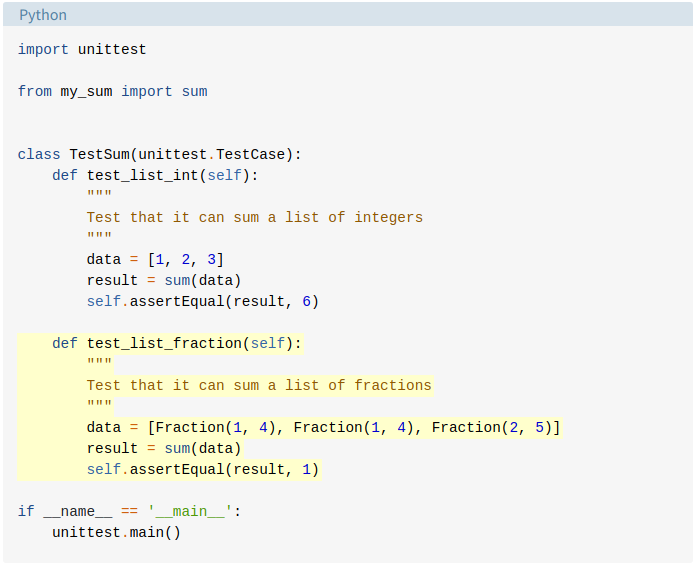
Модуль csv — чтение и запись CSV файлов
Формат CSV (Comma Separated Values) является одним из самых распространенных форматов импорта и экспорта электронных таблиц и баз данных. CSV использовался в течение многих лет до того, как был стандартизирован в RFC 4180. Запоздание четко определенного стандарта означает, что в данных, создаваемых различными приложениями, часто существуют незначительные различия. Эти различия могут вызвать раздражение при обработке файлов CSV из нескольких источников. Тем не менее, хотя разделители, символы кавычек и некоторые другие свойства различаются, общий формат достаточно универсален. Значит, возможно написать один модуль, который может эффективно манипулировать такими данными, скрывая детали чтения и записи данных от программиста.
Функции обработки CSV-файлов
csv.reader(csvfile, dialect=’excel’, **fmtparams) — возвращает объект reader, который построчно итерирует csvfile. Если csvfile является файловым объектом, то его нужно открыть с параметром newline=». Дополнительный параметр dialect используется для определения ряда параметров, характерных для специфического CSV диалекта. Он может быть подклассом Dialect или одной из строк, возвращаемой функцией list_dialects(). Также могут передаваться дополнительные ключевые аргументы fmtparams для переопределения отдельных параметров форматирования в текущем диалекте.
Дополнительный параметр dialect используется для определения ряда параметров, характерных для специфического CSV диалекта. Он может быть подклассом Dialect или одной из строк, возвращаемой функцией list_dialects(). Также могут передаваться дополнительные ключевые аргументы fmtparams для переопределения отдельных параметров форматирования в текущем диалекте.
Подробнее см. раздел «Диалекты и параметры форматирования».
Каждая строка, считанная из файла csv, возвращается в виде списка строк. Автоматическое преобразование типов данных не выполняется, если не указан параметр формата QUOTE_NONNUMERIC (в этом случае все поля без кавычек преобразуются в числа с плавающей точкой).
Короткий пример использования:
>>> import csv
>>> with open('eggs.csv', 'r', newline='') as csvfile:
... spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|')
... for row in spamreader:
... print(', '.join(row))
Spam, Spam, Spam, Spam, Spam, Baked Beans
Spam, Lovely Spam, Wonderful Spamcsv. writer(csvfile, dialect=’excel’, **fmtparams) — возвращает объект writer, конвертирующий пользовательские данные в CSV-файл csvfile. csvfile может быть любым объектом с методом write(). Если csvfile является файловым объектом, то его нужно открыть с параметром newline=». Параметры dialect и fmtparams идентичны параметрам в функции csv.reader.
writer(csvfile, dialect=’excel’, **fmtparams) — возвращает объект writer, конвертирующий пользовательские данные в CSV-файл csvfile. csvfile может быть любым объектом с методом write(). Если csvfile является файловым объектом, то его нужно открыть с параметром newline=». Параметры dialect и fmtparams идентичны параметрам в функции csv.reader.
Необходимые методы экземпляра класса writer:
csvwriter.writerow(row) — записывает данные, представляющие одну строку CSV в файл, форматируя согласно текущему диалекту writer.
csvwriter.writerows(rows) — записывает данные, представляющие несколько строк CSV в файл, форматируя согласно текущему диалекту writer.
Пример использования writer:
import csv
with open('eggs.csv', 'w', newline='') as csvfile:
spamwriter = csv.writer(csvfile, delimiter=' ',
quotechar='|', quoting=csv.QUOTE_MINIMAL)
spamwriter.writerow(['Spam'] * 5 + ['Baked Beans'])
spamwriter.writerow(['Spam', 'Lovely Spam', 'Wonderful Spam'])csv. field_size_limit([new_limit]) — текущий максимальный размер поля. Если задан new_limit, то он становится новым макс. размером.
field_size_limit([new_limit]) — текущий максимальный размер поля. Если задан new_limit, то он становится новым макс. размером.
class csv.DictReader(f, fieldnames=None, restkey=None, restval=None, dialect=’excel’, *args, **kwds) — как reader, но отображает информацию о столбцах в словарь, ключи которого заданы в параметре fieldnames.
fieldnames это последовательность ключей. Если параметр опущен, в качестве ключей используются значения из первой строки файла. Если строка имеет больше полей, чем длина
Остальные аргументы пробрасываются далее в экземпляр reader.
Пример использования:
>>> import csv
>>> with open('names.csv', newline='') as csvfile:
... reader = csv.DictReader(csvfile)
... for row in reader:
... print(row['first_name'], row['last_name'])
. ..
Eric Idle
John Cleese
>>> print(row)
{'first_name': 'John', 'last_name': 'Cleese'}
..
Eric Idle
John Cleese
>>> print(row)
{'first_name': 'John', 'last_name': 'Cleese'}class csv.DictWriter(f, fieldnames, restval=», extrasaction=’raise’, dialect=’excel’, *args, **kwds) — как writer, но отображает словари в CSV-файл.
Обязательный параметр fieldnames — последовательность ключей, определяющие порядок, в котором значения из словаря будут записаны в строке CSV-файла f.
Параметр restval определяет значение в случае, если в словаре будет отсутствовать запись с данным ключом. Если словарь содержит лишние ключи, то поведение определяется параметром extrasaction. Если он ‘raise’, то выдаст ошибку. Если ‘ignore’, то такие ключи игнорируются.
Остальные аргументы пробрасываются далее в экземпляр writer.
Помимо методов writerow и writerows, DictWriter имеет также метод
Пример использования DictWriter:
import csv
with open('names.csv', 'w', newline='') as csvfile:
fieldnames = ['first_name', 'last_name']
writer = csv. DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'first_name': 'Baked', 'last_name': 'Beans'})
writer.writerow({'first_name': 'Lovely', 'last_name': 'Spam'})
writer.writerow({'first_name': 'Wonderful', 'last_name': 'Spam'})
DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'first_name': 'Baked', 'last_name': 'Beans'})
writer.writerow({'first_name': 'Lovely', 'last_name': 'Spam'})
writer.writerow({'first_name': 'Wonderful', 'last_name': 'Spam'})Диалекты и параметры форматирования
class csv.Dialect — для упрощения задания формата входных и выходных записей, конкретные параметры форматирования группируются в диалекты, подклассы csv.Dialect. Диалекты поддерживают следующие атрибуты:
Dialect.delimiter — разделитель столбцов в строке CSV-файла. По умолчанию ‘,’.
Dialect.quotechar — символ, использующийся для «склейки» поля, содержащего специальные символы, такие как delimiter, quotechar, или символы новой строки. По умолчанию используется значение ‘»‘.
Dialect.doublequote — как Dialect.quotechar, появляющийся внутри поля, должен экранироваться. Когда True, символ удваивается. Когда False, Dialect.escapechar используется как префикс к quotechar. По умолчанию True.
По умолчанию True.
При записи файла, если doublequote=False и не установлен escapechar, выдаст ошибку при обнаружении quotechar в столбце.
Dialect.escapechar — символ, используемый writer для экранирования delimiter, если quoting установлен в QUOTE_NONE и quotechar, если doublequote=False. При чтении escapechar удаляет какое-либо особое значение со следующего символа. По умолчанию используется значение None, которое отключает экранирование.
Dialect.lineterminator — символы, используемые для завершения строки при записи. По умолчанию ‘\r\n’.
Dialect.skipinitialspace — если True, пробелы, непосредственно следующие за delimiter, игнорируются. Значение по умолчанию — False.
Dialect.strict — когда True, поднимает исключение если CSV файл не распознается. По умолчанию — False.
Dialect.quoting — контролирует, когда кавычки должны генерироваться writer и распознаваться reader.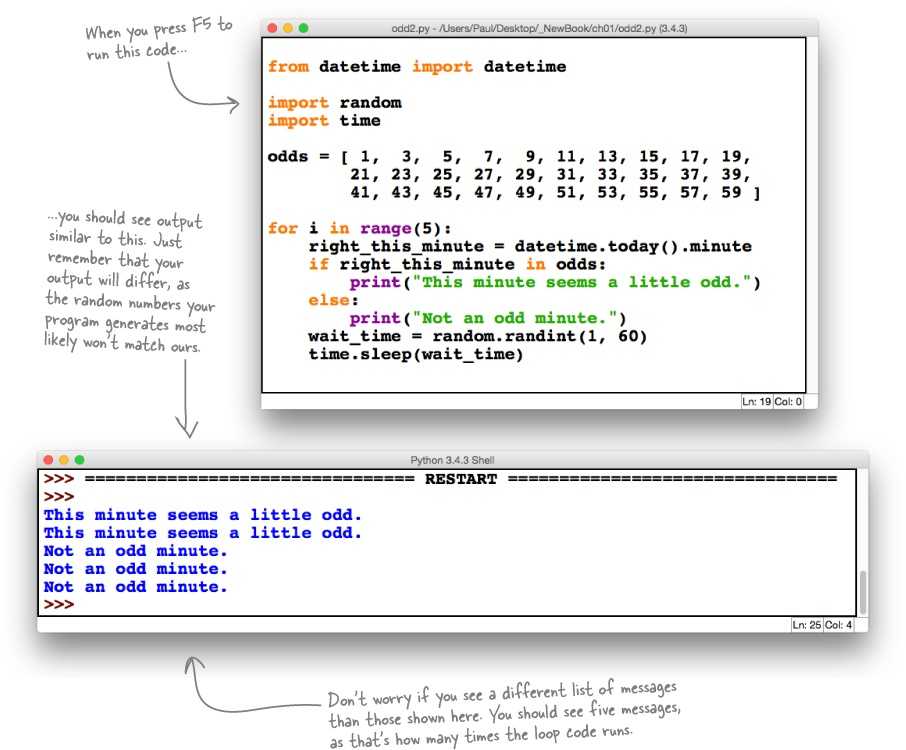 Он может принимать любые константы QUOTE_* и по умолчанию имеет значение QUOTE_MINIMAL.
Он может принимать любые константы QUOTE_* и по умолчанию имеет значение QUOTE_MINIMAL.
csv.QUOTE_ALL — writer оборачивает в кавычки все поля.
csv.QUOTE_MINIMAL — writer оборачивает в кавычки только поля, содержащие специальные символы (delimiter, quotechar, lineterminator).
csv.QUOTE_NONNUMERIC — writer оборачивает в кавычки все поля, не являющиеся числами. reader преобразует все поля без кавычек к типу float.
csv.QUOTE_NONE — writer не оборачивает никакие поля в кавычки. Если в данных попадается delimiter или lineterminator, он предваряется символом escapechar, если установлен (исключение, если не установлен). reader не обрабатывает кавычки.
csv.register_dialect(name[, dialect[, **fmtparams]]) — связывает dialect с именем name. Подробности о диалектах см. в разделе «Диалекты и параметры форматирования»
csv.unregister_dialect(name) — удаляет связь диалекта с данным именем.
csv.get_dialect(name) — возвращает класс диалекта, свзанного с именем name.
csv.list_dialects() — список доступных диалектов. На данный момент это ‘excel’, ‘excel-tab’, ‘unix’.
Предустановленные диалекты
class csv.excel — диалект CSV-файла, обычно генерируемого программой Excel.
class csv.excel_tab — диалект CSV-файла, обычно генерируемого программой Excel с настройкой «разделитель с помощью TAB».
class csv.unix_dialect — диалект CSV-файла, обычно генерируемого в UNIX-системах (‘\n’ для новой строки, закавычивание всех полей).
Определение диалекта
class csv.Sniffer — используется для угадывания диалекта CSV-файла. Имеет следующие методы:
csvsniffer.sniff(sample, delimiters=None) — анализирует пример и возвращает Dialect, соответствующий обнаруженным параметрам. Если задан параметр delimiters, он интерпретируется как все возможные разделители.
Методы определения диалекта являются эвристическими; это означает, что Sniffer может ошибаться.
Пример использования Sniffer:
with open('example. csv', newline='') as csvfile:
dialect = csv.Sniffer().sniff(csvfile.read(1024))
csvfile.seek(0)
reader = csv.reader(csvfile, dialect)
# ... process CSV file contents here ...
csv', newline='') as csvfile:
dialect = csv.Sniffer().sniff(csvfile.read(1024))
csvfile.seek(0)
reader = csv.reader(csvfile, dialect)
# ... process CSV file contents here ...Примеры
Простейший пример чтения CSV файла:
import csv
with open('some.csv', newline='') as f:
reader = csv.reader(f)
for row in reader:
print(row) Чтение файла формата passwd:
import csv
with open('passwd', newline='') as f:
reader = csv.reader(f, delimiter=':', quoting=csv.QUOTE_NONE)
for row in reader:
print(row)Простейший пример записи CSV файла:
import csv
with open('some.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerows(someiterable)Для вставки кода на Python в комментарий заключайте его в теги <pre><code>Ваш код</code></pre>
Модуль shutil | Python 3 для начинающих и чайников
Модуль shutil содержит набор функций высокого уровня для обработки файлов, групп файлов, и папок. В частности, доступные здесь функции позволяют копировать, перемещать и удалять файлы и папки. Часто используется вместе с модулем os.
В частности, доступные здесь функции позволяют копировать, перемещать и удалять файлы и папки. Часто используется вместе с модулем os.
Операции над файлами и директориями
shutil.copyfileobj(fsrc, fdst[, length]) — скопировать содержимое одного файлового объекта (fsrc) в другой (fdst). Необязательный параметр length — размер буфера при копировании (чтобы весь, возможно огромный, файл не читался целиком в память).
При этом, если позиция указателя в fsrc не 0 (т.е. до этого было сделано что-то наподобие fsrc.read(47)), то будет копироваться содержимое начиная с текущей позиции, а не с начала файла.
shutil.copyfile(src, dst, follow_symlinks=True) — копирует содержимое (но не метаданные) файла src в файл dst. Возвращает dst (т.е. куда файл был скопирован). src и dst это строки — пути к файлам. dst должен быть полным именем файла.
Если src и dst представляют собой один и тот же файл, исключение shutil.SameFileError.
Если dst существует, то он будет перезаписан.
Если follow_symlinks=False и src является ссылкой на файл, то будет создана новая символическая ссылка вместо копирования файла, на который эта символическая ссылка указывает.
shutil.copymode(src, dst, follow_symlinks=True) — копирует права доступа из src в dst. Содержимое файла, владелец, и группа не меняются.
shutil.copystat(src, dst, follow_symlinks=True) — копирует права доступа, время последнего доступа, последнего изменения, и флаги src в dst. Содержимое файла, владелец, и группа не меняются.
shutil.copy(src, dst, follow_symlinks=True) — копирует содержимое файла src в файл или папку dst. Если dst является директорией, файл будет скопирован с тем же названием, что было в src. Функция возвращает путь к местонахождению нового скопированного файла.
Если follow_symlinks=False, и src это ссылка, dst будет ссылкой.
Если follow_symlinks=True, и src это ссылка, dst будет копией файла, на который ссылается src
copy() копирует содержимое файла, и права доступа.
shutil.copy2(src, dst, follow_symlinks=True) — как copy(), но пытается копировать все метаданные.
shutil.copytree(src, dst, symlinks=False, ignore=None, copy_function=copy2, ignore_dangling_symlinks=False) — рекурсивно копирует всё дерево директорий с корнем в src, возвращает директорию назначения.
Директория dst не должна существовать. Она будет создана, вместе с пропущенными родительскими директориями.
Права и времена у директорий копируются copystat(), файлы копируются с помощью функции copy_function (по умолчанию shutil.copy2()).
Если symlinks=True, ссылки в дереве src будут ссылками в dst, и метаданные будут скопированы настолько, насколько это возможно.
Если False (по умолчанию), будут скопированы содержимое и метаданные файлов, на которые указывали ссылки.
Если symlinks=False, если файл, на который указывает ссылка, не существует, будет добавлено исключение в список ошибок, в исключении shutil.Error в конце копирования.
Можно установить флаг ignore_dangling_symlinks=True, чтобы скрыть данную ошибку.
Если ignore не None, то это должна быть функция, принимающая в качестве аргументов имя директории, в которой сейчас copytree(), и список содержимого, возвращаемый os.listdir(). Т.к. copytree() вызывается рекурсивно, ignore вызывается 1 раз для каждой поддиректории. Она должна возвращать список объектов относительно текущего имени директории (т.е. подмножество элементов во втором аргументе). Эти объекты не будут скопированы.
shutil.ignore_patterns(*patterns) — функция, которая создаёт функцию, которая может быть использована в качестве ignore для copytree(), игнорируя файлы и директории, которые соответствуют glob-style шаблонам.
Например:
copytree(source, destination, ignore=ignore_patterns('*.pyc', 'tmp*'))
# Скопирует все файлы, кроме заканчивающихся на .pyc или начинающихся с tmpshutil.rmtree(path, ignore_errors=False, onerror=None) — Удаляет текущую директорию и все поддиректории; path должен указывать на директорию, а не на символическую ссылку.
Если ignore_errors=True, то ошибки, возникающие в результате неудавшегося удаления, будут проигнорированы. Если False (по умолчанию), эти ошибки будут передаваться обработчику onerror, или, если его нет, то исключение.
На ОС, которые поддерживают функции на основе файловых дескрипторов, по умолчанию используется версия rmtree(), не уязвимая к атакам на символические ссылки.
На других платформах это не так: при подобранном времени и обстоятельствах «хакер» может, манипулируя ссылками, удалить файлы, которые недоступны ему в других обстоятельствах.
Чтобы проверить, уязвима ли система к подобным атакам, можно использовать атрибут rmtree.avoids_symlink_attacks.
Если задан onerror, это должна быть функция с 3 параметрами: function, path, excinfo.
Первый параметр, function, это функция, которая создала исключение; она зависит от платформы и интерпретатора. Второй параметр, path, это путь, передаваемый функции. Третий параметр, excinfo — это информация об исключении, возвращаемая sys..files/image029.png) exc_info(). Исключения, вызванные onerror, не обрабатываются.
exc_info(). Исключения, вызванные onerror, не обрабатываются.
shutil.move(src, dst, copy_function=copy2) — рекурсивно перемещает файл или директорию (src) в другое место (dst), и возвращает место назначения.
Если dst — существующая директория, то src перемещается внутрь директории. Если dst существует, но не директория, то оно может быть перезаписано.
shutil.disk_usage(path) — возвращает статистику использования дискового пространства как namedtuple с атрибутами total, used и free, в байтах.
shutil.chown(path, user=None, group=None) — меняет владельца и/или группу у файла или директории.
shutil.which(cmd, mode=os.F_OK | os.X_OK, path=None) — возвращает путь к исполняемому файлу по заданной команде. Если нет соответствия ни с одним файлом, то None. mode это права доступа, требующиеся от файла, по умолчанию ищет только исполняемые.
Архивация
Высокоуровневые функции для созданиия и чтения архивированных и сжатых файлов.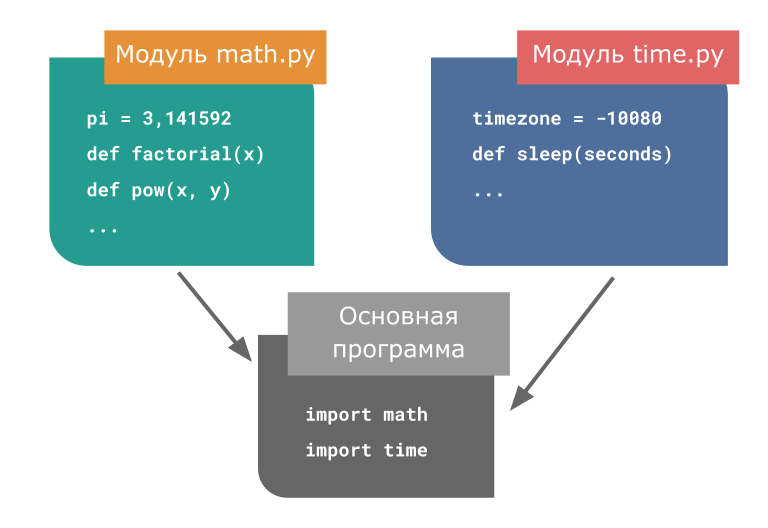 Основаны на функциях из модулей zipfile и tarfile.
Основаны на функциях из модулей zipfile и tarfile.
shutil.make_archive(base_name, format[, root_dir[, base_dir[, verbose[, dry_run[, owner[, group[, logger]]]]]]]) — создаёт архив и возвращает его имя.
base_name это имя файла для создания, включая путь, но не включая расширения (не нужно писать «.zip» и т.д.).
format — формат архива.
root_dir — директория (относительно текущей), которую мы архивируем.
base_dir — директория, в которую будет архивироваться (т.е. все файлы в архиве будут в данной папке).
Если dry_run=True, архив не будет создан, но операции, которые должны были быть выполнены, запишутся в logger.
owner и group используются при создании tar-архива.
shutil.get_archive_formats() — список доступных форматов для архивирования.
>>> shutil.get_archive_formats()
[('bztar', "bzip2'ed tar-file"),
('gztar', "gzip'ed tar-file"),
('tar', 'uncompressed tar file'),
('xztar', "xz'ed tar-file"),
('zip', 'ZIP file')]shutil.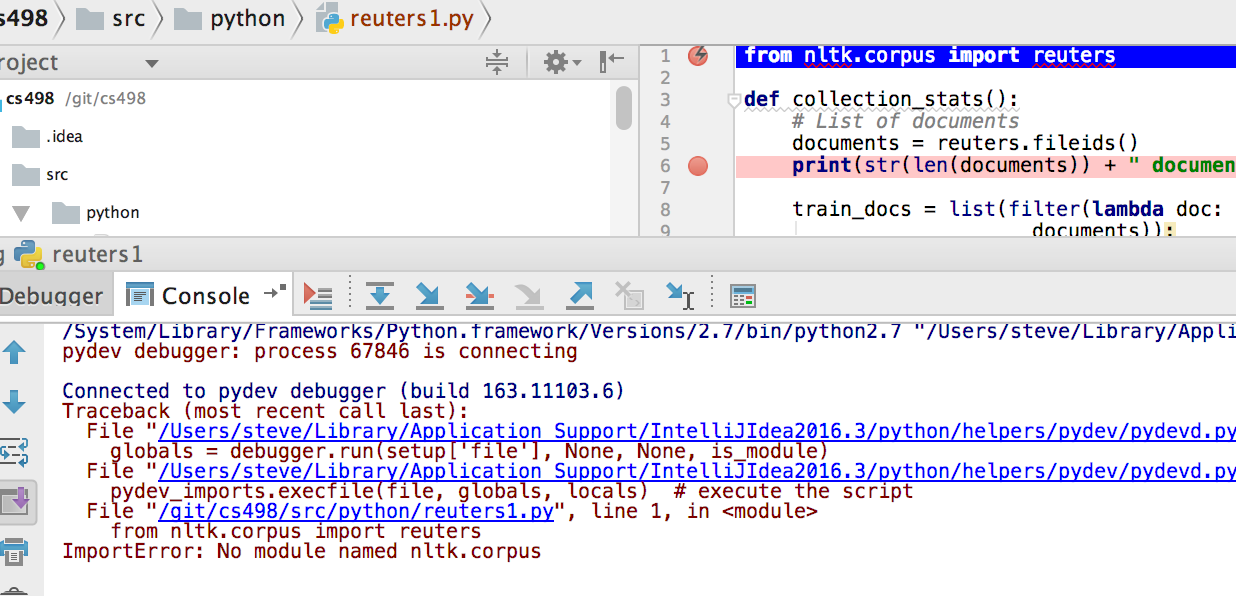 unpack_archive(filename[, extract_dir[, format]]) — распаковывает архив. filename — полный путь к архиву.
unpack_archive(filename[, extract_dir[, format]]) — распаковывает архив. filename — полный путь к архиву.
extract_dir — то, куда будет извлекаться содержимое (по умолчанию в текущую).
format — формат архива (по умолчанию пытается угадать по расширению файла).
shutil.get_unpack_formats() — список доступных форматов для разархивирования.
Запрос размера терминала вывода
shutil.get_terminal_size(fallback=(columns, lines)) — возвращает размер окна терминала.
fallback вернётся, если не удалось узнать размер терминала (терминал не поддерживает такие запросы, или программа работает без терминала). По умолчанию (80, 24).
>>> shutil.get_terminal_size() os.terminal_size(columns=102, lines=29) >>> shutil.get_terminal_size() # Уменьшили окно os.terminal_size(columns=67, lines=17)
Для вставки кода на Python в комментарий заключайте его в теги <pre><code>Ваш код</code></pre>
Даты Python
❮ Предыдущая Далее ❯
Даты Python
Дата в Python не является собственным типом данных, но мы можем импортировать модуль
named datetime для работы с датами как с датами
объекты.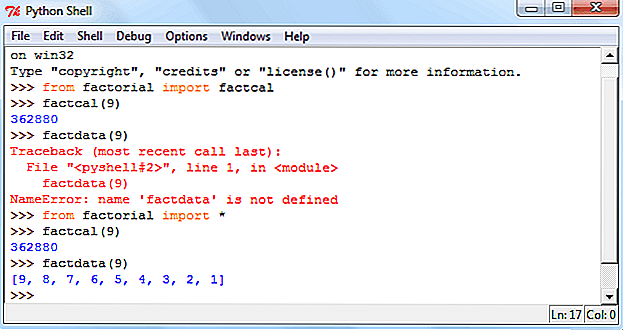
Пример
Импорт модуля datetime и отображение текущей даты:
import datetime
x = datetime.datetime.now()
print(x)
Попробуйте сами »
Вывод даты
Когда мы выполним код из приведенного выше примера, результатом будет:
Дата содержит год, месяц, день, час, минуту, секунду и микросекунду.
Модуль datetime имеет множество методов для возврата информации о дате
объект.
Вот несколько примеров, вы узнаете о них позже в этом глава:
Пример
Вернуть год и название дня недели:
import datetime
x = datetime.datetime.now()
print(x.year)
print(x.strftime(«%A»))
Попробуйте сами »
Создание объектов даты
Чтобы создать дату, мы можем использовать класс datetime() (конструктор) класса модуль даты и времени .
Класс datetime() требует три параметра для создания даты: год,
день месяца.
Пример
Создать объект даты:
import datetime
x = datetime.datetime(2020, 5, 17)
print(x)
Попробуйте сами »
datetime() 9Класс 0009 также принимает параметры для времени и часового пояса (час,
минута, секунда, микросекунда, tzone), но они являются необязательными и имеют значение по умолчанию.
значение 0 , ( Нет для часового пояса).
Метод strftime()
Объект datetime имеет метод для форматирования объектов даты в читаемые строки.
Метод называется strftime() и принимает один параметр, формат , чтобы указать формат возвращаемой строки:
Пример
Показать название месяца:
import datetime
x = datetime. datetime(2018, 6, 1)
datetime(2018, 6, 1)
print(x.strftime("%B"))
Попробуйте сами »
Ссылка на все коды юридических форматов:
| Директива | Описание | Пример | Попробуй |
|---|---|---|---|
| %а | Будний день, короткая версия | Ср | Попробуй » |
| %А | Будний день, полная версия | Среда | Попробуй » |
| % вес | День недели в виде числа 0-6, 0 — воскресенье | 3 | Попробуй » |
| %д | День месяца 01-31 | 31 | Попробуй » |
| %b | Название месяца, короткая версия | декабрь | Попробуй » |
| %В | Название месяца, полная версия | декабря | Попробуй » |
| %м | Месяц в виде числа 01-12 | 12 | Попробуй » |
| %г | Год, короткая версия, без века | 18 | Попробуй » |
| %Y | Год, полная версия | 2018 | Попробуй » |
| %Н | Час 00-23 | 17 | Попробуй » |
| %I | Час 00-12 | 05 | Попробуй » |
| %р | утра/вечера | PM | Попробуй » |
| %М | Минута 00-59 | 41 | Попробуй » |
| %S | Второй 00-59 | 08 | Попробуй » |
| %f | Микросекунда 000000-999999 | 548513 | Попробуй » |
| %z | Смещение UTC | +0100 | |
| %Z | Часовой пояс | КСТ | |
| %j | Номер дня года 001-366 | 365 | Попробуй » |
| %U | Номер недели в году, воскресенье как первый день недели, 00-53 | 52 | Попробуй » |
| %W | Номер недели в году, понедельник как первый день недели, 00-53 | 52 | Попробуй » |
| %с | Локальная версия даты и времени | Пн Дек 31 17:41:00 2018 | Попробуй » |
| %С | Век | 20 | Попробуй » |
| %х | Локальная версия даты | 31. 12.18 12.18 | Попробуй » |
| %Х | Локальная версия времени | 17:41:00 | Попробуй » |
| %% | Символ % | % | Попробуй » |
| %G | ИСО 8601 год | 2018 | Попробуй » |
| %u | ISO 8601 рабочий день (1-7) | 1 | Попробуй » |
| %В | Номер недели ISO 8601 (01-53) | 01 | Попробуй » |
❮ Предыдущий Следующий ❯
ВЫБОР ЦВЕТА
Лучшие учебники
Учебник по HTMLУчебник по CSS
Учебник по JavaScript
Учебник How To
Учебник по SQL
Учебник по Python
Учебник по W3.CSS
Учебник по Bootstrap
Учебник по PHP
Учебник по Java
Учебник по C++
Учебник по jQuery
900 Справочник
900
Справочник по HTML
Справочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3. CSS
CSS
Справочник по Bootstrap
Справочник по PHP
Цвета HTML
Справочник по Java
Справочник по Angular
Справочник по jQuery
Основные примеры
Примеры HTMLПримеры CSS
Примеры JavaScript
Примеры инструкций
Примеры SQL
Примеры Python
Примеры W3.CSS
Примеры Bootstrap
Примеры PHP
Примеры Java
Примеры XML
Примеры jQuery
FORUM | О
W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения. Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания. Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования, куки-файлы и политика конфиденциальности.
Copyright 1999-2023 Refsnes Data. Все права защищены.
W3Schools работает на основе W3.CSS.
Модули Python — javatpoint
следующий → ← предыдущая В этом руководстве объясняется, как создавать и импортировать пользовательские модули Python. Что такое модульное программирование?Модульное программирование — это практика разделения одной сложной задачи кодирования на несколько более простых и простых в управлении подзадач. Мы называем эти подзадачи модулями. Следовательно, мы можем построить большую программу, собрав различные модули, которые действуют как строительные блоки. Модульность нашего кода в большом приложении имеет много преимуществ. Упрощение: Модуль часто концентрируется на одной сравнительно небольшой области общей проблемы, а не на всей задаче. Если мы сконцентрируемся только на одном модуле, у нас будет более решаемая проблема проектирования. Разработка программы стала проще и менее подвержена ошибкам. Гибкость: Модули часто используются для установления концептуального разделения между различными проблемными областями. Маловероятно, что изменения в одном модуле повлияют на другие части программы, если модули сконструированы таким образом, чтобы уменьшить взаимосвязь. Повторное использование: Функции, созданные в конкретном модуле, могут быть легко доступны из различных разделов задания (через соответствующим образом установленный API). В результате дублирующийся код больше не нужен. Область действия: Модули часто объявляют отдельное пространство имен, чтобы предотвратить конфликты идентификаторов в различных частях программы. В Python модульность кода поощряется за счет использования функций, модулей и пакетов. Что такое модули в Python?Документ с определениями функций и различными операторами, написанными на Python, называется модулем Python. В Python мы можем определить модуль одним из 3 способов:
Модуль — это файл, содержащий код Python, определения функций, операторов или классов. Файл example_module.py — это модуль, который мы создадим, и имя которого — example_module. Мы используем модули для разделения сложных программ на более мелкие и понятные части. Модули также позволяют повторно использовать код. Вместо того, чтобы дублировать их определения в нескольких приложениях, мы можем определить наиболее часто используемые функции в отдельном модуле, а затем импортировать модуль целиком. Давайте построим модуль. Сохраните файл как example_module.py после ввода следующего. Код# Программа Python, показывающая, как создать модуль. # определение функции в модуле для ее повторного использования квадрат защиты (число): """Эта функция возведет в квадрат переданное ей число""" результат = число ** 2 вернуть результат Здесь модуль с именем example_module содержит определение функции square(). Как импортировать модули в Python?В Python мы можем импортировать функции из одного модуля в нашу программу или, как мы говорим, в другой модуль. Для этого мы используем ключевое слово import Python. В окне Python мы добавляем ключевое слово next to import, имя модуля, который нам нужно импортировать. Мы импортируем модуль, который мы определили ранее, example_module. Код импортировать example_module Функции, которые мы определили в модуле example_module, не сразу импортируются в текущую программу. Здесь импортируется только имя модуля, т. е. пример_модуля. Мы можем использовать оператор точки для использования функций, использующих имя модуля. Например: Код результат = example_module.square( 4 ) print("Используя квадрат модуля числа: ", результат) Вывод: При использовании модуля квадрат числа: 16 Существует несколько стандартных модулей для Python. Подобно тому, как мы импортировали наш модуль, определяемый пользователем модуль, мы можем использовать оператор импорта для импорта других стандартных модулей. Импорт модуля можно выполнить различными способами. Ниже приведен их список. Заявление об импорте PythonИспользуя ключевое слово import Python и оператор точки, мы можем импортировать стандартный модуль и получить доступ к определенным в нем функциям. Вот иллюстрация. Код # Программа Python, показывающая, как импортировать стандартный модуль # Мы импортируем математический модуль, который является стандартным модулем импортировать математику print("Значение числа Эйлера равно", math.e ) Вывод: Значение числа Эйлера равно 2,718281828459045. Импорт, а также переименование При импорте модуля мы также можем изменить его имя. Код # Программа Python, показывающая, как импортировать модуль и переименовывать его # Мы импортируем математический модуль и дадим ему другое имя импортировать математику как mt print("Значение числа Эйлера равно", mt.e ) Вывод: Значение числа Эйлера равно 2,718281828459045. Математический модуль в этой программе теперь называется mt. В некоторых случаях это может помочь нам печатать быстрее, если модули имеют длинные имена. Обратите внимание, что теперь в нашу программу не входит термин математика. Таким образом, mt.pi — это правильная реализация модуля, а math.pi — недопустимая. Python из... заявления об импортеМы можем импортировать определенные имена из модуля, не импортируя модуль в целом. Вот пример. Код # Программа Python, показывающая, как импортировать определенные объекты из модуля # Мы будем импортировать число Эйлера из математического модуля, используя ключевое слово from из математического импорта e print("Значение числа Эйлера равно", e) Вывод: Значение числа Эйлера равно 2,718281828459045. В этом случае была импортирована только константа e из математического модуля. Мы избегаем использования оператора точки (.) в этих сценариях. Таким образом, мы можем импортировать множество атрибутов одновременно: Код # Программа Python, показывающая, как импортировать несколько объектов из модуля из математики импортировать е, тау print("Значение константы тау: ", тау) print("Значение числа Эйлера: ", e) Вывод: Значение константы тау: 6,283185307179586 Значение числа Эйлера: 2,718281828459045. Импорт всех имен — из импорта * ЗаявлениеЧтобы импортировать все объекты из модуля в пределах существующего пространства имен, используйте символ * и ключевое слово from и import. Синтаксис: из импорта name_of_module * Использование символа * имеет свои преимущества и недостатки. Не рекомендуется использовать *, если мы не уверены в наших конкретных требованиях от модуля; в противном случае сделайте это. Вот такой же пример. Код # импорт полного математического модуля с помощью * из математического импорта * # доступ к функциям математического модуля без использования оператора точки print("Вычисление квадратного корня: ", sqrt(25)) print("Вычисление тангенса угла: ", tan(pi/6)) # здесь число пи также импортируется из математического модуля Вывод: Вычисление квадратного корня: 5,0 Вычисление тангенса угла: 0,5773502691896257 Поиск путей модулейИнтерпретатор выполняет поиск во множестве мест при импорте модуля в программу Python. Поиск осуществляется в нескольких каталогах, если встроенный модуль отсутствует. Доступ к списку каталогов можно получить с помощью sys.path. Интерпретатор Python ищет модуль следующим образом: Первоначально модуль ищется в текущем рабочем каталоге. Затем Python исследует каждый каталог в параметре оболочки PYTHONPATH, если модуль не может быть расположен в текущем каталоге. Вот пример печати пути. Код # Мы будем импортировать модуль sys импорт системы # мы будем импортировать sys.path печать (системный путь) Вывод: ['/home/pyodide', '/home/pyodide/lib/Python310.zip', '/lib/Python3.10', '/lib/Python3.10/lib-dynload', '', '/lib /Python3.10/сайт-пакеты'] Встроенная функция dir()Мы можем использовать метод dir() для идентификации имен, объявленных в модуле. Например, у нас есть следующие имена в стандартном модуле str. Чтобы напечатать имена, мы будем использовать метод dir() следующим образом: Код # Программа Python для печати каталога модуля print("Список функций:\n", dir(str), end=", ") Вывод: Список функций: ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', ' __gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__' , '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', ' encode', 'endswith', 'expandtabs', 'найти', 'формат', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier' , 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', ' removeprefix», «removesuffix», «заменить», «rfind», «rindex», «rjust», «rpartition», «rsplit», «rstrip», «split», «splitlines», «startwith», «strip» , 'swapcase', 'title', 'перевод', 'верхний', 'zfill'] Пространства имен и область видимости Объекты представлены именами или идентификаторами, называемыми переменными. Оператор Python может получить доступ как к локальным, так и к глобальным переменным пространства имен. Когда две переменные с одинаковыми именами являются локальными и глобальными, локальная переменная берет на себя роль глобальной переменной. Для каждой функции существует отдельное локальное пространство имен. Правило области видимости для методов класса такое же, как и для обычных функций. Python определяет, являются ли параметры локальными или глобальными, на основе разумных прогнозов. Любая переменная, которой присвоено значение в методе, считается локальной. Поэтому мы должны использовать глобальную инструкцию, прежде чем мы сможем предоставить значение глобальной переменной внутри функции. Python получает информацию о том, что Var_Name является глобальной переменной, с помощью строки global Var_Name. Python перестает искать переменную внутри локального пространства имен. Оставить комментарий
|
 Кроме того, мы можем импортировать или интегрировать встроенные модули Python различными способами.
Кроме того, мы можем импортировать или интегрировать встроенные модули Python различными способами. (Мы можем даже быть в состоянии редактировать модуль, несмотря на то, что знакомы с программой за его пределами.) Это увеличивает вероятность того, что группа многочисленных разработчиков сможет сотрудничать в большом проекте.
(Мы можем даже быть в состоянии редактировать модуль, несмотря на то, что знакомы с программой за его пределами.) Это увеличивает вероятность того, что группа многочисленных разработчиков сможет сотрудничать в большом проекте.
 Функция возвращает квадрат заданного числа.
Функция возвращает квадрат заданного числа. Доступен полный список стандартных модулей Python. Список можно увидеть с помощью команды help.
Доступен полный список стандартных модулей Python. Список можно увидеть с помощью команды help. Вот пример, чтобы показать.
Вот пример, чтобы показать.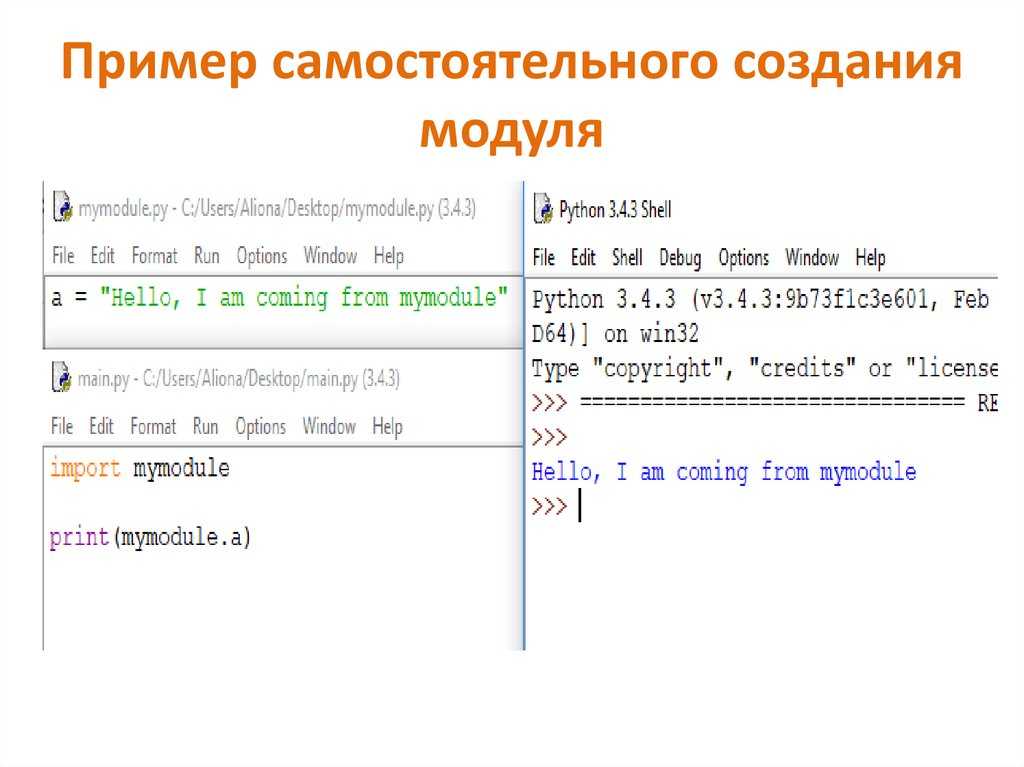
 Список папок составляет переменную среды, известную как PYTHONPATH. Python проверяет зависящий от установки набор папок, настроенных при загрузке Python, если это также не удается.
Список папок составляет переменную среды, известную как PYTHONPATH. Python проверяет зависящий от установки набор папок, настроенных при загрузке Python, если это также не удается. Пространство имен — это словарь, содержащий имена переменных (ключей) и связанных с ними объектов (значения).
Пространство имен — это словарь, содержащий имена переменных (ключей) и связанных с ними объектов (значения).