python — Узнать кодировку файла
Задать вопрос
Вопрос задан
Изменён 2 года 1 месяц назад
Просмотрен 13k раз
Есть файл не понятно в какой кодировке, нужно определить кодировку, написал вот такой вариант, но уверен что есть способ определения кодировки на много проще, подскажите.
# какой то файл скачанный с интернета в неизвестной кодировке.
open('test.txt', 'w', encoding='cp500').write('Hello\n')
# сюда можно впихнуть все известные кодировки.
encoding = [
'utf-8',
'cp500',
'utf-16',
'GBK',
'windows-1251',
'ASCII',
'US-ASCII',
'Big5'
]
correct_encoding = ''
for enc in encoding:
try:
open('test.txt', encoding=enc).
read()
except (UnicodeDecodeError, LookupError):
pass
else:
correct_encoding = enc
print('Done!')
break
print(correct_encoding)

- python
0
Можно использовать chardet:
from chardet.universaldetector import UniversalDetector
detector = UniversalDetector()
with open('test.txt', 'rb') as fh:
for line in fh:
detector.feed(line)
if detector.done:
break
detector.close()
print(detector.result)
3
Все очень просто.
with open(file_path, "r") as f:
print(f)
В выводе будет информация об объекте файла в том числе и кодировка.
3
Зарегистрируйтесь или войдите
Регистрация через GoogleРегистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Модуль chardet в Python, определение кодировки.
Распознавание кодировки символов Python.
Когда мы думаем о тексте, то представляем слова и буквы, которые видим на экране компьютера. Но компьютеры не работают с буквами и символами. Они имеют дело с битами и байтами. Каждый фрагмент текста, который выводится на экране, на самом деле хранится в определенной кодировке символов. Существует множество различных кодировок, некоторые из которых оптимизированы для определенных языков, таких как русский, китайский или английский, а другие могут использоваться для нескольких языков. Грубо говоря, кодировка символов обеспечивает соответствие между тем, что мы видим на экране, и тем, что компьютер фактически хранит в памяти и на диске.
Модуль chardet, это автоматический детектор кодировки текста и является портом кода автоопределения в Mozilla. Этот модуль поможет определить кодировку символов, если вдруг на экране появятся «кракозябры«.
Модуль chardet отлично поддерживает и определяет русские кодировки: KOI8-R, MacCyrillic, IBM855, IBM866, ISO-8859-5, windows-1251(Cyrillic)
Установка модуля
chardet в виртуальное окружение.
# создаем виртуальное окружение, если нет $ python3 -m venv .venv --prompt VirtualEnv # активируем виртуальное окружение $ source .venv/bin/activate # ставим модуль chardet (VirtualEnv):~$ python -m pip install -U chardet
Примеры автоматического определения кодировки символов:
Самый простой способ автоматически определить кодировку — это использовать функцию обнаружения detect() модуля chardet.
>>> import urllib.request, chardet
>>> rawdata = urllib.request.urlopen('http://yandex.ru/').read()
>>> chardet.detect(rawdata)
# {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
>>> rawdata = urllib.request.urlopen('https://www.zeit.de/index').read()
>>> chardet.detect(rawdata)
# {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
Расширенное использование модуля
chardet.Если имеется большой объем текста/данных, то можно вызывать обнаружение кодировки постепенно.
Для такого поведения необходимо создать объект UniversalDetector(), затем повторно вызывать его метод подачи .feed() с каждым блоком текста. Если созданный детектор достигнет минимального порога достоверности, он установит для Detector.done значение True.
В конце работы детектора необходимо вызвать Detector.close(), который выполнит некоторые окончательные вычисления в случае, если детектор не достиг минимального порога достоверности.
import urllib.request
from chardet.universaldetector import UniversalDetector
usock = urllib.request.urlopen('https://www.zeit.de/index')
# создаем детектор
detector = UniversalDetector()
for line in usock.readlines():
# скармливаем детектору строки
detector.feed(line)
if detector.done:
# если детектор определил
# кодировку, то прерываем цикл
break
# закрываем детектор
detector.close()
# закрываем соединение с сайтом
usock.
close()
print(detector.result)
# {'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
Пример определения кодировки нескольких файлов.
Для определения кодировки текстовых файлов, их необходимо открывать в режиме чтения байтов: more='rb'
import glob
from chardet.universaldetector import UniversalDetector
# создаем детектор
detector = UniversalDetector()
for filename in glob.glob('*.xml'):
print(filename.ljust(60), end='')
# сбрасываем детектор
# в исходное состояние
detector.reset()
# проходимся по строкам очередного
# файла в режиме 'rb'
for line in open(filename, 'rb'):
detector.feed(line)
if detector.done: break
detector.close()
print(detector.result)
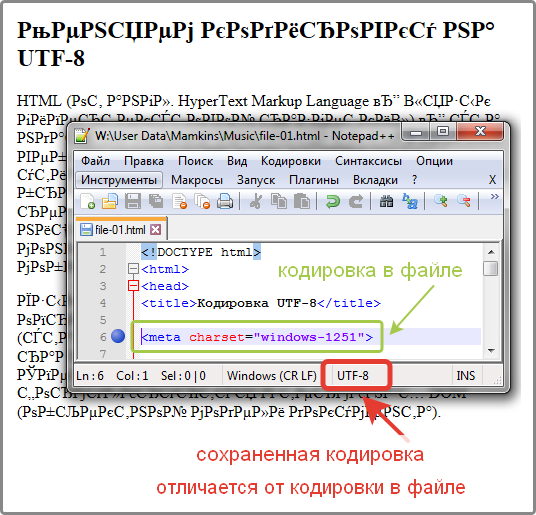
Получить кодировку файла в Windows
На самом деле это не вопрос программирования, существует ли командная строка или инструмент Windows (Windows 7) для получения текущей кодировки текстового файла? Конечно, я могу написать небольшое приложение на C#, но я хотел знать, есть ли что-то уже встроенное?
- окна
- кодировка
3
Откройте файл с помощью обычного старого ванильного блокнота, который поставляется с Windows.
Он покажет вам кодировку файла, когда вы нажмете « Сохранить как… «.
Это будет выглядеть так:
Какой бы ни была кодировка, выбранная по умолчанию, это текущая кодировка файла.
Если это UTF-8, вы можете изменить его на ANSI и нажать «Сохранить», чтобы изменить кодировку (или наоборот).
Я понимаю, что существует множество различных типов кодирования, но это было все, что мне было нужно, когда мне сообщили, что наши экспортные файлы были в UTF-8 и для них требовался ANSI. Это был одноразовый экспорт, поэтому Блокнот мне подошёл.
К вашему сведению: Насколько я понимаю, я думаю, что « Unicode » (как указано в Блокноте) является неправильным названием UTF-16.
Подробнее об опции Блокнота « Unicode »: Windows 7 — UTF-8 и Unicdoe
14
Если на вашем компьютере с Windows есть «git» или «Cygwin», перейдите в папку, в которой находится ваш файл, и выполните команду:
файл *
Это даст вам информацию о кодировке всех файлов в этой папке.
4
Файл инструмента командной строки (Linux) доступен в Windows через GnuWin32:
http://gnuwin32.sourceforge.net/packages/file.htm
Если у вас установлен git, он находится в C: \Program Files\git\usr\bin.
Пример:
C:\Users\SH\Downloads\SquareRoot>файл *
_UpgradeReport_Files; каталог
Отлаживать; каталог
продолжительность.ч; Текст программы ASCII C++ с разделителями строк CRLF
ипч; каталог
основной.cpp; Текст программы ASCII C с разделителями строк CRLF
Точность.txt; Текст ASCII с разделителями строк CRLF
Выпускать; каталог
Скорость.txt; Текст ASCII с разделителями строк CRLF
SquareRoot.sdf; данные
SquareRoot.sln; Текст UTF-8 Unicode (с спецификацией), с разделителями строк CRLF
SquareRoot.sln.docstates.suo; PCX вер. 2.5 данные изображения
SquareRoot.suo; Документ CDF V2 поврежден: невозможно прочитать сводную информацию
SquareRoot.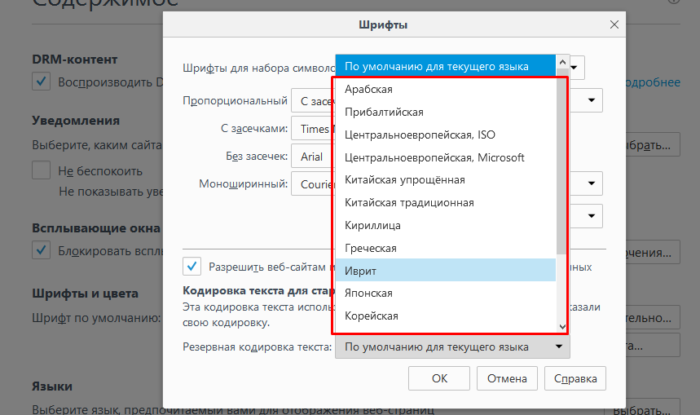 vcproj; Текст XML-документа
SquareRoot.vcxproj; Текст XML-документа
SquareRoot.vcxproj.фильтры; Текст XML-документа
SquareRoot.vcxproj.пользователь; Текст XML-документа
методы квадратного корня.ч; Текст программы ASCII C с разделителями строк CRLF
Журнал обновления.XML; Текст XML-документа
C:\Users\SH\Downloads\SquareRoot>
vcproj; Текст XML-документа
SquareRoot.vcxproj; Текст XML-документа
SquareRoot.vcxproj.фильтры; Текст XML-документа
SquareRoot.vcxproj.пользователь; Текст XML-документа
методы квадратного корня.ч; Текст программы ASCII C с разделителями строк CRLF
Журнал обновления.XML; Текст XML-документа
C:\Users\SH\Downloads\SquareRoot> файл --mime-encoding *
_UpgradeReport_Files; бинарный
Отлаживать; бинарный
продолжительность.ч; us-ascii
ипч; бинарный
основной.cpp; us-ascii
Точность.txt; us-ascii
Выпускать; бинарный
Скорость.txt; us-ascii
SquareRoot.sdf; бинарный
SquareRoot.sln; утф-8
SquareRoot.sln.docstates.suo; бинарный
SquareRoot.suo; Документ CDF V2 поврежден: не удается прочитать сводную информацию.
SquareRoot.vcproj; us-ascii
SquareRoot.vcxproj; утф-8
SquareRoot.vcxproj.фильтры; утф-8
SquareRoot.vcxproj.пользователь; утф-8
методы квадратного корня.ч; us-ascii
Журнал обновления.XML; us-ascii
7
Установите git (в Windows вы должны использовать консоль git bash).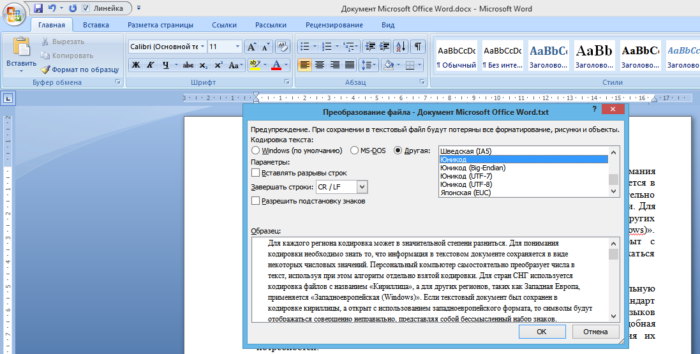
файл --mime-encoding *
для всех файлов в текущем каталоге или
file --mime-encoding */*
для файлов во всех подкаталогах
2
Еще один полезный инструмент: https://archive.codeplex.com/?p=encodingchecker EXE можно найти здесь
9
Вот мой способ определить семейство текстовых кодировок Unicode с помощью BOM. Точность этого метода низкая, так как этот метод работает только с текстовыми файлами (в частности, с файлами Unicode) и по умолчанию имеет значение ascii , когда отсутствует спецификация (как и в большинстве текстовых редакторов, значение по умолчанию будет UTF8 , если вы хотите соответствуют HTTP/веб-экосистеме).
Обновление 2018
feff’ {возврат ‘utf32’} по умолчанию {возврат ‘ascii’} } } каталог ~\Documents\WindowsPowershell -File | выберите Имя,@{Имя=’Кодировка’;Выражение={Get-FileEncoding $_.
 FullName}} |
футов -Авторазмер
FullName}} |
футов -Авторазмер Рекомендация: Это может работать достаточно хорошо, если dir , ls или Get-ChildItem проверяет только известные текстовые файлы и когда вы ищете только «плохие кодировки» из известного списка инструментов. (т. е. SQL Management Studio по умолчанию использует UTF16, что сломало GIT auto-cr-lf для Windows, которое использовалось по умолчанию в течение многих лет.)
8
Простым решением может быть открытие файла в Firefox.
- Перетащите файл в Firefox
- Нажмите Ctrl+I, чтобы открыть информацию о странице
и кодировка текста появится в окне «Информация о странице».
Примечание: Если файл не в формате txt, просто переименуйте его в txt и повторите попытку.
П.С. Для получения дополнительной информации см. эту статью.
1
Я написал ответ №4 (на момент написания). Но в последнее время я установил git на все свои компьютеры, поэтому теперь я использую решение @Sybren. Вот новый ответ, который делает это решение удобным из powershell (без помещения всего git/usr/bin в PATH, что для меня слишком много беспорядка).
Но в последнее время я установил git на все свои компьютеры, поэтому теперь я использую решение @Sybren. Вот новый ответ, который делает это решение удобным из powershell (без помещения всего git/usr/bin в PATH, что для меня слишком много беспорядка).
Добавьте это в свой профиль .ps1 :
$global:gitbin = 'C:\Program Files\Git\usr\bin' Установить псевдоним file.exe $gitbin\file.exe
И используется как: file.exe --mime-encoding * . Вы должны включить .exe в команду, чтобы псевдоним PS работал.
Но если вы не настроите свой профиль PowerShell.ps1, я предлагаю вам начать с моего: https://gist.github.com/yzorg/8215221/8e38fd722a3dfc526bbe4668d1f3b08eb7c08be0
и сохраните его по адресу ~\Documents\WindowsPowerShell . Безопасно использовать на компьютере без git, но выдаст предупреждение, если git не найден.
.exe в команде так же, как я использую C:\WINDOWS\system32\where. из powershell; и многие другие команды командной строки ОС, которые «по умолчанию скрыты» в PowerShell, *пожал плечами*. exe
exe
4
вы можете просто проверить это, открыв свой git bash в расположении файла, а затем выполнив команду file -i имя_файла
пример
пользовательские файлыДанные $ файл -i data.csv data.csv: текст/csv; кодировка = utf-8
Некоторый код C здесь для надежного обнаружения ascii, bom и utf8: https://unicodebook.readthedocs.io/guess_encoding.html
Только ASCII, UTF-8 и кодировки с использованием BOM (UTF-7 с BOM, UTF-8 с BOM, UTF-16 и UTF-32) имеют надежные алгоритмы для получения кодировки документа. Для всех других кодировок вы должны доверять эвристике, основанной на статистике.
РЕДАКТИРОВАТЬ:
Powershell-версия ответа С# от: Эффективный способ найти кодировку любого файла. Работает только с подписями (boms).
# get-encoding.ps1
param([Parameter(ValueFromPipeline=$True)] $filename)
начинать {
# установить текущую директорию .net
[Среда]::CurrentDirectory = (pwd).path
}
процесс {
$reader = [System.IO.StreamReader]::new($filename,
[System.Text.Encoding]::default,$true)
$Peek = $reader.Peek()
$кодирование = $reader.currentencoding
$reader.close()
[pscustomobject]@{Name=split-path $filename -leaf
BodyName=$encoding.BodyName
EncodingName=$encoding.EncodingName}
}
.\get-encoding chinese8.txt
Имя Имя Тела EncodingName
---- -------- ------------
chinese8.txt utf-8 Юникод (UTF-8)
получить дочерний файл | .\получить кодировку
1
Ищете решение Node.js/npm? Попробуйте кодировку-проверку:
npm install -g encoding-checker
Использование
Использование: encoding-checker [-p шаблон] [-i кодировка] [-v] Параметры: --help Показать справку [логическое значение] --version Показать номер версии [логическое значение] --pattern, -p, -d [по умолчанию: "*"] --игнорировать-кодирование, -i [по умолчанию: ""] --verbose, -v [по умолчанию: ложь]
Примеры
Получить кодировку всех файлов в текущем каталоге:
encoding-checker
Вернуть кодировку всех файлов md в текущем каталоге:
encoding-checker -p "*.md"
Получить кодировку всех файлов в текущем каталоге и его подпапках (для огромных папок это займет довольно много времени; по-видимому, не отвечает):
encoding-checker -p "**"
Дополнительные примеры см. в документе npm или в официальном репозитории.
0
Подобно решению, указанному выше, с Блокнотом, вы также можете открыть файл в Visual Studio, если вы его используете. В Visual Studio вы можете выбрать «Файл > Дополнительные параметры сохранения…»
В поле со списком «Кодировка:» будет указано, какая кодировка в настоящее время используется для файла. В нем указано гораздо больше текстовых кодировок, чем в Блокноте, поэтому он полезен при работе с различными файлами со всего мира и чем угодно еще.
Как и в Блокноте, вы также можете изменить кодировку из списка параметров, а затем сохранить файл, нажав «ОК». Вы также можете выбрать нужную кодировку с помощью параметра «Сохранить с кодировкой. ..» в диалоговом окне «Сохранить как» (щелкнув стрелку рядом с кнопкой «Сохранить»).
..» в диалоговом окне «Сохранить как» (щелкнув стрелку рядом с кнопкой «Сохранить»).
2
Единственный найденный мной способ сделать это — VIM или Notepad++.
1
EncodingChecker
File Encoding Checker — это инструмент с графическим интерфейсом, который позволяет вам проверять кодировку текста в одном или нескольких файлах. Инструмент может отображать кодировку для всех выбранных файлов или только для файлов, которые не имеют указанной вами кодировки.
Для запуска File Encoding Checker требуется .NET 4 или выше.
Зарегистрируйтесь или войдите
Зарегистрироваться через Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Как проверить кодировку файла CSV
спросил
Изменено 1 месяц назад
Просмотрено 275 тысяч раз
У меня есть CSV-файл, и я хочу понять его кодировку. Есть ли пункт меню в Microsoft Excel, который может помочь мне обнаружить его
Есть ли пункт меню в Microsoft Excel, который может помочь мне обнаружить его
ИЛИ мне нужно использовать языки программирования, такие как C # или PHP, чтобы вывести его.
- csv
- кодирование
2
Вы можете использовать Notepad++ для оценки кодировки файла без необходимости написания кода. Оцененная кодировка открытого файла будет отображаться на нижней панели справа. Поддерживаемые кодировки можно увидеть, перейдя в «Настройки » -> «Настройки» -> «Новый документ/Каталог по умолчанию» и просмотрев раскрывающийся список.
8
В системах Linux вы можете использовать команду file . Это даст правильную кодировку
Пример:
файл blah.csv
Вывод:
blah.csv: текст ISO-8859 с очень длинными строками
2
Если вы используете Python, просто используйте функцию print() для проверки кодировки CSV-файла. Например:
Например:
с open('file_name.csv') как f:
печать (е)
Вывод примерно такой:
<_io.TextIOWrapper name='file_name.csv' mode='r' encoding='utf8'>
5
Вы также можете использовать библиотеку chardet для Python
# установить библиотеку chardet
!pip установить чардет
# импортируем библиотеку charde
импортировать чарде
# используем метод обнаружения, чтобы найти кодировку
# 'rb' означает, что файл читается как двоичный
с open("test.csv", 'rb') в виде файла:
печать (chardet.detect (file.read ()))
Используйте charde https://github.com/chardet/chardet (документация короткая и легко читаемая).
Установите python, затем pip установите chardet, наконец, используйте команду командной строки.
Тестировал под GB2312, довольно точно. (Убедитесь, что у вас есть по крайней мере несколько символов, образец с одним символом может легко выйти из строя).
файл , как видите, ненадежен.
2
Или вы можете выполнить в консоли Python или в Jupyter Notebook:
импорт CSV
данные = открыть ("файл.csv", "r")
данные
Вы увидите информацию об объекте данных следующим образом:
<_io.TextIOWrapper name='arch.csv' mode='r' encoding='cp1250'>
Как видите, он содержит информацию о кодировке.
Файлы CSV не имеют заголовков, указывающих на кодировку.
Вы можете только догадываться, глядя на:
- платформа/приложение, на котором был создан файл
- байт в файле
В 2021 году смайлики широко используются, но многие инструменты импорта не могут их импортировать. В ответах выше часто рекомендуется библиотека chardet , но эта библиотека плохо обрабатывает смайлики.
мороженое = '🍦'
импортировать CSV
с open('test.csv', 'w') как f:
wf = csv. write(f)
wf.writerow(['мороженое', мороженое])
импортировать чарде
с open('test.csv', 'rb') как f:
печать (chardet.detect (f.read ()))
{'кодировка': 'Windows-1254', 'достоверность': 0.3864823918622268, 'язык': 'турецкий'}
write(f)
wf.writerow(['мороженое', мороженое])
импортировать чарде
с open('test.csv', 'rb') как f:
печать (chardet.detect (f.read ()))
{'кодировка': 'Windows-1254', 'достоверность': 0.3864823918622268, 'язык': 'турецкий'}
Это дает UnicodeDecodeError при попытке прочитать файл с этой кодировкой.
Кодировка по умолчанию на Mac — UTF-8. Это явно включено здесь, но в этом даже нет необходимости … но в Windows это может быть.
с open('test.csv', 'r', encoding='utf-8') как f:
печать (f.read())
мороженое,🍦
Команда file также подобрала этот файл
test.csv test.csv: текст Unicode UTF-8 с разделителями строк CRLF.
Мой совет в 2021 году, если автоматическое определение пойдет не так: попробуйте UTF-8 перед использованием chardet .
В Python вы можете попробовать…
из encodings.aliases импортировать псевдонимы псевдонимы = установить (псевдонимы. значения ()) для кодирования в наборе (aliases.values()): пытаться: df=pd.read_csv("test.csv", кодировка=кодировка) печать('успешно', кодировка) кроме: проходить
Как упоминалось @ 3724913 (Jitender Kumar) для использования команды file (она также работает в WSL в Windows), я смог получить информацию о кодировке файла csv, выполнив 9Файл 0070 —exclude encoding blah.csv с использованием информации, доступной в справочном файле , поскольку файл blah.csv не будет отображать информацию о кодировке в моей системе.
импортировать панд как pd импортировать чарде def read_csv (путь: str, размер: float = 0,10) -> pd.DataFrame: """ Читает CSV-файл, расположенный по пути, и возвращает его как Pandas DataFrame. Если nrows, будут доступны только первые nrows строк CSV-файла. читать. В противном случае будут прочитаны все строки. Аргументы: path (str): путь к CSV-файлу. размер (с плавающей запятой): часть файла, используемая для обнаружения кодирование.