Методы строк
str.capitalize()
Возвращает копию строки, переводя первую буквы в верхний регистр, а остальные в нижний.
'нАЧАТЬ С ЗАГЛАВНОЙ '.capitalize() # Начать с заглавной
str.casefold()
Возвращает копию строки в сложенном регистре.
Преобразование в сложенный регистр похоже на преобразование к нижнему регистру, однако более агрессивно. Например: буква «ß» в нижнем регистре в немецком языке соответствует сочетанию «ss», однако, ввиду того, что символ «ß» уже имеет нижний регистр, метод .lower() ни к чему не приведёт, в то время как casefold() приведёт символ к «ss».
'ß'.lower() # 'ß' 'ß'.casefold() # 'ss' 'groß'.casefold() == 'gross' # True
str.center(width[, fillchar])
Позиционирует по центру указанную строку, дополняя её справа и слева до указанной длины указанным символом.
width : Желаемая минимальная длина результирующей строки.
fillchar : Символ, которым следует расширять строку. По умолчанию — пробел.
По умолчанию — пробел.
Изначальная строка не обрезается, даже если в ней меньше символов, чем указано в параметре желаемой длины.
''.center(3, 'w') # www '1'.center(2, 'w') # 1w '1'.center(4, 'w') # w1ww '1'.center(0, 'w') # 1 '1'.center(4) # ' 1 '
Символ добавляется к строке циклично сначала справа, затем слева.
Чтобы позиционировать строку вправо используйте str.rjust(). Чтобы позиционировать строку влево используйте str.ljust().
str.count(sub[, start[, end]])
Для строки возвращает количество непересекающихся вхождений в неё указанной подстроки.
sub : Подстрока, количество вхождений которой следует вычислить.
start=0 : Позиция в строке, с которой следует начать вычислять количество вхождений подстроки.
end=None : Позиция в строке, на которой следует завершить вычислять количество вхождений подстроки.
my_str = 'подстрока из строк'
my_str.count('строка') # 1
my_str. count('стр') # 2
my_str.count('стр', 0, -1) # 2
my_str.count('стр', 8) # 1
my_str.count('стр', 1, 5) # 0
my_str.count('стр', 1, 6) # 1
count('стр') # 2
my_str.count('стр', 0, -1) # 2
my_str.count('стр', 8) # 1
my_str.count('стр', 1, 5) # 0
my_str.count('стр', 1, 6) # 1
Позиции начала и конца трактуются также как в срезах.
str.encode(encoding=»utf-8», errors=»strict»)
Кодирует строку в байты/байтстроку, используя зарегистрированный кодек.
encoding : Название кодировки. По умолчанию — системная кодировка, доступная из sys.getdefaultencoding().
errors=strict : Наименование схемы обработки ошибок. По умолчанию — strict.
Имена доступных кодировок лучше всего узнавать из документации к модулю codecs.
from sys import getdefaultencoding
getdefaultencoding() # utf-8
my_string = 'кот cat'
type(my_string) # str
my_string.encode()
# b'\xd0\xba\xd0\xbe\xd1\x82 cat'
my_string.encode('ascii')
# UnicodeDecodeError
my_string.encode('ascii', errors='ignore')
# b' cat'
my_string.encode('ascii', errors='replace')
# b'??? cat'
my_string.encode('ascii', errors='xmlcharrefreplace')
# b'кот cat'
my_string.
encode('ascii', errors='backslashreplace')
# b'\\u043a\\u043e\\u0442 cat'
my_string.encode('ascii', errors='namereplace')
# b'\\N{CYRILLIC SMALL LETTER KA}\\N{CYRILLIC SMALL LETTER O}\\N{CYRILLIC SMALL LETTER TE} cat'
surrogated = '\udcd0\udcba\udcd0\udcbe\udcd1\udc82 cat'
surrogated.encode()
# UnicodeEncodeError
surrogated.encode(errors='surrogateescape')
# b'\xd0\xba\xd0\xbe\xd1\x82 cat'
surrogated.encode(errors='surrogatepass')
# b'\xed\xb3\x90\xed\xb2\xba\xed\xb3\x90\xed\xb2\xbe\xed\xb3\x91\xed\xb2\x82 cat'
Зарегистрировать новую схему можно при помощи codecs.register_error().
str.endswith(suffix[, start[, end]])
Возвращает флаг, указывающий на то, заканчивается ли строка указанным постфиксом.
suffix : Строка-постфикс, в наличии которой требуется удостовериться.
start : Позиция (индекс символа), с которой следует начать поиск. Поддерживает отрицательные значения.
end : Позиция (индекс символа), на которой следует завершить поиск. Поддерживает отрицательные значения.
Поддерживает отрицательные значения.
my_str = 'Discworld'
my_str.endswith('jockey') # False
my_str.endswith('world') # True
my_str.endswith('jockey', 2) # False
my_str.endswith('Disc', 0, 4) # True
str.expandtabs(tabsize=8)
Возвращает копию строки, в которой символы табуляций заменены пробелами.
tabsize=8 : Максимальное количество пробелов на которое может быть заменена табуляция.
В возвращаемой копии строки все табуляции заменяются одним или несколькими пробелами, в зависимости от текущего номера столбца и указанного максимального размера табуляции.
my_str = '\t1\t10\t100\t1000\t10000' my_str.expandtabs() # ' 1 10 100 1000 10000' my_str.expandtabs(4) # ' 1 10 100 1000 10000'
Для замены табуляций изначально номер столбца задаётся равным нулю и начинается посимвольный проход по строке.
Если очередной символ является табуляцией (\t), то на его место вставляется столько пробелов, сколько требуется для того, что текущий номер столбца стал равным позиции следующей табуляции. При этом сам символ табуляции не копируется.
При этом сам символ табуляции не копируется.
Если очередной символ является переносом строки (\n) или возвратом каретки (\r), он копируется, а текущий номер столбца задаётся равным нулю.
Другие символы копируются в неизменном виде, а текущий номер столбца увеличивается на единицу (вне зависимости от того, как символ будет представлен при выводе).
str.find(sub[, start[, end]])
Возвращает наименьший индекс, по которому обнаруживается начало указанной подстроки в исходной.
sub : Подстрока, начальный индекс размещения которой требуется определить.
start=0 : Индекс начала среза в исходной строке, в котором требуется отыскать подстроку.
end=None : Индекс конца среза в исходной строке, в котором требуется отыскать подстроку.
Если подстрока не найдена, возвращает −1.
my_str = 'barbarian'
my_str.find('bar') # 0
my_str.find('bar', 1) # 3
my_str.find('bar', 1, 2) # -1
Необязательные параметры start и end могут принимать любые значения, поддерживаемые механизмом срезов, а значит и отрицательные.
Метод должен использоваться только в случае необходимости найти индекс начала подстроки. Для обычного определения вхождения подстроки используйте оператор in:
my_str = 'barbarian' 'bar' in my_str # True
str.format(
args, *kwargs)Возвращает копию строки, отформатированную указанным образом.
args : Позиционные аргументы.
kwargs : Именованные аргументы.
Строка, для которой вызывается данный метод может содержать как обычный текст, так и маркеры в фигурных скобках {}, которые следует заменить. Обычный текст, вне скобок будет выведен как есть без именений.
Метод возвращает копию строки, в которой маркеры заменены текстовыми значениями из соответствующих аргументов.
Наименование состоит из имени аргумента (либо его индекса). Числовой индекс при этом указывает на позиционный аргумент; имя указывает на именованный аргумент.
Если используются числа, и они составляют последовательность (0, 1, 2…), то они могут быть опущены разом (но не выборочно). Например, {}-{}-{} и {0}-{1}-{2} эквивалентны.
Например, {}-{}-{} и {0}-{1}-{2} эквивалентны.
'{}-{}-{}'.format(1, 2, 3) # Результат: '1-2-3'
'{}-{}-{}'.format(*[1, 2, 3]) # Результат: '1-2-3'
'{one}-{two}-{three}'.format(two=2, one=1, three=3) # Результат: '1-2-3'
'{one}-{two}-{three}'.format(**{'two': 2, 'one': 1, 'three': 3}) # Результат: '1-2-3'
После наименования может следовать любое количество выражений доступа к атрибуту или адресации по индексу.
- Атрибут объекта адресуется при помощи
.(точки). - Доступ к элементу при помощи
[](квадратных скобок).
import datetime
obj = {'one': {'sub': 1}, 'two': [10, 2, 30], 'three': datetime.datetime.now()}
'{one[sub]}-{two[1]}-{three.year}'.format(**obj)
Приведение используется для приведения типов перед форматированием.
Обычно возврат отформатированого значения возлагается на метод __format__(), однако бывают случаи, что требуется произвести принудительное приведение, например, к строке, в обход имеющейся реализации.
Результат
Начало 7Конец Начало8 Конец Начало 9Конец
Вывод вещественных чисел
print('{0}'.format(4/3))
print('{0:f}'.format(4/3))
print('{0:.2f}'.format(4/3))
print('{0:10.3f}'.format(4/3))
Результат
1.3333333333333333
1.333333
1.33
1.333
str.index(sub[, start[, end]])
Возвращает наименьший индекс, по которому обнаруживается начало указанной подстроки в исходной.
sub : Подстрока, начальный индекс размещения которой требуется определить.
start=0 : Индекс начала среза в исходной строке, в котором требуется отыскать подстроку.
end=None : Индекс конца среза в исходной строке, в котором требуется отыскать подстроку.
Работа данного метода аналогична работе str.find(), однако, если подстрока не найдена, возбуждается исключение
my_str = 'barbarian' my_str.index('bar') # 0 my_str.index('bar', 1) # 3 my_str.index('bar', 1, 2) # ValueError
Необязательные параметры start и end могут принимать любые значения, поддерживаемые механизмом срезов, а значит и отрицательные.
Метод должен использоваться только в случае необходимости найти индекс начала подстроки. Для обычного определения вхождения подстроки используйте оператор in:
my_str = 'barbarian' 'bar' in my_str # True
str.isalnum()
Возвращает флаг, указывающий на то, содержит ли строка только цифры и/или буквы.
Вернёт True, если в строке хотя бы один символ и все символы строки являются цифрами и/или буквами, иначе — False.
''.isalnum() # False ' '.isalnum() # False '!@#'.isalnum() # False 'abc'.isalnum() # True '123'.isalnum() # True 'abc123'.isalnum() # True
str.isalpha()
Возвращает флаг, указывающий на то, содержит ли строка только буквы.
Вернёт True, если в строке есть хотя бы один символ, и все символы строки являются буквами, иначе — False.
''.isalpha() # False ' '.isalpha() # False '!@#'.isalpha() # False 'abc'.isalpha() # True '123'.isalpha() # False 'abc123'.isalpha() # False
str.isascii()
Возвращает флаг, указывающий на то, содержит ли строка только ASCII-символы.
Вернет True, если в строке содержаться только ASCII-символы или строка пустая, иначе вернет False.
str.isdigit()
Возвращает флаг, указывающий на то, содержит ли строка только цифры.
Вернёт True, если в строке хотя бы один символ и все символы строки являются цифрами, иначе — False.
''.isdigit() # False ' '.isdigit() # False '!@#'.isdigit() # False 'abc'.isdigit() # False '123'.isdigit() # True 'abc123'.isdigit() # False
str.isidentifier()
Возвращает флаг, указывающий на то, является ли строка идентификатором.
Речь идёт об идентификаторах языка. Более подробная информация об идентификаторах и ключевых словах Питона содержится в разделе оригинальной документации Identifiers and keywords.
'continue'.isidentifier() # True 'cat'.isidentifier() # True 'function_name'.isidentifier() # True 'ClassName'.isidentifier() # True '_'.isidentifier() # True 'number1'.isidentifier() # True '1st'.isidentifier() # False '*'.isidentifier() # False
Для проверки на то является ли строка зарезервированным идентификатором (например: def, class), используйте keyword.iskeyword().
str.islower()
Возвращает флаг, указывающий на то, содержит ли строка символы только нижнего регистра.
Вернёт True, если все символы строки поддерживающие приведение к регистру приведены к нижнему, иначе — False.
'нижний lower'.islower() # True
Внимание str.islower() может возвращать False, например, если строка содержит только символы не поддерживающие приведение к регистру:
'12'.islower() # False
Для приведения символов строки к нижнему регистру используйте метод lower().
str.isnumeric()
Возвращает флаг, указывающий на то, содержит ли строка только числа.
Вернёт True, если в строке есть символы и все они присущи числам.
''.isnumeric() # False 'a'.isnumeric() # False '0'.isnumeric() # True '10'.isnumeric() # True '⅓'.isnumeric() # True 'Ⅻ'.isnumeric() # True
К символам чисел относятся цифры, а также все символы, имеющие признак числа в Unicode, например: U+2155 (VULGAR FRACTION ONE FIFTH) — это любые символы, у которых признак Numeric_Type установлен равным Digit, или Decimal, или Numeric.
str.isprintable()
Возвращает флаг, указывающий на то, все ли символы строки являются печатаемыми.
Вернёт True, если строка пустая, либо если все её символы могут быть выведены на печать.
''.isprintable() # True ' '.isprintable() # True '1'.isprintable() # True 'a'.isprintable() # True ''.isprintable() # False (Group Separator) ''.isprintable() # False (Escape)
Непечатаемыми символами являются символы Юникод из категории Other или Separator, исключая символ пробела из ASCII (0x20), который считается печатаемым.
Печатаемые символы не требуется экранировать в случае применения repr() к строке. Они не влияют на обработку строк, отправляемых в sys.stdout или sys.stderr.
str.isspace()
Возвращает флаг, указывающий на то, содержит ли строка только пробельные символы.
Вернёт True, если в строке есть символы и все они являются пробельными, иначе — False.
' '.isspace() # True '\n'.isspace() # True '\t'.isspace() # True ' '.isspace() # True (OGHAM SPACE MARK) ''.isspace() # False '!@#'.isspace() # False 'abc'.isspace() # False '123'.isspace() # False 'abc123'.isspace() # False
Пробельными символами являются символы Юникод из категории Other или Separator, а также те, у которых свойство бинаправленности принимает значение WS, B, или S.
str.istitle()
Возвращает флаг, указывающий на то, начинается ли каждое из «слов» строки с заглавной буквы.
Вернёт True, если в строке хотя бы один символ или все «слова» в строке начинаются с заглавных букв, иначе — False.
'S'.istitle() # True 'Some Text'.istitle() # True 'Some text'.istitle() # False 'S1 T2%'.istitle() # True
str.isupper()
Возвращает флаг, указывающий на то, содержит ли строка символы только верхнего регистра.
Вернёт True, если все символы строки поддерживающие приведение к регистру приведены к верхнему, иначе — False.
str.join(iterable)
Возвращает строку, собранную из элементов указанного объекта, поддерживающего итерирование.
iterable : Объект со строками, поддерживающий итерирование.
В качестве соединительного элемента между указанными используется объект строки, предоставляющий данный метод.
dots = '..'
my_str = dots.join(['1', '2']) # '1..2'
my_str = dots.join('ab') # 'a..b'
Ожидается, что итерируемый объект выдаёт строки. Для массового приведения к строке можно воспользоваться функцией map(): dots.join(map(str, [100, 200])) # ‘100…200’
str.ljust(width[, fillchar])
Позиционирует влево указанную строку, дополняя её справа до указанной длины указанным символом.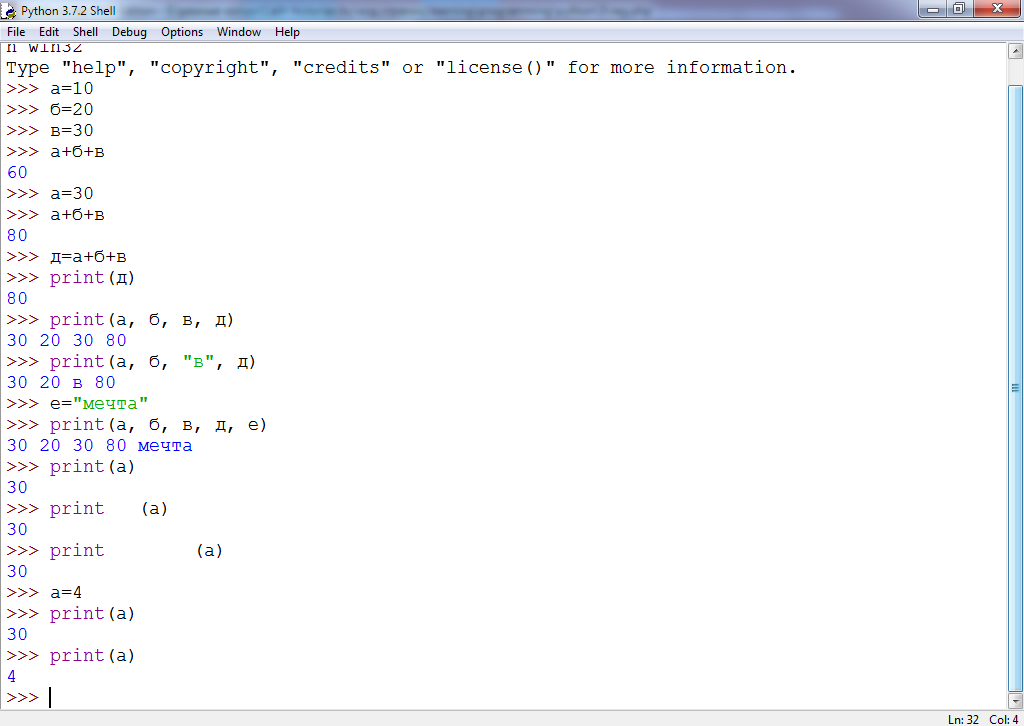
width : Желаемая минимальная длина результирующей строки.
fillchar : Символ, которым следует расширять строку. По умолчанию — пробел.
Изначальная строка не обрезается, даже если в ней меньше символов, чем указано в параметре желаемой длины.
''.ljust(3, 'w') # www '1'.ljust(4, 'w') # 1www '1'.ljust(0, 'w') # 1 '1'.ljust(4) # '1 '
Антонимом функции, позиционирующим строку вправо, является str.rjust().
Для расширения строки в обоих направлениях используйте str.center().
str.lower()
Возвращает копию исходной строки с символами приведёнными к нижнему регистру.
Алгоритм приведения к нижнему регистру описан в параграфе 3.13 стандарта Unicode.
'SoMe СлОнов'.lower() # some слонов'
Для приведения символов строки к верхнему регистру используйте метод upper().
Для проверки того, содержит ли строка только символы в нижнем регистре используйте islower().
str.lower().islower() может возвращать False, если строка содержит только символы не поддерживающие приведение к регистру: ’12’. lower().islower() # False
lower().islower() # False
str.lstrip([chars])
Возвращает копию указанной строки, с начала (слева l — left) которой устранены указанные символы.
chars=None : Строка с символами, которые требуется устранить. Если не указана, будут устранены пробельные символы. Это не префикс и не суффикс, это перечисление нужных символов.
'abca'.lstrip('ac') # 'bca'
str.maketrans(x[, y[, z]])
Возвращает таблицу переводов, которую можно использовать в методе translate. В примере ниже букве «а» будет соответствовать «1», «b» — «2», а «с» — «3»
intab = "abc" outtab = "123" trantab = str.maketrans(intab, outtab)
str.partition(sep)
Разбивает строку на три составляющие (начало, разделитель, конец) и возвращает в виде кортежа. Направление разбиения: слева направо.
sep : Строка-разделитель, при помощи которой требуется разбить исходную строку. Может содержать как один, так и несколько символов.
Возвращает кортеж из трёх элементов.
my_str = ''
my_str.partition('.') # ('', '', '')
my_str = '12'
my_str.partition('.') # ('12', '', '')
my_str = '.1.2'
my_str.partition('.') # ('', '.', '1.2')
В случаях, когда требуется, чтобы разбиение строки происходило справа налево, используйте str.rpartition.
Когда требуется разбить строку на множество составляющих, используйте str.split.
str.replace(old, new[, count])
Возвращает копию строки, в которой заменены все вхождения указанной строки указанным значением.
old : Искомая подстрока, которую следует заменить.
new : Подстрока, на которую следует заменить искомую.
maxcount=None : Максимальное требуемое количество замен. Если не указано, будут заменены все вхождения искомой строки.
my_str = 'barbarian'
my_str = my_str.replace('bar', 'mur') # 'murmurian'
my_str = my_str.replace('mur', 'bur', 1) # 'burmurian'
str.rfind(sub[, start[, end]])
Возвращают индексы последнего вхождения искомой подстроки. Если же подстрока не найдена, то метод возвращает значение −1.
Если же подстрока не найдена, то метод возвращает значение −1.
str.rindex(sub[, start[, end]])
Возвращает наибольший индекс, по которому обнаруживается конец указанной подстроки в исходной.
sub : Подстрока, начальный индекс размещения которой требуется определить.
start=0 : Индекс начала среза в исходной строке, в котором требуется отыскать подстроку.
end=None : Индекс конца среза в исходной строке, в котором требуется отыскать подстроку.
Работа данного метода аналогична работе str.rfind(), однако, если подстрока не найдена, возбуждается исключение
my_str = 'barbarian'
my_str.rindex('bar') # 3
my_str.rindex('bar', 1) # 3
my_str.rindex('bar', 1, 2) # ValueError
Необязательные параметры start и end могут принимать любые значения, поддерживаемые механизмом срезов, а значит и отрицательные.
str.rjust(width[, fillchar])
Позиционирует вправо указанную строку, дополняя её слева до указанной длины указанным символом.
width : Желаемая минимальная длина результирующей строки.
fillchar : Символ, которым следует расширять строку. По умолчанию — пробел.
Изначальная строка не обрезается, даже если в ней меньше символов, чем указано в параметре желаемой длины.
''.rjust(3, 'w') # www '1'.rjust(4, 'w') # www1 '1'.rjust(0, 'w') # 1 '1'.rjust(4) # ' 1'
Антонимом функции, позиционирующим строку влево, является str.ljust().
Для расширения строки в обоих направлениях используйте str.center().
Когда требуется дополнить строку нулями слева, используйте str.zfill().
str.rpartition(sep)
Разбивает строку на три составляющие (начало, разделитель, конец) и возвращает в виде кортежа. Направление разбиения: справа налево.
sep : Строка-разделитель, при помощи которой требуется разбить исходную строку. Может содержать как один, так и несколько символов. Возвращает кортеж из трёх элементов.
Поведение метода аналогично поведению str. partition за исключением направления разбиения строки.
partition за исключением направления разбиения строки.
my_str = ''
my_str.rpartition('.') # ('', '', '')
my_str = '12'
my_str.rpartition('.') # ('', '', '12')
my_str = '.1.2'
my_str.rpartition('.') # ('.1', '.', '2')
str.rsplit(sep=None, maxsplit=-1)
Разбивает строку на части, используя разделитель, и возвращает эти части списком. Направление разбиения: справа налево.
sep=None : Строка-разделитель, при помощи которой требуется разбить исходную строку. Может содержать как один, так и несколько символов. Если не указан, то используется специальный алгоритм разбиения, для которого разделителем считается последовательность пробельных символов.
maxsplit=-1 : Максимальное количество разбиений, которое требуется выполнить. Если −1, то количество разбиений не ограничено.
Поведение метода аналогично поведению str.split за исключением направления разбиения строки.
str.rstrip([chars])
Возвращает копию указанной строки, с конца (справа r — right) которой устранены указанные символы.
chars=None : Строка с символами, которые требуется устранить. Если не указана, будут устранены пробельные символы. Это не префикс и не суффикс, это перечисление нужных символов.
'abca'.rstrip('ac') # 'ab'
Когда требуется разбить строку на три составляющие (начало, разделитель, конец), используйте str.rpartition.
str.split(sep=None, maxsplit=-1)
Разбивает строку на части, используя разделитель, и возвращает эти части списком. Направление разбиения: слева направо.
sep=None : Строка-разделитель, при помощи которой требуется разбить исходную строку. Может содержать как один, так и несколько символов. Если не указан, то используется специальный алгоритм разбиения, для которого разделителем считается последовательность пробельных символов.
maxsplit=-1 : Максимальное количество разбиений, которое требуется выполнить. Если −1, то количество разбиений не ограничено.
Если указан разделитель, разбиение пустой строки вернёт список с единственным элементом — пустой строкой: [''].
'1,2,3'.split(',') # ['1', '2', '3']
'1,2,3'.split(',', maxsplit=1) # ['1', '2,3']
'1,2,,3,'.split(',') # ['1', '2', '', '3', '']
'1 2 3'.split(' ') # ['1', '', '', '2', '', '', '3']
Если разделитель не указан, разбиение пустой строки вернёт пустой список: [].
'1 2 3'.split() # ['1', '2', '3'] '1 2 3'.split(maxsplit=1) # ['1', '2 3'] '1 2 3'.split() # ['1', '2', '3']
В случаях, когда требуется, чтобы разбиение строки происходило справа налево, используйте str.rsplit. Когда требуется разбить строку на три составляющие (начало, разделитель, конец), используйте str.partition.
str.splitlines([keepends])
Разбивает строку на множество строк, возвращая их списком.
keepends=False — Флаг, указывающий на то следует ли оставлять в результирующем списке символы переноса строк. По умолчанию символы удаляются.
Разбиение строки на подстроки производится в местах, где встречаются символы переноса строк.
my_str = 'ab c\n\nde fg\rkl\r\n' my_str.splitlines() # ['ab c', '', 'de fg', 'kl'] my_str.splitlines(True) # ['ab c\n', '\n', 'de fg\r', 'kl\r\n']
В отличие от split(), которому можно передать символ-разделитель, данный метод для пустой строки вернёт пустой список, а символ переноса строки в конце не добавит в список дополнительного элемента.
''.splitlines() # []
''.split('\n') # ['']
my_str = 'ab\n cd\n'
my_str.splitlines() # ['ab', 'cd']
my_str.split('\n') # ['ab', 'cd', '']
str.startswith(prefix[, start[, end]])
Возвращает флаг, указывающий на то, начинается ли строка с указанного префикса.
prefix : Строка-префикс, в наличии которой требуется удостовериться.
start : Позиция (индекс символа), с которой следует начать поиск. Поддерживает отрицательные значения.
end : Позиция (индекс символа), на которой следует завершить поиск. Поддерживает отрицательные значения.
Поддерживает отрицательные значения.
my_str = 'Discworld'
my_str.startswith('Mad') # False
my_str.startswith('Disc') # True
my_str.startswith('Disc', 1) # False
my_str.startswith('world', 4, 9) # True
Для определения наличия постфикса в строке используйте str.endswith().
str.strip([chars])
Возвращает копию указанной строки, с обоих концов которой устранены указанные символы.
chars=None : Строка с символами, которые требуется устранить. Если не указана, будут устранены пробельные символы. Это не префикс и не суффикс, это перечисление нужных символов.
'abca'.strip('ac') # 'b'
str.swapcase()
Возвращает копию строки, в которой каждая буква будет иметь противоположный регистр.
В ходе смены регистра, буквы в нижнем регистре преобразуются в верхний, а буквы в верхнем преобразуются в нижний.
'Кот ОбОрмот!'.swapcase() # кОТ оБоРМОТ!
Внимание
Для 8-битных строк (Юникод) результат метода зависит от локали.
Следующее выражение не обязано быть истинным: `str`.swapcase().swapcase() == `str`.
str.title()
Возвращает копию строки, в которой каждое новое слово начинается с заглавной буквы и продолжается строчными.
В результирующей строке первая буква каждого нового слова становится заглавной, в то время как остальные становятся строчными. Такое написание характерно для заголовков в английском языке.
'кот ОбОрмот!'.title() # Кот Обормот! "they're bill's friends from the UK".title() # They'Re Bill'S Friends From The Uk
Алгоритм использует простое, независящее от языка определение слова — это группа последовательных букв. Такого определения во многих случаях достаточно, однако, в словах с апострофами (в английском они используются, например, в сокращениях и притяжательных формах) оно приводит к неожиданным результатам (см. пример выше). И в таких случаях лучше всего будет воспользоваться методом замены в регулярных выражениях (см. модуль re).
Для 8-битных строк (Юникод) результат метода зависит от текущей локали.
str.translate(table)
Возвращает строку, преобразованную с помощью таблицы переводов, которую в свою очередь можно получить с помощью str.maketrans. В примере ниже все буквы «а» будут заменены на «1», а «b» — на «2».
trantab = str.maketrans("ab", "12")
print('abc test'.translate(trantab))
str.upper()
Возвращает копию исходной строки с символами приведёнными к верхнему регистру.
Алгоритм приведения к верхнему регистру описан в параграфе 3.13 стандарта Unicode.
'SoMe СлОнов'.upper() # SOME СЛОНОВ
Для приведения символов строки к нижнему регистру используйте метод lower().
Для проверки того, содержит ли строка только символы в верхнем регистре используйте isupper().
str.zfill(width)
Дополняет указанную строку нулями слева до указанной минимальной длины.
width : Желаемая минимальная длина результирующей строки.
Изначальная строка не обрезается, даже если в ней меньше символов, чем указано в параметре желаемой длины.
В ходе компоновки результирующей строки ведущие знаки *+* и *-* сохраняют своё место в её начале.
''.zfill(3) # 000 '1'.zfill(4) # 0001 '1'.zfill(0) # 1 '-1'.zfill(4) # -001 'a'.zfill(4) # 000a '-a'.zfill(4) # -00a
Условно сходного результата можно также добиться при использовании метода str.rjust(), передав 0 в качестве второго аргумента.
Условным антонимом функции, добавляющим нули справа можно считать str.ljust(), передав 0 в качестве второго аргумента.
Методы строк в Python — Документация по языку программирования Python
Строка-это последовательность символов, заключенных в кавычки. На этой справочной странице собраны все методы, работают со строковыми объектами. Например, вы можете использовать метод find() для поиск подстроки в строке.
Python String capitalize() — Преобразует первый символ в заглавную букву
Python String casefold() — преобразуется в строки в сложенном виде
Python String center() — Выравнивание строк
Python String count() — Количество вхождений подстроки
Python String encode() — возвращает кодированную строку заданной строки
Python String endswith() — Проверка окончания(суффикса) строки
Python String find() — Возвращает индекс первого вхождения подстроки
Python String format() — Форматирование строки
Python String isupper() — все ли символы прописные
Python String join() — Объединяет строки
Python String format_map() — Форматирование строки с помощью словаря
Python String index() — Возвращает индекс подстроки
Python String isalnum() — Проверка буквенно-цифровых символов
Python String isalpha() -Проверка, являются ли все символы алфавитными буквами
Python String isdecimal()-Проверка десятичных символов
Python String isdigit() — Проверка цифровых символов
Python String islower() -Проверка, являются ли все символы строчными
Python String isnumeric()-Проверяет цифровые символы
Python String lower() — Возвращает строку в нижнем регистре
Python String replace() — Заменяет подстроку внутри строки
Python String strip() -Удаляет как начальные, так и конечные символы
Python String split() — Разделяет строку слева
Python String isidentifier() — Проверка идентификатора
Python String isprintable() — Проверяет, является ли символ печатаемым
Python String isspace() — Проверка пробелов
Python String istitle() — Проверка наличия строки с заголовком
Python String ljust() — Выравнивает строку по левому краю, по заданной ширине
Python String lstrip() — Удаляет Ведущие Символы
Python String maketrans() -Возвращает словарь с подменой
Python String partition() — Возвращает кортеж
Python String expandtabs()— Заменяет символ Табуляции Пробелами
Python String rfind() — Возвращает самый высокий индекс подстроки
Python String rindex() — Возвращает Наивысший индекс подстроки
Python String rjust() — Возвращает строку с выравниванием по правому краю заданной ширины
Python String rpartition() — Возвращает кортеж
Python String rsplit() — Разделяет строку Справа
Python String rstrip() — Удаляет завершающие символы
Python String splitlines() — Разбивает строку по границам строк
Python String startswith() — Проверяет, начинается ли строка с указанной строки
Python String swapcase() -Заменяет прописные символы на строчные; наоборот
Python String title() -Возвращает строку в заголовке
Python String translate()— Возвращает сопоставленную строку с символами
Python String upper() — Возвращает строку в верхнем регистре
Python String zfill() — Возвращает Копию Строки, заполненную Нулями
Метод разделения строки Python
❮ Строковые методы
Пример
Разбить строку на список, где каждое слово является элементом списка:
txt = «добро пожаловать в джунгли»
x = txt. split()
split()
print(x)
Попробуйте сами »
Определение и использование
Метод split() разбивает строку на
список.
Вы можете указать разделитель, по умолчанию разделителем является любой пробел.
Примечание: Если указано значение maxsplit, список будет содержать указанное количество элементов плюс один .
Синтаксис
string .split( разделитель, maxsplit )
Значения параметров
| Параметр | Описание |
|---|---|
| сепаратор | Дополнительно. Указывает разделитель, используемый при разделении строки. По умолчанию любой пробел является разделителем |
| макссплит | Дополнительно. Определяет, сколько разбиений нужно сделать. Значение по умолчанию равно -1, т.е. «все вхождения» |
Другие примеры
Пример
Разделите строку, используя запятую и пробел в качестве разделителя:
txt = «привет, меня зовут Петр, мне 26 лет»
x = txt. split(«, «)
split(«, «)
print(x)
Попробуйте сами »
Пример
Использовать решетку в качестве разделителя:
txt = «apple#banana#cherry#orange»
x = txt.split(«#»)
print(x)
Попробуйте сами »
Пример
Разбить строку на список, содержащий не более 2 элементов :
txt = «apple#banana#cherry#orange»
# установка параметра maxsplit
к 1, вернет список с 2 элементами!
x = txt.split(«#», 1)
print(x)
Попробуйте сами »
❮ Строковые методы
ВЫБОР ЦВЕТА
Лучшие учебники
Учебник по HTMLУчебник по CSS
Учебник по JavaScript
Учебник How To
Учебник по SQL
Учебник по Python
Учебник по W3.CSS
Учебник по Bootstrap
Учебник по PHP
Учебник по Java
Учебник по C++
Учебник по jQuery
9003 Справочник по Tops
9003
Справочник по HTML
Справочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3. CSS
CSS
Справочник по Bootstrap
Справочник по PHP
Цвета HTML
Справочник по Java
Справочник по Angular
Справочник по jQuery
Основные примеры
Примеры HTMLПримеры CSS
Примеры JavaScript
Примеры How To Примеры
Примеры SQL
Примеры Python
Примеры W3.CSS
Примеры Bootstrap
Примеры PHP
Примеры Java
Примеры XML
Примеры jQuery
4 | О
W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения. Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания. Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования, куки-файлы и политика конфиденциальности.
Copyright 1999-2022 Refsnes Data. Все права защищены.
W3Schools работает на основе W3.CSS.
строковых методов Python, которые нужно знать
Строки Python содержат 47 методов. Это почти столько же строковых методов, сколько встроенных функций в Python!
Какие строковые методы следует изучить в первую очередь?
Это почти столько же строковых методов, сколько встроенных функций в Python!
Какие строковые методы следует изучить в первую очередь?
Существует около дюжины очень полезных строковых методов, которые стоит запомнить. Давайте рассмотрим самые полезные строковые методы , а затем кратко обсудим оставшиеся методы и почему они менее полезны.
Наиболее полезные строковые методы
Вот несколько десятков строковых методов Python, которые я рекомендую зафиксировать в памяти.
| Метод | Связанные методы | Описание |
|---|---|---|
присоединиться | Соединение итерируемых строк с помощью разделителя | |
сплит | Разделить | Разделить (по умолчанию с пробелами) на список строк |
заменить | Заменить все копии одной подстроки на другую | |
лента | R-полоска и L-полоска | Удалить пробелы в начале и в конце |
чехол | нижний и верхний | Возвращает нормализованную по регистру версию строки |
начинается с | Проверить, начинается ли строка с одной или нескольких других строк | |
заканчивается | Проверить, заканчивается ли строка одной или несколькими другими строками | |
линии разделения | Разделить на список строк | |
формат | Отформатировать строку (рассмотрите f-строку перед этим) | |
количество | Подсчитать, сколько раз встречается заданная подстрока | |
удалить префикс | Удалить данный префикс | |
удалить суффикс | Удалить указанный суффикс |
У вас может возникнуть вопрос: «Подождите, почему моего любимого метода нет в этом списке?»
Я кратко объясню остальные методы и мои мысли о них ниже. Но сначала давайте рассмотрим каждый из вышеперечисленных способов.
Но сначала давайте рассмотрим каждый из вышеперечисленных способов.
join
Если вам нужно преобразовать список в строку в Python, вам нужен метод string join .
>>> colors = ["фиолетовый", "синий", "зеленый", "оранжевый"] >>>joined_colors = ", ".join(цвета) >>> объединенные_цвета 'фиолетовый, синий, зеленый, оранжевый'
Метод join может объединить список строк в одну строку , но он также примет любые другие итерируемые строки.
>>> цифры = диапазон(10) >>> digit_string = "".join(str(n) для n в цифрах) >>> цифра_строка '0123456789'
split
Если вам нужно разбить строку на более мелкие строки на основе разделителя, вам нужен метод string split .
>>> время = "1:19:48"
>>> части = time.split(":")
>>> части
['1', '19', '48']
Разделителем может быть любая подстрока.
Мы разделяем на : выше, но мы также можем разделить на -> :
>>> graph = "A->B->C->D" >>> график.split("->") («А», «Б», «С», «Г»)
Обычно вы не хотите называть split пробелом:
>>> langston = "Он сохнет\nкак изюм на солнце?\n"
>>> langston.split(" ")
['Это', 'это', 'сухой', 'на\nподобный', 'а', 'изюм', 'в', 'это', 'солнце?\n']
Разделение по символу пробела работает, но часто при разделении по пробелам на самом деле полезнее разделить по всем пробелам.
Вызов метода split никакие аргументы не будут разделены на любые последовательные пробельные символы:
>>> langston = "Он сохнет\nкак изюм на солнце?\n" >>> langston.split() ['Это', 'это', 'сухой', 'вверху', 'как', 'а', 'изюм', 'в', 'то', 'солнце?']
Обратите внимание, что разделяет без каких-либо аргументов, а также удаляет начальные и конечные пробелы.
Есть еще одна особенность split , которую люди иногда упускают из виду: аргумент maxsplit .
При вызове split со значением maxsplit Python разделит строку на несколько раз. Это удобно, когда вас интересует только первые одно или два вхождения разделителя в строку:
Это удобно, когда вас интересует только первые одно или два вхождения разделителя в строку:
>>> line = "Резиновая уточка|5|10"
>>> item_name, the_rest = line.split("|", maxsplit=1)
>>> имя_элемента
'Резиновая утка'
Если вам нужна последняя пара вхождений разделителя, вы можете вместо этого использовать метод строки rsplit :
>>> the_rest, amount = line.rsplit("|", maxsplit=1 )
>>> сумма
«10»
За исключением вызова метода split без каких-либо аргументов, невозможно игнорировать повторяющиеся разделители или конечные/начальные разделители или одновременно поддерживать несколько разделителей.
Если вам нужна какая-либо из этих функций, вы захотите изучить регулярные выражения (в частности, вместо функции ).
replace
Нужно заменить одну подстроку (строку в строке) другой?
Вот для чего нужен метод замены строки на !
>>> message = "JavaScript прекрасен" >>> сообщение.заменить("JavaScript", "Python") «Питон прекрасен»
Метод replace также можно использовать для удаления подстрок, заменив их пустой строкой:
>>> message = "Python прекрасен!!!!"
>>> сообщение.заменить("!", "")
«Питон прекрасен»
Существует также необязательный аргумент count , если вы хотите заменить только первые вхождения N :
>>> message = "Python прекрасен!!!!"
>>> сообщение.заменить("!", "?", 2)
'Питон прекрасен??!!'
strip
Метод strip предназначен для удаления пробелов с начала и конца строки:
>>> text = """ ... Привет! ... Это многострочная строка. ... """ >>> текст '\nЗдравствуйте!\nЭто многострочная строка.\n' >>> stripped_text = text.strip() >>> stripped_text 'Здравствуйте!\nЭто многострочная строка.'
Если вам просто нужно удалить пробелы с конца строки (но не с начала), вы можете использовать метод rstrip :
>>> line = "Строка с отступом и конечными пробелами \n" >>> строка.rstrip() 'Строка с отступом и пробелами в конце'
А если вам нужно удалить пробелы с самого начала, вы можете использовать метод lstrip :
>>> line = "Строка с отступом и конечными пробелами \n" >>> строка.lstrip() 'Строка с отступом и пробелами в конце \n'
Обратите внимание, что по умолчанию strip , lstrip и rstrip удаляют все пробельные символы (пробел, табуляцию, новую строку и т. д.).
Вы также можете указать конкретный символ для удаления.
Здесь мы удаляем все завершающие символы новой строки, но оставляем остальные пробелы нетронутыми:
>>> line = "Line 1\n"
>>> строка
'Строка 1\n'
>>> строка.rstrip("\n")
'Линия 1'
Обратите внимание, что полоска , полоска lполоска и полоска rstrip также примет строку из нескольких символов для удаления.
>>> words = ['Я', 'наслаждаюсь', 'Python!', 'Делаю', 'ты?', 'Я', 'надеюсь', 'так.'] >>> [w.strip(".!?") для w прописью] ['Я', 'наслаждаюсь', 'Питон', 'Делай', 'ты', 'я', 'надеюсь', 'так']
Передача нескольких символов удалит все этих символов, но они будут рассматриваться как отдельные символы (а не как подстрока).
Если вам нужно удалить многосимвольную подстроку вместо отдельных символов, см. removesuffix и removeprefix ниже.
футляр
Нужно перевести строку в верхний регистр?
Для этого есть метод upper :
>>> name = "Trey" >>> имя.верхнее() ТРЕЙ
Нужно перевести строку в нижний регистр?
Для этого есть нижний метод :
>>> name = "Trey" >>> имя.нижнее() 'трей'
Что делать, если вы пытаетесь выполнить сравнение строк без учета регистра?
Вы можете строчными или прописными буквами все ваши строки для сравнения.
Или вы можете использовать строку casefold method:
>>> name = "Trey" >>> "т" в имени ЛОЖЬ >>> "t" в name.casefold() Истинный
Но подождите, разве чехол не то же самое, что нижний ?
>>> имя = "Трей" >>> имя.casefold() 'трей'
Почти.
Если вы работаете с символами ASCII, метод casefold делает то же самое, что и метод string lower .
Но если у вас есть символы, отличные от ASCII (см. кодировку символов Unicode в Python), есть около символов, которые casefold обрабатывает однозначно.
Существует несколько сотен символов, которые нормализуются по-разному в методах нижнего и casefold .
Если вы работаете с текстом, использующим международный фонетический алфавит, или с текстом, написанным на греческом, кириллице, армянском, чероки и многих других языках, вам, вероятно, следует использовать casefold вместо нижний .
Имейте в виду, что портфель 9Однако 0022 не решает всех проблем с нормализацией текста. В Python можно представлять одни и те же данные несколькими способами, поэтому вам нужно изучить нормализацию данных Unicode и модуль Python
В Python можно представлять одни и те же данные несколькими способами, поэтому вам нужно изучить нормализацию данных Unicode и модуль Python unicodedata , если вы думаете, что будете часто сравнивать текст, отличный от ASCII.
начинается с
Метод строки начинается с может проверить, является ли одна строка префиксом другой строки :
>>> property_id = "UA-1234567"
>>> property_id.startswith("UA-")
Истинный
Альтернативой , начинающейся с , является нарезка большей строки и проверка на равенство:
>>> property_id = "UA-1234567" >>> префикс = "UA-" >>> property_id[:len(префикс)] == префикс Истинный
Это работает, но неудобно.
Вы также можете быстро проверить, начинается ли одна строка со многих разных подстрок , передав кортеж подстрок в начинается с .
Здесь мы проверяем, начинается ли каждая строка в списке с гласной, чтобы определить, следует ли использовать артикль «an» или «a»:
>>> имена = ["Go", "Эликсир", "OCaml", "Rust"] >>> для имени в именах: ... если name.startswith(("A", "E", "I", "O", "U")): ... print(f"Программа {имя}") ... еще: ... print(f"Программа {имя}") ... Программа Го Эликсирная программа Программа OCaml Программа на Rust
Обратите внимание, что начинается с , возвращает Истина , если любые , если строка начинается с любых заданных подстрок.
Многие опытные программисты Python часто упускают из виду тот факт, что , начинающийся с , будет принимать либо одну строку, либо , либо , кортеж строк.
endwith
Метод endwith может проверить, является ли одна строка суффиксом другой строки .
Метод строки заканчивается работает почти так же, как метод начинается с .
Работает с одной строкой:
>>> filename = "3c9a9fd05f404aefa92817650be58036.min.js"
>>> имя_файла.заканчивается(".min.js")
Истинный
Но он также принимает кортеж строк:
>>> filename = "3c9a9fd05f404aefa92817650be58036.min.js" >>> имя_файла.заканчивается((".min.js", ".min.css")) Истинный
Точно так же, как если начинается с , когда заканчивается и получает кортеж, он возвращает True , если наша строка заканчивается на любых строк в этом кортеже.
splitlines
Метод splitlines специально предназначен для разделения строк на строки.
>>> text = "Я Никто! Кто ты?\nТы тоже Никто?" >>> text.splitlines() ["Я Никто! Кто ты?", "Ты - Никто - тоже?"]
Зачем делать отдельный метод только для разбиения на строки?
Не могли бы мы вместо этого просто использовать метод split с \n ?
>>> text.split("\n")
["Я Никто! Кто ты?", "Ты - Никто - тоже?"]
Хотя в некоторых случаях это работает, иногда символы новой строки обозначаются цифрой 9.0021 \r\n или просто \r вместо \n .
Если вы точно не знаете, какие окончания строк используются в вашем тексте, разделительные линии могут оказаться удобными.
>>> text = "Может быть, он просто провисает\r\nкак тяжелый груз.\r\nИли он взрывается?"
>>> text.split("\n")
['Может, просто провисает\r', 'как тяжелый груз.\r', 'Или взрывается?']
>>> text.splitlines()
['Может быть, он просто провисает', 'как тяжелый груз.', 'Или он взрывается?']
Но есть еще более важная причина использовать splitlines : текст довольно часто заканчивается завершающим символом новой строки.
>>> zen = "Плоский лучше, чем вложенный.\nРазреженный лучше, чем плотный.\n"
Метод splitlines удалит конечный символ новой строки, если он его найдет, тогда как метод split разделит этот конечный символ новой строки, что даст нам пустую строку в конце (скорее всего, это не то, что мы на самом деле хотим при разделении на строки ).
>>> зен.split("\n")
['Плоский лучше, чем вложенный.', 'Разреженный лучше, чем плотный.', '']
>>> zen.splitlines()
['Плоский лучше, чем вложенный.', 'Разреженный лучше, чем плотный. ']
']
В отличие от split , метод splitlines также может разделять строки, сохраняя существующие окончания строк, указав keepends=True :
>>> zen.splitlines(keepends=True) ['Плоский лучше, чем вложенный.\n', 'Разреженный лучше, чем плотный.\n']
При разбиении строк на строки в Python я рекомендую использовать splitlines вместо split .
Формат Python 9Метод 0022 используется для форматирования строк (он же интерполяция строк).
>>> version_message = "Требуется версия {версия} или выше."
>>> print(version_message.format(version="3.10"))
Требуется версия 3.10 или выше
F-строки Python были развитием метода формата .
>>> имя = "Трей"
>>> print(f"Здравствуйте, {имя}! Добро пожаловать в Python.")
Привет, Трей! Добро пожаловать в Python.
Можно подумать, что 9Метод 0021 формата не имеет большого применения сейчас, когда f-строки уже давно являются частью Python. Но метод формата
Но метод формата удобен для случаев, когда вы хотите определить строку шаблона в одной части кода, а использовать эту строку шаблона в другой части.
Например, мы можем определить строку для форматирования в верхней части модуля, а затем использовать эту строку позже в нашем модуле:
BASE_URL = "https://api.stackexchange.com/2.3/questions /{идентификаторы}?сайт={сайт}"
# Здесь больше кода
question_ids = ["33809864", "2759323", "9321955"]
url_for_questions = BASE_URL.format(
сайт = "переполнение стека",
ids=";".join(question_id),
)
Мы предварительно определили нашу строку шаблона BASE_URL , а затем использовали ее для создания действительного URL-адреса с помощью метода формата .
count
Метод string count принимает подстроку и возвращает количество раз, которое эта подстрока встречается в нашей строке:
>>> time = "3:32"
>>> время.счет(":")
1
>>> время = "2:17:48"
>>> время. счет(":")
2
счет(":")
2
Вот и все. Метод count довольно прост.
Обратите внимание, что если вам не важно фактическое число, а вместо этого важно, больше ли количество 0 :
has_underscores = text.count("_") > 0
Вам не нужен метод подсчета .
Почему?
Потому что оператор Python в — лучший способ проверить, содержит ли строка подстроку:
has_underscores = "_" в тексте
Это имеет дополнительное преимущество, заключающееся в том, что оператор в остановится, как только найдет совпадение, тогда как count всегда должен перебирать всю строку.
removeprefix
Метод removeprefix удалит необязательный префикс из начала строки.
>>> hex_string = "0xfe34"
>>> hex_string.removeprefix("0x")
'fe34'
>>> шестнадцатеричная_строка = "ac6b"
>>> hex_string.removeprefix("0x")
'ac6b'
Метод removeprefix был добавлен в Python 3. 9.
До
9.
До removeprefix было принято проверять, начинается ли строка с префикса , а затем удалять ее с помощью нарезки:
if hex_string.startswith("0x"):
шестнадцатеричная_строка = шестнадцатеричная_строка[len("0x"):]
Теперь вместо этого можно просто использовать removeprefix :
hex_string = hex_string.removeprefix("0x")
Метод removeprefix немного похож на lstrip , за исключением того, что lstrip удаляет одиночные символы из конца строки и удаляет столько символов, сколько находит.
Итак, пока это удалит все ведущие символы v из начала строки:
>>> a = "v3.11.0"
>>> a.lstrip("v")
«3.11.0»
>>> б = "3.11.0"
>>> b.lstrip("v")
«3.11.0»
>>> с = "vvv3.11.0"
>>> c.lstrip("v")
«3.11.0»
Это удалит не более один v с начала строки:
>>> a = "v3.11.0"
>>> a.removeprefix("v")
«3.11.0»
>>> б = "3. 11.0"
>>> b.lstrip("v")
«3.11.0»
>>> с = "vvv3.11.0"
>>> c.removeprefix("v")
"вв3.11.0"
11.0"
>>> b.lstrip("v")
«3.11.0»
>>> с = "vvv3.11.0"
>>> c.removeprefix("v")
"вв3.11.0"
removesuffix
Метод removesuffix удалит необязательный суффикс с конца строки.
>>> time_readings = ["0", "5 сек", "7 сек", "1", "8 сек"]
>>> new_readings = [t.removesuffix(" сек") для t в time_readings]
>>> новые_показания
['0', '5', '7', '1', '8']
Делает почти то же самое, что и removeprefix , за исключением того, что удаляет с конца, а не с начала.
Изучите эти методы позже
Сегодня я бы не стал запоминать эти строковые методы, но вы могли бы со временем изучить их.
| Метод | Связанные методы | Описание |
|---|---|---|
кодировать | Кодировать строку до байт объект | |
найти | найти | Возвращает индекс подстроки или -1 , если не найдено |
индекс | индекс | Возвращает индекс подстроки или повышает ValueError |
название | с большой буквы | Заглавная строка |
раздел | рраздел | Разделение на 3 части на основе разделителя |
просто | справа и по центру | Выравнивание строки по левому/правому/центру |
заполнение | Дополнить числовую строку нулями (до ширины) | |
идентификатор | Проверить, является ли строка допустимым идентификатором Python |
Вот почему я не рекомендую записывать каждый из них в память:
-
encode: обычно вы можете избежать ручного кодирования строк, но вы обнаружите этот метод по необходимости, когда не сможете (см. преобразование между двоичные данные и строки в Python)
преобразование между двоичные данные и строки в Python) -
findиrfind: мы редко заботимся о поиске индексов подстрок: обычно нам нужно включение (например, мы используем'y' в именивместоимя.найти('у') != -1) -
indexиrindex: они вызывают исключение, если данный индекс не найден, поэтому эти методы редко используются -
titleииспользовать заглавные буквы: методtitleне всегда работает так, как вы ожидаете (см. Заглавие строки в Python), аиспользовать заглавные буквытолько с заглавной буквы -
разделиrpartition: это может быть очень удобно при разделении при проверке 9 модификаторы форматирования строки вместо этого (см. строки форматирования) -
zfill: этот метод заполняет строки нулями, чтобы сделать их определенной ширины, и я обычно предпочитаю использовать форматирование строки для заполнения нулями (см. Заполнение нулями при форматировании строки)
Заполнение нулями при форматировании строки) -
isidentifier: это ниша, но она полезна для проверки того, что строка является действительным идентификатором Python, хотя обычно для этого требуется сочетание сkeyword.iskeyword, чтобы исключить ключевые слова Python
Альтернативы регулярным выражениям
Эти методы используются для вопросов о ваших строках.
Большинство из них задают вопрос о через каждые символов в строке, за исключением метода istitle .
| Метод | Связанные методы | Описание |
|---|---|---|
Десятичный | — цифра и — цифра | Проверить, представляет ли строка число |
исасский | Проверить, все ли символы ASCII | |
для печати | Проверить, все ли символы печатаются | |
isspace | Проверить, состоит ли строка полностью из пробелов | |
исальфа | нижний и верхний | Проверить, содержит ли строка только буквы |
Изальнум | Проверить, содержит ли строка буквы или цифры | |
название | Проверить, введена ли строка в заглавном регистре |
Эти методы могут быть полезны в очень специфических обстоятельствах. Но когда вы задаете такого рода вопросы, использование регулярного выражения может быть более подходящим.
Но когда вы задаете такого рода вопросы, использование регулярного выражения может быть более подходящим.
Также имейте в виду, что эти методы не всегда могут работать так, как вы ожидаете.
Все isdigit , isdecimal и isnumeric соответствуют более чем просто 0 до 9 и ни одно из них не соответствует - или . .
Метод isdigit соответствует всему, что соответствует isdecimal и больше, а метод isnumeric соответствует всему, чему соответствует isdecimal плюс больше.
Таким образом, пока только isnumeric соответствует ⅷ , isdigit и isnumeric соответствует ⓾ , и все они совпадают с ۸ .
Вам, скорее всего, не нужны эти методы
Эти 5 методов довольно редко встречаются:
-
expandtabs: конвертировать символы табуляции в пробелы (количество пробелов, необходимое для перехода к следующей 8-символьной позиции табуляции) -
swapcase: преобразовать верхний регистр в нижний и нижний регистр в верхний -
format_map: вызовmy_string.аналогичен format_map(mapping)
format_map(mapping) my_string.format(**отображение) -
maketrans: создать словарь, отображающий кодовые точки символов между ключами и значениями (для передачи наstr.translate) -
перевести: сопоставить всю одну кодовую точку с другой в данной строке
Узнайте, что вам нужно
Строки Python содержат тонн методов. На самом деле не стоит запоминать их все: поберегите время для чего-нибудь более полезного.
Запоминать все это пустая трата времени, вместо стоит зафиксировать в памяти более полезные строковые методы. Если метод будет полезен почти каждую неделю, зафиксируйте его в памяти.
Я рекомендую запомнить самые полезные строковые методы Python, примерно в таком порядке:
-
join: Соединить итерацию строк с помощью разделителя -
split: Разделить (по умолчанию с пробелами) на список строк -
заменить: заменить все копии одной подстроки на другую -
полоса: Удалить пробелы в начале и в конце -
casefold(илиниже, если хотите): возвращает версию строки , нормализованную по регистру.
