Как выглядел сайт раньше — пошаговая инструкция, как посмотреть
Как узнать, как сайт выглядел раньше?
Иногда хочется вспомнить те времена, когда по интернетам бродили динозавры, а одна песня загружалась 10 минут. Смотрим в прошлое и ностальгуем, спасибо за это онлайн-сервису: Wayback Machine – Internet Archive. Работает с 1996 года, за это время собрал в базе данных более 279 миллиардов веб-страниц.
Переходим по ссылке: http://archive.org/web/web.php В строку вводим: адрес интересующего сайта и нажимаем «Browse History». Система выдаст всю историю по конкретному порталу.
Синими кругами на календаре обведены даты резервных копий. Выбираем нужный год, дату и заглядываем в прошлое веб-страницы.
Где посмотреть, как выглядели страницы сайтов в разные годы
Яндекс в это время открыл первый удаленный офис в Питере, запустил Яндекс.пробки и «словари». А майл.ру начали использовать поисковик на своем портале.
Google запускают календарь, финансы и переводчик. Открывают бесплатный хостинг изображений Picasa и объявляют о покупке YouTube. В 2007 компания установит крупнейшую систему солнечных батарей (Сейчас она обеспечивает энергией 30% офисов) и объявит о появлении Android. А сотрудники начинают ездить по офисам на велосипедах gBikes.
История Facebook уникальна. Только в 2004 году сервис вышел за стены Гарварда, а уже в 2008 вырос так, что количество пользователей перевалило за 50 млн. человек, а состояние Марка Цукерберга уже оценивалось в 1.5 млдр. долларов.
Как раньше выглядел наш сайт
А вот так менялся наш сайт с 2006 года:
iPipe – надёжный хостинг-провайдер с опытом работы более 15 лет.
Мы предлагаем:
Как узнать историю сайта | SeoProfy.ua
Если вы задумывались о том, есть ли история у сайтов? То она таки есть, и ее можно посмотреть.
Данная статья про то, как посмотреть и узнать историю сайта. Ведь дизайны сайта меняются постоянно, а так же у доменных имен появляются разные владельцы, и облик сайтов меняется.
В интернете существует сайт, который еще называют машина времени, только она работает только для прошлого. С помощью этого сайта мы и сможем узнать историю.
Принцип работы сайта заключается в том, что он индексирует сайты интернета, и сохраняет их в разное время.
Для начала переходим по ссылке: http://archive.org/web/web.php
Вводим адрес, например Google.com, и нажимаем смотреть:
Как мы видим, история для поисковой системы Гугл учитывается с 1998 года, дальше выбираем 1998 год, выбираем доступную дату и смотрим:
Дальше смотрим, как выглядел сайт поискового гиганта в то время.
А так выглядела поисковая система Яндекс в 1998 году:
Таким образом, мы сможем посмотреть любой нас интересующий сайт, особенно если сайт популярный, то его история записывалась постоянно.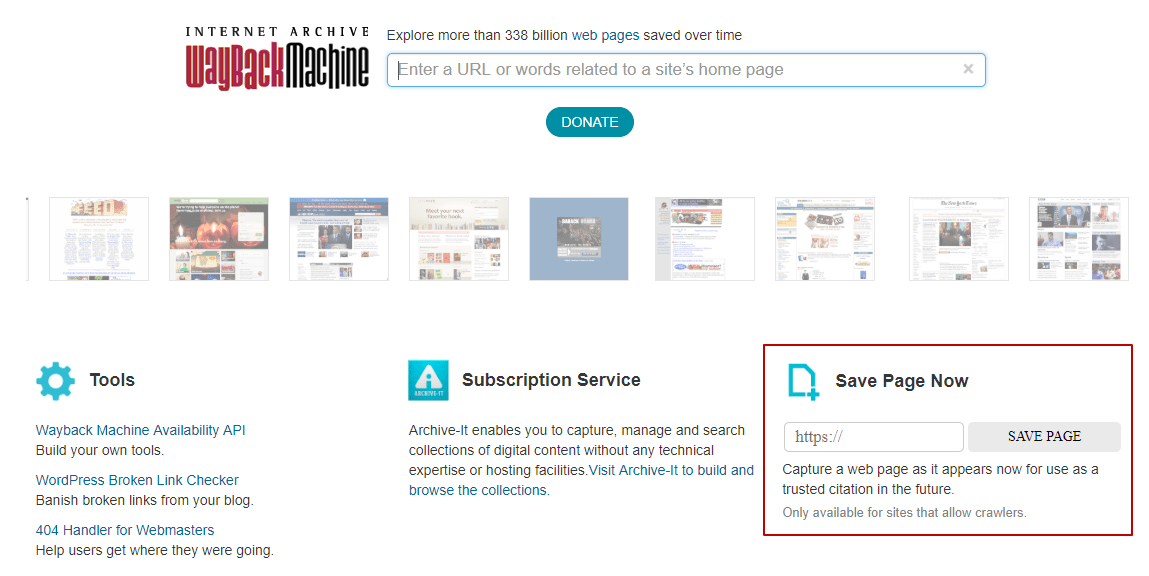
В базе сервиса веб архива более 450 миллионов сайтов. Конечно, там не сохранены все сайты, но очень много. Сервис по просмотру истории сайтов абсолютно бесплатный и может пригодиться в разных случаях.
Основные моменты, когда нужно узнать историю сайта:
1. Узнать тематику сайта
С помощью веб архива мы сможем посмотреть содержание, которое было на домене, и узнать тематику ресурса.
2. Посмотреть каким сайт был в разные времена
Как я уже говорил, довольно таки часто люди забрасывают сайты, и многие seo оптимизаторы охотятся на такие домены, что бы сделать на них сайты. С помощью веб архива мы смотрим его содержание, его историю, и решаем, нужен ли нам такой домен.
Если вы хотите посмотреть и узнать историю сайта – используйте веб архив, это довольно таки полезный инструмент.
Помимо сайтов в веб архиве можно смотреть видео, музыку, картинки.
Оцените статью
Загрузка. ..
..Как узнать историю сайта, домена в прошлом?
История сайта – как ее узнать?
Многие пользователи Интернета даже не подозревают, что у каждого ресурса есть своя история. Это общедоступная информация и узнать историю сайта может каждый пожелавший.
Часто бывает такое, что может измениться дизайн какого-либо ресурса, смениться логотип, доменное имя, структура, меню и многие другие параметры. В общем, меняется внешний вид и это нормально, ведь с каждым днем разрабатываются новые стили, новые шаблоны, грех не воспользоваться.
Все изменения, произведенные на площадке, будут сохранены на специальном ресурсе, название которому — машина времени для сайтов (или «веб архив»). К сожалению, у нее есть только функция перемещения в прошлое.
Суть работы сервиса в том, что он сохраняет все изменения на сайтах, реализованные в различные периоды времени. Как проверить историю домена? Допустим, вы захотели узнать, сколько лет дядьке Гуглу, и какая у него история. Клацаем сюда archive.org/web/web.php. В поисковой строке пишем Google.com и жмем BROWSE HISTORY!
Клацаем сюда archive.org/web/web.php. В поисковой строке пишем Google.com и жмем BROWSE HISTORY!
Откроется специальный календарь с синими и зелеными отпечатками. Сверху панель с разными годами, а небольшой график черного цвета на ней показывает, в какие даты происходило больше изменений, а в какие меньше. Google было положено начало в 1998 году. Нажав на него, нам представится такая картина в 2002 году:
То же самое можно проделать с поисковой системой Яндекс, а увидим мы следующее:
Подобным способом можно найти любую информацию о каждом сайте, интересующем вас. На сегодняшний день около 324 миллиардов веб страниц сохранено в архиве. И это еще не все площадки. Пригодиться веб архив может в различных ситуациях, а его бесплатное использование дает возможность любому человеку черпать знания из него.
Машина времени может понадобиться в таких ситуациях:
- Если необходимо узнать, какая была тематика.
 Покупая домен у его владельца, хорошо бы знать историю площадки, какое было содержимое, хороший контент или нет, и какая вообще была тематика ранее. Это поможет в дальнейшем продвижении.
Покупая домен у его владельца, хорошо бы знать историю площадки, какое было содержимое, хороший контент или нет, и какая вообще была тематика ранее. Это поможет в дальнейшем продвижении. - Узнать, что из себя представлял ресурс. Множество площадок остаются без присмотра, а история домена хранится, поэтому любители посидеть в архиве ведут охоту на такие доменные имена, дабы ими воспользоваться для повторного создания площадки, только уже своей.
Благодаря веб архиву вы всегда сможете оценить, какой была история сайта целиком, а потом уже решать, приобретать такой домен или нет.
Webarchive — веб-архив всего интернета и сайтов или машина времени на archive.org
Главная / Лучшие онлайн-сервисы3 января 2021
- Как можно использовать архив сайтов интернета?
- Условия попадания сайта в archive.org
- Как найти нужный веб-архив и восстановить из него сайт?
- Как вытянуть из Webarchive уникальный контент?
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo. ru. Не так давно я писал про то, что такое народная энциклопедия Википедия, которая безусловно заслуживает всяких лестных эпитетов, несмотря на присущие ей небольшие недостатки и критику ее статей со стороны научного сообщества.
ru. Не так давно я писал про то, что такое народная энциклопедия Википедия, которая безусловно заслуживает всяких лестных эпитетов, несмотря на присущие ей небольшие недостатки и критику ее статей со стороны научного сообщества.
Сам факт того, что некоммерческий проект уже не одно десятилетие трудится на благо всего интернет сообщества, заслуживает огромного уважения. Но в сети есть еще подобный масштабный проект, который не получая с этого дохода выполняет очень важную роль — сохраняет архивы сайтов, видео, аудио и печатной продукции.
Я говорю, конечно же, про web.archive.org — глобальный проект с казалось бы невыполнимой миссией — создание архива всех сайтов, когда либо размещенных в интернете. Причем, сайты сохраняются не в виде скриншотов, а в виде полноценно работающих веб-страниц со всеми ссылками, картинками и стилевым оформлением (CSS). Причем, для каждого сайта за время его существования в сети в этом архиве может накопиться и по несколько сотен копий, датированных разными этапами жизни ресурса.
Как можно использовать архив сайтов интернета
Чем же может быть полезен данный webarchive?
- Ну, во-первых, вы можете погрузиться в приятную ностальгию путешествуя по вашему сайту многолетней давности. Проследить историю изменений можно будет для любого другого ресурса интернета (например, я брал скриншоты для статей про уже умерший Апорт именно из это вебархива, да и скриншоты, иллюстрирующие эволюцию главной страницы Яндекса, имеют тоже самое происхождение).
- Но это не все. Если страница добавленного вами в закладки сайта не открывается, то вы, конечно же, можете попробовать вытащить ее из кеша Яндекса или Гугла (читайте подробнее про то, как лучше искать в Google). Но если ресурс недоступен уже очень давно, то такие мертвые ссылки нигде кроме archive.org открыть уже будет не возможно (правда, и там его может не оказаться по описанным чуть ниже причинам).
- Так же, если вы по каким-либо форс-мажорным обстоятельствам не делали бэкап (резервное копирование) вашего сайта, то данный web archive будет единственной возможностью восстановить свой сайт.
 Имеется возможность очистить все ссылки от привязки к web.archive.org и сделать их прямыми именно для вашего ресурса (читайте об этом ниже).
Имеется возможность очистить все ссылки от привязки к web.archive.org и сделать их прямыми именно для вашего ресурса (читайте об этом ниже). Ну, и последнее, что приходит в голову — поиск уникального контента. Если вы не способны сами создавать уникальный контента для сайта (писать статьи), то здесь вы сможете ими разжиться, правда, усилия приложить все равно придется. Суть такова, что многие сайты умирают и становятся недоступны вместе с имеющимся на них контентом.
Отыскав такие ресурсы вы сможете вытащить тексты из интернет-архива и разместить их у себя, предварительно проверив их на уникальность. Таким образом вы не занимаетесь плагиатом и не нарушаете авторские права (копирайт), но искать в вебархиве многим может показаться очень уж трудоемкой задачей.
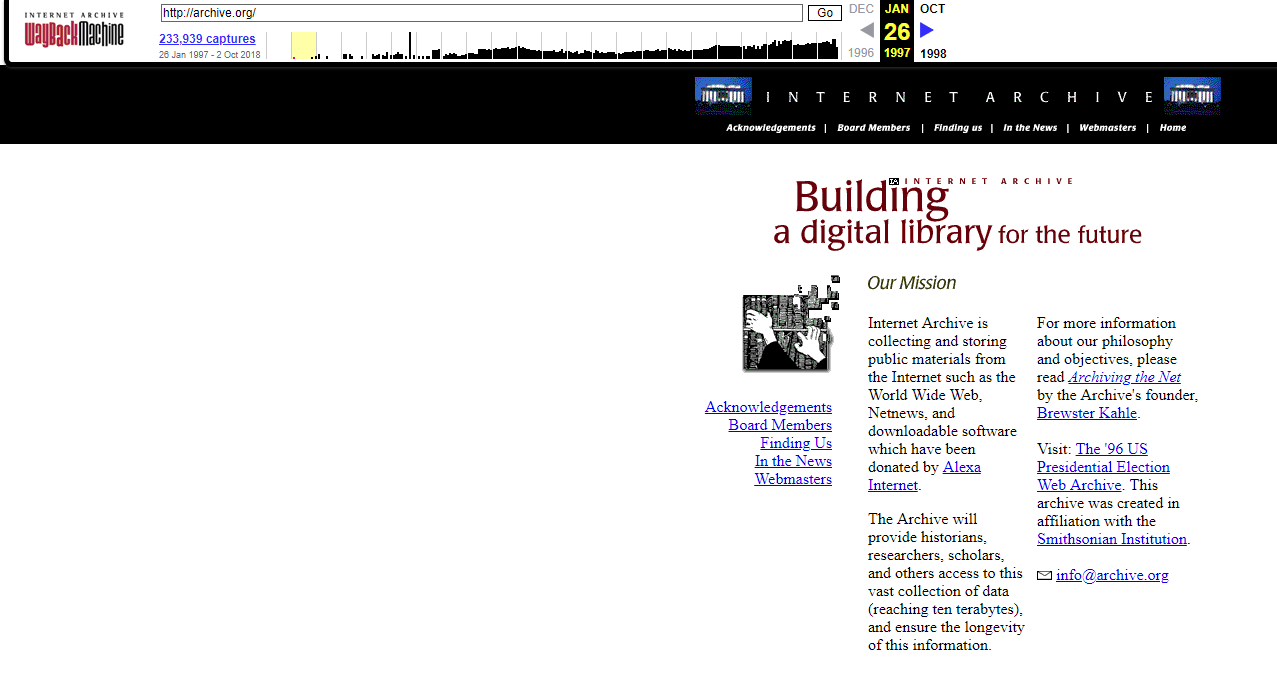
Онлайн сервис Webarchive ведет свою историю аж с 1996 года. Поставленная перед проектом задача казалась невыполнимой даже с учетом того, что сайтов на то время в интернете было значительно меньше, чем сейчас (на несколько порядков). По началу, сайты архивировались не очень часто, но со временем, повышая мощности хранилищ, Веб-архив стал делать все больше и больше слепков сайтов.
По началу, сайты архивировались не очень часто, но со временем, повышая мощности хранилищ, Веб-архив стал делать все больше и больше слепков сайтов.
Сам себя этот веб архив занес в базу лишь в 1997 году и выглядела его главная страница тогда так:
Сейчас на все про все (включая аудио, видео и отсканированные книги) у этой некоммерческой организации задействовано дисковое пространство чудовищных размеров, измеряемое десяткой с пятнадцатью нулями байт. Сайт имеет зеркала в различных дата центрах, а сам проект с недавних пор получил официальный статус библиотеки. Если рассматривать только архив страниц сайтов, то их уже там насчитывается около ста миллиардов (тут учитываются все слепки страниц когда-либо снятые и сохраненные).
На главной странице доступен не только архив страниц интернета Wayback Machine, но и архивы различных кинохроник, телепередач, аудио записей и отсканированных в различных библиотеках книг:
Но нас интересует именно область WEB с логотипом Wayback Machine. В расположенную там форму можно ввести URL или доменное имя интересующего вас сайта (читайте про то, что такое домен и чем он отличается от URL), чтобы попасть на страницу с календарем:
В расположенную там форму можно ввести URL или доменное имя интересующего вас сайта (читайте про то, что такое домен и чем он отличается от URL), чтобы попасть на страницу с календарем:
Из приведенного примера видно, что мой блог был впервые архивирован 27 августа 2009 года (через пять дней после регистрации (покупки) домена ktonanovenkogo.ru). За прошедший интервал времени было создано 125 архивных копий сайта, каждую из которым можно будет посмотреть и потрогать руками (осуществляя переходы по внутренним ссылкам).
Открытие мертвых ссылок и условия попадания сайта в archive.org
В календаре голубыми кружочками отмечены даты, в которые был создан слепок (вебархив) данного сайта. Естественно, что моменты снятия слепка никак не будет коррелироваться с производимыми на вашем ресурсе изменениями, и их время Webarchive определяет строго исходя из своих внутренних алгоритмов и таймеров.
Поэтому использовать архив интернета, как инструмент для открытия временно недоступных сайтов, наверное, не всегда будет резонным.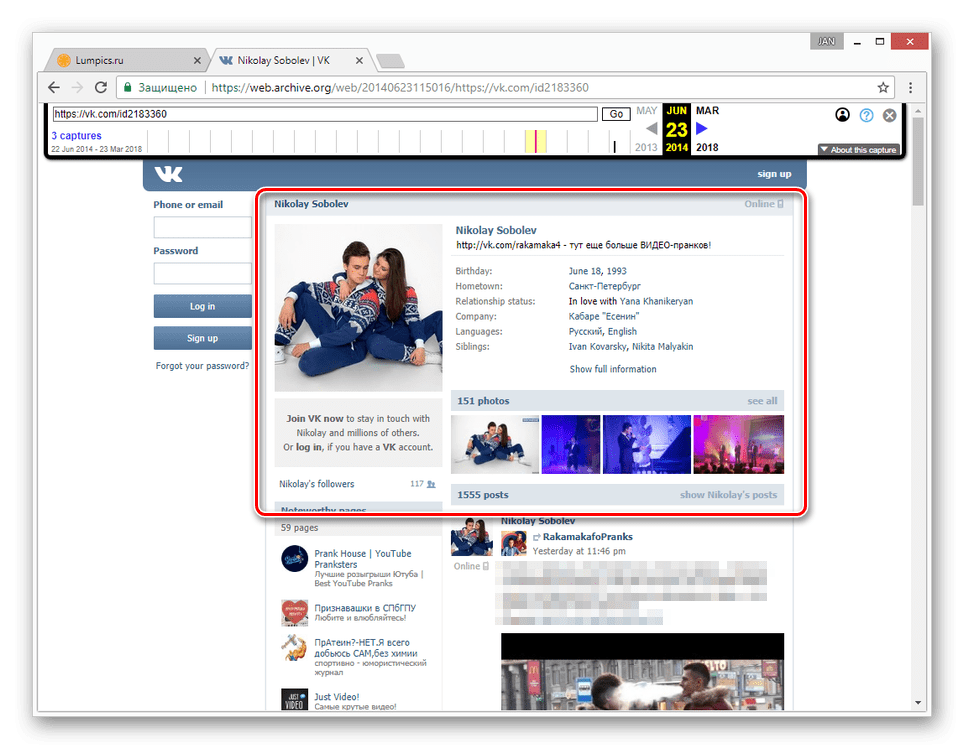
Да, и в Google можно всегда посмотреть сохраненную копию веб-страницы:
Данный же онлайн сервис понадобится в особо тяжелых случаях, когда искомая страница уже не существует и вряд ли уже будет существовать в реальном интернете, но зато она по прежнему будет доступна в машине времени.
Правда, тут должно быть соблюдено несколько условий того, чтобы сайт попал в archive.org:
Он не должен содержать в своем файле robots.txt запрет для его индексации роботом с web.archive.org. Такой запрет, обычно выглядит так:
User-agent: ia_archiver Disallow: /
Когда я писал статью про электронную почту mail.ru, то не смог найти в Архиве Интернета сохраненных копий сайта mail.ru, т.к. его файл robots.txt содержал в себе похожий запрет:
- Некоторые сайты Вебархив по каким-либо причинам банально не нашел. Вероятность попадания ресурса в базу повышается, если он будет добавлен в каталог Dmoz или же если на него будут проставлены ссылки с других популярных ресурсов, которые в Webarchive уже находятся.
 В общем то, даже простой запрос через форму на главной странице этого сервиса может послужить толчком к привлечению внимания этого архиватора к вашему ресурсу.
В общем то, даже простой запрос через форму на главной странице этого сервиса может послужить толчком к привлечению внимания этого архиватора к вашему ресурсу.
Как найти нужный веб-архив и восстановить сайт без бекапа
По архивам можно перемещаться и с помощью временной шкалы расположенной вверху страницы, где вертикальными черными черточками отмечены имеющиеся для этого сайта слепки. Иногда, веб-архивы могут быть битыми, тогда придется открыть ближайший к нему слепок.
Щелкнув по голубому кружочку мы можем увидеть ссылки на несколько архивов, отличающихся временем их снятия.
Возможно, что это делается во избежании потери данных за счет неизбежной порчи жестких дисков в хранилищах. Перейдя к просмотру одного из веб-архивов, вы увидите копию своего (в данном примере моего) сайта с работающими внутренними ссылками и подключенным стилевым оформлением. Правда, не идеально работающим.
Например, кое-что из дизайна у меня все же перекосило и боковое меню работающее на ДжаваСкрипте полностью исчезло:
Но это не столь важно, ибо в исходном коде страницы с web. archive.org это меню, естественно, присутствует. Однако, просто так скопировать текст этой страницы к себе на сайт взамен утерянной не получится. Почему? Да потому что путешествие внутри сайта из прошлого будет возможно лишь в случае замены всех внутренних ссылок на те, что генерит Webarchive (в противном случае вас перебросило бы на современную версию ресурса).
archive.org это меню, естественно, присутствует. Однако, просто так скопировать текст этой страницы к себе на сайт взамен утерянной не получится. Почему? Да потому что путешествие внутри сайта из прошлого будет возможно лишь в случае замены всех внутренних ссылок на те, что генерит Webarchive (в противном случае вас перебросило бы на современную версию ресурса).
Выглядят эти ссылки примерно так:
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/seo/search/samostoyatelnoe-prodvizhenie-sajta-kak-prodvigat-samomu-vnutrennej-optimizaciej.html
Понятно, что можно будет вручную отсечь вступительную часть ссылок (http://web.archive.org/web/20111013120145/), получив таким образом рабочий вариант. Можно этот процесс даже автоматизировать с помощью инструмента поиска и замены редактора Notepad, но еще проще будет воспользоваться встроенной в этот сервис возможностью замены внутренних ссылок на оригинальные.
Для этого копируете адрес страницы с нужным слепком вашего сайта (из адресной строки браузера — начинается с http://web.). Он будет иметь примерно такой вид: archive.org/
archive.org/
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/
И вставляете в него конструкцию «id_» в конце даты (20111013120145), чтобы получилось так:
http://web.archive.org/web/20111013120145id_/https://ktonanovenkogo.ru/
Теперь измененный адрес обратно возвращаете в адресную строку браузера и жмете на Enter. После этого страница c архивом вашего сайта обновится и все внутренние ссылки станут прямыми. Можно будет копировать текст статьи из исходного кода вебархива.
Понятно, что восстановление таким образом огромного сайта займет чудовищное количество времени, но когда другого варианта нет, то и такой покажется манной небесной. К тому же, страдают невозвратной потерей контента обычно только начинающие вебмастера, у которых этого самого контента было мало, а более-менее опытные сайтовладельцы, уж не раз обжигавшиеся на подобных вещах, делают бэкапы файлов и базы по пять раз на дню.
Если вы захотите увидеть все страницы вашего (или чужого) сайта, которые содержатся в недрах этого мастодонта, то вам нужно будет вставить в адресную строку браузера следующий адрес и нажать Enter:
http://wayback.archive.org/web/*/ktonanovenkogo.ru*
Вместо моего домена можно использовать свой. На открывшейся странице вы получите возможность наложить фильтр в предназначенной для этого форме:
Например, я захотел увидеть лишь текстовые файлы своего блога, которые заглотил Web Archive. Зачем — не знаю, но захотел.
Как вытянуть из Webarchive уникальный контент для сайта
Описанный ниже способ лично я не использовал, но чисто теоретически все должно работать. Саму идею я почерпнул на этом молодом ресурсе, где и были описаны все шаги. Принцип метода состоит в том, что каждый день умирают и никогда не возрождаются десятки сайтов.
Причин этому может быть много и большинство из почивших в бозе ресурсов никакой особой ценности в плане контента никогда и не представляли. Но из всякого правила бывают исключения и нужно будет всего-навсего отделить зерна от плевел. Главное чтобы исчезнувшие сайты с более-менее удобоваримым контентом были бы представлены в Web Archive, хотя бы одной копией.
Но из всякого правила бывают исключения и нужно будет всего-навсего отделить зерна от плевел. Главное чтобы исчезнувшие сайты с более-менее удобоваримым контентом были бы представлены в Web Archive, хотя бы одной копией.
Т.к. после смерти контент этих сайтов постепенно выпадет из индекса поисковых систем, то взяв его из интернет-архива вы, по идее, станете его законным владельцем и первоисточником для поисковых систем. Замечательно, если будет именно так (есть вариант, что еще при жизни ресурса его нещадно могли откопипастить). Но кроме проблемы уникальности текстов, существует проблема их отыскания.
Во-первых, нам нужен список сайтов, которые скоро умрут или уже померли. Автор метода предлагает скачать с сайта регистратора доменных имен Nic.ru список освобождающихся или уже освободившихся доменов.
Что примечательно, в последней колонке этого списка (его можно открыть в Excel) будет отображаться количество архивов, созданных для каждого сайта в Web Archive (правда, проверить наличие домена в веб-архиве можно и в ряде онлайн сервисов).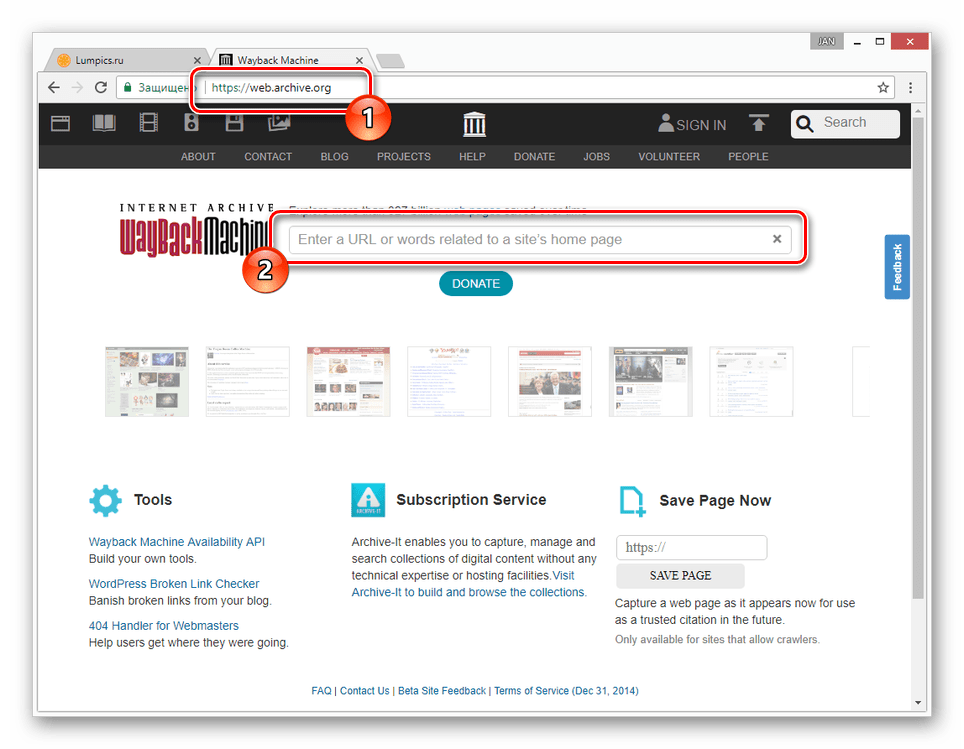
Список буржуйских доменных имен, освобождающихся или уже освободившихся, предлагается скачать по этой ссылке. Ну, а дальше просматриваем содержимое сайтов, которое сохранил Web Archive и пытаемся найти что-то стоящее. Потом проверяем уникальность этих материалов (ссылку приводил чуть выше) и в случае удачи публикуем их на своем ресурсе, либо продаем в какой-нибудь бирже контента.
Да, способ муторный и мною лично не проверенный. Но, думаю, что при некоторой степени автоматизации и обмозговывания он может давать неплохой выхлоп. Наверное, кто-нибудь уже это поставил на поток. А вы как думаете?
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Использую для заработка
Как узнать историю сайта и домена или назад в прошлое.
Прошлое должно оставаться в прошлом, но иногда нужно вернуться, чтобы рассмотреть детали…
Здравствуйте, дорогие мои читатели!
Я очень люблю узнавать что-то новое. Ведь так здорово, когда наш багаж знаний пополняется.
Пару лет назад я совершенно случайно узнала об одном сервисе. Привело меня к этому простое любопытство. Просто захотелось узнать, как выглядел определённый сайт на самом первом этапе развития, и каков был его первоначальный дизайн.
Разве это не интересно?
А ещё интересно это не просто как банальное любопытство. Если человек захотел купить себе уже готовый, используемый раньше домен, то не мешало бы посмотреть, какой на нём был раньше сайт, какой тематики он был и как он выглядел. Это очень важно. Так надо делать, чтобы быть уверенным в том, что вы покупаете на самом деле. Ведь кота в мешке покупать не очень то хочется.
И ещё. Нам нравятся не все сайты подряд, даже если они выглядят аккуратно и всё там реализовано так, как положено.
Мы посещаем самые различные сайты, и на одних сайтах мы бываем мимолетом, а на других задерживаемся и ставим на них закладки, чтобы возвращаться вновь и вновь.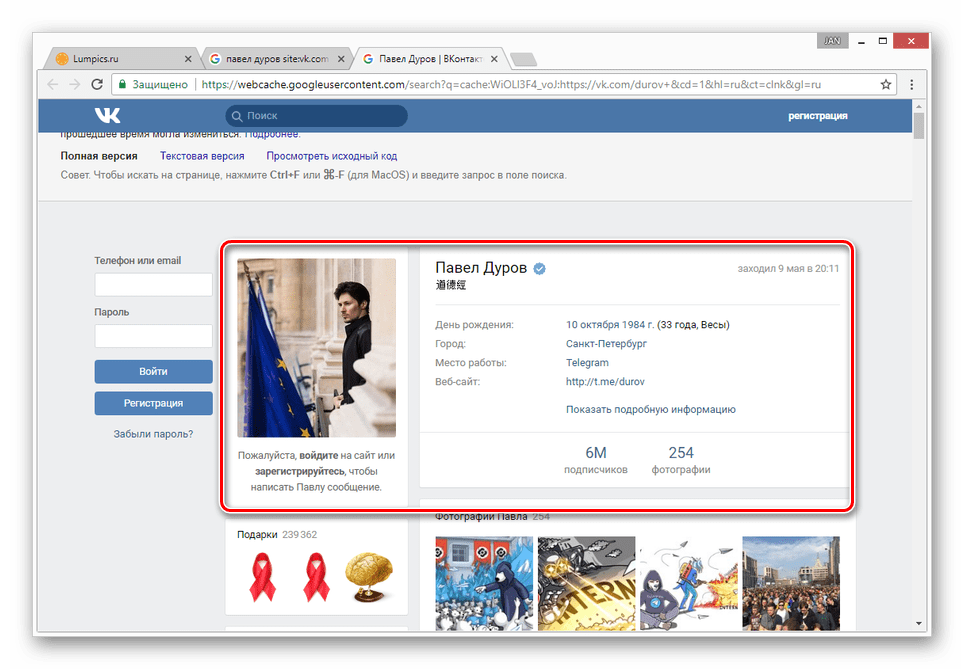
От чего это зависит?
У всех по разному, и как бы блогер или администрация сайта не старались, всем понравится не возможно. И не стоит расстраиваться по этому поводу, если ваш блог кому то не понравился.
Кому не нравится,те пройдут мимо. А если уж блог понравился, то у человека возникает естественное чувство любопытства, особенно если это веб. мастер:
КАК УЗНАТЬ ИСТОРИЮ САЙТА И ДОМЕНА?
То, какими мы сейчас видим сайты в интернете, на это влияет мода, прогресс и просто удобство для читателей. Это всё изучает каждый веб. мастер, ведь для того чтобы быть любимым и интересным, надо соответствовать.
А любому веб.мастеру всегда интересен вопрос:
Как же все-таки можно узнать историю сайта блоггера, живущего по соседству в интернете=)?
Всё просто. Это узнать можно быстро. Для этого сядем поудобнее перед компьютером и переместимся на специальной машине времени назад, в прошлое.
В интернете существует специальный веб-архив и в нем сохраняются все изменения сайта на протяжении нескольких лет.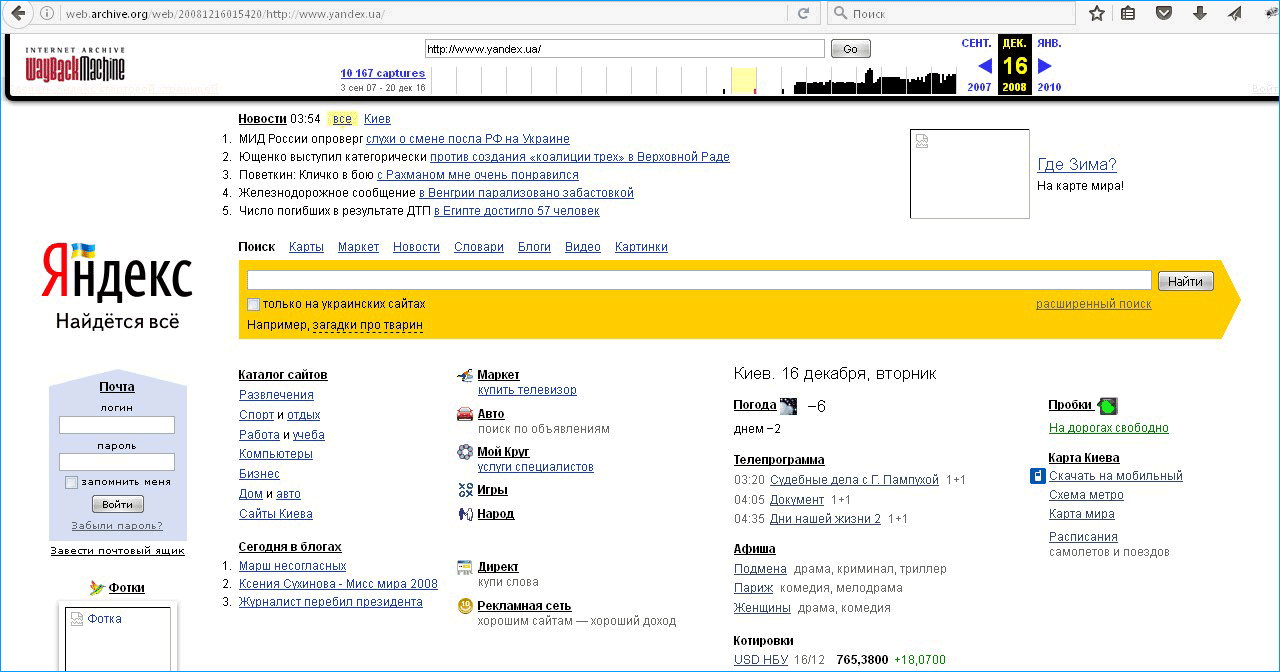 Просто делаются скриншоты (фотографии) всех страниц сайта.
Просто делаются скриншоты (фотографии) всех страниц сайта.
Стоит отметить, что история сайта сохраняется не в виде простых скриншотов, а в виде работающих веб-страниц со всеми файлами.
Если сайт достаточно популярный, то фотографии делаются чаще, если нет, то бот-фотограф заходит туда реже или не заходит совсем, если сайт перестал обновляться. Это из личных наблюдений. Так как этот сайт веб- архив работает по своим правилам, и не всегда поддаётся логике.
Этот сайт, на который мы сейчас попадём, некоммерческий проект, и он уже достаточно долгое время работает на благо всех интернет пользователей.
Этот факт заслуживает к нему уважения. Это как Википедия, только немного с другими целями.
Как посмотреть историю сайта в архиве?
Нам нужно перейти по ссылке:
http://www.archive.org/web/web.php
Откроется страница, с формой поиска, в которую нужно вписать адрес сайта.
Далее, нажимаем: ПРОСМОТРЕТЬ ИСТОРИЮ.
Например, вот один из известных сайтов:
http://www.fast-torrent.ru/
Вписываем адрес сайта и смотрим, что получилось:
Перед вами откроется новая страница, где будет показан календарь и указаны даты, когда это сайт был сфотографирован. Вы сможете проследить всю историю развития сайта, исходя из сохранённых фотографий.
В календаре голубыми кружочками отмечены даты, когда был создан снимок данного сайта.
Нужно просто нажать на число, выделенное голубым цветом. Вы увидите скриншот, как выглядел сайт в тот момент. Будет виден дизайн, и последние статьи и новости.
Кстати, если вы по каким-либо причинам не сделали бэкап сайта, то не стоит совсем отчаиваться от потерянной навеки информации. Данный ресурс поможет вам восстановить сайт.
Понятно, что восстановление таким образом своего сайта займет огромное количество времени, но когда другого варианта нет, как бы это не звучало, то любая возможность будется казаться самой лучшей.
К тому же, такая беда может случится обычно у начинающих веб мастеров, и значит контента будет не так то много, так что берите в руки своё терпение и по детально восстанавливайте свои статьи.
Хотя всем желаю, чтобы таким образом этот ресурс вам не пригодился никогда!
Как можно посмотреть страницы определённого сайта?
Итак, надо ввести в адресную строку Яндекса или Гугла такой адрес:
http://wayback.archive.org/web/*/internetkapusta.ru/*
Вместо моего введите тот, что надо для просмотра.
Вы попадёте на машине времени назад, где можно посмотреть все сохранённые страницы, если они были запротоколированы.
Вот такие адреса у меня были в начале ведения блога:
А вот такие, красивые, уже впоследствии:
Нажимаем на любую ссылку и смотрим, какой был сайт в это время по этой ссылке:
Мы попадём на страницу, где будет показано, сколько раз был сделан снимок сайта:
Даже фавикон будет тот, что был на тот момент:)
Немного истории:
Вот представьте масштаб этого хранилища на данный момент времени!!! Это сколько нужно места!!!
Некоторые сайты всё же не попадают в историю веб. архива, потому что владельцы сайта могут не захотеть, чтобы было разрешение на сканирование веб-сайта боту этого ресурса: The Wayback Machine.
архива, потому что владельцы сайта могут не захотеть, чтобы было разрешение на сканирование веб-сайта боту этого ресурса: The Wayback Machine.
Для этого в robots.txt.ставят запрет на просмотр страниц ботом. Приблизительно это будет так:
User-agent: ia_archiver
Disallow: /
Как посмотреть нужную копию сайта?
Чтобы посмотреть архивы, надо обратить внимание на временную шкалу, расположенную вверху страницы, где вертикальными черными черточками отмечены имеющиеся для этого сайта копии. Иногда, при неудачной фотографии сайта, например, когда у вас были технические работы или ещё что то и снимок получился битым, тогда следует обратится к другой копии и открыть снимок.
Нажав на голубой кружок, вы увидете ссылки на несколько архивов, отличающихся временем их снятия. Это делается во избежании потери данных за счет форс мажорных обстоятельств на сайте.
И вот, именно 25 июня 2014 года мы смотрим фотографию:
В итоге, перейдя к просмотру вы увидите копию нужного сайта с работающими внутренними ссылками и подключенным стилевым оформлением.
Стоит заметить, что эта машина работает иногда не совсем корректно, но этих случаев немного на практике и это скорее всего это временное явление.
Теперь вы знаете:
КАК УЗНАТЬ ИСТОРИЮ САЙТА И ДОМЕНА.
Всем пока! До новых встреч!
С уважением, автор блога, Интернет Капуста, Лара Мазурова.
Прочитайте ещё очень интересные статьи из рубрик:
Как выглядели сайты раньше: 20 примеров
Karina | 17.08.2016
С тех пор, как родился Интернет (более 25 лет назад), веб-сайты претерпели тысячи изменений, и их развитие ушло далеко вперёд благодаря стремительно прогрессирующим технологиям. Уже сложно вспомнить, как выглядели сайты в прошлом, а ведь ранние версии многих известных ресурсов были совершенно другими. Давайте взглянем на них.
Вид раньше и сейчас
1. Google.com: старт в 1996 году
Google.com: старт в 1996 году
Поисковая система Google, созданная в 1996 году в качестве учебного проекта студентами Стэнфордского университета Ларри Пейджем и Сергеем Брином, сегодня является крупнейшей компанией в мире. На первом скриншоте изображен один из самых ранних вариантов внешнего вида Google, а на втором — современный дизайн:
2. Facebook.com: старт в 2004
Спустя 8 лет после Google был изобретён Facebook — Марком Цукербергом в Гарвардском университете. Известный как TheFacebook, изначально проект был доступен только однокурсникам Гарварда. Сегодня же посещаемость данной социальной сети составляет 1,71 млрд активных пользователей в месяц.
3. MySpace.com: старт в 2003
Прежде чем появился Facebook, популярной социальной сетью была площадка MySpace. Она является одной из первых соцсетей, но с лидирующего места её уже вытеснили такие сайты как Twitter и Facebook. В 2005 году Руперт Мердок выкупил MySpace за $580 млн у основателей Криса Девульфа и Тома Андерсона.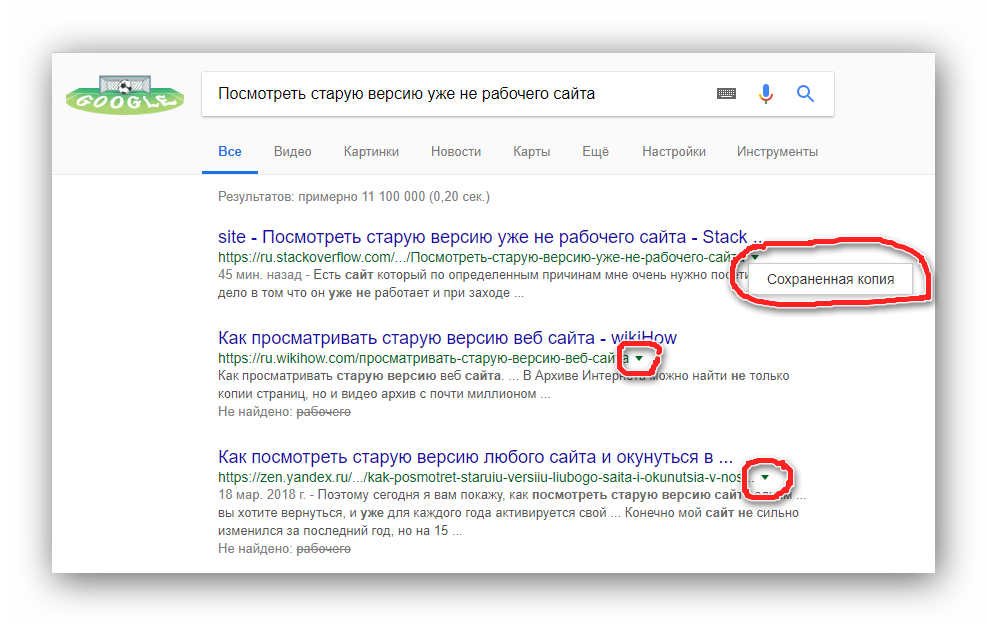 После того, как MySpace стал стремительно терять аудиторию, Мердок, по слухам, продал его за $35 млн, назвав покупку «огромной ошибкой».
После того, как MySpace стал стремительно терять аудиторию, Мердок, по слухам, продал его за $35 млн, назвав покупку «огромной ошибкой».
4. Yahoo.com: старт в 1994
В начале 1994 года аспиранты Стэнфордского университета Дэвид Фило и Джерри Янг создали портал под названием «Путеводитель Джерри по Всемирной Паутине», представляющий собой каталог других веб-сайтов. Позже, в этом же году сайт был переименован в Yahoo!.
Версий происхождения данного имени существует несколько. Одни утверждают, что Yahoo! является акронимом фразы «Yet Another Hierarchical Officious Oracle». Другие же считают, что название было позаимствовано из книги «Путешествия Гулливера» Д. Свифта, где словом «yahoo» называются грубые человекообразные существа. Кстати, именно вторую версию основатели компании называют правильной.
5. YouTube.com: старт в 2005
Если у компании Yahoo! есть две версии появления её названия, то у сервиса YouTube существует две версии появления его самого. В первом варианте утверждается, что автором идеи был программист Джавед Карим, которого посетила мысль создать такой сервис, когда он не смог найти в Сети видео с участием Джанет Джексон и Джастина Тимберлейка. По второй версии, YouTube возник, когда его будущие основатели Стив Чен, Чад Хёрли и Джавед Карим захотели поделиться друг с другом видеороликами с вечеринки, но не нашли в Интернете удобного сервиса для этого. После чего было решено создать сайт, куда пользователи смогут легко загружать видео, а оно будет автоматически конвертироваться в нужный для просмотра в браузерах формат.
В первом варианте утверждается, что автором идеи был программист Джавед Карим, которого посетила мысль создать такой сервис, когда он не смог найти в Сети видео с участием Джанет Джексон и Джастина Тимберлейка. По второй версии, YouTube возник, когда его будущие основатели Стив Чен, Чад Хёрли и Джавед Карим захотели поделиться друг с другом видеороликами с вечеринки, но не нашли в Интернете удобного сервиса для этого. После чего было решено создать сайт, куда пользователи смогут легко загружать видео, а оно будет автоматически конвертироваться в нужный для просмотра в браузерах формат.
6. Wikipedia.org: старт в 2001
Объёмная онлайн-энциклопедия Wikipedia навсегда изменила подход к получению информации для целых поколений. И хотя с момента запуска в 2001 Википедия мало изменилась в плане внешнего вида, за это время она сильно разрослась: на сайте насчитывается уже более 30 млн статей.
7. MSN.com: старт в 1995
MSN (Microsoft Network) был запущен в 1995 году. В начале 2000-х компания MSN являлась вторым по популярности интернет-провайдером (после AOL LLC). Сам сайт
В начале 2000-х компания MSN являлась вторым по популярности интернет-провайдером (после AOL LLC). Сам сайт msn.com представляет собой новостной портал с видео, акциями и опросами.
8. Apple.com: старт в 1997
Нынешний вид сайта Apple кардинально отличается от его ранней версии с заманчивым предложением получить бесплатный CD-ROM. Однако уже тогда компания демонстрировала свою любовь к белому цвету. А Apple eMate 300, рекламирующийся в правой части страницы, одно время был популярным КПК (с 1997 по 1998 год).
9. Twitter.com: старт в 2006
Сайт Twitter был запущен в марте 2006 года и, по сравнению со своей старой версией, стал практически неузнаваем. В настоящее время Твиттер входит в десятку самых посещаемых ресурсов в мире и считается одним из самых успешных стартапов всех времён с точки зрения рыночной капитализации.
10. eBay.com (ранее известный как AuctionWeb): старт в 1995
Кто бы мог подумать, что этот серый, мало чем примечательный сайт превратится в крупнейший онлайн-аукцион в мире? Его основатель, программист Пьер Омидьяр, изначально хотел зарегистрировать доменное имя EchoBay., но, как оказалось, им уже владела одна золотодобывающая компания, поэтому название было решено сократить до com
eBay.com.
11. LinkedIn.com: старт в 2003
Сайт LinkedIn был создан в 2003 году предпринимателем Ридом Хоффманом и позиционировался как социальная сеть для поиска и установления деловых контактов. В одном только США насчитывается 93 млн пользователей данной сети. С самого начала сайт обладает достаточно сложной структурой.
12. Amazon.com: старт в 1995
Изначально на сайте Amazon продавались только книги. Придумывая название своему проекту, Джефф Безос просматривал словарь и остановился на слове «Amazon», поскольку Амазонка является экзотической, непохожей на другие и самой большой рекой в мире. Именно таким он хотел сделать и свой магазин.
Интересно и то, что ранее, в сентябре 1994, Безос приобрел домен Relentless.com и планировал назвать своё детище словом Relentless (рус. безжалостный, неустанный), но друзья сказали ему, что такое имя звучит немного зловеще. Домен всё ещё принадлежит Безосу — с него идёт перенаправление на
Домен всё ещё принадлежит Безосу — с него идёт перенаправление на Amazon.com.
13. Instagram.com: старт в 2010
Такой популярный нынче сайт Instagram начинал своё существование под названием Burbn. Создатели проекта, Кевин Систром и Майк Кригер, в какой-то момент поняли, что их сервис стал сильно напоминать Foursquare, и приняли решение сделать его более специализированным, сделав упор на мобильную фотографию. Так появился Instagram. Название представляет собой объединение двух выражений — «instant camera» и «telegram».
С тех пор проект признан одним из самых успешных в мире. В 2012 году Facebook купил Instagram за $1 млрд.
Все вышеперечисленные ресурсы на сегодняшний день уже имеют абсолютно другой дизайн, и узнать, как выглядели эти сайты раньше, можно лишь благодаря сохранившимся скриншотам. Но есть некоторые сайты, которые сохранились в первозданном виде! Если вам мало одного скриншота, и вы хотите устроить настоящий сёрфинг по сайтам в стиле 90-х, взгляните на список ниже.
Рабочие сайты в стиле 90-х
На момент публикации этой статьи все сайты рабочие.
14. Space Jam: старт в 1996
Забавный кусочек истории: подсайт Space Jam домена warnerbros.com, который никак не изменялся с момента своего запуска в 1996 году. Здесь можно переходить по ссылкам и ощутить перемещение во времени!
15. MillionDollarHomepage.com: старт в 2005
Этот сайт принёс своему создателю, 21-летнему студенту из Великобритании Алексу Тью, заработок в размере $1 037 100. Главная страница имеет размер 1000×1000 = 1 млн пикселей. Каждый пиксель продавался за $1, а минимальным размером покупки был блок 10×10 пикселей. В распоряжении покупателя была та площадь, которую он купил — он мог разместить на ней картинку и сделать из неё ссылку.
Целью автора сайта была продажа всех пикселей, следовательно, заработок должен был составить 1 миллион долларов. Но заработал Алекс Тью немного больше, поскольку последнюю тысячу пикселей он выставил на аукцион eBay, заработав на продаже $38 100. Вид сайта сохранён для истории и доступен для просмотра.
16. DPGraph.com: старт в 1997
Сайт программного обеспечения для математической и физической 3D-визуализации. Здесь поражает не только тематика, но и внешний вид страницы — анимированные gif-ки объемных графиков, раскрашенные во все цвета радуги, и дизайн в стиле 90-х — что может быть более психоделичным?…
17. Aliweb.com: запуск в 1993
ALIWEB (Archie Like Indexing for the WEB) — одна из первых поисковых систем в мире. Её запуск состоялся в ноябре 1993 года. К счастью, спустя 23 года у нас есть возможность полюбоваться таким раритетом в нетронутом виде.
18. Taco.com: старт в 1997
«Мы не продаем тако. Мы не готовим тако. По правде говоря, некоторые из нас даже не очень их любят», — сказано на одной из страниц сайта taco.com, принадлежащего компании, которая предлагает различную компьютерную помощь. Название TACO произошло от сокращения Technical Advisors Company. Этот сайт 90-х годов до сих пор блистает благодаря чувству юмора сисадминов.
Этот сайт 90-х годов до сих пор блистает благодаря чувству юмора сисадминов.
19. IFindIt.com: старт в 1995
I Find It — огромное руководство по поиску в Интернете. Год создания — 1995. На сайте размещен совет: «Пожалуйста, задайте разрешение экрана 800×600 для оптимального просмотра»…
Google, а где был ты в 1995? По-видимому, ещё играл с погремушками.
20. Instanet.com: старт в 1995
Если бы страницы HTML 2.0 (версия, одобренная как стандарт 22 сентября 1995 года) можно было продавать на аукционах, то сайт instanet.com сейчас стоил бы миллионы. Вы только взгляните на этот исходный код:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0 plus SQ/ICADD Tables//EN" "html.dtd">
Вау.
Как посмотреть, как раньше выглядела страница «ВКонтакте»
Пользователи в социальной сети «ВКонтакте» довольно часто меняют свои персональные страницы, а также стоит учитывать, что и сам этот сайт иногда обновляется разработчиками. Из-за этого некоторые пользователи могут захотеть посмотреть на то, как раньше выглядела их или чужая страница. На самом деле, имеется довольно большое количество различных инструментов, которые позволяют посмотреть это довольно быстро и просто.
Из-за этого некоторые пользователи могут захотеть посмотреть на то, как раньше выглядела их или чужая страница. На самом деле, имеется довольно большое количество различных инструментов, которые позволяют посмотреть это довольно быстро и просто.
В этой статье мы подробно расскажем о том, как посмотреть старую версию любой страницы «ВКонтакте» с помощью:
- Поисковой системы;
- Сторонних инструментов в Интернете.
Как посмотреть, как раньше выглядела страница «ВКонтакте» через поиск Google?
В данной статье мы рассмотрим способы просмотра старых копий страниц, но здесь нужно отметить, что таким способом можно посмотреть только профили тех людей, что не были скрыты настройками приватности, которые закрывают страницу от поисковых систем. При этом здесь можно посмотреть даже те страницы, что ранее были удалены.
Сначала мы расскажем о том, как посмотреть старую версию страницы, пользуясь популярным поисковиком Google, который умеет сохранять различные страницы в Интернете в их ранних версиях. Но здесь нужно понимать, что все эти сохраненные страницы остаются в памяти поисковика на ограниченный период времени, то есть старая версия удаляется после того, как она будет сканирована снова.
Но здесь нужно понимать, что все эти сохраненные страницы остаются в памяти поисковика на ограниченный период времени, то есть старая версия удаляется после того, как она будет сканирована снова.
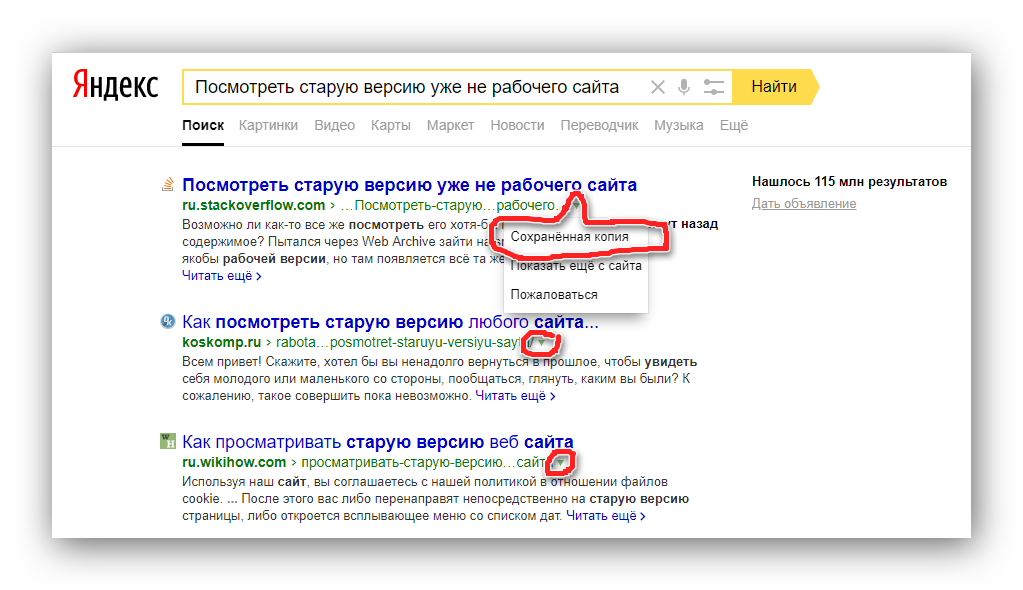
В поисковой строке нужно ввести запрос с именем человека «ВКонтакте», а также со специальным добавлением site:vk.com, чтобы Google показывал результаты только внутри этой социальной сети. В поисковой выдаче далее нужно найти требуемую страницу и рядом с нею нажать на кнопку с зеленым треугольником, чтобы открыть меню с дополнительными функциями. Далее в отобразившемся списке нужно выбрать пункт «Сохраненная копия».
После этого пользователь попадет на страницу искомого человека, причем на ту ее версию, что сканировалась поисковиком Google в предыдущий раз. В зависимости от того, насколько старая версия в итоге откроется, может изменяться даже сам интерфейс социальной сети «ВКонтакте».
Также стоит отметить, что даже если пользователь уже авторизовался в этой социальной сети, он увидит данную страницу со стороны человека, которые не зарегистрирован «ВКонтакте», то есть как анонимный посетитель, потому что именно так видят профили на данном сайте роботы Google. Если же пользователь решит зайти в свой профиль, чтобы подробнее просмотреть материалы, размещенные на сохраненной версии найденной страницы, он просто попадет на оригинальную текущую версию «ВКонтакте». Это значит, что таким способом можно посмотреть только ту основную информацию, что была размещена непосредственно на самой странице человека, а все остальные дополнительные материалы просто не получится открыть. Именно поэтому здесь нельзя будет, например, просмотреть список подписчиков или все фотографии человека. Также стоит заметить, что смотреть старые сохраненные версии профилей известных и популярных людей в этой социальной сети, по сути, не имеет никакого смысла, потому что на эти страницы заходит слишком много людей, а потому они намного чаще сканируются поисковыми системами.
Если же пользователь решит зайти в свой профиль, чтобы подробнее просмотреть материалы, размещенные на сохраненной версии найденной страницы, он просто попадет на оригинальную текущую версию «ВКонтакте». Это значит, что таким способом можно посмотреть только ту основную информацию, что была размещена непосредственно на самой странице человека, а все остальные дополнительные материалы просто не получится открыть. Именно поэтому здесь нельзя будет, например, просмотреть список подписчиков или все фотографии человека. Также стоит заметить, что смотреть старые сохраненные версии профилей известных и популярных людей в этой социальной сети, по сути, не имеет никакого смысла, потому что на эти страницы заходит слишком много людей, а потому они намного чаще сканируются поисковыми системами.
Как посмотреть, как раньше выглядела страница «ВКонтакте» через Internet Archive?
Этот способ отличается от вышеописанного тем, что в архиве нет никаких особых требований к тому, как именно должна выглядеть и быть настроенной страница, но при этом здесь есть не все профили, так как загружать в архив их нужно ручным способом.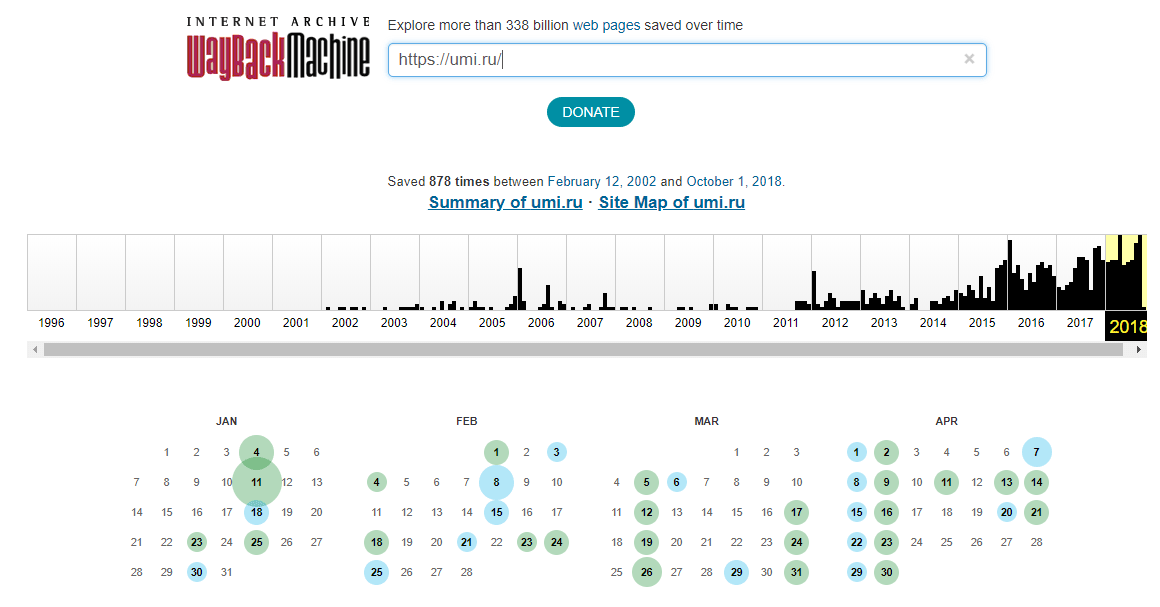 Для начала нужно перейти в сам архив по этой ссылке. Далее здесь в соответствующем поле нужно ввести непосредственно сам адрес к тому профилю, старую версию которого требуется посмотреть. Если поиск будет проведен успешно, то пользователь увидит специальную шкалу времени, а также календарь с разными датами обновлений сохраненных копий профиля. При этом нужно понимать, что непопулярные страницы реже сохраняются в этом архиве, либо не сохраняются здесь вовсе. На временной шкале здесь нужно просто переключаться между разными периодами активности. Далее в отобразившемся календаре следует выбрать требуемую дату, за которую нужно посмотреть копию страницы. Нажимать и смотреть можно только те даты, которые подсвечены в этом календаре. После наведения курсора мыши на нужную дату появятся также разные варианты с ссылками на время сохранения страницы. Здесь нужно просто выбрать правильное время, чтобы старая версия профиля открылась.
Для начала нужно перейти в сам архив по этой ссылке. Далее здесь в соответствующем поле нужно ввести непосредственно сам адрес к тому профилю, старую версию которого требуется посмотреть. Если поиск будет проведен успешно, то пользователь увидит специальную шкалу времени, а также календарь с разными датами обновлений сохраненных копий профиля. При этом нужно понимать, что непопулярные страницы реже сохраняются в этом архиве, либо не сохраняются здесь вовсе. На временной шкале здесь нужно просто переключаться между разными периодами активности. Далее в отобразившемся календаре следует выбрать требуемую дату, за которую нужно посмотреть копию страницы. Нажимать и смотреть можно только те даты, которые подсвечены в этом календаре. После наведения курсора мыши на нужную дату появятся также разные варианты с ссылками на время сохранения страницы. Здесь нужно просто выбрать правильное время, чтобы старая версия профиля открылась.
После этого пользователь попадет на выбранную страницу с указанными датой и временем.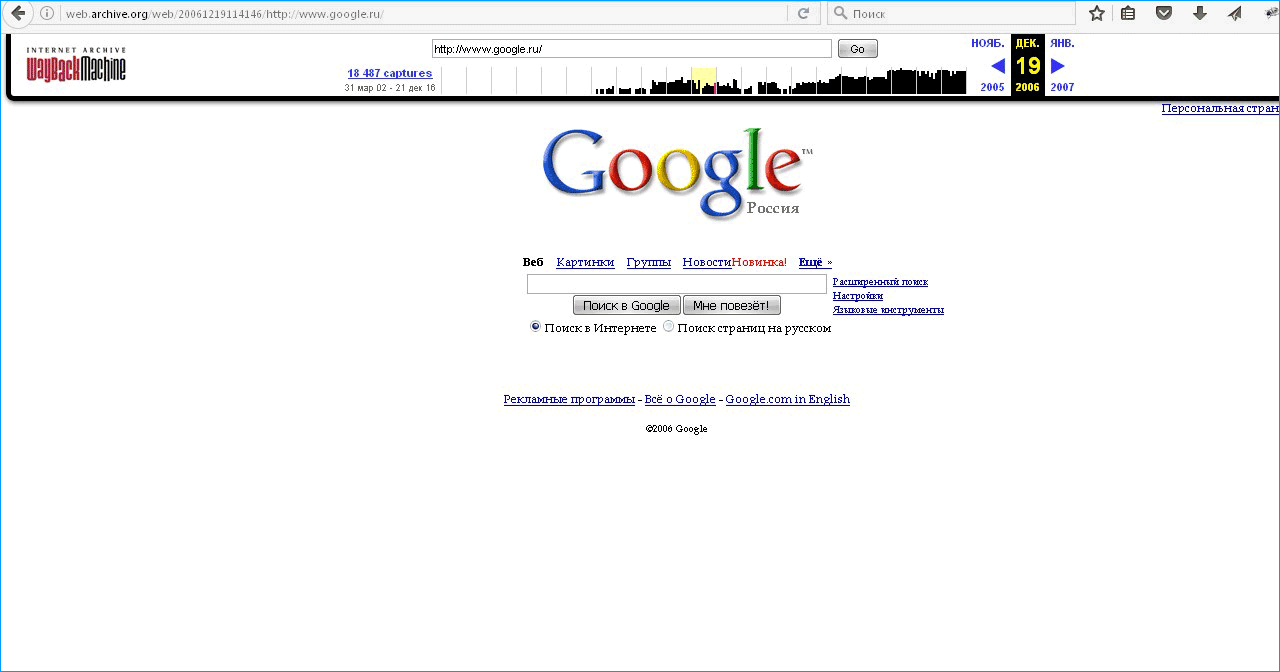 Если это достаточно старая дата, можно будет увидеть даже прошлый интерфейс сайта «ВКонтакте». При этом важно заметить, что данный ресурс сканирует страницы на английском языке, поэтому здесь нет русских версий профилей «ВКонтакте». В то же время, если на странице публиковался контент на русском, он будет отображен именно в таком виде, то есть на английском языке будет только весь интерфейс сайта. Если же пользователь хочет посмотреть страницу на русском языке, он может прибегнуть к следующему методу, описанному в этой статье.
Если это достаточно старая дата, можно будет увидеть даже прошлый интерфейс сайта «ВКонтакте». При этом важно заметить, что данный ресурс сканирует страницы на английском языке, поэтому здесь нет русских версий профилей «ВКонтакте». В то же время, если на странице публиковался контент на русском, он будет отображен именно в таком виде, то есть на английском языке будет только весь интерфейс сайта. Если же пользователь хочет посмотреть страницу на русском языке, он может прибегнуть к следующему методу, описанному в этой статье.
Как посмотреть, как раньше выглядела страница «ВКонтакте» через Web Archive?
Этот сервис не такой популярный, как вышеописанный архив, но все же он работает довольно хорошо. Также к этому архиву часто прибегают в тех случаях, когда прошлый сервис не может показать старую версию нужной страницы. Открыть Web Archive можно по этой ссылке. Здесь в соответствующей строке сначала нужно ввести ссылку на тот профиль «ВКонтакте», старую версию которого нужно посмотреть.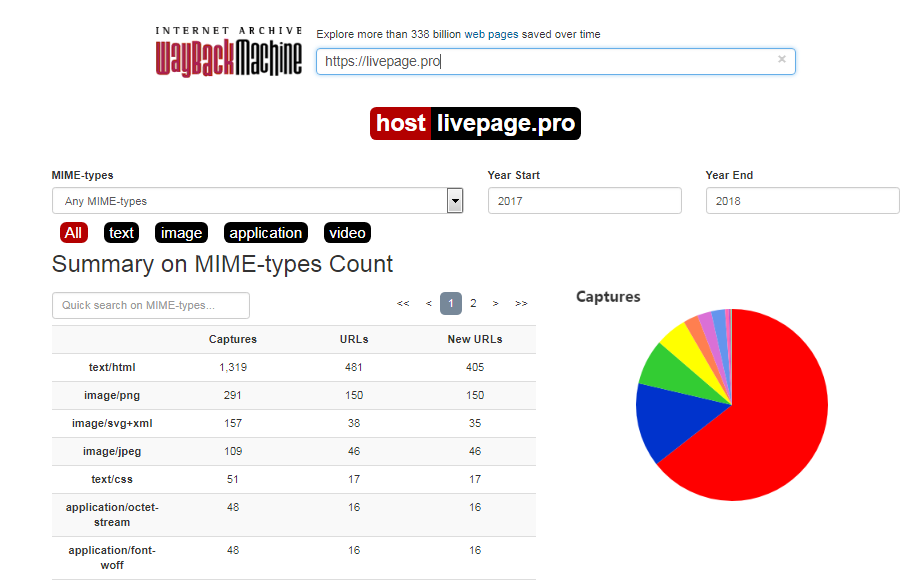 Далее в появившемся разделе «Результаты» можно выбрать требуемые год и месяц, за которые нужно посмотреть версию искомой страницы. После того, как пользователь выберет нужные год и месяц, откроется специальный календарь, в котором нужно будет также указать день.
Далее в появившемся разделе «Результаты» можно выбрать требуемые год и месяц, за которые нужно посмотреть версию искомой страницы. После того, как пользователь выберет нужные год и месяц, откроется специальный календарь, в котором нужно будет также указать день.
После нажатия на кнопку с нужным днем в календаре, пользователь попадет на старую версию того профиля «ВКонтакте», ссылку на который он указал. В левой верхней части страницы можно посмотреть, за какую именно дату и время показана здесь старая версия профиля. При этом стоит отметить, что данный архив показывает сайт «ВКонтакте» на русском языке. Также в Интернете можно найти множество других подобных архивов, в которых есть выдача на русском.
Заключение
Как можно понять из этой статьи, найти старую версию профиля «ВКонтакте», чтобы посмотреть, как он выглядел раньше, довольно легко, причем сделать это можно разными способами либо через Google, либо с помощью других сторонних архивов.
Как выглядел сайт раньше — пошаговая инструкция, как посмотреть
Как узнать, как сайт выглядел раньше?
Иногда хочется вспомнить те времена, когда по интернетам бродили динозавры, а одна песня загружалась 10 минут. Смотрим в прошлое и ностальгуем, спасибо за это онлайн-сервису: Wayback Machine — Интернет-архив. Работает с 1996 года, за это время собрано на базе данных более 279 миллиардов веб-страниц.
Смотрим в прошлое и ностальгуем, спасибо за это онлайн-сервису: Wayback Machine — Интернет-архив. Работает с 1996 года, за это время собрано на базе данных более 279 миллиардов веб-страниц.
Переходим по ссылке: http: // archive.org / web / web.php Введите вводим: адрес интересующего сайта и нажимаем «Просмотреть историю». Система выдаст всю историю по конкретному порталу.
Синими кругами на календаре обведены даты резервных копий. Выбираем нужный год, дату и заглядываем в прошлое веб-страницы.
Где посмотреть, как выглядели страницы сайтов в разные годы
Яндекс в это время открыл первый удаленный офис в Питере, запустил Яндекс.пробки и «словари».А почту.ру начали использовать поисковик на своем портале. Через год Яндекс купит мобильного разработчика софта «Смартком» и соц. сеть «Мой круг». Запустит «Календари», блого-сервис Я.ру, портал Яндекс.Зеркало и откроет услуги анализа данных — бесплатный образовательный курс.
Google запускают календарь, финансы и переводчик. Открывают бесплатный хостинг изображений Picasa и объявляют о покупке YouTube. В 2007 году компания обеспечивает энергией 30% офисов и объявит о появлении Android.А сотрудники начинают ездить по офисам на велосипедах gBikes.
История Facebook уникальна. Только в 2004 году сервис вышел за стены Гарварда, а уже в 2008 году вырос так, что количество пользователей перевалило за 50 млн. человек, а состояние Марка Цукерберга уже оценивалось в 1.5 млдр. долларов.
Как раньше выглядел наш сайт
А вот так менялся наш сайт с 2006 года:
iPipe — надёжный хостинг-провайдер с опытом работы более 15 лет.
Мы предлагаем:
Как узнать историю сайта | SeoProfy.ua
Если вы задумывались о том, есть ли история у сайтов? То она таки есть, и ее можно посмотреть.
Данная статья про то, как посмотреть и узнать историю сайта. Ведьны сайта меняются постоянно, именные дизайны разные владельцы.
Ведьны сайта меняются постоянно, именные дизайны разные владельцы.
В интернете существует сайт, который еще называют машина времени, только она работает только для прошлого.С помощью этого сайта мы и сможем узнать историю.
Принцип работы сайта заключается в том, что он индексирует сайты интернета, и сохраняет их в разное время.
Для начала переходим по ссылке: http://archive.org/web/web.php
Вводим адрес, например Google.com, и нажимаем смотреть:
Как мы видим, история для поисковой системы Гугл учитывается с 1998 года, дальше выбираем 1998 год, выбираем доступную дату и смотрим:
Дальше смотрим, как выглядел сайт поискового гиганта в то время.
А так выглядела поисковая система Яндекс в 1998 году:
Таким образом, мы сможем узнать нас интересующий сайт, особенно если сайт популярный, то его история записывалась постоянно.
В базе сервиса веб архива более 450 миллионов сайтов. Конечно, там не сохранены все сайты, но очень много. Сервис по просмотру истории сайтов абсолютно бесплатный и может пригодиться в разных случаях.
Сервис по просмотру истории сайтов абсолютно бесплатный и может пригодиться в разных случаях.
Основные моменты, когда нужно узнать историю сайта:
1.Узнать тематику сайта
С помощью веб архива мы сможем посмотреть содержание, которое было на домене, и узнать тематику ресурса.
2. Посмотреть каким сайт был в разные времена
Как я уже говорил, довольно таки часто люди забрасывают сайты, многие оптимизаторы оптимизируются на такие домены, что бы сделать на них сайты. С помощью веб архива мы смотрим его содержание, его историю, и решаем, нужен ли нам такой домен.
. Если вы хотите узнать историю сайта — используйте веб архив, это довольно таки полезный инструмент.
Помимо сайтов в веб архиве можно смотреть видео, музыку, картинки.
Оцените статью
Загрузка …Как узнать историю сайта, домена в прошлом?
История сайта — как ее узнать?
Многие пользователи Интернета даже не подозревают, что у каждого ресурса есть своя история. Это общедоступная информация и узнать историю сайта может каждый пожелавший.
Это общедоступная информация и узнать историю сайта может каждый пожелавший.
Часто бывает такое, что может измениться дизайн какого-либо ресурса, смениться логотип, доменное имя, структура, меню и многие другие параметры. В общем, меняется внешний вид и это нормально, внедряются новые стили, новые шаблоны, внедряются новые шаблоны.
Все изменения, созданные на специальном ресурсе, будут сохранены на специальном ресурсе, которому присвоено название машина времени для сайтов (или «архив»). К сожалению, у нее есть функция перемещения в прошлое.
Суть работы сервиса в том, что он сохраняет все изменения на сайтех, реализованные в различные периоды времени. Как проверить историю домена ? Допустим, вы захотели узнать, сколько лет дядьке Гуглу, и какая у него история. Клацаем сюда archive.org/web/web.php. В поисковой строке пишем Google.com и жмем ПРОСМОТРЕТЬ ИСТОРИЮ!
Откроется специальный календарь с синими и зелеными отпечатками. Сверху панель с разными годами, а небольшой черного цвета на ней показывает, в какие даты произошло больше изменений, а в какие меньше. Google было положено начало в 1998 году. Нажав на него, нам представится такая картина в 2002 году:
Сверху панель с разными годами, а небольшой черного цвета на ней показывает, в какие даты произошло больше изменений, а в какие меньше. Google было положено начало в 1998 году. Нажав на него, нам представится такая картина в 2002 году:
То же самое можно проделать с поисковой системой Яндекс , а увидим следующее:
Подобным способом можно найти любую информацию о каждом сайте, интересующем вас. На сегодняшний день около 324 миллиардов веб страниц сохранено в архиве . И это еще не все площадки. Пригодиться веб-архив может в различных ситуациях, а его бесплатное использование дает возможность любому человеку черпать знания из него.
Машина времени может понадобиться в таких ситуациях:
- Если необходимо узнать, какая была тематика. Покупая домен у его владельца, хорошо бы знать историю площадки, какое было содержимое, хороший контент или нет, и какая вообще была тематика ранее.
 Это поможет в дальнейшем продвижении.
Это поможет в дальнейшем продвижении. - Узнать, что из себя представлял ресурс. Множество площадок остается без присмотра, а история домена хранится, поэтому любители посидели в архиве ведут охоту на такие доменные имена, дабыеть ими, использовать для повторного создания площадки, только уже своей.
Вы можете оценить, какой была история сайта целиком, а потом уже решать, приобрести такой домен или нет .
Webarchive — веб-архив всего интернета и сайтов или машина времени на archive.org
Главная / Лучшие онлайн-сервисы3 января 2021 г.
- Как можно использовать архив сайтов интернета?
- Условия попадания сайта в archive.org
- Как найти нужный веб-архив и восстановить из него сайт?
- Как вытянуть из веб-архива уникальный контент?
Здравствуйте, уважаемые читатели блога КтоНаНовенького.RU. Не так давно я писал про то, что такое народная энциклопедия Википедия безусловно заслуживает всяких лестных эпитетов, несмотря на присущие ей небольшие недостатки и критику ее статей со стороны научного сообщества.
Сам факт того, что некоммерческий проект уже не одно десятилетие трудится на благо всего интернет сообщества, заслуживает уважения. В сети есть еще один подобный масштабный проект, который не будет располагать этим местом для установки в Интернете.
Я говорю, конечно же, про web.archive.org — глобальный проект с кажущейся невыполнимой миссией — создание архива всех сайтов, когда либо размещенных в интернете. Причем, сайты сохраняются в виде скриншотов, а в виде полноценно работающих веб-страниц со всеми ссылками, картинками и стилевым оформлением (CSS). Причем, для каждого сайта за время его существования в сети в этом архиве может накопиться и по несколько сотен копий, дат разными этапами жизни ресурса.
Как можно использовать архив сайтов интернета
Чем же может быть полезен данный веб-архив?
- Ну, во-первых, вы можете погрузиться в приятную ностальгию путешествуя по вашему сайту многолетней давности.Проследить историю изменений можно для любого другого ресурса интернета (например, я брал скриншоты для статей про уже умерший Апорт именно из этого вебархива, да и скриншоты, иллюстрирующие эволюцию главной страницы Яндекса, имеют тоже самое происхождение).

- Но это не все. Если страница добавленного вами в закладки сайта не открывается, то вы, конечно же, можете попробовать вытащить ее из кеша Яндекса или Гугла (читайте подробнее про то, как лучше искать в Google). Но если ресурс недоступен уже очень давно, то такие мертвые ссылки нигде кроме архива.org открыть уже будет не возможно (правда, и там его может не оказаться по описанным чуть ниже причинам).
- Так же, если вы по каким-либо форс-мажорным обстоятельствам не делали резервное копирование вашего сайта, то данный веб-архив будет единственно восстановить свой сайт. Имеется возможность очистить все ссылки от привязки к web.archive.org и сделать их прямыми именно для вашего ресурса (читайте об этом ниже).
Ну, и последнее, что приходит в голову — поиск уникального контента.Вы не можете сделать это самостоятельно, приложив все усилия, чтобы сделать это. Суть такова, что многие сайты умирают и становятся недоступны вместе с имеющимся на них контентом.
Отыскав такие ресурсы вы сможете вытащить тексты из интернет-архива и связать их у себя, предварительно проверив их на уникальность.
 Таким образом вы не занимаетесь плагиатом и не нарушаете авторские права (копирайт), но искать в вебархиве многим может показаться очень уж трудоемкой проверкой.
Таким образом вы не занимаетесь плагиатом и не нарушаете авторские права (копирайт), но искать в вебархиве многим может показаться очень уж трудоемкой проверкой.
Онлайн сервис Webarchive ведет свою историю аж с 1996 года. Поставленная перед проектом задача казалась невыполнимой даже с учетом того, что сайтов на то время в интернете было значительно меньше, чем сейчас (на несколько порядков). По началу сайты архивировались не очень часто, но со временем, Интернет-архив стал делать больше и больше слепков сайтов.
. с пятнадцатью нулями байт.Сайт имеет зеркала в различных датах центрах, а сам проект с недавних пор получил официальный статус библиотеки. Всего ста просмотров страниц уже насчитывается около миллиардов (здесь учитываются все слепки страниц когда-либо снятые и сохраненные).
На главной странице доступны только архив страниц интернета Wayback Machine, но и архивы различных кинохроник, телепередач, аудио записей и отсканированных в различных библиотеках книг:
Но нас интересует именно область WEB с логотипом Wayback Machine. Чтобы попасть на страницу с календарем:
Чтобы попасть на страницу с календарем:
Из приведенного примера видно, что мой блог был впервые заархивирован 27, предоставленную там форму можно достичь URL или доменное имя интересующего вас сайта (читайте про то, что такое домен и чем он отличается от URL), чтобы попасть на страницу с календарем:
. августа 2009 года (через пять дней после регистрации (покупки) домена ktonanovenkogo.ru). За прошедший интервал времени было создано 125 архивных копий сайта, каждую из которых можно посмотреть и потрогать руками (осуществляя переходы по внутренним ссылкам).
Открытие мертвых ссылок и условий попадания сайта в archive.org
В календаре голубыми кружочками отмечены даты, которые был создан слепок (вебархив) данного сайта. Естественно, что моменты снятия слепка никак не будет коррелироваться с производимыми на вашем ресурсе изменениями, и их время Webarchive определяет строго исходя из своих внутренних алгоритмов и таймеров.
Поэтому использовать архив интернета, как инструмент для открытия временно недоступных сайтов, наверное, не всегда будет резонным. Для этого у Яндекса имеется возможность просмотра архивной копии документа:
Да, и в Google можно всегда посмотреть копию копии веб-страницы:
Данный же онлайн сервис понадобится в особо тяжелых случаях, когда искомая страница уже не и вряд ли уже будет существовать в реальном интернете, но зато она по-прежнему доступна в машине времени.
Правда, должно быть соблюдено несколько условий того, чтобы сайт попал в archive.org:
Он не должен содержать в своем файле robots.txt запрет для его индексации роботом с web.archive.org. Такой запрет, обычно выглядит так:
User-agent: ia_archiver Disallow: /
Когда я писал статью про электронную почту mail.ru, то не смог найти в Архиве Интернет сохраненных копий сайта mail.ru, т.к. его файл robots.txt содержал в себе похожий запрет:
- Некоторые сайты Вебархив по каким-либо причинам банально не нашел. Вероятность попадания ресурса в базу данных, если он будет добавлен в каталог Dmoz или на него будут добавлены ссылки на другие популярные ресурсы, в Webarchive уже есть.
 В общем то, даже простой запрос через форму на главной странице этого сервиса может служить толчком к привлечению внимания архиватора к вашему сервсу.
В общем то, даже простой запрос через форму на главной странице этого сервиса может служить толчком к привлечению внимания архиватора к вашему сервсу.
Как нужный веб-архив и восстановить сайт без бекапа
По архивам можно перемещаться и с помощью временной шкалы расположенной вверху страницы, где вертикальными черточками отмечены системат для этого сайта слепки. Иногда, веб-архивы могут быть битыми, тогда придется открыть ближайший к нему слепок.
Щелкнув по голубому кружочку, мы можем увидеть ссылки на несколько архивов, отличающихся временем их снятия.
Возможно, что это делается во избежании потерь данных за счет неизбежной порчи жестких дисков в хранилищах. Перейдя к просмотру из веб-архивов, вы увидите копию своего сайта с работающими внутренними ссылками и подключенным стилевым оформлением. Правда, не идеально работающим.
Например, кое-что из дизайна у меня все же перекосило и боковое меню работающего на ДжаваСкрипте полностью исчезло:
Но это не так важно, потому что в исходном коде страницы с web. archive.org это меню, естественно, присутствует. Однако просто так скопировать текст этой страницы на сайт взамен утерянной не получится. Почему? Да потому что путешествие внутри сайта из будет возможно лишь в случае замены всех внутренних ссылок на те, что генерит Webarchive (в случае если вас перебросило бы на современную версию ресурса).
archive.org это меню, естественно, присутствует. Однако просто так скопировать текст этой страницы на сайт взамен утерянной не получится. Почему? Да потому что путешествие внутри сайта из будет возможно лишь в случае замены всех внутренних ссылок на те, что генерит Webarchive (в случае если вас перебросило бы на современную версию ресурса).
Выглядят эти ссылки примерно так:
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/seo/search/samostoyatelnoe-prodvizhenie-sajta-kak-prodvigat-samomj-vnutrenne optimizaciej.html
Понятно, что можно будет вручную отсечь начальную часть ссылок ( http://web.archive.org/web/20111013120145/ ), получив таким образом рабочий вариант. Можно даже автоматизировать с помощью инструмента поиска и замены редактора Notepad, но еще проще будет использовать встроенную службу замены внутренних ссылок на оригинальные.
Для этого копируете адрес страницы с нужным слепком вашего сайта (из адресной строки — начинается с http: // web.). Он будет иметь примерно такой вид: archive.org/
archive.org/
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/
И вставляете в него конструкцию «id_» в конце даты ( 20111013120145 ), чтобы получилось так:
http://web.archive.org/web/20111013120145id_/https://ktonanovenkogo.ru/
Теперь измененный адрес обратно возвращаете в адресную строку и жмете на Enter. После этой страницы c архивом вашего сайта обновится и все внутренние ссылки станут прямыми.Можно будет копировать текст статьи из исходного кода вебархива.
Понятно, что такое восстановление огромного места займет чудовищное количество времени, но когда другой вариант нет, то и такой покажется манной небесной. К тому же, страдают не обжигавшиеся на подобных вещах, обычно только начинающие вебмастера, у которых самого контента было мало, а уж не раз обжигавшиеся на подобных вещах, делают бэкапы файлов и базы по пять раз на дню.
Если вы захотите увидеть все страницы вашего (или чужого) сайта, которые есть в недрах этого мастодонта, то вам нужно будет вставить в адресную строку следующий адрес и нажать Введите:
http://wayback.archive.org/web /*/ktonanovenkogo.ru*
Вместо моего домена можно использовать свой. На открывшейся странице вы получите возможность наложить фильтр в предназначенной для этой формы:
, я захотел увидеть лишь текстовые файлы своего блога, которые заглотил Web Archive.Зачем — не знаю, но захотел.
Как вытянуть из Webarchive уникальный контент для сайта
Описанный ниже способ я не использовал, но теоретически все должно работать. Саму идею я почерпнул на этом молодом ресурсе, где и были все шаги. Принцип метода заключается в том, что каждый день умирают и никогда не возрождаются десятки сайтов.
Причин этого может быть много и больше из почивших в бозе ресурсов никакой особой ценности в плане контента никогда и не представляет.Всего-навсего отделить зерна от плевел. Главное чтобы исчезнувшие сайты с более-менее удобоваримым контентом были представлены в веб-архиве, хотя бы одной копией.
Т.к. после смерти контента этих сайтов постепенно выпадет его законным владельцем и первоисточником для систем поисковых систем. Замечательно, если будет именно так (есть вариант, что еще при жизни ресурса нещадно могли откопипастить).Но кроме проблемы уникальности текстов, существует проблема их отыскания.
Замечательно, если будет именно так (есть вариант, что еще при жизни ресурса нещадно могли откопипастить).Но кроме проблемы уникальности текстов, существует проблема их отыскания.
Во-первых, нам нужен список сайтов, которые скоро умрут или уже померли. Автор метода предлагает скачать с сайта регистратора доменных имен Nic.ru список освобождающихся или уже освободившихся доменов.
Что примечательно, в последней колонке этого списка (это можно открыть в Excel) будет обеспечивать количество архивов, созданных для каждого сайта в веб-архиве (правда, проверить наличие домена в веб-архиве можно и в нескольких онлайн сервисах).
Список буржуйских доменных имен, освобождающихся или уже освобождающихся, предлагается скачать по этой ссылке. Ну, а дальше просматриваем содержимое сайтов, которое сохранил Интернет-архив и пытаемся найти что-то стоящее. Потом проверяем уникальность этих материалов (ссылка приводил чуть выше) и в случае удачи публикуем их на своем ресурсе, либо продаем в какой-нибудь бирже контент.
Да, способ муторный и мною лично не проверенный. Он может давать неплохой выхлоп.Наверное, кто-нибудь уже это поставил на поток. А вы как думаете?
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Использую для заработка
Как выглядели сайты раньше: 20 примеров
Карина | 17.08.2016
С тех пор, как родился Интернет (более 25 лет назад), веб-сайты претерпели тысячи изменений, и их развитие ушло далеко вперёд благодаря стремительно прогрессирующим технологиям.Уже сложно вспомнить, как выглядели сайты в прошлом. Давайте взглянем на них.
Вид раньше и сейчас
1. Google.com: старт в 1996 году
Поисковая система Google, созданная в 1996 году в качестве учебного проекта студентами Стэнфордского университета Ларри Пейджем и Сергеем Брином, сегодня является крупнейшей компанией в мире. На первом скриншоте изображен один из самых ранних вариантов внешнего вида Google, а на втором — современный дизайн:
2.Facebook.com: старт в 2004
Спустя 8 лет после Google был изобретён Facebook — Марком Цукербергом в Гарвардском университете. Известный как TheFacebook, изначально проект был доступен только однокурсникам Гарварда. Сегодня же посещаемость данной социальной сети составляет 1,71 млрд активных пользователей в месяц.
3. MySpace.com: старт в 2003
Прежде чем появилась Facebook, популярной социальной сетью была площадка MySpace. Она является одной из первых соцсетей, но с лидирующего места ее уже вытеснили такие сайты, как Twitter и Facebook.В 2005 году Руперт Мердок выкупил MySpace за 580 млн у основателей Криса Девульфа и Тома Андерсона. После того, как MySpace стал стремительно терять аудиторию, Мердок, по слухам, продал его за $ 35 млн, назвав покупку «огромной ошибкой».
4. Yahoo.com: старт в 1994
В начале 1994 года аспиранты Стэнфордского университета Фило и Джерри Янг создал портал под названием «Путеводитель Джерри по Всемирной Паутине», представляющий собой каталог других веб-сайтов. Позже, в этом же году сайт был переименован в Yahoo !.
Позже, в этом же году сайт был переименован в Yahoo !.
Версий происхождения данного имени несколько. Одни утверждают, что Yahoo! является акронимом фразы «Еще один иерархический служебный оракул». Другие же считают, что название было позаимствовано из книги «Путешествия Гулливера» Д. Свифта, где словом «yahoo» называются грубые человекообразные существа. Кстати, именно вторую версию основатели компании называют правильной.
5. YouTube.com: старт в 2005
Если у компании Yahoo! есть две версии появления её названия, то у сервиса YouTube существует две версии его самого.В первом варианте утверждается, что автором идеи был программист Джавед Карим, которого посетила мысль создать такой сервис, когда он не смог найти в Сети видео с участием Джанет Джексон и Джастина Тимберлейка. По второй версии, YouTube возник, когда его будущие основатели Стив Чен, Чад Хёрли и Джавед Карим захотели поделиться с другом видеороликами с вечеринки, но не нашли в Интернете удобного сервиса для этого. После чего было решено создать сайт, куда можно легко загрузить видео, а оно будет автоматически конвертироваться в нужный для просмотра в браузерах формат.
После чего было решено создать сайт, куда можно легко загрузить видео, а оно будет автоматически конвертироваться в нужный для просмотра в браузерах формат.
6. Wikipedia.org: старт в 2001
Объёмная онлайн-энциклопедия Wikipedia навсегда изменила подход к получению информации для целых поколений. И с момента запуска в 2001 г. Википедия мало изменилась в плане внешнего вида, за это время она сильно разрослась: на сайте просматривается уже более 30 миллионов статей.
7. MSN.com: старт в 1995
MSN (Microsoft Network) был запущен в 1995 году. В начале 2000-х компания MSN являлась вторым по интернет-провайдерам (после AOL LLC).Сам сайт msn.com представляет собой новостной портал с видео, акциями и опросами.
8. Apple.com: старт в 1997
Нынешний вид сайта Apple кардинально отличается от его ранней версии с заманчивым предложением получить бесплатный CD-ROM. Однако уже тогда компания демонстрировала свою любовь к белому цвету. Apple eMate 300, рекламирующийся в правой части страницы, одно время был популярным КПК (с 1997 по 1998 год).
Apple eMate 300, рекламирующийся в правой части страницы, одно время был популярным КПК (с 1997 по 1998 год).
9. Twitter.com: старт в 2006
Сайт Twitter был запущен в марте 2006 года, по сравнению со своей старой версией, стал практически неузнаваем.В настоящее время Твиттер входит в десятку самых популярных ресурсов в мире и считается одним из самых успешных стартапов всех времён точки зрения рыночной капитализации.
10. eBay.com (ранее известный как AuctionWeb): старт в 1995 г.
Кто бы мог подумать, что этот серый, мало чем примечательный сайт превратится в самый онлайн-аукцион в мире? Его основатель, программист Пьер Омидьяр, изначально хотел зарегистрировать доменное имя EchoBay.com , но, как оказалось, им уже владела одна золотодобывающая компания, поэтому название было решено сократить до eBay.com .
11. LinkedIn.com: старт в 2003 г.
Сайт LinkedIn был создан в 2003 году предпринимателем Ридом Хоффманом и позиционировался как социальная сеть для поиска и деловых контактов. В одном только США насчитывается 93 млн пользователей данной сети. С самого начала обладает достаточно сложной сложной структурой.
В одном только США насчитывается 93 млн пользователей данной сети. С самого начала обладает достаточно сложной сложной структурой.
12. Amazon.com: старт в 1995
Изначально на сайте Amazon продавались только книги. Придумывая название своему проекту, Джефф Безос просматривал словарь и остановился на слове «Amazon», поскольку Амазонка является экзотической, непохожей на другие и самой большой рекой в мире.Именно таким он хотел сделать и свой магазин.
Интересно и то, что ранее, в сентябре 1994 г., Безос приобрел домен Relentless.com и планировал назвать свое детище словом Relentless (рус. безжалостный, неустанный ), но друзья сказали ему, что такое имя звучит немного зловеще. Домен всё принадлежит Безосу — с ним идёт перенаправление на Amazon.com .
13. Instagram.com: старт в 2010
Такой популярный нынче сайт Instagram начинал своё существование под названием Burbn.Создатели проекта, Кевин Систром и Майк Кригер, в какой-то момент поняли, что их сервис стал сильно напоминать Foursquare, и приняли решение сделать его более специализированным, сделав упор на мобильную. Так появился Instagram. Название представляет собой объединение двух выражений — « мгновенная камера » и « телеграмма ».
Так появился Instagram. Название представляет собой объединение двух выражений — « мгновенная камера » и « телеграмма ».
С тех пор проект признан одним из самых успешных в мире. В 2012 году Facebook купил Instagram за 1 млрд долларов.
Все вышеперечисленные ресурсы на сегодняшний день уже имеют абсолютно другой дизайн, и узнать, как выглядели эти сайты раньше, можно лишь сохранившимся скриншотам.Но есть некоторые сайты, которые сохранились в первозданном виде! Если вам мало одного скриншота, и вы хотите устроить настоящий сёрфинг по сайту в стиле 90-х, взгляните на список ниже.
Рабочие сайты в стиле 90-х
На момент публикации этой статьи все сайты рабочие.
14. Space Jam: старт в 1996
Забавный кусочек истории: подсайт Space Jam домена warnerbros.com , который никак не изменялся с момента своего запуска в 1996 году.Здесь можно переходить по ссылкам и ощутить перемещение во времени!
15. MillionDollarHomepage.com: старт в 2005
MillionDollarHomepage.com: старт в 2005
Этот сайт принёс своему создателю, 21-летнему студенту из Великобритании Алексу Тью, заработок в размере $ 1 037 100. Главная страница имеет размер 1000 × 1000 = 1 млн пикселей. Каждый пиксель продавался за 1 доллар, а минимальным размером покупки был блок 10 × 10 пикселей. В распоряжении покупателя была та площадь, которую он купил — он мог связать на ней картинку и сделать из нее ссылку.
Целью автора сайта была продажа всех долларов, следовательно, заработок должен был составить 1 миллион долларов. Но заработал Алекс Тью немного больше, поскольку последнюю тысячу пикселей он выставил на аукционе eBay, заработав на продаже $ 38 100. Вид сайта сохранён для истории и доступен просмотр.
16. DPGraph.com: старт в 1997
Сайт программного обеспечения математической и физической 3D-визуализации. Здесь поражает не только тематика, но и внешний вид страницы — анимированные gif-ки объемных графиков, раскрашенные во все цвета радуги, и дизайн в стиле 90-х — что может быть более психоделичным?…
17. Aliweb.com: запуск в 1993
Aliweb.com: запуск в 1993
ALIWEB (Archie Like Indexing для WEB) — одна из первых систем в мире. Её запуск состоялся в ноябре 1993 года. К счастью, спустя 23 года у нас есть возможность полюбоваться таким раритетом в нетронутом виде.
18. Taco.com: старт в 1997
« Мы не продаем тако. Мы не готовим тако. По правде говоря, некоторые из нас даже не очень их любят », — сказано на одной из страниц сайта taco.com , принадлежащего компании, которая предлагает различную компьютерную помощь.Название TACO произошло от сокращения T echnical A dvisors Co mpany. Этот сайт 90-х годов до сих пор блистает благодаря юмора сисадминов.
19. IFindIt.com: старт в 1995
I Find It — огромное руководство по поиску в Интернете. Год создания — 1995. На сайте размещен совет: « Пожалуйста, задайте разрешение экрана 800 × 600 для оптимального просмотра »…
Google, а где ты был в 1995? По-предположительно, ещё играл с погремушками.
20. Instanet.com: старт в 1995
Если бы страницы HTML 2.0 (версия, одобренная как стандарт 22 сентября 1995 года) можно было продавать на аукционах, то сайт instanet.com сейчас стоил бы миллионы. Вы только взгляните на этот исходный код:
Вау.
Как посмотреть историю сайта в прошлом? Инструкция и сервисы.- Блог TRINET
Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
- Если необходимо купить домен, который уже был в использовании, нужно посмотреть контент какой тематики на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.
 д.
д. - Нужен уникальный контент.Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
- Нужно восстановить сайт, когда нет его бэкапа.
- Нужно проанализировать конкурентов. Этот способ понадобится для просмотра истории изменений на их сайтах, какие ошибки они допускали или, наоборот, какие «фишки» стоит позаимствовать.
- Необходимо посмотреть страницу, если она теперь недоступна напрямую.
- Интересно, как выглядел ресурс 10-20 лет назад.
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
Как посмотреть сайт в прошлом
Есть несколько сервисов, в можно посмотреть, как менялось визуальное оформление страниц, его измененных страниц и контент, положение в поисковой выдаче и какие изменения вносятся в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https: // web. archive.org/ и после вводим адрес страницы.
archive.org/ и после вводим адрес страницы.
График ниже показывает количество сохранений: первое было в 1998 году.
Дни, которые были сохранены, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:
Как выгрузить сайт из ВебАрхива, расскажем дальше.
Сервис История Whois
Для его использования заходим на сайт http://whoishistory.ru/ и вводим данные в поиск по доменам и IP, либо по домену:
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен.Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Сохранение копий страниц в систему дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
В этой строке поиска Яндекс вводит адрес сайта с оператором site: или url: в зависимости от того, что мы хотим проверить конкретную страницу или ресурс целиком.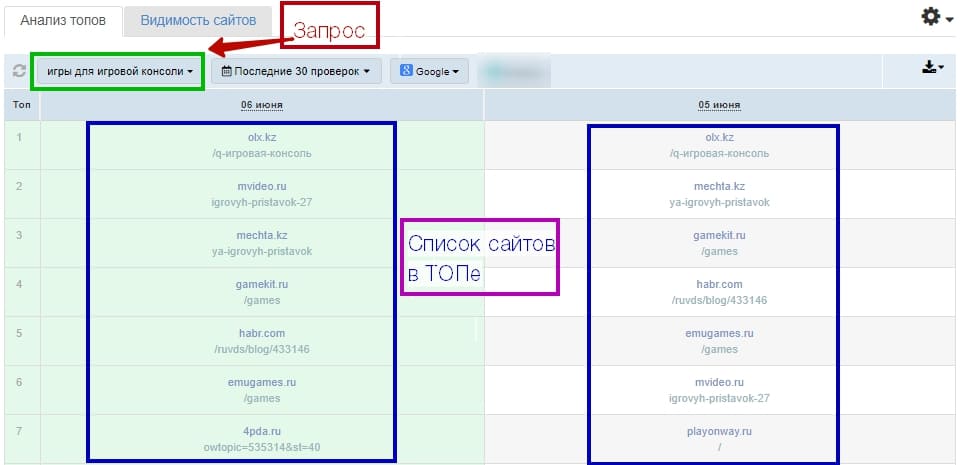 Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.
Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора кеша. Например, вводим кеш: trinet.ru и получаем:
Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
- использовать оператор site: указать сразу необходимый URL
- найти страницу в выдаче
- нажать на стрелочку рядом с URL
- выбрать «Сохраненная копия»
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП — 1, ТОП — 3 и т.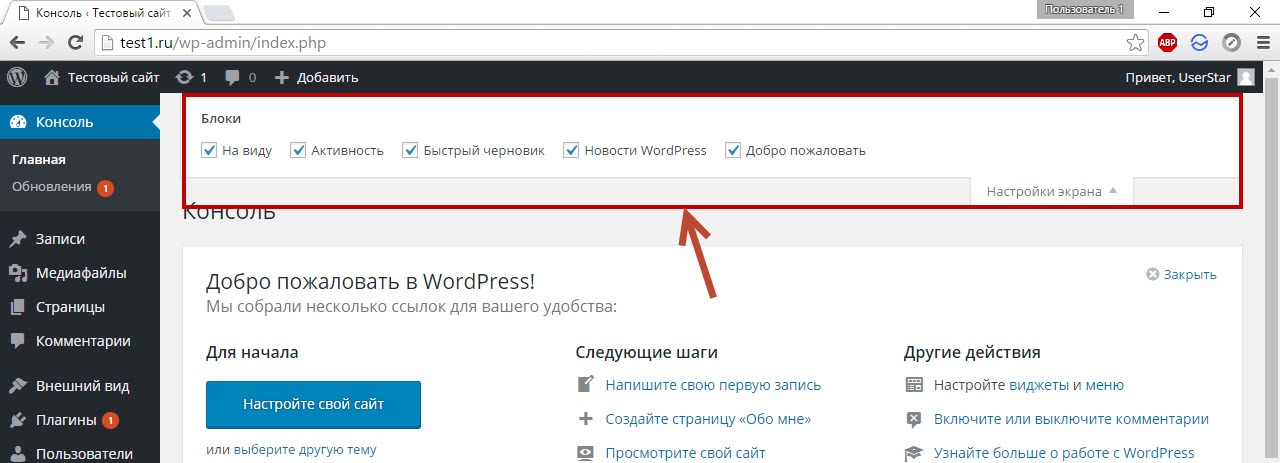 д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты.Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/ и нажать кнопку «Восстановить».
Для работы с полученными файловыми системами Архиварикс собственная система CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную загрузку для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т. Д.д.
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов.Единственный минус — сервис не русифицирован.
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Плагины
Восстановить сайт из бэкапа можно автоматически с помощью плагинов для CMS. Таких инструментов множество. Например, плагины Duplicator, UpdraftPlus для системы WordPress. Все, что нужно — это иметь копию, которую также можно сделать с помощью этих плагинов, если сайтомете вы.
Все, что нужно — это иметь копию, которую также можно сделать с помощью этих плагинов, если сайтомете вы.
Можество сервисов, предоставляющие хостинг для сайта, сохраняют бэкапы и можно восстановить предыдущую версию собственного проекта.
ение
Мы привели примеры основных сервисов, в которых можно посмотреть изменения сайтов и восстановить их содержимое.Список не ограничивается только этим инструментами.
Если у вас есть интересные и проверенные сервисы, которые мы не закрыли, расскажите в комментариях. А если нужна помощь со скачиванием контента, обращайтесь к специалистам.
И до встречи в следующей публикации!
Как получить доступ к сайтам, которые не открываются
Приходилось вам когда-нибудь кликать по ссылке и показать экран с ошибкой? Сайт «упал», страницу удалили, ресурс закрыли… Вам же получить доступ к информации необходимо.Makeuseof.com предлагает несколько вариантов, позволяющих «добраться» до сайтов, которые по каким-то причинам не открываются.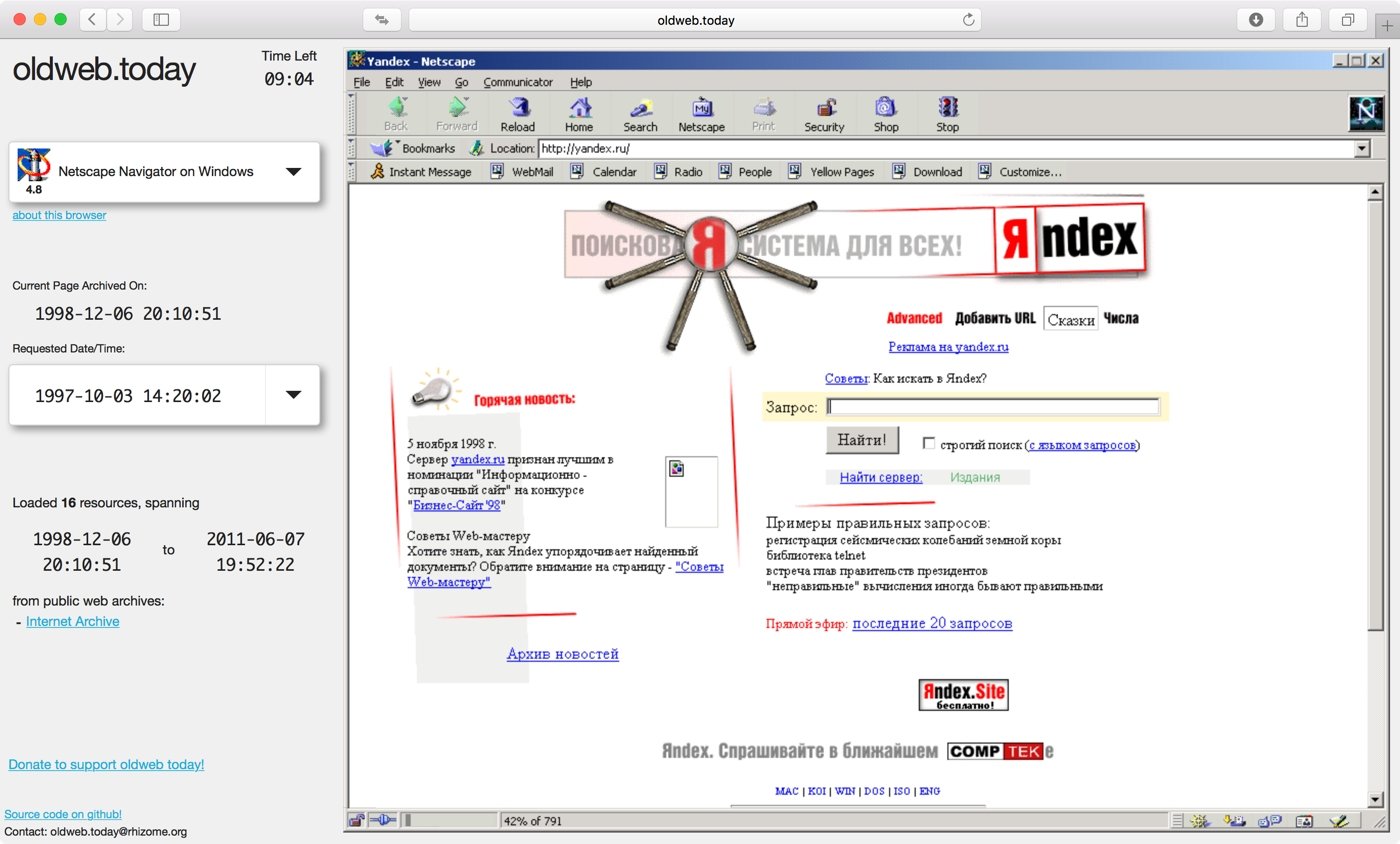
Google, Coral Content Distribution Network и «машина времени» Archive.org — эти сервисы делают «снимки» веб-страниц, позволяя видеть все кэшированные (спрятанные) версии. Если хотите ускорить процесс, можно использовать расширение веб-обозревателя или инструмент закладки панели вашего обозревателя.
Кэш Google
Кэш («тайник») является быстрым способом просмотреть сайт, который не функционирует.Раньше ссылки на кэшированные страницы Google были на самом видном месте на поисковой странице, но теперь их спрятали позади стрелки, которая возникает, когда вы «зависаете» над результатом поиска («сохраненная копия»).
Есть более быстрый способ получить доступ к кэшированным страницам, о котором вы могли не знать. Просто наберите cache: в строке поиска, после которого введите адрес ве-страницы, которые хотите посмотреть (например, cache: newreporter.org).
Гугл не кэширует картинки, поэтому вам может понадобиться использовать ссылку «Текстовая версия» (текстовая версия).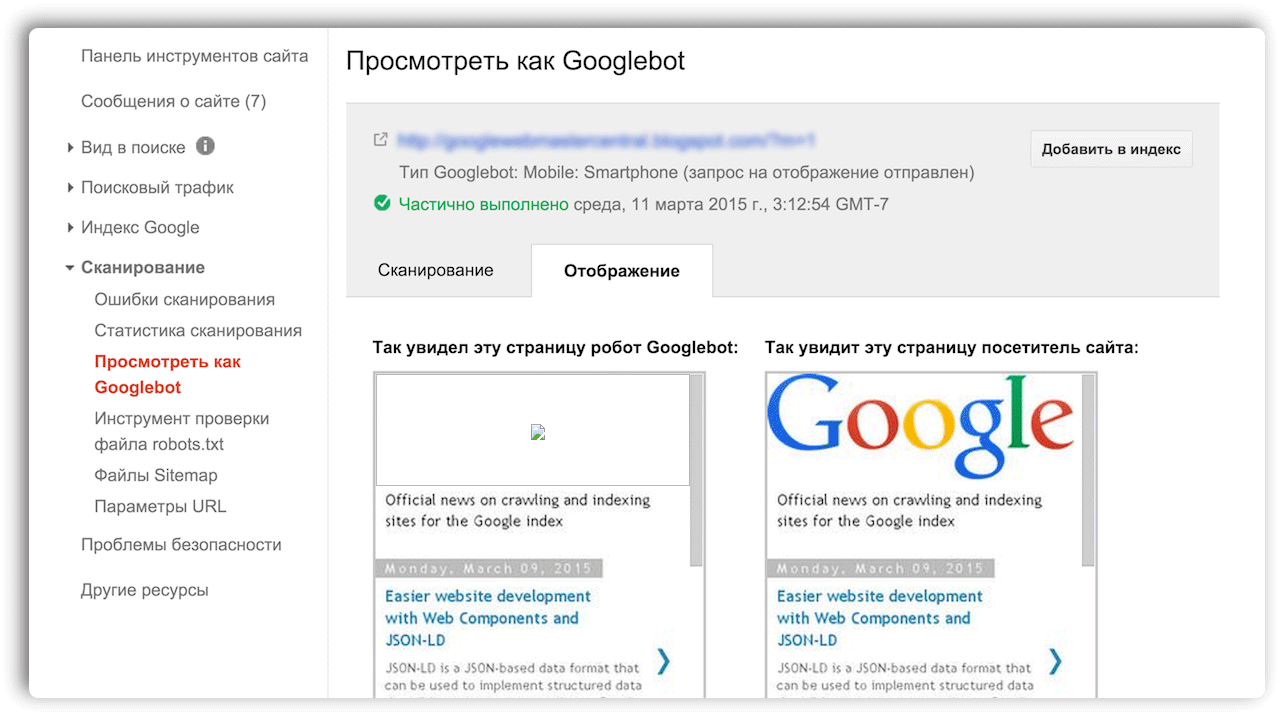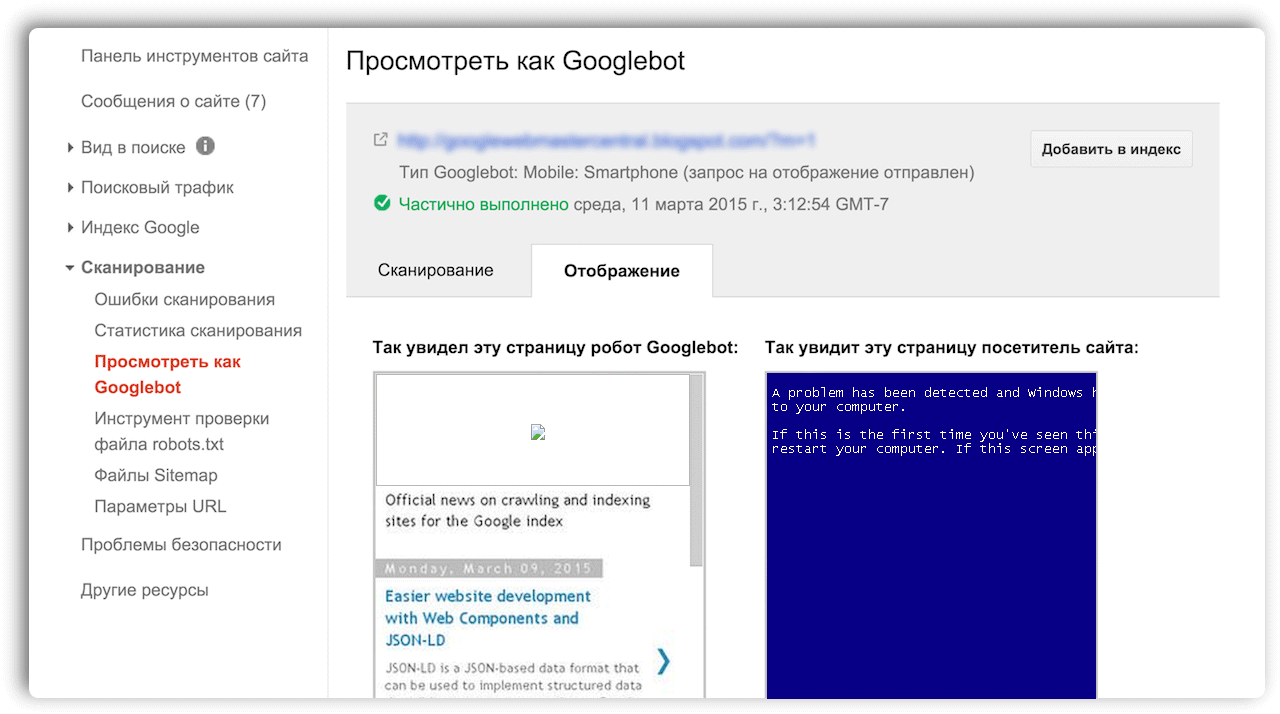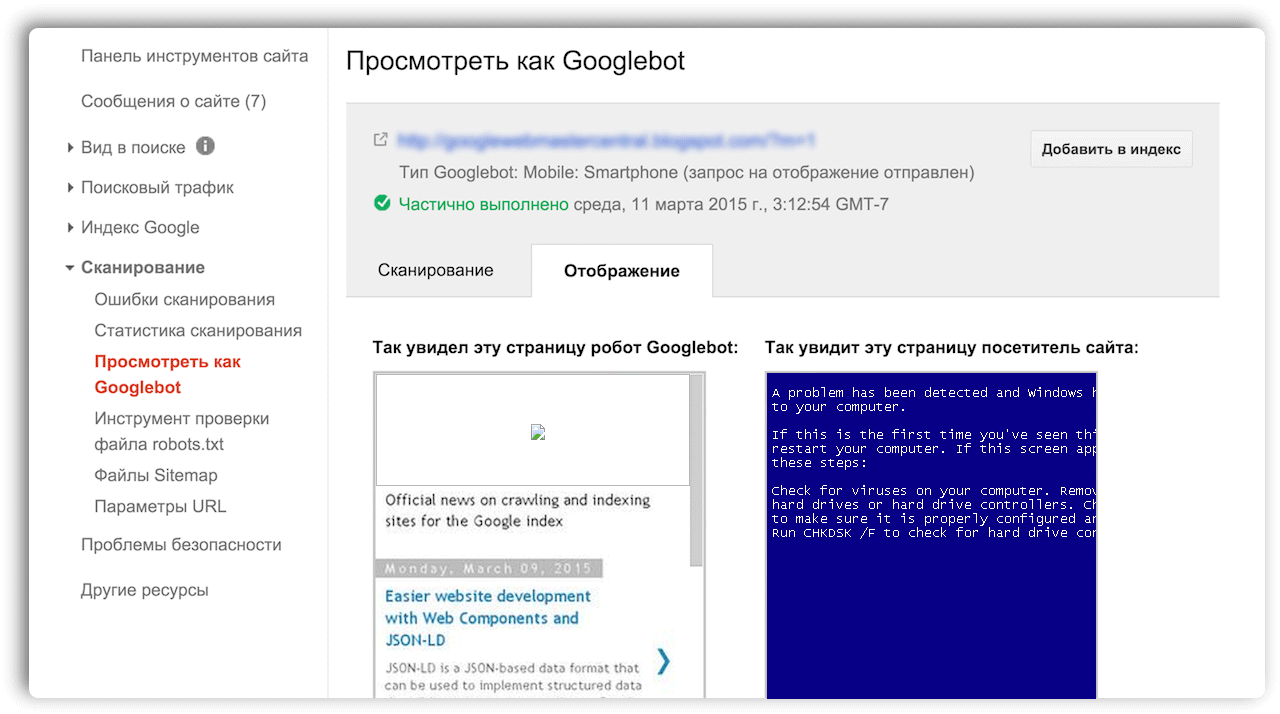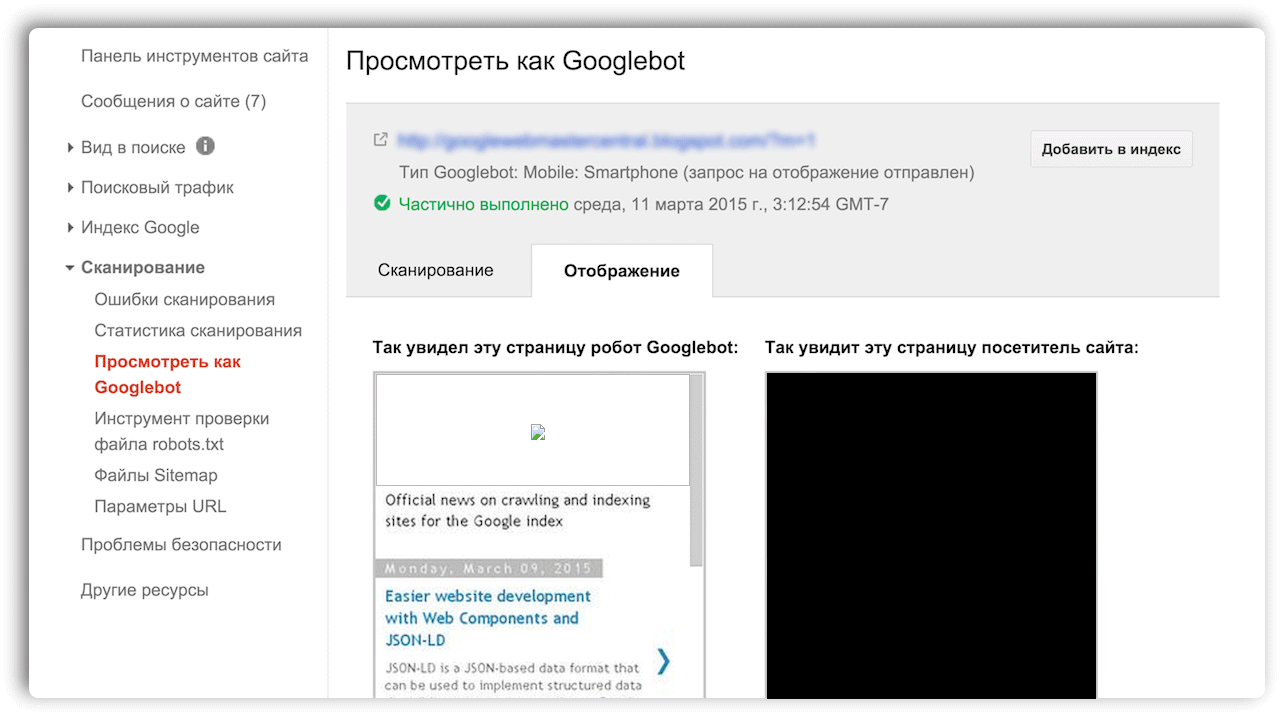
Coral CDN
Сеть распространения материалов «Коралл» (Coral CDN) идеально подходит для доступа к веб-сайтам, которые не работают по большой площади трафика. Использовать эту систему просто: надо добавить .nyud.net к доменному имени веб-сайта или веб-страницы.
Если это выглядит немного сложным, не волнуйтесь: вы также можете зайти на домашнюю страницу Coral CDN и добиться адрес сайта или страницы.
Машина времени (Wayback machine)
Это не только способ просматривать сайты, которые не загружаются, но и возможность совершить путешествие в прошлое и посмотреть, как выглядел сайт в прошлом.Незаменимый инструмент, если вы пытаетесь зайти на сайт, который уже какой-то время закрыт или просмотреть страницу, которую вы удалили.
Зайдите на домашнюю страницу Archive.org, введите адрес сайта и нажмите «Перенести меня в прошлое» (Верните меня).
Машина времени предоставит вам снэпшоты сайта, взятые в разное время. Вы можете увидеть самый недавний снэпшот или даже самый старый.
Вы можете увидеть самый недавний снэпшот или даже самый старый.
Вот таких тонах был Новый репортер в мае 2011 года:
Расширения веб-обозревателя
А еще лучше, пусть веб-обозреватель делает за вас всю работу.Resurrect Pages — (воскрешение страниц) популярное расширение обозревателя Firefox, которое делает ваши страницы ошибок более полезными, добавляя ссылки на службы более полезными.
Обозреватель Google Chrome сам по себе показывает ссылку на кэш Google на своей странице ошибок, что в кэше гугла что-то есть. Расширение веб-кэша и другие похожие небольшое меню со ссылками на службы.
Закладки
Bookmarklets– это маленькие ссылки, которые вы можете перетаскивать на и с панели закладок.Когда вы кликаете по этому ссылкам, они запускают маленький кусочек JavaScript-кода, который выполняется на текущей странице, например, загрузка в одном из описанных служб. Эти закладки работают в любом другом состоянии.