Базы данных: какие бывают
В статье рассказывается о роли баз данных в современных реалиях и сформировано определение. Помимо этого, указываются виды баз данных и их классификация на основе структуры хранения данных. MySQL как эталонная СУБД для хранения данных в интернет-пространстве.
И кстати, у нас вы можете бесплатно пройти курс по MySQL.
Ещё до появления информационных технологий у людей возникала необходимость в упорядоченном хранении тех или иных данных. Для удобства их разделяли по определённому признаку, объединяли в группы, создавали иерархическое представление и применяли множество других способов.
С развитием компьютерной техники и интернета большинство методов, которые ранее использовались в библиотеках и архивах, были взяты за основу для хранения данных уже на носителях информации. В случае с интернет-пространствам данные хранятся на конкретном носителе, который присутствует в серверной машине. Сервер под размещение базы данных можно заказать у Rackstore тут.
База данных с точки зрения информатики — это хранение информации в упорядоченном виде, следуя определённой, заранее установленной разработчиком, системе.
Выделяются следующие виды баз данных по структуре:
- иерархические;
- сетевые;
- реляционные;
Рассмотрим каждый из них.
Иерархическая база данных
Под иерархической понимается такая база данных, в которой хранение данных и их структурирование осуществляется по принципу разделения элементов на родительские и дочерние. Преимуществом таких баз является лёгкость в чтении запрашиваемой информации и её быстрое предоставление пользователю.
Компьютер способен быстро ориентироваться в ней. Иерархический принцип взят за основу в структурировании файлов и папок в операционной системе Windows, а реестр хранит информацию о параметрах работы тех или иных приложений в структурированном иерархическим способом виде.
Все интернет-ресурсы также построены по иерархическому принципу, так как при его использовании ориентироваться в рамках сайта очень легко.
В качестве примера можно привести базу данных на языке XML, содержащую в себе очерки о состоянии сельского хозяйства в регионах России. В этом случае родительским элементом выступит государство, далее пойдёт разделение на субъекты, а в рамках субъектов будет своё разветвление. В данном случае от верхнего элемента к нижнему идёт строго одно обращение.
Сетевая база данных
Под сетевой базой данных понимается модифицированная иерархическая. Её особенность заключается в том, что элементы могут быть связаны с друг другом в нарушение иерархии. То есть дочерний элемент одновременно может иметь несколько предков.
В этом случае также примером выступает база данных на основе языка XML.
Реляционная база данных
Под данным типом баз данных понимается их представление в рамках двумерной таблицы. Она имеет несколько столбцов, в которых устанавливаются такие параметры, как, например, тип вводимых данных (текст, число, дата и др.).
Таблица здесь является способом хранения введённых в неё данных и способна реагировать на любые обращения со стороны СУБД. Главная проблема в работе с реляционными базами данных состоит в их правильном проектировании.
Во время проектирования базы данных следует учесть следующие два фактора:
- база данных должна быть компактной и не содержать избыточных компонентов;
- обработка базы данных должны происходить просто.
Проблема в том, что эти факторы друг другу противоречат. А ведь проектирование — важнейший момент при составлении базы данных и дальнейшей работе с ней. Заниматься им рекомендуется администратору сервера, обладающему определённым опытом.
В крупных проектах задействовано множество таблиц, которых может быть более сотни. При этом обойтись без них невозможно, если человек имеет дело с важным и сложным проектом.
Перед составлением таблицы следует составить диаграмму или схему, в которой содержится информация о видах хранимой информации, а также о типе данных, который лучше всего подойдёт для таких целей.
СУБД
Система управления базами данных — это термин, который не нужно расшифровывать. Она представляет собой встраивыемый модуль или полноценную программу, которая способна работать с данными и вносить изменения в базы.
Существует две модели СУБД — реляционная и безсхемная. О том, что такое реляционные базы данных, уже рассказано выше. Безсхемные СУБД основанные на принципах неструктурированного подхода избавляют программиста от проблем реляционной модели, в число которых входит низкая производительность и трудное масштабирование данных в горизонтальном формате.
Неструктурированные базы данных (NoSQL) создают структуру по ходу и убирают необходимость в создании жёстко определённых связей между данными. Здесь можно экспериментировать с разными способами доступа к тем или иным видам данных.
К реляционным базам данных относятся:
- SQLite;
- MySQL;
- PostgreSQL.
Из них наиболее распространённой является база данных MySQL, но остальные тоже имеют популярность и с ними можно столкнуться.
Принцип работы таких систем заключается в слежении за строгой структурой данных, которая представлена в виде комплекса таблиц. В свою очередь внутри таблицы есть ячейки и поля, которыми также управляет MySQL.
По принципу NoSQL работает база данных MongoDB. Они хранят все данные как единое целое в одной базе. При этом данные могут быть и одиночным объектом, но в то же время любой запрос не останется без ответа.
Каждая NoSQL имеет собственную систему запросов, что требует дополнительного изучения данной системы.
Сравнение SQL и NoSQL
- Если SQL-системы основаны исключительно на строгом представлении данных, то NoSQL-системы предоставляют свободу и способны работать с любым типом данных.
- SQL-системы стандартизированы, за счёт чего запросы формируются с использованием языка SQL. В то же время NoSQL-системы базируются на специфической для каждой из них технологии, что является недостатком.
- Масштабируемость. Обе СУБД способны обеспечить вертикальное масштабирование, то есть увеличить объём системных ресурсов на обработку данных. При этом NoSQL, будучи более новой разновидностью баз данных, позволяет применять простые методы горизонтального масштабирования.
- В плане надёжности SQL обладает уверенным лидерством.
- У SQL-баз есть качественная техническая поддержка за счёт их продолжительной истории, в то время как NoSQL-системы весьма молоды и и решить какую-либо проблему сложнее.
- Хранение данных и доступ к их структурам в рамках реляционных систем лучше всего происходит в SQL-системах.
Таким образом, хоть NoSQL и является стремительно развивающейся разновидностью систем управления базами данных, однако на данном этапе рекомендуется остановить свой выбор на SQL.
Надёжность SQL-систем, особенно MySQL, подтверждается временем и массовостью. Сегодня любой уважающий себя ресурс использует для хранения данных именно систему MySQL.

Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем рубрику Заметки о MySQL, в которой я уже успел рассмотреть установку и настройку MySQL сервера баз данных, а также рассмотрел способы изменения кодировок сервера MySQL при помощи команды SET NAMES и файла конфигураций my.ini. Сегодня будет краткая и если можно так сказать теоретическая статья, посвященная вопросу — что такое базы данных и какие базы данных бывают
.
В этой статье я постараюсь изложить кратко какие виды и типы баз данных бывают и остановлюсь на некоторых из них более подробно. Мы поговорим о структуре иерархических баз данных, уделим внимание структуре сетевых баз данных, и более подробно остановимся на структуре реляционных базах данных, рассмотрим особенности реляционных баз данных. И в конце статьи немного затронем тему проектирования баз данных, естественно реляционных, так сервер MySQL это по сути математическая модель реляционных баз данных. Проектирование баз данных и типы данных, с которыми может работать MySQL сервер — это темы для последующих публикаций.
База данных. Математические модели, структура, определение.
Содержание статьи:
Я хоть и не собираюсь на своем блоге подробно рассказывать про математические законы и теории описывающие реляционные базы данных, но принцип того, как они устроены я рассказать должен, если вас заинтересует данная тема, то вы всегда можете посетить специализированный математический ресурс или почитать соответствующую литературу, а можете всегда задать вопрос в комментариях к данной публикации, и я по мере своих возможностей постараюсь вам ответить. Как я уже говорил, тема данной статьи – реляционные базы данных. Я постараюсь ответить на вопрос, что такое реляционные базы данных простым и понятным языком. Затрону основные понятия, относящиеся к реляционным базам данных, терминологию, историю возникновения баз данных вообще и реляционных в частности.
Наверное, самое простое определения баз данных, база данных – это упорядоченное хранение какой-либо информации. То есть, информация хранится в упорядоченном или систематизированном виде. Видов систематизации, упорядочивания и хранения информации может быть множество. Каждый из способов хранения информации отвечает каким-либо специфическим требованиям или предназначен для выполнения каких-либо определенных действий. На страницах своего блога я уже писал, про язык XML, данные в XML структурируются в виде дерева с разветвлениями, узлами и корнем. Но это лишь один из множества способов хранения информации. Более подробно обо всем этом читайте в рубрике Заметки о XML и XLST.Виды и типы баз данных
Как я уже говорил, видов и типов баз данных очень и очень много и описать их все в данной публикации я просто не смогу, но самые распространенные виды хранения информации или виды баз данных я постараюсь описать. Понятно, что база данных хранит в себе информацию о каких-то объектах, например, информацию о товаре в интернет-магазине. Любой товар в базе данных – это объект с какими-то определенными параметрами и свойствами. Перейдем к конкретным примерам.
Иерархическая база данных, структура иерархических баз данных
Иерархическая база данных – каждый объект при таком хранение информации представляется в виде определенной сущности, то есть, у этой сущности могут быть дочерние элементы, родительские элементы, а у тех дочерних могут быть еще дочерние элементы, но есть один объект, с которого все начинается. Получается своеобразное дерево. Примером иерархической базы данных может быть, документ в формате XML или файловая система компьютера, пример с файловой системой компьютера я приводил, когда рассматривал структуру XML документа, в рубрике Заметки о XML.
Следует сказать, что базы данных подобного вида оптимизированы под чтение информации, то есть, базы данных, имеющие иерархическую структуру умеют очень быстро выбирать, запрашиваемую информацию и отдавать ее пользователям. Но такая структура не позволяет столь же быстро перебирать информацию, тут можно привести пример из жизни, компьютер может легко работать с каким-либо конкретным файлом или папкой (которые, по сути являются объектами иерархической структуры) но проверка компьютера антивирусам осуществляется очень долго. Второй пример – реестр Windows.

На рисунке вы можете увидеть структуру иерархической базы данных, в самом верху находится родитель или корневой элемент, ниже находятся дочерние элементы, элементы, находящиеся на одном уровне называются братьями, ну или соседними элементами. Соответственно чем ниже уровень элемента, тем вложенность этого элемента больше.
Сетевая база данных, структура сетевых баз данных
Сетевые базы данных, являются своеобразной модификацией иерархических баз данных. Если вы внимательно смотрели на рисунок выше, то наверное обратили внимание, что к каждому нижнему элементу идет только одна стрелочка от верхнего элемента. То есть у иерархических баз данных у каждого дочернего элемента может быть только один потомок. Сетевые базы данных отличаются от иерархических тем, что у дочернего элемента может быть несколько предков, то есть, элементов стоящих выше него. Для большей наглядности и понимания структуры сетевых баз данных обратите внимание на рисунок:
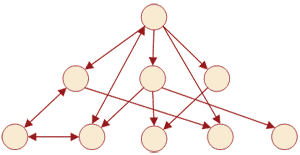
Стоит заметить, что сетевые базы данных обладают примерно теми же характеристиками, что и иерархические базы данных. Но, в данной рубрике нас не сильно интересуют иерархические и сетевые базы данных, данная тема больше относится к формату XML, и возможно в рубрике посвященной языку расширяемой разметки, я постараюсь более подробно рассмотреть эту тему. А в рубрике посвященной MySQL нас интересуют реляционные базы данных, на которых мы и остановимся более подробно.
Реляционные базы данных, структура реляционных баз данных
Реляционные базы данных получили очень широкое распространение и многие пытаются писать огромные статьи, посвященные вопросу – почему реляционные базы данных получили такое широкое распространение, делают глубокомысленные выводы и замечания. Но на самом деле все очень просто – реляционные базы данных очень легко описываются в математике, то есть, под них очень хорошо написана математика.
Был когда-то такой математик – Эдгар Франк Кодд, умерший в 2003 году, который в восьмидесятых годах очень подробно описал структуру реляционных баз данных математическим языком. А если есть хорошо написанная математика, то соответственно есть и программная реализация. Останавливаться на биографии Э.Ф. Кодда я не буду, для этого есть различные энциклопедии. Именно благодаря Кодду реляционные базы данных стали активно развиваться. Поэтому-то, когда мы говорим базы данных, чаще всего мы подразумеваем именно реляционные базы данных.
Особенности реляционных баз данных
Главной особенностью реляционных баз данных является, то, что объекты внутри таких баз данных хранятся в виде набора двумерных таблиц. То есть, таблица состоит из набора столбцов, в котором может указываться: название, тип данных(дата, число, строка, текст и т.д.). Еще одной важной особенность реляционных БД является, то, что число столбцов фиксировано, то есть, структура базы данных известна заранее, а вот число строк или рядов в реляционных базах данных ничем не ограничено, если говорить грубо, то строки в реляционных базах данных и есть объекты, которые хранятся в базе данных.
На самом деле, базы данных – это абстрактное понятие, таблица – это всего лишь способ хранения информации, набор таблиц может быть связан логически и этот набор называют база данных. Поэтому неправильно говорить, что MySQL это база данных, база данных – это хранящаяся информация. А вот такое понятие, как СУБД – система управления базами данных, это и есть MySQL сервер, именно при помощи него мы управляем хранящимися данными. Или иначе MySQL – это программное воплощение математических идей.
Самой трудной задачей при работе с реляционными базами данных, является проектирование структуры баз данных. Проектирование структуры базы данных, заключается не только в том, чтобы создать таблицу и указать тип данных и наименование столбцов. На самом деле проектирование – это самый сложный этап при работе с базами данных. Потому что мощности ваших компьютеров ограничены. Пока данных мало, мало таблиц и строк в этих таблицах, машина будет их обрабатывать очень и очень быстро. Но, со временем количество информации будет увеличиваться, и мы получим замедление, которое будет увеличиваться, поскольку машине необходимо время на обработку тех или иных запросов(обработка информации). В прошлой статье я уже писал, что реляционные БД прежде всего ориентированы на модификацию(OLTP), то есть, добавить новую запись в таблицу – это очень простая операция для реляционной СУБД, а вот сделать выборку данных, это уже трудоемкая операция. Также есть и изменение данных, это как бы промежуточное звено между чтением и добавлением. Хотя MySQL сервер всегда можно настроить.
Проектирование базы данных
Ну что же, мы немного поговорили о достоинствах и недостатках реляционных баз данных. И теперь, вкратце, я затрону вопрос проектирования баз данных. Под проектированием я понимаю следующее: садится человек за стол, берет бумагу и ручку, и исходя из поставленной задачи, а также, исходя из достоинств и недостатков той или иной системы, в нашем случае СУБД MySQL начинает составлять структуру будущей базы данных. Требование к проектируемой базе данных обычно ставятся следующее:
- База данных должна быть как можно более компактна, то есть, неизыбыточна.
- База данных должна быть простой с точки зрения обработки.
И как вы, наверное, поняли, данные требования противоречат друг другу. Проектирование — это самый важный аспект при работе с базами данных. Обычно, проектировщик – это опытный администратор сервера баз данных, либо архитектор баз данных, с большим опытом работы. В серьезных проектах может быть несколько десятков, а то и сотен таблиц, которые связаны между собой самыми замысловатыми способами связи. Конечно, я не собираюсь углубляться в проектирование баз данных, да и не смогу это сделать, но, кое какие основы проектирования баз данных я попытаюсь осветить на страницах своего блога. Прежде чем приступить к проектированию базы данных, нужно понять, а что мы вообще собираемся проектировать. То есть, должны понять, что у нас должно получиться на выходе.
А на выходе мы должны получить так называемую диаграмму или как ее еще называют схема. Диаграмма – это определение: какая информация будет храниться, в какой таблице она будет храниться, в каком столбце какой тип данных, как называется таблица, сколько столбцов в таблице и их тип, как связаны между собой таблицы. Да, типы данных в столбцах могут быть разными, например, номер телефона или индекс можно записать, как с помощью символов, так и с помощью числового типа данных. Но появляется вопрос: какой тип данных лучше для хранения номера телефона или почтового индекса? Чисто интуитивно на этот вопрос чаще всего отвечают правильно – номер телефона в базе данных должен иметь символьный тип, а вот объяснить, почему именно символьный тип могут немногие. Объяснение очень простое, например, нам потребовались все почтовые индексы, начинающиеся на 637 или номера телефонов начинающиеся на 952, так вот, сделать такую выборку из данных имеющих числовой тип задача довольно проблематичная, а сделать такую же выборку из данных символьного типа довольно легко.
При проектировании баз данных очень часто встречаются такие задачи и поверьте, от того, как вы будете их решать, будет зависеть, то, насколько быстро будет работать ваша система, в следующей статье я продолжу вопрос проектирования баз данных.
На этом всё, спасибо за внимание, надеюсь, что был хоть чем-то полезен и до скорых встреч на страницах блога для начинающих вебразработчиков и вебмастеров ZametkiNaPolyah.ru
 Без баз данных (БД) практически невозможно себе представить работу современных информационных технологий. В этой статье мы рассмотрим назначение и понятие базы данных, поговорим о том, что же такое база данных, и какая база вам лучше подойдёт. Узнаем, какие существуют типы и виды баз данных и какие из них встречаются сегодня чаще. Также поговорим о структуре иерархических баз данных, упомянем сетевые базы данных, уделим пристальное внимание реляционным базам данных.
Без баз данных (БД) практически невозможно себе представить работу современных информационных технологий. В этой статье мы рассмотрим назначение и понятие базы данных, поговорим о том, что же такое база данных, и какая база вам лучше подойдёт. Узнаем, какие существуют типы и виды баз данных и какие из них встречаются сегодня чаще. Также поговорим о структуре иерархических баз данных, упомянем сетевые базы данных, уделим пристальное внимание реляционным базам данных.
Напоследок рассмотрим особенности проектирования БД и их назначение на примере СУБД MySQL, т. к. эта система управления является, по сути, математической моделью реляционных баз данных. Итак, поехали!
База данных: назначение, понятие, классификация
В нашей статье мы не будем углубляться в математические теории и законы, описывающие базы данных, т. к. подробности всегда можно узнать из специализированной литературы. Но принципы работы БД, особенности управления, терминологию, устройство, назначение, а также такое понятие, как классификация баз данных, сегодня должен знать каждый, кто так или иначе сталкивается с ИТ-сферой, а уж тем более в ней работает.
Итак, самое простое определение баз данных звучит следующим образом: база данных — это упорядоченное хранение информации в систематизированном виде. При этом виды упорядочивания, хранения, систематизации и управления могут быть разные. И каждый из них отвечает определённым требованиям либо предназначен для выполнения определённых действий.
Типы и виды баз данных, классификация
Существует достаточно много типов и видов баз данных, поэтому описывать их все в данной публикации мы не будем. Однако самые распространённые всё же упомянем.
Важно понять, что, говоря о данных, мы подразумеваем определенную информацию, например, о товаре в интернет-магазине. И в этих данных содержатся конкретные параметры и свойства. Однако лучше всего рассматривать БД на конкретных примерах.
Иерархическая база данных, структура иерархических данных
Когда речь идёт о хранении иерархических данных, каждый объект хранит информацию в виде определенной сущности, и у каждой сущности могут быть родительские и дочерние элементы, а у дочерних, в свою очередь, тоже могут быть дочерние элементы. Таким образом, можно сказать, что это данные, которые подлежат строгой иерархии (представьте себе своеобразное дерево).
Простой пример иерархических данных — документ в формате XML либо файловая система компьютера.
Нельзя не упомянуть и то, что базы данных этого вида оптимизированы под чтение информации. При такой структуре данные можно быстро выбирать из нужной области, отдавая запрашиваемую информацию пользователям. Например, компьютер легко работает с конкретной папкой либо файлом, которые, по сути, можно назвать объектами структуры иерархических данных. Но когда нужно перебрать всю информацию, это может занять время (если вернуться к вышеописанному примеру, то проверка антивирусом всех уголков нашего компьютера выполняется не так быстро, как хотелось бы).  На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
Сетевые базы данных, структура сетевых данных
В каком-то смысле сетевые базы данных — это своеобразная модификация иерархических баз данных. Разница заключается в том, что в структуре иерархических данных у дочернего элемента бывает лишь один потомок (к каждому элементу, расположенному ниже, идёт лишь одна стрелочка с элемента, размещённого выше). А вот в сетевых базах данных у дочернего элемента бывает несколько предков (элементов, находящихся выше него). Для наглядного понимания структуры сетевых данных смотрите очередной рисунок:  Следует отметить, что сетевые базы данных имеют примерно те же характеристики, что и иерархические данные. Однако в рамках этой статьи мы не будем углубляться в особенности управления сетевыми и иерархическими данными, а лучше подробнее поговорим о реляционных базах данных.
Следует отметить, что сетевые базы данных имеют примерно те же характеристики, что и иерархические данные. Однако в рамках этой статьи мы не будем углубляться в особенности управления сетевыми и иерархическими данными, а лучше подробнее поговорим о реляционных базах данных.
Реляционные базы данных, структура реляционных данных
Реляционные базы данных сегодня распространены очень широко, поэтому в сети можно найти огромное количество материалов на соответствующую тему разного уровня сложности. Кроме того, их проходят на уроках информатики, плюс эти БД хорошо описываются в математике. Структуру данных впервые подробно описал математик Эдгар Франк Кодд (умер в 2003 году), сделав это ещё в 80-х гг. прошлого века. В результате его работ и была создана программная реализация. Реляционные БД стали активно развиваться, поэтому сегодня каждый, кто знаком с базами данных, знает реляционные БД.
Особенности реляционных данных
Главная особенность — все объекты хранятся в виде набора 2-мерных таблиц. Каждая таблица включает в себя набор столбцов, где указываются следующие параметры: — название; — тип данных (число, строка и т. д.).
Вторая важная особенность заключается в том, что число столбцов фиксировано. Это значит, что структура БД известна заранее, при этом количество рядов либо строк данных практически не ограничено. Грубо говоря, строки в реляционных БД — есть объекты, хранимые в базе.
По большему счёту, БД — это абстрактное понятие, а в случае с реляционной структурой таблица — есть не более чем удобный способ хранения информации. Причём набор таблиц превращается в базу данных тогда, когда он связан логически. А чтобы этим всем управлять, используют СУБД. Классический пример СУБД — система управления MySQL. Иными словами, СУБД MySQL — есть программное воплощение математических идей.
Проектирование баз данных
Проектирование — самая трудная задача при работе с данными. Оно заключается не только в том, чтобы создать таблицу, указав наименование столбцов и тип данных. Это гораздо более сложный процесс, требующий специализированных знаний и умений. Говоря о типах баз данных в столбцах, подразумевается, например, способ их записи, который бывает символьный (строковый), числовой, календарный, NULL.
Основная сложность заключается в том, что мощность наших компьютеров ограничена. И пока данных мало, таблиц и строк тоже немного, поэтому машина обрабатывает информацию достаточно быстро. Но с течением времени информации становится всё больше, что может стать причиной снижения быстродействия. Работа машины будет замедляться, времени на обработку запросов потребуется всё больше. Добавить новую запись в таблицу не станет проблемой для реляционной СУБД, а вот выборка данных может превратиться в весьма ресурсоёмкую операцию. Хотя, многое будет зависеть и от настроек СУБД.
Требования к проектированию БД
О видах и особенностях реляционных БД мы уже поговорили. Теперь давайте подробнее обсудим сложности их проектирования. В данном случае этот процесс начинается с постановки задач, исходя из нужных требований, особенностей использования, недостатков либо достоинств той либо иной системы управления. В случае с СУБД MySQL необходимо правильно составить общую структуру.
Требования обычно следующие: 1. База данных должна быть относительно простой в плане обработки информации. 2. Она должна быть максимально компактной и неизбыточной настолько, насколько это возможно без ущерба для функциональности.
Возможны и другие требования, причём нередко они противоречат друг другу. Именно поэтому важно найти оптимальный баланс с точки зрения архитектуры, учитывая назначение конечного продукта.
Так как проектирование — важнейший процесс, им занимается проектировщик. Обычно к работе привлекают профессиональных администраторов серверов либо архитекторов БД, имеющих большой практический опыт. Нужно четко понимать, что проектируется и какие результаты должны получиться на выходе. Это бывает непросто, так как, если речь идёт о серьёзных проектах, готовая структура может включать в себя десятки и сотни таблиц, которые бывают связаны друг с другом как простыми, так и замысловатыми способами.
Результат проектирования — диаграмма или схема. Это подробное схематическое описание, в котором указываются, какие данные будут храниться, сколько столбцов в таблице, тип столбцов в таблице, как связаны таблицы между собой и многое другое. При правильном и грамотном проектировании система будет работать стабильно и без сбоев. В обратном случае ожидайте проблем, так как нет ничего хуже, чем ошибиться на этапе построения архитектуры проекта.
Если вы хотите овладеть базами данных на высоком профессиональном уровне, записывайтесь на соответствующий курс в OTUS. Практикующие эксперты научат вас особенностям управления БД и тому, как эффективно взаимодействовать с любой реляционной СУБД, используя для этого язык структурированных запросов SQL.
ТОП-10 систем управления базами данных в 2019 году
Умение выбрать СУБД важно при разработке любого ПО. Мы собрали 10 систем управления базами данных и разобрались в их преимуществах.
Популярные системы управления базами данных
| Разработчик | Лицензия | Написана на | |
| Oracle | Oracle Corporation | Проприетарная | Assembly, C, C++ |
| MySQL | Oracle Corporation | GPL v2 или проприетарная | C, C++ |
| Microsoft SQL Server | Microsoft Corporation | Проприетарная | C, C++ |
| PostgreSQL | PostgreSQL Global Development Group | Лицензия PostgreSQL (бесплатное ПО с открытым исходным кодом, либеральная лицензия) | C |
| MongoDB | MongoDB Inc. | Различные варианты лицензирования | C++, C, JavaScript |
| DB2 | IBM | Проприетарная EULA | Assembly, C, C++ |
| Microsoft Access | Microsoft Corporation | Пробное ПО | |
| Redis | Salvatore Sanfilippo | Лицензия BSD | ANSI C |
SQL-базы данных
1. Oracle
Oracle RDBMS (она же Oracle Database) на первом месте среди СУБД. Система популярна у разработчиков, проста в использовании, у нее понятная документация, поддержка длинных наименований, JSON, улучшенный тег списка и Oracle Cloud.
- Разработчик: Oracle Corporation
- Написана на:Assembly, C, C++
- Блог: Oracle NoSQL
- Скачать: Oracle NoSQL
- Последняя версия: 18.3
Особенности
- Обрабатывает большие данные.
- Поддерживает SQL, к нему можно получить доступ из реляционных БД Oracle.
- Oracle NoSQL Database с Java/C API для чтения и записи данных.
2. MySQL
MySQL работает на Linux, Windows, OSX, FreeBSD и Solaris. Можно начать работать с бесплатным сервером, а затем перейти на коммерческую версию. Лицензия GPL с открытым исходным кодом позволяет модифицировать ПО MySQL.
Эта система управления базами данных использует стандартную форму SQL. Утилиты для проектирования таблиц имеют интуитивно понятный интерфейс. MySQL поддерживает до 50 миллионов строк в таблице. Предельный размер файла для таблицы по умолчанию 4 ГБ, но его можно увеличить. Поддерживает секционирование и репликацию, а также Xpath и хранимые процедуры, триггеры и представления.
- Разработчик: Oracle Corporation
- Написана на C, C++
- Последняя версия: 8.0.16
- Скачать: MySql
Особенности
- Масштабируемость.
- Лёгкость использования.
- Безопасность.
- Поддержка Novell Cluster.
- Скорость.
- Поддержка многих операционных систем.
3. Microsoft SQL Server
Самая популярная коммерческая СУБД. Она привязана к Windows, но это плюс, если вы пользуетесь продуктами Microsoft. Зависит от платформы. И графический интерфейс, и программное обеспечение основаны на командах. Поддерживает SQL, непроцедурные, нечувствительные к регистру и общие языки баз данных.
Особенности
- Высокая производительность.
- Зависимость от платформы.
- Возможность установить разные версии на одном компьютере.
- Генерация скриптов для перемещения данных.
4. PosgreSQL
Масштабируемая объектно-реляционная база данных, работающая на Linux, Windows, OSX и некоторых других системах. В PostgreSQL 10 есть такие функции, как логическая репликация, декларативное разбиение таблиц, улучшенные параллельные запросы, более безопасная аутентификация по паролю на основе SCRAM-SHA-256.
- Разработчик: PostgreSQL Global Development Group
- Написана на C
- Используется в компаниях: Apple, Cisco, Fujitsu, Skype, and IMDb
- Последняя версия: 11.2
- Блог: PostgreSQL
- Скачать: PostgreSQL
Особенности
- Поддержка табличных пространств, а также хранимых процедур, объединений, представлений и триггеров.
- Восстановление на момент времени (PITR).
- Асинхронная репликация.
NoSQL-базы данных
5. MongoDB
Самая популярная NoSQL система управления базами данных. Лучше всего подходит для динамических запросов и определения индексов. Гибкая структура, которую можно модифицировать и расширять. Поддерживает Linux, OSX и Windows, но размер БД ограничен 2,5 ГБ в 32-битных системах. Использует платформы хранения MMAPv1 и WiredTiger.
- Разработчик: MongoDB Inc. в 2007
- Написана на C++
- Последняя версия: 4.1.9
- Блог: MongoDB
- Скачать: MongoDB
Особенности
- Высокая производительность.
- Автоматическая фрагментация.
- Работа на нескольких серверах.
- Поддержка репликации Master-Slave.
- Данные хранятся в форме документов JSON.
- Возможность индексировать все поля в документе.
- Поддержка поиска по регулярным выражениям.
6. DB2
Работает на Linux, UNIX, Windows и мейнфреймах. Эта СУБД идеально подходит для хост-сред IBM. Версию DB2 Express-C нельзя использовать в средах высокой доступности (при репликации, кластеризации типа active-passive и при работе с синхронизируемым доступом к разделяемым данным).
- Разработчик: IBM
- Написана на C, C++, Assembly
- Последняя версия: 11.1
- Скачать: DB2
Особенности DB2 11.1
- Улучшенное встроенное шифрование.
- Упрощённая установка и развёртывание.
7. Microsoft Access
Система управления базами данных от Microsoft, которая сочетает в себе реляционное ядро БД Microsoft Jet с графическим интерфейсом пользователя и инструментами разработки ПО.
Идеально подходит для начала работы с данными, но производительность не рассчитана на большие проекты. В MS Access можно использовать C, C#, C++, Java, VBA и Visual Rudimental.NET. Access хранит все таблицы БД, запросы, формы, отчёты, макросы и модули в базе данных Access Jet в виде одного файла.
- Разработчик: Microsoft Corporation
- Последняя версия: 16.0
- Скачать: Microsoft Access
Особенности
- Можно использовать VBA для создания многофункциональных решений с расширенными возможностями управления данными и пользовательским контролем.
- Импорт и экспорт в форматы Excel, Outlook, ASCII, dBase, Paradox, FoxPro, SQL Server и Oracle.
- Формат базы данных Jet.
8. Cassandra
СУБД активно используется в банковском деле, финансах, а также в Facebook и Twitter. Поддерживает Windows, Linux и OSX. Для запросов к БД Cassandra используется SQL-подобный язык — Cassandra Query Language (CQL).
- Разработчик: Apache Software Foundation
- Написана на: Java
- Последняя версия: 3.11.4
- Блог: Cassandra
- Скачать: Cassandra
Особенности
- Линейная масштабируемость.
- Быстрое время отклика.
- Поддержка MapReduce и Apache Hadoop.
- Максимальная гибкость.
- P2P архитектура.
9. Redis
Redis или Remote Dictionary Server — СУБД с открытым исходным кодом, которая снабжена механизмами журналирования и снимков. Поддерживаются списки, строки, хэши, наборы. Используется для БД, брокеров сообщений и кэшей. Все операции в Redis атомарные. Система написана на языке C и поддерживается практически всеми языками программирования.
- Разработчик: Salvatore Sanfilippo
- Последняя версия: 5.0.5
- Блог: Redis
- Скачать: Redis
Особенности
- Автоматическая обработка отказа.
- Транзакции.
- Сценарии LUA.
- Вытеснение LRU-ключей.
- Поддержка Publish/Subscribe.
10. Elasticsearch
Легко масштабируемая поисковая система корпоративного уровня с открытым исходным кодом. Благодаря обширному и продуманному API обеспечивает чрезвычайно быстрый поиск, работает в том числе с приложениями для обнаружения данных. Используется такими компаниями, как Википедия, The Guardian, StackOverflow, GitHub. ElasticSearch позволяет создавать копии индексов и сегментов.
- Разработчик: Elastic NV
- Написана на Java
- Последняя версия: 7.2.0
- Блог: Elasticsearch
- Скачать: Elasticsearch
Особенности
- Масштабируемость вплоть до нескольких петабайт структурированных и неструктурированных данных.
- Многопользовательская поддержка.
- Масштабируемый поиск, поиск в режиме реального времени.
Рейтинги СУБД
| Рейтинг | СУБД | Модель базы данных | Балл | ||||
| Июль 2017 | Июнь 2017 | Июль 2016 | Июль 2017 | Июнь 2017 | Июль 2016 | ||
| 1 | 1 | 1 | Oracle | Реляционная СУБД | 1374.88 | +23.11 | -66.65 |
| 2 | 2 | 2 | MySQL | Реляционная СУБД | 1349.11 | +3.8 | -14.18 |
| 3 | 3 | 3 | Microsoft SQL Server | Реляционная СУБД | 1226 | +27.03 | +33.11 |
| 4 | 4 | 5↑ | PostgreSQL | Реляционная СУБД | 369.44 | +0.89 | +58.28 |
| 5 | 5 | 4↓ | MongoDB | Документная СУБД | 332.77 | -2.23 | +17.77 |
| 6 | 6 | 6 | DB2 | Реляционная СУБД | 191.25 | +3.74 | +6.17 |
| 7 | 7 | 8↑ | Microsoft Access | Реляционная СУБД | 126.13 | -0.42 | +1.23 |
| 8 | 8 | 7↓ | Cassandra | СУБД типа BigTable | 124.12 | -0.0 | -6.58 |
| 9 | 9 | 10↑ | Redis | СУБД типа «ключ-значение» | 121.51 | +2.63 | +13.48 |
| 10 | 11↑ | 11↑ | Elasticsearch | Поисковая система | 115.98 | +4.42 | +27.36 |
А какую СУБД предпочитаете вы? Аргументируйте свой выбор 😉
Казалось бы, база данных она и в Африке database, но читая аутентичную техническую литературу по СУБД (которую русские переводчики традиционно переводят как DBMS — database management system), я ни разу этот термин — DBMS — там не увидел (не исключаю, что плохо смотрел, но ей-богу не вру).
Получается, этот термин выдуман? И много ли такого самопала?
В этой публикации я собрал из разной ИТ-литературы англоязычных авторов так называемое «семантическое поле» вокруг термина database — какие базы данных бывают, что с ними делают и с чем их едят. Мне показалось, что это будет явно нагляднее и достовернее, чем обычные глоссарии. Решать, конечно же, вам.
Итак, поехали.
Какие бывают?
Объектные базы данных появились в конце 1980-х — начале 1990-х годов и снова вышли из моды.
Object databases came and went again in the late 1980s and early 1990s.В начале 2000-х появились базы данных XML, но нашли только узкое применение.
XML databases appeared in the early 2000s, but have only seen niche adoption.Существует несколько основных причин широкого внедрения баз данных NoSQL…
There are several driving forces behind the adoption of NoSQL databases……JSON. Преимущество данного формата в том, что он намного проще, чем XML. Эту модель данных поддерживают такие документоориентированные БД, как MongoDB, RethinkDB, CouchDB и Espresso.
JSON has the appeal of being much simpler than XML. Document-oriented databases like MongoDB, RethinkDB, CouchDB, and Espresso support this data model.В документоориентированных БД для древовидных структур соединения не нужны, так что их поддержка часто очень слаба.
In document databases, joins are not needed for one-to-many tree structures, and support for joins is often weak.Оптимизаторы запросов для реляционных баз данных — непростые вещи, они потребовали многих лет исследований и разработки
Query optimizers for relational databases are complicated beasts, and they have consumed many years of research and development effortПример 2.3 демонстрирует запрос на языке Cypher, предназначенный для вставки левой части рис. 2.5 в графовую базу данных.
Example 2-3 shows the Cypher query to insert the lefthand portion of Figure 2-5 into a graph databaseВ большинстве баз данных OLTP хранилище располагается построчно: все значения из одной строки таблицы хранятся рядом друг с другом.
In most OLTP databases, storage is laid out in a row-oriented fashion: all the values from one row of a table are stored next to each other.Многие наборы данных попросту не настолько велики, так что вполне допустимо держать их полностью в оперативной памяти, возможно распределенной по нескольким машинам. Этот факт привел к разработке размещаемых в оперативной памяти БД.
Many datasets are simply not that big, so it’s quite feasible to keep them entirely in memory, potentially distributed across several machines. This has led to the development of in-memory databases.По аналогии с управлением параллельным доступом к многопользовательской базе данных, блокировка требует, чтобы перед вызовом или обновлением значения глобальной переменной ее помечали для изменений.
Similar to concurrency control in a multiuser database environment, locking requires that before the value of a global variable can be used or updated, the variable must be «checked out.»Исследователям, работающим с геномными данными, часто приходится выполнять поиск сходства последовательностей, означающий сравнение очень длинной строки (соответствующей молекуле ДНК) со схожими, но не идентичными строками из большой базы данных. Ни одна из описанных выше БД не способна справиться с этим, вследствие чего исследователями было написано такое специализированное ПО для геномной базы данных, как GenBank.
Researchers working with genome data often need to perform sequence-similarity searches, which means taking one very long string (representing a DNA molecule) and matching it against a large database of strings that are similar, but not identical. None of the databases described here can handle this kind of usage, which is why researchers have written specialized genome database software like GenBank.Многие одноранговые сети, такие как BitTorrent, не имеют никакой центральной базы данных контента.
Many peer-to-peer systems, such BitTorrent, do not have any central database of content.Этот процесс поиска может повторяться сколь угодно долго, чтобы в результате создать большую местную базу данных того, что имеется в наличии.
This lookup process can be repeated indefinitely to build up a large local database of what is out there.Все вышеупомянутые приложения вовлекают взаимодействия между человеком и удаленной базой данных, полной информации.
All of the above applications involve interactions between a person and a remote database full of information.
Что они делают? Что с ними делают?
Почему вас как разработчика приложений должны волновать внутренние нюансы того, как БД хранит данные и как она их находит?
Why should you, as an application developer, care how the database handles storage and retrieval internally?Полнотекстовый поиск — вид модели данных, часто используемый в БД.
Full-text search is arguably a kind of data model that is frequently used alongside databases.Многие БД используют очень похожий на db_set механизм, журнал, представляющий собой файл, предназначенный только для добавления данных в его конец.
Similarly to what db_set does, many databases internally use a log, which is an append-only data file.Сценарий восстановления в SQL Server — процесс восстановления данных из одной или более резервных копий и возврат в исходное состояние базы данных.
A restore scenario in SQL Server is the process of restoring data from one or more backups and then recovering the database.В SQL Server инструкция CREATE создает базу данных, используемые для нее файлы и их файловые группы.
In SQL Server, CREATE statement creates a new database and the files used and their filegroups.В SQL Server инструкция ALTER изменяет базу данных или файлы и файловые группы, связанные с базой данных.
In SQL Server, ALTER statement modifies a database, or the files and filegroups associated with the database.Удаленная база данных может быть повторно создана только с помощью восстановления из резервной копии.
A dropped database can be re-created only by restoring a backup.При удалении база данных удаляется из экземпляра SQL Server. Также с физического диска удаляются файлы, используемые базой данных.
Dropping a database deletes the database from an instance of SQL Server and deletes the physical disk files used by the database.
(Прим. пер.: Хоть на русском эти «изменение» и «удаление» звучат одинаково, на английском это разные инструкции:
— ALTER и DROP для объектов;
— UPDATE и DELETE для записей).
В случае ошибки можно будет восстановить базу данных путем возврата ее в предыдущее состояние с помощью моментального снимка.
If you make a mistake, you can use the snapshot to recover by reverting the database to the snapshot.
(Прим. пер: вообще, сам факт — «восстанавливаем базу из копии» — это restore. Чтобы помимо этого привести БД в рабочее состояние (накатить или откатить изменения) и позволить пользователям что-то с ней делать — это recover).
Потенциально процедура возврата занимает гораздо меньше времени, чем восстановление [базы данных] из резервной копии, но при этом она не поддерживает накат.
Reverting is potentially much faster for this purpose than restoring from a backup; however, you cannot roll forward afterward.
(Прим. пер: речь идет о накате транзакций, где могли быть указаны операции, которые еще происходили с БД после снимка. В устной речи «накатить изменения» встречалось неоднократно).
Использование одного класса для чтения и записи БД является формой централизованного управления.
Using one class to read from and write to a database is a form of centralized control.PHP-код может быть встроен в Web-страницы для получения доступа к БД и отображения содержащейся в ней информации.
It [PHP] can be embedded in Web pages to access and present database information.SQL «де-факто» является стандартным языком выполнения запросов, обновлений реляционнных БД и управления ими.
SQL is the de facto standard language for querying, updating, and managing relational databases.Как они будут себя чувствовать, если база данных неожиданно окажется испорченной?
How would they feel if that database was suddenly corrupted?… предикат within_recursive возвращает все содержащиеся в нашей базе данных географические пункты в Северной Америке (или в любом другом месте).
… the within_recursive predicate can tell us all the locations in North America (or any other location name) contained in our database.Вместо этого каждый пользователь поддерживает свою собственную базу данных в местном масштабе и обеспечивает список других людей по соседству, которые являются членами системы.
Instead, each user maintains his own database locally and provides a list of other nearby people who are members of the system.
Связанные словосочетания
Для эффективного поиска значения конкретного ключа в БД необходима другая структура данных: индекс.
In order to efficiently find the value for a particular key in the database, we need a different data structure: an index.Поддерживаемые сценарии восстановления зависят от модели восстановления базы данных и выпуска SQL Server.
The supported restore scenarios depend on the recovery model of the database and the edition of SQL Server.Модель восстановления — это свойство базы данных, которое управляет процессом регистрации транзакций, определяет, требуется ли для журнала транзакций резервное копирование, а также определяет, какие типы операций восстановления доступны.
A recovery model is a database property that controls how transactions are logged, whether the transaction log requires (and allows) backing up, and what kinds of restore operations are available.Для большинства сценариев восстановления необходимо применить резервную копию журналов транзакций и позволить компоненту SQL Server Database Engine запустить процесс восстановления для подключения базы данных к сети.
For most restore scenarios, it is necessary to apply a transaction log backup and allow the SQL Server Database Engine to run the recovery process for the database to be brought online.Восстановление — это процесс, используемый SQL Server для запуска каждой базы данных в транзакционно-согласованном (чистом) состоянии.
Recovery is the process used by SQL Server for each database to start in a transactionally consistent — or clean — state.Еще одна прекрасная причина создания класса — сокрытие деталей реализации, и таких сложных, как мудреный способ доступа к БД, и столь банальных, как отдельный элемент данных, хранимый в форме числа или строки.
The desire to hide implementation details is a wonderful reason to create a class whether the details are as complicated as a convoluted database access or as mundane as whether a specific data member is stored as a number or a string.Виды рефакторинга, предполагающие изменение интерфейса класса или метода, схемы БД или булевых тестов, обычно более рискованны.
Refactorings that involve class or routine interface changes, database schema changes, or changes to boolean tests, among others, tend to be more risky.Так [словарями данных] называются базы данных, которые описывают важную для проекта информацию. Во многих случаях словарь связан преимущественно со схемами баз данных.
A data dictionary is a database that describes all the significant data in a project. In many cases, the data dictionary focuses primarily on database schemas.Вы можете неграмотно спроектировать таблицы БД…
Errors can include <…> improperly designing database tables…Инструменты генерации кода обычно ориентированы на приложения для баз данных, но к этому классу относятся и другие программы.
Code-generating tools tend to focus on database applications, but that includes a lot of applications.Архитектура должна включать план управления ограниченными ресурсами, такими как соединения с БД, потоки и дескрипторы.
The architecture should describe a plan for managing scarce resources such as database connections, threads, and handles.Архитектура должна описывать, как система будет реагировать на рост числа пользователей, серверов, сетевых узлов, записей в БД, транзакций и т. д.
The architecture should describe how the system will address growth in number of users, number of servers, number of network nodes, number of database records, size of database records, transaction volume, and so on.Приведено ли описание организации и содержания БД?
Is the database organization and content specified?Поэтому я принял конвенцию, в соответствии с которой файлам .frm (файлам формы) дозволялось только извлекать данные из БД и сохранять их обратно, но не передавать эти данные другим частям программы.
Consequently, I adopted a design convention that the .frm file (the form file) was allowed only to retrieve data from the database and store data back into the database. It wasn’t allowed to communicate that data directly to other parts of the program.Они [подсистемы] позволяют легко изменять структуру БД без изменения большей части программы.
They [subsystems] make it easy to change the database design structure without changing most of the program.Вопрос «Будет ли эта организация базы данных работать?» недостаточно хорошо определяет направление прототипирования.
A design question like «Will this database framework work?» does not provide enough direction for prototyping.Вы можете даже не знать специфику базы данных.
You don’t even need to know the database specifics.Мы также коснулись вопроса CSS и XSL/ XPath, не являющихся языками запросов БД, но имеющих с ними интересные параллели.
We also touched on CSS and XSL/XPath, which aren’t database query languages but have interesting parallels.… центральное место в моделях обработки данных стали отводить не компьютерам, а базам данных.
… data processing was changing from a computer-centered view of information systems to a database-centered view.Суть изменения заключалась в отведении центрального места пулу данных, над которыми компьютер выполняет некоторые действия (подход, ориентированный на БД).
The change was to focus on a pool of data on which the computer happened to act (a database-oriented view).Возможно, вы используете также встроенные библиотеки классов-контейнеров, научные функции, классы пользовательского интерфейса и классы для работы с БД.
You might also use prebuilt libraries of container classes, scientific functions, user interface classes, and database-manipulation classes.Чтобы добыть у бухгалтерии необходимые данные, нам, возможно, нужно на скорую руку собрать индивидуальные отчеты, а это значит, нужно будет подключить к делу разработчиков или программистов, работающих с базами данных.
To get Finance the data they need, we may have to cobble together some custom reports, which means bringing in the application developers or database people.Обновить тридцать пять инстанций баз данных Oracle…
Upgrade thirty-five instances of Oracle databases…Вэс говорит: «Это не изменение! Это просто запуск скрипта баз данных».
But Wes says, “That’s not a change! That’s just running a database script.Прежде чем запрос на такое изменение поступил бы к нам, нужно было, чтобы он получил согласие ото всех владельцев приложений и баз данных, а также от бизнес-отдела.
Before that change request would even come to us, I would expect him to get the nod from the application and database owners, and also the business.Декларативные языки … скрывают подробности реализации ядра базы данных, благодаря чему у СУБД появляется возможность повышать производительность без необходимости вносить изменения в запросы.
A declarative query language … hides implementation details of the database engine, which makes it possible for the database system to introduce performance improvements without requiring any changes to queries.
Вот и все (хотя, конечно, список можно продолжать и продолжать). Надеюсь, было познавательно.
Отбирали примеры: Квасникова Ирина, Смирнова Юлия, Панибратова Надежда, Евгений Бартов
Раскладывал по полкам: Евгений Бартов
Используемая литература:
- Code Complete by Steve McConnell
- Computer networks by Andrew Tannenbaum
- Designing Data-Intensive Applications by Martin Kleppmann
- The Phoenix Project by Gene Kim
- Microsoft SQL documentation и др.
P.S. Уже после публикации мы с коллегами выяснили, что DBMS не попадался мне на глаза потому, что термин слегка устарел, и в новой литературе по базам данных почти не используется. В старой литературе — сплошь и рядом. Пардон.
СУБД используют различные модели данных. Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
В иерархической модели элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
Иерархическая модель организует данные в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Рассмотрим в качестве примера иерархической модели данных организацию, хранящую информацию о своём работнике: имя, номер сотрудника, отдел и зарплату. Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. В иерархической базе данных отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Схема иерархической базы данных состоит из нескольких иерархических схем.
В сетевой модели данных у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД. Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Первая модель данных, иерархическая, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Данная публикация представляет собой перевод статьи «Types of Database Models | Database Management System» , подготовленной дружной командой проекта Интернет-технологии.ру
Содержание статьи:
Вступление
Напомню, что база данных это большой объем данных, которая в ней хранится, может обрабатываться, дополняться, удаляться, причем в удобной для пользователя форме. Также нужно четко понимать, что в БД хранится не всякая информация, а информация, которую можно организовать по тем или иным свойствам. Например, большое количество различных фотографий или документов это не данные, а информация. Но мы можем организовать фотографии, например по сути: фото людей, фото животных, фото городов и т.д. или организовать их по размеру: большие, средние, маленькие. Организованная, таким образом информация превращается в данные и пригодна для автоматической обработки с использованием баз данных. Переходим к классификации баз данных.
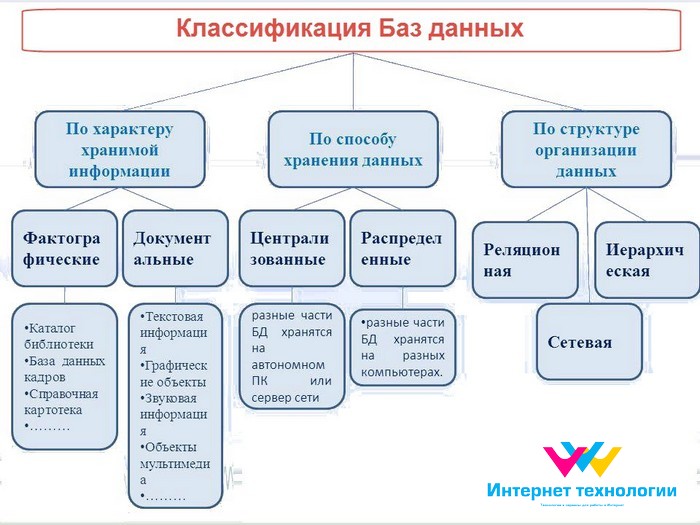
Классификация баз данных пи типу хранимых данных
Базы данных, объединяющие документы, сгруппированные (организованные) по разным свойствам, классифицируются, как документальные БД.
Под документом понимается текстовой документ или ссылка на него. Документальные БД разделили по типу документов на полнотекстовые, реферативные (рефераты) и библиографические. Это деление не так важно, как важен способ хранения информации. Здесь следующее разделение: базы данных хранящие исходный документ или хранящие ссылки, по которым можно обратиться к исходному документу.
Фактографические БД объединяют данные по факту совершения события (дата выпуска товара, год рождения сотрудника).
Лексикографические БД объединяют словари, классификаторы, и т.л. документы.
Характерным примером, документальных баз данных могут послужить базы объединяющие документы по нормативным «формам». Вы встречались с такими документами, например в паспортом столе или отделе кадров, заполняя «бумажку» по форме № такой то.
Классификация баз данных по обращению к ним
Базы данных индивидуального пользования классифицируют, как персональные или локальные базы данных.
Интегрированные иначе централизованные базы данный предоставляют коллективный доступ к данным. Такой доступ может быть как многопользовательский (сразу все), так и параллельный (независимый).
Распределительные базы данных аналогичны интегрированным, но могут быть физически разнесены на разные машины, и при этом логически считаться единым целым.
Перечисленные выше классификации не особо интересны пользователям. Для пользователя интересна классификация по способу организации данных и по типу используемой модели.
Классификация БД по способу организации данных
Не буду останавливаться на неструктурированных и частично структурированных базах данных. Они имеют узкое применение. Более важно понятие структурированной базы данных, в которых данные хранятся по предварительно спроектированной модели.
Модели БД
Моделями структурированной БД могут быть:
- БД иерархической модели;
- Сетевой модели;
- И самой используемой моделью БД – реляционной базой данных.
Реляционная база данных
Реляционная база данных самая используемая и самая математическая модель БД. Эта модель используется везде, где есть формализованная информация. Основа этой модели таблица, а взаимоотношения данных происходят по «доменам», «атрибутам», «кортежам» или более понятно и знакомо, по «типам данных», «столбцам» и «строкам».
В завершении замечу, что классификации БД перечисленных в статье, с уверенностью применяются для классификации СУБД.
©WebOnTo.ru
Другие статьи раздела: База данных

Опубликовано: 23.09
Содержание статьи: Вход в phpMyAdminФорма авторизации в phpmyAdminВспомним что такое база данныхСамые используемые базы данных:СУБД MySQLПравила устройства БДЯзык базы данныхДругие статьи для прочтенияЗачем нужен выделенный сервер (dedicated server) для вашего бизнесаСетевые новости UsenetЧто такое брендинговое агентство и зачем оно вам нужно?Протокол HTTP — что такое HyperText Transfer ProtocolFTP сервис Интернет — что такое File Transfer ProtocolКак создать […]
Поделиться ссылкой:

Опубликовано: 21.10
В этой статье вы познакомитесь с основными функциями СУБД системами управления базами данных.
Поделиться ссылкой:

Опубликовано: 16.10
Содержание статьи: Что такое база данных в информатикеЧто такое СУБД и SQLСУБД MySQLСтатьи по теме «База данных» Информация основа современного общества. Объем ее огромен и растет с каждым годом. Огромный объем информации уже давно поставил задачу ее хранения и обработки. Решает эту задачу понятие база данных. Похожие постыПеренос данных на Galaxy программой Smart Switch
Поделиться ссылкой:
Поделиться ссылкой:
Похожие статьи
Что такое база данных? Что такое SQL?
- Home
Тестирование
- 9000 9000
- J0005 000
- Ручное тестирование
- Мобильное тестирование S000S0005 Управление тестированием
- S0005
SAP
- Назад
- ABAP
- APO 9000 5
- Новичок
- Базис
- БПК
- 9000 9000
- Назад
- PI / PO
- PP
- SD
- Solution Manager
- SAPUI5
- Безопасность
- Successfactors
- SAP Обучение
веб
- Назад
- Apache
- Android
- AngularJS
- ASP.Чистая
- C
- C #
- C ++
- CodeIgniter
- СУБД
- Назад
- Java
- JavaScript
- JSP
- Kotlin
M000
- Back
- Perl
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL5000
- SQL000
- UML
- VB.Net
- VBScript
- Веб-сервисы
- WPF
Необходимо учиться!
- Назад
- Учет
- Алгоритмы
- Blockchain
- Бизнес-аналитик
- Сложение Сайт
- CCNA
- Cloud Computing
- COBOL
- Compiler Design
- Embedded Systems
- Назад
- Ethical Hacking
- Excel Учебники
- Go Программирование
- IoT
- ITIL
- Дженкинс
- MIS
- Networking
- Операционная система
- Prep
- Назад
- PMP
- Photoshop Управление
- Проект
- Отзывы
- Salesforce
- SEO
- Разработка программного обеспечения
- VBA
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Складирование данных 000000000 HBB
- Назад
Базы данных входят в число наиболее важных структурных элементов Всемирной паутины сегодня. Лежащие в основе большинства управляемых контентом веб-сайтов и приложений, базы данных выполняют особую задачу — обеспечить хорошо организованный механизм манипулирования данными. Подход с использованием базы данных в разработке веб-сайтов / приложений теперь управляет сетью, предлагая быстрый и автоматизированный способ хранения, управления, удаления или извлечения информации.Мощный набор возможностей баз данных определил появление динамических веб-сайтов, которые открыли новую страницу в истории эволюции Интернета.
Что такое база данных?
Что на самом деле представляют базы данных? Как мы все знаем, гениальные вещи просты. То же самое относится и к базам данных. База данных — это таблица, состоящая из столбцов (полей) и строк (записей), где каждый столбец содержит определенный атрибут, а каждая строка содержит определенное значение для соответствующего атрибута.Количество столбцов в одной таблице зависит от того, сколько различных типов / категорий информации нам нужно хранить в базе данных, а количество строк определяется количеством объектов, для которых должны быть введены классифицированные записи. Этот вид простой организации данных в таблицах базы данных позволяет компьютерной программе быстро выбирать и обрабатывать необходимые фрагменты информации.
Системы управления базами данных (СУБД)
Связь между базами данных и компьютерными программами, работающими с ними, осуществляется через систему управления базами данных (она же СУБД).Последний представляет собой набор программ, которые принимают запросы данных от прикладной программы и инструктируют операционную систему, как обрабатывать запрошенную информацию. Это выполняется с помощью различных управляющих операций, которые поддерживает СУБД, таких как организация, хранение, удаление или извлечение данных в базе данных. Все эти действия выполняются через определенные команды SQL. Пользователи также могут легко добавлять новые категории / атрибуты данных в базу данных, не вызывая перебоев в работе системы.Системы управления базами данных работают со всеми доступными базовыми моделями баз данных, такими как модель сети и реляционная модель.
В связи с фундаментальной ролью баз данных в работе динамических веб-сайтов, подход к базе данных используется практически на каждом новом веб-сайте, появляющемся сегодня в World Wide Web. Например, на коммерческих веб-сайтах базы данных используются для хранения и управления различными данными, такими как информация для входа посетителей, информация о покупке, журналы заказов, отчеты компаний, схемы ценообразования и т. Д.Они обычно управляются с помощью корпоративных СУБД, которые предназначены для обработки больших объемов данных. Использование базы данных на личных веб-сайтах имеет решающее значение в различных случаях, когда необходимо регулярно обновлять контент, например, при ведении блога или при настройке фотоальбомов, веб-сайтов сообщества и т. Д. Здесь управление осуществляется с помощью личных СУБД
.Базы данных плоского типа
В базах данных плоского типа каждая строка может содержать только одну запись. Они чаще всего используются в текстовом формате.Из-за их простоты к ним очень быстро обращаются или запрашивают, что делает их очень полезными для простых задач.
Иерархические базы данных
Иерархическая модель базы данных представляет собой древовидную структуру, и очень хорошая ассоциация — проводник Windows. Чтобы объяснить это лучше, мы можем использовать структуру parent-child. У каждого родителя может быть столько детей, сколько он хочет, но у каждого ребенка только один родитель. Наиболее популярной иерархической базой данных является IMS (система управления информацией), созданная IBM.
Реляционные базы данных
Самый популярный тип базы данных, широко используемый в World Wide Web. В них информация легко хранится и запрашивается. В реляционной базе данных данные хранятся в таблицах. Новая информация может быть добавлена без необходимости реорганизации таблицы.
В реляционной базе данных может быть бесконечное количество таблиц, каждая таблица содержит различную, хотя и связанную, информацию. Если мы создадим базу данных, называемую «пользовательские данные», там у нас может быть несколько таблиц для хранения различных наборов информации — таблица личных персональных данных пользователя, таблица для его / ее регистрационной информации, таблица, содержащая заказанные услуги, таблица для использования его / ее учетной записи и т. д.Эти таблицы не обязательно должны быть в определенной структуре, как в случае иерархической базы данных, поскольку они одинаково важны.
Наиболее известным стандартом реляционных баз данных является язык SQL, на котором основано несколько программ для работы с базами данных, в том числе MySQL и PostgreSQL.
,Что мне нужно знать о базах данных?
Переполнение стека- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
- реклама Связаться с разработчиками по всему миру
Загрузка…
- Авторизоваться зарегистрироваться
типов баз данных
типов баз данных
База данных — это набор данных или записей. Системы управления базами данных предназначены для управления базами данных. Система управления базами данных (СУБД) — это программная система, которая использует стандартный метод для хранения и организации данных. Данные могут быть добавлены, обновлены, удалены или просмотрены с использованием различных стандартных алгоритмов и запросов.
Типы систем управления базами данных
Существует несколько типов систем управления базами данных.Вот список из семи распространенных систем управления базами данных:
- Иерархические базы данных
- Сетевые базы данных
- Реляционные базы данных
- Объектно-ориентированные базы данных
- Графовые базы данных
- Базы данных модели ER
- Базы данных документов
- Базы данных NoSQL
Иерархические базы данных
В модели иерархической системы управления базами данных (иерархические СУБД) данные хранятся в узле родительско-дочерних отношений.В иерархической базе данных, помимо фактических данных, записи также содержат информацию об их группах родительских / дочерних отношений.
В иерархической модели базы данных данные организованы в древовидную структуру. Данные хранятся в виде набора полей, где каждое поле содержит только одно значение. Записи связаны друг с другом через ссылки в родительско-дочерних отношениях. В иерархической модели базы данных каждая дочерняя запись имеет только одного родителя. Родитель может иметь несколько детей.
Чтобы получить данные поля, нам нужно пройти через каждое дерево, пока не будет найдена запись.
Иерархическая структура системы баз данных была разработана IBM в начале 1960-х годов. Хотя иерархическая структура проста, она негибкая из-за отношения «один-ко-многим» родитель-ребенок. Иерархические базы данных широко используются для создания приложений высокой производительности и доступности, обычно в банковской и телекоммуникационной отраслях.
IBM Information Management System (IMS) и реестр Windows — два популярных примера иерархических баз данных.
Advantage
Иерархическая база данных может быть быстро доступна и обновлена. Как показано на рисунке выше, его модельная структура похожа на дерево, и отношения между записями определены заранее. Эта особенность — обоюдоострый меч.
Недостаток Этот тип структуры базы данных состоит в том, что у каждого дочернего элемента в дереве может быть только один родительский элемент.Отношения или связи между детьми не допускаются, даже если они имеют смысл с логической точки зрения. Иерархические базы данных таковы в своем дизайне. Добавление нового поля или записи требует переопределения всей базы данных.Сетевые базы данных
Системы управления сетевыми базами данных (сетевые СУБД) используют сетевую структуру для создания отношений между объектами. Сетевые базы данных в основном используются на больших цифровых компьютерах.Сетевые базы данных являются иерархическими базами данных, но в отличие от иерархических баз данных, где один узел может иметь только одного родителя, сетевой узел может иметь связь с несколькими объектами. Сетевая база данных больше похожа на паутину или взаимосвязанную сеть записей.
В сетевых базах данных дети называются членами, а родители — оккупантами. Разница между каждым ребенком или членом заключается в том, что он может иметь более одного родителя.
Утверждение сетевой модели данных аналогично иерархической модели данных.Данные в сетевой базе данных организованы во взаимосвязи «многие ко многим».
Структура сетевой базы данных была изобретена Чарльзом Бахманом. Некоторые из популярных сетевых баз данных — это интегрированное хранилище данных (IDS), IDMS (интегрированная система управления базами данных), менеджер баз данных Raima, TurboIMAGE и Univac DMS-1100.
Реляционные базы данных
В системах управления реляционными базами данных (RDBMS) отношения между данными являются реляционными, и данные хранятся в виде столбцов и строк в виде таблиц.Каждый столбец, если таблица представляет атрибут, и каждая строка в таблице представляет запись. Каждое поле в таблице представляет значение данных.
Язык структурированных запросов (SQL) — это язык, используемый для запросов к СУБД, включая вставку, обновление, удаление и поиск записей. Реляционные базы данных работают с каждой таблицей, в которой есть ключевое поле, однозначно указывающее на каждую строку. Эти ключевые поля можно использовать для соединения одной таблицы данных с другой.
Реляционные базы данных — самые популярные и широко используемые базы данных.Некоторые популярные DDBMS — это Oracle, SQL Server, MySQL, SQLite и IBM DB2.
Реляционная база данных имеет два основных преимущества:
- Реляционные базы данных могут использоваться практически без обучения.
- Записи базы данных могут быть изменены без указания всего тела.
Свойства реляционных таблиц
В реляционной базе данных мы должны следовать приведенным ниже свойствам:
- Значения являются атомными
- Каждая строка одна.
- Значения столбца — это одно и то же.
- Колонны ничем не примечательны.
- Последовательность строк незначительна.
- Каждая колонка имеет общее название.
Объектно-ориентированная модель
В этой модели мы должны обсудить функциональность объектно-ориентированного программирования. Это занимает больше, чем хранение объектов языка программирования. Объектные СУБД увеличивают семантику C ++ и Java. Он обеспечивает полнофункциональные возможности программирования баз данных, а также совместимость с родным языком.Это добавляет функциональность базы данных к объектным языкам программирования. Этот подход аналогичен разработке приложений и баз данных в постоянной модели данных и языковой среде. Приложения требуют меньше кода, используют более естественное моделирование данных, а базы кода проще в обслуживании. Разработчики объектов могут написать законченные приложения базы данных с приличным количеством дополнительных усилий.
Объектно-ориентированное создание баз данных — это целостность систем объектно-ориентированного языка программирования и согласованных систем.Сила объектно-ориентированных баз данных заключается в циклической обработке как согласованных данных, обнаруживаемых в базах данных, так и переходных данных, обнаруживаемых в исполняемых программах.
Объектно-ориентированные базы данных используют небольшие, пригодные для повторного использования, отделенные от программного обеспечения, называемого объектами. Сами объекты хранятся в объектно-ориентированной базе данных.
Каждый объект содержит два элемента:
- Кусок данных (например, звук, видео, текст или графика).
- Инструкции или программы, называемые методами, что делать с данными.
Объектно-ориентированные системы управления базами данных (OODBM) были созданы в начале 1980-х годов. Некоторые OODBM были разработаны для работы с языками ООП, такими как Delphi, Ruby, C ++, Java и Python. Некоторые популярные OODBM: TORNADO, Gemstone, ObjectStore, GBase, VBase, InterSystems Cache, База данных объектов Versant, ODABA, ZODB, Poet. JADE и Informix.
Недостатки объектно-ориентированных баз данных
- Объектно-ориентированные базы данных более дороги в разработке.
- Большинство организаций не хотят отказываться от этих баз данных и конвертировать их.
Преимущества объектно-ориентированных баз данных
Преимущества объектно-ориентированных баз данных неоспоримы. Возможность смешивать и сопоставлять повторно используемые объекты обеспечивает невероятные мультимедийные возможности.
Графовые базы данных
Графические базы данных являются базами данных NoSQL и используют структуру графов для семантических запросов.Данные хранятся в форме узлов, ребер и свойств. В графической базе данных узел представляет собой объект или экземпляр, такой как клиент, человек или автомобиль. Узел эквивалентен записи в системе реляционной базы данных. Край в базе данных графа представляет отношение, которое соединяет узлы. Свойства — это дополнительная информация, добавляемая к узлам.
Neo4j, Azure Cosmos DB, SAP HANA, Sparksee, Oracle Spatial и Graph, OrientDB, ArrangoDB и MarkLogic являются одними из популярных графовых баз данных.Структура базы данных графов также поддерживается некоторыми RDBM, включая Oracle и SQL Server 2017 и более поздние версии.
Базы данных модели ER
Модель ER обычно реализуется как база данных. В простой реализации реляционной базы данных каждая строка таблицы представляет один экземпляр типа сущности, а каждое поле в таблице представляет тип атрибута. В реляционной базе данных связь между объектами реализуется путем сохранения первичного ключа одного объекта в качестве указателя или «внешнего ключа» в таблице другого объекта.
Модель взаимосвязи сущностей была разработана Питером Ченом в 1976 году.
Базы документов
Базы документов (Document DB) также являются базой данных NoSQL, в которой хранятся данные в форме документов. Каждый документ представляет данные, их связь между другими элементами данных и атрибуты данных. База данных документов хранит данные в форме значения ключа.
Document DB в последнее время стала популярной благодаря своему хранилищу документов и свойствам NoSQL.NoSQL хранилище данных обеспечивает более быстрый механизм хранения и поиска документов.
Популярными базами данных NoSQL являются Hadoop / Hbase, Cassandra, Hypertable, MapR, Hortonworks, Cloudera, Amazon SimpleDB, Apache Flink, IBM Informix, Elastic, MongoDB и Azure DocumentDB.
Базы данных NoSQL
Базы данных NoSQL — это базы данных, которые не используют SQL в качестве основного языка доступа к данным. Графическая база данных, сетевая база данных, база данных объектов и базы данных документов являются общими базами данных NoSQL.Эта статья отвечает на вопрос, что такое база данных NoSQL.
База данных NoSQL не имеет предопределенных схем, что делает базы данных NoSQL идеальным кандидатом для быстро меняющихся сред разработки.
NoSQL позволяет разработчикам вносить изменения на лету, не затрагивая приложения.
Базы данных NoSQL можно разделить на следующие пять основных категорий: базы данных столбцов, документов, графиков, значений ключей и объектов.
Вот список из 10 популярных баз данных NoSQL:
- Cosmos DB
- ArangoDB
- Couchbase Server
- CouchDB
- Amazon DocumentDB
- MongoDB, CouchBase
- Elasticsearch Informix 900A
- Informix SAP 9009
- Informix 900A
- Informix HAN 900A Neo4j
Хотите узнать больше?
Вот еще несколько статей, которые могут вас заинтересовать: