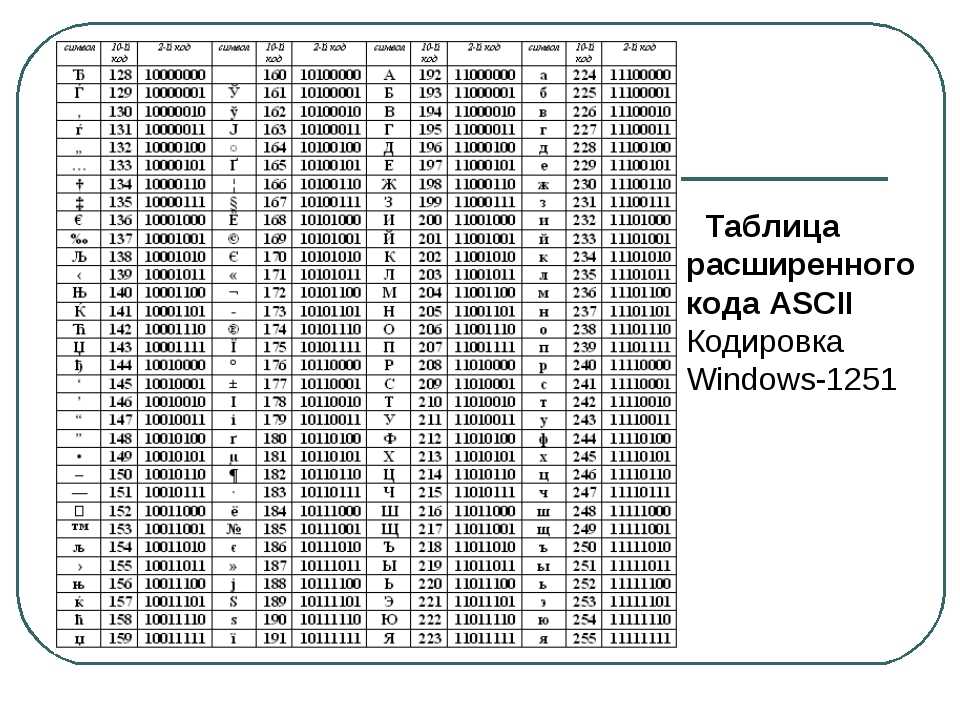
В какой кодировке всё же лучше делать сайт?
По моим ощущениям люди часто не делают различий между понятиями «набор символов» и «кодировка», а зря. В большинстве кодировок разница, возможно, и невелика, но имея дело с Юникодом, нужно чётко понимать что есть что. Особенно больно по этим граблям ходят изучающие язык Python.
Набор символов (character set) — это некий набор значков, символов, каждому символу приписан номер.
Кодировка (encoding) — это способ представить (т. е. закодировать) последовательность из символов в виде последовательности байтов.
Рассмотрим пару примеров.
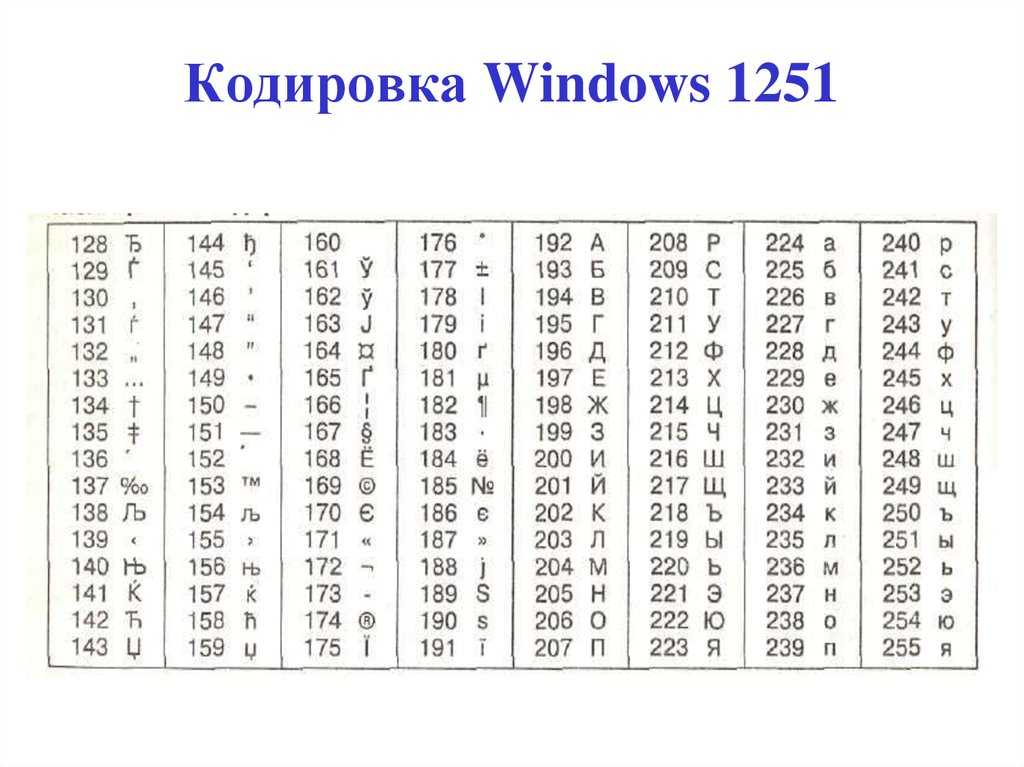
В набор символов Windows-1251 (http://en.wikipedia.org/wiki/Windows-1251) входят 256 различных символов со своими номерами. Символ «0» имеет номер 48, символ «R» — номер 82, символ «ы» — 251. Ещё раз — это пока абстрактный набор, просто список, который существует только в головах программистов.
Теперь рассмотрим кодировку Windows-1251. Эта кодировка позволяет представить символы из набора Windows-1251 в виде последовательности байтов.
Набор символов ASCII содержит всего 128 символов. Кодировка ASCII тоже прямолинейна — берём и пишем в байт номер символа. Кстати, получается, что не всякую последовательность байтов можно считать текстом, закодированным с помощью ASCII: байтами со значением больше 127 никакие символы ASCII не кодируются.
Из-за того, что подобные кодировки записывали символы просто как их номера из набора, разница между этими понятиями была довольно размыта. С Юникодом дело обстоит иначе, здесь эта разница существенна.
Юникод — это набор символов (с номерами), в котором стараются собрать все-все алфавиты и даже больше.
Кодировок для этого набора придумали множество. Кодировка USC-2, например, устроена примерно как и Windows-1251: берём номер символа и записываем его как два байта. Увы, в два байта можно записать только значения от 0 до 65535, то есть USC-2 позволяет закодировать только часть знаков Юникода, да и то довольно накладным образом: любой символ, даже латинский, кодируются двумя байтами.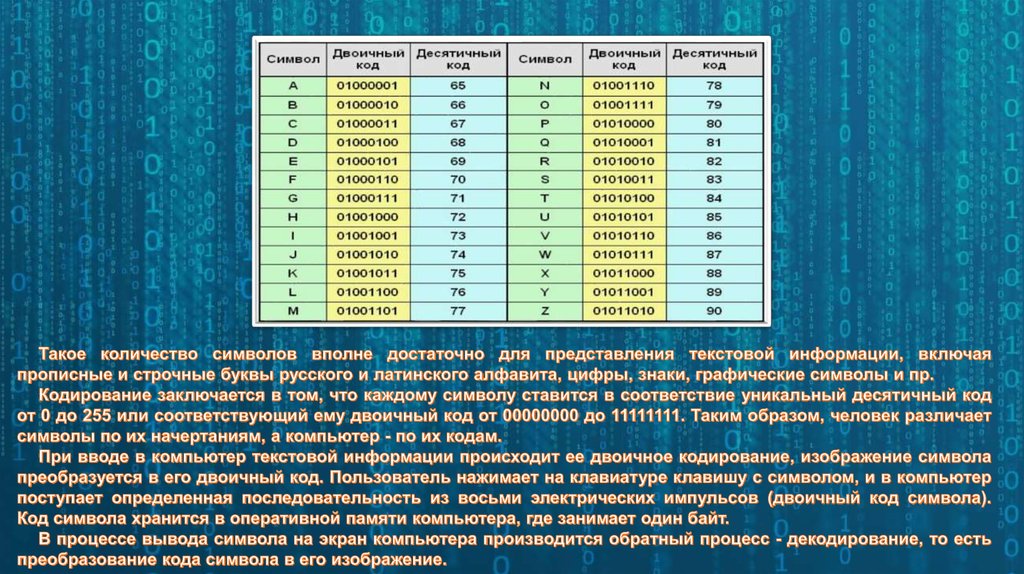
Кодировка UTF-8 хитрее. Первые 128 символов Юникода совпадают с символами ASCII. Эти символы UTF-8 кодирует как один байт, отсюда обратная совместимость: если мы используем только это подмножество символов, то нет разницы как их кодировать: последовательность байтов, полученных с помощью UTF-8 и ASCII будет совпадать. То есть если взять закодированный ASCII текст, и раскодировать его с помощью UTF-8, то в итоге получится тот же самый текст. Что UTF-8 делает с остальными символами, номера которых в Юникоде больше 128 — это уже отдельная увлекательная тема.
К сожалению, эти понятия иногда путаются даже в стандартах: в элементе в атрибуте «charset» указывается именно кодировка (encoding).
Хорошая статья на эту тему у Джоэла Сполски: http://www.joelonsoftware.com/articles/Unicode.html, очень её рекомендую всем, кто хочет раз и навсегда разобраться в этом предмете и больше никогда не путаться 😉
Как поменять кодировку в Word
ГлавнаяMicrosoft Word
Когда человек работает с программой «MS Word», у него редко возникает потребность вникать в нюансы кодировки. Но как только появляется необходимость поделиться документом с коллегами, существует вероятность того, что отправленный пользователем файл может просто-напросто не быть прочитан получателем. Это случается из-за несовпадения настроек, а конкретно кодировок в разных версиях программы.
Но как только появляется необходимость поделиться документом с коллегами, существует вероятность того, что отправленный пользователем файл может просто-напросто не быть прочитан получателем. Это случается из-за несовпадения настроек, а конкретно кодировок в разных версиях программы.
Как поменять кодировку в Word
Содержание
- Что представляет собой кодировка и от чего она зависит?
- Изменение кодировки текста в «Word 2013»
- Первый способ изменения кодировки в «Word»
- Второй способ изменения кодировки в «Word»
- Изменение кодировки в программе «Notepad ++»
- Корректировка кодировки веб-страниц
- Как поменять кодировку в «Mozilla Firefox»
- Установка кодировки в интерфейсе Блокнота
- Видео — Как изменить кодировку в Word
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может в значительной степени разниться. Для понимания кодировки необходимо знать то, что информация в текстовом документе сохраняется в виде некоторых числовых значений.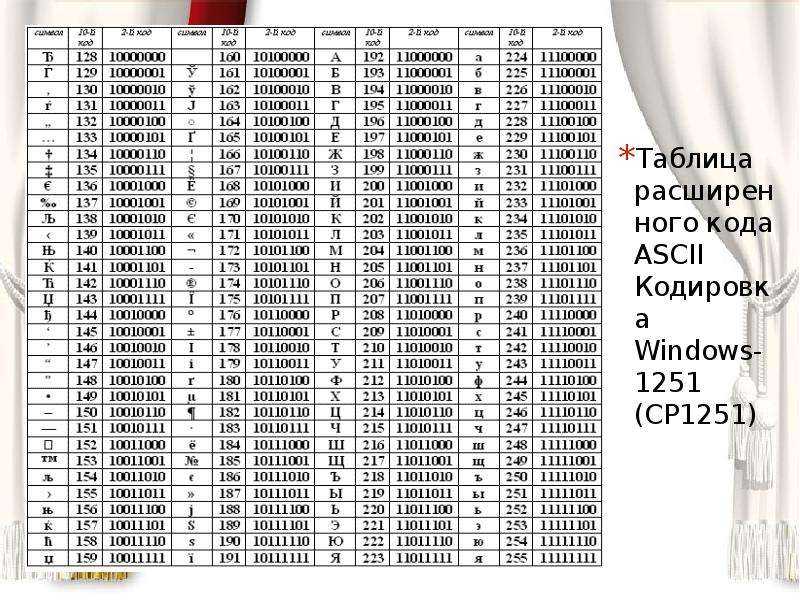 Персональный компьютер самостоятельно преобразует числа в текст, используя при этом алгоритм отдельно взятой кодировки. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, таких как Западная Европа, применяется «Западноевропейская (Windows)». Если текстовый документ был сохранен в кодировке кириллицы, а открыт с использованием западноевропейского формата, то символы будут отображаться совершенно неправильно, представляя собой бессмысленный набор знаков.
Персональный компьютер самостоятельно преобразует числа в текст, используя при этом алгоритм отдельно взятой кодировки. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, таких как Западная Европа, применяется «Западноевропейская (Windows)». Если текстовый документ был сохранен в кодировке кириллицы, а открыт с использованием западноевропейского формата, то символы будут отображаться совершенно неправильно, представляя собой бессмысленный набор знаков.
При открытии документа, сохраненного одним типом кодировки, в другом формате кодировки невозможно будет прочитать
Во избежание недоразумений и облегчения работы разработчики внедрили специальную единую кодировку для всех алфавитов – «Юникод». Этот общепринятый стандарт кодировки содержит в себе практически все знаки большинства письменных языков нашей планеты. К тому же он преобладает в интернете, где так необходима подобная унификация для охвата большего количества пользователей и удовлетворения их потребностей.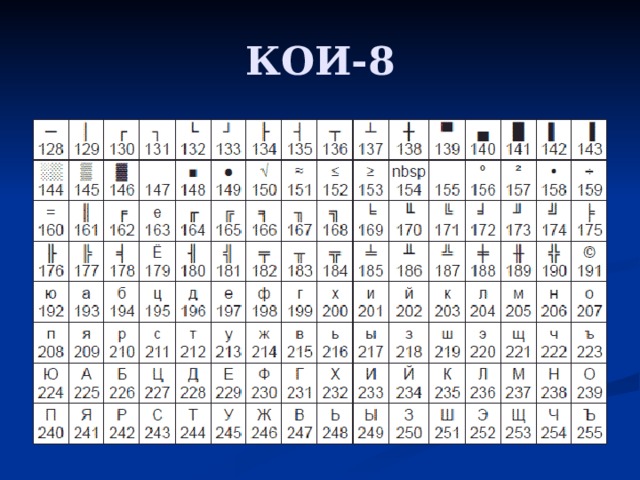
Тип кодировок, которые используются, как стандартные для всех языков
«Word 2013» работает как раз на основе Юникода, что позволяет обмениваться текстовыми файлами без применения сторонних программ и исправления кодировок в настройках. Но нередко пользователи сталкиваются с ситуацией, когда при открытии вроде бы простого файла вместо текста отображаются только знаки. В таком случае программа «Word» неправильно определила существующую первоначальную кодировку текста.
Справка! Некоторые кодировки применяются к определенным языкам. Для японского языка специально была разработана кодировка «Shift JIS», для корейского – «EUC-KR», а для китайского «ISO-2022» и «EUC».
Изменение кодировки текста в «Word 2013»
Первый способ изменения кодировки в «Word»
Для исправления текстового документа, которому была неправильно определена изначальная кодировка, необходимо:
Шаг 1. Запустить текстовый документ и открыть вкладку «Файл».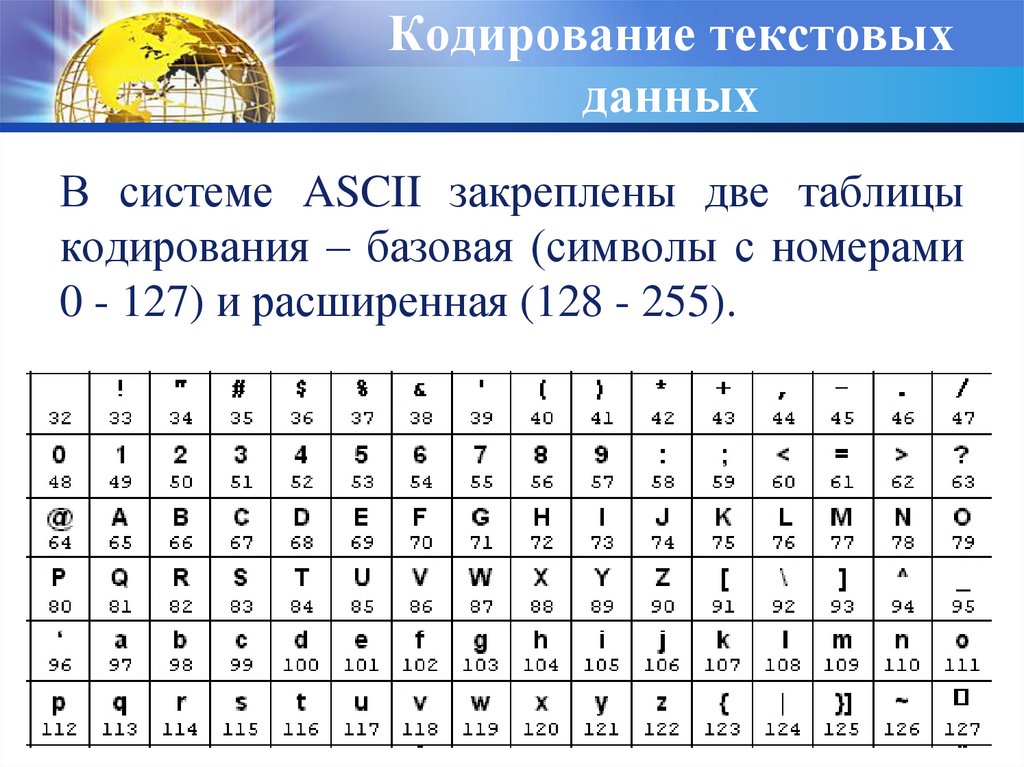
Открываем вкладку «Файл»
Шаг 2. Перейти в меню настроек «Параметры».
Переходим в меню настроек «Параметры»
Шаг 3. Выбрать пункт «Дополнительно» и перейти к разделу «Общие».
Выбираем пункт «Дополнительно»
Прокрутив список вниз, переходим к разделу «Общие»
Шаг 4. Активируем нажатием по соответствующей области настройку в графе «Подтверждать преобразование формата файла при открытии».
Отмечаем галочкой графу «Подтверждать преобразование формата файла при открытии», нажимаем «ОК»
Шаг 5. Сохраняем изменения и закрываем текстовый документ.
Шаг 6. Повторно запускаем необходимый файл. Перед пользователем появится окно «Преобразование файла», в котором необходимо выбрать пункт «Кодированный текст», и сохранить изменения нажатием «ОК».
Выбираем пункт «Кодированный текст», сохраняем изменения нажатием «ОК»
Шаг 7. Всплывет еще одна область, в которой необходимо выбрать пункт кодировки «Другая» и выбрать в списке подходящую.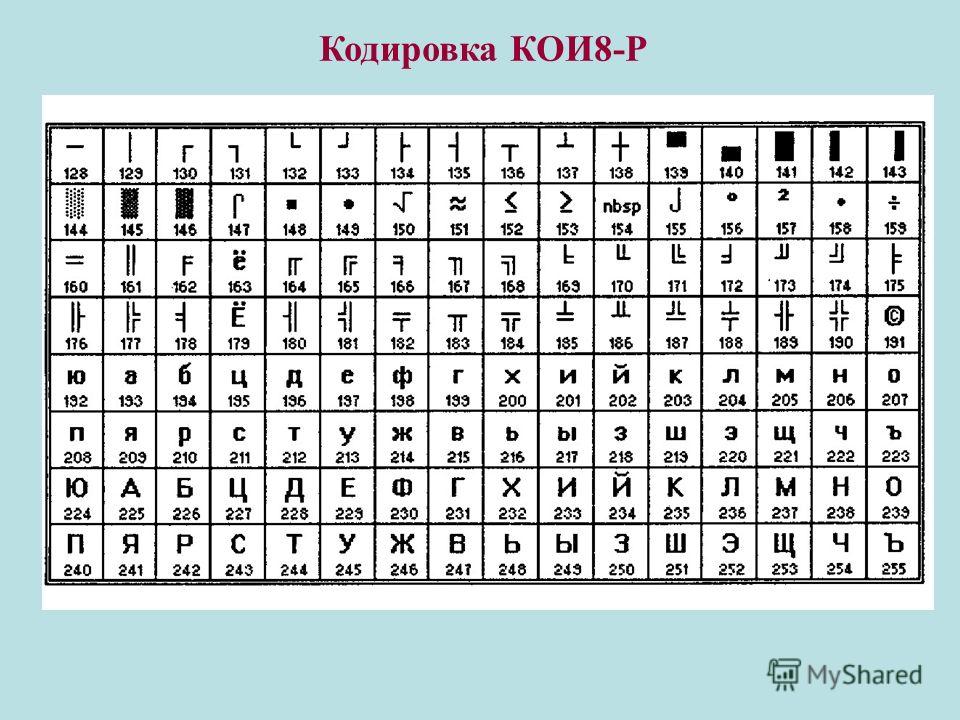
Отмечаем пункт кодировки «Другая», выбираем в списке подходящую, нажимаем «ОК»
Второй способ изменения кодировки в «Word»
- Производим запуск файла, кодировку текста которого необходимо произвести.
- Переходим во вкладку «Файл».
Открываем вкладку «Файл»
- Кликаем «Сохранить как».
Кликаем «Сохранить как»
- В области «Тип файла» необходимо выбрать «Обычный текст» и нажать «Сохранить».
В области «Тип файла» выбираем «Обычный текст», нажимаем «Сохранить»
- В появившемся «Преобразование файла» выбираем кодировку «Другая» и в списке активируем нужную.
Отмечаем опцию «Другая», в списке активируем нужную, нажимаем «ОК»
Читайте полезную информацию, как работать в ворде для чайников, в новой статье на нашем портале.
Изменение кодировки в программе «Notepad ++»
Подобное приложение используется многими программистами для создания сайтов, различных приложений и многого другого. Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Шаг 1. Запустить программу и в верхнем контекстном меню выбрать вкладку «Кодировки».
Выбираем вкладку «Кодировки»
Шаг 2. В выпадающем списке пользователю требуется выбрать из списка необходимую для него кодировку и щелкнуть на нее.
Выбираем из списка необходимую кодировку, щелкаем на ней
Шаг 3. Правильность проведения процедуры легко проверить, обратив внимание на нижнюю панель программы, которая будет отображать только что измененную кодировку.
В нижней панели программы можно увидеть измененную кодировку
Важно! Перед началом работы в «Notepad ++» в первую очередь рекомендуется проверить установленную кодировку. При необходимости ее нужно изменить при помощи инструкции, приведенной ранее.
Корректировка кодировки веб-страниц
Кодировка символов – неотъемлемая часть работы браузеров для серфинга в интернете.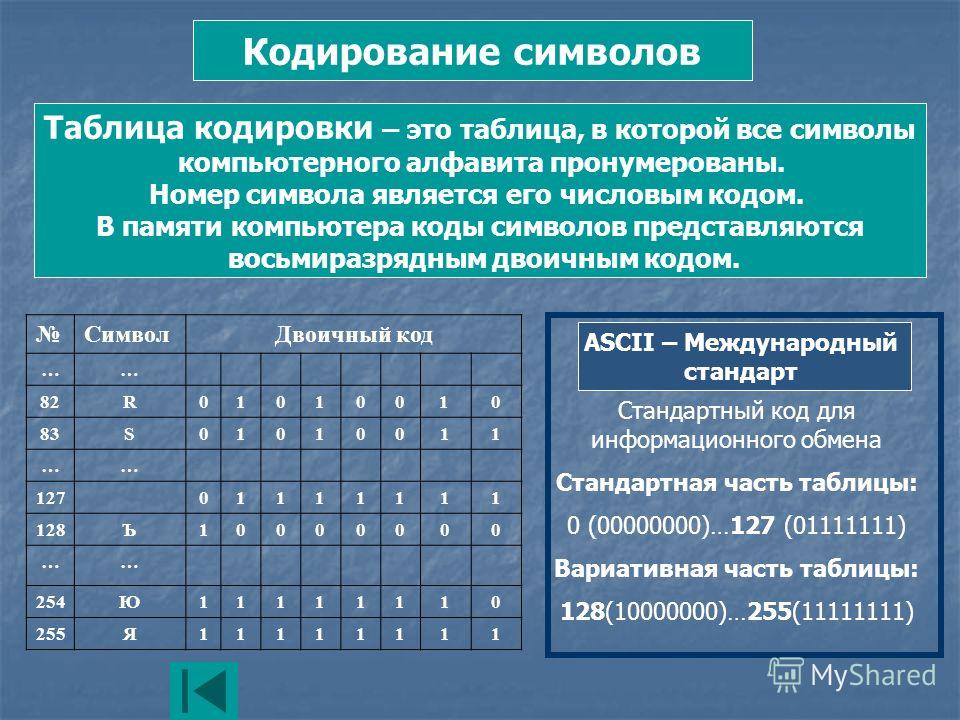 Поэтому каждому из пользователей просто необходимо уметь ее настраивать. Чтобы быстро изменить кодировку «Google Chrome», необходимо будет установить дополнительное расширение, так как разработчики убрали возможность изменения данного параметра.
Поэтому каждому из пользователей просто необходимо уметь ее настраивать. Чтобы быстро изменить кодировку «Google Chrome», необходимо будет установить дополнительное расширение, так как разработчики убрали возможность изменения данного параметра.
Для того, чтобы сменить кодировку на необходимую, нужно:
- Запустить браузер.
- Перейти по ссылке chrome://extensions/.
В адресную строку вводим указанный адрес, нажимаем «Enter»
- Затем кликнуть в левом верхнем углу по опции «Расширения».
Нажимаем по опции «Расширения» в левом верхнем углу страницы
- Внизу найти и открыть интернет-магазин браузера Хром.
В левом нижнем углу щелкаем по ссылке «Открыть Интернет-магазин Chrome»
- В поиске найти расширение и установить «Set Character Encoding», нажать «Enter».
В поле для поиска вводим Set Character Encodin, нажимаем «Enter»
- Рядом с приложением нажать «Установить».
Нажимаем по кнопке «Установить»
- Для того, чтобы с легкостью поменять значение кодировки, необходимо убедится в работоспособности расширения, после чего на любом сайте на пустой области правой кнопкой мыши вызвать контекстное меню.
 В нем следует перейти в «Set Character Encoding» и выбрать необходимое значение.
В нем следует перейти в «Set Character Encoding» и выбрать необходимое значение.На пустой области нажимаем правой кнопкой мышки, левой кнопкой по пункту «Set Character Encoding», выбираем необходимое значение
Как поменять кодировку в «Mozilla Firefox»
Для этого пользователю потребуется:
Шаг 1. Запустить браузер и открыть меню, нажав по иконке трех линий левой клавишей мыши в правом верхнем углу страницы.
Нажимаем по иконке из трех линий в правом верхнем углу
Шаг 2. В контекстном меню запустить «Настройки».
Открываем «Настройки»
Шаг 3. Перейти во вкладку «Содержимое».
Переходим во вкладку «Содержимое»
Шаг 4. В разделе «Шрифты и цвета» нажать на блок «Дополнительные».
В разделе «Шрифты и цвета» нажимаем по блоку «Дополнительно»
Шаг 5. Перед пользователем отобразится специальная панель, на которой будет указана использующаяся кодировка.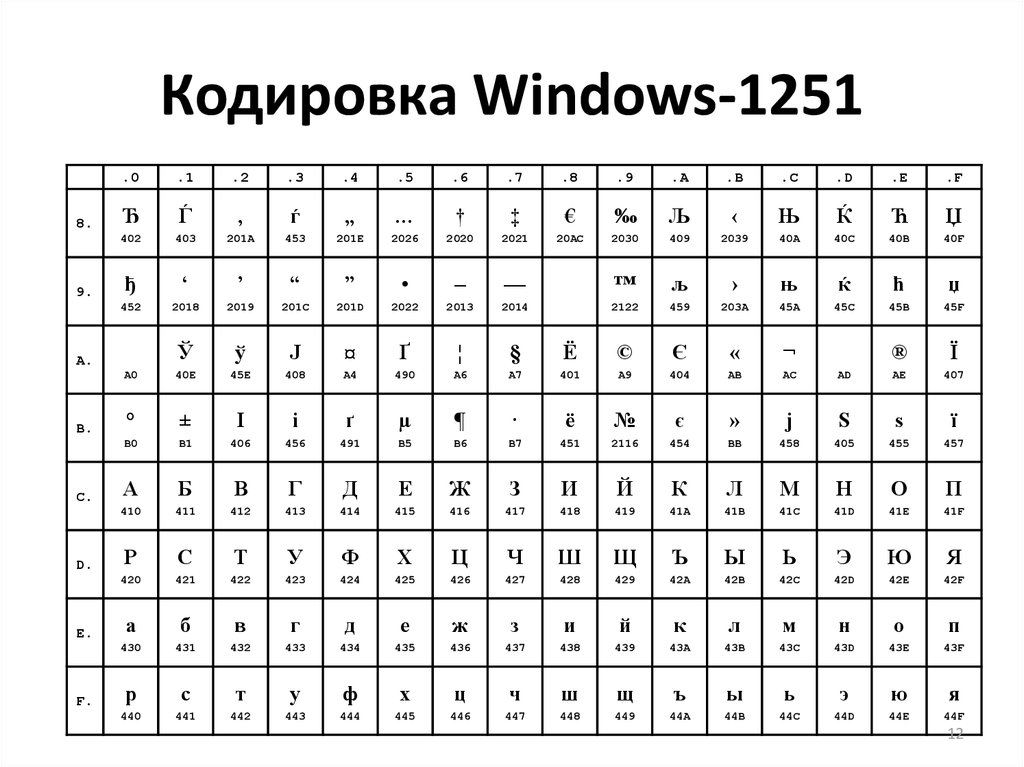 Для ее изменения потребуется нажать на название кодировки и выбрать нужную.
Для ее изменения потребуется нажать на название кодировки и выбрать нужную.
Нажимаем на название кодировки
Выбираем подходящую кодировку, нажимаем «ОК»
Установка кодировки в интерфейсе Блокнота
Тем юзерам, кому необходимо пользоваться стандартным приложением «Блокнот» , будет полезно знать о том, что изменить кодировку можно следующим образом:
- Открыть текстовый документ и повторно сохранить его, нажав «Файл» и затем «Сохранить как».
Нажимаем по вкладке «Файл», затем по опции «Сохранить как»
- В появившемся окне помимо директории следует выбрать и кодировку, найдя необходимый формат, нажать «Сохранить».
В параметре «Кодировка» выбираем подходящий формат, нажимаем «Сохранить»
После этого без труда можно открывать необходимый текст в нужной кодировке.
Благодаря правильно подобранной и установленной кодировке пользователь может избежать неприятностей при отправке файла другим юзерам. Все, что для этого требуется, – это выставлять перед началом работы необходимое значение.
Видео — Как изменить кодировку в Word
Понравилась статья?
Сохраните, чтобы не потерять!
Рекомендуем похожие статьи
Что такое кодирование? — Определение Techslang
Кодирование — это процесс преобразования данных в другой формат. Когда вы конвертируете показания температуры из градусов Цельсия в градусы Фаренгейта или деньги из японских иен в доллары США, исходные значения остаются прежними. Они просто представлены в другой форме.
В мире компьютеров кодирование работает точно так же. Компьютер преобразует данные из одной формы в другую. Это делается для экономии места для хранения или повышения эффективности передачи.
Одним из примеров кодирования является преобразование огромного аудиофайла .WAV в крошечный файл .MP3, который можно легко отправить другу по электронной почте. Файлы закодированы в разных форматах, но будут воспроизводить одну и ту же песню.
Другие интересные термины…
- Что такое декодирование?
- Что такое цифровизация?
Основной целью кодирования является обеспечение безопасного и адекватного использования данных различными пользователями, использующими различные системы.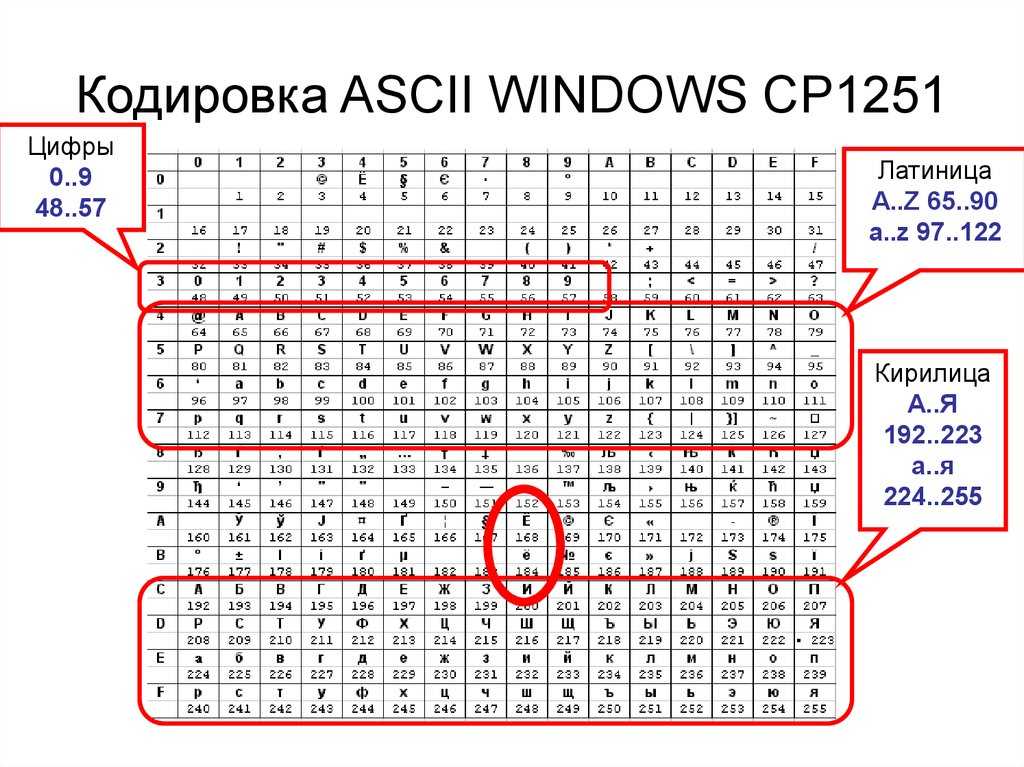 Идея состоит в том, чтобы сделать данные читаемыми и доступными для всех возможных конечных пользователей. Этот процесс можно сравнить с эффективным переводом текста, например, с иврита на английский, что делает информацию доступной для большего числа пользователей.
Идея состоит в том, чтобы сделать данные читаемыми и доступными для всех возможных конечных пользователей. Этот процесс можно сравнить с эффективным переводом текста, например, с иврита на английский, что делает информацию доступной для большего числа пользователей.
Без кодировки символов веб-сайт будет отображать текст совсем не так, как предполагалось. Неправильное кодирование ухудшает читабельность текста, что также может привести к тому, что поисковые системы не смогут правильно отображать данные или что машины будут неправильно обрабатывать вводимые данные.
Какие существуют типы стандартов кодирования? Американский стандартный код для обмена информацией Американский стандартный код для обмена информацией (ASCII) — наиболее часто используемый компьютерами язык для текстовых файлов. Он был разработан Американским национальным институтом стандартов (ANSI). Он представляет буквы алфавита (как строчные, так и прописные), цифры, символы и знаки препинания с использованием семибитных двоичных чисел (строки, состоящие из комбинаций семи нулей или единиц). ASCII имеет 128 символов.
ASCII имеет 128 символов.
Стандарт Unicode — это универсальный набор символов, позволяющий писать на большинстве языков на компьютерах. Он подразделяется на 8-, 16- и 32-битные наборы символов, насчитывающие более миллиарда символов.
Кодирование URL-адресовКодирование унифицированного указателя ресурсов (URL), также известное как «процентное кодирование», часто используется, когда некоторые символы не могут быть включены в URL-адреса. Таким образом, кодирование URL-адресов позволяет представлять нераспознанные символы ASCII в формате Unicode, чтобы все компьютеры могли их читать.
Кодировка Base64 Ранее Base64 использовался только для представления двоичных данных в печатных символах. Он обычно используется в базовой аутентификации по протоколу передачи гипертекста (HTTP) при кодировании учетных данных пользователя. Он также используется для кодирования вложений электронной почты, чтобы обеспечить их передачу по простому протоколу передачи почты (SMTP), и отправки двоичных данных в файлах cookie, чтобы сделать их менее читаемыми для злоумышленников.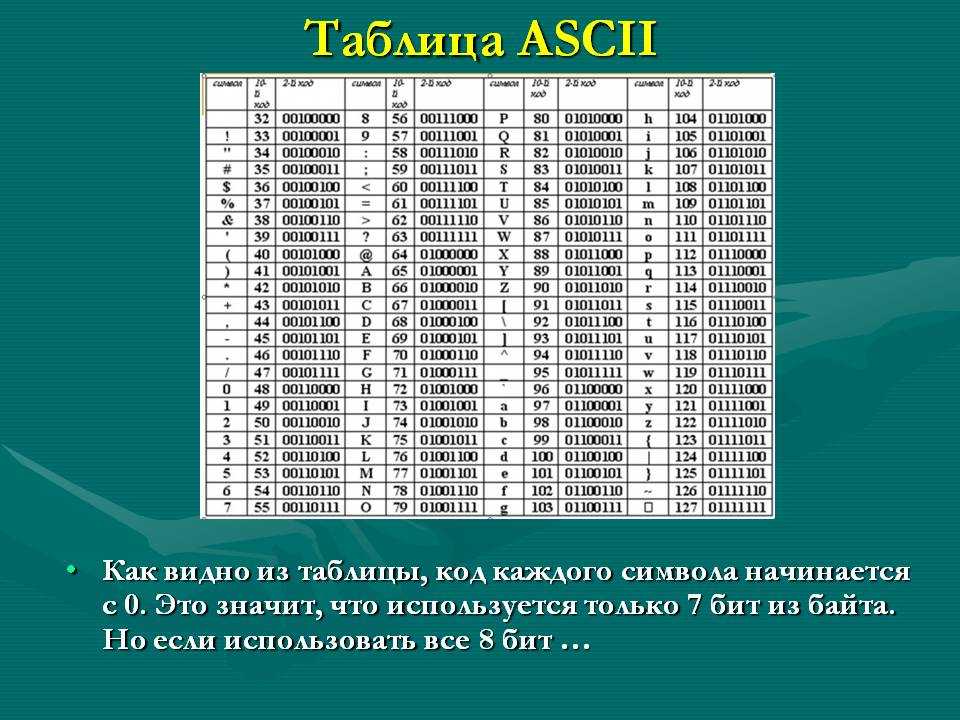
Большинство почтовых систем не могут работать с двоичными данными. Без кодировки Base64 изображения или другие отправленные файлы будут повреждены. Компьютеры работают с данными в байтах, что делает кодировку ASCII непригодной для передачи.
В чем разница между кодированием и декодированием?Кодирование означает преобразование данных в другую форму, а декодирование — обратное преобразование данных в исходную форму.
Для компьютеров процесс кодирования происходит каждый раз, когда вы сохраняете файл. Поскольку они могут понимать только последовательности нулей и единиц, ваши файлы преобразуются в такой формат. Когда вы просматриваете файл, компьютер декодирует его обратно в исходный формат, чтобы сделать файл удобочитаемым.
Что такое кодирование в человеческом общении? Этот процесс настолько естественен в человеческом общении, что мы редко обращаем на него внимание. Тем не менее, кодирование происходит каждый раз, когда мы формулируем сообщение, будь то голосовое или цифровое. Когда вы набираете текстовое сообщение для друга, кодирование происходит, когда вы думаете о том, как сформулировать сообщение.
Когда вы набираете текстовое сообщение для друга, кодирование происходит, когда вы думаете о том, как сформулировать сообщение.
Когда ваш друг получает сообщение, он или она пытается понять его смысл. По сути, он или она расшифровывает сообщение.
Что такое кодирование при передаче данных?Кодирование при передаче данных — это процесс преобразования данных в цифровые сигналы или значения, понятные компьютерам. Как упоминалось ранее, это последовательности двоичных цифр, значение которых может быть только 0 или 1.
Что такое кодирование в программировании?Кодирование в программировании — это важнейший процесс преобразования данных в различные форматы для облегчения их передачи по сети. Процесс может отличаться в зависимости от языка программирования.
Например, кодирование в Python происходит при передаче экземпляра по сети. С другой стороны, кодирование в Java происходит при передаче данных через Интернет.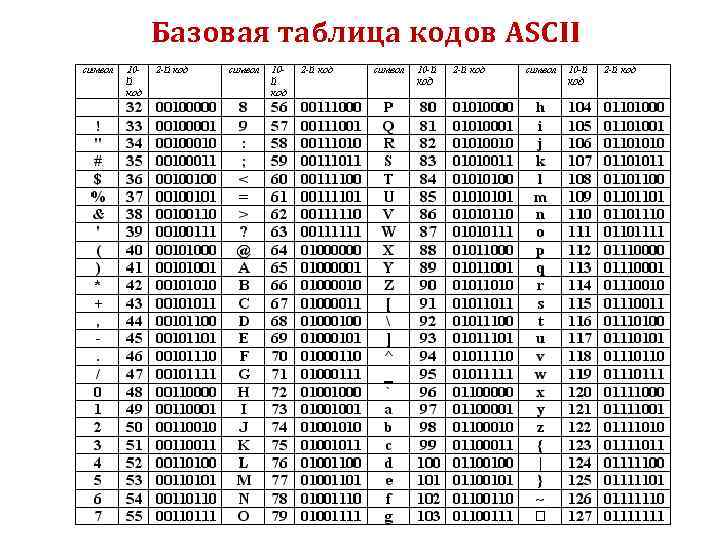
- Кодирование — это просто преобразование данных в различные форматы для облегчения их передачи.
- Кодирование и декодирование — противоположные процессы.
- Компьютеры могут понимать только двоичные числа, поэтому кодирование необходимо.
- Кодирование происходит при повседневном общении с другими людьми, а также при работе с компьютерами и языками программирования.
Что такое кодирование?: Часть 1 раздела Кодирование и декодирование | Журнал ИМСЕ | IMSE
«Чтение и письмо считались противоположностями: чтение считалось воспринимающим, а письмо — продуктивным. Исследователи обнаружили, что чтение и письмо — это «по существу один и тот же процесс смыслообразования» и что читатели и писатели имеют удивительное количество общих характеристик» (Кэрол Бут Олсон, 2003).
Таким образом, четкие инструкции по стратегиям кодирования и декодирования способствуют прогрессу в достижении мастерства, то есть способности читать, писать и писать как единое целое.
Нужны ли подробные инструкции по чтению и письму?
В то время как устная речь является более естественным процессом развития человека, письменной речи (включая чтение и письмо) необходимо обучать.
Обучение чтению, письму и правописанию может быть сложной задачей для учащихся, а поиск возможностей для постепенного успеха с помощью четкого, последовательного, мультисенсорного обучения оказывается невероятно мотивирующим. Это особенно актуально для изучающих английский язык и людей с диагностированными нарушениями обучаемости, такими как дислексия и дисграфия.
Соучредитель IMSE Жанна Жеп.
Когда что-то сложно выучить, проще полностью отбросить это. — Это действительно необходимо? или «Я могу сделать это, не зная более сложных слов, потому что я уже знаю базовое слово, которое означает то же самое».
Так почему же так важно продолжать обучение грамоте? Почему я должен читать? Как изучение этих [новых фонетических понятий или стратегий] поможет мне в долгосрочной перспективе? Есть много причин, по которым важны чтение, письмо и правописание.
Что такое кодирование?
Орфография имеет решающее значение при заполнении заявлений о приеме на работу, установлении доверия к писателю, использовании буквального или онлайн-словаря или определении наилучшего варианта при проверке орфографии (Liuzzo, 2020).
По словам Марсии Генри (Unlocking Literacy, 2004), чтобы правильно читать и правильно писать, нужно знать:
- Фонология: изучение звуков
- Орфография: изучение систем письма и буквенно-звуковых соответствий
- Морфология: изучение частей слова, формирующих значение слова
- Этимология: изучение истории слов
По словам Питера Бауэрса (2009 г.), «четкие инструкции о роли фонологии и этимологии не являются обязательными, если мы берем на себя задачу предложить учащимся точное и всестороннее обучение».
Кодирование — это процесс разбиения произносимого слова на отдельные звуки, известные как фонемы.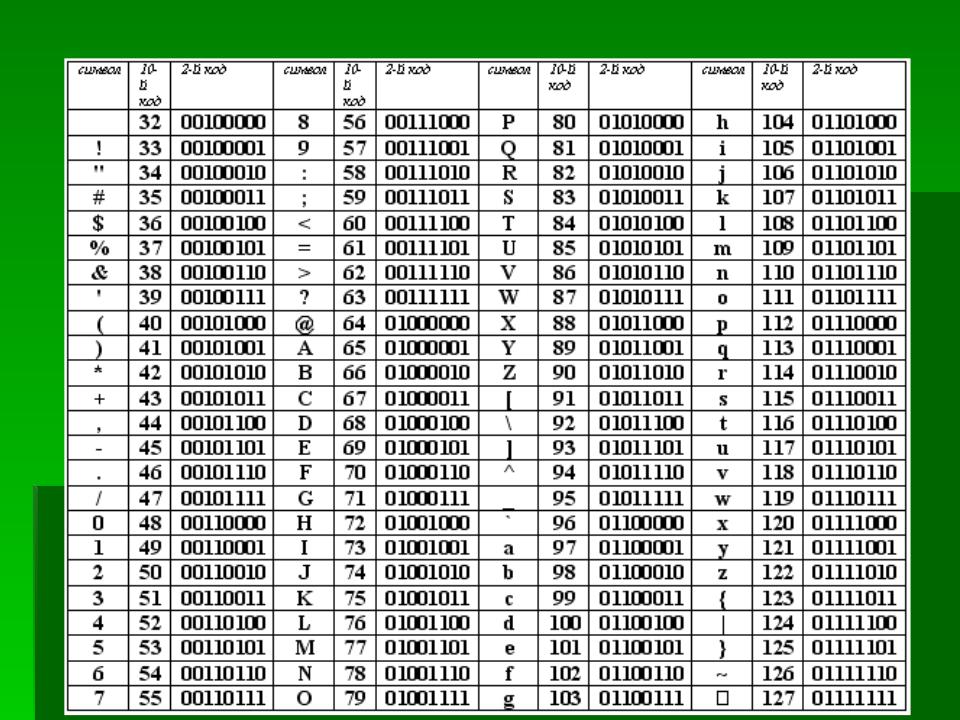 Фонемы — это мельчайшие единицы нашего разговорного языка, которые отличают одно слово от другого.
Фонемы — это мельчайшие единицы нашего разговорного языка, которые отличают одно слово от другого.
«Развитие автоматического распознавания слов зависит от неповрежденного, умелого восприятия фонем, знания соответствий звука и символа (фонема-графема), распознавания печатных паттернов, таких как повторяющиеся последовательности букв и написания слогов, и распознавания значимых частей слов (морфем). )» (Moats, 2020) и (Ehri, 2014).
Знание моделей и правил правописания связывает воедино слои английского языка, поскольку учащиеся используют фонологию, орфографию и морфологию, чтобы определить, как правильно писать слова. Например, понимание того, почему суффикс -ed дает каждый из трех звуков, /id/, /d/ или /t/, зависит от определения последнего звука основного слова. Студенты должны сначала услышать глагол в прошедшем времени и выделить основное слово.
В глаголе прошедшего времени ask основа слова ask , оканчивающаяся на глухой звук /k/. Следовательно, в спрашиваемом глаголе в прошедшем времени суффикс -ed произведет свой глухой звук /t/. Когда учащийся кодирует слово, он должен применить свои знания, например: «Я слышу /t/, но пишу -ed». Чрезвычайно важно обеспечить овладение навыками фонологического восприятия в качестве основы, на которой учащиеся строят фонетические знания.
Когда учащийся кодирует слово, он должен применить свои знания, например: «Я слышу /t/, но пишу -ed». Чрезвычайно важно обеспечить овладение навыками фонологического восприятия в качестве основы, на которой учащиеся строят фонетические знания.
Учащиеся сегментируют произношение фонем в односложных и многосложных словах с увеличивающимся автоматизмом. Так рождается беглый писатель.
Обязательно ознакомьтесь с остальной частью нашей серии блогов о кодировании и декодировании:
- Декодирование, часть 2 раздела Кодирование и декодирование
- Неправильные слова, часть 3, кодирование и декодирование
- Что мы должны прочитать? Часть 4 Кодирования и декодирования
Пожалуйста, свяжитесь с нами по телефону Facebook , Twitter , Instagram , LIK0171 , чтобы получать советы и рекомендации от ваших коллег и от нас. Прочтите Журнал IMSE , чтобы узнать об успехах других школ и округов, и обязательно ознакомьтесь с нашими цифровыми ресурсами , чтобы получить дополнительную информацию и советы.
Об авторе
Джинни Симанк — мастер-инструктор IMSE OG уровня 4, проживающая в Далласе, штат Техас. Она имеет степень магистра (M.Ed.) с сертификатом специалиста по чтению и имеет сертификаты в области специального образования, английского как второго языка и общего образования для детей младшего возраста до 6-го класса и ELA 4-8 классы. Она является сертифицированным IDA учителем структурированной грамотности и штатным инструктором Института мультисенсорного образования (IMSE), чья миссия состоит в обучении других людей по всей стране (учителей, администраторов, воспитателей, специалистов в области образования и родителей) в Ортоне. Методология Джиллингема мультисенсорного обучения языку. Г-жа Симанк ранее работала в национальном совете директоров Ассоциации людей с ограниченными возможностями обучения и была членом комитетов LDA по образованию и назначениям.
Источники
- Бауэрс, Питер (2009). Обучение тому, как работает письменное слово.
 www.wordworkskingston.com.
www.wordworkskingston.com. - Эри, Л. «Орфографическое картирование при чтении слов с листа, орфографической памяти и изучении словарного запаса», Научные исследования чтения 18 (2014): 5–21; и Килпатрик, Основы оценки.
- Эри Л. и др., «Систематическое обучение фонетике помогает учащимся научиться читать: данные метаанализа Национальной группы по чтению», Review of Educational Research 71 (2001): 393–447.
- Галлахер, К. (2003). Причины чтения: мотивационные мини-уроки для средней и старшей школы. Портленд, Мэн: Издательство Steinhouse.
- Генри, Марсия (2004). Открытие грамотности, издательство Пола Х. Брукса, второе издание.
- Лиуццо, Жанна (2020). Учебное пособие для среднего уровня, Институт мультисенсорного образования, стр. 53–56.
- Рвы, Луиза С. (2020). Преподавание чтения — это ракетостроение (2020): что должны знать и уметь опытные учителя чтения. Вашингтон, округ Колумбия: Американская федерация учителей.
- Олсон, Кэрол Бут.
