PDF с точки зрения программиста / Хабр
Я имею дело с PDF не только как пользователь, а, прежде всего, как разработчик софта, умеющего его читать и писать (возможно, вы сталкивались с продуктами компании ABBYY, работающими с PDF – ABBYY FineReader, ABBYY PDF Transformer). Я предполагаю, что вы прочитали статью habrahabr.ru/company/abbyy/blog/105006 и далее пишу только про некоторые особенности и ограничения PDF, которые больше интересны продвинутым пользователям. Никаких сложных технических деталей при этом не буду касаться, так что программистам, желающим научиться читать или писать PDF, лучше сразу перейти к чтению спецификацию версии 1.7 со страницы www.adobe.com/devnet/pdf/pdf_reference_archive.html 🙂
Назначение и особенности PDF
Изначально формат PDF задумывался компанией Adobe ещё в конце 80х годов прошлого века как «электронная твёрдая копия» странично-структурированных документов, которую можно просматривать и печатать в виде, идентичном оригинальному, на разных машинах и платформах, но который не предполагается редактировать. Это определение отличает PDF от большинства других форматов хранения и распространения человеко-читаемых документов. За прошедшие годы PDF сильно эволюционировал, являясь в настоящее время контейнером для самого разнообразного контента (текст, векторная и растровая графика, интерактивные элементы, формы, аудио, видео, аннотации разных видов), но его исходное предназначение до сих пор остаётся источником как его возможностей, так и многочисленных ограничений.
Это определение отличает PDF от большинства других форматов хранения и распространения человеко-читаемых документов. За прошедшие годы PDF сильно эволюционировал, являясь в настоящее время контейнером для самого разнообразного контента (текст, векторная и растровая графика, интерактивные элементы, формы, аудио, видео, аннотации разных видов), но его исходное предназначение до сих пор остаётся источником как его возможностей, так и многочисленных ограничений.
Так, форматы текстовых документов (DOC, RTF, DOCX и т.д.) в основном ориентированы не на просмотр, а на редактирование документов. Созданный разумным пользователем 🙂 документ логично реагирует на вставку/замену/удаление текста, картинок, таблиц в разных местах, изменение размеров и полей страниц, изменение форматирования фрагментов текста любого размера и тому подобные действия. Интернет страницы в формате HTML не слишком ориентированы на редактирование (хотя и допускают его), но при условии прямых рук автора нормально переносят отображение не только на экране монитора своего создателя, но и на устройствах с совершенно другими экранами и взаимодействием с пользователем.
У PDF же особый путь – наибольшее распространение он получил как формат-паразит, в котором документы не создаются человеком «с нуля», а чаще всего порождаются из других форматов путём глубокой машинной переработки, теряющей многие или даже все детали, ненужные для отображения документа в фиксированном виде. Cамым распространенным способом получения PDF является печать на виртуальный PDF-принтер из любого приложения, имеющего в меню команду «Print».
PDF-принтер переводит GDI(«интерфейс графических устройств»)-команды вывода в нужные места символов, линий, кривых, прямоугольников, растровых изображений и прочих геометрических примитивов в соответствующие им PDF-команды с сохранением в файл. При этом, разумеется, сохраняются количество и размер страниц, на которое выполнялась печать.
Такое преобразование способно очень точно передать внешний вид того, что получилось, перед печатью (например, линии и символы не теряют своей чёткости при любом масштабировании и при этом хранятся достаточно компактно), но совершенно игнорирует устройство документа, из которого это получилось. Например, для подчёркивания слова или другого фрагмента текста в PDF не предусмотрено выделенной команды или атрибута символов – вместо этого отдельно выводятся символы (группами, которые обычно даже не совпадают со словами или строками), а отдельно рисуются линии или тоненькие прямоугольники нужной толщины и цвета в нужных местах страницы. Таблицы, которые человек воспринимает как целостный набор ячеек, для приложения, отображающего PDF, – просто хаотический набор символов и линий, по случайному совпадению образовавших нечто, воспринимаемое человеком как таблица. Гиперссылки, которые в исходном документе можно было использовать как для навигации внутри документа, так и для перехода на Веб-адреса, при печати исчезают как средство навигации, остаются лишь окрашенные и/или подчёркнутые надписи. В общем, сплошные имитация и надувательство. Такие PDF я ниже буду называть «векторными» (как состоящие из векторных команд, к которым относится и рисование символов).
Например, для подчёркивания слова или другого фрагмента текста в PDF не предусмотрено выделенной команды или атрибута символов – вместо этого отдельно выводятся символы (группами, которые обычно даже не совпадают со словами или строками), а отдельно рисуются линии или тоненькие прямоугольники нужной толщины и цвета в нужных местах страницы. Таблицы, которые человек воспринимает как целостный набор ячеек, для приложения, отображающего PDF, – просто хаотический набор символов и линий, по случайному совпадению образовавших нечто, воспринимаемое человеком как таблица. Гиперссылки, которые в исходном документе можно было использовать как для навигации внутри документа, так и для перехода на Веб-адреса, при печати исчезают как средство навигации, остаются лишь окрашенные и/или подчёркнутые надписи. В общем, сплошные имитация и надувательство. Такие PDF я ниже буду называть «векторными» (как состоящие из векторных команд, к которым относится и рисование символов).
Другой способ получения PDF-документов, ставший особенно популярным в последние годы, – переработка в него отсканированных бумажных страниц.
Некоторые современные приложения (в том числе приложения комплекта OpenOffice, Microsoft Office новых версий, ABBYY FineReader и ABBYY PDF Transformer) умеют создавать PDF самостоятельно, пользуясь при этом гораздо большим арсеналом средств, чем PDF-принтеры, ибо знают об исходном документе гораздо больше, чем нужно передать принтеру. Это позволяет сохранить, например, гиперссылки как таковые (а не просто как окрашенный и/или подчёркнутый текст) или описать некоторые элементы структуры документа для его переформатирования и показа на экранах малых разрешений.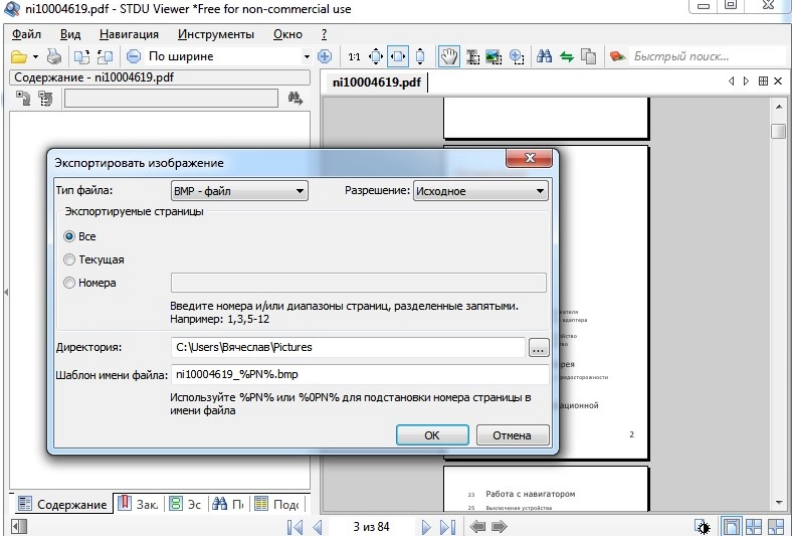
Преобразование PDF-документов в другие форматы
Желание отредактировать содержимое PDF-документа или преобразовать его в другие, желательно редактируемые форматы (как для немедленного редактирования, так и для хранения с возможностью поиска/редактирования «когда-нибудь»), возникает по разным причинам. Простейшие средства извлечения текстового содержимого предоставляет любое приложение, отображающее PDF – я имею привычный Copy-Paste, который работает довольно примитивно – как правило, теряется символьное и абзацное форматирование, игнорируются таблицы и сложная вёрстка PDF-документа. Есть приложения, которые позволяют «точечно» редактировать PDF без преобразования в другие форматы – но их арсенал средств редактирования очень ограничен, ну просто никакого сравнения с привычными текстовыми процессорами 🙂 В дорогущем Adobe Acrobat для многих документов единственным работающим видом редактирования является «аннотирование» – есть инструменты для добавления комментариев, выделения текста маркером, зачёркивания и т.п. Да, более продвинутое редактирование как бы есть, но вы, случайно, не встречали забавного сообщения «All or part of the selection has no available system font. You cannot add or delete text using the currently selected font.» при невинной попытке удалить символ или слово из «хорошего», «векторного» PDF-документа в Акробате? А не пробовали заменить фрагмент строки на более длинный, грустно наблюдая уползающие вправо хвосты строк? Если нет, значит любовь к продуктам Adobe у вас ещё впереди! К простым и привычным для текстовых процессоров задачам – например, «заменить за несколько секунд по всему документу слово «MS» на «Microsoft», с изменением размещения текста по колонкам и страницам» – такое «редактирование» и близко не стоит.
Простейшие средства извлечения текстового содержимого предоставляет любое приложение, отображающее PDF – я имею привычный Copy-Paste, который работает довольно примитивно – как правило, теряется символьное и абзацное форматирование, игнорируются таблицы и сложная вёрстка PDF-документа. Есть приложения, которые позволяют «точечно» редактировать PDF без преобразования в другие форматы – но их арсенал средств редактирования очень ограничен, ну просто никакого сравнения с привычными текстовыми процессорами 🙂 В дорогущем Adobe Acrobat для многих документов единственным работающим видом редактирования является «аннотирование» – есть инструменты для добавления комментариев, выделения текста маркером, зачёркивания и т.п. Да, более продвинутое редактирование как бы есть, но вы, случайно, не встречали забавного сообщения «All or part of the selection has no available system font. You cannot add or delete text using the currently selected font.» при невинной попытке удалить символ или слово из «хорошего», «векторного» PDF-документа в Акробате? А не пробовали заменить фрагмент строки на более длинный, грустно наблюдая уползающие вправо хвосты строк? Если нет, значит любовь к продуктам Adobe у вас ещё впереди! К простым и привычным для текстовых процессоров задачам – например, «заменить за несколько секунд по всему документу слово «MS» на «Microsoft», с изменением размещения текста по колонкам и страницам» – такое «редактирование» и близко не стоит.
Неслучайно в софтверной индустрии сформировалась целая отрасль, производящая средства конверсии с лучшей функциональностью. Из написанного выше (и особенно – ниже), должно стать понятно, насколько это непростая задача. Большинство пользователей, не читавших этого креатива, так не считают – поэтому я его и пишу 🙂
Основные проблемы при преобразовании PDF в другие форматы
Часто в обсуждении связанных с PDF вопросов употребляется понятие «текстового слоя». Интуитивно многими пользователями предполагается, что в PDF-файлах есть такие выделенные части, где логично и понятно описаны все нужные характеристики видимого текста – или невидимого, но находимого поиском или выделяемого мышью. Хочу открыть вам страшную тайну (вероятно, с риском в ближайшее время получить пулю от киллера, подосланного авторами формата PDF и их отделом маркетинга) – никакого текстового слоя в указанном смысле в PDF нет! На деле для каждой страницы есть общий поток команд её рисования, в котором совершенно произвольно перемешаны разнотипные команды – задания областей отсечения, смены текущих толщины, цвета и шаблона пунктирности линий, изменения системы координат, смены шрифта, рисования прямых и кривых (с текущими атрибутами), вывода группы символов с текущими атрибутами и указанными «номерами глифов» (глиф – описание изображение символа, без учёта других его характеристик), вывода растровых картинок и т.
Хуже другое – даже в пределах одной страницы PDF можно использовать (слишком) широкий набор средств изображения похожего глазу текста: буквы могут быть видны как части растрового изображения – например, в логотипах (задача их распознавания – в чистом виде задача OCR-приложений, того же ABBYY FineReader), как результат рисования кривыми Безье или специальными текстовыми командами. Этот последний случай – самый лучший для обработки, но даже здесь не обязательно указываются общепринятые коды символов из Unicode или других кодировок – ибо в PDF-файл можно записывать особые шрифты из подмножества только реально использованных символов и ссылаться на символы по совершенно условным «номерам глифов», а не по кодам. То есть не всегда просто как обнаружить символы в нужном месте, так и определить их коды! С форматированием, в том числе с выбором похожего шрифта при отсутствии точного аналога, всё ещё хитрее.
Символы, даже если их присутствие и коды тем или иным способом установлены, своим порядком вывода на страницу очень часто никак не соответствуют исходной последовательности их размещения и чтения на странице. Например, на двухколоночной странице команды вывода текста из правой и левой колонок могут быть произвольно перемешаны. На такой странице нужно выделить области, в каждой из которых размещён логически связный текст – это тоже задача, много лет решаемая OCR-приложениями. Некоторую помощь даёт структурная информация из тегированных PDF – но часто даже у сделанных сейчас PDF эта информация либо отсутствует – как при выводе через PDF-принтер – либо бывает недостаточно полна.
Когда мы решили, что в некоторых местах страницы есть связный текст (а где-то даже поняли, как он сгруппирован в таблицы – это очень нетривиальная задача!), и нашли, какие символы и в какие строчки складываются, нужно преобразовать эти строчки в абзацы и более высокоуровневые элементы, привычные пользователям как текстовых процессоров, так и HTML – колонки, таблицы, врезки. Данных об абзацном форматировании в PDF обычно нет, так что все эти характеристики тоже нужно вычислять – как при всём том же распознавании. Если пытаться игнорировать элементы текста сложнее строчек или абзацев, то, выведя всё в коротких врезках, получим документ, который выглядит как настоящий, но почти не редактируется – помните задачу о замене по всему документу слова «MS» на «Microsoft»? Это очень хороший тест на редактируемость. Для редактируемого документа важна способность текста перетекать из одних зон в другие – в нужных случаях, которые ещё надо суметь отличить от ненужных.
Данных об абзацном форматировании в PDF обычно нет, так что все эти характеристики тоже нужно вычислять – как при всём том же распознавании. Если пытаться игнорировать элементы текста сложнее строчек или абзацев, то, выведя всё в коротких врезках, получим документ, который выглядит как настоящий, но почти не редактируется – помните задачу о замене по всему документу слова «MS» на «Microsoft»? Это очень хороший тест на редактируемость. Для редактируемого документа важна способность текста перетекать из одних зон в другие – в нужных случаях, которые ещё надо суметь отличить от ненужных.
Только проделав всё это, можно превратить содержимое PDF в файл редактируемого формата, выглядящий похоже на оригинал и удобный для работы. Конечно, за многие годы многие умные люди в разных компаниях научились решать каждую из этих задач хорошо или даже отлично, но идеального решения всей задачи в целом я ещё не встречал. Но мы над этим работаем 🙂
Вячеслав Сапроненко SlaSapro
Департамент продуктов для распознавания текстов
Файл PDF – чем открыть, описание формата
Чем открыть, описание – 1 формат файла
Документ PDF
Portable Document Format File
Тип файла: Размеченные документы
Тип данных: Двоичный файл
Mime-type: application/pdf
Разработчик: Adobe Systems
Заголовок и ключевые строки
HEX: 25 50 44 46 2D
ASCII: %PDF-
Подробное описание
Файл . PDF — документ, созданный с помощью программы Adobe Acrobat, соответствующего плагина для web-браузера, либо стороннего софта. Формат PDF на сегодняшний день приобрел огромную популярность благодаря тому, что он поддерживается практически всеми устройствами и операционными системами. Поэтому документы этого формата отлично подходят для обмена данными между пользователями.
PDF — документ, созданный с помощью программы Adobe Acrobat, соответствующего плагина для web-браузера, либо стороннего софта. Формат PDF на сегодняшний день приобрел огромную популярность благодаря тому, что он поддерживается практически всеми устройствами и операционными системами. Поэтому документы этого формата отлично подходят для обмена данными между пользователями.
PDF-документы могут быть открыты с помощью бесплатной версии Adobe Reader или web-плагина, который доступен для большинства интернет-браузеров. В некоторых браузерах, в частности, в Google Chrome обеспечена поддержка этого формата даже без установленного плагина. Редактировать файлы PDF можно с помощью платной версии Adobe Reader. Также, существует огромное количество программ как для открытия и работы с данным форматом, так и для конвертации других документов из/в этот формат.
Файлы PDF могут содержать текст, изображения, формы, аннотации и другие данные. Примечательно то, что отображение документа не зависит от платформы — что в Windows, что, к примеру, в Mac OS, документы будут выглядеть одинаково, также, как и при печати.
Как, чем открыть файл .pdf?
WindowsОнлайнAndroidiOSMac OSLinux
|
 iWare GoodReader
iWare GoodReaderИнструкция — как выбрать программу из списка, скачать и использовать ее для открытия файла
Для более точного определения формата и программ для открытия файла используйте функцию определения формата файла по расширению и по данным (заголовку) файла.
4. Структура документа — Объяснение PDF [Книга]
Глава 4. Структура документа
В этой главе мы оставляем биты и байты файла PDF, и рассмотрим логическую структуру. Рассматриваем прицеп словарь , каталог документов и дерево страниц . Перечислим необходимые записи в каждом объект. Затем мы рассмотрим две общие структуры в файлах PDF: текст строки и даты .
На рис. 4-1 показана логическая структура типового документа.
Рис. 4-1. Типичная структура двухстраничного PDF-документа
Trailer Dictionary
Этот словарь, находящийся в трейлере файла, а не в основном тело файла, является одной из первых вещей, которые должны быть обработаны, когда программа хочет прочитать документ PDF. Он содержит записи, позволяющие таблицу перекрестных ссылок — и, следовательно, объекты файла — для чтения. Его важные записи сведены в Таблицу 4-1.
Таблица 4-1. Entries in a trailer dictionary (*denotes required entry)
Entries in a trailer dictionary (*denotes required entry)
| Key | Value type | Value |
/Size * | Integer | Total number of entries in таблица перекрестных ссылок файла (обычно равно количеству объектов в файле плюс один). |
/Root * | Косвенная ссылка на словарь | Каталог документов . |
/Информация | Косвенная ссылка на словарь | Информация о документе документа словарь . |
/ID | Массив из двух строк | Уникально идентифицирует файл в рабочем процессе. Первый
строка определяется, когда файл сначала создается, второй
изменены системами рабочего процесса, когда они изменяют файл. |
Вот пример словаря трейлера:
<< /Размер 421 /Корень 377 0 Р /Информация 375 0 Р /ID [<75ff22189ceac848dfa2afec93deee03> <057928614d9711db835e000d937095a2>] >>
После обработки словаря трейлера мы можем перейти к чтению словарь информации о документе и каталог документов .
Информационный словарь документов
Информационный словарь документов содержит даты создания и изменения файла, а также некоторые простые метаданные (не путать с более полными метаданными XMP). обсуждается в метаданных XML).
Записи словаря информации о документе описаны в таблице 4-2. Типичный словарь информации о документе приведено в Примере 4-1.
Таблица 4-2. Записи в словаре информации о документе. Типы «текст строка» и «строка даты» объясняются далее в этой главе.
| Ключ | Тип значения | Значение |
/ Название | текстовая строка | Название документа. Обратите внимание, что это не имеет ничего общего с
любой заголовок, отображаемый на первой странице. Обратите внимание, что это не имеет ничего общего с
любой заголовок, отображаемый на первой странице. |
/Тема | текстовая строка | Тема документа. Опять же, это просто метаданные без особых правил о содержании. |
/Ключевые слова | текстовая строка | Ключевые слова, связанные с этим документом. Советов не дают как их структурировать. |
/Автор | текстовая строка | Имя автора документа. |
/Дата создания | строка даты | Дата создания документа. |
/ModDate | строка даты | Дата последнего изменения документа. |
/Создатель | текстовая строка | Имя программы, которая первоначально создала это
документ, если он начинался как другой формат (например,
«Microsoft Word»).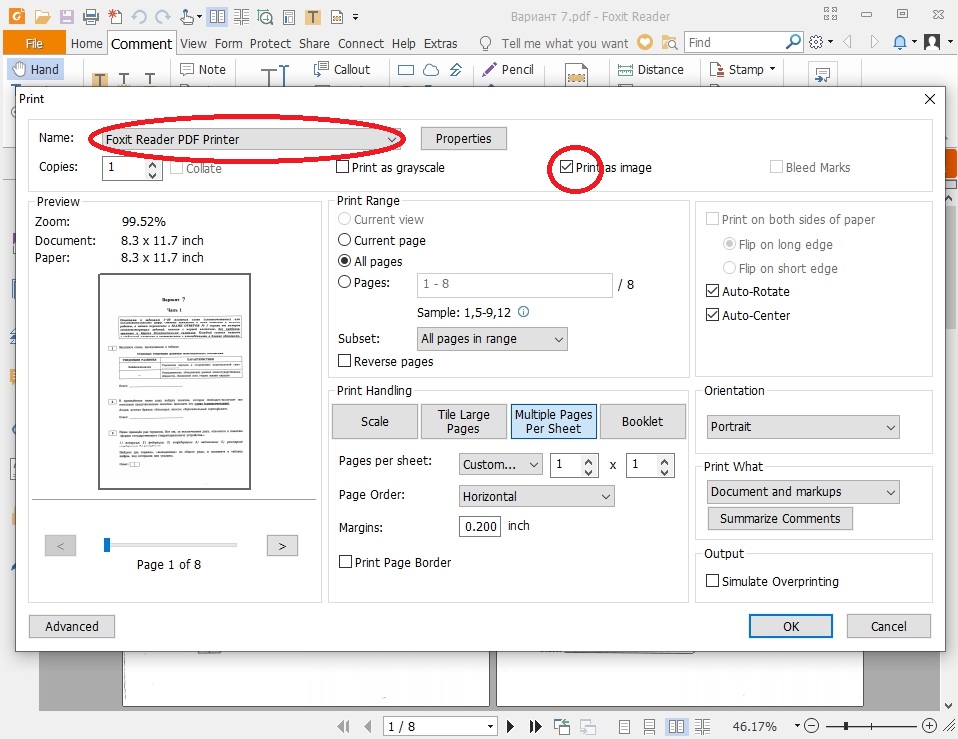 |
/Производитель | текстовая строка | Имя программы, конвертировавшей этот файл в PDF, если он начинался как другой формат (например, формат слова процессор). |
Пример 4-1. Типовой информационный словарь документов
<< /ModDate (D:20060926213913+02'00') /CreationDate (D:20060926213913+02'00') /Название (catalogueproduit-UK.qxd) /Creator (QuarkXPress: фильтр pictwpstops 1.0) /Producer (Acrobat Distiller 6.0 для Macintosh) /Автор (Джеймс Смит) >>
Формат строки даты (для /CreationDate и /ModDate ) обсуждается в разделе Даты. Формат текстовой строки (который
описывает, как различные кодировки могут использоваться в строковом типе)
описано в текстовых строках.
Каталог документов
Каталог документов является корневым объектом
основной граф объектов, из которого все другие объекты могут быть достигнуты через
косвенные ссылки. В Таблице 4-3 мы перечисляем
словарные статьи каталога документов, которые требуются, и некоторые из
много необязательных, чтобы представить краткие темы PDF, которые мы не охватываем
в другом месте на этих страницах.
В Таблице 4-3 мы перечисляем
словарные статьи каталога документов, которые требуются, и некоторые из
много необязательных, чтобы представить краткие темы PDF, которые мы не охватываем
в другом месте на этих страницах.
Таблица 4-3. Каталог документов ( * Обозначает требуемый вход)
| Ключ | Тип значения | Значение |
/. | . | |
/страниц * | косвенная ссылка на словарь | Корневой узел дерева страниц. Деревья страниц обсуждаются в Страницы и деревья страниц. |
/PageLabels | Числовое дерево | Числовое дерево, задающее метки страниц для этого документа.
Этот механизм позволяет страницам в документе иметь больше
сложная нумерация, чем просто 1,2,3….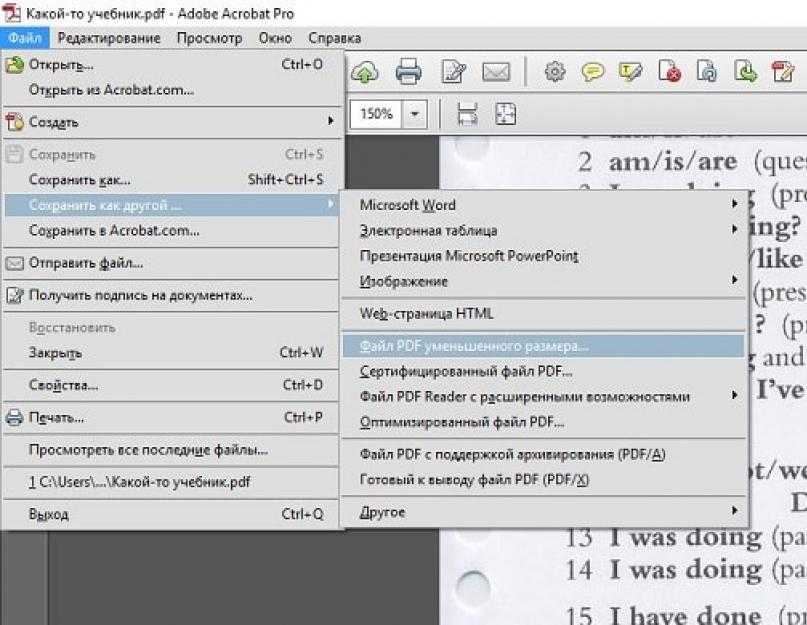 Например, предисловие
книги могут быть пронумерованы i,ii,iii…, в то время как основное содержание
начинается снова с 1,2,3… Эти метки страниц отображаются в PDF
зрители — они не имеют ничего общего с печатной продукцией. Например, предисловие
книги могут быть пронумерованы i,ii,iii…, в то время как основное содержание
начинается снова с 1,2,3… Эти метки страниц отображаются в PDF
зрители — они не имеют ничего общего с печатной продукцией. |
/ Имена | словарь | Словарь имен. Это содержит различные имена деревья , которые сопоставляют имена с сущностями, чтобы предотвратить использовать номера объектов для прямой ссылки на них. |
/Назначения | словарь | Словарь, сопоставляющий имена адресатам. Пункт назначения представляет собой описание места в документе PDF, к которому гиперссылка отправляет пользователя. |
/ViewerPreferences | словарь | словарь предпочтений зрителя , который
позволяет флагам определять поведение средства просмотра PDF, когда
документ просматривается на экране, например страница, на которой он открыт,
начальный масштаб просмотра и так далее. |
/PageLayout | имя | Задает макет страницы, используемый средствами просмотра PDF. Ценности /SinglePage , /OneColumn , /TwoColumnLeft , /TwoColumnRight , /TwoPageLeft , /TwoPageRight .
(По умолчанию: /Одностраничный ). Подробности в таблице
28 ИСО 32000-1:2008. |
/Пейджмоде | имя | Указывает режим страницы, используемый средствами просмотра PDF. Ценности /UseNone , /UseOutlines , /UseThumbs , /FullScreen , /UseOC , /UseAttachments . (По умолчанию: /UseNone ). Подробности в Таблице 28
ИСО 32000-1:2008. |
/Контуры | косвенная ссылка на словарь | Структурный словарь является корнем схема документа , широко известная как
закладки. |
/ Метаданные | косвенная ссылка на stream | Метаданные XMP документа — см. Метаданные XML. |
Страницы и деревья страниц
Дерево страниц , построенное из словарей страниц , приносит вместе инструкции по рисованию графического и текстового контента (который мы рассмотрим в главе 5 и главе 6) с ресурсами (шрифты, изображения и другие внешние данные), которые используются этими инструкциями. Он также включает в себя размер страницы вместе с рядом других коробки определение кадрирования и так далее.
Записи в словаре страниц сведены в Таблицу 4-4.
Таблица 4-4. Entries in a page dictionary (*denotes required entry)
| Key | Value type | Value |
/Type * | name | Must be /Page . |
/ Родительский * | косвенная ссылка на словарь | Родительский узел данного узла в дереве страниц. |
/Ресурсы | словарь | Ресурсы страницы (шрифты, изображения и т. д.). Если это запись полностью опущена, ресурсы наследуются от родительский узел в дереве страниц. Если ресурсов действительно нет, включите эту запись, но используйте пустой словарь. |
/Содержание | косвенная ссылка на поток или массив таких references | Графическое содержимое страницы в одном или нескольких разделах. Если эта запись отсутствует, страница пуста. |
/Повернуть | целое число | Поворот страницы в градусах по часовой стрелке от
север. Значение должно быть кратно 90. Значение по умолчанию: 0. Это
относится как к просмотру, так и к печати. Если эта запись отсутствует,
его значение наследуется от его родительского узла на странице
дерево. Значение по умолчанию: 0. Это
относится как к просмотру, так и к печати. Если эта запись отсутствует,
его значение наследуется от его родительского узла на странице
дерево. |
/MediaBox * | прямоугольник | Медиабокс страницы (размер ее носитель, например, бумага). Для большинства целей размер страницы. Если это запись отсутствует, она унаследована от своего родительского узла на странице дерево. |
/CropBox | прямоугольник | Поле обрезки страницы. Это определяет область страницы отображается по умолчанию при отображении или печати страницы. Если отсутствует, его значение определено таким же, как поле мультимедиа. |
Структура данных прямоугольник для медиа-блок и другие блоки представляют собой массив из четырех
числа. Они определяют диагонально противоположные углы прямоугольника.
первые два элемента массива x и y координаты одного угла, двух последних элементов
быть таковыми другого. Обычно левый нижний и правый верхний углы
дано. Так, например:
Они определяют диагонально противоположные углы прямоугольника.
первые два элемента массива x и y координаты одного угла, двух последних элементов
быть таковыми другого. Обычно левый нижний и правый верхний углы
дано. Так, например:
/MediaBox [0 0 500 800] /CropBox [100 100 400 700]
определяет страницу размером 500 на 800 точек с рамкой обрезки, удаляющей 100 точек с каждой стороны страницы.
Страницы связаны друг с другом с помощью страницы дерево , а не простой массив. Такая древовидная структура делает его быстрее найти нужную страницу в документе с сотнями или тысячами страницы. Хорошие PDF-приложения строят сбалансированное дерево (один с минимальной высотой по количеству узлов). Это гарантирует, что конкретная страница может быть найдена быстро. Узлы без потомков сами страницы. Показан пример структуры дерева страниц для семи страниц. на Рисунке 4-2.
Это будет записано в объектах PDF, как показано в примере 4-2. Записи в промежуточном или корневом
узел дерева страниц (т. е. не сама страница) сведены в Табл. 4-5.
Записи в промежуточном или корневом
узел дерева страниц (т. е. не сама страница) сведены в Табл. 4-5.
Рис. 4-2. Дерево страниц на семь страниц. Точная форма дерева осталась в отдельное приложение PDF. Показан код PDF для этого дерева в примере 4-2.
Пример 4-2. Объекты PDF, используемые для построения дерева страниц, показанного на рисунке 4-2
1 0 obj Корневой узел << /Тип /Страницы /Детские [2 0 R 3 0 R 4 0 R] /Количество 7 >> эндообъект 2 0 obj Промежуточный узел << /Тип /Страницы /Дети [5 0 R 6 0 R 7 0 R] /Родитель 1 0 R /Количество 3 >> эндообъект 3 0 obj Промежуточный узел << /Тип /Страницы /Дети [8 0 R 9 0 R 10 0 R] /Родитель 1 0 R /Количество 3 >> эндообъект 4 0 обж Страница 7 << /Type /Page /Parent 1 0 R /MediaBox [0 0 500 500] /Resources << >> >> эндообъект 5 0 обж Страница 1 << /Type /Page /Parent 2 0 R /MediaBox [0 0 500 500] /Resources << >> >> эндообъект 6 0 объект Страница 2 << /Type /Page /Parent 2 0 R /MediaBox [0 0 500 500] /Resources << >> >> эндообъект 7 0 обж Страница 3 << /Type /Page /Parent 2 0 R /MediaBox [0 0 500 500] /Resources << >> >> эндообъект 8 0 обж Страница 4 << /Type /Page /Parent 3 0 R /MediaBox [0 0 500 500] /Resources << >> >> эндообъект 9 0 обж Страница 5 << /Type /Page /Parent 3 0 R /MediaBox [0 0 500 500] /Resources << >> >> эндообъект 10 0 объект Страница 6 << /Type /Page /Parent 3 0 R /MediaBox [0 0 500 500] /Resources << >> >> endobj
Таблица 4-5. Записи в промежуточном или корневом узле дерева страниц (* обозначает
Требуется вход)
Записи в промежуточном или корневом узле дерева страниц (* обозначает
Требуется вход)
| Ключ | Тип значения | Значение | |||||||||||||
/Тип * | 89.988888888888 8. | . | |||||||||||||
/Kids * | массив косвенных ссылок | Непосредственные дочерние узлы дерева страниц этого узла. | |||||||||||||
/Count * | целое число | Количество узлов страницы (не других узлов дерева страниц), которые являются возможными дочерними элементами этого узла. | |||||||||||||
/ Родительский | косвенная ссылка на узел дерева страниц | Ссылка на родителя этого узла (узел которого
это ребенок). Должен присутствовать, если не является корневым узлом страницы
дерево. |
В этом дереве на любую страницу можно найти не более двух косвенных ссылок вдали от корневого узла.
Текстовые строки
Строки вне фактического текстового содержимого страницы (например, названия закладок, информация о документе и т. д.) известны как текст . строки . Они кодируются с использованием либо PDFDocEncoding или (в более поздних документах) Юникод. PDFDocEncoding основан на кодировке ISO Latin-1. Это полностью задокументировано в Приложении D стандарта ISO 32000-1:2008.
Текстовые строки, закодированные как Unicode, отличаются глядя на первые два байта: это будет 254, за которым следует 255. Это маркер порядка байтов Unicode U+FEFF, который указывает UTF16BE кодирование. Это означает, что строка PDFDocEncoding не может начинаться с þ (254). следует ÿ (255), но это вряд ли произойдет в любом разумном случае. обстоятельство.
Даты создания и изменения /CreationDate и /ModDate в словаре информации о документе
являются примерами формата даты PDF, который кодирует дату в строке,
включая информацию о часовом поясе.
Строка даты имеет формат:
(ГГГГММДДЧЧммССОНЧ'мм')
, где скобки, как обычно, обозначают строку. Другие части даты приведены в Таблице 4-6.
Таблица 4-6. Составляющие формата даты PDF
| Часть | Значение |
ГГГГ | Год, состоящий из четырех цифр, например, 2008 . |
ММ | Месяц, двумя цифрами от 01 до 12 . |
ДД | День, двумя цифрами от 01 до 31 . |
ЧЧ | Час, двумя цифрами от 00 до 23 . |
мм | Минуты, две цифры от 00 до 59 . |
нержавеющая сталь | Второй, двумя цифрами от 00 до 59 . |
О | Отношение местного времени к универсальному времени, либо +, - или Z . + означает, что местное время позже, чем UT, - раньше, а Z равно всемирному времени. |
ЧЧ' | Абсолютное значение смещения от универсального времени в
часов, двумя цифрами от 00 до 23 . |
мм' | Абсолютное значение смещения от универсального времени в
минут, двумя цифрами от 00 до 59 . |
Все части даты после года являются необязательными. Например,
Например, (D:1999) вполне допустимо. Очевидно,
хотя, если вы опустите одну часть, вы должны опустить и все последующее,
иначе результат был бы неоднозначным. Значения по умолчанию для DD и MM
равен 01, для всех остальных частей по умолчанию используются нули.
Например:
(D:20060926213913+02'00')
означает 26 сентября 2006 г., 21:39:13, во втором часовом поясе. часов опережает всемирное время.
Собираем вместе
Это текст, созданный вручную, который необходимо преобразовать в действительный PDF-файл. файл по pdftk с помощью метода представлена в главе 2. Это трехстраничный документ, со словарем информации о документе и деревом страниц. На рис. 4-3 показан этот документ, отображаемый в Acrobat. Читатель. Рисунок 4-4 – соответствующий объект график.
Пример 4-3. Трехстраничный документ с информацией о документе словарь
%PDF-1.1 Заголовок 1 0 obj Верхний уровень дерева страниц: имеет двух дочерних элементов — первую страницу и промежуточный узел дерева страниц << /Дети [2 0 R 3 0 R] /Тип /Страницы /Количество 3 >> эндообъект 4 0 obj Поток содержимого первой страницы << >> транслировать 1.0.000000 0.000000 1. 50. 770. см BT /F0 36. Tf (Page One) Tj ET конечный поток эндообъект 2 0 obj Первая страница << /Повернуть 0 /Родитель 1 0 Р /Ресурсы << /Font << /F0 << /BaseFont /Times-Italic /Subtype /Type1 /Type /Font >> >> >> /MediaBox [0,000000 0,000000 595,2755 841,88976378] /Тип /Страница /Содержание [4 0 Р] >> эндообъект 5 0 obj Каталог документов << /PageLayout /TwoColumnLeft /Pages 1 0 R /Type /Catalog >> эндообъект 6 0 obj Третья страница << /Повернуть 0 /Родитель 3 0 Р /Ресурсы << /Font << /F0 << /BaseFont /Times-Italic /Subtype /Type1 /Type /Font >> >> >> /MediaBox [0,000000 0,000000 595,2755 841,88976378] /Тип /Страница /Содержание [7 0 Р] >> эндообъект 3 0 объект Промежуточный узел дерева страниц, ссылающийся на вторую и третью страницы << /Родитель 1 0 R /Дети [8 0 R 6 0 R] /Количество 2 /Тип /Страницы >> эндообъект 8 0 obj Вторая страница << /Повернуть на 270 /Родитель 3 0 Р /Ресурсы << /Font << /F0 << /BaseFont /Times-Italic /Subtype /Type1 /Type /Font >> >> >> /MediaBox [0,000000 0,000000 595,2755 841,88976378] /Тип /Страница /Содержание [9 0 Р] >> эндообъект 9 0 obj Поток контента для второй страницы << >> транслировать q 1.
0.000000 0.000000 1. 50. 770. cm BT /F0 36. Tf (Page Two) Tj ET Q 1. 0.000000 0.000000 1. 50. 750 см BT /F0 16 Tf ((Повернута на 270 градусов)) Tj ET конечный поток эндообъект 7 0 obj Поток контента для третьей страницы << >> транслировать 1. 0.000000 0.000000 1. 50. 770. см BT /F0 36. Tf (Страница третья) Tj ET конечный поток эндообъект 10 0 obj Словарь информации о документе << /Title (Объяснение примера в формате PDF) /Автор (Джон Уитингтон) /Producer (создано вручную) /ModDate (D:20110313002346Z) /Дата создания (D:2011) >> внешняя ссылка эндообъекта 0 11 трейлер Словарь прицепа << /Информация 10 0 Р /Корень 5 0 R /Размер 11 /ID [<75ff22189ceac848dfa2afec93deee03> <75ff22189ceac848dfa2afec93deee03>] >> startxref 0 %%EOF
Рисунок 4-3. Пример 4-3 преобразован в допустимый PDF-файл с pdftk и отображается в Acrobat Reader
Рисунок 4-4. Граф объектов для примера 4-3
Что означает PDF? | Определение PDF
Глоссарий
Portable Document Format (PDF) — это формат цифрового файла, который содержит полное описание плоского документа с фиксированным макетом (включая текст, шрифт(ы), графику, сведения о форматировании и любую другую информацию, необходимую для отображения документа) и используется для отображения и передачи документов независимо от используемого программного обеспечения, оборудования или операционной системы.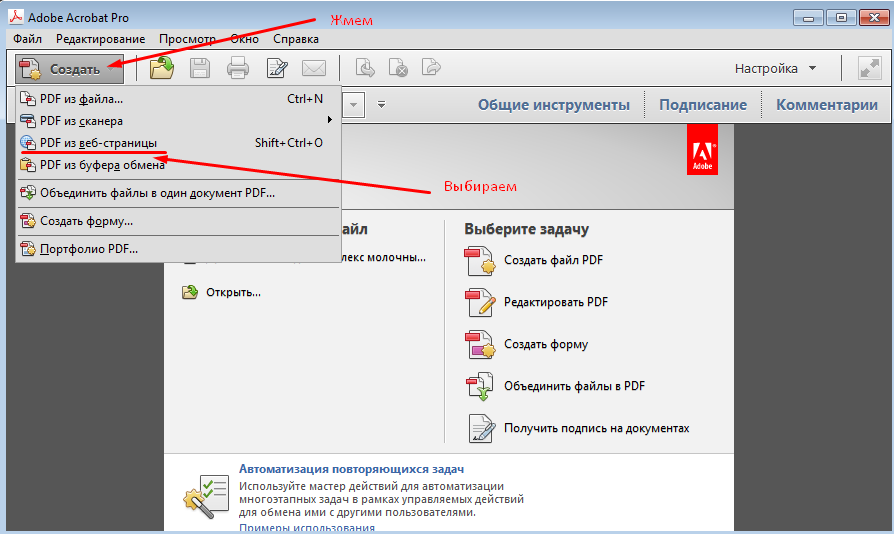
Разработанный Adobe в начале 1990-х как способ обмена документами (особенно файлами для настольных издательских систем), PDF был официально выпущен в качестве открытого стандарта и опубликован в качестве международного стандарта (ISO 32000-1:2008) 19 июля.0828 ст 2008.
Этот формат объединяет три технологии; подмножество PostScript (язык программирования описания страниц) для создания макета и графики, система встраивания/замены шрифтов, позволяющая передавать шрифты вместе с документом, и структурированная система хранения для объединения вышеупомянутых элементов (и любого связанного содержимого) в один файл (при необходимости со сжатием данных). PDF-файлы могут содержать векторную и растровую графику, текст и шрифты, а также интерактивные элементы (например, аннотации, поля форм, видео, флэш-анимацию и ссылки) и специальные возможности (например, текстовые эквиваленты, подписи и аудиоописания).
PDF-файлы могут обрабатываться различными способами с помощью различных программ, хотя большинство из них сможет выполнять только одну (или несколько) из этих функций, включая просмотр/чтение, редактирование, создание, преобразование и комментирование файла. . Например, существует огромное количество бесплатных программ просмотра/чтения PDF, которые могут читать PDF-файлы, но не могут редактировать PDF-файлы (хотя некоторые из них могут предлагать некоторые базовые функции модификации, такие как аннотации).
. Например, существует огромное количество бесплатных программ просмотра/чтения PDF, которые могут читать PDF-файлы, но не могут редактировать PDF-файлы (хотя некоторые из них могут предлагать некоторые базовые функции модификации, такие как аннотации).
В Label Planet мы предоставляем шаблоны PDF (в портретном и альбомном форматах, а также форматы выпуска под обрез, где это возможно) для всех наших размеров этикеток, чтобы клиенты могли использовать их для разработки и печати своих собственных этикеток. Эти шаблоны необходимо редактировать с помощью графического пакета (например, InDesign, Illustrator, Photoshop и т. д.).
Вернуться к словарюСвязанные вопросы
Вектор — Что означает вектор?
Кровотечение — Что означает кровотечение?
PostScript — что такое PostScript?
Графика — Что означает графика?
Графическое программное обеспечение — Что такое графическое программное обеспечение?
Шрифт — Что означает шрифт?
Программное обеспечение для настольных издательских систем.