— 5.2.1.
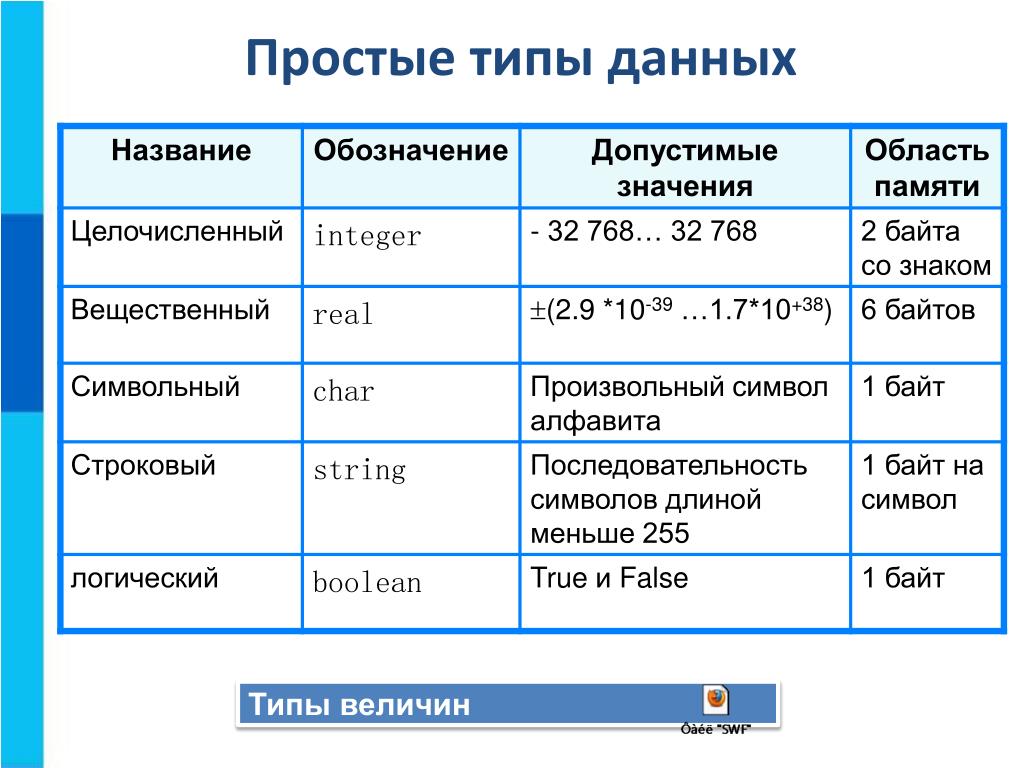
5.2.1. Типы данных
Тип данных – понятие из теории программирования. Тип данных определяет диапазон значений и операций, которые могут быть применены к этим значениям. Например, если переменная имеет числовой тип данных, то таким образом определен диапазон значений, которые могут быть сохранены в этой переменной (числа) и определены операции, которые могут быть применены к этой переменной (арифметические). Каждый язык программирования поддерживает один или несколько типов данных.
Вообще говоря, в памяти компьютера хранятся только последователь-ности битов. Если имя переменной указывает адрес в памяти, по которому хранится информация, то тип данных (тип переменной) указывает, каким обра-зом следует обращаться с этой информацией, то есть с битами, находящимися по данному адресу.
Преимущества от использования типов данных:
- Надежность. Типы данных защищают от трех видов ошибок:
1. Некорректное присваивание. Пусть переменная объявлена как имеющая числовой тип. Тогда попытка присвоить ей символьное или какое-либо другое значение приведет к ошибке еще на этапе компиляции и позволит избежать многих трудностей, поскольку такого рода ошибки трудно отследить обычными средствами. Предварительное объявление используемых переменных сейчас обязательно практически во всех языках.
Некорректное присваивание. Пусть переменная объявлена как имеющая числовой тип. Тогда попытка присвоить ей символьное или какое-либо другое значение приведет к ошибке еще на этапе компиляции и позволит избежать многих трудностей, поскольку такого рода ошибки трудно отследить обычными средствами. Предварительное объявление используемых переменных сейчас обязательно практически во всех языках.
2. Некорректная операция. Позволяет избежать попыток применения выражений вида «Hello world» + 1. Поскольку, как уже говорилось, все переменные в памяти хранятся как наборы битов, то при отсутствии типов подобная операция была выполнима (и могла дать результат вроде «Hello wordle»!). С использованием типов такие ошибки отсекаются на этапе компиляции.
3. Некорректная передача параметров. Если функция «синус» ожидает, что ей будет передан числовой аргумент, то передача ей в качестве параметра строки «Hello world» может иметь непредсказуемые последствия. При помощи контроля типов такие ошибки также отсекаются на этапе компиляции.
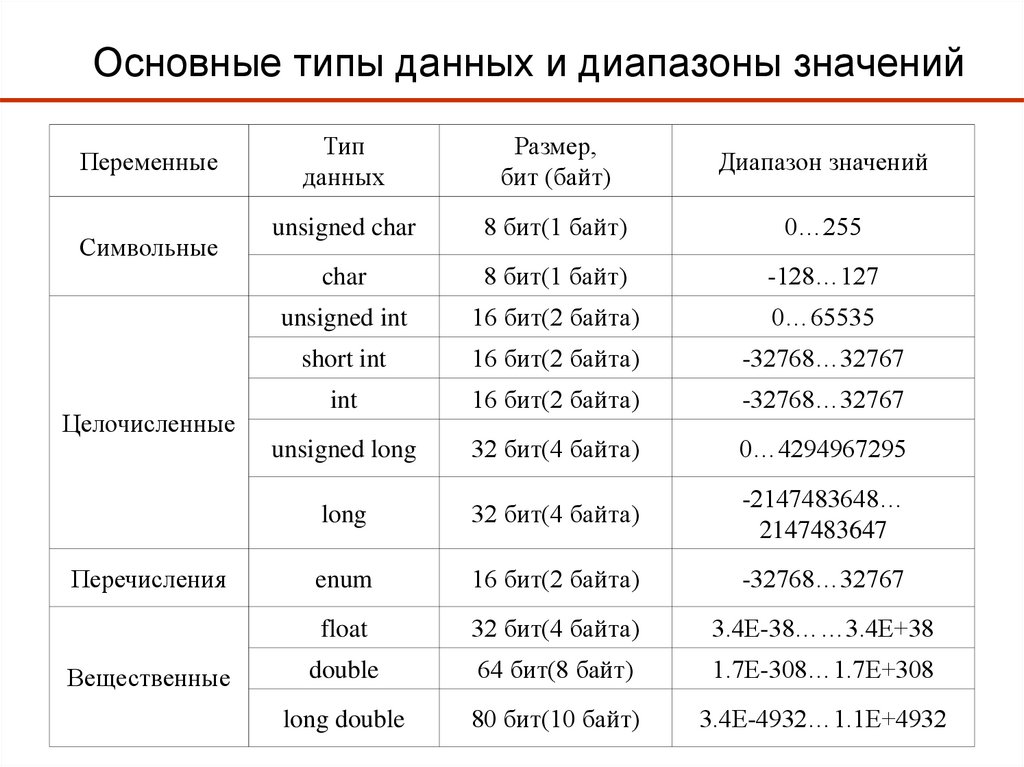
Классификация типов данных. Согласно стандартной классификации, типы данных бывают следующие:
1. Простые.
1.1. Числовые. Хранятся числа. Могут применяться обычные арифметические операции.
1.1.1. Целочисленные: со знаком, то есть могут принимать как положительные, так и отрицательные значения; и без знака, то есть могут принимать только неотрицательные значения.
1.1.2. Вещественные: с фиксированной точкой, то есть хранятся знак и цифры целой и дробной частей и с плавающей точкой, то есть число приводится к виду m*2e, где m — мантисса, e — экспонента причем 1/2<=m<=1, а e — целое число и хранятся знак, и числа m и e.
1.2. Символьный тип. Хранит один символ. Могут использоваться различные кодировки.
1.3. Строковый тип. Хранит строку символов. Может применяться операция конкатенация (сложение строк). Вообще говоря, может рассматриваться как массив символов, но как правило выделяется в качестве простого.
1.4. Логический тип. Имеет два значения: истина(true) и ложь(false). Могут применяться логические операции. Используется в операторах ветвления и циклах. В некоторых языках является подтипом числового типа, при этом false=0, true=1.
1.5. Перечислимый тип. Может хранить только те значения, которые прямо указаны в его описании.
2. Составные. Формируются на основе комбинаций простых типов.
2.1. Массив. Является индексированным набором элементов одного типа. Одномерный массив — вектор, двумерный массив — таблица.
2.2. Запись. Набор различных элементов (полей записи), хранимый как единое целое. Возможен доступ к отдельным полям записи.
2.3. Множество (тип данных). В основном совпадает с обычным математическим понятием множества. Допустимы стандартные операции с множествами и проверка на принадлежность элемента множеству.
3. Другие типы данных. Если описанные выше типы данных представляли какие-либо объекты реального мира, то рассматриваемые здесь типы данных представляют объекты компьютерного мира, то есть являются исключительно компьютерными терминами.
3.1. Указатель (тип данных). Хранит адрес в памяти компьютера, указывающий на какую-либо информацию, как правило — указатель на переменную.
3.2. Ссылки (тип данных).
Типы данных для баз данных Access для настольных компьютеров
Access
Таблицы
Типы данных
Типы данных для баз данных Access для настольных компьютеров
Access для Microsoft 365 Access 2021 Access 2019 Access 2016 Access 2013 Access 2010 Access 2007 Еще…Меньше
При создании таблиц в Access необходимо выбрать тип данных для каждого столбца данных. Тип данных «Короткий текст» является популярным вариантом, так как позволяет вводить практически любой символ (букву, символ или число). Однако тщательный выбор типов данных поможет вам воспользоваться дополнительными возможностями Access (такими как проверка данных и функции) и повысить точность данных, которые вы хотите хранить. В таблице ниже приведены типы данных, доступные в классических базах данных Access (ACCDB и MDB).
В таблице ниже приведены типы данных, доступные в классических базах данных Access (ACCDB и MDB).
Полный список свойств полей, доступных для каждого типа данных см. в статье Введение в использование типов данных и свойств полей.
В таблице ниже перечислены типы данных, доступные в классических базах данных в Access 2013 и более поздних версиях.
|
Тип данных |
Использование |
Размер |
|---|---|---|
|
Краткий текст (ранее назывался «Текст») |
Буквенно-цифровые данные (имена, названия и т. |
До 255 знаков. |
|
Длинный текст (ранее назывался «Поле MEMO») |
Большие объемы буквенно-цифровых данных: предложения и абзацы. Дополнительные сведения о типе данных «Длинный текст» см. в статье Длинный текст (ранее — тип данных «Поле MEMO»). |
До 1 гигабайта (ГБ), но в элементах управления отображаются только первые 64 000 символов. |
|
Число |
Числовые данные. |
1, 2, 4, 8 или 16 байт. |
|
Bigint |
Числовые данные. |
8 байт. Дополнительные сведения см. в статье Использование типа данных bigint. |
|
Дата и время |
Значения даты и времени. |
|
|
Date/Time Extended |
Значения даты и времени. |
Строка кодировки из 42 байтов Дополнительные сведения см. в типе данных «Дата/время». |
|
Денежный |
Денежные данные, хранящиеся с точностью до 4 десятичных знаков после запятой. |
8 байт. |
|
Счетчик |
Уникальное значение, создаваемое Access для каждой новой записи. |
4 байта (16 байт для кода репликации). |
|
Логический |
Логические данные (истина/ложь). Access хранит числовое значение 0 (нуль) для лжи и -1 для истины. |
1 байт. |
|
Объект OLE |
Изображения, графики или другие объекты ActiveX из другого приложения Windows. |
До 2 ГБ. |
|
Гиперссылка |
Адрес ссылки на документ или файл в Интернете, интрасети, локальной сети или на локальном компьютере. |
До 8192 (каждая часть типа данных «Гиперссылка» может содержать до 2048 знаков). |
|
Вложение |
Вы можете вложите файлы, например рисунки, документы, электронные таблицы или диаграммы. Каждое поле вложения может содержать неограниченное количество вложений для каждой записи в пределах размера файла базы данных. Обратите внимание, что тип данных «Вложение» не доступен в форматах файлов MDB. |
До 2 ГБ. |
|
Вычисляемый |
Вы можете создать выражение, использующее данные из одного или более полей. |
Зависит от типа данных свойства «Тип результата». Результат с типом данных «Краткий текст» может содержать до 243 знаков. Значения типа «Полный текст», «Число», «Логический» и «Дата/время» должны соответствовать своим типам данных. |
|
Мастер подстановок |
Запись «Мастер подстановок» в столбце «Тип данных» в Конструкторе фактически не является типом данных. При выборе этой записи запускается мастер, помогающий определить простое или сложное поле подстановки. Простое поле подстановки использует содержимое другой таблицы или списка значений для проверки правильности содержимого единственного значения в строке. |
Зависит от типа данных поля подстановки. |
 д.)
д.)


 Выражения могут возвращать данные разных типов. Тип данных «Вычисляемый» недоступен в файлах формата MDB.
Выражения могут возвращать данные разных типов. Тип данных «Вычисляемый» недоступен в файлах формата MDB. Сложное поле подстановки позволяет хранить несколько значений одного типа данных в каждой строке.
Сложное поле подстановки позволяет хранить несколько значений одного типа данных в каждой строке.В таблице ниже представлены типы данных, доступные в классических базах данных в Access 2010 и Access 2007.
|
Тип данных |
Использование |
Размер |
|---|---|---|
|
Текст |
Буквенно-цифровые данные (имена, названия и т. |
До 255 знаков. |
|
Memo |
Большие объемы буквенно-цифровых данных: предложения и абзацы. |
До 1 гигабайта (ГБ), но в элементах управления отображаются только первые 64 000 символов. |
|
Число |
Числовые данные. |
1, 2, 4, 8 или 16 байт. |
|
Дата/время |
Значения даты и времени. |
8 байт. |
|
Денежный |
Денежные данные, хранящиеся с точностью до 4 десятичных знаков после запятой. |
8 байт. |
|
Счетчик |
Уникальное значение, создаваемое Access для каждой новой записи. |
4 байта (16 байт для кода репликации). |
|
Логический |
Логические данные (истина/ложь). |
1 байт. |
|
Объект OLE |
Изображения, графики или другие объекты ActiveX из другого приложения Windows. |
До 2 ГБ. |
|
Гиперссылка |
Адрес ссылки на документ или файл в Интернете, интрасети, локальной сети или на локальном компьютере. |
До 8192 (каждая часть типа данных «Гиперссылка» может содержать до 2048 знаков). |
|
Вложение |
Вы можете вложите файлы, например рисунки, документы, электронные таблицы или диаграммы. Каждое поле вложения может содержать неограниченное количество вложений для каждой записи в пределах размера файла базы данных. Обратите внимание, что тип данных «Вложение» не доступен в форматах файлов MDB. |
До 2 ГБ. |
|
Вычисляемый |
Вы можете создать выражение, использующее данные из одного или более полей. Выражения могут возвращать данные разных типов. Тип данных «Вычисляемый» недоступен в файлах формата MDB. Примечание: тип данных «Вычисляемый» отсутствует в Access 2007. |
Зависит от типа данных свойства «Тип результата». Результат с типом данных «Краткий текст» может содержать до 243 знаков. Значения типа «Полный текст», «Число», «Логический» и «Дата/время» должны соответствовать своим типам данных. |
|
Мастер подстановок |
Запись «Мастер подстановок» в столбце «Тип данных» в Конструкторе фактически не является типом данных. При выборе этой записи запускается мастер, помогающий определить простое или сложное поле подстановки. Простое поле подстановки использует содержимое другой таблицы или списка значений для проверки правильности содержимого единственного значения в строке. |
Зависит от типа данных поля подстановки. |
 д.)
д.)
 Access хранит числовое значение 0 (нуль) для лжи и -1 для истины.
Access хранит числовое значение 0 (нуль) для лжи и -1 для истины.

 Сложное поле подстановки позволяет хранить несколько значений одного типа данных в каждой строке.
Сложное поле подстановки позволяет хранить несколько значений одного типа данных в каждой строке.Типы данных — Основы программирования
Кеннет Лерой Басби и Дэйв Брауншвейг
Обзор
Тип данных — это классификация данных, которая сообщает компилятору или интерпретатору, как программист намерен использовать данные. Большинство языков программирования поддерживают различные типы данных, включая целые, действительные, символьные или строковые, а также логические значения. [1]
Обсуждение
Наши взаимодействия (входы и выходы) с программой обрабатываются на многих языках как поток байтов. Эти байты представляют данные, которые можно интерпретировать как представляющие значения, которые мы понимаем. Кроме того, внутри программы мы обрабатываем эти данные различными способами, например, складываем их или сортируем. Эти данные поступают в различных формах. Примеры включают:
Кроме того, внутри программы мы обрабатываем эти данные различными способами, например, складываем их или сортируем. Эти данные поступают в различных формах. Примеры включают:
- ваше имя – строка символов
- ваш возраст — обычно целое число
- сумма денег в вашем кармане – обычно стоимость измеряется в долларах и центах (что-то с дробной частью)
Большая часть понимания того, как проектировать и кодировать программы, сосредоточена на понимании типов данных, которыми мы хотим манипулировать, и того, как манипулировать этими данными.
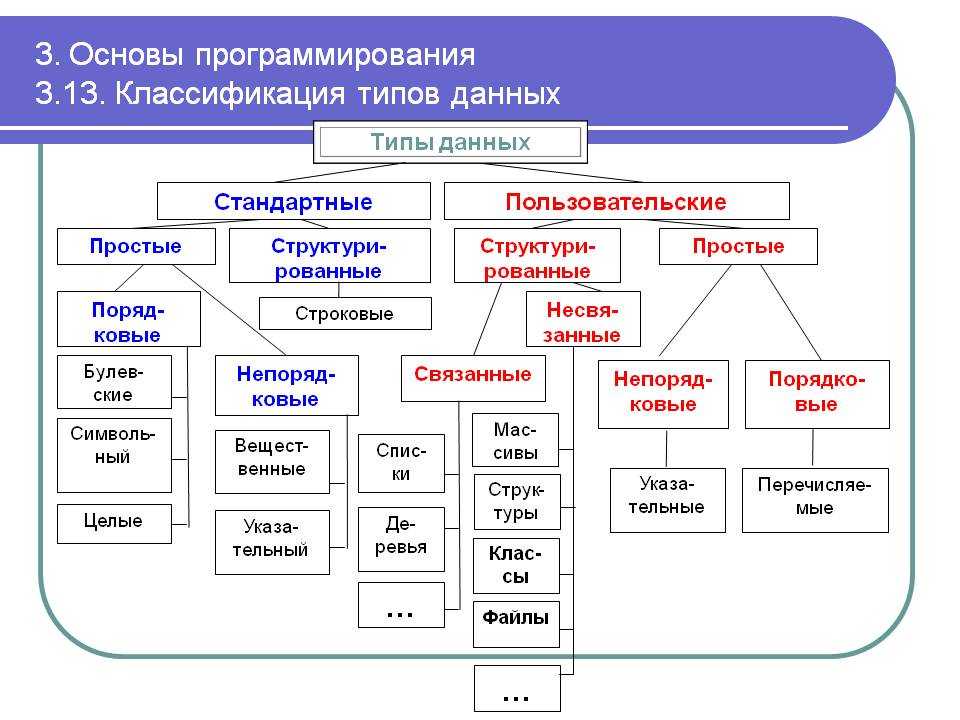
Общие типы данных включают:
| Тип данных | Представляет | Примеры |
|---|---|---|
| целое число | целых чисел | -5 , 0 , 123 |
| с плавающей запятой (действительная) | дробные числа | -87,5 , 0,0 , 3,14159 |
| строка | Последовательность символов | "Привет, мир!" |
| Логический | логическое истинное или ложное | правда , ложь |
| ничего | нет данных | ноль |
Общие типы данных обычно существуют в большинстве языков программирования и действуют или ведут себя одинаково от языка к языку.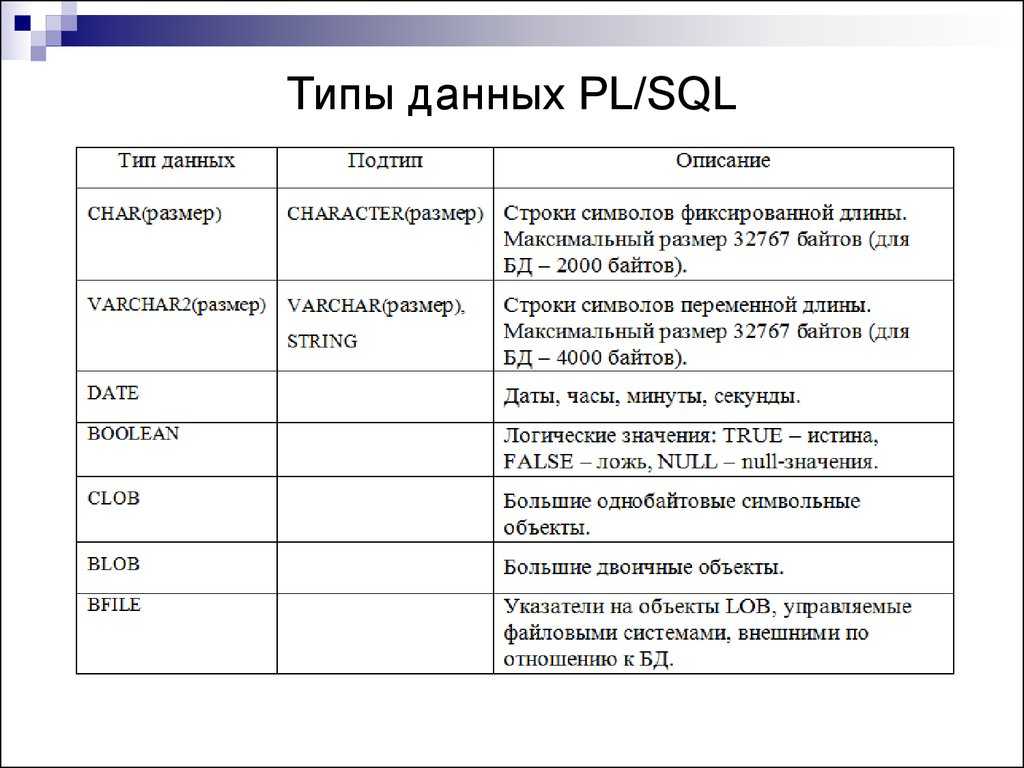 Дополнительные сложные и/или составные типы данных могут существовать и различаться от языка к языку.
Дополнительные сложные и/или составные типы данных могут существовать и различаться от языка к языку.
Псевдокод
Основная функция
... Эта программа демонстрирует переменные, литеральные константы и типы данных.
Объявить целое число i
Объявить реальный р
Объявить строку s
Объявить логическое значение b
Присвоить я = 1234567890
Присвоить г = 1,2345678Выход
Целое число i = 1234567890 Действительное г = 1,2345678
Блок-схема
Ключевые термины
- Булево значение
- Тип данных, представляющий логическую истину или ложь.
- тип данных
- Определяет набор значений и набор операций, которые можно применять к этим значениям.

- с плавающей запятой
- Тип данных, представляющий числа с дробными частями.
- целое число
- Тип данных, представляющий целые числа.
- строка
- Тип данных, представляющий последовательность символов.
Ссылки
- cnx.org: основы программирования — модульный структурированный подход с использованием C++
- Flowgorithm — язык программирования блок-схем
- Википедия: Тип данных ↵
13 типов данных
Адриан Брофи @ Xtrashot Photographic Данные — сложная тема. Во-первых, мы не уверены, как мы должны ссылаться на это, то есть данные — это множественное число данных. Строго говоря, мы должны говорить о данных, которые «являются», а не «являются» доступными для поддержки теории и т. Д. Газета Guardian обсуждала здесь дебаты и, по-видимому, предположила, что (несмотря на разделение инфинитивов и нюансы идиоматической латыни) наша повседневная жизнь использование этого термина может оставаться удобным грамматически неверным.
«Что бы это ни стоило, я могу с уверенностью сказать, что это, вероятно, будет единственный раз, когда я напишу слово «датум» в сообщении [блог]. Термин «данные» во множественном числе может быть правильным использованием, но язык развивается, и мы хотим писать в терминах, понятных всем, и это не кажется смешным», — написал Саймон Роджерс в 2012 году, прежде чем перейти на должность редактора данных в Google.
Итак, можем ли мы сгруппировать множество различных экземпляров отдельных данных (извините, данных) по отдельным типам, категориям, разновидностям и классификациям? В этом мире так называемой цифровой трансформации и облачных вычислений, которые определяют наш постоянно подключенный образ жизни, безусловно, было бы полезно понять, что, когда, где и почему данные на нашем пути к тому, чтобы начать понимать, как фактор.
1 — Большие данные
Основной фаворит, большие данные стали определяться как что-то вроде: тот объем данных, который практически не помещается в стандартную (реляционную) базу данных для анализа и обработки из-за огромных объемов информации, создаваемой человеческими и машинными процессами.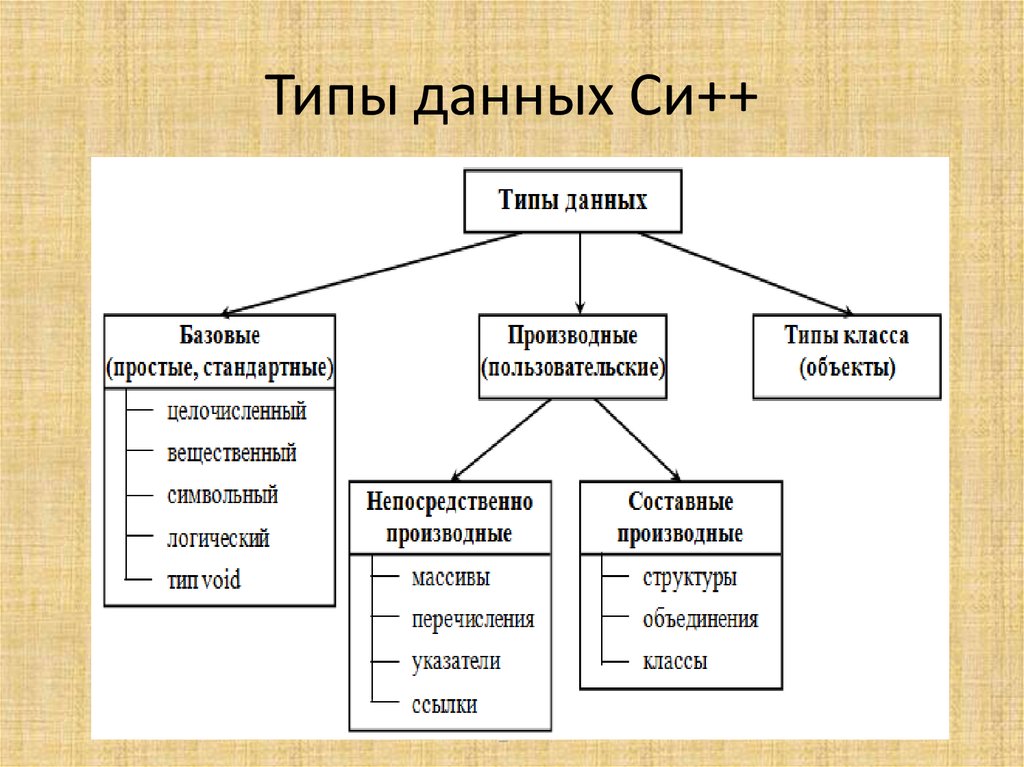
«Хотя определения «больших данных» могут немного различаться, в основе каждого из них лежат очень большие, разнообразные наборы данных, которые включают структурированные, полуструктурированные и неструктурированные данные из разных источников и в разных объемах, от терабайтов до зеттабайтов. Речь идет о наборах данных, настолько больших и разнообразных, что традиционным реляционным базам данных трудно, если не невозможно, собирать, управлять и обрабатывать их с малой задержкой», — сказал Роб Томас, генеральный менеджер IBM Analytics.
Томас предполагает, что большие данные имеют большое значение, потому что они являются топливом для таких вещей, как машинное обучение, которые образуют строительные блоки искусственного интеллекта (ИИ). Он говорит, что, изучая (и анализируя) большие данные, люди могут обнаруживать закономерности, чтобы лучше понять, почему что-то произошло. Затем они также могут использовать ИИ, чтобы предсказывать, как они могут произойти в будущем, и предписывать стратегические направления на основе этих идей.
2 — Структурированные, неструктурированные, полуструктурированные данные
Все данные имеют некоторую структуру. Различие между структурированными и неструктурированными данными сводится к тому, имеют ли данные заранее определенную модель данных и организованы ли они заранее определенным образом.
Мэт Кип — старший директор по продуктам и решениям в MongoDB. Keep объясняет, что в прошлом структуры данных были довольно простыми и часто были известны до проектирования модели данных, поэтому данные обычно хранились в табличном формате строк и столбцов реляционных баз данных.
«Однако развитие современных веб-приложений, мобильных, социальных приложений, ИИ и IoT в сочетании с современным объектно-ориентированным программированием ломает эту парадигму. Данные, описывающие объект (то есть клиент, продукт, связанный актив), управляются в коде как полные объекты, содержащие глубоко вложенные элементы. Структура этих объектов может варьироваться (полиморфизм) — например, у некоторых клиентов есть профиль в социальных сетях, который отслеживается, а у некоторых нет.
А благодаря гибким методологиям разработки структуры данных также быстро меняются по мере создания новых функций приложения», — сказал Кип.
В результате всего этого полиморфизма сегодня многие разработчики программного обеспечения ищут более гибкие альтернативы реляционным базам данных для размещения данных любой структуры.
3 — Данные с отметками времени
Данные с отметками времени — это набор данных, который имеет концепцию упорядочения по времени, определяющую последовательность, в которой каждая точка данных была либо захвачена (время события), либо собрана (время обработки).
«Этот тип данных обычно используется при сборе данных о поведении (например, о действиях пользователей на веб-сайте) и, таким образом, представляет собой истинное представление действий во времени. Такой набор данных имеет неоценимое значение для ученых, работающих с данными, которые работают с системами, которым поручено прогнозировать или оценивать следующие лучшие модели стиля действий или выполнять анализ пути, поскольку можно воспроизвести шаги пользователя в системе, учиться на изменениях. время и ответ», — сказал Алекс Оливье, менеджер по продукту компании Qubit, занимающейся программной платформой для персонализации маркетинга.
время и ответ», — сказал Алекс Оливье, менеджер по продукту компании Qubit, занимающейся программной платформой для персонализации маркетинга.
4 — Машинные данные
Проще говоря, машинные данные — это цифровая выхлопная система, созданная системами, технологиями и инфраструктурой, обеспечивающими работу современного бизнеса.
Мэтт Дэвис, руководитель отдела маркетинга Splunk в регионе EMEA, просит нас нарисовать картину и представить свой обычный рабочий день, поездку в офис на подключенном автомобиле, вход в систему на компьютере, телефонные звонки, ответы на электронные письма, доступ к приложениям. . Дэвис объясняет, что вся эта деятельность создает множество машинных данных в множестве непредсказуемых форматов, которые часто игнорируются.
«Машинные данные включают данные из таких различных областей, как интерфейсы прикладного программирования (API), конечные точки безопасности, очереди сообщений, события изменений, облачные приложения, подробные записи вызовов и данные датчиков из промышленных систем», — сказал Дэвис.
«Тем не менее, машинные данные ценны, потому что они содержат точную запись в реальном времени всей активности и поведения клиентов, пользователей, транзакций, приложений, серверов, сетей и мобильных устройств».
Утверждается, что если сделать машинные данные доступными и удобными для использования, они смогут помочь организациям устранять проблемы, выявлять угрозы и использовать машинное обучение для прогнозирования будущих проблем.
5 — Пространственно-временные данные
Пространственно-временные данные описывают как место, так и время одного и того же события и могут показать нам, как явления в физическом местоположении меняются с течением времени.
«Пространственные данные — это «пространство» в пространственно-временном. Он может описывать точечные местоположения или более сложные линии, такие как траектории транспортных средств, или многоугольники (плоские фигуры), которые составляют географические объекты, такие как страны, дороги, озера или следы зданий», — пояснил Тодд Мостак, генеральный директор MapD.

Временные данные содержат информацию о дате и времени в отметке времени. Действительное время – период времени, охватываемый реальным миром. Время транзакции – это время, когда факт, хранящийся в базе данных, был известен.
«Примеры того, как аналитики могут визуализировать пространственно-временные данные и взаимодействовать с ними, включают: отслеживание движущихся транспортных средств, описание изменения численности населения с течением времени или выявление аномалий в телекоммуникационной сети. Лица, принимающие решения, также могут запускать вычисления в базе данных, чтобы найти расстояния между объектами или сводную статистику по объектам, содержащимся в определенных местах», — сказал Мостак из MapD.
6 — Открытые данные
Открытые данные – это данные , которые находятся в свободном доступе для всех с точки зрения их использования (возможности применять к ним аналитику) и прав на повторную публикацию без ограничений авторского права, патентов или других механизмов контроля. Институт открытых данных заявляет, что открытые данные полезны только в том случае, если ими делятся таким образом, чтобы люди могли их понять. Им необходимо делиться в стандартизированном формате и легко отслеживать, откуда оно пришло.
Институт открытых данных заявляет, что открытые данные полезны только в том случае, если ими делятся таким образом, чтобы люди могли их понять. Им необходимо делиться в стандартизированном формате и легко отслеживать, откуда оно пришло.
«Было бы интересно, если бы мы могли сделать некоторые частные данные [формы, экстраполированные тенденции, совокупные значения и аналитику] доступными для всего мира, не отказываясь от идентификации источника и владельца этих данных? Появляются некоторые технологии, такие как многосторонние вычисления и дифференциальная конфиденциальность, которые могут помочь нам в этом», — сказал Майк Бурсел, главный архитектор безопасности в Red Hat.
Берселл объясняет, что на данный момент это все еще академические методы, но в течение следующих десяти лет, по его словам, люди будут по-разному думать о том, что мы подразумеваем под открытыми данными. Мир открытого исходного кода понимает некоторые из этих вопросов и может стать лидером. Специалист по безопасности Red Hat говорит, что организациям, которые построили свой бизнес на хранении секретов, может быть трудно. Теперь им нужно посмотреть, как они откроют это, чтобы создать возможности для создания богатства и инноваций.
Специалист по безопасности Red Hat говорит, что организациям, которые построили свой бизнес на хранении секретов, может быть трудно. Теперь им нужно посмотреть, как они откроют это, чтобы создать возможности для создания богатства и инноваций.
7 — Темные данные
Темные данные — это цифровая информация, которая не используется и находится в неактивном виде в той или иной форме.
Аналитический дом Gartner Inc. описывает скрытые данные как «информационные активы, которые организация собирает, обрабатывает и хранит в ходе своей обычной деловой деятельности, но обычно не использует для других целей».
8 — Данные в режиме реального времени
Одной из самых взрывоопасных тенденций в аналитике является возможность потоковой передачи и обработки данных в реальном времени. Некоторые люди утверждают, что сам термин является неправильным, т. е. данные могут перемещаться со скоростью, равной скорости связи, которая не быстрее, чем само время… поэтому, логически, даже данные в реальном времени немного отстают от фактического хода времени. в реальном мире. Тем не менее, мы все еще можем использовать этот термин для обозначения мгновенных вычислений, которые происходят настолько быстро, насколько может воспринимать человек.
в реальном мире. Тем не менее, мы все еще можем использовать этот термин для обозначения мгновенных вычислений, которые происходят настолько быстро, насколько может воспринимать человек.
«Тенденции, такие как периферийные вычисления и надвигающийся рост 5G, набирают обороты благодаря возможностям, предоставляемым данными в реальном времени. Сила оперативности данных станет катализатором для создания умных городов», — сказал Дэниел Ньюман, главный аналитик чикагской компании Futurum Research.
Ньюман говорит, что данные в режиме реального времени могут помочь во всем: от развертывания экстренных ресурсов при дорожно-транспортном происшествии до обеспечения более плавного движения транспорта во время общегородского мероприятия. Он говорит, что данные в режиме реального времени также могут обеспечить лучшую связь между потребителями и брендами, позволяя доставлять наиболее релевантные предложения в точные моменты в зависимости от местоположения и предпочтений. «Данные в режиме реального времени — это настоящая электростанция, и ее потенциал будет полностью реализован в ближайшем будущем», — добавил Ньюман.
«Данные в режиме реального времени — это настоящая электростанция, и ее потенциал будет полностью реализован в ближайшем будущем», — добавил Ньюман.
9 — Геномные данные
Бхарат Гауда, вице-президент по маркетингу продуктов компании Databricks, указывает на геномные данные как на еще одну область, требующую специального понимания. Данные геномики включают анализ ДНК пациентов для выявления новых лекарств и улучшения ухода за ними с помощью персонализированных методов лечения.
Он объясняет: «Данные, связанные с геномикой, огромны — ожидается, что к 2020 году геномные данные будут на несколько порядков больше, чем данные, созданные Twitter и YouTube. На сборку первого генома ушло более десяти лет. Сегодня геном пациента можно секвенировать за пару дней. Тем не менее, генерация данных является легкой частью. Превратить данные в понимание — непростая задача. Инструменты, используемые исследователями, не могут справиться с огромными объемами геномных данных».
Какие здесь проблемы? По словам Гауда, обработка данных и последующая аналитика являются новыми узкими местами, которые мешают нам получать больше пользы от геномных данных. Так что же отличает геномные данные?
«Это требует значительной обработки данных и должно быть смешано с данными сотен тысяч пациентов для получения информации. Кроме того, вам необходимо подумать о том, как вы можете унифицировать рабочие процессы аналитики для всех групп — от специалистов по биоинформатике, подготавливающих данные, до клинических специалистов, лечащих пациентов, — чтобы максимизировать их ценность», — сказал Гауда.
10 — Оперативные данные
Колин Фернандес (Colin Fernandes) — директор по маркетингу продукции в регионе EMEA компании Sumo Logic. Фернандес говорит, что у компаний есть большие данные, у них есть журналы приложений и метрики, у них есть данные о событиях, а также информация от приложений микросервисов и третьих сторон.
Вопрос в том, как они могут превратить эти данные в бизнес-инсайты, которые могут использовать лица, принимающие решения, и нетехнические группы, в дополнение к специалистам по данным и ИТ-специалистам?
«Именно здесь в игру вступает операционная аналитика, — сказал Фернандес. «Анализ операционных данных превращает данные ИТ-систем в ресурсы, которые сотрудники могут использовать в своих ролях. Здесь важно то, что мы превращаем данные из специализированного ресурса в активы, понятные всем, от генерального директора до рядовых работников, когда им необходимо принять решение».
Фернандес отмечает, что на практике это означает совместный поиск новых приложений и бизнес-целей для обратного проектирования того, какими должны быть метрики ваших операционных данных. На микросервисах можно разрабатывать новые сервисы, ориентированные на клиентов, но как убедиться, что мы извлекаем правильные данные с самого начала? Применяя это мышление «оперативных данных», мы, возможно, сможем получать нужную информацию нужным людям, когда они в ней нуждаются.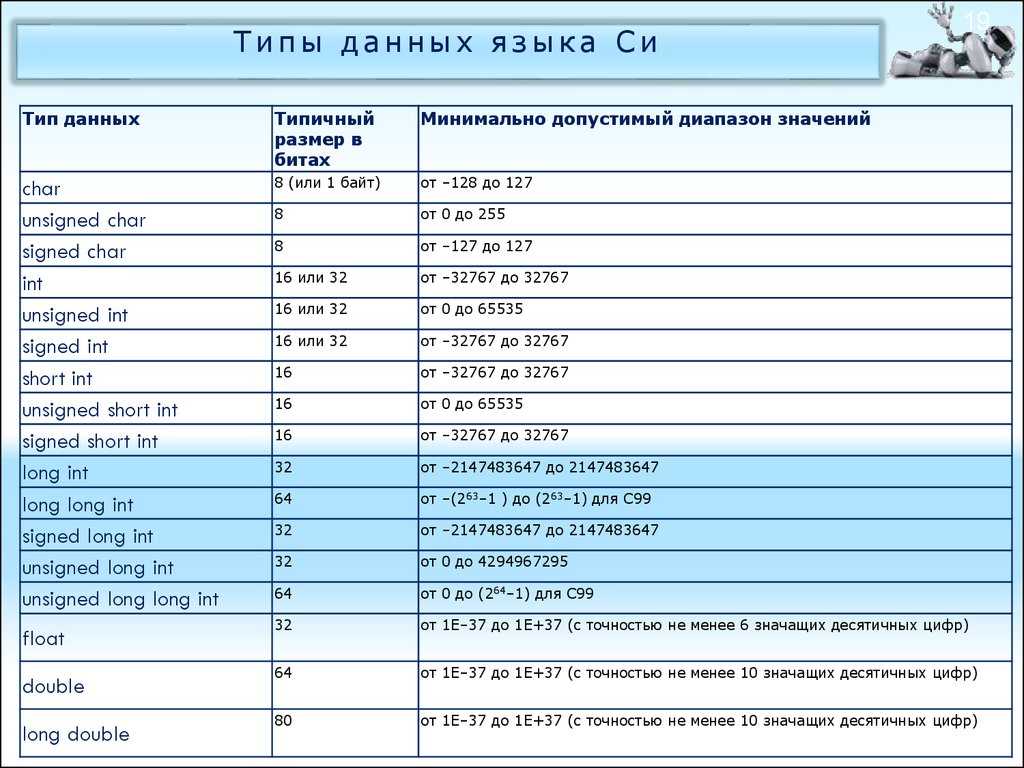
11 — Многомерные данные
Многомерные данные — это термин, популяризируемый в связи с технологиями распознавания лиц. Из-за чрезвычайно сложного количества контуров на человеческом лице нам нужны новые выражения данных, которые были бы достаточно многогранными, чтобы иметь возможность обрабатывать вычисления, способные описать все нюансы и индивидуальности, существующие в физиогномике лица. С этим связана концепция собственных лиц, название, данное набору собственных векторов, когда они используются в вычислениях для обработки распознавания человеческого лица.
12 — Непроверенные устаревшие данные
Ранее цитировавшийся Майк Бурсел из Red Hat также указывает на то, что он называет непроверенными устаревшими данными. Это данные, которые были собраны, но никто не знает, являются ли они актуальными, точными или даже правильными. Мы можем предположить, что с точки зрения бизнеса, если вы доверяете данным, которые вы не проверили, то вы не должны доверять никаким решениям, которые принимаются на их основе. Берселл говорит, что Garbage In, Garbage Out все еще держится… и без проверки данные — это просто мусор.
Берселл говорит, что Garbage In, Garbage Out все еще держится… и без проверки данные — это просто мусор.
«Возможно, даже хуже, чем непроверенные данные, которые могут иметь хоть какую-то достоверность и которым вы должны хотя бы знать, что им не следует доверять, данные, которые устарели и раньше были релевантными. Но многие реальные свидетельства, из которых мы получаем наши данные, меняются, и если данные не меняются, чтобы отразить это, то во многих случаях их использование определенно опасно», — сказал Берселл.
13 — Транслитические данные
Утверждается, что сочетание «транзакций» и «анализа» транслитических данных позволяет обрабатывать по запросу в режиме реального времени и создавать отчеты с новыми показателями, ранее недоступными на месте действия. Это мнение Марка Дарбишира, технического директора по управлению данными и базами данных в SAP UK.
Дарбишир говорит, что традиционно анализ проводился на копии транзакционных данных. Но сегодня, благодаря доступности вычислений в оперативной памяти, компании могут выполнять аналитику «окна транзакций». По его словам, это поддерживает задачи, повышающие ценность бизнеса, такие как интеллектуальный таргетинг, кураторские рекомендации, альтернативная диагностика и мгновенное обнаружение мошенничества, а также предоставляет тонкие, но ценные бизнес-идеи.
Но сегодня, благодаря доступности вычислений в оперативной памяти, компании могут выполнять аналитику «окна транзакций». По его словам, это поддерживает задачи, повышающие ценность бизнеса, такие как интеллектуальный таргетинг, кураторские рекомендации, альтернативная диагностика и мгновенное обнаружение мошенничества, а также предоставляет тонкие, но ценные бизнес-идеи.
По словам Дарбишира из SAP, «для транслитических данных требуется упрощенная технологическая архитектура и гибридные системы транзакционных аналитических баз данных, которые поддерживаются технологией in-memory. Это также обеспечивает дополнительное преимущество простоты архитектуры — одна система для обслуживания без перемещения данных. Компании, которые совершают сделки в режиме реального времени, мгновенно получая представление о соответствующих ключевых показателях, которые имеют значение во время совершения сделки, получают более высокую операционную эффективность, а также более быстрый доступ и улучшенную видимость своих данных в реальном времени».