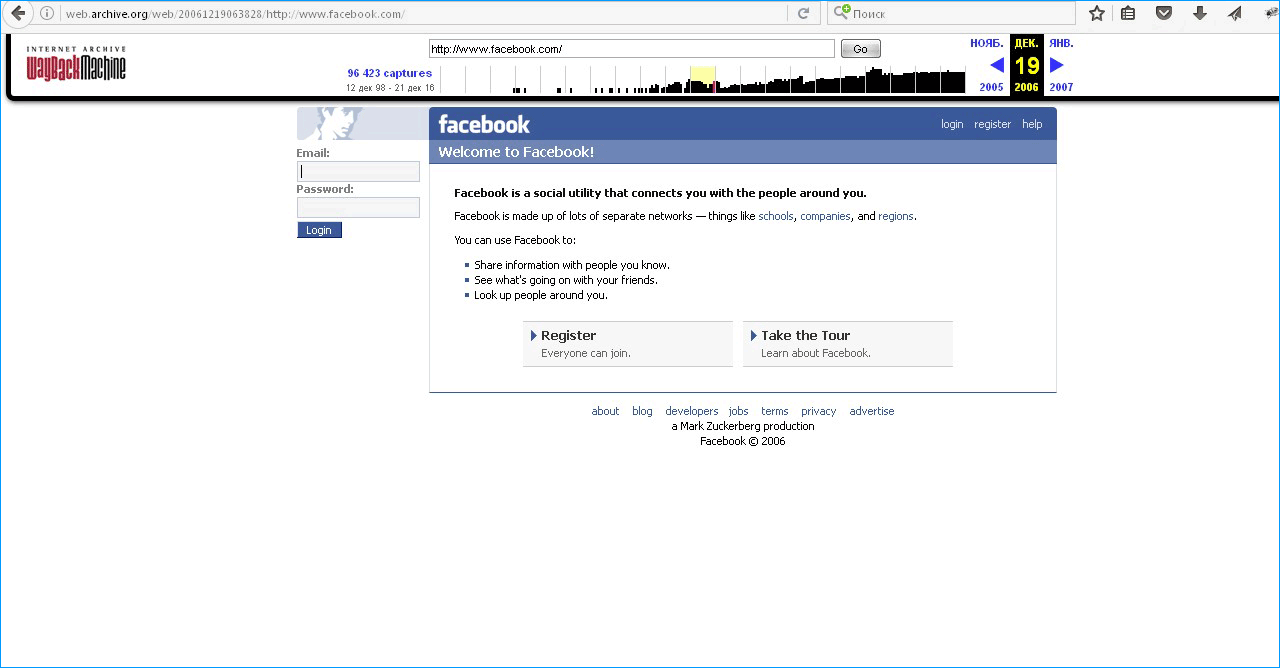 Это вызвало бурю эмоций среди пользователей.
Это вызвало бурю эмоций среди пользователей.
И тут и там кипели возгласы: «Верните стену, нет микроблогу». Павел Дуров был не преклонен. В моей памяти эти воспоминания все еще свежи, а тем не менее с той поры прошло 6 лет. Военные действия разворачивались в 2010 году. Согласитесь, сейчас смотришь на этот кошмар и думаешь, что там могло нравиться, за что воевали?
Интересный момент, но благодаря социальным сетям люди не только общаются между собой и , но и достигают других интересных целей. Хоть в свое время дизайн стены не вернули, зато деятельность пользователей на Facebook и Вконтакте вернула в мультсериал «Гриффины» умершего пса Брайна.
Мне очень понравилось, как они потом подшутили над этим фактом. После «воскрешения» в одной из серий они не показали ни единого кадра с псом, а в конце написали какую-то забавную фразу из серии: «Кто-нибудь вообще заметил, что в этой серии не было Брайана? Нам ждать возмущений по этому поводу в социальных сетях?».
Если вы переживаете, что ничего не умеете и не знаете, просто посмотрите как изначально выглядел любой сайт, тот же Яндекс.
Прошлое должно оставаться в прошлом, но иногда нужно вернуться, чтобы рассмотреть детали…
Здравствуйте, дорогие мои читатели!
Я очень люблю узнавать что-то новое. Ведь так здорово, когда наш багаж знаний пополняется. И самое хорошее здесь то, что такой багаж знаний нести совсем не тяжело. Наоборот, это придаёт нам уверенности в жизни. Естественно, всё знать невозможно, но здоровая любознательность это очень хорошее качество.
Пару лет назад я совершенно случайно узнала об одном сервисе. Привело меня к этому простое любопытство. Просто захотелось узнать, как выглядел определённый сайт на самом первом этапе развития, и каков был его первоначальный дизайн.
Разве это не интересно?
А ещё интересно это не просто как банальное любопытство. Если человек захотел купить себе уже готовый, используемый раньше домен, то не мешало бы посмотреть, какой на нём был раньше сайт, какой тематики он был и как он выглядел. Это очень важно. Так надо делать, чтобы быть уверенным в том, что вы покупаете на самом деле. Ведь кота в мешке покупать не очень то хочется.
Это очень важно. Так надо делать, чтобы быть уверенным в том, что вы покупаете на самом деле. Ведь кота в мешке покупать не очень то хочется.
И ещё. Нам нравятся не все сайты подряд, даже если они выглядят аккуратно и всё там реализовано так, как положено.
Мы посещаем самые различные сайты, и на одних сайтах мы бываем мимолетом, а на других задерживаемся и ставим на них закладки, чтобы возвращаться вновь и вновь.
От чего это зависит?
У всех по разному, и как бы блогер или администрация сайта не старались, всем понравится не возможно. И не стоит расстраиваться по этому поводу, если ваш блог кому то не понравился.
Кому не нравится,те пройдут мимо. А если уж блог понравился, то у человека возникает естественное чувство любопытства, особенно если это веб. мастер:
КАК УЗНАТЬ ИСТОРИЮ САЙТА И ДОМЕНА?
То, какими мы сейчас видим сайты в интернете, на это влияет мода, прогресс и просто удобство для читателей. Это всё изучает каждый веб. мастер, ведь для того чтобы быть любимым и интересным, надо соответствовать.
А любому веб.мастеру всегда интересен вопрос:
Как же все-таки можно узнать историю сайта блоггера, живущего по соседству в интернете=)?
Всё просто. Это узнать можно быстро. Для этого сядем поудобнее перед компьютером и переместимся на специальной машине времени назад, в прошлое.
В интернете существует специальный веб-архив и в нем сохраняются все изменения сайта на протяжении нескольких лет. Просто делаются скриншоты (фотографии) всех страниц сайта.
Стоит отметить, что история сайта сохраняется не в виде простых скриншотов, а в виде работающих веб-страниц со всеми файлами.
Если сайт достаточно популярный, то фотографии делаются чаще, если нет, то бот-фотограф заходит туда реже или не заходит совсем, если сайт перестал обновляться. Это из личных наблюдений. Так как этот сайт веб- архив работает по своим правилам, и не всегда поддаётся логике.
Этот сайт, на который мы сейчас попадём, некоммерческий проект, и он уже достаточно долгое время работает на благо всех интернет пользователей.
Этот факт заслуживает к нему уважения. Это как Википедия , только немного с другими целями.
Как посмотреть историю сайта в архиве?
Откроется страница, с формой поиска, в которую нужно вписать адрес сайта.
Например, вот один из известных сайтов:
http://www.fast-torrent.ru/
Вписываем адрес сайта и смотрим, что получилось:
Перед вами откроется новая страница, где будет показан календарь и указаны даты, когда это сайт был сфотографирован. Вы сможете проследить всю историю развития сайта, исходя из сохранённых фотографий.
В календаре голубыми кружочками отмечены даты, когда был создан снимок данного сайта.
Нужно просто нажать на число, выделенное голубым цветом. Вы увидите скриншот, как выглядел сайт в тот момент. Будет виден дизайн, и последние статьи и новости.
Кстати, если вы по каким-либо причинам не сделали , то не стоит совсем отчаиваться от потерянной навеки информации. Данный ресурс поможет вам восстановить сайт.
Понятно, что восстановление таким образом своего сайта займет огромное количество времени, но когда другого варианта нет, как бы это не звучало, то любая возможность будется казаться самой лучшей.
К тому же, такая беда может случится обычно у начинающих веб мастеров, и значит контента будет не так то много, так что берите в руки своё терпение и по детально восстанавливайте свои статьи.
Хотя всем желаю, чтобы таким образом этот ресурс вам не пригодился никогда!
Как можно посмотреть страницы определённого сайта?
Итак, надо ввести в адресную строку Яндекса или Гугла такой адрес:
http://wayback.archive.org/web/*/сайт/*
Вместо моего введите тот, что надо для просмотра.
Вы попадёте на машине времени назад, где можно посмотреть все сохранённые страницы, если они были запротоколированы.
Вот такие адреса у меня были в начале ведения блога:
А вот такие, красивые, уже впоследствии:
Мы попадём на страницу, где будет показано, сколько раз был сделан снимок сайта:
Даже фавикон будет тот, что был на тот момент:)
Немного истории:
Вот представьте масштаб этого хранилища на данный момент времени!!! Это сколько нужно места!!!
Некоторые сайты всё же не попадают в историю веб. архива, потому что владельцы сайта могут не захотеть, чтобы было разрешение на сканирование веб-сайта боту этого ресурса: The Wayback Machine.
архива, потому что владельцы сайта могут не захотеть, чтобы было разрешение на сканирование веб-сайта боту этого ресурса: The Wayback Machine.
Для этого в robots.txt.ставят запрет на просмотр страниц ботом. Приблизительно это будет так:
User-agent: ia_archiver
Disallow: /
Как посмотреть нужную копию сайта?
Чтобы посмотреть архивы, надо обратить внимание на временную шкалу, расположенную вверху страницы, где вертикальными черными черточками отмечены имеющиеся для этого сайта копии. Иногда, при неудачной фотографии сайта, например, когда у вас были технические работы или ещё что то и снимок получился битым, тогда следует обратится к другой копии и открыть снимок.
И вот, именно 25 июня 2014 года мы смотрим фотографию:
В итоге, перейдя к просмотру вы увидите копию нужного сайта с работающими внутренними ссылками и подключенным стилевым оформлением.
Стоит заметить, что эта машина работает иногда не совсем корректно, но этих случаев немного на практике и это скорее всего это временное явление.
Теперь вы знаете:
КАК УЗНАТЬ ИСТОРИЮ САЙТА И ДОМЕНА.Всем пока! До новых встреч!
Говорят, прогресс не остановить. Проходят месяцы и годы, технологии становятся всё лучше и совершеннее, уже никого не удивишь с мобильным телефоном со спутниковой навигацией. А сеть Интернет позволяет нам общаться в реальном времени находясь на противоположных концах планеты. Время летит так быстро, что подчас мы не замечаем существенных изменений во многих вещах, с которыми имеем дело. Касается это и сети Интернет, в которой развитие сетевых протоколов, стандартов и технологий просто преобразило внешний вид и функционал имеющихся сайтов. В этом материале я предлагаю вам поднять покров времени и заглянуть в прошлое, посмотреть, как выглядел сайт раньше, каков был внешний вид и функционал ресурсов тех лет, и, возможно, это поможет понять, как далеко мы шагнули вперёд в развитии цифровых технологий наших дней.
Итак, как же выглядел сайт в прошлом, и какие инструменты могут нам помочь заглянуть в веб-историю 5-10 летней давности? Более 20 лет назад, в 1996 году энтузиаст Кейл Брюстер основал цифровой архив под названием «Архив Интернета» («The Internet Archive»), слоганом которого был провозглашён «Всеобщий доступ к знаниям».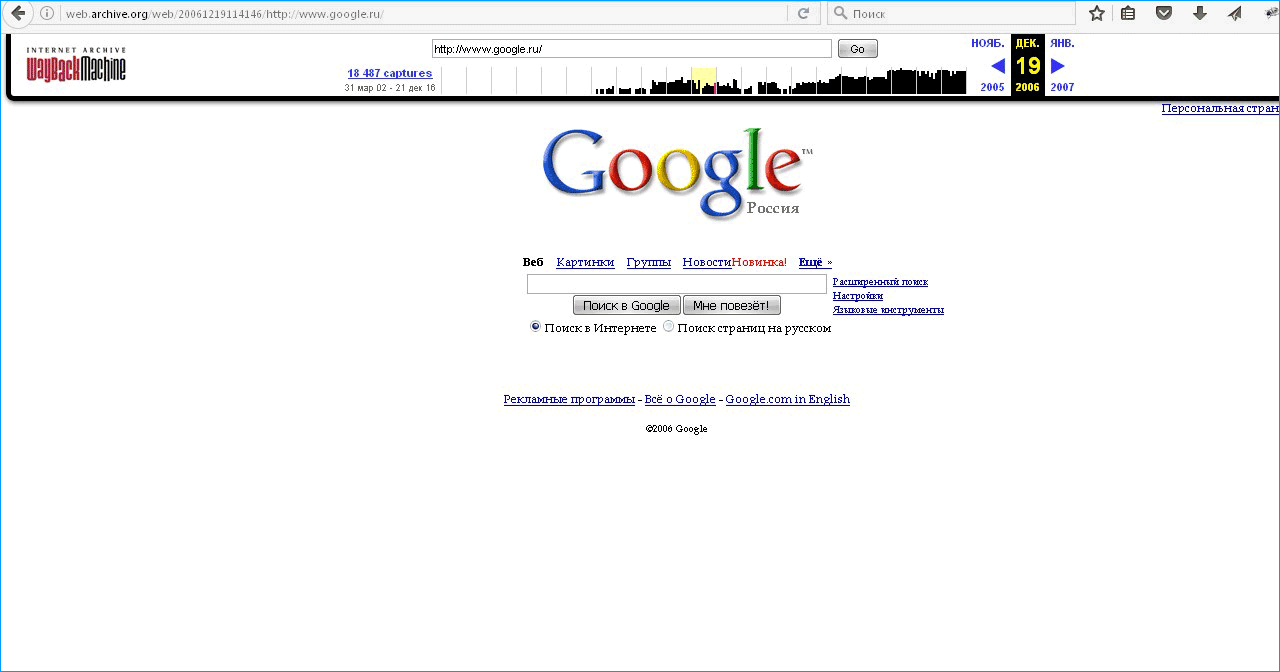 С того времени указанный архив собирает и хранит копии веб-страниц, графики, аудио и видео, различных программ, обеспечивая свободный доступ к накопленной информации для всех желающих.
С того времени указанный архив собирает и хранит копии веб-страниц, графики, аудио и видео, различных программ, обеспечивая свободный доступ к накопленной информации для всех желающих.
На состояние октября 2016 года архив уже имел 15 петабайт информации, а веб-архив проекта содержал уже более 150 миллиардов веб-страниц различных сайтов.
Именно благодаря данному архиву сегодня мы имеем возможность посмотреть, как выглядели многие ресурсы 10-15-20 лет тому назад. Историю действий на вашем компьютере можно узнать в написанной мной ранее.
Смотрим каким был сайт ранее
Итак, как же посмотреть сохранённые копии сайтов? Воспользуемся возможностями данного проекта и попробуем приоткрыть покровы времени.
Перейдите на данный сервис (он носит название Wayback Machine), введите в поисковой строке адрес интересующего вас сайта (например, www.youtube.com) и нажмите на кнопку «Browse history» (просмотреть историю) справа.
Система обработает запрос и выдаст вам результат.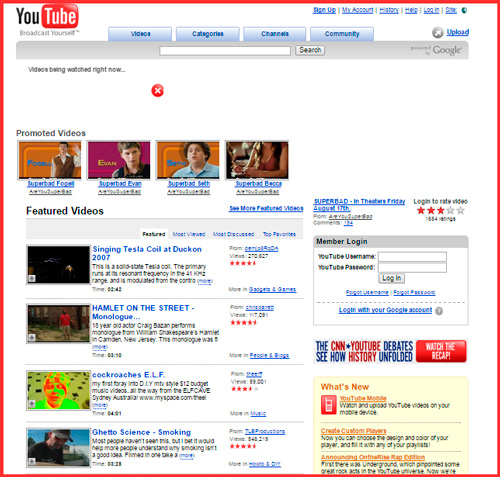 Сверху будет располагаться разбивка по годам, и вы увидите, в каком году впервые была отслежена активность данного сайта и сделан его снимок.
Сверху будет располагаться разбивка по годам, и вы увидите, в каком году впервые была отслежена активность данного сайта и сделан его снимок.
Кликните, к примеру, на самый ранний год (в случае Ютуб это 2005 год), внизу отобразится полный календарь данного года по месяцам. Дни, когда были сделаны «снимки» сайта будут подсвечены голубоватым цветом, в нашем случае первый «снимок» был сделан 28 апреля данного года.
Соответствующим образом вы можете просмотреть любой из интересующих вас сайтов.
Также можно работать с данным сервисом напрямую, введя в адресной строке вашего браузера:
http://web.archive.org/web/*/http://url нужного сайта
Например:
http://web.archive.org/web/*/http://google.com
Соответственно, введя данную строку в адресной строке браузера и нажав на ввод, вы сразу попадёте в отображение снимков нужного вам сайта по годам, месяцам и днём.
Смотрим как выглядели сайты ранее
С помощью ресурса archive. org каждый желающий может получить доступ к миллиардам страниц сохранённого веб-контента, буквально по дням, месяцам и годам наблюдая, как менялся внешний облик множества популярных ресурсов. Воочию видя, как развивалась визуальная составляющая сети, мы можем отчётливо понять, какой скачок сделали интернет технологии за эти годы, и в какое великое время расцвета технического прогресса нам выпала удача жить.
org каждый желающий может получить доступ к миллиардам страниц сохранённого веб-контента, буквально по дням, месяцам и годам наблюдая, как менялся внешний облик множества популярных ресурсов. Воочию видя, как развивалась визуальная составляющая сети, мы можем отчётливо понять, какой скачок сделали интернет технологии за эти годы, и в какое великое время расцвета технического прогресса нам выпала удача жить.
Вконтакте
Иногда может быть полезно узнать, какой была ранее страница в интернете или узнать содержимое удаленной страницы.
Не слишком выдающийся случай: покупатель приобрел через интернет магазин смартфон, после получения возмутился, что получил уже бывшее в употреблении устройство.
«Полюбовно» договорится не получилось. Директор интернет магазина, утверждает, что покупатель был предупрежден, показывая, что на странице товара стоит приставка ref .
Покупатель «по обыкновению», не помнит такого предупреждения на странице.
Ref — Refurbishment .
В частности, рефербишмент в сфере информационных технологий — в отношении персонального компьютера или другого сложного устройства подразумевает: скупка (или сервис) некондиционных устройств — неработающих или не удовлетворяющих современным техническим требованиям с последующим восстановлением после поломки (замена или ремонт части деталей) или модернизацией (апгрейд).
Википедия.
Директор показывает страницу описания товара, где явно указано ref :
Скриншот страницы товара от 25.05.2016
Вроде на этом можно можно поставить точку, осуждая незадачливого покупателя оправдавшего пословицу «кроилово ведет к попадалову», нашедшего «дешевле чем в других магазинах».
Но мы живем во время контроля «всего», не только уполномоченными органами, но и под присмотром корпораций.
И использовав кеш Google, мы с вами можем посмотреть как выглядела страница товара ранее.
А три месяца назад страница выглядела вот так:
Скриншот страницы товара по состоянию на 01. 04.2016
04.2016
Т.е. действительно, покупатель приобретал новое, не восстановленное устройство (совпадает все, от адреса страницы, до кода товара в базе продавца).
В итоге для покупателя все закончилось хорошо.
Вот так, вроде не очень полезные знания могут помочь.
Если вы хотите самостоятельно увидеть снимок страницы или сайта, из кеша Google, используйте вот этот адрес, где после двоеточия вставьте интересующий вас адрес сайта или определенной страницы:
webcache.googleusercontent.com/search?q=cache:нужный_сайт
Помните: снимки страниц в кеше Google тоже хранятся не бесконечно.
Внимание: возможно Google отключил прямой поиск снимков сайта.
В это случае попробуйте поискать в сервисе Web Archive.
В этом случае создавайте запрос вида: http://web.archive.org/web/*/нужный_сайт
Например, снимки нашего сайта доступны по ссылке: http://web.archive.org/web/*/сайт
Так же, можете обратить внимание, в результатах выдачи поиска Google, справа от адреса сайта присутствует небольшой треугольник, по нажатию на него, будет предложено открыть сохраненную копию страницы.
Кстати: в Казахстане, был несколько похожий случай, с гос.структурой опубликовавшей документ о контроле интернета, вызвавший обсуждение, после чего документ был удален сайта, но «Google помнит все».
Пользовательские страницы ВКонтакте, включая и ваш персональный профиль, часто меняются под влиянием тех или иных факторов. В связи с этим становится актуальной тема просмотра раннего внешнего вида страницы, и для этого необходимо использовать сторонние средства.
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных.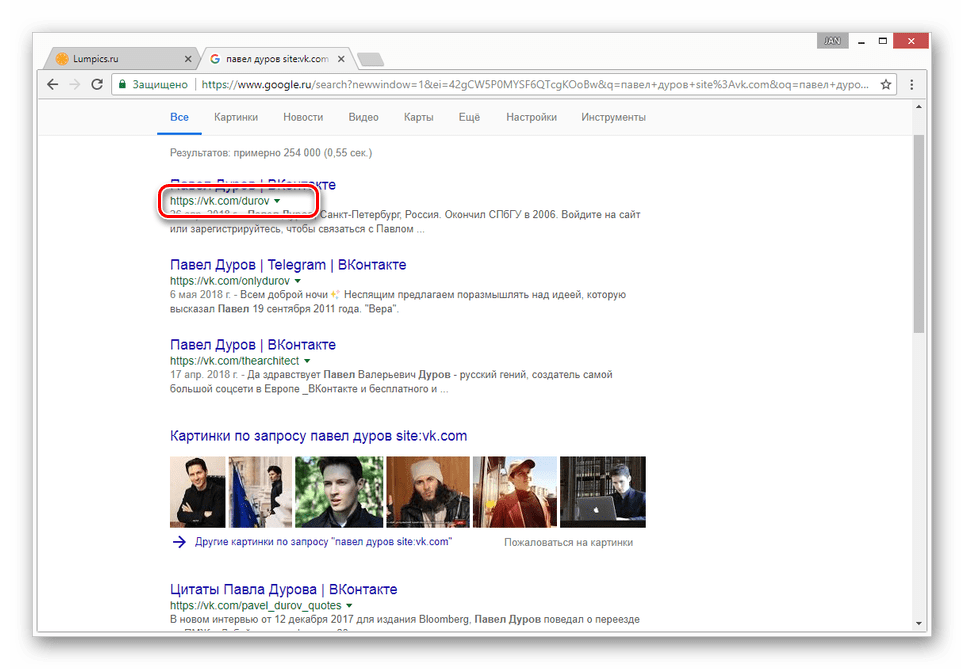 При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
Примечание: Нами будет затронут только поиск Google, но аналогичные веб-сервисы требуют тех же действий.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
- Среди представленных результатов отыщите нужный и кликните по иконке с изображением стрелочки, расположенной под основной ссылкой.
- Из раскрывшегося списка выберите пункт «Сохраненная копия» .
- После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
Допускается просмотр только той информации, что загружается вместе со страницей.
 То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
- После открытия ресурса по представленной выше ссылке в основное текстовое поле вставьте полный URL-адрес страницы, копию которой вам необходимо посмотреть.
- В случае успешного поиска вам будет представлена временная шкала со всеми сохраненными копиями в хронологическом порядке.
Примечание: Чем меньшей популярностью пользуется владелец профиля, тем ниже будет количество найденных копий.
- Переключитесь к нужной временной зоне, кликнув по соответствующему году.
- С помощью календаря найдите интересующую вас дату и наведите на нее курсор мыши. При этом кликабельными являются только подсвеченные определенным цветом числа.
- Из списка «Snapshot» выберите нужное время, кликнув по ссылке с ним.
- Теперь вам будет представлена страница пользователя, но лишь на английском языке.
Вы можете просматривать только ту информацию, которая не была скрыта настройками приватности на момент ее архивирования. Любые кнопки и прочие возможности сайта будут недоступны.
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Способ 3: Web Archive
Данный сайт является менее популярным аналогом предыдущего ресурса, но со своей задачей справляется более чем хорошо. Кроме того, вы всегда можете воспользоваться этим веб-архивом, если ранее рассмотренный сайт по каким-либо причинам оказался временно недоступен.
- Открыв главную страницу сайта, заполните основную поисковую строку ссылкой на профиль и нажмите кнопку «Найти» .
- После этого под формой поиска появится поле «Результаты» , где будут представлены все найденные копии страницы.
- В списке «Другие даты» выберите колонку с нужным годом и кликните по наименованию месяца.
- С помощью календаря кликните по одному из найденных чисел.
- По завершении загрузки вам будет представлена анкета пользователя, соответствующая выбранной дате.
- Как и в прошлом методе, все возможности сайта, кроме непосредственного просмотра информации, будут блокированы.
 Однако на сей раз содержимое полностью переведено на русский язык.
Однако на сей раз содержимое полностью переведено на русский язык.Примечание: В сети присутствует много похожих сервисов, адаптированных под разные языки.
Вы также можете прибегнуть к еще одной статье на нашем сайте, рассказывающей о возможности . Мы же завершаем данный способ и статью, так как изложенного материала более чем достаточно для просмотра ранней версии страницы ВКонтакте.
Как посмотреть как выглядел сайт раньше?
Задумывались ли вы когда-нибудь о том, что интересующий вас сайт, например сайт многомиллионной корпорации, интернет-магазина, чей-то блог ранее мог выглядеть абсолютно по-другому? С течением времени меняется дизайн, может поменяться доменное имя, и наполнение сайта также, может стать другим. Да, у каждого сайта есть своя уникальная история. Возможность узнать больше может быть полезна для того, чтобы узнать первоначальную тему сайта, а также о том, каким он был в разное время. При помощи так называемого веб-архива можно посмотреть историю конкретного сайта, узнать, как он использовался. Кроме того в веб-архиве можно найти множество полезных файлов: фотографии, картинки, музыкальные композиции.
При помощи так называемого веб-архива можно посмотреть историю конкретного сайта, узнать, как он использовался. Кроме того в веб-архиве можно найти множество полезных файлов: фотографии, картинки, музыкальные композиции.
Для того чтобы узнать о том, как сайт выглядел раньше стоит обратиться к сервису, который заслуживает отдельных аплодисментов. Он индексирует сайты в разное время и сохраняет их. Название сервиса — web archive. Его создал американский программист Брюстер Кейл в 1996 году.
До 1999 года это была вариация текстового архива, но начиная с 1999 года сервис функционирует как полноценное программное обеспечение и помимо всего прочего сохраняет фото, видео и аудиоматериалы. Основной целью его создателя стала идея о создании так называемой «библиотеки» в едином интернет-пространстве.
Современные веб-архивы хранят в себе действительно большое количество данных. Важно уметь верно отсортировывать информацию и среди кучи «мусора» находить то, что действительно важно именно для вас. Для большинства пользователей очень важно: получить доступ к когда-то потерянным данным, изучить контент для будущего сайта, провести грамотную аналитику, собрать статистику. Веб-архив является публичным и каждый желающий может получить доступ к нему без каких-либо проблем.
Для большинства пользователей очень важно: получить доступ к когда-то потерянным данным, изучить контент для будущего сайта, провести грамотную аналитику, собрать статистику. Веб-архив является публичным и каждый желающий может получить доступ к нему без каких-либо проблем.
Для того чтобы увидеть принцип работы этого сервиса в действии — переходим сюда. Далее указываем адрес интересующего нас сайта: например: yandex.ru
Теперь мы сможем увидеть, что история для этой поисковой системы сохраняется с 1997 года. Достаточно просто выбрать интересующую вас дату, и вы увидите, как выглядел сайт Яндекса в то время.
А вот так портал Яндекс выглядел уже в 2005 году:
Аналогичным образом можно проверить подавляющее большинство сайтов, причём как зарубежных, так и отечественных.
Многие, только планируя создать собственный сайт находятся в поисках уникального, авторского контента. В связи с этим стоит отметить, что материал, который хранится на заброшенных интернет-ресурсах не несет в себе какой-либо ценности для бывших владельцев.
Множество фотографий, текстовых материалов и прочих файлов можно получить абсолютно бесплатно. Люди, знающие об этом, с удовольствием пользуются подобной возможностью. Достаточно просто открыть перечень блогов на reg.ru, скопировать перечень свободных на данный момент доменов, далее снова перейти на сервис web archive с целью поиска сохранённых копий, во избежание неприятных ситуаций, проверьте понравившиеся тексты с помощью специализированных сервисов антиплагиата (дело в том, что тот или иной материал может быть уже размещён на других интернет-ресурсах). Убедившись, в том, что материал свободен и уникален его можно будет разместить в собственном блоге.
Кроме того, существует еще одна небольшая хитрость. При желании, можно сделать так, чтобы сайт никогда не попал в web archive. Для этого при создании и обслуживании сайта необходимо использовать следующую команду:
User-agent: ia_archiver Disallow: / User-agent: ia_archiver-web.archive.org Disallow: /
После внесения подобных корректировок сервис web archive перестанет создавать копии для своего реестра, но это будет работать лишь в том случае, если регистрация домена будет продлена. В противном случае после окончания срока регистрации домена все подобные корректировки будут аннулированы.
В противном случае после окончания срока регистрации домена все подобные корректировки будут аннулированы.
Таким образом, с помощью сервиса web archive можно узнать историю практически любого сайта, особенно если этот сайт действительно популярен. С каждым годом сервис становится все более обширным и функциональным. На сегодняшний день в базе этого сервиса представлено около полумиллиона самых разнообразных сайтов.
Сервис web archive можно использовать совершенно бесплатно и на самом деле он может оказаться полезным в совершенно разных случаях.
Как выглядела страница раньше или увидеть удаленную страницу » MHelp.kz
Иногда может быть полезно узнать, какой была ранее страница в интернете или узнать содержимое удаленной страницы.
Не слишком выдающийся случай: покупатель приобрел через интернет магазин смартфон, после получения возмутился, что получил уже бывшее в употреблении устройство.
«Полюбовно» договорится не получилось. Директор интернет магазина, утверждает, что покупатель был предупрежден, показывая, что на странице товара стоит приставка ref.
Покупатель «по обыкновению», не помнит такого предупреждения на странице.
Ref — Refurbishment. В частности, рефербишмент в сфере информационных технологий — в отношении персонального компьютера или другого сложного устройства подразумевает: скупка (или сервис) некондиционных устройств — неработающих или не удовлетворяющих современным техническим требованиям с последующим восстановлением после поломки (замена или ремонт части деталей) или модернизацией (апгрейд).
Википедия.
Директор показывает страницу описания товара, где явно указано ref:
Скриншот страницы товара от 25.05.2016Вроде на этом можно можно поставить точку, осуждая незадачливого покупателя оправдавшего пословицу «кроилово ведет к попадалову», нашедшего «дешевле чем в других магазинах».
Но мы живем во время контроля «всего», не только уполномоченными органами, но и под присмотром корпораций.
Этом случае «Большим братом» выступает корпорация Google, которая в недрах своих хранит то, что «когда-то было в интернете».
Google сохраняет резервные копии веб-страниц на случай, если они станут недоступны. Эти копии хранятся в кеше на серверах Google.
Перейдя по ссылке на копию, сохраненную в кеше, можно узнать, как выглядела веб-страница, когда робот Google в последний раз сканировал ее.
Справка Google.
И использовав кеш Google, мы с вами можем посмотреть как выглядела страница товара ранее.
А три месяца назад страница выглядела вот так:
Скриншот страницы товара по состоянию на 01.04.2016Т.е. действительно, покупатель приобретал новое, не восстановленное устройство (совпадает все, от адреса страницы, до кода товара в базе продавца).
Приставку ref продавец добавил позже, когда началось «суд, да дело», но с честными глазами продолжал настаивать на вине покупателя.
В итоге для покупателя все закончилось хорошо.
Ситуация взята здесь.
Вот так, вроде не очень полезные знания могут помочь.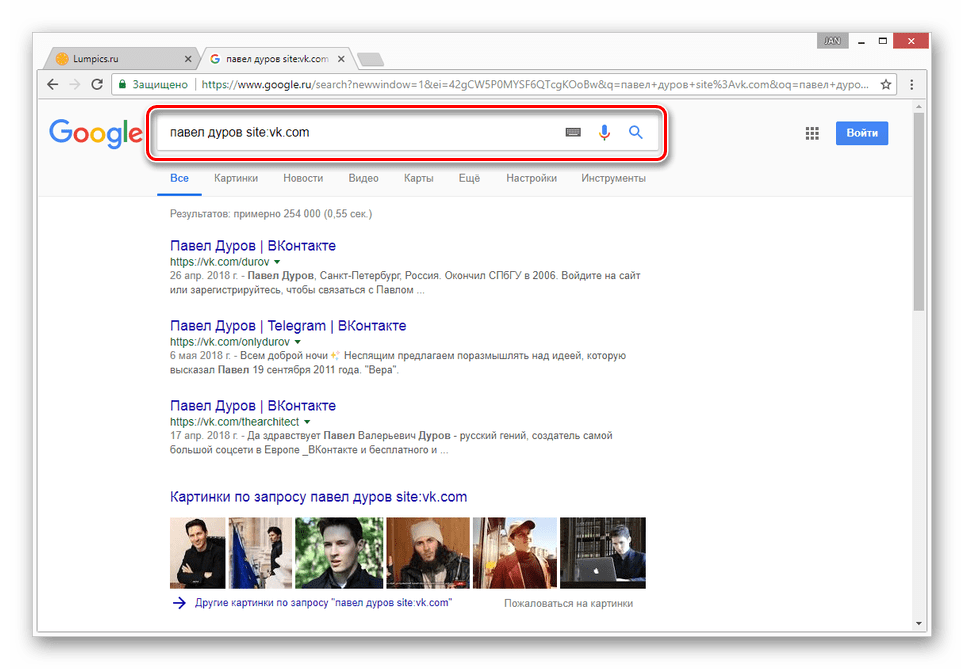
Если вы хотите самостоятельно увидеть снимок страницы или сайта, из кеша Google, используйте вот этот адрес, где после двоеточия вставьте интересующий вас адрес сайта или определенной страницы:
webcache.googleusercontent.com/search?q=cache:нужный_сайт
Помните: снимки страниц в кеше Google тоже хранятся не бесконечно.
Внимание: возможно Google отключил прямой поиск снимков сайта.
В это случае попробуйте поискать в сервисе Web Archive.
В этом случае создавайте запрос вида: http://web.archive.org/web/*/нужный_сайт
Например, снимки нашего сайта доступны по ссылке: http://web.archive.org/web/*/mhelp.kz
Так же, можете обратить внимание, в результатах выдачи поиска Google, справа от адреса сайта присутствует небольшой треугольник, по нажатию на него, будет предложено открыть сохраненную копию страницы.
Кстати: в Казахстане, был несколько похожий случай, с гос.структурой опубликовавшей документ о контроле интернета, вызвавший обсуждение, после чего документ был удален сайта, но «Google помнит все».
Удачных покупок в интернете!
[nx_heading style=»coloredline» heading_tag=»h5″ size=»24″ align=»left»]От автора:[/nx_heading]
Если проблема решена, один из способов сказать «Спасибо» автору — здесь.
Если же проблему разрешить не удалось или появились дополнительные вопросы, задать их можно на нашем форуме, в специальном разделе.
[nx_box title=»Поделиться этой статьей» style=»glass» box_color=»#ED303C»]Если данная статья вам помогла и вы хотели бы в ответ помочь проекту Mhelp.kz, поделитесь этой статьей с другими:
[/nx_box]
Как узнать какая страница была раньше. Как выглядит страница вконтакте
Иногда может быть полезно узнать, какой была ранее страница в интернете или узнать содержимое удаленной страницы.
Не слишком выдающийся случай: покупатель приобрел через интернет магазин смартфон, после получения возмутился, что получил уже бывшее в употреблении устройство.
«Полюбовно» договорится не получилось. Директор интернет магазина, утверждает, что покупатель был предупрежден, показывая, что на странице товара стоит приставка ref .
Директор интернет магазина, утверждает, что покупатель был предупрежден, показывая, что на странице товара стоит приставка ref .
Покупатель «по обыкновению», не помнит такого предупреждения на странице.
Ref — Refurbishment . В частности, рефербишмент в сфере информационных технологий — в отношении персонального компьютера или другого сложного устройства подразумевает: скупка (или сервис) некондиционных устройств — неработающих или не удовлетворяющих современным техническим требованиям с последующим восстановлением после поломки (замена или ремонт части деталей) или модернизацией (апгрейд).
Директор показывает страницу описания товара, где явно указано ref :
Скриншот страницы товара от 25.05.2016
Вроде на этом можно можно поставить точку, осуждая незадачливого покупателя оправдавшего пословицу «кроилово ведет к попадалову», нашедшего «дешевле чем в других магазинах».
Но мы живем во время контроля «всего», не только уполномоченными органами, но и под присмотром корпораций.
И использовав кеш Google, мы с вами можем посмотреть как выглядела страница товара ранее.
А три месяца назад страница выглядела вот так:
Скриншот страницы товара по состоянию на 01.04.2016
Т.е. действительно, покупатель приобретал новое, не восстановленное устройство (совпадает все, от адреса страницы, до кода товара в базе продавца).
В итоге для покупателя все закончилось хорошо.
Вот так, вроде не очень полезные знания могут помочь.
Если вы хотите самостоятельно увидеть снимок страницы или сайта, из кеша Google, используйте вот этот адрес, где после двоеточия вставьте интересующий вас адрес сайта или определенной страницы:
webcache.googleusercontent.com/search?q=cache:нужный_сайт
Например: http://webcache.googleusercontent.com/search?q=cache:сайт
Помните: снимки страниц в кеше Google тоже хранятся не бесконечно.
Так же, можете обратить внимание, в результатах выдачи поиска Google, справа от адреса сайта присутствует небольшой треугольник, по нажатию на него, будет предложено открыть сохраненную копию страницы.
Кстати: в Казахстане, был несколько похожий случай, с гос.структурой опубликовавшей документ о контроле интернета, вызвавший обсуждение, после чего документ был удален сайта, но «Google помнит все».
Если проблема решена, один из способов сказать «Спасибо» автору — .
Если же проблему разрешить не удалось или появились дополнительные вопросы, задать их можно на нашем , в специальном разделе.
Говорят, прогресс не остановить. Проходят месяцы и годы, технологии становятся всё лучше и совершеннее, уже никого не удивишь с мобильным телефоном со спутниковой навигацией. А сеть Интернет позволяет нам общаться в реальном времени находясь на противоположных концах планеты. Время летит так быстро, что подчас мы не замечаем существенных изменений во многих вещах, с которыми имеем дело. Касается это и сети Интернет, в которой развитие сетевых протоколов, стандартов и технологий просто преобразило внешний вид и функционал имеющихся сайтов. В этом материале я предлагаю вам поднять покров времени и заглянуть в прошлое, посмотреть, как выглядел сайт раньше, каков был внешний вид и функционал ресурсов тех лет, и, возможно, это поможет понять, как далеко мы шагнули вперёд в развитии цифровых технологий наших дней.
Итак, как же выглядел сайт в прошлом, и какие инструменты могут нам помочь заглянуть в веб-историю 5-10 летней давности? Более 20 лет назад, в 1996 году энтузиаст Кейл Брюстер основал цифровой архив под названием «Архив Интернета» («The Internet Archive»), слоганом которого был провозглашён «Всеобщий доступ к знаниям». С того времени указанный архив собирает и хранит копии веб-страниц, графики, аудио и видео, различных программ, обеспечивая свободный доступ к накопленной информации для всех желающих.
На состояние октября 2016 года архив уже имел 15 петабайт информации, а веб-архив проекта содержал уже более 150 миллиардов веб-страниц различных сайтов.
Именно благодаря данному архиву сегодня мы имеем возможность посмотреть, как выглядели многие ресурсы 10-15-20 лет тому назад. Историю действий на вашем компьютере можно узнать в написанной мной ранее.
Смотрим каким был сайт ранее
Итак, как же посмотреть сохранённые копии сайтов? Воспользуемся возможностями данного проекта и попробуем приоткрыть покровы времени.
Перейдите на данный сервис (он носит название Wayback Machine), введите в поисковой строке адрес интересующего вас сайта (например, www.youtube.com) и нажмите на кнопку «Browse history» (просмотреть историю) справа.
Система обработает запрос и выдаст вам результат. Сверху будет располагаться разбивка по годам, и вы увидите, в каком году впервые была отслежена активность данного сайта и сделан его снимок.
Кликните, к примеру, на самый ранний год (в случае Ютуб это 2005 год), внизу отобразится полный календарь данного года по месяцам. Дни, когда были сделаны «снимки» сайта будут подсвечены голубоватым цветом, в нашем случае первый «снимок» был сделан 28 апреля данного года.
Соответствующим образом вы можете просмотреть любой из интересующих вас сайтов.
Также можно работать с данным сервисом напрямую, введя в адресной строке вашего браузера:
http://web.archive.org/web/*/http://url нужного сайта
Например:
http://web. archive.org/web/*/http://google.com
archive.org/web/*/http://google.com
Соответственно, введя данную строку в адресной строке браузера и нажав на ввод, вы сразу попадёте в отображение снимков нужного вам сайта по годам, месяцам и днём.
Смотрим как выглядели сайты ранее
С помощью ресурса archive.org каждый желающий может получить доступ к миллиардам страниц сохранённого веб-контента, буквально по дням, месяцам и годам наблюдая, как менялся внешний облик множества популярных ресурсов. Воочию видя, как развивалась визуальная составляющая сети, мы можем отчётливо понять, какой скачок сделали интернет технологии за эти годы, и в какое великое время расцвета технического прогресса нам выпала удача жить.
Вконтакте
2 голосаДоброго дня, уважаемые посетители моего блога. Сегодня я не буду рассказывать о создании сайтов, заработке и других полезных штуках. Я решил немного поразвлечься. Конечно же, это мы будем делать с пользой.
Мы отправимся в прошлое интернета и посмотрим на то, как выглядел дизайн много лет назад. Я научу вас делать это в любое удобное для вас время. С этого момента машина времени будет для вас доступна по первому требованию.
Я научу вас делать это в любое удобное для вас время. С этого момента машина времени будет для вас доступна по первому требованию.
Итак, как посмотреть сайт в прошлом? Сегодня я покажу, а заодно поведаю вам о некоторых интересных фактах из жизни популярных сайтов. Ну что ж, не будем тянуть.
Как смотреть в прошлое
В сожалению, вы не сможете увидеть как выглядел конкретно ваш сайт, но множество популярных ресурсов находится в базе archive.org/web/web.php . По словам самого сервиса, у них сохранилось 500 биллионов страниц.
Просто зайдите на этот портал, введите в поисковую строчку адрес сайта, который хотите увидеть, например Яндекс, и выбирайте Browse History.
Синим цветом на календаре отмечены дни, в которые добавлены скриншоты. Полоса сверху показывает годы. Черные полоски – количество изображений. Чем они выше, тем больше вы можете увидеть. Как вы видите, ближе к нашему времени скриншоты стали добавлять чаще.
Выбираете год, затем дату. Наводите на нее стрелкой, а затем кликаете на время добавления. В данном случае 03:42 или 03:44. Рекомендую последнее действие (с временем) производить через правую кнопку мыши, а в открывшемся меню выбирать «Открыть в новой вкладке». На мой взгляд так удобнее.
И вот перед вами скриншот того, как выглядел Яндекс 12 декабря 1998 года. Эта информация высвечивается в верхнем баре, который можно закрыть при желании. Или, через него же выбирать другую дату. Путешествие во времени осуществляется очень просто. Даже несмотря на то, что «машина» на английском.
Это Яндекс постарше, образец 2000 года.
Так он выглядел в 2005, 11 лет назад.
Ну а так эта поисковая система отображалась в прошлом году. Изменения есть!
Ну вот в принципе и все, но не спешите покидать мой блог. Мне бы хотелось показать вам еще несколько популярных проектов и рассказать интересные факты об этих сайтах.
Изначально, популярнейший поисковик Гугл назывался BackRub. И выглядел как-то стрёмно и совершенно непонятно.
Лишь в 1998 он принял более современный внешний вид. Тогда еще, в конце слова Google стоял восклицательный знак. Представляете, это бета версия, то есть тестовая. Тогда еще разработчики исправляли ошибки и проверяли как все работает. Эх, где мои 16 лет.
Уже тогда здесь было две кнопки. Одна со стандартным поиском, а вторая выбирает случайную страницу с информацией. Если бы администраторы убрали кнопку «Мне повезет», которая пользуется бешенной популярностью и по сей день, то смогли бы получать дополнительный доход с рекламы. Он составил бы примерно 100 миллионов долларов в год. Но, они не жадные.
Кстати о деньгах, компания Mozilla ежегодно получает от гугла 300 миллионов за то, что в их браузере по умолчанию стоит поисковая система от Google.
YouTube
Компания YouTube открылась 14 февраля, в день всех влюбленных. В России же его начали использовать лишь в 2007 году, а первым выложенным роликом стала песня Петра Налича «Гитар». С той поры прошло 10 лет.
Если бы ютуб был не видеохостингом, а кинокомпанией, то каждую неделю они смогли бы выпускать по 60 тысяч фильмов. Материала для этого предостаточно.
Кстати, сейчас у ютуба столько же посетителей, сколько было пользователей в интернете в целом в 2000 году. Ежедневно ролики набирают около 2 миллиарда .
YouTube не только стал одной из самых популярных компаний, но еще и делает знаменитыми простых людей. Многим россиянам известны такие люди как Макс Голопогосов (+100500), Рома Желудь, BadComedian, mrFreeman. А вот певица Адель и Джастин Бибер получили всемирную славу благодаря этой социальной сети. Я уже молчу о том, сколько людей благодаря ним .
Вконтакте
Чего только не скрывалось под популярным ныне доменом vk.com. Кстати, использовать его стали не сразу, изначально в контакт можно было зайти только по URL: vkontakte.ru, но потом ситуация изменилась и администрация решила облегчить нашу с вами жизнь.
Изначально проект был создан как закрытый справочник студентов и выпускников. Об этом свидетельствует надпись на главной странице того периода.
Мог ли тогда представить Павел Дуров, насколько популярным станет его проект? Сейчас даже смешно смотреть на горделивую надпись: «Нас уже 350 000». Сейчас численность проекта насчитывает миллионы.
Интересных историй о этой социальной сети предостаточно, но на мой взгляд самая впечатляющая заключается в том, что вплоть до 2014 года через Одноклассники нельзя было послать ссылку на информацию, находящуюся Вконтакте. Система не блокировала их, а просто заменяла буквы в словах.
Еще один интересный факт, о котором многие пользователи помнят. В какой-то момент администрация сайта решила поменять дизайн личных страниц. Это вызвало бурю эмоций среди пользователей.
И тут и там кипели возгласы: «Верните стену, нет микроблогу». Павел Дуров был не преклонен. В моей памяти эти воспоминания все еще свежи, а тем не менее с той поры прошло 6 лет. Военные действия разворачивались в 2010 году. Согласитесь, сейчас смотришь на этот кошмар и думаешь, что там могло нравиться, за что воевали?
Интересный момент, но благодаря социальным сетям люди не только общаются между собой и , но и достигают других интересных целей. Хоть в свое время дизайн стены не вернули, зато деятельность пользователей на Facebook и Вконтакте вернула в мультсериал «Гриффины» умершего пса Брайна.
Мне очень понравилось, как они потом подшутили над этим фактом. После «воскрешения» в одной из серий они не показали ни единого кадра с псом, а в конце написали какую-то забавную фразу из серии: «Кто-нибудь вообще заметил, что в этой серии не было Брайана? Нам ждать возмущений по этому поводу в социальных сетях?».
Если вы переживаете, что ничего не умеете и не знаете, просто посмотрите как изначально выглядел любой сайт, тот же Яндекс. Время решает многое. Мы растем, двигаемся вперед и учимся на своих ошибках.
Поделись статьей:
Похожие статьи
Как выглядел старый вк. Вид раньше и сейчас
Говорят, прогресс не остановить. Проходят месяцы и годы, технологии становятся всё лучше и совершеннее, уже никого не удивишь с мобильным телефоном со спутниковой навигацией. А сеть Интернет позволяет нам общаться в реальном времени находясь на противоположных концах планеты. Время летит так быстро, что подчас мы не замечаем существенных изменений во многих вещах, с которыми имеем дело. Касается это и сети Интернет, в которой развитие сетевых протоколов, стандартов и технологий просто преобразило внешний вид и функционал имеющихся сайтов. В этом материале я предлагаю вам поднять покров времени и заглянуть в прошлое, посмотреть, как выглядел сайт раньше, каков был внешний вид и функционал ресурсов тех лет, и, возможно, это поможет понять, как далеко мы шагнули вперёд в развитии цифровых технологий наших дней.
Итак, как же выглядел сайт в прошлом, и какие инструменты могут нам помочь заглянуть в веб-историю 5-10 летней давности? Более 20 лет назад, в 1996 году энтузиаст Кейл Брюстер основал цифровой архив под названием «Архив Интернета» («The Internet Archive»), слоганом которого был провозглашён «Всеобщий доступ к знаниям». С того времени указанный архив собирает и хранит копии веб-страниц, графики, аудио и видео, различных программ, обеспечивая свободный доступ к накопленной информации для всех желающих.
На состояние октября 2016 года архив уже имел 15 петабайт информации, а веб-архив проекта содержал уже более 150 миллиардов веб-страниц различных сайтов.
Именно благодаря данному архиву сегодня мы имеем возможность посмотреть, как выглядели многие ресурсы 10-15-20 лет тому назад. Историю действий на вашем компьютере можно узнать в написанной мной ранее.
Смотрим каким был сайт ранее
Итак, как же посмотреть сохранённые копии сайтов? Воспользуемся возможностями данного проекта и попробуем приоткрыть покровы времени.
Перейдите на данный сервис (он носит название Wayback Machine), введите в поисковой строке адрес интересующего вас сайта (например, www.youtube.com) и нажмите на кнопку «Browse history» (просмотреть историю) справа.
Система обработает запрос и выдаст вам результат. Сверху будет располагаться разбивка по годам, и вы увидите, в каком году впервые была отслежена активность данного сайта и сделан его снимок.
Кликните, к примеру, на самый ранний год (в случае Ютуб это 2005 год), внизу отобразится полный календарь данного года по месяцам. Дни, когда были сделаны «снимки» сайта будут подсвечены голубоватым цветом, в нашем случае первый «снимок» был сделан 28 апреля данного года.
Соответствующим образом вы можете просмотреть любой из интересующих вас сайтов.
Также можно работать с данным сервисом напрямую, введя в адресной строке вашего браузера:
http://web.archive.org/web/*/http://url нужного сайта
Например:
http://web.archive.org/web/*/http://google.com
Соответственно, введя данную строку в адресной строке браузера и нажав на ввод, вы сразу попадёте в отображение снимков нужного вам сайта по годам, месяцам и днём.
Смотрим как выглядели сайты ранее
С помощью ресурса archive.org каждый желающий может получить доступ к миллиардам страниц сохранённого веб-контента, буквально по дням, месяцам и годам наблюдая, как менялся внешний облик множества популярных ресурсов. Воочию видя, как развивалась визуальная составляющая сети, мы можем отчётливо понять, какой скачок сделали интернет технологии за эти годы, и в какое великое время расцвета технического прогресса нам выпала удача жить.
Вконтакте
Пользовательские страницы ВКонтакте, включая и ваш персональный профиль, часто меняются под влиянием тех или иных факторов. В связи с этим становится актуальной тема просмотра раннего внешнего вида страницы, и для этого необходимо использовать сторонние средства.
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных. При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
Примечание: Нами будет затронут только поиск Google, но аналогичные веб-сервисы требуют тех же действий.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
- Среди представленных результатов отыщите нужный и кликните по иконке с изображением стрелочки, расположенной под основной ссылкой.
- Из раскрывшегося списка выберите пункт «Сохраненная копия» .
- После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
Допускается просмотр только той информации, что загружается вместе со страницей. То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
- После открытия ресурса по представленной выше ссылке в основное текстовое поле вставьте полный URL-адрес страницы, копию которой вам необходимо посмотреть.
- В случае успешного поиска вам будет представлена временная шкала со всеми сохраненными копиями в хронологическом порядке.
Примечание: Чем меньшей популярностью пользуется владелец профиля, тем ниже будет количество найденных копий.
- Переключитесь к нужной временной зоне, кликнув по соответствующему году.
- С помощью календаря найдите интересующую вас дату и наведите на нее курсор мыши. При этом кликабельными являются только подсвеченные определенным цветом числа.
- Из списка «Snapshot» выберите нужное время, кликнув по ссылке с ним.
- Теперь вам будет представлена страница пользователя, но лишь на английском языке.
Вы можете просматривать только ту информацию, которая не была скрыта настройками приватности на момент ее архивирования. Любые кнопки и прочие возможности сайта будут недоступны.
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Способ 3: Web Archive
Данный сайт является менее популярным аналогом предыдущего ресурса, но со своей задачей справляется более чем хорошо. Кроме того, вы всегда можете воспользоваться этим веб-архивом, если ранее рассмотренный сайт по каким-либо причинам оказался временно недоступен.
- Открыв главную страницу сайта, заполните основную поисковую строку ссылкой на профиль и нажмите кнопку «Найти» .
- После этого под формой поиска появится поле «Результаты» , где будут представлены все найденные копии страницы.
- В списке «Другие даты» выберите колонку с нужным годом и кликните по наименованию месяца.
- С помощью календаря кликните по одному из найденных чисел.
- По завершении загрузки вам будет представлена анкета пользователя, соответствующая выбранной дате.
- Как и в прошлом методе, все возможности сайта, кроме непосредственного просмотра информации, будут блокированы. Однако на сей раз содержимое полностью переведено на русский язык.
Примечание: В сети присутствует много похожих сервисов, адаптированных под разные языки.
Вы также можете прибегнуть к еще одной статье на нашем сайте, рассказывающей о возможности просмотра удаленных страниц . Мы же завершаем данный способ и статью, так как изложенного материала более чем достаточно для просмотра ранней версии страницы ВКонтакте.
С тех пор, как родился Интернет (более 25 лет назад), веб-сайты претерпели тысячи изменений, и их развитие ушло далеко вперёд благодаря стремительно прогрессирующим технологиям. Уже сложно вспомнить, как выглядели сайты в прошлом, а ведь ранние версии многих известных ресурсов были совершенно другими. Давайте взглянем на них.
Вид раньше и сейчас
1. Google.com : старт в 1996 году
Поисковая система Google, созданная в 1996 году в качестве учебного проекта студентами Стэнфордского университета Ларри Пейджем и Сергеем Брином, сегодня является крупнейшей компанией в мире. На первом скриншоте изображен один из самых ранних вариантов внешнего вида Google, а на втором — современный дизайн:
2. Facebook.com : старт в 2004
Спустя 8 лет после Google был изобретён Facebook — Марком Цукербергом в Гарвардском университете. Известный как TheFacebook, изначально проект был доступен только однокурсникам Гарварда. Сегодня же посещаемость данной социальной сети составляет 1,71 млрд активных пользователей в месяц.
3. MySpace.com : старт в 2003
Прежде чем появился Facebook, популярной социальной сетью была площадка MySpace. Она является одной из первых соцсетей, но с лидирующего места её уже вытеснили такие сайты как Twitter и Facebook. В 2005 году Руперт Мердок выкупил MySpace за $580 млн у основателей Криса Девульфа и Тома Андерсона. После того, как MySpace стал стремительно терять аудиторию, Мердок, по слухам, продал его за $35 млн, назвав покупку «огромной ошибкой».
4. Yahoo.com : старт в 1994
В начале 1994 года аспиранты Стэнфордского университета Дэвид Фило и Джерри Янг создали портал под названием «Путеводитель Джерри по Всемирной Паутине», представляющий собой каталог других веб-сайтов. Позже, в этом же году сайт был переименован в Yahoo!.
Версий происхождения данного имени существует несколько. Одни утверждают, что Yahoo! является акронимом фразы «Yet Another Hierarchical Officious Oracle». Другие же считают, что название было позаимствовано из книги «Путешествия Гулливера» Д. Свифта, где словом «yahoo» называются грубые человекообразные существа. Кстати, именно вторую версию основатели компании называют правильной.
5. YouTube.com : старт в 2005
6. Wikipedia.org : старт в 2001
Объёмная онлайн-энциклопедия Wikipedia навсегда изменила подход к получению информации для целых поколений. И хотя с момента запуска в 2001 Википедия мало изменилась в плане внешнего вида, за это время она сильно разрослась: на сайте насчитывается уже более 30 млн статей.
7. MSN.com : старт в 1995
MSN (Microsoft Network) был запущен в 1995 году. В начале 2000-х компания MSN являлась вторым по популярности интернет-провайдером (после AOL LLC). Сам сайт msn.com представляет собой новостной портал с видео, акциями и опросами.
8. Apple.com : старт в 1997
Нынешний вид сайта Apple кардинально отличается от его ранней версии с заманчивым предложением получить бесплатный CD-ROM. Однако уже тогда компания демонстрировала свою любовь к белому цвету. А Apple eMate 300, рекламирующийся в правой части страницы, одно время был популярным КПК (с 1997 по 1998 год).
9. Twitter.com : старт в 2006
Сайт Twitter был запущен в марте 2006 года и, по сравнению со своей старой версией, стал практически неузнаваем. В настоящее время Твиттер входит в десятку самых посещаемых ресурсов в мире и считается одним из самых успешных стартапов всех времён с точки зрения рыночной капитализации.
10. eBay.com (ранее известный как AuctionWeb): старт в 1995
Кто бы мог подумать, что этот серый, мало чем примечательный сайт превратится в крупнейший онлайн-аукцион в мире? Его основатель, программист Пьер Омидьяр, изначально хотел зарегистрировать доменное имя EchoBay.com , но, как оказалось, им уже владела одна золотодобывающая компания, поэтому название было решено сократить до eBay.com .
11. LinkedIn.com : старт в 2003
Сайт LinkedIn был создан в 2003 году предпринимателем Ридом Хоффманом и позиционировался как социальная сеть для поиска и установления деловых контактов. В одном только США насчитывается 93 млн пользователей данной сети. С самого начала сайт обладает достаточно сложной структурой.
12. Amazon.com : старт в 1995
Изначально на сайте Amazon продавались только книги. Придумывая название своему проекту, Джефф Безос просматривал словарь и остановился на слове «Amazon», поскольку Амазонка является экзотической, непохожей на другие и самой большой рекой в мире. Именно таким он хотел сделать и свой магазин.
Интересно и то, что ранее, в сентябре 1994, Безос приобрел домен Relentless.com и планировал назвать своё детище словом Relentless (рус. безжалостный, неустанный ), но друзья сказали ему, что такое имя звучит немного зловеще. Домен всё ещё принадлежит Безосу — с него идёт перенаправление на Amazon.com .
13. Instagram.com : старт в 2010
Такой популярный нынче сайт Instagram начинал своё существование под названием Burbn. Создатели проекта, Кевин Систром и Майк Кригер, в какой-то момент поняли, что их сервис стал сильно напоминать Foursquare, и приняли решение сделать его более специализированным, сделав упор на мобильную фотографию. Так появился Instagram. Название представляет собой объединение двух выражений — «instant camera » и «telegram ».
С тех пор проект признан одним из самых успешных в мире. В 2012 году Facebook купил Instagram за $1 млрд.
Все вышеперечисленные ресурсы на сегодняшний день уже имеют абсолютно другой дизайн, и узнать, как выглядели эти сайты раньше, можно лишь благодаря сохранившимся скриншотам. Но есть некоторые сайты, которые сохранились в первозданном виде! Если вам мало одного скриншота, и вы хотите устроить настоящий сёрфинг по сайтам в стиле 90-х, взгляните на список ниже.
Рабочие сайты в стиле 90-х
На момент публикации этой статьи все сайты рабочие.
14. Space Jam : старт в 1996
Забавный кусочек истории: подсайт Space Jam домена warnerbros.com , который никак не изменялся с момента своего запуска в 1996 году. Здесь можно переходить по ссылкам и ощутить перемещение во времени!
15. MillionDollarHomepage.com : старт в 2005
Этот сайт принёс своему создателю, 21-летнему студенту из Великобритании Алексу Тью, заработок в размере $1 037 100. Главная страница имеет размер 1000×1000 = 1 млн пикселей. Каждый пиксель продавался за $1, а минимальным размером покупки был блок 10×10 пикселей. В распоряжении покупателя была та площадь, которую он купил — он мог разместить на ней картинку и сделать из неё ссылку.
Целью автора сайта была продажа всех пикселей, следовательно, заработок должен был составить 1 миллион долларов. Но заработал Алекс Тью немного больше, поскольку последнюю тысячу пикселей он выставил на аукцион eBay, заработав на продаже $38 100. Вид сайта сохранён для истории и доступен для просмотра.
16. DPGraph.com : старт в 1997
Сайт программного обеспечения для математической и физической 3D-визуализации. Здесь поражает не только тематика, но и внешний вид страницы — анимированные gif-ки объемных графиков, раскрашенные во все цвета радуги, и дизайн в стиле 90-х — что может быть более психоделичным?…
17. Aliweb.com : запуск в 1993
ALIWEB (Archie Like Indexing for the WEB) — одна из первых поисковых систем в мире. Её запуск состоялся в ноябре 1993 года. К счастью, спустя 23 года у нас есть возможность полюбоваться таким раритетом в нетронутом виде.
18. Taco.com : старт в 1997
«Мы не продаем тако. Мы не готовим тако. По правде говоря, некоторые из нас даже не очень их любят », — сказано на одной из страниц сайта taco.com , принадлежащего компании, которая предлагает различную компьютерную помощь. Название TACO произошло от сокращения T echnical A dvisors Co mpany. Этот сайт 90-х годов до сих пор блистает благодаря чувству юмора сисадминов.
19. IFindIt.com : старт в 1995
I Find It — огромное руководство по поиску в Интернете. Год создания — 1995. На сайте размещен совет: «Пожалуйста, задайте разрешение экрана 800×600 для оптимального просмотра »…
Google, а где был ты в 1995? По-видимому, ещё играл с погремушками.
20. Instanet.com : старт в 1995
Если бы страницы HTML 2.0 (версия, одобренная как стандарт 22 сентября 1995 года) можно было продавать на аукционах, то сайт instanet.com сейчас стоил бы миллионы. Вы только взгляните на этот исходный код:
Иногда может быть полезно узнать, какой была ранее страница в интернете или узнать содержимое удаленной страницы.
Не слишком выдающийся случай: покупатель приобрел через интернет магазин смартфон, после получения возмутился, что получил уже бывшее в употреблении устройство.
«Полюбовно» договорится не получилось. Директор интернет магазина, утверждает, что покупатель был предупрежден, показывая, что на странице товара стоит приставка ref .
Покупатель «по обыкновению», не помнит такого предупреждения на странице.
Ref — Refurbishment . В частности, рефербишмент в сфере информационных технологий — в отношении персонального компьютера или другого сложного устройства подразумевает: скупка (или сервис) некондиционных устройств — неработающих или не удовлетворяющих современным техническим требованиям с последующим восстановлением после поломки (замена или ремонт части деталей) или модернизацией (апгрейд).
Википедия.
Директор показывает страницу описания товара, где явно указано ref :
Скриншот страницы товара от 25.05.2016
Вроде на этом можно можно поставить точку, осуждая незадачливого покупателя оправдавшего пословицу «кроилово ведет к попадалову», нашедшего «дешевле чем в других магазинах».
Но мы живем во время контроля «всего», не только уполномоченными органами, но и под присмотром корпораций.
И использовав кеш Google, мы с вами можем посмотреть как выглядела страница товара ранее.
А три месяца назад страница выглядела вот так:
Скриншот страницы товара по состоянию на 01.04.2016
Т.е. действительно, покупатель приобретал новое, не восстановленное устройство (совпадает все, от адреса страницы, до кода товара в базе продавца).
В итоге для покупателя все закончилось хорошо.
Вот так, вроде не очень полезные знания могут помочь.
Если вы хотите самостоятельно увидеть снимок страницы или сайта, из кеша Google, используйте вот этот адрес, где после двоеточия вставьте интересующий вас адрес сайта или определенной страницы:
webcache.googleusercontent.com/search?q=cache:нужный_сайт
Помните: снимки страниц в кеше Google тоже хранятся не бесконечно.
Внимание: возможно Google отключил прямой поиск снимков сайта.
В это случае попробуйте поискать в сервисе Web Archive.
В этом случае создавайте запрос вида: http://web.archive.org/web/*/нужный_сайт
Например, снимки нашего сайта доступны по ссылке: http://web.archive.org/web/*/сайт
Так же, можете обратить внимание, в результатах выдачи поиска Google, справа от адреса сайта присутствует небольшой треугольник, по нажатию на него, будет предложено открыть сохраненную копию страницы.
Кстати: в Казахстане, был несколько похожий случай, с гос.структурой опубликовавшей документ о контроле интернета, вызвавший обсуждение, после чего документ был удален сайта, но «Google помнит все».
Если проблема решена, один из способов сказать «Спасибо» автору — .
Если же проблему разрешить не удалось или появились дополнительные вопросы, задать их можно на нашем , в специальном разделе.
Иногда хочется вспомнить те времена, когда по интернетам бродили динозавры, а одна песня загружалась 10 минут. Смотрим в прошлое и ностальгуем, спасибо за это онлайн-сервису: Wayback Machine – Internet Archive. Работает с 1996 года, за это время собрал в базе данных более 279 миллиардов веб-страниц.
Переходим по ссылке: http://archive.org/web/web.php В строку вводим: адрес интересующего сайта и нажимаем «Browse History». Система выдаст всю историю по конкретному порталу.
Синими кругами на календаре обведены даты резервных копий. Выбираем нужный год, дату и заглядываем в прошлое веб-страницы.
Виртуальный хостинг сайтов для популярных CMS:
Где посмотреть, как выглядели страницы сайтов в разные годы.
Яндекс в это время открыл первый удаленный офис в Питере, запустил Яндекс.пробки и «словари». А майл.ру начали использовать поисковик на своем портале. Через год Яндекс купит разработчика мобильного софта «Смартком» и соц. сеть «Мой круг». Запустит «Календари», блого-сервис Я.ру, портал Яндекс.Mirror и откроет школу анализа данных — бесплатный образовательный курс.
Google запускают календарь, финансы и переводчик. Открывают бесплатный хостинг изображений Picasa и объявляют о покупке YouTube. В 2007 компания установит крупнейшую систему солнечных батарей (Сейчас она обеспечивает энергией 30% офисов) и объявит о появлении Android. А сотрудники начинают ездить по офисам на велосипедах gBikes.
История Facebook уникальна. Только в 2004 году сервис вышел за стены Гарварда, а уже в 2008 вырос так, что количество пользователей перевалило за 50 млн. человек, а состояние Марка Цукерберга уже оценивалось в 1.5 млдр. долларов.
Как раньше выглядел наш сайт.
А вот так менялся наш сайт с 2006 года.
Старые версии сайтов вебархив
Что такое веб-архив
21 октября 2017 года. Опубликовано в разделах: Азбука терминов. 30445
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Это настоящая библиотека, в которой каждый желающий может открыть интересующий его веб-ресурс, и посмотреть на его содержимое, на ту дату, в которую вебархив посетил сайт и сохранил копию.
Знакомство с archive org или как Валерий нашел старые тексты из веб-архива
В 2010-м году, Валерий создал сайт, в котором он писал статьи про интернет-маркетинг. Одну из них он написал о рекламе в Гугл (AdWords) в виде краткого конспекта. Спустя несколько лет ему понадобилась эта информация. Но страница с текстами, некоторое время назад, была им ошибочно удалена. С кем не бывает.
Однако, Валерий знал, как выйти из ситуации. Он уверенно открыл сервис веб-архива, и в поисковой строке ввел нужный ему адрес. Через несколько мгновений, он уже читал нужный ему материал и еще чуть позже восстановил тексты на своем сайте.
История создания Internet Archive
В 1996 году Брюстер Кайл, американский программист, создал Архив Интернета, где он начал собирать копии веб-сайтов, со всей находящейся в них информацией. Это были полностью сохраненные в реальном виде страницы, как если бы вы открыли необходимый сайт в браузере.
Данными веб-архива может воспользоваться каждый желающий совершенно бесплатно. Создавая его, у Брюстера Кайла была основная цель – сохранить культурно-исторические ценности интернет-пространства и создать обширную электронную библиотеку.
В 2001 году был создан основной сервис Internet Archive Wayback Machine, который и сегодня можно найти по адресу https://archive.org . Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
Чтобы не ограничиваться коллекцией сайтов, в 1999 году начали архивировать тексты, изображения, звукозаписи, видео и программные обеспечения.
В марте 2010 года, на ежегодной премии Free Software Awards, Архив Интернета был удостоен звания победителя в номинации Project of Social Benefit.
С каждым годом библиотека разрастается, и уже в августе 2016 года объем Webarchive составил 502 миллиарда копий веб-страниц. Все они хранятся на очень больших серверах в Сан-Франциско, Новой Александрии и Амстердаме.
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
Согласно полученной информации, можно узнать, что главная страница нашего сайта была впервые найдена сервисом 24 мая 2014 года. И, с этого времени, по сегодняшний день, ее копия сохранялась 38 раз. Даты изменений на странице отмечены на календаре голубым цветом. Для того, чтобы посмотреть историю изменений и увидеть как выглядел определенный участок веб-ресурса в интересующий вас день, следует выбрать нужный период в ленте с предыдущими годами, и дату в календаре из тех, что предлагает сервис.
Через мгновение, веб-архив откроет запрашиваемую версию на своей платформе, где можно увидеть как выглядел наш сайт в самом первоначальном виде.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
– Только качественный трафик из Яндекса и Google
– Понятная отчетность о работе и о планах работ
– Полная прозрачность работ
Как скачать сайт из вебархива
Обращаю ваше внимание на то, что все операции производятся в операционной системе Ubuntu (Linux). Как все это провернуть на Windows я не знаю. Если хотите все проделать сами, а у вас Windows, то можете поставить VirtualBox, а на него установить ту же Ubuntu. И приготовьтесь к тому, что сайт будет качаться сутки или даже двое. Однажды один сайт у меня скачивался трое суток.
По сути, на текущий момент мы имеем два сервиса с архивом сайтов. Это российский сервис web-archiv.ru и зарубежный archive.org. Я скачивал сайты с обоих сервисов. Только вот в случае с первым, тут не все так просто. Для этого был написан скрипт, который требует доработки, но поскольку мне он более не требуется, соответственно я не стал его дорабатывать. В любом случае его вполне достаточно на то, что бы скачать страницы сайта, но приготовьтесь к ошибкам, поскольку очень велика вероятность появления непредусмотренных особенностей того или иного сайта.
Первым делом я расскажу о том, как скачать сайт с web.archive.org, поскольку это самый простой способ. Вторым способом имеет смысл воспользоваться если по каким-то причинам копия сайта на web.archive.org окажется неполной или её не окажется совсем. Но скорее всего вам вполне хватит первого способа.
Принцип работы веб-архива
Прежде чем пытаться восстанавливать сайт из веб-архива, необходимо понять принцип его работы, который является не совсем очевидным. С особенностями работы сталкиваешься только тогда, когда скачаешь архив сайта. Вы наверняка замечали, попадая на тот или иной сайт, сообщение о том, что домен не продлен или хостинг не оплачен. Поскольку бот, который обходит сайты и скачивает страницы, не понимает что подобная страница не является страницей сайта, он скачивает её как новую версию главной страницы сайта.
Таким образом получается если мы скачаем архив сайта, то вместо главной страницы будем иметь сообщение регистратора или хостера о том, что сайт не работает. Чтобы этого избежать, нам необходимо изучить архив сайта. Для этого потребуется просмотреть все копии и выбрать одну или несколько где на главной странице страница сайта, а не заглушка регистратора или хостера.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
- http://web.archive.org/web/ 20180330034350 /http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
- wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Качаем сайт с web-arhive.ru
Это самый геморройный вариант ибо у данного сервиса нет возможности скачать сайт как у описанного выше. Соответственно пользоваться этим вариантом есть смысл пользоваться только в случае если нужно скачать сайт, которого нет на web.archive.org. Но я сомневаюсь что такое возможно. Этим вариантом я пользовался по причине того, что не знал других вариантов,а поискать поленился.
В итоге я написал скрипт, который позволяет скачать архив сайта с web-arhive.ru. Но велика вероятность того, что это будет сопровождаться ошибками, поскольку скрипт сыроват и был заточен под скачивание определенного сайта. Но на всякий случай я выложу этот скрипт.
Пользоваться им довольно просто. Для запуска скачивания необходимо запустить этот скрипт все в той же командной строке, где в качестве параметра вставить ссылку на копию сайта. Должно получиться что-то типа такого:
- php get_archive.php “http://web-arhive.ru/view2?time=20160320163021&url=http%3A%2F%2Fremontistroitelstvo.ru%2F”
Заходим на сайт web-arhive.ru, в строке указываем домен и жмем кнопку «Найти». Ниже должны появится года и месяцы в которых есть копии.
Обратите внимание на то, что слева и справа от годов и месяцев есть стрелки, кликая которые можно листать колонки с годами и месяцами.
Остается найти дату с нужной копией, скопировать ссылку из адресной строки и отдать её скрипту. Не забывает помещать ссылку в кавычки во избежание ошибок из-за наличия спецсимволов.
Мало того, что само скачивание сопровождается ошибками, более того, в выбранной копии сайта может не быть каких-то страниц и придется шерстить все копии на предмет наличия той или иной страницы.
Помощь в скачивании сайта из веб-архива
Если у вас вдруг возникли трудности в том, что бы скачать сайт, можете воспользоваться моими услугами. Буду рад помочь. Для начала заполните и отправьте форму ниже. После этого я с вами свяжусь и мы все обсудим.
Как посмотреть удаленную страницу ВКонтакте
Для многих пользователей, ВК – это хранилище личной информации. Фотографии с памятными моментами, видео с прогулки вашей компании, члены которой уже давно разъехались по разным городам и странам. Вы хранили это в социальной сети, а вашу страницу заблокировали? А может друг удалил свой профиль с ценной информацией. Не огорчайтесь! Не все еще потеряно. Можно использовать веб архив ВКонтакте.
Существует выражение «Все, что попадает в интернет, остается там навсегда». Оно очень близко к истине, ведь даже удаленные страницы в ВК и других соц. сетях можно просмотреть. Для этой цели используется три рабочих инструмента.
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.
Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.
Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.
Попытайте удачу в поисках архивной версии профиля на этих сайтах:
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Справка. Веб-архивы сохраняют всю информацию, которая попадает в интернет без разбора. Видимо по этой причине, доступ к большинству существующих сервисов заблокирован на территории России Роскомнадзором. Чтобы работать с этими сайтами, воспользуйтесь анонимайзером или прокси-сервером.
Просмотр копии страницы в поисковиках
Зная алгоритмы работы поисковых роботов, можно использовать их возможности в своих целях. Каждый созданный сайт, попадает в Яндекс и Гугл не сразу. Он размещается на специальном сервере и ждет, пока поисковик найдет его и добавит в свою базу. Такие обходы поисковые системы выполняют в среднем один раз в 14 дней. Во время этого процесса они не только добавляют в свою базу новые сайты, но удаляют неработающие. Это значит, что если страничка ВКонтакте была удалена совсем недавно, то возможно ее копия еще сохранилась на серверах поисковиков.
- Скопируйте адрес страницы, которую нужно найти, из адресной строки браузера.
- Вставьте эту ссылку в поисковую строку Яндекса или Гугла и нажмите «Поиск».
- Если страница все еще храниться в поисковике, то она будет первой в результатах выдачи. Справа от ссылки находится еле заметный треугольник. Нажмите на него.
- В открывшемся меню выберите «Сохранённая копия».
Перед вами откроется последняя версия страницы, которую сохранил Яндекс или Гугл. Сохраните фото, видео и всю прочую необходимую информацию себе на компьютер, так как совсем скоро сохраненная копия будет удалена с серверов поисковых машин.
Справка. Страница должна быть открыта для индексирования поисковиками в настройках аккаунта ВКонтакте. Если она была скрыта от них, то, соответственно, и сохраненной копии вы найти не сможете.
Кэш браузера
Если ни один из представленных ваше способов не помог вам найти нужную страницу, остается надеяться только на то, что копия уже сохранена на вашем компьютере. Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
В браузере Mozilla Firefox это делается следующим образом:
- зайдите в меню, нажав кнопку в виде трех горизонтальных полос;
- выберите пункт «Веб-разработка»;
- в этом подменю нажмите «Работать автономно».
Когда вы перешли в автономный режим, браузер не сможет загружать никакую информацию из интернета. Он будет использовать только те данные, которые сохранил на компьютере. Введите в адресную строку адрес нужной вам страницы и нажмите «Enter». Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Важно! После проведенного эксперимента не забудьте отключить автономный режим. Если этого не сделать, браузер не сможет подключиться к интернету.
Как видите, даже из самых, казалось бы, безвыходных ситуаций можно найти выход. Если же ни один из способов вам не помог, то позвоните другу и попросите восстановить страницу. А также отправьте ему ссылку на сайт vkbaron.ru, чтобы он видел, сколько всего интересного можно делать в социальной сети Вконтакте. В случае если вы пытаетесь сохранить информацию со своей страницы, которую кому-то удалось взломать, обязательно ознакомьтесь со статьей о составлении пароля, который не сможет подобрать ни один хакер.
Как работать с WebArchive: инструкция
Интернет появился около 37 лет назад, за этот период он все время менялся — что-то совершенствовалось, что-то убиралось, а что-то наоборот появлялось. Сайты постоянно меняли оформление, контент, кнопки и т.д. Для того, чтобы отследить эти изменения в целом или же какой-то конкретной нише, просмотреть сайт конкурентов, который уже не ведется или просмотреть историю интересующего вас сайта/домена — существует Web Archive.
Что такое Web Archive
WebArchive — бесплатный сервис, так называемая машина времени, которая ориентирована исключительно на сайты. Данный сервис хранит архивные данные с историей каждого ресурса, которые включают в себя целые страницы с контентом, заголовками, ссылками, изображениями и т.д.
Отслеживание истории домена необходимо не только в целях интересного времяпровождения, но и позволит вам узнать необходимую для продвижения вашего сайта информацию, такую как:
- Возраст домена, здесь мы уже описывали зачем вам нужны эти данные;
- Тематичность домена — WebArchive позволит вам узнать, не менялась ли тематика данного домена за время его существования, а если менялась, то когда и на какую;
- Увидеть, как сайт выглядел раньше — такая информация будет полезна при покупке б/у доменов;
- Просмотреть удаленный контент на сайте;
- Проверить домен на “чистоту” перед покупкой;
- Восстановить сайт, если до этого вы не сделали резервную копию;
- Отыскать уникальный контент с ресурсов в необходимой для вас нише.
Машина времени сайтов (англ. Wayback Machine) — один из главных проектов archive.org. Данный сервис не является коммерческим и был создан в 1996 году американским программистом Брюстером Кейлом. Архив сайтов имеет четкую цель — искать и собирать копии ресурсов вместе с изображениями, ссылками и контентом для дальнейшей возможности свободного просматривания информации любыми пользователями.
База web archive собиралась на протяжении 20 лет, в ней находится 280 миллиардов страницы, 12 миллионов статей и книг, миллион картинок, а также 100 тысяч программ.
Как пользоваться WebArchive
Сервис крайне прост и удобен в использовании. Приведем пошаговую инструкцию:
1. Заходим на главную страницу сайта — https://web.archive.org/
2. Введите в поиск интересующий вас сайт или же ключевое слово в нужном вам нише и нажмите Enter(подойдет для тех, кто хочет просмотреть все сайты, которые подходят для введенного КС)
3. Появится информация о ресурсе: сколько было сделано резервных копий сайта и с какой даты хранится информация о данном сайте
4. Внизу также будет календарь с отметками по годам, вы можете выбрать интересующий вас год
Проверьте позиции своего сайта прямо сейчас!
После этого на календаре голубым цветом будут выделены отметки, которые указывают на создание копий, вы можете выбрать любую из этих отметок.
5. После выбора отметки вас перебросит на копию сайта в выбранную вами дату. Например, вот так выглядел ресурс Liveinternet 27 марта 2012 года
6. Также вы можете получить общие статистические данные о нужном вам проекте. Для этого под строкой ввода нужно нажать Summary of
7. Еще вы можете ознакомиться с картой сайта, для этого необходимо нажать на кнопку Site Map под строкой ввода сайта
Алгоритм действий прост, а работа с сайтом не займет более 10-ти минут.
Как исключить свой сайт из WebArchive
Если вы по определенным причинам не хотите, чтобы ваш сайт попал в веб архив, то можно прописать запретную директиву в robots.txt вашего сайта, она должна выглядеть так:
После изменений в robots.txt машина времени перестанет делать резервные копии на ваш сайт, а уже имеющиеся сохранения будут удалены. Однако не забывайте, что данные изменения работают только тогда, когда есть доступ к robots.txt вашего сайта и если вы не будете продлевать использование вашего домена, то все изменения будут аннулированы и ваш сайт снова появится на WebArchive для просмотра всех желающих.
Похожие статьи
Руководство по созданию и внедрению микроразметки для вашего сайта
Как использовать микроразметку, чтобы выделить свой сайт в результате поиска и пользователи чаще переходили на него. Самый действенный метод достижения этой цели – работа со структурированными данными. В этой статье мы постараемся разобраться, что же такое структурированные данные и как их можно внедрить на свой сайт.
Микроразметка Schema.org: как использовать для SEO-продвижения
Schema.org — это стандарт семантической разметки (микроразметки) данных на сайтах в сети Интернет. В этой статье мы рассмотрим, что из себя представляет микроразметка, как она позволяет передавать поисковикам основную информацию со страницы, а также в чем её польза для SEO-оптимизации.
12 уникальных SEO-инструментов для эффективных заголовков
Существует огромное количество инструментов, которые помогут вам создать идеальное название страницы. Выбор зависит только от ваших целей и предпочитаемых методов.
Программа для восстановления сайтов из
вебархива.WebArchive Downloader 6.0 – профессиональное программное обеспечение для скачивания сайта и страниц из интернет архива web.archive.org.
Основные преимущества программы:
- Сохраняет все файлы — стили CSS, скрипты, изображения, страницы
- Создает внутреннюю перелинковку страниц сайта
- Возможны два вида внутренних ссылок: файловые и доменные
- Удаляет из текста страниц всю служебную информацию
- Восстанавливать сайт из вебархива на конкретную дату
- Поддерживает три вида кодировки страниц
- Автоматический процесс закачки контента сайта
- Сохраняет полную навигацию по сайту
Применяя WebArchive Downloader 6.0 вы выбираете:
Экономию
денег
Не нужно платить каждый раз за скачивание сайта из web архива. Достаточно один раз просто купить программу.
Автоматизацию
процесса
WebArchive Downloader 6.0 автоматизирует процесс сохранения страниц сайта, изображений и прочего контента.
Больше
времени
Ручной метод сохранения страниц из вебархива очень нудный и занимает много времени. WebArchive Downloader делает это пока вы отдыхаете.
Готовый
сайт
Скачанный сайт, при нормальном его качестве, практически сразу можно размещать на хостинг.
Уникальный
контент
Найдите брошенный домен и получите уникальные статьи и материал для своего сайта.
как выглядел твой город 20 лет назад
Всегда интересно заглянуть в прошлое, если, конечно, оно не свое. Речь скорее пойдет о том, как выглядел в прошлом родной город, в котором ты родился или любой другой край, который интересует тебя.
TimeLapse – как менялась земля за 20 лет
В сети нашел уникальный проект, с помощью которого можно посмотреть, как развивалась планета Земля за последние 20 лет, а также как развивались города нашей планеты.
Речь пойдет о сервисе TimeLapse от Google. В нем собраны снимки со спутников различных мест планеты: города, пустыни, климатические изменения и т.д.
Пользователю остается ввести название города (на английском языке) и получить результат в виде анимации, которая состоит из множества снимков со спутников с 20 летней давности. Тем самым увидеть, как изменялись местности и города.
Можно выбрать город или определенную территорию, которая предоставляется на главной странице или ввести название города (на английском языке).
Вот, например, как менялся город Дубай, в течение 20 лет.
Интерактивная историческая карта с 3000 г. до н. э.
Interactive World History Atlas since 3000 BC – интерактивная историческая карта с 3000 г. до н. э., где можно за любой промежуток времени посмотреть как выглядел мир на карте. Можно просматривать, как менялась карта мира с 3000 года до нашей эры.
Вводим интересующийся год в специальное поле и нажимаем Enter. Получаем результат в виде карты. Интерактивную карту можно увеличивать и уменьшать, и с помощью указателя мыши передвигаться.
Подойдет для учителей и преподавателей географии и истории.
Вот таким образом можно узнать, как выглядели города, территории и всемирная карта не только 20 лет назад, но даже 3000 лет до нашей эры.
Интересное на сайте:
Добавить комментарий
Как найти старые или просроченные веб-сайты
Q. Иногда я захожу на старый веб-сайт и обнаруживаю, что он заменен страницей с рекламой. Куда делись все оригинальные сайты?
A. Многие действующие веб-сайты с годами потемнели, поскольку их владельцы отключили серверы, на которых размещались страницы, для публичного просмотра и отказались от зарегистрированных доменных имен, которые когда-то направляли посетителей на сайт. Известно, что другие предприниматели используют доменные имена с истекшим сроком действия для других целей, например, размещая страницы с рекламными ссылками (или другим контентом), чтобы приветствовать людей, ищущих исходный веб-сайт.
Если вы испытываете ностальгию по тому, как раньше выглядели некоторые старые сайты, вы можете увидеть копии страниц такими, какими они когда-то были, посетив Wayback Machine, расширяющуюся коллекцию из 455 миллиардов веб-страниц, которая продолжает расти. (И да, сайт был назван в честь машины времени, которую использовал персонаж мистера Пибоди из мультсериала, впервые вышедшего в эфир в конце 1950-х.)
Хотя запасы Wayback Machine датируются серединой 1990-х, не все сайт включен в коллекцию.Но вы, вероятно, сможете найти образцы большинства коммерческих сайтов за последние 15 лет или около того. Просто введите адрес сайта, который вы ищете, чтобы увидеть, что могло быть сохранено.
The Wayback Machine является частью Интернет-архива, бесплатной онлайн-библиотеки цифровых носителей и электронных артефактов. Помимо коллекции веб-страниц, Интернет-архив также содержит исследовательскую библиотеку программ телевизионных новостей, записей живой музыки и других аудио- и текстовых файлов, а также электронных книг, фильмов и тысяч старых компьютерных программ, включая видеоигры для игровых автоматов. , компьютеры и консоли.
Поиск подходящей скорости широкополосного доступа
Q. Моя текущая широкополосная услуга медленная, и загрузка фильма занимает целую вечность. Я хочу перейти на более быстрый уровень, но это становится дорого. Какая скорость мне нужна для потоковой передачи фильма Netflix без остановки, видеозвонка или загрузки взятого напрокат цифрового фильма за меньшее время, чем требуется для его просмотра?
A. При расчете необходимой скорости учитывайте все действия в сети, которые вы хотите выполнять (потоковая передача, загрузка, игры, видеоконференции и т. Д.), И проверьте минимальную скорость соединения, необходимую для каждого из них.Обычно вы можете найти рекомендации, перечисленные на веб-сайтах компаний и служб, которыми вы пользуетесь. Действия, связанные с видео, обычно требуют большей скорости и пропускной способности сети, чем такие вещи, как потоковая передача звука или базовый просмотр веб-страниц.
Например, Netflix рекомендует соединение со скоростью не менее трех мегабит в секунду для потоковой передачи видео в стандартном разрешении и соединение со скоростью пять мегабит в секунду для просмотра контента высокой четкости без заиканий или буферизации. (Если вы выбираете новую широкополосную компанию, исходя из ваших потребностей в потоковой передаче видео, Netflix ежемесячно публикует в своем блоге собственный рейтинг скорости интернет-провайдеров.Как и в случае с потоковой передачей, скорость загрузки файлов может пострадать из-за общей перегрузки Интернета и сервера, но соединение со скоростью 25 мегабит в секунду может позволить вам загрузить файл фильма размером шесть гигабайт менее чем за 20 минут.
Служба видеозвонков Skype от Microsoft рекомендует подключение со скоростью 1,5 мегабит в секунду для видеозвонков высокой четкости, а на странице поддержки Google Hangouts предлагается скорость 2,6 мегабит в секунду в качестве «идеальной пропускной способности для наилучшего взаимодействия». Сайты поддержки большинства онлайн-видеоигр должны также указать минимальную скорость широкополосного подключения среди требований к процессору, памяти и другим аппаратным факторам.Если вы планируете публиковать собственные фотографии или видео в Интернете, план, предлагающий приличную скорость загрузки данных, заставит вас меньше ждать этого.
После того, как вы собрали свои выводы о скоростях подключения для предпочитаемых вами онлайн-сервисов, проверьте пакеты, доступные у местных интернет-провайдеров, предлагающих кабельное, спутниковое, оптоволоконное или широкополосное соединение DSL. Например, если вам в первую очередь нужны плавные потоки фильмов высокой четкости от Netflix, получите тарифный план, который предлагает как минимум рекомендуемое соединение со скоростью пять мегабит в секунду.Также следует учитывать количество людей, одновременно использующих широкополосное соединение, поэтому вы можете получить более быстрый план, если в семье есть онлайн-геймеры, а также любители кино.
По мере того, как интернет-провайдеры на протяжении многих лет наращивали свои широкополосные сети, они смогли расширить свои предложения, чтобы удовлетворить более широкий диапазон потребностей клиентов и бюджетов, поэтому вы можете увидеть четыре или пять предлагаемых планов обслуживания; максимальная скорость загрузки и выгрузки должна быть указана для каждого уровня обслуживания.В январе этого года Федеральная комиссия по связи обновила свой эталонный показатель для «широкополосного доступа» на 2010 год со скорости загрузки с четырех мегабит в секунду до 25 мегабит в секунду, поэтому названия и типы планов, предлагаемые провайдерами, могут снова измениться в будущем.
Как просмотреть кешированную версию веб-сайта
Легко забыть о непостоянстве Интернета. Страницы редактируются без предупреждения, и веб-сайты могут исчезнуть в мгновение ока.
Существует множество способов потерять доступ к сайту или веб-странице.Возможно, серверы не работают, или, возможно, владелец сайта изменил или удалил контент, который вы пытаетесь найти. В этих случаях одним из вариантов является просмотр кэшированной версии.
Google регулярно сканирует Интернет в поисках новых страниц для индексации, а также сохраняет резервные копии сканируемых страниц. Веб-браузеры делают то же самое, чтобы страницы загружались быстрее. Эти снимки сохраняются в кэше — области вашего локального жесткого диска, которая временно становится доступной, если сайт выходит из строя или удаляется определенное содержимое.Не все веб-сайты индексируются Google или сохраняются в кеше, но вот как получить к ним доступ.
Объявление
Поиск Гугл
Просмотр кэшированной страницы Google начинается так же, как и любой другой поиск. После того, как вы ввели свой запрос и нашли результат поиска, щелкните стрелку рядом с URL-адресом и выберите опцию Кэширование, чтобы просмотреть самую последнюю сохраненную версию страницы Google.
Когда сайт загрузится, Google сообщит вам, что это более старая версия, и укажет, когда был сделан снимок.У вас также будет возможность просмотреть текстовую версию страницы, а также ее исходный код. Однако имейте в виду, что вы не сможете переходить к другим страницам и оставаться в кэшированной версии; вы попадете на действующий сайт, если попытаетесь.
Адресная строка Chrome
Если вы используете веб-браузер Chrome, введите cache: в адресной строке и добавьте URL-адрес, не оставляя пробела. Браузер откроет кешированную версию рассматриваемого веб-сайта, как если бы вы прошли через Google.
Wayback Machine
Пока что просмотр кешированных версий веб-сайтов. Ряд организаций посвящены сохранению истории Интернета; наиболее известным является некоммерческий Интернет-архив, в котором размещаются веб-сайты, тексты, видео, аудио, программное обеспечение и изображения, которые трудно найти где-либо еще. Вы можете просматривать даже более старые версии веб-сайтов с помощью Wayback Machine, которая работает как для живых, так и для автономных веб-сайтов.
Введите URL-адрес, который вы хотите изучить, и поисковая машина по архивам покажет календарь, который указывает, когда Wayback Machine просканировала эту страницу.Щелкните дату в календаре, чтобы увидеть, как сайт выглядел в тот день. Wayback Machine — отличный способ просмотреть историю Интернета; заархивированные версии PCMag.com датируются 19 декабря 1996 г.
Архив сегодня
Архивный веб-сайт Archive.Today позволяет пользователям сохранять текущие веб-страницы, а также искать существующие записи, которые были ранее сохранены. Ввод URL-адреса для сохранения позволяет просматривать веб-страницу в том виде, в котором она существует в настоящее время, сохранять ее на сайте и загружать страницу на свой компьютер.
Если вы хотите просмотреть заархивированные версии веб-сайта, введите URL-адрес в соответствующую строку поиска, и Archive.Today заполнит результаты для домашней страницы и связанных отдельных страниц. Если существует несколько версий одной и той же страницы, они будут сложены вместе для удобства просмотра.
Веб-сайт PCMag, например, заархивирован еще в 2012 году и в настоящее время имеет четыре различных версии домашней страницы, сохраненных в сервисе.
Расширения браузера
Расширения браузера также могут обращаться к кэшированным сайтам.Добавьте средство просмотра веб-кэша в Chrome и щелкните правой кнопкой мыши любую страницу, чтобы просмотреть версию веб-страницы для Google или Wayback Machine. Расширение View Page Archive & Cache для Chrome и Firefox идет еще дальше, позволяя просматривать кешированные версии веб-страниц из более чем десятка поисковых систем, включая Bing, Baidu и Yandex.
Как очистить кеш в любом браузере
Не позволяйте вашей истории Интернета попасть в чужие руки. Это не всегда простой процесс, но рекомендуется время от времени удалять историю браузера и интернет-кеш.Вот как это сделать на настольном компьютере и мобильном устройстве.
Этот информационный бюллетень может содержать рекламу, предложения или партнерские ссылки. Подписка на информационный бюллетень означает ваше согласие с нашими Условиями использования и Политикой конфиденциальности. Вы можете отказаться от подписки на информационные бюллетени в любое время.
Пять способов вернуться в прошлое в Интернете
Всемирная паутина работает с начала 1990-х годов, и с тех пор было загружено бесчисленное количество текста, изображений, видео и аудио.Тем не менее, запустите поиск в Интернете сегодня, и в первую очередь он предоставит вам самые новые страницы. Не очень хорошо, если вы ищете что-то постарше.
Копаться в прошлом Интернета можно, но для этой работы нужны подходящие инструменты и методы. Отточив свои навыки, вы сможете использовать все: от первого твита до известных веб-страниц прошлого века.
Найти старые страницы в Интернете
Запустите стандартный поиск Google, и по умолчанию он покажет вам самые последние и релевантные результаты, но вы можете это изменить.На странице результатов поиска щелкните Инструменты , В любое время и Пользовательский диапазон , чтобы найти страницы, опубликованные в определенные даты. Нет предела тому, как далеко вы можете вернуться, хотя вы обнаружите убывающую отдачу, когда углубитесь в исторические архивы.
Попробуйте найти политиков-ветеранов или давних телешоу, но измените даты на 2000–2010 годы, и вы увидите, как могут резко измениться мнения, когда дело касается людей или развлечений.Если вы ищете конкретную старую статью, инструмент диапазона дат может значительно упростить задачу, и вы также можете добавить другие фильтры (например, site: popsci.com , чтобы ограничить поиск определенным доменом).
Эта функция не является эксклюзивной для Google — если вы предпочитаете Bing, нажмите кнопку Дата на странице результатов, чтобы открыть настраиваемый селектор даты, который работает так же, как в Google. К сожалению, такая же функция поиска по дате недоступна в DuckDuckGo, ориентированном на конфиденциальность, — возможно, потому, что ее уже давно нет.
Во многих случаях сайты будут отображать старые страницы с использованием их текущего макета и стиля, представляя старый контент по-новому. Если вы хотите увидеть сайты такими, какими они были в прошлом, или найти страницы, недоступные для Google и Bing, вы можете обратиться к Wayback Machine. В нем сотни миллиардов страниц, сохраненных в том виде, в котором они были изначально опубликованы.
Введите имя веб-сайта, например www.popsci.com , в поле поиска на Wayback Machine, и вы увидите обзор страниц, сохраненных из этого домена.Вы можете щелкнуть по годам, месяцам и дням, чтобы увидеть, как эти страницы выглядели, когда они впервые появились. Эти кешированные страницы также доступны для просмотра, так что это похоже на просмотр веб-страниц в старые времена.
The Wayback Machine — лучший вариант для загрузки старых страниц в том виде, в котором они были изначально, но есть альтернативы. Time Travel выполняет поиск в небольших веб-архивах, в том числе в тех, что находятся в Стэнфорде и отдельных странах. Вы также можете найти ограниченное количество официальных и правительственных сайтов, заархивированных Библиотекой Конгресса США.
Если сайт, который вы ищете, особенно известен, вы можете найти его в цифровом музее. Музей веб-дизайна собрал воедино несколько сотен значимых страниц, демонстрирующих некоторые тенденции цифрового дизайна прошлых лет, в то время как Музей версий запечатлел меняющийся стиль крупных сайтов, таких как Amazon, Apple, Wikipedia, , The New York Times , Google и Facebook.
Найти старые сообщения в социальных сетях
Функция расширенного поиска в Twitter позволяет вернуться в прошлое. Дэвид НилдДля поиска в старых публикациях в социальных сетях Twitter и Facebook требуется другой подход. Эти платформы поставляются со встроенными функциями поиска и работают с рядом сторонних инструментов, которые вы можете использовать для поиска прошлых лет сообщений в социальных сетях, созданных вами или другими людьми.
Страница расширенного поиска в Твиттере позволяет искать твиты по дате их публикации (с момента запуска Твиттера в 2006 году). Помимо даты, вам нужно будет ввести еще один критерий поиска, например конкретную учетную запись пользователя или ключевое слово, по которому вы хотите выполнять поиск.
Вы можете использовать этот инструмент поиска для поиска ваших старых твитов или твитов, написанных кем-либо еще, если учетная запись является общедоступной. Существуют даже фильтры для сужения области поиска в зависимости от степени вовлеченности публикации — если вы выполняете поиск с большим количеством совпадений, приоритезация популярных твитов может помочь отфильтровать шум.
Если вы хотите вернуться к самому началу учетной записи Twitter, дата создания учетной записи указана на странице профиля пользователя, что должно помочь вам сфокусировать поиск.Вы также можете запросить загрузку вашего архива Twitter с этой страницы, нажав Скачать архив ваших данных . Вы можете открыть полученный файл в своем веб-браузере и быстро перейти к самому раннему твиту, используя список лет и месяцев.
В Facebook сообщения гораздо реже становятся общедоступными и видны всем. Вы можете искать сообщения своих друзей, открыв профиль и нажав на три точки справа, а затем на Профиль поиска .Когда вы запустите поиск, вы увидите фильтры поиска внизу слева, в том числе один для Дата публикации .
Те же фильтры появляются, когда вы запускаете общий поиск из поля в верхнем левом углу интерфейса Facebook: введите ключевое слово или два, затем нажмите Введите , чтобы запустить поиск. Щелкните Сообщения и Дата публикации , чтобы сузить результаты по годам. Это не точный инструмент, но он может помочь вам быстрее найти то, что вам нужно.
Поиск в собственном профиле — это гораздо более хирургическая операция. Щелкните три точки в правой части профиля, затем Журнал активности и Фильтр , чтобы найти сообщения за определенный год или месяц. Facebook может отображать поисковые запросы, которые вы выполняли, и публикации, которые вам понравились и комментировались, а также все, что вы разместили сами, за выбранный период времени.
Получение и архивирование информации с веб-сайтов — документация The Kit 1.0
Вкратце: Вы изучите способы найти и восстановить исторические и «потерянные» информация с веб-сайтов, чтобы служить доказательством того, что что-то существовало онлайн, а также способы архивирования и сохранения ваших собственных копий веб-страниц для дальнейшего использования.
Иногда, когда вы хотите проверить информацию в Интернете, вы попадаете в следуя по следу, ведущему к неработающим ссылкам или к веб-сайтам, которые не являются доступно больше.
В других случаях вы встретите веб-сайты с важной информацией, которая может повысить ценность истории, но вы не осознаете ее ценность, пока позже.
При повторном посещении этого веб-сайта, чтобы задокументировать его, вы можете обнаружить, что он больше не существует, что конкретная веб-страница, которую вы помните был удален или что нужная вам информация больше не доступен и был заменен новым контентом.
Вы, вероятно, столкнетесь со всеми этими проблемами в какой-то момент во время ход ваших расследований.
Что, если бы существовал способ отправиться в прошлое и получить копию эта веб-страница или даже ее часть до того, как она была изменена или взята вниз?
К счастью, есть несколько простых способов восстановить старый контент и удалить его. страниц, чтобы вы по-прежнему могли ссылаться на них в своем расследовании. Ты можешь также сохраните доступные в данный момент страницы, чтобы вы могли использовать их позже, даже если они тем временем изменены или удалены.
Есть несколько таких сервисов, которые автоматически архивируют предыдущие версии сайтов. Помимо контента, эти цифровые архивы часто содержат информацию, которая может помочь вам идентифицировать другие важные данные, такие как как владелец веб-сайта, полезные имена, контактные данные, документы и ссылки на другие сайты. Некоторые из этих услуг позволяют вам вносить свой вклад в список веб-сайтов, которые они архивируют, время от времени сохраняя веб-страницы вручную на ваш выбор. Затем вы (и другие) можете получить снимки этих веб-сайты позже.
Скриншот копии Wayback удаленной в настоящее время веб-страницы Facebook в разделе «Истории успеха — Правительство и политика».
Что еще важнее, некоторые старые контент доступен, так как некоторые старые ссылки с заархивированной страницы все еще работают, поэтому вы можете на самом деле читал о деталях их проектов политической кампании.
В заархивированных версиях веб-сайтов, подобных этим, сохраняется информация, которая может быть невероятно ценным для следователей.
Безопасность прежде всего!
Когда вы направляете службу архивации на интересующую вас веб-страницу, она просканирует эту веб-страницу и сохранит ее копию.Когда это произойдет, веб-страница, находящаяся в архиве, автоматически добавит запись к текущему «Журнал доступа» (который ведется на большинстве веб-сайтов) о том, когда и по какому IP адресов, он был посещен.
Внимательный администратор сайта или автоматизированный процесс может затем поймите, что часть их сайта была заархивирована Wayback Machine.
Это, в свою очередь, может дать им ключ к разгадке того, что кто-то расследует конкретный фрагмент контента или лицо, имеющее к ним отношение. В некоторых случаях это само по себе может уменьшить влияние вашего расследования, если вы являются деликатными и должны храниться вдали от посторонних глаз, поскольку хоть какое-то время.
Как минимум, администратор сайта может иметь архивные материалы. удалено из Wayback Machine. (Это одна из причин, почему это хороший идея сделать свою собственную офлайн-копию всего, что важно для вашего расследование.) Этот администратор может также удалить или изменить аналогичные контент, который вы еще не нашли.
Большинство служб архивирования также хранят журналы доступа.
Webcite , например, записывает операционную систему компьютера и Интернет браузер каждого пользователя, а также доменное имя интернет-службы каждого пользователя провайдеры (политика конфиденциальности Webcite).это поэтому рекомендуется активировать виртуальную частную сеть (VPN) или использовать Tor Браузер при работе с архивами.
Кроме того, некоторые службы требуют, чтобы каждый пользователь создал учетную запись, чтобы выбрать имя пользователя, предоставить платежную информацию, подтвердить электронную почту адресов или связать профиль в социальных сетях.
Вам следует рассмотреть возможность создания отдельного набора учетных записей для использования с такими сервисами, чтобы разделить (отделить) ваши следственная работа с использованием вашей личной информации в Интернете.
В некоторых случаях вы можете даже захотеть создать одноразовую «идентификационную информацию» для конкретного расследования и избавиться от нее после завершения исследования.
В любом случае первым шагом будет создание относительно безопасного, разделенная учетная запись электронной почты, которую вы можете довольно легко сделать на tutanota.de или protonmail.com.
Оплата коммерческих услуг способом, не имеющим обратной связи с вашим личность намного сложнее. Если вы живете в регионе, где вы можете купить предоплаченную кредитную карту наличными, это может быть вашим лучшим вариант.
В потенциальной ситуации выше — администратор сайта, который замечает внезапный интерес со стороны Wayback Machine — стоит отметить что предмет вашего расследования не обязательно может отследить это интерес вернулся к вам. Если вы, ваша служба архивирования заслуживает доверия, и если никто не имеет доступа как к журналам веб-сайта, так и к архиву журналы службы, этому администратору может быть трудно подключиться точки.
Тем не менее, лучше принять меры предосторожности, рекомендованные выше, чем полагаться на это предположение.- Предположим, например, что только горстка IP-адресов просмотрели заархивированную страницу в тот же день, когда она была добавлен в Wayback Machine. Было бы легко понять выяснилось, что за ними наблюдают с определенного места.
Любое небольшое вложение времени, прежде чем вы начнете свое расследование, может помочь вам ограничить такого рода риски.
Архивирование и получение контента с помощью Wayback Machine
The Wayback Machine является проектом некоммерческий Интернет в Сан-Франциско Архив, цифровая библиотека, которая была посвященный сохранению миллиардов веб-сайтов с 1996 года, в рамках усилия по архивированию Интернета и обеспечению всеобщего доступа для всех знание.По состоянию на начало 2019 года в нем хранится около 345 миллиардов веб-сайты.
Машина обратного пути
The Wayback Machine — незаменимый инструмент для исследователей, историков, исследователи и ученые. Он находится в свободном доступе для общественности и может помочь вам получить доступ к архивным снимкам веб-страниц, сделанным в различных точках во время.
Автоматические сканеры Wayback Machine (также называемые пауками) могут получать доступ и архивировать практически любой общедоступный веб-сайт. Однако у роботов нет фиксированного шаблон принятия решения о том, какие веб-сайты они посещают и как часто они это делают, поскольку они подвержены ограниченным ресурсам и политическим решениям, которые влияют на их работу.
В результате вы не всегда можете найти архивную версию из определенного день, месяц или даже год. Кроме того, веб-сайты могут отказаться от заархивированы такими сервисами, как Wayback Machine. Публикуя набор ограничения в текстовом файле robots.txt, веб-сайт может указать поисковые роботы, чтобы исключить часть или все его содержание из архива или индексация. Тем не менее, огромный массив данных Wayback Machine будет вероятно, будет незаменим во многих ваших исследованиях.
Примечание:
Роботы.txt — это файл, который находится на веб-сайте и перечисляет части сайт, который должен или не должен быть доступен сканерам. Если на сайте есть файл robots.txt, вы можете просмотреть его, добавив «/robots.txt» в его домен. или субдомен. Например: https://google.com/robots.txt.
Веб-сайты могут использовать этот файл для блокировки поисковых роботов от Wayback Machine, из поисковых систем, таких как Google, или из любого другого индексирования или архивирования услуга. Есть ряд причин, по которым некоторые администраторы веб-сайтов выберите роботов с ограничениями.txt: чтобы ограничить расходы на пропускную способность и снизить нагрузку на перегруженные серверы, чтобы защитить изображения товарных знаков или оставить незаконченными например, не показывать веб-сайты в результатах поиска. В некоторых случаях, однако они делают это для того, чтобы скрыть потенциально конфиденциальный контент.
В то время как Wayback Machine не всегда исполнять с этими ограничениями по-прежнему есть много веб-сайтов, которые его сканеры отказаться от архивации из-за директив robots.txt. Если у тебя есть проблемы с использованием Wayback Machine для просмотра или архивирования некоторых, но не всех страницы на веб-сайте, вы можете проверить его robots.txt, чтобы узнать, есть ли части сайта «запрещены».
Помимо простого интерфейса для автоматического получения заархивированные веб-сайты, Wayback Machine также позволяет вручную сохранять снимки веб-страниц, чтобы вы могли убедиться, что они внезапно не пропадать.
Эта служба может не только архивировать веб-страницы, относящиеся к вашему расследования, но это также дает вам простой способ цитировать исследования и ссылку на контент по мере того, как ваше расследование обретает форму
Хотя часто бывает полезно сохранять копии важных файлов в формате HTML или PDF, веб-страниц на свои устройства, чтобы убедиться, что у вас есть несколько резервные копии, архивирование их с помощью Wayback Machine может добавить элемент нейтралитет и доверие, если вы в конечном итоге поделитесь этими архивами с другими. Кроме того, для большинства людей это намного удобнее, чем поддерживать автономная библиотека цифровых файлов.
Поиск страниц с помощью Wayback Machine
Чтобы найти страницу, которая больше не доступна, или просмотреть старую версию веб-страницы, просто перейдите на https: // web.archive.org и войдите в сеть адрес, который вы ищете.
Если страница ранее была заархивирована, даты ее сохранения будут появляются в календаре текущего года. Вы можете перейти к предыдущему лет, используя временную шкалу, которая также отображает график того, как часто страница архивировалась каждый год. После нажатия на год, в котором вы находитесь интересно, архивы этого года будут отмечены в календаре значком цветные точки.
Здесь мы используем пример https: // cambridgeanalytica.org /, веб-сайт, который был закрыт в 2018 году из-за закрытия компании (см. выше пример скандала с Cambridge Analytica).
Скриншот календаря Wayback Machine для доступа к веб-сайту Cambridge Analytica
Синяя точка означает, что на данном веб-сайте был сделан полный захват веб-страницы. Дата. Обычно это именно те архивы, которые вы ищете. Зеленые точки указывает на то, что когда сканер получил доступ к этому веб-адресу, он был автоматически перенаправляется на другую страницу того же сайта.Эти архивы могут не содержать того контента, который вы ищете. Оранжевые и красные точки указывают на то, что во время архивирования произошла ошибка. процесс, возможно, из-за ошибки сканера или веб-сайта сервер. Большая точка означает, что несколько архивы хранились в тот день. Вы можете навести на них курсор, чтобы выбрать конкретные архивируются в зависимости от времени суток.
После выбора архивной версии страницы Wayback Machine панель навигации отображается в верхней части экрана.Это позволяет вам просматривать различные архивы этой страницы с помощью шкалы времени или нажав на кнопки «следующий» и «предыдущий».
* Заархивированная страница Cambridge Analytica в Wayback Machine *
Совет:
Чтобы помочь установить действительность ваших онлайн-доказательств, вам может потребоваться проверить точную дату и время, когда Wayback Machine просканировала и заархивировала веб-страницу. Вы можете сделать это, проверив «отметку времени», встроенную в веб-адрес архива.Эта метка времени отформатирована с использованием четырехзначного числа года, за которым следуют двузначные обозначения месяца, дня и т. Д. час, минута и секунда, когда архив был захвачен. Вы можете найти его между «https://archive.org/web/» и веб-адресом заархивированной страницы. Например, следующий архив был снят в 2017 году, 31 st августа, в 06:00 и 27 секунд: https://web.archive.org/web/20170831060027/https://cambridgeanalytica.org.
Методы быстрого поиска с помощью браузера
The Wayback Machine также позволяет запрашивать определенный веб-сайт. архив, который он хранит, не просматривая его интерфейс поиска.Вместо этого вы можете сделать это в собственном браузере, правильно зайдя в отформатированный веб-адрес.
Просто добавьте адрес веб-сайта в конец Wayback Machine. адрес:
«https://web.archive.org/www.yoursite.com/» (где «www.yoursite.com/» — это любой сайт, на котором вы хотите выполнить поиск)
- в вашем браузере будет отображаться последняя заархивированная версия сайта, который вы желаю посмотреть.
Далее:
- Если вы разделите два адреса звездочкой (*), ваш браузер загрузит представление календаря архива: «Https: // web.archive.org/*/www.yoursite.com/ ”
- Если вы также добавите звездочку в конец, Wayback Machine будет показать вам все архивы в этом домене, а не только домашняя страница: «https://web.archive.org/*/www.yoursite.com/*»
Например, переход к https://web.archive.org/web/*/cambridgeanalytica.org/* отобразит постраничный список всех cambridgeanalytica.org страницы, заархивированные Wayback Machine.
Список страниц Cambridge Analytica в Wayback Machine
Использование Wayback Machine для архивирования веб-страниц
Еще одной ключевой особенностью Wayback Machine является возможность архивирования веб-страницы по запросу.
Если вы хотите сохранить и сохранить информацию для расследование или обеспечение доступности вашей опубликованной работы, вы можете перейти на https://archive.org/web и найти «Сохранить страницу Сейчас »к нижнему правому углу страницы. Просто введите веб-адрес (например, «http://www.yoursite.com/projects») и щелкните кнопку «СОХРАНИТЬ СТРАНИЦУ».
Если только указанный вами веб-сайт не запретил доступ к Интернет-архиву краулеры, как описано в файле robots.txt выше, Wayback Машина начнет его архивирование. Вы увидите индикатор выполнения, который будет сообщит вам, когда страница будет сохранена. В этот момент вы будете может просматривать архив страницы, а на временной шкале будут отображаться любые предыдущие снимки с этого сайта.
Веб-страница Saving Guardian на сайте Cambridge Analytica в Wayback Machine
Сохраненная веб-страница Guardian на Cambridge Analytica в Wayback Machine
Примечание:
Приведенные выше шаги будут архивировать только отправленную вами страницу. («Http: // www.yoursite.com/projects », в данном случае) не весь контент на этом веб-сайте. Если вы хотите заархивировать весь веб-сайт с помощью этого метода, вы нужно подавать каждую страницу отдельно.
Кроме того, эта функция не гарантирует, что регулярные архивы страница будет сохранена в будущем, так что вы можете захотеть вернуться Wayback Machine время от времени запрашивать дополнительные снимки.
Скачивание содержимого архива
К сожалению, Интернет-архив не позволяет выполнять поиск в полный текст всех сайтов в огромном архиве.Хотя он предлагает функция поиска по основным страницам определенных архивов, она не в настоящее время индексируются все 345 миллиардов страниц. Если вы хотите искать через заархивированный контент из определенного домена, однако есть способ сделать это.
Если вы установите язык программирования Ruby на своем компьютер (версия 1.9.2 или выше), вы можете использовать Wayback Машина Загрузчик сценарий для загрузки всех заархивированных файлов в данном домене. Этот сценарий позволяет указать диапазон дат, который вы хотите загрузить, что может будет полезно, если вы работаете с сайтами, которые были заархивированы для несколько лет.
Ограничения машины обратного пути
Как упоминалось выше, не все веб-сайты автоматически или регулярно заархивировано Wayback Machine.
сайтов выбираются на основе алгоритмов, использующих такие критерии, как частота люди посещают их и как часто другие веб-сайты ссылаются на них (что также показатель достоверности). Некоторые из этих данных получены из рейтинги составлены Alexa , ведущим веб-трафик, статистика и аналитика компании.
Кроме того, Интернет-архив запускает собственные поисковые роботы и работает с сотни добровольцев, которые выполняют поиск и архивируют веб-сайты в сохранить изобилие информации в Интернете.
Хотя вы можете архивировать определенные страницы вручную, как показано выше, вы не можете влиять на набор веб-сайтов, которые Wayback Machine будет автоматически и регулярно архивировать.
У Wayback Machine есть и другие ограничения. Примеры включают:
- Сайты, защищенные паролем, не архивируются.
- Динамические веб-сайты, которые в значительной степени полагаются на JavaScript, не могут быть заархивированы должным образом.
- Администраторы веб-сайтов могут явно требовать, чтобы их сайты не можно заархивировать, опубликовав ограничительный файл robots.txt, как см. выше, или отправив прямой запрос в Интернет-архив.
- Администраторы веб-сайта могут запросить ранее заархивированный контент быть удаленным из Wayback Machine.
- В настоящее время полнотекстовый поиск в Интернете недоступен. Архив.
Пример:
Чтобы проиллюстрировать, как иногда могут исчезать архивы, был использован Интернет-архив. недавно был в центре дебатов по поводу блога журналиста Джой-Энн. Рид. Адвокаты Рейда обратились к Интернет-архиву и попытались удалить заархивированные версии ее блога, утверждая, что некоторые из ее статьями манипулировала неизвестная сторона, вставившая мошенническое содержание в ее трудах — содержание, которое затем было заархивировано с блог.
Когда это не помогло, Блог Рида просто изменили свои robots.txt файл, чтобы ограничить доступ сканеров Wayback Machine. Когда поисковые роботы уловили изменение и автоматически удалили архив в целом. Этот случай показывает, как люди и организации может использовать как юридические, так и технические средства для удаления содержания из этих сторонние архивы.
В Европейском Союзе и некоторых других регионах Право на забвение предоставляет людям возможность запрашивать поисковые системы и цифровые архивы удаляют связанный с ними проиндексированный контент, который, по их мнению, вредные или клеветнические.Это право имеет ограничения, поэтому не все могут или будут удалены по запросу, но стоит помнить, что некоторые субъекты вашего расследования (политики, преступники и др. противоречивые цифры) могли использовать возможность снести связанный с ними интернет-контент, имеющий отношение к вашему расследованию.
Примечание:
Имейте в виду, что доменные имена можно продавать, а заброшенные доменные имена можно перерегистрировать. Как В результате иногда одним доменом с течением времени управляют несколько владельцев.В таких случаях веб-сайт архивная история может быть непостоянной, а старые материалы могут не иметь отношения к вашему расследованию.
Другие способы получения и архивирования веб-страниц
Архив сегодня
Archive.today (ранее archive.is) веб-страницы очень похожи на Wayback Machine.
Archive.today отличается тем, что хранит только отдельные страницы, а чем целые веб-сайты, и делает это только по запросу пользователей, не автоматически.
Вот пример заархивированных страниц из https://cambridgeanalytica.org/:
* Cambridge Analytica доступно в Archive.today *
Поскольку он не сканирует сайты, у него нет почти полного информацию вы можете найти на Wayback Machine.
Однако он предоставляет три ключевые функции:
- Во-первых, в отличие от Wayback Machine, он позволяет искать по всему текст его архивов.
- Во-вторых, он игнорирует любые ограничения, которые могут быть указаны в роботы.txt веб-сайтов, которые он архивирует. В результате это может сохранять снимки некоторых страниц, которые Wayback Machine не может, такие как общедоступные профили в Facebook и сообщения в Twitter.
- В-третьих, он также сохраняет как текстовую копию, так и графический снимок экрана заархивированных страниц. Иногда это дает большая точность, чем сохранение самой страницы, особенно когда архивирование быстро меняющегося содержимого (например, прокручивающихся изображений или снимки сообщений форума и т. д.).
Вы можете найти архив веб-страницы, введя ее точный веб-адрес (например, как «https: // cambridgeanalytica.org ») или используйте подстановочный знак (*) чтобы найти заархивированные поддомены или подкаталоги веб-сайта (например, «* .Cambridgeanalytica.org»). Вот поиск * .cambridgeanalytica.org в архиве. сегодня:
Найдите Cambridge Analytica в архиве. Сегодня
Как и Wayback Machine, archive.today предоставляет вам прямые ссылки к заархивированному контенту с использованием веб-адресов со встроенными отметками даты, вроде следующего: http://archive.today/2018.01.01-042001/ https://ocean.cambridgeanalytica.org/
Совет:
Archive.today также предлагает сервис Tor onion на сайте archivecaslytosk.onion. Доступ к сервисам Onion можно получить только через браузер Tor, но они упрощают сохранение ваших взаимодействие с сервисом анонимно. Это особенно полезно и жизненно важно, если вы исследуете деликатная тема, или вы подозреваете, что ваши действия в Интернете могут отслеживаться.
Кэш Google
Google Cache — еще один способ найти страницу, которая была недавно занята вниз или недоступен по иным причинам.
Когда Google обращается к веб-странице, он создает кэшированную версию или копию этой страницы в качестве резервное копирование. Он часто делает эти копии доступными в результатах поиска.
Чтобы получить доступ к кэшированной версии страницы Google, используйте поисковая система для поиска страницы, которую вы хотите найти, нажмите на маленькая стрелка справа от веб-адреса результата поиска и выберите «Кэшировано». Это загрузит кешированную версию веб-сайта, который был поддержан поднял Google, когда его сканеры ранее проиндексировали сайт.
Скриншот Google Cache
В приведенном выше случае мы попытались найти кеш ныне несуществующей веб-сайт http://cambridgeanalytica.org/, но по состоянию на 28 февраля 2019 г. больше не доступен в поиске Google (мы могли найти только веб-форму вместо). Однако его кешированная версия все еще была доступна 26 января. Февраль 2019 г., и, как показано ниже, мы смогли захватить с помощью archive.today
Cambridge Analytica в архиве.сегодня
В отличие от упомянутых выше служб архивирования, кеш Google не предоставить исторические записи о страницах, которые он хранит.
Вместо этого он отображает содержимое этих страниц в последний раз, когда сканеры получили к ним доступ, поэтому они могут выявить контент, который отсутствует в текущую версию веб-страницы или предоставить вам доступ к странице, на которой с тех пор был снят.
Обнаружение кэшированной веб-страницы указывает на то, что она когда-то существовала, но кеши часто перезаписываются обновленным содержимым или полностью исчезают (как в нашем случае выше).Кроме того, администраторы веб-сайтов могут запросить у Google удаление страниц из кеша.
По той или иной причине Google не может долго хранить кешированную страницу. достаточно, чтобы вы могли использовать его в качестве доказательства в своем расследовании, так что это часто бывает полезно создать резервную копию самой кэшированной страницы с помощью дополнительных сервис, такой как archive.today, и сделать свою собственную автономную копию как резервное копирование. Скриншоты и PDF-файлы полезны для документирования того, как вы нашли конкретная версия страницы и может помочь вам позже, если вам нужно продемонстрировать, что информация точна.
Совет:
Когда вы архивируете веб-страницу с помощью службы, такой как Wayback Machine или archive.today, особенно если у нее длинный и сложный веб-адрес, например, заархивированная копия записи в Google Cache, обязательно запишите эту ссылку где-нибудь в файле на вашем компьютере. компьютер, в защищенной облачной папке или в другом месте. Полагаться на историю вашего браузера, чтобы найти такие вещи, — это верный путь к катастрофе.
Веб-сайт
Webcite — это бесплатный сервис, предлагает способ сохранить ссылки, которые были процитированы в статьях или журналы, включая веб-страницы или другой цифровой контент в Интернете.
Веб-сайт
Этой службой обычно пользуются авторы, редакторы, исследователи и издатели, которые хотят сохранить онлайн-ссылки в своей работе.
WebCite позволяет быстро и вручную сохранять отдельные веб-страницы. адреса. Также есть служба, которая автоматически «прочесывает» загруженные текстовые документы, чтобы сохранить все цитаты из онлайн-источники.
WebCite поддерживает несколько различных способов поиска цитируемого материала. В Помимо удобочитаемых и сокращенных веб-адресов, WebCite также предоставляет цитаты с более продвинутыми справочными форматами, такими как DOI (Digital Идентификатор объекта) и криптографические хэши.
Вы можете отправлять контент в WebCite, используя букмарклет или веб-форму по адресу https://www.webcitation.org/archive.
Примечание: Визуальные мониторы
Еще одна возможность получать содержимое веб-сайта и оставаться в курсе, если таковые имеются изменения происходят, это использование визуальных мониторов сайта. Это услуги, которые может отслеживать и отслеживать визуальные изменения на веб-страницах, происходят ли они в код, изображения, текст и т. д. Они могут быть очень полезны для исследователей и помочь автоматизировать часть работы, если вам нужно отслеживать множество веб-сайтов, полезны в вашем расследовании.
Visual site отслеживает архивные веб-страницы иначе, чем инструменты и услуги, которые мы исследовали выше. Вы оказываете услугу особую раздел веб-страницы для просмотра, и он делает снимок, а затем отслеживает страницу для видимых изменений.
Если будут какие-то изменения, большие или маленькие, монитор сайта пришлет вам электронное письмо, чтобы вы знали.
В электронном письме будет ссылка на веб-сайт, на котором вы можете увидеть больше подробности. Некоторые мониторы сайтов прикрепляют скриншоты до и после менять.
Как следователь, вы можете использовать монитор участка в сочетании с служба архивации, чтобы быть в курсе важных обновлений веб-сайта.
Чтобы уведомлять вас об изменениях, эти инструменты требуют, чтобы вы настроили учетной записи и предоставить им доступ к адресу электронной почты или телефону номер. Вы можете избежать раскрытия своей истинной личности и контактных данных, создание отдельного адреса электронной почты, особенно если вы работаете с конфиденциальными расследования.
Визуализация
Visualping предлагает бесплатный план, который позволяет отслеживать до 62 веб-страниц в месяц.Это означает, что он может проверить все, что находится между двумя веб-страниц в день (он дает вам обновления для двух разных веб-страниц ежедневно, если происходят изменения) или несколько страниц в неделю, до 62 веб-страниц a в месяц (где он проверяет 62 страницы на предмет изменений один раз в месяц) — или другое комбинации, которые работают на вас. Бесплатная версия может запускать проверки ежечасно, ежедневно, еженедельно или ежемесячно для сравнения веб-страницы с ее предыдущими версиями и сообщать вам по электронной почте об изменениях текста, изображений, ключевых слов или любые выбранные области страницы занимают место.Сервис также работает через Tor Браузер, и мы рекомендуем использовать эту опцию для дополнительного уровня конфиденциальность и безопасность.
Скриншот Visualping
ChangeTower
ChangeTower предлагает бесплатный план, который отслеживает до трех веб-сайтов и проводит до шести проверок в день (в этом случае может сканировать веб-сайт для смены два раза в день). Он может отслеживать определенный URL (веб-страницу), весь веб-сайт или различные варианты (вы можете выбрать, какие страницы веб-сайт, который вы хотите отслеживать).Он может искать изменения в содержании (текст), визуальный контент, HTML, ключевые слова и т. д. В бесплатном плане хранятся ваши мониторинг результатов до месяца. Сервис также работает через Tor Браузер, и мы рекомендуем использовать эту опцию для дополнительного уровня конфиденциальность и безопасность.
Снимок экрана ChangeTower
Опубликовано в апреле 2019 г.
Глоссарий
журнал доступа к терминам
Протокол доступа — a файл, который записывает каждый просмотр веб-сайта и документов, изображений и другие цифровые объекты на этом веб-сайте.Он включает такую информацию как кто посещал сайт, откуда, как долго и какой контент они доступ
терм-алгоритм
Алгоритм — установленная последовательность шагов для решения конкретной проблема.
полоса пропускания
Пропускная способность — в вычислениях максимальная скорость передачи информации на единица времени по заданному пути.
термин-букмарклет
Букмарклет — сложный веб-адрес, который вы можете добавить в свой список «закладки» или «избранное» браузера.Когда вы щелкаете букмарклет, он обычно отправляет информацию о странице, которую вы в настоящее время посещаете сторонний сервис.
термин-сломанная ссылка
Неработающая ссылка — URL-адрес, к которому больше не прикреплены нужные данные.
term-browserextension
Расширение браузера — также называемые надстройками, это небольшие части программное обеспечение, используемое для расширения функциональных возможностей веб-браузера. Эти могут быть чем угодно из расширений, которые позволяют делать скриншоты посещаемые вами веб-страницы на тех, кто проверяет и исправляет вашу орфографию или блокирование нежелательных добавлений с веб-сайтов.
термокэш
Кэш — временное высокоскоростное хранилище данных, которые были использованы или обрабатывается и может быть быстро восстановлен, вместо того, чтобы посещать исходный источник или повторные вычисления, связанные с запрошенными данными.
поисковые машины
Crawlers — программное обеспечение, которое автоматически просматривает интернет-страницы для выполнять типично исследовательские функции.
термин-криптографический хэш
Криптографический хеш — способ идентификации данных путем отправки файла или другая часть информации через алгоритм, который суммирует ее с буквенно-цифровая строка фиксированной длины (комбинация букв и числа до 100 знаков).Эту струну очень сложно сломать математически, что означает, что вы можете передать его кому-нибудь в помощь определить, является ли файл большего размера правильным или нетронутым.
справочник терминов
Каталог — контейнер, который используется для категоризации файлов или других контейнеры файлов и данных.
term-doi
Идентификатор цифрового объекта (DOI) — уникальный идентификатор, который относится к опубликованной работе, аналогично ISBN, но для работ, опубликованных в цифровом виде.Распределение и администрирование DOI координируется DOI Foundation https://www.doi.org/.
термин-доменное имя
Доменное имя — также называемое веб-доменом, обычно используется для доступа к веб-сайту, который преобразуется в IP-адрес.
терм-ip
IP-адрес — набор числа, используемые для идентификации компьютера или местоположения данных, к которому вы подключаетесь на (например, 213.108.108.217)
термин-вредоносное ПО
Вредоносное ПО — вредоносное ПО, которое обычно скрыто от пользователей.
термин-роботstxt
Robots.txt — файл на веб-сайте, который инструктирует автоматизированные программы (боты / роботы / сканеры) о том, как вести себя с данными на веб-сайте.
терм-сервер
Веб-сервер — также известный как «Интернет-сервер», система, которая размещает веб-сайты и доставляет их контент и услуги в конечные пользователи через Интернет.
термин-скриншот
Скриншот — изображение экрана устройства, снятое в цифровом формате.
термин-сценарий
Скрипт — список команд, выполняемых программой.
термин-поддомен
Поддомен — обычно дополнительный идентификатор добавляется перед доменным именем, чтобы указать подкатегорию данных или страниц. например, google.com — это доменное имя, translate.google.com — это субдомен.
термин-сторонний
Третье лицо — физическое или юридическое лицо, не являющееся непосредственно часть контракта, но, тем не менее, может иметь связанную с ним функцию.
терминал
Браузер Tor — а браузер, который сохраняет конфиденциальность ваших действий в Интернете, маскируя ваши идентичность и защита вашего веб-трафика от многих форм Интернета наблюдение
база терминов
Userbase — список пользователей, связанных с определенной платформой или системой.
термин-vpn
VPN — программное обеспечение, которое создает зашифрованный «туннель» из ваше устройство на сервер, управляемый вашим поставщиком услуг VPN, маскируя ваши фактический IP-адрес при посещении веб-сайтов
термин-сайт
Сайт — набор страниц или данные, предоставляемые удаленно, обычно для людей с Интернетом или сетью доступ.
term-webpage
Веб-страница — документ (страница), который доступны через Интернет, отображаются в веб-браузере.
Как узнать, когда была опубликована веб-страница
Когда вы проводите исследование по какой-либо теме, очень важно следить за тем, чтобы ваши источники были актуальными. Если вы пишете научную статью, в цитировании часто указываются даты публикации.
В большинстве случаев получить дату легко: просто загляните на сайт и найдите дату публикации, чтобы узнать, насколько недавней она была.Все становится немного сложнее, когда на веб-странице нет даты. Когда это происходит, как узнать, когда веб-страница была опубликована?
Внутри страницы и вокруг нее
Первый порт вызова при определении того, когда веб-страница была опубликована, находится на самой странице и вокруг нее. В большинстве случаев дату публикации статьи следует указывать рядом с именем автора прямо над статьей. В более редких случаях эта информация может быть под статьей.
Менее точный, но все же полезный способ оценки даты публикации веб-страницы — это просмотреть комментарии. Когда был написан первый комментарий? Это даст вам представление о том, насколько устарела статья и, следовательно, насколько актуальна содержащаяся в ней информация.
Наконец, некоторые блоги и сайты автоматически форматируют дату статьи в URL-адресе страницы, поэтому загляните в адресную строку, чтобы увидеть, сможете ли вы найти какие-нибудь подсказки.
Последнее замечание: посмотрите, есть ли на странице дата обновления.В более старой статье может быть сказано, что она была первоначально опубликована пять лет назад, но в конце сообщения вы можете найти вторую дату, в которой говорится, что сообщение было обновлено шесть месяцев назад.
Посмотреть исходный код
Вы можете использовать свой браузер для просмотра исходного кода большинства веб-сайтов. Часто вы можете узнать, когда была опубликована веб-страница, выполнив поиск по коду.
Начните с посещения веб-сайта или статьи, для которой вам нужна дата. Вы должны быть на конкретной странице, а не только на главной странице веб-сайта.
Щелкните эту веб-страницу правой кнопкой мыши, и во всплывающем меню появится список параметров. Выберите «Просмотр источника страницы» из списка.
Макет веб-страницы будет изменен, и справа откроется панель, показывающая исходный код страницы. Это HTML-код, который выполняется браузером для отображения версии страницы, которая отображается на вашем экране. Каждая деталь, касающаяся создания и макета веб-страницы, упоминается в исходном коде, если вы знаете, что искать.
4. После открытия источника страницы используйте ярлык Ctrl + F , чтобы открыть панель поиска.
5. На панели введите «Опубликовать», чтобы выделить каждую строку исходного кода, где используется это слово.
Все, что вам нужно сделать, это прочитать всю строку, где есть слово «Опубликовать». Одна из этих строк будет содержать дату создания веб-страницы.
Кроме того, вы можете выполнить поиск по запросу «Изменено» и выполнить те же действия, что и выше, чтобы узнать даты, когда статья была изменена.
Использование Google
Часто поиск Google по вашему веб-сайту показывает, когда веб-страница была опубликована. Откройте веб-страницу с неизвестной датой публикации. Скопируйте URL-адрес в окно поиска Google и выполните поиск. Хотя есть гораздо более сложный способ сделать это, более простой способ — выбрать временной диапазон, чтобы начать показывать даты рядом с каждым результатом в списке поиска.
Иногда дата последней публикации веб-страницы автоматически отображается в Google, как, например, в этом поиске, показанном ниже.
Если вы не видите дату, нажмите Инструменты над результатами поиска. Откройте раскрывающийся список «В любое время» и выберите «Пользовательский диапазон».
Введите широкий диапазон. Обычно если вернуться примерно на 10–15 лет назад, даже на старых веб-страницах будет указана дата. В противном случае, если веб-страница старше указанного вами диапазона, результат исчезнет из списка результатов поиска. Если вы знаете, что страница была опубликована в течение установленного периода, вам нужно только вернуться на этот срок.
Использование машины Wayback
The Wayback Machine — это сайт, который следит за развитием веб-сайтов с годами.Если веб-страница не слишком популярна, она может не отображаться в Wayback Machine; тем не менее, если вы все-таки получите доступ к машине, вы сможете приблизительно оценить, когда была опубликована веб-страница.
Сначала перейдите к Wayback Machine, затем введите адрес сайта, который вы хотите проверить, в адресную строку на сайте.
Когда вы нажимаете «Обзор истории», Wayback Machine проверит, может ли он найти журналы веб-сайта. Если это так, он отобразит календарь со всеми собранными снимками.Найдите как можно более раннюю дату для приблизительной оценки того, когда страница была опубликована; по крайней мере, вы будете знать, что эта страница хотя бы существовала в тот период!
Использование углеродных знакомств в Интернете
Carbon Dating the Web — удобный инструмент, который дает приблизительную оценку времени создания веб-страницы. Когда разработчики протестировали его на страницах, для которых была известна дата создания, у него было 75% успеха при угадывании того, когда оно было создано. Его очень легко использовать: просто вставьте URL-адрес веб-страницы в поле и нажмите «Carbon Date!»
Затем сайт сообщит вам приблизительную дату создания сайта, который вы предоставили.
Вы даже можете загрузить веб-приложение Carbon Dating для локального использования, если обнаружите, что выполняете много поисков. Просто нажмите ссылку на сайте, чтобы скачать.
Заключение
Независимо от того, проводите ли вы исследование для статьи или просто хотите узнать, когда была опубликована веб-страница, может быть неприятно, когда веб-мастер не добавляет дату к своим статьям. К счастью, есть способы получить приблизительное представление о том, когда страница открылась. Это может быть неточно в 100% случаев, но может дать вам хорошее представление о том, насколько актуальна статья.
Какой метод вам больше нравится? Вы знаете метод, который мы упустили? Сообщите нам об этом ниже.
Связанный:
Эта статья полезна? да Нет
Кристальный КраудерКристал Краудер более 15 лет проработала в сфере высоких технологий, сначала в качестве ИТ-специалиста, а затем в качестве писателя.Она работает, чтобы научить других максимально эффективно использовать свои устройства, системы и приложения. Она всегда в курсе последних тенденций и всегда находит решения общих технических проблем.
веб-сайтов выглядят неправильно или выглядят иначе, чем должны
В этой статье рассматриваются веб-сайты, некорректно отображаемые в Firefox.
Примечание: Если у вас возникли проблемы с веб-сайтом, щелкните значок в адресной строке, чтобы узнать, не заблокировал ли Firefox небезопасные части страницы.См. Подробности в разделе «Блокировка смешанного содержимого в Firefox».Firefox кэширует веб-сайты, что означает, что он сохраняет некоторые файлы на вашем компьютере, чтобы вам не приходилось повторно загружать все, когда вы посещаете сайты. Если веб-сайт обновил свой код, Firefox может по-прежнему использовать часть старого кода вместе с частью нового, что может привести к неправильному отображению веб-страницы. Чтобы исправить это, вам необходимо очистить файлы cookie и кеш:
- Щелкните кнопку меню, чтобы открыть панель меню. Нажмите кнопку «Библиотека» на панели инструментов.(Если вы не видите его там, нажмите кнопку меню, а затем щелкните.)
- Щелкните и выберите.
- В раскрывающемся списке Диапазон времени для очистки: выберите Все .
- В раскрывающемся меню выберите Cookies и Cache . Убедитесь, что другие элементы, которые вы хотите сохранить, не выбраны.
- Нажмите ОК.
Некоторые веб-сайты могут некорректно отображаться при разных уровнях масштабирования. Чтобы сбросить настройку масштабирования, для сайта нажмите Ctrl + 0команда + 0, а для всех сайтов см. Документацию об используемом надстройке Zoom.
Некоторые сайты не отображаются должным образом с минимальным размером шрифта. Чтобы сбросить минимальный размер шрифта:
В строке меню вверху экрана щелкните и выберите. Нажмите кнопку меню и выберите Параметры Настройки. Нажмите кнопку меню и выберите Настройки.
- Выберите панель панели и перейдите к Язык и внешний вид .
- В разделе Fonts & Colors щелкните Advanced….
- Измените минимальный размер шрифта с на Нет .
Возможно, вы случайно установили стиль страницы. Чтобы убедиться, что Firefox настроен на использование стиля страницы по умолчанию:
- Нажмите клавишу Alt, чтобы временно вызвать традиционные меню Firefox В строке меню В верхней части окна Firefox щелкните меню, затем выберите, затем щелкните.
Теперь, когда для страницы используется стиль по умолчанию, он может отображаться правильно.
Вам следует проверить, есть ли у вас расширение (например, NoScript) или программа безопасности в Интернете (например, брандмауэр, антивирус или программа защиты от шпионского ПО), которая может блокировать JavaScript.
В некоторых случаях загрузка и проверка защищенного веб-содержимого будет зависеть от времени, поэтому вам следует проверить правильность установки даты, времени и часового пояса в вашей системе.
Некоторые расширения могут мешать отображению веб-сайтов или вашей видеокарте и драйверам некорректно отображать веб-контент при включенном аппаратном ускорении.Следуйте инструкциям в статье Устранение неполадок расширений, тем и аппаратного ускорения, чтобы решить общие проблемы Firefox, чтобы узнать, не является ли одно из них причиной проблемы.
Иногда вы можете встретить страницу, которая просто не работает в Firefox. Если это произойдет, сообщите о проблеме, посетив Webcompat.com.
Если вы используете Firefox Beta, Developer Edition или Nightly, щелкните меню действий страницы (три точки в адресной строке) и выберите. Вы также можете перейти в меню Firefox и щелкнуть, затем выбрать.
На основании информации с веб-сайтов выглядит неправильно (mozillaZine KB)
Как просматривать потерянные веб-страницы
Если веб-страница, которую вы хотели открыть, недоступна — причины могут варьироваться от временной проблемы с сетью до полного удаления страницы с веб-сайта — тогда вам не нужно терять надежду. На самом деле можно восстановить резервные копии большинства страниц из Интернета с помощью небольшого ноу-хау. Весь процесс невероятно прост, и вы найдете его очень полезным, если изучите тему и обнаружите, что ссылки, которые вы сохраняли в течение недель или даже месяцев, больше не работают.
Если вы хотите прочитать веб-страницу, которая была удалена или недоступна по иным причинам, это то, что вы можете сделать.
Wayback Machine
Archive.org Wayback, вероятно, лучший инструмент для восстановления любой удаленной веб-страницы. Это часть Интернет-архива, некоммерческой организации, которая пытается дублировать весь контент в Интернете. Он сохранил более 435 миллиардов веб-страниц, что, вероятно, не весь контент в Интернете, но все же впечатляет.Страницы фиксируются несколько раз, поэтому, например, мы использовали Wayback Machine, чтобы просмотреть домашнюю страницу NDTV Gadgets в течение нескольких разных лет, и увидели, что наш дизайн со временем эволюционировал.
Вот как им пользоваться.
Откройте сайт Wayback.
Введите URL-адрес отсутствующего веб-сайта или веб-страницы, которую вы хотите открыть, в поле вверху.
Щелкните Обзор истории .
Вы увидите представление календаря.Выберите год вверху, а затем дату из списка месяцев ниже.
Вот и все! Вам будет показана сохраненная версия страницы с этой даты.
Кэш поисковой системы
Если вы ищете страницу, которая была недавно удалена, то, возможно, будет проще найти ее с помощью поисковой системы, такой как Google, Yahoo или Bing. Пока вы можете найти веб-страницу в поисковой системе, вы также сможете загрузить резервную копию страницы.Вот как это работает:
Откройте понравившуюся поисковую систему. Кеширование Google очень хорошее, поэтому мы рекомендуем вам его использовать.
Вставьте ссылку на отсутствующую веб-страницу в строку поиска, если вы ее знаете, или просто выполните поиск страницы, чтобы найти нужную ссылку.
Под синим текстом ссылки вы увидите строку зеленого текста, которая представляет собой URL-адрес веб-страницы. Щелкните стрелку вниз рядом с зеленым текстом URL-адреса.
Нажмите Кэшировано .Это покажет вам сохраненную версию нужной страницы, а также подробную информацию о том, когда была сделана резервная копия.
Если эта страница не загружается должным образом, вы можете попробовать щелкнуть Текстовая версия в правом верхнем углу. Это приведет к потере всех изображений, которые были на странице, но, если они загружаются неправильно, это все равно позволит вам получить важные данные, которые вам нужны.
Сохранение необходимых веб-страниц
Если вы хотите сохранить веб-страницы для исследовательских целей, лучше сохранить их заранее.Сделать это из браузера очень просто:
Перейдите на веб-сайт, который хотите сохранить.