Что выбрать DataLife Engine UTF-8 или windows-1251
Так как многие задают этот вопрос при выборе движка для своего сайта, хотелось бы разъяснить об особенностях UTF кодировки и для чего она нужна, а также стоит или нет переходит на эту кодировку, если ваш сайт уже стоит с использованием кодировки windows-1251.
Итак, для начала развеем миф о том, что UTF-8 является новинкой, и то что каждый сайт просто обязан ее иметь
Это неверно утверждение.
Кодировка UTF-8 предназначена исключительно для одной вещи: использование на одной странице нескольких языков, а также для организации сайтов использующих язык отличный от русского.
Кодировка windows-1251 поддерживает базовую латиницу (читайте английский язык, ну и американский соответственно), русский, украинский, белорусский, сербский. Иными словами, 1251 подходит для большинства обычных пользователей. Если вы планируете создавать международный проект, с поддержкой расширенной латиницы: немецкого, польского, французского, а также различных других языков: арабского, иврита и более сложных письмён, вам нужен именно UTF-версия.
Так же UTF-8 обладает немного большим количеством символов для некоторых сайтов это необходимо. Также по мнению некоторых UTF-8 любят зарубежные поисковики. Если ваш сайт на русском языке и вы не планируете использование какого либо другого языка, то переход на UTF лишен какого-либо смысла.
Более того для русскоязычных сайтов данная кодировка обладает рядом недостатков, а именно:
1. Размер базы данных русскоязычного сайта будет примерно на 70% больше по сравнению с использованием национальной кодировки windows-1251, что соответственно скажется на производительности сайтов с большими базами данных.
2. Шаблоны и языковые файлы для кодировки имеют специфический формат файлов (UTF формат без BOM байтов), соответственно для редактирования файлов шаблона вам понадобятся специализированные редакторы, поддерживающие этот формат. Из бесплатных это например notepad++. Сохранение этих файлов в неверном формате приведет к не читаемости вашего сайта.
3. Сторонний модуль или шаблон придется конвертировать для кодировки UTF,а большая часть из низ (90%) сделаны для кодировки windows-1251.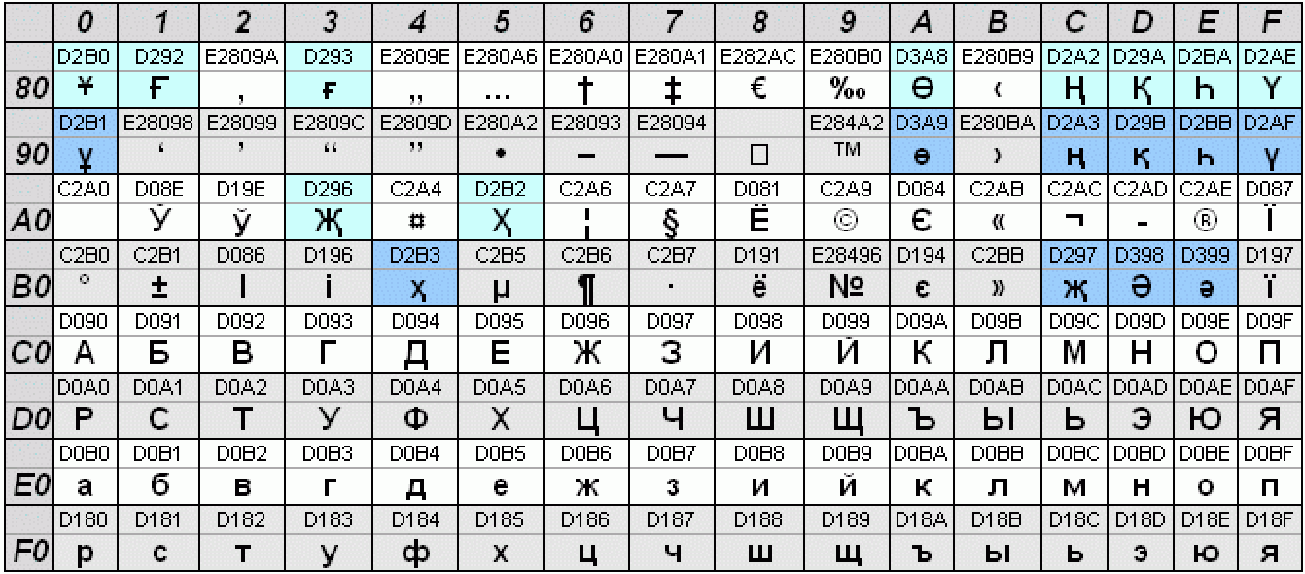 При этом шаблоны на dle можно перевести,а вот для модулей сложнее понадобиться изменять код
При этом шаблоны на dle можно перевести,а вот для модулей сложнее понадобиться изменять код
Поэтому мы не рекомендуем использовать кодировку UTF-8 на сайте, если вы не планируете использование на сайте других языков, отличных от русского, английского, украинского языков.
Обновление сайта с кодировки windows-1251 на кодировку UTF-8:
Если вы все таки решились на обновление кодировки своего сайта, то вы должны знать, что из-за различий форматов, вы не можете просто обновить файлы скрипта и без новой установки скрипта вам не обойтись, поэтому для обновления сайта вы должны выполнить следующие шаги:
1. Сделать бекап базы данных существующего сайта в кодировке win-1251 DLE
2. Произвести новую установку скрипта используя дистрибутив скрипта для UTF версии.
3. Произвести повторные настройки скрипта для вашего сайта.
4. Сконвертировать файлы вашего шаблона в формат UTF-8 (для пакетного конвертирования мы рекомендуем использовать утилиту Sisulizer’s Kaboom), при конвертировании снимите галочку «Записывать BOM байты»
5. Скопировать файл бекапа базы данных от вашего сайта в папку /backup/, который вы делали в первом пункте.
Скопировать файл бекапа базы данных от вашего сайта в папку /backup/, который вы делали в первом пункте.
6. Зайти в админпанель скрипта и сделать восстановление базы данных а админпанели, скрипт автоматически распознает несоответствие кодировок и при восстановлении сконвертирует базу данных в формат UTF.
Внимание: Действия по переносу сайта с кодировки windows-1251 на кодировку UTF-8 являются необратимыми и любая ошибка может привести к потери данных вашего сайта, поэтому мы настоятельно рекомендуем производить данные действия на локальном компьютере, а уже потом переносить все на рабочий сайт.
Наш ресурс dle9.com «все для DataLife Engine» предлагает полезную статью что такое dle, теперь надеюсь вы знаете что выбрать движок DataLife Engine UTF-8 — win-1251
Как быстро изменить кодировку сайта, например, из windows-1251 в UTF-8 — Code Depth
Имеется сайт на PHP, существующий уже много-много лет. Сайт создавался и развивался в кодировке windows-1251, но дальше так жить невозможно, надо весь PHP-код преобразовать в UTF-8, то же самое сделать с html-, css-, js- и прочими файлами, сконвертировать базу данных MySQL и ещё кое-что подправить.
Как быстро выполнить переход сайта на кодировку UTF-8?
Нам помогут знания из статьи про recode и enconv, добавим к ним ещё кое-что.
Все действия можно свести в один bash-скрипт, отдельные части которого рассмотрим в статье.
1. Создать копию всех файлов сайта. Например, сайт находится в /var/www/site. Для работы сайта ещё используются /var/www/dir1, /var/www/dir2, /var/www/dir3, причём dir1 и dir2 надо перекодировать вместе с site, а dir3 не надо трогать. Скопируем всё в /var/www-u8. Для удобства будем использовать переменные, в которых сохраним часто используемые строки.
dir_source=’/var/www’
dir_u8=’/var/www-u8′
cp -R ${dir_source}/* ${dir_u8}
Массив, содержащий имена подкаталогов, в которых надо обработать файлы:
subdirs=(site dir1 dir2)
Во всех подкаталогах надо перекодировать из windows-1251 в UTF-8 все файлы с расширениями: php, txt, js, css, htm. Нам поможет enconv. Затем найти подстроки «windows-1251» или «cp1251» и заменить на «UTF-8».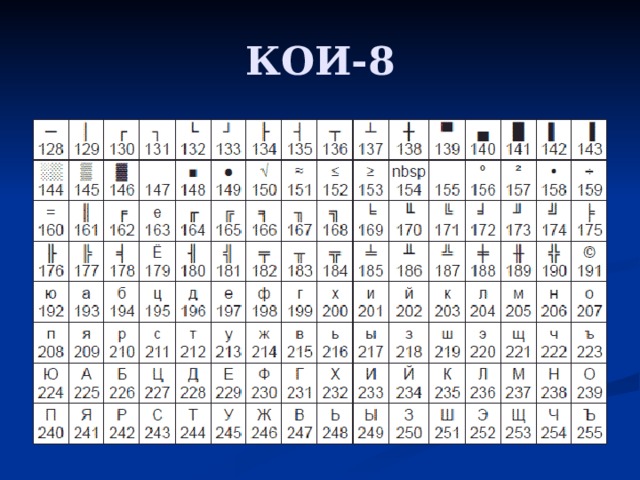 Наконец, найти в php-файлах короткий открывающий тег «<?» и заменить его на полный «<?php». Регулярное выражение для поиска короткого тега ищет строку ‘<?’, после которой следует пробел, конец строки или символ ‘=’ (для файлов, в которых php-код используется вперемешку с html для вставки значений переменных: ‘<?=$var;?>’). Все замены поможет выполнить могучий sed, а с подбором файлов для обработки отлично справится find. Поскольку обработку надо выполнить в нескольких подкаталогах (их имена хранятся в массиве $subdirs), то перебираем элементы массива в цикле (подробнее про использование массивов в bash) и из них составляем путь для поиска командой find.
Наконец, найти в php-файлах короткий открывающий тег «<?» и заменить его на полный «<?php». Регулярное выражение для поиска короткого тега ищет строку ‘<?’, после которой следует пробел, конец строки или символ ‘=’ (для файлов, в которых php-код используется вперемешку с html для вставки значений переменных: ‘<?=$var;?>’). Все замены поможет выполнить могучий sed, а с подбором файлов для обработки отлично справится find. Поскольку обработку надо выполнить в нескольких подкаталогах (их имена хранятся в массиве $subdirs), то перебираем элементы массива в цикле (подробнее про использование массивов в bash) и из них составляем путь для поиска командой find.
for item in ${subdirs[*]}
do
sPath=${dir_u8}/${item}
find ${sPath} -iregex '.*\.\(txt\|php\|css\|js\|html?\)' -exec enconv -L russian -x utf8/LF '{}' \;
find ${sPath} -iregex '.*\.\(txt\|php\|css\|js\|html?\)' -exec sed -i -r 's/windows-1251|cp1251/UTF-8/ig' '{}' \;
find ${sPath} -iname '*\.php' -exec sed -i -r 's/(<\?)(\s|$|=)/<?php\2/ig' '{}' \;
doneС перекодировкой базы данных MySQL вообще всё просто.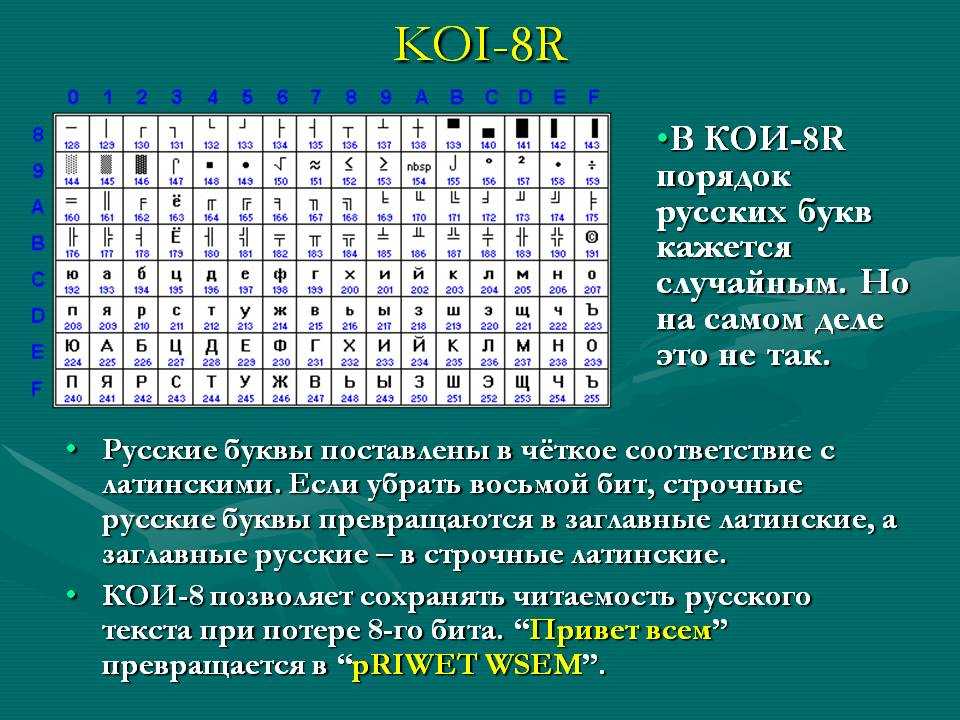
HOST_1='localhost'
USER_1='user1'
PASSWORD_1='password1'
DATABASE_1='database1'
HOST_2='localhost'
USER_2='user2'
PASSWORD_2='password2'
DATABASE_2='database2'
DUMPFILE_1="db-${DATABASE_1}.sql"
DUMPFILE_2="db-${DATABASE_2}.sql"
# dump from the original DB
mysqldump -u ${USER_1} -h ${HOST_1} -p${PASSWORD_1} --opt ${DATABASE_1} > ${DUMPFILE_1}
# Replace charset settings from cp1251 to utf8
sed -r 's/CHARSET=cp1251/CHARSET=utf8/ig' ${DUMPFILE_1} > ${DUMPFILE_2}
# Load data from the dump
mysql -u ${USER_2} -h ${HOST_2} -p${PASSWORD_2} ${DATABASE_2} < ${DUMPFILE_2}В скрипте все переменные, имена которых оканчиваются на «1», относятся к исходной базе данных, работающей в кодировке cp1251. Все переменные, имена которых оканчиваются на «2», относятся к новой базе данных, которая будет использоваться в перекодированном в utf-8 сайте.
Осталось установить для файлов в ${dir_u8} нужные права доступа, при необходимости настроить контекст безопасности SELinux и, наконец, настроить вебсервер для визуальной проверки перекодированного сайта.
Если свести воедино все фрагменты bash-скрипта, написанные на этой странице, то, фактически, весь процесс изменения кодировки сайта на utf-8 окажется простым и быстрым.
Понравилось это:
Нравится Загрузка…
Объявление внутренней кодировки «windows-1251» не соответствует фактической кодировке документа («utf-8»).
Rocket Validator интегрирует средство проверки HTML W3C Validator. в автоматизированный поисковый робот.
Бесплатная пробная версия Пробная версия Pro
- кодирование
- утф-8
- окна-1251
Было объявлено, что документ использует кодировка windows-1251 , но фактическое содержимое выглядит как utf-8 . Вы должны обновить кодировку, как в этом примере:
Вы должны обновить кодировку, как в этом примере:
Связанные с валидатором проблемы W3C
Неверное значение «text/html; charset=windows-1251» для атрибута «content» элемента «meta»: за «charset=» должно следовать «utf-8».
- кодировка
- содержание
- мета
- утф-8
- окна-1251
В документе был найден тег , в котором указано, что кодировка windows-1251
, но на самом деле это utf-8 . Вы должны обновить тег, чтобы отразить фактическую кодировку документа, например:Запрещенная кодовая точка X
- кодирование
- утф-8
- кодовая точка
В документе обнаружен символ, недопустимый в используемой кодировке.
Документ не должен включать как элемент «мета» с атрибутом «http-equiv», значением которого является «тип контента», так и элемент «мета» с атрибутом «charset».
- кодировка
- мета
- http-эквивалент
- Тип содержимого
- утф-8
Чтобы определить кодировку HTML-документа, обе эти опции допустимы, но только одна из них должна присутствовать в документе :
<мета-кодировка="UTF-8">
Неверное значение (.*) для атрибута «href» элемента «a»: недопустимый символ в сегменте пути
- кодирование
- плохое значение
- href
- а
Атрибут href элемента содержит недопустимый символ, который должен быть правильно закодирован как символ с процентным кодированием URI.
6 250 проверок HTML в неделю. Полностью автоматизирован.
Экономьте время, используя нашу автоматическую веб-проверку. Позвольте нашему сканеру проверить ваши веб-страницы на W3C Validator.
Rocket Validator Basic
6 250 проверок HTML, 18 долл. США в неделю
Неверное значение атрибута «src» элемента «img»: недопустимый символ в данных схемы: «<» не допускается.
- кодирование
- изображение
- источник
- плохое значение
Атрибут src в элементе содержит недопустимый символ, который должен быть правильно закодирован как символ с процентным кодированием URI.
Неверное значение «text/html; charset=windows-1252» для атрибута «content» элемента «meta»: за «charset=» должно следовать «utf-8».
- кодировка
- содержание
- мета
- утф-8
- окна-1252
В документе был найден тег , в котором указано, что кодировка windows-1252 , но на самом деле это utf-8 .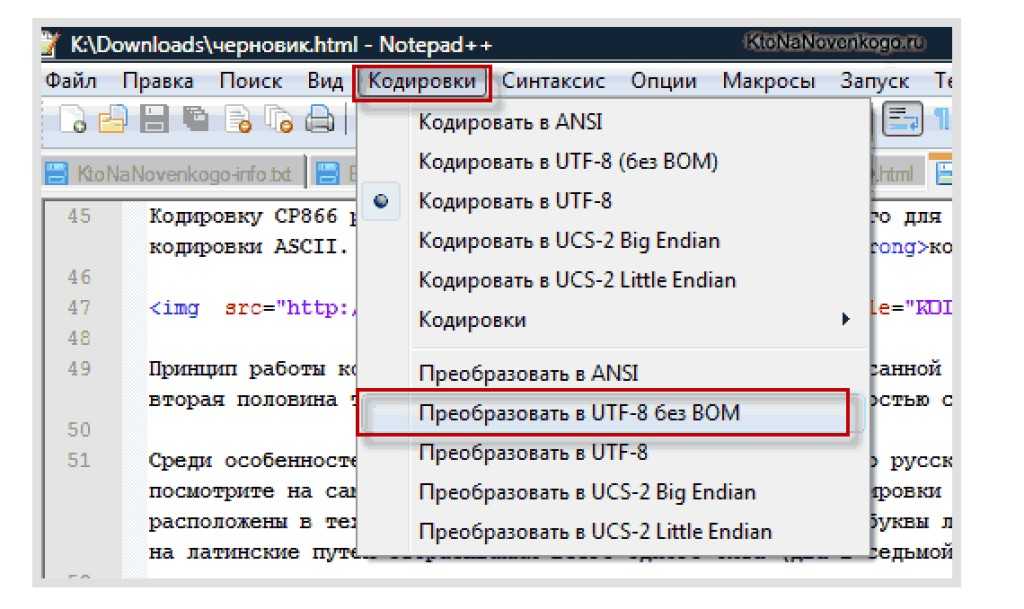 Вы должны обновить тег, чтобы отразить фактическую кодировку документа, например:
Вы должны обновить тег, чтобы отразить фактическую кодировку документа, например:
Все еще проверяете свои большие сайты постранично?
Экономьте время, используя нашу автоматическую веб-проверку. Позвольте нашему сканеру проверить ваши веб-страницы на W3C Validator.
Rocket Validator Micro
5000 проверок HTML в месяц, 12 долларов США в месяц
Неверное значение «X» для атрибута «accept» элемента «input»: ожидался символ токена или «/», но вместо этого было «,».
- принимать
- кодирование
- вход
Атрибут accept может быть указан, чтобы предоставить браузерам подсказку о том, какие типы файлов будут приняты в элементе . Ожидается список разрешенных типов файлов, разделенных запятыми.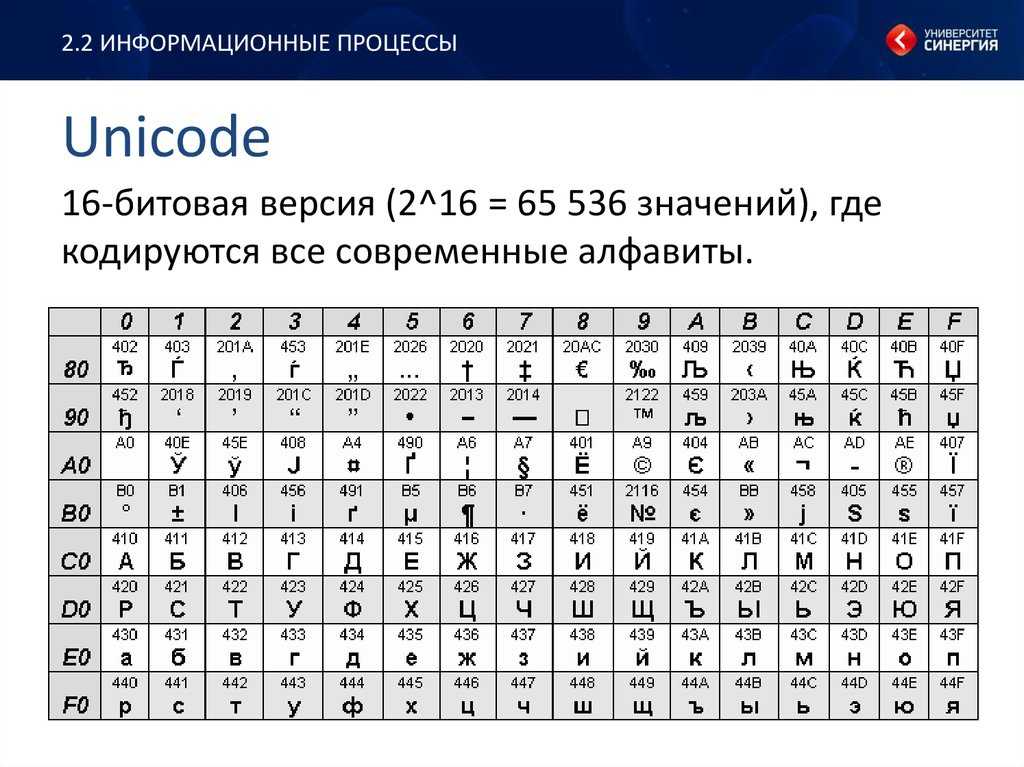 Обратитесь к списку типов носителей, чтобы проверить принятые токены. В этом примере первая строка недействительна, а вторая действительна:
Обратитесь к списку типов носителей, чтобы проверить принятые токены. В этом примере первая строка недействительна, а вторая действительна:
Неверное значение X для атрибута «href» элемента «a»: недопустимый символ во фрагменте: пробел не допускается.
- а
- кодирование
- href
Пробелы не допускаются в href атрибуты. Вместо этого их следует преобразовать в %20 . В этом примере первая строка недействительна, а вторая допустима:
invalid действительно
Недопустимое значение «X» для атрибута «href» элемента «a»: недопустимый символ в запросе: пробел не допускается.
- а
- кодирование
- href
Атрибут href в теге содержит пробел, что недопустимо. Рассмотрите возможность замены символов пробела на «%20».
Неверное значение «X» для атрибута «src» элемента «img»: недопустимый символ в сегменте пути: пробел не допускается.
- кодирование
- источник
- изображение
Символы пробела не допускаются в атрибутах src . Вместо этого их следует преобразовать в %20 . В этом примере первая строка недействительна, а вторая допустима:
Все еще проверяете свои большие сайты постранично?
Экономьте время, используя нашу автоматическую веб-проверку.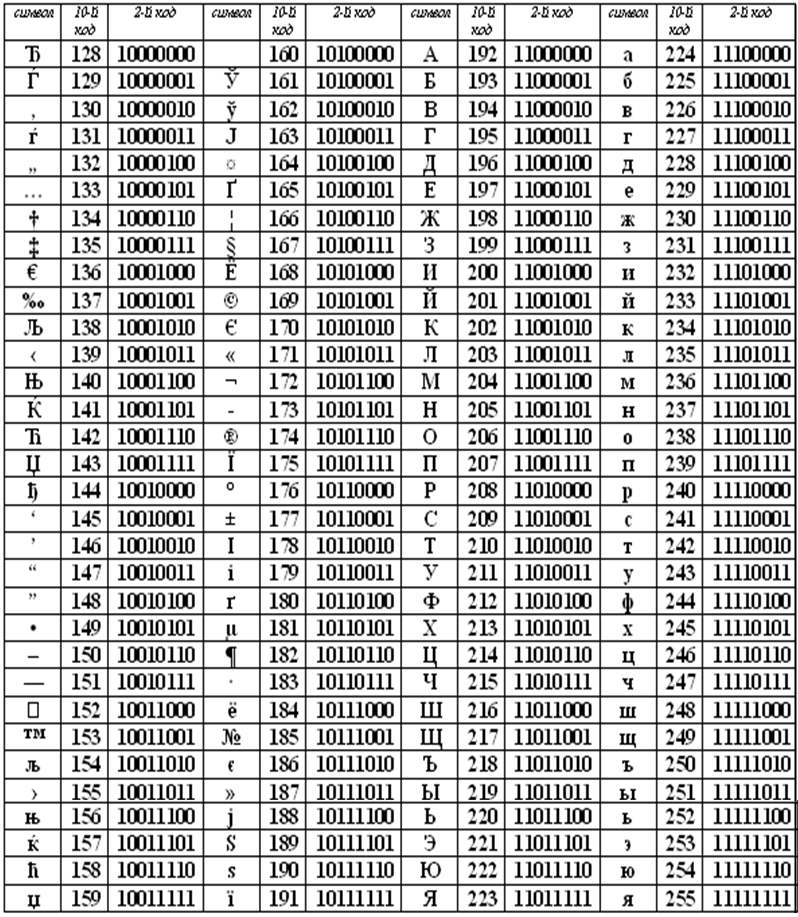 Позвольте нашему сканеру проверить ваши веб-страницы на W3C Validator.
Позвольте нашему сканеру проверить ваши веб-страницы на W3C Validator.
Rocket Validator Micro
1250 проверок HTML в неделю, 6 долларов США в неделю
символов. Как преобразовать текстовый файл в UTF-8 из Windows-1251?
спросил
Изменено 1 год, 6 месяцев назад
Просмотрено 10 тысяч раз
Windows 10, Emacs 25.
Когда я хочу преобразовать файл из Windows-1251 в UTF-8, я использую Notepad++.
Перед преобразованием:
преобразованием:
после преобразования:
Мой вопрос: возможно ли это преобразование в Emacs?
- character-encoding
Следует использовать команду set-buffer-file-coding-system ( C-x RET f ), установить кодировку, а затем сохранить файл.
Обратите внимание, что вы можете сначала revert-buffer-with-coding-system ( C-x RET r ) перед выполнением вышеуказанного шага, если файл изначально открыт с неправильной кодировкой.
1
Самый простой способ сделать это:
- Тип C-x RET c
- Выберите нужную систему кодирования (в данном случае возможно
utf-8-dos) - Передайте C-x C-w в качестве команды и передайте имя файла для записи
3
Это должно помочь:
- Посетите файл с C-x C-f .
- Вернуть открытый буфер к исходной кодировке файла (
cp-1251in в этом случае) с M-x +revert-buffer-wth-coding-system. - Используйте M-x +
set-buffer-file-coding-system, чтобы установить кодировку utf-8.