OBDPROG 501 Auto Key Ключевой Программист OBD2 Автомобильный Сканер IMMO PIN Code Reader Многоязычное Программирование Автомобиля Диагностический Инструмент От 138 697 руб.
OBDPROG 501 Auto Key Программист OBD2 Автомобильный сканер IMMO PIN Code Reader Многоязычная ключ программирования автомобиля диагностический инструмент
Краткое введение M501
OBDPROG кодификация монстр 501 программист автомобиль авто ключа новая на основе Android 5inch таблетка, специализированная для программирования ключей, Стирание ключей, иммобилайзер пин-кода Чтения, EEPROM чип функции чтения. Он наследует последнюю программу ключа автоматического добавления, все ключ потерял технологию программы от компании OBDPROG с различными преимуществами простой в использовании, во всем мире новейшего охвата модели транспортного средства, быстрой работу и долговечных особенностями, которые могут удовлетворить реальные потребности различных пользователей узнать, такие как личный владелец автомобиля, автомобильные слесарные мастерские и быстрый ремонт гараж
OBDPROG кодификация монстр 501 Ключевые Мастер Основные характеристики:
1. Цикл обновления короткий и быстрый (обновляется каждые 15-30 дней) 2. Бесплатное обновление Интернет в течение одного года (через год он будет стоить $ 300 за year.?Dealer кодекса: 860755B1) 3. Сильные модели advantage4.?Some конкурентоспособности и промышленности могут поддерживать 18/19 лет автомобиля (например, для GM / Mazda / Рено) 5.World Широкого Охват корабля и One-Click Upgrade Online6.Add новой функции справки, как показано ниже: (Применимо для некоторых моделей, информация RD в настоящее время обновление)
Цикл обновления короткий и быстрый (обновляется каждые 15-30 дней) 2. Бесплатное обновление Интернет в течение одного года (через год он будет стоить $ 300 за year.?Dealer кодекса: 860755B1) 3. Сильные модели advantage4.?Some конкурентоспособности и промышленности могут поддерживать 18/19 лет автомобиля (например, для GM / Mazda / Рено) 5.World Широкого Охват корабля и One-Click Upgrade Online6.Add новой функции справки, как показано ниже: (Применимо для некоторых моделей, информация RD в настоящее время обновление)
OBDSTAR кодификация монстр 501Key Master Функция:
Программирование KeysErase KeysProgramming RemoteRead Key NumbersPincode ReadingEEPROM Чип ReadOBDII / EOBD Диагностика
OBDPROG кодификация монстр 501 ключ программист Поддержка автомобилей Список моделей:
Европа: forBMW, forBenz, forBorgward, forPeugeot, forCitroen, броды, forDacia, forFiat, forJaguar, forLancia, FORLAND Rover, forOpel, forPorsche, forRenault, forSmart, forVolvo, forIveco, forVW / forAudi / forSkoda / forSeatJapan: forHonda, forISUZU, forMazda , forMitsubishi, forNissan, forSubaru, forSuzuki, forToyota, forLexusKorea: forHyundai, forKIA, forSsangyongAmerica: для FORD / для LINCOLN, для CHRYSLER, для GM, для Шевроле, для Cadillac, для джипа, для DodgeChina: forBaic, forBesturn, forBisu, forBrilliance , forBYD, forChangan, forChanghe, forChery, forCowin, forDFFengshen, forDFFG, forDfliuzhou, Efornranger, forFoton, forGeely, forGreatwall, forHafei, forHanteng, forHawtai, forHimikoforHongqi, forHuanghai, forJAC, forJiabao, forJMC, forLifan, forLufeng, forLuxgen, forMaxus, forQnlotus , forQoros, forRoewe, forSgmw, forSWN, forSOUTHEAST, forTJFAW, forTraum, forTrumpchi, forXenia, forYema, forZD, forZhongxing, forZotye для ChangfengNote: поддержка 1. Not люксовые бренды ключевые function2.Even программирования, хотя он совместим с большинством автомобилей, но разные поддержка регионов й е список транспортных средств в разное время, или какая-то машина особый дизайн, поэтому он не может совместим с некоторым автомобилем, пожалуйста, оставьте нам сообщение ниже формата, мы ответим Вам в течение 8 часов. например: для Audi A4 2005, 2.0cc дизель
Not люксовые бренды ключевые function2.Even программирования, хотя он совместим с большинством автомобилей, но разные поддержка регионов й е список транспортных средств в разное время, или какая-то машина особый дизайн, поэтому он не может совместим с некоторым автомобилем, пожалуйста, оставьте нам сообщение ниже формата, мы ответим Вам в течение 8 часов. например: для Audi A4 2005, 2.0cc дизель
OBDPROG кодификация Монстр 501 Key Master Пакет включает в себя:
1шт х OBDPROG кодификация монстр 501 Main Unit1pc х? Charger1pack х Многофункциональный Jumper и adapters1pc х Конфигурация List1pc х? Упаковочная коробка
Веб-разработка и программирование в категории «Подарки, хобби, книги» в Покровске
Разработка веб-приложений с помощью PHP и MySQL. 4 изд
Заканчивается
Доставка по Украине
900 грн
Купить
Книжкова Лавка
React и Redux: функциональная веб-разработка, Алекс Бэнкс, Ева Порселло
На складе в г. Львов
Львов
Доставка по Украине
390 грн
Купить
Купи-книгу
Львов
React и Redux. Функциональная веб-разработка, Алекс Бэнкс, Ева Порселло
На складе
Доставка по Украине
550 грн
Купить
Книга Разработка веб-приложений с использованием Flask на языке Python. Автор — Мигель Гринберг (ДМК)
Заканчивается
Доставка по Украине
460 грн
Купить
СТРОДО
Веб-разработка с применением Node и Express. Полноценное использование стека JavaScript. 2-е издание. И. Браун
Доставка из г. Харьков
530 грн
Купить
Интернет-магазин «Книжный дом»
Харьков
Изучаем Python: программирование игр, визуализация данных, веб-приложения. 3-е изд. Мэтиз Э.
Доставка из г. Харьков
520 грн
Купить
Интернет-магазин «Книжный дом»
Харьков
Выразительный JavaScript. Современное веб-программирование. 3-е издание. Марейн Хавербеке.
Современное веб-программирование. 3-е издание. Марейн Хавербеке.
Доставка по Украине
530 грн
Купить
Интернет-магазин «Книжный дом»
HTML5 и CSS3. Веб-разработка по стандартам нового поколения. 2-е изд., Хоган Б.
Доставка из г. Львов
415 грн
Купить
Купи-книгу
Львов
Веб-разработка с применением Node и Express. Полноценное использование стека JavaScript, Браун И.
Доставка по Украине
439 грн
Купить
Купи-книгу
Разработка веб-приложений GraphQL с React, Node.js и Neo4j, Уильям Леон
Доставка по Украине
950 грн
Купить
Купи-книгу
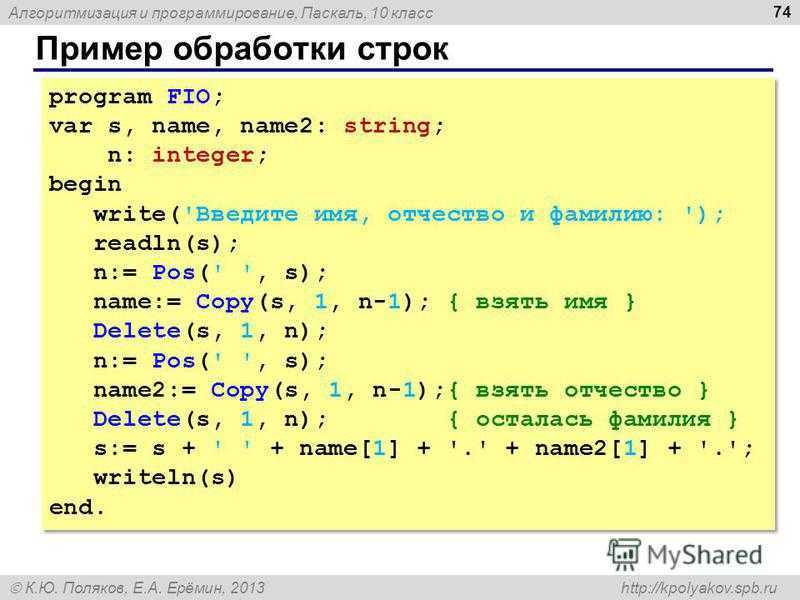
Разработка современных веб-приложений. Анализ предметных областей и технологий (978-5-9908910-3-6)
На складе в г. Киев
Доставка по Украине
761 грн
Купить
Интернет — магазин «BookSide.COM.UA»
Киев
PHP и MySQL. Разработка веб-приложений.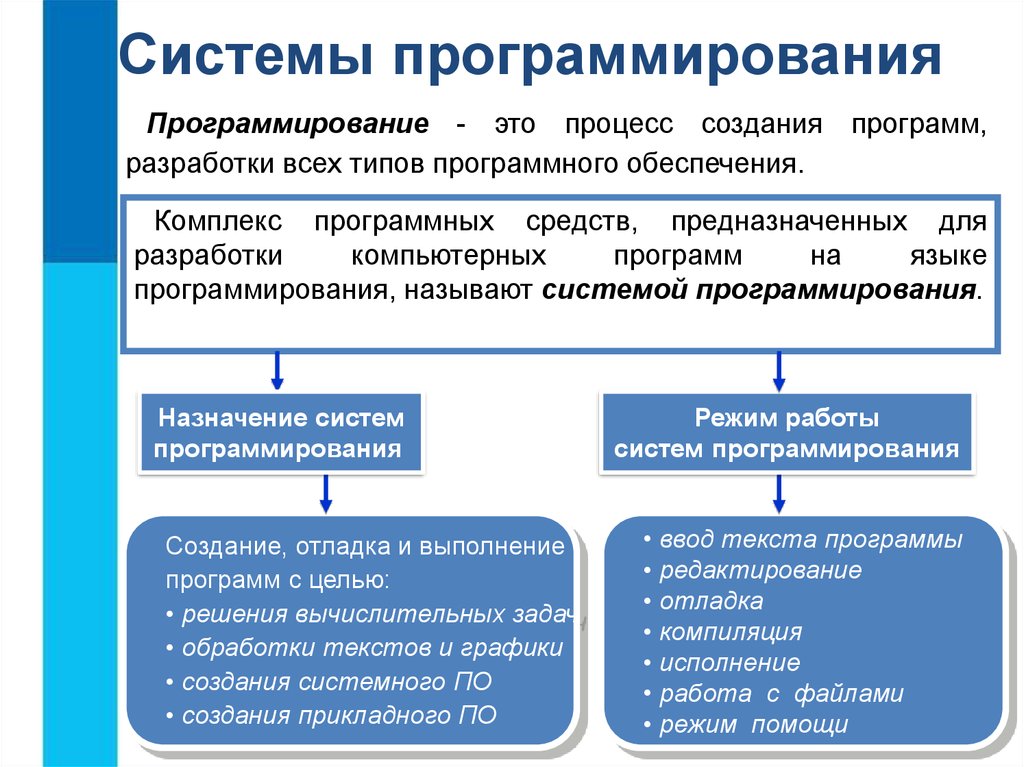 6-е изд.
6-е изд.
Под заказ
Доставка по Украине
660 — 705 грн
от 4 продавцов
660 грн
Купить
HTML5 и CSS3. Веб-разработка по стандартам нового поколения
Доставка по Украине
345 — 370 грн
от 4 продавцов
345 грн
Купить
React и Redux. Функциональная веб-разработка
Под заказ
Доставка по Украине
420 — 445 грн
от 4 продавцов
420 грн
Купить
Разработка современных веб-приложений: анализ предметных областей и технологий
Доставка по Украине
750 грн
Купить
Хитун-Бовтун — книги та вініл
Смотрите также
Разработка веб-приложений с помощью Node.js, MongoDB и Angular: исчерпывающее руководство по использованию
Доставка по Украине
1 250 грн
Купить
Хитун-Бовтун — книги та вініл
AJAX и PHP. Разработка динамических веб-приложений, Кристиан Дари, Богдан Бринзаре, Михай Бусика, Филип
Доставка по Украине
673 грн
Купить
HTML5 и CSS3. Веб-разработка по стандартам нового поколения, Брайан П. Хоган
Веб-разработка по стандартам нового поколения, Брайан П. Хоган
Доставка из г. Львов
494 грн
Купить
Разработка веб-сайта. Взаимодействие с заказчиком, дизайнером и программистом, Дэниэл М. Браун
Доставка по Украине
494 грн
Купить
Веб-разработка с применением Node и Express. Полноценное использование стека JavaScript. 2-е издание, Браун
Доставка по Украине
550 грн
Купить
Экспертные системы: принципы разработки и программирование, 4-е издание
Доставка по Украине
650 грн
Купить
Хитун-Бовтун — книги та вініл
Книга «Javascript и jQuery. Интерактивная веб-разработка.» — Джон Дакетт
Доставка по Украине
по 1 250 грн
от 2 продавцов
1 250 грн
Купить
Bambook
C# 9 и .NET 5. Разработка и оптимизация. (+ Приложение) Прайс М.
Доставка из г. Харьков
950 грн
Купить
Интернет-магазин «Книжный дом»
Харьков
Паттерны разработки на Python: TDD, DDD и событийно-ориентированная архитектура. Персиваль Г., Грегори Б.
Персиваль Г., Грегори Б.
Доставка из г. Харьков
680 грн
Купить
Интернет-магазин «Книжный дом»
Харьков
Изучаем Python. 3-е издание. Программирование игр, визуализация данных, веб-приложения. Э. Мэтиз
Доставка из г. Житомир
495 грн
Купить
BOOKZT
Житомир
Выразительный JavaScript. Современное веб-программирование. 3-е издание. М. Хавербеке (твердая)
Доставка из г. Житомир
495 грн
Купить
BOOKZT
Житомир
AJAX и PHP. Разработка динамических веб-приложений
Доставка по Украине
610 грн
Купить
Диоген
Веб-разработка с применением Node и Express. Полноценное использование стека JavaScript — Итан Браун
Доставка по Украине
550 грн
Купить
«ТАКнuга» интернет-магазин
HTML5 и CSS3. Веб-разработка по стандартам нового поколения
Под заказ
Доставка по Украине
440 грн
Купить
Книжный Дом Instagram @domknig. prom.ua
prom.ua
Чем больше, тем лучше — зачем становиться мультиязычным программистом
Иногда изучение первого языка программирования может превратиться в тяжелое мучение, поэтому у вас не возникнет желания заняться изучением второго или третьего языка. Однако остановка на одной технологии может повлиять на карьерный рост и потенциальные выгоды. Кроме того, технологии быстро меняют мир, и вы не можете позволить себе остаться в стороне в этот динамичный век. Итак, изучение второго, третьего или даже четвертого языка программирования или хотя бы базовое его понимание означает инвестиции в свое будущее и открытие для вас новых карьерных возможностей, например, получение работы в крупной технологической компании.
Я рассмотрел все возможные преимущества владения несколькими языками программирования и собрал наиболее важные из них. Вы также узнаете, что об этом думают опытные кодеры. В конце я предложу лучшие языки для изучения и ресурсы, которые будут очень полезны для вас.
Почему важно изучать несколько языков программирования?
Если у вас уже есть опыт программирования, вам будет интересно узнать, почему владение несколькими технологиями имеет значение и как оно влияет на ваши возможности трудоустройства.
Дополнительные знания. Конечная цель разработчика — определить проблему и решить, какой стек технологий использовать для ее решения. Поскольку вы знаете несколько языков, вы можете служить уникальным целям. Когда у вас есть более одного языка программирования и вы различаете такие факторы, как эффективность, производительность и удобство использования, вы можете просто выбрать наиболее подходящий вариант для решения конкретной проблемы.
Больше возможностей. Теперь для разработчика обычное дело знать пул технологий и несколько языков для разных целей даже в рамках одного проекта. Хорошее знание нескольких языков программирования сегодня оказывает большое влияние на вашу карьеру. Это делает вас конкурентоспособными и расширяет круг вакансий, на которые вы можете претендовать.
Следовательно, вы больше не ограничены в выборе карьеры и, следовательно, можете получить любую предпочитаемую роль.
Больше денег. Ваш потенциальный доход пропорционален количеству языков, которые вы освоили. Есть компании, которые ищут универсала с глубокими знаниями алгоритмов, структур данных, масштабируемых систем и хорошим владением одним или несколькими языками. Эти компании обычно платят больше, имеют более интересные проекты, имеют варианты спонсорства визы и т. д. Лучшим примером здесь являются так называемые компании «FAANG», сленговая аббревиатура от Facebook, Apple, Amazon, Netflix, Google. Я бы еще добавил к этому Microsoft, а их на самом деле намного больше. Это трудный карьерный путь, но попробовать стоит.
Больше удовольствия. В однообразии и повторении нет ничего интересного. Прохождение одних и тех же вещей в течение многих лет заставляет людей скучать, и это нормально. Кодеры не исключение. Именно здесь наличие нескольких языков программирования в вашем распоряжении может принести вам больше интересных проектов, держать вас в курсе и позволить вам мыслить нестандартно, что крайне важно для профессионалов.

Что говорят об этом опытные программисты?
Я спросил своих коллег и посетил множество популярных дискуссионных форумов, включая Quora, чтобы узнать, что другие профессионалы с многолетним опытом программирования думают об изучении нескольких языков. Большинство согласны с тем, что оптимально владеть тремя разными технологиями. Принимая во внимание, что все как один утверждали, что вы не должны прекращать изучение новых языков программирования только ради внешней привлекательности.
Какие языки хороши для начала?
Принимая во внимание упомянутые преимущества, становится ясно, что изучение нескольких языков программирования — это то, к чему нужно стремиться. Однако здесь можно застрять в раздумьях, какую технологию выбрать дальше и какой ресурс идеально подходит для обучения. Далее идет список самых востребованных языков и платформ для их изучения.
Джава
Когда люди спрашивают меня, с чего начать свое путешествие в программирование, я обычно первым делом рекомендую Java. Это довольно простой в освоении язык, который часто используется для ознакомления с концепциями ООП.
Это довольно простой в освоении язык, который часто используется для ознакомления с концепциями ООП.
Java также известна своей философией «Напиши один раз, работай где угодно», которая делает ее стандартом для различных приложений, используемых на любой платформе. Варианты использования Java практически безграничны — на нем работают огромные серверные приложения корпоративного уровня, финансовые, банковские, торговые веб-приложения, мобильные приложения, большие данные и т. д.
Java имеет обширное и поддерживающее сообщество разработчиков, которые активно участвуют в различных форумах, делятся своим опытом и помогают новичкам решать их проблемы. Получение помощи, а также наставничества и действенных отзывов о вашем коде от сообщества — это то, что вам крайне необходимо, особенно на начальном этапе вашего обучения.
Где изучать Java
1. CodeGym.cc
CodeGym популярен благодаря практическому подходу к изучению Java. Вы напишете свою первую строчку кода практически сразу после регистрации на платформе. Вы получите доступ к 1200 практическим задачам возрастающей сложности, которые перенесут вас от основ Java к более сложным темам, таким как классы и коллекции. Когда некоторые из моих учеников впервые попробовали курс, они обнаружили, что обучение настолько увлекательное, что даже не думали сдаваться.
Вы получите доступ к 1200 практическим задачам возрастающей сложности, которые перенесут вас от основ Java к более сложным темам, таким как классы и коллекции. Когда некоторые из моих учеников впервые попробовали курс, они обнаружили, что обучение настолько увлекательное, что даже не думали сдаваться.
2. Основы Java от Pluralsight
Pluralsight предлагает онлайн-курс, который обеспечивает полный охват языка программирования Java и обеспечивает прочную основу для начала разработки приложений Java.
3. Кодакадемия
Codecademy — это интерактивный ресурс, предназначенный для обучения вас основам Java. Из курса вы изучите основные концепции программирования с использованием Java и в конечном итоге получите семь Java-проектов.
питон
Python используется для разработки программного обеспечения уже почти тридцать лет и стал популярным среди многих специалистов, стремящихся писать понятный, логичный код для различных проектов.
Python повсюду и установлен на многих машинах. Этот язык хорош для написания сценариев, поэтому его используют многие DevOps. Помимо серверной части веб-сайта, сценариев, веб-приложений, научного программирования и многих программных продуктов, включая Abaqus, FreeCAD, Lightware, modo, он успешно используется для решения небольших задач, «склейки» больших частей проекта или любых других целей DevOps. . Он также стал предпочтительным языком в новых технологиях, включая научные вычисления, искусственный интеллект, машинное обучение, информационную безопасность и многое другое. Помимо этого, расширенный список библиотек Python и готовых решений позволяет очень быстро реализовать то, что вам нужно.
Где изучать Python
1.
 Изучайте Python
Изучайте PythonLearn Python предоставляет бесплатное интерактивное руководство по Python для всех, независимо от предыдущего опыта. Платформа охватывает различные темы, от основ Python до науки о данных и других передовых концепций, что делает ее универсальным ресурсом для учащихся. Вы также можете присоединиться к дискуссионным группам и посмотреть видео опытных инструкторов.
2. Изучайте Python трудным путем
Зед Шоу написал эту книгу, чтобы помочь вам легко освоиться в программировании. Он проинструктирует вас о Python и поможет установить мастерство посредством практики и запоминания. Выполнив все 52 упражнения, вы приобретете навыки, необходимые для изучения более сложных тем программирования.
- GitConnected
На GitConnected вы узнаете, как изучать такие языки программирования, как Python. Сайт предлагает множество бесплатных курсов от начального до продвинутого уровня, представленных опытными программистами. Контент оценивается программистами, которые уже использовали его, что позволяет другим учащимся выбрать лучший курс.
Контент оценивается программистами, которые уже использовали его, что позволяет другим учащимся выбрать лучший курс.
С
C# — мультипарадигмальный язык программирования, разработанный в 2000 году компанией Microsoft. Сегодня он активно используется при создании программ для сред Windows и веб-приложений в сочетании с .NET framework. Поскольку синтаксис C# аналогичен синтаксису C, C++ и Java, предыдущий опыт работы с любой из упомянутых технологий будет плюсом для программиста, планирующего освоить C#.
Поскольку C# поддерживается Microsoft Visual C++, он подходит для приложений, работающих на iOS, Android и Windows. Кроме того, C Sharp вместе с игровым движком Unity используется для создания видеоигр. Теперь в Unity C# является основным вариантом.
Где учиться С
1. Основы C# от Tree House
На Treehouse вы изучите основы C#, включая синтаксис, типы, строки, числа и операторы if. По окончании курса вы обретете уверенность в программировании на C# и сможете двигаться дальше.
2. Основы C# для начинающих: изучите основы C# с помощью кодирования
Этот курс Моша Хамедани на Udemy — идеальное решение для полных новичков без предыдущего опыта или тех, кто планирует освежить свои знания в C#. Это заставит вас изучать C# с нуля. Сразу после освоения основ вы перейдете к операторам и выражениям, массивам и спискам, алгоритмам и ООП. Эта учебная программа также предлагает короткие тесты и упражнения, которые позволят вам сразу же применить свои знания на практике.
3. Основы C#, Скотт Аллен.
Создатель этого курса по Pluralsight, Скотт Аллен, поставил перед собой цель объяснить вам, как использовать расширенные возможности языка C Sharp. Вы начнете с синтаксиса C# и перейдете к концепциям и методам ООП, необходимым для решения проблем. Вы получите знания и навыки, которых вполне достаточно для реальных проектов.
JavaScript
Сегодня JavaScript — это больше, чем язык программирования, используемый для реализации клиентских функций и создания динамических веб-сайтов. Теперь он встроен в различные программные системы для развертывания серверных веб-сайтов и небраузерных приложений с помощью таких проектов, как Node.js. Обладая мастерством в JS, вы можете преуспеть как во фронтенде, так и во бэкенде.
Теперь он встроен в различные программные системы для развертывания серверных веб-сайтов и небраузерных приложений с помощью таких проектов, как Node.js. Обладая мастерством в JS, вы можете преуспеть как во фронтенде, так и во бэкенде.
Где изучать JavaScript
1. Freecodecamp.org
Freecodecamp — отличное место для изучения JavaScript, если вы новичок в этом языке. В этом трехчасовом курсе есть все необходимое, чтобы начать программирование на JS и получить достаточные знания для создания реальных проектов.
2. КодБой
Без сомнения, изучение языка программирования может быть сложным. Вот почему CodeCombat придумал курс, который позволяет вам изучать программирование, играя в игры. Благодаря этому уникальному методу обучения процесс обучения будет увлекательным и быстрым.
3. Кодовая школа
Code School позволяет бесплатно изучать программирование. Учебники интерактивны и увлекательны, и каждый раз, когда вы проходите курс, вы получаете оценки, значки и перекрестные уровни. Это поддерживает мотивацию студентов во время обучения программированию.
Это поддерживает мотивацию студентов во время обучения программированию.
Подведение итогов
Изучение нескольких языков дает программистам ряд преимуществ, начиная от более широких возможностей для карьерного роста и заканчивая более высоким потенциалом заработка и более интересными проектами. Тем не менее, ваша конечная цель не должна состоять в том, чтобы стать экспертом в каждом языке, который вы видите. Это почти невозможно и не принесет много пользы. Овладение одним языком, а затем знакомство с другим — лучший способ научиться программированию. Следование этому подходу сделает ваши знания более глубокими, а путь обучения – более простым.
Впервые опубликовано на LevelUp GitConnected.
Переход к многоязычному программированию с помощью Python
Недавняя ветка на python-dev побудила меня обобщить текущее состояние продолжающегося в масштабах всей отрасли перехода от двуязычного к многоязычному программированию в связи с кроссплатформенной поддержкой Python. Это также связано с причинами, по которым Python 3 оказался более разрушительным, чем изначально ожидала основная команда разработчиков.
Это также связано с причинами, по которым Python 3 оказался более разрушительным, чем изначально ожидала основная команда разработчиков.
Хорошей отправной точкой для всех, кто заинтересован в дальнейшем изучении этой темы, является раздел «Происхождение и развитие» статьи Википедии о Unicode, но ниже я остановлюсь на ключевых моментах.
Одноязычные вычисления
По своей сути компьютеры понимают только отдельные биты. Все вышеперечисленное основано на соглашениях, которые приписывают значения более высокого уровня определенным последовательностям битов. Одним из важных наборов соглашений для общения между людьми и компьютерами являются «текстовые кодировки»: соглашения, которые отображают определенные последовательности битов в текст на реальных языках, которые люди читают и пишут.
Одной из старейших кодировок, до сих пор широко используемых, является ASCII (что означает «Американский стандартный код для обмена информацией»), разработанный в 1960-х (в 2013 году ему исполнилось 50 лет). Эта кодировка отображает буквы английского алфавита (как в верхнем, так и в нижнем регистре), десятичные цифры, различные знаки препинания и некоторые дополнительные «управляющие коды» в 128 чисел, которые можно закодировать как 7-битную последовательность.
Эта кодировка отображает буквы английского алфавита (как в верхнем, так и в нижнем регистре), десятичные цифры, различные знаки препинания и некоторые дополнительные «управляющие коды» в 128 чисел, которые можно закодировать как 7-битную последовательность.
Многие современные компьютерные системы по-прежнему корректно работают только с английским языком. Когда вы сталкиваетесь с такой системой, вполне вероятно, что либо сама система, либо что-то, от чего она зависит, ограничена работой с текстом ASCII. (если тебе действительно не повезло, вы можете даже работать с модальными 5-битными кодировками, такими как ITA-2, как у меня. Наследие телеграфа живет!)
Работа с местными языками
Первые попытки справиться с этим ограничением ASCII просто присваивали значения всему диапазону 8-битных последовательностей. Каждая из этих систем, известных под общим названием «Расширенный ASCII», допускала дополнительные 128 символов, чего было достаточно для обработки многих европейских и кириллических шрифтов. Однако даже 256 символов было недостаточно для работы с индийскими или восточноазиатскими языками, поэтому на этот раз также наблюдалось распространение несовместимых с ASCII кодировок, таких как ShiftJIS, ISO-2022 и Big5. Вот почему Python поставляется с поддержкой десятков кодеков со всего мира.
Однако даже 256 символов было недостаточно для работы с индийскими или восточноазиатскими языками, поэтому на этот раз также наблюдалось распространение несовместимых с ASCII кодировок, таких как ShiftJIS, ISO-2022 и Big5. Вот почему Python поставляется с поддержкой десятков кодеков со всего мира.
Это быстрое распространение кодировок требовало способа сообщить программному обеспечению, какую кодировку следует использовать для чтения данных. Для протоколов, которые изначально были разработаны для связи между компьютерами, согласование общей кодировки текста обычно обрабатывается как часть протокола. В тех случаях, когда информация о кодировке не предоставляется (или для обработки случаев, когда существует несоответствие между заявленной кодировкой и фактической кодировкой), приложения могут использовать алгоритмы «обнаружения кодировки», подобные тем, которые предоставляются пакетом chardet для Python. Эти алгоритмы не идеальны, но могут дать хорошие ответы при наличии достаточного количества данных для работы.
Однако локальные интерфейсы операционной системы — это отдельная история. Они не только не передают информацию о кодировании, но природа проблемы такова, что попытки использовать обнаружение кодирования нецелесообразны. В попытке решить эту проблему возникли две ключевые системы:
- Кодовые страницы Windows
- Кодировки локали POSIX
В обеих этих системах программа выбирает кодовую страницу или локаль и использует соответствующую кодировку текста, чтобы решить, как интерпретировать текст для отображения пользователю или в сочетании с другим текстом. Это может включать решение о том, как отображать информацию о содержимом самого компьютера (например, список файлов в каталоге).
Фундаментальная предпосылка этих двух систем заключается в том, что компьютер должен говорить только на языке своих непосредственных пользователей. Таким образом, хотя компьютер теоретически способен общаться на любом языке, он может эффективно общаться с людьми только на одном языке за раз. Все данные, с которыми работало данное приложение, должны были быть в кодировке , согласованной с кодировкой , иначе результат был бы неинтерпретируемой чепухой, что японцы (и, в конце концов, все остальные) стали называть моджибаке.
Все данные, с которыми работало данное приложение, должны были быть в кодировке , согласованной с кодировкой , иначе результат был бы неинтерпретируемой чепухой, что японцы (и, в конце концов, все остальные) стали называть моджибаке.
Неслучайно название этой концепции пришло из азиатской страны: проблемы с кодировкой, встречающиеся там, по сравнению с европейскими и кириллическими языками кажутся тривиальными.
К сожалению, этот подход «двуязычных вычислений» (названный так потому, что компьютер, как правило, может работать с английским языком в дополнение к местному языку) вызывает некоторые серьезные проблемы, когда вы рассматриваете связь между компьютерами. Хотя некоторые из этих проблем характерны для сетевых протоколов, есть и более серьезные проблемы, возникающие при работе с номинально «локальными» интерфейсами:
- сетевые вычисления означают, что одно имя пользователя может использоваться в нескольких системах, включая разные операционные системы Сетевые диски
- позволяют получить доступ к одному файловому серверу с нескольких клиентов, включая разные операционные системы
- переносные носители (такие как DVD и USB-накопители) позволяют получить доступ к одной и той же файловой системе с нескольких устройств в разные моменты времени Службы синхронизации данных
- , такие как Dropbox, должны точно воспроизводить иерархию файловой системы не только в различных настольных средах, но и на мобильных устройствах
Для этих протоколов, которые изначально были разработаны только для локальной совместимости, передача информации о кодировке, как правило, затруднена, и она не обязательно соответствует заявленной кодировке платформы, на которой вы работаете.
Unicode и развитие многоязычных вычислений
Путь к устранению фундаментальных ограничений двуязычных вычислений начался более 25 лет назад, еще в конце 1980-х. Первоначальный проект предложения по 16-битной «универсальной кодировке» был выпущен в 1919 г.88, Консорциум Unicode был сформирован в начале 1991 года, и в том же году был опубликован первый том первой версии Unicode.
Microsoft добавила новые API-интерфейсы для обработки текста и операционной системы в Windows на основе 16-разрядного типа wchar_t уровня C, а Sun также приняла Unicode как часть основного дизайна подхода Java к обработке текста.
Однако возникла проблема. Первоначальный дизайн Unicode решил, что «16 бит должно быть достаточно для всех», ограничив их цель только современными сценариями и только часто используемыми символами в этих сценариях. Однако, если вы посмотрите на «редко используемые» иероглифы кандзи и хань для японского и китайского языков, вы обнаружите, что они включают в себя много символов, которые — это , которые регулярно используются для имен людей и мест — они просто в основном ограничены именами собственными, и поэтому не будут отображаться при обычном поиске по словарю. Таким образом, Unicode 2.0 был определен в 1996 году, расширив систему до 21 бита на кодовую точку (используя до 32 битов на кодовую точку для хранения).
Таким образом, Unicode 2.0 был определен в 1996 году, расширив систему до 21 бита на кодовую точку (используя до 32 битов на кодовую точку для хранения).
В результате Windows (включая CLR) и Java теперь используют вариант UTF-16 с прямым порядком байтов, чтобы их текстовые API-интерфейсы могли обрабатывать произвольные кодовые точки Unicode. Исходное 16-битное кодовое пространство теперь называется базовой многоязычной плоскостью.
Пока все это происходило, мир POSIX в конце концов принял другую стратегию перехода на полную поддержку Unicode: попытку стандартизировать совместимую с ASCII текстовую кодировку UTF-8.
Выбор между использованием UTF-8 и UTF-16-LE в качестве предпочтительной кодировки локального текста связан с некоторыми сложными компромиссами, и это отражено в том факте, что они оказались в основе двух конкурирующих подходов к многоязычным вычислениям. .
Выбор UTF-8 направлен на то, чтобы форматирование текста для связи с пользователем рассматривалось как «просто проблема с отображением». Это ненавязчивый дизайн, который будет «просто работать» для большого количества программного обеспечения, но он имеет свою цену:
Это ненавязчивый дизайн, который будет «просто работать» для большого количества программного обеспечения, но он имеет свою цену:
- , так как проверки согласованности кодирования в основном избегают, данные в разных кодировках могут свободно объединяться и передаваться другим приложениям. Такие данные обычно не могут использоваться принимающим приложением.
- для интерфейсов без доступной информации о кодировке часто необходимо принять подходящую кодировку, чтобы отобразить информацию пользователю, или преобразовать ее в другую кодировку для связи с другой системой, которая может не разделять предположения о кодировании локальной системы. Эти предположения могут быть неверными, но не обязательно приведут к ошибке — данные могут быть просто неверно истолкованы как нечто отличное от того, что изначально предполагалось.
- , поскольку данные обычно декодируются далеко от того места, где они были введены, может быть трудно обнаружить источник ошибок кодирования.
- в качестве кодировки с переменной шириной, разработать эффективные алгоритмы работы со строками для UTF-8 сложнее.
 Алгоритмы, изначально разработанные для кодирования с фиксированной шириной, больше не будут работать.
Алгоритмы, изначально разработанные для кодирования с фиксированной шириной, больше не будут работать. - как конкретный экземпляр предыдущего пункта, невозможно разделить текст в кодировке UTF-8 в произвольных местах. Необходимо позаботиться о том, чтобы расщепления происходили только на границах кодовых точек.
UTF-16-LE разделяет последние две проблемы, но в меньшей степени (просто из-за того, что наиболее часто используемые кодовые точки находятся в 16-битной базовой многоязычной плоскости). Однако, поскольку он в целом не подходит для использования в сетевых протоколах и форматах файлов (без существенных дополнительных маркеров кодирования), требуемое явное декодирование и кодирование поощряет проекты с четким разделением между двоичными данными (включая закодированный текст) и декодированным текстом. данные.
Через призму Python
Python и Unicode родились на противоположных сторонах Атлантического океана примерно в одно и то же время (1991). Растущее внедрение Unicode в компьютерной индустрии оказало глубокое влияние на эволюцию языка.
Растущее внедрение Unicode в компьютерной индустрии оказало глубокое влияние на эволюцию языка.
Python 1.x был чисто продуктом эпохи двуязычных вычислений — он вообще не поддерживал обработку текста на основе Unicode и, следовательно, был в значительной степени ограничен 8-битными кодировками, совместимыми с ASCII, для обработки текста.
Python 2.x по-прежнему в основном был продуктом двуязычной эпохи, но в него была добавлена многоязычная поддержка в качестве дополнительного дополнения в виде unicode и поддерживает широкий спектр текстовых кодировок. PEP 100 включает в себя множество технических деталей, которые необходимо было охватить, чтобы включить эту функцию. С помощью Python 2 вы можете заставить работать многоязычное программирование, но это требует активного решения со стороны разработчика приложения или, по крайней мере, того, чтобы он следовал рекомендациям фреймворка, который решает проблему от его имени.
В отличие от этого, Python 3. x разработан, чтобы быть родным обитателем многоязычного компьютерного мира. Поддержка нескольких языков распространяется на систему именования переменных, так что языки, отличные от английского, поддерживаются почти так же хорошо, как английский язык уже был в Python 2. В то время как ключевые слова, вдохновленные английским языком, и английское наименование в стандартной библиотеке и в пакете Python Индекс означает, что «родным» языком Python и предпочтительным языком для глобального сотрудничества всегда будет английский, новый дизайн обеспечивает гораздо большую гибкость при работе с данными на других языках.
x разработан, чтобы быть родным обитателем многоязычного компьютерного мира. Поддержка нескольких языков распространяется на систему именования переменных, так что языки, отличные от английского, поддерживаются почти так же хорошо, как английский язык уже был в Python 2. В то время как ключевые слова, вдохновленные английским языком, и английское наименование в стандартной библиотеке и в пакете Python Индекс означает, что «родным» языком Python и предпочтительным языком для глобального сотрудничества всегда будет английский, новый дизайн обеспечивает гораздо большую гибкость при работе с данными на других языках.
Рассмотрим обработку таблицы данных, в которой заголовки являются именами японцев, и мы хотели бы использовать collections.namedtuple для обработки каждой строки. Python 2 просто не справляется с этой задачей:
>>> из коллекций импортировать namedtuple
>>> Люди = namedtuple("Люди", u"陽斗 慶子 七海")
Traceback (последний последний вызов):
Файл "", строка 1, в
Файл "/usr/lib64/python2. 7/collections.py", строка 310, в namedtuple
field_names = карта (str, field_names)
UnicodeEncodeError: кодек ascii не может кодировать символы в позиции 0-1: порядковый номер не в диапазоне (128)
7/collections.py", строка 310, в namedtuple
field_names = карта (str, field_names)
UnicodeEncodeError: кодек ascii не может кодировать символы в позиции 0-1: порядковый номер не в диапазоне (128)
Пользователям необходимо либо ограничиться поиском в стиле словаря, а не доступом к атрибутам, либо использовать романизированные версии своих имен (например, Харуто, Кейко, Нанами). Тем не менее, случай с «Харуто» интересен, так как существует как минимум 3 различных способов написания этого кандзи (陽斗, 陽翔, 大翔), но все они латинизированы как одна и та же строка (Харуто) . Если вы попытаетесь использовать romaaji для обработки набора данных, содержащего более одного варианта этого имени, вы получите ложные коллизии.
Python 3 подходит к этой проблеме совсем по-другому. Он говорит, что должен просто работать, и гарантирует, что он работает:
>>> из коллекций импортировать namedtuple
>>> Люди = namedtuple("Люди", u"陽斗 慶子 七海")
>>> d = Люди(1, 2, 3)
>>> д. 陽斗
1
>>> д.慶子
2
>>> д.七海
3
陽斗
1
>>> д.慶子
2
>>> д.七海
3
Это изменение значительно расширяет количество вариантов использования, управляемых данными, Python может поддерживать в областях, где предположения Python 2, основанные на ASCII, могут вызвать серьезные проблемы.
Однако Python 3 по-прежнему должен иметь дело с неправильно закодированными данными, поэтому он предоставляет механизм для «контрабандной передачи» произвольных двоичных данных через текстовые строки в младшей суррогатной области Unicode. Эта функция была добавлена PEP 383 и управляется с помощью обработчика ошибок surrogateescape , который используется по умолчанию в большинстве интерфейсов операционных систем. Это воссоздает старое поведение Python 2, когда неправильно закодированные данные передаются без изменений при работе исключительно с локальными интерфейсами операционной системы, но жалуются, когда такие неправильно закодированные данные внедряются в другой интерфейс. Система обработки ошибок кодека предоставляет несколько инструментов для работы с этими файлами, и мы рассматриваем возможность добавления еще нескольких удобных функций для Python 3.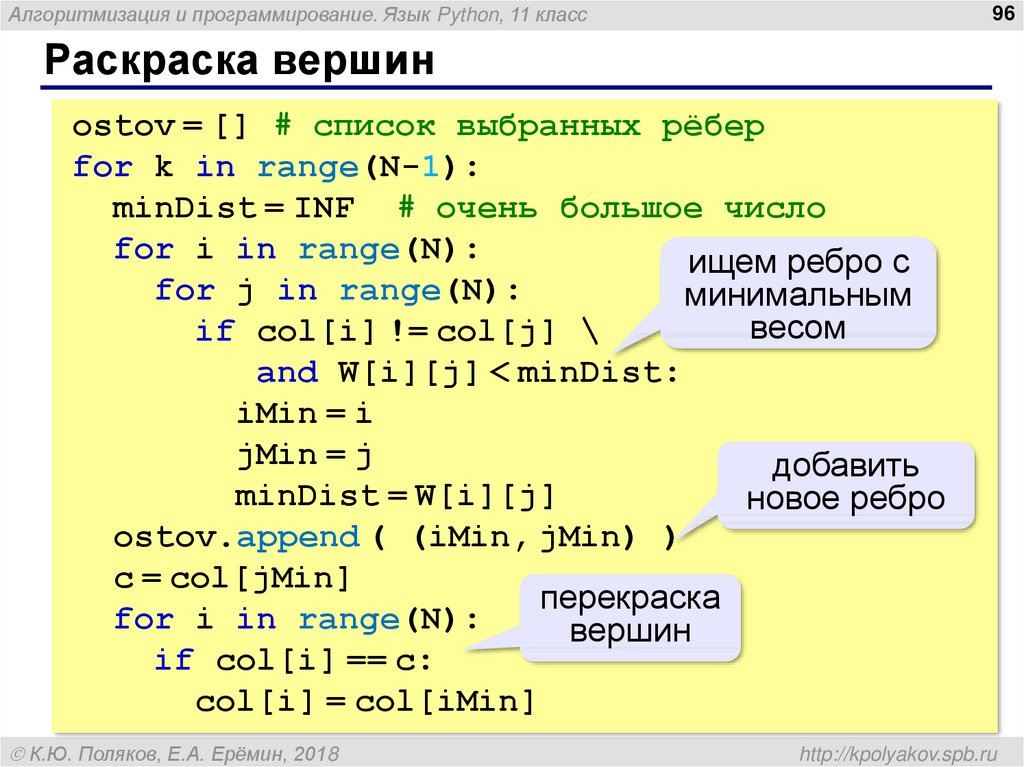 5.
5.
Основные изменения Unicode в Python 3 также сделали возможным PEP 393, который изменил способ внутреннего хранения текста интерпретатором CPython. В Python 2 даже чистые строки ASCII будут занимать четыре байта на кодовую точку в системах Linux. Использование опции «узкой сборки» (как это делают сборки Python 2 для Windows с сайта python.org) уменьшило всего два байта на кодовую точку при работе в базовой многоязычной плоскости, но за счет потенциального получения неправильных ответов при запросе для работы с кодовыми точками за пределами базовой многоязычной плоскости. Напротив, начиная с Python 3.3, CPython теперь хранит текст внутри, используя наименьшую возможную единицу данных фиксированной ширины. то есть 9В тексте 0211 latin-1 используется 8 бит на кодовую точку, в тексте UCS-2 (базовая многоязычная плоскость) используется 16 бит на кодовую точку, и только текст, содержащий кодовые точки за пределами базовой многоязычной плоскости, будет расширяться до требуемых полных 32 битов.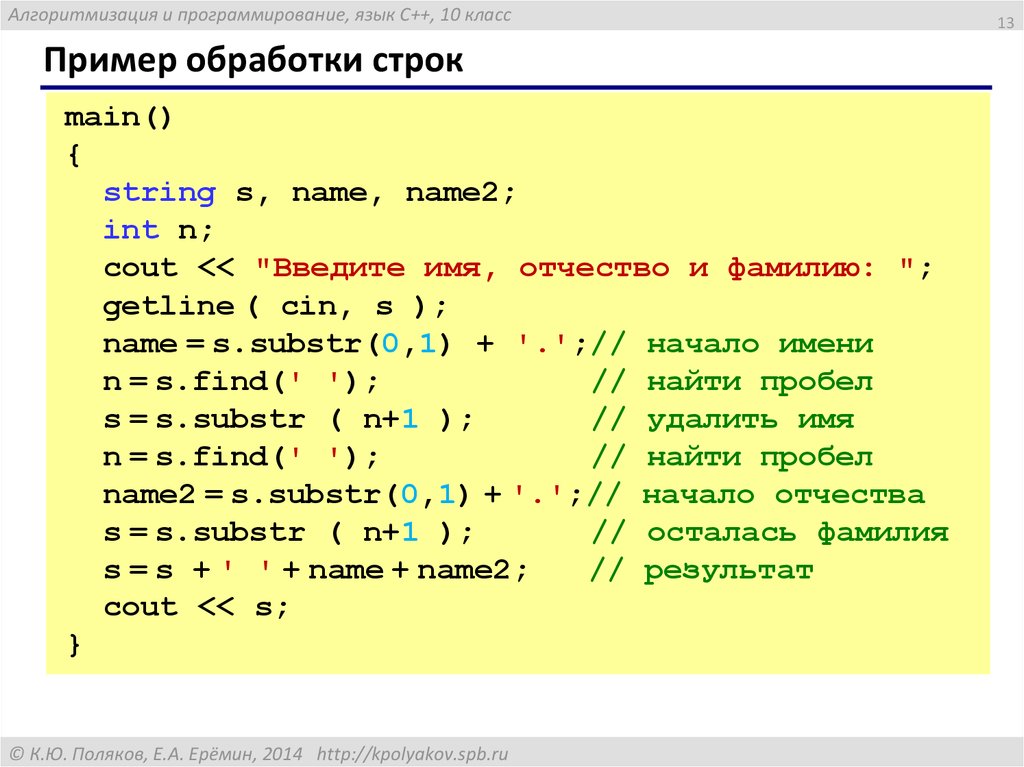 бит на кодовую точку. Это может не только значительно уменьшить объем памяти, необходимый для многоязычных приложений, но также может увеличить их скорость (поскольку сокращение использования памяти также сокращает время, затрачиваемое на копирование данных).
бит на кодовую точку. Это может не только значительно уменьшить объем памяти, необходимый для многоязычных приложений, но также может увеличить их скорость (поскольку сокращение использования памяти также сокращает время, затрачиваемое на копирование данных).
Мы уже на месте?
Одним словом, нет. Не для Python 3.4 и не для компьютерной индустрии в целом. Однако мы гораздо ближе, чем когда-либо прежде. Большинство систем POSIX теперь по умолчанию используют UTF-8 в качестве кодировки по умолчанию, и многие системы предлагают локаль C.UTF-8 в качестве альтернативы традиционной локали C на основе ASCII. При работе исключительно с правильно закодированными данными и метаданными, а также с правильно сконфигурированными системами Python 3 должен «просто работать», даже при обмене данными между разными платформами.
Для Python 3 оставшиеся проблемы относятся к нескольким областям:
- помочь существующим пользователям Python 2 внедрить дополнительные многоязычные функции, которые подготовят их к возможному переходу на Python 3 (а также успокоить тех пользователей, которые не хотят для миграции, что Python 2 по-прежнему полностью поддерживается и останется таковым, по крайней мере, в течение следующих нескольких лет и, возможно, дольше для клиентов коммерческих распространителей)
- , возвращающий некоторые функции для работы полностью в двоичном домене, которые были удалены при первоначальном переходе на Python 3 из-за первоначальной оценки того, что эти операции имели смысл только с текстовыми данными (резюме PEP 461: 9).
 0211 bytes.__mod__ возвращается в Python 3.5 как допустимая операция с двоичным доменом,
0211 bytes.__mod__ возвращается в Python 3.5 как допустимая операция с двоичным доменом, bytes.formatостается в прошлом как операция, которая имеет смысл только при работе с фактическими текстовыми данными) - улучшенная обработка неправильно декодированных данных, включая плохие рекомендации по кодированию от операционной системы (например, Python 3.5 будет более скептически настроен, когда операционная система сообщит ему, что предпочтительной кодировкой является
ASCII, и включитsurrogateescapeобработчик ошибок наsys.stdout, когда это происходит) - устраняет большую часть оставшегося использования устаревшей кодовой страницы и систем кодирования локалей в интерпретаторе CPython (это наиболее заметно влияет на интерфейс консоли Windows и декодирование аргументов в POSIX. адрес их для Python 3.5)
В более широком смысле у каждой крупной платформы есть свои серьезные проблемы, которые необходимо решить:
- для систем POSIX, все еще есть много систем, которые не используют UTF-8 в качестве предпочтительной кодировки, а предположение о том, что ASCII является предпочтительной кодировкой в локали
Cпо умолчанию, явно архаично. Также все еще существует множество программ POSIX, которые все еще верят в предположение, что «текст — это просто закодированные байты», и с радостью создают моджибаке, которые не имеют смысла для других приложений или систем.
Также все еще существует множество программ POSIX, которые все еще верят в предположение, что «текст — это просто закодированные байты», и с радостью создают моджибаке, которые не имеют смысла для других приложений или систем. - для Windows, сохранение старых 8-битных API было сочтено необходимым для обратной совместимости, но это также означает, что все еще существует много программного обеспечения Windows, которое просто неправильно обрабатывает многоязычные вычисления.
- как для Windows, так и для JVM, значительная часть номинально многоязычного программного обеспечения на самом деле правильно работает только с данными в базовой многоязычной плоскости. Это меньшая проблема, чем полное отсутствие поддержки многоязычных вычислений, но она была довольно заметной проблемой в собственной поддержке Windows в Python 2.
Mac OS X является платформой, наиболее жестко контролируемой какой-либо одной организацией (Apple), и они на самом деле находятся в лучшем положении из всех существующих основных платформ, когда речь идет о правильной обработке многоязычных вычислений. Они были одним из основных драйверов Unicode с самого начала (двое из авторов первоначального предложения Unicode были инженерами Apple) и могли принудительно вносить необходимые изменения конфигурации во все свои системы вместо того, чтобы работать с обширная сеть OEM-партнеров (Windows, коммерческие поставщики Linux) или относительно свободное сотрудничество отдельных лиц и организаций (общие дистрибутивы Linux).
Они были одним из основных драйверов Unicode с самого начала (двое из авторов первоначального предложения Unicode были инженерами Apple) и могли принудительно вносить необходимые изменения конфигурации во все свои системы вместо того, чтобы работать с обширная сеть OEM-партнеров (Windows, коммерческие поставщики Linux) или относительно свободное сотрудничество отдельных лиц и организаций (общие дистрибутивы Linux).
Современные мобильные платформы, как правило, находятся в лучшем положении, чем настольные операционные системы, в основном в силу того, что они новее и, следовательно, определены после лучшего понимания Unicode. Тем не менее, различие между UTF-8 и UTF-16-LE для обработки текста существует даже там, благодаря основанной на Java виртуальной машине Dalvik в Android (плюс облачная природа современных смартфонов означает, что вы даже на 90 163 больше, чем 90 164). сталкиваться с файлами с нескольких компьютеров при работе на мобильном устройстве).
Также размещено здесь: Переход на многоязычное программирование | Любопытная эффективность.