Как убрать кодировку текста в ворде
Выбор и изменение кодировки в Microsoft Word
MS Word заслужено является самым популярным текстовым редактором. Следовательно, чаще всего можно столкнуться с документами в формате именно этой программы. Все, что может в них отличаться, это лишь версия Ворда и формат файла (DOC или DOCX). Однако, не смотря на общность, с открытием некоторых документов могут возникнуть проблемы.
Одно дело, если вордовский файл не открывается вовсе или запускается в режиме ограниченной функциональности, и совсем другое, когда он открывается, но большинство, а то и все символы в документе являются нечитабельными. То есть, вместо привычной и понятной кириллицы или латиницы, отображаются какие-то непонятные знаки (квадраты, точки, вопросительные знаки).
Если и вы столкнулись с аналогичной проблемой, вероятнее всего, виною тому неправильная кодировка файла, точнее, его текстового содержимого. В этой статье мы расскажем о том, как изменить кодировку текста в Word, тем самым сделав его пригодным для чтения. К слову, изменение кодировки может понадобиться еще и для того, чтобы сделать документ нечитабельным или, так сказать, чтобы “конвертировать” кодировку для дальнейшего использования текстового содержимого документа Ворд в других программах.
К слову, изменение кодировки может понадобиться еще и для того, чтобы сделать документ нечитабельным или, так сказать, чтобы “конвертировать” кодировку для дальнейшего использования текстового содержимого документа Ворд в других программах.
Примечание: Общепринятые стандарты кодировки текста в разных странах могут отличаться. Вполне возможно, что документ, созданный, к примеру, пользователем, проживающим в Азии, и сохраненный в местной кодировке, не будет корректно отображаться у пользователя в России, использующего на ПК и в Word стандартную кириллицу.
Что такое кодировка
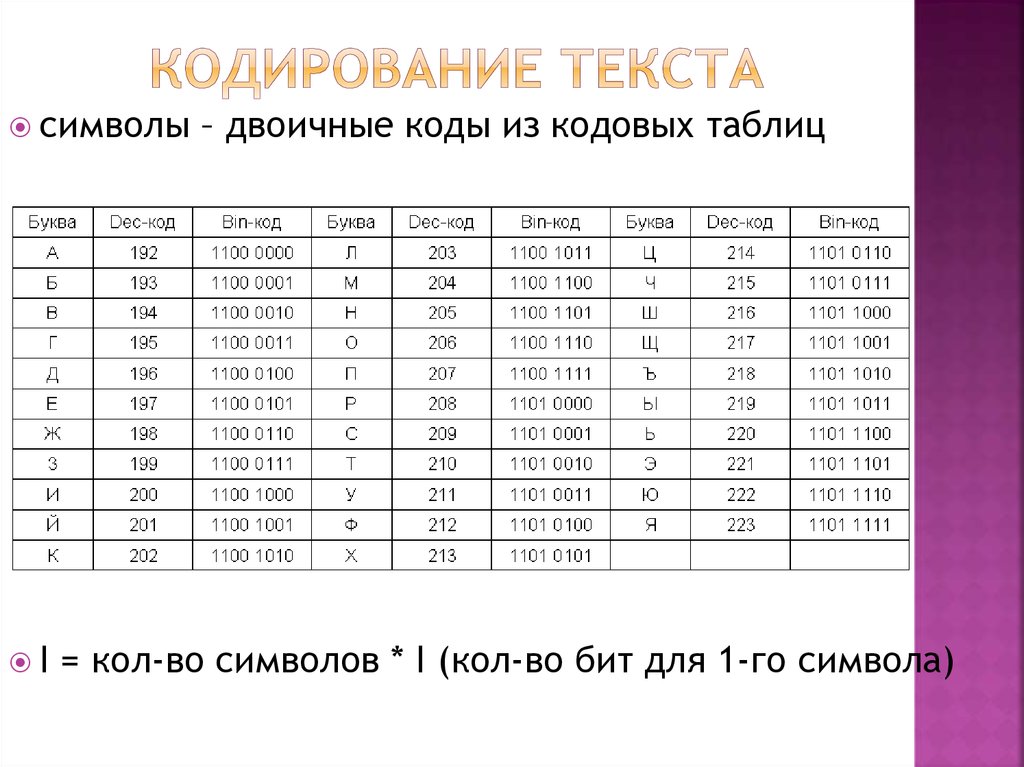
Вся информация, которая отображается на экране компьютера в текстовом виде, на самом деле хранится в файле Ворд в виде числовых значений. Эти значения преобразовываются программой в отображаемые знаки, для чего и используется кодировка.
Кодировка — схема нумерации, в которой каждому текстовому символу из набора соответствует числовое значение. Сама же кодировка может содержать буквы, цифры, а также другие знаки и символы. Отдельно стоит сказать о том, что в разных языках довольно часто используются различные наборы символов, именно поэтому многие кодировки предназначены исключительно для отображения символов конкретных языков.
Сама же кодировка может содержать буквы, цифры, а также другие знаки и символы. Отдельно стоит сказать о том, что в разных языках довольно часто используются различные наборы символов, именно поэтому многие кодировки предназначены исключительно для отображения символов конкретных языков.
Выбор кодировки при открытии файла
Если текстовое содержимое файла отображается некорректно, например, с квадратами, вопросительными знаками и другими символами, значит, MS Word не удалось определить его кодировку. Для устранения этой проблемы необходимо указать правильную (подходящую) кодировку для декодирования (отображения) текста.
1. Откройте меню “Файл” (кнопка “MS Office” ранее).
2. Откройте раздел “Параметры” и выберите в нем пункт “Дополнительно”.
3. Прокрутите содержимое окна вниз, пока не найдете раздел “Общие”. Установите галочку напротив пункта “Подтверждать преобразование формата файла при открытии”. Нажмите “ОК” для закрытия окна.
Нажмите “ОК” для закрытия окна.
Примечание: После того, как вы установите галочку напротив этого параметра, при каждом открытии в Ворде файла в формате, отличном от DOC, DOCX, DOCM, DOT, DOTM, DOTX, будет отображаться диалоговое окно “Преобразование файла”. Если же вам часто приходится работать с документами других форматов, но при этом не требуется менять их кодировку, снимите эту галочку в параметрах программы.
4. Закройте файл, а затем снова откройте его.
5. В разделе “Преобразование файла” выберите пункт “Кодированный текст”.
6. В открывшемся диалоговом окне “Преобразование файла” установите маркер напротив параметра “Другая”. Выберите необходимую кодировку из списка.
- Совет: В окне “Образец” вы можете увидеть, как будет выглядеть текст в той или иной кодировке.

7. Выбрав подходящую кодировку, примените ее. Теперь текстовое содержимое документа будет корректно отображаться.
В случае, если весь текст, кодировку для которого вы выбираете, выглядит практически одинаков (например, в виде квадратов, точек, знаков вопроса), вероятнее всего, на вашем компьютере не установлен шрифт, используемый в документе, который вы пытаетесь открыть. О том, как установить сторонний шрифт в MS Word, вы можете прочесть в нашей статье.
Выбор кодировки при сохранении файла
Если вы не указываете (не выбираете) кодировку файла MS Word при сохранении, он автоматически сохраняется в кодировке Юникод, чего в большинстве случаев предостаточно. Данный тип кодировки поддерживает большую часть знаков и большинство языков.
В случае, если созданный в Ворде документ вы (или кто-то другой) планируете открывать в другой программе, не поддерживающей Юникод, вы всегда можете выбрать необходимую кодировку и сохранить файл именно в ней.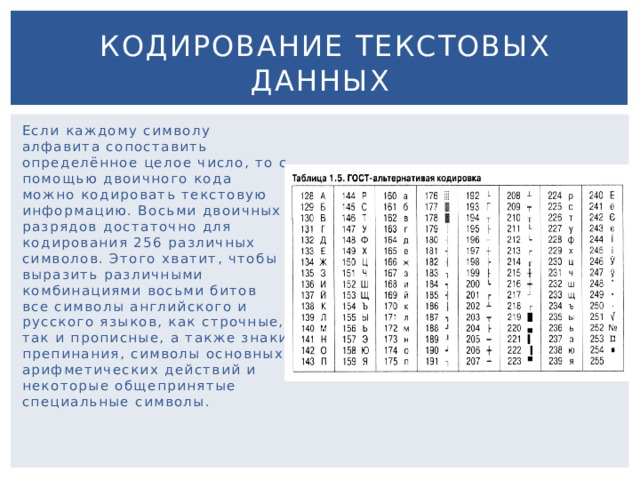 Так, к примеру, на компьютере с русифицированной операционной системой вполне можно создать документ на традиционном китайском с применением Юникода.
Так, к примеру, на компьютере с русифицированной операционной системой вполне можно создать документ на традиционном китайском с применением Юникода.
Проблема лишь в том, что в случае, если данный документ будет открываться в программе, поддерживающей китайский, но не поддерживающей Юникод, куда правильнее будет сохранить файл в другой кодировке, например, “Китайская традиционная (Big5)”. В таком случае текстовое содержимое документа при открытии его в любой программе с поддержкой китайского языка, будет отображаться корректно.
Примечание: Так как Юникод является самым популярным, да и просто обширным стандартном среди кодировок, при сохранении текста в других кодировках возможно некорректное, неполное, а то и вовсе отсутствующее отображение некоторых файлов. На этапе выбора кодировки для сохранения файла знаки и символы, которые не поддерживаются, отображаются красным цветом, дополнительно высвечивается уведомление с информацией о причине.
1. Откройте файл, кодировку которого вам необходимо изменить.
2. Откройте меню “Файл” (кнопка “MS Office” ранее) и выберите пункт “Сохранить как”. Если это необходимо, задайте имя файла.
3. В разделе “Тип файла” выберите параметр “Обычный текст”.
4. Нажмите кнопку “Сохранить”. Перед вами появится окно “Преобразование файла».
5. Выполните одно из следующих действий:
Примечание: Если при выборе той или иной (“Другой”) кодировки вы видите сообщение “Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке”, выберите другую кодировку (иначе содержимое файла будет отображаться некорректно) или же установите галочку напротив параметра “разрешить подстановку знаков”.
Если подстановка знаков разрешена, все те знаки, которые отобразить в выбранной кодировке невозможно, будут автоматически заменены на эквивалентные им символы. Например, многоточие может быть заменено на три точки, а угловые кавычки — на прямые.
Например, многоточие может быть заменено на три точки, а угловые кавычки — на прямые.
6. Файл будет сохранен в выбранной вами кодировке в виде обычного текста (формат “TXT”).
На этом, собственно, и все, теперь вы знаете, как в Word сменить кодировку, а также знаете о том, как ее подобрать, если содержимое документа отображается некорректно.
Мы рады, что смогли помочь Вам в решении проблемы.
Помимо этой статьи, на сайте еще 12560 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Как поменять кодировку в Word
Когда человек работает с программой «MS Word», у него редко возникает потребность вникать в нюансы кодировки. Но как только появляется необходимость поделиться документом с коллегами, существует вероятность того, что отправленный пользователем файл может просто-напросто не быть прочитан получателем. Это случается из-за несовпадения настроек, а конкретно кодировок в разных версиях программы.
Это случается из-за несовпадения настроек, а конкретно кодировок в разных версиях программы.
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может в значительной степени разниться. Для понимания кодировки необходимо знать то, что информация в текстовом документе сохраняется в виде некоторых числовых значений. Персональный компьютер самостоятельно преобразует числа в текст, используя при этом алгоритм отдельно взятой кодировки. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, таких как Западная Европа, применяется «Западноевропейская (Windows)». Если текстовый документ был сохранен в кодировке кириллицы, а открыт с использованием западноевропейского формата, то символы будут отображаться совершенно неправильно, представляя собой бессмысленный набор знаков.
Во избежание недоразумений и облегчения работы разработчики внедрили специальную единую кодировку для всех алфавитов – «Юникод». Этот общепринятый стандарт кодировки содержит в себе практически все знаки большинства письменных языков нашей планеты. К тому же он преобладает в интернете, где так необходима подобная унификация для охвата большего количества пользователей и удовлетворения их потребностей.
Этот общепринятый стандарт кодировки содержит в себе практически все знаки большинства письменных языков нашей планеты. К тому же он преобладает в интернете, где так необходима подобная унификация для охвата большего количества пользователей и удовлетворения их потребностей.
«Word 2013» работает как раз на основе Юникода, что позволяет обмениваться текстовыми файлами без применения сторонних программ и исправления кодировок в настройках. Но нередко пользователи сталкиваются с ситуацией, когда при открытии вроде бы простого файла вместо текста отображаются только знаки. В таком случае программа «Word» неправильно определила существующую первоначальную кодировку текста.
Справка! Некоторые кодировки применяются к определенным языкам. Для японского языка специально была разработана кодировка «Shift JIS», для корейского – «EUC-KR», а для китайского «ISO-2022» и «EUC».
Изменение кодировки текста в «Word 2013»
Первый способ изменения кодировки в «Word»
Для исправления текстового документа, которому была неправильно определена изначальная кодировка, необходимо:
Шаг 1. Запустить текстовый документ и открыть вкладку «Файл».
Запустить текстовый документ и открыть вкладку «Файл».
Шаг 2. Перейти в меню настроек «Параметры».
Шаг 3. Выбрать пункт «Дополнительно» и перейти к разделу «Общие».
Шаг 4. Активируем нажатием по соответствующей области настройку в графе «Подтверждать преобразование формата файла при открытии».
Шаг 5. Сохраняем изменения и закрываем текстовый документ.
Шаг 6. Повторно запускаем необходимый файл. Перед пользователем появится окно «Преобразование файла», в котором необходимо выбрать пункт «Кодированный текст», и сохранить изменения нажатием «ОК».
Шаг 7. Всплывет еще одна область, в которой необходимо выбрать пункт кодировки «Другая» и выбрать в списке подходящую. Поле «Образец» поможет пользователю подобрать необходимую кодировку, отображаемую изменения в тексте. После выбора подходящей сохраняем изменения кнопкой «ОК».
Второй способ изменения кодировки в «Word»
- Производим запуск файла, кодировку текста которого необходимо произвести.
- Переходим во вкладку «Файл».
Читайте полезную информацию, как работать в ворде для чайников, в новой статье на нашем портале.
Изменение кодировки в программе «Notepad ++»
Подобное приложение используется многими программистами для создания сайтов, различных приложений и многого другого. Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Шаг 1. Запустить программу и в верхнем контекстном меню выбрать вкладку «Кодировки».
Шаг 2. В выпадающем списке пользователю требуется выбрать из списка необходимую для него кодировку и щелкнуть на нее.
Шаг 3. Правильность проведения процедуры легко проверить, обратив внимание на нижнюю панель программы, которая будет отображать только что измененную кодировку.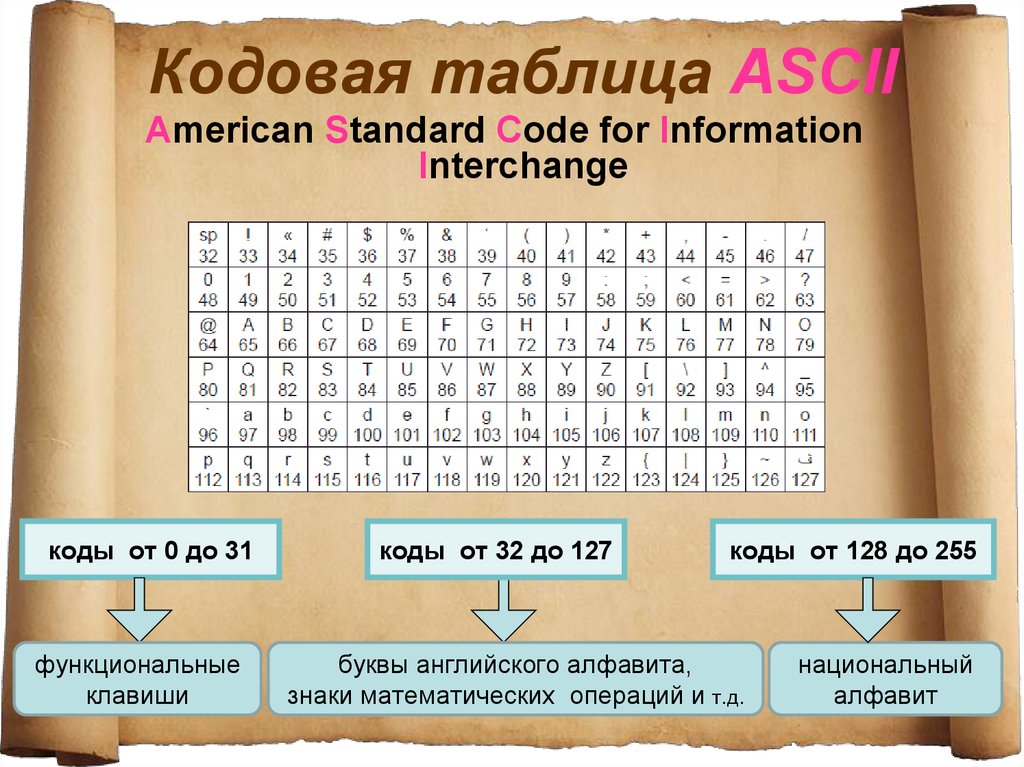
Важно! Перед началом работы в «Notepad ++» в первую очередь рекомендуется проверить установленную кодировку. При необходимости ее нужно изменить при помощи инструкции, приведенной ранее.
Корректировка кодировки веб-страниц
Кодировка символов – неотъемлемая часть работы браузеров для серфинга в интернете. Поэтому каждому из пользователей просто необходимо уметь ее настраивать. Чтобы быстро изменить кодировку «Google Chrome», необходимо будет установить дополнительное расширение, так как разработчики убрали возможность изменения данного параметра.
Для того, чтобы сменить кодировку на необходимую, нужно:
- Запустить браузер.
- Перейти по ссылке chrome://extensions/.
Как поменять кодировку в «Mozilla Firefox»
Для этого пользователю потребуется:
Шаг 1. Запустить браузер и открыть меню, нажав по иконке трех линий левой клавишей мыши в правом верхнем углу страницы.
Шаг 2. В контекстном меню запустить «Настройки».
Шаг 3. Перейти во вкладку «Содержимое».
Шаг 4. В разделе «Шрифты и цвета» нажать на блок «Дополнительные».
Шаг 5. Перед пользователем отобразится специальная панель, на которой будет указана использующаяся кодировка. Для ее изменения потребуется нажать на название кодировки и выбрать нужную.
Установка кодировки в интерфейсе Блокнота
Тем юзерам, кому необходимо пользоваться стандартным приложением «Блокнот» , будет полезно знать о том, что изменить кодировку можно следующим образом:
- Открыть текстовый документ и повторно сохранить его, нажав «Файл» и затем «Сохранить как».
После этого без труда можно открывать необходимый текст в нужной кодировке.
Благодаря правильно подобранной и установленной кодировке пользователь может избежать неприятностей при отправке файла другим юзерам.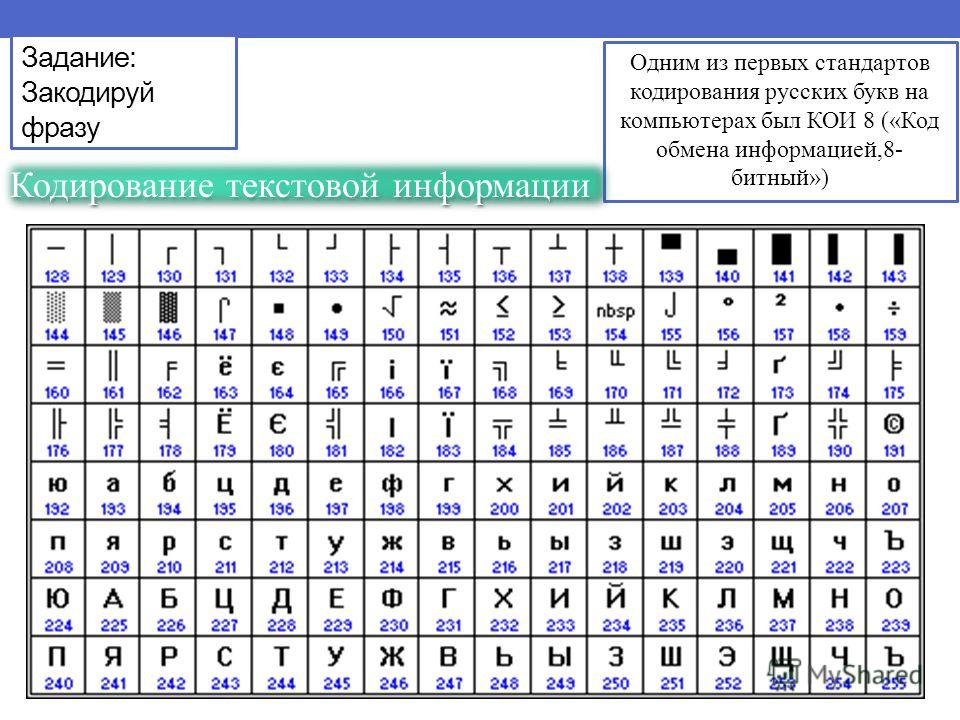 Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.
Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.
Смена кодировки текста в Microsoft Word
Набор символов, которые мы видим на экране при открытии документа, называется кодировкой. Когда она выставлена неправильно, вместо понятных и привычных букв и цифр вы увидите бессвязные символы. Эта проблема часто возникала на заре развития технологий, но сейчас текстовые процессоры умеют сами автоматически выбирать подходящие комплекты. Свою роль сыграло появление и развитие utf-8, так называемого Юникода, в состав которого входит множество самых разных символов, в том числе русских. Документы в такой кодировке не нуждаются в смене и настройке, так как показывают текст правильно по умолчанию.
Современные текстовые редакторы определяют кодировку при открытии документа
С другой стороны, такая ситуация всё же иногда случается. И получить нечитаемый документ очень досадно, особенно если он важный и нужный. Как раз для таких случаев в Microsoft Word есть возможность указать для текста кодировку. Это вернёт его в читаемый вид.
Это вернёт его в читаемый вид.
Принудительная смена
Если вы получили из какого-то источника текстовый файл, но не можете прочитать его содержимое, то нужна операция ручной смены кодировки. Для этого зайдите в раздел «Сведения» во вкладке «Файл». Тут собраны глобальные настройки распознавания и отображения, и если вы будете изменять их в открытом документе, то для него они станут индивидуальными, а для остальных — не изменятся. Воспользуемся этим. В разделе «Дополнительно» появившегося окна находим заголовок «Общие» и ставим галочку «Подтверждать преобразование файлов при открытии». Подтвердите изменения и закройте Word. Теперь откройте документ снова, как бы применяя настройки, и перед вами появится окно преобразования файла. В нём будет список возможных форматов, среди которых находим «Кодированный текст», и получим следующий диалог.
В этом новом окне будет три переключателя. Первый, по умолчанию, — это CP-1251, кодировка Windows. Второй — MS-DOS. Нам нужен третий пункт — ручной выбор, справа от него перечислены разнообразные наборы символов. Но, как правило, пользователь не знает, какими символами был набран текст предыдущим автором, поэтому в нижней части этого окна есть поле под названием «Образец», в котором фрагмент из текста будет в реальном времени отображаться при выборе того или иного комплекта символов. Это очень удобно, потому что не нужно каждый раз закрывать и отрывать документ снова, чтобы подобрать нужную.
Но, как правило, пользователь не знает, какими символами был набран текст предыдущим автором, поэтому в нижней части этого окна есть поле под названием «Образец», в котором фрагмент из текста будет в реальном времени отображаться при выборе того или иного комплекта символов. Это очень удобно, потому что не нужно каждый раз закрывать и отрывать документ снова, чтобы подобрать нужную.
Перебирая варианты по одному и глядя на текст в поле образцов, выберите ту кодировку, при которой символы будут русскими. Но обратите внимание, что это ещё ничего не значит, — внимательно смотрите, чтобы они складывались в осмысленные слова. Дело в том, что для русского языка есть не одна кодировка, и текст в одной из них не будет отображаться корректно в другой. Так что будьте внимательны.
Нужно сказать, что с файлами, сделанными на современных текстовых процессорах, крайне редко возникают подобные проблемы. Однако есть ещё и такой бич современного информационного общества, как несовместимость форматов. Дело в том, что существует целый ряд текстовых редакторов, и каждым кто-то пользуется. Возможно, для кого-то не нужна функциональность Ворда, кто-то не считает нужным за него платить и т. п. Причин может быть множество.
Дело в том, что существует целый ряд текстовых редакторов, и каждым кто-то пользуется. Возможно, для кого-то не нужна функциональность Ворда, кто-то не считает нужным за него платить и т. п. Причин может быть множество.
Если при сохранении документа автор выбрал формат, совместимый в MS Word, то проблем возникнуть не должно. Но так бывает нечасто. Например, если текст сохранён с расширением .rtf, то диалог выбора кодировки отобразится перед вами сразу же при открытии текста. А вот форматы другого популярного текстового процессора OpenOffice Ворд даже не откроет, поэтому, если им пользуетесь, не забывайте выбирать пункт «Сохранить как», когда отправляете файл пользователю Office.
Сохранение с указанием кодировки
У пользователя может возникнуть ситуация, когда он специально указывает определённую кодировку. Например, такое требование ему предъявляет получатель документа. В этом случае нужно будет сохранить документ как обычный текст через меню «Файл». Смысл в том, что для заданных форматов в Ворде есть привязанные глобальными системными настройками кодировки, а для «Обычного текста» такой связи не установлено. Поэтому Ворд предложит самостоятельно выбрать для него кодировку, показав уже знакомое нам окно преобразования документа. Выбирайте для него нужную вам кодировку, сохраняйте, и можно отправлять или передавать этот документ. Как вы понимаете, конечному получателю нужно будет сменить в своём текстовом редакторе кодировку на такую же, чтобы прочитать ваш текст.
Поэтому Ворд предложит самостоятельно выбрать для него кодировку, показав уже знакомое нам окно преобразования документа. Выбирайте для него нужную вам кодировку, сохраняйте, и можно отправлять или передавать этот документ. Как вы понимаете, конечному получателю нужно будет сменить в своём текстовом редакторе кодировку на такую же, чтобы прочитать ваш текст.
Заключение
Вопрос смены кодировки в Вордовских документах перед рядовыми пользователями встаёт не так уж часто. Как правило, текстовый процессор может сам автоматически определить требуемый для корректного отображения набор символов и показать текст в читаемом виде. Но из любого правила есть исключения, так что нужно и полезно уметь сделать это самому, благо, реализован процесс в Word достаточно просто.
То, что мы рассмотрели, действительно и для других программ из пакета Office. В них также могут возникнуть проблемы из-за, скажем, несовместимости форматов сохранённых файлов. Здесь пользователю придётся выполнить всё те же действия, так что эта статья может помочь не только работающим в Ворде. Унификация правил настройки для всех программ офисного пакета Microsoft помогает не запутаться в них при работе с любым видом документов, будь то тексты, таблицы или презентации.
Унификация правил настройки для всех программ офисного пакета Microsoft помогает не запутаться в них при работе с любым видом документов, будь то тексты, таблицы или презентации.
Напоследок нужно сказать, что не всегда стоит обвинять кодировку. Возможно, всё гораздо проще. Дело в том, что многие пользователи в погоне за «красивостями» забывают о стандартизации. Если такой автор выберет установленный у него шрифт, наберёт с его помощью документ и сохранит, у него текст будет отображаться корректно. Но когда этот документ попадёт к человеку, у которого такой шрифт не установлен, то на экране окажется нечитаемый набор символов. Это очень похоже на «слетевшую» кодировку, так что легко ошибиться. Поэтому перед тем как пытаться раскодировать текст в Word, сначала попробуйте просто сменить шрифт.
Как убрать кодировку текста в ворде?
Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
- Откройте вкладку Файл.
- Нажмите кнопку Параметры.

- Нажмите кнопку Дополнительно.
- Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии. …
- Закройте, а затем снова откройте файл.
Как перевести иероглифы в нормальный текст?
нажать левый ALT — чтобы сверху показалось меню. Нажать меню «Вид»; выбрать пункт «Кодировка текста», далее выбрать Юникод. И, ву-а-ля — иероглифы на странички сразу же стали обычным текстом (скрин ниже )!
Как изменить кодировку текста в ворде?
Выполните следующие действия:
- Откройте двойным кликом файл, который необходимо перекодировать.
- Кликните по пункту «Кодированный текст», что находится в разделе «Преобразование файла».
- В появившемся окне установите переключатель на пункт «Другая».
- В выпадающем списке, что расположен рядом, определите нужную кодировку.
Что делать если вместо текста иероглифы в Word?
Если вместо текста иероглифы в Microsoft Word
Обычно, в «старом» Word нельзя открыть новые форматы файлов, но случается иногда так, что эти «новые» файлы открываются в старой программе. Просто откройте свойства файла, а затем посмотрите вкладку «Подробно» (как на рис. 5).
Просто откройте свойства файла, а затем посмотрите вкладку «Подробно» (как на рис. 5).
Как восстановить кодировку в Word?
Способ второй: во время сохранения документа
- Нажмите «Файл».
- Выберите «Сохранить как».
- В выпадающем списке, что находится в разделе «Тип файла», выберите «Обычный текст».
- Кликните по «Сохранить».
- В окне преобразования файла выберите предпочитаемую кодировку и нажмите «ОК».
Как открыть файл формата PDF в Word?
- Выберите Файл > Открыть.
- Найдите PDF-файл и откройте его (для этого может потребоваться нажать кнопку Обзор и найти файл в папке).
- Появится предупреждение о том, будет создана копия PDF-файла, преобразованная в поддерживаемый формат. Исходный PDF-файл при этом не изменяется. Нажмите кнопку ОК.
Как преобразовать файл в ворде?
Откройте вкладку Файл. Выполните одно из указанных ниже действий. Чтобы преобразовать документ без сохранения копии, выберите пункт Сведения, а затем — команду Преобразовать. Чтобы создать копию документа в формате Word 2010, выберите команду Сохранить как и укажите расположение и папку для сохранения копии.
Выполните одно из указанных ниже действий. Чтобы преобразовать документ без сохранения копии, выберите пункт Сведения, а затем — команду Преобразовать. Чтобы создать копию документа в формате Word 2010, выберите команду Сохранить как и укажите расположение и папку для сохранения копии.
Как определить в какой кодировке файл?
Открыть искомый текстовый файл в Блокноте Windows и выбрать пункт меню «Файл» -> «Сохранить как…». Пример текстового файла, в котором русский текст задан в формате UTF, но это не очевидно при открытии. 2. В открывшемся диалоговом окне вы сразу видите, в какой кодировке был сохранён текст в текстовом файле.
Какая кодировка поддерживает кириллицу?
Наиболее распространёнными кодировками с поддержкой Русского языка (с использованием символов Кириллицы) являются: UTF-8, Windows-1251, CP-866, KOI-8R, ISO-8859-5.
Как изменить кодировку текстового файла?
Изменить кодировку текстового файла, создаваемого в Windows можно легко с помощью встроенной программы «Блокнот».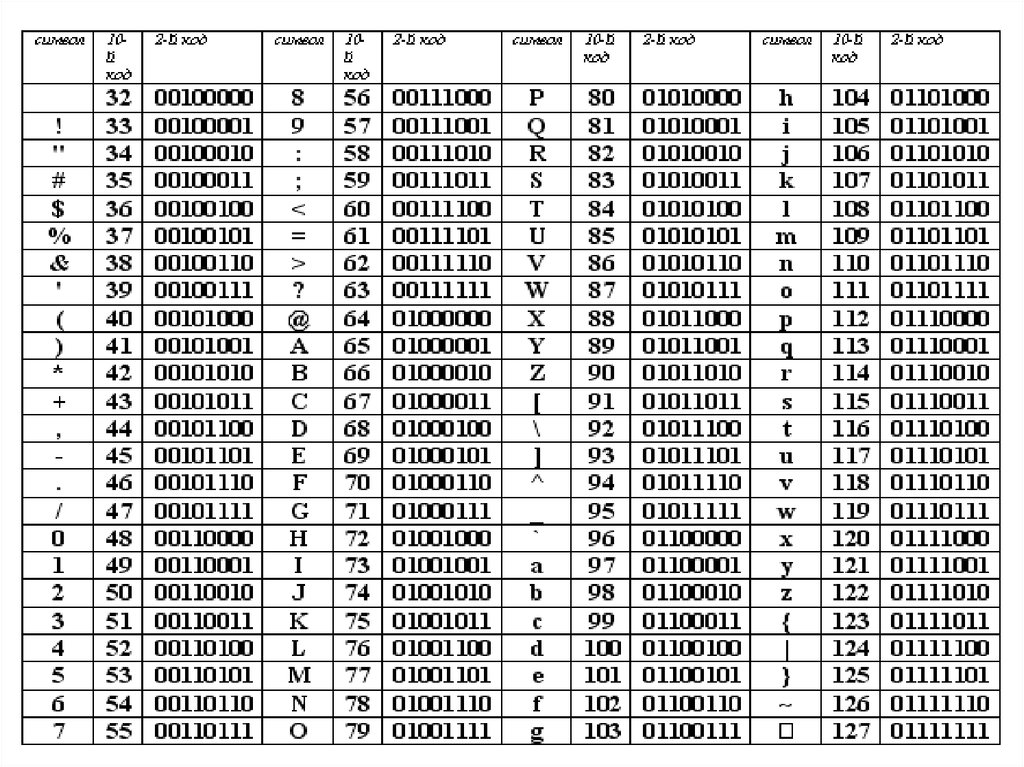 Для этого достаточно открыть требуемый файл и нажать «Файл» -> «Сохранить как». В выпавшем меню выбрать требуемую кодировку и сохранить текстовой файл.
Для этого достаточно открыть требуемый файл и нажать «Файл» -> «Сохранить как». В выпавшем меню выбрать требуемую кодировку и сохранить текстовой файл.
Как изменить кодировку текста в LibreOffice?
В первую очередь необходимо посмотреть настройки кодировки в самом текстовом редакторе LibreOffice. Для этого откройте пункт меню «Сервис» — «Параметры». И во всех пунктах выберите нужную кодировку. Как правило, необходима кодировка «Стандарт — Русский».
Представление наборов символов и кодировки
Представление наборов символов и кодировкиЭта страница ориентирует новичков в веб интернационализации, которые действительно не знают с чего начать. Цель — облегчить понимание некоторых материалов на сайте.
С помощью ссылок справа вы можете найти подборку более подробных статей. После того как вы ознакомитесь с этой страницей, вы, вероятно, просто используете тематический перечень, технический перечень, или поиск на сайте.
Что это такое?
Набор символов — набор букв и символов, используемых для письма. Например, набор символов ASCII охватывает буквы и символы для англоязычного текста, ISO-8859-6 охватывает буквы и символы, необходимые для многих языков, основанные на арабском скрипте, и набор символов Unicode содержит символы для большинства существующих языков и скриптов мира.
Символы в наборе символов хранятся в виде одного или нескольких байтов на компьютере. Каждый байт или последовательность байтов представляет обусловленный символ. Кодування символів розподіляє окремий байт або послідовність байтів в окремі символи, які відображаються шрифтом, як текст.
Есть много разных кодировок символов. Если неправильная кодировка применяется к байтам в памяти, то в результате будет непонятен текст. Чтобы люди могли читать ваш контент, важно правильно выбрали кодировку.
Узнайте больше…
Кодировка для начинающих объясняет некоторые основные понятия о кодировке, и зачем вам это нужно.
Основные определения, связанные с кодировками объясняет такие термины, как Unicode, наборы символов, кодировка наборов символов, кодировка символов, набор символов документа, и экранированные символы.
Выбор кодировки
Каждый разработчик контента, будь то автор или программист, должен решить какую кодировку символов он будет использовать. На сегодняшний день рекомендуют использовать кодировку UTF-8 , но все еще могут быть вещи, которые вы должны рассмотреть перед ее использованием.
Назначение и приминненя кодировки символов
Как только было решено, какую кодировку использовать, разработчики контента и программисты должны убедиться, что она правильно назначена.
В XHTML, назначить кодирования не просто; нужно понимать ‘стандартный’ режим по сравнению с режимом ‘совместимости’ , и влияние XML назначения.
Вы также должны убедиться, что ваши данные хранятся в кодировке, которую вы выбрали, не достаточно только назвать ее.
Разработчикам контента и веб-мастерам необходимо будет убедиться, что сервер передает контент с правильной кодировкой символов
, ибо настройки сервера могут отвергать назначения записаные в вашем документе.
Экранированные символы
Экранированные символы — используются для отображения символов, используя только текст ASCII. Они являются средством отображения символов, которые не доступны в кодировке, что вы используете, помогают избежать использования символов по другим причинам (например, когда они могут конфликтовать с синтаксисом). Вы должны понять, когда и как следует использовать эти экранированные символы.
Веб адреса
На сегодняшний день веб адреса могут содержать non-ASCII символы. Пользователь делает немного другое, чем нажимает на соответствующей ссылке или вводит текст, так как он его видит, тяжелую работу выполняет клиентское приложение (поисковый робот), но вас может заинтересовать, как это работает.
Разработчики спецификаций должны проектировать их так, чтобы можно было использовать non-ASCII символов в веб адресах.
vim — Как исправить неправильную кодировку текстового файла?
спросил
Изменено 8 лет, 9 месяцев назад
Просмотрено 6к раз
У меня есть текстовый файл, который якобы имеет кодировку UTF-8. То есть, когда я вызываю файл
То есть, когда я вызываю файл -I $file , он печатает $file: text/plain; кодировка=utf-8 . Но когда я открываю его с кодировкой UTF-8, некоторые символы кажутся поврежденными. То есть файл должен быть немецким, но специальные немецкие символы, такие как ö , отображаются как ö .
Я догадался, что заявление о кодировке UTF-8 неверно, и выполнил скрипт enca, чтобы угадать реальную кодировку. Но, к сожалению, enca сообщает мне, что язык de (немецкий) не поддерживается.
Есть ли другой способ исправить файл?
- vim
- кодировка
- utf-8
- character-encoding
Форма «ö» U+00F6 в кодировке UTF-8 равна 0xC3 0xB6, и если эти байты интерпретируются в соответствии с ISO-8859-1, они равны «Ã¶» (U +00C3 U+00B6). Таким образом, либо файл на самом деле читается и интерпретируется как ISO-8859-1, даже если вы ожидаете иного, либо имело место двойное кодирование: ранее файл или его часть читались, как если бы это был ISO-8859-1.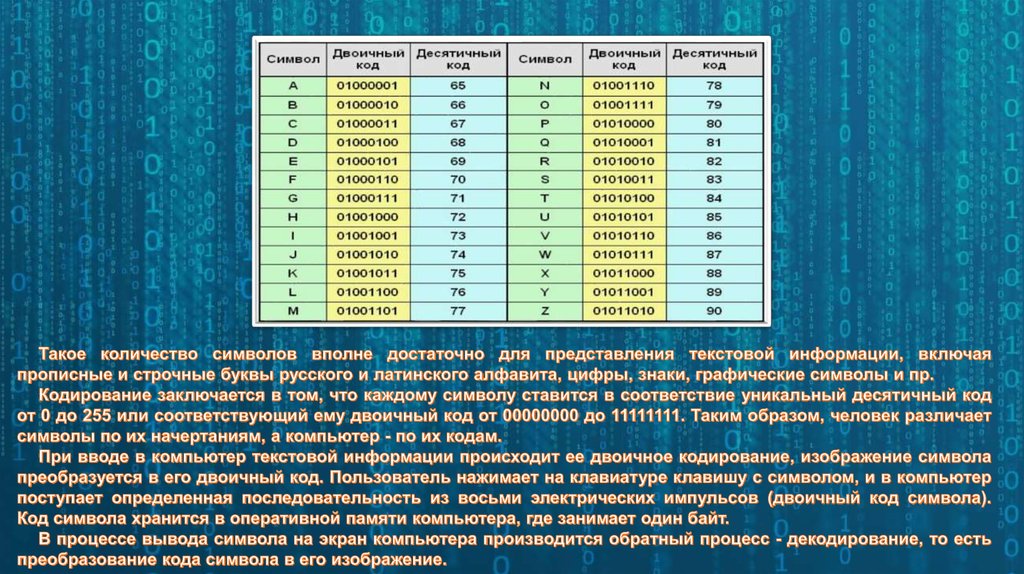 (даже несмотря на то, что это была UTF-8), а неверно истолкованные данные затем записывались в кодировке UTF-8.
(даже несмотря на то, что это была UTF-8), а неверно истолкованные данные затем записывались в кодировке UTF-8.
2
Чтобы файл правильно читался в заданной кодировке, вам нужны три вещи:
- «кодировка», управляющая символами, которые Vim может хранить и отображать, должна быть способна представлять все символы в вашем файле.
- ‘fileencodings’, которые определяют, какие кодировки Vim будет пытаться распознать, должны быть установлены таким образом, чтобы кодировка вашего файла распознавалась
- ‘fileencoding’ должен быть установлен правильно, обычно путем автоматического обнаружения настройкой ‘fileencodings’, на кодировку, в которой хранится ваш файл.
Обратите внимание, что (2) не является строго обязательным, но если кодировка файла определяется неправильно, вам нужно будет вручную перечитать файл в правильной кодировке. Например, используя :e ++enc=utf-8 для файла utf-8, который не был обнаружен как таковой.
См. http://vim.wikia.com/wiki/Working_with_Unicode, чтобы правильно понять все три эти концепции.
1
Вы также можете проверить кодировку с помощью :установить кодировку
:set encoding=utf-8 . Если вы все еще видите неправильные символы, это означает, что они не записаны в файле как utf-8, и вам нужно их преобразовать.РЕДАКТИРОВАТЬ : если бы вы могли отправить свой файл, это помогло бы
4
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
utf 8 — Как исправить кодировку файла?
спросил
Изменено 5 лет, 9 месяцев назад
Просмотрено 210 тысяч раз
У меня есть текстовый файл в кодировке ANSI, который не должен был быть закодирован как ANSI, так как там были акценты
символы, которые не поддерживает ANSI. Я бы предпочел работать с UTF-8.
Я бы предпочел работать с UTF-8.
Могут ли данные декодироваться правильно или они теряются при перекодировании?
Какие инструменты можно использовать?
Вот пример того, что у меня есть:
ç é
Из контекста я могу сказать (кафе должно быть кафе), что это должны быть два символа:
ç é
- кодировка
- utf-8
- кодировка символов
- текстовые файлы
- кодовые страницы
3
Выполните следующие действия с помощью Notepad++
1- Скопируйте исходный текст
2- В Notepad++ откройте новый файл, измените кодировку -> выберите кодировку, по которой, по вашему мнению, следует исходный текст. Попробуйте также кодировку «ANSI», так как иногда файлы Unicode читаются как ANSI некоторыми программами
3- Вставить
4- Затем, чтобы преобразовать в Unicode, снова перейдя в то же меню: Кодировка -> «Кодировать в UTF-8» (не «Преобразовать в UTF-8»), и, надеюсь, он станет читаемым
Вышеуказанные шаги применимы для большинства языки.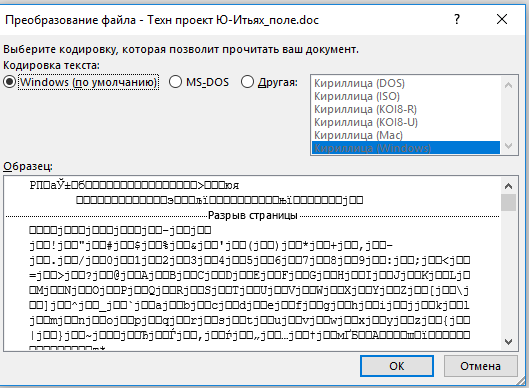
Большинство языков существует в двух формах кодировки: 1- Старая устаревшая форма ANSI (ASCII), всего 8 бит, изначально использовалась большинством компьютеров. 8 бит допускали только 256 возможностей, 128 из них, где обычные латинские и управляющие символы, последние 128 бит читались по-разному в зависимости от языковых настроек ПК. 2- Новый стандарт Unicode (до 32 бит) дает уникальный код для каждого символа. на всех известных в настоящее время языках и на многих других. если файл имеет формат unicode, он должен быть понятен на любом ПК с установленным языковым шрифтом. Обратите внимание, что даже UTF-8 доходит до 32 бит и так же широк, как UTF-16 и UTF-32, только он пытается оставаться 8-битным с латинскими символами только для экономии места на диске
5
РЕДАКТИРОВАТЬ: Простую возможность исключить, прежде чем переходить к более сложным решениям: вы пытались установить набор символов на utf8 в текстовом редакторе, в котором вы читаете файл? Это может быть просто тот случай, когда кто-то отправляет вам файл utf8, который вы читаете в редакторе, настроенном на cp1252.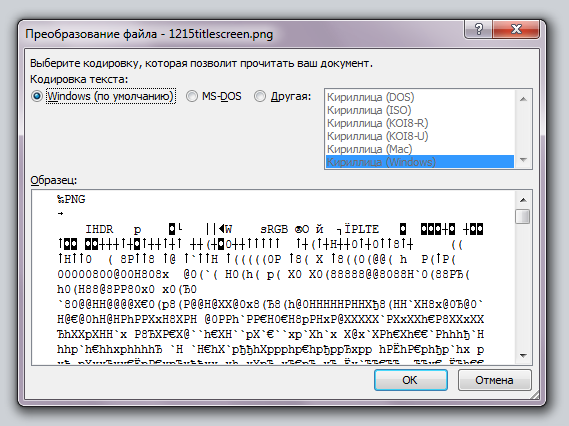
Просто взяв два примера, это случай чтения utf8 через призму однобайтовой кодировки, вероятно, одной из iso-8859.-1, iso-8859-15 или cp1252. Если вы можете опубликовать примеры других проблемных персонажей, это можно будет еще больше сузить.
Поскольку визуальный осмотр символов может ввести в заблуждение, вам также необходимо посмотреть на базовые байты: §, который вы видите на экране, может быть либо 0xa7, либо 0xc2a7, и это определит тип преобразования набора символов, который вам нужно преобразовать. делать.
Можете ли вы предположить, что все ваши данные были искажены точно таким же образом — что они взяты из одного источника и претерпели одну и ту же последовательность преобразований, так что, например, в вашем тексте нет ни одной буквы é, это всегда ç? Если это так, проблема может быть решена с помощью последовательности преобразований набора символов. Если вы можете более конкретно указать среду, в которой вы находитесь, и базу данных, которую вы используете, кто-нибудь здесь, вероятно, может рассказать вам, как выполнить соответствующее преобразование.
В противном случае, если проблемные символы встречаются только в некоторых местах ваших данных, вам придется брать их экземпляр за экземпляром, основываясь на предположениях вроде «ни один автор не собирался помещать ç в свой текст, поэтому всякий раз, когда видите, замените на ç». Последний вариант более рискован, во-первых, потому что эти предположения о намерениях авторов могут быть неверны, во-вторых, потому что вам придется самостоятельно выявлять каждого проблемного персонажа, что может быть невозможно, если текста слишком много для визуального осмотра или если он написан. на чужом для вас языке или системе письма.
2
С vim из командной строки:
vim -c "set encoding=utf8" -c "set fileencoding=utf8" -c "wq" имя файла
Когда вы видите такие последовательности символов, как ç и é, это обычно указывает на то, что файл UTF-8 был открыт программой, которая считывает его как ANSI (или аналогичный).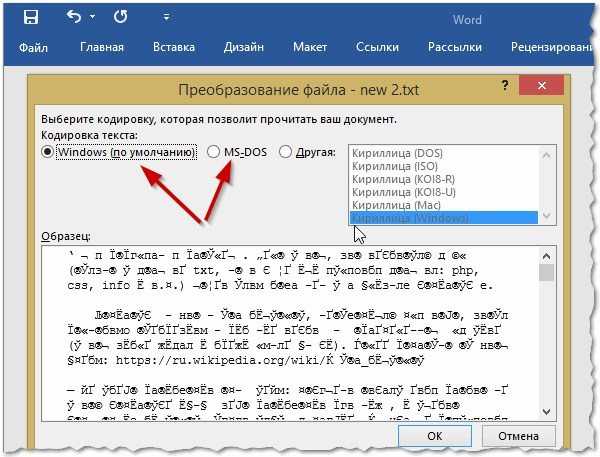 Такие символы Юникода:
Такие символы Юникода:
U+00C2 Заглавная латинская буква A с циркумфлексом
U+00C3 Заглавная латинская буква A с тильдой
U+0082 Здесь разрешен разрыв
U+0083 Здесь нет разрыва
имеют тенденцию появляться в тексте ANSI из-за стратегии переменных байтов, которую использует UTF-8. Эта стратегия очень хорошо объясняется здесь.
Преимущество для вас состоит в том, что появление этих странных символов позволяет относительно легко найти и, таким образом, заменить экземпляры неправильного преобразования.
Я считаю, что, поскольку ANSI всегда использует 1 байт на символ, вы можете справиться с этой ситуацией с помощью простой операции поиска и замены. Или, что более удобно, с помощью программы, которая включает в себя табличное сопоставление между оскорбительными последовательностями и нужными символами, например:
—> » # должен быть открывающей двойной фигурной кавычкой
—? -> ” # должен быть закрывающей двойной фигурной кавычкой
Любой данный текст, при условии, что он на английском языке, будет иметь относительно небольшое количество различных типов замен.
Надеюсь, это поможет.
0
В возвышенном текстовом редакторе файл -> открыть заново с кодировкой -> выбрать правильную кодировку.
Как правило, кодировка определяется автоматически, но если нет, вы можете использовать описанный выше метод.
Если вы видите вопросительные знаки в файле или акценты уже потеряны, возврат к utf8 не поможет вашему делу. например если кафе стало кафе — одной сменой кодировки не поможет (нужны исходные данные).
Не могли бы вы вставить сюда какой-нибудь текст, это поможет нам точно ответить.
Я нашел простой способ автоматического определения кодировок файлов — изменить файл на текстовый (на Mac переименовать расширение файла в .txt) и перетащить его в окно Mozilla Firefox (или Файл -> Открыть). Firefox обнаружит кодировку — вы можете увидеть, что она придумала, в разделе «Вид» -> «Кодировка символов».
Я изменил кодировку файла с помощью TextMate, как только узнал правильную кодировку.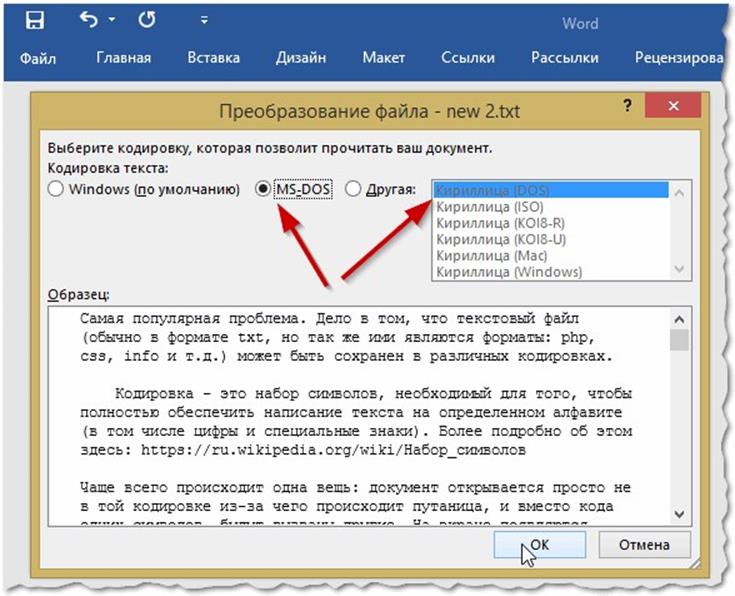 Файл -> Открыть заново, используя кодировку, и выберите свою кодировку. Затем «Файл» -> «Сохранить как» и измените кодировку на UTF-8 и окончания строк на LF (или что вы хотите)
Файл -> Открыть заново, используя кодировку, и выберите свою кодировку. Затем «Файл» -> «Сохранить как» и измените кодировку на UTF-8 и окончания строк на LF (или что вы хотите)
Я нашел этот вопрос при поиске решения проблемы с кодовой страницей, которая у меня была с китайскими иероглифами, но в В конце концов, моя проблема заключалась в том, что Windows неправильно отображала их в пользовательском интерфейсе.
Если у кого-то еще есть такая же проблема, вы можете решить ее, просто изменив локальный в Windows на Китай, а затем обратно.
Я нашел решение здесь:
http://answers.microsoft.com/en-us/windows/forum/windows_7-desktop/how-can-i-get-chinesejapanese-characters-to/fdb1f1da-b868- 40d1-a4a4-7acadff4aafa?page=2&auth=1
Также проголосовал за ответ Габриэля, поскольку просмотр данных в блокноте ++ был тем, что подсказало мне об окнах.
И еще есть более старая программа перекодирования.
Существуют программы, которые пытаются определить кодировку файла, например chardet.