большой обзор типов и подходов. Доклад Яндекса / Блог компании Яндекс / Хабр
Это конспект лекции Татьяны Денисовой tdenisova — бэкенд-разработчика в Яндекс.Учебнике. Вы узнаете, какие бывают базы данных, какие их особенности важно помнить, как в работе с данными учитывать характеристики системы и планы масштабирования, в какую из тем нужно углубиться для решения конкретной задачи. А также как при возникновении багов определить, является ли работа с БД источником проблемы (и если да, то в какую сторону копать).— О чем именно мы будем говорить? Не о примитивных селектах и джойнах — о них, я думаю, большинство из вас уже знает.
Мы будем говорить о реальном применении баз, о том, с какими сложностями вы можете столкнуться и что вам как бэкенд-разработчику нужно знать.
И нужно знать, как какие проблемы решаются, чтобы, когда у вас будет задача построить структуру, сохранить данные, вы знали, какую модель данных выбрать и как их сохранить. Или предположим, у вас проблема, вы видите, что база данных не работает, работает медленно, или возникли проблемы с данными, несогласованность. Тогда вы должны понимать, куда копать. То есть нужно знать, какие понятия существуют и с какой стороны подойти к проблемам.
Сначала мы с вами поговорим о данных. Что это такое вообще? Вокруг нас много фактов, много сведений, но пока они никак не собраны, они для нас бесполезны. Мы их собираем, структурируем и сохраняем. И именно это сохраненное структурирование называется данными, а то, что их хранит, — базой данных. Но пока эти данные просто где-то лежат собранные, они для нас тоже в принципе бесполезны.
Мы обсудим, как структурировать сведения и факты, хранить их, в каком виде данных, в какой модели. И как их достать так, чтобы много пользователей одновременно могли обращаться к данным и получить корректный результат, чтобы наши итоговые знания, которые мы будем применять, были правдивыми и верными.
Для начала мы с вами поговорим о реляционных базах данных. Думаю, реляционная модель многим из вас знакома. Это модель типа таблиц и отношений между таблицами. Представим, что у нас есть мессенджер, в который мы записываем данные и сообщения между пользователями. Мы можем их записать все в одну такую большую объемную таблицу, широкую, где у нас будет много повторяющихся данных — от кого, кто, кому, в какой чат.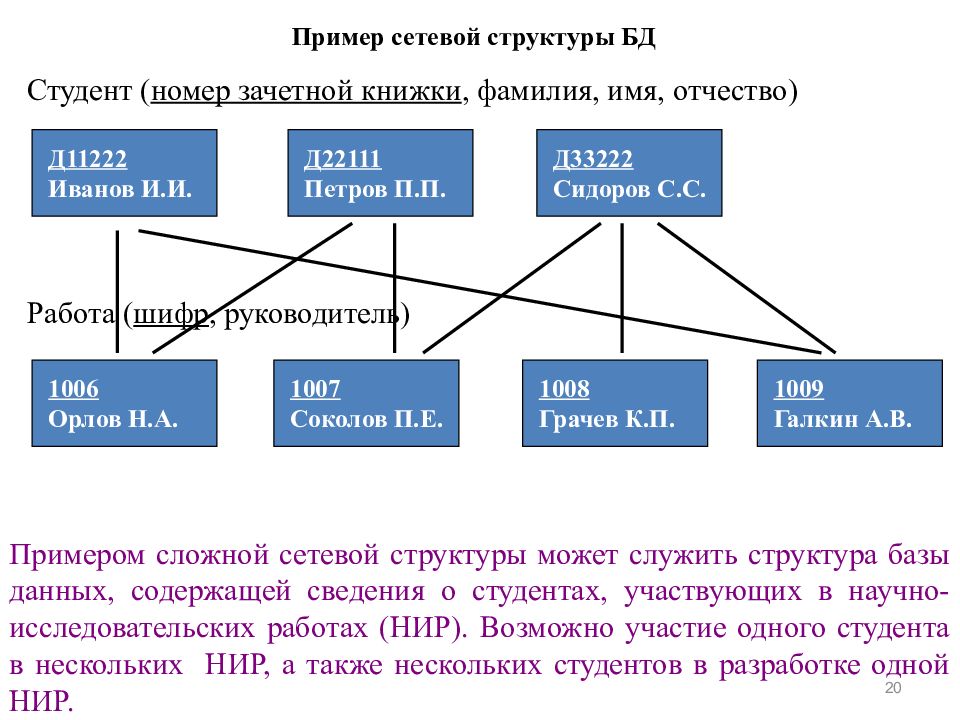
На слайдах есть примечания и ссылочки. Мы не будем сейчас углубляться в каждое понятие. Я постараюсь технические понятия, которые могут быть вам незнакомы, не говорить. Но все, что я говорю, вы найдете в примечаниях к слайдам. В том числе по нормализации тоже будет ссылочка, вы сможете почитать, если это понятие вам не знакомо.
В общих словах, нормализация — это разбиение данных на таблицы с целью, чтобы эти данные стали более структурированы. Например, здесь есть теперь таблица юзера, чата мессенджера и сообщений. Такая структура обеспечивает, что сюда будут записаны сообщения именно тех пользователей, которых мы знаем, и из известных нам чатов. То есть мы обеспечиваем целостность данных. Мы обеспечиваем факт того, что мы всегда можем собрать общую картинку целиком. Но при этом мы храним, например, в таблице сообщений только айдишники, только идентификаторы.
Если говорить про нормализацию, она вообще очень упрощает видение системы, потому что очень графична, и нам сразу становится понятно, какие взаимоотношения между какими таблицами у нас есть.
Мы уменьшаем количество ошибок при записи данных, потому что если мы записываем сообщение в месседжере и такого пользователя у нас еще нет, то нам придется его завести. Но итоговая картина, общие данные у нас останутся целостными.
Про уменьшение размера базы данных я уже сказала. Нам в таблице сообщений не придется каждый раз писать все данные о пользователе. Чтобы посмотреть профиль, мы можем просто зайти в таблицу User.
О несогласованной зависимости также предупредила. Это как раз ссылки на айдишники других таблиц, идентификаторы являются уникальными значениями в рамках одной таблицы. По-другому они называются primary key, и когда у нас есть ссылка на эти primary key, то сама ссылка в другой таблице называется foreign key.
По-другому они называются primary key, и когда у нас есть ссылка на эти primary key, то сама ссылка в другой таблице называется foreign key.
Такая структура также защищает наши данные от случайного удаления. Мы не можем удалить юзера, потому что, например, у него есть сообщение. Это такая небольшая, но подстраховка.
Казалось бы, мы сделали отличную структуру, все понятно, все зависимо, все цельно. С чем еще нужно работать?
Представим, что мы реально запустили это в эксплуатацию, у нас стало много пользователей и, соответственно, много сообщений. Они постоянно друг с другом общаются. Что происходит в нашей таблице сообщений? Она постоянно растет. И чтобы искать в не данные, нам нужно постоянно перебирать абсолютно все сообщения, проверять, от этого пользователя они или нет, в этом чате или нет, и только тогда их выводить.
Естественно, чем больше пользователей, чем больше сообщений, тем дольше будут проходить запросы полного перебора. Нам нужно решение, которое позволит быстро искать сообщения в таблице.
Для такого случая, для ускорения поиска, используют индексы. Самая простая ассоциация с индексами — это содержание в книге. Если вам нужно в книге найти информацию, вы можете просто пролистать книгу, а можете зайти в оглавление. Индексы — это своего рода оглавление.
Есть еще хороший пример с телефонной книжкой. Вы можете нажать на букву на своем телефоне, и вас сразу перекинет ссылочно на фамилии, начинающиеся с этой буквы. Индексы баз данных работают по очень похожему принципу. Давайте посмотрим нашу таблицу с сообщениями и то, как мы эти данные будем доставать.
Прошу обратить внимание, как именно мы будем работать с данными. Не с тем, какие у нас есть строки в таблице, а вообще. Индексы строятся по принципу того, какие запросы вы делаете.
Представим, что мы делаем в основном запросы по чату, то есть узнаём, какие сообщения есть в этом чате. Построим индекс именно по столбцу чатов. Индексы в базе данных — это отдельная структура. Таблица от нее не зависима. То есть индекс вы можете в любой момент удалить и перестроить заново, и таблица от этого не пострадает.
То есть индекс вы можете в любой момент удалить и перестроить заново, и таблица от этого не пострадает.
Здесь видно, что мы выделили, поставили индекс на столбец, и у нас выделилась отдельная структурка, которая уже немножко сократила количество записей, потому что в 11 чате уже есть несколько сообщений. СУБД обеспечивает быстрый поиск по вот этой маленькой таблице чата. Как это делается? Естественно, поиск происходит не простым перебором. Есть много алгоритмов быстрого поиска, мы с вами рассмотрим один из самых популярных алгоритмов, которые используются по умолчанию в большинстве баз данных. Это сбалансированное дерево.
Как оно работает? У нас есть номер чата, это целое значение, и дерево выстраивается по такому принципу: то, что слева от узла значений меньше, справа от узла значений больше. Что нам дает такая структура? Если посмотреть на итоговые листы этого дерева, то все значения внизу упорядочены. Это огромный плюс в приросте производительности. Сейчас покажу, почему.
Например, мы ищем значение. Одно значение искать очень просто. Мы проходим вниз по дереву или влево, вправо — в зависимости от того, больше это значение или меньше.
А если мы хотим найти, например, диапазон, то смотрите, как просто и быстро это получается. Мы доходим до значения и дальше по ссылкам в листьях уже по упорядоченным значениям просто идем до конца.
Если нам нужен диапазон, определенный от и до, — делаем абсолютно то же самое. Находим начальное значение и уже по ссылкам листьев идем до максимального значения. Мы по дереву прошли только один раз. Это очень удобно, очень быстро.
Точно так же у нас будут искаться максимальные и минимальные значения. Пройти совсем влево, совсем вправо. Так же у нас будет происходит получение упорядоченного списка. То есть если нам нужно просто получить все чаты упорядоченно, мы доходим до первого и уже по листьям идем до самого правого значения, получаем упорядоченный список. Именно по такому принципу база данных очень быстро ищет в таблице индексов те строчки, которые нам нужны для выборки, и возвращает их.
Что тут важно знать? Казалось бы, классная структура — мы сейчас на каждый столбец построим по такому дереву и будем искать. Как вы думаете, почему это не сработает? Почему у нас не будет прироста скорости, если мы на каждый столбец построим по дереву? (…)
У нас действительно ускорятся селекты. Каждый раз, когда нам нужно пройти по какому-то значению, мы заходим в индекс, находим там ссылку на сами значения. Индексы, как правило, содержат именно ссылки на строки, а не сами строки. И для селектов это работает идеально. Но как только мы захотим задать данные таблицы, проапдейтить либо удалить данные, то все эти деревья придется перестраивать.
На самом деле удаление не перестроит, а просто фрагментирует это дерево, и у нас получатся много пустых значений. Будет огромное дерево с пустыми значениями. Но именно при update и при create эти деревья каждый раз будут перестраиваться. В итоге мы получим огромный overhead над всех этой структурой. И вместо того, чтобы быстренько достать данные и ускорить базу данных, мы будем замедлять наши запросы.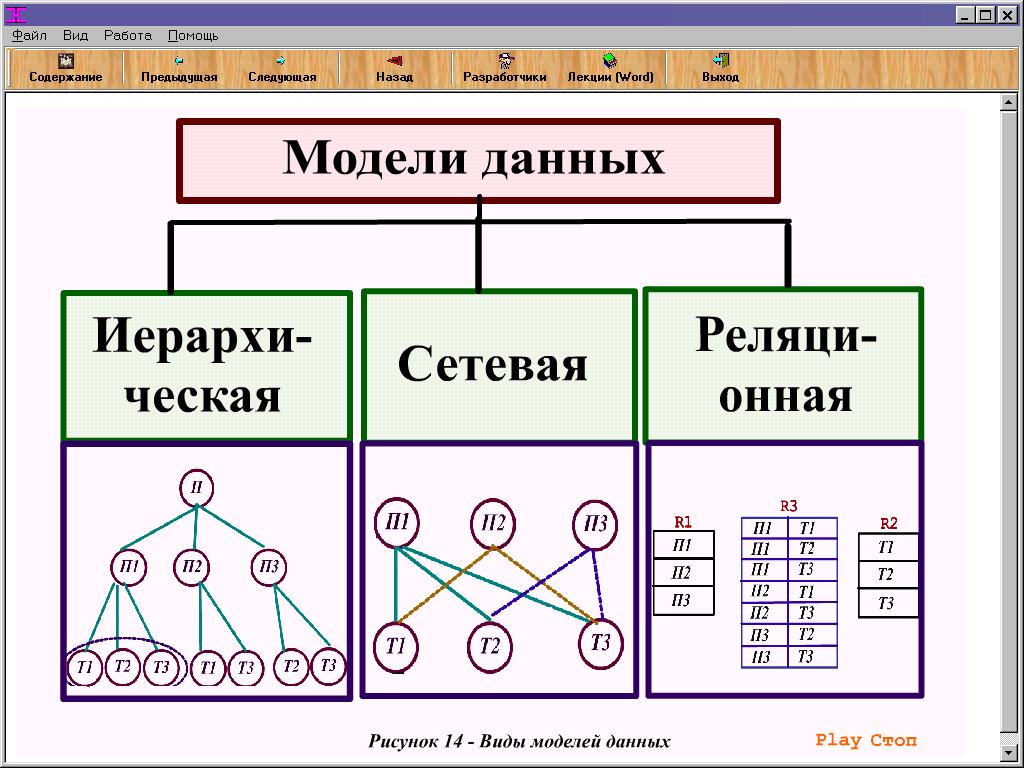
Что еще важно знать? Когда вы будете работать с базой, посмотрите, почитайте, какие индексы в ней существуют, потому что в каждой базе свои реализации, свои разные индексы. Есть индексы для ускорения, есть индексы для обеспечения целостности. Один из самых простых — как раз primary key. Это тоже индекс уникальности. И относительно вашей базы смотрите, как он устроен, как с ним работать, потому что это такие знания, которые вам помогут писать наиболее оптимальные запросы.
Мы обсудили, что нужно иметь в виду накладные расходы на поддержание индексов при вставке данных. Забыла сказать, что когда вы выстраиваете индекс, он должен обладать высокой селективностью. Что это значит?
Посмотрим на это дерево. Мы понимаем, что если стоит индекс на true false, то получается просто два огромных куска дерева слева и справа. И мы проходимся в лучшем случае по 50% таблицы, что на самом деле не очень эффективно. Лучше всего делать индекс именно на те столбцы, у которых наиболее разные значения. Таким образом мы ускорим наши выборки.
Таким образом мы ускорим наши выборки.
Про фрагментацию я сказала, при удалении данных ее нужно иметь в виду. Если у нас часто проходит удаление по данным, содержащимся в индексе, то его, возможно, придется дефрагментировать, и за этим тоже нужно следить. Также важно понимать, что вы строите индекс исходя не из того, какие у вас столбцы, а из того, как вы эти данные используете. И запросы, которые включают индексы, нужно писать очень аккуратно. Что значит аккуратно? Когда вы пишете запрос, отправляете его в базу данных, он отправляется не напрямую в базу, а в некую программную прослойку, которая называется планировщиком запросов.
Планировщик имеет у себя определенную таблицу соответствия того, какая операция сколько стоит и насколько она дорогая. В примере с PostgreSQL есть специальные технические таблицы, которые собирают информацию о ваших данных, о ваших таблицах. Планировщик смотрит, какой у вас запрос, какие данные хранятся в таблице pg_stat. Это как раз таблица, которая хранит общую информацию о том, сколько у вас данных и какие столбцы в вашей таблице, какие индексы на ней. Исходя из этого он смотрит планы выполнения вашего запроса, считает, сколько времени по какому плану уйдет на запрос, и выбирает самый оптимальный.
Если вы хотите посмотреть прогнозируемое время выполнения вашего запроса, можете использовать операцию Explain. Если хотите фактическое выполнение, можете использовать Explain analyze. Какая разница? Как я и говорила, планировщик изначально рассчитывает время выполнения, исходя из примерного времени на каждую операцию. Поэтому реальное время может отличаться в зависимости от машины и от особенностей ваших данных. Так что если вам нужно именно фактическое выполнение, то, конечно, лучше использовать Explain analyze.
На этом слайде вы можете посмотреть пример. Он показывает, что иногда запросы с учетом вашего столбца, на котором есть индексы, могут использовать не индекс scan, а просто full scan по всей таблице. Это происходит, если у нас невысокая селективность индекса и если планировщик считает, что запрос полным scan по таблице будет выгоднее.
Представим, что у нас есть наш мессенджер и мы хотим в списке чатов, например, показывать имя чата либо количество непрочитанных сообщений. Если мы каждый раз, открывая чатик, будем пересчитывать все данные по всем чатам, это будет очень невыгодно.
Есть такое понятие — денормализация. Это копирование наиболее горячих используемых данных либо предрасчет нужных данных и сохранение их в таблицу.
Так может выглядеть соотношение юзера с чатом. То есть помимо ID юзера и ID чата мы кратко туда сохраним имя чата, лог чата и количество непрочитанных сообщений. Таким образом нам каждый раз не нужно будет нагружать все наши таблицы, делать селект и все это пересчитывать.
В чем плюс денормализации? Мы ускоряем процесс выборки данных. То есть наши селекты проходят максимально быстро, мы максимально быстро отдаем пользователям ответ.
Сложность в том, что каждый раз, когда мы добавляем новые данные, нам все эти столбцы нужно пересчитывать и очень велика вероятность ошибки. То есть если наши селекты становятся гораздо проще и нам не нужно все время джойнить, то наши update и create становятся очень громоздкими, потому что нам нужно повесить туда триггеры, пересчитать и ничего не забыть.
Поэтому денормализацию нужно использовать, только когда она вам действительно нужна. И как мы сейчас шли по вот этой всей логике, сначала нужно данные нормализовать, посмотреть, как вы их будете использовать, настроить индексы. Если у вас есть запросы, которые, как вы считаете, плохо работают, то перед денормализацией посмотрите Explain. Узнайте, как они реально выполняются, как планировщик их выполняет. И только потом, когда вы уже придете к тому, что денормализация все-таки нужна, тогда вы можете ее сделать. Но такая практика есть, и в реальных проектах денормализация данных достаточно часто используется.
Пойдем дальше. Даже если вы хорошо структурировали данные, выбрали модель данных, собрали, все денормализовали, придумали индексы, — все равно очень многое в IT-мире может пойти не так.
Может отказать ПО, может выключиться электроэнергия, может отказать аппаратное обеспечение или сеть. Есть и второй класс проблем: нашими базами данных одновременно пользуется очень много пользователей. Они могут одновременно обновлять одни и те же данные. Все эти проблемы мы должны уметь решать.
Давайте посмотрим на конкретных примерах, о чем идет речь.
Представим, что есть два пользователя, которые хотят забронировать переговорку. Пользователь 1 видит, что переговорка в это время свободна, и начинает ее бронировать. У него открывается окошко, и он думает, кого же из коллег я позову. Пока он думает, пользователь 2 тоже видит, что переговорка свободна, и открывает себе окошко редактирования.
В итоге, когда пользователь 1 сохранил эти данные, он ушел и думает, что все отлично, переговорка забронирована. Но в это время пользователь 2 перезаписывает его данные, и получается так, что переговорка закрепилась за пользователем 2. Это называется конфликтом данных. И мы должны уметь показывать эти конфликты людям и как-то их разрешать. Именно в этом месте у нас будет перезапись.
Как это сделать? Мы можем просто заблокировать переговорку на какое-то время, пока пользователь 1 думает. Если он сохранил данные, то пользователю 2 мы не разрешим это делать. Если он данные отпустил и не стал сохранять, то пользователь 2 сможет забронировать переговорку. Подобную картину вы могли видеть, когда покупаете билеты в кино. Вам дается 15 минут на то, чтобы оплатить билеты, иначе они вновь предоставляются другим людям, которые тоже могут их взять и оплатить.
Вот другой пример, который нам покажет, насколько важно следить, чтобы наши операции выполнялись полностью. Допустим, я хочу с банковского счета 1 перекинуть деньги на счет 2. В этом моменте у меня есть три операции. Я проверяю, что у меня достаточно средств, вычитаю со своего первого счета средства и кидаю на второй счет. Понятное дело, что если в любой из этих моментов у меня произойдет сбой, то что-то пойдет не так.
Например, если вот на этом этапе произойдет другая транзакция, которая считывает данные, то средств на моем счете будет уже недостаточно, я не смогу выполнить другие операции. Если на втором моменте произойдет проблема, то мы, например, сняли с одного счета деньги, а на второй не закинули. Получается, что в итоге на моем банковском счету, на всех моих счетах станет на какую-то сумму меньше. Эти деньги уже никак не вернуть.
Для решения таких проблем существует понятие транзакции — атомарного, целостного выполнения всех трех операций одновременно.
Как это делает база данных? Она записывает все эти изменения в определенный журнал и применяет их, только когда у нас транзакция коммитится. Таким образом мы гарантируем, что все вот эти операции будут выполнены как единое целое либо не будут выполнены вовсе.
Если в любой момент этого времени у нас произойдет сбой, то с первого счета не будут вычтены деньги и, соответственно, мы их не потеряем.
У транзакций есть четыре свойства, четыре требования к ним. Это Atomicity, Consistency, Isolation и Durability — атомарность, согласованность, изоляция и сохраняемость данных. Что это за свойства?
- Atomicity или атомарность — гарантия того, что операция, которую вы выполняете, будет выполнена полностью, что она не будет выполнена частично. Таким образом мы гарантируем, что общая согласованность данных в нашей базе будет и до операции, и после.
- Consistency или согласованность — больше бизнес-правило, скорее не со стороны СУБД или самой базы данных. Согласованность не нужно путать с целостностью (Integrity). Если кто-то из вас работал с базами данных и передавал данные с айдишника, который не существует, то вы могли получать Integrity Error, ошибку целостности: система не понимала, что с ним делать. Именно наличие взаимосвязи отношений и уникальности ключей называется целостностью. А согласованность — то, что мы пишем в самой транзакции.
Например, в этом примере, когда мы пишем транзакцию, нужно с одного счета снимать столько же денег, сколько мы кидаем на второй счет. То есть в итоге у нас данные по общему балансу в начале и в конце должны быть одинаковыми. Это и есть согласованность.
- Isolation или изоляция — это как раз то, что мы с вами смотрели на примере переговорки. Ваша система должна вести себя предсказуемо и контролируемо относительно параллельного выполнения операций. Она должна гарантировать, что параллельно работающие пользователи не будут мешать друг другу и что не будет неожиданных изменений.
- Durability или сохраняемость — свойство транзакции, которое говорит о том, что если ответ пришел пользователю, то эти данные уже точно будут сохранены, что они не пропадут.
Поговорим побольше про изоляцию. Изолированность транзакций — очень дорогое свойство, на него тратится очень много ресурсов, из-за этого у нас в базах существует несколько уровней изоляции. Давайте посмотрим, какие проблемы могут быть, и исходя из этого уже обсудим, как их решать.
Существует четыре основных класса проблем — потерянное обновление, «грязное» чтение, неповторяющееся чтение и фантомное чтение. Рассмотрим подробнее.
Потерянное обновление — это как в примере с переговорками, когда у пользователя 1 перезаписались данные и он об этом не знает. То есть мы не блокировали данные, которые этот пользователь изменяет, и, соответственно, получили их перезапись.
Проблема «грязного» чтения возникает, когда пользователь видит временные изменения другого пользователя, которые потом могут быть откатаны или просто сделаны временно.
В данном случае пользователь 1 что-то записал в базу данных. Пользователь 2 в это время что-то оттуда считал и строит аналитику по этим данным. А пользователь 1 столкнулся с ошибкой, несоответствием и эти данные откатывает. Таким образом, аналитика, которую записал пользователь 2, будет ненастоящая, неверная, потому что уже нет тех данных, исходя из которых он ее рассчитывал. Такую проблему тоже нужно уметь решать.
Неповторяемое чтение — это когда у нас у пользователя 1 долгая транзакция. Он выбирает данные из базы, а в это время пользователь 2 изменяет часть тех же самых данных.
В данном случае получается, что пользователь 1 не заблокировал изменения тех данных, которые у него есть. И несмотря на то, что он сам получил слепок данных, при повторном запросе на тот же самый селект он может получить другие значения в этих строках. Таким образом, у него будет конфликт, несоответствие данных, которые он записывает.
Похожая проблема может быть, если пользователь 2 добавил или удалил данные. То есть пользователь 1 сделал запрос, а потом при повторном запросе этих же самых данных у него появились или пропали строки. В этом случае в рамках транзакции очень сложно понять, что с ними делать, как их вообще обрабатывать.
Чтобы решать эти проблемы, есть четыре уровня изоляции. Первый, самый низкий уровень — Read uncommitted. Это то, что в PostgreSQL описывается как No lock. Когда мы читаем или пишем данные, мы не блокируем другим пользователям ни чтение, ни запись этих данных. Получается, что мы не блокируем никакие изменения. Все четыре перечисленные проблемы по-прежнему могут произойти. Но от чего защищает этот уровень изоляции? Он гарантирует, что все транзакции, которые пришли в базу данных, будут выполнены. Если два пользователя одновременно начали выполнять запросы с одними и теми же данными, то обе эти транзакции будут выполнены последовательно.
Для чего это может быть полезно? Этот уровень изоляции очень редко используется в практике, но он может быть полезен, например, когда есть большой аналитический запрос и вы хотите во втором запросе почитать и посмотреть, на каком этапе находится ваша аналитика, какие данные уже записаны а какие нет. И тогда второй запрос — который для дебага, отладки, проверки — вы запускаете как раз в таком уровне изоляции. И он видит все изменения вашего первого аналитического запроса, которые в итоге могут быть откатаны. Или не откатаны, но в текущий момент вы можете посмотреть состояние системы.
Read committed, чтение фиксированных данных. Этот уровень изоляции используется по умолчанию в большинстве реляционных баз, в том числе и в PostgreSQL, и в Oracle. Он гарантирует, что вы никогда не прочитаете «грязные» данные. То есть другая транзакция никогда не видит промежуточных этапов первой транзакции. Преимущество в том, что это очень хорошо подходит для маленьких коротких запросов. Мы гарантируем, что у нас никогда не будет ситуации, когда мы видим какие-то части данных, недописанные данные. Например, увеличиваем зарплату целому отделу и не видим, когда только часть людей получили прибавку, а вторая часть сидит с неиндексированной зарплатой. Потому что если у нас будет такая ситуация, логично, что наша аналитика сразу «поедет».
От чего не защищает этот уровень изоляции? Он не защищает от того, что данные, которые вы проселектили, могут быть изменены. В случае небольших запросов этого уровня изоляции вполне достаточно, но для больших, долгих запросов, сложной аналитики, естественно, можно использовать более сложные уровни, которые блокируют ваши таблицы.
Уровень изоляции Repeatable read защищает от первых трех проблем, которые мы с вами обсуждали. Это и потерянное обновление, когда перезаписали нашу переговорку; «грязное» чтение — чтение незафиксированных данных; и это неповторяющееся чтение — чтение данных, обновленных другими транзакциями.
Как оно обеспечивается? С помощью блокировки таблицы, то есть блокировки нашего селекта. Когда мы берем селект в нашу транзакцию, то получается как будто слепок данных. И мы в этот момент не видим изменений других пользователей, все время работаем именно с этим слепком данных. Минус в том, что мы блокируем данные и, соответственно, у нас меньше параллельных запросов, которые могут работать с данными. Это очень важный аспект. И вообще, почему этих уровней изоляции так много?
Чем выше уровень, тем больше блоков и меньше пользователей, которые параллельно могут работать с базой. Каждая транзакция видит определенный слепок данных, который не может меняться. Но могут появиться новые данные. Так что этот уровень изоляции нас не спасает от появления новых данных, которые подходят под селект.
Есть еще один уровень изоляции — сериализация. Часто ее называют упорядочиваемостью. Это полная блокировка данных в таблице. Она спасает от фантомного чтения, то есть от чтения как раз тех данных, которые у нас добавились или удалились, потому что мы блокируем таблицу, не разрешаем в нее писать. И выполняем наши запросы целостно.
Это очень полезно для сложных, больших аналитических запросов, в которых очень важна точность и целостность данных. Не получится так, что мы в какой-то момент считали данные пользователя, а потом в другой таблице появились новые статистики и получился рассинхрон.
Это самый высокий уровень изоляции. Здесь самое большое количество блокировок и самая маленькая возможность параллелизации запросов.
Что нужно знать о транзакциях? Что они нам упрощают жизнь, потому что реализованы на уровне СУБД и нам нужно только правильно делать наши запросы, правильно их формировать, так, чтобы данные в итоге были согласованы. И чтобы блокировать именно те данные, с которыми наши пользователи работают. Нужно иметь в виду, что плохо блокировать всё и везде. В зависимости от того, какая у вас система и кто сколько читает/пишет, у вас будет разный уровень изолированности. Если вам нужна максимально быстрая система, которая допускает какие-то ошибки, вы можете выбрать минимальный уровень изоляции. Если у вас банковская система, которая должна гарантировать, что данные согласованы, все выполнено и ничего не потерялось — тогда, конечно, нужно выбирать максимальный уровень изоляции.
Мы уже достаточно классно продвинулись в понимании того, как выстраивать структуру базы данных и что может произойти. Пойдем дальше.
Насколько безопасно хранить одну базу данных. Конечно, не безопасно. Если с ней что-то случается, мы теряем все данные. Если есть бекап, мы можем его накатить, но тогда возникнет время простоя системы. Если у нас ломается сеть или узел становится недоступен, система тоже будет какое-то время находиться в простое, в downtime.
Как это можно разрешить? Есть такое понятие — репликация. Это дублирование базы данных на другие узлы и серверы.
Это именно дублирование полностью, копия базы данных. Как мы можем этот механизм использовать?
Во-первых, если с БД что-то случилось, мы можем перенаправить запросы на другую копию базы данных, что в принципе логично. Это основное применение. Как еще мы можем это использовать?
Представим, что пользователь находится далеко от сервера. Мы можем распределить серверы так, чтобы покрывать максимальное количество пользователей и максимально быстро отдавать им запросы. На каждом из этих серверов будет одинаковая с другими копия, но запросы будут возвращаться пользователям быстрее.
Еще одно очень популярное использование — распределение нагрузки. Так как у нас одинаковые копии данных, мы можем читать не из головы, не из одной базы данных, а из разных. Таким образом мы разгружаем наш сервер.
Также у нас есть понятие OLTP-запросов и OLAP-запросов. Что это такое? OLTP — короткие транзакционные запросы. OLAP — долгая аналитика. Это когда мы берем огромный джойн, огромный селект, всё мёржим и нам очень важно, чтобы в этот момент все данные были залочены, чтобы не было никаких изменений и БД была целостна.
Для таких ситуаций можно делать аналитику на отдельной копии базы данных. Так мы не будем аффектить наших пользователей, они смогут тоже делать записи в базу, просто потом эти записи придут и на нашу копию.
Чтобы грамотно распределить копии баз данных, вводится понятие ведущего узла и ведомого узла, Master и Slave. Slave очень часто называют репликой либо follower. Master — узел, в который наш пользователь, наше приложение пишет. Master применяет все изменения, ведет журнал изменений, и этот журнал отправляет на Slave. Slave не принимает изменения от пользователей, а применяет лишь изменения журнала от Master. Прошу заметить, что Master не отправляет каждый раз копию, а отправляет именно изменения. Slave накатывает эти изменения и получает такую же копию данных, как и в Master.
Очень важный параметр реплицируемой системы — синхронно или асинхронно выполняются запросы. Что такое синхро
Зачем нужны базы данных
Если вы будете делать веб-приложение — например интернет-магазин, блог или игры, — почти наверняка вы столкнётесь с базой данных. Вот что это такое с точки зрения программирования, какие тут основные понятия и что с ними делать.
Данные
Вокруг нас всегда много разных данных, например:
- телефонные номера;
- дела на день;
- записи на бумажках, стикерах и в блокнотах;
- опубликованные мысли разных людей;
- фотографии в смартфоне;
- и всё остальное, что можно прочитать, увидеть или услышать.
Если это компьютерная игра, то данными будут типы и местоположения врагов, их уровень здоровья, уровень здоровья героя, тип героя, его положение, характеристики карты.
Если это приложение для работы с клиентом, то там будут храниться имя клиента, его заказы, номер телефона, уровень в программе лояльности.
Если это служба слежения за гражданами — фотография, имя, посещённые станции метро и улицы, место работы.
База данных и СУБД
Есть понятие базы данных — это набор данных, организованных каким-то способом. Например, если у вас в квартире есть гардеробная или кладовка, то всё это помещение со всем её содержимым может считаться базой (но не данных, а вещей или банок с огурцами, что не меняет сути).
Есть понятие системы управления базой данных (СУБД) — это когда семья села за стол и самого младшего отправляют в кладовку за огурцами, он приносит её и не разбивает по дороге. То есть СУБД — это какое-то средство для манипуляции данными в базе, например программа.
Для чего нужны
Вот основные задачи БД на примере гардеробной:
- Сохранить наши данные по запросу — чтобы вы могли открыть дверь, повесить куртку, закрыть дверь и больше не думать ни о куртке, ни о гардеробной.
- Изменить наши данные по запросу — чтобы можно было легко извлечь из гардеробной все дырявые носки и положить на их место целые.
- Найти эти данные по запросу — чтобы быстро найти приличный пиджак или парный носок.
- Не дать прочитать эти данные тем, кому не следует, а кому надо — дать. Например, младший брат может смотреть на ваши кроссовки, но не может их брать. А девушка (или парень) может положить свои вещи, но только на определённую полку.
- Поддерживать порядок и не дать захламиться — если вам было лень и вы просто кинули толстовку куда попало, чтобы гардеробная либо сама нашла, куда эту толстовку правильно положить, либо сказала: «Э БРАТ ЗАЧЕМ ЗАХЛАМЛЯЕШЬ ПОЛОЖИ НОРМАЛЬНО ДАВАЙ»
- Масштабироваться — чтобы вы могли просто вешать в гардеробную вещи и не думать об объёме полок.
- Не потерять данные — если квартира будет гореть, приличная гардеробная не должна даже нагреться. Или, если она всё-таки горит, чтобы где-то в защищённом подземном гараже была точная копия этой гардеробной со всеми актуальными вещами.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
🤔 Представьте, что у вас есть экселька со списком клиентов. Это не база данных, это просто таблица. Чтобы прочитать или записать что-то в эту эксельку, вам нужно её открыть, сделать дело, сохранить.
❌ Допустим, экселька с клиентами лежит на сетевом диске. Вы открыли её и ковыряетесь в данных, вносите изменения. Пока вы это делаете, ваш коллега тоже её открыл и тоже вносит изменения. Потом вы сохранились и закрыли эксельку. Экселька перезаписалась вашими данными. Но у вашего коллеги эти данные не отобразились, он-то открыл её раньше. Теперь, когда он сохранит свою эксельку, его данные перезапишутся поверх ваших, а ваши данные пропадут. Это полный ахтунг: вся ваша работа потеряна.
❌ Или у вас в компании правило: экселька всегда на одной флешке, работаем только с неё. Сейчас флешка в вашем компьютере, вы с ней работаете. А вашему коллеге нужно с ней тоже поработать. Он говорит: «Дай». Вы ему «Отстань». Ну и слово за слово…
✅ Но можно организовать своего рода СУБД. Один ответственный сотрудник назначается главным по эксельке. Она открыта на его компьютере, а вы ему говорите: «Петруха, добавь в клиента такого-то вот такие данные». «Петруха, а шо, когда дедлайн по поставке для этих ребят из Воронежа?», «Петруха, питерские отказались, поставь там отказ».
Петруха — ваша система управления базой данных. А экселька — это его база данных.
Понятно, что Петруха медленный и не всегда многозадачный, но хотя бы он избавляет от проблемы рассинхрона версий и потери данных.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
База данных — это отдельный файл?
Чаще всего да, все данные СУБД хранит внутри одного большого файла. Но если данных много или сама база так устроена, то она может разбиваться на несколько файлов поменьше.
Но для пользователей нет разницы, как физически хранится база, это забота СУБД. Главное — уметь общаться с базой через СУБД.
Где их используют
Базы данных сейчас используются почти везде:
- На сайтах, чтобы хранить контент для страниц. Все статьи в «Коде» на самом деле хранятся в базе данных и извлекаются оттуда по вашему запросу.
- В смартфонах, чтобы хранить все ваши данные — фото, сообщения, заметки, контакты и музыку. Так как всего этого много, а доступ к этому должен быть молниеносный, используют разные виды СУБД.
- В почтовых сервисах, чтобы можно было найти нужное письмо. Там строятся сложные индексные массивы, по которым ваш почтовый клиент ищет данные.
- Везде, где есть личные кабинеты и регистрация, — чтобы запоминать пользователей и отличать их друг от друга.
- В соцсетях и блогах почти всё хранится в базах данных.
Если у вас в работе появляется много одинаковых или похожих данных, то самый надёжный способ не потерять ничего из них — поместить их в базу данных.
Как это работает
Возьмём простой пример реляционной базы данных (можно упрощённо сказать, что это база данных в виде таблицы).
Каждая запись в реляционной базе данных раскладывается в одну или несколько ячеек. Например, запись в телефонной книге может выглядеть так:
В нашем примере у базы есть поля — Имя, Фамилия, Телефон и Фото, в которых могут храниться данные. Одна строчка — одна запись с данными.
Если пользователю нужно будет найти телефон Михаила Максимова по фамилии, происходит следующее:
Запрос от пользователя: Выдай мне из базы «Контакты» все записи, где поле «Фамилия» равно «Максимов»
Ответ от базы данных: ЛОЛ КЕК Ты кто такой
Запрос пользователя: Я хозяин этой базы Админ Админыч, пароль •••••. Выдай мне из базы «Контакты» все записи, где поле «Фамилия» равно «Максимов»
Ответ от базы данных: Найдена одна запись: [Михаил, Максимов, +79057362163, вот фото]
Разные базы — разные правила
Внутри каждой базы данных и её управляющей системы свои строгие правила:
- какие данные могут храниться: текст, цифры, фото, видео или всё вместе;
- какие свойства есть у этих данных: дата записи, кто записал, кто может прочитать;
- что делать, если с базой хотят работать одновременно несколько человек: разрешать только одному или пусть все вместе работают.
Рабочая ситуация: допустим, вы работаете в банке и открыли карточку клиента, чтобы поменять ему кредитный лимит. В этот же момент другой сотрудник из соседнего офиса тоже хочет поменять лимит этому же клиенту, но уже на другую сумму. Как база отреагирует на такое? Должна ли она разрешать второму сотруднику открывать карточку или её нужно заблокировать, пока первый не закончит? А если она разрешит открыть карточку, то что будет, если двое сотрудников напишут там разный лимит — какой из них сохранять в итоге? СУБД задаёт эти правила и следит за их выполнением.
Что дальше
В следующей статье поговорим про MySQL — бурерождённую мать всех баз. Если разобраться, как она работает, то можно творить чудеса.
Ключи и ключевые атрибуты в базах данных.
Здравствуйте, уважаемые посетители сайта ZametkiNaPolyah.ru. Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. В данной публикации мы разберем, что такое ключи и ключевые атрибуты в реляционных базах данных, для чего нужны ключевые атрибуты и какими могут быть ключи в базах данных.
Ключи и ключевые атрибуты в базах данных
Рассмотрим одну из самых простых, но очень важных тем в теории баз данных – ключи и ключевые атрибуты.
Давайте посмотрим, какие ключи и ключевые атрибуты бывают в таблицах баз данных:
- Ключи или ключевой атрибут — атрибут (читай столбец) или набор атрибутов, который однозначно идентифицирует сущность/объект/таблицу в базе данных.
- Первичный ключ — ключ, который используется для идентификации объекта.
- Ключ-кандидат (альтернативный ключ) — ключ, по каким-либо причинам неиспользуемый как первичный.
- Составной ключ — ключ, который использует несколько атрибутов.
- Суррогатный ключ — ключ, значение которого генерируется СУБД.
Ключевые атрибуты или ключи по своему виду делятся на: простые и составные, естественные и суррогатные, первичные ключи и ключи кандидаты.
Рассмотрим различие между естественными и суррогатными ключами, естественно, на примере. Для этого обратимся к таблице с городами из базы данных World.
Таблица с суррогатным ключом
В этой таблице ключом является столбец ID, данный столбец автоматически генерируется СУБД при добавлении новой записи в таблицу, следовательно, атрибут ID–суррогатный ключ. В данной таблице мы видим столбец с именем CountryCode, который может выступать в роли ключа для таблицы Country, такой ключ будет естественным.
Как нам определить, что столбец может быть ключом? Есть два очень простых признака того, что столбец является ключом или ключевым атрибутом: ключ уникален и ключ вечен. Но хочу отметить, что ключ – абстрактное понятие. Например, представим, что у нас есть таблица, в которой хранится информация о учениках класса, в принципе, ничего страшного не будет, если в такой таблице столбец ФИО будет выступать в роли ключа. Но, когда наша база данных работает в масштабах города, области, региона или страны, то столбец ФИО никак не может выступать в роли ключа, даже номер паспорта – это не ключ, так как со временем мы меняем паспорт, а у несовершеннолетних его нет.
Поясню принцип составного ключа. Представим, что гражданин Петров был задержан сотрудниками полиции в нетрезвом виде за нарушение правопорядка. По факту задержания составляется рапорт (гражданин Петров не имеет при себе паспорта). Сотрудник полиции в рапорте укажет ФИО задержанного, но ФИО в масштабах города никак не идентифицируют Петрова Петра Петровича, поэтому сотрудник записывает дату рождения, если город большой, то Петр Петрович Петров, родившийся 14 февраля 1987 года в нем не один, поэтому записывается адрес фактического проживание и адрес прописки, для достоверности указывается время задержания. Сотрудник полиции составил набор характеристик, которые однозначно идентифицируют гражданина Петрова. Другими словами, все эти характеристики – составной ключ.
Итак, мы рассмотрели ключи и ключевые атрибуты в базах данных. Надеюсь, что теперь вы разобрались с понятием ключ или ключевой атрибут в реляционной базе данных.
Базы данных и их разновидности
База данных (БД) –это совокупность массивов и файлов данных, организованная по определённым правилам, предусматривающим стандартные принципы описания, хранения и обработки данных независимо от их вида.
Основные классификации баз данных
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям. Основные из них:
- Классификация по модели данных
Центральным понятием в области баз данных является понятие модели.
Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
Виды:
- Иерархическая.
- Объектная и объектно-ориентированная.
- Объектно-реляционная.
- Реляционная.
- Сетевая.
- Функциональная.
1) Иерархическая база данных – каждый объект, при таком хранение информации, представляется в виде определенной сущности, то есть у этой сущности могут быть дочерние элементы, родительские элементы, а у тех дочерних могут быть еще дочерние элементы, но есть один объект, с которого все начинается. Получается своеобразное дерево. Примером иерархической базы данных может быть документ в формате XML или файловая система компьютера.
Следует сказать, что базы данных подобного вида оптимизированы под чтение информации, то есть базы данных, имеющие иерархическую структуру умеют очень быстро выбирать запрашиваемую информацию и отдавать ее пользователям. Но такая структура не позволяет столь же быстро перебирать информацию. Здесь можно привести первый пример из жизни: компьютер может легко работать с каким-либо конкретным файлом или папкой (которые, по сути, являются объектами иерархической структуры), но проверка компьютера антивирусам осуществляется очень долго. Второй пример – реестр Windows.
На изображении Вы можете увидеть структуру иерархической базы данных. В самом верху находится родитель или корневой элемент, ниже находятся дочерние элементы, элементы находящиеся на одном уровне называются братьями или соседними элементами. Соответственно, чем ниже уровень элемента, тем вложенность этого элемента больше.
Объектные базы данных — это модель работы с объектными данными.
Такая модель баз данных, несмотря на то, что она существует уже много лет, считается новой. И её создание открывает большие перспективы, в связи с тем, что использование объектной модели баз данных легко воспринимается пользователем, так как создается высокий уровень абстракции. Объектная модель идеально подходит для трактовки такого рода объектных данных как изображение, музыка, видео, разного вида текст.
Объектно-ориентированная база данных (ООБД) — база данных, в которой данные моделируются в виде объектов, их атрибутов, методов и классов.
Объектно-ориентированные базы данных обычно рекомендованы для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру.
2) Объектно-реляционные СУБД объединяют в себе черты реляционной и объектной моделей. Их возникновение объясняется тем, что реляционные базы данных хорошо работают со встроенными типами данных и гораздо хуже — с пользовательскими, нестандартными. Когда появляется новый важный тип данных, приходится либо включать его поддержку в СУБД, либо заставлять программиста самостоятельно управлять данными в приложении.
Не всякую информацию имеет смысл интерпретировать в виде цепочек символов или цифр. Представим себе музыкальную базу данных. Песню, закодированную в виде аудиофайла, можно поместить в текстовое поле большого размера, но как в таком случае будет ли осуществляться текстовый поиск?
3) Реляционная(или табличная) БД содержит перечень объектов одного типа, т.е. объектов с одинаковым набором свойств.
Такую базу удобно представлять в виде двумерной таблицы (или, чаще всего, нескольких связанных между собой таблиц).
Примером такой таблицы может служить БД «Учащиеся», представляющая собой перечень объектов (учеников), каждый из которых имеет фамилию, имя, отчество, дату рождения, класс, номер личного дела и др.
Столбцы такой таблицы называют полями; каждое поле характеризуется своим именем (названием соответствующего свойства объекта) и типом данных, которые это поле может хранить. Каждое поле обладает определенным набором свойств (размер, формат и т. п.). Т. о., поле БД — это столбец таблицы, содержащий значения определенного свойства объектов.
Строки таблицы являются записями. Записи разбиты на поля. Каждая строка таблицы содержит запись об одном единственном объекте, включая все его свойства.
В каждой таблице должно быть хотя бы одно ключевое поле, содержимое которого уникально для любой записи в этой таблице. Значения ключевого поля однозначно определяют каждую запись в таблице. В приведенном выше примере ключевым полем может являться поле «Номер личного дела». Очень часто в качестве ключевого поля используется поле, содержащее данные типа счетчик.
4) Сетевые базы данных являются своеобразной модификацией иерархических баз данных. Если Вы внимательно смотрели на изображение выше, то наверняка обратили внимание, что к каждому нижнему элементу идет только одна стрелочка от верхнего элемента. То есть у иерархических баз данных у каждого дочернего элемента может быть только один потомок. Сетевые базы данных отличаются от иерархических тем, что у дочернего элемента может быть несколько предков, то есть элементов стоящих выше него. Для большей наглядности и понимания структуры сетевых баз данных обратите внимание на изображение:
Стоит заметить, что сетевые базы данных обладают примерно теми же характеристиками, что и иерархические базы данных. Но сейчас нас не особо интересуют иерархические и сетевые базы данных, данная тема больше относится к формату XML.
5) Функциональные базы данных используются для решения аналитических задач: финансовое моделирование и управление производительностью. Функциональная база данных или функциональная модель отличается от реляционной модели. Функциональная модель также отличается от других аналогично названных концепций, включая модель функциональной базы данных DAPLEX и базы данных функциональных языков.
Функциональная модель является частью категории оперативной аналитической обработки (OLAP электронной таблице,), поскольку она включает многомерное иерархическое объединение. Но она выходит за рамки OLAP, требуя ориентирования ячейки, подобно тому, где ячейки могут быть введены или рассчитаны как функции других ячеек. Также, как и в электронных таблицах, данная модель поддерживает интерактивные вычисления, в которых значения всех зависимых ячеек автоматически обновляются каждый раз, когда изменяется значение ячейки.
- Классификация по содержимому
Примеры:
- Географическая.
- Историческая.
- Научная.
- Мультимедийная.
- Клиентская.
- Классификация по степени распределённости:
- Централизованная или сосредоточенная (англ. centralized database): БД, которая полностью поддерживается на одном компьютере.
- Распределённая (англ. distributed database): БД, составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
- Неоднородная (англ. heterogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД.
- Однородная (англ. homogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
- Фрагментированная или секционированная (англ. partitioned database): методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
- Тиражированная (англ. replicated database): методом распределения данных является тиражирование.
- Классификация БД по среде физического хранения:
- БД во вторичной памяти (традиционные): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — это, как правило, жёсткий диск. В оперативную память СУБД помещает лишь кэш и данные для текущей обработки.
- БД в оперативной памяти (in-memory databases): все данные находятся в оперативной памяти.
- БД в третичной памяти (tertiary databases): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило, на основе магнитных лент или оптических дисков. Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кэш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
SQL
SQL — язык структурированных запросов, основной задачей которого является предоставление простого способа считывания и записи информации в базу данных.
Функции языка SQL:
- Организация данных – создание и изменение структуры баз данных.
- Чтение данных.
- Обработка данных – удаление, добавление и корректировка данных.
- Управление доступа к данным – предоставление привилегий (ограничение возможностей) пользователю для чтения и изменения данных.
- Совместное использование данных — координация общего пользования данных многими пользователями.
- Целостность данных – защита данных от разрушения при сбое системы или других обстоятельствах.
СУБД
Большинство современных СУБД построено на реляционной модели данных. Для получения информации из отношений (таблиц) базы данных в качестве языка манипулирования данными в теоретическом плане используется язык SQL
СУБД — система управления базами данных, совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных
Основные функции СУБД:
- Управление данными во внешней памяти (на дисках).
- Управление данными в оперативной памяти с использованием дискового кэша.
- Журнализация изменений, резервное копирование и восстановление базы данных после сбоев.
- Поддержка языков БД (язык определения данных, язык манипулирования данными).
Типы данных в SQL
Каждый столбец в таблице базы данных должен иметь имя и тип данных.
SQL разработчики должны решить, какие типы данных будут храниться внутри каждого столбца таблицы при создании таблицы SQL. Тип данных представляет собой метку и ориентир для SQL, чтобы понять, какой тип данных, как ожидается, внутри каждого столбца, а также определяет, как SQL будут взаимодействовать с хранимыми данными.
В следующей таблице перечислены общие типы данных в SQL:
SQL Data Type — Краткий справочник в разрезе БД
Тем не менее, различные базы данных предлагают различные варианты для определения типа данных.
В следующей таблице приведены некоторые из общих названий типов данных между различными платформами баз данных:
НОУ ИНТУИТ | Лекция | Базы данных и СУБД. Введение в SQL
Аннотация: В лекции рассматриваются понятия базы данных и СУБД, дается краткое описание существующих типов баз данных (сетевые, реляционные, иерархические). Рассматриваются основы языка запросов SQL: операции выбора, добавления, изменения и удаления строки, а также операции создания, изменения и удаления таблицы. База данных MySql. Использование PhpMyAdmin для взаимодействия с базой данных MySql. Обсуждаются основные принципы отображения объектной модели документа на реляционную структуру базы данных. Пример – проектирование базы данных виртуального музея истории.
В данной лекции мы рассмотрим основные понятия теории баз данных и познакомим читателей с системой управления базами данных MySql, способами работы с ней, ее особенностями и реализацией языка запросов SQL в этой СУБД. В основе приводимых в лекции примеров лежит информационная модель виртуального музея истории информатики. Эта модель есть набор коллекций описания исторических личностей, экспонатов музея (артефактов), статей и изображений.
Базы данных: основные понятия
В жизни мы часто сталкиваемся с необходимостью хранить какую-либо информацию, а потому часто имеем дело и с базами данных. Например, мы используем записную книжку для хранения номеров телефонов своих друзей и планирования своего времени. Телефонная книга содержит информацию о людях, живущих в одном городе. Все это своего рода базы данных. Ну а раз это базы данных, то посмотрим, как в них хранятся данные. Например, телефонная книга представляет собой таблицу (табл. 10.1).
В этой таблице данные – это собственно номера телефонов, адреса и ФИО., т.е. строки «Иванов Иван Иванович», «32-43-12» и т.п., а названия столбцов этой таблицы, т.е. строки «ФИО», «Номер телефона» и «Адрес» задают смысл этих данных, их семантику.
| ФИО | Номер телефона | Адрес |
|---|---|---|
| Иванов Иван Иванович | 32-43-12 | ул. Ленина, 12, 43 |
| Ильин Федор Иванович | 32-32-34 | пр. Маркса, 32, 45 |
Теперь представьте, что записей в этой таблице не две, а две тысячи, вы занимаетесь созданием этого справочника и где-то произошла ошибка (например, опечатка в адресе). Видимо, тяжеловато будет найти и исправить эту ошибку вручную. Нужно воспользоваться какими-то средствами автоматизации. Для управления большим количеством данных программисты (не без помощи математиков) придумали системы управления базами данных ( СУБД ). По сравнению с текстовыми базами данных электронные СУБД имеют огромное число преимуществ, от возможности быстрого поиска информации, взаимосвязи данных между собой до использования этих данных в различных прикладных программах и одновременного доступа к данным нескольких пользователей.
Для точности дадим определение базы данных, предлагаемое Глоссарий.ру
База данных – это совокупность связанных данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования, независимая от прикладных программ. База данных является информационной моделью предметной области. Обращение к базам данных осуществляется с помощью системы управления базами данных ( СУБД ). СУБД обеспечивает поддержку создания баз данных, централизованного управления и организации доступа к ним различных пользователей.
Итак, мы пришли к выводу, что хранить данные независимо от программ, так, что они связаны между собой и организованы по определенным правилам, целесообразно. Но вопрос, как хранить данные, по каким правилам они должны быть организованы, остался открытым. Способов существует множество (кстати, называются они моделями представления или хранения данных). Наиболее популярные – объектная и реляционная модели данных.
Автором реляционной модели считается Э. Кодд, который первым предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение) и показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение.
Таким образом, реляционная база данных представляет собой набор таблиц (точно таких же, как приведенная выше), связанных между собой. Строка в таблице соответствует сущности реального мира (в приведенном выше примере это информация о человеке).
Примеры реляционных СУБД: MySql, PostgreSql.
В основу объектной модели положена концепция объектно-ориентированного программирования, в которой данные представляются в виде набора объектов и классов, связанных между собой родственными отношениями, а работа с объектами осуществляется с помощью скрытых (инкапсулированных) в них методов.
Примеры объектных СУБД: Cache, GemStone (от Servio Corporation), ONTOS (ONTOS).
В последнее время производители СУБД стремятся соединить два этих подхода и проповедуют объектно-реляционную модель представления данных. Примеры таких СУБД – IBM DB2 for Common Servers, Oracle8.
Поскольку мы собираемся работать с Mysql, то будем обсуждать аспекты работы только с реляционными базами данных. Нам осталось рассмотреть еще два важных понятия из этой области: ключи и индексирование, после чего мы сможем приступить к изучению языка запросов SQL.
Ключи
Для начала давайте подумаем над таким вопросом: какую информацию нужно дать о человеке, чтобы собеседник точно сказал, что это именно тот человек, сомнений быть не может, второго такого нет? Сообщить фамилию, очевидно, недостаточно, поскольку существуют однофамильцы. Если собеседник человек, то мы можем приблизительно объяснить, о ком речь, например вспомнить поступок, который совершил тот человек, или еще как-то. Компьютер же такого объяснения не поймет, ему нужны четкие правила, как определить, о ком идет речь. В системах управления базами данных для решения такой задачи ввели понятие первичного ключа.
Первичный ключ (primary key, PK) – минимальный набор полей, уникально идентифицирующий запись в таблице. Значит, первичный ключ – это в первую очередь набор полей таблицы, во-вторых, каждый набор значений этих полей должен определять единственную запись (строку) в таблице и, в-третьих, этот набор полей должен быть минимальным из всех обладающих таким же свойством. Поскольку первичный ключ определяет только одну уникальную запись, то никакие две записи таблицы не могут иметь одинаковых значений первичного ключа .
Например, в нашей таблице (см. выше) ФИО и адрес позволяют однозначно выделить запись о человеке. Если же говорить в общем, без связи с решаемой задачей, то такие знания не позволяют точно указать на единственного человека, поскольку существуют однофамильцы, живущие в разных городах по одному адресу. Все дело в границах, которые мы сами себе задаем. Если считаем, что знания ФИО, телефона и адреса без указания города для наших целей достаточно, то все замечательно, тогда поля ФИО и адрес могут образовывать первичный ключ. В любом случае проблема создания первичного ключа ложится на плечи того, кто проектирует базу данных (разрабатывает структуру хранения данных). Решением этой проблемы может стать либо выделение характеристик, которые естественным образом определяют запись в таблице (задание так называемого логического, или естественного, PK), либо создание дополнительного поля, предназначенного именно для однозначной идентификации записей в таблице (задание так называемого суррогатного, или искусственного, PK). Примером логического первичного ключа является номер паспорта в базе данных о паспортных данных жителей или ФИО и адрес в телефонной книге (таблица выше). Для задания суррогатного первичного ключа в нашу таблицу можно добавить поле id (идентификатор), значением которого будет целое число, уникальное для каждой строки таблицы. Использование таких суррогатных ключей имеет смысл, если естественный первичный ключ представляет собой большой набор полей или его выделение нетривиально.
Кроме однозначной идентификации записи, первичные ключи используются для организации связей с другими таблицами.
Например, у нас есть три таблицы: содержащая информацию об исторических личностях (Persons), содержащая информацию об их изобретениях (Artifacts) и содержащая изображения как личностей, так и артефактов (Images) (рис 10.1).
Первичным ключом во всех этих таблицах является поле id (идентификатор). В таблице Artifacts есть поле author, в котором записан идентификатор, присвоенный автору изобретения в таблице Persons. Каждое значение этого поля является внешним ключом для первичного ключа таблицы Persons. Кроме того, в таблицах Persons и Artifacts есть поле photo, которое ссылается на изображение в таблице Images. Эти поля также являются внешними ключами для первичного ключа таблицы Images и устанавливают однозначную логическую связь Persons-Images и Artifacts-Images. То есть если значение внешнего ключа photo в таблице личности равно 10, то это значит, что фотография этой личности имеет id=10 в таблице изображений. Таким образом, внешние ключи используются для организации связей между таблицами базы данных (родительскими и дочерними) и для поддержания ограничений ссылочной целостности данных.
Рис. 10.1. Пример использования первичных ключей для организации связей с другими таблицами
Индексирование
Одна из основных задач, возникающих при работе с базами данных, – это задача поиска. При этом, поскольку информации в базе данных, как правило, содержится много, перед программистами встает задача не просто поиска, а эффективного поиска, т.е. поиска за сравнительно небольшое время и с достаточной точностью. Для этого (для оптим
НОУ ИНТУИТ | Лекция | Основные понятия баз данных
Аннотация: В лекции рассматривается общий смысл понятий базы данных (БД) и системы управления базами данных (СУБД). Даются основные понятия, относящиеся к базе данных такие, как алгоритм, кортеж, объект, сущность. Основные требования, предъявляемые к банку данных. Определения БД и СУБД.
Цель лекции: Уяснить разницу между базой данных и системой управления базой данных. Ознакомиться с основными требованиями, которые предъявляются к банку данных и основными определениями, относящимися к БД и СУБД.
Рассмотрим общий смысл понятий базы данных (БД) и системы управления базами данных (СУБД).
С самого начала развития вычислительной техники образовались два основных направления использования ее.
Первое направление — применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ.
Второе направление, это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. В самом широком смысле информационная система представляет собой программный комплекс, функции которого состоят в поддержке надежного хранения информации в памяти компьютера, выполнении специфических для данного приложения преобразований информации и/или вычислений, предоставлении пользователям удобного и легко осваиваемого интерфейса. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т.д.
На самом деле, второе направление возникло несколько позже первого. Это связано с тем, что на заре вычислительной техники компьютеры обладали ограниченными возможностями в части памяти. Понятно, что можно говорить о надежном и долговременном хранении информации только при наличии запоминающих устройств, сохраняющих информацию после выключения электрического питания. Оперативная память этим свойством обычно не обладает. В начале, использовались два вида устройств внешней памяти: магнитные ленты и барабаны. При этом емкость магнитных лент была достаточно велика, но по своей физической природе они обеспечивали последовательный доступ к данным. Магнитные же барабаны (они больше всего похожи на современные магнитные диски с фиксированными головками) давали возможность произвольного доступа к данным, но были ограниченного размера.
Легко видеть, что указанные ограничения не очень существенны для чисто численных расчетов. Даже если программа должна обработать (или произвести) большой объем информации, при программировании можно продумать расположение этой информации во внешней памяти, чтобы программа работала как можно быстрее.
С другой стороны, для информационных систем, в которых потребность в текущих данных определяется пользователем, наличие только магнитных лент и барабанов неудовлетворительно. Представьте себе покупателя билета, который стоя у кассы должен дождаться полной перемотки магнитной ленты. Одним из естественных требований к таким системам является средняя быстрота выполнения операций.
Именно требования к вычислительной технике со стороны не численных приложений вызвали появление съемных магнитных дисков с подвижными головками, что явилось революцией в истории вычислительной техники. Эти устройства внешней памяти обладали существенно большей емкостью, чем магнитные барабаны, обеспечивали удовлетворительную скорость доступа к данным в режиме произвольной выборки, а возможность смены дискового пакета на устройстве позволяла иметь практически неограниченный архив данных.
С появлением магнитных дисков началась история систем управления данными во внешней памяти. До этого каждая прикладная программа, которой требовалось хранить данные во внешней памяти, сама определяла расположение каждой порции данных на магнитной ленте или барабане и выполняла обмены между оперативной и внешней памятью с помощью программно-аппаратных средств низкого уровня (машинных команд или вызовов соответствующих программ операционной системы). Такой режим работы не позволяет или очень затрудняет поддержание на одном внешнем носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации данных во внешней памяти.
Историческим шагом стал переход к использованию систем управления файлами. С точки зрения прикладной программы файл — это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Правила именования файлов, способ доступа к данным, хранящимся в файле, и структура этих данных зависят от конкретной системы управления файлами и, возможно, от типа файла. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса внешней памяти и обеспечение доступа к данным.
Любая задача обработки информации и принятия решений может быть представлена в виде схемы, показанной на рис. 1.1.
Рис. 1.1. Схема решения задач обработки информации и принятия решений: x-штрих, y-штрих — входная и выходная информация; f — внутреннее операторное описание
Определение основных терминов
Дадим определения основных терминов. В качестве составных частей схемы выделяются информация (входная и выходная) и правила ее преобразования.
Правила могут быть в виде алгоритмов, процедур и эвристических последовательностей.
| Алгоритм | — последовательность правил перехода от исходных данных к результату. Правила могут выполняться компьютером или человеком. |
| Данные | — совокупность объективных сведений. |
| Информация | — сведения, неизвестные ранее получателю информации, пополняющие его знания, подтверждающие или опровергающие положения и соответствующие убеждения. Информация носит субъективный характер и определяется уровнем знаний субъекта и степенью его восприятия. Информация извлекается субъектом из соответствующих данных. |
| Знания | — совокупность фактов, закономерностей и эвристических правил, с помощью которых решается поставленная задача. |
Последовательность операций обработки данных называют информационной технологией (ИТ). В силу значительного количества информации в современных задачах она должна быть упорядочена. Существует два подхода к упорядочению.
- Данные связаны с конкретной задачей (технология массивов) — упорядочение по использованию. Вместе с тем алгоритмы более подвижны (могут чаще меняться), чем данные. Это вызывает необходимость переупорядочения данных, которые к тому же могут повторяться в различных задачах.
- В связи с этим предложена другая, широко используемая технология баз данных, представляющая собой упорядочение по хранению.
| КОДАСИЛ (CODASYL) | — набор стандартов для сетевых БД. |
| Кортеж | — совокупность полей или запись. |
| Объект | — термин, обозначающий факт, лицо, событие, предмет, о котором могут быть собраны данные. |
| Сущность | — примитивный объект данных, отображающий элемент предметной области (человек, место, вещь и т.д.). |
Под базой данных (БД) понимают совокупность хранящихся вместе данных при наличии такой минимальной избыточности, которая допускает их использование оптимальным образом для одного или нескольких приложений. Целью создания баз данных, как разновидности информационной технологии и формы хранения данных, является построение системы данных, не зависящих от принятых алгоритмов (программного обеспечения), применяемых технических средств и физического расположения данных в ЭВМ; обеспечивающих непротиворечивую и целостную информацию при нерегламентируемых запросах. БД предполагает многоцелевое ее использование (несколько пользователей, множество форм документов и запросов одного пользователя).
База знаний (БЗ) представляет собой совокупность БД и используемых правил, полученных от лиц, принимающих решения (ЛПР).
Наряду с понятием «база данных» существует термин «банк данных», который имеет две трактовки.
- В настоящее время данные обрабатываются децентрализовано (на рабочих местах) с помощью персональных компьютеров (ПК). Первоначально же использовалась централизованная обработка на больших ЭВМ. В силу централизации базу данных называли банком данных и потому часто не делают различия между базами и банками данных.
- Банк данных — база данных и система управления ею (СУБД). СУБД (например, FoxPro) представляет собой приложение для создания баз данных как совокупности двумерных таблиц.
| Банк данных (БнД) | — это система специально организованных данных, программных, языковых, организационных и технических средств, предназначенных для централизованного накопления и коллективного многоцелевого использования данных. |
| Базы данных (БД) | — это именованная совокупность данных, отображающая состояние объектов и их отношения в рассматриваемой предметной области. Характерной чертой баз данных является постоянство: данные постоянно накапливаются и используются; состав и структура данных, необходимы для решения тех или иных прикладных задач, обычно постоянны и стабильны во времени; отдельные или даже все элементы данных могут меняться — но и это есть проявления постоянства — постоянная актуальность. |
| Система управления базами данных (СУБД) | — это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями. |
Иногда в составе банка данных выделяют архивы. Основанием для этого является особый режим использования данных, когда только часть данных находится под оперативным управлением СУБД. Все остальные данные обычно располагаются на носителях, оперативно не управляемых СУБД. Одни и те же данные в разные моменты времени могут входить как в базы данных, так и в архивы. Банки данных могут не иметь архивов, но если они есть, то в состав банка данных может входить и система управления архивами.
Эффективное управление внешней памятью являются основной функцией СУБД. Эти обычно специализированные средства настолько важны с точки зрения эффективности, что при их отсутствии система просто не сможет выполнять некоторые задачи уже по тому, что их выполнение будет занимать слишком много времени. При этом ни одна из таких специализированных функций не является видимой для пользователя. Они обеспечивают независимость между логическим и физическим уровнями системы: прикладной программист не должен писать программы индексирования, распределять память на диске и т. д.
Основные требования, предъявляемые к банкам данных
Развитие теории и практики создания информационных систем, основанных на концепции баз данных, создание унифицированных методов и средств организации и поиска данных позволяют хранить и обрабатывать информацию о все более сложных объектах и их взаимосвязях, обеспечивая многоаспектные информационные потребности разных пользователей. Основные требования, предъявляемые к банкам данных, можно сформулировать так:
- Многократное использование данных: пользователи должны иметь возможность использовать данные различным образом.
- Простота: пользователи должны иметь возможность легко узнать и понять, какие данные имеются в их распоряжении.
- Легкость использования: пользователи должны иметь возможность осуществлять (процедурно) простой доступ к данным, при этом все сложности доступа к данным должны быть скрыты в самой системе управления базами данных.
- Гибкость использования: обращение к данным или их поиск должны осуществляться с помощью различных методов доступа.
- Быстрая обработка запросов на данные: запросы на данные должны обрабатываться с помощью высокоуровневого языка запросов, а не только прикладными программами, написанными с целью обработки конкретных запросов.
- Язык взаимодействия конечных пользователей с системой должен обеспечивать конечным пользователям возможность получения данных без использования прикладных программ.
База данных — это основа для будущего наращивания прикладных программ: базы данных должны обеспечивать возможность быстрой и дешевой разработки новых приложений.
- Сохранение затрат умственного труда: существующие программы и логические структуры данных не должны переделываться при внесении изменений в базу данных.
- Наличие интерфейса прикладного программирования: прикладные программы должны иметь возможность просто и эффективно выполнять запросы на данные; программы должны быть изолированными от расположения файлов и способов адресации данных.
- Распределенная обработка данных: система должна функционировать в условиях вычислительных сетей и обеспечивать эффективный доступ пользователей к любым данным распределенной БД, размещенным в любой точке сети.
- Адаптивность и расширяемость: база данных должна быть настраиваемой, причем настройка не должна вызывать перезаписи прикладных программ. Кроме того, поставляемый с СУБД набор предопределенных типов данных должен быть расширяемым — в системе должны иметься средства для определения новых типов и не должно быть различий в использовании системных и определенных пользователем типов.
- Контроль целостности данных: система должна осуществлять контроль ошибок в данных и выполнять проверку взаимного логического соответствия данных.
- Восстановление данных после сбоев: автоматическое восстановление без потери данных транзакции. В случае аппаратных или программных сбоев система должна возвращаться к некоторому согласованному состоянию данных.
- Вспомогательные средства должны позволять разработчику или администратору базы данных предсказать и оптимизировать производительность системы.
- Автоматическая реорганизация и перемещение: система должна обеспечивать возможность перемещения данных или автоматическую реорганизацию физической структуры.
Компоненты банка данных
Определение банка данных предполагает, что с функционально-организационной точки зрения банк данных является сложной человеко-машинной системой, включающей в себя все подсистемы, необходимые для надежного, эффективного и продолжительного во времени функционирования.
В структуре банка данных выделяют следующие компоненты:
- Информационная база;
- Лингвистические средства;
- Программные средства;
- Технические средства;
Что такое база данных?
База данных — это набор данных. Это может показаться слишком упрощенным, но в значительной степени суммирует, что такое любая база данных.
База данных может быть такой же простой, как текстовый файл со списком имен. Или это может быть такая же сложная система, как большая система управления реляционной базой данных, со встроенными инструментами, которые помогут вам поддерживать данные.
Методы хранения данных
Прежде чем мы перейдем к выделенным системам управления базами данных, давайте рассмотрим некоторые распространенные методы хранения данных.
Текстовый файл
Представьте, что у нас есть текстовый файл с именем Artists.csv , и его содержимое выглядит как на снимке экрана.
Это текстовый файл. В частности, это файл со значениями, разделенными запятыми (CSV). Запятые разделяют каждое поле в строке.
Запятые определяют структуру. Это позволяет нам отличить идентификатор исполнителя от имени исполнителя.Мы могли бы легко добавить больше полей и разделить их запятыми.
Каждая строка представляет отдельную запись. В этом случае каждая строка представляет отдельного исполнителя.
Технически это база данных. Он содержит данные, структурированные таким образом, чтобы их было легко извлечь.
С таким небольшим списком текстовый файл может идеально служить нашим целям.
Таблица
Другой вариант — сохранить данные в электронной таблице с помощью программного обеспечения для работы с электронными таблицами (например, Microsoft Excel).Таким образом, мы могли бы сделать некоторые дополнительные вещи с нашим списком (например, отформатировать его, отсортировать по имени исполнителя и т. Д.).
Программа для работы с электронными таблицами, такая как Excel, упрощает выполнение этих задач. Кроме того, такие программы, как Excel, организуют данные в строки и столбцы, что упрощает понимание ваших данных.
Программное обеспечение для баз данных
Лучшим вариантом было бы хранить данные в таблице базы данных с помощью специального программного обеспечения для баз данных, например Microsoft Access.
Подобные системы управления базами данныхсозданы специально для хранения и поиска данных.
Так в чем же разница?
Вам может быть интересно, в чем разница между двумя последними примерами (Excel и Access). В конце концов, в обоих примерах данные организованы в строки и столбцы.
Между программами для работы с электронными таблицами и базами данных существует много различий. Остальная часть этого руководства покажет вам, почему программное обеспечение баз данных является гораздо лучшим вариантом для создания баз данных.
Что такое система управления базами данных — DBMS Tutotials
Что такое СУБД? Пользователи, типы, архитектура, функции, примеры. Вы можете найти множество руководств по СУБД, где они дадут вам краткое введение в некоторые концепции СУБД. Но здесь мы составили для вас полное руководство по системе управления базами данных. В этой статье вы узнаете все подробности о СУБД из истории, от настоящего до будущего. Ниже приводится таблица содержания по различным темам СУБД.
Что такое СУБД? Пользователи, типы, архитектура, функции, примеры.
Традиционная файловая система
До того, как компьютер перестал существовать, для ручного хранения данных и записей использовалась файловая система. Файлы использовались для хранения данных, а также облегчили поиск любой информации из файлов. Но область применения этой системы значительно меньше в небольших организациях, но она хороша для небольшого количества данных в небольших организациях.
Чтобы преодолеть проблемы ручной файловой системы, была представлена традиционная файловая система, которая была полностью основана на компьютере. В этой системе вся информация хранится в разных файлах компьютера. В нем также хранятся все данные таким образом, чтобы отделам крупных отраслей было легко иметь свои разные файлы, и это обеспечивает избыточность данных.
В качестве примера, чтобы лучше понять утверждение, мы возьмем пример данных колледжа, где данные студентов хранятся в трех разных файлах, таких как отдельный файл данных для библиотеки, второй — для экзаменов, а последний. хранится для регистрации.Все эти файлы создают повторяющиеся данные, такие как количество учащихся, их имя и имя отца.
Чтобы прояснить эту концепцию, воспользуйтесь простой схемой, представленной ниже:
Данные и независимость — основные моменты на этой диаграмме. Это означает, что данные и программы зависят друг от друга. Из-за этой зависимости изменения в одном файле могут повлиять и на другие файлы.
Ниже приведены некоторые характеристики традиционной файловой системы:
- Все данные организации хранятся в группе файлов.
- Все файлы данных зависят друг от друга.
- Файлы созданы с помощью таких языков программирования, как COBOL, C и C ++.
- Данные, хранящиеся в каждом файле, относятся к определенной области, такой как плата за обучение, библиотека и студенческие экзамены.
- Гибкость довольно низкая и содержит ряд ограничений.
- Трудно поддерживать систему обработки файлов.
- Одно изменение в одном файле может повлиять и на другие, увеличивая нагрузку на программиста.
- Плоские файлы — это файлы, хранящиеся в традиционных системах обработки файлов.
В целом, эта система является хорошим подходом для хранения файлов данных по сравнению с ручной системой хранения, но все же у нее было много ограничений, которые можно преодолеть только с помощью системы управления базами данных.
Также читайте: Узнайте больше о традиционной файловой системе
Что такое база данных?
База данных — это набор организованных данных, которые упрощают доступ, управление, манипулирование и обновление.Короче говоря, это упрощает управление данными. Более того, данные могут быть в любой форме, относящиеся к фактам, таким как изображения, файл, изображения, PDF-файлы и так далее.
Вот несколько примеров из нашей повседневной жизни. Например, онлайн-телефонный справочник использует базу данных для всех данных, связанных с клиентами, включая их имя, контактный номер, адрес и так далее. В то же время база данных также используется в электроэнергетических службах для обработки счетов, вопросов, связанных с клиентами, управления данными о неисправностях и многого другого.Более того, вы также можете взять пример Facebook, которому необходимо хранить все данные, относящиеся к их участникам, друзьям, действиям, сообщениям и рекламным объявлениям.
Также читайте: Узнайте больше о базе данных
История СУБД
База данных возникла еще до изобретения компьютера, так как она нужна в библиотеках, правительственных, деловых и медицинских записях. Более того, было замечено, что им требовалось поддерживать и хранить данные для поиска, и в то время они находили некоторые способы.С появлением компьютера это становится довольно просто, экономно по времени и требует меньше места для сбора и обслуживания базы данных.
- Древние времена: ОЗУ было дорогим и ограниченным, что снижает производительность программиста.
- 1960-е: файловая система и данные, хранящиеся в плоском файле.
- 1970-е: Эра нереляционных баз данных (модель CODASYL DSTG, популярна была IDMS)
- 1980-е: Эра реляционных баз данных и систем управления базами данных (СУБД).
- 1990-е годы: эпоха OODBMS, ORDBMS и XML
- Early 21 st : началось с проблемы 2000 года (2000 года), и прямо сейчас для обработки всех баз данных используются Sybase или SQL Server Transact SQL, PostgresSQL и Oracle PL или SQL. IBM, Microsoft и Oracle доминировали на рынке баз данных
Введение в СУБД
Система управления базами данных, т.е. СУБД, представляет собой набор программ для управления данными и одновременно поддерживает разные типы пользователей для создания, управления, извлечения, обновления и хранения информации.
Например, от небольшой начинающей фирмы до транснациональных компаний и отраслей, управляющих огромным объемом данных, становится беспорядок. Таким образом, программное обеспечение, такое как СУБД, произвело революцию во многих областях в отношении эффективного управления информацией.
СУБД и файловая система
Ниже приведены различия между СУБД и файловой системой:
| Основа разницы | Система управления базами данных | Файловая система |
| Требования к пользователю | Это набор данных, и пользователю не требуется писать процессы в СУБД. | Это также набор данных, но пользователю необходимо написать процедуры для работы с базой данных. |
| Механизм защиты | СУБДобеспечивает блестящий механизм защиты. | Сложно защитить файл. |
| Методы | Он имеет множество различных методов для хранения и извлечения данных. | Неэффективно хранить данные и извлекать их надлежащим образом. |
| Блокировка | Он использует своего рода блокировку для контроля несанкционированного доступа к данным. | В системе данных этого типа нет контроля над перенаправлением и обновлением информации. |
| Резервирование данных | Минимизирует вероятность дублирования данных. | Резервирование данных больше в этом типе системы. |
| Несогласованность данных | Меньше противоречивости в данных. | Дополнительная несогласованность данных. |
Определение СУБД
- По словам Пракаша Навина, «База данных — это механизированная совместно используемая, формально определенная и централизованная система сбора данных, используемая в организации.”
- М. Мартин Описал: «База данных — это набор взаимосвязанных данных, хранящихся вместе без вредной или ненужной избыточности для обслуживания нескольких приложений». В словаре
- Mac-Millan по информационным технологиям база данных объясняется как «набор взаимосвязанных данных, хранящихся таким образом, чтобы к ним могли получить доступ авторизованные пользователи с помощью простых удобных диалогов».
Функции СУБД
Основным мотивом разработки системы управления базами данных является управление информацией в целом.Его цель — сделать данные легкодоступными, быстрыми, менее затратными и гибкими для пользователей.
- Это уменьшает дублирование данных и минимизирует избыточность данных. Таким образом, дополнительное пространство, занятое дублированными данными, можно использовать для других целей, и больше не будет потерь пространства.
- СУБД проста в использовании и изучении. Кроме того, пакеты СУБД удобны и очень гибки.
- Существует независимость данных, поскольку пользователь может вносить изменения на любом уровне базы данных, не оказывая отрицательного воздействия на другие уровни, такие как аппаратные и программные процессы.
- Этот экономически выгоден всем. Можно использовать, хранить и манипулировать данными по очень доступной цене.
- Он может быть доступен нескольким пользователям и помогает восстанавливать данные, если они не были сохранены пользователем. Система может легко восстановить данные в кратчайшие сроки, при этом сохраняя точность и целостность.
- Он предотвращает несанкционированный доступ к данным, и данные остаются конфиденциальными. Благодаря централизованному контролю СУБД обеспечивает надлежащую безопасность данных.
- Это полезно для получения, анализа и хранения данных.
Архитектура СУБД
Дизайн СУБД зависит от ее архитектуры. Большой объем данных на персональных компьютерах, веб-серверах, серверах баз данных и других элементах, связанных с сетями, может обрабатываться с помощью базовой клиентской или серверной архитектуры. Многие ПК и рабочие станции являются частью клиентской архитектуры, которая подключена по сети. Архитектура СУБД зависит от того, как пользователи связаны с базой данных.Ниже будут рассмотрены три типа архитектуры СУБД:
- Архитектура уровня 1 : В этом типе архитектуры данные напрямую предоставляются заказчику, и пользователь может напрямую использовать базу данных через
Что такое база данных?
Обновлено: 16.11.2019 компанией Computer Hope
Также называемая банком данных или хранилищем данных , а иногда сокращенно DB , база данных представляет собой большое количество индексированной цифровой информации.Его можно искать, ссылаться, сравнивать, изменять или иным образом манипулировать с оптимальной скоростью и минимальными затратами на обработку.
База данных создается и поддерживается с помощью языка программирования баз данных. Наиболее распространенным языком баз данных является SQL, но существует несколько разновидностей SQL, в зависимости от типа используемой базы данных. Каждый вариант SQL имеет различный синтаксис SQL и предназначен для использования с конкретным типом базы данных. Например, база данных Oracle использует PL / SQL и Oracle SQL (версия SQL для Oracle).База данных Microsoft использует T-SQL (Transact-SQL).
НаконечникПрограмма, использующая базу данных, иногда называется ядром базы данных .
Компоненты базы данных
База данных состоит из нескольких основных компонентов.
- Схема — База данных содержит одну или несколько схем, которые представляют собой набор из одной или нескольких таблиц данных.
- Таблица — Каждая таблица содержит несколько столбцов, которые похожи на столбцы в электронной таблице.В таблице может быть от двух столбцов до 4096, в зависимости от типа хранимых данных.
- Столбец — Каждый столбец содержит один из нескольких типов данных или значений, таких как даты, числовые или целочисленные значения и буквенно-цифровые значения (также известные как varchar).
- Строка — данные в таблице перечислены в строках, которые похожи на строки данных в электронной таблице. Часто в таблице есть сотни или тысячи строк данных.
Как произносится «база данных»?
Произношение «база данных» зависит от того, как вы произносите слово «данные», которое варьируется во всем мире.См. Наше определение данных для получения дополнительной информации.
Связанные страницы
- Computer Hope можно рассматривать как базу данных бесплатной компьютерной информации.
Доступ, Запись добавления, Компьютерные сокращения, Термины базы данных, DBASE, СУБД, Распределенная база данных, eXist, Плоский файл, FoxPro, MySQL, Pick, PostgreSQL, QBE, RDBMS, RDMS
Что такое диаграмма отношений сущностей (ERD)?
База данных— это абсолютно неотъемлемая часть программных комплексов. Полноценное использование ER-диаграммы в проектировании баз данных гарантирует вам создание высококачественного дизайна базы данных для использования при создании, управлении и обслуживании баз данных.Модель ER также предоставляет средства для общения.
Сегодня мы расскажем вам все, что вам нужно знать об ER-диаграммах. Прочитав это руководство по ERD, вы получите необходимые знания и навыки о диаграммах ER и проектировании баз данных. Вы узнаете такие вещи, как ERD, почему ERD, обозначения ERD, как рисовать ERD и т. Д., А также множество примеров ERD.
Вы ищете бесплатный инструмент ERD для более быстрого, простого и быстрого создания моделей данных? Visual Paradigm Community Edition предоставляет вам редактор ERD для проектирования баз данных.Это отмеченный международными наградами разработчик моделей, при этом он прост в использовании, интуитивно понятен и полностью бесплатен.
Скачать бесплатноЧто такое диаграмма ER (ERD)?
Прежде всего, что такое диаграмма отношений сущностей?
Entity Relationship Diagram, также известная как ERD, ER-диаграмма или ER-модель, представляет собой тип структурной диаграммы для использования при проектировании базы данных. ERD содержит различные символы и соединители, которые визуализируют две важные информации: Основные сущности в области действия системы и взаимосвязи между этими сущностями .
И поэтому она называется диаграммой «Сущность» и «Связь» (ERD)!
Когда мы говорим об объектах в ERD, очень часто мы имеем в виду бизнес-объекты, такие как люди / роли (например, Студент), материальные бизнес-объекты (например, Продукт), нематериальные бизнес-объекты (например, журнал) и т. Д. «Взаимосвязь» касается как эти объекты соотносятся друг с другом в системе.
В типичном дизайне электронной отчетности можно найти символы, такие как прямоугольники со скругленными углами и соединители (с разными стилями их концов), которые изображают сущности, их атрибуты и взаимосвязи.
Когда рисовать диаграммы ER?
Итак, когда мы будем рисовать ERD? Хотя модели ER в основном разрабатываются для проектирования реляционных баз данных с точки зрения визуализации концепций и с точки зрения физического дизайна базы данных, существуют и другие ситуации, когда диаграммы ER могут помочь. Вот несколько типичных случаев использования.
- Дизайн базы данных — В зависимости от масштаба изменений, изменение структуры базы данных непосредственно в СУБД может быть рискованным. Чтобы не испортить данные в производственной базе данных, важно тщательно спланировать изменения.ERD — это инструмент, который помогает. Рисуя ER-диаграммы для визуализации идей дизайна базы данных, у вас есть возможность выявить ошибки и недостатки дизайна, а также внести исправления перед внесением изменений в базу данных.
- Отладка базы данных — Отладка проблем с базой данных может быть сложной задачей, особенно когда база данных содержит много таблиц, которые требуют написания сложного SQL для получения необходимой информации. Визуализируя схему базы данных с помощью ERD, вы получаете полную картину всей схемы базы данных.Вы можете легко находить объекты, просматривать их атрибуты и определять отношения, которые они имеют с другими. Все это позволяет анализировать существующую базу данных и легче выявлять проблемы с базой данных.
- Создание базы данных и установка исправлений — Visual Paradigm, инструмент ERD, поддерживает инструмент создания базы данных, который может автоматизировать процесс создания базы данных и исправления с помощью диаграмм ER. Таким образом, с помощью этого инструмента ER-диаграммы ваша ER-структура больше не является статической диаграммой, а является зеркалом, которое действительно отражает физическую структуру базы данных.
- Помощь в сборе требований — Определите требования информационной системы, нарисовав концептуальную ERD, которая отображает бизнес-объекты высокого уровня системы. Такую начальную модель также можно развить в физическую модель базы данных, которая помогает создавать реляционную базу данных или помогает в создании карт процессов и режимов потока данных.
Руководство по нотациям ERD
Диаграмма ER содержит сущности, атрибуты и отношения.В этом разделе мы подробно рассмотрим символы ERD.
Организация
Сущность ERD — это определяемая вещь или концепция в системе , такая как человек / роль (например, студент), объект (например, счет-фактура), концепция (например, профиль) или событие (например, транзакция) (примечание: в ERD, термин «сущность» часто используется вместо «таблица», но они одинаковы). При определении сущностей воспринимайте их как существительные. В моделях электронной отчетности объект отображается в виде прямоугольника с закругленными углами, его имя находится вверху, а его атрибуты перечислены в теле формы объекта.В приведенном ниже примере ERD показан пример объекта ER.
Атрибуты объекта
Также известный как столбец, атрибут — это свойство или характеристика объекта, который его содержит .
Атрибут имеет имя, которое описывает свойство, и тип, который описывает тип атрибута, например, varchar для строки и int для целого числа. Когда ERD создается для разработки физической базы данных, важно обеспечить использование типов, которые поддерживаются целевой СУБД.
На приведенном ниже примере ER-диаграммы показан объект с некоторыми атрибутами.
Первичный ключ
Также известный как PK, первичный ключ — это особый вид атрибута объекта, который однозначно определяет запись в таблице базы данных . Другими словами, не должно быть двух (или более) записей с одинаковым значением атрибута первичного ключа. В приведенном ниже примере ERD показан объект «Продукт» с атрибутом первичного ключа «ID» и предварительный просмотр записей таблицы в базе данных.Третья запись недействительна, поскольку значение идентификатора «PDT-0002» уже используется другой записью.
Внешний ключ
Также известный как FK, внешний ключ — это ссылка на первичный ключ в таблице . Он используется для определения отношений между сущностями. Обратите внимание, что внешние ключи не обязательно должны быть уникальными. Несколько записей могут иметь одни и те же значения. В приведенном ниже примере ER-диаграммы показан объект с некоторыми столбцами, среди которых внешний ключ используется для ссылки на другой объект.
Отношения
Связь между двумя объектами означает, что два объекта связаны друг с другом каким-то образом . Например, студент может записаться на курс. Таким образом, объект «Студент» связан с Курсом, и связь представлена как соединительный элемент между ними.
Мощность
Количество элементов определяет возможное количество вхождений в одном объекте, которое связано с количеством вхождений в другом .Например, в ОДНОЙ команде МНОГИЕ игроков. Находясь в ERD, команда сущности и игрок связаны отношениями «один ко многим».
На диаграмме ER мощность представлена в виде гусиной лапки на концах соединителя. Три основных кардинальных отношения — один к одному, один ко многим и многие ко многим.
Пример однозначного числа элементов
Отношение «один-к-одному» в основном используется для разделения объекта на две части, чтобы предоставить информацию кратко и сделать ее более понятной.На рисунке ниже показан пример однозначного отношения.
Пример мощности «один ко многим»
Отношение «один ко многим» относится к отношениям между двумя объектами X и Y, в которых экземпляр X может быть связан со многими экземплярами Y, но экземпляр Y связан только с одним экземпляром X. Рисунок ниже показывает пример отношения «один ко многим».
Пример числа «многие ко многим»
Отношение «многие ко многим» относится к отношениям между двумя объектами X и Y, в которых X может быть связан со многими экземплярами Y и наоборот.На рисунке ниже показан пример отношения «многие ко многим». Обратите внимание, что отношение «многие ко многим» разделено на пару отношений «один ко многим» в физическом ERD. В следующем разделе вы узнаете, что такое физический ERD.
Концептуальные, логические и физические модели данных
ER-модель обычно строится на трех уровнях абстракции:
Хотя все три уровня модели ER содержат сущности с атрибутами и отношениями, они различаются целями, для которых они созданы, и аудиториями, для которых они предназначены.
Общее понимание трех моделей данных состоит в том, что бизнес-аналитик использует концептуальную и логическую модель для моделирования бизнес-объектов, существующих в системе, в то время как разработчик базы данных или инженер базы данных разрабатывает концептуальную и логическую модель ER для создания физической модели, которая представляет собой физическая структура базы данных готова для создания базы данных. В таблице ниже показаны различия между тремя моделями данных.
Концептуальная модель против логической модели против модели данных:
| Характеристики ERD | Концептуальный | Логический | Физический |
|---|---|---|---|
| Организация (название) | Есть | Есть | Есть |
| Отношения | Есть | Есть | Есть |
| Колонны | Есть | Есть | |
| Типы столбцов | Дополнительно | Есть | |
| Первичный ключ | Есть | ||
| Внешний ключ | Есть |
Концептуальная модель данных
Conceptual ERD моделирует бизнес-объектов, которые должны существовать в системе, и отношения между ними .Концептуальная модель разработана для представления общей картины системы путем распознавания вовлеченных бизнес-объектов. Он определяет, какие сущности существуют, а НЕ какие таблицы. Например, таблицы «многие ко многим» могут существовать в логической или физической модели данных, но они просто показаны как отношения без количества элементов в концептуальной модели данных.
Пример концептуальной модели данных
ПРИМЕЧАНИЕ. Концептуальный ERD поддерживает использование обобщения при моделировании «своего рода» отношений между двумя объектами, например, треугольник является разновидностью формы.Использование похоже на обобщение в UML. Обратите внимание, что только концептуальный ERD поддерживает обобщение.
Логическая модель данных
Logical ERD — это подробная версия концептуального ERD . Логическая модель ER разработана для обогащения концептуальной модели путем явного определения столбцов в каждой сущности и введения операционных и транзакционных сущностей. Хотя логическая модель данных по-прежнему не зависит от фактической системы базы данных, в которой будет создана база данных, вы все равно можете принять это во внимание, если это повлияет на дизайн.
Пример логической модели данных
Физическая модель данных
Physical ERD представляет собой реальный проект реляционной базы данных . Физическая модель данных развивает логическую модель данных, присваивая каждому столбцу тип, длину, допускающее значение NULL и т. Д. Поскольку физический ERD представляет, как данные должны быть структурированы и связаны в конкретной СУБД, важно учитывать соглашение и ограничение фактическая система базы данных, в которой будет создана база данных.Убедитесь, что типы столбцов поддерживаются СУБД и зарезервированные слова не используются при именовании сущностей и столбцов.
Пример физической модели данных
Как нарисовать диаграмму ER?
Если вам трудно начать рисовать диаграмму ER, не волнуйтесь. В этом разделе мы дадим вам несколько советов по ERD. Попробуйте выполнить следующие шаги, чтобы понять, как эффективно нарисовать диаграмму ER.
- Убедитесь, что вы четко понимаете цель рисования ERD.Вы пытаетесь представить общую архитектуру системы, которая включает определение бизнес-объектов? Или вы разрабатываете ER-модель, готовую для создания базы данных? Вы должны четко понимать цель разработки ER-диаграммы на нужном уровне детализации (более подробно читайте в разделе Концептуальные, логические и физические модели данных)
- Убедитесь, что вы четко представляете объем модели. Знание области моделирования не позволяет вам включать в проект избыточные объекты и связи.
- Нарисуйте основные объекты, участвующие в области.
- Определите свойства сущностей, добавив столбцы.
- Внимательно просмотрите ERD и проверьте, достаточно ли сущностей и столбцов для хранения данных системы. Если нет, рассмотрите возможность добавления дополнительных сущностей и столбцов. Обычно на этом этапе можно идентифицировать некоторые транзакционные, операционные и событийные сущности.
- Рассмотрите отношения между всеми сущностями и соотнесите их с надлежащей мощностью (например,g Связь «один ко многим» между сущностью «Клиент» и «Заказ»). Не беспокойтесь, если есть сиротские сущности. Хотя это нечасто, но вполне законно.
- Примените метод нормализации базы данных для реструктуризации сущностей таким образом, чтобы уменьшить избыточность данных и улучшить целостность данных. Например, сведения о производителе могут изначально храниться в сущности Product. В процессе нормализации вы можете обнаружить, что детали повторяют записи по записям, затем вы можете разделить их как отдельную сущность «Изготовитель» и с внешним ключом, связывающим Продукт и «Изготовитель».
Примеры моделей данных
Пример ERD — Система проката фильмов
Пример ERD — Кредитная система
ПримерERD — Интернет-магазин
Использование ERD с диаграммой потока данных (DFD)
В системном анализе и проектировании, поток данных D
.