PostgreSQL : Документация: 9.5: 22.3. Поддержка кодировок : Компания Postgres Professional
RU
EN
RU EN
- 22.3.1. Поддерживаемые кодировки
- 22.3.2. Настройка кодировки
- 22.3.3. Автоматическая перекодировка между сервером и клиентом
- 22.3.4. Дополнительные источники информации
- 22.3.2. Настройка кодировки
Поддержка кодировок в PostgreSQL позволяет хранить текст в различных кодировках, включая однобайтовые кодировки, такие как входящие в семейство ISO 8859 и многобайтовые кодировки, такие как EUC (Extended Unix Code), UTF-8 и внутренний код Mule. Все поддерживаемые кодировки могут прозрачно использоваться клиентами, но некоторые не поддерживаются сервером (в качестве серверной кодировки). Кодировка по умолчанию выбирается при инициализации кластера базы данных PostgreSQL при помощи initdb. Она может быть переопределена при создании базы данных, что позволяет иметь несколько баз данных с разными кодировками.
Важным ограничением, однако, является то, что кодировка каждой базы данных должна быть совместима с параметрами локали базы данных LC_COLLATE (порядок сортировки строк). Для локали C или POSIX подойдёт любой набор символов, но для других локалей есть только одна кодировка, которая будет работать правильно. (Однако, в среде Windows кодировка UTF-8 может использоваться с любой локалью.)
22.3.1. Поддерживаемые кодировки
Таблица 22.1 показывает кодировки, доступные для использования в PostgreSQL.
Таблица 22.1. Кодировки PostgreSQL
| Имя | Описание | Язык | Поддержка на сервере | Байтов на символ | Псевдонимы |
|---|---|---|---|---|---|
BIG5 | Big Five | Традиционные китайские иероглифы | Нет | 1-2 | WIN950, Windows950 |
EUC_CN | Extended UNIX Code-CN | Упрощённые китайские иероглифы | Да | 1-3 | |
EUC_JP | Extended UNIX Code-JP | Японский | Да | 1-3 | |
EUC_JIS_2004 | Extended UNIX Code-JP, JIS X 0213 | Японский | Да | 1-3 | |
EUC_KR | Extended UNIX Code-KR | Корейский | Да | 1-3 | |
EUC_TW | Extended UNIX Code-TW | Традиционные китайские иероглифы, тайваньский | Да | 1-3 | |
GB18030 | Национальный стандарт | Китайский | Нет | 1-4 | |
GBK | Расширенный национальный стандарт | Упрощённые китайские иероглифы | Нет | 1-2 | WIN936, Windows936 |
ISO_8859_5 | ISO 8859-5, ECMA 113 | Латинский/Кириллица | Да | 1 | |
ISO_8859_6 | ISO 8859-6, ECMA 114 | Латинский/Арабский | Да | 1 | |
ISO_8859_7 | ISO 8859-7, ECMA 118 | Латинский/Греческий | Да | 1 | |
ISO_8859_8 | ISO 8859-8, ECMA 121 | Латинский/Иврит | Да | 1 | |
JOHAB | JOHAB | Корейский (Хангыль) | Нет | 1-3 | |
KOI8R | KOI8-R | Кириллица (Русский) | Да | 1 | KOI8 |
KOI8U | KOI8-U | Кириллица (Украинский) | Да | 1 | |
LATIN1 | ISO 8859-1, ECMA 94 | Западноевропейские | Да | 1 | ISO88591 |
LATIN2 | ISO 8859-2, ECMA 94 | Центральноевропейские | Да | 1 | ISO88592 |
LATIN3 | ISO 8859-3, ECMA 94 | Южноевропейские | Да | 1 | ISO88593 |
LATIN4 | ISO 8859-4, ECMA 94 | Североевропейские | Да | 1 | ISO88594 |
LATIN5 | ISO 8859-9, ECMA 128 | Турецкий | Да | 1 | ISO88599 |
LATIN6 | ISO 8859-10, ECMA 144 | Скандинавские | Да | 1 | ISO885910 |
LATIN7 | ISO 8859-13 | Балтийские | Да | 1 | ISO885913 |
LATIN8 | ISO 8859-14 | Кельтские | Да | 1 | ISO885914 |
LATIN9 | ISO 8859-15 | LATIN1 c европейскими языками и диалектами | Да | 1 | ISO885915 |
LATIN10 | ISO 8859-16, ASRO SR 14111 | Румынский | Да | 1 | ISO885916 |
MULE_INTERNAL | Внутренний код Mule | Мультиязычный редактор Emacs | Да | 1-4 | |
SJIS | Shift JIS | Японский | Нет | 1-2 | Mskanji, ShiftJIS, WIN932, Windows932 |
SHIFT_JIS_2004 | Shift JIS, JIS X 0213 | Японский | Нет | 1-2 | |
SQL_ASCII | не указан (см. текст) текст) | any | Да | 1 | |
UHC | Унифицированный код Хангыль | Корейский | Нет | 1-2 | WIN949, Windows949 |
UTF8 | Unicode, 8-bit | все | Да | 1-4 | Unicode |
WIN866 | Windows CP866 | Кириллица | Да | 1 | ALT |
WIN874 | Windows CP874 | Тайский | Да | 1 | |
WIN1250 | Windows CP1250 | Центральноевропейские | Да | 1 | |
WIN1251 | Windows CP1251 | Кириллица | Да | 1 | WIN |
WIN1252 | Windows CP1252 | Западноевропейские | Да | 1 | |
WIN1253 | Windows CP1253 | Греческий | Да | 1 | |
WIN1254 | Windows CP1254 | Турецкий | Да | 1 | |
WIN1255 | Windows CP1255 | Иврит | Да | 1 | |
WIN1256 | Windows CP1256 | Арабский | Да | 1 | |
WIN1257 | Windows CP1257 | Балтийские | Да | 1 | |
WIN1258 | Windows CP1258 | Вьетнамский | Да | 1 | ABC, TCVN, TCVN5712, VSCII |
Не все клиентские API поддерживают все перечисленные кодировки. Например, драйвер интерфейса JDBC PostgreSQL не поддерживает
Например, драйвер интерфейса JDBC PostgreSQL не поддерживает MULE_INTERNAL, LATIN6, LATIN8 и LATIN10.
Поведение кодировки SQL_ASCII существенно отличается от других. Когда набором символов сервера является SQL_ASCII, сервер интерпретирует значения от 0 до 127 байт согласно кодировке ASCII, тогда как значения от 128 до 255 воспринимаются как незначимые. Перекодировка не будет выполнена при выборе SQL_ASCII. Таким образом, этот вариант является не столько объявлением того, что используется определённая кодировка, сколько объявлением того, что кодировка игнорируется. В большинстве случаев, если вы работаете с любыми данными, отличными от ASCII, не стоит использовать SQL_ASCII, так как PostgreSQL не сможет преобразовать или проверить символы, отличные от ASCII.
22.3.2. Настройка кодировки
initdb определяет кодировку по умолчанию для кластера PostgreSQL. Например,
Например,
initdb -E EUC_JP
настраивает кодировку по умолчанию на EUC_JP (Расширенная система кодирования для японского языка). Можно использовать --encoding вместо -E в случае предпочтения более длинных имён параметров. Если параметр -E или --encoding не задан, initdb пытается определить подходящую кодировку в зависимости от указанной или заданной по умолчанию локали.
При создании базы данных можно указать кодировку, отличную от заданной по умолчанию, если эта кодировка совместима с выбранной локалью:
createdb -E EUC_KR -T template0 --lc-collate=ko_KR.euckr --lc-ctype=ko_KR.euckr korean
Это создаст базу данных с именем korean, которая использует кодировку EUC_KR и локаль ko_KR. Также, получить желаемый результат можно с помощью данной SQL-команды:
CREATE DATABASE korean WITH ENCODING 'EUC_KR' LC_COLLATE='ko_KR.euckr' LC_CTYPE='ko_KR.euckr' TEMPLATE=template0;
Заметьте, что приведённые выше команды задают копирование базы данных template0. При копировании любой другой базы данных, параметры локали и кодировку исходной базы изменить нельзя, так как это может привести к искажению данных. Более подробное описание приведено в Разделе 21.3.
Кодировка базы данных хранится в системном каталоге pg_database. Её можно увидеть при помощи параметра psql -l или команды \l.
$psql -lList of databases Name | Owner | Encoding | Collation | Ctype | Access Privileges -----------+----------+-----------+-------------+-------------+------------------------------------- clocaledb | hlinnaka | SQL_ASCII | C | C | englishdb | hlinnaka | UTF8 | en_GB.UTF8 | en_GB.UTF8 | japanese | hlinnaka | UTF8 | ja_JP.UTF8 | ja_JP.UTF8 | korean | hlinnaka | EUC_KR | ko_KR.euckr | ko_KR.euckr | postgres | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | template0 | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka} template1 | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka} (7 rows)
Важно
На большинстве современных операционных систем PostgreSQL может определить, какая кодировка подразумевается параметром LC_CTYPE, что обеспечит использование только соответствующей кодировки базы данных. На более старых системах необходимо самостоятельно следить за тем, чтобы использовалась кодировка, соответствующая выбранной языковой среде. Ошибка в этой области, скорее всего, приведёт к странному поведению зависимых от локали операций, таких как сортировка.
PostgreSQL позволит суперпользователям создавать базы данных с кодировкой SQL_ASCII, даже когда значение LC_CTYPE не установлено в C или POSIX. Как было сказано выше,
Как было сказано выше, SQL_ASCII не гарантирует, что данные, хранящиеся в базе, имеют определённую кодировку, и таким образом, этот выбор чреват сбоями, связанными с локалью. Использование данной комбинации устарело и, возможно, будет полностью запрещено.
22.3.3. Автоматическая перекодировка между сервером и клиентом
PostgreSQL поддерживает автоматическую перекодировку между сервером и клиентом для определённых комбинаций кодировок. Информация, касающаяся перекодировки, хранится в системном каталоге pg_conversion. PostgreSQL включает в себя некоторые предопределённые кодировки, как показано в Таблице 22.2. Есть возможность создать новую перекодировку при помощи SQL-команды CREATE CONVERSION.
Таблица 22.2. Клиент-серверные перекодировки наборов символов
| Серверная кодировка | Доступные клиентские кодировки |
|---|---|
BIG5 | не поддерживается как серверная кодировка |
EUC_CN | EUC_CN, MULE_INTERNAL, UTF8 |
EUC_JP | EUC_JP, MULE_INTERNAL, SJIS, UTF8 |
EUC_JIS_2004 | EUC_JIS_2004, SHIFT_JIS_2004, UTF8 |
EUC_KR | EUC_KR, MULE_INTERNAL, UTF8 |
EUC_TW | EUC_TW, BIG5, MULE_INTERNAL, UTF8 |
GB18030 | не поддерживается как серверная кодировка |
GBK | не поддерживается как серверная кодировка |
ISO_8859_5 | ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
ISO_8859_6 | ISO_8859_6, UTF8 |
ISO_8859_7 | ISO_8859_7, UTF8 |
ISO_8859_8 | ISO_8859_8, UTF8 |
JOHAB | не поддерживается как серверная кодировка |
KOI8R | KOI8R, ISO_8859_5, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
KOI8U | KOI8U, UTF8 |
LATIN1 | LATIN1, MULE_INTERNAL, UTF8 |
LATIN2 | LATIN2, MULE_INTERNAL, UTF8, WIN1250 |
LATIN3 | LATIN3, MULE_INTERNAL, UTF8 |
LATIN4 | LATIN4, MULE_INTERNAL, UTF8 |
LATIN5 | LATIN5, UTF8 |
LATIN6 | LATIN6, UTF8 |
LATIN7 | LATIN7, UTF8 |
LATIN8 | LATIN8, UTF8 |
LATIN9 | LATIN9, UTF8 |
LATIN10 | LATIN10, UTF8 |
MULE_INTERNAL | MULE_INTERNAL, BIG5, EUC_CN, EUC_JP, EUC_KR, EUC_TW, ISO_8859_5, KOI8R, LATIN1 to LATIN4, SJIS, WIN866, WIN1250, WIN1251 |
SJIS | не поддерживается как серверная кодировка |
SHIFT_JIS_2004 | не поддерживается как серверная кодировка |
SQL_ASCII | любая (перекодировка не будет выполнена) |
UHC | не поддерживается как серверная кодировка |
UTF8 | все поддерживаемые кодировки |
WIN866 | WIN866, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN1251 |
WIN874 | WIN874, UTF8 |
WIN1250 | WIN1250, LATIN2, MULE_INTERNAL, UTF8 |
WIN1251 | WIN1251, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866 |
WIN1252 | WIN1252, UTF8 |
WIN1253 | WIN1253, UTF8 |
WIN1254 | WIN1254, UTF8 |
WIN1255 | WIN1255, UTF8 |
WIN1256 | WIN1256, UTF8 |
WIN1257 | WIN1257, UTF8 |
WIN1258 | WIN1258, UTF8 |
Чтобы включить автоматическую перекодировку символов, необходимо сообщить PostgreSQL кодировку, которую вы хотели бы использовать на стороне клиента. Это можно выполнить несколькими способами:
Это можно выполнить несколькими способами:
Использование команды
\encodingв psql.\encodingпозволяет оперативно изменять клиентскую кодировку. Например, чтобы изменить кодировку наSJIS, введите:\encoding SJIS
libpq (Раздел 31.10) имеет функции, для управления клиентской кодировкой.
Использование
SET client_encoding TO. Клиентская кодировка устанавливается следующей SQL-командой:SET CLIENT_ENCODING TO '
value';Также, для этой цели можно использовать стандартный синтаксис SQL
SET NAMES:SET NAMES '
value';Получить текущую клиентскую кодировку:
SHOW client_encoding;
Вернуть кодировку по умолчанию:
RESET client_encoding;
Использование
PGCLIENTENCODING. Если установлена переменная окруженияPGCLIENTENCODING, то эта клиентская кодировка выбирается автоматически при подключении к серверу. (В дальнейшем это может быть переопределено при помощи любого из методов, указанных выше.)
(В дальнейшем это может быть переопределено при помощи любого из методов, указанных выше.)Использование переменной конфигурации client_encoding. Если задана переменная
client_encoding, указанная клиентская кодировка выбирается автоматически при подключении к серверу. (В дальнейшем это может быть переопределено при помощи любого из методов, указанных выше.)
Если перекодировка определённого символа невозможна (предположим, выбраны EUC_JP для сервера и LATIN1 для клиента, и передаются некоторые японские иероглифы, не представленные в LATIN1), возникает ошибка.
Если клиентская кодировка определена как SQL_ASCII, перекодировка отключается вне зависимости от кодировки сервера. Что же касается сервера, не стоит использовать SQL_ASCII, если только вы не работаете с данными, которые полностью соответствуют ASCII.
22.3.4. Дополнительные источники информации
Рекомендуемые источники для начала изучения различных видов систем кодирования.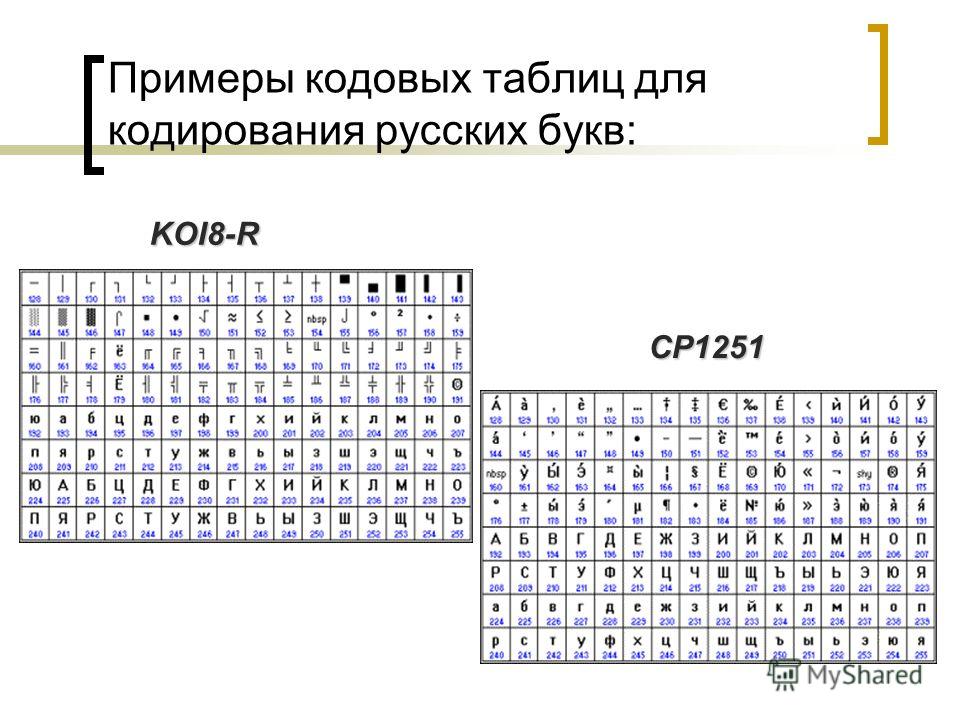
- Обработка информации на китайском, японском, корейском & вьетнамском языках.
Содержит подробные объяснения по
EUC_JP,EUC_CN,EUC_KR,EUC_TW.- http://www.unicode.org/
Сайт Unicode Consortium.
- RFC 3629
UTF-8 (формат преобразования 8-битного UCS/Unicode) определён здесь.
Кодировки, брр… | Калина Алексей
У меня всегда была фобия взаимодействия с кодировками, особенно программно. Да, я достаточно читал и слышал про условные ASCII и UTF-8, но глубокого понимания как с этим работать, а также полной картины у меня так и не возникло. Для меня любые проблемы, связанные с кодировками, становятся в один ряд с инвалидацией кэша и именованием переменных (гики поймут). И вот на этой неделе такая проблема возникла. Связана она с индексацией различных файлов в Elasticsearch, но суть не в этом. Суть в том, что я твердо решил разобраться в многообразии кодировок и поделюсь этим с вами.
На самом деле все достаточно просто. В любой кодировке символ представляется одним или несколькими байтами. Также в любой кодировке есть набор символов, которые могут быть закодированы, и кодовая таблица, по которой можно распознать каждый символ. Проблема в том, что есть множество языков, и по историческим причинам было придумано большое количество кодировок, покрывающих разные наборы символов и использующие для этого разное количество байт.
С этой кодировки, расшифровывающейся как American Standard Code for Information Interchange, мы начнем наше погружение в тему. В стандартном ASCII используется только 7 бит, следовательно таблица символов содержит 128 символов. Среди них — латинские буквы, арабские цифры, знаки препинания и различные служебные символы. Причем эти 128 символов являются стандартом, который соблюдается в большинстве других кодировок.
Однако, на свете есть множество других языков кроме английского, а в байте 8 бит… Поэтому появилось большое число расширений ASCII, которые задействовали оставшиеся 128 символов под нужды своего алфавита. Также существуют и другие 7-битные кодировки, которые ориентированы на конкретный алфавит. Рассмотрим некоторые из подобных семейств.
Также существуют и другие 7-битные кодировки, которые ориентированы на конкретный алфавит. Рассмотрим некоторые из подобных семейств.
КОИ-8 (код обмена информацией) была широко распространена как основная русская кодировка в Unix-подобных системах. Она расширяла код ASCII таким образом, что буквы русского алфавита располагались в нижней части таблицы на тех же позициях, что и созвучные им английские. Таким образом, если убрать последний бит для каждого символа из текста, написанном в кодировке КОИ-8, получится текст в транслите. Есть несколько вариантов этой кодировки, для разных алфавитов стран СНГ (
Интересной особенностью этой и некоторых других кодировок того времени (CP866) является наличие среди символов различной псевдографики (палочки, уголочки и так далее). Это связано с тем, что она создавалась тогда, когда были распространены неграфические операционные системы. Тем не менее, текст, написанный в КОИ-8 можно встретить до сих пор.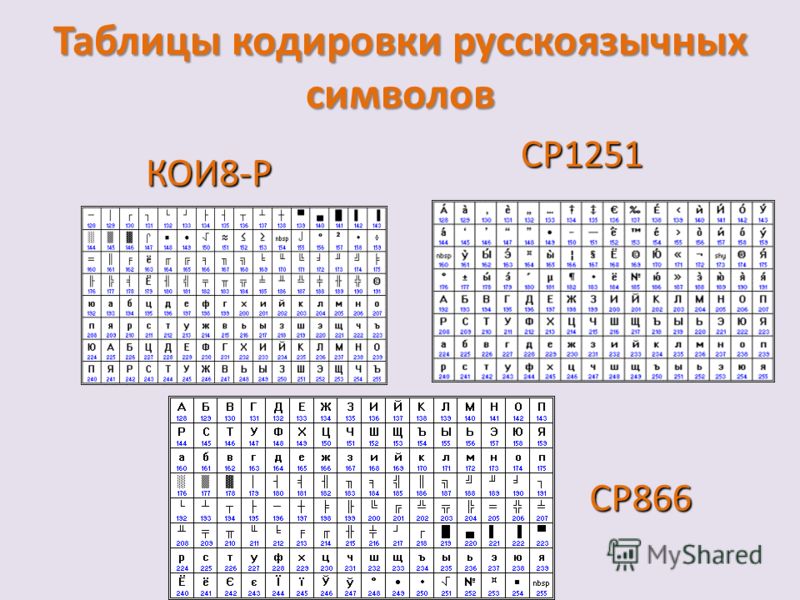 Также существует 7-битный вариант этой кодировки (КОИ-7), который, соответственно, не поддерживает стандарт ASCII, поэтому изжил себя уже достаточно давно.
Также существует 7-битный вариант этой кодировки (КОИ-7), который, соответственно, не поддерживает стандарт ASCII, поэтому изжил себя уже достаточно давно.
Еще одно семейство однобайтовых ASCII-совместимых кодировок. Содержит порядка пятнадцати кодовых страниц для разных языков, в том числе и кириллицу (ISO-8859-5). Так как разрабатывалась как средство обмена информацией, она не предназначена для обеспечения высококачественной типографики, при этом содержит много символов управления терминалом. Также как и предыдущее семейство, ISO-8859 использовалось как правило в юниксоподобных системах, хотя в России была распространена именно КОИ-8.
В Windows существует свой набор кодовых страниц, который используется как стандартный в этой ОС. К слову, в MacOS таковой является Mac Cyrillic или Mac Roman. В данном же случае кодировки носят название Windows-125*. Это также восьмибитные варианты ASCII. Для отображения кириллицы используется кодировка Windows-1251, с которой собственно у меня и были проблемы при индексации текстовых файлов.
Глядя на эту картину, мне становится не по себе. При таком обилии кодировок, я не нашел какого-либо эффективного способа проверки того, в какой кодировке был написан конкретный текст. Тем не менее, еще в 1991 году было предложено логичное решение, благодаря которому сейчас все не так уж и плохо.
Именно в 1991 году был создан консорциум Юникод. Благодаря ему был создан стандарт с одноименным названием, который объединял все кодировки. Юникод — это огромная таблица из 1 114 112 элементов, содержащая всевозможные символы, и в которой достаточно места для будущих языков. Однако, это не кодировка, это только кодовая таблица. Другими словами, Юникод говорит о символе только то, под каким номером он стоит в таблице, а каким образом представлять его в байтах уже задача кодировок, о которых мы и поговорим далее.
Для кодирования такого числа символов нужно не менее трех байт. По понятным причинам программистам все же ближе число 4, поэтому на свет появился UTF-32, в котором под каждый символ отведено 32 бита. При таком подходе очевидна проблема: если пользователь использует только символы из таблицы ASCII, UTF-32 будет хранить в 4 раза больше данных, чем этого требуется.
При таком подходе очевидна проблема: если пользователь использует только символы из таблицы ASCII, UTF-32 будет хранить в 4 раза больше данных, чем этого требуется.
Для решения этой проблемы были придуманы кодировки с переменной длинной: UTF-8 и UTF-16. UTF-8 позволяет кодировать символы длиной от 1 до 4 байтов. При этом старшие биты сообщают о том, какого размера этот символ. Для ASCII символов происходит экономия памяти, но за счет сигнальных символов двухбайтные значения могут превратиться в трехбайтные. Альтернативой этой кодировке является UTF-16, минимальная длина символа в которой равна двум байтам и может увеличиваться до четырех.
При работе с текстовыми файлами с кодировками, поддерживающими Юникод, иногда существует возможность понять как закодирован текст по первым байтам документа.  Однако, нужно учитывать, что UTF документы могут и не иметь BOM.
Однако, нужно учитывать, что UTF документы могут и не иметь BOM.
И напоследок, полезная картинка о том, как распознать в какой кодировке должен был быть открыт текстовый файл по внешнему виду содержимого. Источник
Обилие несовместимых кодировок, из-за которых мы видим вместо текста “крокозябры”, по-прежнему доставляет пользователям проблемы. Однако, благодаря Юникоду сегодня они уже не стоят столь остро. Надеюсь, этот небольшой обзор был вам полезен.
Written on December 23rd , 2017 by Alexey Kalina
Feel free to share!
Ubuntu Manpage: cp1251 — набор символов CP 1251, закодированный в восьмеричной, десятичной и шестнадцатеричной системе счисления
Предоставлено: manpages_3.54-1ubuntu1_all
ИМЯ
cp1251 - набор символов CP 1251, закодированный в восьмеричной, десятичной и шестнадцатеричной системе счисления.
ОПИСАНИЕ
Кодовые страницы Windows включают несколько 8-битных расширений набора символов ASCII (также
известный как ISO 646-IRV). CP 1251 кодирует символы, используемые в кириллице.
В следующей таблице показаны символы в CP 1251, которые доступны для печати и не перечислены в
ascii (7) страница руководства. В четвертом столбце будут отображаться только правильные глифы в
среда настроена для CP 1251.
Октябрь Декабрь Шестнадцатеричный Символ Описание
─диимобилил ────────────────────
200 128 80 ЗАГЛАВНАЯ БУКВА DJE
201 129 81 ЗАГЛАВНАЯ БУКВА ГЖЕ
202 130 82 ОДИНАРНАЯ МЛАДШАЯ-9 КАВАТЫ
203 131 83 СТРОЧНАЯ БУКВА ГЖЕ
204 132 84 ДВОЙНОЙ НИЗКИЙ-9КАВЫЧКА
205 133 85 ГОРИЗОНТАЛЬНЫЙ ЭЛЛИПСИС
206 134 86 КИНЖАЛ
207 135 87 ДВОЙНОЙ КИНЖАЛ
210 136 88 ЗНАК ЕВРО
211 137 89 НА ТЫСЯЧУ ЗНАКОВ
212 138 8A ЗАГЛАВНАЯ БУКВА LJE
213 139 8B ОДИНОЧНЫЙ УГОЛ, УКАЗЫВАЮЩИЙ ВЛЕВО КАвычки
214 140 8C КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА NJE
215 141 8D ЗАГЛАВНАЯ БУКВА KJE
216 142 8E ЗАГЛАВНАЯ БУКВА ТШЕ
217 143 8F ЗАГЛАВНАЯ БУКВА ДЖЕ
220 144 90 СТРОЧНАЯ БУКВА DJE
221 145 91 ЛЕВАЯ ОДИНАРНАЯ КАВАТЫ
222 146 92 ПРАВАЯ ОДИНАРНАЯ КАВАКА
223 147 93 ЛЕВАЯ ДВОЙНАЯ КАВАТЫ
224 148 94 ПРАВАЯ ДВОЙНАЯ КАВАЧКА
225 149 95 ПУЛЯ
226 150 96 РУКОЯТКА
227 151 97 ЭМ ТИРЕ
230 152 98 НЕОПРЕДЕЛЕН
231 153 99 ЗНАК ТОРГОВОЙ МАРКИ
232 154 9A СТРОЧНАЯ БУКВА LJE
233 155 9B ОДИНОЧНЫЙ УГОЛ, УКАЗЫВАЮЩИЙ ВПРАВО КАвычки
234 156 9C СТРОЧНАЯ БУКВА NJE
235 157 9D СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА KJE
236 158 9E СТРОЧНАЯ БУКВА ТШЕ
237 159 9F СТРОЧНАЯ БУКВА ДЖЕ
240 160 A0 НЕРАЗРЫВНЫЙ ПРОБЕЛ
241 161 A1 ¡ КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА U
242 162 A2 ¢ СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА U
243 163 A3 £ ЗАГЛАВНАЯ БУКВА JE
244 164 A4 ¤ ЗНАК ВАЛЮТЫ
245 165 A5 ¥ ЗАГЛАВНАЯ БУКВА GHE С ПЕРЕВЕРТОМ
246 166 A6 ¦ Сломанный стержень
247 167 A7 § ЗНАК РАЗДЕЛА
250 168 A8 ¨ ЗАГЛАВНАЯ БУКВА IO
251 169A9 © ЗНАК АВТОРСКОГО ПРАВА
252 170 АА ª ЗАГЛАВНАЯ БУКВА УКРАИНСКИЙ ИЕ
253 171 AB « ДВУХУГОЛЬНАЯ КАВАЧКА, УКАЗЫВАЮЩАЯ ВЛЕВО
254 172 AC ¬ НЕ ЗНАК
255 173 ОБЪЯВЛЕНИЕ МЯГКИЙ ДЕФЕС
256 174 ЗАРЕГИСТРИРОВАННЫЙ ЗНАК AE ®
257 175 AF ¯ ЗАГЛАВНАЯ БУКВА ЙИ
260 176 B0 ЗНАК ГРАДУСОВ
261 177 B1 ± ЗНАК ПЛЮС-МИНУС
262 178 B2 ² ЗАГЛАВНАЯ БУКВА БЕЛОРУССКИЙ-УКРАИНСКИЙ I
263 179B3 ³ СТРОЧНАЯ КИРИЛЛИЧНАЯ БЕЛОРУССКО-УКРАИНСКАЯ БУКВА I
264 180 B4 ´ СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА GHE С ПЕРЕВЕРТОМ
265 181 B5 µ МИКРОЗНАК
266 182 B6 ¶ ЗНАК НАШИВКИ
267 183 B7 · СРЕДНЯЯ ТОЧКА
270 184 B8 ¸ СТРОЧНАЯ БУКВА IO
271 185 B9 ¹ ЗНАК ЦИФРЫ
272 186 ВА º КИРИЛЛИЧЕСКАЯ СТРОЧНАЯ УКРАИНСКАЯ БУКВА IE
273 187 BB » ДВУХУГОЛЬНАЯ КАВАЧКА, УКАЗЫВАЮЩАЯ ВПРАВО
274 188 г.
CP 1251 кодирует символы, используемые в кириллице.
В следующей таблице показаны символы в CP 1251, которые доступны для печати и не перечислены в
ascii (7) страница руководства. В четвертом столбце будут отображаться только правильные глифы в
среда настроена для CP 1251.
Октябрь Декабрь Шестнадцатеричный Символ Описание
─диимобилил ────────────────────
200 128 80 ЗАГЛАВНАЯ БУКВА DJE
201 129 81 ЗАГЛАВНАЯ БУКВА ГЖЕ
202 130 82 ОДИНАРНАЯ МЛАДШАЯ-9 КАВАТЫ
203 131 83 СТРОЧНАЯ БУКВА ГЖЕ
204 132 84 ДВОЙНОЙ НИЗКИЙ-9КАВЫЧКА
205 133 85 ГОРИЗОНТАЛЬНЫЙ ЭЛЛИПСИС
206 134 86 КИНЖАЛ
207 135 87 ДВОЙНОЙ КИНЖАЛ
210 136 88 ЗНАК ЕВРО
211 137 89 НА ТЫСЯЧУ ЗНАКОВ
212 138 8A ЗАГЛАВНАЯ БУКВА LJE
213 139 8B ОДИНОЧНЫЙ УГОЛ, УКАЗЫВАЮЩИЙ ВЛЕВО КАвычки
214 140 8C КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА NJE
215 141 8D ЗАГЛАВНАЯ БУКВА KJE
216 142 8E ЗАГЛАВНАЯ БУКВА ТШЕ
217 143 8F ЗАГЛАВНАЯ БУКВА ДЖЕ
220 144 90 СТРОЧНАЯ БУКВА DJE
221 145 91 ЛЕВАЯ ОДИНАРНАЯ КАВАТЫ
222 146 92 ПРАВАЯ ОДИНАРНАЯ КАВАКА
223 147 93 ЛЕВАЯ ДВОЙНАЯ КАВАТЫ
224 148 94 ПРАВАЯ ДВОЙНАЯ КАВАЧКА
225 149 95 ПУЛЯ
226 150 96 РУКОЯТКА
227 151 97 ЭМ ТИРЕ
230 152 98 НЕОПРЕДЕЛЕН
231 153 99 ЗНАК ТОРГОВОЙ МАРКИ
232 154 9A СТРОЧНАЯ БУКВА LJE
233 155 9B ОДИНОЧНЫЙ УГОЛ, УКАЗЫВАЮЩИЙ ВПРАВО КАвычки
234 156 9C СТРОЧНАЯ БУКВА NJE
235 157 9D СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА KJE
236 158 9E СТРОЧНАЯ БУКВА ТШЕ
237 159 9F СТРОЧНАЯ БУКВА ДЖЕ
240 160 A0 НЕРАЗРЫВНЫЙ ПРОБЕЛ
241 161 A1 ¡ КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА U
242 162 A2 ¢ СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА U
243 163 A3 £ ЗАГЛАВНАЯ БУКВА JE
244 164 A4 ¤ ЗНАК ВАЛЮТЫ
245 165 A5 ¥ ЗАГЛАВНАЯ БУКВА GHE С ПЕРЕВЕРТОМ
246 166 A6 ¦ Сломанный стержень
247 167 A7 § ЗНАК РАЗДЕЛА
250 168 A8 ¨ ЗАГЛАВНАЯ БУКВА IO
251 169A9 © ЗНАК АВТОРСКОГО ПРАВА
252 170 АА ª ЗАГЛАВНАЯ БУКВА УКРАИНСКИЙ ИЕ
253 171 AB « ДВУХУГОЛЬНАЯ КАВАЧКА, УКАЗЫВАЮЩАЯ ВЛЕВО
254 172 AC ¬ НЕ ЗНАК
255 173 ОБЪЯВЛЕНИЕ МЯГКИЙ ДЕФЕС
256 174 ЗАРЕГИСТРИРОВАННЫЙ ЗНАК AE ®
257 175 AF ¯ ЗАГЛАВНАЯ БУКВА ЙИ
260 176 B0 ЗНАК ГРАДУСОВ
261 177 B1 ± ЗНАК ПЛЮС-МИНУС
262 178 B2 ² ЗАГЛАВНАЯ БУКВА БЕЛОРУССКИЙ-УКРАИНСКИЙ I
263 179B3 ³ СТРОЧНАЯ КИРИЛЛИЧНАЯ БЕЛОРУССКО-УКРАИНСКАЯ БУКВА I
264 180 B4 ´ СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА GHE С ПЕРЕВЕРТОМ
265 181 B5 µ МИКРОЗНАК
266 182 B6 ¶ ЗНАК НАШИВКИ
267 183 B7 · СРЕДНЯЯ ТОЧКА
270 184 B8 ¸ СТРОЧНАЯ БУКВА IO
271 185 B9 ¹ ЗНАК ЦИФРЫ
272 186 ВА º КИРИЛЛИЧЕСКАЯ СТРОЧНАЯ УКРАИНСКАЯ БУКВА IE
273 187 BB » ДВУХУГОЛЬНАЯ КАВАЧКА, УКАЗЫВАЮЩАЯ ВПРАВО
274 188 г. до н.э. ¼ СТРОЧНАЯ БУКВА ДЖЕ
275 189BD ½ ЗАГЛАВНАЯ БУКВА ДЗЕ
276 190 БЭ ¾ СТРОЧНАЯ БУКВА ДЗЕ
277 191 БФ ¿ СТРОЧНАЯ БУКВА ЙИ
300 192 C0 À ЗАГЛАВНАЯ БУКВА A
301 193 C1 Á ЗАГЛАВНАЯ БУКВА BE
302 194 C2 Â ЗАГЛАВНАЯ БУКВА VE
303 195 C3 Ã ЗАГЛАВНАЯ БУКВА GHE
304 196 C4 Ä ЗАГЛАВНАЯ БУКВА DE
305 197 C5 Å ЗАГЛАВНАЯ БУКВА IE
306 198 C6 Æ ЗАГЛАВНАЯ БУКВА ЖЕ
307 199 C7 v ЗАГЛАВНАЯ БУКВА ZE
310 200 C8 È ЗАГЛАВНАЯ БУКВА I
311 201 C9 É ЗАГЛАВНАЯ БУКВА КОРОТКАЯ I
312 202 CA Ê ЗАГЛАВНАЯ БУКВА КА
313 203 CB Ë ЗАГЛАВНАЯ БУКВА EL
314 204 CC Ì ЗАГЛАВНАЯ БУКВА EM
315 205 CD Í ЗАГЛАВНАЯ БУКВА RU
316 206 CE Î ЗАГЛАВНАЯ БУКВА O
317 207 CF Ï ЗАГЛАВНАЯ БУКВА PE
320 208 D0 Ð ЗАГЛАВНАЯ БУКВА ER
321 209D1 Ñ ЗАГЛАВНАЯ БУКВА ES
322 210 D2 Ò ЗАГЛАВНАЯ БУКВА TE
323 211 D3 Ó ЗАГЛАВНАЯ БУКВА U
324 212 D4 Ô ЗАГЛАВНАЯ БУКВА EF
325 213 D5 Õ ЗАГЛАВНАЯ БУКВА HA
326 214 D6 Ö ЗАГЛАВНАЯ БУКВА ТСЭ
327 215 D7 × ЗАГЛАВНАЯ БУКВА ЧЕ
330 216 D8 Ø ЗАГЛАВНАЯ БУКВА ША
331 217 D9 Ù ЗАГЛАВНАЯ БУКВА ЩА
332 218 DA Ú КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ПРОЧНЫЙ ЗНАК
333 219DB Û ЗАГЛАВНАЯ БУКВА ЕРУ
334 220 DC Ü КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА МЯГКИЙ ЗНАК
335 221 DD Ý ЗАГЛАВНАЯ БУКВА E
336 222 DE Þ ЗАГЛАВНАЯ БУКВА Ю
337 223 DF ß ЗАГЛАВНАЯ БУКВА Я
340 224 E0 à КИРИЛЛИЧЕСКАЯ СТРОЧНАЯ БУКВА A
341 225 E1 á СТРОЧНАЯ БУКВА BE
342 226 E2 â Кириллическая СТРОЧНАЯ БУКВА VE
343 227 E3 ã СТРОЧНАЯ БУКВА GHE
344 228 E4 ä СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА DE
345 229E5 å СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА IE
346 230 E6 æ СТРОЧНАЯ БУКВА ЖЕ
347 231 E7 ç СТРОЧНАЯ БУКВА ZE
350 232 E8 è СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА I
351 233 E9 é СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КОРОТКАЯ I
352 234 EA ê СТРОЧНАЯ БУКВА KA
353 235 EB ë СТРОЧНАЯ БУКВА EL
354 236 EC ì СТРОЧНАЯ БУКВА EM
355 237 ED í СТРОЧНАЯ БУКВА EN
356 238 EE î СТРОЧНАЯ БУКВА О
357 239EF ï СТРОЧНАЯ БУКВА PE
360 240 F0 ð СТРОЧНАЯ БУКВА ER
361 241 F1 – СТРОЧНАЯ БУКВА ES
362 242 F2 ò СТРОЧНАЯ БУКВА TE
363 243 F3 — СТРОЧНАЯ БУКВА U
364 244 F4 ô СТРОЧНАЯ БУКВА EF
365 245 F5 х Кириллическая СТРОЧНАЯ БУКВА HA
366 246 F6 ö СТРОЧНАЯ БУКВА ТСЕ
367 247 F7 ÷ СТРОЧНАЯ БУКВА ЧЕ
370 248 F8 ø СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ША
371 249F9 ù СТРОЧНАЯ БУКВА ЩА
372 250 FA ú СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ПРОЧНЫЙ ЗНАК
373 251 FB û СТРОЧНАЯ БУКВА ЕРУ
374 252 FC ü МЯГКИЙ ЗНАК СТРОЧНОЙ БУКВЫ КИРИЛЛИЦЫ
375 253 FD ý СТРОЧНАЯ БУКВА E
376 254 ФЭ þ СТРОЧНАЯ БУКВА Ю
377 255 FF ÿ СТРОЧНАЯ БУКВА Я
до н.э. ¼ СТРОЧНАЯ БУКВА ДЖЕ
275 189BD ½ ЗАГЛАВНАЯ БУКВА ДЗЕ
276 190 БЭ ¾ СТРОЧНАЯ БУКВА ДЗЕ
277 191 БФ ¿ СТРОЧНАЯ БУКВА ЙИ
300 192 C0 À ЗАГЛАВНАЯ БУКВА A
301 193 C1 Á ЗАГЛАВНАЯ БУКВА BE
302 194 C2 Â ЗАГЛАВНАЯ БУКВА VE
303 195 C3 Ã ЗАГЛАВНАЯ БУКВА GHE
304 196 C4 Ä ЗАГЛАВНАЯ БУКВА DE
305 197 C5 Å ЗАГЛАВНАЯ БУКВА IE
306 198 C6 Æ ЗАГЛАВНАЯ БУКВА ЖЕ
307 199 C7 v ЗАГЛАВНАЯ БУКВА ZE
310 200 C8 È ЗАГЛАВНАЯ БУКВА I
311 201 C9 É ЗАГЛАВНАЯ БУКВА КОРОТКАЯ I
312 202 CA Ê ЗАГЛАВНАЯ БУКВА КА
313 203 CB Ë ЗАГЛАВНАЯ БУКВА EL
314 204 CC Ì ЗАГЛАВНАЯ БУКВА EM
315 205 CD Í ЗАГЛАВНАЯ БУКВА RU
316 206 CE Î ЗАГЛАВНАЯ БУКВА O
317 207 CF Ï ЗАГЛАВНАЯ БУКВА PE
320 208 D0 Ð ЗАГЛАВНАЯ БУКВА ER
321 209D1 Ñ ЗАГЛАВНАЯ БУКВА ES
322 210 D2 Ò ЗАГЛАВНАЯ БУКВА TE
323 211 D3 Ó ЗАГЛАВНАЯ БУКВА U
324 212 D4 Ô ЗАГЛАВНАЯ БУКВА EF
325 213 D5 Õ ЗАГЛАВНАЯ БУКВА HA
326 214 D6 Ö ЗАГЛАВНАЯ БУКВА ТСЭ
327 215 D7 × ЗАГЛАВНАЯ БУКВА ЧЕ
330 216 D8 Ø ЗАГЛАВНАЯ БУКВА ША
331 217 D9 Ù ЗАГЛАВНАЯ БУКВА ЩА
332 218 DA Ú КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ПРОЧНЫЙ ЗНАК
333 219DB Û ЗАГЛАВНАЯ БУКВА ЕРУ
334 220 DC Ü КИРИЛЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА МЯГКИЙ ЗНАК
335 221 DD Ý ЗАГЛАВНАЯ БУКВА E
336 222 DE Þ ЗАГЛАВНАЯ БУКВА Ю
337 223 DF ß ЗАГЛАВНАЯ БУКВА Я
340 224 E0 à КИРИЛЛИЧЕСКАЯ СТРОЧНАЯ БУКВА A
341 225 E1 á СТРОЧНАЯ БУКВА BE
342 226 E2 â Кириллическая СТРОЧНАЯ БУКВА VE
343 227 E3 ã СТРОЧНАЯ БУКВА GHE
344 228 E4 ä СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА DE
345 229E5 å СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА IE
346 230 E6 æ СТРОЧНАЯ БУКВА ЖЕ
347 231 E7 ç СТРОЧНАЯ БУКВА ZE
350 232 E8 è СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА I
351 233 E9 é СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА КОРОТКАЯ I
352 234 EA ê СТРОЧНАЯ БУКВА KA
353 235 EB ë СТРОЧНАЯ БУКВА EL
354 236 EC ì СТРОЧНАЯ БУКВА EM
355 237 ED í СТРОЧНАЯ БУКВА EN
356 238 EE î СТРОЧНАЯ БУКВА О
357 239EF ï СТРОЧНАЯ БУКВА PE
360 240 F0 ð СТРОЧНАЯ БУКВА ER
361 241 F1 – СТРОЧНАЯ БУКВА ES
362 242 F2 ò СТРОЧНАЯ БУКВА TE
363 243 F3 — СТРОЧНАЯ БУКВА U
364 244 F4 ô СТРОЧНАЯ БУКВА EF
365 245 F5 х Кириллическая СТРОЧНАЯ БУКВА HA
366 246 F6 ö СТРОЧНАЯ БУКВА ТСЕ
367 247 F7 ÷ СТРОЧНАЯ БУКВА ЧЕ
370 248 F8 ø СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ША
371 249F9 ù СТРОЧНАЯ БУКВА ЩА
372 250 FA ú СТРОЧНАЯ КИРИЛЛИЧНАЯ БУКВА ПРОЧНЫЙ ЗНАК
373 251 FB û СТРОЧНАЯ БУКВА ЕРУ
374 252 FC ü МЯГКИЙ ЗНАК СТРОЧНОЙ БУКВЫ КИРИЛЛИЦЫ
375 253 FD ý СТРОЧНАЯ БУКВА E
376 254 ФЭ þ СТРОЧНАЯ БУКВА Ю
377 255 FF ÿ СТРОЧНАЯ БУКВА Я
ПРИМЕЧАНИЯ
CP 1251 также известен как кириллица Windows.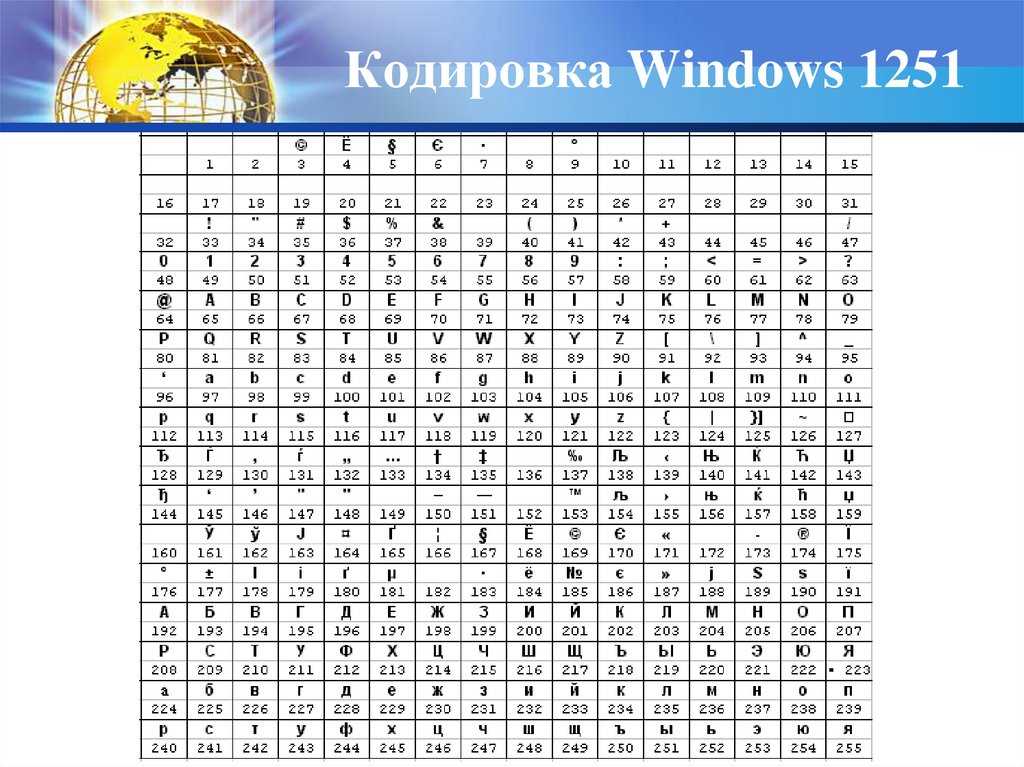
СМ. ТАКЖЕ
ascii (7)
КОЛОФОН
Эта страница является частью выпуска 3.54 проекта Linux man-pages . Описание
проекта, а информацию о сообщениях об ошибках можно найти по адресу
http://www.kernel.org/doc/man-pages/.
о кодировке символов — PowerShell
- Статья
- 5 минут на чтение
Краткое описание
Описывает, как PowerShell использует кодировку символов для ввода и вывода строки. данные.
Подробное описание
Юникод — это всемирный стандарт кодирования символов. В системе используется Юникод.
исключительно для манипуляций с символами и строками. Подробное описание
обо всех аспектах Unicode см. Стандарт Юникод.
Стандарт Юникод.
Windows поддерживает Unicode и традиционные наборы символов. Традиционный персонаж наборы, такие как кодовые страницы Windows, используют 8-битные значения или комбинации 8-битных значения для представления символов, используемых в определенном языке или географическом настройки региона.
PowerShell по умолчанию использует набор символов Unicode. Однако несколько командлетов иметь параметр Encoding , который может указывать кодировку для другого набор символов. Этот параметр позволяет выбрать конкретного персонажа кодирование, необходимое для взаимодействия с другими системами и приложениями.
Следующие командлеты имеют параметр Encoding :
- Microsoft.PowerShell.Management
- Дополнительный контент
- Получить содержимое
- Set-Content
- Microsoft.PowerShell.Утилита
- Экспорт-Clixml
- Экспорт-CSV
- Экспорт-PSSession
- Формат-Hex
- Импорт-CSV
- Исходящий файл
- Строка выбора
- Отправить MailMessage
Знак порядка байтов
Знак порядка байтов (BOM) представляет собой подпись Unicode в первых нескольких байтах
файл или текстовый поток, которые указывают, какая кодировка Unicode используется для данных.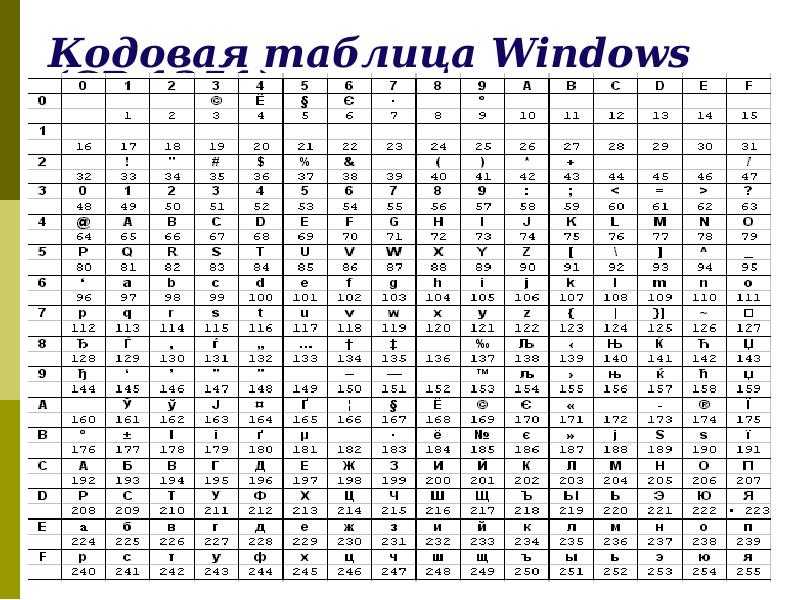 За
дополнительную информацию см.
Документация по меткам порядка байтов.
За
дополнительную информацию см.
Документация по меткам порядка байтов.
В Windows PowerShell любая кодировка Unicode, кроме UTF7 , всегда создает
Спецификация PowerShell (v6 и выше) по умолчанию использует utf8NoBOM для всего вывода текста.
Для лучшей общей совместимости избегайте использования спецификаций в файлах UTF-8. Unix-платформы и утилиты наследия Unix, также используемые на платформах Windows, не поддерживают спецификации.
Точно так же следует избегать кодирования UTF7 . UTF-7 не является стандартным Unicode
кодировке и записывается без спецификации во всех версиях PowerShell.
Создание сценариев PowerShell на Unix-подобной платформе или с использованием кросс-платформенного
редактор в Windows, такой как Visual Studio Code, приводит к созданию файла, закодированного с использованием UTF8NoBOM . Эти файлы отлично работают в PowerShell, но могут сломаться в Windows.
PowerShell, если файл содержит символы, отличные от Ascii.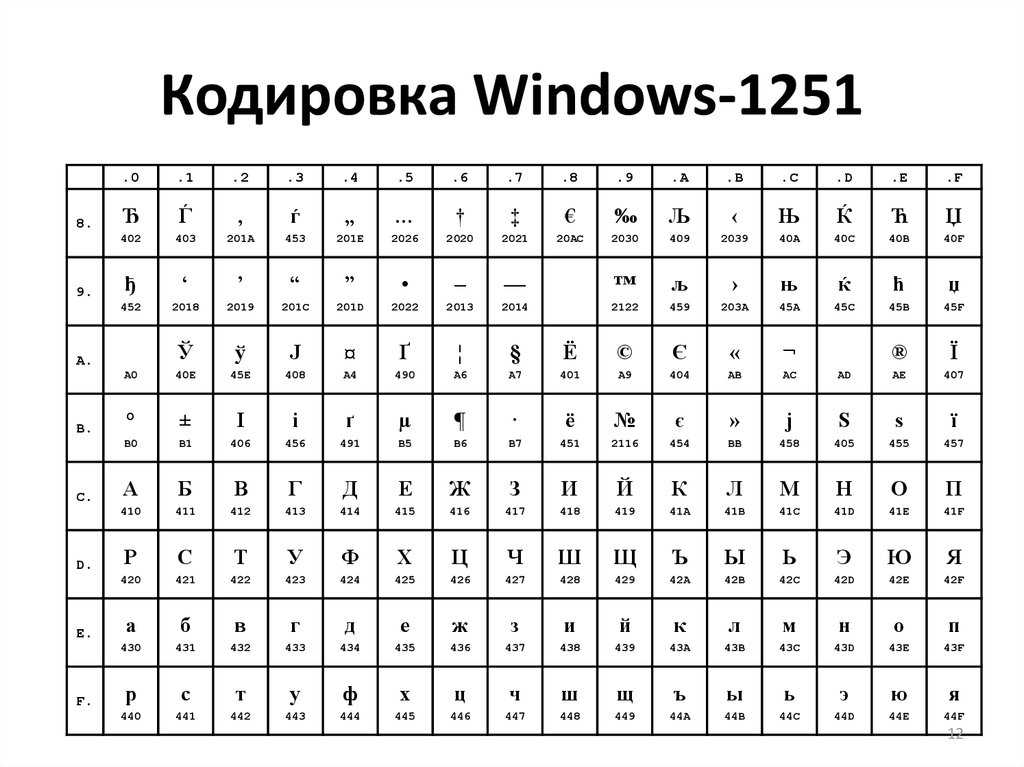
Если вам нужно использовать символы, отличные от Ascii, в ваших скриптах, сохраните их как UTF-8
с спецификацией. Без спецификации Windows PowerShell неправильно интерпретирует ваш сценарий как
кодируются в устаревшей кодовой странице «ANSI». И наоборот, файлы, которые имеют
Спецификация UTF-8 может быть проблематичной на Unix-подобных платформах. Многие инструменты Unix, такие как cat , sed , awk , а некоторые редакторы, такие как gedit не знают как лечить
спецификация.
Кодировка символов в Windows PowerShell
В PowerShell 5.1 параметр Encoding поддерживает следующие значения:
-
AsciiИспользует набор символов Ascii (7-разрядный). -
BigEndianUnicodeИспользует кодировку UTF-16 с прямым порядком байтов. -
BigEndianUTF32Использует UTF-32 с порядком байтов от старшего к старшему. -
БайтКодирует набор символов в последовательность байтов.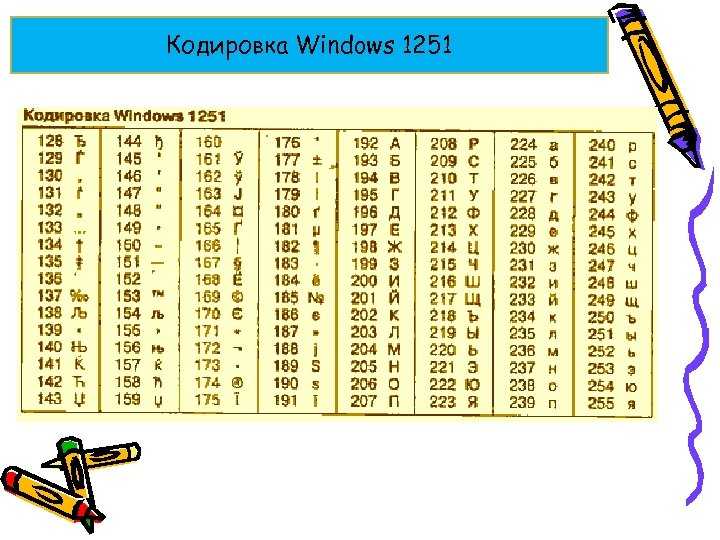
-
По умолчаниюИспользует кодировку, соответствующую активной кодовой странице системы. (обычно ANSI). -
OEMИспользует кодировку, соответствующую текущему OEM-коду системы. страница. -
СтрокаТо же, что иUnicode. -
UnicodeИспользует UTF-16 с прямым порядком байтов. -
НеизвестноТо же, что иЮникод. -
UTF32Использует UTF-32 с прямым порядком байтов. -
UTF7Использует UTF-7. -
UTF8Использует UTF-8 (со спецификацией).
Обычно Windows PowerShell использует Unicode Кодировка UTF-16LE по умолчанию. Однако, кодировка по умолчанию, используемая командлетами в Windows PowerShell, несовместима.
Примечание
При использовании любой кодировки Unicode, кроме UTF7 , всегда создается спецификация.
Для командлетов, записывающих выходные данные в файлы:
Out-Fileи операторы перенаправления>и>>создают кодировку UTF-16LE, которая заметно отличается отSet-ContentиAdd-Content.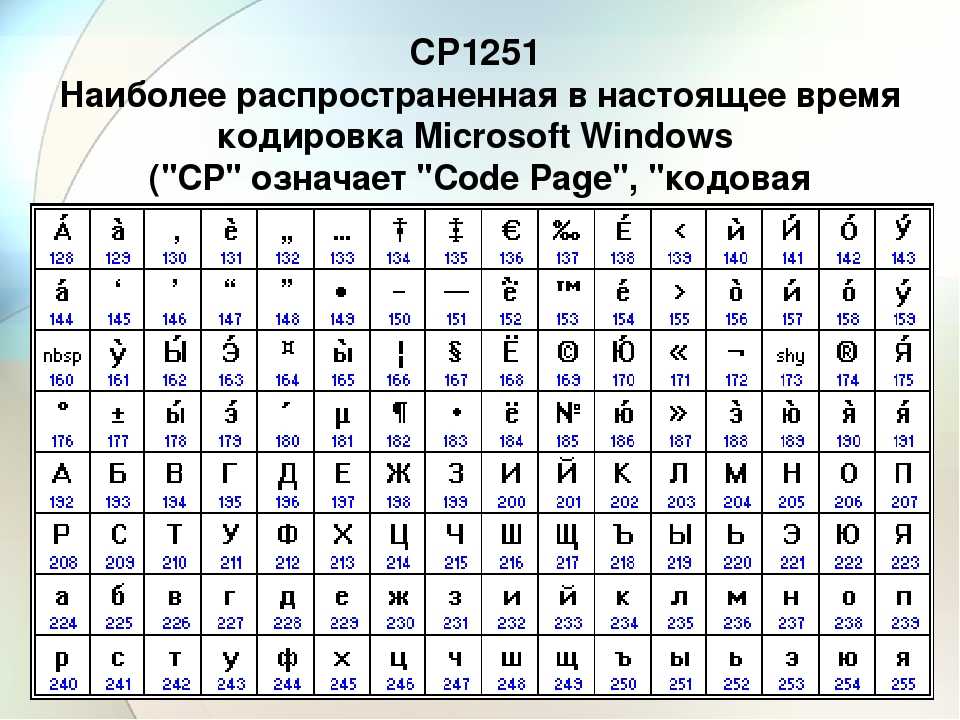
New-ModuleManifestиExport-CliXmlтакже создают файлы UTF-16LE.Если целевой файл пуст или не существует,
Set-ContentиAdd-Contentиспользовать кодировкупо умолчанию.По умолчанию— это кодировка, указанная устаревшая кодовая страница ANSI локали активной системы.Export-Csvсоздаетфайлов Ascii, но использует другую кодировку при использовании Добавить параметр (см. ниже).Export-PSSessionсоздает файлы UTF-8 с BOM по умолчанию.New-Item -Type File -Valueсоздает файл UTF-8 без спецификации.Send-MailMessageпо умолчанию использует кодировкуDefault.Start-Transcriptсоздаетфайлов Utf8со спецификацией. Когда добавить используется параметр, кодировка может быть другой (см. ниже).
Когда добавить используется параметр, кодировка может быть другой (см. ниже).
Для команд, которые добавляются к существующему файлу:
Out-File -Appendи оператор перенаправления>>не пытаются сопоставить кодировка содержимого существующего целевого файла. Вместо этого они используют кодировка по умолчанию, если только Используется параметр кодировки . Вы должны использовать исходная кодировка файлов при добавлении содержимого.При отсутствии явного параметра Encoding
Add-Contentобнаруживает существующую кодировку и автоматически применяет ее к новому содержимому. Если существующее содержимое не имеет спецификации,По умолчанию используется кодировкаANSI. ПоведениеAdd-Content— то же самое в PowerShell (v6 и выше), за исключением значения по умолчанию. кодировкаUtf8.Export-Csv -Appendсоответствует существующей кодировке, когда целевой файл содержит спецификацию.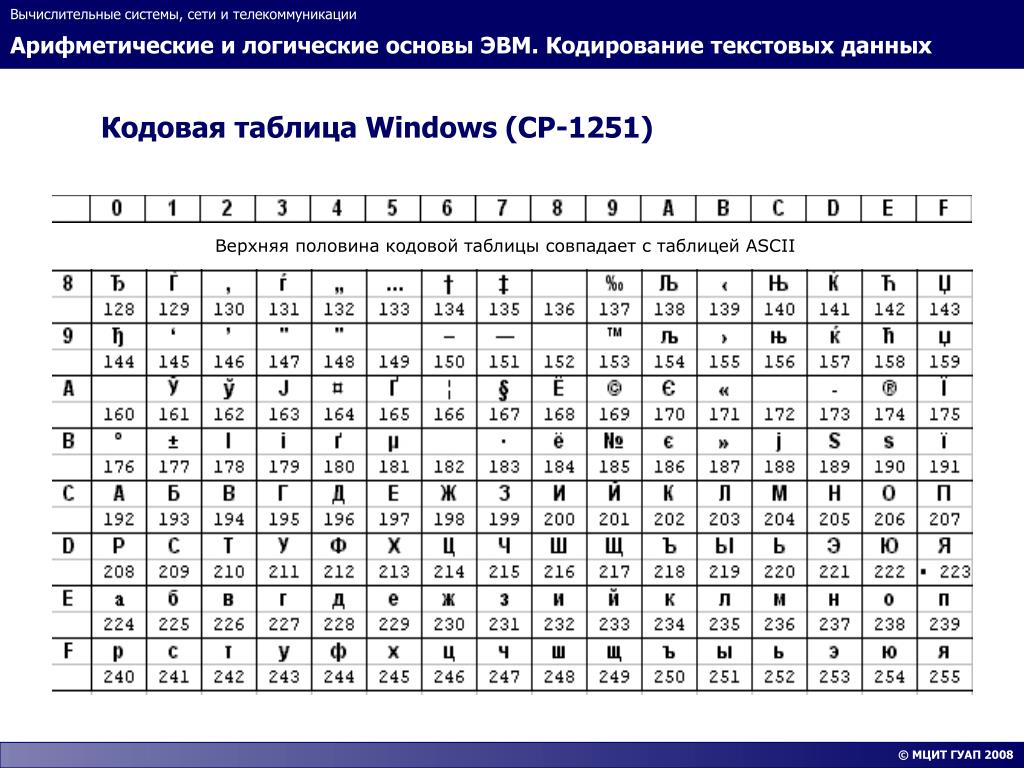 При отсутствии спецификации используется кодировка
При отсутствии спецификации используется кодировка Utf8.Start-Transcript -Appendсоответствует существующей кодировке файлов, которые включить спецификацию. При отсутствии спецификации по умолчанию используется кодировкаAscii. Этот кодирование может привести к потере данных или повреждению символов, когда данные в расшифровка содержит многобайтовые символы.
Для командлетов, считывающих строковые данные при отсутствии спецификации:
Get-ContentиImport-PowerShellDataFileиспользуетImport-Csv,Import-CliXmlиSelect-StringпредполагаютUtf8в отсутствие спецификации.
Кодировка символов в PowerShell
В PowerShell (v6 и выше) параметр Encoding поддерживает следующие значения:
-
ascii: Использует кодировку для набора символов ASCII (7-бит).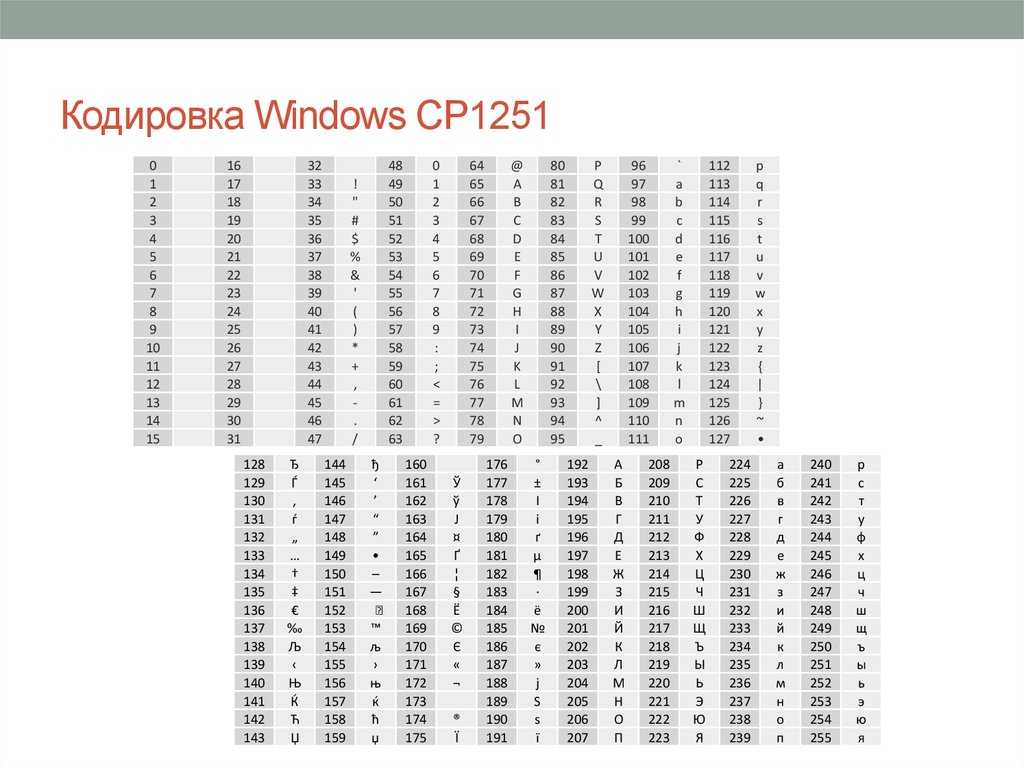
-
bigendianunicode: кодирует в формате UTF-16 с использованием порядка байтов с прямым порядком байтов. -
oem: Использует кодировку по умолчанию для MS-DOS и консольных программ. -
unicode: Кодирует в формате UTF-16, используя обратный порядок байтов. -
utf7: Кодирует в формате UTF-7. -
utf8: кодирует в формате UTF-8 (без спецификации). -
utf8BOM: Кодирует в формате UTF-8 с меткой порядка байтов (BOM) -
utf8NoBOM: Кодирует в формате UTF-8 без метки порядка байтов (BOM) -
utf32: Кодирует в формате UTF-32.
PowerShell по умолчанию использует utf8NoBOM для всех выходных данных.
Начиная с PowerShell 6.2, Параметр кодирования также допускает числовое
Идентификаторы зарегистрированных кодовых страниц (например, -Encoding 1251 ) или строковые имена
зарегистрированные кодовые страницы (например, -Кодировка "windows-1251" ).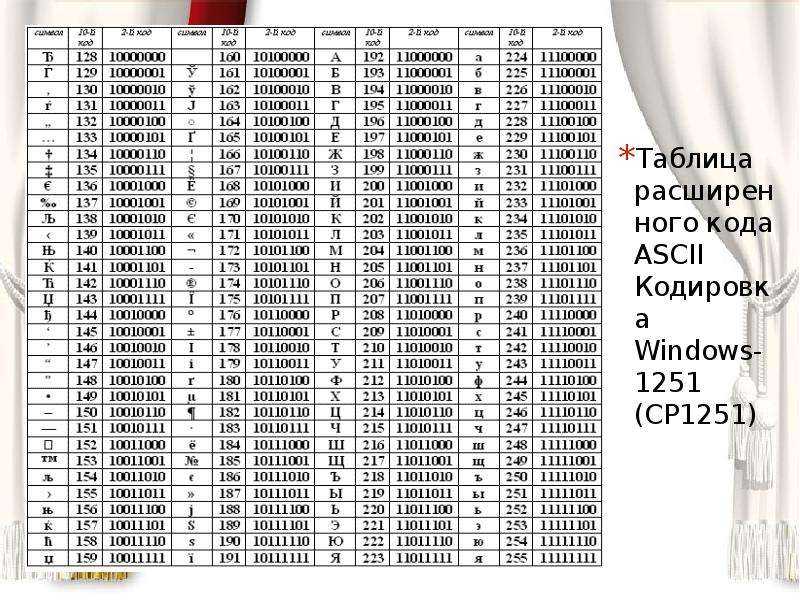 Чтобы получить больше информации,
см. документацию .NET для
Кодировка.Кодовая Страница.
Чтобы получить больше информации,
см. документацию .NET для
Кодировка.Кодовая Страница.
Изменение кодировки по умолчанию
PowerShell имеет две переменные по умолчанию, которые можно использовать для изменения кодировки по умолчанию. поведение при кодировании.
-
$PSDefaultParameterValues -
$OutputEncoding
Для получения дополнительной информации см. about_Preference_Variables.
Начиная с PowerShell 5.1 операторы перенаправления ( > и >> ) вызывают Командлет Out-File . Поэтому вы можете установить для них кодировку по умолчанию, используя
привилегированная переменная $PSDefaultParameterValues , как показано в этом примере:
$PSDefaultParameterValues['Out-File:Encoding'] = 'utf8'
Используйте следующую инструкцию, чтобы изменить кодировку по умолчанию для всех командлетов, которые
есть Кодирование параметра .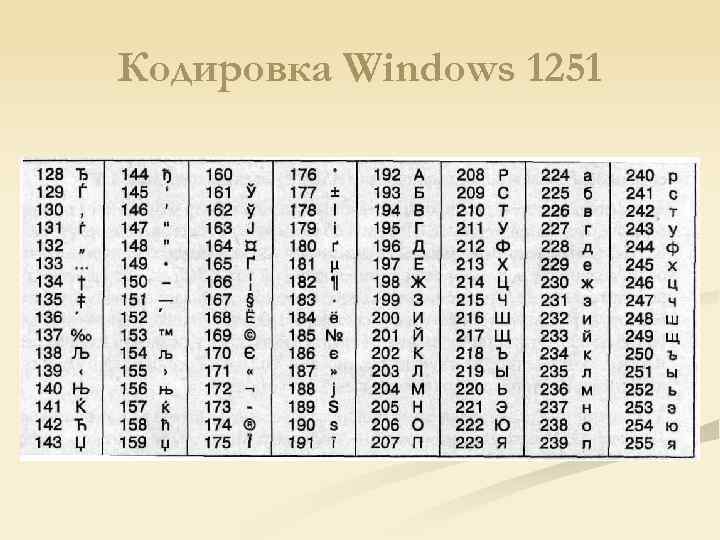
$PSDefaultParameterValues['*:Кодировка'] = 'utf8'
Important
Помещение этой команды в ваш профиль PowerShell делает параметр глобальная настройка сеанса, влияющая на все команды и сценарии, которые не явно указать кодировку.
Точно так же вы должны включать в свои скрипты или модули такие команды, которые вы хотите вести себя так же. Использование этих команд гарантирует, что командлеты вести себя так же, даже когда запускается другим пользователем на другом компьютере, или в другой версии PowerShell.
Автоматическая переменная $OutputEncoding влияет на кодировку, используемую PowerShell.
для связи с внешними программами. Это не влияет на кодировку, которую
операторы перенаправления вывода и командлеты PowerShell используют для сохранения в файлы.
См. также
- about_Preference_Variables
- Метка порядка байтов
- Кодовые страницы — приложения Win32
- Кодировка.CodePage
- Введение в кодировку символов в .
