Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).

Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.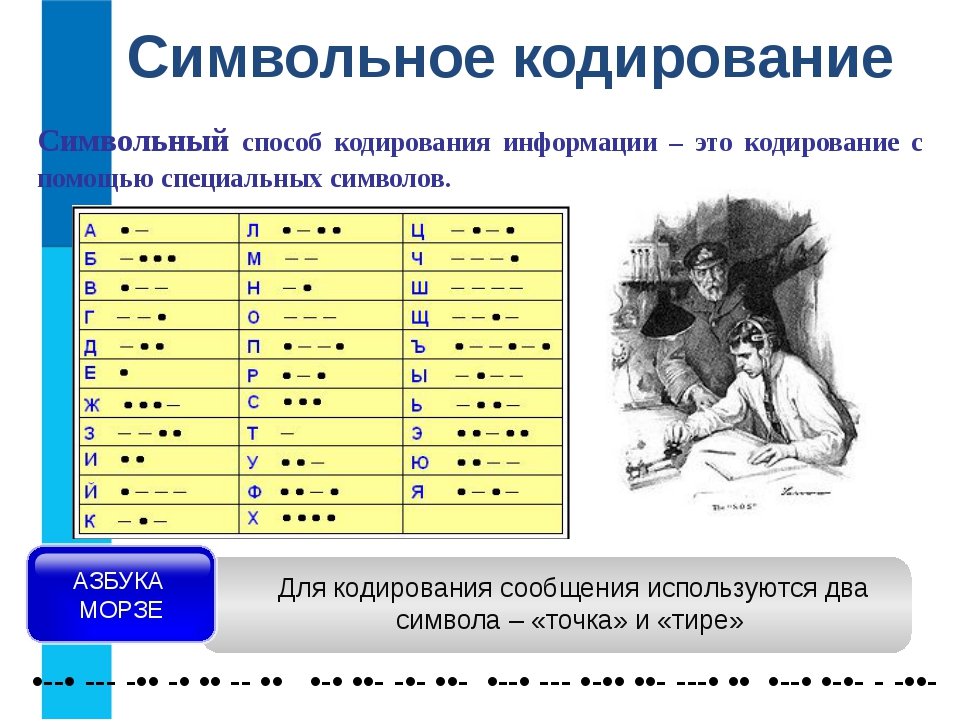
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и
01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную —
Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять. Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков.
 Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII —
 А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII.
 То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111

Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.
В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8.
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона.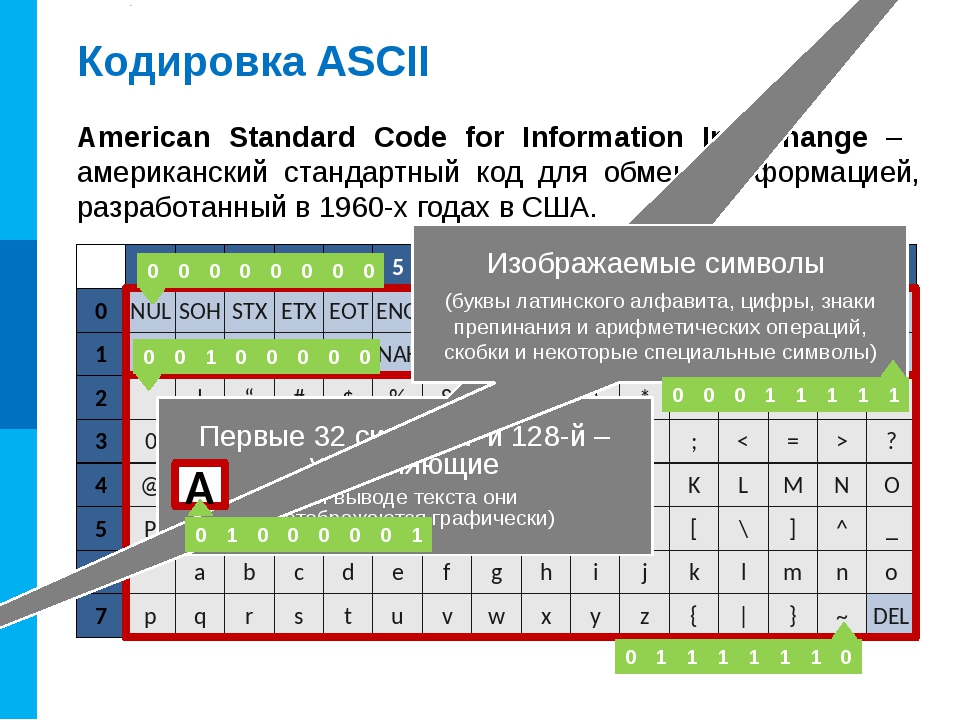 Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.

Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16
Раскодирование алкоголизма в клинике -безопасно и эффективно
Как работает раскодирование?
Раскодирование − это процедура нейтрализации препаратов-блокаторов Дисульфирам (Эспераль) и Налтрексон (Вивитрол).
При кодировке Дисульфирам блокирует выработку фермента печени, отвечающего за быструю переработку этанола в организме – так при употреблении спиртного алкоголик чувствует симптомы отравления. А препарат-антидот нейтрализует действие Дисульфирама и возвращает человеку возможность принимать спиртосодержащие напитки и лекарства без болезненных ощущений и риска для здоровья.
При кодировке Налтрексоном у пациента блокируются опиоидные рецепторы головного мозга, что лишает его возможности получать удовольствие от этанола. Антидот Налтрексона активирует работу этих рецепторов и позволяет человеку получать наслаждение от спиртных напитков.
Причины для проведения процедуры
- Посещение важных мероприятий. Зависимые часто решают раскодироваться от алкоголя после укола и вшивания в преддверии важных семейных торжеств – например, свадьбы близких родственников.
- Желание вернуться к употреблению алкоголя. Кодировку снимают ради возвращения привычного образа жизни с алкогольными застольями. Чаще всего это происходит, если зависимый проходил кодирование под давлением родственников – именно поэтому мы настоятельно рекомендуем добиваться добровольного и сознательного согласия больных.
- Непереносимость препарата. Процедура показана при аллергических реакциях на Дисульфирам, появлении функциональных и психосоматических нарушений – потери сна и аппетита, головных болей, импотенции.
- Конфликт с другими препаратами. Нейтрализация Дисульфирама нужна в случае лечения, где препарат-блокатор будет конфликтовать с другими медикаментами – например, при приеме спиртосодержащих лекарств.
- Частые срывы. Пациента нужно раскодировать от алкоголя, если он регулярно подвергает себя сознательному риску – употребляет алкоголь, провоцируя опасную для здоровья интоксикацию, или пытается самостоятельно извлечь капсулу с блокатором в домашних условиях.
Как проходит консультация
В ходе беседы с пациентом нарколог уточняет причины раскодирования – при наличии у пациента сомнений или психоэмоциональной нестабильности часто возможно обойтись без процедуры и решить имеющиеся проблемы психотерапией и медикаментозной поддержкой.
Также, если кодирование проводилось не в нашей клинике, наркологу нужна информация о способе, расположении, дате и выбранном вами сроке кодировки – только так он сможет провести эффективную и безопасную нейтрализацию блокировки. При необходимости нарколог назначает дополнительные обследования.
Как проходит процедура
Пациенту в клинике или с выездом на дом делают инъекцию с антидотом – в то место, куда был введен гель или капсула с препаратом-блокатором.
Уже через 3-4 часа после процедуры пациент сможет употреблять спиртосодержащие напитки и медикаменты без риска для самочувствия.
Эффективное лечение алкоголизма без кодировки
Кодирование от алкоголизма – не панацея, и популярность услуги раскодирования это доказывает. Такой способ помощи зависимым эффективен только в виде поддерживающей терапии – кодировка помогает быстрее адаптироваться к трезвой жизни и защищает от возможных срывов.
Но кодирование не лечит главную проблему алкоголизма – предпосылки, которые подтолкнули человека к злоупотреблению и заставляют продолжать разрушительный образ жизни:
- Психологические травмы. Детские травмы из-за слишком строгого воспитания или безразличия родителей, пережитое физическое и психологическое насилие, потеря близких и другие тяжелые жизненные эпизоды, из-за которых человек ищет утешения в спиртном.
- Низкий самоконтроль. К злоупотреблению подталкивает неумение человека самостоятельно справляться со стрессом, контролировать «эмоциональные качели», отказываться от соблазнов.
- Социальные проблемы. Алкоголь также может быть допингом для более комфортного социального общения: чтобы повысить самооценку и справиться с зажатостью, быть более общительным, преодолеть страхи и комплексы.
Все эти проблемы не решаются введением препарата-блокатора. Поэтому для действительно эффективного и полноценного избавления от зависимости мы рекомендуем комплексное лечение:
- Психотерапия. Индивидуальные и групповые занятия помогают устранить психологические травмы, комплексы и страхи, развить стрессоустойчивость и самообладание, получить навыки здорового социального общения, построить личные границы для защиты от провокаций пьющего окружения, наладить отношения с близкими.
- Поддерживающая медикаментозная терапия. Индивидуально подобранный комплекс препаратов помогает устранить тревожность, раздражительность, подавленное настроение и апатию, нарушения сна и питания, и другие проблемы зависимых на пути к трезвой жизни.
- Профилактика срывов. Для эффективной защиты от срывов мы рекомендуем придерживаться правил безопасности: не иметь дома алкоголь и атрибутику для его приема, не прикасаться к бутылкам или стопкам, исключить пьющих людей из близкого окружения, найти трезвые увлечения и новые приятные знакомства для компенсации «допинга».
Кодирование
+
Психотерапия
+
Медикаментознаяподдержка
Добро пожаловать в клинику доктора Шурова
Василий Александрович Шуров
- Психиатр, нарколог, главный врач наркологической клиники «Первый шаг»
- Врачебный стаж более 15 лет
- Член Национальной Наркологической лиги
- Обладатель премии Brand Awards’19 в сфере медицины
- Эксперт популярных телешоу на федеральных каналах
Василий Шуров – главный врач и ведущий нарколог-психиатр нашей клиники, член Российской Наркологической Лиги, популярный приглашенный врач-эксперт российских телепередач и судебных заседаний. На счету Василия Александровича – более 15 лет успешного лечения алкоголизма и наркомании различной степени тяжести, а также сопутствующих психических расстройств.
Лицензии
Наша наркологическая клиника работает по лицензии, выданной Минздравом России.
Наркологическая клиника «Первый шаг» — официальное медицинское учреждение, лицензированное Министерством Здравоохранения РФ
Лицензия на осуществление медицинской деятельности №ЛО-77-01-018683
А врачи клиники – дипломированные специалисты со стажем работы в сфере наркологии и психиатрии не менее 5 лет.
Дипломы специалистов
Кодирование и шифрование — в чём разница?
👉 Эта статья — для расширения кругозора. Если нужна практика, заходите в раздел «Это баг», там вагон практики.
«Данные закодированы» и «данные зашифрованы» — это не одно и то же. После этой статьи вы тоже сможете различать эти два подхода к данным.
Кодирование
Кодирование — это представление данных в каком-то виде, с которым удобно работать человеку или компьютеру.
Кодирование нужно для того, чтобы все, кто хочет, могли получать, передавать и работать с данными так, как им хочется. Благодаря кодированию мы можем обмениваться данными между собой — мы просто кодируем их в понятном для всех виде.
Например, древний человек видит волка, это для него данные. Ему нужно передать данные своему племени. Он произносит какой-то звук, который у других его соплеменников вызывает ассоциации с понятием «волк» или «опасность». Все мобилизуются. В нашем случае звук — это был способ кодирования.
Слово «волк» и сопутствующий ему звук — это вид кодирования. Сам волк может не использовать такую кодировкуДля следующего примера возьмём букву «а». Её можно произнести как звук — это значит, что мы закодировали эту букву в виде звуковой волны. Также эту букву можно написать прописью или в печатном виде. Всё это примеры кодирования буквы «а», удобные для человека.
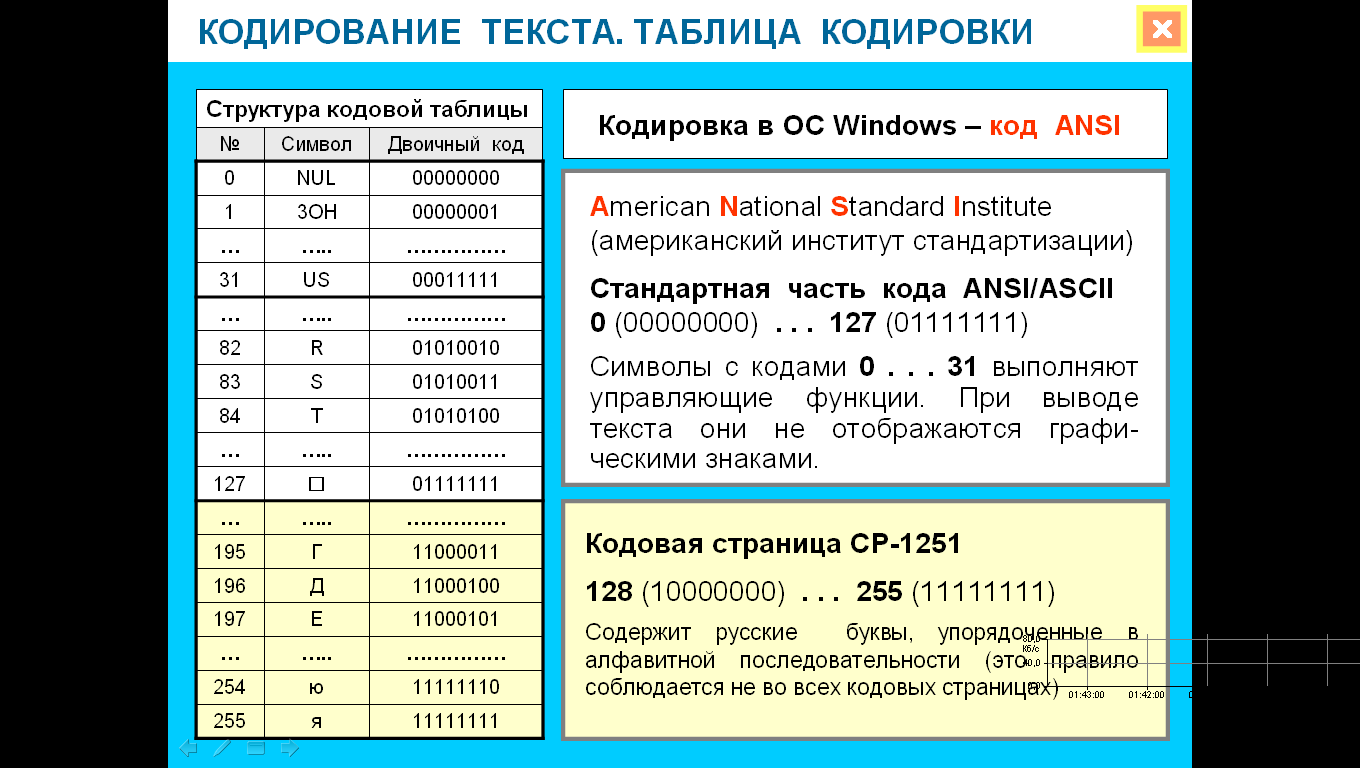
В компьютере буква «а» кодируется по-разному, в зависимости от выбранной кодировки внутри операционной системы:
Кодирование — это то, как удобнее воспринимать информацию тем, кто ей пользуется. Например, моряки кодируют букву «а» последовательностью из короткого и длинного сигнала или точкой и тире. На языке жестов, которым пользуются глухонемые, она обозначается сложенными почти в кулак пальцами.
Сломанная кодировка
Когда встречаем незнакомую кодировку, то можно подумать, что перед нами зашифрованные данные. Например, если посмотреть на двух людей, которые общаются языком жестом, можно подумать, что они зашифровали своё общение. На самом деле вы просто не были готовы воспринимать информацию в этой кодировке.
Похожая ситуация в компьютере. Допустим, вы увидели такой текст:
рТЙЧЕФ, ЬФП ЦХТОБМ лПД!
Здесь написано «Привет, это журнал Код!», только в кодировке КОИ-8, которую интерпретировали через кодировку CP-1251. Компьютер не знал, какая здесь должна быть кодировка, поэтому взял стандартную для него CP-1251, посмотрел символы по таблице и выдал то, что получилось. Если бы компьютер знал, что для этой кодировки нужна другая таблица, мы бы всё прочитали правильно с первого раза.
Ещё кодирование
Кодированием пользуется весь мир на протяжении всей своей истории:
- наскальные рисунки кодируют истории древних людей;
- египетская клинопись на табличках и берестяные грамоты — примеры алфавитного кодирования. Обычно нужны были, чтобы закодировать и зафиксировать численность голов скота и мешков зерна;
- ноты у музыкантов — кодируют музыку, а точнее, инструкцию по исполнению музыки;
- дорожные знаки и сигналы светофора кодируют правила дорожного движения;
- иконки в смартфоне — тоже пример кодирования;
- разные народы кодируют одни и те же слова по-разному, каждый на своём языке;
- значки на ярлычке одежды кодируют информацию о том, как стирать и ухаживать за вещью.e
Здесь зашифрована та же самая фраза — «Привет, это журнал Код!». Но не зная ключа для расшифровки и принципа шифрования, вы не сможете её прочитать.
Шифрование нужно, например, чтобы передать данные от одного к другому так, чтобы по пути их никто не прочитал. Шифрование используют:
- госорганы, чтобы защитить персональные данные граждан;
- банки, чтобы хранить информацию о клиентах и о переводах денег;
- мессенджеры, чтобы защитить переписку;
- сайты;
- мобильные приложения;
- и всё остальное, что связано с безопасностью или тайнами.
Шифрование бывает аналоговое и компьютерное, простое и сложное, взламываемое и нет. Обо всём этом ещё расскажем, подписывайтесь.
Текст и иллюстрации:
Миша ПолянинРедактор и картинка с волком:
Максим ИльяховКорректор:
Ира МихееваИллюстратор:
Даня БерковскийВёрстка:
Маша ДроноваДоставка:
Олег ВешкурцевКак выбрать кодировку и исправить все проблемы с ней
ыЙТПЛБС ØàÞÚÐï ╒┌тр╪ф╪┌ПрЎ.ТруНЬ_аЭШЩ ФРбв ЬЮ!…
Нет, мы не сошли с ума. Просто сегодня будем разбираться, как устранить ошибки кодировки и вернуть на сайт читаемый текст. Узнаем, как кодировка влияет на SEO-оптимизацию, и познакомимся с полезными сервисами, которые позволят вовремя идентифицировать ошибки.
Что такое кодировка, и когда возникают ошибки с отображением текста
Если вместо нормального текста на вашем сайте отображается странный набор символов, значит, есть проблемы с кодировкой. Впрочем, иногда кодировка на сайте является стандартизированной и выбрана корректно, но вместо текста все равно отображаются иероглифы.
Кодировка – это набор символов и система их передачи для последующего вывода на экран. Кроме алфавита при помощи кодировки передаются также специальные символы и цифры.
Сегодня массово используются 2 вида кодировки: Windows-1251 и UTF-8. Чаще всего «кракозябра» появляется, когда на одном сайте используется сразу несколько видов кодировки (да, такое бывает чаще, чем может показаться на первый взгляд).
Можно выделить и другие причины неполадок:
- Используется устаревший браузер.
- В браузере / программе установлена одна кодировка, на сайте – другая. В таком случае нужно поменять кодировку в программе.
- В БД и других файлах сайта указаны несовпадающие кодировки. В этом случае нужно выбрать одну кодировку для всего сайта.
Как поменять кодировку в браузере
Проблему с кодировкой на стороне браузера исправить легко.
Internet Explorer
- Открываем проблемную веб-страницу.
- Вызываем контекстное меню, кликнув правой кнопкой мыши по любому месту на странице.
- Выбираем «Кодировка».
- Кликаем Unicode (UTF-8).
Chrome
Chrome современный и модный браузер, но вот кодировку стандартными средствами поменять в нем нельзя (сюрприз!). Будем делать это через расширение.
- Открываем магазин Chrome.
- Кликаем «Расширения» в левой части экрана.
- Указываем слово «кодировка».
- Устанавливаем любое подходящее расширение.
Safari
- Выбираем пункт «Вид».
- Кликаем по разделу «Кодировка текста».
- Выбраем вариант Unicode (UTF-8).
Firefox
- Выбираем пункт «Вид».
- Кликаем по раздел «Кодировка текста».
- Нужно выбрать вариант Unicode (UTF-8).
Как выбрать кодировку
Если в качестве CMS вы используете WordPress, Joomla, Drupal, OpenCart или TYPO3, то дополнительно настраивать ничего не нужно. Эти движки по умолчанию работает именно с UTF-8. Все должно работать из коробки. Просто убедитесь, что везде прописана UTF-8.
В самых сложных случаях придется отдельно скачивать шаблоны под конкретную кодировку, предварительно создав MySQL. Последнее актуально, например, для DLE. Если же ваш cайт полностью самописный, просто проследите за тем, чтобы везде была установлена идентичная кодировка, желательно – UTF-8.
Какую кодировку выбрать
Сегодня большинство экспертов солидарны в том, что наиболее удобной кодировкой является UTF-8. Этот стандарт поддерживает большинство браузеров, баз данных, серверов и языков. Еще одно преимущество – она изначально была кроссплатформенной.
Сквозная аналитика для чайников: подводные камни и тонкости настройкилучшие виды и современные средства
ВойтиПоиск Найти
- Главная
- Кулинария
- Бульоны и супы
- Горячие блюда
- Десерты
- Закуски
- Консервация
- Напитки
- Продукты питания
- Салаты
- Здоровье
- Медицина
- Ангиология
- Гастроэнтерология
- Гематология
- Гинекология
- Дерматология
- Инфекционные болезни
- Кардиология
- Лечебные диеты
- Неврология
- Нетрадиционная медицина
- Онкология
- Отоларингология
- Офтальмология
- Педиатрия
- Проктология
- Пульмонология
- Ревматология
- Стоматология
- Токсикология и Наркология
- Травматология
- Урология
- Фармакология
- Эндокринология
- Красота
- Женские прически
- Косметическая продукция
- Косметология
- Макияж
- Массаж и СПА
- Похудение
- Спорт и фитнес
- Уход за волосами
- Уход за кожей
- Уход за лицом
- Уход за ногтями
- Уход за телом
- Мода и стиль
- Аксессуары
- Женская одежда
- Модные тенденции
- Мужская одежда
- Обувь
- Шоппинг
- Ювелирные украшения
что это такое, как установить, поменять ее, и какие проблемы с настройками могут возникнуть
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Кодировка сайта – это набор взаимосвязанных кодов и соответствующего им графического отображения печатных элементов на экране.
Что такое кодировка сайта
Все виды кодировок на сайтах, в сообщениях электронной почты, файлах и текстах нужны для одной и той же цели – сохранить информацию в привычном для машины, двоичном представлении.
Представьте, что у вас есть друг, который из всех символов понимает только ноль и единицу. Он с детства не знает ни букв, ни других цифр, и может читать сообщения, состоящие исключительно из сочетаний этих двух символов. Как с ним общаться, как говорить ему слова, как понимать его ответы – типичные вопросы, которые бы возникли у вас в начале общения. Решение следующее: составьте таблицу, по которой каждая буква, символ, цифра или знак препинания будут означать какую-то последовательность из нулей и единиц. Начните общаться с вашим другом по этому правилу, шифруйте все свои слова в двоичный вид и расшифровывайте его ответы.
А что, если таких человек в мире несколько десятков? Каждый имеет своих друзей, и каждый придумал собственную таблицу перевода букв в цифры. Если они встретятся друг с другом, никто ничего не поймёт, все они используют разные табличные языки общения. У одного буква «А» значит — 000101, а у другого этому коду соответствует вопросительный знак. Возникнет страшная путаница, каждый подумает, что его собеседник ошибся или не умеет говорить.
Вернёмся в реальность. Наши необычные друзья – это компьютеры. А их выдуманные языки с таблицами – те самые кодировки.
Какие существуют кодировки
Перечислим несколько наиболее удобных и популярных способов кодирования:
UTF-8
Unicode Transformation Format. Восьмибитное представление Юникода. Был изобретён в 1992 году и до сих пор является золотым стандартом всего программного обеспечения в мире. Для кириллицы в Юникоде выделено два раздела: Cyrillic и Cyrillic Supplement.
Windows-1251
Создана в 1990 году специально для русификаторов операционной системы Microsoft Windows. Кириллическая восьмибитная кодировка, занимает второе место по популярности.
KOI8-R
Восьмибитный стандарт кириллического кодирования. Если убрать у каждого символа восьмой бит, мы получим транскрипцию русских букв на латиницу. Иногда его применяют в электронной почте, но на сегодняшний день в интернете встречается редко.
Как узнать кодировку сайта
Иногда для устранения проблемы на сайте возникает необходимость определить кодировку открытой страницы. Сделать это можно несколькими способами:
По метатегу
- Откройте исходный код страницы. Обычно это реализуется нажатием правой кнопки мыши по пустому месту открытого окна и выбором пункта меню «Исходный код страницы».
- В области <head> найдите тег<meta>.
- В нем должна быть строка с параметром charset.
- Значение этого параметра обозначает кодировку открытого сайта.
Через инструментарий браузера
- Найдите в вашем обозревателе меню с выбором «Информация о странице» или «Подробнее», пункт зависит от используемой программы.
- Выберите вкладку с основной информацией в открывшемся окне.
- Одним из свойств страницы будет «Кодировка текста».
Как установить кодировку сайта
Вы открыли сайт, но вместо текста видите непонятные закорючки, иностранные символы или цифры. Чтобы привести страницу к обычному виду, нужно вручную задать используемую кодировку.
- Mozilla Firefox
- Заходим в меню – три горизонтальные полосы справа.
- Выбираем категорию «Еще».
- Далее раздел «Кодировка текста».
- Выбираем необходимую опцию.
Opera
- Заходим настройки.
- Выбираем «Веб-сайты».
- Переходим в блок «Отображение».
- Далее – «Настроить шрифты».
- В конце выбираете кодировку.
Google Chrome
- Перейдите в меню – три точки справа вверху.
- Выберите пункт «Дополнительные инструменты».
- Откройте раздел «Кодировка».
- Откроется окно с выбором различных кодировок.
Настройка кодировки сайта
Если вы владелец проблемного сайта, на который жалуются посетители за неправильно работающую кодировку, стоит заново настроить портал для правильной работы по следующим пунктам. Главное правило, которое должно действовать для всего проекта – единая кодировка файлов, скриптов, баз данных и сервера.
- Сохраните все файлы сайта в единой кодировке. При необходимости измените её с помощью специальных программ, например Notepad++.
- Установите в html кодетеги кодировок. Для UTF8 кодировки это будет.
- Задайте кодировку серверных заголовков по умолчанию. Без этого браузер будет игнорировать даже метатеги.
- Отредактируйте файл httpd.conf. Найдите параметр AddDefaultCharset и установите необходимое значение.
- Если у вас нет доступа к корневым настройкам веб-сервера, отредактируйте файл .htaccess в папке ресурса. Укажите вручную параметр AddDefaultCharset с вашей кодировкой сайта.
- Существует возможность отправки заголовков средствами скриптов. Например, в PHP-скриптах достаточно добавить header(«Content-type: text/html; Charset=utf-8»). Отправка заголовков – приоритетная задача, и она должна выполняться в первую очередь перед выводом контента.
Придется вручную установить верную кодировку соединения для подключаемых модулей. Приведем пример конфигурации для популярной БД MySQL:
- Откройте на сервере конфиг my.cnf.
- В области [client] добавьте блок default-character-set=utf8.
- В области [mysqld] добавьте блок character_set_server=utf8 и
collation_server=utf8_unicode_ci. - Задайте принудительную кодировку при каждом обращении в PHP.
- mysqli_query(‘SET NAMES utf8 COLLATE utf8_general_ci’).
Неверная настройка кодировки сайта может навредить вашим посетителям, за счёт чего вы потеряете посещаемость и доход. Заходя на сайт, аудитория увидит непонятные отталкивающие наборы несвязанных символов. Никто не станет настраивать все вручную, чтобы поменять кодировку сайта на правильную, 95% пользователей просто уйдут со страницы. Подходите к этой проблеме с максимальной ответственностью. От правильного выбора кодировки зависит дальнейшая работа всего проекта.
3. Определения — Программирование с помощью Unicode
3.1. Персонаж
Общий термин для семантического символа. В контексте кодирования существует множество возможных интерпретаций.
В вычислениях наиболее важным аспектом является то, что символы могут быть буквами, пробелами или управляющими символами, которые представляют конец файла или могут использоваться для запуска звука.
3.2. Глиф
Одна или несколько форм, которые можно объединить в графему.
В латинском языке глиф часто имеет 2 варианта, например «A» и «a», а в арабском языке — четыре.) также являются глифами, которые иногда представлены другим символом в одной точке, например à в ISO 8859-1, или двумя отдельными глифами, поэтому a и объединение `(U + 0300 и U + 0061 объединены как U + 00E0) .
3.3. Кодовая точка
Кодовая точка является целым числом без знака. Самая маленькая кодовая точка — ноль. Код точки обычно записываются в шестнадцатеричном формате, например «0x20AC» (8,364 в десятичной системе).
3.4. Набор символов (charset)
Набор символов , сокращенно charset , является отображением кода точки и персонажи.Отображение имеет фиксированный размер. Например, большинство 7-битных кодировок имеют 128 записей, а большинство 8-битных кодировки имеют 256 записей. Самая большая кодировка — это символ Юникода. Установите 6.0 с 1,114,112 записями.
В некоторых наборах символов не все кодовые точки являются смежными. Например, cp1252 charset отображает кодовые точки от 0 до 255, но имеет только 251 запись: 0x81, 0x8D, 0x8F, 0x90 и 0x9D кодовые точки не назначаются.
Примеры кодировки ASCII: цифра пять («5», U + 0035) — это присвоена кодовая точка 0x35 (53 в десятичной системе) и заглавная буква «A» (U + 0041) в кодовую точку 0x41 (65).7-1 \))
Примеры кодировки:
Кодировка Кодовая точка Персонаж ASCII 0x35 5 (U + 0035) ASCII 0x41 А (U + 0041) ISO-8859-15 0xA4 € (U + 20AC) Набор символов Юникода 0x20AC € (U + 20AC) 3.5. Строка символов
Строка символов или «строка Unicode» — это строка, каждая единица которой является персонаж. В зависимости от реализации каждый персонаж может быть любым символом Юникода или только символами в диапазоне U + 0000 — U + FFFF, диапазон, называемый Basic Multilingual Plane (BMP). Есть 3 различные реализации символьных строк:
- массив 32-битных целых чисел без знака (кодировка UCS-4): полный Диапазон Unicode
- массив 16-битных целых чисел без знака (UCS-2): только BMP
- массив 16-битных целых чисел без знака с суррогатными парами (UTF-16): полный диапазон Unicode
UCS-4 использует вдвое больше памяти, чем UCS-2, но поддерживает все Unicode. символы.UTF-16 — это компромисс между UCS-2 и UCS-4: символы в В диапазоне BMP используется один блок UTF-16 (16 бит), символы вне этого диапазона используют два Модули UTF-16 (суррогатная пара, 32 бита). Это преимущество также главный недостаток такой символьной строки.
Длина символьной строки, реализованной с использованием UTF-16, представляет собой количество UTF-16, а не количество символов, что сбивает с толку. За Например, символ U + 10FFFF кодируется как две единицы UTF-16: {U + DBFF, U + DFFF}.Если строка символов содержит только символы диапазона BMP, длина — это количество символов. Получение символа n th или длина в символах с использованием UTF-16 имеет сложность \ (O (n) \), тогда как он имеет сложность \ (O (1) \) для строк UCS-2 и UCS-4.
Язык Java, библиотека Qt и Windows 2000 реализуют символьные строки с UTF-16. Языки C и Python используют UTF-16 или UCS-4 в зависимости от: размера
wchar_tтип (16 или 32 бита) для C, и режим компиляции (узкий или широкий) для Python.Windows 95 использует строки UCS-2.Что такое кодирование URL и как оно работает?
Введение
URL (унифицированный указатель ресурсов) — это адрес ресурса во всемирной паутине. URL-адреса имеют четко определенную структуру, которая была сформулирована в RFC 1738 Тимом Бернерсом-Ли, изобретателем всемирной паутины.
Каждый URL-адрес соответствует общему синтаксису , который выглядит так —
схема: [// [пользователь: пароль @] хост [: порт]] путь [? Запрос] [Некоторые части синтаксиса URL, например
.[user: password @], устарели и редко используются из соображений безопасности.Ниже приведен пример URL-адреса, который вы чаще всего видите в Интернете —https://www.google.com/search?q=hello+worldВ первоначальный RFC, определяющий синтаксис унифицированных указателей ресурсов (URL), было внесено множество улучшений. Текущий RFC, определяющий универсальный синтаксис URI, — RFC 3986. Этот пост содержит информацию из последнего документа RFC.
Кодировка URL (процентное кодирование)
URL-адрес состоит из ограниченного набора символов, принадлежащих набору символов US-ASCII.Эти символы включают цифры (0-9), буквы (A-Z, a-z) и несколько специальных символов (
"-",".","_","~").управляющих символов ASCII (например, пробел, вертикальная табуляция, горизонтальная табуляция, перевод строки и т. Д.), Небезопасные символы, такие как
пробел,\,<,>,{,}и т. Д. И любой символ вне кодировки ASCII нельзя размещать непосредственно в URL-адресах.Более того, есть некоторые символы, которые имеют особое значение в URL-адресах.Эти символы называются зарезервированными символами. Примеры зарезервированных символов:
?,/,#,:и т. Д. Любые данные, передаваемые как часть URL-адреса, будь то в строке запроса или сегменте пути, не должны содержать эти символы.Итак, что нам делать, когда нам нужно передать какие-либо данные в URL-адресе, содержащие эти запрещенные символы? Ну мы их кодируем!
Кодирование URL-адресаURL Encoding преобразует зарезервированные, небезопасные и не-ASCII символы в URL-адресах в формат, который повсеместно принят и понятен всеми веб-браузерами и серверами.Сначала он преобразует символ в один или несколько байтов. Тогда каждый байт представлен двумя шестнадцатеричными цифрами, которым предшествует знак процента (
%) - (например,% xy). Знак процента используется как escape-символ.также называется процентным кодированием, поскольку оно использует знак процента (
%) в качестве escape-символа.Пример кодировки URL
Пробел: Один из наиболее частых символов в кодировке URL, с которыми вы, вероятно, столкнетесь, - это
пробел.Значение ASCIIпробеласимвола в десятичном виде составляет32, которое при преобразовании в шестнадцатеричное получается как20. Теперь мы просто ставим перед шестнадцатеричным представлением знак процента (%), который дает нам значение в кодировке URL -% 20.Справочник по кодировке символов ASCII
В следующей таблице приведены ссылки на символы ASCII на их соответствующую закодированную форму URL.
Обратите внимание, что кодирование буквенно-цифровых символов ASCII не требуется.Например, вам не нужно кодировать символ
'0'в% 30, как показано в следующей таблице. Его можно передавать как есть. Но кодировка по-прежнему действительна согласно RFC. Все символы, которые можно безопасно передавать внутри URL-адресов, в таблице окрашены в зеленый цвет.В следующей таблице используются правила, определенные в RFC 3986 для кодирования URL.
Кодирование данныхДесятичный Символ Кодировка URL (UTF-8) 0 NUL (нулевой символ) % 00 1 SOH (начало заголовка) % 01 2 STX (начало текста) % 02 3 ETX (конец текста) % 03 4 EOT (конец передачи) % 04 5 ENQ (запрос) % 05 6 ACK (подтверждение) % 06 7 BEL (звонок (звонок)) % 07 8 BS (возврат) % 08 9 HT (горизонтальная табуляция) % 09 10 LF (перевод строки) % 0A 11 VT (ve rtical tab) % 0B 12 FF (подача формы) % 0C 13 CR (возврат каретки) % 0D 14 SO (сдвиг ) % 0E 15 SI (сдвиг) % 0F 16 DLE (выход из канала данных) % 10 17 DC1 (управление устройством 1 ) % 11 18 DC2 (управление устройством 2) % 12 19 DC3 (управление устройством 3) % 13 20 DC4 (управление устройством 4) % 14 21 NAK (отрицательное подтверждение) % 15 22 SYN (синхронизация) % 16 23 ETB (блок конечной передачи) % 17 90 05224 CAN (отменить) % 18 25 EM (конец среды) % 19 26 SUB (заменить) % 1A 27 ESC (escape) % 1B 28 FS (разделитель файлов) % 1C 29 GS (разделитель групп) % 1D 30 RS (разделитель записей) % 1E 31 US (разделитель единиц) % 1F 32 пространство % 20 33 ! % 21 34 " % 22 35 # % 23 36 $ % 24 37 % % 25 38 и % 26 39 ' % 27 40 ( % 28 41 ) % 29 42 * % 2A 43 + % 2B 44 , % 2C 45 - % 2D 46 . % 2E 47 / % 2F 48 0 % 30 49 1 % 31 50 2 % 32 51 3 % 33 52 4 % 34 53 5 % 35 54 6 % 36 55 7 % 37 56 8 % 38 57 9 % 39 58 : % 3A 59 ; % 3B 60 < % 3C 61 = % 3D 62 > % 3E 63 ? % 3F 64 @ % 40 65 A % 41 66 B % 42 67 C % 43 68 D % 44 69 E % 45 70 F % 46 71 G % 47 72 H % 48 73 I % 49 74 J % 4A 75 K % 4B 76 L % 4C 77 M % 4D 78 N % 4E 79 O 9 0056% 4F80 P % 50 81 Q % 51 82 R % 52 83 S % 53 84 T % 54 85 U % 55 86 V % 56 87 W % 57 88 X % 58 89 Y % 59 90 Z % 5A 91 [ % 5B 92 \ % 5C 93 ] % 5D 94 ^ % 5E 95 _ % 5F 96 ` % 60 97 a % 61 98 b % 62 99 c % 63 100 d % 64 101 e % 65 102 f % 66 103 g % 67 104 h % 68 105 i % 69 106 j % 6A 107 k % 6B 108 л % 6C 109 м % 6D 110 n % 6E 111 o % 6F 112 p % 70 113 q % 71 114 r % 72 115 s % 73 116 t % 74 117 u % 75 118 v % 76 119 w % 77 120 x % 78 121 y % 79 122 z % 7A 123 { % 7B 124 | % 7C 125 } % 7D 126 ~ % 7E 127 DEL (удалить (стирание)) % 7F - Учебное пособие по QR-коду
Каждый режим кодирования предназначен для создания максимально короткой строки битов. для символов, которые используются в этом режиме.В каждом режиме используются разные метод преобразования входящего текста в строку битов. Эта страница объясняет весь этап кодирования данных.
Шаг 1. Выберите уровень коррекции ошибок
Перед кодированием данных выберите уровень исправления ошибок. Как упоминалось во введении, QR-коды используют код Рида-Соломона исправление ошибки. Этот процесс создает кодовые слова (байты) исправления ошибок на основе закодированных данные. Считыватель QR-кода может использовать эти байты исправления ошибок для определить, не читал ли он данные правильно, и кодовые слова исправления ошибок могут быть использованы для исправьте эти ошибки.Есть четыре уровня ошибки коррекция: L, M, Q, H. Следующая таблица перечислены уровни и их возможности исправления ошибок.
Уровень коррекции ошибок Возможность коррекции ошибок L Восстанавливает 7% данных M Восстанавливает 15% данных Q Восстанавливает 25% данных H Восстанавливает 30% данных Имейте в виду, что для более высокого уровня исправления ошибок требуется больше байтов, поэтому чем выше уровень исправления ошибок, тем больше QR-код должен быть.
Шаг 2: Определите наименьшую версию для данных
QR-коды разных размеров называются версиями . Доступно сорок версий. Самая маленькая версия - это версия 1, и она Размер 21 на 21 пиксель. Версия 2 - 25 пикселей на 25 пикселей. Самая большая версия - это версия 40 и имеет размер 177 на 177 пикселей. Каждая версия на 4 пикселя больше предыдущей.
Каждая версия имеет максимальную емкость в зависимости от используемого режима.К тому же, уровень исправления ошибок еще больше ограничивает емкость. В таблица возможностей персонажей перечисляет возможности всех версий QR для данного режима кодирования и уровень коррекции ошибок.
Как определить наименьшую версию
На этом этапе подсчитайте количество символов, которые нужно закодировать, и определите наименьшая версия, которая может содержать такое количество символов для режима кодирования и желаемого уровня исправления ошибок.
Например, фраза HELLO WORLD состоит из 11 символов.Если кодирование с исправлением ошибок уровня Q, то способности персонажа В таблице указано, что код версии 1 с исправлением ошибок уровня Q может содержат 16 символов в буквенно-цифровом режиме, поэтому версия 1 является самой маленькой версией который может содержать это количество символов. Если бы фраза была длиннее, чем 16 символов, например HELLO THERE WORLD (17 символов) версия 2 будет самой маленькой версия.
Верхние пределы
Самая высокая вместимость QR-код - 40-L (версия 40, уровень исправления ошибок L).Ниже представлена таблица, в которой перечисляет емкость 40-литрового QR-кода для четырех режимов кодирования. Это максимально возможное количество символов, которое может содержать один QR-код. Версии 40-M, 40-Q и 40-H имеют меньшую производительность, потому что им требуется больше место для дополнительных кодовых слов исправления ошибок. Для таблицы вместимости всех версии, пожалуйста, посмотрите возможности персонажей стол.
Режим кодирования Максимальное количество символов, которое может содержать 40-литровый код в этом режиме Цифровой 7089 символов Буквенно-цифровой 4296 символов Байт 2953 символа Кандзи 1817 символов Шаг 3: Добавьте индикатор режима
Каждый режим кодирования имеет четырехбитовый индикатор режима, который его идентифицирует.В закодированные данные должны начинаться с соответствующего индикатора режима, который указывает режим, используемый для битов, следующих за ним. В следующей таблице перечислены индикаторы режима для каждого режима.
Например, при кодировании HELLO WORLD в буквенно-цифровом режиме, индикатор режима 0010.
Имя режима Индикатор режима Цифровой режим 0001 Алфавитно-цифровой режим 0010 Байтовый режим 0100 Режим кандзи 1000 ECC Режим 0111 Шаг 4: Добавьте индикатор количества символов
Индикатор количества символов представляет собой строку битов. который представляет количество кодируемых символов.Индикатор количества символов должен быть размещен после индикатор режима. Кроме того, индикатор количества символов должен быть определенным числом. бит, в зависимости от версии QR.
Подсчитайте количество символов в исходном тексте ввода, затем преобразуйте это число в двоичном формате. Длина индикатора количества символов зависит от режим кодирования и версия QR-кода, которая будет использоваться. Чтобы сделать двоичную строку соответствующей длины, дополните ее слева нулями.
В следующие списки содержат размеры индикаторов количества символов для каждого режим и версия.Например, если кодируется HELLO WORLD в версии 1 QR-код в буквенно-цифровом режиме, индикатор количества символов должен иметь длину 9 бит. Количество символов HELLO WORLD равно 11. В двоичной системе 11 равно 1011. Заполните его слева, чтобы сделать его длиной 9 бит: 000001011. Поместите это после индикатора режима из шаг 3, чтобы получить следующую битовую строку: 0010 000001011
Версии с 1 по 9
- Числовой режим: 10 бит
- Буквенно-цифровой режим: 9 бит
- Байтовый режим: 8 бит
- Японский режим: 8 бит
Версии с 10 по 26
- Числовой режим: 12 бит
- Буквенно-цифровой режим: 11 бит
- Байтовый режим: 16
- Японский режим: 10 бит
Версии с 27 по 40
- Числовой режим: 14 бит
- Буквенно-цифровой режим: 13 бит
- Байтовый режим: 16 бит
- Японский режим: 12 бит
Шаг 3. Кодирование с использованием выбранного режима
Предыдущая страница, анализ данных, объясняет, как выбрать подходящий режим кодирования для данной строки.Процесс для каждого режима кодирования объясняется на отдельной странице. Щелкните ссылку ниже, чтобы узнать о процесс кодирования для каждого режима.
HELLO WORLD закодирован на кодирование в буквенно-цифровом режиме страница. Продолжая пример HELLO WORLD, битовая строка на данный момент выглядит так:
Индикатор режима Индикатор количества символов Закодированные данные 0010 000001011 01100001011 01111000110 10001011100 10110111000 1001011088 4: Разбить на 8-битные кодовые слова и добавить байты заполнения, если необходимо После получения строки битов, состоящей из индикатор режима, индикатор количества символов и биты данных как описано в шагах с 1 по 3 на этой странице, может потребоваться добавить 0 и байты заполнения, потому что Спецификация QR-кода требует, чтобы битовая строка полностью заполняла общая емкость QR-кода.В следующих разделах объясняется процесс добавления 0 и заполнить байты битовой строкой.
Определите необходимое количество бит для этого QR-кода
Чтобы определить, сколько бит данных требуется для конкретного QR-кода, см. таблицу исправления ошибок. Найди версия и уровень исправления ошибок, который используется для кодируемого QR-кода, и найдите число в столбец с пометкой «Общее количество кодовых слов данных для этой версии и уровня EC». Умножьте это число на 8, чтобы получить общее количество бит данных, необходимых для этой версии. и уровень исправления ошибок.
Например, согласно таблице, код версии 1-Q имеет всего 13 кодовых слов данных. Следовательно, общее количество битов, необходимых для этого QR-кода, составляет 13 * 8 или 104 бита.
Добавьте терминатор нулей, если необходимо
Если битовая строка короче, чем общее количество требуемых битов, знак конца строки до четырех нулей должен быть добавлен с правой стороны строки. Если битовая строка более чем на четыре бита короче требуемого количества битов, добавьте четыре нуля до конца.Если битовая строка менее чем на четыре бита короче, добавьте только число нулей, необходимых для достижения необходимого количества бит.
Например, при кодировании HELLO WORLD в версии 1-Q QR-код, общее количество требуемых битов, как указано в предыдущем разделе, составляет 104 бит. Строка битов данных, показанная на шаге 3 на этой странице, имеет длину 74 бита. Терминатор должен иметь длину не более 4 бита, поэтому добавьте четыре нуля справа от строки. Результирующая строка все еще слишком коротка, чтобы заполнить 104-битную емкость, но спецификация QR-кода требует, чтобы терминатор быть не более четырех нулей в длину.Если бы вместо этого строка была 102 бита, терминатор будет иметь длину всего 2 бита.
Вот пример строки HELLO WORLD с добавленным терминатором:
Индикатор режима Индикатор количества символов Закодированные данные Терминатор 0010 000001011 01100001011 0111100011011011011010001 0000 Добавьте еще 0, чтобы длина была кратна 8
После добавления терминатора если количество бит в строке не кратно 8, сначала заполните строка справа с нулями, чтобы длина строки была кратной 8.
Например, после добавления терминатора к строке HELLO WORLD, длина стала 78 бит. Это не кратно 8. Здесь показана битовая строка. разбит на 8-битные двоичные байты:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 010000В конце шесть битов. Добавьте два нуля, чтобы получился 8-битный двоичный байт:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 010000 00
Добавить байты заполнения, если строка все еще слишком короткая
Если длина строки все еще недостаточна для заполнения максимальной емкости, добавьте следующие байты в конец строки, повторяя до тех пор, пока строка достигла максимальной длины:
11101100 00010001Эти байты эквивалентны 236 и 17 соответственно.Они особенно необходимы спецификацией QR-кода, которая будет добавлена, если битовая строка слишком коротка на этом этапе.
Например, строка HELLO WORLD выше имеет длину 80 бит. Требуемая емкость для кода 1-Q, как указано ранее на странице, составляет 104 бита. Количество битов, которые необходимо добавить для заполнения оставшаяся емкость составляет 104 - 80 или 24. Разделите это на 8: 24/8 = 3. Следовательно, три байта заполнения необходимо добавить в конец строки данных. Это показано ниже:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000 11101100 00010001 11101100Далее: Кодирование коррекции ошибок
Теперь, когда биты необработанных данных получены, следующим шагом будет генерировать ошибку корректирующие кодовые слова для данных.
.Оставить комментарий