Как создать и выполнить SQL запрос к базе данных. Обзор основных инструментов | Info-Comp.ru
Приветствую Вас на сайте Info-Comp.ru! Сегодня я продолжаю рассказ о языке SQL, и в этом материале я немного расскажу о том, как создаются и выполняются SQL запросы к базе данных, а точнее какие инструменты (программы) для этого используются.
Содержание
- Как создать SQL запрос? Где писать SQL код?
- Инструменты для создания SQL запросов
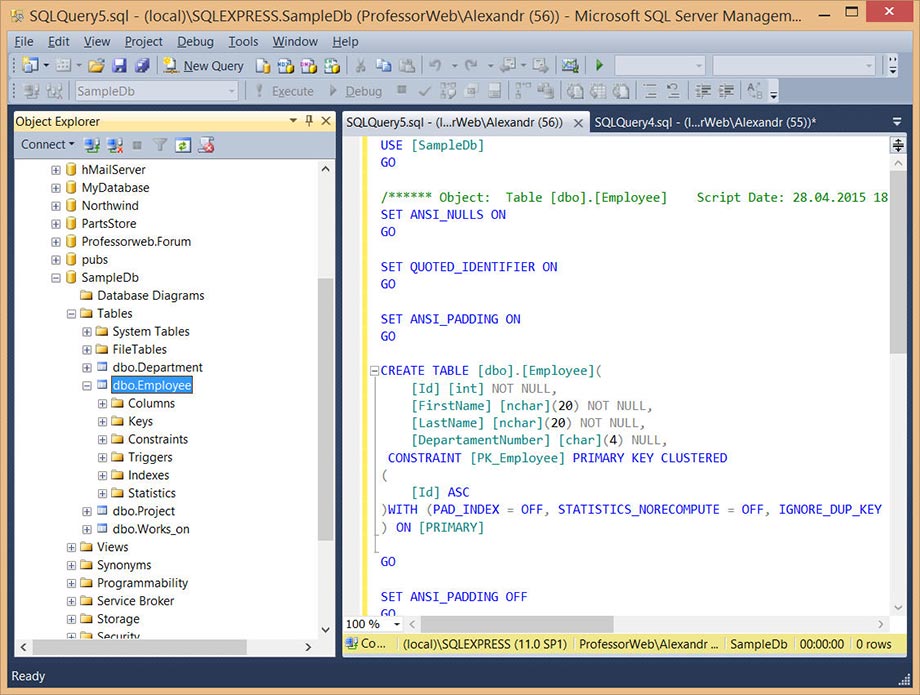
- Microsoft SQL Server
- Oracle Database
- MySQL
- PostgreSQL
- Выводы
Как создать SQL запрос? Где писать SQL код?
В одной из прошлых статей я рассказал Вам, что такое SQL и какие СУБД бывают, но у начинающих, кто только начинает работать с базами данных, могут возникнуть определённые вопросы, например, как работать с этими базами данных, как подключиться к базе и как выполнить SQL запрос?
Обычный случай, когда человек только что установил себе какую-нибудь СУБД (например, для изучения SQL) и не знает, что делать дальше, где писать SQL код? какую программу запустить?
Или другой, еще более распространённый вариант, когда уже есть установленный SQL сервер, а начинающему программисту (IT-ку), которому сказали, что он будет еще сопровождать SQL сервер, нужно подключиться к этому серверу и выполнить какой-нибудь SQL запрос или инструкцию, а он, так как никогда не работал с серверами баз данных, конечно же, не знает, как это сделать. И все это на самом деле логично, ведь наличие установленного сервера баз данных не говорит о том, что на сервере также есть средства управления этим сервером и средства разработки SQL инструкций, так как это отдельные программы, которые устанавливаются на клиентском компьютере (но можно установить и на самом сервере).
И все это на самом деле логично, ведь наличие установленного сервера баз данных не говорит о том, что на сервере также есть средства управления этим сервером и средства разработки SQL инструкций, так как это отдельные программы, которые устанавливаются на клиентском компьютере (но можно установить и на самом сервере).
Поэтому сегодня, специально для начинающих SQL программистов, я расскажу о том, какие инструменты нужны для того, чтобы создавать и выполнять SQL запросы к базе данных, иными словами, где писать SQL запросы. При этом я расскажу про инструменты для всех популярных СУБД: Microsoft SQL Server, Oracle Database, MySQL и PostgreSQL. Так как для каждой СУБД используются отдельные инструменты, но есть, конечно же, и универсальные инструменты, которые умеют работать одновременно практически со всеми из вышеперечисленных баз данных.
Если у Вас возникает вопрос, как послать SQL запрос к базе данных из приложения при его разработке (например, Вы начинающий программист Java, C# или других языков), то это делается непосредственно из самой IDE (среды программирования), используя специальные драйверы для подключения к БД. Устанавливать перечисленные в данной статье инструменты необязательно, они нужны для прямой работы с базой данных: разработка и отладка SQL инструкций, выполнение административных задач и так далее.
Устанавливать перечисленные в данной статье инструменты необязательно, они нужны для прямой работы с базой данных: разработка и отладка SQL инструкций, выполнение административных задач и так далее.
Инструменты для создания SQL запросов
Сейчас я перечислю и коротко расскажу про инструменты, которые можно использовать для написания SQL запросов и их выполнения на различных SQL серверах, при этом функционал этих инструментов не ограничивается редактором SQL запросов, на самом деле большинство современных программ для работы с базами данных являются многофункциональными, их могут использовать как разработчики, так и администраторы баз данных.
В этом материале я перечислю только некоторые инструменты, так как на самом деле их очень много. Кстати, если Вы знаете или уже пользуетесь каким-нибудь инструментом, но его в перечисленном ниже списке не обнаружили, то пишите об этом в комментариях, я думаю, всем читателям будет интересно узнать, какие еще существуют средства создания SQL запросов.
Также обязательно отмечу, что, так как здесь перечислены качественные и многофункциональные инструменты, большинство из них, конечно же, платные, но у них есть бесплатные версии или пробный период. Если Вы будете заниматься SQL разработкой на более-менее нормальном уровне, то возможно стоит и отдать деньги за понравившееся Вам решение.
Однако с другой стороны, для начинающих в целях обучения или для небольших проектов покупать отдельный, пусть и очень функциональный и удобный инструмент, я думаю, не стоит, так как достаточно будет использовать стандартные средства, которые обычно разработчики конкретной СУБД предоставляют бесплатно. Основные стандартные средства я буду отмечать, чтобы Вы понимали, от чего Вам нужно отталкиваться, если Вы начинающий.
Microsoft SQL Server
Начну я, конечно же, с Microsoft SQL Server, так как я уже достаточно долго работаю с данной СУБД. Microsoft SQL Server – это система управления базами данных от компании Microsoft. Она очень популярна в корпоративном секторе, особенно в крупных компаниях.
Она очень популярна в корпоративном секторе, особенно в крупных компаниях.
Инструментов для работы с Microsoft SQL Server много, однако самый распространённый и популярный вариант – это, конечно же, SQL Server Management Studio.
SQL Server Management Studio
SQL Server Management Studio (SSMS) — это бесплатная графическая среда для управления инфраструктурой SQL Server, разработанная компанией Microsoft. С помощью Management Studio Вы можете разрабатывать и выполнять инструкции T-SQL, а также администрировать Microsoft SQL Server.
Среда SQL Server Management Studio – это основной, стандартный инструмент для работы с Microsoft SQL Server.
Если стандартного функционала SSMS Вам недостаточно, то для этой среды разработано очень много различных плагинов и надстроек, которые расширяют функционал Management Studio.
Более подробно про SQL Server Management Studio, включая то, как установить данную среду, я рассказывал в статье – Обзор и установка SQL Server Management Studio.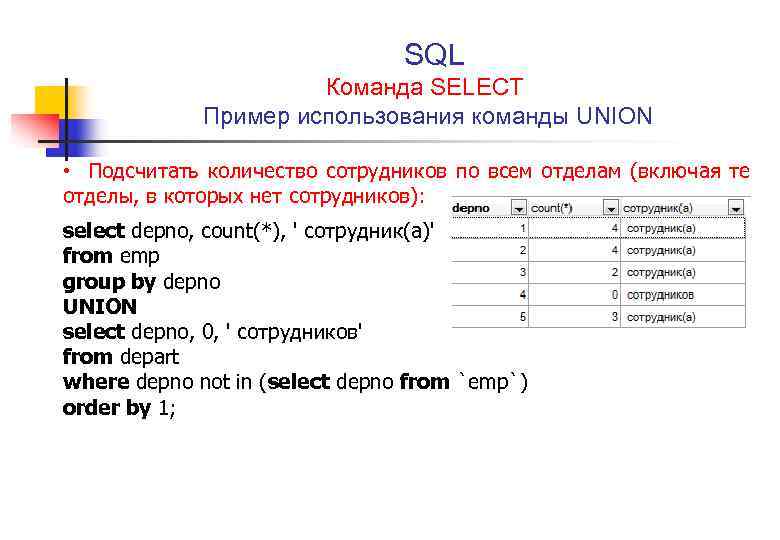
Дополнительные материалы:
- Страница продукта – https://docs.microsoft.com/ru-RU/sql/ssms/download-sql-server-management-studio-ssms;
- SQL код – книга для изучения языка SQL.
SQL Server Data Tools
SQL Server Data Tools – это еще один инструмент для работы с Microsoft SQL Server, разработанный компанией Microsoft. Данный инструмент входит в состав Visual Studio, и устанавливается он как отдельная рабочая нагрузка. Предназначен SQL Server Data Tools в первую очередь для разработчиков приложений.
Если Вы разрабатываете программы с помощью Visual Studio, при этом у Вас возникла необходимость работы с Microsoft SQL Server, то SQL Server Data Tools будет для Вас очень удобным и привычным инструментом.
Страница продукта – https://docs.microsoft.com/ru-ru/sql/ssdt/download-sql-server-data-tools-ssdt
dbForge Studio for SQL Server
dbForge Studio for SQL Server – это мощная среда для разработки и администрирования баз данных в Microsoft SQL Server.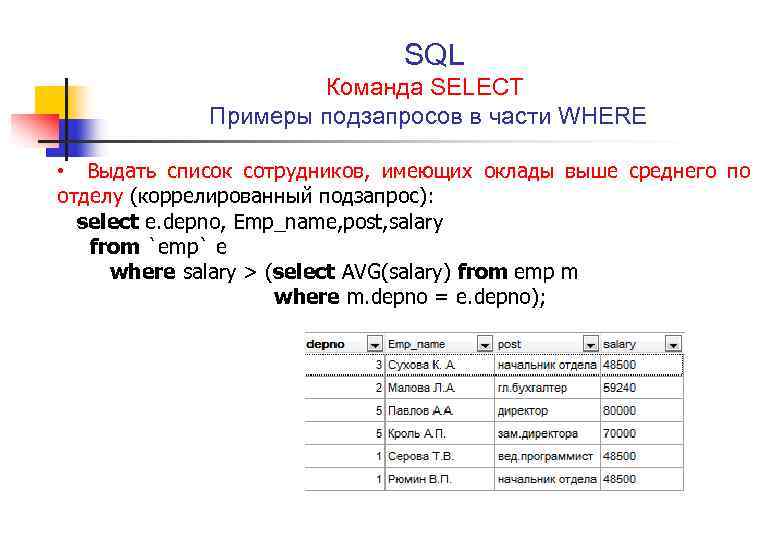 Разработчиком данной среды является компания Devart, у которой, кстати, есть много инструментов для работы с Microsoft SQL Server, про один инструмент я уже рассказывал в статье – Как сравнить и синхронизировать две базы данных в Microsoft SQL Server? Кроме того, у Devart есть и инструменты для работы с другими СУБД, про некоторые я сегодня еще расскажу.
Разработчиком данной среды является компания Devart, у которой, кстати, есть много инструментов для работы с Microsoft SQL Server, про один инструмент я уже рассказывал в статье – Как сравнить и синхронизировать две базы данных в Microsoft SQL Server? Кроме того, у Devart есть и инструменты для работы с другими СУБД, про некоторые я сегодня еще расскажу.
Страница продукта – https://www.devart.com/ru/dbforge/sql/studio/
Red Gate SQL Prompt
Red Gate SQL Prompt – еще один мощнейший инструмент для работы с Microsoft SQL Server. С помощью него также можно разрабатывать SQL инструкции и администрировать SQL сервер. Данную среду разрабатывает компания Redgate Software, которая специализируется на работе с данными, у нее есть инструменты и для работы с другими СУБД, но основным направлением является Microsoft SQL Server.
Страница продукта – https://www.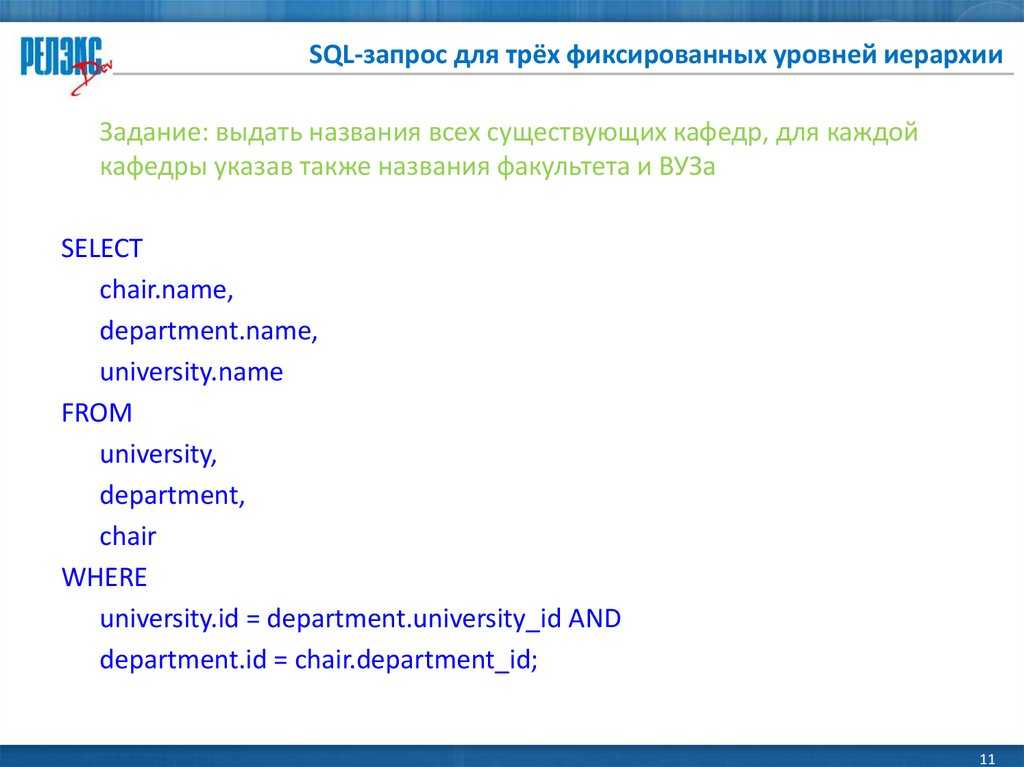 red-gate.com/products/sql-development/sql-prompt/
red-gate.com/products/sql-development/sql-prompt/
Navicat for SQL Server
Navicat for SQL Server – это графический инструмент для разработки и администрирования баз данных в Microsoft SQL Server. С помощью него можно создавать, редактировать и удалять любые объекты базы данных, разрабатывать и выполнять SQL запросы и инструкции, а также просматривать данные в таблицах, включая двоичные и шестнадцатеричные данные.
Страница продукта – https://www.navicat.com/en/products/navicat-for-sqlserver
EMS SQL Management Studio for SQL Server
EMS SQL Management Studio for SQL Server – это комплексное решение для разработки и администрирования баз данных в Microsoft SQL Server. Разработкой занимается компания EMS, которая специализируется на разработке инструментов администрирования баз данных и приложений для управления данными.
Страница продукта – https://www.sqlmanager.net/products/studio/mssql/
DataGrip
DataGrip – это универсальный инструмент для работы с базами данных, он умеет работать с Microsoft SQL Server, PostgreSQL, MySQL, Oracle, Sybase, DB2 и другими. Разработчиком DataGrip выступает JetBrains.
Страница продукта – https://www.jetbrains.com/datagrip/
SQL Enlight
SQL Enlight – еще одно приложение для разработки T-SQL кода. Разработкой занимается компания Ubitsoft.
Страница продукта – https://ubitsoft.com/
SQLCMD
SQLCMD – это стандартный консольный инструмент для работы с Microsoft SQL Server от компании Microsoft. Его использовать как основное средство разработки и администрирования SQL Server не получится, он в основном предназначен для каких-то служебных задач, выполнения скриптов и так далее.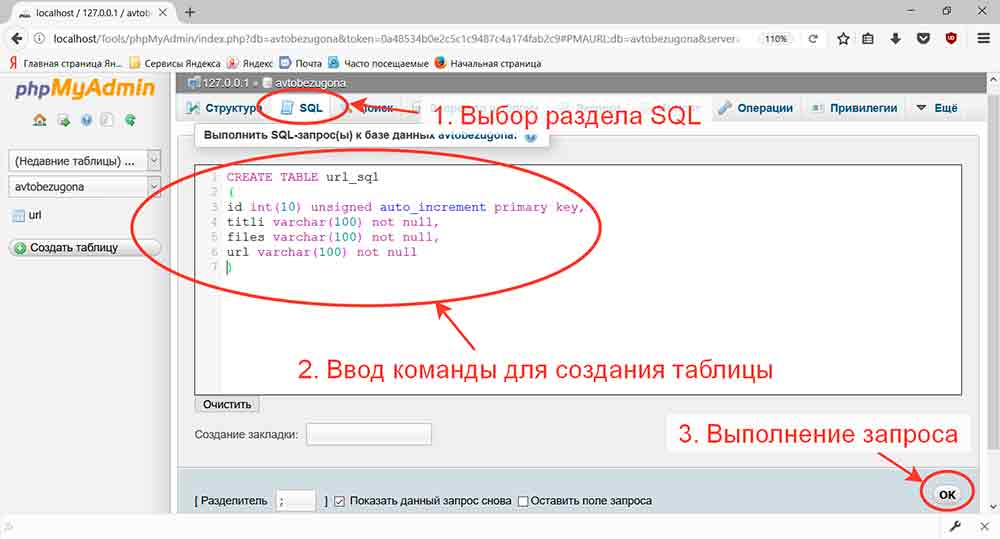 Его я сюда включил, так как начинающим программистам и администраторам SQL сервера об этом инструменте знать нужно.
Его я сюда включил, так как начинающим программистам и администраторам SQL сервера об этом инструменте знать нужно.
Oracle Database
Oracle Database – это система управления базами данных от компании Oracle. Это также очень популярная СУБД, и также среди крупных компаний.
Инструментов для работы с Oracle Database также много, вот некоторые из них.
Oracle SQL Developer
Oracle SQL Developer – это стандартный, бесплатный и основной инструмент для разработчика баз данных Oracle.
Разработкой занимается компания Oracle. С помощью Oracle SQL Developer можно разрабатывать инструкции на PL/SQL и выполнять SQL запросы.
Страница продукта – https://www.oracle.com/database/technologies/appdev/sql-developer.html
SQL Navigator for Oracle
SQL Navigator for Oracle – это удобный и не менее популярный инструмент для работы с Oracle Database.
Страница продукта – https://www.quest.com/products/sql-navigator/
Navicat for Oracle
Navicat for Oracle – это инструмент для разработки и администрирования баз данных Oracle Database. Этот инструмент имеет широкий набор функций для облегчения управления данными, таких как инструмент моделирования данных, синхронизация данных, импорт и экспорт данных.
Страница продукта – https://www.navicat.com/en/products/navicat-for-oracle
EMS SQL Management Studio for Oracle
EMS SQL Management Studio for Oracle – это комплексное решение для разработки и администрирования баз данных Oracle Database. Разработкой занимается компания EMS, продукты которой я уже упоминал сегодня.
Страница продукта – https://www.sqlmanager.net/ru/products/studio/oracle
dbForge Studio for Oracle
dbForge Studio for Oracle – еще один продукт компании Devart, который предназначен для разработки и обслуживания баз данных Oracle Database, он также имеет очень мощный функционал.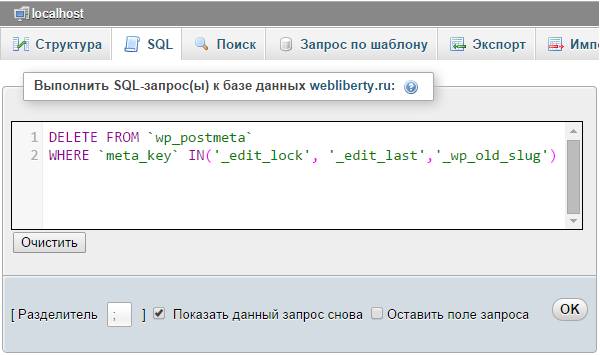
Страница продукта – https://www.devart.com/ru/dbforge/oracle/
MySQL
MySQL – это система управления базами данных также от компании Oracle, но только она распространяется бесплатно. MySQL получила широкое применение в интернете как средство хранения данных сайтов.
Для работы с MySQL существует очень много инструментов, вот самые популярные и функциональные.
MySQLWorkbench
MySQL Workbench – это основной и стандартный инструмент для работы с MySQL.
Он позволяет осуществлять разработку на SQL и администрировать MySQL сервер.
Страница продукта – https://www.mysql.com/products/workbench/
PHPMyAdmin
PHPMyAdmin – это бесплатный веб-инструмент для работы с MySQL. Очень широкую популярность он приобрел в интернете, так как именно PHPMyAdmin используют для разработки баз данных на многих web-сайтах, а также на большинстве хостинг-провайдерах для управления базой MySQL используется именно PHPMyAdmin.
Дополнительные материалы:
- Страница продукта – https://www.phpmyadmin.net/
- Пример установки PHPMyAdmin на Linux Mint
Navicat for MySQL
Navicat for MySQL – это инструмент для администрирования и разработки баз данных MySQL и MariaDB. Navicat for MySQL позволяет подключаться и работать с базами данных в MySQL и MariaDB одновременно.
Страница продукта – https://www.navicat.com/en/products/navicat-for-mysql
dbForge Studio for MySQL
dbForge Studio for MySQL – это мощное решение для разработки и управления базами данных MySQL и MariaDB. Данный инструмент позволяет создавать и выполнять SQL запросы, разрабатывать и отлаживать процедуры и функции, а также управлять объектами баз данных MySQL с помощью удобного графического пользовательского интерфейса.
Страница продукта – https://www.devart.com/ru/dbforge/mysql/
EMS SQL Management Studio for MySQL
EMS SQL Management Studio for MySQL – это еще одно комплексное и мощное решение от компании EMS, на этот раз для разработки и администрирования баз данных MySQL. Данный инструмент содержит все необходимые компоненты для работы с MySQL: редактор SQL запросов, средство импорта, экспорта и сравнения данных и много других, предназначенных не только для разработчиков, но и для администраторов и аналитиков данных.
Страница продукта – https://www.sqlmanager.net/ru/products/studio/mysql
SQL Maestro for MySQL
SQL Maestro for MySQL – это еще один инструмент разработки и администрирования баз данных MySQL и MariaDB.
Страница продукта – https://www.sqlmaestro.com/products/mysql/maestro/
PostgreSQL
PostgreSQL – эта бесплатная система управления базами данных, и она очень популярна и функциональна.
Для работы с PostgreSQL можно использовать следующие инструменты.
pgAdmin
pgAdmin – это основное, стандартное средство для разработки баз данных PostgreSQL, которое распространяется бесплатно.
pgAdmin достаточно удобный инструмент для разработчика, с помощью него можно разрабатывать SQL инструкции, выполнять SQL запросы, создавать объекты базы данных и многое другое.
Дополнительные материалы:
- Страница продукта – https://www.pgadmin.org/
- Пример установки pgAdmin 4 на Windows 7
EMS SQL Management Studio for PostgreSQL
EMS SQL Management Studio for PostgreSQL – это комплексное решение для разработки и администрирования баз данных PostgreSQL. Данный инструмент так же, как все остальные продукты компании EMS, имеет очень широкий функционал от простого редактора SQL запросов до инструмента сравнения данных.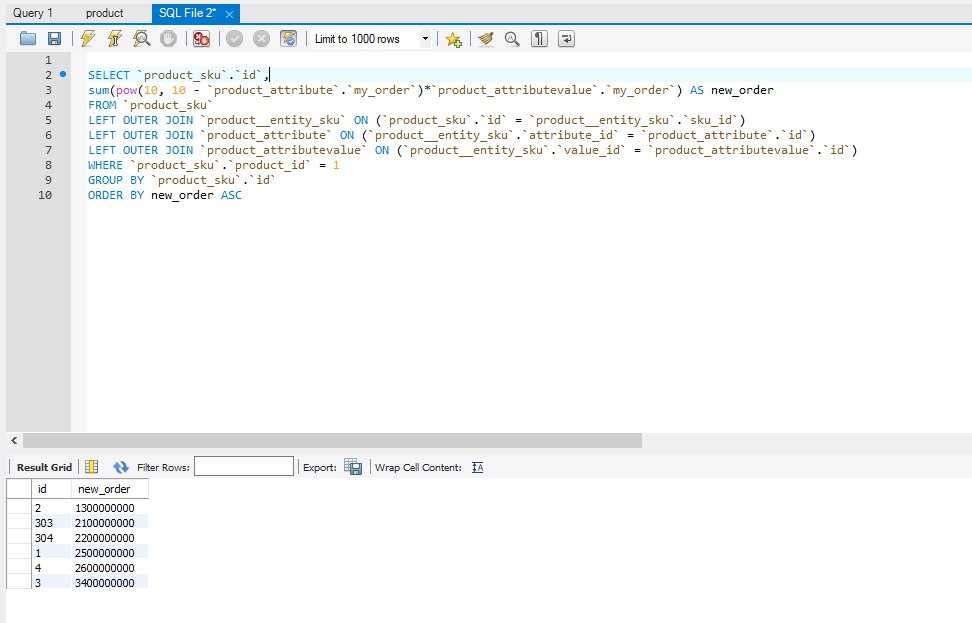
Страница продукта – https://www.sqlmanager.net/ru/products/studio/postgresql
Navicat for PostgreSQL
Navicat for PostgreSQL – это простой графический инструмент для разработки баз данных PostgreSQL. Он позволяет писать и выполнять SQL запросы любой сложности.
Страница продукта – https://www.navicat.com/en/products/navicat-for-postgresql
dbForge Studio for PostgreSQL
dbForge Studio for PostgreSQL – это еще один мощный инструмент от компании Devart, на этот раз для работы с PostgreSQL. Он позволяет разрабатывать и выполнять запросы, редактировать код в удобном интерфейсе, формировать отчеты, модифицировать данные, а также осуществлять импорт и экспорт данных.
Страница продукта – https://www.devart.com/dbforge/postgresql/studio/
psql
psql – это стандартная консольная утилита для работы с PostgreSQL.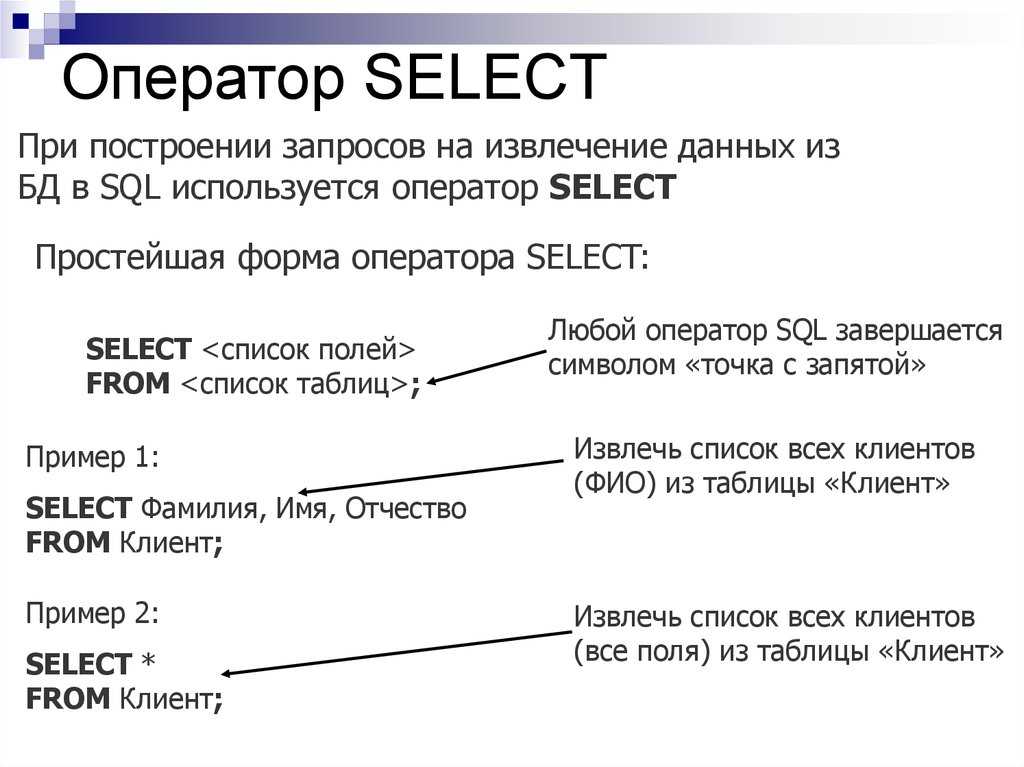 Используется в основном для автоматизации различных служебных задач, хотя вести SQL разработку в ней также можно.
Используется в основном для автоматизации различных служебных задач, хотя вести SQL разработку в ней также можно.
DataGrip
Также осуществлять разработку баз данных PostgreSQL можно и с помощью уже упомянутого в этой статье универсального инструмента DataGrip от компании JetBrains.
Выводы
Как видите, существует очень много инструментов для работы с базами данных, при этом многие компании специализируется на выпуске программ для баз данных, и у них есть версии для каждой популярной СУБД. Такие инструменты очень функциональны, и они, конечно же, платные. Но, как я уже отмечал, функционала стандартных средств, которые предоставляются бесплатно, для создания и выполнения SQL запросов будет вполне достаточно.
На сегодня это все, удачи Вам, пока!
Как в системе сделать SQL запрос или выполнить php-код?
+7 495 008 8452
Анализ
Проект
Дизайн
Маркетинг
Разработка
Наполнение
Техподдержка
- Веб-студия АКРИТ. разработка модулей и сайтов интернет магазинов на 1С Битрикс
- Кладовка программиста
- База знаний
- Дополнительные вопросы
- Как в системе сделать SQL запрос или выполнить php-код?
 org/BreadcrumbList»>
org/BreadcrumbList»>Если у вас возникли какие либо вопросы которые вы не смогли решить по нашим публикациям самостоятельно,
то ждем ваше обращение в нашей службе тех поддержки.
Источник: https://dev.1c-bitrix.ru/learning/course/index. php?COURSE_ID=35&LESSON_ID=2029 php?COURSE_ID=35&LESSON_ID=2029 |
SQL запрос |
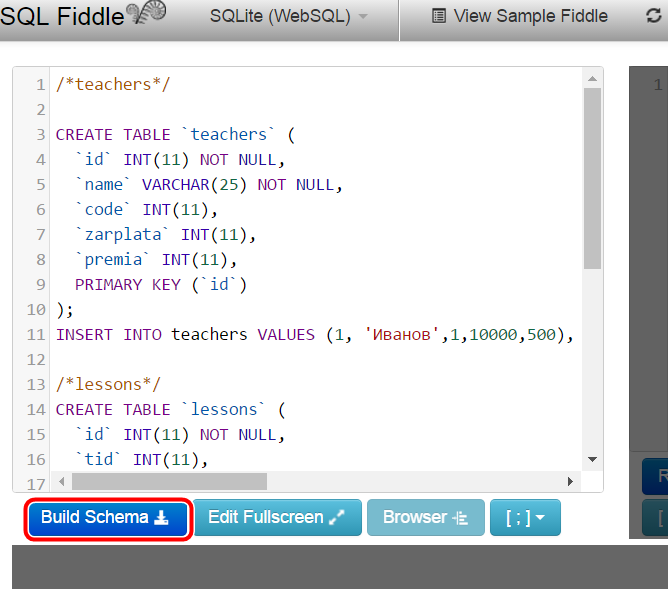
Форма SQL запрос (Настройки > Инструменты > SQL запрос) предназначена для выполнения SQL запросов к базе данных. Возможно выполнение любых запросов на языке SQL.
Важно! Система не устанавливает никаких ограничений на SQL запросы, поэтому будьте крайне внимательны при выполнении запросов типа UPDATE, DELETE, DROP и т.п.
Командная PHP-строка |
Форма Командная PHP-строка (Настройки > Инструменты > Командная PHP-строка) предназначена для исполнения некоторого кода, вызывающего функции API Битрикса без создания новых страниц на сайте. Доступно несколько закладок для выполнения разного кода одновременно.
Доступно несколько закладок для выполнения разного кода одновременно.
Назад в раздел
Подписаться на новые материалы раздела:
Загрузка…
Веб студия «АКРИТ»
Узнать больше
Рассылка
Услуги
- Внедрение, разработка, техподдержка
- Настройки торговых площадок
- Экспертиза производительности
- Пакет услуг по переходу на новые версии модуля
- Пакеты услуг
- Продление решений
- Сопровождение и поддержка сайтов
Популярные теги
Загрузка
Карта сайта
Веб-студия «АКРИТ»
Настройка производительности SQL-запросов | Расширенный SQL
Начиная здесь? Этот урок является частью полного учебника по использованию SQL для анализа данных.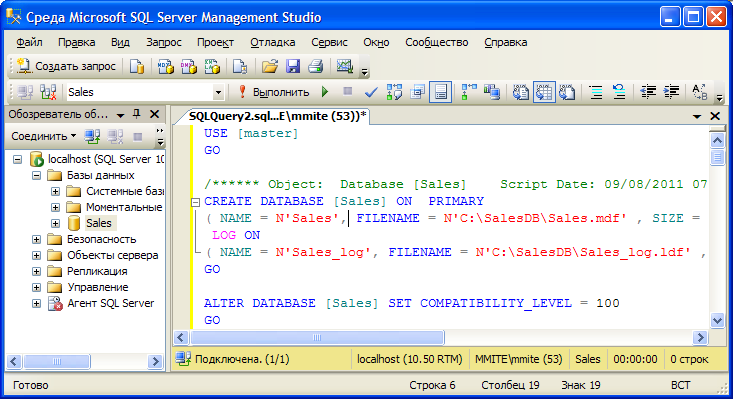 Проверьте начало.
Проверьте начало.
В этом уроке мы рассмотрим:
- Теорию выполнения запроса
- Размер редукционного стола
- Упрощение соединений
- ОБЪЯСНИТЬ
Что такое настройка производительности SQL?
Настройка SQL — это процесс улучшения запросов SQL для повышения производительности серверов. Его общая цель — сократить время, необходимое пользователю для получения результата после выдачи запроса, и уменьшить количество ресурсов, используемых для обработки запроса. В уроке о подзапросах была представлена идея о том, что иногда вы можете создать тот же желаемый набор результатов с помощью более быстрого запроса. На этом уроке вы научитесь определять, когда ваши запросы можно улучшить, и как их улучшить.
Теория, лежащая в основе времени выполнения запроса
База данных — это часть программного обеспечения, которое работает на компьютере и имеет те же ограничения, что и любое другое программное обеспечение — оно может обрабатывать столько информации, сколько его аппаратное обеспечение способно обработать.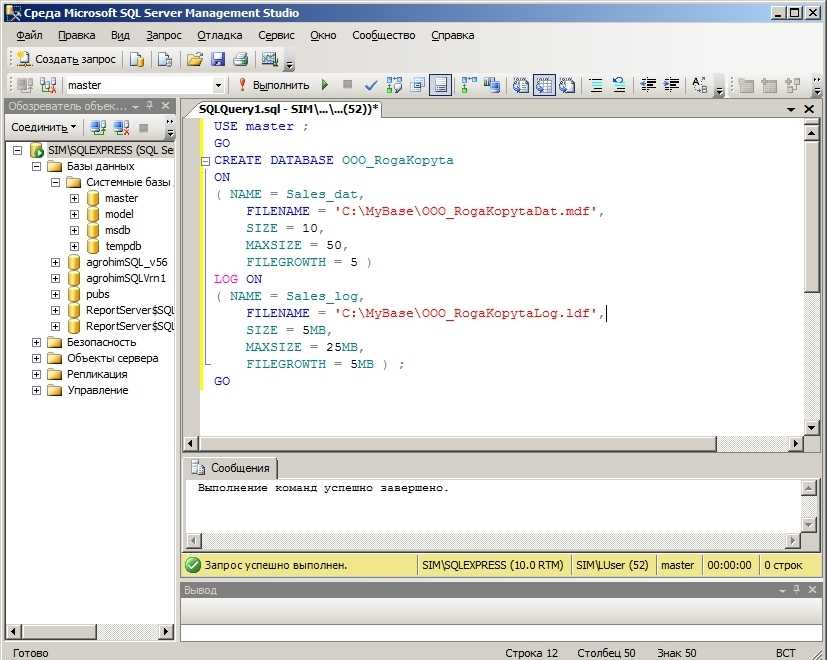 Чтобы ускорить выполнение запроса, нужно уменьшить количество вычислений, которые должно выполнять программное обеспечение (и, следовательно, аппаратное обеспечение). Для этого вам потребуется некоторое понимание того, как SQL на самом деле производит вычисления. Во-первых, давайте рассмотрим некоторые высокоуровневые вещи, которые повлияют на количество вычислений, которые вам нужно сделать, и, следовательно, на время выполнения ваших запросов:
Чтобы ускорить выполнение запроса, нужно уменьшить количество вычислений, которые должно выполнять программное обеспечение (и, следовательно, аппаратное обеспечение). Для этого вам потребуется некоторое понимание того, как SQL на самом деле производит вычисления. Во-первых, давайте рассмотрим некоторые высокоуровневые вещи, которые повлияют на количество вычислений, которые вам нужно сделать, и, следовательно, на время выполнения ваших запросов:
- Размер таблицы: Если ваш запрос касается одной или нескольких таблиц с миллионами строк или более, это может повлиять на производительность.
- Соединения: Если ваш запрос объединяет две таблицы таким образом, что количество строк в результирующем наборе существенно увеличивается, скорее всего, ваш запрос будет медленным. Пример этого есть в уроке о подзапросах.
- Агрегации: Объединение нескольких строк для получения результата требует больше вычислений, чем просто получение этих строк.
Время выполнения запроса также зависит от некоторых вещей, которые вы не можете контролировать, связанных с самой базой данных:
- Другие пользователи, выполняющие запросы: заданное время и тем медленнее все будет работать. Это может быть особенно плохо, если другие выполняют особенно ресурсоемкие запросы, которые удовлетворяют некоторым из вышеперечисленных критериев.
- Программное обеспечение для баз данных и оптимизация: Это то, что вы, вероятно, не можете контролировать, но если вы знаете систему, которую используете, вы можете работать в ее пределах, чтобы сделать ваши запросы более эффективными.
Пока что давайте игнорировать то, что вы не можете контролировать, и работать над тем, что вы можете.
Уменьшение размера таблицы
Фильтрация данных для включения только тех наблюдений, которые вам нужны, может значительно повысить скорость выполнения запросов. То, как вы это сделаете, будет полностью зависеть от проблемы, которую вы пытаетесь решить. Например, если у вас есть данные временных рядов, ограничение небольшим временным окном может значительно ускорить выполнение ваших запросов:
Например, если у вас есть данные временных рядов, ограничение небольшим временным окном может значительно ускорить выполнение ваших запросов:
ВЫБОР * ОТ benn.sample_event_table ГДЕ event_date >= '2014-03-01' И event_date < '2014-04-01'
Имейте в виду, что вы всегда можете выполнить исследовательский анализ подмножества данных, преобразовать свою работу в окончательный запрос, затем снять ограничение и выполнить свою работу по всему набору данных. Выполнение окончательного запроса может занять много времени, но, по крайней мере, промежуточные шаги можно выполнить быстро.
Вот почему Mode по умолчанию применяет условие LIMIT — 100 строк часто больше, чем вам нужно для определения следующего шага в анализе, и это достаточно маленький набор данных, чтобы он быстро возвращался.
Стоит отметить, что LIMIT не совсем так работает с агрегациями — выполняется агрегация, затем результаты ограничиваются указанным количеством строк.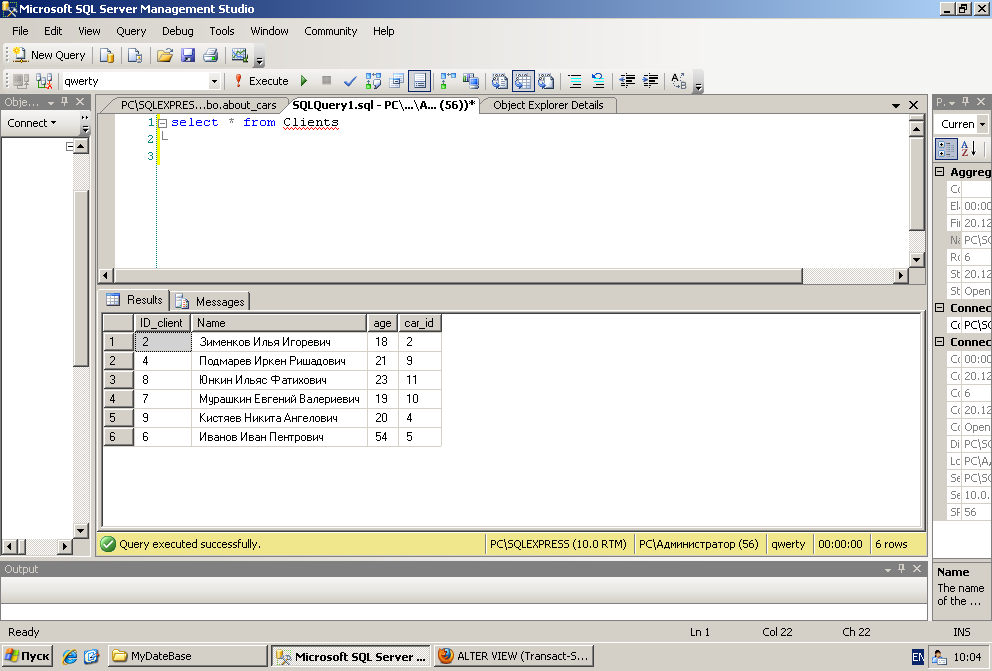 Поэтому, если вы агрегируете в одну строку, как показано ниже,
Поэтому, если вы агрегируете в одну строку, как показано ниже, LIMIT 100 не ускорит ваш запрос:
SELECT COUNT(*) ОТ benn.sample_event_table ПРЕДЕЛ 100
Если вы хотите ограничить набор данных перед выполнением подсчета (чтобы ускорить процесс), попробуйте сделать это в подзапросе:
ВЫБЕРИТЕ СЧЕТ(*)
ИЗ (
ВЫБРАТЬ *
ОТ benn.sample_event_table
ПРЕДЕЛ 100
) суб
Примечание. Использование LIMIT резко изменит ваши результаты, поэтому его следует использовать для проверки логики запроса, но не для получения фактических результатов.
В общем, при работе с подзапросами вы должны обязательно ограничить объем данных, с которыми вы работаете, в том месте, где они будут выполняться в первую очередь. Это означает размещение LIMIT в подзапросе, а не во внешнем запросе. Опять же, это делается для того, чтобы запрос выполнялся быстро, чтобы вы могли протестировать — НЕ за хорошие результаты.
Упрощение соединений
В каком-то смысле это продолжение предыдущего совета. Точно так же, как лучше уменьшать данные в точке запроса, который выполняется раньше, лучше уменьшать размеры таблиц перед их объединением. Возьмем этот пример, в котором информация о спортивных командах колледжа объединяется со списком игроков в различных колледжах: player.school_name, COUNT(1) КАК игроков ОТ игроков benn.college_football_players ПРИСОЕДИНЯЙТЕСЬ к командам benn.college_football_teams ON team.school_name = игроки.school_name СГРУППИРОВАТЬ НА 1,2
В benn.college_football_players 26 298 строк. Это означает, что 26 298 строк необходимо оценить на наличие совпадений в другой таблице. Но если бы таблица benn.college_football_players была предварительно агрегирована, вы могли бы уменьшить количество строк, которые необходимо оценить в соединении. Во-первых, давайте посмотрим на агрегацию:
SELECT player.school_name,
COUNT(*) КАК игроков
ОТ игроков benn. college_football_players
СГРУППИРОВАТЬ ПО 1
college_football_players
СГРУППИРОВАТЬ ПО 1
Приведенный выше запрос возвращает 252 результата. Таким образом, удаление этого в подзапросе и последующее присоединение к нему во внешнем запросе существенно снизит стоимость соединения:0005
ВЫБЕРИТЕ команды.конференция,
суб.*
ИЗ (
ВЫБЕРИТЕ player.school_name,
COUNT(*) КАК игроков
ОТ игроков benn.college_football_players
СГРУППИРОВАТЬ ПО 1
) суб
ПРИСОЕДИНЯЙТЕСЬ к командам benn.college_football_teams
ON team.school_name = sub.school_name
В этом конкретном случае вы не заметите огромной разницы, потому что 30 000 строк не так сложно обработать базе данных. Но если бы вы говорили о сотнях тысяч строк или больше, вы бы увидели заметное улучшение за счет агрегирования перед объединением. Когда вы делаете это, убедитесь, что то, что вы делаете, логически последовательно — вы должны беспокоиться о точности своей работы, прежде чем беспокоиться о скорости выполнения.
EXPLAIN
Вы можете добавить EXPLAIN в начале любого (рабочего) запроса, чтобы понять, сколько времени это займет. Это не совсем точный, но полезный инструмент. Попробуйте запустить это:
EXPLAIN ВЫБРАТЬ * ОТ benn.sample_event_table ГДЕ event_date >= '2014-03-01' И event_date < '2014-04-01' ПРЕДЕЛ 100
Вы получите этот вывод. Он называется планом запроса и показывает порядок, в котором будет выполняться ваш запрос:
Запись внизу списка выполняется первой. Таким образом, это показывает, что предложение WHERE , которое ограничивает диапазон дат, будет выполнено первым. Затем база данных просканирует 600 строк (это приблизительное число). Вы можете увидеть стоимость, указанную рядом с количеством строк — чем больше число, тем больше время выполнения. Вы должны использовать это больше как ссылку, чем как абсолютную меру. Чтобы уточнить, это наиболее полезно, если вы запускаете EXPLAIN для запроса, изменяете дорогостоящие шаги, а затем запускаете EXPLAIN еще раз, чтобы увидеть, уменьшилась ли стоимость. Наконец, предложение
Наконец, предложение LIMIT выполняется последним и очень дешевое в исполнении (24,65 против 147,87 для предложения WHERE ).
Для получения более подробной информации ознакомьтесь с документацией Postgres.
Использование SQL Runner для создания запросов и исследований | Looker
SQL Runner предоставляет способ прямого доступа к вашей базе данных и использования этого доступа различными способами. Используя SQL Runner, вы можете легко перемещаться по таблицам в вашей схеме, использовать специальное исследование из SQL-запроса, запускать предварительно написанные описательные запросы к вашим данным, просматривать историю SQL Runner, загружать результаты, обмениваться запросами, добавлять в проект LookML как производную таблицу и выполнять другие полезные задачи.
На этой странице описано, как выполнять запросы в SQL Runner, создавать специальные исследования и как использовать SQL Runner для отладки запросов. Дополнительные сведения см.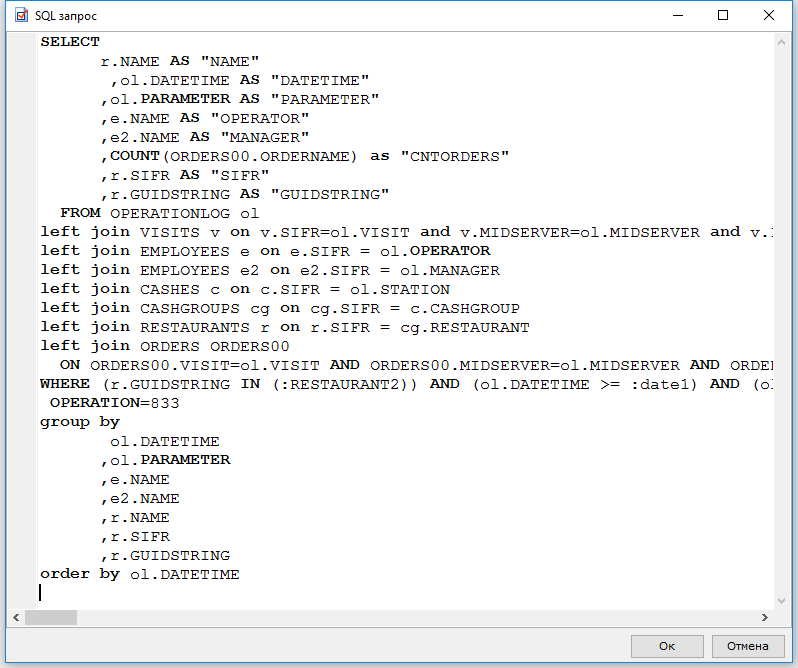 на других страницах документации:
на других страницах документации:
- Основы SQL Runner
- Использование SQL Runner для создания производных таблиц
- Управление функциями базы данных с помощью SQL Runner
Выполнение запросов в SQL Runner
Чтобы выполнить запрос к базе данных, вы можете написать запрос SQL с нуля, использовать Explore для создания запроса или выполнить запрос к модели LookML. Вы также можете использовать историю для повторного выполнения предыдущего запроса.
Написание SQL-запроса с нуля
Вы можете использовать SQL Runner для написания и запуска собственных SQL-запросов к вашей базе данных. Looker передает ваш запрос в вашу базу данных так, как вы его написали, поэтому убедитесь, что синтаксис вашего SQL-запроса действителен для вашего диалекта базы данных. Например, у каждого диалекта есть немного разные функции SQL с определенными параметрами, которые должны быть переданы в функцию.
- Щелкните в области запроса SQL и введите команду SQL.
- При необходимости дважды щелкните имя таблицы или поле в списке полей, чтобы включить его в запрос в месте расположения курсора.
- Нажмите Выполнить , чтобы выполнить запрос к вашей базе данных.
- Просмотрите результаты в области результатов. SQL Runner загрузит до 5000 строк набора результатов запроса. Для диалектов SQL, поддерживающих потоковую передачу, вы можете загрузить результаты, чтобы увидеть весь набор результатов.
Некоторые программы SQL позволяют выполнять несколько запросов подряд. Однако вы можете выполнять только один запрос за раз в SQL Runner. SQL Runner также имеет ограничение в 65 535 символов для запросов, включая пробелы.
Если у вас есть запрос, который вам нравится, вы можете добавить его в проект, получить LookML для производной таблицы или поделиться запросом.
Вы также можете использовать SQL Runner, чтобы поиграть с новыми запросами или протестировать существующие запросы. Подсветка ошибок SQL Runner помогает тестировать и отлаживать запросы.
Подсветка ошибок SQL Runner помогает тестировать и отлаживать запросы.
Использование Исследователя для создания SQL-запроса
Вы также можете использовать Исследователь для создания запроса, а затем получить команду SQL для этого запроса для использования в SQL Runner:
- В Исследовании щелкните вкладку SQL на панели Данные .
- Выберите текст SQL-запроса и скопируйте его в SQL Runner или
- Нажмите Открыть в SQL Runner или Объяснение в SQL Runner , чтобы открыть запрос в SQL Runner.
После добавления запроса в область SQL-запросов SQL Runner можно щелкнуть Run , чтобы запросить базу данных. Кроме того, вы можете отредактировать запрос, а затем запустить новый запрос.
Создание визуализаций с помощью SQL Runner
Если ваш администратор Looker включил функцию SQL Runner Vis Labs, вы можете создавать визуализации непосредственно в SQL Runner.
При включении SQL Runner Vis панели SQL Runner реорганизованы. Панель визуализации отображается вверху, панель результатов — посередине, а панель запросов — внизу.
- После создания и выполнения SQL-запроса вы можете открыть Визуализация , чтобы просмотреть визуализацию и выбрать тип визуализации, как на странице Исследовать.
- Вы можете редактировать визуализацию с помощью меню Настройки .
- Вы можете поделиться визуализациями, созданными с помощью SQL Runner, поделившись URL-адресом. Любые настройки, сделанные с помощью меню настроек визуализации, будут сохранены, а ссылка не изменится.
При работе с визуализацией SQL Runner следует помнить о некоторых вещах:
- Таблица результатов и визуализация интерпретируют любое числовое поле как меру.
- Полное имя поля всегда используется в таблице результатов и визуализации. Поэтому параметр Показать полное имя поля в меню Настройки неактивен.

- Чтобы использовать настраиваемые поля, табличные вычисления, сводные данные, итоги по столбцам и промежуточные итоги, изучите запрос SQL Runner.
- Визуализации статической карты (регионов) не поддерживаются визуализациями SQL Runner, однако поддерживаются карты, использующие данные широты и долготы (карта и статическая карта (точки) визуализации).
- Визуализации временной шкалы не поддерживаются визуализациями SQL Runner.
Сводные измерения
Вы можете отредактировать результаты запроса, чтобы свести их по одному или нескольким измерениям в визуализациях SQL Runner. Чтобы повернуть поле:
- Щелкните значок шестеренки столбца в области Результаты , чтобы открыть параметры столбца.
- Нажмите Сводная колонка .
Сводные результаты отображаются в визуализации SQL Runner:
Результаты в области Results не отображаются сводными.

Чтобы развернуть результатов, нажмите на значок шестеренки сводного столбца и выберите Развернуть столбец :
Изменение типа поля
любое нечисловое поле в качестве измерения. Вы можете переопределить тип поля по умолчанию и преобразовать измерение в меру или наоборот:
- Щелкните значок шестеренки столбца в области Результаты , чтобы открыть параметры столбца.
- Нажмите Преобразовать в измерение или Преобразовать в меру , чтобы изменить тип поля.
В визуализации будет отображаться новый тип поля:
Выполнение запроса к модели LookML
Вы можете использовать SQL Runner для написания и выполнения запросов SQL к модели LookML, а не непосредственно к базе данных. При построении запроса к модели вы можете использовать операторы замены LookML, такие как ${view_name. или 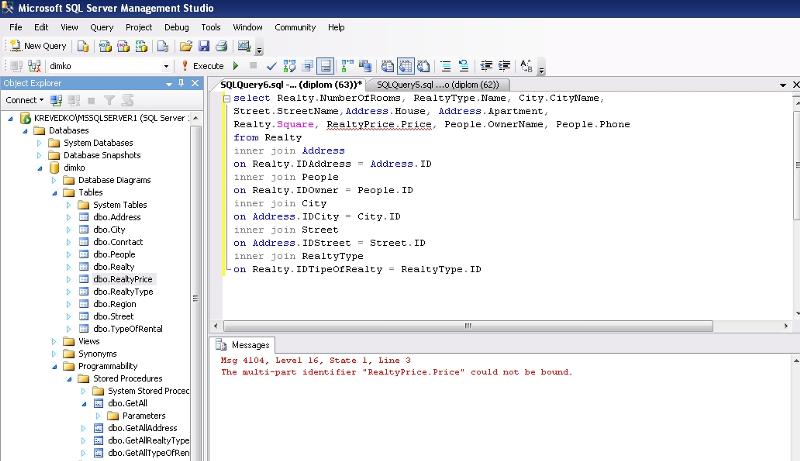 field_name}
field_name} ${view_name.SQL_TABLE_NAME} . Это может сэкономить время при построении запроса, например, для устранения неполадок в производной таблице.
Looker разрешает любые замены LookML, а затем передает ваш запрос в вашу базу данных, поэтому запрос должен быть в допустимом SQL для вашего диалекта базы данных. Например, у каждого диалекта есть немного разные функции SQL с определенными параметрами, которые должны быть переданы в функцию.
Чтобы выполнить запрос к вашей модели LookML в SQL Runner:
- Перейдите на вкладку Модель .
- Выберите модель, которую вы хотите запросить.
- Щелкните в области запроса SQL и введите запрос SQL, используя поля LookML.
- При необходимости дважды щелкните представление в списке представлений, чтобы включить представление в запрос в том месте, где находится курсор.
- Чтобы просмотреть список полей в представлении, щелкните представление в разделе Представления .
 При желании вы можете дважды щелкнуть поле в списке полей, чтобы включить его в свой запрос в том месте, где находится курсор.
При желании вы можете дважды щелкнуть поле в списке полей, чтобы включить его в свой запрос в том месте, где находится курсор. - В области Подготовленный SQL-запрос можно просмотреть результирующий SQL-запрос, созданный после преобразования любых замен LookML в SQL.
- Нажмите Выполнить , чтобы запустить запрос для вашей модели.
- Просмотрите результаты в области Результаты . SQL Runner загружает до 5000 строк набора результатов запроса. Для диалектов SQL, поддерживающих потоковую передачу, вы можете загрузить результаты, чтобы увидеть весь набор результатов.
Если у вас есть запрос, который вам нравится, вы можете добавить его в проект, получить LookML для производной таблицы или поделиться запросом.
Вы также можете использовать SQL Runner, чтобы играть с новыми запросами, тестировать существующие запросы или открывать новое исследование из результатов. Подсветка ошибок SQL Runner помогает тестировать и отлаживать запросы.
Просмотр LookML поля из SQL Runner
Из списка полей на вкладке Model можно также просмотреть LookML для поля. Наведите указатель мыши на поле в списке полей и щелкните значок Looker справа от имени поля:
Looker открывает IDE LookML и загружает файл, в котором определено поле.
История SQL Runner
Вы также можете просмотреть недавнюю историю всех запросов, которые вы выполняли в SQL Runner.
Чтобы просмотреть историю, щелкните вкладку История в верхней части панели навигации. SQL Runner отображает все запросы, выполняемые при подключении к базе данных. Красный цвет означает, что запрос не был выполнен из-за ошибки.
Щелкните запрос в истории, чтобы заполнить этот запрос в SQL Runner, затем щелкните Выполнить , чтобы повторно запустить запрос:
Сортировка запроса
Порядок сортировки в таблице указывается стрелкой вверх или вниз рядом с именем отсортированного поля, в зависимости от того, в каком порядке находятся результаты: по возрастанию или по убыванию. Вы можете сортировать по нескольким столбцам, удерживая нажатой клавишу Shift, а затем щелкая заголовки столбцов в том порядке, в котором вы хотите их отсортировать. Порядок сортировки поля также обозначается числом, которое отличает его порядок сортировки по сравнению с другими полями, стрелкой рядом с именем поля, показывающей направление сортировки (по возрастанию или убыванию), и всплывающим окном, которое появляется при наведении курсора на имя поля.
Вы можете сортировать по нескольким столбцам, удерживая нажатой клавишу Shift, а затем щелкая заголовки столбцов в том порядке, в котором вы хотите их отсортировать. Порядок сортировки поля также обозначается числом, которое отличает его порядок сортировки по сравнению с другими полями, стрелкой рядом с именем поля, показывающей направление сортировки (по возрастанию или убыванию), и всплывающим окном, которое появляется при наведении курсора на имя поля.
Дополнительные сведения и примеры см. в разделе «Сортировка данных» на странице документации Изучение данных в Looker .
Совместное использование запросов
Вы можете поделиться запросом в SQL Runner с другим пользователем с доступом к SQL Runner. Чтобы поделиться запросом, просто скопируйте URL-адрес в адресную строку:
Загрузка результатов
После выполнения SQL-запроса вы можете загрузить результаты в различных форматах.
- Напишите запрос в Блок запроса SQL . (На данный момент вам не нужно запускать запрос в SQL Runner.)
- Выберите Загрузить из меню шестеренки в правом верхнем углу.
- Выберите формат загружаемого файла (текстовый файл, CSV, JSON и т. д.).
Щелкните Открыть в браузере , чтобы просмотреть результаты в новом окне браузера, или щелкните Загрузить , чтобы загрузить результаты в файл на свой компьютер.
Когда вы нажимаете Открыть в браузере или Download , Looker повторно запустит запрос, а затем выполнит загрузку.
Для диалектов SQL, поддерживающих потоковую передачу, параметр SQL Runner Download загрузит весь набор результатов. Для диалектов SQL, не поддерживающих потоковую передачу, параметр SQL Runner Загрузить загрузит только те строки запроса, которые показаны в разделе Результаты (до 5000 строк).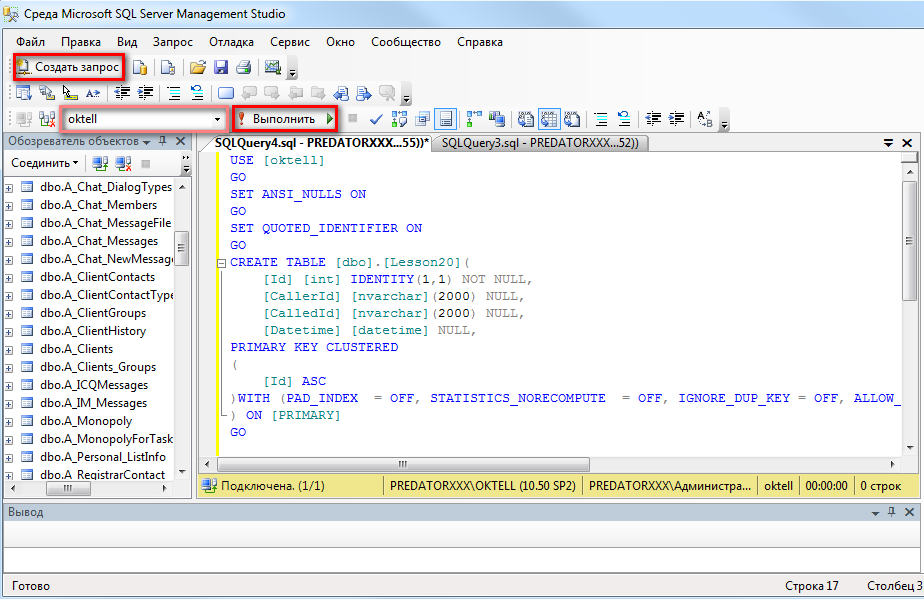
Копирование значений столбцов
Вы можете копировать значения столбцов из Раздел результатов в SQL Runner. Щелкните меню шестеренки столбца, чтобы скопировать значения в буфер обмена. Оттуда вы можете вставить значения столбца в текстовый файл, документ Excel или другое место.
Если ваш администратор Looker включил функцию SQL Runner Vis Labs, у вас также есть другие параметры в меню шестеренки столбца:
- Заморозить и разморозить
- Авторазмер всех столбцов
- Сбросить ширину всех столбцов
Вы также можете вручную перемещать, закреплять и изменять размер столбцов в таблице результатов.
Оценка стоимости запросов SQL Runner
Для подключений BigQuery, MySQL, Amazon RDS для MySQL, Snowflake, Amazon Redshift, Amazon Aurora, PostgreSQL, Cloud SQL для PostgreSQL и Microsoft Azure PostgreSQL SQL Runner предоставляет оценку стоимости запрос.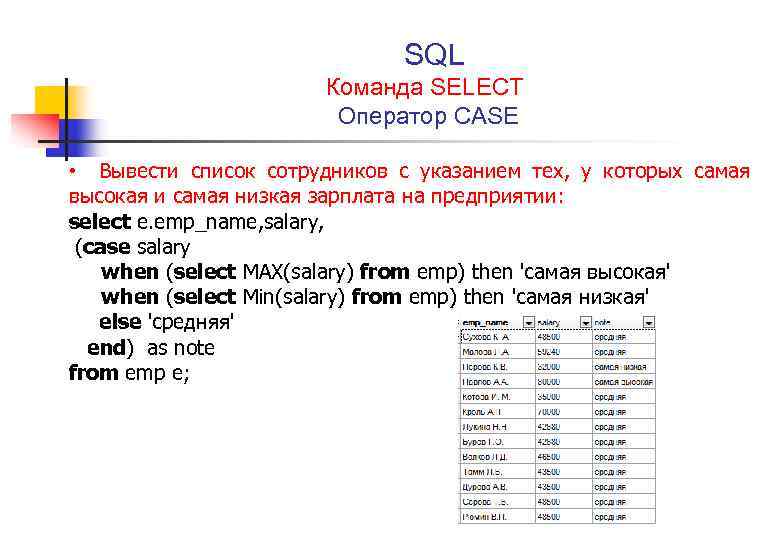 После того, как вы введете SQL-запрос, SQL Runner рассчитает объем данных, которые потребуются для запроса, и отобразит информацию рядом с кнопкой Run .
После того, как вы введете SQL-запрос, SQL Runner рассчитает объем данных, которые потребуются для запроса, и отобразит информацию рядом с кнопкой Run .
Для подключений BigQuery, MySQL и Amazon RDS для MySQL оценка затрат всегда включена. Для подключений к базам данных Snowflake, Amazon Redshift, Amazon Aurora, PostgreSQL, Cloud SQL для PostgreSQL и Microsoft Azure PostgreSQL необходимо включить Оценка стоимости вариант подключения. Вы можете включить Cost Estimate при создании соединения. Для существующих подключений вы можете редактировать подключение на странице Connections в разделе Database панели Looker Admin .
Создание специального исследования
С помощью SQL Runner вы можете быстро получить представление о данных, создав специальное исследование для SQL-запроса или таблицы базы данных.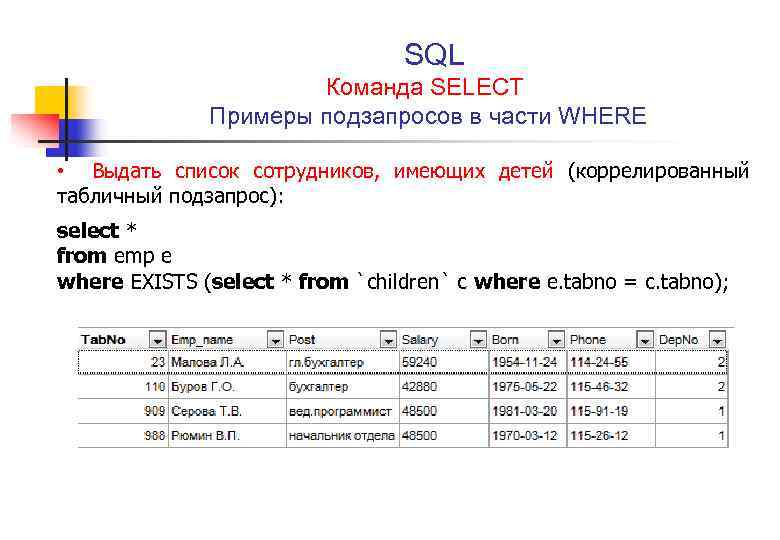 Вы можете использовать Looker Explore для выбора полей, добавления фильтров, визуализации результатов и создания SQL-запросов.
Вы можете использовать Looker Explore для выбора полей, добавления фильтров, визуализации результатов и создания SQL-запросов.
Существует два способа открыть специальное исследование из SQL Runner:
- Исследование из результатов запроса SQL Runner
- Исследование из списка таблиц SQL Runner
Исследование из результатов запроса SQL Runner
SQL Runner позволяет открыть исследование из запроса SQL. Это создает временное исследование из запроса, написанного в SQL Runner. Это позволяет проверить, что возвращает запрос, а также визуализировать результаты. Это можно использовать для любого запроса, но особенно полезно для тестирования запросов, которые вы планируете использовать для производных таблиц.
Если ваш администратор Looker включил функцию SQL Runner Vis Labs, вы можете создавать визуализации непосредственно в SQL Runner.
- Используйте SQL Runner для создания SQL-запроса, который вы хотите использовать.

- Нажмите Исследовать в меню шестеренки в правом верхнем углу. Это приведет вас к новому исследованию, где вы сможете исследовать SQL-запрос, как если бы это была сохраненная таблица в вашей модели.
- Вы можете скопировать URL-адрес этого обзора для совместного использования.
- Чтобы добавить этот запрос как производную таблицу в свой проект прямо отсюда, нажмите Добавить представление в проект .
Создание настраиваемых полей при изучении в SQL Runner
Если у вас есть доступ к функции настраиваемых полей, вы можете использовать настраиваемые поля для визуализации несмоделированных полей в SQL Runner. Как описано в предыдущем разделе, щелкните Explore в меню шестеренки. Затем в поле выбора:
- Щелкните раздел Custom Fields , чтобы открыть его, а затем щелкните Добавьте , чтобы начать создание пользовательского параметра, пользовательской меры или табличного вычисления.
 (Если у вас нет раздела Custom Fields , то у вас нет доступа для создания настраиваемых полей.)
(Если у вас нет раздела Custom Fields , то у вас нет доступа для создания настраиваемых полей.) - Щелкните трехточечное меню меры Options ](/exploring-data/exploring-data#three-dot_options_menu и выберите Filter Measure , чтобы создать отфильтрованную пользовательскую меру из существующей меры.
- Щелкните трехточечное меню измерения Параметры и выберите тип меры (например, сумма или количество), чтобы создать пользовательскую меру из измерения.
Изучение таблицы, указанной в SQL Runner
Используйте параметр Исследовать таблицу на вкладке База данных , чтобы создать нерегламентированное исследование для любой таблицы в соединении. Это позволяет вам использовать Looker для таблицы до того, как вы ее смоделировали, исследуя таблицу точно так же, как представление LookML.
После того, как вы откроете окно просмотра для таблицы, вы сможете решить, добавлять ли эту таблицу в свой проект. Вы также можете использовать вкладку Explorer SQL , чтобы просмотреть SQL-запросы, которые Looker отправляет в базу данных, а затем использовать Кнопка "Открыть в SQL Runner" , чтобы вернуть запрос обратно в SQL Runner.
Вы также можете использовать вкладку Explorer SQL , чтобы просмотреть SQL-запросы, которые Looker отправляет в базу данных, а затем использовать Кнопка "Открыть в SQL Runner" , чтобы вернуть запрос обратно в SQL Runner.
- Перейдите на вкладку База данных .
- В SQL Runner щелкните шестеренку для таблицы и выберите Исследовать таблицу .
- Looker создает временную модель с представлением для таблицы, а затем отображает файл Explore.
- Looker предоставляет поле измерения для каждого столбца в таблице. (Таким же образом Looker создает модель в начале проекта.)
- Looker автоматически включает временные рамки для любых полей даты.
- Looker также включает меру подсчета.
При использовании опции Explore Table файл LookML не связан с Explore — это просто специальное представление таблицы.
Отладка с помощью SQL Runner
SQL Runner также является полезным инструментом для проверки ошибок SQL в запросах.
Выделение ошибок SQL Runner
SQL Runner выделяет расположение ошибок в команде SQL и включает положение ошибки в сообщение об ошибке:
Предоставляемая информация о местоположении зависит от диалекта базы данных. Например, MySQL предоставляет номер строки, содержащей ошибку, а Redshift предоставляет позицию символа ошибки. Другие диалекты базы данных могут иметь один из этих или других вариантов поведения.
SQL Runner также выделяет расположение первой синтаксической ошибки в команде SQL, подчеркивая ее красным цветом и помечая строку знаком «x». Наведите указатель мыши на «x», чтобы просмотреть дополнительную информацию об ошибке. После устранения этой проблемы нажмите Запустите , чтобы проверить, есть ли еще ошибки в запросе.
Использование SQL Runner для проверки ошибок в Explorer
Если вы столкнулись с синтаксическими ошибками SQL в Explore, вы можете использовать SQL Runner, чтобы определить место ошибки и тип ошибки, например орфографические ошибки или отсутствующие команды.