теория, инструменты и советы от практика
Рассказывает программист Вильям В. Вольд
На протяжении последних шести месяцев я работал над созданием языка программирования (ЯП) под названием Pinecone. Я не рискну назвать его законченным, но использовать его уже можно — он содержит для этого достаточно элементов, таких как переменные, функции и пользовательские структуры данных. Если хотите ознакомиться с ним перед прочтением, предлагаю посетить официальную страницу и репозиторий на GitHub.
Введение
Я не эксперт. Когда я начал работу над этим проектом, я понятия не имел, что делаю, и всё еще не имею. Я никогда целенаправленно не изучал принципы создания языка — только прочитал некоторые материалы в Сети и даже в них не нашёл для себя почти ничего полезного.
Тем не менее, я написал абсолютно новый язык. И он работает. Наверное, я что-то делаю правильно.
В этой статье я постараюсь показать, каким образом Pinecone (и другие языки программирования) превращают исходный код в то, что многие считают магией. Также я уделю внимание ситуациям, в которых мне приходилось искать компромиссы, и поясню, почему я принял те решения, которые принял.
Текст точно не претендует на звание полноценного руководства по созданию языка программирования, но для любознательных будет хорошей отправной точкой.
Первые шаги
«А с чего вообще начинать?» — вопрос, который другие разработчики часто задают, узнав, что я пишу свой язык. В этой части постараюсь подробно на него ответить.
Компилируемый или интерпретируемый?
Компилятор анализирует программу целиком, превращает её в машинный код и сохраняет для последующего выполнения. Интерпретатор же разбирает и выполняет программу построчно в режиме реального времени.
Технически любой язык можно как компилировать, так и интерпретировать. Но для каждого языка один из методов подходит больше, чем другой, и выбор парадигмы на ранних этапах определяет дальнейшее проектирование.
Я хотел создать простой и при этом производительный язык, каких немного, поэтому с самого начала решил сделать Pinecone компилируемым. Тем не менее, интерпретатор у Pinecone тоже есть — первое время запуск был возможен только с его помощью, позже объясню, почему.
Прим. перев. Кстати, у нас есть краткий обзор серии статей по созданию собственного интерпретатора — это отличное упражнение для тех, кто изучает Python.
Выбор языка
Своеобразный мета-шаг: язык программирования сам является программой, которую надо написать на каком-то языке. Я выбрал C++ из-за производительности, большого набора функциональных возможностей, и просто потому что он мне нравится.
Но в целом совет можно дать такой:
- интерпретируемый ЯП крайне рекомендуется писать
- компилируемый ЯП можно писать на интерпретируемом ЯП (Python, JS). Возрастёт время компиляции, но не время выполнения программы.
Проектирование архитектуры
У структуры языка программирования есть несколько ступеней от исходного кода до исполняемого файла, на каждой из которых определенным образом происходит форматирование данных, а также функции для перехода между этими ступенями. Поговорим об этом подробнее.
Лексический анализатор / лексер
Строка исходного кода проходит через лексер и превращается в список токенов.
Первый шаг в большинстве ЯП — это лексический анализ. Говоря по-простому, он представляет собой разбиение текста на токены, то есть единицы языка: переменные, названия функций (идентификаторы), операторы, числа. Таким образом, подав лексеру на вход строку с исходным кодом, мы получим на выходе список всех токенов, которые в ней содержатся.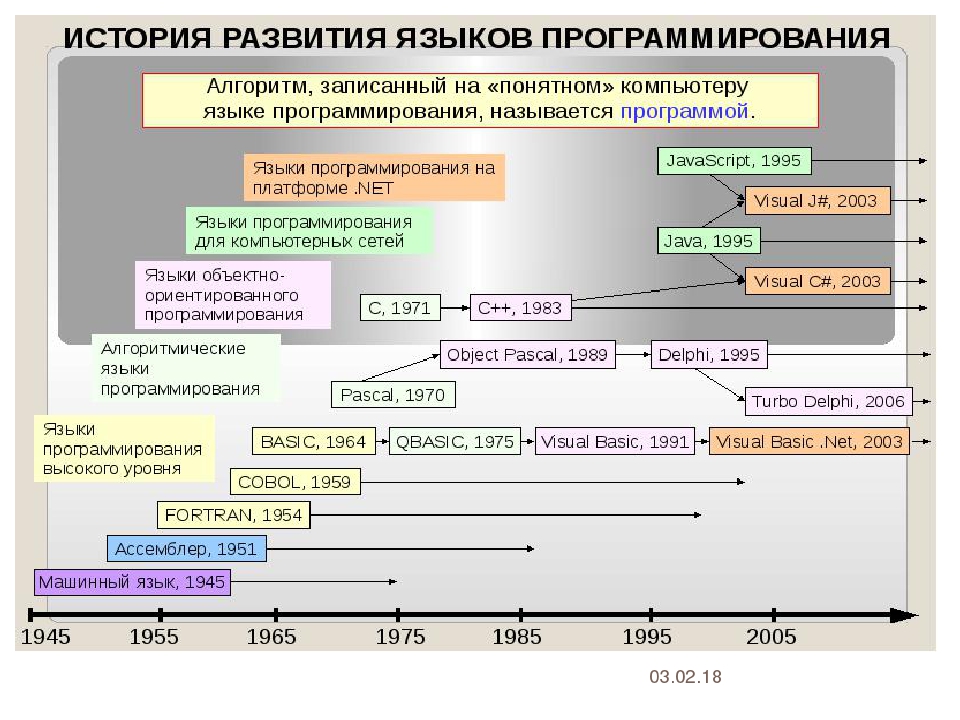
Обращения к исходному коду уже не будет происходить на следующих этапах, поэтому лексер должен выдать всю необходимую для них информацию.
Flex
При создании языка первым делом я написал лексер. Позже я изучил инструменты, которые могли бы сделать лексический анализ проще и уменьшить количество возникающих багов.
Одним из основных таких инструментов является Flex — генератор лексических анализаторов. Он принимает на вход файл с описанием грамматики языка, а потом создаёт программу на C, которая в свою очередь анализирует строку и выдаёт нужный результат.
Моё решение
Я решил оставить написанный мной анализатор. Особых преимуществ у Flex я в итоге не увидел, а его использование только создало бы дополнительные зависимости, усложняющие процесс сборки. К тому же, мой выбор обеспечивает больше гибкости — например, можно добавить к языку оператор без необходимости редактировать несколько файлов.
Синтаксический анализатор / парсер
Список токенов проходит через парсер и превращается в дерево.
Следующая стадия — парсер. Он преобразует исходный текст, то есть список токенов (с учётом скобок и порядка операций), в абстрактное синтаксическое дерево, которое позволяет структурно представить правила создаваемого языка. Сам по себе процесс можно назвать простым, но с увеличением количества языковых конструкций он сильно усложняется.
Bison
На этом шаге я также думал использовать стороннюю библиотеку, рассматривая Bison для генерации синтаксического анализатора. Он во многом похож на Flex — пользовательский файл с синтаксическими правилами структурируется с помощью программы на языке C. Но я снова отказался от средств автоматизации.
Преимущества кастомных программ
С лексером моё решение писать и использовать свой код (длиной около 200 строк) было довольно очевидным: я люблю задачки, а эта к тому же относительно тривиальная. С парсером другая история: сейчас длина кода для него — 750 строк, и это уже третья попытка (первые две были просто ужасны).
Тем не менее, я решил делать парсер сам. Вот основные причины:
В целесообразности решения меня убедило высказывание Уолтера Брайта (создателя языка D) в одной из его статей:
Я бы не советовал использовать генераторы лексических и синтаксических анализаторов, а также другие так называемые «компиляторы компиляторов». Написание лексера и парсера не займёт много времени, а использование генератора накрепко привяжет вас к нему в дальнейшей работе (что имеет значение при портировании компилятора на новую платформу). Кроме того, генераторы отличаются выдачей не релевантных сообщений об ошибках.
Абстрактный семантический граф
Переход от синтаксического дерева к семантическому графу
В этой части я реализовал структуру, по своей сути наиболее близкую к «промежуточному представлению» (intermediate representation) в LLVM. Существует небольшая, но важная разница между абстрактным синтаксическим деревом (АСД) и абстрактным семантическим графом (АСГ).
АСГ vs АСД
Грубо говоря, семантический граф — это синтаксическое дерево с контекстом. То есть, он содержит информацию наподобие какой тип возвращает функция или в каких местах используется одна и та же переменная. Из-за того, что графу нужно распознать и запомнить весь этот контекст, коду, который его генерирует, необходима поддержка в виде множества различных поясняющих таблиц.
Запуск
После того, как граф составлен, запуск программы становится довольно простой задачей. Каждый узел содержит реализацию функции, которая получает некоторые данные на вход, делает то, что запрограммировано (включая возможный вызов вспомогательных функций), и возвращает результат. Это — интерпретатор в действии.
Варианты компиляции
Вы, наверное, спросите, откуда взялся интерпретатор, если я изначально определил Pinecone как компилируемый язык. Дело в том, что компиляция гораздо сложнее, чем интерпретация — я уже упоминал ранее, что столкнулся с некоторыми проблемами на этом шаге.
Написать свой компилятор
Сначала мне понравилась эта мысль — я люблю делать вещи сам, к тому же давно хотел изучить язык ассемблера. Вот только создать с нуля кроссплатформенный компилятор — сложнее, чем написать машинный код для каждого элемента языка. Я счёл эту идею абсолютно не практичной и не стоящей затраченных ресурсов.
LLVM
LLVM — это коллекция инструментов для компиляции, которой пользуются, например, разработчики Swift, Rust и Clang. Я решил остановиться на этом варианте, но опять не рассчитал сложности задачи, которую перед собой поставил. Для меня проблемой оказалось не освоение ассемблера, а работа с огромной многосоставной библиотекой.
Транспайлинг
Дальнейшие планы
Сейчас мне не достаёт необходимой практики, но в будущем я собираюсь от начала и до конца реализовать компилятор Pinecone с помощью LLVM — инструмент мне нравится и руководства к нему хорошие. Пока что интерпретатора хватает для примитивных программ, а транспайлер справляется с более сложными.
Заключение
Надеюсь, эта статья окажется кому-нибудь полезной. Я крайне рекомендую хотя бы попробовать написать свой язык, несмотря на то, что придётся разбираться во множестве деталей реализации — это обучающий, развивающий и просто интересный эксперимент.
Вот общие советы от меня (разумеется, довольно субъективные):
- если у вас нет предпочтений и вы сомневаетесь, компилируемый или интерпретируемый писать язык, выбирайте второе. Интерпретируемые языки обычно проще проектировать, собирать и учить;
- с лексерами и парсерами делайте, что хотите.
 Использование средств автоматизации зависит от вашего желания, опыта и конкретной ситуации;
Использование средств автоматизации зависит от вашего желания, опыта и конкретной ситуации; - если вы не готовы / не хотите тратить время и силы (много времени и сил) на придумывание собственной стратегии разработки ЯП, следуйте цепочке действий, описанной в этой статье. Я вложил в неё много усилий и она работает;
- опять же, если не хватает времени / мотивации / опыта / желания или ещё чего-нибудь для написания классического ЯП, попробуйте написать эзотерический, типа Brainfuck. (Советуем помнить, что если язык написан развлечения ради, это не значит, что писать его — тоже сплошное развлечение. — прим. перев.)
Я делал довольно много ошибок по ходу разработки, но большую часть кода, на которую они могли повлиять, я уже переписал. Язык сейчас неплохо функционирует и будет развиваться (на момент написания статьи его можно было собрать на Linux и с переменным успехом на macOS, но не на Windows).
О том, что ввязался в историю с созданием Pinecone, ни в коем случае не жалею — это отличный эксперимент, и он только начался.
Перевод статьи: «I wrote a programming language. Here’s how you can, too»
Как создать свой язык программирования? Теория и практика
Создание языка программирования очень сложная задача, но выполнимая. Мы расскажем основные факторы при создании своего первого языка.
Желание создать что-то своё и оставить след в истории посещает всех людей, в том числе программистов. Создание собственного языка программирования – это подходящая возможность. Мотивы бывают различные: от нечего делать, решения вечных проблем в других языках, разработка комфортного варианта для себя.
Создание языков – это посильная задача, которую может выполнить читатель, руководствуясь пошаговым алгоритмом из 12 этапов. Вероятно, что именно за вашим языком будущее.
Статья содержит специфические термины, без понимания которых не обойтись: лексеры, парсеры, интерпретаторы, компиляторы, деревья синтаксиса и остальное. Значительно проще вникнуть в суть, черпая информацию из интернета или при совместном изучении данных с опытным программистом. Базовые понятия терминологии – это фундаментальная величина для создания своего языка программирования.
Значительно проще вникнуть в суть, черпая информацию из интернета или при совместном изучении данных с опытным программистом. Базовые понятия терминологии – это фундаментальная величина для создания своего языка программирования.
Изучение компьютера
Это совет и необходимость одновременно, знание операционных систем поможет работать, изучать новые языки, стать на путь программиста. Невозможно создать быстрый, качественный и многофункциональный язык без понимания способа преобразования кода и его обработки. Познание функционирования системной машины – это обязательный этап дальнейшего развития.
Зачем вам новый язык программирования?
Заранее определитесь с предназначением языка. Существует 2 основных направления – универсальный инструмент или узкоспециализированное решение.
Востребованными оказываются языки с обоих направлений, но более популярны универсальные. Учтите, что многофункциональные языки требуют больше времени и усилий, а также у них множество конкурентов.
Сейчас стоит оценить количество предстоящей работы, установить цели и желания. Немаловажно определиться, вы планируете стать знаменитостью, а язык должен стать одним из лучших, или вам достаточно интересно провести время и расширить мировоззрение?
Каких концепций будет придерживаться новый язык?
На этапе планирования следует ответить на ряд ключевых вопросов, они зададут направление развития:
- интерпретация или компиляция? Код для компилирования будет преобразовываться в машинный, затем исполняться. При использовании интерпретатора код обрабатывается построчно. На вопрос нет правильного ответа, перед разработчиком стоит сложный выбор, в какую сторону уклон делать: функциональность, безопасность, скорость работы, удобство и т. д.;
- типизация? Если да, то разработчику будет необходимо вручную устанавливать типы данных. В противном случае придётся описывать систему, которая будет определять типы;
- в языке будет встроен автоматический алгоритм очистки мусора или управление отдать в руки пользователя?
- планируемая модель языка программирования: структурное, ООП, функциональная логика.
 Кто знает, может вам удастся разработать что-то совсем иное;
Кто знает, может вам удастся разработать что-то совсем иное; - как язык будет себя вести в отношении конкурентов, вставка из других языков планируется? Учитывать этот аспект важно при изначальной разработке языка;
- планируется поддержка базового функционала языка или передать все функции на сторону фреймворков?
- какой ожидается конечный вид архитектуры программы?
Последовательно отвечая на поставленные вопросы, в голове начнёт формировать облик детища, но появятся и другие вытекающие вопросы, требующие ответов.
Придумайте синтаксис для языка
При использовании особых символов можно существенно упростить работу компьютеру и повысить производительность кода. Недостатком является отталкивание нового пользователя. Подобный выбор стоит в отношении функций: либо элементарные и понятные, либо максимально информативные.
При этом синтаксис может быть каким вы только сами захотите. К примеру, существует язык от отечественных разработчиков, который называется YoptaScript. Он имеет очень забавный синтаксис и писать программы на нем приносит лишь смех 🙂
PS: этот язык является лишь шуткой и его не стоит воспринимать как реальный язык. Посмотреть язык вы можете на их официальном сайте.
Назовите ваше детище
Вопрос с одной стороны простой, с другой – нет. Многие разработчики не выбирают глубокое и замысловатое название, отдают предпочтение простоте и лёгкости запоминания. Особенно эффективно давать имя языку с явной ассоциацией, чтобы потенциальный пользователь запоминал название после первого-второго произнесения. Сложные аббревиатуры и названия из 3 и больше слов – сложно запоминаются и быстро теряются в памяти. Имя должно быть относительно коротким и запоминающимся.
Выберите фундамент языка
Выбор языка, который будет взят за основу – это важнейший шаг. Если знаний достаточно, можно писать на ассемблере или даже машинном коде, но в современном мире лучше присмотреться к другим высокоуровневым языкам: C, C++, Swift, Pascal и другие компилируемые варианты пригодные для интерпретируемых решений. В качестве достойных языков с интерпретаторами стоит присмотреться к: Java, JavaScript, Ruby, Python – для компиляторов. Перечисленные пары снизят потерю скорости работы.
В качестве достойных языков с интерпретаторами стоит присмотреться к: Java, JavaScript, Ruby, Python – для компиляторов. Перечисленные пары снизят потерю скорости работы.
Лексер и парсер
Лексер – это инструмент для анализа лексики, деления написанного кода на отдельные элементы, их называют токены. Далее вступает в работы парсер для синтаксического анализа, его роль – организация иерархии с учётом токенов, он восстанавливает цепь событий. В качестве графического примера рассмотрим простую схему:
Пугаться не стоит, так как уже есть готовые библиотеки для быстрого формирования лексеров и парсеров. Приложения упростят выполнение сложного этапа работы.
Создание основной библиотеки
Независимо от наличия встроенных возможностей в языке для работы с элементарным функционалом или максимального использования внешних библиотек, потребуется создание функций. Они помогут продемонстрировать возможности хотя бы очень базисно.
Создание и написание тестов
Процесс создания в большей мере сводится к оттачиванию работы, так как сформировать нормально работающий язык весьма сложно. Задача разработчика – выявить работоспособность встроенных элементов и механизмов их взаимодействия, здесь на помощь приходят тесты. По результатам тестирования делается вывод о недопустимом и разрешённом синтаксисе и сочетании функций. Возможно удастся расширить функционал языка.
Выпуск языка в свет
После завершения работы обязательно следует загрузить язык в сеть. Здесь вы найдёте единомышленников и людей, которые помогут совершенствовать детище. Публикация – это логическое завершение процесса, не стоит прятать работу в ящик, поделитесь ей.
Как создать свой язык программирования: теория, инструменты и советы от практика | ДНЕВНИК СТУДЕНТА
На протяжении последних шести месяцев я работал над созданием языка программирования (ЯП) под названием Pinecone. Я не рискну назвать его законченным, но использовать его уже можно — он содержит для этого достаточно элементов, таких как переменные, функции и пользовательские структуры данных.
Введение
Я не эксперт. Когда я начал работу над этим проектом, я понятия не имел, что делаю, и всё еще не имею. Я никогда целенаправленно не изучал принципы создания языка — только прочитал некоторые материалы в Сети и даже в них не нашёл для себя почти ничего полезного.
Тем не менее, я написал абсолютно новый язык. И он работает. Наверное, я что-то делаю правильно.
В этой статье я постараюсь показать, каким образом Pinecone (и другие языки программирования) превращают исходный код в то, что многие считают магией. Также я уделю внимание ситуациям, в которых мне приходилось искать компромиссы, и поясню, почему я принял те решения, которые принял.
Текст точно не претендует на звание полноценного руководства по созданию языка программирования, но для любознательных будет хорошей отправной точкой.
Первые шаги
«А с чего вообще начинать?» — вопрос, который другие разработчики часто задают, узнав, что я пишу свой язык. В этой части постараюсь подробно на него ответить.
Компилируемый или интерпретируемый?
Компилятор анализирует программу целиком, превращает её в машинный код и сохраняет для последующего выполнения. Интерпретатор же разбирает и выполняет программу построчно в режиме реального времени.
Технически любой язык можно как компилировать, так и интерпретировать. Но для каждого языка один из методов подходит больше, чем другой, и выбор парадигмы на ранних этапах определяет дальнейшее проектирование. В общем смысле интерпретация отличается гибкостью, а компиляция обеспечивает высокую производительность, но это лишь верхушка крайне сложной темы.
Я хотел создать простой и при этом производительный язык, каких немного, поэтому с самого начала решил сделать Pinecone компилируемым. Тем не менее, интерпретатор у Pinecone тоже есть — первое время запуск был возможен только с его помощью, позже объясню, почему.
Прим. перев. Кстати, у нас есть краткий обзор серии статей по созданию собственного интерпретатора — это отличное упражнение для тех, кто изучает Python.

Выбор языка
Своеобразный мета-шаг: язык программирования сам является программой, которую надо написать на каком-то языке. Я выбрал C++ из-за производительности, большого набора функциональных возможностей, и просто потому что он мне нравится.
Но в целом совет можно дать такой:
- интерпретируемый ЯП крайне рекомендуется писать на компилируемом ЯП (C, C++, Swift). Иначе потери производительности будут расти как снежный ком, пока мета-интерпретатор интерпретирует ваш интерпретатор;
- компилируемый ЯП можно писать на интерпретируемом ЯП (Python, JS). Возрастёт время компиляции, но не время выполнения программы.
Проектирование архитектуры
У структуры языка программирования есть несколько ступеней от исходного кода до исполняемого файла, на каждой из которых определенным образом происходит форматирование данных, а также функции для перехода между этими ступенями. Поговорим об этом подробнее.
Лексический анализатор / лексер
Строка исходного кода проходит через лексер и превращается в список токенов.
Первый шаг в большинстве ЯП — это лексический анализ. Говоря по-простому, он представляет собой разбиение текста на токены, то есть единицы языка: переменные, названия функций (идентификаторы), операторы, числа. Таким образом, подав лексеру на вход строку с исходным кодом, мы получим на выходе список всех токенов, которые в ней содержатся.
Обращения к исходному коду уже не будет происходить на следующих этапах, поэтому лексер должен выдать всю необходимую для них информацию.
Flex
При создании языка первым делом я написал лексер. Позже я изучил инструменты, которые могли бы сделать лексический анализ проще и уменьшить количество возникающих багов.
Одним из основных таких инструментов является Flex — генератор лексических анализаторов. Он принимает на вход файл с описанием грамматики языка, а потом создаёт программу на C, которая в свою очередь анализирует строку и выдаёт нужный результат.
Моё решение
Я решил оставить написанный мной анализатор. Особых преимуществ у Flex я в итоге не увидел, а его использование только создало бы дополнительные зависимости, усложняющие процесс сборки. К тому же, мой выбор обеспечивает больше гибкости — например, можно добавить к языку оператор без необходимости редактировать несколько файлов.
Синтаксический анализатор / парсер
Список токенов проходит через парсер и превращается в дерево.
Следующая стадия — парсер. Он преобразует исходный текст, то есть список токенов (с учётом скобок и порядка операций), в абстрактное синтаксическое дерево, которое позволяет структурно представить правила создаваемого языка. Сам по себе процесс можно назвать простым, но с увеличением количества языковых конструкций он сильно усложняется.
Bison
На этом шаге я также думал использовать стороннюю библиотеку, рассматривая Bison для генерации синтаксического анализатора. Он во многом похож на Flex — пользовательский файл с синтаксическими правилами структурируется с помощью программы на языке C. Но я снова отказался от средств автоматизации.
Преимущества кастомных программ
С лексером моё решение писать и использовать свой код (длиной около 200 строк) было довольно очевидным: я люблю задачки, а эта к тому же относительно тривиальная. С парсером другая история: сейчас длина кода для него — 750 строк, и это уже третья попытка (первые две были просто ужасны).
Тем не менее, я решил делать парсер сам. Вот основные причины:
- минимизация переключения контекста;
- упрощение сборки;
- желание справиться с задачей самостоятельно.
Я бы не советовал использовать генераторы лексических и синтаксических анализаторов, а также другие так называемые «компиляторы компиляторов». Написание лексера и парсера не займёт много времени, а использование генератора накрепко привяжет вас к нему в дальнейшей работе (что имеет значение при портировании компилятора на новую платформу).Кроме того, генераторы отличаются выдачей не релевантных сообщений об ошибках.
Абстрактный семантический граф
Переход от синтаксического дерева к семантическому графу
В этой части я реализовал структуру, по своей сути наиболее близкую к «промежуточному представлению» (intermediate representation) в LLVM. Существует небольшая, но важная разница между абстрактным синтаксическим деревом (АСД) и абстрактным семантическим графом (АСГ).
АСГ vs АСД
Грубо говоря, семантический граф — это синтаксическое дерево с контекстом. То есть, он содержит информацию наподобие какой тип возвращает функция или в каких местах используется одна и та же переменная. Из-за того, что графу нужно распознать и запомнить весь этот контекст, коду, который его генерирует, необходима поддержка в виде множества различных поясняющих таблиц.
Запуск
После того, как граф составлен, запуск программы становится довольно простой задачей. Каждый узел содержит реализацию функции, которая получает некоторые данные на вход, делает то, что запрограммировано (включая возможный вызов вспомогательных функций), и возвращает результат. Это — интерпретатор в действии.
Варианты компиляции
Вы, наверное, спросите, откуда взялся интерпретатор, если я изначально определил Pinecone как компилируемый язык. Дело в том, что компиляция гораздо сложнее, чем интерпретация — я уже упоминал ранее, что столкнулся с некоторыми проблемами на этом шаге.
Написать свой компилятор
Сначала мне понравилась эта мысль — я люблю делать вещи сам, к тому же давно хотел изучить язык ассемблера. Вот только создать с нуля кроссплатформенный компилятор — сложнее, чем написать машинный код для каждого элемента языка. Я счёл эту идею абсолютно не практичной и не стоящей затраченных ресурсов.
LLVM
LLVM — это коллекция инструментов для компиляции, которой пользуются, например, разработчики Swift, Rust и Clang. Я решил остановиться на этом варианте, но опять не рассчитал сложности задачи, которую перед собой поставил. Для меня проблемой оказалось не освоение ассемблера, а работа с огромной многосоставной библиотекой.
Для меня проблемой оказалось не освоение ассемблера, а работа с огромной многосоставной библиотекой.
Транспайлинг
Мне всё же нужно было какое-то решение, поэтому я написал то, что точно будет работать: транспайлер (transpiler) из Pinecone в C++ — он производит компиляцию по типу «исходный код в исходный код», а также добавил возможность автоматической компиляции вывода с GCC. Такой способ не является ни масштабируемым, ни кроссплатформенным, но на данный момент хотя бы работает почти для всех программ на Pinecone, это уже хорошо.
Дальнейшие планы
Сейчас мне не достаёт необходимой практики, но в будущем я собираюсь от начала и до конца реализовать компилятор Pinecone с помощью LLVM — инструмент мне нравится и руководства к нему хорошие. Пока что интерпретатора хватает для примитивных программ, а транспайлер справляется с более сложными.
Заключение
Надеюсь, эта статья окажется кому-нибудь полезной. Я крайне рекомендую хотя бы попробовать написать свой язык, несмотря на то, что придётся разбираться во множестве деталей реализации — это обучающий, развивающий и просто интересный эксперимент.
Вот общие советы от меня (разумеется, довольно субъективные):
- если у вас нет предпочтений и вы сомневаетесь, компилируемый или интерпретируемый писать язык, выбирайте второе. Интерпретируемые языки обычно проще проектировать, собирать и учить;
- с лексерами и парсерами делайте, что хотите. Использование средств автоматизации зависит от вашего желания, опыта и конкретной ситуации;
- если вы не готовы / не хотите тратить время и силы (много времени и сил) на придумывание собственной стратегии разработки ЯП, следуйте цепочке действий, описанной в этой статье. Я вложил в неё много усилий и она работает;
- опять же, если не хватает времени / мотивации / опыта / желания или ещё чего-нибудь для написания классического ЯП, попробуйте написать эзотерический, типа
Как мне создать свой собственный язык программирования и компилятор для него [закрыто]
В этой теме есть отличные ответы, но я просто хотел добавить свой, поскольку у меня тоже когда-то был тот же вопрос. (Также я хотел бы отметить, что книга, предложенная Joe-Internet, является отличным ресурсом.)
(Также я хотел бы отметить, что книга, предложенная Joe-Internet, является отличным ресурсом.)
Сначала вопрос о том, как работает компьютер? Вот как: ввод -> вычисление -> вывод.
Сначала рассмотрим часть «Compute». Мы рассмотрим, как работает ввод и вывод.
Компьютер по существу состоит из процессора (или процессора) и некоторой памяти (или оперативной памяти). Память представляет собой набор местоположений, в каждом из которых может храниться конечное число битов, и на каждое такое местоположение в памяти может быть указано число, это называется адресом ячейки памяти. Процессор представляет собой гаджет, который может извлекать данные из памяти, выполнить некоторые операции на основе данных и записать некоторые данные обратно в память. Как процессор определяет, что читать и что делать после чтения данных из памяти?
Чтобы ответить на это, нам нужно понять структуру процессора. Ниже приведен довольно простой вид. Процессор по существу состоит из двух частей. Одним из них является набор областей памяти, встроенных в процессор, которые служат его рабочей памятью. Они называются «регистрами». Второй представляет собой набор электронных механизмов, созданных для выполнения определенных операций с использованием данных в регистрах. Есть два специальных регистра, называемых «счетчик программ» или ПК и «регистр команд» или ир. Процессор считает, что память разделена на три части. Первая часть — это «память программ», в которой хранится исполняемая компьютерная программа. Второе — это «память данных». Третий используется для каких-то особых целей, об этом мы поговорим позже. Счетчик программ содержит местоположение следующей инструкции для чтения из памяти программ. Счетчик команд содержит номер, который относится к текущей выполняемой операции. Каждая операция, которую может выполнить процессор, указывается номером, который называется кодом операции операции. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Счетчик команд содержит номер, который относится к текущей выполняемой операции. Каждая операция, которую может выполнить процессор, указывается номером, который называется кодом операции операции. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Счетчик команд содержит номер, который относится к текущей выполняемой операции. Каждая операция, которую может выполнить процессор, указывается номером, который называется кодом операции операции. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Каждая операция, которую может выполнить процессор, указывается номером, который называется кодом операции операции. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции).
Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Счетчик команд содержит номер, который относится к текущей выполняемой операции. Каждая операция, которую может выполнить процессор, указывается номером, который называется кодом операции операции. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Счетчик команд содержит номер, который относится к текущей выполняемой операции. Каждая операция, которую может выполнить процессор, указывается номером, который называется кодом операции операции. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Каждая операция, которую может выполнить процессор, указывается номером, который называется кодом операции операции. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Каждая операция, которую может выполнить процессор, указывается номером, который называется кодом операции операции. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр.
Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Каждая операция, которую может выполнить процессор, указывается номером, который называется кодом операции операции. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр. Принцип работы компьютера заключается в том, что он считывает ячейку памяти, на которую ссылается счетчик программ, в регистр команд (и увеличивает счетчик программ так, чтобы он указывал на ячейку памяти следующей инструкции). Затем он читает регистр команд и выполняет требуемую операцию. Например, инструкция может состоять в том, чтобы считывать определенную ячейку памяти в регистр, или записывать в какой-либо регистр, или выполнять некоторую операцию, используя значения двух регистров, и записывать вывод в третий регистр.
Теперь, как компьютер выполняет ввод / вывод? Я приведу очень упрощенный ответ. См. Http://en.wikipedia.org/wiki/Input/output и http://en.wikipedia.org/wiki/Interrupt, для большего. Он использует две вещи, третью часть памяти и нечто, называемое прерываниями. Каждое устройство, подключенное к компьютеру, должно иметь возможность обмениваться данными с процессором. Это делается с использованием третьей части памяти, упомянутой ранее. Процессор выделяет часть памяти каждому устройству, и устройство и процессор обмениваются данными через этот фрагмент памяти. Но как процессор узнает, какое местоположение относится к какому устройству и когда ему нужно обмениваться данными? Это то место, где приходят прерывания. Прерывание — это, по сути, сигнал процессору приостановить текущее состояние и сохранить все свои регистры в известном месте, а затем начать делать что-то еще. Там много прерываний, каждое из которых идентифицируется уникальным номером. Для каждого прерывания существует специальная программа, связанная с ним. Когда происходит прерывание, процессор выполняет программу, соответствующую прерыванию. Теперь, в зависимости от BIOS и того, как аппаратные устройства подключены к материнской плате компьютера, каждое устройство получает уникальное прерывание и часть памяти. При загрузке операционной системы с помощью биоса определяется прерывание и место в памяти каждого устройства, а также настраиваются специальные программы для прерывания для правильной обработки устройств. Поэтому, когда устройству нужны какие-то данные или они хотят отправить какие-то данные, оно сигнализирует о прерывании. Процессор приостанавливает то, что он делает, обрабатывает прерывание и затем возвращается к тому, что он делает. Существует много видов прерываний, например, для жесткого диска, клавиатуры и т. Д. Важным является системный таймер, который вызывает прерывания через равные промежутки времени. Также есть коды операций, которые могут вызывать прерывания, называемые программными прерываниями.
Теперь мы можем почти понять, как работает операционная система. Когда он загружается, ОС устанавливает прерывание по таймеру, чтобы оно давало контроль над ОС через регулярные промежутки времени. Он также настраивает другие прерывания для обработки других устройств и т. Д. Теперь, когда на компьютере запущена куча программ, и происходит прерывание по таймеру, ОС получает контроль и выполняет важные задачи, такие как управление процессами, управление памятью и т. Д. Также ОС обычно предоставляет абстрактный способ доступа программ к аппаратным устройствам, а не прямой доступ к ним. Когда программа хочет получить доступ к устройству, она вызывает некоторый код, предоставленный операционной системой, который затем обращается к устройству. В них много теории, которая касается параллелизма, потоков, блокировок, управления памятью и т. Д.
Теперь теоретически можно написать программу напрямую, используя коды операций. Это то, что называется машинным кодом. Это явно очень больно. Теперь язык ассемблера для процессора — не что иное, как мнемоника для этих кодов операций, которая облегчает написание программ. Простой ассемблер — это программа, которая берет программу, написанную на ассемблере, и заменяет мнемонику соответствующими кодами операций.
Как можно разрабатывать процессор и язык ассемблера? Чтобы знать, что вы должны прочитать некоторые книги по компьютерной архитектуре. (см. главы 1-7 книги, на которую ссылается joe-internet). Это включает в себя изучение булевой алгебры, как создавать простые комбинаторные схемы для сложения, умножения и т. Д., Как строить память и последовательные схемы, как создавать микропроцессор и так далее.
Теперь, как писать компьютерные языки. Можно начать с написания простого ассемблера в машинном коде. Затем используйте этот ассемблер, чтобы написать компилятор для простого подмножества C. Затем используйте это подмножество C, чтобы написать более полную версию C. Наконец, используйте C, чтобы написать более сложный язык, такой как python или C ++. Конечно, чтобы написать язык, вы должны сначала спроектировать его (так же, как и процессор). Снова посмотрите на некоторые учебники по этому вопросу.
И как можно написать ОС. Сначала вы нацелены на платформу, такую как x86. Затем вы выясните, как он загружается и когда будет запущен ваш ОС. Типичный компьютер загружается таким образом. Он запускается, и BIOS выполняет некоторые тесты. Затем биос читает первый сектор жесткого диска и загружает содержимое в определенное место в памяти. Затем он устанавливает процессор, чтобы начать выполнение этих загруженных данных. Это точка, которую вы вызываете. Типичная операционная система в этот момент загружает остальную часть памяти. Затем он инициализирует устройства и настраивает другие функции, и, наконец, он приветствует вас с помощью экрана входа.
Таким образом, чтобы написать ОС, вы должны написать «загрузчик». Затем вы должны написать код для обработки прерываний и устройств. Затем вы должны написать весь код для управления процессами, управления устройствами и т. Д. Затем вы должны написать API, который позволяет программам, запущенным в вашей ОС, получать доступ к устройствам и другим ресурсам. И, наконец, вы должны написать код, который читает программу с диска, устанавливает ее как процесс и начинает выполнять ее.
Конечно, мой ответ явно упрощен и, вероятно, мало практичен. В свою защиту я теперь аспирант по теории, поэтому я забыл многие из этих вещей. Но вы можете погуглить многие из этих вещей и узнать больше.
создайте свой собственный язык программирования
Возможные Дубликаты:
Ссылки, необходимые для реализации интерпретатора в C/C++
Как создать язык в наши дни?
Учимся писать компилятор
Я знаю некоторые c++, VERY хорошо в php, профи в css html, хорошо в javascript. Итак, я думал о том, как был создан c++, я имею в виду, как компьютер может понять, что означают коды? Как он может читать… так возможно ли, что я могу создать свой собственный язык и как?
c++ compiler-construction programming-languages interpreterПоделиться Источник Ramilol 07 сентября 2010 в 20:22
13 ответов
48
Если вас интересует дизайн компилятора («как компьютер может понять, что означают коды»), я настоятельно рекомендую Dragon Book . Я использовал его еще в колледже и дошел до того, что сам создал язык программирования.
Поделиться Nikita Rybak 07 сентября 2010 в 20:27
Поделиться anthony 07 сентября 2010 в 20:39
20
Если вы хотите понять, как компьютер понимает код, вы можете изучить какой-нибудь язык assembly. Это язык гораздо более низкого уровня, и он даст вам лучшее представление о том, какие простые инструкции действительно выполняются. Вы также должны иметь возможность почувствовать, как реализуются конструкции более высокого уровня, такие как циклы с только условными переходами.
Для еще более низкого уровня понимания вам нужно будет изучить электронику. Цифровая логика показывает вам, как вы можете взять электронный «gates» и реализовать универсальный CPU, который может понять машинный код, сгенерированный из кода языка assembly.
Для действительно низкоуровневых вещей вы можете изучать материаловедение, которое может научить вас, как на самом деле заставить ворота работать на атомном уровне.
Ты говоришь как находчивый человек. Вы захотите найти книги и / или веб-сайты по этим темам, адаптированные к вашему уровню понимания и сосредоточенные на том, что вас интересует больше всего. Довольно полное понимание всего этого приходит со степенью BS в области компьютерных наук или компьютерной инженерии, но многие вещи вполне понятны мотивированному человеку в вашем положении.
Поделиться Mr Fooz 07 сентября 2010 в 20:29
- Как добавить свой собственный язык программирования в IDE?
Существует простой интерпретирующий язык программирования и, собственно, консоль interpreter.exe. Нужно сделать раскрашивание синтаксиса, автозаполнение и выполнение нажатием клавиши F5. (если можно сделать ‘debug’-это будет потрясающе!) Я никогда не делал таких вещей. Есть много IDE, которые…
- Создайте язык программирования JVM
Я создал компилятор в C (используя lex & bison) для динамического типизированного языка программирования, который поддерживает циклы, объявления функций внутри функций, рекурсивные вызовы и т. д. Я также создал виртуальную машину, которая запускает промежуточный код, созданный компилятором….
11
Да, можно создать свой собственный язык. Взгляните на компиляторы компиляторов. Или исходный код некоторых скриптовых языков, если вы осмелитесь. Некоторые полезные инструменты — это yacc, bison и lexx.
Другие упоминали книгу о драконах. Мы использовали книгу, которая, по-моему, называлась «compiler theory and practice» еще в мои университетские дни.
Нет необходимости изучать ассемблер, чтобы написать язык. Например, Javascript работает в так называемом интерпретаторе, который представляет собой приложение, выполняющее файлы javascript. В этом случае интерпретатор обычно встроен в браузер.
Самым простым языком запуска программы может быть написание простого текстового калькулятора, то есть взятие текстового файла, запуск через него и выполнение вычислений. Вы могли бы написать это в C++ очень легко.
Моим первым языком для проекта в колледже был язык, определенный в BNF году, данный нам. Затем мы должны были написать парсер, который разбирал его в древовидную структуру в памяти, а затем в нечто, называемое 3-адресным кодом (который похож на ассемблер). Вы вполне можете превратить 3-адресный код в настоящий ассемблер или написать для него интерпретатор.
Поделиться Matt 07 сентября 2010 в 20:35
8
Ага! Это определенно возможно. Другие упоминали книгу о драконах, но в интернете также есть много информации. llvm, например, имеет учебник по реализации языка программирования: http://llvm.org/docs/tutorial/
Поделиться Niki Yoshiuchi 07 сентября 2010 в 20:30
4
Я действительно рекомендую прагматику языка программирования . Это отличная книга, которая проведет вас через весь путь от того, что такое язык, до того, как работают компиляторы и как вы создаете свой собственный. Это немного более доступно, чем книга о драконах, и объясняет, как все работает, прежде чем прыгать головой вперед.
Поделиться Rohan Singh 07 сентября 2010 в 22:27
3
Это возможно. Вы должны узнать о компиляторах и / или интерпретаторах: для чего они предназначены и как они сделаны.
Поделиться Bernard 07 сентября 2010 в 20:27
3
Начните изучать ASM и читать о том, как работает байт-код, и у вас может появиться шанс 🙂
Поделиться Marc Towler 07 сентября 2010 в 20:27
3
Если вы знаете C-это звучит так, как будто вы знаете-возьмите подержанный экземпляр этой древней книги:
В ней есть глава, где автор создает интерпретатор «C», в C. Это не академически серьезно, как книга о драконе, но я помню, что она довольно проста, очень практична и легка для понимания, и поскольку вы только начинаете, это будет потрясающее введение в идеи «grammar» для языков и «tokenizing» для программ.
Это было бы идеальным местом для начала. Кроме того, в $0.01 за подержанный экземпляр, дешевле, чем книга Дракона. 😉
Поделиться Ben Zotto 07 сентября 2010 в 20:34
3
Начните с создания парсера. Почитайте о EBNF грамматиках. Это ответит на ваш вопрос о том, как компьютер может читать код. Это очень продвинутая тема, так что не ждите от себя слишком многого, но получайте удовольствие. Некоторые ресурсы, которые я использовал для этого, — это bison, flex и PLY .
Поделиться gtrak 07 сентября 2010 в 20:37
3
Да! Интерес к компиляторам был моим крючком в профессиональном CS (ранее я был на пути к EE и только формально перешел на другую сторону в колледже), это отличный способ узнать TON о широком спектре тем информатики. Вы немного моложе (я учился в средней школе, когда начал дурачиться с парсерами и интерпретаторами), но в наши дни у вас под рукой гораздо больше информации.
Начните с малого: разработайте самый крошечный язык, который только можно придумать, — начните с простого математического калькулятора, который позволяет присваивать и заменять переменные. Когда вам захочется приключений, попробуйте добавить «if» или петли. Забудьте о тайных инструментах, таких как lex и yacc, попробуйте написать простой рекурсивный парсер спуска вручную, возможно, преобразовать его в простые байт-коды и написать интерпретатор для него (избегайте всех трудных частей понимания assembly для конкретной машины, выделения регистров и т. д.). Только с этим проектом вы узнаете огромное количество нового.
Как и другие, я рекомендую книгу «Дракон» (издание 1986 года, Честно говоря, мне не нравится новая).
Я добавлю, что для других ваших проектов я рекомендую использовать C или C++, ditch PHP, не потому, что я фанатик языка, а просто потому, что я думаю, что работа с трудностями в C/C++ научит вас гораздо большему о базовой архитектуре машины и проблемах компилятора.
(Примечание: если бы Вы были профессионалом, совет был бы NOT создать новый язык. Это почти никогда не бывает правильным решением. Но как проект для обучения и исследования, это фантастика.)
Поделиться Larry Gritz 08 сентября 2010 в 00:27
1
Если вы хотите действительно общее (но очень хорошо написанное) введение в эту тему-Основы вычислительной техники — я настоятельно рекомендую книгу под названием » Код » Чарльза Петцольда. Он объясняет ряд тем, которые вас интересуют, и оттуда вы можете решить, что вы хотите создать сами.
Поделиться Ulysses 07 сентября 2010 в 21:25
Поделиться cirons42 07 сентября 2010 в 21:44
Похожие вопросы:
Язык программирования GUI
Не волнуйся, я не собираюсь снова задавать этот вопрос… Я хочу создать свой собственный язык программирования, просто ради обучения. Я не хочу ничего, кроме, возможно, нескольких ссылок, чтобы…
Как сделать свой собственный язык программирования?
Возможный Дубликат : Учимся писать компилятор Я огляделся вокруг, пытаясь узнать больше о разработке языка программирования, но не смог найти много информации в интернете. Я нашел несколько…
Вы написали свой собственный эзотерический (или нет) язык? На что это было похоже?
Я видел несколько вопросов, касающихся любимых эзотерических (или нет) языков программирования пользователей stackoverflow. Есть также вопросы, касающиеся реализации языков. Однако мне было…
Как бы выглядел ваш собственный язык программирования?
Как бы выглядел ваш собственный (Я полагаю, идеальный) язык программирования? Приведите небольшой пример и объясните свои новые идеи! Меня действительно интересует синтаксис.
Название класса языков программирования, выполняющих собственный код
Как вы называете язык программирования, который может выполнять свой собственный код (передаваемый в виде строкового литерала)? Установка в моем сознании примерно такая (забыв на мгновение набирать…
Как добавить свой собственный язык программирования в IDE?
Существует простой интерпретирующий язык программирования и, собственно, консоль interpreter.exe. Нужно сделать раскрашивание синтаксиса, автозаполнение и выполнение нажатием клавиши F5. (если можно…
Создайте язык программирования JVM
Я создал компилятор в C (используя lex & bison) для динамического типизированного языка программирования, который поддерживает циклы, объявления функций внутри функций, рекурсивные вызовы и т….
Как язык программирования может быть «implemented»?
может быть, это просто небольшое недоразумение, но как можно реализовать язык программирования ? Я говорю не о том, как реализовать свой собственный язык программирования, а о слове implemented? Я…
Как я могу создать свой собственный язык программирования, ориентированный на JVM?
Я хотел бы создать свой собственный язык программирования, ориентированный на JVM. Я не знаю, как это сделать. Должен ли я создать свой собственный компилятор? Есть ли у всех языков программирования…
Почему Neto/Shopify используют свой собственный язык шаблонов?
Почему Neto/Shopify используют свой собственный язык шаблонов вместо использования любого популярного популярного языка ?
Как создать свой язык программирования
Серия видеоуроков по созданию своего языка программирования на Java без использования генераторов парсеров. По мере выхода уроков, буду обновлять статью.Репозиторий проекта: https://github.com/aNNiMON/Own-Programming-Language-Tutorial
Плейлист на YouTube: https://www.youtube.com/playli…soWX0qTeQ9_-MFBE552C
#1. Заготовка, калькулятор
#1. Заготовка, калькулятор
#2. Вещественные числа, константы
#2. Вещественные числа, константы
#3. Оператор присвоения, переменные
#3. Оператор присвоения, переменные
#4. Строки, оператор print
#4. Строки, оператор print
#5. Логические выражения, if/else
#5. Логические выражения, if/else
#6. Улучшаем логические выражения и лексер
#6. Улучшаем логические выражения и лексер
#7. Циклы, блок операторов
#7. Циклы, блок операторов
#8. break, continue, цикл do/while
#8. break, continue, цикл do/while
#9. Функции
#9. Функции
#10. Пользовательские функции
#10. Пользовательские функции
#11. Одномерные массивы
#11. Одномерные массивы
#12. Многомерные массивы
#12. Многомерные массивы
#13. Шаблон проектирования «Посетитель» (Visitor)
#13. Шаблон проектирования «Посетитель» (Visitor)
#14. Программируем на OwnLang
#14. Программируем на OwnLang
Также прикрепляю плагин OwnLang для Netbeans. Для установки заходим в меню Tools -> Plugins -> вкладка Downloaded -> Add Plugins и выбираем nbm файл.
com-annimon-ownlang.nbm
Создать язык программирования для JVM
Потому что вы знаете, в конце концов, каждый хочет создать свой собственный язык программирования.
Я давно интересовался парсерами и языками. Я работал с Xtext, Jetbrains MPS, создал несколько DSL и т. Д. И т. Д. Я также написал свою кандидатскую диссертацию на эту тему, но до сих пор я не начал создавать полный язык программирования с нуля.
Зачем создавать новый язык?
Ну, есть много неправильных ответов на этот вопрос. Мой разделен на две части: во-первых, я думаю, что это может быть большим опытом, чтобы выучить еще несколько вещей, и, во-вторых, язык программирования для меня — это инструмент, позволяющий смотреть на реальность, описывать ее и рассуждать о ней, чтобы лучше ее понять , Смейся, если хочешь, но для меня это в основном инструмент мышления. Часто это неуклюжий инструмент, потому что меня отвлекают технические обходные пути или детали, которые вряд ли подходят или важны для того, что я пытаюсь сделать. Например, мне надоело щелкать здесь и там, чтобы генерировать методы equals и hashCode (да, я знаю о Lombok и некоторых других приемах).
Хорошо, малыш … но чтобы сделать язык пригодным для использования, нужно много вещей
Я думаю, что сейчас барьеры для создания языка программирования и использования его разумными людьми значительно ниже, чем раньше. Я думаю, что язык нуждается в отличном синтаксисе и семантике, конечно, но также в большом количестве библиотек и приличной поддержке инструментов.
Чтобы получить библиотеки, просто запустите его на JVM. В самом деле. Если он работает на JVM, вы можете повторно использовать gazzillion библиотек. Ваш язык программирования включает батареи. Рассмотрим также развертывание: я увлечен многими языками, но каждый раз, когда я пытаюсь развернуть что-то за пределами JVM, я в конечном итоге сожалею об этом. Спросите моего со-сопровождающего WorldEngine (программа на Python), насколько интересно поддерживать библиотеки в Linux, Mac, Windows, в разных версиях Python. Много веселья.
Конечно, вам также нужна поддержка инструментов: для меня это в основном хороший редактор и хорошая интеграция с эталонной платформой. У меня есть преимущество, потому что у меня есть опыт разработки плагинов IDE, и я только что закончил писать решатель типов для Java . В дополнение к этому я участвую в JavaParser . Итак, я знаю кое-что об инструментах, которые я мог бы использовать в будущем для интеграции с Java.
На практике я планирую:
- Создайте плагин для IntelliJ, который знает ссылки на файл на моем языке и на файлы Java. Приятно то, что в основном я написал библиотеки для этого.
- Создайте плагин Maven, потому что Maven ужасен, но жизнь без Maven еще более ужасна
- Напишите парсер с ANTLR (это самая простая часть)
- Написать генератор байт-кода с ASM (какая замечательная библиотека!)
Хорошо, расскажи мне больше об этом языке
Я только начал работать над этим, но … у меня есть основной компилятор, работающий и поддерживающий несколько конструкций.
Это статический язык с выводом типа, и это пример фрагмента корректного кода, который можно уже скомпилировать и запустить:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
Итак, у меня есть план, у меня уже кое-что работает, и мне очень весело.
Может быть, идиотизм, возможно, писать еще на одном языке, но, черт возьми … это так весело!
Я написал язык программирования. Вот как вы тоже можете это сделать.
Уильям Уолд
Последние 6 месяцев я работал над языком программирования Pinecone. Я бы не назвал его зрелым, но в нем уже есть достаточно функций, которые можно использовать, например:
- переменных
- функций
- пользовательских структур
Если вам это интересно, посмотрите лендинг Pinecone page или ее репозитория на GitHub.
Я не эксперт. Когда я начинал этот проект, я понятия не имел, что делаю, и до сих пор не понимаю. Я ноль курсов по созданию языков, лишь немного читал об этом в Интернете и не следовал многим советам, которые мне давали.
И все же я все же сделал совершенно новый язык. И это работает. Так что я должен что-то делать правильно.
В этом посте я углублюсь под капот и покажу вам конвейер, который Pinecone (и другие языки программирования) использует для превращения исходного кода в волшебство.
Я также коснусь некоторых компромиссов, на которые мне пришлось пойти, и почему я принял такие решения.
Это ни в коем случае не полное руководство по написанию языка программирования, но это хорошая отправная точка, если вам интересно узнать о разработке языков.
Начало работы
«Я совершенно не знаю, с чего бы начать» — это то, что я часто слышу, когда говорю другим разработчикам, что пишу язык. Если это ваша реакция, я сейчас рассмотрю некоторые исходные решения, которые принимаются, и шаги, которые предпринимаются при запуске любого нового языка.
Скомпилированный и интерпретируемый
Существует два основных типа языков: компилируемый и интерпретируемый:
- Компилятор вычисляет все, что делает программа, превращает ее в «машинный код» (формат, который компьютер может работать очень быстро), затем сохраняет это для выполнения позже.
- Интерпретатор последовательно просматривает исходный код, выясняя, что он делает.
Технически любой язык может быть скомпилирован или интерпретирован, но тот или иной обычно имеет больше смысла для конкретного языка.Как правило, интерпретация имеет тенденцию быть более гибкой, в то время как компиляция имеет тенденцию к более высокой производительности. Но это лишь поверхностная часть очень сложной темы.
Я очень ценю производительность, и я заметил нехватку языков программирования, которые были бы одновременно высокопроизводительными и ориентированными на простоту, поэтому я выбрал скомпилированный для Pinecone.
Это было важное решение, которое нужно было принять на раннем этапе, потому что оно влияет на многие решения по языковому дизайну (например, статическая типизация — большое преимущество для компилируемых языков, но не для интерпретируемых).
Несмотря на то, что Pinecone разрабатывался с учетом компилирования, у него есть полнофункциональный интерпретатор, который какое-то время был единственным способом его запустить. Для этого есть ряд причин, которые я объясню позже.
Выбор языка
Я знаю, что это немного мета, но язык программирования сам по себе является программой, и поэтому вам нужно написать его на языке. Я выбрал C ++ из-за его производительности и большого набора функций. Кроме того, мне действительно нравится работать с C ++.
Если вы пишете интерпретируемый язык, имеет смысл написать его на скомпилированном языке (например, C, C ++ или Swift), потому что производительность, потерянная на языке вашего интерпретатора и интерпретатора, который интерпретирует ваш интерпретатор, будет сложный.
Если вы планируете компилировать, более медленный язык (например, Python или JavaScript) более приемлем. Время компиляции может быть плохим, но, на мой взгляд, это не так страшно, как плохое время выполнения.
Дизайн высокого уровня
Язык программирования обычно имеет структуру конвейера.То есть имеет несколько этапов. На каждом этапе данные отформатированы определенным, четко определенным образом. Он также имеет функции для преобразования данных от каждого этапа к следующему.
Первый этап — это строка, содержащая весь входной исходный файл. Заключительный этап — это то, что можно запустить. Все это станет ясно по мере того, как мы шаг за шагом пройдемся по конвейеру Pinecone.
Lexing
Первый шаг в большинстве языков программирования — это лексирование или токенизация. «Lex» — это сокращение от лексического анализа, очень красивое слово для разделения кучи текста на токены.Слово «токенизатор» имеет гораздо больше смысла, но слово «лексер» так забавно произносить, что я все равно использую его.
Токены
Токен — это небольшая единица языка. Токеном может быть имя переменной или функции (также известное как идентификатор), оператор или число.
Задача лексера
Лексер должен принимать строку, содержащую целые файлы исходного кода, и выдавать список, содержащий каждый токен.
Будущие этапы конвейера не будут ссылаться на исходный исходный код, поэтому лексер должен выдать всю необходимую им информацию.Причина этого относительно строгого конвейерного формата заключается в том, что лексер может выполнять такие задачи, как удаление комментариев или определение того, является ли что-то числом или идентификатором. Вы хотите сохранить эту логику внутри лексера, чтобы вам не приходилось думать об этих правилах при написании остальной части языка, и чтобы вы могли изменить этот тип синтаксиса в одном месте.
Flex
В тот день, когда я начал работать с языком, первое, что я написал, был простой лексер. Вскоре после этого я начал изучать инструменты, которые якобы упростят лексирование и уменьшат количество ошибок.
Преобладающим таким инструментом является Flex, программа, генерирующая лексеры. Вы даете ему файл со специальным синтаксисом для описания грамматики языка. Исходя из этого, он генерирует программу C, которая анализирует строку и производит желаемый результат.
Мое решение
Я решил пока оставить написанный мною лексер. В конце концов, я не увидел значительных преимуществ использования Flex, по крайней мере, недостаточных, чтобы оправдать добавление зависимости и усложнение процесса сборки.
Мой лексер состоит всего из нескольких сотен строк и редко доставляет мне какие-либо проблемы.Сворачивание собственного лексера также дает мне большую гибкость, например возможность добавлять оператор к языку без редактирования нескольких файлов.
Парсинг
Второй этап конвейера — это синтаксический анализатор. Парсер превращает список токенов в дерево узлов. Дерево, используемое для хранения данных этого типа, называется абстрактным синтаксическим деревом или AST. По крайней мере, в Pinecone в AST нет информации о типах или о том, какие идентификаторы какие. Это просто структурированные токены.
Обязанности анализатора
Анализатор добавляет структуру к упорядоченному списку токенов, созданных лексером.Чтобы устранить двусмысленность, синтаксический анализатор должен учитывать скобки и порядок операций. Простой синтаксический анализ операторов не так уж и сложен, но по мере добавления новых языковых конструкций синтаксический анализ может стать очень сложным.
Bison
И снова было принято решение использовать стороннюю библиотеку. Преобладающая библиотека синтаксического анализа — Bison. Bison во многом похож на Flex. Вы пишете файл в настраиваемом формате, в котором хранится информация о грамматике, а затем Bison использует его для создания программы на языке C, которая будет выполнять ваш синтаксический анализ.Я не выбрал Bison.
Почему Custom лучше
С лексером решение использовать мой собственный код было довольно очевидным. Лексер — это такая тривиальная программа, что не написать свою собственную было почти так же глупо, как не написать свой собственный «левый блокнот».
С парсером другое дело. В моем синтаксическом анализаторе Pinecone сейчас 750 строк, и я написал три из них, потому что первые две были мусором.
Первоначально я принял решение по ряду причин, и, хотя оно не прошло полностью гладко, большинство из них верны.Основными из них являются следующие:
- Минимизация переключения контекста в рабочем процессе: переключение контекста между C ++ и Pinecone достаточно плохо, не добавляя грамматику Bison
- Сохраняйте простоту сборки: каждый раз при изменении грамматики Bison должен запускаться перед сборкой . Это можно автоматизировать, но при переключении между системами сборки это становится проблемой.
- Мне нравится создавать крутое дерьмо: я не создавал Pinecone, потому что думал, что это будет легко, так зачем мне делегировать центральную роль, если я могу делать это сам? Пользовательский парсер может быть нетривиальным, но вполне выполнимым.
Вначале я не был полностью уверен, иду ли я по жизнеспособному пути, но меня вселило уверенность в том, что Уолтеру Брайту (разработчику ранней версии C ++ и создателю языка D) пришлось сказать по этой теме:
«Несколько более спорно, я бы не стал тратить время LeXeR или анализатора генераторов и других так называемых„компиляторов компиляторов“. Это пустая трата времени. Написание лексера и парсера — это крошечный процент от работы по написанию компилятора.Использование генератора займет примерно столько же времени, как его написание вручную, и приведет к заключению брака с генератором (что имеет значение при переносе компилятора на новую платформу). К тому же генераторы имеют неудачную репутацию выдачи паршивых сообщений об ошибках ».
Дерево действий
Мы вышли из области общих, универсальных терминов, или, по крайней мере, я больше не знаю, что это за термины. Насколько я понимаю, то, что я называю «деревом действий», больше всего похоже на IR LLVM (промежуточное представление).
Существует тонкая, но очень существенная разница между деревом действий и абстрактным синтаксическим деревом. Мне потребовалось довольно много времени, чтобы понять, что между ними должна быть даже разница (что привело к необходимости перезаписи парсера).
Дерево действий против AST
Проще говоря, дерево действий — это AST с контекстом. Этот контекст — это информация, например, какой тип возвращает функция или что два места, в которых используется переменная, на самом деле используют одну и ту же переменную.Поскольку ему необходимо выяснить и запомнить весь этот контекст, код, который генерирует дерево действий, нуждается в большом количестве таблиц поиска пространств имен и других вещей.
Запуск дерева действий
Когда у нас есть дерево действий, запускать код становится легко. Каждый узел действия имеет функцию «выполнить», которая принимает некоторые входные данные, делает то, что должно действовать (включая, возможно, вызывая вспомогательное действие), и возвращает результат действия. Это интерпретатор в действии.
Параметры компиляции
«Но подождите!» Я слышал, вы говорите: «Разве Pinecone не компилируется?» Да, это.Но компилировать сложнее, чем интерпретировать. Есть несколько возможных подходов.
Build My Own Compiler
Поначалу это показалось мне хорошей идеей. Я действительно люблю делать вещи сам, и мне не терпелось найти повод, чтобы хорошо разбираться в сборке.
К сожалению, написать портативный компилятор не так просто, как написать некоторый машинный код для каждого элемента языка. Из-за большого количества архитектур и операционных систем для любого человека нецелесообразно писать бэкэнд кроссплатформенного компилятора.
Даже команды, стоящие за Swift, Rust и Clang, не хотят возиться со всем этим в одиночку, поэтому вместо этого все они используют…
LLVM
LLVM — это набор инструментов компилятора. По сути, это библиотека, которая превратит ваш язык в скомпилированный исполняемый двоичный файл. Это показалось мне идеальным выбором, поэтому я прыгнул прямо в воду. К сожалению, я не проверил, насколько глубока была вода, и сразу утонул.
LLVM, хотя и не является сложным языком ассемблера, представляет собой гигантскую сложную библиотеку.Это возможно, и у них есть хорошие руководства, но я понял, что мне нужно немного попрактиковаться, прежде чем я буду готов полностью реализовать компилятор Pinecone с ним.
Транспилинг
Мне нужен был какой-то скомпилированный Pinecone, и я хотел его быстро, поэтому я обратился к одному методу, который, как я знал, мог заставить работать: транспилирование.
Я написал транспилятор из Pinecone в C ++ и добавил возможность автоматически компилировать исходный код с помощью GCC. В настоящее время это работает почти для всех программ Pinecone (хотя есть несколько крайних случаев, которые его нарушают).Это не особо портативное или масштабируемое решение, но пока оно работает.
Future
Если я продолжу разрабатывать Pinecone, рано или поздно он получит поддержку компиляции LLVM. Я не подозреваю, сколько бы я ни работал над этим, транспилятор никогда не будет полностью стабильным, а преимущества LLVM многочисленны. Вопрос лишь в том, когда у меня будет время сделать несколько примеров проектов в LLVM и освоиться.
До тех пор интерпретатор отлично подходит для тривиальных программ, а транспиляция C ++ работает для большинства вещей, требующих большей производительности.
Заключение
Надеюсь, я сделал языки программирования менее загадочными для вас. Если вы действительно хотите сделать его самостоятельно, я очень рекомендую его. Есть масса деталей реализации, которые нужно выяснить, но схемы здесь должно быть достаточно, чтобы вы начали.
Вот мой совет высокого уровня для начала (помните, я действительно не знаю, что делаю, так что воспринимайте это с недоверием):
- Если сомневаетесь, переводите. Интерпретируемые языки, как правило, легче проектировать, создавать и изучать.Я не отговариваю вас писать скомпилированный вариант, если вы знаете, что это то, что вы хотите сделать, но если вы стоите на грани, я бы пошел интерпретировать.
- Когда дело доходит до лексеров и парсеров, делайте все, что хотите. Есть веские аргументы за и против написания собственного. В конце концов, если вы продумаете свой дизайн и все разумно реализуете, это не имеет особого значения.
- Учитесь на конвейере, с которым я закончил. При разработке того конвейера, который у меня есть сейчас, потребовалось много проб и ошибок.Я попытался устранить AST, AST, которые превращаются в деревья действий на месте, и другие ужасные идеи. Этот конвейер работает, поэтому не меняйте его, если у вас нет действительно хорошей идеи.
- Если у вас нет времени или мотивации для реализации сложного языка общего назначения, попробуйте реализовать эзотерический язык, такой как Brainfuck. Эти интерпретаторы могут содержать всего несколько сотен строк.
Я мало сожалею о разработке Pinecone. По ходу дела я сделал несколько неправильных решений, но я переписал большую часть кода, затронутого такими ошибками.
На данный момент Pinecone находится в достаточно хорошем состоянии, поэтому он хорошо функционирует и может быть легко улучшен. Написание Pinecone было для меня чрезвычайно познавательным и приятным занятием, и это только начало.
Создайте свой собственный язык программирования
Из всех проектов, которые я сделал, больше всего вопросов о языке программирования Ink. Большинство вопросов делятся на три категории:
- Зачем вы сделали язык программирования?
- Я хочу создать свой собственный язык программирования — посоветуете?
- Почему чернила работают именно так?
Цель этого поста — ответить на вопросы (1) и (2) и предоставить некоторые ресурсы, которые помогут вам начать работу на своем родном языке.Я думаю, что (3) лучше оставить для отдельного, более технического поста.
Этот пост состоит из нескольких разделов.
- Зачем?
- Проект
- Реализация
- Прочие соображения
- Начните с малого, проявите творческий подход, задавайте вопросы
Зачем?
Создание интерпретатора для нового языка программирования — это самый технически выгодный проект, над которым я работал. Это подтолкнуло меня к пониманию фундаментальных концепций программного обеспечения и помогло мне понять, как работает компьютер, на более глубоком уровне.
Языки программирования и компиляторы / интерпретаторы могут быть черными ящиками для начинающих программистов. Это инструменты, которые воспринимаются как должное, и вы можете писать хорошее программное обеспечение, не беспокоясь о том, как языки и примитивные инструменты, которые вы используете, работают под капотом. Но написание языка программирования требует понимания самых важных частей вычислительного стека, от ЦП и памяти до операционной системы, структур данных в памяти, процессов, потоков, стека, вплоть до библиотек и приложений.Это ворота к самой интересной математике в вычислениях — теории категорий и системам типов, алгебрам, множеству приложений теории графов, анализу сложности и многому другому. Написав и изучив языки программирования, я обнаружил, что все больше знакомлюсь как с математикой, так и с механическими основами работы компьютеров.
В результате проект сделал меня лучшим разработчиком, даже если моя повседневная работа редко связана с инструментами языка программирования или написанием компиляторов.
У языка программирования также есть много возможностей для расширения, оптимизации и дополнительного творчества даже после того, как первая версия проекта «завершена». Если вы тщательно спроектируете начальную реализацию, вы можете постепенно со временем добавлять новые ключевые слова, новые функции, оптимизации и инструменты к своему языку и интерпретатору / компилятору. Легко превратить язык в долгосрочный проект и творческое средство, и мне понравилось расширять свою первоначальную реализацию, изучая другие языки после того, как была завершена первая версия.
Мир PL широк и глубок; Выбери свои битвы
В отличие от некоторых других областей программного обеспечения, которые следуют циклам шумихи, область языков программирования постоянно и постоянно росла и углублялась как в академических кругах, так и в промышленности. Существует лот литературы, исследований, предшествующего уровня техники и практических советов о миллионе различных концепций, которые можно объединить в новый язык, и миллионе различных вариантов их реализации.
Я считаю, что наиболее плодотворным подходом, особенно для языка личных проектов, является выбрать одну или две интересные идеи из археологии вычислений и создать язык программирования, который исследует и глубоко расширяет эти идеи , вместо того, чтобы пытаться построить Единый истинный язык, лучший во всем и сочетающий в себе лучшие черты всех языков.Мало того, что невозможно создать такой язык для всех случаев использования, я думаю, что такой образ мышления также замедляет разработку, добавляет ненужной работы и не дает вам умственного пространства для изучения нескольких интересных тем, которые вы могли бы интересоваться.
Например, вас может заинтересовать функциональное программирование и неизменяемые структуры данных. Вы можете попытаться создать язык, предназначенный для хранения всего состояния в неизменяемых структурах данных, и изучить, как такие структуры данных можно оптимизировать и эффективно управлять ими в компиляторе.Или, может быть, вас интересуют низкоуровневые языки программирования C и системные языки, и в этом случае вы можете попытаться создать язык сценариев, основные цели которого включают элегантную совместимость с C API и бинарными интерфейсами.
От того, где вы начнете, также зависят проблемы и компромиссы, с которыми вам придется столкнуться. Возможно, вам будет легче написать интерпретатор Лиспа из-за его более простого синтаксиса, потому что его легче анализировать по сравнению, скажем, с более сложным синтаксисом для языка со статической системой типов.Однако у Лиспов есть тенденция иметь семантику, которая еще больше отделена от выполняемого низкоуровневого машинного кода, например замыкания. Таким образом, вы можете найти компромисс между простотой синтаксического анализа и сложностью выполнения.
Тщательно выбирайте свои сражения и придерживайтесь нескольких основных идей, которые вы хотите глубоко изучить.
Дизайн
Прежде чем вы напишете интерпретатор или компилятор, вам нужно спроектировать язык. Вы можете потратить время на изучение теории категорий, систем типов и парадигм программирования, но лучшее, что вы можете сделать для себя на этом этапе, — это изучить идеи самых разных языков программирования.Не ограничивайтесь только «современными» языками, такими как Rust и Python; вернуться в историю вычислений. Есть богатые идеи, которые нужно изобретать и комбинировать интересными способами, уходя по крайней мере столетие назад в вычисления и математику.
Легко застрять в ментальной модели популярных современных ООП-подобных языков (Python, Ruby, Swift, C ++) и провести большую часть времени на этом этапе разработки синтаксиса . Но разработка семантики языка — это то место, на которое вы должны потратить большую часть своего времени, потому что именно там язык получает свое «ощущение» и где вы больше всего усваиваете.Семантику также сложнее изменить постфактум, чем синтаксис. Несколько вопросов, которые стоит задать себе, чтобы задуматься о языковой семантике и эргономике:
- Какие типы есть в вашем языке? Проверяется ли это во время компиляции? При необходимости он автоматически преобразует типы?
- Какая единица организации верхнего уровня программ на вашем языке? Языки обычно называют это модулями, пакетами или библиотеками, но некоторые языки могут изобрести свою собственную концепцию, например, Rust Crates.
- Как язык справляется с исключительными условиями, такими как отсутствие файла, ошибка доступа к сети или ошибка деления на ноль? Вы обрабатываете ошибки как исключения, всплывающие через стек вызовов, или ошибки обрабатываются как значения, как в C и Go?
- Выполняет ли ваш язык оптимизацию хвостовой рекурсии? Или вы предоставляете собственные инструменты управления потоком для создания циклов, например
дляи, а также для циклов? - Сколько утилит вы хотите встроить в язык по сравнению со стандартной библиотекой? C, например, ничего не знает о строках — семантика строк обеспечивается стандартной библиотекой C.Карты и списки являются фундаментальными языковыми конструкциями в большинстве языков высокого уровня, но не в большинстве языков низкого уровня.
- Как ваш язык относится к распределению памяти? Распределяется ли память автоматически по мере необходимости? Нужно ли разработчику для этого писать код? Это сборщик мусора?
Чтобы ответить на эти вопросы, я думаю, что будет очень полезно просто познакомиться с различными языками в естественных условиях. Вот небольшой набор для начинающих, на который я рекомендую вам взглянуть, и какие идеи лично я нашел интригующими для каждого языка или языковой семьи.
- Lua : структура данных, называемая таблицами, программы Lua, использующие строки в качестве байтовых срезов, взаимодействие с C
- Scheme / Clojure : Метапрограммирование с макросами, гомоиконность, замыкания, поток управления с рекурсией. Несгибаемые Common-Lispers могут не соглашаться, но Scheme и Clojure — самые простые языки в семействе языков Lisp для меня. Вы должны изучить хотя бы один вид Лиспа.
- Go : структурная типизация с интерфейсами, параллелизм с блокировкой зеленых потоков
- JavaScript : параллелизм в стиле обратного вызова и асинхронное программирование, первоклассные функции, цикл событий, обещания
- Awk : Awk — отличный пример небольшого простого языка, оптимизированного для одного случая использования: манипулирования текстовыми файлами и текстовыми данными.Он очень хорошо разработан для этого рабочего процесса и служит источником вдохновения для того, насколько эффективным может быть небольшой предметно-ориентированный язык с простой семантикой.
- APL / J : APL и J являются языками массивов, которые представляют собой увлекательную семью языков, хорошо известную своей краткостью
- Ruby : синтаксис. Ruby хорошо известен своим сверхгибким синтаксисом, поскольку он легко поддается DSL на основе Ruby, например ActiveRecord.
- C : Мне нравится C в основном за его простоту и минимализм, а также бескомпромиссную приверженность совместимости
- Haskell : система типов и параметрический полиморфизм, вариантные типы, частичное приложение и синтаксис типа функции.Как только вы осознаете это, Haskell также станет хорошим местом для начала более глубокого погружения в виды элегантных программ, которые возможны при функциональном программировании.
Реализация
Когда у вас есть проект того, как язык должен работать и ощущаться, вы должны сначала «протестировать» его, чтобы увидеть, как программы, написанные на этом языке, ощущаются при использовании.
Тест-драйв
На этом этапе я обычно храню текстовый документ, в котором экспериментирую с синтаксисом, написав небольшие программы на новом, еще не существующем языке.Я пишу для себя заметки и вопросы в комментариях к коду и пытаюсь реализовать небольшие алгоритмы и структуры данных, такие как рекурсивные математические функции, алгоритмы сортировки и небольшие веб-серверы. Обычно я задерживаюсь на этом этапе, пока не получу ответов на большинство моих вопросов о синтаксисе и семантике. Я также использую этот этап, чтобы проверить свои гипотезы об основных идеях, лежащих в основе языкового дизайна. Например, если бы я разрабатывал язык на основе функционального программирования и асинхронного, управляемого событиями параллелизма, я бы написал образец кода на этом этапе, чтобы убедиться, что эти идеи хорошо сочетаются друг с другом и подходят для программ, которые мне нравится писать.Если окажется, что я ошибаюсь, я обновлю свои предположения или поэкспериментирую с языковым дизайном, чтобы отразить то, что я узнал.
Эта фаза конструирования соломенного человека — быстрый способ убедиться, что язык, который вы изобрели в своей голове, может хорошо работать с типами программ, которые вы хотите написать, без необходимости писать много реализаций.
Создать интерпретатор / компилятор
По своей сути интерпретаторы и компиляторы представляют собой слои и уровни небольших преобразований исходного кода (строки текста) в некоторую форму, выполняемую вашим компьютером .Искусство разработки сводится к выбору хороших промежуточных форматов для этих преобразований, с которыми они будут работать, и эффективных структур данных времени выполнения для кодирования значений и функций вашего языка в работающей программе.
Умных людей всю свою карьеру изучают дизайн интерпретаторов и компиляторов, и я определенно не могу отдать должное этой теме в подразделе сообщения в блоге. Поэтому вместо того, чтобы делать попытки напрасно, здесь я направлю вас к ресурсам, которые я нашел наиболее полезными в моей попытке реализовать лучшие интерпретаторы и компиляторы в хобби-проектах.
Два моих любимых ресурса по этой теме — пара электронных книг: Crafting Interpreters Роберта Нистрома и Let’s Build A Simple Interpreter Руслана Спивака. Обе серии статей проведут вас от полного новичка в языках программирования к пошаговой разработке и созданию простого интерпретатора. Хотя в этих книгах не будет подробно рассмотрена каждая тема в интерпретации, они дадут вам отправную точку для того, как работает каждый шаг в процессе, достаточно, чтобы вы могли создать первый рабочий прототип.
Хотя многие люди следовали этим руководствам и строили версии своего интерпретатора построчно из книги, я бегло просматривал их и использовал главы в книгах в качестве справочников на протяжении всего собственного путешествия, вместо того, чтобы следовать пошаговым инструкциям. . Но, тем не менее, эти книги предоставляют очень прочную основу, на которой вы можете изучать дополнительные темы о том, как работают интерпретаторы и компиляторы.
Хотя я не читал, я слышал похвалу за пару книг Написание интерпретатора на Go и Написание компилятора на Go .Они проведут вас через процесс создания языка программирования и интерпретатора / компилятора с нуля на языке программирования Go. Как и две электронные книги, представленные выше, они охватывают все основы и потенциальные ловушки и соображения, с которыми вы столкнетесь при написании интерпретатора или компилятора для реалистичного языка, а не просто при создании простого минимального доказательства концепции.
То, что следует здесь, не является обязательным для чтения — эти статьи варьируются от вводных до продвинутых, и я составил список частично для пользы себя в будущем.Вероятно, вам не будет интересно все до единого, и это нормально.
С учетом сказанного, вот коллекция дополнительных материалов по интерпретаторам и компиляторам в Интернете…
Я также большой поклонник отличных технических бесед. Вот некоторые из них, которые мне показались полезными и интересными за эти годы…
Наконец, я многому научился во время работы с интерпретаторами, читая реализации хорошо спроектированных и хорошо документированных интерпретаторов и компиляторов. Из них мне понравились:
- Ale, простой Лисп, написанный на Go
- Lua, написанный на C.Я написал целую отдельную статью об интересных вариантах дизайна в интерпретаторе Lua, потому что я большой поклонник его архитектуры.
- Wasm3, интерпретатор для WebAssembly. Мне особенно понравился продуманный и уникальный дизайн интерпретатора байт-кода, описанный в проектном документе в репозитории.
- Boa, среда выполнения JavaScript и WebAssembly, написанная на Rust
Приведенный здесь список — лишь верхушка айсберга из статей в блогах, тематических исследований и тем GitHub Issues, которые я изучил, чтобы добавить мяса к скелету, который я представлял себе, о том, как работают интерпретаторы и компиляторы.Языки программирования — это глубокая и обширная тема! Не соглашайтесь только на знание простых основ; действительно исследуйте то, что вас интересует, и погрузитесь глубже, даже если поначалу тема кажется сложной.
Прочие соображения
Как я уже упоминал выше, даже после первоначальной реализации язык программирования игрушек дает вам всю гибкость и творческий запас в мире для реализации более продвинутых функций, концепций и оптимизаций в вашем проекте, чтобы вы могли повозиться.Вот небольшая коллекция идей, которые вы можете изучить как продолжение своего проекта, если захотите.
Более сложные системы типов. Изучение систем типов пробудило у меня интерес к двум связанным темам: теории категорий и реализации элегантных структур данных с расширенными системами типов на таких языках, как Haskell и Elm. Если вы пришли из Java, JavaScript или Python, изучение того, как типы работают в Swift, TypeScript или Rust, может стать хорошей отправной точкой.
Оптимизация. Как сделать ваш интерпретатор или компилятор быстрее? И что вообще значит быть быстрее? Быстрее разбираетесь и компилируете код? В конце концов, производить более быстрый код? Нет предела известному уровню техники и литературе по теме производительности компилятора.
Добавить интерфейс внешних функций C (FFI) . FFI — это уровень взаимодействия между вашим языком и другим, обычно двоичным кодом C. Добавление C FFI может быть хорошим местом для вас, чтобы узнать о низкоуровневых деталях того, как программы компилируются в исполняемые файлы, а также о форматах исполняемых файлов и генерации кода.
JIT-компиляция. Некоторые из наиболее распространенных и быстрых языковых сред выполнения, такие как Chrome V8 и LuaJIT для Lua, на самом деле являются не полностью ванильными интерпретаторами или полными компиляторами, а гибридными JIT-компиляторами, которые генерируют скомпилированный машинный код на лету. JIT иногда могут найти лучший компромисс между производительностью и динамизмом времени выполнения на языке программирования, чем простые интерпретаторы или компиляторы, за счет большей сложности компилятора.
Начните с малого, проявите творческий подход, задавайте вопросы
Я рассмотрел здесь много вопросов, но я начал не с этого, и вам, конечно, не нужно переваривать весь материал, которым я поделился здесь. до того, как вы начнете взламывать свой родной язык. Начни с малого. Будьте амбициозны и креативны, но будьте умны и работайте постепенно.
Вам не нужно понимать все, прежде чем вы начнете писать на своем языке. Многое из того, что я узнал в собственном процессе, было следствием моего погружения в совершенно новые и чужие темы, пока я не понял все большую и большую часть того, что я читал об этом в Интернете.
Языки программирования — одна из моих любимых областей вычислений из-за их разнообразия и глубины. Просто проявите изобретательность и задавайте хорошие вопросы — я надеюсь, что вы найдете возможности создания собственных инструментов для программирования такими же волшебными, как I.
← Сохранение сложности
Как я пишу →
Я делюсь новыми сообщениями в своем информационном бюллетене.Если вам понравился этот, вы должны подумать о том, чтобы присоединиться к списку.
Есть комментарий или ответ? Вы можете написать мне по электронной почте.
Как создать язык программирования с помощью Python?
В этой статье мы узнаем, как создать свой собственный язык программирования с использованием SLY (Sly Lex Yacc) и Python. Прежде чем мы углубимся в эту тему, следует отметить, что это руководство не для новичков, и вам необходимо иметь некоторые знания о предпосылках, указанных ниже.
Предварительные требования
- Приблизительные знания о конструкции компилятора.
- Базовое понимание лексического анализа, синтаксического анализа и других аспектов проектирования компилятора.
- Понимание регулярных выражений.
- Знакомство с языком программирования Python.
Начало работы
Установите SLY для Python. SLY — это инструмент для лексирования и синтаксического анализа, который значительно упрощает наш процесс.
pip install хитрый
Построение лексера
Первая фаза компилятора — преобразовать все символьные потоки (написанная высокоуровневая программа) в токен-потоки.Это делается с помощью процесса, называемого лексическим анализом. Однако этот процесс упрощается с помощью SLY
. Сначала давайте импортируем все необходимые модули.
Теперь давайте создадим класс BasicLexer , который расширяет класс Lexer от SLY. Давайте создадим компилятор, выполняющий простые арифметические операции. Таким образом, нам понадобятся некоторые базовые токены, такие как NAME , NUMBER , STRING . В любом языке программирования между двумя символами будет пробел.Таким образом, мы создаем литерал игнорировать . Затем мы также создаем базовые литералы, такие как ‘=’, ‘+’ и т. Д. NAME токенов — это в основном имена переменных, которые могут быть определены регулярным выражением [a-zA-Z _] [a-zA-Z0- 9 _] *. СТРОКА токенов — это строковые значения, заключенные в кавычки («»). Это можно определить с помощью регулярного выражения \ ”. *? \”.
Всякий раз, когда мы находим цифру / с, мы должны присвоить ее токену НОМЕР , и это число должно быть сохранено как целое число.Мы делаем базовый программируемый скрипт, так что давайте просто сделаем его с целыми числами, однако не стесняйтесь расширять его для десятичных, длинных и т. Д. Мы также можем делать комментарии. Всякий раз, когда мы находим «//», мы игнорируем все, что идет дальше в этой строке. То же самое делаем с символом новой строки. Таким образом, мы создали базовый лексер, который преобразует поток символов в поток токенов.
Python3
(r '\ n +' ) |
Создание синтаксического анализатора
Сначала давайте импортируем все необходимые модули.
Теперь давайте создадим класс BasicParser , который расширяет класс Lexer . Поток токенов от BasicLexer передается переменной токенов. Определен приоритет, который одинаков для большинства языков программирования. Большая часть синтаксического анализа, написанного в приведенной ниже программе, очень проста.Когда ничего нет, утверждение ничего не передаёт. По сути, вы можете нажать Enter на клавиатуре (ничего не вводя) и перейти к следующей строке. Затем ваш язык должен понимать задания, в которых используется знак «=». Это обрабатывается в строке 18 программы ниже. То же самое можно сделать и при присвоении строки.
Python3
def261 902 self , p): |
Синтаксический анализатор также должен выполнять синтаксический анализ в арифметических операциях, это можно сделать с помощью выражений. Допустим, вам нужно что-то вроде показанного ниже. Здесь все они построчно преобразуются в поток токенов и построчно анализируются. Следовательно, согласно приведенной выше программе, a = 10 похоже на строку 22. То же самое для b = 20. a + b напоминает строку 34, которая возвращает дерево синтаксического анализа (‘add’, (‘var’, ‘a’), (‘var’, ‘b’)).
Язык GFG> a = 10 Язык GFG> b = 20 Язык GFG> a + b 30
Теперь мы преобразовали потоки токенов в дерево синтаксического анализа.Следующий шаг - интерпретировать это.
Execution
Устный перевод - это простая процедура. Основная идея состоит в том, чтобы пройти по дереву и иерархически оценить арифметические операции. Этот процесс рекурсивно вызывается снова и снова, пока не будет оценено все дерево и не будет получен ответ. Скажем, например, 5 + 7 + 4. Этот поток символов сначала токенизируется в поток токенов в лексере. Затем поток токенов анализируется для формирования дерева синтаксического анализа. Дерево синтаксического анализа по существу возвращает (‘add’, (‘add’, (‘num’, 5), (‘num’, 7)), (‘num’, 4)).(см. изображение ниже)
Интерпретатор сначала добавит 5 и 7, а затем рекурсивно вызовет walkTree и прибавит 4 к результату сложения 5 и 7. Таким образом, мы получим 16. Приведенный ниже код делает тот же процесс.
Python3
если isinstance (узел, int ):
возврат walkTree (узел [ 1 ]) * сам .walkTree (узел [ 2 ]) |
Отображение вывода
Чтобы отобразить вывод из некоторого интерпретатора, мы должны написать .Код должен сначала вызвать лексер, затем синтаксический анализатор, а затем интерпретатор и, наконец, получить результат. Выходные данные затем отображаются в оболочке.
Python3
2 |
Необходимо знать, что мы не обрабатывали никаких ошибок. Таким образом, SLY будет показывать сообщения об ошибках всякий раз, когда вы делаете что-то, что не указано в написанных вами правилах.
Выполните программу, которую вы написали, используя
python you_program_name.py
Сноски
Интерпретатор, который мы создали, очень прост.Это, конечно, можно расширить, чтобы сделать гораздо больше. Можно добавлять циклы и условные выражения. Могут быть реализованы функции модульного или объектно-ориентированного дизайна. Интеграция модулей, определения методов, параметры методов - вот некоторые из функций, которые могут быть расширены на то же самое.
Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS .
Создание языка программирования с нуля | Жоао Жигмонд | The Startup
В этой статье мы рассмотрим наиболее важные части и концепции разработки нового языка. Мы проанализируем наиболее важные моменты и логику, стоящую за ними, но не конкретные строки кода, которые заставляют их делать то, что они делают. Таким образом, вы сможете следовать указаниям на том языке, который вам удобнее всего.
Сегодня мировое сообщество разработчиков кода использует около 700 языков программирования.Некоторые из них созданы специально для работы в вашем веб-браузере, а другие созданы для работы на спутниках, вращающихся вокруг Земли. При таком количестве доступных языков остается вопрос: зачем нам создавать новый?
Неважно, хотите ли вы создать новый язык для решения конкретной проблемы или просто изучить внутреннюю работу интерпретатора или компилятора - в обоих случаях вам нужно будет понять основные этапы того, как исходный код преобразуется в набор инструкций для выполнения компьютером.
В этой статье мы вместе рассмотрим три основных шага, которые преобразуют текст в инструкции для вычислений. Мы сделаем это, анализируя теорию, лежащую в основе каждого шага создания интерпретируемого языка, используя примеры из исходного кода ZAP! устный переводчик.
ЗАП! language - это интерпретируемый язык javascript с определенным набором ключевых слов. Если вы хотите попробовать язык, прежде чем мы начнем, не стесняйтесь проверить онлайн-переводчик по адресу https: // jzsiggy.github.io/ZAP/.
Исходный код можно найти по адресу: https://github.com/jzsiggy/ZAP/tree/master/jzap
Теперь, когда вы ознакомились с тем, что мы можем создать, давайте перейдем к делу!
Первым шагом в создании нашего интерпретатора является получение входного потока и его разделение на токены, распознаваемые семантикой нашего языка.
Маркер - это структура данных, которая преобразует строку, имеющую базовое значение для нашего языка, во что-то, что наш интерпретатор может понять. Следующее изображение может прояснить ситуацию:
Токенизированная фраза в javascriptВ ZAP !, исходный код вводится в интерпретатор как одна строка.Лексер анализирует вводимый символ за символом, создавая список токенов, которые будет оценивать наш интерпретатор.
Типы токенов
Типы токенов в ZAP!Два основных игрока в любом языке - это выражения и утверждения. сначала мы займемся выражениями, а затем перейдем к синтаксическому анализу полных операторов.
Фактически, выражения - это особый тип операторов. Выражения находятся в любой части исходного кода, где мы должны возвращать единственное значение. На изображении ниже мы разберем несколько примеров.
Оценка выраженияКогда мы инициализируем переменную и устанавливаем ее значение на 3 + 5 , мы также используем выражение в операторе объявления переменной.
Класс Evaluator будет вызываться каждый раз, когда наш интерпретатор находит выражение. Поскольку наш оценщик, как и в Python, Javascript, C и других, следует порядку операций PEMDAS, мы должны соответствующим образом построить наш код.
Логика, лежащая в основе оценщика, заключается в создании дерева операций. Он будет перебирать все токены в выражении справа налево, ища операторы с наименьшим приоритетом.Это разбивает выражение на два других выражения, которые нужно оценить заранее.
Выражения могут быть четырех типов:
Двоичные выражения:
Эти выражения состоят из левого узла выражения, оператора и правого узла выражения. После выполнения это выражение вернет результат операции, вызванной оператором со значениями двух дочерних узлов.
Двоичные выраженияУнарные выражения
Эти выражения представлены одним оператором и дочерним выражением.Оператор может быть «-» (отрицательный) или «!» (Нет). Результирующее значение будет значением дочернего выражения, к которому присоединен оператор.
ВАЖНОЕ ПРИМЕЧАНИЕ! - Оператор not всегда возвращает логическое значение.
Унарные выраженияГруппы
Групповые выражения - это выражения с наивысшим приоритетом. Они будут выполнены первыми. Группы образуются выражениями в скобках.
Групповые выраженияЛитералы
Это самые маленькие части нашего интерпретатора.они представляют первичные значения и могут быть строками, логическими значениями или числами.
Литеральные выраженияНаш вычислитель будет перебирать необработанное выражение, разбивая его на все меньшие и меньшие подвыражения, пока оно не будет работать только с основными.
Чтобы следовать порядку операций PEMDAS, большее выражение всегда сначала разбивается на операторы с наименьшим приоритетом. Затем дерево выполняется снизу вверх, что, например, гарантирует, что умножение всегда происходит перед сложением.
Теперь, когда мы прошли процесс оценки выражений, мы можем приступить к синтаксическому анализу операторов. Именно здесь наш язык программирования начнет больше походить не на алгебраический калькулятор, а на многоцелевой функциональный язык.
Для начала допустим новое правило семантики нашего языка: после всех операторов должна стоять точка с запятой.
Таким образом, мы можем разделить наш список токенов, созданный нашим лексером, на каждую точку с запятой. Каждое подразделение будет проанализировано как утверждение.
В нашем языке будет 5 различных типов операторов:
Операторы выражений
Эти операторы не имеют вывода. В StdOut ничего не печатается, однако наш интерпретатор выполняет некоторую работу за кулисами. Семантика этого оператора очень проста: никаких ключевых слов, только выражение. Затем Интерпретатор вызовет Оценщик, чтобы оценить выражение.
Выражения выражений в ZAP!Объявления переменных
Эти операторы позволяют нам повторно использовать данные и манипулировать ими.В ZAP !, мы инициализируем переменную с помощью ключевого слова « @» . Таким образом, когда наш класс Parser встречает «@» в начале оператора, он знает структуру, которой должна следовать остальная часть оператора: во-первых, имя переменной: идентификатор; Затем знак равенства и, наконец, выражение.
Когда мы посмотрим на Environments , мы узнаем, как наш интерпретатор сохраняет эти значения!
Объявление переменной в ЗАП!Показать утверждения
Эти утверждения позволяют ZAP! для отображения информации о StdOut.Чтобы интерпретатор понял, что он имеет дело с показом , , оператор должен начинаться с ключевого слова «show», за которым следует выражение, значение которого должно отображаться.
Отображение информации о StdOut в ЗАП!Блок-операторы
Блок-операторы - это не что иное, как серия операторов, заключенных в фигурные скобки. Они важны, потому что, как мы скоро увидим, каждый оператор блока имеет свою собственную область видимости; то есть переменные, объявленные в операторе вложенного блока, недоступны извне.
Блок-операторы в ZAP!Условные операторы
Именно здесь наш язык делает большой шаг к полноте по Тьюрингу. Используя операторы If / Else, мы можем выбрать, какую часть исходного кода мы хотим выполнить, в зависимости от состояния нашего интерпретатора. Условный оператор начинается с ключевого слова if, за которым следует выражение и оператор блока.
За оператором блока может следовать или не следовать ключевое слово else и другой оператор блока.
Если выражение, следующее за ключевым словом «if», является истинным, будет выполнен код в следующем операторе блока, в противном случае будет выполнен код в операторе «else».
Условная выписка в ЗАП!Циклы
Операторы цикла являются ключевыми в любом языке программирования. С циклами количество инструкций, выполняемых нашим интерпретатором, может начать становиться намного больше, чем размер нашего исходного кода.
В ZAP !, мы разрешаем только циклы while, определенные с помощью ключевого слова while , за которым следует выражение. Затем мы открываем оператор блока с инструкциями тела нашего цикла. Пока выражение оценивается как истинное значение, оператор body будет выполнен.
Пока цикл в ЗАП!Объявления функций
Мы уже нашли способы повторного использования и хранения данных; переменные. Пришло время научить наш интерпретатор повторно использовать и хранить код. Используя функции, мы можем написать набор инструкций для нашего интерпретатора, которым он будет следовать с доступными нам операторами. Когда мы вызываем нашу функцию, мы можем передать аргументы, к которым будут применяться инструкции.
В ЗАП! Оператор функции начинается с ключевого слова «fn», за которым следует идентификатор, определяющий имя функции.Затем интерпретатор будет искать список аргументов, заключенный в две полосы (например, «|»). После того, как аргументы были указаны, мы должны указать жирную стрелку (т.е. «=>») и оператор блока.
Оператор блока является телом функции. Он определяет инструкции, которые будут применяться к аргументам.
Описание функций в ZAP!Чтобы вызвать функции, мы должны ввести имя функции, а затем список аргументов (если есть), заключенный в полосы.
ВАЖНОЕ ПРИМЕЧАНИЕ! - Наш интерпретатор будет оценивать вызов функции как выражение, а не как инструкцию! - Но в ближайшее время мы рассмотрим это подробнее.
Вызов функции в ЗАП!Как создать язык программирования
Куинн Домбровски на Flickr
Языки программного обеспечения не появляются волшебным образом. Они созданы по замыслу. Первый в серии.
Компьютеры - прекрасное инженерное сооружение, но они бесполезны, если мы не можем дать им инструкции, что делать. Поэтому неудивительно, что почти с тех пор, как у нас были компьютеры, у нас были какие-то особые языки, на которых можно писать, что делает возможным программирование.
Сегодня существуют десятки популярных языков программирования и бесчисленное множество других, созданных людьми для развлечения, исследований или экспериментов. Если вам интересно, как создать свой собственный язык программирования, эта серия статей поможет вам собрать идеи и начать работу. Разработка и реализация языков - не так сложно, как вы думаете, но это большая тема с рядом шагов, которые вам нужно сделать.
В этой первой статье мы поговорим о том, что входит в создание языка, и заставим вас задуматься о том, как будет выглядеть ваш язык.
Дизайн и реализация
Во-первых, я хочу отметить разницу между проектированием и реализацией языка программирования. Реализация языка программирования - это программа, которая превращает текст программ в действия на компьютере. Существует два типа реализаций: интерпретаторы и компиляторы.
И компиляторы, и интерпретаторы запускаются одинаково. Они читают программу, которую вы хотите запустить, из файла, а затем превращают ее в представление программы в виде данных.
Однако то, что происходит оттуда, отличается. Интерпретатор возьмет это представление программы и немедленно выполнит программу. С другой стороны, компилятор - это программа, которая считывает код и переводит его на другой язык. Часто компилятор превращает программу в инструкции низкого уровня для самого процессора: либо фактический машинный код, либо читаемый человеком шаг чуть выше этого, называемый сборкой.
Теперь нам нужно определить несколько терминов. Акт чтения программы из файла называется синтаксическим анализом , а бит кода, который это делает, называется синтаксическим анализатором .Код в виде данных представлен в абстрактном синтаксическом дереве (AST).
Например, представьте, что мы пишем интерпретатор для Python на Python. Это может показаться глупым, но такое случается чаще, чем вы думаете. Наша программа может выглядеть как
для i в диапазоне (0,10):
печать (я)
, но с точки зрения интерпретатора он мог бы представить эту программу как что-то вроде
forLoop = For (Var ("i"),
Функция ("диапазон", Int (0), Int (10)),
BuiltIn ("печать", Var ("i")))
, где For, Var, Function, Int и BuiltIn - это классы, которые должен был создать писатель интерпретатора.Вы можете представить структуру программы как что-то вроде
Пример абстрактного синтаксического дерева (AST)Затем, когда интерпретатор создал этот AST, он выполнит код. Это означает разделение объектов, представляющих программу, и выполнение соответствующих действий. Цикл for превратится в нечто повторяющееся. Переменные становятся отложенными данными, которые можно будет получить позже. Встроенные операции, такие как печать, будут записывать вывод в консоль. В данном случае это будет немного тривиально, потому что концепции Python легко перевести в код Python.Но если вы писали интерпретатор Python в чем-то вроде Haskell, цикл Python выполняется как функция Haskell.
Теперь, чтобы создать язык, я рекомендую начать с интерпретатора. Обычно он менее сложен, чем компилятор, потому что в интерпретаторе вам нужно только выполнить код, а не выяснять, как преобразовать его в код на другом языке, который по-прежнему делает то, что вы хотите.
Вот основные шаги и порядок, которые я рекомендую для написания языка программирования:
- Создание вашего языка
- Создание AST для языка
- Написание кода для выполнения AST
- Выбор языка
- Написание парсера
Первые два из них мы рассмотрим в этой статье, а остальные будут в следующих частях.
Создание вашего языка
На самом деле придумывание языка - это место, где проявятся ваши творческие способности. Начните думать о том, что было бы круто, странно или интересно увидеть в языке программирования.
Тем не менее, вам нужно подумать над некоторыми основными вопросами о том, как язык будет работать.
- Как вы повторяете на своем языке? То есть как выполнить одни и те же шаги несколько раз?
- Как вы делаете выбор на своем языке? Вам понадобится способ принимать решения о том, когда что-то должно произойти.Большинство языков делают это с помощью некоторой формы оператора if.
- Какие данные у вас будут: числа, строки, списки и т. Д.?
- Как будут работать функции?
- Вы хотите иметь возможность создавать параллельные потоки?
- Есть ли языки, которые вас вдохновляют?
- Есть ли языки, которые вы почти любите, но хотели бы исправить?
Можно подумать и о других дизайнерских решениях, но это хорошее начало.
Выбор того, как должен выглядеть ваш язык
Возможно, вы уже представляли себе, как будет выглядеть ваш язык.Фактический способ написания языка называется его синтаксисом. Я рекомендую писать код вручную, чтобы понять, какой синтаксис вы хотите использовать. Если вам не нравится, как работает ваш язык, будет намного сложнее использовать его. Я рекомендую выбрать синтаксис языка, который вам нравится, и использовать его. В конце концов, так много языков украли синтаксис C и немного изменили его, так что вы также можете заимствовать из языков, которые вам нравятся.
Хорошая идея - «подделать» некоторые программы на вашем новом языке ручкой и бумагой, а затем делать заметки о том, что они должны делать.
Если вы потратите некоторое время на размышления об этих двух темах и их планирование, вы будете готовы начать писать код для следующего раза. А пока ознакомьтесь с дополнительными материалами для некоторых других руководств по написанию интерпретаторов.
Это первая часть серии, состоящей из нескольких частей, о том, как люди создают языки программирования. Проверьте следующие несколько выпусков журнала для будущих выпусков этой серии.
Это одна из статей о том, как люди создают языки программирования.Прочтите Часть II.
Узнать больше
Учебное пособие по созданию простого интерпретатора в Python (старое)
http://www.norvig.com/lispy.html
Больше деталей, меньше дизайна
https://ruslanspivak.com/lsbasi-part1/
Haskell и написание простого интерпретатора
https://en.wikibooks.org/wiki/Write_Yourself_a_Scheme_in_48_Hours
Как создать язык программирования
https://www.kidscodecs.com/build-a-programming-language-1/
https: // www.kidscodecs.com/designing-programming-language-part-ii/
index-of.es/
Название Размер Android / - Галерея искусств/ - Атаки / - Переполнение буфера / - C ++ / - CSS / - Компьютер / - Конференции / - Растрескивание / - Криптография / - Базы данных / - Глубокая сеть / - Отказ в обслуживании/ - Электронные книги / - Перечисление / - Эксплойт / - Техники неудачной атаки / - Судебно-медицинская экспертиза / - Галерея / - HTML / - Взломать / - Взлом-веб-сервер / - Взлом беспроводных сетей / - Взлом / - Генератор хешей / - JS / - Ява/ - Linux / - Отмыкание/ - Журналы / - Вредоносное ПО / - Метасплоит / - Разное / - Разное / - Протоколы сетевой безопасности / - Сеть / - ОПЕРАЦИОННЫЕ СИСТЕМЫ/ - Другое / - PHP / - Perl / - Программирование / - Python / - RSS / - Rdbms / - Разобрать механизм с целью понять, как это работает/ - Рубин/ - Сканирование сетей / - Безопасность/ - Захват сеанса / - Снифферы / - Социальная инженерия/ - Поддерживает / - Системный взлом / - Инструменты/ - Учебники / - UTF8 / - Unix / - Вариос-2 / - Варианты / - Видео/ - Вирусы / - Окна / - Беспроводная связь / - Xml / - z0ro-Репозиторий-2 / - z0ro-Репозиторий-3 / -
Зачем писать свой собственный язык программирования?
Создание компилятора Bolt: Часть 1
10 мая 2020 г.
6 мин чтения
Серия: Создание компилятора Bolt
На приведенной выше диаграмме показан компилятор для языка Bolt, который мы будем создавать.Что означают все этапы? Мне нужно изучить OCaml и C ++? Подождите, я даже не слышал об OCaml…
Не волнуйтесь. Когда я начал этот проект 6 месяцев назад, я никогда не создавал компилятор и не использовал OCaml или C ++ в каких-либо серьезных проектах. Я все объясню в свое время. Вопрос, который мы действительно должны задать: , зачем создавать свой собственный язык ? Возможные ответы:
- Это весело
- Круто иметь свой собственный язык программирования
- Это хороший побочный проект
Ментальные модели
Хотя все три из них (или ни одна!) Могут быть правдой, есть более крупный вариант. мотивация: правильные ментальных моделей .Видите ли, когда вы изучаете свой первый язык программирования, вы смотрите на программирование через призму этого языка. Перенесемся на второй язык, и это кажется трудным, вам придется заново учить синтаксис, а этот новый язык работает по-другому. Используя больше языков программирования, вы понимаете, что эти языки имеют общие темы. В Java и Python есть объекты, в Python и JavaScript не нужно писать типы, список можно продолжить. Углубляясь в теорию языков программирования, вы читаете о существующих языковых конструкциях - Java и Python объектно-ориентированных языков программирования , а Python и JavaScript динамически типизированных .
Языки программирования, которые вы использовали, на самом деле основаны на идеях, представленных в более старых языках, о которых вы, возможно, не слышали. Simula и Smalltalk представили концепцию объектно-ориентированных языков программирования. Lisp представил концепцию динамической типизации. И все время появляются новые исследовательские языки, которые вводят новые концепции. Более распространенный пример: Rust встраивает безопасности памяти в язык системного программирования низкого уровня.
Создание собственного языка (особенно если вы добавляете новые идеи) помогает вам более критически относиться к языковому дизайну , так что когда вы пойдете учить новый язык, это будет намного проще.Например, я никогда не программировал на Hack до моей стажировки в Facebook прошлым летом, но знание этих концепций языка программирования облегчило освоение.
Что такое компиляторы?
Итак, вы создали свой модный новый язык, и он собирается произвести революцию в мире, но есть одна проблема. Как это запустить? Это роль компилятора. Чтобы объяснить, как работают компиляторы, давайте сначала вернемся в XIX век, в век телеграфа.У нас есть новый модный телеграф, но как отправлять сообщения? Та же проблема, другой домен. Телеграфисту необходимо принять речь, преобразовать ее в азбуку Морзе и набрать код. Первое, что делает оператор, - это разбирается в речи - они разбивают ее на слова (, lexing ), а затем понимают, как эти слова используются в предложении (, синтаксический анализ ) - являются ли они частью именной группы, придаточное предложение и т. д. Они проверяют, имеет ли это смысл, классифицируя слова по категориям или типов (прилагательное, существительное, глагол), и проверяют, имеет ли предложение грамматический смысл (мы не можем использовать «пробеги» для описания существительного, поскольку это глагол не существительное).Наконец, они переводят ( - ) каждое слово в точки и тире (азбука Морзе), которые затем передаются по сети.
Похоже, это работает, потому что большая часть этого автомат для людей. Компиляторы работают таким же образом, за исключением того, что мы должны явно программировать компьютеры для этого. В приведенном выше примере описывается простой компилятор, состоящий из 4 этапов: lex, синтаксический анализ, проверка типа и затем перевод в машинные инструкции. Оператору также требуются некоторые дополнительные инструменты, чтобы фактически извлечь азбуку Морзе; для языков программирования это среда выполнения .
На практике оператор, вероятно, создает некоторую сокращенную запись, которую он умеет переводить в азбуку Морзе. Теперь вместо того, чтобы напрямую преобразовывать речь в азбуку Морзе, они преобразуют речь в свою стенографию, а затем преобразуют ее в код Морзе. Во многих практических языках вы не можете просто перейти непосредственно от исходного кода к машинному коду, у вас есть этапы для удаления сахара или для понижения этапов, на которых вы удаляете языковые конструкции поэтапно (например.грамм. разворачивая для циклов), пока у нас не останется небольшой набор инструкций, которые можно выполнить. Обессахаривание значительно упрощает последующие стадии, поскольку они работают с более простым представлением. Этапы компилятора сгруппированы в интерфейс, средний и бэкэнд, где интерфейс выполняет большую часть синтаксического анализа / проверки типов, а средний и бэкэнд упрощают и оптимизируют код.
Выбор конструкции компилятора
На самом деле мы можем сформировать множество языков и дизайн компилятора в терминах приведенной выше аналогии:
Переводит ли оператор слова на лету в азбуку Морзе по мере их передачи, или они преобразуют слова в азбуку Морзе заранее, а затем передать азбуку Морзе? Интерпретация языков, таких как Python, делает первое, в то время как опережающих времен скомпилировали языков, таких как C (и Bolt), делают второе.На самом деле Java находится где-то посередине - он использует своевременный компилятор , который выполняет большую часть работы заранее, переводя программы в байт-код, а затем во время выполнения компилирует байт-код в машинный код.
Теперь рассмотрим сценарий, в котором появился новый код Лорзе, который был альтернативой азбуке Морзе. Если операторов научат преобразовывать сокращение в код Лорса, говорящему не нужно знать, как это делается, он получает это бесплатно. Точно так же человеку, говорящему на другом языке, просто нужно сказать оператору, как перевести его в стенографию, а затем он получит перевод на азбуку Морзе и Лорса! Так работает LLVM . LLVM IR (промежуточное представление) действует как ступенька между программой и машинным кодом. C, C ++, Rust и целый ряд других языков (включая Bolt) нацелены на LLVM IR, который затем компилирует код для различных архитектур машин.
Статическая или динамическая типизация? В первом случае оператор либо проверяет грамматический смысл слов до того, как они начнут нажимать. Или они этого не делают, а затем на полпути они говорят: «Ага, в этом нет смысла» и останавливаются.С динамической типизацией можно быстрее экспериментировать (например, Python, JS), но когда вы отправляете это сообщение, вы не знаете, остановится ли оператор на полпути (сбой).
Я объяснил это на примере воображаемого телеграфиста, но любая аналогия работает. Развитие этой интуиции имеет большое значение для понимания того, какие языковые функции подходят для вашего языка: если вы собираетесь экспериментировать, то, возможно, динамический набор текста лучше, поскольку вы можете двигаться быстрее. Если вы используете более крупную кодовую базу, вам будет сложнее все вычитать, и вы с большей вероятностью сделаете ошибки, поэтому вам, вероятно, следует перейти к статической типизации, чтобы избежать поломки.
Типы
Самая интересная часть компилятора (на мой взгляд) - проверка типов. В нашей аналогии оператор классифицировал слова как части речи (прилагательные, существительные, глаголы), а затем проверял, правильно ли они использовались. Типы работают одинаково, мы классифицируем программные ценности на основе того поведения, которое мы хотим, чтобы они имели. Например. int для чисел, которые можно умножать вместе, String для потоков символов, которые могут быть объединены вместе. Роль средства проверки типов состоит в том, чтобы предотвратить нежелательное поведение - например, объединение int s или умножение String s вместе - эти операции не имеют смысла, поэтому их нельзя допускать.С типом , проверяющим , программист аннотирует значения типами, а компилятор проверяет их правильность. При выводе типа компилятор и определяет, и проверяет типы. Мы называем правила проверки типов суждениями о типе , и их совокупность (вместе с самими типами) образует систему типов.
Оказывается, вы можете сделать гораздо больше: системы типов не просто проверяют, правильно ли используются int s или String s.Более богатые системы типов могут доказать более сильные инварианты относительно программ: что они завершаются, безопасно обращаются к памяти или что они не содержат гонок данных. Система типов Rust, например, гарантирует безопасность памяти и свободу от гонки данных, а также проверяет традиционные типы int s и String s.
Присоединяйтесь к моему информационному бюллетеню, чтобы получать больше подобных материалов!
Подписчики электронной почты сначала получают эксклюзивный доступ к последним сообщениям!
Куда подходит Bolt?
Языки программирования до сих пор не решают проблему написания безопасного параллельного кода.Bolt, как и Rust, предотвращает гонку данных (объясняется в этом документе Rust), но использует более детальный подход к параллелизму. Я думаю, что до того, как воины-клавишники набросятся на меня в Твиттере, Rust проделал блестящую работу, чтобы наладить обсуждение этого вопроса - хотя Bolt, скорее всего, никогда не станет мейнстримом, он демонстрирует другой подход.
Если мы сейчас оглянемся на конвейер, то увидим, что Bolt содержит фазы лексирования, синтаксического анализа и обессахаривания / понижения. Он также содержит несколько этапов сериализации и десериализации Protobuf: они предназначены исключительно для преобразования между OCaml и C ++.Он нацелен на LLVM IR, затем мы связываем пару библиотек времени выполнения (pthreads и libc) и, наконец, выводим наш объектный файл , двоичный файл, содержащий машинный код.