HTML кодировка страницы. В какой кодировке сохранять web-страницу? Урок №14
Бывали ли у вас ситуации, когда на web-странице вместо читабельного текста открывались кракозябры? Я уверен, что бывали или, по крайне мере, вы видели их на других сайтах. Если не видели, посмотрите на пример снизу:
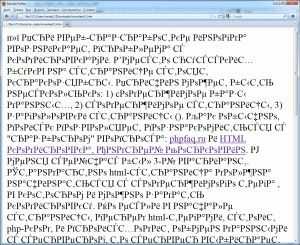
Что такое HTML кодировка?
HTML кодировка – это таблицы соответствия кодов и символов алфавита. То есть, наш компьютер по кодировке поменяет код на понятные читабельные буквы.

Популярные кодировки.
На сегодняшний день существуют две самые популярные кодировки в русскоязычном интернете. Это кодировка windows-1251 и utf-8. Частенько веб-мастерам приходится выбирать, в какой кодировке делать им веб-страничку.
В какой кодировке следует сохранять HTML файл?
Большинство веб-мастеров выбирают кодировку utf-8. И это верный выбор, так как в кодировке utf-8 имеются различные знаки (
Поэтому я рекомендую вам сохранять HTML файлы в кодировке utf-8.
Как задать кодировку UTF-8 для файла?
Чтобы задать кодировку для HTML файла, используют различные редакторы. Я пользуюсь текстовым редактором Notepad++.
Откройте текстовый редактор Notepad++.
Если нужно, создайте новый документ.
Перейдите в меню сверху по вкладке «Кодировки» => «Кодировать в UTF-8 (без BOM)»:

Чтобы сообщить браузеру, в какой кодировке HTML файл, существует специальный META-тег
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
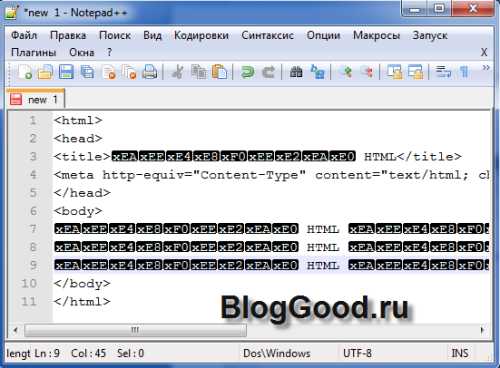
В HTML документе это будет выглядеть вот так:
<html> <head> <title>кодировка HTML</title> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> </head> <body> </body> </html>
Как задать кодировку windows-1251 для файла?
Откройте текстовый редактор Notepad++.
Если нужно, создайте новый документ.
Перейдите в меню сверху по вкладке «Кодировки» => «Кодировать в ANSI»:

Чтобы сообщить браузеру, в какой кодировке HTML файл, существует специальный META-тег
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
В HTML документе это будет выглядеть вот так:
<html> <head> <title>кодировка HTML</title> <meta http-equiv="Content-Type" content="text/html; charset=windows-1251"> </head> <body> </body> </html>
Пример перекодировки файла из windows-1251 в utf-8
Если в HTML документе был прописан код в кодировке windows-1251 (ANSI), а вам нужно перекодировать на utf-8 (или на оборот), тогда сделайте так:
Откройте текстовый редактор Notepad++. В текстовом редакторе перейдите в меню сверху по вкладке «Кодировки» => «Преобразовать в UTF-8 (без BOM)»:

Внимание, если бы вы нажали «Кодировать в UTF-8 (без BOM)», то в результате вы бы увидели вместо любимого русского текста, красивые караказябли .
Понравился пост? Помоги другим узнать об этой статье, кликни на кнопку социальных сетей ↓↓↓
Последние новости категории:
Похожие статьи
Популярные статьи:
Добавить комментарий
Метки: html, основы
bloggood.ru
Как перевести файлы в кодировку UTF-8
Как перевести файлы в кодировку UTF-8
Те, у кого старые сайты, могут столкнуться с такой проблемой, что необходимо перевести файлы в кодировку UTF-8. К их числу я смело могу назвать и себя. Начала делать сайты более 10 лет назад, когда об этой кодировке было мало что известно. На всех страницах у меня стояла кодировка:
<META http-equiv=content-type content=»text/html; charset=windows-1251″>
За эти годы некоторые мои сайты распухли до тысячи и более страниц и переделывать все эти тысячные страницы не хватит никаких сил и времени.
Сейчас уже так не пишут. На смену старому пришло новое — HTML5, где нужно прописать:
<meta charset=»UTF-8″>
Скажу честно, все же решила я все перелопатить вручную и вот как это у меня происходило:
- Открывала файл в Notepad++
- Выделяла весть текст
- Копировала весь текст
- Переводила кодировку в UTF-8
- Вставляла текст
- Проверяла опять — в той ли кодировке стоит?
- Сохраняла файл
И вот два дня я так долбила один свой сайт.
Можно, конечно же и не менять ничего. Но ведь старые сайты мои давно устарели, нужно переводить их и на современную верстку HTML5 и CSS3, плюс мобильную и адаптивную верстку. И лучше это делать в более продвинутых программах, а не в Notepad++.
Короче, приуныла я. Однако приехал сын-программист и все решил!
Оказывается все уже давно придумано. И если у Вас возникла такая же проблема — не отчаивайтесь! Есть прекрасная программа UTFCast Express
Эту программу можно скачать тут — http://www.rotatingscrew.com/utfcast-express.aspx — Это условно бесплатная программа, которая умеет конвертировать текст из разных кодировок в utf8. Доступна для ОС семейства Windows.
Запускаем UTFCast Express и указываем правильные пути: сверху — что конвертировать, снизу — куда складывать конвертированные файлы. Вам нужно просто выбрать нужные директории, программа сама перекодирует все нужные файлы из папки. Нажимаем «Start».
Единственно, заранее создайте новую папку, куда программа закачает все Ваши файлы из нужной папки.
Не забудьте также поставить галочку «Copy Unconverted». Нажимаете кнопочку «Start» и программа заработала!
Всего пара минут и все файлы волшебным образом перекодировались в нужную кодировочку!
Ура, товарищи!!!
Что такое вообще UTF-8
Заметьте, что UTF-8 надо обязательно писать в верхнем регистре и через черточку, то есть никаких там utf-8, utf8 или UTF8. Пишите правильно!
UTF-8 (от англ. Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-битный») — одна из общепринятых и стандартизированных кодировок текста, которая позволяет хранить символы Юникода, используя переменное количество байт (от 1 до 6).
Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D. Кодировка нашла широкое применение в UNIX-подобных операционных системах и веб-пространстве. Сам же формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9. В качестве BOM использует последовательность байт EF16, BB16, BF16 (что у неё самой является трёхбайтовой реализацией символа FEFF16).
Одним из преимуществ является совместимость с ASCII — любые их 7-битные символы отображаются как есть, а остальные выдают пользователю мусор (шум). Поэтому в случае, если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объём текста, UTF-8 даёт выигрыш по объёму по сравнению с UTF-16.
highstar.ru
Проблемы с кодировкой на сайте
Вы здесь: Главная — PHP — PHP Основы — Проблемы с кодировкой на сайте
Одной из самых частых проблем, с которой сталкивается начинающий Web-мастер (да и не только начинающие), это проблемы с кодировкой на сайте. Даже у меня постоянно появляется при создании сайтов «абракадабра«. Но, благо, я прекрасно знаю, как эту проблему решить, поэтому всё привожу в порядок в течение нескольких секунд. И в этой статье я постараюсь научить Вас также быстро
Первое, что стоит отметить, это то, что все проблемы с появлением «абракадабры» связаны с несовпадением кодировки документа и кодировки, выставляемой браузером. Допустим, документ в windows-1251, а браузер почему-то выставляет UTF-8. А уже источником такого несовпадения могут быть следующие причины.
Первая причина
Неправильно прописан мета-тег content-type. Будьте внимательны, в нём всегда должна находиться та кодировка, в котором написан Ваш документ.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
Вторая причина
Вроде бы, мета-тег прописан так, как Вы хотите, и браузер выставляет именно то, что Вы хотите, но почему-то всё равно с кодировкой проблемы. Здесь, почти наверняка, виновато то, что сам документ имеет отличную кодировку. Если Вы работаете в Notepad++, то внизу справа есть название кодировки текущего документа (например, ANSI). Если Вы ставите в мета-теге UTF-8, а сам документ написан в ANSI, то сделайте преобразование в UTF-8 (через меню «Кодировки» и пункт «Преобразовать в UTF-8 без BOM«).
Третья причина
Мета-тег написан правильно, кодировка документа верная, но браузер почему-то настойчиво выбирает другую кодировку. Это уже связано с настройками сервера. Способ решения данной проблемы можно прочитать здесь: как задать кодировку в htaccess.
Четвёртая причина
И, наконец, последняя популярная причина — это проблема с кодировкой в базе данных. Во-первых, убедитесь, что все Ваши таблицы и поля написаны в одной кодировке, которая совпадает с кодировкой остального сайта. Если это не помогло, то сразу после подключения в скрипте выполните следующий запрос:
SET NAMES 'utf8'
Вместо «utf8» может стоять другая кодировка. После этого все данные из базы должны выходить в правильной кодировке.
В данной статье я, надеюсь, разобрал, как минимум, 90% проблем, связанных с появлением «абракадабры» на сайте. Теперь Вы должны расправляться с такой популярной и простой проблемой, как неправильная кодировка, в два счёта.
- Создано 21.05.2012 13:43:04
- Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
<a href=»https://myrusakov.ru» target=»_blank»><img src=»https://myrusakov.ru//images/button.gif» alt=»Как создать свой сайт» /></a>Она выглядит вот так:
-
Текстовая ссылка:
<a href=»https://myrusakov.ru» target=»_blank»>Как создать свой сайт</a>Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):
[URL=»https://myrusakov.ru»]Как создать свой сайт[/URL]
myrusakov.ru
Кодирование и декодирование / Habr
Причиной разобраться в том, как же работает UTF-8 и что такое Юникод заставил тот факт, что VBScript не имеет встроенных функций работы с UTF-8. А так как ничего рабочего не нашел, то пришлось писть/дописывать самому. Опыт на мой взгляд полезный в любом случае. Для лучшего понимания начну с теории.О Юникоде
До появления Юникода широко использовались 8-битные кодировки, главные минусы которых очевидны:
- Всего 255 символов, да и то часть из них не графические;
- Возможность открыть документ не с той кодировкой, в которой он был создан;
- Шрифты необходимо создавать для каждой кодировки.
Так и было решено создать единый стандарт «широкой» кодировки, которая включала бы все символы (при чем сначала хотели в нее включить только обычные символы, но потом передумали и начали добавлять и экзотические). Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
О UTF-8
Когда-то я думал что есть Юникод, а есть UTF-8. Позже я узнал, что ошибался.
UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII. Символы же с кодами от 128 кодируются 2-мя байтами, с кодами от 2048 — 3-мя, от 65536 — 4-мя. Так можно было бы и до 6-ти байт дойти, но кодировать ими уже ничего.
0x00000000 — 0x0000007F: 0xxxxxxx 0x00000080 — 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 — 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 — 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Кодируем в UTF-8
Порядок действий примерно такой:
- Каждый символ превращаем в Юникод.
- Проверяем из какого символ диапазона.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h50
b2 = (c - b1) / &h50
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h50
b2 = ((c - b1) / &h50) Mod &h50
b3 = (c - b1 - (&h50 * b2)) / &h2000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < 0 Then
ToLong = CLng(intVal) + &h20000
Else
ToLong = CLng(intVal)
End If
End Function
Декодируем UTF-8
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Юникода.
Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h4F
b2 = c and &h2F
c = b1 + b2 * &h50
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h4F
b2 = asc(mid(s,i+1,1)) and &h4F
b3 = c and &h0F
c = b3 * &h2000 + b2 * &h50 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function
Ссылки
Юникод на Википедии
Исходник для ASP+VBScript
UPD: Обработка ошибочных последовательностей и ошибка с типом Integer, который возвращает AscW.
habr.com
Как сменить кодировку с UTF-8 на кириллицу — artisteer-rus.com
Чтобы поменять кодировку страницы, напимер с UTF-8 на Windows-1251(кириллицу), можно использовать несколько способов. Для всех надо использовать текстовый редактор Notepad++, или любой подобный.
 Споб первый, самый простой, но не всегда действенный. Открыть нужную Вам страницу HTML или PHP и проделать следующее. В верху страницы между тегами <head> и </head> заменить в строке :
Споб первый, самый простой, но не всегда действенный. Открыть нужную Вам страницу HTML или PHP и проделать следующее. В верху страницы между тегами <head> и </head> заменить в строке :
<meta http-equiv=»content-type» content=»text/html; charset=utf-8″/>
кодировку с utf-8 на Windows-1251 так:
<meta http-equiv=»content-type» content=»text/html; charset=Windows-1251″/>
Дальше выделяем весь код в странице и открываем в Notepad++ вкладку вверху «кодировки»—>еще «кодировки»—> кириллица—>Windows-1251. Смотрим, что получилось. Иногда такой способ помогает, иногда приходится проделать более сложную процедуру. Проделываем все перечисленное выше, до выделения текста, дальше Выделенный код, копируем в простой блакнот Windows (это обязательно, в простой блокнот). Создаем в Notepad++ новую страницу сохраняем её как .html или .php и выбираем для этой новой страницы кодировку, так как описано Выше. После этого обратно копируем текст из простого блакнота Windows (очень важный момент, имено копируем опять из блокнота, а не просто вставляем тот, что находится в буфере обмена (что мы скопировали из Notepad)) Теперь все должно получиться. В описанных процедурах главное понять принип и не запутаться. При проделовании операции, один-два раза вы легко сможете менять кодировку. Аналогичный принцип используется и при обратном преобразовании. Так же иногда нужно преобразовать UTF-8 в UTF-8 без БОМ, Обратите внимание, что кодировки UTF-8 и UTF-8 без БОМ это в принципе очень разные вещи.
artisteer-rus.com
Как быстро изменить кодировку сайта, например, из windows-1251 в UTF-8 — Code Depth
Имеется сайт на PHP, существующий уже много-много лет. Сайт создавался и развивался в кодировке windows-1251, но дальше так жить невозможно, надо весь PHP-код преобразовать в UTF-8, то же самое сделать с html-, css-, js- и прочими файлами, сконвертировать базу данных MySQL и ещё кое-что подправить.
Как быстро выполнить переход сайта на кодировку UTF-8?
Нам помогут знания из статьи про recode и enconv, добавим к ним ещё кое-что.
Все действия можно свести в один bash-скрипт, отдельные части которого рассмотрим в статье.
1. Создать копию всех файлов сайта. Например, сайт находится в /var/www/site. Для работы сайта ещё используются /var/www/dir1, /var/www/dir2, /var/www/dir3, причём dir1 и dir2 надо перекодировать вместе с site, а dir3 не надо трогать. Скопируем всё в /var/www-u8. Для удобства будем использовать переменные, в которых сохраним часто используемые строки.
dir_source=’/var/www’
dir_u8=’/var/www-u8′
cp -R ${dir_source}/* ${dir_u8}
Массив, содержащий имена подкаталогов, в которых надо обработать файлы:
subdirs=(site dir1 dir2)
Во всех подкаталогах надо перекодировать из windows-1251 в UTF-8 все файлы с расширениями: php, txt, js, css, htm. Нам поможет enconv. Затем найти подстроки «windows-1251» или «cp1251» и заменить на «UTF-8». Наконец, найти в php-файлах короткий открывающий тег «<?» и заменить его на полный «<?php». Регулярное выражение для поиска короткого тега ищет строку ‘<?’, после которой следует пробел, конец строки или символ ‘=’ (для файлов, в которых php-код используется вперемешку с html для вставки значений переменных: ‘<?=$var;?>’). Все замены поможет выполнить могучий sed, а с подбором файлов для обработки отлично справится find. Поскольку обработку надо выполнить в нескольких подкаталогах (их имена хранятся в массиве $subdirs), то перебираем элементы массива в цикле (подробнее про использование массивов в bash) и из них составляем путь для поиска командой find.
for item in ${subdirs[*]}
do
sPath=${dir_u8}/${item}
find ${sPath} -iregex '.*\.\(txt\|php\|css\|js\|html?\)' -exec enconv -L russian -x utf8/LF '{}' \;
find ${sPath} -iregex '.*\.\(txt\|php\|css\|js\|html?\)' -exec sed -i -r 's/windows-1251|cp1251/UTF-8/ig' '{}' \;
find ${sPath} -iname '*\.php' -exec sed -i -r 's/(<\?)(\s|$|=)/<?php\2/ig' '{}' \;
doneС перекодировкой базы данных MySQL вообще всё просто. Надо сделать дамп данных, в области описания таблиц заменить строки, определяющие кодировку, загрузить дамп в новую в базу. Примерно так:
HOST_1='localhost'
USER_1='user1'
PASSWORD_1='password1'
DATABASE_1='database1'
HOST_2='localhost'
USER_2='user2'
PASSWORD_2='password2'
DATABASE_2='database2'
DUMPFILE_1="db-${DATABASE_1}.sql"
DUMPFILE_2="db-${DATABASE_2}.sql"
# dump from the original DB
mysqldump -u ${USER_1} -h ${HOST_1} -p${PASSWORD_1} --opt ${DATABASE_1} > ${DUMPFILE_1}
# Replace charset settings from cp1251 to utf8
sed -r 's/CHARSET=cp1251/CHARSET=utf8/ig' ${DUMPFILE_1} > ${DUMPFILE_2}
# Load data from the dump
mysql -u ${USER_2} -h ${HOST_2} -p${PASSWORD_2} ${DATABASE_2} < ${DUMPFILE_2}В скрипте все переменные, имена которых оканчиваются на «1», относятся к исходной базе данных, работающей в кодировке cp1251. Все переменные, имена которых оканчиваются на «2», относятся к новой базе данных, которая будет использоваться в перекодированном в utf-8 сайте.
Осталось установить для файлов в ${dir_u8} нужные права доступа, при необходимости настроить контекст безопасности SELinux и, наконец, настроить вебсервер для визуальной проверки перекодированного сайта.
Если свести воедино все фрагменты bash-скрипта, написанные на этой странице, то, фактически, весь процесс изменения кодировки сайта на utf-8 окажется простым и быстрым.
Поделиться ссылкой:
Понравилось это:
Нравится Загрузка…
Похожее
codedepth.wordpress.com
Как сменить кодировку файла? Notepad++ редактор с подсветкой синтаксиса, кодировка Utf-8 без BOM

Notepad++ — отличный текстовый редактор!
В статье о кодировках текста я описал основные моменты, показывающие, почему необходимо учитывать кодировку файла (например, при создании html-страницы). Здесь же я опишу простой способ выставления нужной кодировки текста с помощью простого и быстрого редактора Notepad++.
Чтобы скачать данную программу, заходим на официальный сайт — Notepad-plus-plus.org — далее ищем ссылку «download», кликаем по ней и выбираем «Notepad++ v*** Installer», где вместо звёздочек будет текущая версия редактора. Скачиваем и устанавливаем, никаких сложностей при установке нет.
Чем вообще хорош этот редактор?
Во-первых, подсветка синтаксиса — редактор Notepad++ неплохо понимает разные языки программирования (тип языка определяется по расширению файла, например file.php — php-файл, index.html — html-файл) и производит автоматическую подсветку управляющих конструкций языка.
Notepad++ понимает php и подсвечивает синтаксис языка. Кликабельно
Во-вторых, в нём можно легко изменить кодировку текстового файла на нужную (чтобы быстро её сменить, щёлкаем вкладку «Кодировки», затем «Преобразовать в …» — кликайте рисунок ниже) и, что самое главное, отредактировать любой файл без изменения текущей кодировки (кодировка не «слетает»).
Последняя особенность очень важна, например, при редактировании шаблонов движка вашего сайта (напр., WordPress). Почему? Потому что все файлы WP по умолчанию имеют кодировку Utf-8. Если менять их стандартным блокнотом Windows, то к кодировке Utf-8 добавляется специальная BOM-последовательность. Необязательно знать, что это такое, но из-за неё некоторые функции движка работать вообще не будут. Поэтому так важно, чтобы все файлы шаблонов WP были сохранены в кодировке Utf-8 без BOM.
Преобразование в кодировку Utf-8 без BOM
Теперь, чтобы открыть текстовый файл данным редактором, надо кликнуть по нему правой кнопкой мышки и выбрать соответствующий пункт меню:
Открытие .txt файлов Notepad++
Таким образом, установив на свой компьютер программу Notepad++ можно получить многофункциональный редактор текста с подсветкой синтаксиса и возможностью манипуляций с кодировками.
Loading…web-ru.net