~d
Открывающая круглая скобка
(
\(
Закрывающая круглая скобка
)
\)
Открывающая фигурная скобка
{
\{
Закрывающая фигурная скобка
}
\}
Открывающая квадратная скобка
[
\[
Закрывающая квадратная скобка
]
\]
Длинное тире
^_
~_
Короткое тире
^=
~=
Дискреционный перенос
^-
~-
Неразделяемый дефис
^~
~~
Идеографический пробел
^(
~(
Круглая шпация
^m
~m
Полукруглая шпация
^>
~>
Шпация 1/3 круглой
^3
~3
Шпация 1/4 круглой
^4
~4
Шпация 1/6 круглой
^%
~%
Концевая шпация
^f
~f
Волосяная шпация
^|
~|
Фиксированный пробел
^s
~s
Фиксированный пробел (Постоянная ширина)
^S
~S
Тонкая шпация
^<
~<
Шпация на цифру
^/
~/
Шпация на точку
^. w
w
\s (вставляет пробел в «Заменить на»)
* Любой символ, за исключением пробела
\S
* Любой символ слова
\w
* Любой символ, за исключением символа слова
\W
* Любая прописная буква
\u
* Любой символ, за исключением прописной буквы
\U
* Любая строчная буква
\l
* Любой символ, за исключением строчной буквы
\L
^ Весь найденный текст
$0
Найденный текст 1-9
$1 (задает номер найденной группы, например $3 для третьей группы; группы взяты в скобки)
* Кандзи
^K
~K
* Начало слова
\<
* Конец слова
\>
* В пределах слова
\b
* Противоположно рамкам слова
\B
* Начало абзаца
^
* Конец абзаца [расположение]
$
* Один раз
?
* Несколько раз
*
* Один или несколько раз
+
* Один раз (Самое короткое совпадение)
??
* Несколько раз (Самое короткое совпадение)
*?
* Один или несколько раз (Самое короткое совпадение)
+?
* Маркировка подвыражения
( )
* Без маркировки подвыражения
(?: )
* Набор символов
[ ]
* Или
|
* Положительный просмотр назад
(?<= )
* Отрицательный просмотр вперед
(?<! )
* Положительный просмотр вперед
(?= )
* Отрицательный просмотр вперед
(?! )
* Режим «Без учета регистра» включен
(?i)
* Режим «Без учета регистра» отключен
(?-i)
* Многострочный режим включен
(?m)
* Многострочный режим выключен
(?-m)
* Однострочный режим включен
(?s)
* Однострочный режим выключен
(?-s)
* Любой буквенно-цифровой символ
[[:alnum:]]
* Любой алфавитный символ
[[:alpha:]]
* Любой пустой символ — пробел или знак табуляции
[[:blank:]]
* Любой управляющий символ
[[:control:]]
* Любой графический символ
[[:graph:]]
* Любой печатаемый символ
[[:печать:]]
* Любой знак препинания
[[:punct:]]
* Любой символ с кодом более 255 (применимо только к классам с расширенным набором признаков)
[[:unicode:]]
* Любой шестнадцатеричный цифровой 0-9, a-f и A-F
[[:xdigit:]]
* Любой символ из определенного набора глифов, например: a, à, á, â, ã, ä, å, A, À, Á, Â, Ã, Ä и Å
[[=a=]]
5.
 7. Поиск и замена. Основы информатики: Учебник для вузов
7. Поиск и замена. Основы информатики: Учебник для вузовЧитайте также
Поиск и замена данных
Поиск и замена данных В программе HtmlPad реализована возможность быстрого поиска данных. Этот механизм полезно использовать при работе с большими программными кодами или с большими объемами данных, поскольку поиск требуемой информации вручную (например, путем просмотра
Быстрый поиск и замена данных в программе NeonHtml
Быстрый поиск и замена данных в программе NeonHtml В программе NeonHtml реализована возможность быстрого поиска данных. Это особенно актуально при работе с большими программными кодами или с большими объемами данных, поскольку поиск требуемой информации вручную (например,
Поиск и замена данных
Поиск и замена данных
В программе Extra Hide Studio имеется удобный механизм для быстрого поиска и замены данных. Эта возможность особенно актуальна при работе с большими исходными кодами, поскольку поиск данных путем просмотра всего кода может занять слишком много времени, и к
Эта возможность особенно актуальна при работе с большими исходными кодами, поскольку поиск данных путем просмотра всего кода может занять слишком много времени, и к
Поиск на научных сайтах с использованием платформы Flexum «Поиск по научным сайтам»
Поиск на научных сайтах с использованием платформы Flexum «Поиск по научным сайтам» Тема научного поиска не прошла мимо разработчиков персональных поисковиков. Подробному рассказу о возможностях таких поисковых систем посвящена отдельная глава нашей книги (см. главу 6).
3.1. Поиск и замена фрагментов
3.1. Поиск и замена фрагментов Текстовый редактор успешно справляется с поиском и заменой текста в отдельном файле. Однако, если это же нужно сделать сразу в нескольких файлах, лучше воспользоваться специальными программами, с помощью которых можно заменить фрагменты
Поиск и замена текста
Поиск и замена текста
В текстовом редакторе Adobe InDesign можно воспользоваться полезнейшей функцией поиска и замены фрагментов текста. Причем, раз мы имеем дело с программой верстки, найденные фрагменты можно не только заменить другими, но и оформить каким-то образом –
Причем, раз мы имеем дело с программой верстки, найденные фрагменты можно не только заменить другими, но и оформить каким-то образом –
Поиск и замена текста с помощью VBA в Word
Поиск и замена форматирования
Поиск и замена форматирования Для поиска текста с определенным форматированием используйте свойства объекта Find, касающиеся форматирования. Они идентичны свойствам, используемым при работе с форматированием диапазона или выделенной области, как я уже отмечал в разделе
Автоматический поиск и замена данных
Автоматический поиск и замена данных
В процессе работы иногда возникает необходимость быстро найти те или иные данные (слово, текстовый фрагмент и т.
Поиск и замена
Поиск и замена В новой версии Excel был полностью изменен пользовательский интерфейс и расширены функциональные возможности средства Найти и заменить. Теперь можно с помощью одной операции производить поиск и замену по всем листам книги, повторно выполнять запросы поиска
Поиск и замена символов
Поиск и замена символов Иногда при подготовке электронных документов возникает задача поиска определенных текстовых фрагментов. Например, вы забыли номер чертежа, но помните, что в его названии или дополнительной информации, размещенной на чертеже, содержится
13.
 3.4. Поиск и замена текста
3.4. Поиск и замена текста
13.3.4. Поиск и замена текста Как вы уже догадались, окно Найти и заменить используется не только для перехода на нужную страницу. Вкладка Найти используется для поиска текста. Для быстрого доступа к этой вкладке нажмите Ctrl+F или выберите команду меню Правка, Найти. Нажмите
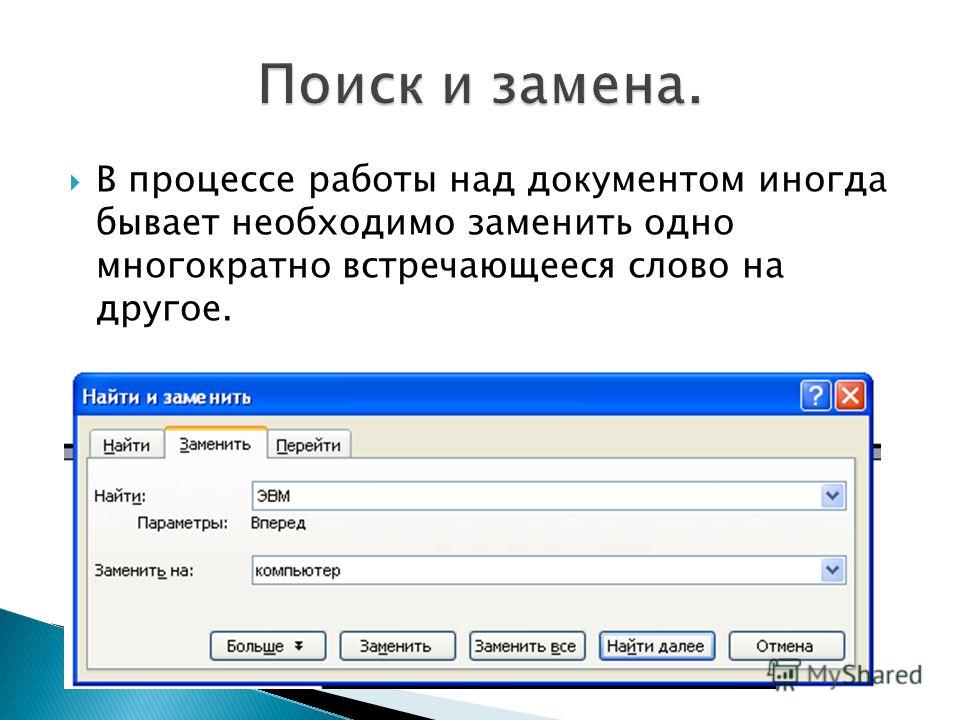
Поиск и замена
Поиск и замена Для поиска в тексте документа нужного слова или сочетания символов служит окно поиска и замены (рис. 9.19), которое открывается нажатием Ctrl+F. Если надо, чтобы оно сразу открылось как окно замены, используйте сочетание Ctrl+H. Рис. 9.19. Окно поиска и замены.Для
Поиск и замена фрагментов фильма
Поиск и замена фрагментов фильма
Очень часто бывает нужно найти в изображении или фильме Flash какой-либо текст и, возможно, заменить его на другой. Специально для этого Flash, как и многие другие программы, работающие с документами, предлагает богатые возможности по поиску и
Специально для этого Flash, как и многие другие программы, работающие с документами, предлагает богатые возможности по поиску и
Поиск и замена текста
Поиск и замена текста Поиск определенного слова или фразы в большом документе является довольно непростой задачей, но ее можно значительно упростить, если воспользоваться командой Главная ? Редактирование ? Найти. В появившемся окне (рис. 5.20) введите искомый текст и
Поиск и замена данных
Поиск и замена данных По современным меркам таблица с несколькими тысячами записей считается небольшой, но даже в такой таблице ручной поиск или отбор нужной информации может занять продолжительное время. С помощью средств поиска, сортировки и фильтрации нужные данные
Поиск и замена текста – Справочный центр BricsCAD
Команда: FIND
Команда FIND позволяет задать параметры поиска текста, найти этот текст на чертеже и выполнить его замену. При необходимости Вы можете приблизить текстовые объекты, содержащие искомый текст, для его просмотра.
При необходимости Вы можете приблизить текстовые объекты, содержащие искомый текст, для его просмотра.
Чтобы открыть диалоговое окно Поиск и замена текста
Запустите команду FIND.
Настройка параметров поиска и замены текста
Запустите команду FIND.
Нажмите кнопку Параметры….
Установите параметры поиска и замены текста.
Нажмите кнопку ОК.
Поиск текста
Запустите команду FIND.
При необходимости, выполните настройку параметров поиска и замены текста.
В поле Искать введите текст для поиска.
При необходимости, нажмите кнопку Указать объекты () для создания набора объектов.
- Окно Поиск и замена текста временно закроется для выбора объектов.
- Щелкните правой кнопкой мыши для завершения выбора объектов.

В поле Искать в опция Весь чертеж будет заменена опцией Выделенные объекты.
Нажмите кнопку Найти далее.
В поле Результаты поиска отобразится текстовый объект, содержащий искомый текст.При необходимости нажмите кнопку Показать.
Найденный текстовый объект отобразится в центре экрана.Выполните одно из следующих действий:
- Повторите действия п. 5 и 6 для поиска других текстовых объектов, содержащих искомый текст.
- Повторите действия п. 2-6 для поиска другого текста.
- Нажмите клавишу Esc или кнопку Закрыть для завершения поиска.
ПРИМЕЧАНИЕ | Если перед запуском команды FIND был создан набор выбранных объектов, поиск текста будет выполняться только в этом наборе. |

Замена текста
Запустите команду FIND.
При необходимости, выполните настройку параметров поиска и замены текста.
В поле Искать введите заменяемый текст.
В поле Заменить на введите новый текст.
При необходимости, нажмите кнопку Указать объекты () для создания набора объектов.
- Окно Поиск и замена текста временно закроется для выбора объектов.
- Щелкните правой кнопкой мыши для завершения выбора объектов.
В поле Искать в опция Весь чертеж будет заменена опцией Выделенные объекты.
При необходимости нажмите кнопку Заменить все.
Все вхождения искомого текста будут заменены новым текстом.При необходимости нажмите кнопку Найти далее.
В поле Результаты поиска отобразится текстовый объект, содержащий искомый текст.
- При необходимости нажмите кнопку Показать.
Найденный текстовый объект отобразится в центре экрана. - Выполните одно из следующих действий:
- Нажмите кнопку Заменить.
- Повторите это действие для поиска других текстовых объектов, содержащих искомый текст.
- При необходимости, повторяйте это действие до тех пор, пока не будут найдены все текстовые объекты на чертеже, содержащие искомый текст.
- При необходимости нажмите кнопку Показать.
Выполните одно из следующих действий:
- Повторите действия п. 2-7.
- Нажмите клавишу Esc или кнопку Закрыть для завершения поиска.
ПРИМЕЧАНИЕ | Если перед запуском команды FIND был создан набор выбранных объектов, поиск текста будет выполняться только в этом наборе. |
Руководство по GNU Emacs — Поиск и замена
Руководство по GNU Emacs — Поиск и замена Go to the first, previous, next, last section, table of contents.
Как и в других редакторах, в Emacs есть команды для поиска случаев появления какой-нибудь строки. Основная команда поиска необычна тем, что она является наращиваемой; она начинает поиск до того, как вы закончили набор строки поиска. Существуют также команды и для ненаращиваемого поиска, более похожие на аналогичные команды в других редакторах.
Кроме обычной команды replace-string, которая находит все
случаи появления одной строки и заменяет их другой, Emacs имеет более
сложную команду замены, названную query-replace, которая
запрашивает в интерактивном режиме, в каких случаях надо произвести
замену.
Наращиваемый поиск начинается, как только вы набрали первый знак
строки поиска. По мере того, как вы набираете строку поиска, Emacs
показывает вам, где эта строка (в том виде, в каком вы ее уже набрали)
может быть найдена. Когда вы набрали достаточно знаков, чтобы
определить желаемое место, вы можете остановиться. В зависимости от
того, что вы собираетесь делать потом, вам может понадобиться, а может и
не понадобиться прекратить поиск явно с помощью RET.
В зависимости от
того, что вы собираетесь делать потом, вам может понадобиться, а может и
не понадобиться прекратить поиск явно с помощью RET.
- C-s
- Наращиваемый поиск вперед (
isearch-forward). - C-r
- Наращиваемый поиск в обратном направлении (
isearch-backward).
C-s начинает наращиваемый поиск. C-s считывает знаки с
клавиатуры и располагает курсор в первом месте появления знаков, которые
вы набрали. Если вы наберете C-s и затем F, то курсор
встанет справа после первой найденной `F’. Наберите О, и
увидите, что курсор встал за первой найденной `FO’. После еще
одной О курсор встанет за первой `FOO’, находящейся за
местом, с которого вы начали поиск. На каждом шаге текст буфера,
совпадающий со строкой поиска, подсвечивается, если терминал может это
сделать; текущая строка поиска обновляется на каждом шаге в эхо-области.
Если вы сделали ошибку в наборе строки поиска, то вы можете сбросить знаки с помощью DEL. Каждый DEL отменяет последний знак строки поиска. Этого не происходит до тех пор, пока Emacs не будет готов считать следующий вводимый знак; сначала знак, который вы хотите сбросить, должен быть либо найден, либо нет. Если же вы не хотите ждать, пока это произойдет, используйте C-g так, как описано ниже.
Когда вы будете удовлетворены достигнутым местом, вы можете набрать RET, что остановит поиск, оставляя курсор там, куда его поместила
команда поиска. Любая команда, не имеющая специального значения при
поиске, также останавливает поиск и затем выполняется сама. Таким
образом, набор C-a привел бы к выходу из поиска и затем передвинул
бы курсор в начало строки. RET необходим только в том случае,
если следующая команда, которую вы хотите набрать, является печатным
знаком, DEL, RET или другим управляющим знаком, имеющим
особое значение во время работы поиска (C-q, C-w, C-r, C-s, C-y, M-y, M-r или M-s).
Иногда вы ищете слово `FOO’ и находите его, но это не то, что вам нужно. Было второе `FOO’, о котором вы забыли, находящееся перед тем, которое вы ищете. В этом случае наберите C-s еще раз, чтобы продвинуться к следующему появлению строки поиска. Это можно проделывать неограниченное число раз. Если вы проскочили, то можете отменить некоторые число знаков C-s с помощью DEL.
После выхода из поиска вы можете снова искать ту же самую строку, просто набрав C-s C-s: первый C-s — это ключ, который запускает наращиваемый поиск, а второй C-s означает «повтор поиска».
Чтобы вы могли снова использовать более ранние строки поиска,
существует список поиска. Команды M-p и M-n передвигают по списку, чтобы вы могли подобрать нужную строку для
повторного поиска. Эти команды оставляют выбранную строку поиска в
минибуфере, где вы можете ее отредактировать. Для завершения
редактирования и начала поиска наберите C-s или C-r.
Для завершения
редактирования и начала поиска наберите C-s или C-r.
Если ваша строка вообще не найдена, то эхо-область говорит `Failing I-Search’. Курсор располагается после того места, где
Emacs нашел из вашей строки вс╠, что смог. Таким образом, если вы ищете `FOOT’, а такой строки нет, вы можете увидеть курсор после `FOO’ в слове `FOOL’. С этого места вы можете сделать
несколько вещей. Если ваша строка неправильно набрана, вы можете что-то
стереть из нее и исправить. Если вы довольны найденным местом, вы
можете набрать RET или любую другую команду Emacs, чтобы «принять
то, что предложил этот поиск», или вы можете набрать C-g, что
уничтожит из строки поиска знаки, которые не были найдены (`Т’ в `FOOT’), оставляя те, что нашлись (`FOO’ в `FOOT’).
Второй C-g в этом месте отменяет поиск полностью, возвращая точку
туда, где она была, когда поиск начался.
Если строка поиска содержит заглавную букву, то поиск производится с учетом регистра. Если вы удалите заглавные буквы из строки поиска, эта особенность исчезает. See section Поиск и регистр букв.
Если поиск был неудачным и вы просите повторить его, набирая C-s еще раз, то он начинается снова с начала буфера. Повторение неудачного поиска в обратном направлении при помощи команды C-r начинает новый поиск с конца. Такой поиск называется круговым. Как только это произошло, в подсказке поиска появляется слово `Wrapped’. Если вы пройдете через точку, где начался поиск, это слово заменяется на `Overwrapped’, что означает, что вы снова проходите через уже виденные вами совпадения.
Знак «выхода» C-g поступает во время поиска особым образом.
Что именно он делает, зависит от статуса поиска. Если поиск нашел то,
что вы хотели, и ожидает ввода, то C-g полностью отменяет поиск.
Курсор возвращается туда, откуда вы начали поиск. Если C-g набирается, когда в строке поиска есть ненайденные знаки — Emacs все
еще ищет их, или он не смог их найти — тогда эти ненайденные знаки
сбрасываются из строки поиска. Сброс этих знаков делает поиск успешным,
и он ждет дальнейшего ввода, таким образом, второй C-g отменит
поиск полностью.
Если C-g набирается, когда в строке поиска есть ненайденные знаки — Emacs все
еще ищет их, или он не смог их найти — тогда эти ненайденные знаки
сбрасываются из строки поиска. Сброс этих знаков делает поиск успешным,
и он ждет дальнейшего ввода, таким образом, второй C-g отменит
поиск полностью.
Чтобы найти символ перевода строки, введите C-j. Для поиска другого управляющего знака, такого как control-S или возврат каретки, вы должны отменить их специальное значение, набирая перед ними C-q. Эта функция C-q аналогична ее назначению как команды для вставки (see section Вставка текста): она заставляет трактовать следующий знак так, как в этом контексте трактовался бы любой «обычный» знак. Вы также можете задать знак по его восьмиричному коду: введите C-q и затем последовательность восьмиричных цифр.
Вы можете изменить направление поиска на обратное при помощи C-r. Вам следует поступить так, если поиск оказался неудачным,
потому что место, с которого вы его начали, находилось слишком близко к
концу файла. Повторение C-r продолжает поиск следующих случаев
появления в обратном порядке, а C-s начинает поиск опять вперед. C-r в поиске может быть отменена при помощи DEL.
Повторение C-r продолжает поиск следующих случаев
появления в обратном порядке, а C-s начинает поиск опять вперед. C-r в поиске может быть отменена при помощи DEL.
Если вы заранее знаете, что вам нужно вести поиск в обратном порядке,
то чтобы начать поиск, вы можете использовать C-r вместо C-s, так как C-r также является ключом, запускающим команду
(isearch-backward) для поиска в обратном порядке. Обратный поиск
находит совпадения, которые расположены перед начальной точкой, так же
как поиск вперед находит совпадения, начинающиеся после точки, где поиск
начался.
Знаки C-y и C-w могут использоваться в наращиваемом
поиске для захвата текста из буфера в строку поиска. Это делает удобным
поиск другого случая появления того текста, который находится в точке. C-w копирует слово после точки в строку поиска, продвигая точку
вперед через это слово. Следующая команда C-s для повторения
поиска будет затем искать строку, включающую это слово. C-y подобна C-w, только копирует в строку поиска весь остаток текущей
строки. И C-y, и C-w преобразуют копируемый текст к нижнему
регистру, если поиск сейчас ведется без учета регистра; таким образом
поиск остается регистронезависимым.
Следующая команда C-s для повторения
поиска будет затем искать строку, включающую это слово. C-y подобна C-w, только копирует в строку поиска весь остаток текущей
строки. И C-y, и C-w преобразуют копируемый текст к нижнему
регистру, если поиск сейчас ведется без учета регистра; таким образом
поиск остается регистронезависимым.
Команда M-y копирует в строку поиска текст из списка уничтожений. Она использует тот же текст, который был бы восстановлен командой C-y. See section Восстановление.
Когда вы выходите из наращиваемого поиска, метка устанавливается в то место, где точка была до начала поиска. Это удобно для возврата к этому месту. В режиме Transient Mark наращиваемый поиск устанавливает метку, не активизируя ее, если только метка уже не активна.
Чтобы настроить специальные знаки, которые понимает наращиваемый
поиск, измените их привязки в таблице ключей isearch-mode-map. Для получения перечня привязок посмотрите документацию на
Для получения перечня привязок посмотрите документацию на isearch-mode с помощью C-h f isearch-mode RET.
Наращиваемый поиск на медленном терминале
Наращиваемый поиск на медленных терминалах использует модифицированный способ отображения, который разработан так, чтобы занимать как можно меньше времени. Вместо показа буфера в каждом месте, до которого добрался поиск, он создает новое окно, состоящее из одиночной строки, и использует его для показа найденной строки. Это окно из одной строки вступает в игру, как только точка выходит за пределы текста, который уже находится на экране.
Когда вы прерываете поиск, однострочное окно убирается. Только в этот момент Emacs перерисовывает окно, в котором производился поиск, чтобы отобразить новое положение точки.
Такой стиль отображения используется, когда скорость терминала в бодах
меньше или равна значению переменной search-slow-speed, чье
начальное значение равно 1200.
Количество строк, показываемых при поиске на медленном терминале,
управляется переменной search-slow-window-lines. Ее обычное
значение равно единице.
В Emacs также есть удобные команды ненаращиваемого поиска, которые требуют от вас полностью набрать строку поиска до начала работы.
- C-s RET строка RET
- Поиск заданной строки.
- C-r RET строка RET
- Поиск строки в обратном направлении.
Чтобы начать ненаращиваемый поиск, наберите сначала C-s RET. Эта команда входит в минибуфер для считывания строки поиска; ограничьте эту строку с помощью RET, и поиск начнется. Если строка не будет найдена, команда поиска выдает ошибку.
Способ работы C-s RET заключается в следующем: C-s запускает наращиваемый поиск, который специально запрограммирован так, что запускает ненаращиваемый поиск, если заданный вами аргумент является пустым. (Такой пустой аргумент в других случаях был бы бесполезен). C-r RET работает аналогично.
Однако, запрошенный с помощью C-s RET ненаращиваемый поиск
не запускает непосредственно search-forward. Первым делом
проверяется, не будет ли следующим знаком C-w, что запустит поиск
слов.
Прямой и обратный ненаращиваемый поиск осуществляются командами search-forward и search-backward. Эти команды могут быть
привязаны к ключам обычным способом. Возможность их запуска через
наращиваемый поиск имеет исторические причины и, помимо этого,
существует для того, чтобы вам не нужно было находить для них подходящие
последовательности ключей.
Поиск по словам применяется для отыскания последовательности слов независимо от того, как эти слова разделены. Более подробно, вы набираете строку из нескольких слов, используя для их разделения одиночные пробелы, и эта строка может быть найдена, даже если в оригинале слова разделены несколькими пробелами, переводами строки, либо любыми знаками препинания.
Поиск слов полезен при редактировании печатных документов, подготовленных в программах для форматирования текста. Если вы редактируете, просматривая уже напечатанную, отформатированную версию, то вы не можете сказать, где прерывается строка в исходом файле. При помощи же поиска слова вы можете искать, не имея этой информации.
- C-s RET C-w слова RET
- Ищет слова, игнорируя пунктуацию между ними.
- C-r RET C-w слова RET
- Ищет слова в обратном направлении, игнорируя пунктуацию между ними.
Поиск слов — это специальный случай ненаращиваемого поиска, и он вызывается с помощью C-s RET C-w. За этим следует строка поиска, которая всегда должна быть ограничена RET. Будучи ненаращиваемым, поиск не начинается до тех пор, пока аргумент не завершен. Этот поиск работает путем создания регулярного выражения и его поиска; смотрите section Поиск регулярного выражения.
Для обратного поиска слов используйте C-r RET C-w.
Прямой и обратный поиск слов реализован в командах word-search-forward и word-search-backward. Эти команды
могут быть привязаны к ключам обычным способом. Возможность их запуска
через наращиваемый поиск существует по историческим причинам и для того,
чтобы вам не нужно было находить для них подходящие последовательности
ключей.
Регулярное выражение (regexp, если кратко) — это образец, который обозначает набор строк, возможно, и неограниченный набор. В GNU Emacs вы можете искать следующее совпадение с регулярным выражением как наращиваемым способом, так и простым.
Наращиваемый поиск регулярного выражения производится набором C-M-s (isearch-forward-regexp). Эта команда считывает
наращиваемую строку поиска, так же, как C-s, но трактует ее как
регулярное выражение, а не ищет в тексте буфера точное совпадение.
Каждый раз, когда вы добавляете текст в строку поиска, вы делаете
регулярное выражение длиннее, и ищется уже новое регулярное выражение.
Вызов C-s с префиксным аргументом (значение не играет роли) —
это другой способ произвести прямой поиск регулярного выражения. Чтобы
запустить поиск регулярного выражения в обратном направлении,
используйте C-M-r (isearch-backward-regexp) или C-r с
префиксным аргументом.
Все управляющие знаки, которые делают специальные вещи в рамках обыкновенного наращиваемого поиска, имеют те же самые функции и в наращиваемом поиске регулярного выражения. Набор C-s или C-r немедленно после начала поиска восстанавливает последнее регулярное выражение, использованное для наращиваемого поиска регулярного выражения; это говорит о том, что наращиваемый поиск регулярного выражения и строки имеют независимые значения по умолчанию. Они также имеют раздельные списки поиска, доступ к которым вы можете получить с помощью M-p и M-n.
Если при наращиваемом поиске регулярного выражения вы наберете SPC, он будет совпадать с произвольной последовательностью пробельных знаков, включая переводы строк. Если вам нужен только один пробел, введите C-q SPC.
Обратите внимание, добавление знаков к регулярному выражению при наращиваемом поиске может вернуть курсор назад и начать поиск снова. Например, если вы искали `foo’ и добавляете `\|bar’, курсор вернется назад, если первый `bar’ предшествовал первому `foo’.
Ненаращиваемый поиск регулярного выражения осуществляется функциями re-search-forward и re-search-backward. Вы можете
запустить их с помощью M-x, или привязать их к ключам или вызывать
через наращиваемый поиск регулярного выражения с помощью C-M-s RET и C-M-r RET.
Если вы используете команды наращиваемого поиска регулярного выражения
с префиксным аргументом, они производят обычный поиск строки, как isearch-forward и isearch-backward.’, `.’, `*’, `+’, `?’, `[‘, `]’ и `\’. Любые другие знаки,
появляющиеся в регулярном выражении, являются обыкновенными, если только
им не предшествует `\’.
Например, `f’ — это неспециальный знак, значит он обыкновенный, поэтому `f’ — это регулярное выражение, которое соответствует строке `f’ и никакой другой. (Оно не соответствует строке `ff’). Аналогично, `о’ — это регулярное выражение, которое соответствует только `о’. (Когда различия в регистре игнорируются, эти регулярные выражения также совпадают с `F’ и `O’, но мы рассматриваем это как обобщение понятия «та же строка», а не как исключение.)
Любые два регулярных выражения a и b могут быть сцеплены. Результатом является регулярное выражение, совпадающее со строкой, в которой a соответствует некоторому началу этой строки, а b соответствует остатку строки.
В качестве простого примера мы можем сцепить регулярные выражения `f’ и `o’, чтобы получить регулярное выражение `fo’, которое соответствует только строке `fo’. Пока все просто. Чтобы сделать что-то нетривиальное, вам необходимо использовать один из специальных знаков. Здесь представлен их перечень.
- . (Точка)
- является специальным знаком, который соответствует любому одиночному знаку, за исключением перевода строки. Используя конкатенацию (сцепление), вы можете составить регулярное выражение, подобное `a.b’, которое соответствует любой трехзнаковой строке, начинающейся с `a’ и кончающейся на `b’.
- *
- сама по себе не является конструкцией; это постфиксный оператор, который означает, что предыдущее регулярное выражение должно быть повторено столько раз, сколько это возможно. Таким образом, `o*’ соответствует любому числу букв `o’ (включая нуль). `*’ всегда относится к наименьшему возможному предыдущему выражению. Таким образом, `fo*’ содержит повторяющуюся `о’, а не `fo’. Оно совпадает с `f’, `fo’, `foo’ и так далее. Конструкция `*’ обрабатывается путем сопоставления с наибольшим количеством повторений, которое сразу может быть найдено. Затем продолжается сравнение с остатком шаблона. Если оно прошло неудачно, то происходит перебор с возвратом. Некоторые из совпадений с конструкцией с модификатором `*’ сбрасываются, чтобы дать возможность поиска соответствия для остатка структуры. Например, сравнивая `ca*ar’ со строкой `caaar’, `a*’ сначала ставится в соответствие со всеми тремя `а’, но остаток шаблона — это `ar’, а в этом случае для подбора остается только `r’, поэтому эта попытка неудачна. Следующий вариант — это поставить в соответствие с `а*’ только две буквы `а’. При таком выборе остаток регулярного выражения успешно соответствует строке.
- +
- это такой же постфиксный оператор, как и `*’, за исключением того, что он требует, чтобы предшествующее ему выражение сопоставлялось по крайней мере один раз. Так например, `ca+r’ будет соответствовать строкам `car’ и `caaar’, но не строке `cr’, тогда как `ca*r’ соответствует всем трем строкам.
- ?
- постфиксный оператор, как и `*’, но он может соответствовать предшествующему выражению либо один раз, либо ни одного. Например, `ca?r’ будет соответствовать `car’ или `cr’ и ничему больше.
- [ ... ]
- это набор знаков, который начинается `[‘ и завершается `]’. В простейшем случае совпадающий набор формируют знаки между этими скобками. Таким образом, `[ad]’ соответствует либо одной `a’, либо одному `d’, а `[ad]*’ соответствует любой строке, составленной просто из `а’ и `d’ (включая пустую строку), из всего этого следует, что `c[ad]*r’ соответствует `cr’, `car’, `cdr’, `caddaar’ и так далее.’, но сравнение происходит только в конце строки. Таким образом, `xx*$’ соответствует строке из одного или более `x’ в конце строки.
- \
- имеет две функции: отменяет особый смысл специальных знаков (включая `\’) и вводит дополнительные специальные конструкции. Так как `\’ отменяет особый смысл специальных знаков, то `\$’ — это регулярное выражение, которое соответствует только `$’, а `\[‘ — регулярное выражение, которое соответствует только `[‘, и так далее.
Замечание: для исторической совместимости специальные знаки трактуются как обычные знаки, если они находятся в контексте, в котором их специальный смысл не имеет значения. Например, `*foo’ трактует `*’ как обыкновенный, так как не существует предыдущего выражения, на которое может подействовать `*’. Плохо быть зависимым от этого правила; лучше всегда явно отменять особый смысл специальных знаков независимо того, где они находятся.
В большинстве случаев `\’, за которым следует любой знак, соответствует только этому знаку. Однако, существует несколько исключений: двухзнаковые последовательности, начинающиеся с `\’, имеющие особый смысл. Второй знак в такой последовательности всегда обычный, когда встречается сам по себе. Здесь представлена таблица конструкций с `\’.
- \|
- описывает альтернативу. Два регулярных выражения a и b с `\|’ между ними формируют выражение, которое соответствует любому из них в отдельности: либо a, либо b. Это работает так: сначала пробуется a, и если соответствие не найдено, пробуется b. Таким образом, `foo\|bar’ соответствует либо `foo’, либо `bar’, но не другой строке. `\|’ применяется к самым большим охватывающим выражениям. Только охватывающие скобки `\( … \)’ могут ограничить группирующую силу `\|’. Существует возможность полного обратного восстановления для обработки многократных использований `\|’.
- \( ... \)
- группирующая конструкция, которая служит для трех целей:
- Чтобы отделить набор альтернатив `\|’ от других операций. Таким образом, `\(foo\|mar\)x’ соответствует либо `foox’, либо `marx’.
- Чтобы ограничить сложное выражение для действия постфиксных операторов `*’, `+’ и `?’. Таким образом, `ba\(na\)*’ соответствует `bananana’ и так далее с любым (нулевым или большим) числом строк `na’.
- Чтобы отметить соответствующую подстроку для будущей ссылки.
- \n
- соответствует тексту, совпавшему с n-ным появлением конструкции `\( … \)’. После конца конструкции `\( … \)’ сопоставление запоминает начало и конец текста, совпавшего с этой конструкцией. Затем, позднее в регулярном выражении, вы можете использовать `\’, за которым следует цифра n, чтобы сказать: «сопоставить с том же текстом, который совпал с n-ным появлением конструкции `\( … \)’«. Строкам, соответствующим первым девяти конструкциями `\( … \)’, появляющимся в регулярном выражении, присваиваются номера от 1 до 9 в том порядке, в каком в регулярном выражении появились открывающие скобки. Конструкции от `\1′ до `\9′ могут использоваться для ссылки на текст конструкции `\( … \)’ с этим номером. Например, `\(.*\)\1′ соответствует любой строке, не содержащей знаков перевода строки, которая состоит из двух одинаковых половин. `\(.*\)’ соответствует первой половине, которая может быть любой, но `\1′, что идет следом, должна соответствовать точно такому же тексту. Если для какой-нибудь конструкции `\( … \)’ найдено более одного соответствия (что может легко произойти, если за ней следует `*’), то запоминается только последнее совпадение.
- \`
- соответствует пустой строке, но только в начале буфера или строки, где происходит поиск.
- \'
- соответствует пустой строке, но только в конце буфера или строки, где происходит поиск.
- \=
- соответствует пустой строке, но только в точке.
- \b
- соответствует пустой строке, если эта конструкция находится в начале или конце слова. Таким образом, `\bfoo\b’ соответствует любому появлению `foo’ как отдельного слова. `bballs?\b’ соответствует `ball’ или `balls’ как отдельным словам. `\b’ находит соответствие в начале или конце буфера, независимо от того, какой текст идет далее.
- \B
- соответствует пустой строке, если только она находится не в начале или конце слова.
- \<
- соответствует пустой строке, если она находится в начале слова. `\<‘ находит соответствие в начале буфера, но только если затем идет знак, являющийся частью слова.
- \>
- соответствует пустой строке, если она находится в конце слова. `\>’ находит соответствие в конце буфера, но только если буфер завершается знаком, являющимся частью слова.
- \w
- соответствует любому знаку, являющемуся частью слова. Какие именно это знаки, определяет синтаксическая таблица. See section Синтаксическая таблица.
- \W
- соответствует любому знаку, не являющемуся частью слова.
- \sc
- соответствует любому знаку, чей синтаксис определяется кодом c. Здесь c — это знак, который представляет собой синтаксический код, например, это `w’ для части слова, `-‘ для пробельных знаков, `(‘ для открывающей скобки, и так далее. Вы можете обозначить пробельный знак (который может быть переводом строки) либо как `-‘, либо одним пробелом.
- \Sc
- соответствует любому знаку, чей синтаксис не определяется кодом c.
Конструкции, имеющие отношение к словам и синтаксису, управляются установками в синтаксической таблице (see section Синтаксическая таблица).
Далее представлено сложное регулярное выражение, используемое Emacs для распознавания конца предложения вместе с любыми пробельными знаками, которые идут следом. Оно дано в синтаксисе Лиспа, чтобы дать вам возможность отличить пробелы от знаков табуляции. В синтаксисе Лиспа, константная строка начинается и заканчивается двойными кавычками. `\»‘ обозначает двойные кавычки как часть регулярного выражения, `\\’ обозначает обратную косую черту, `\t’ обозначает знак табуляции, а `\n’ — знак новой строки.
"[.?!][]\"')]*\\($\\|\t\\| \\)[ \t\n]*"
Здесь последовательно содержатся четыре части: набор знаков, соответствующий точке, `?’ или `!’; набор знаков, соответствующий парным квадратным скобкам, кавычкам или круглым скобкам, повторяемым любое число раз; альтернатива, заключенная в скобки с обратными косыми чертами, которая соответствует концу строки, табуляции или двум пробелам; и набор знаков, соответствующий любым пробельным знакам, повторяющимся любое число раз.
Чтобы ввести это регулярное выражение интерактивно, вы напечатали бы TAB, чтобы получить знак табуляции, и C-j, чтобы получить знак перевода строки. Вы также печатали бы одиночные обратные косые черты как есть, а не дублировали бы их в соответствии с синтаксисом Лиспа.
Все виды наращиваемого поиска в Emacs обычно игнорируют регистр текста, в котором происходит поиск, если вы задали текст в нижнем регистре. Таким образом, если вы запросили поиск `foo’, то совпадениями считаются и `Foo’, и `foo’ . Регулярные выражения, и в частности наборы знаков, также включаются в это правило: `[aB]’ соответствовало бы `a’, или `A’, или `b’ или `B’.
Заглавная буква в любом месте строки наращиваемого поиска делает этот поиск регистрозависимым. Таким образом, поиск `Foo’ не найдет `foo’ или `FOO’. Это применяется также и к поиску регулярного выражения. Этот эффект исчезает, если вы удалили заглавные буквы из строки поиска.
Если вы установите переменную case-fold-search равной nil, все буквы должны будут совпадать точно, включая регистр.
Эта переменная своя для каждого буфера; ее изменение затрагивает только
текущий буфер, но существует значение по умолчанию, которое вы тоже
можете изменить. See section Локальные переменные. Эта переменная
применяется также и к ненаращиваемому поиску, включая те его
разновидности, которые осуществляются командами замены (see section Команды замены)
и командами поиска в истории минибуфера (see section История минибуфера).
Глобальные команды поиска и замены не нужны в Emacs так часто, как в других редакторах(3), но они доступны. Кроме простой команды M-x replace-string, которая аналогична такой же команде в большинстве редакторов, существует команда M-x query-replace, которая для каждого появления образца спрашивает вас, надо ли его заменять.
Команды замены обычно работают с текстом от точки до конца буфера;
однако, в режиме Transient Mark они действуют на область, когда метка
активна. Все команды замены заменяют одну строку (или регулярное
выражение) одной строкой замены. Можно выполнить параллельно несколько
замен, используя команду expand-region-abbrevs (see section Управление расшифровкой сокращения).
Безусловная замена
- M-x replace-string RET строка RET новая-строка RET
- Заменяет каждое вхождение строки на новую-строку.
- M-x replace-regexp RET regexp RET новая-строка RET
- Заменяет каждое совпадение с regexp на новую-строку.
Чтобы заменить каждый случай вхождения `foo’ после точки на `bar’, используется команда M-x replace-string с двумя аргументами `foo’ и `bar’. Замещение происходит только в тексте после точки, так, если вы хотите охватить весь буфер, вы должны сначала отправиться в его начало. Все экземпляры вплоть до конца буфера будут заменены; чтобы ограничиться заменой в части буфера, сузьте его до этой части перед выполнением замены (see section Сужение). В режиме Transient Mark, если область активна, замена ограничена этой областью (see section Режим Transient Mark).
Когда вы выходите из replace-string, точка остается на месте
последней замены. Значение точки в момент, когда была запущена команда replace-string, запоминается в списке пометок. C-u
C-SPC перемещает вас обратно.
Числовой аргумент ограничивает замену совпадениями, которые окружены ограничителями слов. Значение аргумента роли не играет.
Замена регулярных выражений
Команда M-x replace-string заменяет точные совпадения с
одиночной строкой. Аналогичная команда replace-regexp замещает
любое совпадение с заданным образцом.
В replace-regexp, новая-строка не обязательно должна быть
константой: она может ссылаться на все или часть того, что соответствует
регулярному выражению regexp. `\&’ в новой-строке означает полный замещаемый текст. `\n‘, где n — это
цифра, означает то, что было поставлено в соответствие n-ной
заключенной в скобки группе в регулярном выражении regexp. Чтобы
включить в новый текст знак `\’, вы должны ввести `\\’.
Например,
M-x replace-regexp RET c[ad]+r RET \&-safe RET
заменит (например) `cadr’ на `cadr-safe’ и `cddr’ на `cddr-safe’.
M-x replace-regexp RET \(c[ad]+r\)-safe RET \1 RET
делает обратное преобразование.
Команды замены и регистр букв
Если первый аргумент в команде замены набран в нижнем регистре, во
время поиска вхождений для замены регистр игнорируется — при условии,
что case-fold-search не равна nil. Если case-fold-search установлена в значение nil, регистр
учитывается во всех типах поиска.
Кроме того, когда аргумент новая-строка весь или частично написан строчными буквами, команды замены пытаются сохранить образец использования регистра в каждом вхождении. Таким образом, команда
M-x replace-string RET foo RET bar RET
заменяет `foo’ в нижнем регистре на `bar’ в нижнем регистре, `FOO’ в верхнем регистре на `BAR’, а `Foo’ с первой
заглавной буквой на `Bar’. (Три эти альтернативы: все строчные
буквы, все заглавные и первая заглавная — единственные варианты,
которые может распознать replace-string.)
Если в строке подстановки использованы буквы верхнего регистра, то они
остаются такими при каждой вставке этого текста. Если буквы верхнего
регистра используются в первом аргументе, то второй аргумент всегда
вставляется в том виде, в котором он дан, без изменения регистра.
Аналогично, если переменная case-replace или case-fold-search установлена равной nil, замещение
происходит без изменения регистра.
Замена с подтверждением
- M-% строка RET новая-строка RET
- M-x query-replace RET строка RET новая-строка RET
- Заменяет некоторые вхождения строки на новую-строку.
- C-M-% regexp RET новая-строка RET
- M-x query-replace-regexp RET regexp RET новая-строка RET
- Заменяет некоторые совпадения с regexp на новую-строку.
Если вы хотите заменить только некоторые экземпляры `foo’ на `bar’, но не все, вы не можете использовать обыкновенную replace-string. Вместо этого используется M-% (query-replace). Эта команда находит экземпляры `foo’ один
за другим, отображает каждый экземпляр и спрашивает вас, надо ли его
заменять. Числовой аргумент говорит query-replace, что нужно
рассматривать лишь те экземпляры, которые окружены знаками-разделителями
слов. Эта команда сохраняет регистр так же, как и replace-string, при условии, что case-replace не равна nil, как это обычно и бывает.
За исключением запроса подтверждения, query-replace работает
точно так же, как replace-string, а query-replace-regexp — как replace-regexp. Эта команда запускается при помощи C-M-%.
Когда вам показывают вхождение строки или совпадение с регулярным выражением regexp, вы можете набрать следующее:
- SPC
- чтобы заменить это вхождение на новую-строку.
- DEL
- чтобы перейти к следующему вхождению, не заменяя это.
- , (Запятая)
- чтобы заменить это вхождение и показать результат.’ подряд, так как во время работы
query-replaceхранится только одна предыдущая позиция замены. - C-r
- чтобы войти в новый уровень рекурсивного редактирования, в том случае, когда экземпляр нуждается скорее в редактировании, чем просто в замене его новой-строкой. Когда вы сделаете это, выйдите из этого уровня рекурсивного редактирования, набрав C-M-c, чтобы перейти к следующему вхождению. See section Уровни рекурсивного редактирования.
- C-w
- чтобы удалить это вхождение и потом войти в новый уровень рекурсивного редактирования, как в C-r. Используйте рекурсивное редактирование для вставки текста и замены удаленного вхождения строки. Когда вы закончите, выйдите из этого уровня рекурсивного редактирования с помощью C-M-c, чтобы перейти к следующему вхождению.
- C-l
- чтобы восстановить изображение экрана. Потом вы должны набрать еще один знак, чтобы указать, что делать с этим вхождением.
- C-h
- чтобы просмотреть сообщение, резюмирующее эти варианты. Потом вы должны набрать еще один знак, чтобы указать, что делать с этим вхождением.
Некоторые другие знаки являются синонимами перечисленных выше: y, n и q эквивалентны SPC, DEL и RET.
Кроме этих знаков, любой другой выходит из query-replace и
снова считывается как часть последовательности ключей. Таким образом,
если вы напечатаете C-k, она выйдет из query-replace и
уничтожит текст до конца строки.
Чтобы перезапустить query-replace, когда вы уже из нее вышли,
используйте C-x ESC ESC, которая повторит query-replace, так как она использовала минибуфер для чтения
аргументов. See section Повторение команды.
Смотрите также section Преобразование имен файлов в Dired, чтобы узнать о командах Dired для переименования, копирования или создания ссылок на файлы путем замены в их именах совпадений с регулярным выражением.
Здесь представлены некоторые другие команды, которые находят
совпадения с регулярными выражениями. Все они действуют от точки до
конца буфера, и все они игнорируют при сопоставлении регистр, если
образец не содержит заглавных букв, а case-fold-search отлична от nil.
- M-x occur RET regexp RET
- Выводит перечень, показывающий каждую строку буфера, которая содержит совпадение с regexp. Числовой аргумент задает число строк контекста, которые должны быть напечатаны перед и после каждой сравниваемой строки; значений по умолчанию — не печатать контекст. Чтобы ограничить поиск частью буфера, сузьтесь до этой части (see section Сужение). Буфер `*Occur*’, в который записывается вывод, служит в качестве меню для поиска вхождений в их оригинальном контексте. Щелкните Mouse-2 на вхождении, перечисленном в `*Occur*’, или поместите там точку и нажмите RET; это переключит в буфер, где делался поиск, и переместит точку к оригиналу выбранного вхождения.
- M-x list-matching-lines
- Синоним для M-x occur.
- M-x count-matches RET regexp RET
- Печатает число совпадений с regexp после точки.
- M-x flush-lines RET regexp RET
- Удаляет каждую строку, следующую после точки и содержащую совпадение с regexp.
- M-x keep-lines RET regexp RET
- Удаляет каждую строку, следующую после точки и не содержащую совпадение с regexp.
Кроме того, вы можете использовать из Emacs программу @command{grep} для поиска совпадений с регулярным выражением в группе файлов, а затем обратиться к найденным совпадениям последовательно или в произвольном порядке. See section Поиск с Grep под Emacs.
Go to the first, previous, next, last section, table of contents.
Не удается найти страницу | Autodesk Knowledge Network
(* {{l10n_strings.REQUIRED_FIELD}})
{{l10n_strings.CREATE_NEW_COLLECTION}}*
{{l10n_strings.ADD_COLLECTION_DESCRIPTION}}
{{l10n_strings.COLLECTION_DESCRIPTION}} {{addToCollection.description.length}}/500 {{l10n_strings.TAGS}} {{$item}} {{l10n_strings.PRODUCTS}} {{l10n_strings.DRAG_TEXT}}{{l10n_strings.DRAG_TEXT_HELP}}
{{l10n_strings.LANGUAGE}} {{$select.selected.display}}{{article.content_lang.display}}
{{l10n_strings.AUTHOR}}{{l10n_strings.AUTHOR_TOOLTIP_TEXT}}
{{$select.selected.display}} {{l10n_strings.CREATE_AND_ADD_TO_COLLECTION_MODAL_BUTTON}} {{l10n_strings.CREATE_A_COLLECTION_ERROR}}Функция поиска и замены — Р7-Офис
Чтобы найти нужные символы, слова или фразы, которые используются в текущей электронной таблице, щелкните по значку , расположенному на левой боковой панели, или используйте сочетание клавиш Ctrl+F.
Если вы хотите выполнить поиск или замену значений только в пределах определенной области на текущем листе, выделите нужный диапазон ячеек, а затем щелкните по значку .
Откроется окно Поиск и замена:
- Введите запрос в соответствующее поле ввода данных.
- Задайте параметры поиска, нажав на значок рядом с полем для ввода данных и отметив нужные опции:
- С учетом регистра — используется для поиска только тех вхождений, которые набраны в таком же регистре, что и ваш запрос, (например, если вы ввели запрос ‘Редактор’ и выбрали эту опцию, такие слова, как ‘редактор’ или ‘РЕДАКТОР’ и т.д. не будут найдены).
- Все содержимое ячеек — используется для поиска только тех ячеек, которые не содержат никаких других символов, кроме указанных в запросе (например, если вы ввели запрос ’56’ и выбрали эту опцию, то ячейки, содержащие такие данные, как ‘0,56’, ‘156’ и т.д., найдены не будут).
- Выделить результаты — используется для подсветки всех найденных вхождений сразу. Чтобы отключить этот параметр и убрать подсветку, щелкните по этой опции еще раз.
- Искать — используется для поиска только на активном Листе или во всей Книге. Если вы хотите выполнить поиск внутри выделенной области на листе, убедитесь, что выбрана опция Лист.
- Просматривать — используется для указания нужного направления поиска: вправо По строкам или вниз По столбцам.
- Область поиска — используется для указания, надо ли произвести поиск по Значениям ячеек или по Формулам, на основании которых они высчитываются.
- Нажмите на одну из кнопок со стрелками справа. Поиск будет выполняться или по направлению к началу рабочего листа (если нажата кнопка ), или по направлению к концу рабочего листа (если нажата кнопка ), начиная с текущей позиции.
Первое вхождение искомых символов в выбранном направлении будет подсвечено. Если это не то слово, которое вы ищете, нажмите на выбранную кнопку еще раз, чтобы найти следующее вхождение символов, которые вы ввели.
Чтобы заменить одно или более вхождений найденных символов, нажмите на ссылку Заменить, расположенную под полем для ввода данных, или используйте сочетание клавиш Ctrl+H. Окно Поиск и замена изменится:
- Введите текст для замены в нижнее поле ввода данных.
- Нажмите кнопку Заменить для замены выделенного в данный момент вхождения или кнопку Заменить все для замены всех найденных вхождений.
Чтобы скрыть поле замены, нажмите на ссылку Скрыть поле замены.
Вернуться на предыдущую страницуНайти и заменить в Excel
Поиск и замена данных – одна из часто применяемых операций в Excel. Используют даже новички. На ленте есть большая кнопка.
Команда поиска придумана для автоматического обнаружения ячеек, содержащих искомую комбинацию символов. Поиск данных может производиться в определенном диапазоне, целом листе или даже во всей книге. Если активна только одна ячейка, то по умолчанию поиск происходит на всем листе. Если требуется осуществить поиск значения в диапазоне ячеек Excel, то такой диапазон нужно предварительно выделить.
Далее вызываем Главная → Редактирование → Найти и выделить → Найти (кнопка с рисунка выше). Поиск также можно включить с клавиатуры комбинацией клавиш Сtrl+F. Откроется диалоговое окно под названием Найти и заменить.
В единственном поле указывается информация (комбинация символов), которую требуется найти. Если не использовать подстановочные символы или т.н. джокеры (см. ниже), то Excel будет искать строгое совпадение заданных символов. Для вывода результатов поиска предлагается два варианта: выводить все результаты сразу – кнопка Найти все; либо выводить по одному найденному значению – кнопка Найти далее.
После запуска поиска программа Excel быстро-быстро просматривает содержимое листа (или указанного диапазона) на предмет наличия искомой комбинации символов. Если такая комбинация обнаружена, то в случае нажатия кнопки Найти все Excel вываливает все найденные ячейки.
Если в нижней части окна выделить любое значение и затем нажать Ctrl+A, то в диапазоне поиска будут выделены все соответствующие ячейки.
Если же запуск поиска произведен кнопкой Найти далее, то Excel выделяет ближайшую ячейку, соответствующую поисковому запросу. При повторном нажатии клавиши Найти далее (либо Enter с клавиатуры) выделяется следующая ближайшая ячейка (подходящая под параметры поиска) и т.д. После выделения последней ячейки Excel перепрыгивает на самую верхнюю и начинается все заново. На этом познания о поиске данных в Excel у большинства пользователей заканчиваются.
Поиск нестрогого соответствия символов
Иногда пользователь не знает точного сочетания искомых символов что существенно затрудняет поиск. Данные также могут содержать различные опечатки, лишние пробелы, сокращения и пр., что еще больше вносит путаницы и делает поиск практически невозможным. А может случиться и обратная ситуация: заданной комбинации соответствует слишком много ячеек и цель поиска снова не достигается (кому нужны 100500+ найденных ячеек?).
Для решения этих проблем очень хорошо подходят джокеры (подстановочные символы), которые сообщают Excel о сомнительных местах. Под джокерами могут скрываться различные символы, и Excel видит лишь их относительное расположение в поисковой фразе. Таких джокеров два: звездочка «*» (любое количество неизвестных символов) и вопросительный знак «?» (один «?» – один неизвестный символ).
Так, если в большой базе клиентов нужно найти человека по фамилии Иванов, то поиск может выдать несколько десятков значений. Это явно не то, что вам нужно. К поиску можно добавить имя, но оно может быть внесено самым разным способом: И.Иванов, И. Иванов, Иван Иванов, И.И. Иванов и т.д. Используя джокеры, можно задать известную последовательно символов независимо от того, что находится между. В нашем примере достаточно ввести и*иванов и Excel отыщет все выше перечисленные варианты записи имени данного человека, проигнорировав всех П. Ивановых, А. Ивановых и проч. Секрет в том, что символ «*» сообщает Экселю, что под ним могут скрываться любые символы в любом количестве, но искать нужно то, что соответствует символам «и» + что-еще + «иванов». Этот прием значительно повышает эффективность поиска, т.к. позволяет оперировать не точными критериями.
Если с пониманием искомой информации совсем туго, то можно использовать сразу несколько звездочек. Так, в списке из 1000 позиций по поисковой фразе мол*с*м*уход я быстро нахожу позицию «Мол-ко д/сн мак. ГАРНЬЕР Осн.уход д/сух/чув.к. 200мл» (это сокращенное название от «Молочко для снятия макияжа Гараньер Основной уход….»). При этом очевидно, что по фразе «молочко» или «снятие макияжа» поиск ничего бы не дал. Часто достаточно ввести первые буквы искомых слов (которые наверняка присутствуют), разделяя их звездочками, чтобы Excel показал чудеса поиска. Главное, чтобы последовательность символов была правильной.
Есть еще один джокер – знак «?». Под ним может скрываться только один неизвестный символ. К примеру, указав для поиска критерий 1?6, Excel найдет все ячейки содержащие последовательность 106, 116, 126, 136 и т.д. А если указать 1??6, то будут найдены ячейки, содержащие 1006, 1016, 1106, 1236, 1486 и т.д. Таким образом, джокер «?» накладывает более жесткие ограничения на поиск, который учитывает количество пропущенных знаков (равный количеству проставленных вопросиков «?»).
В случае неудачи можно попробовать изменить поисковую фразу, поменяв местами известные символы, сократив их, добавить новые подстановочные знаки и др. Однако это еще не все нюансы поиска. Бывают ситуации, когда в упор наблюдаешь искомую ячейку, но поиск почему-то ее не находит.
Продвинутый поиск
Мало, кто обращается к кнопке Параметры в диалоговом окне Найти и заменить. А зря. В ней скрыто много полезностей, которые помогают решить проблемы поиска. После нажатия кнопки Параметры добавляются дополнительные поля, которые еще больше углубляют и расширяют условия поиска.
С помощью дополнительных параметров поиск в Excel может заиграть новыми красками в прямом смысле слова. Так, искать можно не только заданное число или текст, но и формат ячейки (залитые определенным цветом, имеющие заданные границы и т.д.).
После нажатия кнопки Формат выскакивает знакомое диалоговое окно формата ячеек, только в этот раз мы не создаем, а ищем нужный формат. Формат также можно не задавать вручную, а выбрать из имеющегося, воспользовавшись специальной командой Выбрать формат из ячейки:
Таким образом можно отыскать, к примеру, все объединенные ячейки, что другим способом сделать весьма проблематично.
Поиск формата – это хорошо, но чаще искать приходится конкретные значения. И тут Excel предоставляет дополнительные возможности для расширения и уточнения параметров поиска.
Первый выпадающий список Искать предлагает ограничить поиск одним листом или расширить его до целой книги.
По умолчанию (если не лезть в параметры) поиск происходит только на активном листе. Для повторения поиска на другом листе все действия нужно проделать еще раз. А если таких листов много, то поиск данных может отнять немало времени. Однако если выбрать пункт Книга, то поиск произойдет сразу по всем листам активной книги. Выгода очевидна.
Список Просматривать с выпадающими вариантами по строкам или столбцам, видимо, сохранился от старых версий, когда поиск требовал много ресурсов и времени. Сейчас это не актуально. В общем, я не пользуюсь.
В следующем выпадающем списке находится замечательная возможность поиска по формулам, значениям, а также примечаниям. По умолчанию Excel производит поиск в формулах либо, если их нет, в содержимом ячейки. Например, если искать фамилию Иванов, а фамилия эта есть результат формулы (копируется из соседнего листа), то поиск нечего не даст, т.к. в ячейке нет искомого перечня символов. По той же причине не удастся отыскать число, являющееся результатом работы какой-либо функции. Поэтому бывает смотришь в упор на ячейку, видишь искомое значение, а Excel его почему-то не видит. Это не глюк, это настройка поиска. Измените данный параметр на Значения и поиск будет осуществляться по тому, что отражено в ячейке, независимо от содержимого. Например, если в ячейке содержится результат вычисления 1/6 (как значение, а не формула) и при этом формат отражает только 3 знака после запятой (т.е 0,167), то поиск символов «167» при выборе параметра Формулы эту ячейку не обнаружит (реальное содержимое ячейки — это 0,166666…), а при выборе Значения поиск увенчается успехом (искомые символы совпадают с тем, что отражается в ячейке). И последний пункт в данном списке – Примечания. Поиск осуществляется только в примечаниях. Очень может помочь, т.к. примечания часто скрыты.
В диалоговом окне поиска есть еще две галочки Учитывать регистр и Ячейка целиком. По умолчанию Excel игнорирует регистр, но можно сделать так, чтобы «иванов» и «Иванов» отличались. Галочка Ячейка целиком также может оказаться весьма полезной, если ищется ячейка не с указанным фрагментом, а полностью состоящая из искомых символов. К примеру, как найти ячейки, содержащие только 0? Обычный поиск не подойдет, т.к. будут выдаваться и 10, и 100. Зато, если установить галочку Ячейка целиком, то все пойдет, как по маслу.
Поиск и замена данных
Данные обычно ищутся не просто так, а для каких-то целей. Такой целью часто является замена искомой комбинации (или формата) на другую. Чтобы найти и заменить в выделенном диапазоне Excel одни значения на другие, в окне Найти и заменить необходимо выбрать вкладку Замена. Либо сразу выбрать на ленте команду Главная → Редактирование → Найти и выделить → Заменить.
Еще удобнее применить сочетание горячих клавиш найти и заменить в Excel – Ctrl+H.
Диалоговое окно увеличится на одно поле, в котором указываются новые символы, которые будут вставлены вместо найденных.
По аналогии с простым поиском, менять можно и формат.
Кнопка Заменить все позволяет одним махом заменить одни символы на другие. После замены Excel показывается информационное окно с количеством произведенных замен. Кнопка Заменить позволяет производить замену по одной ячейке после каждого нажатия. Если найти и заменить в Excel не работает, попробуйте изменить параметры поиска.
Напоследок рассмотрим один классный трюк с поиском и заменой. Многие знают, что в ячейку можно вставить разрыв строк с помощью комбинации Alt+Enter.
А как быстро удалить все разрывы строк? Обычно это делают вручную. Однако ловкое использование поиска и замены сэкономит много времени. Вызываем команду поиска и замены с помощью комбинации Ctrl+H. Теперь в строке поиска нажимаем Ctrl+J — это символ разрыва строки — на экране появится точка. В строке замены указываем, например, пробел.
Жмем Ok. Все переносы строк заменились пробелами.
Функция поиска и замены при правильном использовании заменяет часы работы неопытного пользователя. Настоятельно рекомендую использовать все вышеизложенное. Если что-то не ищется в ваших данных или наоборот, выдает слишком много лишних ячеек, то попробуйте уточнить поиск с помощью подстановочных символов «*» и «?» или настраиваемых параметров поиска. Важно понимать, что если вы ничего не нашли, это еще не значит, что там этого нет.
Теперь вы знаете, как в эксель сделать поиск по столбцу, строке, любому диапазону, листу или даже книге.
Поделиться в социальных сетях:
Search and Replace для Windows
Поиск и замена для WindowsСм. Разделы «Замена Studio Pro» и «Замена Studio Business Edition» для получения информации о текстовом поиске нового поколения и замене утилит от Funduc Software. Матрица функций представляет собой сравнение функций трех наших утилит Windows grep.
Search and Replace — это наша «классическая», отмеченная наградами утилита поиска и замены, используемая программистами, веб-мастерами, переводчиками и начинающими пользователями компьютеров во всем мире.
Search and Replace, как и Replace Studio Pro и Replace Studio Business Edition, выполняет поиск строки в одном или нескольких файлах-файлах, а также может заменить это «совпадение поиска» другой строкой. Программа может выполнять поиск в подкаталогах и ZIP-файлах, а также выполнять поиск с учетом регистра или без учета регистра. Обширная поддержка поиска и замены регулярных выражений в стиле grep включает операции, охватывающие более одной строки, увеличение числа замен и вставку пути и имени файла в заменяемые файлы.Также доступен двоичный поиск и замена. Вы можете указать несколько масок и фильтров включения / исключения файлов в зависимости от даты и размера файла. Управление заменами включает настраиваемые подсказки по замене и отображение замен перед их выполнением. Легко понимаемый редактор сценариев упрощает подготовку частых и / или сложных многоэтапных операций поиска / замены. Расширенные операции сценария включают в себя оценщик логических выражений для дополнительного контроля над тем, какие файлы будут обрабатываться сценарием.Средство просмотра внутреннего контекста позволяет редактировать текстовые файлы. «Режим HTML» выполняет замену кода символа простой текст -> HTML. Вы также можете «прикоснуться» к файлам (изменить отметку времени / даты). Функция Search and Replace автоматически определяет, является ли искомый файл текстовым, и может быть настроен для запуска с отдельными внешними редакторами для результатов поиска в текстовых или двоичных файлах. Программа также может запускать связанные программы для «найденных» файлов, например, запускать ваш веб-браузер, если поисковый запрос происходит в .htm или.html файл.
Если вам нужно найти и заменить текст или просто найти текст, эта утилита просто необходима. Это значительно быстрее, чем другие утилиты Windows, работающие только с grep, и позволяет производить замену по той же цене, что и те программы, которые предлагают только возможности grep.
Search and Replace предназначен для Windows Vista, Windows 7, Windows 8 и Windows 10. Доступны отдельные 32-битные и x64 версии.
Дополнительные сведения см. В списке функций поиска и замены.
Главное окно поиска и замены
Характеристики
- Поиск и замена в нескольких файлах в нескольких подкаталогах.
- Поиск файлов .ZIP!
- Расширенный синтаксис egrep для поиска / замены регулярных выражений!
- Сценарии и командные переключатели.
- Просмотр результатов с цветовой кодировкой «в контексте» в настраиваемых пользователем шрифтах и цветах.
- Очень быстро!
- Контекстно-зависимая справка.
- Тысячи довольных клиентов. Доступны международные версии
- . Поддержка
- доступна в файле справки, в разделе часто задаваемых вопросов и по адресу [email protected]
Поиск и замена установщиков
SetupSR.exe (3,8 МБ) — Самоустанавливающаяся версия для 32-битной Windows. См. Раздел «Информация об установке и удалении» для получения инструкций по установке и удалению. Загрузите его во временный каталог и запустите setupsr.exe для установки.
SetupSR64.exe (4,0 МБ) — самоустанавливающаяся версия для 64-битной Windows. См. Раздел «Информация об установке и удалении» для получения инструкций по установке и удалению. Загрузите его во временный каталог и запустите setupsr64.exe для установки.
Примечание : Эти установщики НЕ будут обновлять существующие лицензии.Если вы являетесь зарегистрированным пользователем, следуйте инструкциям по обновлению, которые вы получили от нас, или напишите на [email protected], если вы потеряли свою копию инструкций по обновлению.
Посетите страницу загрузки условно-бесплатной / демонстрационной версии, чтобы узнать о вариантах.
Дополнительная информация
Заявление о лицензии — Положения EULA (Лицензионное соглашение с конечным пользователем)
Вопросы о покупке — Информация о цене и вариантах покупки.
Купить сейчас — https безопасная онлайн-регистрация.
Search and Replace Configuration Utility — бесплатная утилита, которая может быстро выполнять некоторые специальные настройки, недоступные в диалоговом окне параметров программы.
fshsetup.exe (901 КБ) или fshsetup64.exe (972 КБ) — FSHED — Funduc Software Hex Editor — бесплатный шестнадцатеричный редактор, который более сложен, чем наш шестнадцатеричный просмотрщик HexView, представленный ниже. Чтобы использовать шестнадцатеричный редактор FS в качестве средства просмотра / редактирования поиска и замены при обнаружении двоичного файла, перейдите в диалоговое окно Параметры | Общие и укажите путь к шестнадцатеричному редактору.Например:
c: \ tools \ fshed.exe «% путь%» / s% start% / l% length%
FSHED доступен в 32-битной или 64-битной версии. Программа работает в Windows Vista и выше. См. Домашнюю страницу FSHED для получения дополнительной информации.
Сценарий поиска и замены базы данныхв PHP
Информацию о том, как мы используем ваши данные, см. В нашей политике конфиденциальности.
Скачать и / или пожертвовать для поиска замены DB
Перед отправкой просмотрите всю форму.Это электроинструмент, и при неправильном использовании он сопряжен с риском, и мы не несем ответственности за его использование, поэтому помните, что вы делаете. Форма удобна, вам не нужно делать пожертвование, если вы не хотите, и если вы введете 0 долларов, вы все равно получите электронное письмо со ссылкой для скачивания. Вы также можете внести свой вклад и работать со скриптом прямо из репозитория Github. Обязательно проверьте папку нежелательной почты, поскольку мы обнаружили некоторые проблемы с доставляемостью, над решением которых мы работаем. Он лицензирован и распространяется с GPL V3, и вы должны знать условия этой лицензии перед использованием.Установка
Загрузите сценарий по ссылке, полученной по электронной почте, и установите его в секретную папку с обфусцированным именем, если он используется на общедоступном сервере. Ваш сервер также не должен быть настроен на предоставление списков каталогов, если это общедоступный сервер.
Не устанавливайте Search Replace DB в корневую папку, иначе вы рискуете получить всевозможные потенциальные проблемы.Просто не надо. Он должен работать в отдельной папке.
Чтобы узнать, как можно использовать этот инструмент для облегчения миграции, ознакомьтесь с нашей статьей о миграции WordPress или посетите статью WP Tuts +, в которой упоминается этот скрипт.
Если у вас есть какие-либо сомнения относительно того, как использовать этот автономный скрипт, подумайте о том, чтобы привлечь эксперта. Это действительно мощный фрагмент кода, который при неправильном использовании может повредить вашу базу данных без возможности восстановления. Если вам нужна помощь, обратитесь к кому-нибудь вроде нас, например, или к любому из других замечательных ребят, перечисленных на CodePoet.
Лицензия
Код предоставляется под лицензией GPL V3 и является полностью открытым исходным кодом. Имейте в виду, что это означает, что люди могут изменить этот код и предложить его, и что другие версии могут быть хуже… или лучше. Это код для разработчиков, созданный разработчиками, и вам следует использовать только код из источников, которым вы доверяете.
FAQ
Куда мне установить разархивированные файлы?
В каталоге на вашем веб-сервере. Это может быть папка с защитой httpauth, если это общедоступный веб-сервер.
Мне нужно платить?
Нет, это бесплатный открытый исходный код, и вы можете найти его на GitHub. Вы также можете отправлять его копии своим друзьям или использовать код в других проектах. Полная лицензия включена в программное обеспечение. Мы выбираем путь по умолчанию, позволяющий вам сделать пожертвование, но если вы скинт и работаете в одной из тех корпораций, где получение одобрения на трату в 7 долларов не стоит хлопот, вы можете воспользоваться. Просто запомните нас, если сценарий заставит вас хорошо выглядеть и даст вам прибавку!
Я слышал, что этот сценарий небезопасен.Это правда?
Не так опасно, как раньше! Для удобства мы выбрали переменные конфигурации WP, чтобы предварительно заполнить детали базы данных. Проблема в том, что оказывается, что люди неосторожны и оставляют скрипт лежать на своем производственном сервере. Так что пришлось уйти. Удобно для установки разработчика, кошмар на рабочем сервере. Это по-прежнему мощный инструмент, и он дает доступ хакеру, чтобы попытаться перебрать ваши учетные данные в базе данных, поэтому очень важно, чтобы вы не просто оставляли скрипт на месте, но если вы используете его на производственных серверах и вы немного рассеянны, то вас не накажут, если вас так легко взломают.
Я получаю сообщение об ошибке 2: Класс __PHP_Incomplete_Class не имеет десериализатора
Это распространенная ошибка, которая обычно возникает у пользователей плагинов Yoast, а также у некоторых других. Мы знаем об этом. В подавляющем большинстве случаев все нормально. Вы можете попробовать запустить скрипт из другой установки PHP — нет причин, по которым у вас не может быть канала к производственной базе данных и подключаться к ней, например, с вашей рабочей станции. Мы сделали все возможное, чтобы скрипт поподробнее был в нашем репозитории на github.
Журнал изменений:
Мы больше не публикуем журнал изменений на этой странице — вы можете просмотреть его на Github.
Взносы
Мы хотели бы получать сообщения, отчеты об ошибках и многое другое в репозитории Search Replace DB на github. Пожалуйста, приходите — вас будут более чем рады, но вам нужно будет запросить доступ по электронной почте [адрес электронной почты защищен]
Найти и заменить | Советы по Vim вики
Vim предоставляет команду : s (замена) для поиска и замены; этот совет показывает примеры того, как заменить.В некоторых системах gvim имеет Найти и заменить в меню Правка (: help: promptrepl), однако проще использовать команду : s из-за ее истории командной строки и возможности вставки текста (например, слово под курсором) в поля поиска или замены.
Команда : replace выполняет поиск текстового шаблона и заменяет его текстовой строкой. Есть много вариантов, но вы, вероятно, захотите:
-
: s / foo / bar / g - Найдите каждое вхождение «foo» (только в текущей строке) и замените его на «bar».
-
:% s / foo / bar / g - Найдите каждое слово «foo» (во всех строках) и замените его на «bar».
-
:% s / foo / bar / gc - Измените каждое «foo» на «bar», но сначала запрашивайте подтверждение.
-
:% s / \/ bar / gc - Заменить только целые слова, точно соответствующие «foo», на «bar»; просить подтверждения.
-
:% s / foo / bar / gci - Заменить каждый «foo» (без учета регистра из-за флага
i) на «bar»; просить подтверждения. -
:% s / foo \ c / bar / gcто же самое, потому что\ cделает поиск нечувствительным к регистру. - Это может потребоваться после использования
: установите noignorecase, чтобы поиск был чувствительным к регистру (по умолчанию).
-
:% s / foo / bar / gcI - Измените каждое «foo» (с учетом регистра из-за флага
I) на «bar»; просить подтверждения. -
:% s / foo \ C / bar / gcто же самое, потому что\ Cделает поиск чувствительным к регистру. - Это может потребоваться после использования
: set ignorecase, чтобы поиск был нечувствительным к регистру.
Флаг g означает global — изменяется каждое вхождение в строке, а не только первое. Этот совет предполагает настройку по умолчанию для параметра 'gdefault' и 'edcompatible' (выкл.), Который требует, чтобы флаг g был включен в % s /// g для выполнения глобальной замены. Использование : set gdefault создает путаницу, потому что тогда % s /// является глобальным, тогда как % s /// g — нет (то есть g меняет свое значение).Y для прокрутки экрана вниз, удерживая клавишу Ctrl и нажимая Y. Однако последние два варианта доступны только в том случае, если ваш Vim является обычным, большим или огромным, или функция insert_expand была включена во время компиляции (ищите + insert_expand в выводе : версия ).
Также при использовании флага c Vim перейдет к первому найденному совпадению, начиная с верха буфера, и запросит подтверждение для выполнения замены в этом совпадении.Vim применяет группу выделения IncSearch к совпадающему тексту, чтобы дать вам визуальную подсказку о том, с каким соответствием он работает (по умолчанию установлено значение , обратное для всех трех типов терминов, начиная с Vim 7.3). Кроме того, если найдено более одного совпадения и у вас включена подсветка поиска с помощью параметра : set hlsearch , Vim выделяет оставшиеся совпадения с помощью группы выделения Search . Если вы все же используете выделение при поиске, вы должны убедиться, что эти две группы выделения визуально различны, иначе вы не сможете легко определить, какое совпадение Vim предлагает вам заменить.
Диапазон поиска :
: s / foo / bar / g | Заменить каждый «foo» на «bar» в текущей строке. | |
:% s / foo / bar / g | Измените каждый «foo» на «bar» во всех строках. | |
: 5,12 сек / фут / бар / г | Измените каждый «foo» на «bar» для всех строк со строки 5 по строку 12 (включительно). | |
: 'a,' bs / foo / bar / g | Измените каждое «foo» на «bar» для всех строк от отметки a до отметки b включительно (см. примечание ниже). | |
: '<,'> s / foo / bar / g | При компиляции с + visual замените каждое «foo» на «bar» для всех строк в визуальном выделении. Vim автоматически добавляет диапазон визуального выбора (‘<,'>) для любой команды ex, когда вы выбираете область и вводите : . Также см. Note ниже. | |
:., $ S / foo / bar / g | Заменить каждый ‘foo’ на ‘bar’ для всех строк из текущей строки (.баз / с / фоо / бар / г | Замените каждое «foo» на «bar» в каждой строке, начинающейся с «baz». |
- Примечание : Начиная с Vim 7.3, замены, применяемые к диапазону, определяемому метками или визуальным выбором (который использует специальный тип меток ‘<и'>), не ограничиваются положением столбца помечает по умолчанию. Вместо этого Vim применяет замену ко всей строке, в которой появляется каждая метка, если только атом
\% Vне используется в шаблоне, например:: '<,'> s / \% Vfoo / bar / g. M) - После открытия
[, все до следующего закрытия]указывает / collection.1a-c] соответствует любому символу, кроме a, b, c или 1. -
\ {# \}используется для повторения./ foo. \ {2 \}будет соответствовать foo и двум следующим символам.\не требуется на закрывающем}, поэтому/foo.\{2}будет делать то же самое. -
\ (foo \)делает обратную ссылку на foo. Круглые скобки без побегов буквально совпадают. Здесь\требуется для закрытия\).
При замене :
-
\ r— это новая строка,\ n— нулевой байт (0x00). -
\ &— это амперсанд (& — это текст, соответствующий шаблону поиска). -
\ 0вставляет текст, совпадающий со всем шаблоном -
\ 1вставляет текст первой обратной ссылки.\ 2вставляет вторую обратную ссылку и так далее.
Вы можете использовать других разделителей с заменой:
-
: s # http: //www.example.com/index.html#http: //example.com/#
Сохраните ввод, используя \ zs и \ ze для установки начало и конец узора .Например, вместо:
-
: s / Copyright 2007 Все права защищены / Copyright 2008 Все права защищены /
Использование:
-
: s / Copyright \ zs2007 \ ze Все права защищены / 2008/
Использование текущего слова или регистров [править | править источник]
-
:% s // бар / г - Заменить каждое совпадение последнего поискового шаблона на «полосу».
- Например, вы можете сначала навести курсор на слово
foo, а затем нажать*для поиска этого слова. - Вышеупомянутый оператор заменит все слова, точно соответствующие «foo», на «bar».
-
:% s / foo // g - Замените каждое вхождение «foo» словом под курсором.
-
- Слово под курсором будет вставлено так, как если бы вы его набрали.
-
:% s / foo // g - Замените каждое вхождение ‘foo’ СЛОВО под курсором (разделенное пробелом).
-
- СЛОВО под курсором будет вставлено так, как если бы вы его набрали.
-
:% s / foo /a / g - Заменить каждое вхождение «foo» содержимым регистра «a».
-
a a. - Содержимое регистра «a» будет вставлено так, как если бы вы его ввели.
-
:% s / foo /0 / g - То же, что и выше, с использованием регистра 0, который содержит текст из самой последней команды восстановления.Примеры команд yank (копирования):
yi (, который копирует текст в круглых скобках вокруг курсора, иy $, который копирует текст от курсора до конца строки. После команды yank, в которой не указан регистр назначения, скопированный текст можно ввести, нажав Ctrl-R, затем0.
-
:% s / foo / \ = @ a / g - Заменить каждое вхождение «foo» содержимым регистра «a».
-
\ = @ a— это ссылка на регистр ‘a’. - Содержимое регистра «a» не отображается в команде. Это полезно, если регистр содержит много строк текста.
-
:% s //// g - Заменить каждое совпадение последнего шаблона поиска регистром
/(последний шаблон поиска). - После нажатия Ctrl-R, затем
/для вставки последнего шаблона поиска (и перед нажатием Enter для выполнения команды) вы можете редактировать текст, чтобы внести любые необходимые изменения.
-
:% s /* / бар / г - Заменить все вхождения текста в системном буфере обмена (в регистре
*) на ‘bar’ (см. Следующий пример, если многострочный). - В некоторых системах выделение текста (в Vim или другом приложении) — это все, что требуется для помещения этого текста в регистр
*.
-
:% s /a / bar / g - Заменить все вхождения текста в регистре «a» на «bar».M вручную заменяется на ‘\ n’ (два символа: обратная косая черта, ‘n’).
- Эту замену можно выполнить, набирая команду:
-
:% s /= replace (@a, "\ n", '\\ n', 'g') / bar / g
-
-
"\ n"(двойные кавычки) представляет собой односимвольный перевод строки;'\\ n'(одинарные кавычки) представляют собой две обратные косые черты, за которыми следует «n». - Функция
substitute ()оценивается регистром выражения= =); он заменяет каждую новую строку одной обратной косой чертой, за которой следует «n». -
=.
-
:% s /0 / бар / г - То же, что и выше, с использованием регистра 0, который содержит текст из самой последней команды восстановления.
См. Вставить регистры в командах поиска или двоеточия вместо использования буфера обмена.
-
:% s / foo / bar / - В каждой строке замените первое вхождение «foo» на «bar».
-
:% s /.* \ zsfoo / bar / - В каждой строке замените последнее вхождение «foo» на «bar».
-
:% s / \// g - В каждой строке удалите все вхождения слова «foo» целиком.
-
:% s / \. * // - В каждой строке удалите все слово «foo» и весь последующий текст (до конца строки).
-
:% s / \. \ {5} // - Удалите в каждой строке первое вхождение слова «foo» и следующие пять символов.
-
:% s / \\ zs. * // - В каждой строке удалите весь текст, следующий за словом «foo» (до конца строки).
-
:% s /.* \// - В каждой строке удалите все слово «foo» и весь предыдущий текст (с начала строки).
-
:% s /.* \ ze \// - В каждой строке удалите весь текст, предшествующий всему слову «foo» (с начала строки).
-
:% s /.\ (\ w \) / \ u \ 1/ - Если первый символ в начале текущей строки только является нижним регистром, переключите его на верхний регистр, используя
\ u(см. Переключение регистра символов).
-
:% s / \ (. * \ N \) \ {5 \} / & \ r / - Вставлять пустую строку каждые 5 строк.
- Шаблон выполняет поиск
\ (. * \ N \)(любая строка, включая ее окончание), повторяется пять раз (\ {5 \}). - Вместо
и(найденный текст) следует\ r(новая строка).
-
:% s / \/ \ = len (add (list, submatch (1)))? Submatch (0): submatch (0) / g - Получить список результатов поиска. (список должен существовать)
- Устанавливает флаг
изменениз-за замены, но содержимое не изменяется. - Примечание : с достаточно свежим Vim (версия 7.3.627 или выше) вы можете упростить это до:
-
:% s / \/ \ = add (list, submatch (1)) / gn - Это имеет то преимущество, что буфер не будет помечен как измененный, и не будет создано дополнительное состояние отмены.Выражение в заменяющей части выполняется в песочнице, и ему не разрешается изменять буфер.
Для замены шаблонов соответствующим текстом с учетом регистра можно использовать плагин Майкла Геддеса keepcase, например:
-
:% SubstituteCase / \ cHello / goodBye / g - Замените ‘Hello hello helLo HELLO’ на ‘Goodbye goodbye goodBye GOODBYE’
Для изменения смещений в файле патча (номер строки блока) можно использовать этот небольшой фрагмент:
-
с / ^ @@ - \ (\ d \ + \), \ (\ d \ + \) + \ (\ d \ + \), \ (\ d \ + \) @@ $ / \ = "@@ -".eval (submatch (1) + offsetdiff ). ",". submatch (2). "+". eval (submatch (3) + offsetdiff ). ",". submatch (4). "@@" / g
Полезно, когда мы хотим удалить некоторые блоки из патча, чтобы патч не жаловался на различия смещения.
- Note Следует попытаться сделать выражение более компактным, но не знаю, как это сделать без возможности изменения нежелательных линий.
См. Также: использование замены [править | править источник]
См. Также: подставить в буферы / файлы [править | править источник]
TO DO
Большой раздел «см. Также» может быть полезен читателям.Нам нужно объединить некоторые из связанных советов (но не усложняйте результат). Я включил номера чаевых, чтобы помочь редакторам отслеживать.
Требуется небольшой раздел, в котором упоминается, что простые замены часто лучше всего обрабатывать путем поиска, а затем изменения вручную (и нажатия . для повторения последнего изменения). Кроме того, вы можете решить, как изменить каждый экземпляр. См. Копирование или изменение попадания при поиске, где описан метод, при котором вы можете нажать n , чтобы найти следующий экземпляр, а затем ввести cs , чтобы изменить попадание при поиске на любое другое.
Были ли в последнее время изменения в работе% s? Каким-то образом я могу использовать и
- Если вы точно опишите, что вы делаете и что происходит, я мог бы помочь, хотя задавал вопросы. JohnBeckett (обсуждение) 02:15, 1 июня 2019 г. (UTC)
Word 2016: Использование функции поиска и замены
Урок 7: Использование поиска и замены
/ ru / word2016 / форматирование-текст / содержание /
Введение
Когда вы работаете с более длинными документами, поиск определенного слова или фразы может быть трудным и отнимать много времени.Word может автоматически искать в документе с помощью функции Find и позволяет быстро менять слова или фразы с помощью Replace .
Необязательно: загрузите наш практический документ.
Посмотрите видео ниже, чтобы узнать больше об использовании функции «Найти и заменить».
Найти текст
В нашем примере мы написали научную статью и будем использовать команду «Найти», чтобы найти все вхождения определенного слова.
- На вкладке Home щелкните команду Найти .Кроме того, вы можете нажать Ctrl + F на клавиатуре.
- Панель навигации появится в левой части экрана.
- Введите текст, который нужно найти, в поле в верхней части панели навигации. В нашем примере мы введем искомое слово.
- Если текст найден в документе, он будет выделен желтым цветом, и на панели навигации появится предварительный просмотр результатов . Или вы можете щелкнуть один из результатов под стрелками, чтобы перейти к нему.
Когда вы закончите, щелкните X , чтобы закрыть панель навигации. Выделение исчезнет.
Для получения дополнительных параметров поиска щелкните стрелку раскрывающегося списка рядом с полем поиска.
Заменить текст
Иногда вы можете обнаружить, что в документе неоднократно совершали ошибку — например, неправильно написали имя человека — или что вам нужно заменить одно слово или фразу на другое. Вы можете использовать функцию Word «Найти и заменить », чтобы быстро вносить изменения.В нашем примере мы воспользуемся функцией «Найти и заменить», чтобы изменить название журнала, сделав его сокращенным.
- На вкладке Home щелкните команду Replace . Кроме того, вы можете нажать Ctrl + H на клавиатуре.
- Откроется диалоговое окно «Найти и заменить ».
- Введите текст, который вы хотите найти, в поле Find what: .
- Введите текст, которым вы хотите его заменить, в поле Заменить на: .Затем нажмите Найти следующий .
- Word найдет первый экземпляр текста и выделит его, серым цветом.
- Просмотрите текст, чтобы убедиться, что вы хотите его заменить. В нашем примере текст является частью заголовка статьи, и его не нужно заменять. Мы снова нажмем Найти следующий , чтобы перейти к следующему экземпляру.
- Если вы хотите заменить его, вы можете щелкнуть Заменить , чтобы изменить отдельные экземпляры текста. Кроме того, вы можете щелкнуть Заменить все , чтобы заменить все вхождения текста во всем документе.
Текст будет заменен.
Когда вы закончите, нажмите Закрыть или Отмена , чтобы закрыть диалоговое окно.
Для дополнительных параметров поиска щелкните Дополнительно в диалоговом окне «Найти и заменить». Отсюда вы можете выбрать дополнительные параметры поиска, такие как соответствие регистру и игнорирование знаков препинания.
Когда дело доходит до использования «Заменить все», важно помнить, что он может найти совпадения, которые вы не ожидали, и что вы, возможно, не захотите менять.Вам следует использовать эту опцию только в том случае, если вы абсолютно уверены, что она не заменит ничего, чего вы не планировали.
Challenge!
- Откройте наш практический документ.
- Используя функцию Найти , определите, на каких страницах упоминается Кэролайн Гордон .
- Имя Т.С. Элиот написан с ошибкой. Замените все экземпляров Elliot на Eliot . Когда вы закончите, вы должны сделать три замены.
- Имя Аллена Тейта также написано с ошибкой. Найдите и замените Алана на Аллена. Подсказка : Не используйте Замените все . В противном случае вы можете случайно заменить слово сальдо .
/ ru / word2016 / indents-and-tabs / content /
Поиск и замена в vi
vi также имеет мощные возможности поиска и замены. Для поиска в тексте открытого файла определенной строки (комбинации символов или слов) в командном режиме введите двоеточие (:), «s», косую черту (/) и саму строку поиска.То, что вы вводите, будет отображаться в нижней строке экрана дисплея. Наконец, нажмите ENTER, и соответствующая область текста будет выделена, если она существует. Если соответствующая строка находится в области текста, которая в настоящее время не отображается на экране, текст будет прокручиваться, чтобы отобразить эту область.
Формальный синтаксис поиска:
: s / строка
Например, предположим, что вы хотите найти в тексте строку «вишня.»Введите следующее и нажмите ENTER:
: s / вишня
Первое совпадение слова «вишня» в вашем тексте будет выделено. Чтобы узнать, есть ли дополнительные вхождения той же строки в тексте, введите n , и выделение переключится на следующее совпадение, если оно существует.
Синтаксис для замены одной строки другой строкой в текущей строке:
: s / pattern / replace /
Здесь «шаблон» представляет старую строку, а «заменить» представляет новую строку.Например, чтобы заменить каждое вхождение слова «лимон» в строке на «апельсин», введите:
.
: s / лимон / апельсин /
Синтаксис замены каждого вхождения строки во всем тексте аналогичен. Единственное отличие — добавление «%» перед «s»:
:% s / шаблон / заменить /
Таким образом, повторение предыдущего примера для всего текста, а не только для одной строки, будет:
:% s / лимон / апельсин /
Далее: Работа с несколькими файлами
Поиск и замена текста
Поиск и замена текста
Вы можете искать и заменять текст в диалоговом окне Поиск , выбор Найти из меню Правка или нажав кнопку Search .Ты можешь также используйте сочетание клавиш: Ctrl-f .
Это диалоговое окно позволяет искать или заменять текст, используя разные критерии:
- Вы должны ввести строку символов, которую вы хотите найти, в Найдите поле .
- Если выбрана кнопка Игнорировать регистр , поиск без учета регистра; в противном случае ищется строка поскольку оно отображается в поле Искать .
- Строки также можно заменить с помощью той же операции.Введите
текст замены в поле Заменить на и выберите
Режим замены от Заменить коробку . Замена
режимы:
- Замены не подлежат : Замена не производится, даже если Поле замены содержит строку символов.
- Заменить по запросу : Когда искомая строка
найдено, Амайя выбирает его. Затем вы можете щелкнуть один из следующих
кнопки:
- Подтвердите , чтобы заменить выбранную строку и провести поиск еще раз.
- Не заменять для поиска следующего экземпляра без замены найденной строки.
- Автоматическая замена : Все экземпляры искомая строка автоматически заменяется внутри части документ, определенный в Search, где box.
- Поиск , где поле позволяет указать деталь
документа, в котором производится поиск:
- Перед выбором : поиск начинается с начало выделенной части и перемещается назад к началу документ.
- В выбранном диапазоне : поиск выполняется только в пределах выбранную часть от начала до конца.
- После выбора : поиск начинается в конце выбранную часть и продвигается к концу документа.
- По всему документу : Поиск ведется во всем документе от начала до конца независимо от какая часть выбрана.
Чтобы начать поиск, нажмите Подтвердить в нижней части диалогового окна.Если Amaya найдет искомый строка, она выбирается, и документ позиционируется так, чтобы строка видна. Затем вы можете найти следующий экземпляр этой строки с помощью повторное нажатие кнопки Подтвердить . Если строка не найдено, Amaya отображает сообщение «Не найдено» рядом с Подтвердите кнопку .
Поиск или замену можно в любой момент прекратить, нажав кнопку Отмена кнопка.
Операции замены можно отменить, выбрав Отменить из меню Edit или с помощью сочетания клавиш Ctrl-z .
Better Search Replace — плагин для WordPress
При перемещении вашего сайта WordPress на новый домен или сервер вы, вероятно, столкнетесь с необходимостью выполнить поиск / замену в базе данных, чтобы все работало правильно. К счастью, для этой задачи доступно несколько плагинов, однако все они по-разному подходят к некоторым ключевым функциям. Этот плагин объединяет лучшие функции этих плагинов, объединяя следующие функции в одном простом плагине:
- Поддержка сериализации для всех таблиц
- Возможность выбора конкретных таблиц
- Возможность запустить «пробный прогон», чтобы увидеть, сколько полей будет обновлено.
- Нет требований к серверу, кроме работающей установки WordPress
- Поддержка нескольких сайтов WordPress
Функции экономии времени, доступные в версии Pro:
- Посмотреть, что именно изменилось во время поиска / замены
- Резервное копирование и импорт базы данных при выполнении поиска / замены
- Приоритетная поддержка по электронной почте от разработчика плагина
- Сохранение или загрузка пользовательских профилей для быстрого повторения поиска / замены в будущем
- Поддержка и обновления на 1 год
Подробнее о Better Search Replace Pro
Функциональность поиска и замены в значительной степени основана на межсоединении / это отличный сценарий Search Replace DB с открытым исходным кодом, модифицированный для использования собственных функций базы данных WordPress для обеспечения совместимости.
Поддерживаемые языки
- Английский
- Французский
- Немецкий
- Испанский
Хотите внести свой вклад?
Не стесняйтесь открывать вопрос или отправлять запрос на перенос на GitHub.
- В меню «Инструменты» добавлена страница «Улучшенный поиск». Замена.
- После пробного прогона поиска / замены.
Установите Better Search Replace так же, как и любой другой плагин WordPress.
Метод приборной панели:
- Войдите в свою админку WordPress и перейдите в Плагины -> Добавить новый
- Введите «Better Search Replace» в строке поиска и выберите этот плагин.
- Нажмите «Установить», а затем «Активировать плагин».
Метод загрузки:
- Распакуйте плагин и загрузите папку «better-search-replace» в каталог «wp-content / plugins»
- Активируйте плагин через меню плагинов в WordPress
Использование улучшенного поиска Заменить
После активации Better Search Replace добавит страницу в меню «Инструменты» в вашем админке WordPress.
Поддерживается ли мой хост?
Да! Этот плагин должен быть совместим с любым хостом.
Могу ли я повредить свой сайт с помощью этого плагина?
Да! Ввод неправильной строки поиска или замены может повредить вашу базу данных. Из-за этого всегда рекомендуется иметь резервную копию вашей базы данных перед использованием этого плагина.
Как это работает на WordPress Multisite?
При запуске этого плагина в многосайтовой установке WordPress он будет загружен и виден только сетевым администраторам.Сетевые администраторы могут перейти на панель управления любого дочернего сайта, чтобы выполнить поиск / замену только в таблицах этого дочернего сайта, или перейти на панель управления основного / базового сайта, чтобы выполнить поиск / замену во всех таблицах.
Как я могу использовать этот плагин при изменении URL-адресов?
Если вы переносите свой сайт с одного сервера на другой и меняете URL-адрес своей установки WordPress, приведенный ниже подход позволяет сделать это легко, не затрагивая старый сайт:
- Резервное копирование базы данных на вашем текущем сайте
- Установите базу данных на новый хост
- На новом хосте определите новый URL-адрес сайта в файле
wp-config.php, как показано здесь - Войдите в систему со своим новым URL-адресом администратора и запустите Better Search Replace на URL-адресе старого сайта для URL-адреса нового сайта
- Удалите константу site_url, которую вы добавили в
wp-config.php. Вам также может потребоваться регенерировать ваш .htaccess, перейдя в «Настройки» -> «Постоянные ссылки» и сохранив настройки.
Более подробную информацию о переносе WordPress можно найти здесь.
Сделано 600 обновлений в WordPress 5.7.2 и работает просто идеально.
Это сработало как шарм. Шутки в сторону. Я говорю о 70 таблицах, из которых 531 726 ячеек были изменены в 531 726 обновлениях. База данных 3 ГБ. Ни таймаутов, ни ошибок. Конечно, потребовалось время, но результат? Безупречный. Престижность вам, ребята! Отличный плагин.
Установлен и активирован, но не отображается в меню «Инструменты». Так что в принципе бесполезно.
Этот плагин несколько раз спасал мою работу.Такой потрясающий инструмент. Прекрасно работает. Но не забудьте создать резервную копию перед ее использованием. Он делает именно то, что вы ему говорите, но если у вас нет опыта, вы легко можете испортить свой сайт.
Неплохо, но для просмотра подробностей «пробного прогона» требуется версия Pro.
Прочитать 426 отзывов«Better Search Replace» — это программа с открытым исходным кодом. Следующие люди внесли свой вклад в этот плагин.
авторов1.3.4 — 7 декабря 2020 г.
- Улучшение: совместимость с WordPress 5.6 и PHP 8
- Исправление: строки, которые были сериализованы дважды, отображаются как ложные срабатывания
1.3.3 — 26 февраля 2019 г.
- Исправлено: некоторые специальные символы, мешающие поиску / замене
- Безопасность: передать имена файлов шаблонов через
sanitize_file_name () - Безопасность: проверять одноразовый номер при загрузке диагностической информации
1.3.2 — 3 января 2018 г.
- Исправление: в некоторых средах выполнялся поиск только одной таблицы (props @ Ov3rfly)
- Tweak: Обновить текст на боковой панели
1.3.1 — 14 сентября 2017 г.
- Безопасность: проверьте, сериализованы ли данные перед десериализацией
- Улучшение: Увеличен размер выбора таблицы
1.3 — 10 ноября 2016
- Улучшение: Обновлена боковая панель и добавлена скидка на про версию
- Исправление: устаревшие ссылки на старый сайт
- Исправление: предотвращение запросов к недопустимым вкладкам
1.2.10 — 2 июня 2016 г.
- Исправление: CSS не загружается на странице сведений
1.2.9 — 8 декабря 2015 г.
- Исправление: ошибка с поиском без учета регистра в сериализованных объектах
- Исправление: ошибка с ранним пропуском из-за отсутствия первичного ключа
1.2.8 — 25 ноября 2015 г.
- Исправление: ошибка с деталями отчета
1.2.7 — 24 ноября 2015 г.
- Исправление: непереводимая строка
- Tweak: Проверьте BSR_PATH вместо ABSPATH для согласованности
- Проверено с 4.4
1.2.6
- Удален неиспользуемый код / небольшая очистка
1.2,5
- Улучшена информация и стили индикатора выполнения
- Малая уборка
1.2.4
- Добавлено уведомление «Настройки сохранены» при сохранении настроек
- Исправлена ошибка, из-за которой wp_magic_quotes мешал некоторым поисковым строкам
1.2.3
- Исправлена ошибка с поиском обратной косой черты
- Исправлен потенциальный баг с получением таблиц в больших мультисайтах
- Исправлено потенциальное уведомление в append_report
- Улучшена обработка отсутствующих первичных ключей
1.2,2
- Исправлен конфликт AJAX с WooCommerce
- Исправлено несколько проблем с переводами
- Изменена «Информация о системе» для использования get_locale () вместо константы WP_LANG.
- Обновлен немецкий перевод (реквизит @Linus Ziegenhagen)
1.2.1
- Исправлена мелкая проблема с отображением индикатора выполнения
- Обновлен файл перевода
1,2
- Перешел на массовую обработку AJAX для поиска / замены
- Минимальный «Максимальный размер страницы» уменьшен до 1000
- Добавлена вкладка «Справка» с информацией о системе для упрощения поиска и устранения неисправностей.
1.1,1
- Добавлена возможность изменять максимальный размер страницы
- Уменьшен размер страницы по умолчанию для предотвращения появления белого экрана в некоторых средах
1,1
- Добавлена возможность изменять возможности, необходимые для использования плагина
- Мелкие исправления и исправления перевода
1.0.6
- Добавлены размеры таблиц в список таблиц базы данных
- Добавлен французский перевод (реквизит @Jean Philippe)