Как работают операторы SQL LIKE и NOT LIKE
10 декабря, 2022 12:47 пп 473 views | Комментариев нетDevelopment, mySQL | Amber | Комментировать запись
Оператор SQL LIKE используется вместе с WHERE для поиска шаблона для столбца. Подстановочные знаки помогут вам определить требуемый шаблон. Два подстановочных знака, которые используются с оператором LIKE:
- %: символ процента используется для представления одного или нескольких вхождений, а также для определения их отсутствия.
- _: подчеркивание используется для представления одного символа.
Чтобы использовать оператор SQL LIKE, вы должны быть уверены в использовании позиции подстановочного знака, поскольку он будет определять шаблон поиска.
Синтаксис оператора SQL LIKE
Оператор SQL LIKE можно использовать с любым запросом вместе с where. Таким образом, мы можем использовать его с Select, Delete, Update и т. д.
Таким образом, мы можем использовать его с Select, Delete, Update и т. д.
SELECT column FROM table_name WHERE column LIKE pattern; UPDATE table_name SET column=value WHERE column LIKE pattern; DELETE FROM table_name WHERE column LIKE pattern;
В упомянутом выше синтаксисе оператора LIKE шаблон определяется использованием подстановочных знаков.
Примеры использования оператора SQL LIKE
Давайте попробуем понять, как работает оператор SQL LIKE вместе с подстановочными знаками, на некоторых примерах. В качестве примера рассмотрим следующую таблицу Customer.
| CustomerId | CustomerName |
| 1 | Amit |
| 2 | John |
| 3 | Annie |
И попробуем выполнить пару практичных примеров. Допустим, мы хотим найти имя клиента, которое начинается на А:
SELECT CustomerName FROM Customer WHERE CustomerName LIKE 'A%';
Вывод:
Amit Annie
Найдем клиента, имя которого оканчивается на «е».
SELECT CustomerName FROM Customer WHERE CustomerName LIKE '%e'
Вывод:
Annie
Найдем теперь клиента, имя которого начинается с «А» и заканчивается на «т».
SELECT CustomerName FROM Customer WHERE CustomerName LIKE 'A%t'
Вывод:
Amit
Давайте найдем клиента с именем, содержащим символ «n» в любой позиции.
SELECT CustomerName FROM Customer WHERE CustomerName LIKE '%n%'
Вывод:
Annie John
Чтобы найти клиента, вторым символом в имени которого является n, введите:
SELECT CustomerName FROM Customer WHERE CustomerName LIKE '_n%'
Вывод:
Annie
Давайте теперь найдем клиента, третьим символом в имени которого является i, а последним – t.
SELECT CustomerName FROM Customer WHERE CustomerName LIKE '__i%t'
Вывод:
Amit
Оператор SQL NOT LIKE
Иногда мы хотим извлечь записи, которые не соответствуют определенному шаблону. В этом случае можно использовать оператор SQL NOT LIKE. Синтаксис оператора SQL NOT LIKE выглядит так:
В этом случае можно использовать оператор SQL NOT LIKE. Синтаксис оператора SQL NOT LIKE выглядит так:
SELECT column FROM table_name WHERE column NOT LIKE pattern; UPDATE table_name SET column=value WHERE column NOT LIKE pattern; DELETE FROM table_name WHERE column NOT LIKE pattern;
Ради примера предположим, что нам нужно извлечь список имен клиентов, которые не начинаются с буквы «А». Ниже представлен запрос, который даст нам требуемый набор результатов.
SELECT CustomerName FROM Customer WHERE CustomerName NOT LIKE 'A%';
Вывод:
John
Множественный оператор SQL LIKE
Мы можем использовать несколько операторов LIKE в одном SQL-запросе. Например, если нам нужен список имен клиентов, начинающихся с Jo и Am, нам придется использовать несколько операторов LIKE, как показано ниже.
SELECT CustomerName FROM Customer WHERE CustomerName LIKE 'Am%' OR CustomerName LIKE 'Jo%';
Читайте также: Почему стоит начать изучать SQL
Tags: SQLСравнение производительности
команд T-SQL — NOT IN, NOT EXISTS, LEFT JOIN и EXCEPT
В этой статье дается сравнение производительности команд NOT IN, SQL Not Exists, SQL LEFT JOIN и SQL EXCEPT.
Библиотека команд T-SQL, доступная в Microsoft SQL Server и обновляемая в каждой версии новыми командами и улучшениями существующих команд, предоставляет нам различные способы выполнения одного и того же действия. В дополнение к постоянно развивающемуся набору команд разные разработчики будут применять разные методы и подходы к одним и тем же наборам проблем и задачам.
Например, три разных разработчика SQL Server могут получить одни и те же данные, используя три разных запроса, при этом у каждого разработчика будет свой собственный подход к написанию запросов T-SQL для извлечения или изменения данных. Но администратор базы данных не обязательно будет доволен всеми этими подходами, он смотрит на эти методы с разных сторон, на которых они могут не концентрироваться. Хотя все они могут получить одинаковый требуемый результат, каждый запрос будет вести себя по-разному, потребляя разное количество ресурсов SQL Server с разным временем выполнения. Все эти параметры, на которых концентрируется администратор базы данных, определяют производительность запроса.
В этой статье мы опишем различные способы, которые можно использовать для извлечения данных из таблицы, не существующей в другой таблице, и сравним производительность этих различных подходов. Эти методы будут использовать команды NOT IN , SQL NOT EXISTS , LEFT JOIN и EXCEPT T-SQL. Прежде чем приступить к сравнению производительности различных методов, мы дадим краткое описание каждой из этих команд T-SQL.
Команда SQL NOT IN позволяет указать несколько значений в предложении WHERE. Вы можете представить это как серию команд NOT EQUAL TO, разделенных условием ИЛИ. Команда NO IN сравнивает определенные значения столбца из первой таблицы со значениями другого столбца во второй таблице или подзапросе и возвращает все значения из первой таблицы, которые не найдены во второй таблице, без выполнения какого-либо фильтра для уникальных значений.
Команда SQL NOT EXISTS используется для проверки наличия определенных значений в предоставленном подзапросе. Подзапрос не возвращает никаких данных; он возвращает значения TRUE или FALSE в зависимости от проверки существования значений подзапроса.
Команда LEFT JOIN используется для возврата всех записей из первой левой таблицы, совпадающих записей из второй правой таблицы и значений NULL с правой стороны для записей левой таблицы, которые не совпадают в правой таблице.
Команда EXCEPT используется для возврата всех отдельных записей из первого оператора SELECT, которые не возвращаются из второго оператора SELECT, при этом каждый оператор SELECT будет рассматриваться как отдельный набор данных. Другими словами, он возвращает все отдельные записи из первого набора данных и удаляет из этого результата записи, возвращенные из второго набора данных.
Теперь давайте посмотрим на практике, как мы можем получить данные из одной таблицы, которые не существуют в другой таблице, используя разные методы, и сравним производительность этих методов, чтобы сделать вывод, какой из них ведет себя лучше всего. Мы начнем с создания двух новых таблиц с помощью приведенного ниже сценария T-SQL:
1 2 3 4 5 6 7 8 1 30003 11 12 | Использование SQLSHACKDEMO GO CREATE TABLE CATEGORY_A (CAT_ID INT, CAT_NAME VARCHAR (50) ) GO Create Table Category_B (CAT_ID INT, CATE CATEVER_B (CAT_ID INT, CATE CATE_NAMER. ) |
После создания таблиц мы заполним каждую таблицу 10 тысячами записей в целях тестирования, используя ApexSQL Generate, как показано ниже:
Тестовые столы готовы. Мы включим статистику TIME и IO, чтобы использовать эту статистику для сравнения производительности различных методов. После этого мы подготовим запросы T-SQL, которые используются для извлечения данных, которые существуют в таблице Category_A, но не существуют в таблице Category_B, используя четыре метода; Команда NOT IN, команда SQL NOT EXISTS, команда LEFT JOIN и, наконец, команда EXCEPT. Этого можно добиться с помощью приведенного ниже сценария T-SQL:
Мы включим статистику TIME и IO, чтобы использовать эту статистику для сравнения производительности различных методов. После этого мы подготовим запросы T-SQL, которые используются для извлечения данных, которые существуют в таблице Category_A, но не существуют в таблице Category_B, используя четыре метода; Команда NOT IN, команда SQL NOT EXISTS, команда LEFT JOIN и, наконец, команда EXCEPT. Этого можно добиться с помощью приведенного ниже сценария T-SQL:
1 2 3 4 5 6 7 8 10 110003 12 13 14 1999911110001 9000 214 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 23 24 25 26 27 28 29 30 | Используйте SQLSHACKDEMO GO СТАТИСТВЕННОЕ СТАТИСТИКА ВРЕМЯ НА СТАТИСТИКА IO IO на — Не int SELECT CAT_ID Из Category_A, где Cat_ID не в (Select Cat_ID из категории, . — НЕ СУЩЕСТВУЕТ
ВЫБЕРИТЕ A.Cat_ID ИЗ Категории_A A ГДЕ НЕ СУЩЕСТВУЕТ (ВЫБЕРИТЕ B.Cat_ID ИЗ Категории_B B ГДЕ B.Cat_ID = A.Cat_ID) GO — Левое соединение Выберите A.CAT_ID из Category_A A левый соединение Категория_B B на A.CAT_ID = B.CAT_ID , где B.CAT_ID IS NULL GO — За исключением
ВЫБРАТЬ A.Cat_ID ИЗ категории_A A ЗА ИСКЛЮЧЕНИЕМ ВЫБРАТЬ B.Cat_ID ИЗ категории_B B ПЕРЕЙТИ |

Если вы выполните предыдущий сценарий, вы обнаружите, что четыре метода вернут один и тот же результат, как показано в приведенном ниже результате, который содержит количество возвращаемых записей каждой командой:
На этом этапе разработчик SQL Server будет доволен, так как любой метод, который он будет использовать, вернет для него один и тот же результат. Но как насчет администратора базы данных SQL Server, которому необходимо проверить производительность каждого подхода? Если мы просмотрим статистику IO и TIME, сгенерированную после выполнения предыдущего сценария, вы увидите, что сценарий, использующий команду NOT IN, выполняет 10062 логических операций чтения в таблице Category_B, занимает 228 мс для успешного завершения и 63 мс от процессорного времени, как показано ниже:
С другой стороны, сценарий, использующий команду SQL NOT EXISTS, выполняет только 29 логических операций чтения в таблице Category_B, успешно завершает 154 мс и 15 мс из процессорного времени, что намного лучше предыдущего. метод, который использует NOT IN во всех аспектах, как показано ниже:
метод, который использует NOT IN во всех аспектах, как показано ниже:
Для сценария, который использует команду LEFT JOIN, он выполняет то же количество логических операций чтения, что и предыдущий метод SQL NOT EXISTS, то есть 29 логических операций чтения, занимает 151 мс для успешного завершения и 16 мс от процессорного времени. , что чем-то похоже на статистику, полученную из предыдущего метода SQL NOT EXISTS, как показано ниже:
Наконец, статистика, сгенерированная после запуска метода, использующего команду EXCEPT, показывает, что он снова выполняется 29 логических операций чтения, занимает 218 мс для успешного завершения и потребляет 15 мс времени ЦП, что хуже, чем методы SQL NOT EXISTS и LEFT JOIN с точки зрения времени выполнения, как показано ниже:
До этого шага мы можем вывести из статистики IO и TIME, что методы, использующие команды SQL NOT EXISTS и LEFT JOIN, действуют наилучшим образом и обеспечивают наилучшую общую производительность. Но скажут ли нам планы выполнения запросов тот же результат? Давайте проверим планы выполнения, сгенерированные из предыдущих запросов, с помощью ApexSQL Plan, инструмента для анализа планов запросов SQL Server.
Но скажут ли нам планы выполнения запросов тот же результат? Давайте проверим планы выполнения, сгенерированные из предыдущих запросов, с помощью ApexSQL Plan, инструмента для анализа планов запросов SQL Server.
Окно сводки стоимости планов выполнения ниже показывает, что методы, использующие команды SQL NOT EXISTS и LEFT JOIN, имеют наименьшие затраты на выполнение, а метод, использующий команду NOT IN, имеет наибольшую стоимость запроса, как показано ниже:
Давайте углубимся, чтобы понять, как ведет себя каждый метод, изучив планы выполнения для этих методов.
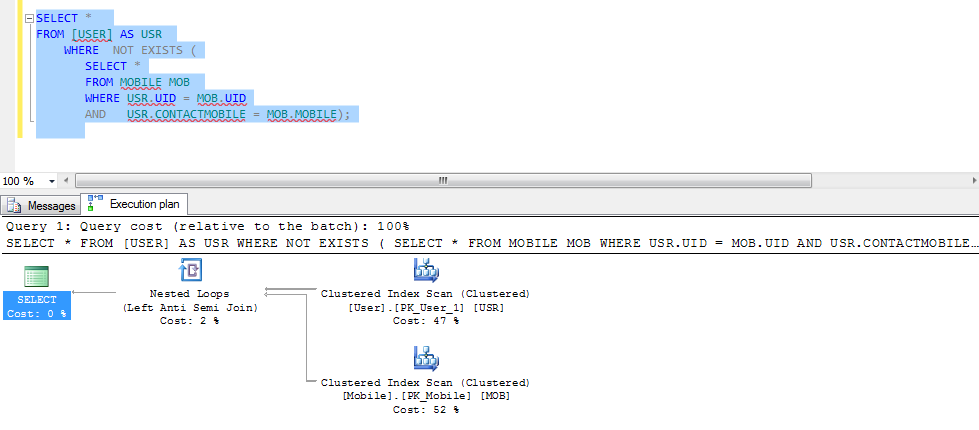
План выполнения запроса, в котором используется команда NOT IN, представляет собой сложный план с большим количеством тяжелых операторов, выполняющих циклические операции и операции подсчета. Здесь мы сконцентрируемся на вложенных циклах операторов для сравнения производительности. Под операторами вложенных циклов вы можете видеть, что эти операторы не являются настоящими операторами соединения, они выполняют нечто, называемое Left Anti Semi Join . Этот оператор частичного соединения вернет все строки из первой левой таблицы без совпадающих строк во второй правой таблице, пропуская все совпадающие строки между двумя таблицами. Самый тяжелый оператор в приведенном ниже плане выполнения, сгенерированном запросом с использованием команды NOT IN, — это Row Count Spool Оператор , который выполняет сканирование несортированной таблицы Category_B, подсчитывая, сколько строк возвращено, и возвращает только количество строк без каких-либо данных, только для проверки существования строк. План выполнения будет следующим:
Под операторами вложенных циклов вы можете видеть, что эти операторы не являются настоящими операторами соединения, они выполняют нечто, называемое Left Anti Semi Join . Этот оператор частичного соединения вернет все строки из первой левой таблицы без совпадающих строк во второй правой таблице, пропуская все совпадающие строки между двумя таблицами. Самый тяжелый оператор в приведенном ниже плане выполнения, сгенерированном запросом с использованием команды NOT IN, — это Row Count Spool Оператор , который выполняет сканирование несортированной таблицы Category_B, подсчитывая, сколько строк возвращено, и возвращает только количество строк без каких-либо данных, только для проверки существования строк. План выполнения будет следующим:
Приведенный ниже план выполнения, сгенерированный запросом с использованием команды SQL NOT EXIST, проще, чем предыдущий план, с самым тяжелым оператором в этом плане — Оператор Hash Match , который снова выполняет операцию частичного соединения Left Anti Semi Join , которая проверяет наличие несовпадающих строк, как описано ранее. Этот план будет следующим:
Этот план будет следующим:
При сравнении предыдущего плана выполнения, сгенерированного запросом с использованием команды SQL NOT EXISTS, с приведенным ниже планом выполнения, сгенерированным запросом с использованием команды LEFT JOIN, новый план заменяет частичное соединение на 9.0009 FILTER оператор, который выполняет фильтрацию IS NULL для данных, возвращаемых оператором Right OUTER JOIN, который возвращает совпадающие строки из второй таблицы, которые могут содержать дубликаты. Этот план будет таким, как показано ниже:
Последний план выполнения, сгенерированный запросом, использующим команду EXCEPT, также содержит Left Anti Semi Join Операция частичного соединения, которая проверяет наличие несовпадающих строк, как показано ранее. Он также выполняет операцию Aggregate из-за большого размера таблицы и несортированных записей в ней. Процесс Hash Aggregate создает в памяти хеш-таблицу, что делает его сложной операцией, и хеш-значение будет вычисляться для каждой обработанной строки и для каждого вычисленного хэш-значения. После этого он проверяет строки в результирующем хэш-сегменте на наличие соединяющихся строк. План будет таким, как показано ниже:
Он также выполняет операцию Aggregate из-за большого размера таблицы и несортированных записей в ней. Процесс Hash Aggregate создает в памяти хеш-таблицу, что делает его сложной операцией, и хеш-значение будет вычисляться для каждой обработанной строки и для каждого вычисленного хэш-значения. После этого он проверяет строки в результирующем хэш-сегменте на наличие соединяющихся строк. План будет таким, как показано ниже:
Мы снова можем сделать вывод из предыдущих планов выполнения, сгенерированных каждой используемой командой, что лучшими двумя методами являются те, которые используют команды SQL NOT EXISTS и LEFT JOIN. Напомним, что данные в предыдущих таблицах не отсортированы из-за отсутствия индексов. Итак, давайте создадим индекс для объединяющего столбца Cat_ID в обеих таблицах, используя сценарий T-SQL ниже:
1 2 3 4 5 6 7 8 10 11 0003 12 13 | Использование [SQLSHACKDEMO] GO Создание некластерезированного индекса [IX_CAT_ID] на [DBO]. ( [CAT_ID] ASC ) GO CRATION CRATION CRATIONSIDEDEX_XID_XIDEX_XIDEX_XIDEX_XIDEX_XIDEX_XIDEX_XIDEX_XIDEX_XIDEX_XIDEX_XIDEX_XIDEXERED. ВКЛ [dbo].[Категория_B] ( [Cat_ID] ASC ) GO |
 [Category_A]
[Category_A]Окно сводки затрат на планы выполнения, созданное с помощью плана ApexSQL после выполнения предыдущих операторов SELECT, показывает, что метод, использующий команду SQL NOT EXISTS, по-прежнему является лучшим, а метод, использующий команду EXCEPT, явно улучшился после добавления индексов в таблицы, как показано ниже:
Проверяя план выполнения команды SQL NOT EXISTS, предыдущая операция частичного соединения теперь исключена и заменена оператором Merge Join , так как данные теперь сортируются в таблицах после добавления индексов. Новый план будет таким, как показано ниже:
Новый план будет таким, как показано ниже:
Запрос, использующий команду EXCEPT, значительно улучшился после добавления индексов в таблицы и стал одним из лучших методов для достижения нашей цели. Это также появилось в приведенном ниже плане выполнения запроса, в котором предыдущая операция частичного соединения также заменена Merge Join Оператор , так как данные сортируются путем добавления индексов. Оператор Hash Aggregate теперь также заменен оператором Stream Aggregate , поскольку он агрегирует отсортированные данные после добавления индексов.
Новый план будет следующим:
Заключение:
SQL Server предоставляет нам различные способы извлечения одних и тех же данных, оставляя разработчику SQL Server возможность следовать своему собственному подходу к разработке для достижения этой цели. Например, существуют различные способы извлечения данных из одной таблицы, которых нет в другой таблице. В этой статье мы описали, как получить такие данные с помощью команд NOT IN, SQL NOT EXISTS, LEFT JOIN и EXCEPT T-SQL после предоставления краткого описания каждой команды и сравнения производительности этих запросов. Мы заключаем, во-первых, что использование команд SQL NOT EXISTS или LEFT JOIN является лучшим выбором с точки зрения производительности. Мы также попытались добавить индекс в столбец соединения в обеих таблицах, где запрос, использующий команду EXCEPT, явно улучшился и показал более высокую производительность, помимо команды SQL NOT EXISTS, которая по-прежнему является лучшим выбором в целом.
Например, существуют различные способы извлечения данных из одной таблицы, которых нет в другой таблице. В этой статье мы описали, как получить такие данные с помощью команд NOT IN, SQL NOT EXISTS, LEFT JOIN и EXCEPT T-SQL после предоставления краткого описания каждой команды и сравнения производительности этих запросов. Мы заключаем, во-первых, что использование команд SQL NOT EXISTS или LEFT JOIN является лучшим выбором с точки зрения производительности. Мы также попытались добавить индекс в столбец соединения в обеих таблицах, где запрос, использующий команду EXCEPT, явно улучшился и показал более высокую производительность, помимо команды SQL NOT EXISTS, которая по-прежнему является лучшим выбором в целом.
Полезные ссылки
- СУЩЕСТВУЕТ (Transact-SQL)
- Подзапросы с EXISTS
- Операторы задания — EXCEPT и INTERSECT (Transact-SQL)
- Left Anti Semi Join Оператор Showplan
- Автор
- Последние сообщения
Ахмад Ясин
Ахмад Ясин — инженер Microsoft по работе с большими данными, обладающий глубокими знаниями и опытом в области SQL BI, администрирования баз данных SQL Server и разработки.
Он является сертифицированным экспертом Microsoft по решениям в области управления данными и аналитики, сертифицированным специалистом Microsoft по решениям в области администрирования и разработки баз данных SQL, специалистом по разработке Azure и сертифицированным тренером Microsoft.
Кроме того, он публикует свои советы по SQL во многих блогах.
Просмотреть все сообщения Ахмада Ясина
Последние сообщения Ахмада Ясина (посмотреть все)
НЕ (Transact-SQL) — SQL Server
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
- 2 минуты на чтение
Применяется к: SQL Server Azure SQL База данных Azure SQL Управляемый экземпляр Azure Synapse Analytics Analytics Platform System (PDW)
Отменяет логический ввод.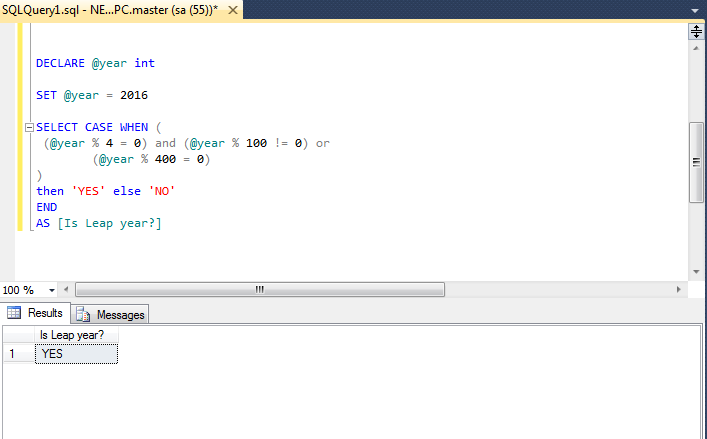
Соглашения о синтаксисе Transact-SQL
Синтаксис
[ НЕ ] логическое_выражение
Примечание
Для просмотра синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий см. документацию по предыдущим версиям.
Аргументы
boolean_expression
Любое допустимое логическое выражение.
Типы результатов
Булево значение
Значение результата
НЕ инвертирует значение любого логического выражения.
Использование НЕ отменяет выражение.
В следующей таблице показаны результаты сравнения значений ИСТИНА и ЛОЖЬ с использованием оператора НЕ.
| НЕ | |
|---|---|
| ИСТИНА | ЛОЖЬ |
| ЛОЖЬ | ИСТИНА |
| НЕИЗВЕСТНО | НЕИЗВЕСТНО |
Примеры
В следующем примере находятся все велосипеды серебристого цвета, стандартная цена которых не превышает 400 долларов.