ТЕСТЫ по дисциплине «Технология разработки и защиты баз данных»
ТЕСТ
Выберите один или несколько вариантов ответа.
Вариант № 1
1. Совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД – это…
система управления базами данных
операционная система
база данных
банк данных
2. Основное назначение СУБД:
обеспечение независимости прикладных программ и данных
представление средств организации данных одной прикладной программе
поддержка сложных математических вычислений
поддержка интегрированной совокупности данных
Что не входит в функции СУБД?
создание структуры базы данных
загрузка данных в базу данных
предоставление возможности манипулирования данными
проверка корректности прикладных программ, работающих с базой данных
Основные цели обеспечения логической и физической целостности базы данных?
защита от неправильных действий прикладного программиста
защита от неправильных действий администратора баз данных
защита от возможных ошибок ввода данных
защита от возможного появления несоответствия между данными после выполнения операций удаления и корректировки
Что такое концептуальная модель?
Интегрированные данные
база данных
обобщенное представление пользователей о данных
описание представления данных в памяти компьютера
Как называются уровни архитектуры базы данных?
нижний
внешний
концептуальный
внутренний
верхний
Основные этапы проектирования базы данных:
изучение предметной области
проектирование обобщенного концептуального представления
проектирование концептуального представления, специфицированного к модели данных СУБД (логической модели)
разработка прикладных программ
База данных – это:
совокупность данных, организованных по определенным правилам
совокупность программ для хранения и обработки больших массивов информации
интерфейс, поддерживающий наполнение и манипулирование данными
определенная совокупность информации
Наиболее точным аналогом иерархической базы данных может служить:
неупорядоченное множество данных;
вектор;
генеалогическое дерево;
двумерная таблица
Реляционная база данных – это?
БД, в которой информация организована в виде прямоугольных таблиц;
БД, в которой элементы в записи упорядочены, т.
 е. один элемент считается главным, остальные подчиненными;
е. один элемент считается главным, остальные подчиненными;БД, в которой записи расположена в произвольном порядке;
БД, в которой существует возможность устанавливать дополнительно к вертикальным иерархическим связям горизонтальные связи.
Основные особенности сетевой базы данных
многоуровневая структура
набор взаимосвязанных таблиц
набор узлов, в котором каждый может быть связан с каждым
Строка, описывающая свойства элемента таблицы базы данных, называется:
полем;
бланком;
записью;
ключом.

Установку отношения между ключевым полем одной таблицы и полем внешнего ключа другой называют:
паролем;
связью;
запросом;
подстановкой.
Определите вид связи между сущностями «Магазин» и «Книга»
«Многие – ко – многим»
«Один – к – одному»
«Один – ко – многим»
«Многие – к – одному»
Для чего предназначены формы:
для хранения данных базы;
для отбора и обработки данных базы;
для ввода данных базы и их просмотра;
для автоматического выполнения группы команд.

Где расположены программы пользователя и программы СУБД в архитектуре файл-сервер?
На компьютере пользователя;
На специально выделенном компьютере – сервере;
Программа пользователя на компьютере пользователя, СУБД на специально выделенном компьютере – сервере;
СУБД расположена на всех компьютерах пользователей в сети.
На каком компьютере происходит работа с базой данных в архитектуре клиент-сервер?
На компьютере одного пользователя;
На специально-выделенном компьютере – сервере;
Прикладные программы работают на компьютере пользователя, программы работают на специально выделенном компьютере-сервере;
Прикладные программы и программы СУБД работают на компьютере пользователя.

Предложение WHERE языка запросов SQL означает:
Сортировку выборки запроса по указанным полям
Группировку выборки запроса по указанным полям
Условие на выбираемые поля
Условие на выбираемые группы
Базы данных — университетский курс
Главная / Базы данных / Базы данных — университетский курс / Тест 14 Упражнение 1:Номер 1
Как характеризуется объект в объектно-ориентированном программировании?
Ответ:
 (1) объект в объектно-ориентированном программировании это сущность предметной области при проектировании баз данных 
 (2) объект это структура, имеющая атрибуты 
 (3) объект это структура, имеющая свои внутренние атрибуты и методы 
 (4) объект это сущность, характеризуемая внутренними состоянием и поведением 
Номер 2
Какими основными понятиями характеризуется объектно-ориентированное программирование?
Ответ:
 (1) инкапсуляция 
 (2) объект 
 (3) наследование 
 (4) полиморфизм 
 (5) класс объектов 
 (6) класс связей 
Номер 3
Какие основные принципы работы с объектами в объектно-ориентированном программировании?
Ответ:
 (1) работать с объектом можно с помощью методов любых объектов 
 (2)
 (3) с помощью методов можно менять значения атрибутов объекта 
 (4) работать с классом объектов можно с помощью только методов соответствующего объекта 
 (5) работать с классом объектов можно с помощью методов любых объектов 
Упражнение 2:
Номер 1
Как характеризуется понятие объекта (сущности) в объектно-ориентированных базах данных по сравнению с традиционными базами данных?
Ответ:
 (1) аналогично понятию объекта в традиционных базах данных 
 (2) в понятие объекта включены методы объекта 
 (3) используется то же понятие атрибута 
 (4) используется то же понятие типа данных 
 (5) понятие тип данных может заменяться понятиями «класс» и «подкласс» 
Номер 2
Какие понятия характеризуют объектно-ориентированную базу данных?
Ответ:
 (1) заимствование свойств класса объектов другим классом 
 (2) взаимодействие классов с помощью установленных связей 
 (3) взаимодействие классов с помощью механизма сообщений 
 (4) внутренняя структура объектов скрыта 
 (5) представление объекта в виде строки таблицы 
Номер 3
Какие основные принципы работы объектно-ориентированной СУБД?
Ответ:
 (1) те же, что и у традиционной СУБД 
 (2) хранит и выполняет программы обработки запросов ко всем объектам базы данных 
 (3) хранит и выполняет определенные программы обработки запросов к соответствующим объектам базы данных 
 (4) хранит данные об объекте вместе с программами обработки этого объекта и обрабатывает соответствующие данные этими программами 
Упражнение 3:
Номер 1
Что является основой объектно-реляционной базы данных?
Ответ:
 (1) понятие объекта 
 (2) реляционная таблица 
 (3) объектно-ориентированная реляционная таблица 
 (4) реляционная таблица, представляющая объект как понятие объектно-ориентированного программирования 
Номер 2
Какие элементы объектно-ориентированного подхода включают существующие объектно-реляционные базы данных?
Ответ:
 (1) ориентированные на определенные классы объектов типы данных 
 (2) возможность создания новых пользовательских типов данных 
 (3) возможность хранения в реляционной таблице методов вместе с объектом 
 (4) инкапсуляцию состояния и поведения объекта 
Номер 3
Каковы основные достоинства объектно-реляционных баз данных?
Ответ:
 (1) основаны на широко используемой реляционной модели 
 (2) будут поддержаны стандартом языка запросов 
 (3) реализуют все принципы объектно-ориентированного программирования 
 (4) поддерживаются известными разработчиками СУБД 
Упражнение 4:
Номер 1
Как данные размещены по компьютерам в распределенной базе данных?
Ответ:
 (1) общая база данных и СУБД размещены на сервере; данные, относящиеся к конкретным пользователям, размещены на их компьютерах 
 (2) общей базы данных нет, данные, относящиеся к конкретным пользователям, и СУБД размещены на их компьютерах 
 (3) база данных разбита на части, части размещены на разных компьютерах, СУБД размещена на сервере и имеет доступ ко всем частям базы данных 
 (4) база данных разбита на части, части базы данных и СУБД размещены на компьютерах пользователей, СУБД на каждом компьютере имеет доступ ко всем частям базы данных 
Номер 2
Как система управления распределенной базой данных распределяется по компьютерам?
Ответ:
 (1) серверная часть СУБД размещается на сервере, клиентская часть на компьютерах –клиентах 
 (2) СУБД копируется на всех компьютерах пользователей 
 (3) часть СУБД, обеспечивающая локальную работу с частью базы данных на компьютере пользователя, размещается на этом компьютере, общая часть СУБД размещается на сервере 
 (4) часть СУБД, обеспечивающая локальную работу с частью базы данных на компьютере пользователя, размещается на этом компьютере, общая часть СУБД также размещается на этом компьютере 
Номер 3
Как пользователь работает с распределенной базой данных?
Ответ:
 (1) только с фрагментом базы данных, расположенным на его компьютере 
 (2) с любыми фрагментами базы данных, расположенных на компьютерах подразделения, в котором он работает 
 (3) только с фрагментами базы данных, расположенных на тех компьютерах, с которыми напрямую соединен его компьютер 
 (4) с любыми фрагментами базы данных 
Упражнение 5:
Номер 1
Какие требования выдвигаются к программному обеспечению в распределенной СУБД?
Ответ:
 (1) однотипность операционных систем всех компьютеров 
 (2) однотипность СУБД на всех компьютерах 
 (3) управление распределенными транзакциями 
 (4) возможность обработки распределенных запросов 
Номер 2
Какие требования выдвигаются к аппаратному обеспечению в распределенной СУБД?
Ответ:
 (1) однотипность всех компьютеров 
 (2) непрерывное функционирование 
 (3) независимость от компьютерной сети 
 (4) независимость от расположения компьютеров 
Номер 3
Каковы основные проблемы создания распределенной базы данных?
Ответ:
 (1) как распределить базу данных по компьютерам 
 (2) как распределить СУБД по компьютерам 
 (3) как составить каталог о размещении фрагментов базы данных 
 (4) как исключить одновременный доступ к одним и тем же данным 
 (5) как передавать данные между компьютерами 
Упражнение 6:
Номер 1
Какова основная цель хранилища данных?
Ответ:
 (1) долговременное хранение данных (архив) 
 (2) хранение резервных копий баз данных для восстановления при машинных сбоях 
 (3) хранение выборок из таблиц баз данных, привязанных к разным моментам времени, с целью их детального анализа 
 (4) хранение выборок из таблиц баз данных, привязанных к одному моменту времени, с целью их детального анализа 
Номер 2
Что понимается под интегрированностью данных в хранилище?
Ответ:
 (1) подведены итоги по разным срезам 
 (2) данные объединены из разных источников 
 (3) объединены данные разных форматов 
 (4) объединены несогласованные данные 
Номер 3
Как изменяются данные хранилища?
Ответ:
 (1) корректируются 
 (2) частично удаляются 
 (3) не изменяются 
 (4) добавляются 
Упражнение 7:
Номер 1
Как загружаются данные в хранилище данных?
Ответ:
 (1) данные вводятся пользователем в ручном режиме 
 (2) данные загружаются из одной базы данных один раз 
 (3) данные загружаются из многих баз данных регулярно 
 (4) данные загружаются из одной базы данных регулярно 
Номер 2
Как обрабатываются данные в хранилище данных?
Ответ:
 (1) данные в хранилище обрабатываются прикладными программами пользователя 
 (2) данные обрабатываются программами анализа данных хранилища и результат обработки доставляется пользователю 
 (3) данные из хранилища доставляются пользователю и обрабатываются пользователем 
 (4) данные обрабатываются средствами системы управления базами данных 
Номер 3
Какие программные средства входят в состав сервера хранилища данных?
Ответ:
 (1) средства извлечения данных из баз данных; 
 (2) средства управления данными хранилища 
 (3) средства анализа данных хранилища 
 (4) средства доставки данных 
 (5) средства визуализации результатов обработки для конечных пользователей 
Упражнение 8:
Номер 1
Какие средства Microsoft SQL Server 2008 используются для построения многомерных кубов?
Ответ:
 (1) SQL Server 2008 Integration Services 
 (2) Business Intelligence Development Studio 
 (3) SQL Server 2008 Analysis Services 
 (4) SQL Server 2008 Reporting Services 
Номер 2
Какие средства Microsoft SQL Server 2008 используются для извлечения данных из баз данных и их преобразования перед загрузкой в хранилище?
Ответ:
 (1) SQL Server 2008 Integration Services 
 (2) Business Intelligence Development Studio 
 (3) SQL Server 2008 Analysis Services 
 (4) SQL Server 2008 Reporting Services 
Номер 3
Какие средства Microsoft SQL Server 2008 используются для формирования пакетов обработки данных хранилища?
Ответ:
 (1) SQL Server 2008 Integration Services 
 (2) Business Intelligence Development Studio 
 (3) SQL Server 2008 Analysis Services 
 (4) SQL Server 2008 Reporting Services 
Файловая СУБД
Файловая СУБД — одна из систем управления базами данных, которую поддерживает платформа. Файловая СУБД разработана фирмой «1С» и является частью платформы.
Файловая СУБД разработана фирмой «1С» и является частью платформы.
Файловая СУБД хранит все данные в одном файле — файловой базе данных. Этот формат хранения данных разработан фирмой «1С» специально для прикладных решений 1С:Предприятия 8.
При создании платформы был необходим эффективный формат для создания на его основе легкого варианта 1С:Предприятия 8 для персонального использования и небольших рабочих групп. Формат должен был удовлетворять определенным требованиям, таким как, эффективность, поддержка UNICODE, возможность размещения всей информационной базы в одном файле. Использование этого варианта не должно было требовать установки дополнительного программного обеспечения у пользователя и каких-либо действий по администрированию.
Должна была обеспечиваться, например, возможность легкого переноса информационной базы на ноутбук или быстрого развертывания удаленного рабочего места на складе. При этом прикладное решение должно было без каких-либо изменений работать как в этом варианте, так и в варианте с использованием сервера баз данных.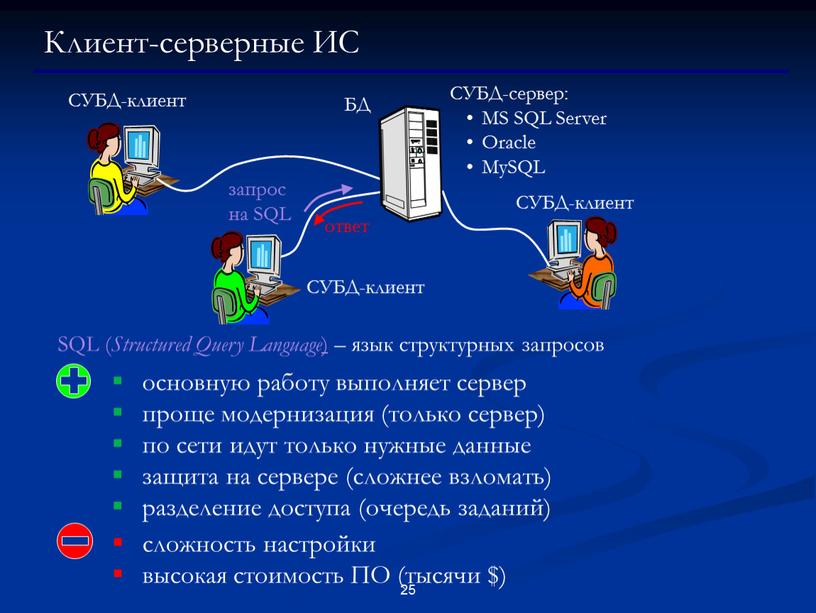
По результатам исследования продуктов сторонних производителей и их анализа было принято решение о создании собственного «движка» базы данных, поддерживающего собственный формат хранения.
Техническая реализация работы с файловой базой данных
Файловая СУБД является частью платформы, поэтому при работе системы в файловом варианте толстый и тонкий клиенты самостоятельно осуществляют всю работу с данными.
В случае веб-клиента подключение к файловой базе данных выполняется через веб-сервер, и непосредственную работу с данными выполняет не клиентское приложение, а модуль расширения веб-сервера, который также содержит в себе файловую СУБД.
Взаимодействие элементов системы с файловой базой данных осуществляется по собственному протоколу обмена данными, разработанному фирмой «1С».
СУБД
Чем крупнее компания, чем дольше она существует на рынке, тем больше данных скапливается в ее архивах. Причем, в соответствии с реалиями сегодняшнего дня, вся информация хранится в электронной форме. По данным исследования Aberdeen Group, три года назад в крупных компаниях объемы хранимой информации увеличивались на 32% ежегодно. Сегодня бизнес-аналитика оперирует уже многотерабайтными объемами данных, а сами хранилища отчетливо перемещаются на облачные платформы.
Причем, в соответствии с реалиями сегодняшнего дня, вся информация хранится в электронной форме. По данным исследования Aberdeen Group, три года назад в крупных компаниях объемы хранимой информации увеличивались на 32% ежегодно. Сегодня бизнес-аналитика оперирует уже многотерабайтными объемами данных, а сами хранилища отчетливо перемещаются на облачные платформы.
Однако какая бы бесценная для бизнеса информация не хранились на серверах компании, она должна соответствовать нескольким критериям, так как если данные заносятся бессистемно и хранятся в разных форматах – польза от затраченных для этого ресурсов весьма сомнительна.
СУБД представляет собой набор программ, которые в общей сложности управляют организацией, хранением данных в БД. В целом такие системы классифицируются в зависимости от их структуры данных и их типов. СУБД принимает запросы прикладных программ и инструктирует операционную систему для передачи соответствующей информации. Новые категории данных, могут быть добавлены в БД без нарушения существующей схемы. Организации могут использовать один вид СУБД для осуществления ежедневных операций, а затем размещать необходимую информацию на другой машине, которая работает с другой системой управления, более подходящей для случайных запросов и анализа. Серверами резервного копирования баз данных, как правило, являются многопроцессорные системы с большим объемом ОЗУ и крупными дисковыми RAID-массивами. СУБД фактически является сердцем большинства приложений для работы с БД.
Организации могут использовать один вид СУБД для осуществления ежедневных операций, а затем размещать необходимую информацию на другой машине, которая работает с другой системой управления, более подходящей для случайных запросов и анализа. Серверами резервного копирования баз данных, как правило, являются многопроцессорные системы с большим объемом ОЗУ и крупными дисковыми RAID-массивами. СУБД фактически является сердцем большинства приложений для работы с БД.Аутсорсинг СУБД
2020: В каких случаях нужно передавать на аутсорсинг СУБД и бизнес-приложения
В апреле 2020 года директор центра технического консалтинга РДТЕХ Павел Шмелев перечислил основные плюсы аутсорсинга и рассказал, зачем компании отдают на сторону сопровождение собственных СУБД. Подробнее здесь.
Каким требованиям должна отвечать современная СУБД?
Информационное хранилище должно постоянно пополняться новыми данными в соответствии с ритмом жизни компании, это же касается и формирование новых категорий учета.
При этом вносить информацию должен иметь возможность любой новый сотрудник. То же касается и обслуживания данной инфраструктуры со стороны системного администратора, формирования новых выборок данных со стороны аналитиков с разным уровнем допуска к информации и с разными профилями анализируемых данных.
Необходимо отметить, что количество информации увеличивается не только в объеме, но и качественно. В результате появляется необходимость одновременной работы с ней нескольких экспертов. Кроме того, появляется возможность привлечения специализированных экспертов для выполнения сложных процедур анализа данных (Data mining Интеллектуальный анализ данных). Сегодня не только для формирования будущей стратегии, но и для выполнения повседневных задач все большее значение имеет прогнозная аналитика, которая для формирования верного вектора развития использует объективные, а не субъективные данные.
Помимо этого единая база данных упрощает формирования отчетности как отдельным подразделениям компании, так и всей компании в целом для подачи документов в государственные инстанции или их предоставления для ознакомления внешним экспертным комиссиям. Единая база позволяет в автоматическом режиме обновлять документацию, относящуюся к нормативно-справочной информации (НСИ). Дополнительно общая база данных позволяет оперировать информацией в своеобразной унифицированной форме, делая процедуры анализа информации более единообразными в рамках компании.
Еще одним плюсом от единого подхода к хранению информации является гораздо более простая процедура резервирования, снижение времени простоя после сбоя, обеспечение безопасности данных в плане распределения прав доступа, более прозрачная процедура миграции на новые версии программного и аппаратного обеспечения.
Рынок СУБД в России
Российские СУБД на сегодняшний день находятся в довольно тяжелом положении — разработки крупных компаний выдавливают из рынка российские системы. Однако, до сих пор есть несколько СУБД, которые продолжают оставаться на плаву за счёт внедрения в государственные структуры.
Классификация
В зависимости от архитектуры построения системы управления базами СУБД могут подразделяться на следующие типы:
Файловые системы
Представим себе, что имеется некоторый носитель информации определенной емкости, устройство для чтения-записи на этот носитель в режиме произвольного доступа и прикладные программы, которые используют конкретный носитель для ввода-вывода информации во внешнюю память. В этом случае, каждая прикладная программа должна знать где и в каком месте хранятся необходимые данные. Так как прикладных программ больше, чем носителей информации, то несколько прикладных программ могут использовать один накопитель. Что произойдет, если одной из прикладных программ потребуется дозаписать свои данные на диск? Может произойти наложение: ситуация в которой данные одной программы будут перезаписаны другой программой. Важным шагом в развитии информационных систем явился переход к использованию централизованных систем управления файлами. С точки зрения прикладной программы, файл – именованная область внешней памяти, в которую можно записывать данные, и из которой можно их считывать. Для того чтобы была возможность считать информацию из какой либо области внешней памяти необходимо знать имя этого сектора(имя файла), размер самой области и его физическое расположение. Сама система управления файлами выполняет следующие функции:
- распределение внешней памяти;
- отображение имеет файлов в соответствующие адреса во внеш-ней памяти;
- обеспечение доступа к данным.
Рассмотрение особенностей реализации отдельных систем управления файлами выходит за рамки данной темы. На данном этапе достаточно знать, что прикладные программы видят файл как линейную последовательность записей и могут выполнить над ним ряд операций. Основные операции сфайлами в СУФ:
- создать файл (определенного типа и размера)
- открыть ранее созданный файл
- прочитать из файла определенную запись
- изменить запись
- добавить запись в конец файла
СУБД крупных ЭВМ
Данный этап развития связан с организацией баз данных на больших машинах типа IBM 360/370, ЕС-ЭВМ и различных моделях фирмы Hewlett Packard. В таком случае информация хранилась во внешней памяти центральной ЭВМ. Пользователями баз данных были фактически задачи, запускаемые в основном в пакетном режиме. Интерактивный режим доступа обеспечивался с помощью консольных терминалов, которые не обладали собственными вычислительными ресурсами (процессором, оперативной памятью, внешней памятью) и служили только устройствами ввода-вывода для центральной ЭВМ. Программы доступа к БД писались на различных языках программирования и запускались как обычные числовые программы. Особенности данного этапа:
- Все СУБД базируются на мощных мультипрограммных ОС (Unix и др.).
- Поддерживается работа с централизованной БД в режиме распределенного доступа. Функции управления распределением ресурсов выполняются операционной системой.
- Поддерживаются языки низкого манипулирования данными, ориентированные на навигационные методы доступа к данным. Значительная роль отводится администрированию данных.
- Проводятся серьезные работы по обоснованию и формализации реляционной модели данных. Была создана первая система (System R), реализующая идеологию реляционной модели данных.
- Проводятся теоретические работы по оптимизации запросов и управлению распределенным доступом к централизованной БД, было введено понятие транзакции.
- Большой поток публикаций по всем вопросам теории БД. Результаты научных исследований активно внедряются в коммерческие СУБД.
- Появляются первые языки высокого уровня для работы с реляционной моделью данных (SQL), однако отсутствуют стандарты для этих языков.
Настольные СУБД
Компьютеры стали ближе и доступнее каждому пользователю. Исчез благоговейный страх рядовых пользователей перед непонятными и сложными языками программирования. Появилось множество программ, предназначенных для работы неподготовленных пользователей. Простыми и понятными стали операции копирования файлов и переноса информации с одного компьютера на другой, распечатка текстов, таблиц и других документов. Системные программисты были отодвинуты на второй план. Каждый пользователь мог себя почувствовать полным хозяином этого мощного и удобного устройства, позволяющего автоматизировать многие аспекты собственной деятельности. И, конечно, это сказалось и на работе с базами данных. Новоявленные СУБД позволяли хранить значительные объемы информации, они имели удобный интерфейс для заполнения, встроенные средства для генерации различных отчетов. Эти программы позволяли автоматизировать многие учетные функции, которые раньше велись вручную. Постоянное снижение цен на персональные компьютеры сделало такое ПО доступным не только для организаций и фирм, но и для отдельных пользователей.
Компьютеры стали инструментом для ведения документации и собственных учетных функций. Это все сыграло как положительную, так и отрицательную роль в области развития баз данных. Кажущаяся простота и доступность персональных компьютеров и их программного обеспечения породила множество дилетантов. Много было создано систем-однодневок, которые не отвечали законам развития и взаимосвязи реальных объектов. Однако доступность персональных компьютеров заставила пользователей из многих областей знаний, которые ранее не применяли вычислительную технику в своей деятельности, обратиться к ним. И спрос на развитые удобные программы обработки данных заставлял поставщиков программного обеспечения поставлять все новые системы, которые принято называть настольными СУБД. Значительная конкуренция среди поставщиков заставляла совершенствовать эти конфигурации, предлагая новые возможности, улучшая интерфейс и быстродействие систем, снижая их стоимость. Наличие на рынке большого числа СУБД, выполняющих сходные функции, потребовало разработки методов экспорта-импорта данных для этих систем и открытия форматов хранения данных. Но и в этот период появлялись любители, которые вопреки здравому смыслу разрабатывали собственные СУБД, используя стандартные языки программирования. Это был тупиковый вариант, потому что дальнейшее развитие показало, что перенести данные из нестандартных форматов в новые СУБД было гораздо труднее, а в некоторых случаях требовало таких трудозатрат, что легче было бы все разработать заново, но данные все равно надо было переносить на новую более перспективную СУБД. И это тоже было результатом недооценки тех функции, которые должна была выполнять СУБД. Особенности этого этапа следующие:
- Стандартизация высокоуровневых языков манипулирования данными (разработка и внедрение стандарта SQL92 во все СУБД).
- Все СУБД были рассчитаны на создание БД в основном с монопольным доступом. И это понятно. Компьютер персональный, он не был подсоединен к сети, и база данных на нем создавалась для работы одного пользователя. В редких случаях предполагалась последовательная работа нескольких пользователей, например, сначала оператор, который вводил бухгалтерские документы, а потом главбух, который определял проводки, соответствующие первичным документам.
- Большинство СУБД имели развитый и удобный пользовательский интерфейс. В большинстве существовал интерактивный режим работы с БД как в рамках описания БД, так и в рамках проектирования запросов. Кроме того, большинство СУБД предлагали развитый и удобный инструментарий для разработки готовых приложений без программирования.
- Во всех настольных СУБД поддерживался только внешний уровень представления реляционной модели, то есть только внешний табличный вид структур данных.
- При наличии высокоуровневых языков манипулирования данными типа реляционной алгебры и SQL в настольных СУБД поддерживались низкоуровневые языки на уровне отдельных строк таблиц.
- В настольных СУБД отсутствовали средства поддержки ссылочной и структурной целостности базы данных. Эти функции должны были выполнять приложения, однако скудость средств разработки приложений иногда не позволяла это сделать, и в этом случае эти функции должны были выполняться пользователем, требуя от него дополнительного контроля при вводе и изменении информации, хранящейся в БД.
- Наличие монопольного режима работы фактически привело к вырождению функций администрирования БД.
- Сравнительно скромные требования к аппаратному обеспечению со стороны настольных СУБД. Вполне работоспособные приложения, разработанные, например, на Clipper, работали на PC 286. В принципе, их даже трудно назвать полноценными СУБД. Яркие представители этого семейства — очень широко использовавшиеся до недавнего времени СУБД Dbase (DbaseIII+, DbaseIV), FoxPro, Clipper, Paradox.
Продукты
Каталог СУБД-решений и проектов доступен на TAdviser.
История
Базы данных использовались в вычислительной технике с незапамятных времен. В первых компьютерах использовались два вида внешних устройств – магнитные ленты и магнитные барабаны. Емкость магнитных лент была достаточно велика. Устройства для чтения-записи магнитных лент обеспечивали последовательный доступ к данным. Для чтения информации, которая находилась в середине или конце магнитной ленты, необходимо было сначала прочитать весь предыдущий участок. Следствием этого являлось чрезвычайно низкая производительность операций ввода-вывода данных во внешнюю память. Магнитные барабаны давали возможность произвольного доступа, но имели ограниченный объем хранимой информации. Разумеется, говорить о какой-либо системе управления данными во внешней памяти, в тот момент не приходилось. Каждая прикладная программа, которой требовалось хранить данные во внешней памяти, сама определяла расположение каждого блока на магнитной ленте. Прикладная программа также брала на себя функции информационного обмена между оперативной памятью и устройствами внешней памяти с помощью программно-аппаратных средств низкого уровня.
Такой режим работы не позволяет или очень затрудняет поддержку на одном носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации во внешней памяти. История БД фактически началась с появлением магнитных дисков. Такие устройства внешней памяти обладали существенно большей емкостью, чем магнитная лента и барабаны, а также обеспечивали во много раз большую скорость доступа в режиме произвольной выборки. В отличие от современных систем управления, которые могут применяться для самых различных баз данных, подавляющее большинство ранее разработанных СУБД были тесно связаны с пользовательской базой для того, чтобы увеличить скорость работы, хоть и в ущерб гибкости. Первоначально СУБД применялись только в крупных организациях с мощной аппаратной поддержкой, необходимой для работы с большими объемами данных.
Рост производительности персональных вычислительных машин спровоцировал развитие СУБД, как отдельного класса. К середине 60-х годов прошлого века уже существовало большое количество коммерческих СУБД. Интерес к базам данных увеличивался все больше, так что данная сфера нуждалась в стандартизации. Автор комплексной базы данных Integrated Data Store Чарльз Бахман (Charles Bachman) организовал целевую группу DTG (Data Base Task Group) для утверждения особенностей и организации стандартов БД в рамках CODASYL — группы, которая отвечала за стандартизацию языка программирования COBOL. Уже в 1971 году был представлен свод утверждений и замечаний, который был назван Подход CODASYL, и спустя некоторое время появились первые успешные коммерческие продукты, изготовленные с учетом замечаний вышеупомянутой рабочей группы. В 1968 году отметилась и компания IBM, которая представила собственную СУБД gпод названием IMS.
Фактически данный продукт представлял собой компиляцию утилит, которые использовались с системами System/360 на шаттлах Аполлон. Решение было разработано согласно коцпетам CODASYL, но при этом была применена строгая иерархия для структуризации данных. В свою очередь в варианте CODASYL за базис была взята сетевая СУБД. Оба варианта, меж тем, были приняты сообществом позднее как классические варианты организации работы СУБД, а сам Чарльз Бахман в 1973 году получил премию Тьюринга за работу Программист как навигатор. В 1970 году сотрудник компании IBM Эдгар Кодд, работавший в одном из отделений Сан Хосе (США), в котором занимались разработкой систем хранения, написал ряд статей, касающихся навигационных моделей СУБД. Заинтересовавшись вопросом он разработал и изложил несколько инновационных подходов касательно оптимальной организаци систем управления БД. Работа Кодда внесла значительный вклад в развитие СУБД и является действительным основоположником теории реляционных баз данных. Уже 1981 году Э.Ф.Кодд создал реляционную модель данных и применил к ней операции реляционной алгебры.
Ссылки
Официальный сайт MySQL
Ресурс об SQL и клиент/серверные технологии
Официальный сайт СУБД ЛИНТЕР
Инструмент для поддержки администрирования MySQL сервера через WWW
Лекции для студентов СКГМИ (СТУ)
Российское системное ПО
Курсы по СУБД (Microsoft SQL Server, Access, Oracle, MySQL)
Курсы по СУБД CronosPRO (Официальный сайт)
См. также
информация
Способы организации СУБД
Иерархические СУБД
Многомерная СУБД
Реляционная СУБД
Сетевая СУБД
Объектно-ориентированная СУБД
Объектно-реляционная СУБД
Информатика
Логика в информатике
СУБД: Способы организации
Файл-серверные
При работе с файл-серверной системой обработка всех данных происходит на рабочих местах, а сервер используется только как разделяемый накопитель. Каждый пользователь непосредственно использует информацию и вносит изменения в файлы данных и в индексные файлы. При больших объемах данных и работе во многопользовательском режиме существенно снижается быстродействие — ведь чем больше пользователей, тем выше требования к разделению данных. Кроме того, может возникнуть повреждение баз данных. Например, в момент записи в файл может возникнуть сбой сети или авария питания. В этом случае компьютер пользователя прерывает работу, база данных может оказаться поврежденной, а индексный файл — разрушенным. Переиндексация, которую необходимо провести после подобных сбоев, может длиться несколько часов. Перечисленные недостатки заставляют пользователей, работающих в сети, отказаться от файл-серверных СУБД.
Примерами СУБД файл-серверной организации являются Borland Paradox, Microsoft Access, Microsoft Visual FoxPro.
Клиент-серверные
При использовании клиент-серверного способа организации вся работа с базой данных происходит на сервере и не зависит от сбоев на рабочих станциях. Все запросы на запись в файл перехватываются сервером. В файл изменения вносятся только после того, как сервер получит сообщение о том, что корректировка файла завершена. Это исключает повреждение индексных файлов и существенно повышает быстродействие системы.
Клиент-серверные СУБД также имеют ряд недостатков:
- высокие требования к пропускной способности коммуникационных каналов с сервером;
- слабая защита данных от взлома, в особенности от недобросовестных пользователей системы;
- высокая сложность администрирования и настройки рабочих мест пользователей системы;
- необходимость использовать на клиентских местах достаточно мощные компьютеры;
- сложность интеграции с унаследованными системами;
- сложность разработки системы из-за необходимости исполнять бизнес-логику и обеспечивать интерфейс с пользователем в одной программе.
Среди клиент-серверных СУБД наиболее распространены такие продукты, как IBM DB2, MS SQL Server, Oracle, MySQL.
Встраиваемые
Встраиваемая система управления базой данных — это система, которая может быть связана с клиентским приложением таким образом, чтобы приложение и СУБД работали в едином адресном пространстве. Вместе со встроенной базой данных приложение может быть развернуто как единая программа, которая функциональна, эффективна и автономна. Благодаря связыванию приложения с базой данных, прикладная система выигрывает от снижения общей сложности и уменьшения затрат на администрирование. Во многих случаях встраиваемая система управления базой данных — самый подходящий вариант для систем с ограниченными ресурсами. Однако, встраиваемые СУБД зачастую подходят лишь для решения задач узкой спецификации.
Встраиваевыми являются такие СУБД, как InterBase SMP, BerkeleyDB, OpenEdge.
См. также
Ссылки
§ 1.6. Система управления базами данных
Информатика. 9 класса. Босова Л.Л. Оглавление
Ключевые слова:
• СУБД
• таблица
• форма
• запрос
• условие выбора
• отчёт
1.6.1. Что такое СУБД
Программное обеспечение для создания баз данных, хранения и поиска в них необходимой информации называется системой управления базами данных (СУБД).
С помощью СУБД пользователь может:
• создавать структуру базы данных;
• заполнять базу данных информацией;
• редактировать (исправлять, дополнять) структуру и содержание базы данных;
• выполнять сортировку (упорядочение) данных;
• осуществлять поиск информации в базе данных;
• выводить нужную информацию на экран монитора, в файл и на бумажный носитель;
• устанавливать защиту базы данных.
Именно наличие СУБД превращает огромный объём хранимых в компьютерной памяти сведений в мощную справочную систему, способную быстро производить поиск и отбор необходимой нам информации.
1.6.2. Интерфейс СУБД
Существуют СУБД, с помощью которых создаются крупные промышленные информационные системы. Для работы с этими системами нужны специальные знания, в том числе владение специализированными языками программирования.
Для ведения личных баз данных, а также баз данных небольших организаций используются более простые СУБД, работать с которыми могут обычные пользователи. Наиболее распространёнными СУБД такого типа являются Microsoft Access и OpenOffice Base. При запуске любой из них на экран выводится окно, имеющее строку заголовка, строку меню, панели инструментов, рабочую область и строку состояния (рис. 1.16).
Рис. 1.16. Среда OpenOffice Base
Основными объектами СУБД являются таблицы, формы, запросы, отчёты.
Таблицы — это главный тип объектов. С ними вы уже знакомы. В таблицах хранятся данные. Реляционная база данных может состоять из множества взаимосвязанных таблиц.
Формы — это вспомогательные объекты. Они создаются для того, чтобы сделать более удобной работу пользователя при вводе, просмотре и редактировании данных в таблицах.
Запросы — это команды и их параметры, с которыми пользователь обращается к СУБД для поиска и сортировки данных.
Отчёты — это документы, сформированные на основе таблиц и запросов и предназначенные для вывода на печать.
1.6.3. Создание базы данных
В качестве примера рассмотрим процесс создания базы данных «Наш класс». Она будет состоять из одной таблицы, имеющей следующую структуру:
С
Бесплатная проверка прокси от RSocks | Проверить прокси бесплатно
Бесплатная проверка прокси от RSocks | Проверить прокси бесплатно | RSocksБесплатная проверка прокси от RSocks
RSocks Proxy Checker — это многофункциональный и простой в использовании инструмент для пользователей прокси. Программа проверяет список прокси и сортирует их по параметрам. Вы можете настроить проверку прокси с помощью фильтров и встроенных функций программы, чтобы максимально эффективно работать с нашим сервисом и проверять любые другие прокси.
Вы можете произвести быструю, надежную и интуитивно понятную проверку работы ваших списков прокси по целому ряду параметров, таких как:
- Наличие IP
- Скорость прокси
- PTR-запись
- Наличие прокси в базах Spamhaus
- Определение реального IP
- Определение страны и города
СКАЧАТЬ БЕСПЛАТНО PROXY CHECKER
Функции проверки прокси
Скачивание списков прокси
Вы можете добавить список прокси любым из следующих способов:
- из файла (одиночного или множественного)
- по ссылке (одиночной или множественной)
- из буфера обмена (путем копирования содержимого из любого источника)
Программа может автоматически распознавать формат данных, используемый большинством списков прокси.Для разных форматов доступен режим редактирования.
Тип запроса: GET, TCP, SMTP
Тип запроса — это метод, используемый для проверки правильности работы прокси-сервера.
Программное обеспечение поддерживает 3 типа запросов:
- GET (HTTP GET) — запрашивает данные с введенного URL через прокси. Результатом будет код ответа HTTP, такой как 200 OK, 404 Not found, 302 Found и т. Д.Любой ответ означает, что прокси работает, а его отсутствие указывает на проблемы.
- TCP — проксируется простое TCP-соединение с введенным хостом.
- SMTP — соединение с выбранным почтовым сервером проксируется. Короткое диалоговое окно SMTP с использованными командами HELO (EHLO), NOOP и QUIT. Результаты теста положительны, если сервер отвечает на все команды и правильно разрывает соединение.
Максимальное время отклика
Период в секундах, предоставляемый серверу для ответа.Если время истекает, прокси считается неактивным.
Максимальное количество тестовых соединений
Максимальное количество тестов, выполняемых одновременно. Для хорошего интернет-соединения рекомендуемое значение — 200 — 300 подключений.
Поддержка протокола: HTTP, HTTPS, Socks4, Socks4a, Socks5
Для начала теста необходимо выбрать хотя бы один протокол.При выборе нескольких протоколов тесты выполняются последовательно, поэтому выполнение тестов займет больше времени. Если в списке прокси есть протокол прокси (пример: socks4: //127.0.0.1: 1080), он будет выбран автоматически.
Реальный IP-адрес
Отображает внешний IP-адрес прокси-сервера. Внешний IP-адрес ищется с помощью доверенного скрипта api4ip.info/api/ip/checker/full.Скрипт также возвращает геолокацию и PTR-запись. Также можно использовать другой скрипт с таким же форматом ответа (см. Опции → Дополнительные запросы).
PTR запись
Использование сценария в пункте 6 возвращает имя хоста, связанное с внешним IP-адресом прокси.
Геолокация IP: Страна, Город
Страна и город вычитаются из баз данных MaxMind по внешнему IP-адресу прокси.Используется тот же скрипт из пункта 6.
Программное обеспечение предоставляет упрощенную и подробную статистику географического местоположения: упрощенное отображает общее количество стран в пакете, а подробное отображает количество прокси-серверов пакета для каждой страны и города.
Список спам-листов
Проверяет, указан ли IP прокси в базах данных ZEN, PBL и CBL.
Скорость загрузки файла
Чтобы измерить скорость прокси, вы должны указать ресурс или файл, который вы хотите загрузить, в Опции → Дополнительные запросы. Скорость рассчитывается по формуле «Скорость = размер / время». Чем больше целевой файл, тем точнее будут результаты. но время тестирования также увеличится.
Рекомендуемый размер файла для этого теста — 300-500 КБ.
Уровень анонимности
Определяет уровень анонимности прокси-серверов HTTP (S):
- N / A — уровень анонимности неизвестен.
- Прозрачный — прокси пересылают подробную информацию о вашем IP-адресе на целевой сервер, к которому вы подключаетесь.
- Анонимный — этот тип прокси не раскрывает ваш IP-адрес серверу, однако сервер будет знать, что соединение было выполнено через прокси.
- Elite — сервер не знает, что соединение было выполнено через прокси, и не знает ваш реальный IP-адрес.
Удаленный DNS
Важная функция для оценки вашей анонимности. Эта опция заставляет прокси Socks 5 выполнять поиск домена на прокси-сервере, избегая поиска в локальном DNS.
Результаты проверки списка прокси
Результаты отображаются в статистике и в виде электронной таблицы.Таблицу можно отсортировать и отфильтровать с помощью вкладки «Фильтры» (например, для отображения только прокси с задержкой менее 1000 мс).
Экспорт результатов тестирования
Результаты могут быть сохранены в исходном формате списка прокси (будут сохранены только функциональные прокси) или в выбранном формате с отображением любых выбранных полей. Параметры сортировки и фильтрации сохранятся.
История версий
История версий Windows ProxyChecker v.2.1.5
2.1.5 07.08.20, 12:19
2.1.4 22.10.19, 13:44
2.1.3 24.09.19, 08:56
2.1.2 17.09.19, 15:58
2.1.1 17.09.19, 15:54
2.1.0 09.08.19, 15:59
2.0.9 26.04.19, 16:02
2.0.8 18.04.19, 11:41
2.0.7 13.03.19, 10:52
2.0.6 13.06.18, 12:50
2.0,5 19.04.18, 12:33
2.0.4 12.04.18, 13:07
2.0.3 06.04.18, 11:32
2.0.2 19.03.18, 14:34
2.0.1 13.03.18, 12:45
2.0.0 12.03.18, 10:59
Linux ProxyChecker v.2.1.5 история версий
2.1.5 07.08.20, 12:19
2.1.4 22.10.19, 13:46
2.1.3 24.09.19, 08:58
2.1.2 17.09.19, 16:01
2.1.1 17.09.19, 16:00
2.1.0 09.08.19, 16:02
2.0,9 26.04.19, 16:04
2.0.8 18.04.19, 11:43
2.0.7 13.03.19, 10:54
2.0.6 13.06.18, 13:44
2.0.5 19.04.18, 12:46
2.0.4 12.04.18, 13:36
2.0.3 06.04.18, 12:03
2.0.2 19.03.18, 15:01
2.0.1 13.03.18, 13:43
2.0.0 12.03.18, 11:33
Mac ProxyChecker v.2.1.5 История версий
2.1.5 07.08.20, 12:15
2.1.4 22.10.19, 13:52
2.1.3 24.09.19, 09:01
2.1.2 17.09.19, 16:08
2.1.1 17.09.19, 16:05
2.1.0 09.08.19, 16:06
2.0.9 26.04.19, 16:10
2.0.8 18.04.19, 11:50
2.0.7 13.03.19, 10:56
2.0.6 13.06.18, 14:08
2.0.5 19.04.18, 11:26
Служба поддержки Сергей Агент службы поддержки набирает…Сообщение может отправляться каждую секунду
Оцените работу службы поддержки:Есть вопросы? ×
Нажмите здесь, и мы ответим
SAP Monitoring & Performance Checks: Complete Tutorial with Tcodes
- Home
Testing
- Back
- Agile Testing
- BugZilla
- Cucumber
- Database Testing 09 9109 JBT Testing
- Назад
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- Центр качества (ALM) 0
- Тестирование RPA
- SoapUI
- Управление тестированием
- TestLink
SAP
- Назад
- ABAP
- APO
- Начинающий
- Basis
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- FICO
09 HAN QM
- Заработная плата
- Назад
- PI / PO
- PP
- SD
- SAPUI5
- Безопасность
- Менеджер решений
- Successfactors
- SAP Tutorials
Интернет Назад
- Назад
- Java
- JSP
- Kotlin
- Linux
- MariaDB
- MS Access
- MS Access js
- Perl
- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL
- Назад SQLite
Обязательно учите!
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Бизнес-аналитик
- Создание веб-сайта
- Облачные вычисления
- COBOL
- Проектирование компиляторов
- Эталонный дизайн
- Этнические системы
- Учебники по Excel
- Программирование на Go
- IoT
- ITIL
- Jenkins
- MIS
- Сеть
- Операционная система
- Назад
- Prep
- PMP
- Управление проектом
- PMP
- Управление проектом
- Salesforce
- SEO
- Разработка программного обеспечения
- VBA
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Хранилище данных
- DevOps
- HBase
0
- HBase
- HBase
09
- Back
- MongoDB
- NiFi
- OBIEE
Как проверить, является ли машина физической или виртуальной
Шабаз 27 марта 2014 г.
Если вы подключаетесь к удаленной машине по протоколу удаленного рабочего стола, вы не всегда можете знать, является ли эта машина виртуальной или физической.Если вы хотите узнать, является ли машина, к которой вы подключены, виртуальной или физической, есть несколько способов сделать это.
1. Проверьте системный лоток
Самый быстрый способ — проверить на панели задач. Обычно вы найдете значок утилит, которые производитель продукта виртуализации предоставляет для повышения производительности гостевой операционной системы виртуальной машины. Такие как VMware Tools.
Значок для инструментов VMware на панели задач.
2. Установите флажок «Программы и компоненты» на панели управления
Другой способ — проверить «Программы и компоненты» на панели управления. Вы узнаете, установлены ли VMware Tools или нет.
3. Проверьте системную информацию
Нажмите «Пуск» → «Записать msinfo32» → нажмите «Ввод».
Элементы «Производитель системы» и «Модель системы» позволят вам узнать, является ли машина физической или виртуальной.
4.Используйте Powershell или командную строку
В Powershell вы можете использовать следующий командлет get-wmiobject win32_computersystem | fl модель
И в командной строке используйте эту команду systeminfo / s% computername% | findstr / c: "Модель:" / c: "Имя хоста" / c: "Имя ОС"
5. Проверить все серверы в домене
Иногда вам может понадобиться узнать эту информацию обо всех серверах в домене, так как же это сделать? Просто используйте следующий скрипт Powershell
import-module activedirectory
get-adcomputer -filter {операционная система-like "windows server *"} | имя объекта выбора | экспорт-csv.\ computers.txt -notypeinformation -encoding UTF8
(Get-Content. \ computers.txt) | % {$ _ -replace '"'," "} | out-file -FilePath. \ computers.txt -force -encoding ascii
$ computers = get-content. \ computers.txt | select -Skip 1
Foreach ($ компьютер в $ компьютерах) {systeminfo / s $ computer | findstr / c: "Модель:" / c: "Имя хоста" / c: "Имя ОС" | out-file -FilePath. \ VirPhys.txt -append}
Вы получите такой вывод в файле с именем VirPhys.txt (находится в том же месте, где вы запускали скрипт)
Как видите, Server01, Server03 и Server05 — это виртуальные машины, а Server02 и Server04 — физические.
Процесс проверки TLS для защиты электронной почты Cisco
Введение
В этом документе описывается процесс проверки подлинности сервера безопасности транспортного уровня (TLS) для Cisco Email Security Appliance (ESA)
Процесс проверки TLS для защиты электронной почты Cisco
Процесс проверки TLS — это, по сути, двухэтапный процесс проверки:
I — ПРОВЕРКА СЕРТИФИКАТА
Это включает проверку:
- срок действия сертификата — срок действия сертификата
- эмитент цепочки сертификатов
- список отзыва и т. Д..
II — ПРОВЕРКА ИДЕНТИФИКАЦИИ СЕРВЕРА
Это процесс проверки подлинности представленного сервером идентификатора (содержащегося в сертификате открытого ключа X.509) относительно эталонного идентификатора сервера .
Фон
Давайте сохраним терминологию идентификационных имен, описанную в RFC 6125.
Примечание : Представленный идентификатор — это идентификатор, представленный сертификатом открытого ключа X.509 сервера, который может включать в себя более одного представленного идентификатора различных типов.В случае службы SMTP он содержится либо как расширение subjectAltName типа dNSName, либо как CN (общее имя), полученное из поля темы.
Примечание : эталонный идентификатор — это идентификатор, созданный на основе полного доменного имени DNS, которое клиент ожидает от службы приложения в сертификате.
Процесс проверки наиболее важен для клиента TLS, поскольку обычно клиент инициирует сеанс TLS, и клиенту необходимо аутентифицировать соединение. Для этого клиенту необходимо проверить, совпадает ли представленный идентификатор с эталонным идентификатором. Важно понимать, что безопасность процесса проверки TLS для доставки почты почти полностью основана на клиенте TLS.
Шаг первый
Первым шагом проверки подлинности сервера является определение эталонного идентификатора клиентом TLS. От приложения зависит, какой список ссылочных идентификаторов клиент TLS считает приемлемым.Кроме того, список допустимых ссылочных идентификаторов должен быть построен независимо от идентификаторов, представленных службой. [rfs6125 # 6.2.1]
Эталонный идентификатор должен быть полностью определенным доменным именем DNS и может быть проанализирован с любого ввода (что приемлемо для клиента и считается безопасным). Эталонным идентификатором должно быть имя хоста DNS, к которому клиент пытается подключиться.
Адрес электронной почты получателя Имя домена является эталонным идентификатором, который напрямую выражается пользователем посредством намерения отправить сообщение определенному пользователю в определенном домене, и это также отвечает требованию, чтобы быть полным доменным именем, на которое пользователь пытается подключиться.Это согласованно только в случае автономного SMTP-сервера, когда SMTP-сервер принадлежит и управляется одним и тем же владельцем, и на сервере не размещено слишком много доменов. Поскольку каждый домен должен быть указан в сертификате (как одно из значений subjectAltName: dNSName). С точки зрения реализации, большинство центров сертификации (ЦС) ограничивают количество значений доменных имен до 25 записей (до 100). Это неприемлемо в случае размещенной среды, давайте подумаем о поставщиках услуг электронной почты (ESP), где на конечных SMTP-серверах размещаются тысячи и более доменов.Это просто не масштабируется.
Явно сконфигурированный эталонный идентификатор кажется ответом, но это налагает некоторые ограничения, так как требуется вручную связать эталонный идентификатор с исходным доменом для каждого целевого домена или «получение данных из сторонней службы сопоставления доменов. в котором пользователь-человек явно выразил доверие и с которым клиент взаимодействует через соединение или ассоциацию, обеспечивающую как взаимную аутентификацию, так и проверку целостности ». [RFC6125 # 6.2.1]
Концептуально это можно представить как однократный «безопасный MX-запрос» во время настройки, с постоянным кэшированием результата на MTA для защиты от любого взлома DNS во время работы. [2]
Это дает более надежную аутентификацию только с «партнерскими» доменами, но для общего домена, который не был сопоставлен, он не проходит экзамен, и это также не застраховано от изменений конфигурации на стороне целевого домена (например, изменения имени хоста или IP-адреса ).
Шаг второй
Следующим шагом в этом процессе является определение представленной личности. Представленная идентичность предоставляется серверным сертификатом открытого ключа X.509 в виде расширения subjectAltName типа dNSName или в виде общего имени (CN), найденного в поле темы. Где вполне допустимо, чтобы поле темы было пустым, если сертификат содержит расширение subjectAltName, которое включает как минимум одну запись subjectAltName.
Хотя использование Common Name все еще практикуется, оно считается устаревшим, и в настоящее время рекомендуется использовать записи subjectAltName.Поддержка идентичности из Common Name остается для обратной совместимости. В таком случае сначала следует использовать dNSName для subjectAltName, и только когда оно пусто, проверяется Общее имя.
Примечание : общее имя не является строго типизированным, поскольку общее имя может содержать понятную для человека строку для службы, а не строку, форма которой соответствует форме полного имени домена DNS
В конце, когда определены оба типа идентификаторов, клиент TLS должен сравнить каждый из своих ссылочных идентификаторов с представленными идентификаторами с целью поиска соответствия.
Проверка TLS ESA
ESA позволяет включить TLS и проверку сертификата при доставке в определенные домены (с помощью страницы «Элементы управления назначением» или команды CLI destconfig ). Когда требуется проверка сертификата TLS, вы можете выбрать один из двух вариантов проверки, начиная с версии AsyncOS 8.0.2. Ожидаемый результат проверки может варьироваться в зависимости от настроенной опции. Из 6 различных настроек для TLS, доступных под контролем пункта назначения, есть два важных, которые отвечают за проверку сертификата:
- Требуется TLS — проверить
- Требуется TLS — проверьте размещенные домены .
CLI: destconfigХотите использовать поддержку TLS?
1. Нет
2. Предпочтительно
3. Обязательно
4. Предпочтительно - Подтвердить
5. Обязательно - Подтвердить
6. Обязательно - Подтвердить размещенные домены
[6]>
Процесс проверки TLS для опции (4) Предпочтительно — Проверить, что идентичен (5) Требуется — Проверить , но действия, предпринятые на основе результатов, отличаются, как показано в таблице ниже.Результаты для варианта (6) Требуется — Проверить размещенные домены идентичен (5) Требуется — Проверить , но поток проверки TLS совершенно другой.
| Настройки TLS | Значение |
| 4. Предпочтительно (Подтвердить) | TLS согласовывается от устройства защиты электронной почты до MTA (ов) домена. Устройство пытается проверить сертификат домена. Возможны три исхода:
|
5. Обязательно (Проверить) | TLS согласовывается от устройства защиты электронной почты до MTA (ов) домена. Требуется проверка сертификата домена. Возможны три исхода:
|
Разница между Требуется TLS — Проверить и Требуется TLS — Проверить размещенный домен Параметры лежат в процессе проверки личности.От того, как обрабатывается представленная идентичность и какие типы ссылочных идентификаторов разрешено использовать, зависит конечный результат. Цель нижеприведенного описания, а также всего документа — приблизить этот процесс к конечному пользователю. Поскольку неправильное или неясное понимание этого предмета может оказать влияние на безопасность пользовательской сети.
Требуется TLS Проверить
Представленная идентичность сначала выводится из расширения subjectAltName — dNSName, и если совпадения нет или расширение subjectAltName не существует, то проверяется CN-ID — Common Name из поля темы.
Список эталонных идентификаторов (REF-ID) состоит из домена получателя или домена получателя и имени хоста, полученного из запроса PTR DNS, выполняемого по IP-адресу, к которому подключен клиент. Примечание. В этом конкретном случае различные ссылочные идентификаторы сравниваются с различными представленными проверками идентичности.
~ = представляет точное соответствие или совпадение с подстановочными знаками
Представленный идентификатор (dNSName или CN-ID) сравнивается с принятыми эталонными идентификаторами до тех пор, пока он не будет сопоставлен, и в том порядке, в котором они перечислены ниже.
- Если существует расширение dNSName для subjectAltName:
- Если CN субъекта DN существует (CN-ID):
- точное совпадение или подстановочный знак выполняется для домена получателя
- точное совпадение или совпадение с подстановочными знаками выполняется для имени хоста, полученного из запроса PTR, выполненного для IP-адреса сервера назначения
Где запись PTR сохраняет согласованность в DNS между сервером пересылки и преобразователем. Здесь необходимо упомянуть, что поле CN сравнивается с именем хоста из PTR только тогда, когда существует запись PTR, а разрешенная запись A (пересылка) для этого имени хоста (ссылочная идентификация) возвращает IP-адрес, который соответствует IP-адресу конечного сервера. который был выполнен PTR-запрос.
A (PTR (IP)) == IP
Эталонный идентификатор в случае CN-ID получен из домена получателя, и при отсутствии совпадения выполняется запрос DNS к записи PTR IP-адреса назначения для получения имя хоста. Если существует PTR, выполняется дополнительный запрос к записи A для имени хоста, полученного из PTR, чтобы подтвердить, что согласованность DNS сохраняется! Никакие другие ссылки не проверяются (например, имя хоста, полученное из запроса MX)
Подводя итог, с опцией ‘TLS Required — Verify’ нет имени хоста MX по сравнению с dNSName или CN, запись DNS PTR RR проверяется только для CN и сопоставляется только при сохранении согласованности DNS A (PTR (IP)) = IP, выполняется как точный, так и подстановочный тест для dNSName и CN.
TLS Требуется проверка — размещенный домен
Представленный идентификатор сначала является производным от расширения subjectAltName типа dNSName. Если нет совпадения между dNSName и одним из принятых эталонных идентификаторов (REF-ID), проверка не выполняется независимо от того, существует ли CN в поле темы и может пройти дальнейшая проверка личности. CN, полученный из поля темы, проверяется только в том случае, если сертификат не содержит никаких расширений subjectAltName типа dNSName.
Напомним, что представленный идентификатор (dNSName или CN-ID) сравнивается с принятыми эталонными идентификаторами до тех пор, пока он не будет сопоставлен, и в том порядке, в котором они перечислены ниже.
- Если существует расширение dNSName для subjectAltName:
Если нет соответствия между dNSName и одним из принятых эталонных идентификаторов, перечисленных ниже, то проверка идентичности не выполняется
- выполняется точное соответствие или совпадение с подстановочными знаками для домена получателя: одно из dNSName должно соответствовать домену получателя
- точное соответствие или совпадение с подстановочными знаками выполняется для явно настроенного имени хоста с помощью SMTPROUTES (*)
- точное совпадение или совпадение с подстановочными знаками выполняется для имени узла MX, полученного из (небезопасного) DNS-запроса к имени домена получателя
Если домен получателя не имеет явно настроенного маршрута SMTP с записями FQDN и домен получателя не был сопоставлен, то полное доменное имя возвращается MX используется запись из (небезопасного) DNS-запроса к домену получателя.Если совпадений нет, дальнейшие тесты не выполняются, записи PTR не проверяются
- Если существует CN субъекта DN (CN-ID):
CN проверяется, только когда dNSName не существует в сертификате. CN-ID сравнивается с приведенным ниже списком принятых эталонных идентификаторов.- точное совпадение или подстановочный знак выполняется для домена получателя
- точное соответствие или совпадение с подстановочными знаками выполняется для явно настроенного имени хоста в SMTPROUTES (*)
- выполняется точное соответствие или совпадение с подстановочными знаками для имени хоста MX, полученного из (небезопасного) DNS-запроса к имени домена получателя
Явно настроенные SMTPROUTES
Когда SMTP-маршрут настроен и представленное удостоверение не соответствует домену получателя электронной почты, сравниваются все имена маршрутов FQDN, и если они не совпадают, дальнейшие проверки не проводятся.При явно сконфигурированных маршрутах SMTP никакое имя хоста MX не сравнивается с представленной идентичностью. Исключением здесь является SMTP-маршрут, который был установлен как IP-адрес.
Следующие правила применяются в случае явно настроенных маршрутов SMTP:
- Если для домена получателя существует SMTP-маршрут и это полное доменное имя DNS (FQDN), он считается эталонным идентификатором. Это имя хоста (имя маршрута) сравнивается с представленной идентичностью, полученной из сертификата, полученного от целевого сервера, на который он указывает.
- Разрешено несколько маршрутов для домена получателя. Если домен получателя имеет более одного маршрута SMTP, маршруты обрабатываются до тех пор, пока представленные идентификаторы из сертификата с сервера назначения не совпадут с именем маршрута, к которому было установлено соединение. Если хосты в списке имеют разные приоритеты, первыми обрабатываются те, которые имеют наивысший (0 — наивысший и значение по умолчанию). Если все имеют одинаковый приоритет, список маршрутов обрабатывается в том порядке, в котором маршруты были установлены пользователем.
- В случае, если хост не отвечает (недоступен) или отвечает, но проверка TLS не удалась, обрабатывается следующий хост из списка. Когда первый хост доступен и проходит проверку, остальные не используются.
- Если несколько маршрутов разрешаются в одни и те же IP-адреса, устанавливается только одно соединение с этим IP-адресом, и представленная идентификация, полученная из сертификата, отправленного сервером назначения, должна соответствовать одному из этих имен маршрутов.
- Если для доменов получателей существует SMTP-маршрут, но он был настроен как IP-адрес, этот маршрут по-прежнему используется для установления соединения, но представленное удостоверение из сертификата сравнивается с доменом получателя и далее с именем хоста, полученным из DNS / MX. запись ресурса.
Когда мы говорим о опции TLS Required Verify для размещенных доменов, способ подключения ESA к целевому серверу важен для процесса проверки TLS из-за явно настроенных маршрутов SMTP, которые обеспечивают дополнительную эталонную идентификацию, которую необходимо учитывать в процессе.
~ = представляет точное соответствие или совпадение с подстановочными знаками
Пример
Возьмем пример из реальной жизни, но для домена получателя: example.com. Ниже я попытался описать все шаги, необходимые для ручной проверки подлинности сервера.
Сначала соберем всю необходимую информацию о сервере-получателе.
example.com -> IN MX mx01. subd .emailhosted.not.
example.com -> IN MX mx02. subd .emailhosted.not.мx01. subd .emailhosted.not. -> В А 192.0.2.1
mx02. subd .emailhosted.not. -> В А 192.0.2.2
PTR (IP):
192.0.2.1 -> В PTR mx0a.emailhosted.not.
192.0.2.2 -> В PTR mx0b.emailhosted.not.
A (PTR (IP)):
mx0a.emailhosted.not. -> В А 192.0.2.1
mx0b.emailhosted.not. -> В А 192.0,2.2
Примечание : имена хостов MX и имена revDNS не совпадают в этом случае
Теперь давайте получим сертификат, предъявленный удостоверение личности:
СЕРТИФИКАТ (И) ИДЕНТИФИКАЦИЯ:
$ echo QUIT | openssl s_client -connect mx0a .emailhosted.not: 25 -starttls smtp 2> / dev / null | openssl x509 -text | grep -iEo 'DNS:. * | CN =. *'CN = thawte SHA256 SSL CA
CN = *. emailhosted.не
DNS: *. emailhosted.not, DNS: emailhosted.not
echo QUIT | openssl s_client -connect mx0b .emailhosted.not: 25 -starttls smtp 2> / dev / null | openssl x509 -text | grep -iEo 'DNS:. * | CN =. *'CN = thawte SHA256 SSL CA
CN = *. emailhosted.not
DNS: *. emailhosted.not, DNS: emailhosted.not
На обоих конечных серверах установлен один и тот же сертификат.Давайте рассмотрим два варианта проверки и сравним результаты проверки.
В случае использования TLS Требуется Подтвердить:
Сеанс TLS устанавливается с одним из серверов MX, и проверка личности начинается с проверки желаемой представленной идентичности:
- представленный идентификатор: dNSName exist (продолжить сравнение с разрешенным эталонным идентификатором)
- эталонный идентификатор = домен получателя (пример .com ) проверяется и не соответствует dNSName DNS: *. emailhosted.not, DNS: emailhosted.not
- представленный идентификатор: CN существует (продолжить со следующим представленным идентификатором, поскольку для предыдущего совпадения не было)
- ссылочный идентификатор = домен получателя ( example.com) проверяется и не соответствует CN * .emailhosted.not
- эталонный идентификатор = PTR (IP): запрос PTR выполняется против IP-адреса сервера, с которым клиент TLS (ESA) установил соединение и получил сертификат, и этот запрос возвращает: mx0a.emailhosted.not.
Доменное имя PTR проверяет идентичность, и поскольку сертификат является сертификатом, подписанным ЦС, оно проверяет весь сертификат и устанавливается сеанс TLS.
В случае использования TLS Обязательно Подтвердите для размещенного домена для того же получателя:
- представленный идентификатор: dNSName exists (поэтому CN не будет обрабатываться в этом случае)
- представляет идентификатор: CN существует, но пропущено , так как dNSName также существует.
Поскольку CN не считается обработанным, в этом случае не выполняется проверка подлинности TLS, а также проверка сертификата, и в результате соединение не может быть установлено.
Что использует мою пропускную способность? 5 советов по мониторингу использования домашней сети
Дети играют в онлайн-игру. Ваш партнер транслирует фильм и загружает что-то для работы. Вы пытаетесь конкурировать с ними за пропускную способность … но этого просто не происходит.
Многие вещи могут истощить вашу пропускную способность в Интернете.В большинстве случаев вы знаете людей в вашей сети. В других случаях это вредоносное ПО или злоумышленник.
Может быть так плохо, что вы кричите: «Что использует мою полосу пропускания ?!» Это хороший вопрос.Вот как вы можете проверить и устранить неполадки, которые (или кто) использует вашу полосу пропускания в вашей домашней сети.
1.Отслеживание использования полосы пропускания через маршрутизатор
Лучшее место для начала выяснения того, что потребляет вашу полосу пропускания, — это ваш маршрутизатор.Ваш маршрутизатор обрабатывает весь входящий и исходящий интернет-трафик для вашего дома.
В настройках вашего маршрутизатора есть страница, содержащая каждое устройство, подключенное к вашей сети в данный момент.Вы можете проверить IP-адреса, MAC-адреса устройств и их текущий статус подключения. В зависимости от вашего маршрутизатора у вас также может быть доступ к сетевой информации, такой как текущая скорость загрузки и выгрузки, а также объем данных, которые использует или использовал каждое устройство.
Например, страница локальной сети на моем маршрутизаторе показывает каждое устройство.
Заметили запись, с которой вы не знакомы? Вы можете удалить его и удалить из своей сети.Убедитесь, что вы не удалили одно из своих устройств в процессе! Если вы это сделаете, это не имеет большого значения. Возможно, вам придется повторно ввести свои учетные данные для входа в сеть, что является незначительным неудобством для большинства устройств.
2.Проверьте использование полосы пропускания с помощью Capsa
Второй способ проверить, что использует вашу полосу пропускания, — через стороннюю программу.В этом случае вы можете использовать Capsa, бесплатное приложение для анализа сети, которое фиксирует каждый пакет данных, взаимодействующий с вашей системой.
- Выберите сетевой адаптер для вашей системы.Для меня это Ethernet. Для вас это может быть адаптер Wi-Fi. Выберите Полный анализ , затем нажмите Старт , чтобы начать работу.
- В обозревателе узлов (слева) перейдите к Protocol Explorer> [тип вашего адаптера]> IP . Дерево протоколов расширяется, но на этом можно остановиться.
- На панели анализа выберите протокол . На вкладке «Протокол» показаны пакеты данных для каждого протокола, используемого вашей системой.
- На панели инструментов анализа в нижней части экрана выберите MAC Endpoint . Если дважды щелкнуть IP-адрес своего устройства, откроется экран подробного анализа пакетов.
Что удобно, так это то, что у большого количества обычного трафика есть легко идентифицируемые адреса.В других местах Capsa отмечает движение за вас.
Вы также можете организовать эту информацию по-разному.На панели анализа перейдите на вкладку IP Endpoint , затем перейдите к IP-адресу вашего устройства. На панели инструментов анализа отображаются все входящие и исходящие соединения для локального хоста, его географическая конечная точка и многое другое. Столбец Node 2 может быть интересным для чтения!
Бесплатная версия имеет некоторые ограничения:
- Отслеживает только десять частных IP-адресов
- Только отслеживает один сетевой адаптер
- Может работать только над одним проектом за раз
Но по большей части эти ограничения не должны влиять на вашу способность выяснить, что крадет вашу полосу пропускания.
Загрузить: Capsa для Windows (бесплатно)
Примечание: Хотите отслеживать всю свою сеть? Вот как превратить Raspberry Pi в инструмент сетевого мониторинга.
3. Просканируйте вашу систему на наличие вредоносных программ
Другая возможность заключается в том, что проблемы с пропускной способностью возникают не из вашей локальной сети.Возможно, вы обнаружили какое-то неприятное вредоносное ПО, которое крадет вашу полосу пропускания, поскольку оно взаимодействует с внешним сервером или действует как бот для спама. Вредоносное ПО может потреблять ваше вредоносное ПО множеством способов, хотя оно не всегда является «всепоглощающим». Тем не менее, если у вас есть вредоносное ПО, независимо от потребления полосы пропускания, вам необходимо очистить вашу систему.
У вас должен быть установлен антивирус.Запустите полное сканирование системы любым антивирусом, который вы используете. Кроме того, я настоятельно рекомендую загрузить Malwarebytes и выполнить полное сканирование системы. Поместите в карантин и удалите все гнусные элементы, обнаруженные при полном сканировании системы. Затем проверьте, увеличивается ли ваша пропускная способность. Вы можете заметить резкое увеличение скорости!
Не знаете, с чего начать? Ознакомьтесь с руководством по удалению вредоносных программ MakeUseOf!
4.Используйте Netstat для обнаружения сетевых проблем
Еще один способ отточить системные процессы, занимающие вашу полосу пропускания, — использовать командную строку и команду netstat.Netstat — это сокращение от «сетевой статистики», и вы можете использовать эту команду для оценки всех сетевых входов и выходов в вашей системе (но не в вашем маршрутизаторе).
В строке поиска меню «Пуск» введите команду , затем щелкните правой кнопкой мыши и выберите Запуск от имени администратора .Когда откроется командная строка, введите netstat -o и нажмите Enter. Далее следует длинный список всех активных сетевых подключений на вашем компьютере, порт, который они прослушивают, внешний адрес и процесс, которому принадлежит сетевое подключение.
Просмотрите список и посмотрите, нет ли необычных записей.Вы можете скопировать и вставить адрес в свой браузер, чтобы найти его. Подавляющее большинство записей относится к серверам или облачным серверам того или иного типа, потому что они являются основой Интернета.
Для быстрого анализа перейдите на страницу urlscan.io и вставьте туда адрес. Вы получите краткий отчет о том, кому принадлежит сервер или адрес.
Вы также можете отметить PID (Process ID) .Откройте диспетчер задач, затем вкладку «Службы» и найдите эквивалентный процесс. Если PID имеет много открытых сетевых подключений в командной строке и это услуга, которую вы не узнаете, вы можете либо остановить службу и посмотреть, устраняет ли она проблемы с пропускной способностью, либо выполнить поиск в Интернете, чтобы выяснить, что процесс есть, и если это то, чего требует ваша система.
5.Проверьте сетевую активность с помощью монитора ресурсов Windows
Находясь в диспетчере задач, чтобы перейти к другому инструменту устранения неполадок с пропускной способностью, щелкните вкладку «Производительность», а затем нажмите кнопку «Монитор ресурсов» внизу.
На мой взгляд, монитор ресурсов — один из самых мощных инструментов, доступных в вашем арсенале устранения неполадок в сети.
Взгляд на столбцы «Отправить» и «Получить» показывает, что на Chrome и Malwarebytes в настоящее время приходится большая часть моей пропускной способности.Видеть Chrome и Malwarebytes вверху списка — это нормально, потому что я доверяю обеим этим программам. Если вы видите неизвестный процесс или приложение в верхней части списка, истощая вашу полосу пропускания, пора начать расследование.
Что использует вашу пропускную способность?
Это хороший вопрос.Я знаю, что в моем доме иногда может быть до десяти устройств, конкурирующих за пропускную способность. В то время я рад, что могу управлять маршрутизатором.
Не то чтобы я предлагал сократить пропускную способность вашей семьи или друзей.Однако, если у вас постоянная утечка пропускной способности и вы уверены, что это устройство не находится под вашим контролем, один из приведенных выше советов по мониторингу использования вашей домашней сети обнаружит преступника.
Если вы держите свой смартфон под рукой, почему бы не превратить его в центр анализа мобильной сети с помощью одного из этих приложений для Android?
Обновление Skype предлагает новые функции к праздникамЭто самое чудесное время года… по скайпу.
Об авторе Гэвин Филлипс (Опубликовано 644 статей)Гэвин — младший редактор отдела Windows and Technology Explained, постоянный участник Really Useful Podcast и редактор дочернего сайта MakeUseOf, посвященного криптографии, Blocks Decoded.У него есть степень бакалавра (с отличием) в области современного письма с использованием методов цифрового искусства, разграбленных на холмах Девона, а также более десяти лет профессионального писательского опыта. Он любит много пить чая, настольные игры и футбол.
Ещё от Gavin PhillipsПодпишитесь на нашу рассылку новостей
Подпишитесь на нашу рассылку, чтобы получать технические советы, обзоры, бесплатные электронные книги и эксклюзивные предложения!
Еще один шаг…!
Пожалуйста, подтвердите свой адрес электронной почты в письме, которое мы вам только что отправили.
NDG Linux Essentials 2.0 Глава 4 Ответы на экзамен
Последнее обновление: 10 мая 2019 г., автор: Admin
NDG Linux Essentials 2.0 Глава 4 Ответы на экзамен
Исходный код Linux доступен по адресу:
- Сотрудники ФБР, ЦРУ и АНБ со сверхсекретным допуском
- Любой, у кого есть знания, необходимые для доступа к нему
- Только университетские исследователи с государственным грантом
- Только сотрудники Linux Foundation
Исходный код ссылается на:
- Версия программы, запускаемой компьютером на ЦП
- Интерфейс, который программное обеспечение использует для взаимодействия с ядром
- Лицензия, определяющая, как вы можете использовать и распространять программное обеспечение
- Версия компьютерного программного обеспечения, читаемая человеком
Средства с открытым исходным кодом:
(выберите два)
- Вы можете просмотреть исходный код программного обеспечения
- Вы должны поделиться своими изменениями
- Вы можете изменить исходный код программного обеспечения.
- Плата за программное обеспечение не взимается
- Вы должны поддерживать используемое вами программное обеспечение
Лицензия, по которой у вас нет доступа к исходному коду, называется:
- Неисправный источник
- Закрытый код
- Открытый исходный код
- Без источника
Лицензии с открытым исходным кодом различаются, но в целом согласны с тем, что:
(выберите два)
- Вам не разрешено продавать программное обеспечение
- Вы должны распространить свои изменения
- Вы должны иметь возможность изменять программное обеспечение по своему желанию
- У вас должен быть доступ к исходному коду программного обеспечения
Ричард Столмен связан с:
- BSD Unix
- Microsoft
- Фонд свободного программного обеспечения
- Фонд Apache
- Инициатива открытого исходного кода
Положение об авторском леве в лицензии на программное обеспечение означает:
- Вы не можете ссылаться на стороннее программное обеспечение с закрытым исходным кодом
- Если вы распространяете программное обеспечение, вы должны распространять исходный код любых вносимых вами изменений.