Исправление ошибок в ПУД 2022: что важно знать вашему бухгалтеру
Содержание
- Что должно быть в первичном документе?
- Какие ошибки можно не исправлять?
- Ошибки, подлежащие исправлению
- Как исправить ПУД?
- Исправлять ПУД можно несколькими способами
Что должно быть в первичном документе?
Каждый факт хозяйственной жизни подлежит оформлению первичным учетным документом (далее — ПУД). Не допускается принятие к бухгалтерскому учету документов, которыми оформляются не имевшие места факты хозяйственной жизни, в том числе лежащие в основе мнимых и притворных сделок. ПУД должен быть составлен при совершении факта хозяйственной жизни, а если это не представляется возможным — непосредственно после его окончания.
Бухгалтерский учет и налоговый учет экономическими субъектами ведется на основании ПУД, которые (включая справку бухгалтера) являются подтверждением их данных. Документы, подтверждающие «налоговые» расходы, произведенные на территории РФ, также должны быть оформлены в соответствии с требованиями бухучета, в том числе, содержать обязательные реквизиты, предусмотренные ч. 2 ст. 9 Закона N 402-ФЗ (ст. 313, п. 1 ст. 252 НК РФ, письма Минфина России от 17.01.2022 N 03-03-06/1/1880, от 03.08.2021 N 03-03-06/1/62194, от 31.05.2018 N 03-07-11/37134, от 14.05.2018 N 03-03-06/1/31933).
В ч. 2 ст. 9 Закона N 402-ФЗ перечислены обязательные реквизиты ПУД:
- наименование документа;
- дата составления документа;
- наименование экономического субъекта, составившего документ;
- содержание факта хозяйственной жизни;
- величина натурального и (или) денежного измерения факта хозяйственной жизни с указанием единиц измерения;
- наименование должности лица (лиц), совершившего (совершивших) сделку, операцию и ответственного (ответственных) за ее оформление, либо наименование должности лица (лиц), ответственного (ответственных) за оформление свершившегося события;
- подписи лиц, предусмотренных п.
 6 ч. 2 ст. 9 Закона N 402-ФЗ, с указанием их фамилий и инициалов либо иных реквизитов, необходимых для идентификации этих лиц.
6 ч. 2 ст. 9 Закона N 402-ФЗ, с указанием их фамилий и инициалов либо иных реквизитов, необходимых для идентификации этих лиц.
В разделе II ФСБУ 27/2021 более подробно разъясняется оформление первичных документов в разных ситуациях, например:
- даты составления документа;
- особенности оформления электронных документов;
- особенности при получении документов на иностранном языке;
- оформление длящихся фактов хозяйственной жизни.
Например, согласно п.12 ФСБУ 27/2021 организация может включать в документ бухгалтерского учета реквизиты, являющиеся дополнительными к обязательным реквизитам, установленным ч. 2 ст. 9 Закона N 402-ФЗ.
Если ПУД не отвечает требованиям ст. 9 Закона N 402-ФЗ (например, в нем отсутствуют обязательные реквизиты, содержатся недостоверные или неполные сведения) и, тем самым, не подтверждает факты реального совершения хозяйственных операций или не позволяет однозначно и полно их идентифицировать, организации может быть отказано в вычете НДС и учете расходов для целей налогообложения (постановление Арбитражного суда Уральского округа от 09. 03.2022 N Ф09-309/22 по делу N А50-2666/2021, постановление Двадцатого арбитражного апелляционного суда от 10.04.2018 N 20АП-669/18 (оставлено без изменения постановлением Арбитражного суда Центрального округа от 13.08.2018 N Ф10-2834/18 по делу N А09-213/2017, Пятнадцатого арбитражного апелляционного суда от 20.09.2017 N 15АП-8584/17).
03.2022 N Ф09-309/22 по делу N А50-2666/2021, постановление Двадцатого арбитражного апелляционного суда от 10.04.2018 N 20АП-669/18 (оставлено без изменения постановлением Арбитражного суда Центрального округа от 13.08.2018 N Ф10-2834/18 по делу N А09-213/2017, Пятнадцатого арбитражного апелляционного суда от 20.09.2017 N 15АП-8584/17).
Кроме того, ошибки в ПУД могут повлечь искажения данных бухгалтерского и налогового учета и налоговые риски.
Какие ошибки можно не исправлять?
При выявлении в ПУД ошибок (недостоверных сведений) стороны обязаны внести исправления в первичные документы в целях их достоверности (п. 30 ФСБУ 27/2021, постановления Десятого арбитражного апелляционного суда от 09.04.2018 N 10АП-20651/17, от 16.01.2015 N 10АП-14763/2014 по делу N А41-53651/14, ФАС Московского округа от 17.06.2013 по делу N А41-13545/12).
Между тем, Минфин России разъясняет, что в случае, если ошибки в ПУД не связаны с обязательными реквизитами, указанными в ч. 2 ст. 9 Закона N 402-ФЗ, то такие ошибки можно не исправлять.
Финансовое ведомство отмечает, что ошибки в первичных учетных документах, которые не мешают налоговым органам при проведении налоговой проверки идентифицировать
- продавца, покупателя товаров (работ, услуг), имущественных прав,
- наименование товаров (работ, услуг), имущественных прав,
- стоимость товаров (работ, услуг), имущественных прав,
- другие обстоятельства документируемого факта хозяйственной жизни, обуславливающие применение соответствующего порядка налогообложения,
не являются основанием для отказа в принятии соответствующих расходов в уменьшение налоговой базы по налогу на прибыль (Письмо Минфина России от 04.02.2015 N 03-03-10/4547 направлено ФНС для сведения и использования в работе налоговыми органами, а также для доведения до сведения налогоплательщиков (письмо ФНС России от 12.02.2015 N ГД-4-3/2104@)). Соответственно исправлять такие ошибки не обязательно.
Таким образом, по мнению автора, при обнаружении ошибок в ПУД необходимость их исправления должна устанавливаться самими хозяйствующими субъектами в зависимости от того, насколько грубыми они являются, и исходя из их возможности повлечь неблагоприятные налоговые последствия для сторон сделки.
Ошибки, подлежащие исправлению
К ситуациям, когда ошибки в оформлении ПУД подлежат обязательному исправлению, на наш взгляд, можно отнести следующие случаи:
- Ошибки в ПУД привели к искажению в бухгалтерском и (или) налоговом учете, и у хозяйствующего субъекта возникает необходимость (обязанность) вносить исправления в учет. В этом случае исправление ошибок в учет должно вносится на основании, в том числе исправленных ПУД.
- ПУД не содержит обязательных реквизитов, предусмотренных ч. 2 ст. 9 Закона N 402-ФЗ, или содержит в качестве этих реквизитов некорректные сведения, что не позволяет однозначно и полно установить содержание факта хозяйственной жизни.
- ПУД не содержит реквизитов (содержит некорректные реквизиты), прямо не предусмотренных ч. 2 ст. 9 Закона N 402-ФЗ, но ключевых для определения фактических обстоятельств и реальности хозяйственной операции.
Как исправить ПУД?
Законодательство РФ исходит из того, что в ПУД допускаются исправления, кроме кассовых и банковских документов. Исправление в ПУД должно содержать дату исправления, а также подписи лиц, составивших документ, в котором произведено исправление, с указанием их фамилий и инициалов либо иных реквизитов, необходимых для идентификации этих лиц (ч. 7 ст. 9 Закона N 402-ФЗ, раздел III ФСБУ 27/2021, п. 16 Положения по ведению бухгалтерского учета и бухгалтерской отчетности в РФ, утвержденного приказом Минфина России от 29.07.1998 N 34н, п. 4.7 Указания Банка России 11.03.2014 N 3210-У).
Исправление в ПУД должно содержать дату исправления, а также подписи лиц, составивших документ, в котором произведено исправление, с указанием их фамилий и инициалов либо иных реквизитов, необходимых для идентификации этих лиц (ч. 7 ст. 9 Закона N 402-ФЗ, раздел III ФСБУ 27/2021, п. 16 Положения по ведению бухгалтерского учета и бухгалтерской отчетности в РФ, утвержденного приказом Минфина России от 29.07.1998 N 34н, п. 4.7 Указания Банка России 11.03.2014 N 3210-У).
Исправлять ПУД можно несколькими способами
1) Путем внесения исправлений в первоначальный документ — для исправления бумажных документов (п. 21 ФСБУ 27/2021).
В этом случае зачеркивается неправильный текст или суммы и надписывается над зачеркнутым исправленный текст или суммы. Зачеркивание производится одной чертой так, чтобы можно было прочитать исправленное. Исправление ошибки в первичном документе должно быть оговорено надписью «исправлено», подтверждено подписью лиц, подписавших документ, а также проставлена дата исправления.
2) Путем составления правильно заполненного (исправленного) документа дополнительно к документу с ошибкой — для исправления электронных документов (п. 20 ФСБУ 27/2021, приказы ФНС России от 30.11.2015 N ММВ-7-10/552@, от 30.11.2015 N ММВ-7-10/551@).
Исправления вносятся путем составления нового электронного документа, в котором указывается номер и дата документа, составленного до внесения в него исправлений, а также порядковый номер и дата исправления.
При этом новый (исправленный) документ должен содержать указание, что он составлен взамен первоначального, а также дату исправления и электронные подписи ответственных лиц. Средства воспроизведения нового (исправленного) электронного документа должны обеспечить невозможность использования его отдельно от первоначального электронного документа.
Обратите внимание! Заменить ПУД с ошибками новым документом нельзя (письма Минфина России от 23.10.2017 N 03-03-10/69280, ФНС России от 12. 01.2018 N СД-4-3/264), т.е. нельзя выбросить неправильно заполненный документ и вместо него подложить новый.
01.2018 N СД-4-3/264), т.е. нельзя выбросить неправильно заполненный документ и вместо него подложить новый.
Порядок исправления ошибок в первичных документах стороны сделки вправе определить самостоятельно.
Исправления в ПУД должны быть заверены представителями сторон, участвовавшими в составлении этого документа.
При исправлении ПУД, оформленных в нескольких экземплярах, исправления нужно внести в каждый из них, в том числе в экземпляры, находящиеся у контрагентов Внесение исправлений в ПУД в одностороннем порядке не допускается и нарушение данного правила может привести, в частности, к тому, что такие документы не будут приняты в качестве документального подтверждения расходов (Постановление Девятого арбитражного апелляционного суда от 02.06.2022 N 09АП-24907/2022-ГК по делу N А40-253174/2021, Постановления Десятого арбитражного апелляционного суда от 09.04.2018 N 10АП-20651/17, от 16.01.2015 N 10АП-14763/14, Первого арбитражного апелляционного суда от 30.06.2015 N 01АП-3125/15, Четвертого арбитражного апелляционного суда от 18. 02.2015 N 04АП-6483/14, Постановления ФАС Уральского округа от 01.04.2013 N Ф09-1090/13 по делу N А76-283/2012).
02.2015 N 04АП-6483/14, Постановления ФАС Уральского округа от 01.04.2013 N Ф09-1090/13 по делу N А76-283/2012).
Если ошибки в ПУД привели к искажению данных бухгалтерского и налогового учета, то необходимо внести исправления в налоговые и бухгалтерские регистры путем отражения сторнировочной записи (на ту же сумму, что и ошибочная, но со знаком минус) (п. 22 ФСБУ 27/2021), а при необходимости представить уточненные налоговые декларации.
О внесении исправлений в бухгалтерскую отчетность в 2022 подробнее здесь >>
Своевременное выявление и исправление ошибок в бухгалтерских документах поможет избежать штрафов и дополнительного внимания к компании со стороны государственных органов. А проведение системного комплексного аудита с юридической поддержкой и действительно работающей страховкой от налоговых претензий даст финансовую защиту компании от налоговых доначислений.
Исправление ошибок в первичных документах
Не ошибается только тот, кто ничего не делает. У бухгалтера работа всегда кипит. Особенно в период изменений в законодательстве и введения новых правил в налогообложении. Как же исправить ошибки, которые закрались в первичных документах? Давайте остановимся на корректурном способе
У бухгалтера работа всегда кипит. Особенно в период изменений в законодательстве и введения новых правил в налогообложении. Как же исправить ошибки, которые закрались в первичных документах? Давайте остановимся на корректурном способе
Бухгалтерская ошибка
Определение бухгалтерской ошибки не стоит искать — его нет ни в Нацстандартах, ни в Законе о бухучете. Однако и без этого бухгалтеры прекрасно понимают его значение. В частности, это — некорректное отражение корреспонденции счетов, указание не той суммы или проведение не той суммы либо не в том периоде, или же неотражение хозяйственной операции вообще и пр.
Международные стандарты предоставляют определение ошибок предыдущих периодов (§ 5 МСБУ 8 «Учетная политика, изменения в бухгалтерских оценках и ошибки»):
«Ошибки предыдущих периодов — пропуски или искажения в финансовой отчетности предприятия за один или несколько предыдущих периодов, возникающие из-за неиспользования или злоупотребления достоверной информацией, которая:
а) присутствовала, когда финансовая отчетность за те периоды была утверждена к выпуску;
б) по обоснованному предположению могла быть получена и учтена при составлении и предоставлении данной финансовой отчетности.
Такие ошибки могут быть ошибками в математических подсчетах, в применении учетной политики, ошибками, допущенными вследствие недосмотра или неправильной интерпретации фактов, а также из-за мошенничества».
Например…
У бухгалтера не было сведений о ликвидации дебитора, и, соответственно, задолженность такого контрагента не перешла к разряду безнадежной, а так и числилась на балансе. Хотя информация в бухгалтерии отстутствовала, однако то, что дебиторская задолженность должника, который ликвидировался, не была списана своевременно, — бухгалтерская ошибка. С «обоснованной ожидаемостью» информацию о ликвидации контрагента предприятие могло проверить, и при составлении финотчетности учесть данный факт.
Или же в первичном документе из-за описки неправильно отражены сумма, название товара и т.п.
Вместе с тем нельзя считать ошибкой изменения в учетных оценках — скажем, что касается срока амортизации, метода амортизации, остаточной стоимости, ведь они основываются на предположениях.
К примеру, сначала установили срок использования основного средства 5 лет, а потом решили, что прослужит он и 10. Понятно, что такое продление срока не является ошибкой.
Ничего общего с ошибками не имеют и изменения в учетной оценке (разве что ретроспективное отражение, присущее обоим).
Бухгалтерская ошибка — искажение в бухгалтерских записях из-за неиспользования информации, которая была либо с достоверным предположением могла быть у предприятия для правильного отражения данных. Это и арифметические неточности (в частности, проводки не на ту сумму, описки), и отражение данных не в тех отчетных периодах, и методологические огрехи (например, начисление амортизации на объекты, которые не могут амортизироваться) и др. Безусловно, всех ошибок не перечесть.
Особенности исправления бухошибок в зависимости от периода их допущения
Правила исправления ошибок слишком зависят от периода их допущения (п.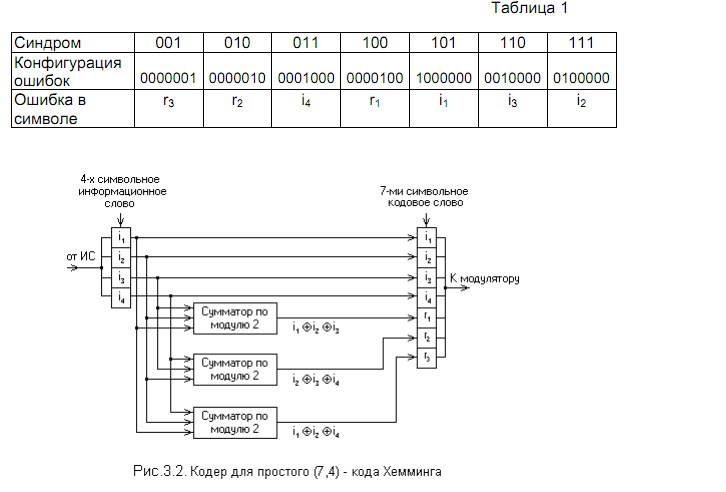 4 П(С)БУ 6 «Исправление ошибок и изменения в финансовых отчетах» и п. 4 Положения № 88 и п. 9 Методрекомендаций № 356). А именно: способ исправления ошибки зависит, когда была неточность — в прошлом году или текущей.
4 П(С)БУ 6 «Исправление ошибок и изменения в финансовых отчетах» и п. 4 Положения № 88 и п. 9 Методрекомендаций № 356). А именно: способ исправления ошибки зависит, когда была неточность — в прошлом году или текущей.
Отразим зависимость метода исправления ошибки от периода ее допущения в схеме.
Схема
Нажмите на картинку для просмотра в увеличенном виде
1 Промежуточный отчетный период — квартал, месяц (п. 1 р. ІІ НП(С)БУ 1 «Общие требования к финансовой отчетности»).
Следовательно, способ исправления зависит от сути ошибки и закрыт ли отчетный период, в котором она допущена. То есть — составлена ли и представлена ли финотчетность с ошибкой, неправильные ли записи содержатся только в первичных документах (например, из-за описки) и регистрах и на финотчетности еще не отразились. Более подробно об исправлениях читайте в материале «Исправление бухгалтерских ошибок».
Общие требования к исправлению ошибок в первичных документах
В тексте и цифровых данных первичных документов, учетных регистров и отчетов подчистки и необусловленные исправления не допускаются (п. 4.1 Положения № 88).
Заметим: не допускаются подправки или проведение уточнений в документах на ценные бумаги, кассовых, банковских документах (п. 4.5 Положения № 88).
Ошибки в первичных документах, созданных вручную, исправляются корректурным способом, то есть неправильный текст или цифры зачеркиваются, и над зачеркнутым надписывается правильный текст или цифры. Зачеркивание осуществляется одной чертой так, чтобы можно было прочесть исправленное (п. 4.2 Положения № 88).
Исправление ошибки должно быть обусловлено надписью «виправлено» и подтверждено подписями лиц на этом документе, с указанием даты исправления.
Важно
Если в первичном документе будут многочисленные исправления (дописки другим почерком и другими чернилами), такие документы могут не принять во внимание ни контролирующие, ни судебные органы. То есть эти документы могут признать недостоверными (см., например, постановление Тячевского районного суда Закарпатской области от 07.10.2013 г. по делу № 307/2787/13-а, постановление Львовского апелляционного админсуда от 20.08.2015 г. по делу № 876/12980/13).
То есть эти документы могут признать недостоверными (см., например, постановление Тячевского районного суда Закарпатской области от 07.10.2013 г. по делу № 307/2787/13-а, постановление Львовского апелляционного админсуда от 20.08.2015 г. по делу № 876/12980/13).
Исправление ошибок в документах и регистрах, созданных в форме электронного документа, осуществляется в соответствии с законодательством (п. 4.6 Положения № 88). Правда, порядок и правила, регулирующие исправления электронных первичных документов, пока отсутствуют.
А как же исправить ошибку в первичном документе, созданном машинным способом? Мы считаем, подход здесь такой же, как и к исправлению ошибок в первичных документах, созданных вручную.
Обратите внимание
Исправляя допущенную ошибку в первичном документе, рекомендуем соблюдать порядок для таких исправлений, предусмотренный законодательством (в частности, Положение № 88). Иначе, налоговики могут признать такой исправленный документ недостоверным (см., например, постановление ВАСУ от 05.10.2011 г. по делу № А38/29-07, решение № К-1123/08).
Иначе, налоговики могут признать такой исправленный документ недостоверным (см., например, постановление ВАСУ от 05.10.2011 г. по делу № А38/29-07, решение № К-1123/08).
Корректурный способ исправления
В первичном документе, регистре неправильную запись зачеркивают (не зарисовывают!) так, чтобы можно было прочитать зачеркнутое. Над зачеркнутым делают правильную запись (п.п. 4.1, 4.2 Положения № 88, п. 9 Методрекомендаций № 356). Около него пишут слово «виправлено», указывают дату исправления и расписываются все, кто составлял исправляемый документ, а также лицо, которое его исправляет (п. 4.4 Положения № 88).
Приведем пример.
Пример
Во время проведения списания основного средства в апреле 2016 года были оприходованы детали. В мае обнаружили арифметическую ошибку в сумме оприходованных активов.
Приведем образец исправления корректурным способом.
Фрагмент
Обратная сторона формы № ОС-3
Публикуется на языке оригинала
Нажмите на картинку для просмотра в увеличенном виде
При исправлении ошибок текущего периода оформлять бухгалтерскую справку не нужно. А вот во время исправления ошибок предыдущих периодов без нее не обойтись. Но это уже другая история и предмет отдельного разговора.
А вот во время исправления ошибок предыдущих периодов без нее не обойтись. Но это уже другая история и предмет отдельного разговора.
Редакция газеты
«Интерактивная бухгалтерия»
Исправление фактических ошибок для моделей абстрактного обобщения
Мэн Цао, Юэ Донг, Цзяпэн Ву, Джеки Чи Кит Чеунг
Abstract
Нейронные системы абстрактного суммирования достигли многообещающего прогресса благодаря наличию крупномасштабных наборов данных и моделей, предварительно обученных с помощью методов самоконтроля. Однако обеспечение фактической непротиворечивости генерируемых сводок для систем абстрактного обобщения является сложной задачей. Мы предлагаем модуль корректора постредактирования для решения этой проблемы путем выявления и исправления фактических ошибок в сгенерированных сводках. Модель нейронного корректора предварительно обучается на искусственных примерах, созданных путем применения ряда эвристических преобразований к эталонным сводкам. Эти преобразования вдохновлены анализом ошибок выходных данных современной модели суммирования.
- Идентификатор антологии:
- 2020.emnlp-main.506
- Том:
- Материалы конференции 2020 г. по эмпирическим методам обработки естественного языка (EMNLP)
- Месяц: 9 0011
- Ноябрь
- Год:
- 2020
- Адрес:
- Интернет
- Место проведения:
- EMNLP
- SIG:
- Издатель:
- Ассоциация компьютерной лингвистики
- Примечание:
- Страниц:
- 6251–6258
- Язык:
- URL:
- https://aclanthology.org/2020.emnlp-main.506
- DOI:
- 10 .
 18653/v1/2020.emnlp-main.506
18653/v1/2020.emnlp-main.506 - Bibkey:
- Cite (ACL):
- Мэн Цао, Юэ Донг, Цзяпэн Ву и Джеки Чи Кит Чунг. 2020. Исправление фактических ошибок для моделей абстрактного суммирования. В материалах конференции по эмпирическим методам обработки естественного языка (EMNLP) 2020 г., страницы 6251–6258, онлайн. Ассоциация компьютерной лингвистики.
- Процитируйте (неофициально):
- Исправление фактических ошибок для моделей абстрактного обобщения (Cao et al., EMNLP 2020)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2020.emnlp-main.506.pdf
- Видео:
- https://slideslive.com/38939120
- Код 9001 1
- mcao610/фактическая ошибка — Исправление
- BibTeX
- MODS XML
- Примечание
- Предварительно отформатировано
@inproceedings{cao-etal-2020-factual,
title = "Исправление фактических ошибок для моделей абстрактного суммирования",
автор = "Цао, Мэн и
Донг, Юэ и
Ву, Цзяпэн и
Чунг, Джеки Чи Кит",
booktitle = "Материалы конференции 2020 г. по эмпирическим методам обработки естественного языка (EMNLP)",
месяц = ноябрь,
год = "2020",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2020.emnlp-main.506",
doi = "10.18653/v1/2020.emnlp-main.506",
страницы = "6251--6258",
abstract = «Нейронные системы абстрактного суммирования достигли многообещающего прогресса благодаря наличию крупномасштабных наборов данных и моделей, предварительно обученных с помощью методов самоконтроля. Однако обеспечение фактической согласованности сгенерированных сводок для систем абстрактного суммирования является проблемой. Мы предлагаем модуль корректора постредактирования для решения этой проблемы путем выявления и исправления фактических ошибок в сгенерированных сводках. Модель нейронного корректора предварительно обучена на искусственных примерах, созданных путем применения серии эвристических преобразований к эталонным сводкам. Эти преобразования вдохновлен анализом ошибок выходных данных современной модели суммирования.
по эмпирическим методам обработки естественного языка (EMNLP)",
месяц = ноябрь,
год = "2020",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2020.emnlp-main.506",
doi = "10.18653/v1/2020.emnlp-main.506",
страницы = "6251--6258",
abstract = «Нейронные системы абстрактного суммирования достигли многообещающего прогресса благодаря наличию крупномасштабных наборов данных и моделей, предварительно обученных с помощью методов самоконтроля. Однако обеспечение фактической согласованности сгенерированных сводок для систем абстрактного суммирования является проблемой. Мы предлагаем модуль корректора постредактирования для решения этой проблемы путем выявления и исправления фактических ошибок в сгенерированных сводках. Модель нейронного корректора предварительно обучена на искусственных примерах, созданных путем применения серии эвристических преобразований к эталонным сводкам. Эти преобразования вдохновлен анализом ошибок выходных данных современной модели суммирования. Экспериментальные результаты показывают, что наша модель способна исправлять фактические ошибки в сводках, созданных другими моделями нейронного суммирования, и превосходит предыдущие модели по оценке фактической согласованности на CNN / DailyMail. набор данных. Мы также обнаружили, что переход от искусственного исправления ошибок к последующим настройкам по-прежнему очень сложен.",
}
Экспериментальные результаты показывают, что наша модель способна исправлять фактические ошибки в сводках, созданных другими моделями нейронного суммирования, и превосходит предыдущие модели по оценке фактической согласованности на CNN / DailyMail. набор данных. Мы также обнаружили, что переход от искусственного исправления ошибок к последующим настройкам по-прежнему очень сложен.",
}
<моды> <информация о заголовке> Исправление фактических ошибок для моделей абстрактного суммирования <название типа="личное">Мэн Цао <роль>автор <название типа="личное">Юэ Донг <роль>автор <название типа="личное">Цзяпэн Ву <роль>автор <название типа="личное">Джеки Чи Комплект Чунг <роль>автор <информация о происхождении>2020-11 текст <информация о заголовке> Материалы конференции 2020 года по эмпирическим методам обработки естественного языка (EMNLP) <информация о происхождении>Ассоциация компьютерной лингвистики <место>Онлайн публикация конференции Нейронные системы абстрактного суммирования достигли многообещающего прогресса благодаря наличию крупномасштабных наборов данных и моделей, предварительно обученных с помощью методов самоконтроля. Однако обеспечение фактической непротиворечивости генерируемых сводок для систем абстрактного обобщения является сложной задачей. Мы предлагаем модуль корректора постредактирования для решения этой проблемы путем выявления и исправления фактических ошибок в сгенерированных сводках. Модель нейронного корректора предварительно обучается на искусственных примерах, созданных путем применения ряда эвристических преобразований к эталонным сводкам. Эти преобразования вдохновлены анализом ошибок выходных данных современной модели суммирования. Экспериментальные результаты показывают, что наша модель способна исправлять фактические ошибки в сводках, созданных другими моделями нейронного суммирования, и превосходит предыдущие модели по оценке фактической согласованности в наборе данных CNN/DailyMail. Мы также обнаружили, что переход от искусственного исправления ошибок к последующим настройкам все еще очень сложен.
cao-etal-2020-factual 10. 18653/v1/2020.emnlp-main.506 <местоположение>
https://aclanthology.org/2020.emnlp-main.506 <часть> <дата>2020-11 <единица экстента="страница">6251 6258
%0 Материалы конференции Исправление фактических ошибок %T для моделей абстрактного суммирования % А Цао, Мэн %А Донг, Юэ %А Ву, Цзяпэн %A Cheung, Джеки Чи Кит %S Материалы конференции по эмпирическим методам обработки естественного языка (EMNLP) 2020 г. %D 2020 %8 ноябрь %I Ассоциация компьютерной лингвистики %С онлайн %F cao-etal-2020-factual %X Нейронные системы абстрактного суммирования достигли многообещающего прогресса благодаря наличию крупномасштабных наборов данных и моделей, предварительно обученных с помощью методов самоконтроля. Однако обеспечение фактической непротиворечивости генерируемых сводок для систем абстрактного обобщения является сложной задачей.Мы предлагаем модуль корректора постредактирования для решения этой проблемы путем выявления и исправления фактических ошибок в сгенерированных сводках. Модель нейронного корректора предварительно обучается на искусственных примерах, созданных путем применения ряда эвристических преобразований к эталонным сводкам. Эти преобразования вдохновлены анализом ошибок выходных данных современной модели суммирования. Экспериментальные результаты показывают, что наша модель способна исправлять фактические ошибки в сводках, созданных другими моделями нейронного суммирования, и превосходит предыдущие модели по оценке фактической согласованности в наборе данных CNN/DailyMail. Мы также обнаружили, что переход от искусственного исправления ошибок к последующим настройкам все еще очень сложен. %R 10.18653/v1/2020.emnlp-main.506 %U https://aclanthology.org/2020.emnlp-main.506 %U https://doi.org/10.18653/v1/2020.emnlp-main.506 %Р 6251-6258
Уценка (неформальная)
[Исправление фактических ошибок для моделей абстрактного суммирования](https://aclanthology. org/2020.emnlp-main.506) (Cao et al., EMNLP 2020)
org/2020.emnlp-main.506) (Cao et al., EMNLP 2020)
- Исправление фактических ошибок для Модели абстрактного суммирования (Cao et al., EMNLP 2020)
ACL
- Мэн Цао, Юэ Донг, Цзяпэн Ву и Джеки Чи Кит Чеунг. 2020. Исправление фактических ошибок для моделей абстрактного суммирования. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , страницы 6251–6258, онлайн. Ассоциация компьютерной лингвистики.
НЛП: построение модели исправления грамматических ошибок | Прия Двиведи
Опубликовано в·
Чтение: 5 мин.·
1 апреля 2022 г. стремиться исправить грамматические ошибки в тексте. Grammarly — пример такого продукта для исправления грамматики. Исправление ошибок может улучшить качество письменного текста в электронных письмах, сообщениях в блогах и чатах. Задачу GEC можно рассматривать как задачу последовательности, в которой модель Transformer обучается принимать неграмматическое предложение в качестве входных данных и возвращать грамматически правильное предложение. В этом посте мы покажем, как вы можете обучить такую модель и использовать веса и смещения для мониторинга производительности модели во время ее обучения. Мы также выпустили нашу обученную модель в Spaces для экспериментов. Код также опубликован на Colab здесь и на Github здесь.
В этом посте мы покажем, как вы можете обучить такую модель и использовать веса и смещения для мониторинга производительности модели во время ее обучения. Мы также выпустили нашу обученную модель в Spaces для экспериментов. Код также опубликован на Colab здесь и на Github здесь.
Ошибки, возникающие в письменной речи, могут быть разных типов, как показано на рисунке ниже.
Для обучения нашего корректора грамматики мы используем набор данных C4_200M, недавно выпущенный Google. Этот набор данных состоит из 200 миллионов примеров синтетически сгенерированных грамматических искажений вместе с правильным текстом.
Одной из самых больших проблем в GEC является получение большого разнообразия данных, которые имитируют ошибки, обычно допускаемые в письменной речи. Если искажения случайны, то они не будут репрезентативными для распределения ошибок, возникающих в реальных случаях использования.
Чтобы сгенерировать повреждение, сначала обучается помеченная модель повреждения. Эта модель обучается на существующих наборах данных, принимая в качестве входных данных чистый текст и генерируя поврежденный текст. Например, входное предложение будет иметь вид «Было a много овец» , а модель искажения изменит его на «Было много овец» . Таким образом, он генерирует грамматически неверный вывод.
Эта модель обучается на существующих наборах данных, принимая в качестве входных данных чистый текст и генерируя поврежденный текст. Например, входное предложение будет иметь вид «Было a много овец» , а модель искажения изменит его на «Было много овец» . Таким образом, он генерирует грамматически неверный вывод.
Для набора данных C4_2OOM авторы сначала определили распределение относительного типа ошибок, возникающих в письменной речи. При генерации искажений они зависели от типа ошибки. Например, ошибка склонения существительного будет принимать правильное предложение в качестве входных данных.
Правильное предложение — «Были a много овец»
Неправильные предложения с ошибкой в существительном —
- «Было много овец »
- «Было много овец»
Это позволяет набору данных C4_200M иметь разнообразный набор ошибок, отражающий их относительную частоту в реальных приложениях. Чтобы узнать больше о процессе создания синтетических искажений, обратитесь к оригинальной статье здесь.
Чтобы узнать больше о процессе создания синтетических искажений, обратитесь к оригинальной статье здесь.
Для этого сообщения в блоге мы извлекли 550 тысяч предложений из C4_200M. Набор данных C4_200M доступен в наборах данных TF. Мы извлекли нужные нам предложения и сохранили их в формате CSV. Код подготовки данных для этого передается в Colab здесь. Если вы заинтересованы в загрузке подготовленных наборов данных, они могут быть доступны здесь.
Скриншот набора данных C4_200M приведен ниже. На входе неверное предложение, на выходе грамматически правильное предложение. Эти случайные примеры показывают, что набор данных охватывает входные данные из разных областей и различных стилей письма.
Скриншот набора данных C4_200MДля этого обучения мы будем использовать универсальную модель T5 от Google.
T5 — это модель преобразования текста в текст, что означает, что его можно обучить переходу от входного текста одного формата к выходному тексту одного формата. Я лично использовал эту модель со многими различными задачами, такими как обобщение (см. блог здесь) и классификацию текста (см. блог здесь). А также использовал его для создания бота-викторины, который может извлекать ответы из памяти без какого-либо контекста. Проверьте этот блог здесь.
Я лично использовал эту модель со многими различными задачами, такими как обобщение (см. блог здесь) и классификацию текста (см. блог здесь). А также использовал его для создания бота-викторины, который может извлекать ответы из памяти без какого-либо контекста. Проверьте этот блог здесь.
Я предпочитаю T5 для многих задач по нескольким причинам — 1. Может использоваться для любой задачи преобразования текста в текст, 2. Хорошая точность в последующих задачах после тонкой настройки, 3. Легко обучается с помощью Huggingface
полный код для обучения модели T5 на примерах 550 000 из C4_200M доступен здесь, на Colab. Также поделился на моем Github здесь.
Шаги высокого уровня для обучения включают:
Мы устанавливаем неверное предложение в качестве входных данных и исправленный текст в качестве метки. И входы, и цели токенизируются с помощью токенизатора T5. Максимальная длина установлена на 64, поскольку большинство входных данных в C4_200M являются предложениями, и предполагается, что эта модель также будет использоваться для предложений. Фрагмент кода, выполняющего токенизацию, приведен ниже.
Фрагмент кода, выполняющего токенизацию, приведен ниже.
2. Обучение модели с помощью обучающего класса seq2seq
Мы используем обучающий класс Seq2Seq в Huggingface для создания экземпляра модели и экземпляра регистрации в wandb. Использовать веса и смещения с HuggingFace очень просто. Все, что нужно сделать, это установить report_to="wandb" в аргументах обучения.
3. Мониторинг и оценка модели
Мы использовали показатель Rouge в качестве показателя для оценки модели. Как видно на графиках ниже от W&B, модель получает 72 балла румян после 1 этапа обучения.
Точность после одного раунда обученияДоступ к этому проекту можно найти здесь.
Мы отправили обученную модель в Spaces сюда, чтобы ее можно было протестировать. Как показано на снимке экрана ниже, его можно запрограммировать на возврат до 2 исправленных последовательностей.