/UTF-8 (установка исходных и исполняемых наборов символов в UTF-8 )
- Чтение занимает 2 мин
В этой статье
Задает как исходную кодировку, так и кодировку выполнения в виде UTF-8 .Specifies both the source character set and the execution character set as UTF-8.
СинтаксисSyntax
/utf-8
RemarksRemarks
С /utf-8 помощью параметра можно указать как кодировку исходного кода, так и кодировку выполнения, используя UTF-8 .You can use the /utf-8 option to specify both the source and execution character sets as encoded by using UTF-8. Он эквивалентен указанию /source-charset:utf-8 /execution-charset:utf-8/source-charset:utf-8 /execution-charset:utf-8 on the command line. Любой из этих параметров также включает /validate-charset параметр по умолчанию.Any of these options also enables the /validate-charset option by default. Список поддерживаемых идентификаторов кодовых страниц и имен наборов символов см. в разделе идентификаторы кодовых страниц.For a list of supported code page identifiers and character set names, see Code Page Identifiers.
По умолчанию Visual Studio обнаруживает метку порядка следования байтов, чтобы определить, имеет ли исходный файл формат в кодировке Юникод, например UTF-16 или UTF-8 .By default, Visual Studio detects a byte-order mark to determine if the source file is in an encoded Unicode format, for example, UTF-16 or UTF-8.
/utf-8 или /source-charset параметра.If no byte-order mark is found, it assumes the source file is encoded using the current user code page, unless you’ve specified a code page by using /utf-8 or the /source-charset option. Visual Studio позволяет сохранить исходный код C++ с помощью любой из нескольких кодировок символов.Visual Studio allows you to save your C++ source code by using any of several character encodings. Сведения о кодировках исходного кода и выполнения см. в разделе наборы символов в документации по языку.For information about source and execution character sets, see Character Sets in the language documentation.Установка параметра в Visual Studio или программным способомSet the option in Visual Studio or programmatically
Установка данного параметра компилятора в среде разработки Visual StudioTo set this compiler option in the Visual Studio development environment
Откройте диалоговое окно Окна свойств проекта.Open the project Property Pages dialog box. Подробнее см. в статье Настройка компилятора C++ и свойств сборки в Visual Studio.For more information, see Set C++ compiler and build properties in Visual Studio.
Выберите страницу свойств Свойства конфигурации > C/C++ > Командная строка .Select the Configuration Properties > C/C++ > Command Line property page.
В окне Дополнительные параметры добавьте
/utf-8параметр, чтобы указать предпочтительную кодировку.In Additional Options, add the/utf-8option to specify your preferred encoding.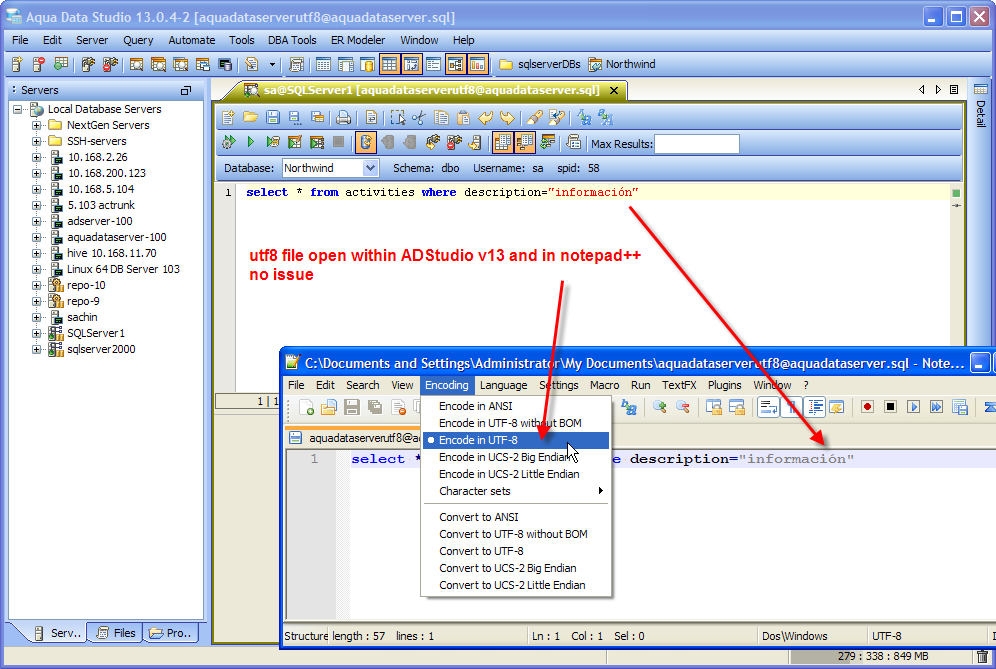
Выберите ОК для сохранения внесенных изменений.Choose OK to save your changes.
Установка данного параметра компилятора программным способомTo set this compiler option programmatically
См. также разделSee also
Параметры компилятора MSVCMSVC Compiler Options
Синтаксис Command-Line компилятора КОМПИЛЯТОРОМ MSVCMSVC Compiler Command-Line Syntax
/Execution-charset (Задание кодировки выполнения)/execution-charset (Set Execution Character Set)
указаны кодировки/Source-charset (задание исходной кодировки)/source-charset (Set Source Character Set)
/validate-charset (проверка совместимости символов)/validate-charset (Validate for compatible characters)
Как сохранить файл в кодировке UTF-8. Как браузер определяет кодировку?
Задача:
1. У нас есть файл: file-01.html.2. Надо сохранить его в кодировке -> UTF-8. Решение 1.
- Открываеем file-01.html в текстовом редакторе Блокнот.
- Выбикаем «Сохранить как…».
- Выбираем кодировку UTF-8.
- Жмем кнопку — Сохранить.
- Открываем file-01.html в текстовом редакторе Notepad++
- Меню -> Кодировки.
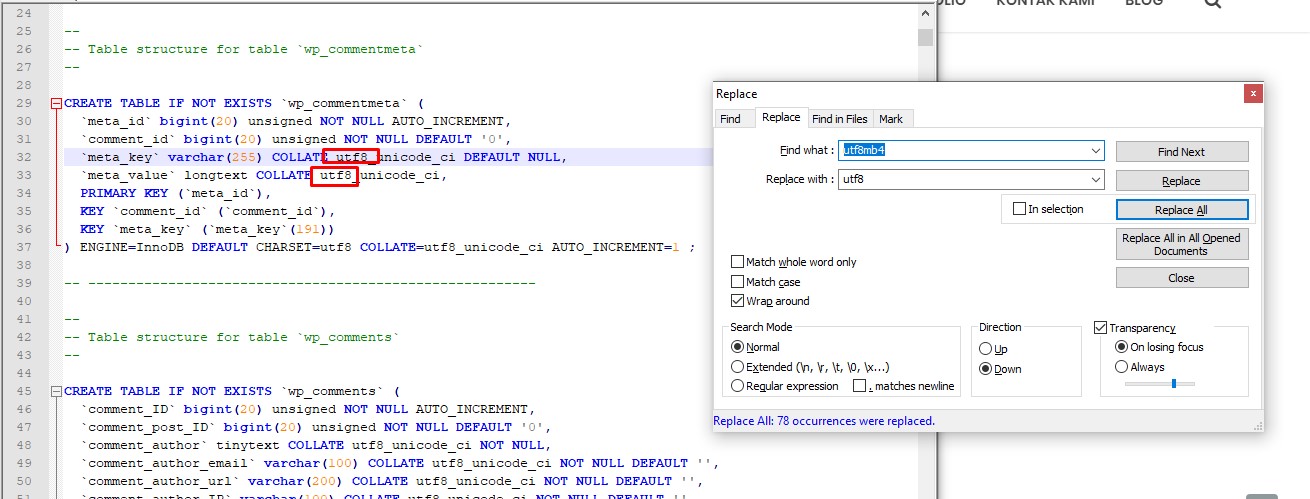
Здесь видим, что Notepad++ определяет сам известную кодировку открытого файла. - Выбираем Преобразовать в UTF-8 .
(Кодироака «UTF-8» отличается от «UTF-8 c BOM» тем, что требует строгого указания кодировки в самом тексте файла). - Меню -> Файл -> Сохранить (не забывать).
Как браузер определяет кодировку?
Мы сами сообщаем браузеру о том, какая кодировка установлена для данного HTML файла.Делается это посредством META-тега и атрибут charset
1) <meta charset="utf-8">
2) <meta charset="windows-1251">
3) <meta Content-Type: text/html; charset=koi8-r>Атрибут charset указывает браузеру в какой кодировке отображать страницу сайта.

Важно!
При перекодировке файлов не забывать изменять директивы в META-теге на актуальные.
Если в META-теге указана одна кодировка, а файл сохранен в другой кодировке, то на экране мы увидем
«абракадабру». Браузер в первую очередь открывает страницу в кодировке указанной в META-теге на странице.
4) В случае
Если в META-теге указана нужная кодировка, а сайт все равно отображает
«абракадабру», то нужно проверить настройку сайта на хостинге (веб-сервере).
Обычно на хостингне в
настройках сайта указана кодировка utf-8.
Если в настройках хостинга указана кодировка windows-1251, то нужно сменить настройку на utf-8.
Настройка charset информации в .htaccess
Многие серверы Apache настроены, чтобы отправлять файлы с использованием кодировки ISO-8859-1 (Latin-1). В примерах в этом документе, мы будем считать, что вы хотите обслуживать ваш файл или файлы, используя другие кодировки, нежели указано в конфигурации по умолчанию. (Для получения консультации по выбору кодирования смотрите Выбор и применение кодирования.)
Ниже приведен пример HTTP заголовка, который сопровождает присланный к клиентскому приложению файл. В этом случае информация о кодировке символов содержится в заголовке Content-Type во второй строке снизу.
HTTP/1.1 200 OK Date: Wed, 05 Nov 2003 10:46:04 GMT Server: Apache/1.3.28 (Unix) PHP/4.2.3 Content-Location: CSS2-REC.en.html Vary: negotiate,accept-language,accept-charset TCN: choice P3P: policyref=http://www.w3.org/2001/05/P3P/p3p.xml Cache-Control: max-age=21600 Expires: Wed, 05 Nov 2003 16:46:04 GMT Last-Modified: Tue, 12 May 1998 22:18:49 GMT ETag: "3558cac9;36f99e2b" Accept-Ranges: bytes Content-Length: 10734 Connection: close Content-Type: text/html; charset=utf-8 Content-Language: en
В примере заголовок Content-Type выражает как MIME тип файла так и кодировку символов. MIME тип описывает
формат файла, что обслуживался. HTML файлы, как правило, обслуживаются, как text/html. Кодировка символов (или ‘charset’)
этого файла — UTF-8.
MIME тип описывает
формат файла, что обслуживался. HTML файлы, как правило, обслуживаются, как text/html. Кодировка символов (или ‘charset’)
этого файла — UTF-8.
Чтобы узнать, как просмотреть HTTP заголовок файла смотрите статью Проверка HTTP Заголовков.
Файлы на сервере Apache могут обслуживаться с кодировкой символов по умолчанию в HTTP заголовке, что конфликтует с фактическим кодированием файла. Кодировка символов, отправляемая сервером может быть новой кодировкой по умолчанию, установленной по умолчанию администратором сервера, либо результатом выполнения различных директив Apache. В других случаях никакую информацию о кодировке символов сервер не отправляет, когда она действительно необходима.
Если сервер настроен так, что позволяет пользователям или администраторам изменять информацию в .htaccess файлах, это может обеспечить способ переопределить настройки по умолчанию. Этот раздел показывает вам, как это сделать.
Имейте в виду, что есть несколько различных сценариев. В первую очередь, вы возможно захотите изменить в директории значения по умолчанию для всех файлов с одинаковым расширением. Кроме того, вы возможно захотите изменить значение по умолчанию для одного файла или небольшого числа файлов. Мы исследуем это по очереди.
В наших примерах мы будем считать, что сервер по умолчанию настроен обслуживать файлы в кодировке ISO-8859-1, но вы хотите, чтобы он обслуживал ваш файл или файлы используя кодировку UTF-8 (очень умная стратегия!).
Этот ответ вам подходит?
Эта статья написана для авторов контента, а не для системных администраторов. Настройки кодирования сервера по умолчанию выходят за рамки данной статьи.
Этот совет подходит только тогда, когда вы согласны назначить кодировку символов документа с помощью HTTP заголовка. В некоторых случаях вы можете этого не захотеть.
Заметим, что эти FAQ (часто задаваемые вопросы) также предполагают, что ваш сервер настроен на использование .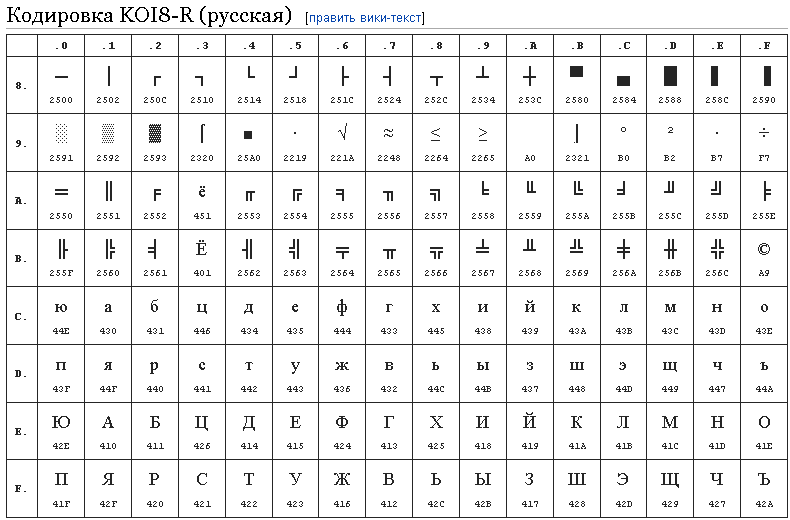 htaccess файлов, и, что директивы, описанные ниже работают в .htaccess файлах на вашем сервере. Предполагается также, что не
достаточно просто изменить настройки по умолчанию на сервере. Если вы не уверены, обратитесь к администратору сервера.
htaccess файлов, и, что директивы, описанные ниже работают в .htaccess файлах на вашем сервере. Предполагается также, что не
достаточно просто изменить настройки по умолчанию на сервере. Если вы не уверены, обратитесь к администратору сервера.
Вы также должны знать о конвенции, которые используются на сервере для объединения информации о кодировке символов с расширениями. В некоторых случаях сервер может быть настроен в ожидании того, что кодировки символов определены специфическими расширениями кодирования, например example.html.utf8 где .utf8 то, что должно быть связано с кодировкой символов, а не .html (о, что может быть связано с типом файла).
Если такие подходы потерпят неудачу, то вы должны пересмотреть руководства Apache (смотрите приложенные ссылки) или обратиться к администратору вашего сервера.
Спецификация по расширению
Используйте директиву AddCharset чтобы связать кодирование символов со всеми файлами, которые имеют определенное расширение в текущем каталоге и его подкаталогах. Например, чтобы обслуживать все файлы с расширением .html как UTF-8, откройте .htaccess файл в текстовом редакторе и введите следующую строку:
Расширение может быть указано с или без начальной точки. Вы можете добавить несколько расширений к одной и той же строке. Это все равно будет работать, если вы имеете такие названия файлов, как example.en.html или example.html.en.
Пример заставит все файлы с расширением .html обслуживаться как UTF-8. Заголовок HTTP Content-Type будет содержать строку, которая заканчивается ‘charset’ информацией, как показано в следующем примере.
Content-Type: text/html; charset=UTF-8
Примечание: Все файлы с таким расширением во всех подкаталогах текущего местоположения будут также обслуживаться как UTF-8. Если,
по некоторым причинам, вы должны обслужить определенный файл с другим кодированием, то вам необходимо переназначить его, используя дополнительные директивы.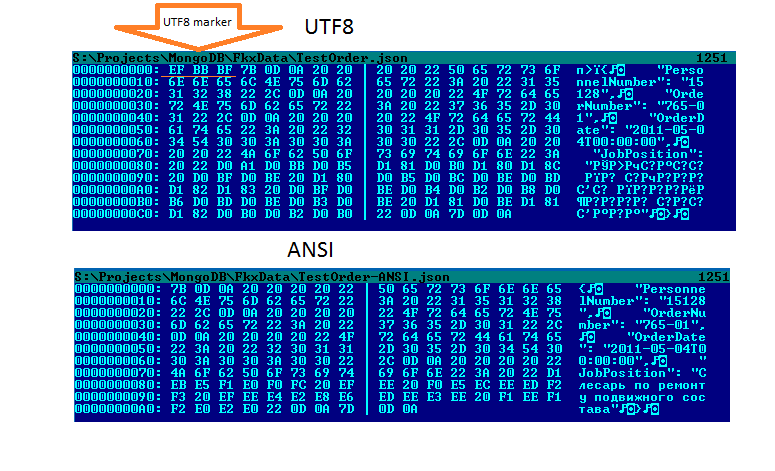
Примечание: Вы можете связать кодировку с любым расширением, которое прилагается к вашему файлу. Предположим, что вы сделали перевод на другой язык и вы имеете страницы на двух языках, что выглядят следующим образом example.en.html и example.ja.html. Давайте также предположим, что вам удобно обслуживать Английские страницы используя кодирование ISO-8859-1 вашего сервера по умолчанию, но вы хотите обслуживать Японские файлы в UTF-8. Чтобы это сделать, вы можете связать кодировку символов с расширением языка, как показано в следующем примере:
Однако, примите к сведению, если вы можете, то лучшим решением будет изменить настройки сервера по умолчанию на UTF-8, или обслуживать все файлы в новых каталогах как UTF-8.
Примечание: Для достижения того же результата можно использовать директиву AddType, хотя это одновременно назначает как кодировку символов так и MIME тип. Решение о том, что является наиболее подходящим, частично будет зависеть от того, как вы используете расширение для обсуждения контента. Менее вероятно, что это будет уместно, если вы используете различные расширения для выражения типа документа и кодировки символов.
AddType 'text/html; charset=UTF-8' html
Изменение случайного файла
Давайте теперь предположим, что вы хотите обслуживать только один файл как UTF-8 в большом каталоге, где все остальные старые файлы правильно обслуживаются как ISO-8859-1. Файл, который вы хотите обслуживать как UTF-8 имеет название example.html. Откройте .htaccess файл в текстовом редакторе и введите следующее:
<Files "example.html"> AddCharset UTF-8 .html </Files>
То, что мы сделали здесь, повернуло директиву, о которой говорилось в предыдущей главе в некоторую разметку, которая идентифицирует конкретный файл с которым мы имеем дело. Если вам необходимо, то
существует также несколько иной синтаксис, который позволяет указать несколько имен файлов при помощи регулярных выражений.
Если вам необходимо, то
существует также несколько иной синтаксис, который позволяет указать несколько имен файлов при помощи регулярных выражений.
Примечание: Возможно также достичь того же результата, используя показанную выше директиву AddType, или, в данном случае, директиву ForceType , хотя она одновременно назначает, как кодировку символов так и MIME тип.
<Files "example.html"> ForceType 'text/html; charset=UTF-8' </Files>
Примечание: Любые файлы с одинаковым названием в подкаталоге текущего местоположения будут также обслуживаться как UTF-8, разве что вы создадите противоположную директиву в соответствующем каталоге.
Более комплексные сценарии
Когда два правила расширение применяется к одному и тому же документу важным является порядок расположения расширений. Так, как в следующем примере
AddCharset UTF-8 .utf8 AddCharset windows-1252 .html
файл ‘example.utf8.html’ будет обслуживаться как «windows-1252» и ‘example.html.utf8’ как UTF-8.
Кодирование и декодирование / Хабр
Причиной разобраться в том, как же работает UTF-8 и что такое Юникод заставил тот факт, что VBScript не имеет встроенных функций работы с UTF-8. А так как ничего рабочего не нашел, то пришлось писть/дописывать самому. Опыт на мой взгляд полезный в любом случае. Для лучшего понимания начну с теории.О Юникоде
До появления Юникода широко использовались 8-битные кодировки, главные минусы которых очевидны:
- Всего 255 символов, да и то часть из них не графические;
- Возможность открыть документ не с той кодировкой, в которой он был создан;
- Шрифты необходимо создавать для каждой кодировки.
Так и было решено создать единый стандарт «широкой» кодировки, которая включала бы все символы (при чем сначала хотели в нее включить только обычные символы, но потом передумали и начали добавлять и экзотические).
 Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.О UTF-8
Когда-то я думал что есть Юникод, а есть UTF-8. Позже я узнал, что ошибался.
UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII. Символы же с кодами от 128 кодируются 2-мя байтами, с кодами от 2048 — 3-мя, от 65536 — 4-мя. Так можно было бы и до 6-ти байт дойти, но кодировать ими уже ничего.
0x00000000 — 0x0000007F: 0xxxxxxx 0x00000080 — 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 — 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 — 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Кодируем в UTF-8
Порядок действий примерно такой:
- Каждый символ превращаем в Юникод.
- Проверяем из какого символ диапазона.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h50
b2 = (c - b1) / &h50
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h50
b2 = ((c - b1) / &h50) Mod &h50
b3 = (c - b1 - (&h50 * b2)) / &h2000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < 0 Then
ToLong = CLng(intVal) + &h20000
Else
ToLong = CLng(intVal)
End If
End Function
Декодируем UTF-8
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.

- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Юникода.
Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h4F
b2 = c and &h2F
c = b1 + b2 * &h50
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h4F
b2 = asc(mid(s,i+1,1)) and &h4F
b3 = c and &h0F
c = b3 * &h2000 + b2 * &h50 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function
Ссылки
Юникод на Википедии
Исходник для ASP+VBScript
UPD: Обработка ошибочных последовательностей и ошибка с типом Integer, который возвращает AscW.
Инструкция по переходу на UTF-8
Вычислительная
система кафедры перешла на использование многобайтовой кодировки UTF-8
для файловых систем и пользовательского окружения вместо однобайтовой
кодировки KOI8-R. В данной инструкции рассматриваются типичные
проблемы, которые могли возникнуть у пользователей в связи с данным
переходом и предлагаются способы их решения (изменения настроек,
команды и т.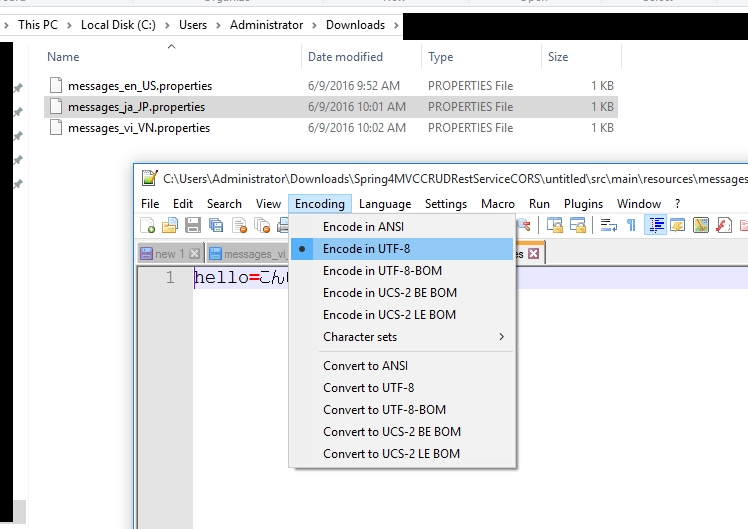 п.).
п.).
Основные понятия
Юнико́д, или Унико́д (англ. Unicode™) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.
UTF-8 (от англ. Unicode Transformation Format — формат преобразования Юникода) — кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста.
Важно понимать, что один символ в кодировке UTF-8 может быть представлен более чем одним байтом. С этим связано, например, то, что файл, содержащий текст в кодировке UTF-8 будет иметь больший размер по сравнению с файлом, содержащим тот-же текст в кодировке KOI8-R.
Пример: команда wc имеет ключ -c для подсчета байтов и ключ -m для подсчета символов.
$ echo -n "Слово." | wc -c 11 $ echo -n "Слово." | wc -m 6
Имена файлов
Имена файлов были перекодированы автоматически с помощью утилиты convmv:
convmv -r -f koi8-r -t utf-8 --notest <каталог>
Каждому пользователю, в домашнем каталоге которого утилита convmv переименовала хотя бы один файл, был автоматически выслан журнал переименований.
При необходимости можно выполнить обратное преобразование:
convmv -r -f utf-8 -t koi8-r <файлы и каталоги>
После проверки вывода команды повторить с ключем —notest. Ключ -r включает рекурсивный обход каталогов.
Содержимое файлов
Для того, чтобы преобразовать содержимое файлов из кодировки KOI8-R в кодировку UTF-8 можно воспользоваться командой:
recode koi8-r..utf-8 <filename>
Для потокового перекодирования используется команда:
iconv -f koi8-r <filename>
Редактор Emacs может автоматически распознать кодировку текста при открытии файла. Принудительно задать кодировку открытия или сохранения файла в редакторе Emacs можно следующим образом:
- Ввести комбинацию клавиш
C-x RET c. - Внизу экрана будет запрошена кодировка, которую вы хотите применить для следующей команды.
- Введите команду, которая будет выполнена с применением введенной на предыдущем шаге кодировки, например:
- комбинацию клавиш для открытия файла:
C-x C-f; - комбинацию клавиш для сохранения файла:
C-x C-s.
- комбинацию клавиш для открытия файла:
Приложения
Текстовый терминал из Windows
Для корректного отображения русского текста при входе на серверы кафедры с помощью терминального клиента PuTTY нужно указать в настройках:
- Раздел Window/Translation
- Character set translation on recieved data: UTF-8
Текстовый терминал из Linux
Если системная локаль не UTF-8, то необходимо запустить X-терминал с поддержкой UTF-8 и выполнить вход по ssh из него.
Если системная локаль UTF-8, то никаких дополнительных действий предпринимать не надо.
Если по какой-то причине при входе по ssh не установились правильно переменные окружения локали (вывод команды locale не содержит строки LANG=ru_RU.UTF-8), то необходимо выполнить команду:
export LANG=ru_RU.UTF-8
WinSCP
Для корректного отображения русских имен файлов:
- Раздел Environment
- UTF-8 encoding for filenames: On
TEX
- После выполнения перекодировки содержимого tex-файла (см. Содержимое файлов) необходимо сменить кодировку в преамбуле:
Было:
\usepackage[koi8-r]{inputenc}
Стало:
\usepackage[utf8x]{inputenc}
- Также необходимо подключить пакет ucs:
\usepackage{ucs}
- Для установки диакритических знаков (ударений) нужно использовать полную форму стандартной записи \’, т.е.:
Б\'{о}льшую
Bibtex
Bib-файлы, содержащие описание литературы, хранятся в кодировке KOI8-R. После выполнения команды bibtex
необходимо сначала перекодировать получившийся bbl-файл в кодировку
UTF-8 (см. Содержимое файлов), а затем выполнять трансляцию
tex-файлов, подключающих этот список литературы.
Как изменить кодировку сайта – База знаний Timeweb Community
Иногда возникают случаи, когда при открытии сайта отображается не привычный нам контент, а сплошной набор нечитаемых символов. Это связано с тем, что кодировка ресурса не совпадает с той кодировкой, которая устанавливается сервером. Например, для чтения файлов используется Windows-1251, а требуется UTF-8.
Что такое кодировка сайта и как ее можно изменить – об этом и поговорим в сегодняшней статье.
Что такое кодировкаКодировка – специальный метод, позволяющий отображать текст на экране таким образом, чтобы он был понятен каждому пользователю. Все символы, которые мы видим в интернете, – это буквы и цифры только для нас, компьютер их не понимает. Он воспринимает информацию в байтах, весь текст на экране монитора – это совокупность байтов. У каждого символа есть свое кодовое значение, которое компьютер использует при выводе слов и чисел на экран.
Вот наглядный пример того, как воспринимается компьютером латинский алфавит и прочие символы:
Если никакая кодировка не установлена, вместо символов мы увидим такие значения. Чтобы понять компьютер, необходимо установить нужную кодировку для расшифровки символов из этой таблицы.
Типы кодировокСуществует несколько типов кодировок:
- ASCII – первая кодировка, которая была признана Американским национальным институтом мировых стандартов. Для ее использования задействуется 7 бит, где первые 128 значений включают в себя весь английский алфавит, числа, знаки и символы. Такая кодировка ранее использовалась на англоязычных ресурсах.
- Кириллица – вариант российской кодировки, используемый на русскоязычных сайтах и блогах.
- КОИ8 (код обмена информацией 8-битный) – была разработана для кодирования букв кириллических алфавитов. Распространена в Unix-подобных ОС и электронной почте. Постепенно исчезает в связи с приходом Юникода.

- Windows 1250-1258 – 8-битные кодировки, зародившиеся после появления операционной системы Windows. Например, 1250 – все языки центральной Европы, 1251 – кириллица. В ней присутствуют все буквы русского алфавита, а также символы (за исключением знака ударения).
- UTF-8 – наиболее используемый тип кодировок, работающий практически со всеми языками мира. Символы занимают от 1 до 4 байт, что дает возможность создавать мультиязычные веб-сайты. Помимо UTF-8, есть такие варианты, как UTF-16 и UTF-32, однако предпочтение отдается первому типу.
Существуют и другие типы кодировок, но они используются в меньшей степени либо не используются вообще.
Как определить кодировку на сайтеУзнать кодировку своего или чужого сайта довольно просто, достаточно просмотреть исходный код страницы. Сделать это можно следующим образом:
- Открываем сайт, на котором необходимо посмотреть кодировку, и кликаем правой кнопкой мыши по любой области. В отобразившемся меню выбираем «Просмотр кода страницы». Также можно воспользоваться комбинацией клавиш «CTRL+U».
- В результате перед нами отобразится новое окно с кодом страницы – в нем воспользуемся комбинацией клавиш «CTRL+F» для поиска строки, отвечающей за кодировку веб-страницы. Вводим запрос «charset» и смотрим результат.
После charset указано значение UTF-8 – это означает, что данная кодировка используется на рассматриваемом сайте. Если вы увидели, что на вашем сайте указана некорректная кодировка, то это можно исправить. Подробнее о том, как это сделать, поговорим далее.
Где и как изменить кодировкуВсе зависит от сайта. Способ установки кодировки может различаться: если используется одностаничник, то достаточно в HTML-файле прописать мета-тег в блоке <head>:
В противном случае нам потребуется отредактировать файл .htaccess. Рассмотрим на примере хостинга Timeweb, как это можно сделать.
- Открываем личный кабинет и переходим в раздел «Файловый менеджер». В нем перемещаемся в директорию с сайтом и находим в корне файл .htaccess – открываем его двойным кликом мыши.
- В начало файла необходимо добавить следующий код:
Для UTF-8: AddDefaultCharset UTF-8 Для Windows-1251: AddDefaultCharset WINDOWS-1251
Открываем свой сайт и видим, что ничего не изменилось – так и должно быть. Чтобы внести изменения, очищаем кэш с помощью комбинации клавиш «CTRL+F5» и смотрим результат.
Как видите, сменить кодировку на своем сайте легко. Аналогичным образом мы можем изменить кодировку и на всем сервере – для этого необходимо выполнить следующее (актуально для веб-сервера Apache):
- Находим файл httpd.conf, который расположен по адресу: «/usr/local/apache/conf/», и открываем его.
- Если нужно поменять Windows-1251 на UTF-8, то меняем строку «AddDefaultCharset windows-1251» на «AddDefaultCharset utf-8».
Если вы поменяете кодировку по умолчанию, то она будет изменена для всех ресурсов, находящихся на данном сервере.
Смена кодировки базы данныхВ данном случае нам потребуется открыть базу данных через личный кабинет хостинга и изменить значение кодировки в разделе «Операции». Давайте рассмотрим, как это можно сделать через админку Timeweb.
- Переходим в свой аккаунт и открываем раздел «Базы данных MySQL» – в нем находим нужную базу данных и кликаем по кнопке «phpMyAdmin».
- В отобразившемся окне вводим пароль и следуем далее.
- Переходим к нужной базе данных и в верхнем меню выбираем «Операции».
- Указываем в нижнем блоке значение «utf8mb4_general_ci» и в правой части жмем на кнопку «Вперед».
- Готово! Теперь база данных использует кодировку UTF-8.
На этом статья подходит к концу. Теперь вы знаете больше о кодировке сайта и можете легко ее изменить в случае необходимости.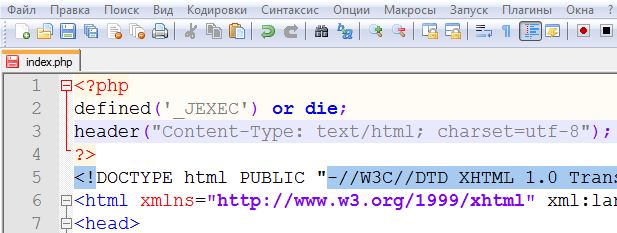 Спасибо за внимание!
Спасибо за внимание!
Новый txt-документ в Windows 7 в кодировке UTF-8
Накануне открываю текстовый файл в своём Notepad++ (это удобный функциональный текстовый редактор, подменяющий стандартный виндовский блокнот), а там в тексте местами крокозябры. Ясно, что проблема с кодировкой. Но откуда она взялась, и почему её раньше не было?
Дело в том, что Windows по умолчанию создаёт файл в кодировке ANSI. Не буду углубляться в подробности, тем более, что я в этом особо и не разбираюсь, скажу только, что это не универсальная кодировка (отсюда и проблемы), коей в свою очередь является UTF-8.
В Notepad++ есть возможность менять кодировку, преобразовывать, задавать кодировку по умолчанию для новых файлов (но только созданных внутри программы Notepad++) и даже автоматически преобразовывать новые файлы из ANSI (если, например, вы их создаёте с помощью контекстного меню).
И вот… в Windows 7 последняя функция почему-то не работает (в отличие, например от Windows XP). Т.е. если вы создали файл в папке из меню Создать => Текстовый документ, то он будет в ANSI и по умолчанию, и при открытии в Notepad++, и при последующем сохранении. Конечно, есть вариант каждый раз пользоваться функцией преобразования кодировки. Но это и неудобно, и запамятовать такое можно легко.
Но есть выход гораздо лучше. Вот он:
- Создайте текстовый документ, назовите его TXTUTF-8.txt и откройте в Notepad++. Далее во вкладке Кодировки кликнете по пункту Преобразовать в UTF-8 без BOM и сохраните файл. Важная деталь: лично у меня пустой документ кодировку не сохраняет. Т.е. если всё сделать как написано выше и открыть документ снова, то кодировка снова вернётся к ANSI.
- Решил я это поставив в документе точку. Можно поставить и пробел, к примеру. С точкой или пробелом кодировка не «слетает». Но здесь есть и нюанс: если оставите что-то в тексте TXTUTF-8.txt, это «что-то» потом будет появляться и в каждом новом txt-документе.
 Так что решайте сами. Мне лично точка мешает гораздо меньше, нежели необходимость перекодировать каждый файл.
Так что решайте сами. Мне лично точка мешает гораздо меньше, нежели необходимость перекодировать каждый файл. - Зайдите в папку WINDOWS, а в ней в папку SHELLNEW. Если не можете найти SHELLNEW, воспользуйтесь стандартным поиском по имени в правом верхнем углу. Скопируйте (или перенесите) ваш файл TXTUTF-8.txt в эту папку.
- Далее вызовите командную строку, для этого можно нажать Win+R или в меню Пуск кликнуть по «Выполнить…». В командной строке напишите regedit и нажмите OK.
- В появившемся проводнике последовательно откройте папки HKEY_CLASSES_ROOT => .txt => ShellNew, далее в правом окне кликнете правой кнопкой мыши и выберете Создать => Строковый параметр. Появившийся файл переименуйте в FileName.
- Кликнете два раза левой кнопкой мыши по файлу FileName и в поле Значение укажите уже знакомое TXTUTF-8.txt.
Это всё, теперь можно идти пить чай.
Выбор и применение кодировки символов
Выбор и применение кодировки символовЦелевая аудитория: Кодировщики HTML (использующие редакторы или сценарии), разработчики сценариев (PHP, JSP и т. Д.), Кодировщики CSS, менеджеры веб-проектов и все, кто плохо знаком с кодировками символов и нуждается в введении в то, как выбирать и применять кодировки символов.
Какую кодировку символов я должен использовать для своего контента и как применить ее к моему контенту?
Контент состоит из последовательности символов.Символы представляют буквы алфавита, знаки препинания и т. Д. Но содержимое хранится в компьютере как последовательность байтов, которые являются числовыми значениями. Иногда для представления одного символа используется более одного байта. Как и коды, используемые в шпионаже, способ преобразования последовательности байтов в символы зависит от того, какой ключ использовался для кодирования текста. В этом контексте этот ключ называется кодировкой символов .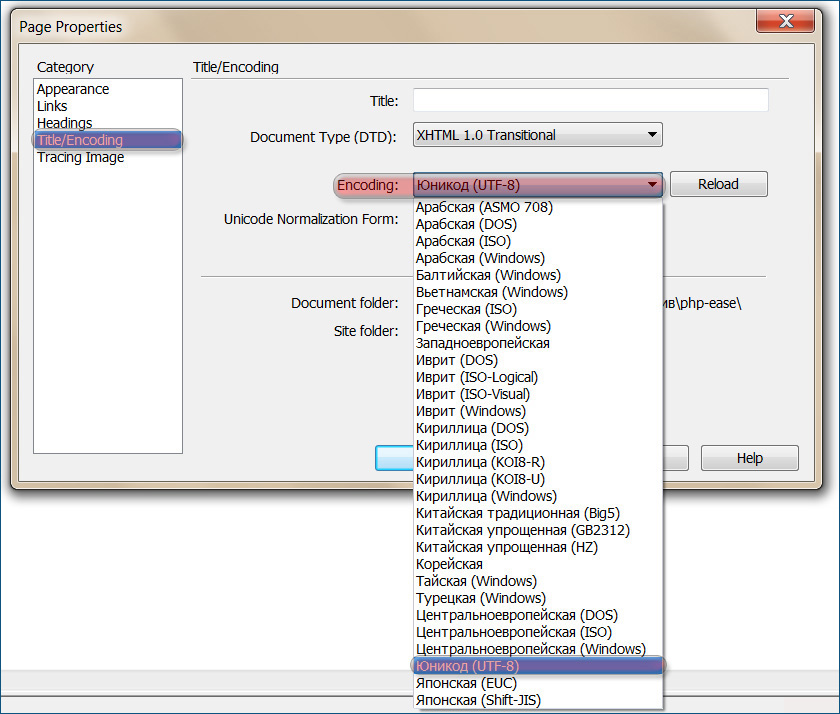
Эта статья предлагает простые советы о том, какую кодировку символов использовать для вашего контента и как ее применять, т. Е.как на самом деле создать документ в этой кодировке.
Если вам нужно лучше понять, что такое символы и кодировки символов, см. Статью Кодировки символов для начинающих .
Выберите UTF-8 для всего содержимого и подумайте о преобразовании любого содержимого из устаревших кодировок в UTF-8.
Если вы действительно не можете использовать кодировку Unicode, убедитесь, что существует широкая поддержка браузером для выбранной вами кодировки страницы, и что эта кодировка не входит в список кодировок, которых следует избегать в соответствии с последними спецификациями.
Проверьте, повлияют ли на ваш выбор настройки HTTP-сервера.
Помимо объявления кодировки документа внутри документа и / или на сервере, вам необходимо сохранить текст в этой кодировке, чтобы применить его к вашему контенту.
Разработчикам также необходимо убедиться, что различные части системы могут взаимодействовать друг с другом.
Применение кодировки к вашему контенту
Авторы контента должны объявить кодировку символов своих страниц, используя один из методов, описанных в Объявление кодировок символов в HTML .
Однако важно понимать, что простое объявление кодировки внутри документа или на сервере фактически не изменит байты; вам нужно сохранить текст в этой кодировке , чтобы применить его к вашему контенту. (Объявление просто помогает браузеру интерпретировать последовательности байтов, в которых хранится текст.)
В статье Настройка кодировки в приложениях веб-разработки даются советы о том, как установить кодировку страницы при ее сохранении для ряда сред редактирования.
Если можете, установите UTF-8 по умолчанию для новых документов в редакторе. На рисунке ниже показано, как это сделать в настройках редактора, такого как Dreamweaver.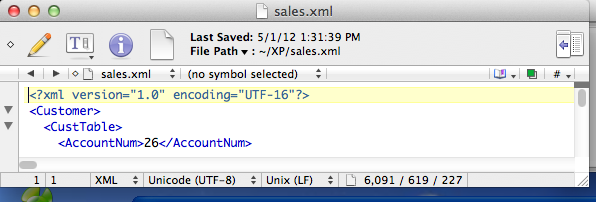
Для получения информации о «Форме нормализации Unicode» см. Нормализация в HTML и CSS . Для получения информации о «Подпись Unicode (BOM)» см. Метка порядка байтов (BOM) в HTML .
Вам также может потребоваться проверить, что ваш сервер обслуживает документы с правильными декларациями HTTP, поскольку в противном случае он переопределит информацию в документе (см. Ниже).
Разработчикам также необходимо убедиться, что различные части системы могут взаимодействовать друг с другом. Веб-страницы должны иметь возможность беспрепятственно взаимодействовать с серверными скриптами, базами данных и т. Д. Все они, конечно, лучше всего работают и с UTF-8. Разработчики могут найти подробный набор вещей, которые следует учитывать, в статье Переход на Unicode .
Зачем использовать UTF-8?
HTML-страница может быть только в одной кодировке. Вы не можете кодировать разные части документа в разных кодировках.
Кодировка на основе Unicode, такая как UTF-8, может поддерживать множество языков и может содержать страницы и формы на любом сочетании этих языков. Его использование также устраняет необходимость в логике на стороне сервера для индивидуального определения кодировки символов для каждой обслуживаемой страницы или каждой входящей отправки формы. Это значительно упрощает работу с многоязычным сайтом или приложением.
Кодировка Unicode также позволяет смешивать намного больше языков на одной странице, чем любой другой выбор кодировки.
Поддержка данной кодировки, даже кодировки Unicode, не обязательно означает, что пользовательский агент будет правильно отображать текст. Многочисленные скрипты, такие как арабский и индийский, требуют дополнительных правил для преобразования последовательности символов в памяти в соответствующую последовательность глифов шрифта для отображения.
В наши дни барьеры для использования Unicode очень низки. Фактически, в январе 2012 года Google сообщил, что более 60% Интернета в их выборке из нескольких миллиардов страниц теперь используют UTF-8.Добавьте к этому цифру для веб-страниц, содержащих только ASCII (поскольку ASCII является подмножеством UTF-8), и эта цифра возрастет примерно до 80%.
Фактически, в январе 2012 года Google сообщил, что более 60% Интернета в их выборке из нескольких миллиардов страниц теперь используют UTF-8.Добавьте к этому цифру для веб-страниц, содержащих только ASCII (поскольку ASCII является подмножеством UTF-8), и эта цифра возрастет примерно до 80%.
Существует три различных кодировки символов Unicode: UTF-8, UTF-16 и UTF-32. Из этих трех только UTF-8 следует использовать для веб-содержимого. Спецификация HTML5 гласит: «Авторам рекомендуется использовать UTF-8. Средства проверки соответствия могут посоветовать авторам не использовать устаревшие кодировки. Инструменты разработки должны по умолчанию использовать UTF-8 для вновь создаваемых документов».
Обратите внимание, в частности, что все символы ASCII в UTF-8 используют в точности те же байты, что и кодировка ASCII, что часто способствует совместимости и обратной совместимости.
Принимая во внимание HTTP-заголовок
Любое объявление кодировки символов в заголовке HTTP переопределит объявления внутри страницы. Если заголовок HTTP объявляет кодировку, отличную от той, которую вы хотите использовать для своего контента, это вызовет проблему, если вы не сможете изменить настройки сервера.
У вас может не быть контроля над объявлениями, которые идут с заголовком HTTP, и вам, возможно, придется обратиться за помощью к людям, которые управляют сервером.С другой стороны, иногда есть способы исправить что-то на сервере, если у вас ограниченный доступ к файлам настройки сервера или если вы создаете страницы с помощью языков сценариев. Например, см. Установка параметра кодировки HTTP для получения дополнительной информации о том, как изменить информацию о кодировке либо локально для набора файлов на сервере, либо для контента, созданного с использованием языка сценариев.
Обычно перед этим необходимо проверить, действительно ли заголовок HTTP объявляет кодировку символов.Вы можете использовать средство проверки интернационализации W3C, чтобы узнать, какая кодировка символов, если таковая имеется, указана в заголовке HTTP.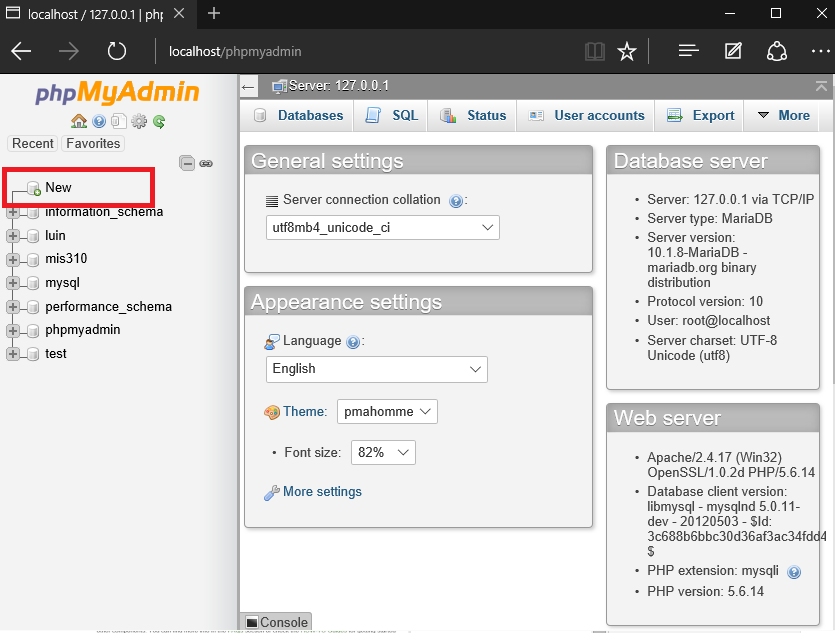 В качестве альтернативы, статья Проверка заголовков HTTP указывает на некоторые другие инструменты для проверки информации о кодировке, передаваемой сервером.
В качестве альтернативы, статья Проверка заголовков HTTP указывает на некоторые другие инструменты для проверки информации о кодировке, передаваемой сервером.
Информация в этом разделе относится к вещам, которые вам обычно не нужно знать, но которые включены сюда для полноты.
Что делать, если я не могу использовать UTF-8?
Если вы действительно не можете избежать использования кодировки символов, отличной от UTF-8, вам нужно будет выбрать из ограниченного набора имен кодировки, чтобы обеспечить максимальную совместимость и максимально долгий срок читабельности вашего контента, а также минимизировать уязвимости безопасности.
До недавнего времени реестр IANA был местом, где можно было найти имена для кодировок. Реестр IANA обычно включает несколько имен для одной и той же кодировки. В этом случае вы должны использовать имя, обозначенное как «предпочтительный».
Новая спецификация Encoding теперь предоставляет список, который был протестирован на реальных реализациях браузеров. Вы можете найти список в таблице в разделе «Кодировки». Лучше всего использовать имена из левого столбца этой таблицы.
Обратите внимание, однако, на , что наличие имени в любом из этих источников не обязательно означает, что использовать эту кодировку можно. В следующем разделе описаны кодировки, которых следует избегать.
Избегайте этих кодировок
Спецификация HTML5 называет ряд кодировок, которых следует избегать.
Документы не должны использовать JIS_C6226-1983 , JIS_X0212-1990 , HZ-GB-2312 , JOHAB (кодовая страница Windows 1361), кодировки на основе ISO-2022 или кодировки на основе EBCDIC .Это связано с тем, что они позволяют кодовым точкам ASCII представлять символы, отличные от ASCII, что представляет собой угрозу безопасности.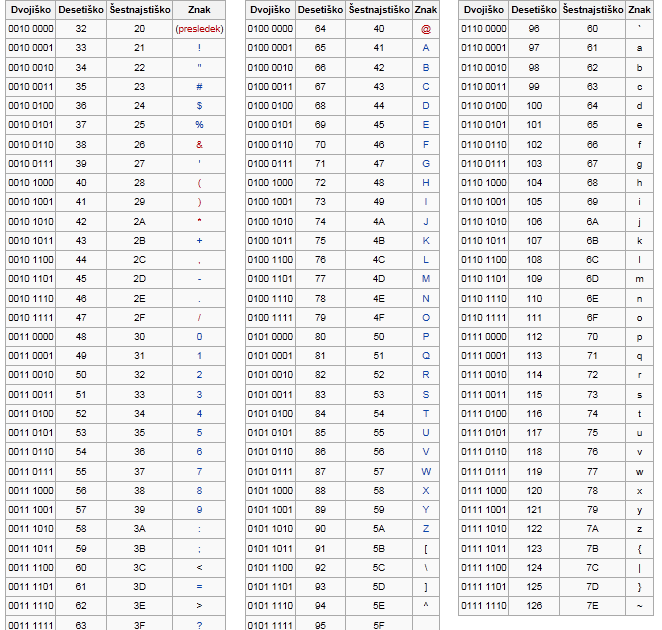
Документы также не должны использовать кодировки CESU-8 , UTF-7 , BOCU-1 или SCSU , поскольку они никогда не предназначались для веб-содержимого, а спецификация HTML5 запрещает браузерам их распознавать.
Спецификация также настоятельно не рекомендует использовать UTF-16 , а использование UTF-32 «особенно не рекомендуется».
Также следует избегать других кодировок символов, перечисленных в спецификации Encoding . К ним относятся кодировки Big5 и EUC-JP , которые имеют проблемы совместимости. ISO-8859-8 (кодировка на иврите для визуально упорядоченного текста) также следует избегать в пользу кодировки, которая работает с логически упорядоченным текстом (например, UTF-8 или в противном случае ISO-8859-8-i).
Кодировка , заменяющая кодировку , указанная в спецификации Encoding , на самом деле не является кодировкой; это резервный вариант, который отображает каждый октет в кодовую точку Unicode U + FFFD REPLACEMENT CHARACTER.Очевидно, что передавать данные в такой кодировке бесполезно.
Определяемая пользователем кодировка x — это однобайтовая кодировка, нижняя половина которой — ASCII, а верхняя половина отображается в область частного использования Unicode (PUA). Как и PUA в целом, лучше избегать использования этой кодировки в общедоступном Интернете, поскольку это ухудшает совместимость и долгосрочное использование.
UTF-8 Кодировка
Сводка
UTF-8 — это компромиссная кодировка символов, которая может быть столь же компактной
как ASCII (если файл представляет собой обычный текст на английском языке), но также может содержать
любые символы юникода (с некоторым увеличением размера файла).
UTF означает формат преобразования Unicode. ‘8’ означает, что он использует 8-битные блоки для представляют собой персонажа. Количество блоков, необходимых для представления персонажа, варьируется от От 1 до 4.
Одной из действительно хороших особенностей UTF-8 является то, что он совместим со строками с завершающим нулем. При кодировании ни один символ не будет иметь нулевой (0) байт. Это означает, что код C, имеющий дело с char [] будет «просто работать».
Вы можете попробовать тестовую страницу UTF-8, чтобы увидеть, насколько хорошо ваш браузер (и шрифт по умолчанию) поддерживает UTF-8.
Если вы разработчик приложений, эта статья Joel On Software о Unicode — довольно хорошее резюме всего, что вам нужно знать.
Дополнительные ссылки:
Деталь
Для любого символа, равного или меньше 127 (шестнадцатеричный 0x7F), представление UTF-8 это один байт. Это всего лишь младшие 7 бит полного значения Unicode. Это также то же самое, что и значение ASCII.
Для символов, равных или меньше 2047 (шестнадцатеричное 0x07FF), представление UTF-8 распространяется на два байта.В первом байте будут установлены два старших бита и третий бит очищен (т.е. от 0xC2 до 0xDF). Второй байт будет иметь установлен верхний бит, а второй бит очищен (например, от 0x80 до 0xBF).
Для всех символов, равных или больше 2048, но меньше 65535 (0xFFFF), представление UTF-8 распространяется на три байта.
В следующей таблице показан формат таких байтовых последовательностей UTF-8 (где «свободные биты», обозначенные в таблице значками x, объединяются в порядок показан и интерпретируется от наиболее значимого до наименее значимого).
Двоичный формат байтов в последовательности
| 1-й байт | 2-й байт | 3-й байт | 4-й байт | Количество свободных битов | Максимальное выражаемое значение Unicode |
|---|---|---|---|---|---|
| 0xxxxxxx | 7 | 007F шестигранник (127) | |||
| 110xxxxx | 10xxxxxx | (5 + 6) = 11 | 07FF шестигранник (2047) | ||
| 1110xxxx | 10xxxxxx | 10xxxxxx | (4 + 6 + 6) = 16 | FFFF шестигранник (65535) | |
| 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | (3 + 6 + 6 + 6) = 21 | 10FFFF шестигранник (1,114,111) |
Значение каждого отдельного байта указывает его функцию UTF-8, как показано ниже:
- 00–7F шестнадцатеричный (от 0 до 127): первый и единственный байт последовательности.

- от 80 до BF шестнадцатеричный (от 128 до 191): продолжающий байт в многобайтовой последовательности.
- C2 в шестнадцатеричный формат DF (от 194 до 223): первый байт двухбайтовой последовательности.
- E0 в шестнадцатеричном формате EF (от 224 до 239): первый байт трехбайтовой последовательности.
- F0 — FF шестнадцатеричный (от 240 до 255): первый байт четырехбайтовой последовательности.
UTF-8 остается простым однобайтовым, совместимым с ASCII методом кодирования до тех пор, пока непосредственно присутствуют символы больше 127. Это означает, что документ HTML технически объявленный как закодированный как UTF-8, может оставаться обычным однобайтовым файлом ASCII.Документ может остаться поэтому, даже если он может содержать символы Unicode выше 127, при условии, что все символы выше 127 упоминаются косвенно с помощью амперсандных сущностей.
Примеры закодированных символов Unicode (в шестнадцатеричной системе счисления)
| 16-битный Unicode | Последовательность UTF-8 |
|---|---|
| 0001 | 01 |
| 007F | 7F |
| 0080 | C2 80 |
| 07FF | DF BF |
| 0800 | E0 A0 80 |
| FFFF | EF BF BF |
| 010000 | F0 90 80 80 |
| 10FFFF | F4 8F BF BF |
Что такое кодировка UTF-8? Руководство для непрограммистов
Текст: его важность в Интернете само собой разумеется.Это первая буква «Т» в «HTTP», единственная буква «Т» в «HTML», и практически каждый веб-сайт так или иначе использует ее, будь то URL-адрес, часть маркетингового текста, обзор продукта, вирусный твит или Сообщение блога. (Привет!)
Но веб-текст на самом деле может быть не таким простым, как вы думаете. Рассмотрим тысячи языков, на которых сегодня говорят, или все знаки препинания и символы, которые мы можем добавить, чтобы улучшить их, или тот факт, что создаются новые смайлики, чтобы уловить каждую человеческую эмоцию.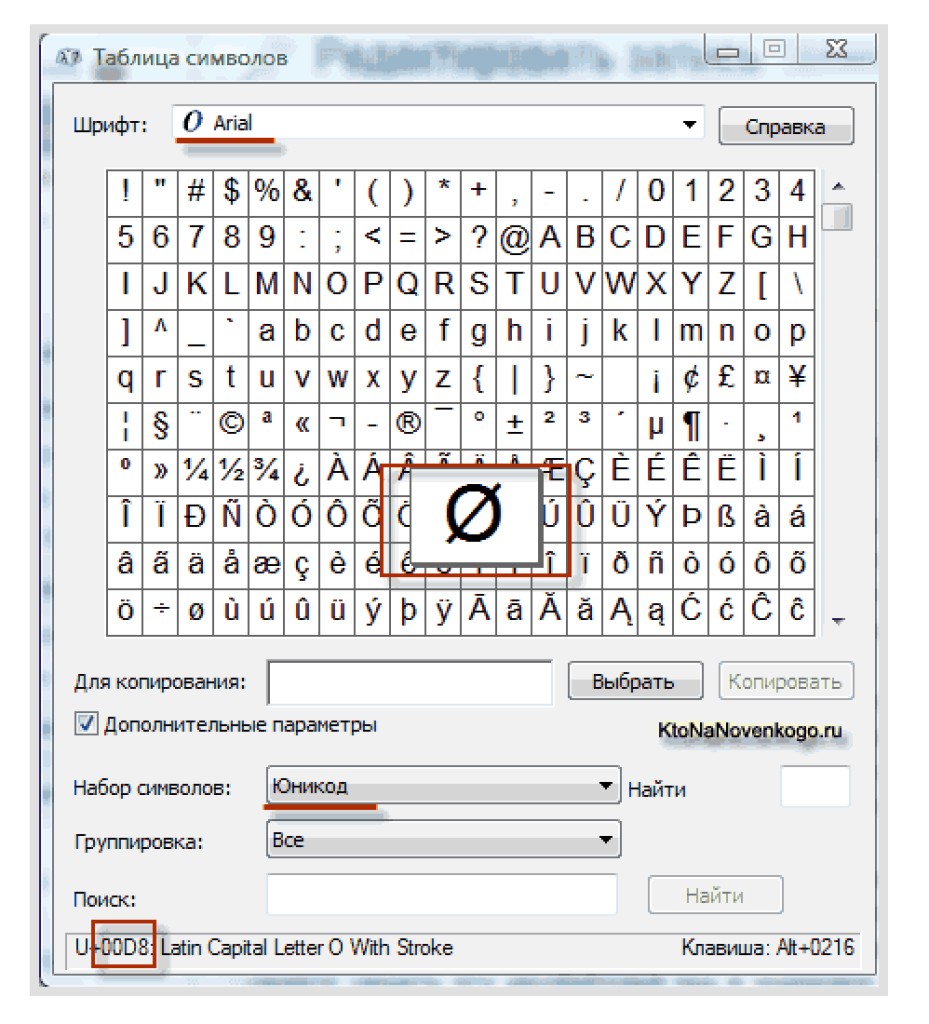 Как веб-сайты все это хранят и обрабатывают?
Как веб-сайты все это хранят и обрабатывают?По правде говоря, даже такая простая вещь, как текст, требует хорошо скоординированной, четко определенной системы для отображения в веб-браузерах.В этом посте я расскажу об основах одной технологии, которая имеет ключевое значение для текста в Интернете, UTF-8 . Мы изучим основы хранения и кодирования текста и обсудим, как это помогает разместить на вашем сайте привлекательные слова.
Прежде чем мы начнем, вы должны быть знакомы с основами HTML и готовы погрузиться в легкую информатику.
Что такое UTF-8?
UTF-8 означает «Формат преобразования Unicode — 8 бит». Пока это нам не помогает, так что давайте вернемся к основам.
Двоичный: как компьютеры хранят информацию
Для хранения информации компьютеры используют двоичную систему. В двоичном формате все данные представлены последовательностями из единиц и нулей. Самая основная двоичная единица — это бит , который представляет собой всего лишь единицу 1 или 0. Следующая по величине двоичная единица, байт, состоит из 8 бит. Пример байта — «01101011».
Каждый цифровой актив, с которым вы когда-либо сталкивались, — от программного обеспечения до мобильных приложений, от веб-сайтов до историй в Instagram — построен на этой системе байтов, которые связаны друг с другом таким образом, чтобы это имело смысл для компьютеров.Когда мы говорим о размерах файлов, мы имеем в виду количество байтов. Например, килобайт — это примерно тысяча байт, а гигабайт — примерно миллиард байтов.
Текст — один из многих ресурсов, которые хранятся и обрабатываются компьютерами. Текст состоит из отдельных символов, каждый из которых представлен в компьютерах строкой битов. Эти строки собираются в цифровые слова, предложения, абзацы, любовные романы и т. Д.
ASCII: преобразование символов в двоичные
Американский стандартный код обмена информацией (ASCII) был ранней стандартизированной системой кодирования текста. Кодирование — это процесс преобразования символов человеческих языков в двоичные последовательности, которые могут обрабатывать компьютеры.
Кодирование — это процесс преобразования символов человеческих языков в двоичные последовательности, которые могут обрабатывать компьютеры.
ASCII включает все прописные и строчные буквы латинского алфавита (A, B, C…), каждую цифру от 0 до 9 и некоторые общие символы (например, /,! И?). Он присваивает каждому из этих символов уникальный трехзначный код и уникальный байт.
В таблице ниже показаны примеры символов ASCII с соответствующими кодами и байтами.
| Символ | Код ASCII | БАЙТ |
| А | 065 | 01000001 |
| 097 | 01100001 | |
| B | 066 | 01000010 |
| б | 098 | 01100010 |
| Z | 090 | 01011010 |
| z | 122 | 01111010 |
| 0 | 048 | 00110000 |
| 9 | 057 | 00111001 |
| ! | 033 | 00100001 |
| ? | 063 | 00111111 |
Подобно тому, как символы объединяются в слова и предложения на языке, двоичный код делает это в текстовых файлах.Итак, фраза «Быстрая коричневая лисица перепрыгивает через ленивого пса». в двоичном формате ASCII будет:
01010100 01101000 01100101 00100000 01110001
01110101 01101001 01100011 01101011 00100000
01100010 01110010 01101111 01110111 01101110
00100000 01100110 01101111 01111000 00100000
01101010 01110101 01101101 01110000 01110011
00100000 01101111 01110110 01100101 01110010
00100000 01110100 01101000 01100101 00100000
01101100 01100001 01111010 01111001 00100000
01100100 01101111 01100111 00101110
Это мало что значит для нас, людей, но это хлеб с маслом для компьютера.
Число символов, которые может представлять ASCII, ограничено числом доступных уникальных байтов, поскольку каждый символ получает один байт. Если вы посчитаете, то обнаружите, что существует 256 различных способов сгруппировать восемь единиц и нулей вместе. Это дает нам 256 различных байтов или 256 способов представления символа в ASCII. Когда в 1960 году был представлен ASCII, это было нормально, поскольку разработчикам требовалось всего 128 байт для представления всех необходимых им английских символов и символов.
Но по мере глобального распространения компьютерных технологий компьютерные системы начали хранить текст не только на английском, но и на других языках, многие из которых использовали символы, отличные от ASCII.Были созданы новые системы для сопоставления других языков с одним и тем же набором из 256 уникальных байтов, но использование нескольких систем кодирования было неэффективным и запутанным. Разработчикам требовался лучший способ кодирования всех возможных символов с помощью одной системы.
Unicode: способ сохранить каждый символ, когда-либо
Введите Unicode, систему кодирования, которая решает проблему пространства для ASCII. Как и ASCII, Unicode присваивает каждому символу уникальный код, называемый кодовой точкой . Однако более сложная система Unicode может генерировать более миллиона кодовых точек, чего более чем достаточно, чтобы учесть каждый символ на любом языке.
Unicode теперь является универсальным стандартом для кодирования всех человеческих языков. И да, он даже включает смайлики.
Ниже приведены несколько примеров текстовых символов и соответствующих им кодовых точек. Каждая кодовая точка начинается с буквы «U» для «Unicode», за которой следует уникальная строка символов, представляющая символ.
| Символ | Кодовая точка |
| А | U + 0041 |
| U + 0061 | |
| 0 | U + 0030 |
| 9 | U + 0039 |
| ! | U + 0021 |
| Ø | U + 00D8 |
| ڃ | U + 0683 |
| ಚ | U + 0C9A |
| 𠜎 | U + 2070E |
| 😁 | U + 1F601 |
Если вы хотите узнать, как генерируются кодовые точки и что они означают в Unicode, ознакомьтесь с этим подробным объяснением.
Итак, теперь у нас есть стандартизированный способ представления каждого символа, используемого каждым человеческим языком, в одной библиотеке. Это решает проблему нескольких систем маркировки для разных языков — любой компьютер на Земле может использовать Unicode.
Но только Unicode не хранит слова в двоичном формате. Компьютерам нужен способ перевода Unicode в двоичный код, чтобы его символы можно было хранить в текстовых файлах. Вот где пригодится UTF-8.
UTF-8: последний фрагмент головоломки
UTF-8 — это система кодирования Unicode.Он может преобразовать любой символ Юникода в соответствующую уникальную двоичную строку, а также может преобразовать двоичную строку обратно в символ Юникода. Это значение «UTF» или «формата преобразования Unicode».
Существуют и другие системы кодирования Unicode, помимо UTF-8, но UTF-8 уникален, поскольку представляет символы в однобайтовых единицах. Помните, что один байт состоит из восьми бит, отсюда и «-8» в его названии.
Более конкретно, UTF-8 преобразует кодовую точку (которая представляет один символ в Unicode) в набор от одного до четырех байтов.Первые 256 символов в библиотеке Unicode, которые включают символы, которые мы видели в ASCII, представлены как один байт. Символы, которые появляются позже в библиотеке Unicode, кодируются как двухбайтовые, трехбайтовые и, возможно, четырехбайтовые двоичные единицы.
Ниже приведена та же таблица символов сверху, с выводом UTF-8 для каждого добавленного символа. Обратите внимание, что некоторые символы представлены одним байтом, а другие используют больше.
| Символ | Кодовая точка | Двоичное кодирование UTF-8 |
| А | U + 0041 | 01000001 |
| U + 0061 | 01100001 | |
| 0 | U + 0030 | 00110000 |
| 9 | U + 0039 | 00111001 |
| ! | U + 0021 | 00100001 |
| Ø | U + 00D8 | 11000011 10011000 |
| ڃ | U + 0683 | 11011010 10000011 |
| ಚ | U + 0C9A | 11100000 10110010 10011010 |
| 𠜎 | U + 2070E | 11110000 10100000 10011100 10001110 |
| 😁 | U + 1F601 | 11110000 10011111 10011000 10000001 |
Почему UTF-8 преобразует одни символы в один байт, а другие — в четыре байта? Короче для экономии памяти. Используя меньше места для представления более общих символов (например, символов ASCII), UTF-8 уменьшает размер файла, позволяя использовать гораздо большее количество менее распространенных символов. Эти менее распространенные символы кодируются в два или более байта, но это нормально, если они хранятся редко.
Используя меньше места для представления более общих символов (например, символов ASCII), UTF-8 уменьшает размер файла, позволяя использовать гораздо большее количество менее распространенных символов. Эти менее распространенные символы кодируются в два или более байта, но это нормально, если они хранятся редко.
Пространственная эффективность — ключевое преимущество кодировки UTF-8. Если бы вместо этого каждый символ Unicode был представлен четырьмя байтами, текстовый файл, написанный на английском языке, был бы в четыре раза больше, чем тот же файл, закодированный с помощью UTF-8.
Еще одним преимуществом кодировки UTF-8 является ее обратная совместимость с ASCII. Первые 128 символов в библиотеке Unicode соответствуют символам в библиотеке ASCII, а UTF-8 переводит эти 128 символов Unicode в те же двоичные строки, что и ASCII. В результате UTF-8 может без проблем принимать текстовый файл, отформатированный в ASCII, и преобразовывать его в читаемый человеком текст.
Символы UTF-8 в веб-разработке
UTF-8 — наиболее распространенный метод кодировки символов, используемый сегодня в Интернете, и набор символов по умолчанию для HTML5.Более 95% всех веб-сайтов, в том числе и ваш собственный, хранят персонажей таким образом. Кроме того, распространенные методы передачи данных через Интернет, такие как XML и JSON, кодируются стандартами UTF-8.
Поскольку в настоящее время это стандартный метод кодирования текста в Интернете, все страницы вашего сайта и базы данных должны использовать кодировку UTF-8. Система управления контентом или конструктор веб-сайтов по умолчанию сохранят ваши файлы в формате UTF-8, но все же рекомендуется следить за тем, чтобы вы придерживались этой передовой практики.
Текстовые файлы, закодированные с помощью UTF-8, должны указывать на это программному обеспечению, обрабатывающему их.В противном случае программа не сможет должным образом преобразовать двоичный код обратно в символы. В файлах HTML вы можете увидеть строку кода, подобную следующему, вверху:
Это сообщает браузеру, что файл HTML закодирован в UTF-8, чтобы браузер мог преобразовать его обратно в разборчивый текст.
UTF-8 против UTF-16
Как я уже упоминал, UTF-8 — не единственный метод кодирования для символов Unicode — существует также UTF-16.Эти методы различаются количеством байтов, необходимых для хранения символа. UTF-8 кодирует символ в двоичную строку из одного, двух, трех или четырех байтов. UTF-16 кодирует символ Unicode в строку из двух или четырех байтов.
Это различие видно из их названий. В UTF-8 наименьшее двоичное представление символа — это один байт или восемь битов. В UTF-16 наименьшее двоичное представление символа составляет два байта или шестнадцать бит.
Как UTF-8, так и UTF-16 могут переводить символы Unicode в удобные для компьютера двоичные файлы и обратно.Однако они несовместимы друг с другом. Эти системы используют разные алгоритмы для сопоставления кодовых точек с двоичными строками, поэтому двоичный вывод для любого заданного символа будет отличаться от обоих методов:
| Символ | Двоичное кодирование UTF-8 | Двоичное кодирование UTF-16 |
| А | 01000001 | 01000001 11011000 00001110 11011111 |
| 𠜎 | 11110000 10100000 10011100 10001110 | 01000001 11011000 00001110 11011111 |
UTF-8 предпочтительнее UTF-16 на большинстве веб-сайтов, поскольку она использует меньше памяти.Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы в двух или четырех байтах. Это означает, что текстовый файл на английском языке с кодировкой UTF-16 будет как минимум в два раза больше размера того же файла с кодировкой UTF-8.
UTF-16 более эффективен, чем UTF-8, только на некоторых неанглоязычных сайтах. Если веб-сайт использует язык с символами, находящимися дальше в библиотеке Unicode, UTF-8 будет кодировать все символы как четыре байта, тогда как UTF-16 может кодировать многие из тех же символов только как два байта. Тем не менее, если ваши страницы заполнены буквами ABC и 123, придерживайтесь UTF-8.
Тем не менее, если ваши страницы заполнены буквами ABC и 123, придерживайтесь UTF-8.
Расшифровка мира кодировки UTF-8
Это было много слов о словах, поэтому давайте резюмируем то, что мы рассмотрели:
- Компьютеры хранят данные, включая текстовые символы, как двоичные (единицы и нули).
- ASCII был ранним способом кодирования или отображения символов в двоичный код, чтобы компьютеры могли их хранить. Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате.
- Unicode был решением этой проблемы. Unicode присваивает уникальный «код» каждому символу на каждом человеческом языке.
- UTF-8 — это метод кодировки символов Юникода. Это означает, что UTF-8 берет кодовую точку для данного символа Юникода и переводит ее в строку двоичного кода. Он также делает обратное, считывая двоичные цифры и преобразуя их обратно в символы.
- UTF-8 в настоящее время является самым популярным методом кодирования в Интернете, поскольку он может эффективно хранить текст, содержащий любые символы.
- UTF-16 — еще один метод кодирования, но он менее эффективен для хранения текстовых файлов (за исключением тех, которые написаны на некоторых неанглийских языках).
Перевод Unicode — это не то, о чем большинству из нас нужно думать при просмотре или разработке веб-сайтов, и именно в этом суть — создать бесшовную систему обработки текста, которая работает для всех языков и веб-браузеров. Если он работает хорошо, вы этого не заметите.
Но если вы обнаружите, что страницы вашего веб-сайта занимают чрезмерно много места или если ваш текст усеян буквами и, пора применить свои новые знания о UTF-8.
Сохранение файла CSV / Excel в кодировке UTF-8 — Импорт продукта WooCommerce Экспорт
При импорте продукта файл CSV должен быть закодирован в UTF-8. Это необходимо для того, чтобы убедиться, что весь импорт товаров, выполненный с помощью подключаемого модуля импорта экспорта товаров для WooCommerce , является точным. Во время импорта продукта можно избежать ненужных символов, таких как ž , ? и т. Д. Если файл CSV не закодирован в UTF-8, то символы типа ™, ®, © и т. Д. Преобразуются в нежелательные символы.
Во время импорта продукта можно избежать ненужных символов, таких как ž , ? и т. Д. Если файл CSV не закодирован в UTF-8, то символы типа ™, ®, © и т. Д. Преобразуются в нежелательные символы.
Содержание
Что такое кодировка UTF-8?
Символ в UTF-8 может иметь длину от 1 до 4 байтов. UTF-8 может представлять любой символ в стандарте Unicode, а также обратно совместим с ASCII. Это наиболее предпочтительная кодировка для электронной почты и веб-страниц. Это основная кодировка символов во всемирной паутине.
Вот два образца:
Sample1: Незакодированная электронная таблица UTF-8
Sample2: Незакодированная электронная таблица UTF-8
В этой статье объясняется, как применять кодировку UTF-8 с основными приложениями для работы с электронными таблицами, такими как Microsoft Excel и Notepad для Windows и Apple Numbers и TextEdit для Mac.Поскольку Google Sheets — широко используемое приложение для работы с электронными таблицами, в этой статье также объясняется кодировка UTF-8 с Google Sheets .
Как сохранить файл CSV в формате UTF-8 с помощью Libre Office?
Чтобы сохранить файл CSV в кодировке UTF-8, выполните следующие действия:
- Откройте LibreOffice и перейдите в меню Files . Нажмите «Открыть» и выберите на компьютере файл, который вы хотите сохранить как файл в кодировке UTF-8.
- После открытия файла перейдите в Файл> Сохранить как .В открывшемся диалоговом окне введите имя файла и выберите Текстовый CSV (.csv) из раскрывающегося списка Сохранить как тип .
- Отметьте Редактировать настройки фильтра опций.
Сохранить файл как CSV
- Нажмите Сохранить .
- В появившемся диалоговом окне Экспорт текстового файла выберите опцию Unicode (UTF-8) из раскрывающегося списка Набор символов .
Установите поля и разделитель текста по своему усмотрению или оставьте как есть.
Кодировать как UTF-8
Это сохранит файл в кодировке UTF-8 в Libre Office.
Как сохранить файл CSV как UTF-8 с помощью Google Spreadsheet?
Чтобы сохранить файл CSV в кодировке UTF-8, вы можете загрузить файл на Google Диск и легко сохранить его как UTF-8. Шаги приведены ниже:
- Сначала откройте свою учетную запись Google Drive . Нажмите кнопку NEW в верхнем левом углу и выберите опцию Загрузить файлы .
Возможность загрузки файла на Google Диск
- Найдите требуемый файл CSV и начните его загрузку.
- Откройте загруженный файл с помощью Google Spreadsheet .
- Перейдите к файлу > Загрузить как, и выберите Значения, разделенные запятыми (.csv, текущий лист) option .
Скачать как CSV вариант в Google Таблицах
Загруженный файл сохраняется в кодировке UTF-8 по умолчанию и может быть правильно импортирован при загрузке в наш плагин импорта и экспорта продукта.
Как сохранить файл CSV как UTF-8 в Microsoft Excel?
Шаги приведены ниже:
- Откройте файл CSV с листом Microsoft Excel .
- Перейдите к пункту меню Файл и нажмите Сохранить как . Появится окно, как показано ниже:
Параметр «Сохранить как» в Microsoft Excel
- Щелкните B rowse , чтобы выбрать место для сохранения файла.
- Откроется окно Сохранить как , как показано ниже:
Параметр «Сохранить как» в Microsoft Excel
- Затем введите имя файла.
- Выберите вариант Сохранить как тип как CSV (с разделителями-запятыми) (* .csv) .
- Щелкните раскрывающийся список Инструменты и щелкните Параметры Интернета .
 Появится новое окно для веб-опций, как показано ниже:
Появится новое окно для веб-опций, как показано ниже:Параметры Интернета
- На вкладке Кодировка выберите вариант Unicode (UTF-8) из Сохранить этот документ как: раскрывающийся список .
- Наконец, нажмите Ok, и сохраните файл.
Как сохранить файл CSV в формате UTF-8 с помощью Блокнота?
Шаги приведены ниже:
- Откройте файл CSV с помощью блокнота .
- Перейдите к файлу > Сохранить как параметр . Снимок экрана меню показан ниже:
Файл меню блокнота
- Затем выберите место для файла. Откроется окно Сохранить как , как показано ниже:
Параметр «Сохранить как» в блокноте
- Выберите вариант Сохранить как тип как Все файлы (*.*) .
- Укажите имя файла с расширением .csv .
- В раскрывающемся списке Кодировка выберите вариант UTF-8 .
- Нажмите Сохранить , чтобы сохранить файл.
Таким образом, вы можете сохранить файл как UTF-8, закодированный с помощью Блокнота.
Как сохранить файл CSV как UTF-8 в Apple Number?
Шаги приведены ниже:
- Откройте файл с Apple Numbers .
- Перейдите к файлу > Экспорт в > CSV .Снимок экрана с настройками показан ниже:
Экспорт в CSV с Apple Numbers
- В разделе Дополнительные параметры выберите вариант Unicode (UTF-8) для кодировки текста. Снимок экрана с настройками показан ниже:
Дополнительные параметры в Apple Numbers
- Нажмите Далее . Дальнейшие настройки отображаются, как показано на скриншоте ниже:
Возможность экспорта в Apple Numbers
- Введите имя файла и нажмите Экспорт , чтобы сохранить файл в кодировке UTF-8.
Как сохранить файл CSV как UTF-8 в TextEdit?
Шаги приведены ниже:
- Откройте файл с помощью TextEdit .

- Перейдите к Формат > Сделать обычный текст . Снимок экрана меню показан ниже:
Меню форматирования в TextEdit
- Затем перейдите к Файл > Сохранить . Это показано ниже:
Меню «Файл» в TextEdit
- В раскрывающемся списке Кодировка обычного текста выберите Unicode (UTF-8) .
- Наконец, нажмите Сохранить , чтобы сохранить файл.
Для запросов клиентов и ответов по этой теме обращайтесь в службу поддержки.
Чтобы узнать больше о других возможностях плагина, прочтите документацию.
Лучший плагин для импорта и экспорта товаров для WooCommerce
# 1 в официальном репозитории плагинов WordPress с 70000+ активных установок
# 1 в Удовлетворенности большинства клиентов 5 Star Отзывы
Гарантия WebToffee : верните деньги, если вы не удовлетворены продуктом
Купить сейчас!- Была ли эта статья полезной?
- Да Нет
Как работает кодировка Unicode UTF-8
UTF-8 — это умный способ кодирования текста Unicode.В последнее время я упоминал об этом пару раз, но я не писал о UTF-8 как таковой. Поехали.
Проблема, которую решает UTF-8
Клавиатуры для США часто могут отображать 101 символ, что предполагает, что 101 символа будет достаточно для большинства английского текста. Семи битов будет достаточно для кодирования этих символов, поскольку 2 7 = 128, и это то, что делает ASCII . Он представляет каждый символ с 8 битами, поскольку компьютеры работают с битами в группах размеров, которые являются степенями двойки, но первый бит всегда равен 0, потому что он не нужен. Extended ASCII использует оставшееся пространство в ASCII для кодирования большего количества символов.
Некоторым пользователям может пригодиться 256 символов, но это не позволит вам представлять, например, китайский язык. Первоначально Unicode хотел использовать два байта вместо одного для представления символов, что позволило бы иметь 2 16 = 65 536 возможностей, что достаточно, чтобы охватить множество мировых систем письма. Но не все, и поэтому Unicode расширился до четырех байтов.
Если бы вы сохраняли английский текст, используя два байта для каждой буквы, половина места была бы потрачена на хранение нулей.А если вы используете четыре байта на букву, три четверти пространства будут потрачены впустую. Без какой-либо кодировки каждый файл, содержащий тест по английскому, был бы в два или четыре раза больше необходимого . И не только на английском, но и на всех языках, которые могут быть представлены с помощью ASCII.
UTF-8 — это способ кодирования Unicode, чтобы текстовый файл ASCII кодировал сам себя. Нет лишнего места, кроме начального бита каждого байта, который ASCII не использует. И если ваш файл в основном представляет собой текст ASCII с добавлением нескольких символов, отличных от ASCII, символы, отличные от ASCII, просто сделают ваш файл немного длиннее.Вам не нужно внезапно заставлять каждый символ занимать в два или четыре раза больше места только потому, что вы хотите использовать, скажем, знак евро € (U + 20AC).
Как это делает UTF-8
Поскольку первый бит символов ASCII установлен в ноль, байты с первым битом, установленным в 1, не используются и могут использоваться специально.
Когда программа, читающая UTF-8, встречает байт, начинающийся с 1, она подсчитывает, сколько единиц следует до появления 0. Например, в байте формы 110xxxxx после начальной 1 стоит одна 1.Пусть n будет числом единиц между начальной 1 и первым 0. Остальные биты в этом байте и некоторые биты в следующих n байтах будут представлять символ Unicode. Нет необходимости, чтобы n было больше 3 по причинам, о которых мы поговорим позже. То есть для представления символа Юникода с использованием UTF-8 требуется не более четырех байтов.
То есть для представления символа Юникода с использованием UTF-8 требуется не более четырех байтов.
Таким образом, байт вида 110xxxxx говорит, что первые пять битов символа Unicode хранятся в конце этого байта, а остальные биты поступают в следующий байт.
Байт формы 1110xxxx содержит четыре бита символа Юникода и говорит, что остальные биты приходятся на следующие два байта.
Байт формы 11110xxx содержит три бита символа Unicode и говорит, что остальные биты прибывают в следующие три байта.
После начального байта, объявляющего начало символа, растянутого на несколько байтов, биты сохраняются в байтах в форме 10xxxxxx. Поскольку начальные байты многобайтовой последовательности начинаются с двух битов 1, двусмысленности нет: байт, начинающийся с 10, не может обозначать начало новой многобайтовой последовательности.То есть UTF-8 является самопунктурирующим.
Итак, многобайтовые последовательности имеют одну из следующих форм.
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Если посчитать крестики в нижнем ряду, их 21. Таким образом, эта схема может представлять только числа длиной до 21 бита. Разве нам не нужны 32 бита? Оказывается, нет.
Хотя символ Unicode якобы является 32-битным числом, на самом деле для кодирования символа Unicode требуется не более 21 бита по причинам, описанным здесь.Вот почему n , количество единиц, следующих за начальной 1 в начале многобайтовой последовательности, должно быть только 1, 2 или 3. Схема кодирования UTF-8 может быть расширена, чтобы разрешить n = 4 , 5 или 6, но в этом нет необходимости.
КПД
UTF-8 позволяет вам взять обычный файл ASCII и рассматривать его как файл Unicode, закодированный с помощью UTF-8. Таким образом, UTF-8 так же эффективен, как ASCII, с точки зрения пространства. Но не по времени. Если программное обеспечение знает, что файл на самом деле является ASCII, оно может принимать каждый байт по номиналу, не проверяя, является ли он первым байтом многобайтовой последовательности.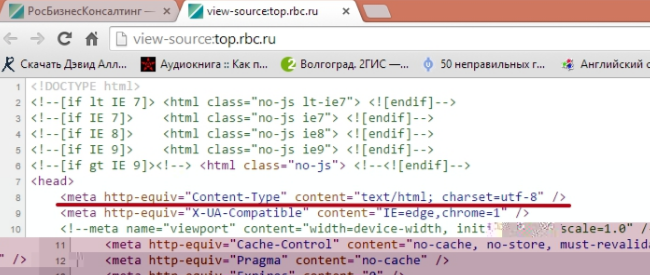
И хотя простой ASCII является допустимым UTF-8, расширенный ASCII — нет. Таким образом, расширенные символы ASCII теперь занимали два байта вместо одного. Мое предыдущее сообщение было о путанице, которая могла возникнуть из-за того, что программное обеспечение интерпретировало файл в кодировке UTF-8 как расширенный файл ASCII.
Похожие сообщения
UTF-8 Encode | Справка Алхимера
Кодирование файлов Excel в формат UTF (UTF-8 или UTF-16) может помочь обеспечить правильное чтение и отображение всего, что вы загружаете в Alchemer.Это особенно важно при работе с иностранными или специальными символами в кампаниях электронной почты, действиях с логином / паролем, списках контактов, импорте данных и тексте и переводах. Все эти функции могут получать загруженные файлы CSV.
Есть несколько разных способов получить правильную кодировку UTF, поэтому мы рассмотрим, как это сделать в более старых версиях Microsoft Excel, OpenOffice, LibreOffice, Google Drive и даже как использовать приложение Terminal для этого!
Как кодировать файлы Excel
Ниже приведены ссылки на видео и пошаговые инструкции о том, как кодировать файлы Excel в UTF-8 и UTF-16.В Excel 2011 и более поздних версиях нет параметров для кодирования файлов UTF.
В зависимости от вашей версии Excel вы можете кодировать файл в UTF-8 во время процесса Сохранить как . Это будет зависеть от вашей версии Excel, а также от того, используете ли вы Mac или ПК.
Версии Excel с 1999 по 2010 год
Посмотрите наше быстрое пошаговое видео: Кодирование видео UTF-8
- Откройте документ Excel.
- Щелкните File (или значок «Цветной круг», в зависимости от вашей версии Excel).
- Выберите Сохранить как и выберите формат файла Excel, который вы хотите использовать.
- Назовите файл и при необходимости обновите путь к файлу.

- Щелкните Инструменты , затем выберите Параметры Интернета .
- Перейдите на вкладку Кодировка .
- В раскрывающемся списке для Сохранить этот документ как: выберите Unicode (UTF-8) .
- Щелкните Ok .
- Щелкните Сохранить .
Excel для Mac
Хотя в старых версиях Excel для Mac нет возможности для кодирования CSV UTF-8, в последней версии Excel это довольно просто.
- Щелкните Файл > Сохранить как .
- Вы увидите диалоговое окно Сохранить . В раскрывающемся меню File Format выберите опцию CSV UTF-8.
- Нажмите Сохранить .
Open Office.org
Если у вас нет доступа к Excel, вы можете загрузить бесплатный пакет офисного программного обеспечения с открытым исходным кодом под названием OpenOffice. Чтобы узнать больше, посетите: http://www.openoffice.org
Краткое пошаговое видео: UTF-8 Open Office Video
- Откройте OpenOffice и откройте свой документ Excel.
- Щелкните File в верхнем левом углу панели инструментов.
- Выберите Сохранить как .
- Назовите файл и при необходимости обновите путь к файлу.
- Сохраните ваш Тип как CSV , а затем установите флажок Изменить настройки фильтра .
- Щелкните Сохранить .
Это займет некоторое время, но появится окно Экспорт текстовых файлов с дополнительными параметрами. - В поле «Набор символов» выберите Unicode (UTF-8) .
- Нажмите ОК , и все готово!
LibreOffice
Еще одна бесплатная альтернатива Microsoft Office для офиса с открытым исходным кодом — LibreOffice.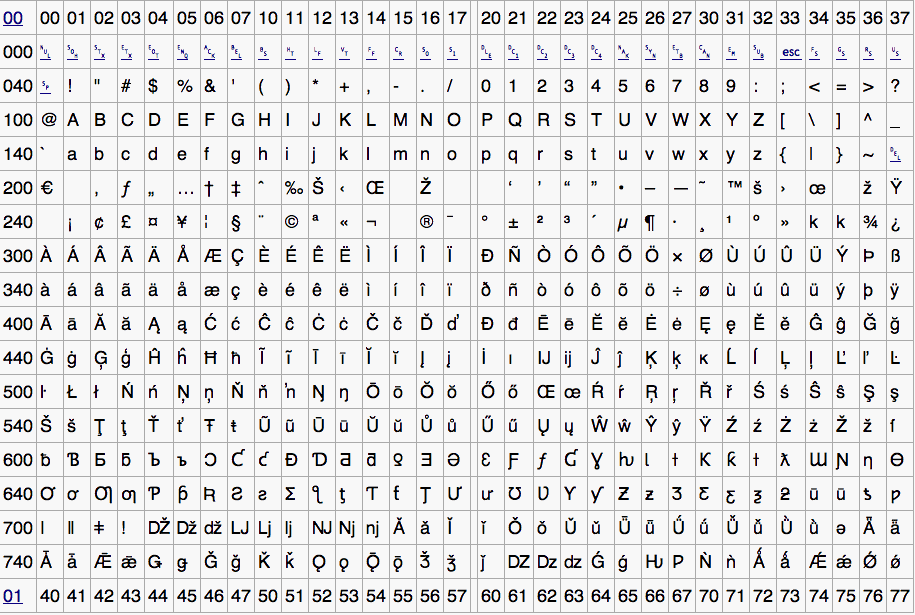 Вы можете скачать его по адресу http://www.libreoffice.org/.
Вы можете скачать его по адресу http://www.libreoffice.org/.
- Откройте LibreOffice и щелкните Открыть файл слева. Выберите свой файл и Откройте .
- Щелкните Файл> Сохранить как … Появится следующее окно, измените Тип файла на Текст CSV и выберите параметр Изменить параметры фильтра , затем щелкните Сохранить .
- Появится окно с ошибкой, но не беспокойтесь об этом. Просто нажмите Использовать текстовый формат CSV .
- В следующем появившемся окне убедитесь, что набор символов — Unicode (UTF-8) . Это должно быть по умолчанию.
- Появится последняя ошибка, сообщающая, что был сохранен только активный лист. Просто нажмите ОК, и все готово!
Google Диск
Одним из широко доступных веб-решений для кодирования файлов XLS в формате UTF-8 CSV является Google Диск, также известный как Документы Google.Вы можете загрузить существующий файл и легко экспортировать его, выполнив следующие действия.
- На главном экране Google Диска нажмите New> File Upload . Выберите файл XLS и нажмите Открыть .
- После загрузки файла дважды щелкните его в меню, чтобы открыть предварительный просмотр файла. Затем щелкните Открыть вдоль верхней панели.
- Электронная таблица загрузится, теперь вы можете щелкнуть Файл> Загрузить как> Значения, разделенные запятыми (.csv, текущий лист) .Загрузка начнется немедленно.
Использование терминала
В качестве последней попытки вы можете легко преобразовать файлы в кодировку UTF-8 с помощью терминала. Вам может потребоваться загрузить эту библиотеку, чтобы использовать команду iconv.
Для начала сохраните CSV-файл на рабочем столе с кратким именем файла.
Apple OSX Steps
- Нажмите command + пробел, чтобы перейти в Spotlight, найдите «Терминал» и нажмите «Терминал», чтобы открыть.

- В командной строке введите ниже и нажмите Enter:
cd desktop
- Вставьте следующее:
iconv -c -t utf8 filename.csv> filename.utf8.csv
- Измените имена файлов, чтобы они соответствовали имени на рабочем столе, и нажмите Enter.
- Et Voila! Ваш файл закодирован в UTF-8. Не открывайте файл после конвертации!
Действия для Windows
- Перейдите в меню «Пуск», найдите «cmd» и щелкните cmd, чтобы открыть.
- В командной строке введите следующее (заменив имя пользователя своим именем пользователя Windows) и нажмите Enter:
cd C: \ Users \ (имя пользователя) \ Desktop
- Вставьте следующее:
iconv -c -t utf8 имя файла.csv> filename.utf8.csv
- Измените имена файлов, чтобы они соответствовали имени на рабочем столе, и нажмите Enter.
- Теперь ваш файл закодирован в UTF-8. Не открывайте файл после преобразования, загрузите его в нашу систему.
Фильтр:
Базовый
Стандарт
Исследования рынка
HR Professional
Полный доступ
Составление отчетов
Бесплатно
Физическое лицо
Команда и предприятие
Как конвертировать файлы в кодировку UTF-8 в Linux
В этом руководстве мы опишем, какая кодировка символов и рассмотрим несколько примеров преобразования файлов из одной кодировки символов в другую с помощью инструмента командной строки.Затем, наконец, мы рассмотрим, как преобразовать несколько файлов из любого набора символов (кодировка ) в кодировку UTF-8 в Linux.
Как вы, возможно, уже имели в виду, компьютер не понимает и не хранит буквы, числа или что-либо еще, что мы, люди, можем воспринимать, кроме битов. Бит имеет только два возможных значения: 0 или 1 , истина или ложь , да или нет . Все остальные вещи, такие как буквы, числа, изображения, должны быть представлены в битах, чтобы компьютер мог их обработать.
Проще говоря, кодировка символов — это способ сообщить компьютеру, как интерпретировать необработанные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы вводим текст в файл, слова и предложения, которые мы формируем, состоят из разных символов, а символы организованы в кодировку .
Существуют различные схемы кодирования, такие как ASCII , ANSI , Unicode и другие.Ниже приведен пример кодировки ASCII .
битов символов A 01000001 B 01000010
В Linux инструмент командной строки iconv используется для преобразования текста из одной формы кодирования в другую.
Вы можете проверить кодировку файла с помощью команды file , используя флаг -i или --mime , который позволяет печатать строку типа mime, как в примерах ниже:
$ файл -i Автомобиль.Ява $ file -i CarDriver.javaПроверка кодировки файла в Linux
Синтаксис использования iconv следующий:
$ опция iconv Параметры $ iconv -f from-encoding -t to-encoding inputfile (s) -o outputfile
Где -f или --from-code означает кодировку ввода, а -t или --to-encoding указывает кодировку вывода.
Чтобы вывести список всех известных наборов кодированных символов, выполните следующую команду:
$ iconv -lСписок кодированных кодировок в Linux
Преобразование файлов из UTF-8 в кодировку ASCII
Далее мы узнаем, как преобразовать одну схему кодирования в другую.Приведенная ниже команда преобразует кодировку ISO-8859-1 в UTF-8 .
Рассмотрим файл с именем input.file , который содержит символы:
� � � �
Давайте начнем с проверки кодировки символов в файле, а затем просмотрим содержимое файла. Точно, мы можем преобразовать все символы в кодировку ASCII .
Точно, мы можем преобразовать все символы в кодировку ASCII .
После выполнения команды iconv мы затем проверяем содержимое выходного файла и новую кодировку символов, как показано ниже.
$ файл -i input.file $ cat input.file $ iconv -f ISO-8859-1 -t UTF-8 // ПЕРЕВЕСТИ input.file -o out.file $ cat out.file $ файл -i out.fileПреобразование UTF-8 в ASCII в Linux
Примечание : в случае добавления строки // IGNORE к кодировке в символы, которые невозможно преобразовать, и ошибка отображается после преобразования.
Опять же, предположим, что строка // TRANSLIT добавлена к кодировке, как в приведенном выше примере ( ASCII // TRANSLIT ), преобразованные символы транслитерируются по мере необходимости и, если это возможно.Это означает, что в случае, если персонаж не может быть представлен в целевом наборе символов, он может быть аппроксимирован одним или несколькими похожими персонажами.
Следовательно, любой символ, который не может быть транслитерирован и не входит в целевой набор символов, заменяется вопросительным знаком (?) в выводе.
Преобразование нескольких файлов в кодировку UTF-8
Возвращаясь к нашей основной теме, чтобы преобразовать несколько или все файлы в каталоге в кодировку UTF-8, вы можете написать небольшой сценарий оболочки, называемый кодировкой .ш следующим образом:
#! / Bin / bash
# введите здесь кодировку ввода
FROM_ENCODING = "здесь_значение"
# кодировка вывода (UTF-8)
TO_ENCODING = "UTF-8"
#перерабатывать
CONVERT = "iconv -f $ FROM_ENCODING -t $ TO_ENCODING"
#loop для преобразования нескольких файлов
для файла в формате * .txt; делать
$ CONVERT "$ file" -o "$ {file% .txt} .utf8.converted"
Выполнено
выход 0
Сохраните файл, затем сделайте скрипт исполняемым. Запустите его из каталога, в котором находятся ваши файлы ( *.) расположены.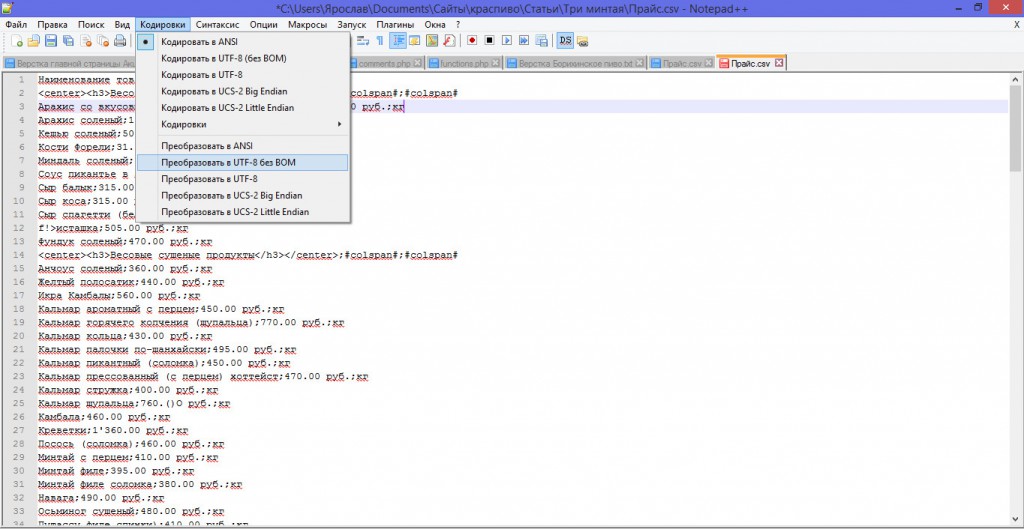 txt
txt
$ chmod + x encoding.sh $ ./encoding.sh
Важно : Вы также можете использовать этот сценарий для общего преобразования нескольких файлов из одной заданной кодировки в другую, просто поиграйте со значениями переменных FROM_ENCODING и TO_ENCODING , не забывая имя выходного файла " $ {file% .txt} .utf8.converted ".
Для получения дополнительной информации просмотрите справочную страницу iconv .
$ человек iconv
Подводя итог этому руководству, понимание кодировки и того, как преобразовывать одну схему кодировки символов в другую, является необходимыми знаниями для каждого пользователя компьютера, в большей степени для программистов, когда дело доходит до работы с текстом.
Наконец, вы можете связаться с нами, используя раздел комментариев ниже, если у вас возникнут какие-либо вопросы или отзывы.
Если вы цените то, что мы делаем здесь, на TecMint, вам следует принять во внимание:
TecMint — это самый быстрорастущий и пользующийся наибольшим доверием сайт сообщества, где можно найти любые статьи, руководства и книги по Linux в Интернете.Миллионы людей посещают TecMint! для поиска или просмотра тысяч опубликованных статей доступны БЕСПЛАТНО для всех.
Если вам нравится то, что вы читаете, пожалуйста, купите нам кофе (или 2) в знак признательности.
Мы благодарны за вашу бесконечную поддержку.
.