Строки. Курс «Python. Введение в программирование»
Мы уже рассматривали строки как простой тип данных наряду с целыми и вещественными числами и знаем, что строка – это последовательность символов, заключенных в одинарные или двойные кавычки.
В Python нет символьного типа, т. е. типа данных, объектами которого являются одиночные символы. Однако язык позволяет рассматривать строки как объекты, состоящие из подстрок длинной в один и более символов. При этом, в отличие от списков, строки не принято относить к структурам данных. Видимо потому, что структуры данных состоят из более простых типов данных, а для строк в Python нет более простого (символьного) типа.
С другой стороны, строка, как и список, – это упорядоченная последовательность элементов. Следовательно, из нее можно извлекать отдельные символы и срезы.
>>> s = "Hello, World!" >>> s[0] 'H' >>> s[7:] 'World!' >>> s[::2] 'Hlo ol!'
В последнем случае извлечение идет с шагом, равным двум, т. е. извлекается каждый второй символ. Примечание. Извлекать срезы с шагом также можно из списков.
Важным отличием от списков является неизменяемость строк в Python. Нельзя перезаписать какой-то отдельный символ или срез в строке:
>>> s[-1] = '.' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Интерпретатор сообщает, что объект типа str не поддерживает присвоение элементам.
Если требуется изменить строку, то следует создать новую из срезов старой:
>>> s = s[0:-1] + '.' >>> s 'Hello, World.'
В примере берется срез из исходной строки, соединяется с другой строкой. Получается новая строка, которая присваивается переменной s. Ее старое значение при этом теряется.
Методы строк
В Python для строк есть множество методов.
Методы split() и join()
Метод split() позволяет разбить строку по пробелам. В результате получается список слов. Если пользователь вводит в одной строке ряд слов или чисел, каждое из которых должно в программе обрабатываться отдельно, то без split() не обойтись.
>>> s = input() red blue orange white >>> s 'red blue orange white' >>> sl = s.split() >>> sl ['red', 'blue', 'orange', 'white'] >>> s 'red blue orange white'
Список, возвращенный методом split(), мы могли бы присвоить той же переменной s, т. е. s = s.split(). Тогда исходная строка была бы потеряна. Если она не нужна, то лучше не вводить дополнительную переменную.
Метод split() может принимать необязательный аргумент-строку, указывающей по какому символу или подстроке следует выполнить разделение:
>>> s.split('e')
['r', 'd blu', ' orang', ' whit', '']
>>> '40030023'.split('00')
['4', '3', '23']Метод строк join() выполняет обратное действие. Он формирует из списка строку. Поскольку это метод строки, то впереди ставится строка-разделитель, а в скобках — передается список:
>>> '-'.join(sl) 'red-blue-orange-white'
Если разделитель не нужен, то метод применяется к пустой строке:
>>> ''.join(sl) 'redblueorangewhite'
Методы find() и replace()
Данные методы строк работают с подстроками. Методы find() ищет подстроку в строке и возвращает индекс первого элемента найденной подстроки. Если подстрока не найдена, то возвращает -1.
>>> s
'red blue orange white'
>>> s.find('blue')
4
>>> s.find('green')
-1Поиск может производиться не во всей строке, а лишь на каком-то ее отрезке.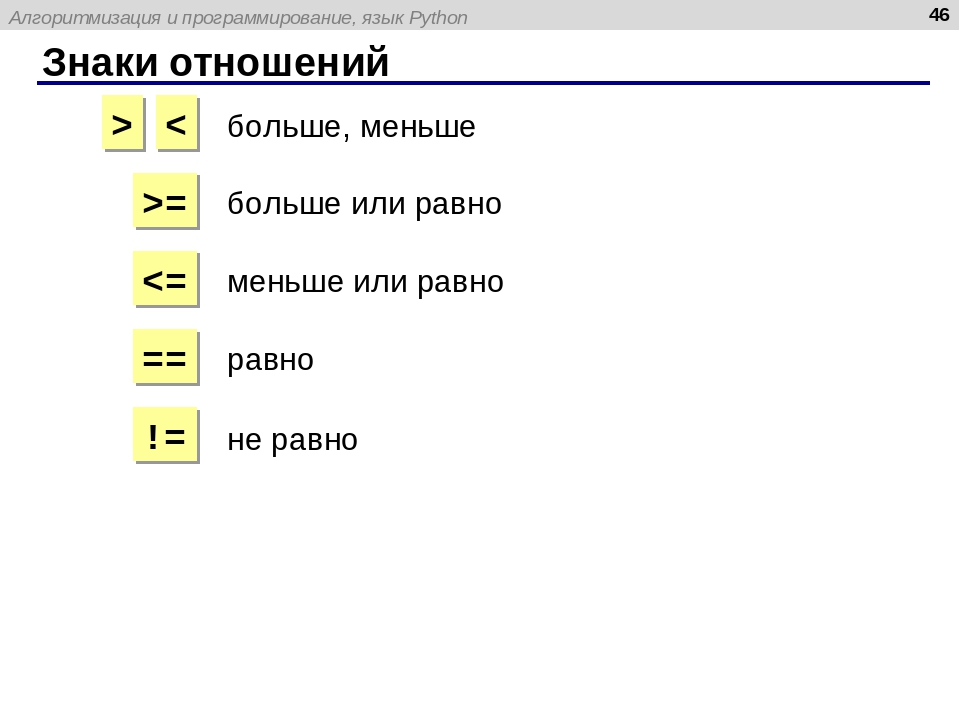
>>> letters = 'ABCDACFDA'
>>> letters.find('A', 3)
4
>>> letters.find('DA', 0, 6)
3Здесь мы ищем с третьего индекса и до конца, а также с первого и до шестого. Обратите внимания, что метод find() возвращает только первое вхождение. Так выражение letters.find('A', 3) последнюю букву ‘A’ не находит, так как ‘A’ ему уже встретилась под индексом 4.
Метод replace() заменяет одну подстроку на другую:
>>> letters.replace('DA', 'NET')
'ABCNETCFNET'Исходная строка, конечно, не меняется:
Так что если результат надо сохранить, то его надо присвоить переменной:
>>> new_letters = letters.replace('DA', 'NET')
>>> new_letters
'ABCNETCFNET'Метод format()
Строковый метод format() уже упоминался при рассмотрении вывода на экран с помощью функции print():
>>> print("This is a {0}. It's {1}."
... .format("ball", "red"))
This is a ball. It's red.Однако к print() он никакого отношения не имеет, а применяется к строкам. Лишь потом заново сформированная строка передается в функцию вывода.
Возможности format() широкие, рассмотрим основные.
>>> size1 = "length - {}, width - {}, height - {}"
>>> size1.format(3, 6, 2.3)
'length - 3, width - 6, height — 2.3'Если фигурные скобки исходной строки пусты, то подстановка аргументов идет согласно порядку их следования. Если в фигурных скобках строки указаны индексы аргументов, порядок подстановки может быть изменен:
>>> size2 = "height - {2}, length - {0}, width - {1}"
>>> size2.format(3, 6, 2.3)
'height - 2.3, length - 3, width - 6' Кроме того, аргументы могут передаваться по слову-ключу:
>>> info = "This is a {subj}. It's {prop}."
>>> info.format(subj="table", prop="small")
"This is a table. It's small."
It's {prop}."
>>> info.format(subj="table", prop="small")
"This is a table. It's small."Пример форматирования вещественных чисел:
>>> "{1:.2f} {0:.3f}".format(3.33333, 10/6)
'1.67 3.333'Практическая работа
Вводится строка, включающая строчные и прописные буквы. Требуется вывести ту же строку в одном регистре, который зависит от того, каких букв больше. При равном количестве преобразовать в нижний регистр. Например, вводится строка «HeLLo World», она должна быть преобразована в «hello world», потому что в исходной строке малых букв больше. В коде используйте цикл for, строковые методы upper() (преобразование к верхнему регистру) и lower() (преобразование к нижнему регистру), а также методы isupper() и islower(), проверяющие регистр строки или символа.
Строковый метод isdigit() проверяет, состоит ли строка только из цифр. Напишите программу, которая запрашивает с ввода два целых числа и выводит их сумму. В случае некорректного ввода программа не должна завершаться с ошибкой, а должна продолжать запрашивать числа. Обработчик исключений try-except использовать нельзя.
Примеры решения и дополнительные уроки в android-приложении и pdf-версии курса
Строки. Функции и методы строк — Документация Python Summary 1
# Литералы строк S = 'str'; S = "str"; S = '''str'''; S = """str""" # Экранированные последовательности S = "s\np\ta\nbbb" # Неформатированные строки (подавляют экранирование) S = r"C:\temp\new" # Строка байтов S = b"byte" # Конкатенация (сложение строк) S1 + S2 # Повторение строки S1 * 3 # Обращение по индексу S[i] # Извлечение среза S[i:j:step] # Длина строки len(S) # Поиск подстроки в строке. Возвращает номер первого вхождения или -1 S.find(str, [start],[end]) # Поиск подстроки в строке. Возвращает номер последнего вхождения или -1 S.rfind(str, [start],[end]) # Поиск подстроки в строке.Возвращает номер первого вхождения или вызывает ValueError S.index(str, [start],[end]) # Поиск подстроки в строке. Возвращает номер последнего вхождения или вызывает ValueError S.rindex(str, [start],[end]) # Замена шаблона S.replace(шаблон, замена) # Разбиение строки по разделителю S.split(символ) # Состоит ли строка из цифр S.isdigit() # Состоит ли строка из букв S.isalpha() # Состоит ли строка из цифр или букв S.isalnum() # Состоит ли строка из символов в нижнем регистре S.islower() # Состоит ли строка из символов в верхнем регистре S.isupper() # Состоит ли строка из неотображаемых символов (пробел, символ перевода страницы ('\f'), "новая строка" ('\n'), "перевод каретки" ('\r'), "горизонтальная табуляция" ('\t') и "вертикальная табуляция" ('\v')) S.isspace() # Начинаются ли слова в строке с заглавной буквы S.istitle() # Преобразование строки к верхнему регистру S.upper() # Преобразование строки к нижнему регистру S.lower() # Начинается ли строка S с шаблона str S.startswith(str) # Заканчивается ли строка S шаблоном str S.endswith(str) # Сборка строки из списка с разделителем S S.join(список) # Символ в его код ASCII ord(символ) # Код ASCII в символ chr(число) # Переводит первый символ строки в верхний регистр, а все остальные в нижний S.capitalize() # Возвращает отцентрованную строку, по краям которой стоит символ fill (пробел по умолчанию) S.center(width, [fill]) # Возвращает количество непересекающихся вхождений подстроки в диапазоне [начало, конец] (0 и длина строки по умолчанию) S.count(str, [start],[end]) # Возвращает копию строки, в которой все символы табуляции заменяются одним или несколькими пробелами, в зависимости от текущего столбца. Если TabSize не указан, размер табуляции полагается равным 8 пробелам S.expandtabs([tabsize]) # Удаление пробельных символов в начале строки S.lstrip([chars]) # Удаление пробельных символов в конце строки S.rstrip([chars]) # Удаление пробельных символов в начале и в конце строки S.strip([chars]) # Возвращает кортеж, содержащий часть перед первым шаблоном, сам шаблон, и часть после шаблона.
Если шаблон не найден, возвращается кортеж, содержащий саму строку, а затем две пустых строки S.partition(шаблон) # Возвращает кортеж, содержащий часть перед последним шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий две пустых строки, а затем саму строку S.rpartition(sep) # Переводит символы нижнего регистра в верхний, а верхнего – в нижний S.swapcase() # Первую букву каждого слова переводит в верхний регистр, а все остальные в нижний S.title() # Делает длину строки не меньшей width, по необходимости заполняя первые символы нулями S.zfill(width) # Делает длину строки не меньшей width, по необходимости заполняя последние символы символом fillchar S.ljust(width, fillchar=" ") # Делает длину строки не меньшей width, по необходимости заполняя первые символы символом fillchar S.rjust(width, fillchar=" ")

Язык программирования «Python». Строки: индексы и срезы
Условие задачи
Найти сумму первой и последней цифр произвольного целого положительного числа.
| № | Входные данные | Выходные данные |
|---|---|---|
| 1 | 10265 79 5 | 6 16 10 |
Strings — Learn Python 3
Строку можно считывать со стандартного ввода, используя функцию input() или определяемую в одинарных или двойных кавычках.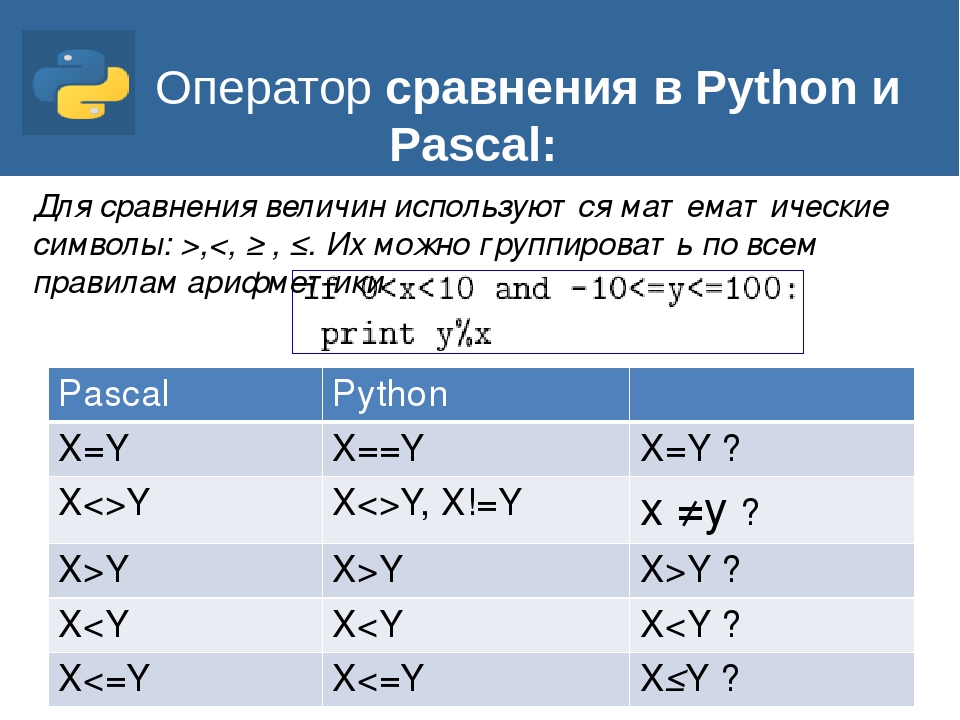 Две строки могут быть объединены, и мы также можем повторить строку n раз, умножая ее на integer:
Две строки могут быть объединены, и мы также можем повторить строку n раз, умножая ее на integer:
None
print('>_< ' * 5) # > _ <> _ <> _ <> _ <> _ <
Строка в Python представляет собой последовательность символов. Функция len(some_string) возвращает количество символов в строке:
None
print(len('abcdefghijklmnopqrstuvwxyz')) # 26
Каждый объект в Python может быть преобразован в строку с помощью функции str(some_object) . Поэтому мы можем преобразовать числа в строки:
None
s = str(2 ** 100) print(s) # 1267650600228229401496703205376 print(len(s)) # 31
Срез дает из заданной строки один символ или некоторый фрагмент: подстрока или подпоследовательность.
Существует три формы срезов. Простейшая форма среза: один фрагмент символа S[i] дает i й символ строки. Мы будем считать символы, начинающиеся с 0. То есть, если S = 'Hello' , S[0] == 'H' , S[1] == 'e' , S[2] == 'l' , S[3] == 'l' , S[4] == 'o' . Обратите внимание, что в Python для символов строки не существует отдельного типа. S[i] также имеет тип str , как и исходная строка.
Число i в S[i] называется индексом .
Если вы укажете отрицательный индекс, то он подсчитывается с конца, начиная с номера -1 . То есть S[-1] == 'o' , S[-2] == 'l' , S[-3] == 'l' , S[-4] == 'e' , S[-5] == 'H' .
Подведем итог в таблице:
| Строка S | ЧАС | е | L | L | о |
|---|---|---|---|---|---|
| Индекс | S [0] | S [1] | S [2] | S [3] | S [4] |
| Индекс | S [-5] | S [-4] | S [-3] | S [-2] | S [-1] |
Если индекс в срезе S[i] больше или равен len(S) или меньше, чем -len(S) , следующая ошибка вызывает IndexError: string index out of range .
Slice с двумя параметрами S[a:b] возвращает подстроку длины b - a , начиная с символа в индексе a и продолжая до символа с индексом b , не считая последнего. Например, S[1:4] == 'ell' , и вы можете получить ту же подстроку, используя S[-4:-1] . Вы можете смешивать положительные и отрицательные индексы в одном и том же фрагменте, например, S[1:-1] — это подстрока без первого и последнего символов строки (срез начинается с символа с индексом 1 и заканчивается индексом от -1, не считая его).
Срез с двумя параметрами никогда не вызывает IndexError . Например, для S == 'Hello' срез S[1:5] возвращает строку 'ello' , и результат будет таким же, даже если второй индекс очень большой, например S[1:100] .
Если вы опустите второй параметр (но сохраните двоеточие), то срез идет до конца строки. Например, чтобы удалить первый символ из строки (ее индекс равен 0), возьмите срез S[1:] . Аналогично, если вы опускаете первый параметр, Python берет срез из начала строки. То есть, чтобы удалить последний символ из строки, вы можете использовать срез S[:-1] . Срез S[:] соответствует самой строке S
Любой фрагмент строки создает новую строку и никогда не изменяет исходную. В Python строки неизменяемы, т. Е. Они не могут быть изменены как объекты. Вы можете назначить переменную только новой строке, но старый останется в памяти.
На самом деле в Python нет переменных. Есть только имена, связанные с любыми объектами. Вы можете сначала связать имя с одним объектом, а затем — с другим. Можно ли связать несколько имен с одним и тем же объектом.
Давайте продемонстрируем, что:
None
s = 'Hello' t = s # s и t указывают на одну и ту же строку t = s[2:4] # теперь t указывает на новую строку 'll' print(s) # печатает «Hello», так как s не изменяется print(t) # отпечатки 'll'
Если вы укажете срез с тремя параметрами S[a:b:d] , третий параметр указывает шаг, такой же, как для range() функций range() . В этом случае берутся только символы со следующим индексом:
В этом случае берутся только символы со следующим индексом: a a + d , a + 2 * d и т. Д. До и без символа с индексом b . Если третий параметр равен 2, срез принимает каждый второй символ, и если шаг среза равен -1 , символы идут в обратном порядке. Например, вы можете изменить строку следующим образом: S[::-1] . Давайте посмотрим на примеры:
None
s = 'abcdefg' print(s[1]) print(s[-1]) print(s[1:3]) print(s[1:-1]) print(s[:3]) print(s[2:]) print(s[:-1]) print(s[::2]) print(s[1::2]) print(s[::-1])Обратите внимание, как третий параметр среза похож на третий параметр
range() функций range() :None
s = 'abcdefghijklm'
print(s[0:10:2])
for i in range(0, 10, 2):
print(i, s[i])
Метод — это функция, привязанная к объекту. Когда метод вызывается, метод применяется к объекту и выполняет некоторые вычисления, связанные с ним. Методы вызываются как object_name.method_name(arguments) . Например, в s.find("e") метод string find() применяется к строке s с одним аргументом "e" .
Метод find() выполняет поиск подстроки, переданной как аргумент, внутри строки, на которую он вызывается. Функция возвращает индекс первого вхождения подстроки. Если подстрока не найдена, метод возвращает -1.
None
s = 'Hello'
print(s.find('e'))
# 1
print(s.find('ll'))
# 2
print(s.find('L'))
# -1
Аналогично, метод rfind() возвращает индекс последнего вхождения подстроки.
None
s = 'abracadabra'
print(s.find('b'))
# 1
print(s.rfind('b'))
# 8
Если вы вызываете find() с тремя аргументами s.find(substring, left, right) , поиск выполняется внутри среза s[left:right] . Если вы укажете только два аргумента, например s. , поиск выполняется в срезе  find(substring, left)
find(substring, left)s[left:] , то есть начиная с символа с индексом left до конца строки. Метод s.find(substring, left, right) возвращает абсолютный индекс относительно всей строки s , а не срез.
None
s = 'my name is bond, james bond, okay?'
print(s.find('bond'))
# 11
print(s.find('bond', 12))
# 23
Метод replace() заменяет все вхождения данной подстроки на другую. Синтаксис: s.replace(old, new) принимает строку S и заменяет все вхождения подстроки old на подстроку new . Пример:
None
print('a bar is a bar, essentially'.replace('bar', 'pub'))
# «Паб - это паб, по сути,
Можно пройти третий count аргумента, например: s.replace(old, new, count) . Это делает replace() , чтобы заменить только первый count вхождений , а затем остановится.
None
print('a bar is a bar, essentially'.replace('bar', 'pub', 1))
# «Паб - это бар,
Этот метод подсчитывает количество вхождений одной строки в другую строку. Простейшая форма: s.count(substring) . Учитываются только неперекрывающиеся вхождения:
None
print('Abracadabra'.count('a'))
# 4
print(('aaaaaaaaaa').count('aa'))
# 5
Если вы укажете три параметра s.count(substring, left, right) , подсчет выполняется внутри среза s[left:right] .
Работа со строками в Python. Готовимся к собеседованию: вспоминаем азы
Петр Смолович
ведущий разработчик хостинг-провайдера и регистратора доменов REG.RU
В этой статье мы разберем работу со строками в Python с необычного угла — глазами интервьюера на собеседовании. Информация будет полезна как новичку, так и уверенному джуну. В первой части поговорим о базовых операциях. Во второй — разберем примеры задач и вопросов, к которым стоит быть готовым.
Информация будет полезна как новичку, так и уверенному джуну. В первой части поговорим о базовых операциях. Во второй — разберем примеры задач и вопросов, к которым стоит быть готовым.
Итак, мы на собеседовании, и я хочу узнать, умеете ли вы обращаться со строками.
Как склеить две строки?
>>> s = "abc" + "def"
>>> s += "xyz"Элементарно? Почти. Важно помнить, что строки — это неизменяемые объекты. Каждый раз, когда мы говорим про «изменение» строки, технически мы создаем новый объект и записываем туда вычисленное значение.
А как склеить три строки? Напрашивается ответ «точно так же», и иногда это самый лучший способ. Но интервьюер скорее всего хочет проверить, знаете ли вы про метод .join().
>>> names = ["John", "Paul", "Ringo", "George"]
>>> ", ".join(names)
'John, Paul, Ringo, George'join() — очень удобный метод, позволяющий склеить N строк, причём с произвольным разделителем.
Здесь важно не только получить результат, но и понимать, как работает приведённая конструкция. А именно, что join() — это метод объекта «строка», принимающий в качестве аргумента список и возвращающий на выходе новую строку.
Кстати, хорошая задачка для интервью — написать свою реализацию join().
Разделить строки?
Есть несколько способов получить часть строки. Первый — это split, обратный метод для join. В отличие от join’а, он применяется к целевой строке, а разделитель передаётся аргументом.
>>> s = "Альфа, Браво, Чарли"
>>> s.split(", ")
['Альфа', 'Браво', 'Чарли']Второй — срезы (slices).
Срез s[x:y] позволяет получить подстроку с символа x до символа y. Можно не указывать любое из значений, чтобы двигаться с начала или до конца строки. Отрицательные значения используются для отсчёта с конца (-1 — последний символ, -2 — предпоследний и т. /]+)(.*)$», s)
>>> print(result.group(1))
https
>>> print(result.group(2))
www.reg.ru
>>> print(result.group(3))
/hosting/
/]+)(.*)$», s)
>>> print(result.group(1))
https
>>> print(result.group(2))
www.reg.ru
>>> print(result.group(3))
/hosting/
А замену в строке сделать сможете?
Во-первых, при помощи срезов и склейки строк можно заменить что угодно.
>>> s = "Hello, darling! How are you?"
>>> s[:7] + "Василий" + s[14:]
'Hello, Василий! How are you?'Во-вторых, умеешь find(), умей и replace().
>>> s.replace("darling", "Василий")
'Hello, Василий! How are you?'В-третьих, любую проблему можно решить регулярными выражениями. Либо получить две проблемы 🙂 В случае с заменой вам нужен метод re.sub().
>>> s = "https://www.reg.ru/hosting/";
>>> import re
>>> print(re.sub('[a-z]', 'X', s))
XXXXX://XXX.XXX.XX/XXXXXXX/Посимвольная обработка?
Есть бесчисленное множество задачек, которые можно решить, пройдясь в цикле по строке. Например, посчитать количество букв «о».
>>> s = "Hello, world!"
>>> for c in s:
>>> if c == "o":
>>> counter += 1
>>> print(counter)
2Иногда удобнее бежать по индексу.
>>> for i in range(len(s)):
>>> if s[i] == "o":
>>> counter += 1Помним, что строки неизменяемы, поэтому подменить i-ый символ по индексу не получится, нужно создавать новый объект:
>>> s[i] = "X"
Traceback (most recent call last):
File "", line 1, in
TypeError: 'str' object does not support item assignment
>>> s[:i] + "X" + s[i+1:]
'HellX, world!'Либо можно преобразовать строку в список, сделать обработку, а потом склеить список обратно в строку:
>>> arr = list(s)
>>> "". join(arr)
'Hello, world!'
join(arr)
'Hello, world!'А форматирование строк?
Типичная жизненная необходимость — сформировать строку, подставив в неё результат работы программы. Начиная с Python 3.6, это можно делать при помощи f-строк:
>>> f"Строка '{s}' содержит {len(s)} символов."
"Строка 'Hello, world!' содержит 13 символов."В более старом коде можно встретить альтернативные способы
>>> "Строка '%s' содержит %d символов" % (s, len(s))
>>> "Строка '{}' содержит {} символов".format(s, len(s))Технически можно было обойтись склейкой, но это менее элегантно, а еще придётся следить, чтобы все склеиваемые кусочки были строками. Не рекомендую:
>>> "Строка '" + s + "' содержит " + str(len(s)) + " символов."
"Строка 'Hello, world!' содержит 13 символов."***
Цель работодателя на собеседовании — убедиться что вы соображаете и что вы справитесь с реальными задачами. Однако погружение в реальные задачи занимает несколько недель, а время интервью ограничено. Поэтому вас ждут учебные задания, которые можно решить за 10-30 минут, а также вопросы на понимание того, как работает код. О них и поговорим в следующей части.
Методы строк в Python для начинающих
Методы строк для начинающих
У строк в Python есть множество полезных методов для того, чтобы дать возможность делать со строками различные полезные и нужные действия.
Методы похожи на функции, из тоже можно вызывать и, так же как и функции, они могут возвращать результат своей работы. Отличие же методов в том, что они привязаны к определенному типу данных и, например, методы строк могут быть вызваны только у строк.
Все методы строк можно посмотреть в нашем справочнике, а вот несколько примеров того, как вызывать методы строк.
string = "Hello world!"
print(string.lower()) # hello world!
print(string. upper()) # HELLO WORLD!
upper()) # HELLO WORLD!
Начинающему программисту важно помнить, что методы не меняют исходную строку. Строки в Python вообще нельзя изменить. Если вы хотите поменять все ее символы, например, на символы нижнего регистра, нужно присвоить строке новое значение
string = "Hello world!"
string = string.lower()
Индексы строк
Бывает так, что иногда появляется необходимость выбирать отдельные символы из строки. В Python для этого необходимо использовать квадратные скобки. В таблице ниже приведены примеры получения символа строки по индексу строки Python, помещенной в переменную string.
| Код | Результат | Описание |
|---|---|---|
| s[0] | P | Первый символ |
| s[1] | y | Второй символ |
| s[-1] | n | Последний символ |
| s[-2] | o | Предпоследний символ |
Как вы видите, необходимо учитывать, что номером индекса первого символа будет [0] Отрицательный индекс будет отсчитывать символы с конца строки. Распространенная ошибка: предположим, что мы пытаемся задать индекс s[12]. Но в примере выше мы имеем всего шесть элементов строки, и логично что Python выдаст ошибку следующего содержания:
IndexError: string index out of range
Срезы строк
Срез используется для выделения части строки. Он состоит из индекса и диапазона. Ниже расположены несколько примеров со строкой
string = 'абвгдежзик'
Индекс
0 1 2 3 4 5 6 7 8 9
Символ
а б в г д е ж з и к
| Фрагмент кода | Результат | Описание |
|---|---|---|
| string[ 2 : 5 ] | вгд | Символы с индексом 2, 3, 4 |
| string[ : 5 ] | абвгд | Первые пять символов |
| string[ 5 : ] | ежзик | Символы, начиная с индекса 5 и до конца |
| string[ −2 : ] | ик | Последние два символа |
| string[ : ] | абвгдежзик | Вся строка |
| string[1 : 7 : 2] | бге | Со второго по шестой символы, через один |
| string[ : : −1 ] | кизжедгвба | Обратный шаг, строка наоборот |
Базовая структура среза выглядит следующим образом: Строка[начальный_символ : конечный_символ + 1]
Срезы не включают явное расположение окончания строки. Например, в приведенном выше примере string[2 : 5], Python выведет символы с индексами 2, 3 и 4, но не символ с индексом 5.
Мы можем оставить, вместо индекса начала или окончания строки, пустоту. Пустота на месте индекса начала будет по умолчанию равна нулю. Итак, string[: 5] выведет первые пять символов строки string. А в случае string[5 :], Python покажет символы, начиная с индекса 5 и до конца строки. Если же использовать отрицательные индексы, мы получим символы с конца строки. Например, string[-2 :] — это последние два символа.
Также существует необязательный третий аргумент, который указывает на шаг среза строки. Например, string[1 : 7 : 2] берет каждый второй символ из строки с индексом 1, 3 и 5.
| S = ‘str’; S = «str»; S = »’str»’; S = «»»str»»» | Литералы строк |
| S = «s\np\ta\nbbb» | Экранированные последовательности |
| S = r»C:\temp\new» | Неформатированные строки (подавляют экранирование) |
| S = b»byte» | Строка байтов |
| S1 + S2 | Конкатенация (сложение строк) |
| S1 * 3 | Повторение строки |
| S[i] | Обращение по индексу |
| S[i:j:step] | Извлечение среза |
| len(S) | Длина строки |
| S.find(str, [start],[end]) | Поиск подстроки в строке. Возвращает номер первого вхождения или -1 |
| S.rfind(str, [start],[end]) | Поиск подстроки в строке. Возвращает номер последнего вхождения или -1 |
| S.index(str, [start],[end]) | Поиск подстроки в строке. Возвращает номер первого вхождения или вызывает ValueError |
S. rindex(str, [start],[end]) rindex(str, [start],[end]) | Поиск подстроки в строке. Возвращает номер последнего вхождения или вызывает ValueError |
| S.replace(шаблон, замена) | Замена шаблона |
| S.split(символ) | Разбиение строки по разделителю |
| S.isdigit() | Состоит ли строка из цифр |
| S.isalpha() | Состоит ли строка из букв |
| S.isalnum() | Состоит ли строка из цифр или букв |
| S.islower() | Состоит ли строка из символов в нижнем регистре |
| S.isupper() | Состоит ли строка из символов в верхнем регистре |
| S.isspace() | Состоит ли строка из неотображаемых символов (пробел, символ перевода страницы (‘\f’), «новая строка» (‘\n’), «перевод каретки» (‘\r’), «горизонтальная табуляция» (‘\t’) и «вертикальная табуляция» (‘\v’)) |
| S.istitle() | Начинаются ли слова в строке с заглавной буквы |
| S.upper() | Преобразование строки к верхнему регистру |
| S.lower() | Преобразование строки к нижнему регистру |
| S.startswith(str) | Начинается ли строка S с шаблона str |
| S.endswith(str) | Заканчивается ли строка S шаблоном str |
| S.join(список) | Сборка строки из списка с разделителем S |
| ord(символ) | Символ в его код ASCII |
| chr(число) | Код ASCII в символ |
| S.capitalize() | Переводит первый символ строки в верхний регистр, а все остальные в нижний |
| S.center(width, [fill]) | Возвращает отцентрованную строку, по краям которой стоит символ fill (пробел по умолчанию) |
| S.count(str, [start],[end]) | Возвращает количество непересекающихся вхождений подстроки в диапазоне [начало, конец] (0 и длина строки по умолчанию) |
S.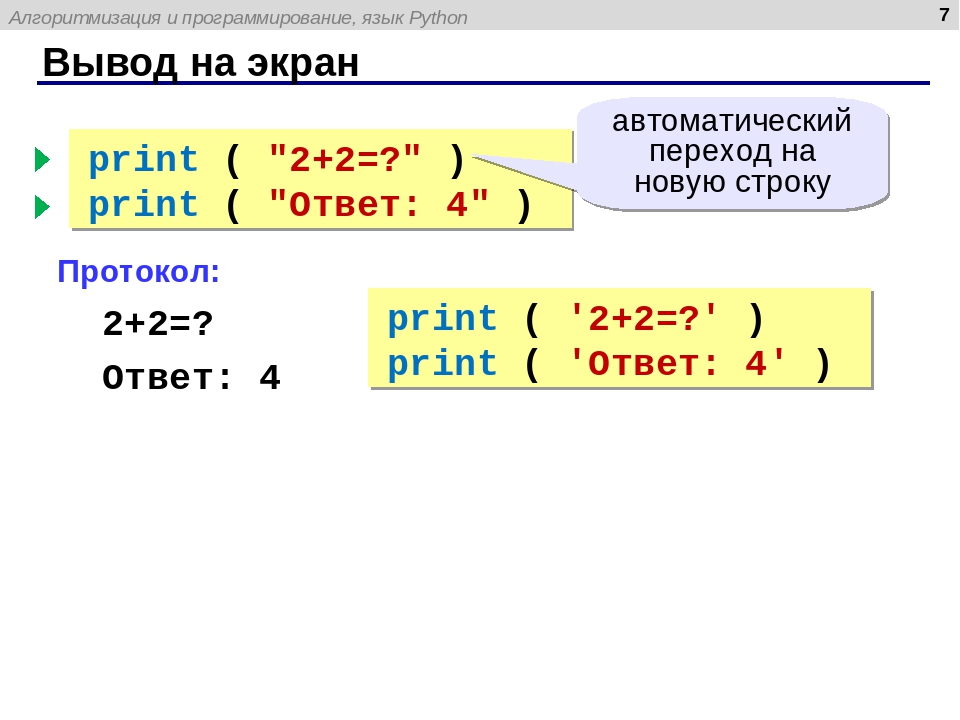 expandtabs([tabsize]) expandtabs([tabsize]) | Возвращает копию строки, в которой все символы табуляции заменяются одним или несколькими пробелами, в зависимости от текущего столбца. Если TabSize не указан, размер табуляции полагается равным 8 пробелам |
| S.lstrip([chars]) | Удаление пробельных символов в начале строки |
| S.rstrip([chars]) | Удаление пробельных символов в конце строки |
| S.strip([chars]) | Удаление пробельных символов в начале и в конце строки |
| S.partition(шаблон) | Возвращает кортеж, содержащий часть перед первым шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий саму строку, а затем две пустых строки |
| S.rpartition(sep) | Возвращает кортеж, содержащий часть перед последним шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий две пустых строки, а затем саму строку |
| S.swapcase() | Переводит символы нижнего регистра в верхний, а верхнего – в нижний |
| S.title() | Первую букву каждого слова переводит в верхний регистр, а все остальные в нижний |
| S.zfill(width) | Делает длину строки не меньшей width, по необходимости заполняя первые символы нулями |
| S.ljust(width, fillchar=» «) | Делает длину строки не меньшей width, по необходимости заполняя последние символы символом fillchar |
| S.rjust(width, fillchar=» «) | Делает длину строки не меньшей width, по необходимости заполняя первые символы символом fillchar |
| S.format(*args, **kwargs) | Форматирование строки |
Как индексировать и нарезать строки в Python 3
Введение
Строковый тип данных Python — это последовательность, состоящая из одного или нескольких отдельных символов, которые могут состоять из букв, цифр, пробелов или символов. Поскольку строка является последовательностью, к ней можно получить доступ так же, как и к другим типам данных на основе последовательностей, посредством индексации и нарезки.
Поскольку строка является последовательностью, к ней можно получить доступ так же, как и к другим типам данных на основе последовательностей, посредством индексации и нарезки.
Из этого туториала Вы узнаете, как получить доступ к строкам с помощью индексации, разрезать их по последовательностям символов, а также познакомиться с некоторыми методами подсчета и определения местоположения символов.
Как индексируются строки
Подобно типу данных списка, элементы которого соответствуют порядковому номеру, каждый из символов строки также соответствует порядковому номеру, начиная с порядкового номера 0.
За шнурок Сэмми Шарк! разбивка индекса выглядит так:
| S | а | м | м | л | S | ч | а | r | к | ! | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
Как видите, первый S начинается с индекса 0, а строка заканчивается с индексом 11 на ! символ.
Мы также заметили, что пробельный символ между Sammy и Shark также соответствует его собственному порядковому номеру. В этом случае порядковый номер, связанный с пробелом, равен 5.
С восклицательным знаком (! ) также связан порядковый номер. Любой другой символ или знак препинания, например * # $ &.;? , также является символом и будет связан с его собственным порядковым номером.
Тот факт, что каждый символ в строке Python имеет соответствующий номер индекса, позволяет нам получать доступ к строкам и управлять ими так же, как и с другими последовательными типами данных.
Доступ к символам по положительному порядковому номеру
Ссылаясь на номера индексов, мы можем выделить один из символов в строке. Мы делаем это, помещая порядковые номера в квадратные скобки. Объявим строку, напечатаем ее и вызовем порядковый номер в квадратных скобках:
ss = "Сэмми Акула!"
печать (ss [4])
Выход
г
Когда мы обращаемся к определенному порядковому номеру строки, Python возвращает символ, который находится в этой позиции.Поскольку буква y находится под номером 4 в строке ss = "Sammy Shark!" , когда мы печатаем ss [4] , на выходе получаем y .
Индексные числа позволяют нам получить доступ к определенным символам в строке.
Доступ к символам по отрицательному номеру индекса
Если у нас есть длинная строка и мы хотим точно определить элемент ближе к концу, мы также можем отсчитывать назад от конца строки, начиная с номера индекса -1 .
За ту же струну Sammy Shark! , отрицательная разбивка индекса выглядит так:
| S | а | м | м | л | S | ч | а | r | к | ! | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| -12 | -11 | -10 | -9 | -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
Используя отрицательные индексные числа, мы можем распечатать символ r , указав его позицию в индексе -3, например:
печать (ss [-3])
Мощность
r
Использование отрицательных индексных чисел может быть полезно для выделения одного символа в конце длинной строки.
Нарезка струн
Мы также можем вызвать ряд символов из строки. Допустим, мы хотели бы просто напечатать слово Shark . Мы можем сделать это, создав срез , который представляет собой последовательность символов в исходной строке. С помощью срезов мы можем вызывать несколько символьных значений, создавая диапазон номеров индексов, разделенных двоеточием [x: y] :
печать (ss [6:11])
Выход
Акула
При создании слайса, как в [6:11] , первый номер индекса — это место, где начинается слайс (включительно), а второй номер индекса — это место, где слайс заканчивается (исключая), поэтому в нашем примере выше диапазон должен быть порядковым номером, который появится сразу после окончания строки.
При нарезке строк мы создаем подстроку , которая по сути является строкой, существующей внутри другой строки. Когда мы вызываем ss [6:11] , мы вызываем подстроку Shark , которая существует в строке Sammy Shark! .
Если мы хотим включить любой конец строки, мы можем опустить одно из чисел в синтаксисе строка [n: n] . Например, если мы хотим вывести первое слово строки ss — «Сэмми» — мы можем сделать это, набрав:
печать (ss [: 5])
Выход
Сэмми
Мы сделали это, опустив номер индекса перед двоеточием в синтаксисе среза и включив только номер индекса после двоеточия, который указывает на конец подстроки.
Чтобы напечатать подстроку, которая начинается в середине строки и печатается до конца, мы можем сделать это, включив только номер индекса перед двоеточием, например:
печать (ss [7:])
Выход
hark!
Если включить только номер индекса перед двоеточием и исключить второй номер индекса в синтаксисе, подстрока будет идти от символа вызываемого номера индекса до конца строки.
Вы также можете использовать отрицательные индексные числа, чтобы разрезать строку.Как мы уже говорили ранее, отрицательные порядковые номера строки начинаются с -1 и отсчитываются оттуда, пока мы не дойдем до начала строки. При использовании отрицательных числовых индексов сначала мы начнем с меньшего числа, поскольку оно встречается раньше в строке.
Давайте используем два отрицательных индексных числа, чтобы разрезать строку ss :
печать (ss [-4: -1])
Выход
ковчег
Подстрока «ark» печатается из строки «Sammy Shark!» потому что символ «a» встречается в позиции порядкового номера -4, а символ «k» встречается непосредственно перед позицией порядкового номера -1.
Указание шага при нарезке строк
Нарезка строки может принимать третий параметр в дополнение к двум индексным номерам. Третий параметр указывает шаг , который указывает, на сколько символов нужно продвинуться вперед после извлечения первого символа из строки. До сих пор мы опускали параметр шага, и Python по умолчанию использует шаг, равный 1, так что извлекается каждый символ между двумя индексными номерами.
Давайте еще раз посмотрим на приведенный выше пример, который выводит подстроку «Акула»:
печать (ss [6:11])
Выход
Акула
Мы можем получить те же результаты, включив третий параметр с шагом 1:
. печать (ss [6: 11: 1])
Выход
Акула
Итак, шаг 1 будет принимать каждый символ между двумя индексными номерами среза.Если мы опустим параметр шага, Python по умолчанию будет использовать 1.
Если вместо этого мы увеличим шаг, мы увидим, что символы пропущены:
печать (ss [0: 12: 2])
Выход
SmySak
Указание шага 2 в качестве последнего параметра в синтаксисе Python ss [0: 12: 2] пропускает все остальные символы. Давайте посмотрим на символы, которые напечатаны красным:
Sammy Shark!
Обратите внимание, что пробельный символ в индексе номер 5 также пропускается с заданным шагом 2.
Если мы используем большее число для нашего параметра шага, у нас будет значительно меньшая подстрока:
печать (ss [0: 12: 4])
Выход
Sya
Указание шага 4 в качестве последнего параметра в синтаксисе Python ss [0: 12: 4] печатает только каждый четвертый символ. Опять же, давайте посмотрим на символы, которые напечатаны красным:
Sammy Shark!
В этом примере также пропускается пробельный символ.
Поскольку мы печатаем всю строку, мы можем опустить два индексных номера и оставить два двоеточия в синтаксисе для достижения того же результата:
печать (ss [:: 4])
Выход
Sya
Если пропустить два индексных номера и оставить двоеточия, вся строка останется в пределах диапазона, а добавление последнего параметра для шага укажет количество пропущенных символов.
Кроме того, вы можете указать отрицательное числовое значение для шага, которое мы можем использовать для печати исходной строки в обратном порядке, если мы установим шаг в -1:
печать (ss [:: - 1])
Выход
! KrahS ymmaS
Два двоеточия без указанного параметра будут включать все символы из исходной строки, шаг 1 будет включать каждый символ без пропуска, а отрицание этого шага изменит порядок символов.
Давайте сделаем это еще раз, но с шагом -2:
печать (ss [:: - 2])
Мощность
! Rh ma
В этом примере, ss [:: - 2] , мы имеем дело со всей исходной строкой, поскольку в параметры не включены номера индексов, и меняем направление строки на отрицательный шаг. Кроме того, имея шаг -2, мы пропускаем каждую вторую букву перевернутой строки:
! KrahS [пробел] ymmaS
В этом примере печатается пробельный символ.
Указывая третий параметр синтаксиса фрагмента Python, вы указываете шаг подстроки, которую вы извлекаете из исходной строки.
Методы подсчета
Пока мы думаем о соответствующих индексных номерах, которые соответствуют символам в строках, стоит рассмотреть некоторые методы, которые подсчитывают строки или возвращают индексные номера. Это может быть полезно для ограничения количества символов, которые мы хотели бы принять в форме пользовательского ввода, или для сравнения строк.Как и другие последовательные типы данных, строки можно подсчитывать несколькими способами.
Сначала мы рассмотрим метод len () , который может получить длину любого типа данных, являющегося последовательностью, упорядоченной или неупорядоченной, включая строки, списки, кортежи и словари.
Выведем длину строки ss :
печать (лен (сс))
Выход
12
Длина строки «Сэмми Шарк!» состоит из 12 символов, включая пробельный символ и восклицательный знак.
Вместо использования переменной мы также можем передать строку прямо в метод len () :
print (len («Напечатаем длину этой строки.»))
Выход
38
Метод len () подсчитывает общее количество символов в строке.
Если мы хотим подсчитать, сколько раз в строке появляется один конкретный символ или последовательность символов, мы можем сделать это с помощью str.count () метод. Давайте поработаем со строкой ss = "Sammy Shark!" и посчитайте, сколько раз встречается символ «а»:
отпечаток (ss.count ("a"))
Выход
2
Мы можем искать другого персонажа:
печать (ss.count ("s"))
Выход
0
Хотя в строке есть буква «S», важно помнить, что каждый символ чувствителен к регистру.Если мы хотим найти все буквы в строке независимо от регистра, мы можем использовать метод str.lower () , чтобы сначала преобразовать строку во все строчные буквы. Вы можете узнать больше об этом методе в «Введение в строковые методы в Python 3».
Давайте попробуем str.count () с последовательностью символов:
Like = "Сэмми любит плавать в океане, запускать серверы и любит улыбаться."
print (like.count ("лайков"))
Выход
3
В строке лайков последовательность символов, эквивалентная «лайкам», встречается в исходной строке 3 раза.
Мы также можем узнать, в какой позиции символ или последовательность символов встречается в строке. Мы можем сделать это с помощью метода str.find () , который вернет позицию символа на основе номера индекса.
Мы можем проверить, где встречается первая буква «m» в строке ss :
отпечаток (ss.find ("m"))
Выход
2
Первый символ «m» встречается в позиции индекса 2 в строке «Sammy Shark!» Мы можем просмотреть позиции порядкового номера строки ss выше.
Давайте посмотрим, где в строке встречается первая последовательность символов «Нравится». Нравится :
распечатать (like.find ("лайки"))
Выход
6
Первый экземпляр последовательности символов «нравится» начинается с позиции номера индекса 6, где располагается символ -1 последовательности лайков .
Что, если мы хотим увидеть, где начинается вторая последовательность лайков? Мы можем сделать это, передав второй параметр в str.find () , который будет запускаться с определенного номера индекса. Итак, вместо того, чтобы начинать с начала строки, давайте начнем после номера индекса 9:
распечатка (like.find ("лайки", 9))
Выход
34
В этом втором примере, который начинается с порядкового номера 9, первое вхождение последовательности символов «нравится» начинается с порядкового номера 34.
Кроме того, мы можем указать конец диапазона в качестве третьего параметра.Как и при нарезке, мы можем сделать это путем обратного отсчета с использованием отрицательного номера индекса:
распечатка (like.find ("лайков", 40, -6))
Выход
64
В этом последнем примере выполняется поиск позиции последовательности «лайков» между индексными номерами 40 и -6. Поскольку последний введенный параметр является отрицательным числом, отсчет будет отсчитываться от конца исходной строки.
Строковые методы len () , str.count () и str.find () может использоваться для определения длины, количества символов или последовательностей символов и позиций индекса символов или последовательностей символов в строках.
Заключение
Возможность вызова определенных порядковых номеров строк или определенного фрагмента строки дает нам большую гибкость при работе с этим типом данных. Поскольку строки, такие как списки и кортежи, являются типом данных на основе последовательности, доступ к ним можно получить с помощью индексации и нарезки.
Вы можете узнать больше о форматировании строк и строковых методах, чтобы продолжить изучение строк.
Нарезка строки в Python — GeeksforGeeks
Нарезка строки в Python
Нарезка строки Python заключается в получении подстроки из заданной строки путем нарезки ее соответственно от начала до конца.
Нарезку Python можно выполнить двумя способами.
- Конструктор slice ()
- Расширение индексации
Конструктор slice ()
Конструктор slice () создает объект среза, представляющий набор индексов, заданных диапазоном (начало, остановка, шаг).
Синтаксис:
- slice (стоп)
- slice (start, stop, step)
Параметры:
start: Начальный индекс, с которого начинается нарезка объекта.
stop: Индекс окончания, на котором останавливается нарезка объекта.
step: Это необязательный аргумент, который определяет приращение между каждым индексом для нарезки.Тип возвращаемого значения: Возвращает нарезанный объект, содержащий элементы только в заданном диапазоне.
Индекс-трекер для положительного и отрицательного индекса:
Отрицательный учитывается при отслеживании строки в обратном порядке.
Пример
|
Нарезка строк AST SR GITA
Расширение индексации
В Python синтаксис индексации может использоваться вместо объекта среза.Это простой и удобный способ разрезать строку как с точки зрения синтаксиса, так и с точки зрения выполнения.
Синтаксис
строка [начало: конец: шаг]
start, end и step имеют тот же механизм, что и конструктор slice () .
Пример
|
AST SR GITA Обратная строка ГНИРЦА
Примечание: Чтобы узнать больше о строках, щелкните здесь.
Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS .
строк Python | Обучение Python | Разработчики Google
Python имеет встроенный строковый класс с именем «str» со многими удобными функциями (есть более старый модуль с именем «string», который вам не следует использовать).Строковые литералы могут быть заключены в двойные или одинарные кавычки, хотя чаще используются одинарные кавычки. Экраны с обратной косой чертой работают обычным образом как в литералах с одинарными, так и в двойных кавычках - например, \ n \ '\ ". Строковый литерал в двойных кавычках может содержать одинарные кавычки без каких-либо проблем (например,« Я этого не делал »), и аналогично строка в одинарных кавычках может содержать двойные кавычки. Строковый литерал может занимать несколько строк, но должен быть обратной косой чертой \ в конце каждой строки, чтобы избежать новой строки. Строковые литералы в тройных кавычках, "" "или '' ', могут охватывать несколько строк текста.
СтрокиPython являются «неизменяемыми», что означает, что они не могут быть изменены после создания (строки Java также используют этот неизменяемый стиль). Поскольку строки не могут быть изменены, мы создаем * новые * строки по мере представления вычисленных значений. Так, например, выражение ('hello' + 'there') принимает две строки 'hello' и 'there' и строит новую строку 'hellothere'.
Доступ к символам в строке можно получить с помощью стандартного синтаксиса [], и, подобно Java и C ++, Python использует индексирование с отсчетом от нуля, поэтому, если s равно 'hello' s [1] равно 'e'.Если индекс выходит за пределы строки, Python выдает ошибку. Стиль Python (в отличие от Perl) заключается в том, чтобы остановиться, если он не может сказать, что делать, а не просто создать значение по умолчанию. Удобный синтаксис «среза» (см. Ниже) также позволяет извлекать любую подстроку из строки. Функция len (строка) возвращает длину строки. Синтаксис [] и функция len () на самом деле работают с любым типом последовательности - строками, списками и т. Д. Python пытается заставить свои операции работать согласованно для разных типов.Новичок в Python: не используйте «len» в качестве имени переменной, чтобы не блокировать функцию len (). Оператор «+» может объединять две строки. Обратите внимание на то, что в приведенном ниже коде переменные не объявлены заранее - просто назначьте их и приступайте.
s = 'привет' печать s [1] ## i распечатать len (s) ## 2 напечатайте s + 'там' ## привет там
В отличие от Java, знак «+» не преобразует автоматически числа или другие типы в строковую форму. Функция str () преобразует значения в строковую форму, чтобы их можно было комбинировать с другими строками.
пи = 3,14 ## text = 'Значение пи' + pi ## НЕТ, не работает text = 'Значение пи' + str (pi) ## да
Для чисел стандартные операторы +, /, * работают как обычно. Оператора ++ нет, но работают + =, - = и т.д. Если вы хотите целочисленное деление, правильнее всего использовать две косые черты - например, 6 // 5 равно 1 (до python 3 единичное / делает деление int с целыми числами в любом случае, но движение вперед // является предпочтительным способом указать, что вы хотите деление int.)
Оператор «print» выводит на печать один или несколько элементов Python, за которыми следует новая строка (оставьте запятую в конце элементов, чтобы запретить перевод строки). "Необработанный" строковый литерал имеет префикс 'r' и пропускает все символы без специальной обработки обратной косой черты, поэтому r'x \ nx 'оценивается как строка длины 4' x \ nx '. Префикс 'u' позволяет вам писать строковый литерал Unicode (Python имеет множество других функций поддержки Unicode - см. Документацию ниже).
raw = r 'это \ t \ n и это' # это \ t \ n и это печать в сыром виде multi = "" "Это были лучшие времена.Это был худший из времен "" " # Это были лучшие времена. # Это были худшие времена. печать мульти
Строковые методы
Вот некоторые из наиболее распространенных строковых методов. Метод похож на функцию, но он запускается «на» объекте. Если переменная s является строкой, то код s.lower () запускает метод lower () для этого строкового объекта и возвращает результат (эта идея метода, работающего на объекте, является одной из основных идей, составляющих Object Ориентированное программирование, ООП).Вот некоторые из наиболее распространенных строковых методов:
- s.lower (), s.upper () - возвращает строчную или прописную версию строки
- s.strip () - возвращает строку с удаленными пробелами в начале и в конце
- s.isalpha () / s.isdigit () / s.isspace () ... - проверяет, все ли строковые символы находятся в различных классах символов
- s.startswith ('other'), s.endswith ('other') - проверяет, начинается ли строка или заканчивается заданной другой строкой
- с.find ('other') - ищет указанную другую строку (не регулярное выражение) в s и возвращает первый индекс, с которого она начинается, или -1, если не найдено
- s.replace ('old', 'new') - возвращает строку, в которой все вхождения 'old' были заменены на 'new'.
- s.split ('delim') - возвращает список подстрок, разделенных заданным разделителем. Разделитель - это не регулярное выражение, это просто текст. 'aaa, bbb, ccc'.split (', ') -> [' aaa ',' bbb ',' ccc ']. Как удобный частный случай s.split () (без аргументов) разбивается на все пробельные символы.
- s.join (list) - противоположно split (), объединяет элементы в данном списке вместе, используя строку в качестве разделителя. например '---'. join (['aaa', 'bbb', 'ccc']) -> aaa --- bbb --- ccc
Поиск в Google по запросу "python str" должен привести вас к официальным строковым методам python.org, в которых перечислены все методы str.
Python не имеет отдельного символьного типа. Вместо этого выражение, подобное s [8], возвращает строку длиной-1, содержащую символ.С этой строкой-1 операторы ==,
Ломтики струн
Синтаксис «slice» - удобный способ ссылаться на части последовательностей - обычно строки и списки. Срез s [начало: конец] - это элементы, начинающиеся с начала и продолжающиеся до конца, но не включая его. Предположим, у нас есть s = "Hello"
- s [1: 4] - это символы, начинающиеся с индекса 1 и продолжающиеся до индекса 4, но не включая его.
- s [1:] - это 'ello' - исключение значений индекса по умолчанию до начала или конца строки
- s [:] - это 'Hello' - исключение обоих всегда дает нам копию целого (это питонический способ скопировать последовательность, такую как строка или список)
- s [1: 100] - это 'ello' - слишком большой индекс усекается до длины строки
Стандартные отсчитываемые от нуля порядковые номера обеспечивают легкий доступ к символам в начале строки.В качестве альтернативы Python использует отрицательные числа для облегчения доступа к символам в конце строки: s [-1] - последний символ 'o', s [-2] - 'l' предпоследний char и так далее. Отрицательные номера индекса отсчитываются от конца строки:
- s [-1] is 'o' - последний символ (первый с конца)
- с [-4] - это 'e' - четвертая с конца
- s [: - 3] - «Он» - идет до последних трех символов, но не включая их.
- s [-3:] - это 'llo' - начиная с 3-го символа от конца и до конца строки.
Это чистый трюизм срезов, что для любого индекса n s [: n] + s [n:] == s . Это работает даже при отрицательном n или за пределами допустимого значения. Или, по-другому, s [: n] и s [n:] всегда разделяют строку на две части, сохраняя все символы. Как мы увидим позже в разделе списков, срезы тоже работают со списками.
Строка%
Python имеет похожее на printf () средство для объединения строк. Оператор% принимает строку формата типа printf слева (% d int,% s строка,% f /% g с плавающей запятой) и соответствующие значения в кортеже справа (кортеж состоит из значений, разделенных символом запятые, обычно сгруппированные в круглых скобках):
#% оператор text = "% d поросят вылезут, или я% s, я% s, и я взорву ваш% s."% (3, 'фырка', 'затяжка', 'хаус')
Вышеупомянутая строка довольно длинная - предположим, вы хотите разбить ее на отдельные строки. Вы не можете просто разделить строку после символа «%», как в других языках, поскольку по умолчанию Python обрабатывает каждую строку как отдельный оператор (с положительной стороны, вот почему нам не нужно вводить точки с запятой для каждого линия). Чтобы исправить это, заключите все выражение в круглые скобки - тогда выражение может занимать несколько строк. Этот метод сквозного кода работает с различными конструкциями группирования, подробно описанными ниже: (), [], {}.
# Добавьте круглые скобки, чтобы длинная строка работала:
текст = (
«Вылезут% d поросят, или я% s, я% s, и я взорву ваш% s».
% (3, 'фырка', 'затяжка', 'хаус'))
Так лучше, но очередь все равно длинновата. Python позволяет разрезать строку на части, которые затем автоматически объединяются. Итак, чтобы сделать эту строку еще короче, мы можем сделать это:
# Разбиваем строку на куски, которые автоматически объединяются Python
текст = (
"% d поросят вышли",
"или я% s, и я% s,"
"и я взорву ваш% s."
% (3, 'фырка', 'затяжка', 'хаус'))
Строки i18n (Unicode)
Обычные строки Python * не * Unicode, это просто байты. Чтобы создать строку Unicode, используйте префикс u в строковом литерале:
> ustring = u'A unicode \ u018e string \ xf1 ' > ustring u'A unicode \ u018e строка \ xf1 '
Строка Юникода - это объект, отличный от обычной строки "str", но строка Юникода совместима (они используют общий суперкласс "basestring"), а различные библиотеки, такие как регулярные выражения, работают правильно, если вместо этого передается строка Юникода обычной строки.
Чтобы преобразовать строку Unicode в байты с кодировкой, такой как 'utf-8', вызовите метод ustring.encode ('utf-8') для строки Unicode. В другом направлении функция unicode (s, encoding) преобразует закодированные простые байты в строку Unicode:
## (ustring сверху содержит строку Unicode)
> s = ustring.encode ('utf-8')
> с
'Строка Unicode \ xc6 \ x8e \ xc3 \ xb1' ## байтов в кодировке utf-8
> t = unicode (s, 'utf-8') ## Преобразование байтов обратно в строку Unicode
> t == ustring ## Он такой же, как оригинал, ура!
Правда
Встроенная функция печати не полностью работает со строками Unicode.Вы можете сначала encode () печатать в utf-8 или что-то еще. В разделе чтения файлов есть пример, который показывает, как открыть текстовый файл с некоторой кодировкой и прочитать строки Unicode. Обратите внимание, что обработка Unicode - это одна из областей, в которой Python 3 значительно очищен по сравнению с поведением Python 2.x, описанным здесь.
Если заявление
Python не использует {} для заключения блоков кода для if / loops / function и т. Д. Вместо этого Python использует двоеточие (:) и отступы / пробелы для группировки операторов.Логический тест для if не обязательно должен быть в скобках (большое отличие от C ++ / Java), и он может иметь предложения * elif * и * else * (мнемоника: слово «elif» имеет ту же длину, что и слово « еще").
Любое значение может использоваться как if-test. Все «нулевые» значения считаются ложными: нет, 0, пустая строка, пустой список, пустой словарь. Существует также логический тип с двумя значениями: True и False (преобразованный в int, это 1 и 0). Python имеет обычные операции сравнения: ==,! =, <, <=,>,> =.В отличие от Java и C, == перегружен для правильной работы со строками. Логические операторы - это прописанные слова * и *, * или *, * not * (Python не использует C-стиль && ||!). Вот как может выглядеть код для полицейского, тянущего спидер - обратите внимание, как каждый блок операторов then / else начинается с:, а операторы сгруппированы по их отступам:
если скорость> = 80:
распечатать 'Лицензия и регистрация, пожалуйста'
если настроение == 'ужасное' или скорость> = 100:
print 'Вы имеете право хранить молчание.'
elif mood == 'bad' или speed> = 90:
print "Мне придется выписать вам билет".
write_ticket ()
еще:
print "Давай попробуем сохранить меньше 80, ладно?"
Я считаю, что пропуск ":" является моей самой распространенной синтаксической ошибкой при вводе кода вышеупомянутого типа, вероятно, потому, что это дополнительная вещь, которую нужно набирать по сравнению с моими привычками C ++ / Java. Кроме того, не помещайте логический тест в скобки - это привычка C / Java. Если код короткий, вы можете поместить его в ту же строку после ":", как это (это относится к функциям, циклам и т. Д.также), хотя некоторые люди считают, что удобнее размещать элементы в отдельных строках.
если скорость> = 80: print 'Вы так разорились' else: print "Хорошего дня"
Упражнение: string1.py
Чтобы попрактиковаться в материале этого раздела, попробуйте упражнение string1.py в Базовых упражнениях.
фрагмент Python ()
Объект среза используется для среза заданной последовательности (строки, байтов, кортежа, списка или диапазона) или любого объекта, который поддерживает протокол последовательности (реализует метод __getitem __ () и __len __ () ).
Синтаксис slice () :
срез (старт, стоп, шаг)
slice () Параметры
slice () может принимать три параметра:
- start (необязательно) - Начальное целое число, с которого начинается нарезка объекта. По умолчанию
Нет, если не указан. - stop - Целое число, до которого выполняется нарезка. Нарезка останавливается на индексе stop -1 (последний элемент) .
- step (необязательно) - Целочисленное значение, определяющее приращение между каждым индексом для нарезки. По умолчанию
Нет, если не указан.
Пример 1. Создание объекта среза для нарезки
# содержит индексы (0, 1, 2)
результат1 = срез (3)
печать (результат1)
# содержит индексы (1, 3)
результат2 = срез (1, 5, 2)
печать (срез (1, 5, 2)) Выход
срез (Нет, 3, Нет) ломтик (1, 5, 2)
Здесь результат1 и результат2 являются объектами среза.
Теперь мы знаем об объектах среза, давайте посмотрим, как мы можем получить подстроку, подсписок, подкортеж и т. Д. Из объектов среза.
Пример 2: Получить подстроку с помощью объекта среза
# Программа для получения подстроки из заданной строки
py_string = 'Python'
# stop = 3
# содержит индексы 0, 1 и 2
slice_object = кусок (3)
print (py_string [slice_object]) # Pyt
# start = 1, stop = 6, step = 2
# содержит индексы 1, 3 и 5
slice_object = срез (1, 6, 2)
print (py_string [slice_object]) # yhn Выход
Pyt yhn
Пример 3: Получить подстроку с отрицательным индексом
py_string = 'Python'
# start = -1, stop = -4, step = -1
# содержит индексы -1, -2 и -3
slice_object = срез (-1, -4, -1)
print (py_string [slice_object]) # noh Выход
noh
Пример 4: Получить подсписок и подкортеж
py_list = ['P', 'y', 't', 'h', 'o', 'n']
py_tuple = ('P', 'y', 't', 'h', 'o', 'n')
# содержит индексы 0, 1 и 2
slice_object = кусок (3)
print (py_list [slice_object]) # ['P', 'y', 't']
# содержит индексы 1 и 3
slice_object = срез (1, 5, 2)
print (py_tuple [slice_object]) # ('y', 'h') Выход
['P', 'y', 't']
('y', 'h')
Пример 5. Получить подсписок и подкортеж с отрицательным индексом
py_list = ['P', 'y', 't', 'h', 'o', 'n']
py_tuple = ('P', 'y', 't', 'h', 'o', 'n')
# содержит индексы -1, -2 и -3
slice_object = срез (-1, -4, -1)
print (py_list [slice_object]) # ['n', 'o', 'h']
# содержит индексы -1 и -3
slice_object = срез (-1, -5, -2)
print (py_tuple [slice_object]) # ('n', 'h') Выход
['n', 'o', 'h']
('п', 'ч')
Пример 6: Использование синтаксиса индексирования для нарезки
Объект среза можно заменить синтаксисом индексации в Python.
Вы также можете использовать следующий синтаксис для нарезки:
obj [начало: стоп: шаг]
Например,
py_string = 'Python'
# содержит индексы 0, 1 и 2
print (py_string [0: 3]) # Pyt
# содержит индексы 1 и 3
print (py_string [1: 5: 2]) # yh Выход
Pyt yh
Как нарезать строки в Python?
Введение
В этом руководстве мы узнаем, как нарезать строки в Python.
Python поддерживает нарезку строк. Это создание новой подстроки из данной строки на основе определенных пользователем начальных и конечных индексов.
Способы нарезки строк в Python
Если вы хотите нарезать строки в Python, это будет так же просто, как эта строка ниже.
res_s = s [start_pos: end_pos: step]
Здесь,
- res_s сохраняет возвращенную подстроку,
- s - заданная строка,
- start_pos - это начальный индекс, от которого нам нужно вырезать строку s,
- end_pos - конечный индекс, перед на котором завершится операция нарезки,
- этап - это шаги, которые процесс нарезки будет выполнять от start_pos до end_pos.
Примечание : Все три вышеперечисленных параметра являются необязательными. По умолчанию для start_pos установлено значение 0 , end_pos считается равным длине строки, а step устанавливается на 1 .
Теперь давайте рассмотрим несколько примеров, чтобы понять, как лучше разрезать строки в Python.
Строки среза в Python - Примеры
Нарезать строки Python можно разными способами.
Обычно мы получаем доступ к строковым элементам (символам), используя простую индексацию, которая начинается с 0 до n-1 (n - длина строки). Следовательно, для доступа к 1-му элементу строки string1 мы можем просто использовать приведенный ниже код.
Опять же, есть другой способ получить доступ к этим символам, то есть использовать с отрицательной индексацией . Отрицательная индексация начинается с -1 до -n (n - длина данной строки).Обратите внимание, что отрицательная индексация выполняется с другого конца строки. Следовательно, чтобы получить доступ к первому символу на этот раз, нам нужно следовать приведенному ниже коду.
Теперь давайте рассмотрим некоторые способы, которыми мы можем разрезать строку, используя вышеупомянутую концепцию.
1. Разрезать строки в Python с началом и концом
Мы можем легко разрезать данную строку, указав начальный и конечный индексы для желаемой подстроки, которую мы ищем. Посмотрите на приведенный ниже пример, в котором объясняется нарезка строк с использованием начального и конечного индексов как для обычного, так и для отрицательного метода индексации.
# нарезка строки с двумя параметрами
s = "Привет, мир!"
res1 = s [2: 8]
res2 = s [-4: -1] # использование отрицательной индексации
print ("Результат1 =", res1)
print ("Результат2 =", res2)
Выход :
Результат1 = llo Wo Результат2 = rld
Здесь,
- Мы инициализируем строку
sкак «Hello World!» , - Сначала мы разрезаем данную строку с начальным индексом 2 и конечным индексом 8 .Это означает, что результирующая подстрока будет содержать символы от s [2] до s [8-1] ,
- Аналогично, для следующей подстроки результирующая подстрока должна содержать символы из s [ -4] от до с [(- 1) -1] .
Значит, наш вывод оправдан.
2. Разрезать строки, используя только начало или конец
Как упоминалось ранее, все три параметра для разделения строки являются необязательными. Следовательно, мы можем легко выполнять наши задачи, используя один параметр.Посмотрите на приведенный ниже код, чтобы получить четкое представление.
# нарезка строки с одним параметром
s1 = "Чарли"
s2 = "Иордания"
res1 = s1 [2:] # значение по умолчанию конечной позиции устанавливается равным длине строки
res2 = s2 [: 4] # значение по умолчанию начальной позиции равно 0
print ("Результат1 =", res1)
print ("Результат2 =", res2)
Выход :
Result1 = arlie Результат2 = Йорд
Здесь,
- Сначала мы инициализируем две строки, s1 и s2 ,
- Для нарезки обеих из них мы просто упоминаем start_pos для s1 и end_pos только для s2,
- Следовательно, для res1 , это содержит подстроку s1 от индекса 2 (как упоминалось) до последнего (по умолчанию он установлен в n-1).В то время как для res2 диапазон индексов лежит от 0 до 4 (упоминалось).
3. Разрезать строки в Python с параметром шага
Значение шага определяет переход, который должна совершить операция разделения от одного индекса к другому. Внимательно посмотрите на приведенный ниже пример.
# нарезка строки с параметром шага
s = "Python"
s1 = "Котлин"
res = s [0: 5: 2]
res1 = s1 [-1: -4: -2] # использование отрицательных параметров
print ("Результирующая нарезанная строка =", res)
print ("Результирующая нарезанная строка (отрицательные параметры) =", res1)
Выход :
Результирующая нарезанная строка = Pto Результирующая нарезанная строка (отрицательные параметры) = nl
В приведенном выше коде
- Мы инициализируем две строки s и s1 и пытаемся разрезать их по указанным начальным и конечным индексам, как мы это делали для нашего первого примера,
- Но на этот раз мы упомянули значение шага , которое было установлено в 1 по умолчанию для предыдущих примеров,
- Для res размер шага 2 означает, что при обходе для получения подстроки с индекса 0 до 4 каждый раз индекс будет увеличиваться на значение 2.То есть первый символ - s [0] ('P'), следующие символы в подстроке будут s [0 + 2] и s [2 + 2] , пока индекс просто меньше 5.
- Для следующего, например, res1 , упомянутый шаг равен (-2). Следовательно, как и в предыдущем случае, символы в подстроке будут иметь вид s1 [-1] , затем s1 [(- 1) + (- 2)] или s1 [-3] , пока индекс не станет чуть меньше (-4).
4. Обращение строки с помощью нарезки в Python
Используя нарезку строки отрицательного индекса в Python, мы также можем перевернуть строку и сохранить ее в другой переменной.Для этого нам просто нужно указать шаг , размер , равный (-1) .
Давайте посмотрим, как это работает, на примере, приведенном ниже.
# изменение направления строки с помощью нарезки строки s = "AskPython" rev_s = s [:: - 1] # обратная строка, сохраненная в rev_s печать (rev_s)
Выход :
Как мы видим, строка s перевернута и сохранена в rev_s . Примечание : и в этом случае исходная струна остается неповрежденной и нетронутой.
Заключение
Итак, в этом руководстве мы узнали о методологии нарезки строк и ее различных формах. Надеюсь, читатели получили четкое представление о теме.
Если у вас возникнут дополнительные вопросы по этой теме, воспользуйтесь комментариями ниже.
Список литературы
Обрезка и нарезка строк в Python
СтрокиPython представляют собой последовательности отдельных символов и имеют общие методы доступа с другими последовательностями Python - списками и кортежами.Самый простой способ извлечь отдельные символы из строк (и отдельных членов из любой последовательности) - распаковать их в соответствующие переменные.
>>> s = 'Don' >>> s 'Don' >>> a, b, c = s # Распаковать в переменные >>> a 'D' >>> b 'o' >>> c 'n' |
К сожалению, не часто мы можем позволить себе заранее знать, сколько переменных нам понадобится для хранения каждого символа в строке.И если количество переменных, которые мы предоставляем, не совпадает с количеством символов в строке, Python выдаст нам ошибку.
s = 'Don Quijote' a, b, c = s Отслеживание (последний вызов последним): Файл "", строка 1, в ValueError: слишком много значений для распаковки |
Обычно более полезно получить доступ к отдельным символам строки, используя синтаксис индексирования Python, подобный массиву.Здесь, как и во всех последовательностях, важно помнить, что индексирование начинается с нуля; то есть первый элемент в последовательности - номер 0.
>>> s = 'Don Quijote' >>> s [4] # Получить 5-й символ 'Q' |
Если вы хотите начать отсчет с конца строки, а не с начала, используйте отрицательный индекс.Например, индекс -1 относится к крайнему правому символу строки.
СтрокиPython неизменяемы, что является просто причудливым способом сказать, что после того, как они были созданы, вы не можете их изменить. Попытка сделать это вызывает ошибку.
>>> s [7] 'j' >>> s [7] = 'x' Traceback (последний вызов последним): Файл "", строка 1, в TypeError : объект 'str' не поддерживает присвоение элемента |
Если вы хотите изменить строку, вы должны создать ее как совершенно новую строку.На практике это просто. Посмотрим, как это сделать через минуту.
До этого, что, если вы хотите извлечь фрагмент из более чем одного символа с известной позицией и размером? Это довольно просто и интуитивно понятно. Мы немного расширили синтаксис квадратных скобок, чтобы мы могли указывать не только начальную позицию нужного фрагмента, но и то, где он заканчивается.
Давайте посмотрим, что здесь происходит. Как и раньше, мы указываем, что хотим начать с позиции 4 (отсчитываемой от нуля) в строке.Но теперь, вместо того чтобы довольствоваться одним символом из строки, мы говорим, что нам нужно больше символов, до , но не включая символа в позиции 8.
Вы могли подумать, что вы также собираетесь получить персонажа на позиции 8. Но это не так. Не волнуйтесь - вы к этому привыкнете. Если это помогает, подумайте о втором индексе ( после , двоеточие) как о указании первого символа, который вам не нужен для .Кстати, преимуществом этого механизма является то, что вы можете быстро определить, сколько символов у вас останется, просто вычтя первый индекс из второго.
Используя этот синтаксис, вы можете опустить один или оба индекса. Первый индекс, если он опущен, по умолчанию равен 0, так что ваш кусок начинается с начала исходной строки; второй по умолчанию занимает наивысшую позицию в строке, так что ваш кусок заканчивается в конце исходной строки. Отсутствие обоих индексов вряд ли принесет большую практическую пользу; как вы могли догадаться, он просто возвращает всю исходную строку.
>>> s [4:] 'Quijote' # Возврат с позиции 4 до конца строки >>> s [: 4] 'Don' # Возврат с начала на позицию 3 >>> s [:] 'Дон Кихот' |
Если вы все еще изо всех сил пытаетесь понять тот факт, что, например, s [0: 8] возвращает все до , но не включая , символ в позиции 8, это может помочь, если вы перевернете это немного в голове: для любого значения индекса n , которое вы выберете, значение s [: n] + s [n:] всегда будет таким же, как исходная целевая строка.Если бы механизм индексации был включающим, символ в позиции n появился бы дважды.
>>> s [6] 'i' >>> s [: 6] + s [6:] 'Don Quijote' |
Как и раньше, вы можете использовать отрицательные числа в качестве индексов, и в этом случае подсчет начинается с конца строки (с индексом -1), а не с начала.
Последним вариантом синтаксиса квадратных скобок является добавление третьего параметра, который определяет «шаг» или количество символов, которые вы хотите переместить вперед после того, как каждый символ будет извлечен из исходной строки. Первый полученный символ всегда соответствует индексу перед двоеточием; но после этого указатель перемещается вперед на столько символов, которые вы укажете в качестве шага, и извлекает символ в этой позиции. И так до тех пор, пока конечный индекс не будет достигнут или превышен.Если, как в случаях, которые мы встречали до сих пор, параметр опущен, он по умолчанию равен 1, так что извлекается каждый символ в указанном сегменте. Пример проясняет это.
>>> s [4: 8] 'Quij' >>> s [4: 8: 1] # 1 в любом случае является значением по умолчанию, поэтому тот же результат 'Quij' >>> s [4: 8: 2] # Вернуть символ, затем переместиться на 2 позиции вперед и т. д. «Ци» # Довольно интересно! |
Вы также можете указать отрицательный шаг. Как и следовало ожидать, это означает, что вы хотите, чтобы Python возвращался назад при извлечении символов.
Как видите, поскольку мы идем в обратном направлении, имеет смысл, чтобы начальный индекс был выше конечного индекса (иначе ничего не было бы возвращено).
По этой причине, если вы указываете отрицательный шаг, но опускаете первый или второй индекс, Python по умолчанию устанавливает для отсутствующего значения все, что имеет смысл в данных обстоятельствах: начальный индекс до конца строки и конечный индекс до конца строки. начало строки.Я знаю, от мысли об этом может заболеть голова, но Python знает, что делает.
>>> s [4 :: - 1] # Конечный индекс по умолчанию равен началу строки 'Q noD' >>> s [: 4: -1] # Начальный индекс по умолчанию до конца строка 'etojiu' |
Итак, это синтаксис квадратных скобок, который позволяет вам извлекать фрагменты символов, если вы знаете точное положение требуемого фрагмента в строке.
Но что, если вы хотите получить фрагмент на основе содержимого строки, о котором мы можем не знать заранее?
Осмотр содержимого
Python предоставляет строковые методы, которые позволяют нам разрезать строку в соответствии с указанными разделителями. Другими словами, мы можем сказать Python искать определенную подстроку в нашей целевой строке и разбить целевую строку вокруг этой подстроки. Он делает это, возвращая список результирующих подстрок (без разделителей).Кстати, мы можем не указывать разделитель явно, и в этом случае по умолчанию используется символ пробела (пробел, '\ t', '\ n', '\ r', '\ f') или последовательность таких персонажей.
Помните, что эти методы не влияют на строку, для которой вы их вызываете; они просто возвращают новую строку.
>>> s.split () ['Don', 'Quijote'] >>> s # 'Don Quijote' # s не были изменены |
Более полезно, мы можем собрать возвращенный список непосредственно в соответствующие переменные.
>>> title, handle = s.split () >>> title 'Don' >>> handle 'Quijote' |
Оставив на мгновение нашего испанского героя на его ветряных мельницах, представим, что у нас есть строка, содержащая время в часах, минутах и секундах, разделенное двоеточиями. В этом случае мы могли бы разумно собрать отдельные части в переменные для дальнейших манипуляций.
>>> tim = '16: 30: 10 ' >>> часы, минуты, секунды = tim.split (': ') >>> часы ' 16 ' >>> минут '30' >>> сек '10' |
Мы можем захотеть разделить целевую строку только один раз, независимо от того, сколько раз встречается разделитель. Метод split () принимает второй параметр, указывающий максимальное количество выполняемых разделений.
>>> tim.split (':', 1) # split () только один раз ['16', '30: 10 '] |
Здесь строка разбивается на первое двоеточие, а остальная часть остается нетронутой. А если мы хотим, чтобы Python начал искать разделители с другого конца строки? Что ж, есть вариантный метод под названием rsplit () , который делает именно это.
>>> тим.rsplit (':', 1) ['16: 30 ',' 10 '] |
Строительство перегородки
Аналогичный строковый метод - partition () . Это также разбивает строку на основе содержимого, разница в том, что результатом является кортеж , и он сохраняет разделитель вместе с двумя частями целевой строки по обе стороны от него. В отличие от split () , partition () всегда выполняет только одну операцию разделения, независимо от того, сколько раз разделитель появляется в целевой строке.
>>> tim = '16: 30: 10 ' >>> tim.partition (': ') (' 16 ',': ', '30: 10') |
Как и метод split () , существует вариант partition () , rpartition () , который начинает поиск разделителей с другого конца целевой строки.
>>> тим.rpartition (':') ('16: 30 ',': ',' 10 ') |
А теперь вернемся к нашему Дон Кихоту. Ранее, когда мы пытались преобразовать его имя в английский язык, заменив 'j' на 'x', присвоив 'x' непосредственно s [7] , мы обнаружили, что не можем этого сделать, потому что вы можете ' t изменить существующие строки Python. Но мы можем обойти это, создав новую строку, которая нам больше нравится, на основе старой строки. Это можно сделать с помощью строкового метода replace () .
>>> s.replace ('j', 'x') 'Дон Кихот' >>> s # Дон Кихот не изменен |
Опять же, наша строка вообще не изменилась. Случилось так, что Python просто вернул новую строку в соответствии с инструкциями, которые мы дали, а затем немедленно отбросил ее, оставив исходную строку без изменений.Чтобы сохранить нашу новую строку, нам нужно присвоить ее переменной.
>>> new_s = s.replace ('j', 'x') >>> s 'Don Quijote' >>> new_s 'Don Quixote' |
Но, конечно, вместо того, чтобы вводить новую переменную, мы можем просто повторно использовать существующую.
>>> с = с.replace ('j', 'x') >>> s 'Дон Кихот' |
И здесь, хотя может показаться, что мы изменили исходную строку, на самом деле мы просто отбросили ее и сохранили на ее месте новую строку.
Обратите внимание, что по умолчанию replace () заменяет каждое вхождение подстроки поиска новой подстрокой.
>>> s = 'Don Quijote' >>> s.replace ('o', 'a') 'Dan Quijate' |
Мы можем контролировать эту расточительность, добавив дополнительный параметр, определяющий максимальное количество раз, которое должна быть заменена подстрока поиска.
>>> s.replace ('o', 'a', 1) 'Dan Quijote' |
Наконец, метод replace () не ограничивается действиями с отдельными символами.Мы можем заменить целую часть целевой строки некоторым указанным значением.
>>> s.replace ('Qui', 'key') 'Donkey jote' |
Ссылки на используемые строковые методы см. В следующих статьях:
Python: обозначение фрагментов в строке
Введение
Термин нарезка в программировании обычно относится к получению подстроки, подкортежа или подсписка из строки, кортежа или списка соответственно.
Python предлагает множество простых способов разрезать не только эти три, но и любой итеративный . Итерация - это, как следует из названия, любой объект, который можно повторять.
В этой статье мы рассмотрим все, что вам нужно знать о Slicing Strings в Python .
Нарезка строки в Python
Существует несколько способов разрезания строки, наиболее распространенный из которых - использование оператора : со следующим синтаксисом:
строка [начало: конец]
строка [начало: конец: шаг]
Параметр start, представляет начальный индекс, end, - конечный индекс, а step, - количество элементов, которые «перешагнули».
Давайте продолжим и разрежем строку:
строка = 'Нет. Я твой отец.'
print (строка [4:20])
При этом будут пропущены первые четыре символа в строке:
я твой отец
Нахождение префикса и суффикса длины n с помощью среза
Чтобы найти префикс или суффикс длины n строки, мы будем использовать тот же подход, который можно использовать для поиска хвоста или начала списка. Мы разрежем от начала до n и от -n до конца строки.
В этом случае -n начнет отсчет с конца строки в обратном направлении, что даст нам суффикс:
п = 4
string = 'Теперь, молодой Скайуокер, ты умрешь.'
# Префикс длины n
печать (строка [: n])
# Суфикс длины n
печать (строка [-n:])
Это приводит к:
Сейчас,
умри.