Инструкция по переходу на UTF-8
Вычислительная система кафедры перешла на использование многобайтовой кодировки UTF-8 для файловых систем и пользовательского окружения вместо однобайтовой кодировки KOI8-R. В данной инструкции рассматриваются типичные проблемы, которые могли возникнуть у пользователей в связи с данным переходом и предлагаются способы их решения (изменения настроек, команды и т.п.).
Основные понятия
Юнико́д, или Унико́д (англ. Unicode™) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.
UTF-8 (от англ. Unicode Transformation Format — формат преобразования Юникода) — кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста.
Важно понимать, что один символ в кодировке UTF-8 может быть
представлен более чем одним байтом. С этим связано, например, то, что
файл, содержащий текст в кодировке UTF-8 будет иметь больший размер по
сравнению с файлом, содержащим тот-же текст в кодировке KOI8-R.
Пример: команда wc имеет ключ -c для подсчета байтов и ключ -m для подсчета символов.
$ echo -n "Слово." | wc -c 11 $ echo -n "Слово." | wc -m 6
Имена файлов
Имена файлов были перекодированы автоматически с помощью утилиты convmv:
convmv -r -f koi8-r -t utf-8 --notest <каталог>
Каждому пользователю, в домашнем каталоге которого утилита convmv переименовала хотя бы один файл, был автоматически выслан журнал переименований.
При необходимости можно выполнить обратное преобразование:
convmv -r -f utf-8 -t koi8-r <файлы и каталоги>
После проверки вывода команды повторить с ключем —notest. Ключ -r включает рекурсивный обход каталогов.
Содержимое файлов
Для того, чтобы преобразовать содержимое файлов из кодировки KOI8-R в кодировку UTF-8 можно воспользоваться командой:
recode koi8-r..utf-8 <filename>
Для потокового перекодирования используется команда:
iconv -f koi8-r <filename>
Редактор Emacs может автоматически распознать кодировку текста при
открытии файла. Принудительно задать кодировку открытия или сохранения
файла в редакторе Emacs можно следующим образом:
Принудительно задать кодировку открытия или сохранения
файла в редакторе Emacs можно следующим образом:
- Ввести комбинацию клавиш
C-x RET c. - Внизу экрана будет запрошена кодировка, которую вы хотите применить для следующей команды.
- Введите команду, которая будет выполнена с применением введенной на предыдущем шаге кодировки, например:
- комбинацию клавиш для открытия файла:
C-x C-f; - комбинацию клавиш для сохранения файла:
C-x C-s.
- комбинацию клавиш для открытия файла:
Приложения
Текстовый терминал из Windows
Для корректного отображения русского текста при входе на серверы кафедры с помощью терминального клиента PuTTY нужно указать в настройках:
- Раздел Window/Translation
- Character set translation on recieved data: UTF-8
Текстовый терминал из Linux
Если системная локаль не UTF-8, то необходимо запустить X-терминал с поддержкой UTF-8 и выполнить вход по ssh из него.
Если системная локаль UTF-8, то никаких дополнительных действий предпринимать не надо.
Если по какой-то причине при входе по ssh не установились правильно переменные окружения локали (вывод команды locale не содержит строки LANG=ru_RU.UTF-8), то необходимо выполнить команду:
export LANG=ru_RU.UTF-8
WinSCP
Для корректного отображения русских имен файлов:
- Раздел Environment
- UTF-8 encoding for filenames: On
TEX
- После выполнения перекодировки содержимого tex-файла (см. Содержимое файлов) необходимо сменить кодировку в преамбуле:
Было:
\usepackage[koi8-r]{inputenc}
Стало:
\usepackage[utf8x]{inputenc}
- Также необходимо подключить пакет ucs:
\usepackage{ucs}
- Для установки диакритических знаков (ударений) нужно использовать полную форму стандартной записи \’, т.е.:
Б\'{о}льшую
Bibtex
Bib-файлы, содержащие описание литературы, хранятся в кодировке KOI8-R. После выполнения команды bibtex
необходимо сначала перекодировать получившийся bbl-файл в кодировку
UTF-8 (см. Содержимое файлов), а затем выполнять трансляцию
tex-файлов, подключающих этот список литературы.
После выполнения команды bibtex
необходимо сначала перекодировать получившийся bbl-файл в кодировку
UTF-8 (см. Содержимое файлов), а затем выполнять трансляцию
tex-файлов, подключающих этот список литературы.
man UTF-8 (7): ASCII-совместимая многобайтная юникодная кодировка
ОПИСАНИЕ
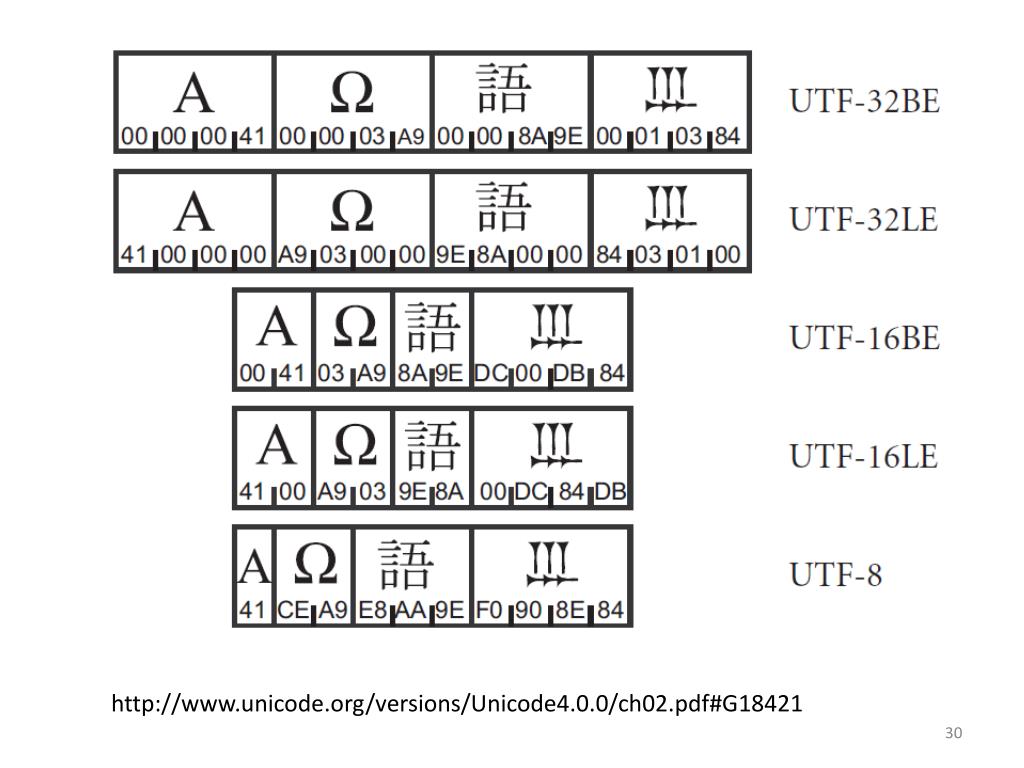
Набор символов Unicode 3.0 занимает 16-битное кодовое пространство. Наиболее
распространённая юникодная кодировка, известная как UCS-2, содержит
последовательности 16-битных слов. Закодированные таким образом строки могут
состоять из частей 16-битных символов например, ‘\0’ или ‘/’,
которые имеют специальное значение в именах файлов и других параметрах
функций библиотеки языка Си. Кроме того, большинство утилит UNIX
предназначено для обработки ASCII-файлов и не может воспринимать 16-битные
слова как символы. По этим причинам UCS-2 является неподходящей кодировкой
Юникода для имён файлов, текстовых файлов, переменных окружения и т.
Кодировка UTF-8 для представления Юникода и UCS лишена этих недостатков и поэтому в UNIX-подобных операционных системах используется наиболее часто.
Свойства
Кодировка UTF-8 обладает следующими полезными свойствами:
- *
- UCS-символы с кодами от 0x00000000 до 0x0000007f (стандартный набор US-ASCII) кодируются как байты с кодами от 0x00 до 0x7f (для совместимости с кодовой таблицей ASCII). Это означает, что файлы и строки, содержащие только 7-битные ASCII-символы, будут иметь одинаковое представление как в ASCII так и в UTF-8.
- *
- Все UCS-символы с кодами больше чем 0x7f кодируются как многобайтовые
последовательности, содержащие только байты в диапазоне от 0x80 до 0xfd, так
что ASCII-байты не могут оказаться частью другого символа и, как следствие,
не будет проблем с использованием ‘\0’ или ‘/’.
 31 значения UCS.
31 значения UCS. - *
- В кодировке UTF-8 никогда не используются байты с кодами 0xc0, 0xc1, 0xfe и 0xff.
- *
- Первый байт многобайтовой последовательности, представляющей один не ASCII UCS-символ, всегда находится в диапазоне от 0xc2 до 0xfd и указывает на длину мульбайтовой последовательности. Все последующие байты в многобайтовой последовательности находятся в диапазоне от 0x80 до 0xbf. Это позволяет облегчить ресинхронизацию, устраняет необходимость учитывать состояние кодировки (statelessness) и делает кодировку независимой от пропущенных байтов.
- *
- Символы UCS, закодированные в UTF-8, могут занимать до шести байтов, однако в стандарте Юникода не определены символы выше 0x10ffff, поэтому в UTF-8 юникодные символы могут иметь максимальный размер 4 байта.
Кодирование
Приведённые ниже последовательности байтов используются для отображения символа. Конкретная последовательность зависит от номера символа в кодировке UCS:
- 0x00000000 — 0x0000007F:
- 0xxxxxxx
- 0x00000080 — 0x000007FF:
- 110xxxxx 10xxxxxx
- 0x00000800 — 0x0000FFFF:
- 1110xxxx 10xxxxxx 10xxxxxx
- 0x00010000 — 0x001FFFFF:
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- 0x00200000 — 0x03FFFFFF:
- 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
- 0x04000000 — 0x7FFFFFFF:
- 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Позиции битов, обозначенные как xxx, заполняются соответствующими битами
из кода символа в двоичном виде. Используется самая короткая из возможных
многобайтовых последовательностей, которые могут представить код символа.
Используется самая короткая из возможных
многобайтовых последовательностей, которые могут представить код символа.
Значения кодов UCS 0xd00-0xdfff (суррогаты UTF-16), а также 0xfffe и 0xffff (несимвольные значения UCS), не должны появляться в потоках UTF-8.
Пример
- 11000010 10101001 = 0xc2 0xa9
а символ с кодом 0x2260 = 0010 0010 0110 0000 (знак неравенства) кодируется так:
- 11100010 10001001 10100000 = 0xe2 0x89 0xa0
Замечания к применению
Для включения поддержки UTF-8 в приложениях, пользователи должны выбрать локаль UTF-8, например с помощью
- export LANG=en_GB.UTF-8
Программы, в которых учитывается используемая пользователем кодировка, должны всегда устанавливать локаль с помощью
- setlocale(LC_CTYPE, «»)
и затем проверять выражением
- strcmp(nl_langinfo(CODESET), «UTF-8») == 0
что локаль UTF-8 выбрана и во всех стандартных текстовых потоках ввода и
вывода, на терминалах, в содержимом простых текстовых файлов, именах файлов
и переменных окружения будет использоваться кодировка UTF-8.
Программисты, привыкшие к однобайтовым кодировкам, таким как, US-ASCII или ISO 8859, должны учесть, что два предположения, действовавших ранее, в локалях UTF-8 не работают. Первое: один байт теперь не обязательно соответствует одному символу. Второе: современные эмуляторы терминала в режиме UTF-8 также поддерживают китайские, японские и корейские символы двойной ширины (double-width characters), а также комбинированные символы без пробелов, и вывод одного символа необязательно смещает курсор на одну позицию, как это было в ASCII. Для подсчёта количества символов и позиций курсора нужно использовать библиотечные функции, такие как mbsrtowcs(3) и wcswidth(3).
Стандартной ESC-последовательностью для переключения из схемы кодировки ISO
2022 (используется в терминалах VT100) в UTF-8 является ESC % G
(«\x1b%G»). Соответственно, обратной последовательностью для переключения
из UTF-8 в ISO 2022 будет ESC % @ («\x1b%@»). Остальные последовательности
ISO 2022 (такие, как переключение в наборы G0 и G1) в режиме UTF-8 не
работают.
Безопасность
Стандарты Юникода и UCS требуют, чтобы генераторы UTF-8 использовали самую короткую возможную форму представления символов, то есть создание двухбайтной последовательности с первым байтом, равным 0xc0, запрещено. В стандарте Unicode 3.1 это правило расширено и запрещает программам воспринимать не самую короткую форму при вводе. Это сделано из соображений безопасности: если вводимые пользователем символы проверяются системой безопасности на возможные нарушения, то программам остаётся проверить только ASCII версии символов «/../», «;» или NUL, так как для этих символов может быть очень много не ASCII способов представления при не самом коротком кодировании в UTF-8.Стандарты
ISO/IEC 10646-1:2000, Unicode 3.1, RFC 3629, Plan 9.| Кодовая точка Unicode | символ | UTF-8 (шестнадцатеричный) | имя |
|---|---|---|---|
| U+0000 | 00 | <управление> | |
| U+0001 | 01 | <управление> | |
| U+0002 | 02 | <управление> | |
| U+0003 | 03 | <управление> | |
| U+0004 | 04 | <управление> | |
| U+0005 | 05 | <управление> | |
| U+0006 | 06 | <управление> | |
| U+0007 | 07 | <управление> | |
| U+0008 | 08 | <управление> | |
| U+0009 | 09 | <управление> | |
| U+000A | 0a | <управление> | |
| U+000B | 0b | <управление> | |
| U+000C | 0c | <управление> | |
| U+000D | 0d | <управление> | |
| U+000E | 0e | <управление> | |
| U+000F | 0f | <управление> | |
| U+0010 | 10 | <управление> | |
| U+0011 | 11 | <управление> | |
| U+0012 | 12 | <управление> | |
| U+0013 | 13 | <управление> | |
| U+0014 | 14 | <управление> | |
| U+0015 | 15 | <управление> | |
| U+0016 | 16 | <управление> | |
| U+0017 | 17 | <управление> | |
| U+0018 | 18 | <управление> | |
| U+0019 | 19 | <управление> | |
| U+001A | 1a | <управление> | |
| U+001B | 1b | <управление> | |
| U+001C | 1c | <управление> | |
| U+001D | 1d | <управление> | |
| U+001E | 1e | <управление> | |
| U+001F | 1f | <управление> | |
| U+0020 | 20 | ПРОБЕЛ | |
| U+0021 | ! | 21 | ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК |
| U+0022 | » | 22 | КАвычки |
| U+0023 | # | 23 | НОМЕР ЗНАК |
| U+0024 | $ | 24 | ЗНАК ДОЛЛАРА |
| U+0025 | % | 25 | ЗНАК ПРОЦЕНТА |
| U+0026 | и | 26 | АМПЕРСАНД |
| U+0027 | ‘ | 27 | АПОСТРОФ |
| U+0028 | ( | 28 | ЛЕВАЯ СКОБКА |
| U+0029 | ) | 29 | ПРАВАЯ СКОБКА |
| U+002A | * | 2a | ЗВЕЗДОЧКА |
| U+002B | + | 2b | ЗНАК ПЛЮС |
| U+002C | , | 2c | ЗАПЯТАЯ |
| U+002D | — | 2d | ДЕФИС-МИНУС |
| U+002E | . | 2e | ПОЛНЫЙ СТОП |
| U+002F | / | 2f | SOLIDUS |
| U+0030 | 0 | 30 | ЦИФРА НОЛЬ |
| U+0031 | 1 | 31 | ЦИФРА ЕДИНИЦА |
| U+0032 | 2 | 32 | ДВА ЦИФРЫ |
| U+0033 | 3 | 33 | ЦИФРА ТРИ |
| U+0034 | 4 | 34 | ЧЕТВЕРТАЯ ЦИФРА |
| U+0035 | 5 | 35 | ПЯТАЯ ЦИФРА |
| U+0036 | 6 | 36 | ЦИФРА ШЕСТЬ |
| U+0037 | 7 | 37 | СЕДЬМАЯ ЦИФРА |
| U+0038 | 8 | 38 | ЦИФРА ВОСЕМЬ |
| U+0039 | 9 | 39 | ЦИФРА ДЕВЯТЬ |
| U+003A | : | 3a | ДВОРОЦ |
| U+003B | ; | 3b | ТОЧКА С ЗАПЯТОЙ |
| U+003C | < | 3c | ЗНАК МЕНЬШЕ |
| U+003D | = | 3d | ЗНАК РАВНО |
| U+003E | > | 3e | ЗНАК БОЛЬШЕ |
| U+003F | ? | 3f | ВОПРОСИТЕЛЬНЫЙ ЗНАК |
| U+0040 | @ | 40 | КОММЕРЧЕСКИЙ НОМЕР |
| U+0041 | A | 41 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A |
| U+0042 | B | 42 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА B |
| U+0043 | C | 43 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА C |
| U+0044 | Д | 44 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА D |
| U+0045 | E | 45 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E |
| U+0046 | F | 46 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА F |
| U+0047 | G | 47 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА G |
| U+0048 | H | 48 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА H |
| U+0049 | Я | 49 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I |
| U+004A | J | 4a | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА J |
| U+004B | K | 4b | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА K |
| U+004C | L | 4c | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L |
| U+004D | M | 4d | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА M |
| U+004E | Н | 4e | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА N |
| U+004F | O | 4f | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O |
| U+0050 | P | 50 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА P |
| U+0051 | Q | 51 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Q |
| U+0052 | R | 52 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА R |
| U+0053 | S | 53 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА S |
| U+0054 | T | 54 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА T |
| U+0055 | U | 55 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U |
| U+0056 | V | 56 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА V |
| U+0057 | W | 57 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА W |
| U+0058 | X | 58 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА X |
| U+0059 | Y | 59 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА Y |
| U+005A | Z | 5a | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Z |
| U+005B | [ | 5b | ЛЕВЫЙ КВАДРАТНЫЙ КРОНШТЕЙН |
| U+005C | \ | 5с | ОБРАТНЫЙ СОЛИДУС |
| U+005D | 95e | ЦИРКУМФЛЕКС АКЦЕНТ | |
| U+005F | _ | 5f | НИЗКАЯ ЛИНИЯ |
| U+0060 | ` | 60 | ГРЕЙВ АКЦЕНТ |
| U+0061 | a | 61 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A |
| U+0062 | b | 62 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА B |
| U+0063 | в | 63 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C |
| U+0064 | d | 64 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА D |
| U+0065 | e | 65 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E |
| U+0066 | f | 66 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА F |
| U+0067 | g | 67 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G |
| U+0068 | h | 68 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА H |
| U+0069 | i | 69 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I |
| U+006A | j | 6a | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА J |
| U+006B | k | 6b | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА K |
| U+006C | l | 6c | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L |
| U+006D | m | 6d | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА M |
| U+006E | n | 6e | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N |
| U+006F | o | 6f | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O |
| U+0070 | p | 70 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА P |
| U+0071 | q | 71 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Q |
| U+0072 | r | 72 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R |
| U+0073 | s | 73 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S |
| U+0074 | t | 74 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА T |
| U+0075 | u | 75 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U |
| U+0076 | v | 76 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА V |
| U+0077 | w | 77 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА W |
| U+0078 | x | 78 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА X |
| U+0079 | y | 79 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y |
| U+007A | z | 7a | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z |
| U+007B | { | 7b | ЛЕВАЯ ФИГУРНАЯ СКОБКА |
| U+007C | | | 7c | ВЕРТИКАЛЬНАЯ ЛИНИЯ |
| U+007D | } | 7d | ПРАВАЯ ФИГУРНАЯ СКОБКА |
| U+007E | ~ | 7e | ТИЛЬДА |
| U+007F | 7f | <управление> | |
| U+0080 | c2 80 | <управление> | |
| U+0081 | c2 81 | <управление> | |
| U+0082 | c2 82 | <управление> | |
| U+0083 | c2 83 | <управление> | |
| U+0084 | c2 84 | <управление> | |
| U+0085 | c2 85 | <управление> | |
| U+0086 | c2 86 | <управление> | |
| U+0087 | c2 87 | <управление> | |
| U+0088 | c2 88 | <управление> | |
| U+0089 | c2 89 | <управление> | |
| U+008A | c2 8a | <управление> | |
| U+008B | c2 8b | <управление> | |
| U+008C | c2 8c | <управление> | |
| U+008D | c2 8d | <управление> | |
| U+008E | c2 8e | <управление> | |
| U+008F | c2 8f | <управление> | |
| U+0090 | c2 90 | <управление> | |
| U+0091 | c2 91 | <управление> | |
| U+0092 | c2 92 | <управление> | |
| U+0093 | c2 93 | <управление> | |
| U+0094 | c2 94 | <управление> | |
| U+0095 | c2 95 | <управление> | |
| U+0096 | c2 96 | <управление> | |
| U+0097 | c2 97 | <управление> | |
| U+0098 | c2 98 | <управление> | |
| U+0099 | c2 99 | <управление> | |
| U+009A | c2 9a | <управление> | |
| U+009B | c2 9b | <управление> | |
| U+009C | c2 9c | <управление> | |
| U+009D | c2 9d | <управление> | |
| U+009E | c2 9e | <управление> | |
| U+009F | c2 9f | <управление> | |
| U+00A0 | c2 a0 | НЕРАЗРЫВНЫЙ ПРОБЕЛ | |
| U+00A1 | ¡ | c2 a1 | ПЕРЕВЕРНУТЫЙ ВОСКЛИЦАТЕЛЬНЫЙ ЗНАК |
| U+00A2 | ¢ | c2 a2 | ЗНАК ЦЕНТА |
| U+00A3 | £ | c2 a3 | ЗНАК ФУНТА |
| U+00A4 | ¤ | c2 a4 | ЗНАК ВАЛЮТЫ |
| U+00A5 | ¥ | c2 a5 | ЗНАК ЙЕНЫ |
| U+00A6 | ¦ | c2 a6 | СЛОМАННЫЙ БАР |
| U+00A7 | § | c2 a7 | ЗНАК СЕКЦИИ |
| U+00A8 | ¨ | c2 a8 | ДИЭРЕЗИС |
| U+00A9 | © | c2 a9 | ЗНАК АВТОРСКИХ ПРАВ |
| U+00AA | ª | c2 aa | ЖЕНСКИЙ ОРДИНАЛ ИНДИКАТОР |
| U+00AB | « | c2 ab | ДВУХУГОЛЬНАЯ КАВАЧКА, УКАЗЫВАЮЩАЯ ВЛЕВО |
| U+00AC | ¬ | c2 ac | НЕ ЗНАК |
| U+00AD | c2 объявление | МЯГКИЙ ДЕФЕС | |
| U+00AE | ® | c2 ae | ЗАРЕГИСТРИРОВАННЫЙ ЗНАК |
| U+00AF | ¯ | c2 af | Макрон |
| U+00B0 | ° | c2 b0 | ЗНАК СТЕПЕНИ |
| U+00B1 | ± | c2 b1 | ЗНАК ПЛЮС-МИНУС |
| U+00B2 | ² | c2 b2 | НАДПИСЬ ДВА |
| U+00B3 | ³ | c2 b3 | НАДСТРОЙКА ТРИ |
| U+00B4 | ´ | c2 b4 | ОСТРЫЙ АКЦЕНТ |
| U+00B5 | µ | c2 b5 | МИКРОЗНАК |
| U+00B6 | ¶ | c2 b6 | ЗНАК ПОДШИВКИ |
| U+00B7 | · | c2 b7 | СРЕДНЯЯ ТОЧКА |
| U+00B8 | ¸ | c2 b8 | СЕДИЛЬЯ |
| U+00B9 | ¹ | c2 b9 | НАДПИСЬ ОДИН |
| U+00BA | º | c2 ba | МУЖСКОЙ ОРДИНАЛ |
| U+00BB | » | c2 bb | ДВУХУГОЛЬНАЯ КАВАЧКА, УКАЗЫВАЮЩАЯ ВПРАВО |
| U+00BC | ¼ | c2 bc | ОБЫЧНАЯ Дробь ЧЕТВЕРТЬ |
| U+00BD | ½ | c2 bd | ВУЛГАРНАЯ Дробь ОДНА ПОЛОВИНА |
| U+00BE | ¾ | c2 be | ОБЫЧНАЯ Дробь ТРИ ЧЕТВЕРТИ |
| U+00BF | ¿ | c2 bf | ПЕРЕВЕРНУТЫЙ ВОПРОСИТЕЛЬНЫЙ ЗНАК |
| U+00C0 | À | c3 80 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С ГРАВОЙ |
| U+00C1 | Á | c3 81 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A С АКТРОЙ |
| U+00C2 | Â | c3 82 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С CIRCUMFLEX |
| U+00C3 | Ã | c3 83 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С ТИЛЬДОЙ |
| U+00C4 | Ä | c3 84 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С ДИЕРЕЗИСОМ |
| U+00C5 | Å | c3 85 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА A С КОЛЬЦОМ НАД |
| U+00C6 | Æ | c3 86 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА AE |
| U+00C7 | Ç | c3 87 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА C С СЕДИЛЬЕЙ |
| U+00C8 | È | c3 88 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E С ГРАВОЙ |
| U+00C9 | É | c3 89 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E С ОСТРОЙ СТОЙКОЙ |
| U+00CA | Ê | c3 8a | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С CIRCUMFLEX |
| U+00CB | Ë | c3 8b | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА E С ДИЭРЕЗИСОМ |
| U+00CC | Ì | c3 8c | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С ГРАВОЙ |
| U+00CD | Í | c3 8d | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С ОСТРОЙ |
| U+00CE | Î | c3 8e | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С CIRCUMFLEX |
| U+00CF | Ï | c3 8f | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА I С ДИЭРЕЗИСОМ |
| U+00D0 | Ð | c3 90 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА ETH |
| U+00D1 | Ñ | c3 91 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА N С ТИЛЬДОЙ |
| U+00D2 | Ò | c3 92 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С ГРАВОЙ |
| U+00D3 | Ó | c3 93 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ОСТРОЙ |
| U+00D4 | Ô | c3 94 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С CIRCUMFLEX |
| U+00D5 | Õ | c3 95 | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ТИЛЬДОЙ |
| U+00D6 | Ö | c3 96 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С ДИЕРЕЗИСОМ |
| U+00D7 | × | c3 97 | ЗНАК УМНОЖЕНИЯ |
| U+00D8 | Ø | c3 98 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С ШТРИХОМ |
| U+00D9 | Ù | c3 99 | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U С ГРАВОЙ |
| U+00DA | Ú | c3 9a | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С ОСТРОЙ |
| U+00DB | Û | c3 9b | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С CIRCUMFLEX |
| U+00DC | Ü | c3 9c | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА U С ДИЕРЕЗИСОМ |
| U+00DD | Ý | c3 9d | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Y С ОСТРОЙ БУКВОЙ |
| U+00DE | Þ | c3 9e | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА THORN |
| U+00DF | ß | c3 9f | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА SHARP S |
| U+00E0 | à | c3 a0 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ГРАВОЙ |
| U+00E1 | á | c3 a1 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ОСТРОЙ БУКВОЙ |
| U+00E2 | â | c3 a2 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С CIRCUMFLEX |
| U+00E3 | ã | c3 a3 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ТИЛЬДОЙ |
| U+00E4 | ä | c3 a4 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С ДИЭРЕЗИСОМ |
| U+00E5 | å | c3 a5 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С КОЛЬЦОМ НАД |
| U+00E6 | æ | c3 a6 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА AE |
| U+00E7 | ç | c3 a7 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C С СЕДИЛЬЕЙ |
| U+00E8 | и | c3 a8 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ГРАВОЙ |
| U+00E9 | é | c3 a9 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ОСТРОЙ ЧАСТЬЮ |
| U+00EA | ê | c3 aa | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С CIRCUMFLEX |
| U+00EB | ë | c3 ab | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ДИЭРЕЗИСОМ |
| U+00EC | ì | c3 ac | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ГРАВОЙ |
| U+00ED | í | c3 ad | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ОСТРОЙ БУКВОЙ |
| U+00EE | î | c3 ae | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С CIRCUMFLEX |
| U+00EF | ï | c3 af | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ДИЭРЕЗИСОМ |
| U+00F0 | ð | c3 b0 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА ETH |
| У+00Ф1 | – | c3 b1 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N С ТИЛЬДОЙ |
| U+00F2 | ò | c3 b2 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ГРАВОЙ |
| U+00F3 | ó | c3 b3 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ОСТРОЙ БУКВОЙ |
| U+00F4 | ô | c3 b4 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С CIRCUMFLEX |
| U+00F5 | х | c3 b5 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ТИЛЬДОЙ |
| U+00F6 | ö | c3 b6 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ДИЕРЕЗИСОМ |
| U+00F7 | ÷ | c3 b7 | ЗНАК РАЗДЕЛА |
| U+00F8 | ø | c3 b8 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ШТРИХОМ |
| U+00F9 | ù | c3 b9 | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ГРАВОЙ |
| U+00FA | ú | c3 ba | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ОСТРОЙ |
| U+00FB | û | c3 bb | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С CIRCUMFLEX |
| U+00FC | ü | c3 bc | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ДИЭРЕЗИСОМ |
| U+00FD | ý | c3 bd | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y С ОСТРОЙ |
| U+00FE | þ | c3 be | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА THORN |
| U+00FF | ÿ | c3 bf | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y С ДИЭРЕЗИСОМ |
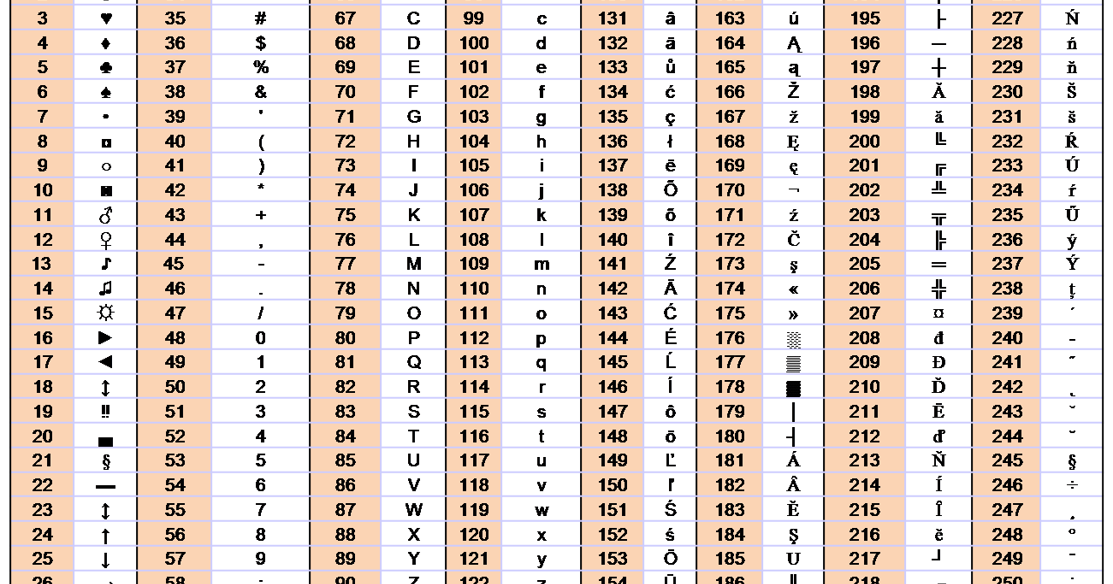
Инструмент отладки символов UTF-8
i18nqa. com -> utf8-debug
com -> utf8-debug
Вот таблица проблем с кодировкой, которая помогает в отладке распространенных проблем с кодировкой символов UTF-8. Посмотрите эти 3 типичных сценария проблем, с которыми может помочь диаграмма.
- Проблема кодирования 1: обработка байтов UTF-8 как Windows-1252 или ISO-8859-1
- Проблема кодирования 2: неправильное двойное неправильное преобразование
- Проблема кодирования 3: ISO-8859-1 против Windows-1252
В следующей таблице показаны символы в Windows-1252 от 128 до 255 (шестнадцатеричные от 80 до FF). Кодовая точка Unicode для каждого
указан символ и шестнадцатеричные значения для каждого из байтов в кодировке UTF-8 для тех же символов.
Эти байты UTF-8 также отображаются, как если бы они были символами Windows-1252.
Вы можете использовать эту диаграмму для отладки
проблемы, в которых встречаются эти последовательности латинских символов, где ожидался только один символ. Если вы сопоставите последовательность, которая встречается с последовательностью на диаграмме,
и ожидаемое значение на диаграмме соответствует значению, которое вы ожидали увидеть, то проблема вызвана тем, что байты UTF-8 интерпретируются как
Windows-1252 (или ISO 8859-1) байт. См. Проблема с кодировкой: обработка байтов UTF-8 как Windows-1252 или ISO-8859-1.
для более подробного объяснения.
См. Проблема с кодировкой: обработка байтов UTF-8 как Windows-1252 или ISO-8859-1.
для более подробного объяснения.
| Кодовая точка | Символы | Байты UTF-8 | Кодовая точка | Символы | Байты UTF-8 | ||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Юникод | Windows 1252 | Ожидаемый | Фактический | Unicode | Windows 1252 | Ожидаемый | Фактический | ||||||||||||||||||||||||||||||||||||||||||||
| U+20AC | 0x80 | € | € | %E2 %82 %AC | U+00C0 | 0xC0 | À | À | %C3 %80 | ||||||||||||||||||||||||||||||||||||||||||
| 0x81 | U+00C1 | 0xC1 | Á | Ã | %C3 %81 | ||||||||||||||||||||||||||||||||||||||||||||||
| U+201A | 0x82 | ‚ | ‚ | %E2 % | U+00C2 | 0xC2 |  | Â | %C3 %82 | ||||||||||||||||||||||||||||||||||||||||||
| U+0192 | 0x83 | ƒ | Æ’ | %C6 %92 | U+00C3 | 0xC3 | à | Ã | %C3 %83 | ||||||||||||||||||||||||||||||||||||||||||
| U+201E | 0x84 | „ | – | %E2 %80 %9E | U+00C4 | 0xC4 | ä | ã | %C3 % | ||||||||||||||||||||||||||||||||||||||||||
| U+2026 | 0X85 | … | 140016. | 669.6916. | U+00C5 | 0xC5 | Å | Ã… | %C3 %85 | ||||||||||||||||||||||||||||||||||||||||||
| U+2020 | 0x86 | † | † | %E2 %80 %A0 | U+00C6 | 0xC6 | Æ | Æ | %C3 %86 | ||||||||||||||||||||||||||||||||||||||||||
| U+2021 | 0x87 | ‡ | ‡ | %E2 %80 %A1 | U+00C7 | 0xC7 | Ç | Ç | %C3 %87 | ||||||||||||||||||||||||||||||||||||||||||
| 9 U+002C6 | 0x88 | ˆ | ˆ | %CB %86 | U+00C8 | 0xC8 | È | È | %C3 %88 | ||||||||||||||||||||||||||||||||||||||||||
| U+2030 | 0x89 | ‰ | ‰ | %E2 %80 %B0 | U+00C9 | 0xC9 | E | ã ‰ | %C3 %89 | ||||||||||||||||||||||||||||||||||||||||||
| U+0160 | 0X8A | š | 0X8A | 9 | 9 | 9 | 0x | 0x | 0x | ||||||||||||||||||||||||||||||||||||||||||
. 0017 0017 | Å | %C5 %A0 | U+00CA | 0xCA | Ê | Ê | %C3 %8A | ||||||||||||||||||||||||||||||||||||||||||||
| U+2039 | 0x8B | ‹ | ‹ | %E2 %80 %B9 | U+00CB | 0xCB | ë | ã | %C3 % | ||||||||||||||||||||||||||||||||||||||||||
| U+0152 | 0X8C | U+0152 | 0X8C | .2 | U+00CC | 0xCC | Ì | ÃŒ | %C3 %8C | ||||||||||||||||||||||||||||||||||||||||||
| 0x8D | U+00CD | 0xCD | í | ã | %C3 % | ||||||||||||||||||||||||||||||||||||||||||||||
| U+017D | 0X8E | U+017D | 0X8E | . | U+00CE | 0xCE | О | ÃŽ | %C3 %8E | ||||||||||||||||||||||||||||||||||||||||||
| 0x8F | U+00CF | 0xCF | Ï | Ã | %C3 %8F | ||||||||||||||||||||||||||||||||||||||||||||||
| 0x90 | U+00D0 | 0xD0 | Ð | Ã | %C3 %90 | ||||||||||||||||||||||||||||||||||||||||||||||
| U+2018 | 0x91 | ‘ | – | %E2 %80 %98 | U+00D1 | 0xD1 | Ñ | Ñ | %C3 %91 | ||||||||||||||||||||||||||||||||||||||||||
| U+2019 | 0x92 | ’ | ’ | %E2 %80 %99 | U+00D2 | 0xD2 | Ò | Ã’ | %C3 %92 | ||||||||||||||||||||||||||||||||||||||||||
| U+201C | 0x93 | “ | “ | %E2 %80 %9С | U+00D3 | 0xD3 | Ó | Ó | %C3 %93 | ||||||||||||||||||||||||||||||||||||||||||
| U+201D | 0x94 | ” | †| %E2 %80 %9D | U+00D4 | 0xD4 | ô | ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ã ” | %C3 %94 | ||||||||||||||||||||||||||||||||||||||||||
| U+2022 | 0x95 | • | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | . | U+00D5 | 0xd5 | õ | ã • | %C3 %95 | ||||||||||||||||||||||||||||
| U+2013 | 0x96 | — | 0x96 | — | 0x96 | — | . | U+00D6 | 0xd6 | ö | ã- | %C3 %96 | |||||||||||||||||||||||||||||||||||||||
| U+2014 | 0x97 | – | . | . | .U+00D7 | 0xd7 | × | ã— | %C3 %97 | ||||||||||||||||||||||||||||||||||||||||||
| U+02DC | 0x98 | ˜ | ë 40017 | %CB16. | ë. | U+00D8 | 0xd8 | Ø | ã | %C3 %98 | |||||||||||||||||||||||||||||||||||||||||
| U+2122 | 0X99 | U+2122 | 0X99 | 69. 2 2 | 9.2 | 9.2 | 9.2 | . | U+00D9 | 0xD9 | ٠| Ù | %C3 %99 | ||||||||||||||||||||||||||||||||||||||
| U+0161 | 0x9A | š | Å¡ 7 | %AU+00DA | 0xDA | Ú | Ú | %C3 %9A | |||||||||||||||||||||||||||||||||||||||||||
| U+203A | 0x9B | › | › | %E2 %80 %BA | U+00DB | 0xDB | Û | Û | %C3 %9B | ||||||||||||||||||||||||||||||||||||||||||
| U+0153 | 0x9C | – | Å“ | %C5 %93 | U+00DC | 0xDC | Ü | Ãœ | %C3 %9C | ||||||||||||||||||||||||||||||||||||||||||
| 0x9D | U+00DD | 0XDD | ý | ã | %C3 %9D | ||||||||||||||||||||||||||||||||||||||||||||||
| U+017E | 0X | 6. | 0x | .0017 | ¾ | %C5 %BE | U+00DE | 0xDE | Þ | Þ | %C3 %9E | ||||||||||||||||||||||||||||||||||||||||
| U+0178 | 0x9F | Ÿ | Ÿ | %C5 %B8 | U+00DF | 0xDF | ß | ß | %C3 %9F | ||||||||||||||||||||||||||||||||||||||||||
| U+00A0 | 0xA0 | Â | %C2 %A0 | U+00E0 | 0xE0 | à | Ã | %C3 %A0 | |||||||||||||||||||||||||||||||||||||||||||
| U+00A1 | 0xA1 | ¡ | ¡ | %C2 %A1 | U+00E1 | 0xE1 | á | á | %C3 %A1 | ||||||||||||||||||||||||||||||||||||||||||
| U+00A2 | 0xA2 | ¢ | ¢ | %C2 %A2 | U+00E2 | 0xE2 | â | ã | %C3 %A2 | ||||||||||||||||||||||||||||||||||||||||||
| U+00A3 | 0XA3 | £ | ~ | %£ | ~ | %£ | $ | % | £ | £ | % | £ | £ | %£ | £ | %£ | £ | .U+00E3 | 0xE3 | ã | ã | %C3 %A3 | |||||||||||||||||||||||||||||
| U+00A4 | 0xA4 | ¤ | ¤ | %C2 %A4 | U+00E4 | 0xE4 | ä | ä | %C3 %A4 | ||||||||||||||||||||||||||||||||||||||||||
| U+00A5 | 0xA5 | ¥ |  7A %C | U+00E5 | 0xE5 | å | Ã¥ | %C3 %A5 | |||||||||||||||||||||||||||||||||||||||||||
| U+00A6 | 0xA6 | ¦ | ¦ | %C2 %A6 | U+00E6 | 0xE6 | æ | æ | %C3 %A6 | ||||||||||||||||||||||||||||||||||||||||||
| U+00A7 | 0xA7 | § | § | %C2 %A7 | U+00E7 | 0xE7 | ç | ç | %C3 %A7 | ||||||||||||||||||||||||||||||||||||||||||
| U+00A8 | 0xA8 | ¨ | ¨ | %C2 %A8 | U+00E8 | 0xE8 | и | è | %C3 %A8 | ||||||||||||||||||||||||||||||||||||||||||
| U+00A9 | 0xA9 | © | © | %C2 %A9 | U+00E9 | 0xE9 | é | é | %C3 %A9 | ||||||||||||||||||||||||||||||||||||||||||
| U+00AA | 0xAA | ª | ª | %C2 %AA | U+00EA | 0XEA | ê | ª | %C3 %AA | ||||||||||||||||||||||||||||||||||||||||||
| U+00AB | 0XAB | « | 0XAB | « | 0XAB | « | 0XAB | « | 0XAB | « | 0XAB | « | 0XAB | 0017 | « | %C2 %AB | U+00EB | 0xEB | ë | ë | %C3 %AB | ||||||||||||||||||||||||||||||
| U+00AC | 0xAC | ¬ | ¬ | %C2 %AC | U+00EC | 0XEC | ì | ã | %C3 %AC | ||||||||||||||||||||||||||||||||||||||||||
| U+00AD | 0XAD | . 0017 0017 | U+00ED | 0XED | í | ã | %C3 %AD | ||||||||||||||||||||||||||||||||||||||||||||
| U+00AE | 0XAE | ® | . | U+00EE | 0xEE | î | î | %C3 %AE | |||||||||||||||||||||||||||||||||||||||||||
| U+00AF | 0xAF | ¯ | ¯ | %C2 %AF | U+00EF | 0XEF | ï | ã | %C3 %AF | ||||||||||||||||||||||||||||||||||||||||||
| U+00B0 | 0xB0 | ° | â € â ° | %° | â € ° | % | ° | â ° | %. | U+00F0 | 0xF0 | ð | ð | %C3 %B0 | |||||||||||||||||||||||||||||||||||||
| U+00B1 | 0xB1 | ± | ± | %C2 %B1 | U+00F1 | 0xF1 | – | ± | %C3 %B1 | ||||||||||||||||||||||||||||||||||||||||||
| U+00B2 | 0xB2 | ² | ² | 190 %B% | U+00F2 | 0xF2 | ò | ò | %C3 %B2 | ||||||||||||||||||||||||||||||||||||||||||
| U+00B3 | 0xB3 | ³ | ³ | %C2 %B3 | U+00F3 | 0xF3 | — | ó | %C3 %B3 | ||||||||||||||||||||||||||||||||||||||||||
| U+00B4 | 0xB4 | ´ | ´ | %C2 %B4 | U+00F4 | 0xF4 | ô | ô | %C3 %B4 | ||||||||||||||||||||||||||||||||||||||||||
| U+00B5 | 0xB5 | µ | µ | %C2 %B5 | U+00F5 | 0xF5 | х | õ | %C3 %B5 | ||||||||||||||||||||||||||||||||||||||||||
| U+00B6 | 0xB6 | ¶ | ¶ | %C2 %B6 | U+00F6 | 0xF6 | ö | ö | %C3 %B6 | ||||||||||||||||||||||||||||||||||||||||||
| U+00B7 | 0xB7 | · | · | %C2 %B7 | U+00F7 | 0xf7 | ÷ | ã · | %C3 %B7 | ||||||||||||||||||||||||||||||||||||||||||
| U+00B8 | 0XB8 | . 0017 0017 | → | %C2 %B8 | U+00F8 | 0xF8 | ø | ø | %C3 %B8 | ||||||||||||||||||||||||||||||||||||||||||
| U+00B9 | 0xB9 | ¹ | ¹ | %C2 %B9 | U+00F9 | 0xf9 | ù | ã | %C3 %B9 | ||||||||||||||||||||||||||||||||||||||||||
| U+00BA | 0XBA | . % | .0017 | U+00FA | 0xFA | ú | 㺠| %C3 %BA | |||||||||||||||||||||||||||||||||||||||||||
| U+00BB | 0XBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBIN | U+00FB | 0xFB | û | û | %C3 %BB | |||||||||||||||||||||||||||||||||||||||||||||
| U+00BC | 0xBC | ¼ | ¼ | %C2 %BC | U+00FC | 0xfc | ü | ã | %C3 %BC | ||||||||||||||||||||||||||||||||||||||||||
| U+00BD | 0xBD | ½ | ½ | %½ | % | ½ | ½ | % | ½ | ½ | % | ½ | ½ | % | ½ | ½ | % | ½ | ½ | % | ½ | . Оставить комментарий
| |||||||||||||||||||||||||||||