Создание электронной книги или PDF-файла из статей Википедии для чтения в автономном режиме
НЕКЕШЕРОВАННЫЙ КОНТЕНТ
Предпочитаете ли вы читать на компьютере, в eBook Reader или на бумаге, иногда бывает приятно провести совместное исследование в книжном формате. Вот как превратить статьи Википедии в PDF-файл для чтения в автономном режиме или распечатать как бумажную книгу.
Превратите статью из Википедии в PDF
Хотите сохранить любимую статью Википедии в формате PDF, чтобы читать в автономном режиме или поделиться с друзьями? Конечно, вы можете просто распечатать статью как PDF прямо из вашего браузера , но это будет не очень красиво. Однако мы можем использовать новые инструменты, встроенные в Википедию, для автоматического создания PDF-копии статьи, которая больше похожа на традиционную книгу, чем на обычную веб-распечатку. Для этого нажмите кнопку Печать / экспорт ссылка на левой боковой панели в Википедии, когда вы читаете статью, которую хотите сохранить.
Это покажет несколько вариантов использования этой статьи. Нажмите Скачать как PDF чтобы Википедия автоматически создавала копию этой статьи в формате PDF.
Через несколько секунд Википедия откроет новую страницу, сообщающую вам, что ваш новый документ создан. Щелкните значок Скачать файл ссылку, чтобы просмотреть PDF-файл прямо в браузере, или щелкните правой кнопкой мыши и выберите Сохранить как чтобы сохранить его на свой компьютер как обычно.
Вот наш PDF-файл в Adobe Reader в нашем браузере. Википедия создает очень красивые PDF-файлы, которые будет приятно читать на вашем компьютере, для чтения электронных книг или даже распечатать и поделиться.
Создать книгу в Википедии
Если вам нужно несколько разных статей из Википедии для автономного использования, возможно, лучше создать электронную книгу Википедии. Это позволяет легко собрать всю необходимую статью, организовать и отформатировать ее, как в традиционной книге. Для этого нажмите Создать книгу под Печать / экспорт на левой боковой панели в Википедии.
Это позволяет легко собрать всю необходимую статью, организовать и отформатировать ее, как в традиционной книге. Для этого нажмите Создать книгу под Печать / экспорт на левой боковой панели в Википедии.
Это откроет страницу создания книги; щелкнуть Начать создание книги для начала.
Вы вернетесь к предыдущей статье Википедии, но на этот раз у вас будет новая панель создания книги в верхней части страницы. Нажмите Добавьте эту страницу в свою книгу
Эта новая панель для создания книг теперь будет следовать за вами в Википедии, так что вы можете посетить любую страницу и добавить ее в свою электронную книгу. Вы можете быстро добавить похожие статьи в статьи, которые вы добавляете, так как вы увидите новый Добавьте связанную вики-страницу в свою книгу всплывающая подсказка при наведении курсора на ссылки в статьях. Щелкните по нему, и эта страница будет добавлена в вашу электронную книгу без необходимости посещения страницы.
Щелкните по нему, и эта страница будет добавлена в вашу электронную книгу без необходимости посещения страницы.
После того, как вы добавили все нужные страницы, нажмите кнопку Показать книгу ссылка вверху.
Откроется страница, на которой вы можете переупорядочить, отсортировать или удалить статьи из своей электронной книги. Просто перетащите статьи, чтобы расположить их в нужном вам порядке.
Вы можете организовать его еще больше с помощью разделителей глав. Нажмите Создать главу вверху коробки.
Теперь просто введите название главы во всплывающем окне и нажмите В порядке чтобы добавить его в свою книгу.
Перетащите маркеры глав, как вы хотите организовать свою книгу.![]() Не забудьте также добавить заголовок и подзаголовок.
Не забудьте также добавить заголовок и подзаголовок.
Когда вы закончите, вы можете загрузить свою электронную книгу в формате PDF или ODT или заказать печатную копию своей электронной книги Википедии в PediaPress.
Если вы выбрали загрузку PDF-файла, вам придется подождать несколько секунд, пока вся книга будет обработана и объединена.
Когда он будет готов, вы можете просмотреть его в браузере или загрузить, чтобы прочитать на своем компьютере, как и раньше. Обратите внимание на наше красивое оглавление, которое было создано автоматически; это выглядит очень красиво, но, к сожалению, не имеет гиперссылок на сами разделы в электронной книге.
Электронные книги Википедии получаются довольно красиво и включают таблицы, множество изображений и ссылки из исходной статьи, оформленные в красивом книжном формате. Теперь вы можете читать и делиться своей электронной книгой со своего компьютера, распечатать ее или перенести в электронную книгу, чтобы читать свою книгу Википедию на ходу.
Теперь вы можете читать и делиться своей электронной книгой со своего компьютера, распечатать ее или перенести в электронную книгу, чтобы читать свою книгу Википедию на ходу.
В качестве альтернативы, как упоминалось выше, вы можете приобрести печатную книгу Википедии в PediaPress. Если вы выберете этот вариант, вы будете перенаправлены на сайт PediaPress, где сможете выбрать цвет обложки и изображение из включенных статей.
Вы также можете предварительно просмотреть, как ваша книга будет выглядеть в печатном виде. Предварительные просмотры книг выглядят очень красиво, поэтому, если вам нужна печатная копия книги, это выглядит как очень хороший вариант.
Независимо от того, как вам нужно использовать Википедию, новые функции PDF и электронных книг позволяют легко создавать ремиксы и брать Википедию с собой. Мы нашли средство создания электронных книг очень простым в использовании и были довольны тем, насколько хороши были готовые PDF-файлы.
Дополнительная информация о создателе книг Википедии
PediaPress
PDF с точки зрения программиста / Хабр
Я имею дело с PDF не только как пользователь, а, прежде всего, как разработчик софта, умеющего его читать и писать (возможно, вы сталкивались с продуктами компании ABBYY, работающими с PDF – ABBYY FineReader, ABBYY PDF Transformer). Я предполагаю, что вы прочитали статью habrahabr.ru/company/abbyy/blog/105006 и далее пишу только про некоторые особенности и ограничения PDF, которые больше интересны продвинутым пользователям. Никаких сложных технических деталей при этом не буду касаться, так что программистам, желающим научиться читать или писать PDF, лучше сразу перейти к чтению спецификацию версии 1.7 со страницы www.adobe.com/devnet/pdf/pdf_reference_archive. html 🙂
html 🙂
Назначение и особенности PDF
Изначально формат PDF задумывался компанией Adobe ещё в конце 80х годов прошлого века как «электронная твёрдая копия» странично-структурированных документов, которую можно просматривать и печатать в виде, идентичном оригинальному, на разных машинах и платформах, но который не предполагается редактировать. Это определение отличает PDF от большинства других форматов хранения и распространения человеко-читаемых документов. За прошедшие годы PDF сильно эволюционировал, являясь в настоящее время контейнером для самого разнообразного контента (текст, векторная и растровая графика, интерактивные элементы, формы, аудио, видео, аннотации разных видов), но его исходное предназначение до сих пор остаётся источником как его возможностей, так и многочисленных ограничений.
Так, форматы текстовых документов (DOC, RTF, DOCX и т.д.) в основном ориентированы не на просмотр, а на редактирование документов. Созданный разумным пользователем 🙂 документ логично реагирует на вставку/замену/удаление текста, картинок, таблиц в разных местах, изменение размеров и полей страниц, изменение форматирования фрагментов текста любого размера и тому подобные действия. Интернет страницы в формате HTML не слишком ориентированы на редактирование (хотя и допускают его), но при условии прямых рук автора нормально переносят отображение не только на экране монитора своего создателя, но и на устройствах с совершенно другими экранами и взаимодействием с пользователем.
Интернет страницы в формате HTML не слишком ориентированы на редактирование (хотя и допускают его), но при условии прямых рук автора нормально переносят отображение не только на экране монитора своего создателя, но и на устройствах с совершенно другими экранами и взаимодействием с пользователем.
У PDF же особый путь – наибольшее распространение он получил как формат-паразит, в котором документы не создаются человеком «с нуля», а чаще всего порождаются из других форматов путём глубокой машинной переработки, теряющей многие или даже все детали, ненужные для отображения документа в фиксированном виде. Cамым распространенным способом получения PDF является печать на виртуальный PDF-принтер из любого приложения, имеющего в меню команду «Print».
PDF-принтер переводит GDI(«интерфейс графических устройств»)-команды вывода в нужные места символов, линий, кривых, прямоугольников, растровых изображений и прочих геометрических примитивов в соответствующие им PDF-команды с сохранением в файл.
Такое преобразование способно очень точно передать внешний вид того, что получилось, перед печатью (например, линии и символы не теряют своей чёткости при любом масштабировании и при этом хранятся достаточно компактно), но совершенно игнорирует устройство документа, из которого это получилось. Например, для подчёркивания слова или другого фрагмента текста в PDF не предусмотрено выделенной команды или атрибута символов – вместо этого отдельно выводятся символы (группами, которые обычно даже не совпадают со словами или строками), а отдельно рисуются линии или тоненькие прямоугольники нужной толщины и цвета в нужных местах страницы. Таблицы, которые человек воспринимает как целостный набор ячеек, для приложения, отображающего PDF, – просто хаотический набор символов и линий, по случайному совпадению образовавших нечто, воспринимаемое человеком как таблица. Гиперссылки, которые в исходном документе можно было использовать как для навигации внутри документа, так и для перехода на Веб-адреса, при печати исчезают как средство навигации, остаются лишь окрашенные и/или подчёркнутые надписи.
Другой способ получения PDF-документов, ставший особенно популярным в последние годы, – переработка в него отсканированных бумажных страниц. Сейчас большинство сканеров и многофункциональных устройств могут выдавать результат в виде «растровых» PDF – при этом предыдущий способ «имитации печати» не нужен, а драйвер или утилита устройства самостоятельно формирует страницы PDF так, чтобы на каждой из них оказалось нужное «растровое» изображение, благо набор форматов графики, которые можно использовать в PDF, покрывают большинство запросов. Такие «растровые» PDF-документы занимают больше места и выглядят менее качественными, чем «векторные».
Некоторые современные приложения (в том числе приложения комплекта OpenOffice, Microsoft Office новых версий, ABBYY FineReader и ABBYY PDF Transformer) умеют создавать PDF самостоятельно, пользуясь при этом гораздо большим арсеналом средств, чем PDF-принтеры, ибо знают об исходном документе гораздо больше, чем нужно передать принтеру. Это позволяет сохранить, например, гиперссылки как таковые (а не просто как окрашенный и/или подчёркнутый текст) или описать некоторые элементы структуры документа для его переформатирования и показа на экранах малых разрешений. Такие документы со структурной информацией называются «тегированными» или «tagged» PDF. По замыслу Adobe, «тегирование», добавленное начиная с Acrobat 5, призвано скрыть наиболее вопиющие недостатки ранних версий PDF. Например, для нетегированных документов не гарантируется корректная работа механизма копирования фрагментов текста в буфер обмена Windows (всем привычный Copy-Paste). При этом даже сегодня тегированными являются не все создаваемые PDF, в том числе из-за ограниченных возможностей программ-генераторов (или незнания пользователями, где включить нужную для этого галочку в настройках), или просто из-за большего размера таких PDF, когда остро стоит вопрос экономии дискового пространства при хранении больших архивов.
Это позволяет сохранить, например, гиперссылки как таковые (а не просто как окрашенный и/или подчёркнутый текст) или описать некоторые элементы структуры документа для его переформатирования и показа на экранах малых разрешений. Такие документы со структурной информацией называются «тегированными» или «tagged» PDF. По замыслу Adobe, «тегирование», добавленное начиная с Acrobat 5, призвано скрыть наиболее вопиющие недостатки ранних версий PDF. Например, для нетегированных документов не гарантируется корректная работа механизма копирования фрагментов текста в буфер обмена Windows (всем привычный Copy-Paste). При этом даже сегодня тегированными являются не все создаваемые PDF, в том числе из-за ограниченных возможностей программ-генераторов (или незнания пользователями, где включить нужную для этого галочку в настройках), или просто из-за большего размера таких PDF, когда остро стоит вопрос экономии дискового пространства при хранении больших архивов.
Преобразование PDF-документов в другие форматы
Желание отредактировать содержимое PDF-документа или преобразовать его в другие, желательно редактируемые форматы (как для немедленного редактирования, так и для хранения с возможностью поиска/редактирования «когда-нибудь»), возникает по разным причинам. Простейшие средства извлечения текстового содержимого предоставляет любое приложение, отображающее PDF – я имею привычный Copy-Paste, который работает довольно примитивно – как правило, теряется символьное и абзацное форматирование, игнорируются таблицы и сложная вёрстка PDF-документа. Есть приложения, которые позволяют «точечно» редактировать PDF без преобразования в другие форматы – но их арсенал средств редактирования очень ограничен, ну просто никакого сравнения с привычными текстовыми процессорами 🙂 В дорогущем Adobe Acrobat для многих документов единственным работающим видом редактирования является «аннотирование» – есть инструменты для добавления комментариев, выделения текста маркером, зачёркивания и т.п. Да, более продвинутое редактирование как бы есть, но вы, случайно, не встречали забавного сообщения «All or part of the selection has no available system font. You cannot add or delete text using the currently selected font.» при невинной попытке удалить символ или слово из «хорошего», «векторного» PDF-документа в Акробате? А не пробовали заменить фрагмент строки на более длинный, грустно наблюдая уползающие вправо хвосты строк? Если нет, значит любовь к продуктам Adobe у вас ещё впереди! К простым и привычным для текстовых процессоров задачам – например, «заменить за несколько секунд по всему документу слово «MS» на «Microsoft», с изменением размещения текста по колонкам и страницам» – такое «редактирование» и близко не стоит.
Простейшие средства извлечения текстового содержимого предоставляет любое приложение, отображающее PDF – я имею привычный Copy-Paste, который работает довольно примитивно – как правило, теряется символьное и абзацное форматирование, игнорируются таблицы и сложная вёрстка PDF-документа. Есть приложения, которые позволяют «точечно» редактировать PDF без преобразования в другие форматы – но их арсенал средств редактирования очень ограничен, ну просто никакого сравнения с привычными текстовыми процессорами 🙂 В дорогущем Adobe Acrobat для многих документов единственным работающим видом редактирования является «аннотирование» – есть инструменты для добавления комментариев, выделения текста маркером, зачёркивания и т.п. Да, более продвинутое редактирование как бы есть, но вы, случайно, не встречали забавного сообщения «All or part of the selection has no available system font. You cannot add or delete text using the currently selected font.» при невинной попытке удалить символ или слово из «хорошего», «векторного» PDF-документа в Акробате? А не пробовали заменить фрагмент строки на более длинный, грустно наблюдая уползающие вправо хвосты строк? Если нет, значит любовь к продуктам Adobe у вас ещё впереди! К простым и привычным для текстовых процессоров задачам – например, «заменить за несколько секунд по всему документу слово «MS» на «Microsoft», с изменением размещения текста по колонкам и страницам» – такое «редактирование» и близко не стоит.
Неслучайно в софтверной индустрии сформировалась целая отрасль, производящая средства конверсии с лучшей функциональностью. Из написанного выше (и особенно – ниже), должно стать понятно, насколько это непростая задача. Большинство пользователей, не читавших этого креатива, так не считают – поэтому я его и пишу 🙂
Основные проблемы при преобразовании PDF в другие форматы
Часто в обсуждении связанных с PDF вопросов употребляется понятие «текстового слоя». Интуитивно многими пользователями предполагается, что в PDF-файлах есть такие выделенные части, где логично и понятно описаны все нужные характеристики видимого текста – или невидимого, но находимого поиском или выделяемого мышью. Хочу открыть вам страшную тайну (вероятно, с риском в ближайшее время получить пулю от киллера, подосланного авторами формата PDF и их отделом маркетинга) – никакого текстового слоя в указанном смысле в PDF нет! На деле для каждой страницы есть общий поток команд её рисования, в котором совершенно произвольно перемешаны разнотипные команды – задания областей отсечения, смены текущих толщины, цвета и шаблона пунктирности линий, изменения системы координат, смены шрифта, рисования прямых и кривых (с текущими атрибутами), вывода группы символов с текущими атрибутами и указанными «номерами глифов» (глиф – описание изображение символа, без учёта других его характеристик), вывода растровых картинок и т.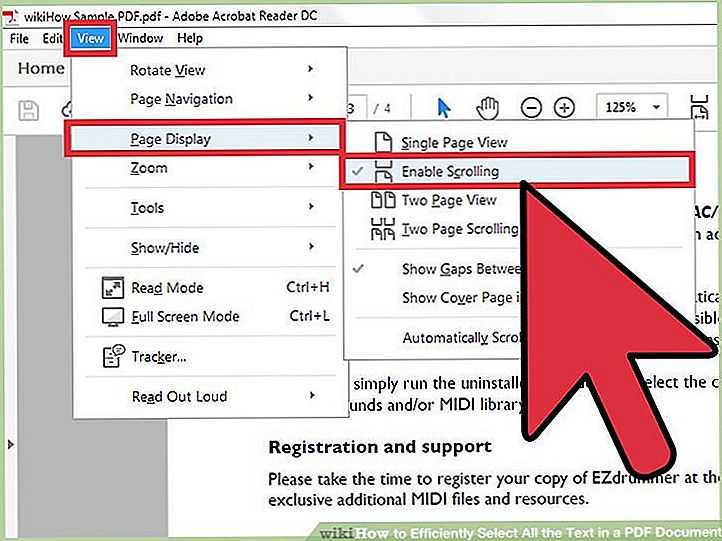 п. То есть даже специальные текстовые команды – это просто один из многих инструментов рисования, не выделенный в отдельные потоки.
п. То есть даже специальные текстовые команды – это просто один из многих инструментов рисования, не выделенный в отдельные потоки.
Хуже другое – даже в пределах одной страницы PDF можно использовать (слишком) широкий набор средств изображения похожего глазу текста: буквы могут быть видны как части растрового изображения – например, в логотипах (задача их распознавания – в чистом виде задача OCR-приложений, того же ABBYY FineReader), как результат рисования кривыми Безье или специальными текстовыми командами. Этот последний случай – самый лучший для обработки, но даже здесь не обязательно указываются общепринятые коды символов из Unicode или других кодировок – ибо в PDF-файл можно записывать особые шрифты из подмножества только реально использованных символов и ссылаться на символы по совершенно условным «номерам глифов», а не по кодам. То есть не всегда просто как обнаружить символы в нужном месте, так и определить их коды! С форматированием, в том числе с выбором похожего шрифта при отсутствии точного аналога, всё ещё хитрее.![]()
Символы, даже если их присутствие и коды тем или иным способом установлены, своим порядком вывода на страницу очень часто никак не соответствуют исходной последовательности их размещения и чтения на странице. Например, на двухколоночной странице команды вывода текста из правой и левой колонок могут быть произвольно перемешаны. На такой странице нужно выделить области, в каждой из которых размещён логически связный текст – это тоже задача, много лет решаемая OCR-приложениями. Некоторую помощь даёт структурная информация из тегированных PDF – но часто даже у сделанных сейчас PDF эта информация либо отсутствует – как при выводе через PDF-принтер – либо бывает недостаточно полна.
Когда мы решили, что в некоторых местах страницы есть связный текст (а где-то даже поняли, как он сгруппирован в таблицы – это очень нетривиальная задача!), и нашли, какие символы и в какие строчки складываются, нужно преобразовать эти строчки в абзацы и более высокоуровневые элементы, привычные пользователям как текстовых процессоров, так и HTML – колонки, таблицы, врезки. Данных об абзацном форматировании в PDF обычно нет, так что все эти характеристики тоже нужно вычислять – как при всём том же распознавании. Если пытаться игнорировать элементы текста сложнее строчек или абзацев, то, выведя всё в коротких врезках, получим документ, который выглядит как настоящий, но почти не редактируется – помните задачу о замене по всему документу слова «MS» на «Microsoft»? Это очень хороший тест на редактируемость. Для редактируемого документа важна способность текста перетекать из одних зон в другие – в нужных случаях, которые ещё надо суметь отличить от ненужных.
Данных об абзацном форматировании в PDF обычно нет, так что все эти характеристики тоже нужно вычислять – как при всём том же распознавании. Если пытаться игнорировать элементы текста сложнее строчек или абзацев, то, выведя всё в коротких врезках, получим документ, который выглядит как настоящий, но почти не редактируется – помните задачу о замене по всему документу слова «MS» на «Microsoft»? Это очень хороший тест на редактируемость. Для редактируемого документа важна способность текста перетекать из одних зон в другие – в нужных случаях, которые ещё надо суметь отличить от ненужных.
Только проделав всё это, можно превратить содержимое PDF в файл редактируемого формата, выглядящий похоже на оригинал и удобный для работы. Конечно, за многие годы многие умные люди в разных компаниях научились решать каждую из этих задач хорошо или даже отлично, но идеального решения всей задачи в целом я ещё не встречал. Но мы над этим работаем 🙂
Вячеслав Сапроненко SlaSapro
Департамент продуктов для распознавания текстов
Вся документация — Документация DSpace
Перейти к концу баннера
Перейти к началу баннера
Перейти к концу метаданных
- Создано Тимом Донохью, последнее изменение: 17 января 2023 г.

Перейти к началу метаданных
Все политики поддержки версий подробно описаны в нашей Политике поддержки программного обеспечения DSpace
Version | Latest Release | Supported Until | Change History | Documentation | | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DSpace 7.x | 7.4 (2022-10-06) | Поддерживается до выпуска версии 10.0. См. Политику поддержки программного обеспечения DSpace | Изменения | Обзор | | ||||||||
DSPACE 6. x x | 6,4 (2022-07-28) | ОдерЖНА ОСНОВАЯ ОСНОВА 1 июля 2023 г. См. Поддержка DSPACE 5 и 6 заканчивается в 2023 | Изменения | 333333 и 6 в 2023 | 33333333 и 6 Download PDF | JavaDocs 6 | |||||||
DSpace 5.x | 5.11 (2022-07-28) | End of Life / Unsupported Support ended on January 1, 2023. См. Поддержка DSpace 5 и 6 заканчивается в 2023 г. | Изменения | Обзор | Download PDF | JavaDocs 5 | ||||||||
DSpace 4.x | 4.9 (2018-06-25) | End of Life / Unsupported | Changes | Обзор | Скачать PDF | JavaDocs 4 | ||||||||
DSpace 3. | 3.6 (21.03.2016) | Конец жизни / Не поддерживается | Изменения | Обзор | Скачать PDF | Javadocs 3 | ||||||||
DSPACE 1,8.X | 1,8,3 (2013-07-25) | Конечный Обзор | Скачать PDF | JavaDocs 1.8 | ||||||||||
DSpace 1.7.x | 1.7.3 (25.07.2013) | Конец срока службы / не поддерживается Download PDF | | ||||||||||
DSpace 1.6.x | 1.6.2 (2010-06-15) | End of Life / Unsupported | See Ch. 16 в документах | Скачать PDF | JavaDocs 1.6 | ||||||||
DSpace 1.5.x | 1. | End of Life / Unsupported | See Ch.14 in docs | Download PDF | | ||||||||
DSpace 1.4.x | 1.4.2 (2007-05-10) | End of Life / Unsupported | See docs | Documentation in ‘docs’ directory of Source Download | | ||||||||
DSpace 1.3.x | 1.3.2 (2005-10-09) | End of Life / Unsupported | See docs | Documentation in ‘docs’ directory of Source Download | | ||||||||
DSpace 1.2.x | 1.2.2 (2005-05-05) | End of Life / Unsuppored | DOCS 9003 | DOCS | DOCS | DOCS | 3 | DOCS | 3 | . | |||
DSpace 1.1.x | 1.1.1 (2003-05-08) | End of Life / Unsupported | See docs | Документация в каталоге «docs» исходной загрузки | | ||||||||
DSpace 1.0. | 1.0.1 (2002-11-04) | End of Life / Unsuppored | См. Документы | Документация в доке. |
 x
x 5.2 (2009-04-14)
5.2 (2009-04-14)- документация
Обзор
Content Tools
Apps
Весь контент на LYRASIS Wiki находится под лицензией CC BY (Attribution) , если не указано иное.
IMSLP: Бесплатная загрузка нот в формате PDF
Эта категория включает следующие 200 подкатегорий из 26 111.
(предыдущие 200) (следующие 200)
0
А
| А прод.
|
 , Зубец
, Зубец
 Ф.
Ф.