Как обучение ассемблеру помогает в программировании? [закрыто]
Запись на ассемблере не даст вам волшебного увеличения скорости, так как из-за количества деталей (распределение регистров и т. Д.) Вы, вероятно, напишете самый тривиальный алгоритм за всю историю.
Кроме того, с современными (читай — спроектированными после 70-80-х годов) сборка процессоров не даст вам достаточного количества деталей, чтобы знать, что происходит (то есть — на большинстве процессоров). Современные PU (процессоры и графические процессоры) довольно сложны в отношении инструкций по планированию. Знание основ сборки (или псевдосборки) позволит понять книги / курсы по компьютерной архитектуре, которые дадут дополнительные знания (кеширование, выполнение вне очереди, MMU и т. Д.). Обычно вам не нужно знать сложные ISA, чтобы понять их (MIPS 5 довольно популярен в IIRC).
Зачем понимать процессор? Это может дать вам гораздо больше понимания того, что происходит. Допустим, вы пишете матричное умножение наивным способом:
for i from 0 to N
for j from 0 to N
for k from 0 to N
A[i][j] += B[i][k] + C[k][j]
Это может быть «достаточно хорошо» для вашей цели (если это матрица 4×4, она может быть скомпилирована в векторные инструкции в любом случае). Однако при компиляции массивных массивов существуют довольно важные программы — как их оптимизировать? Если вы пишете код на ассемблере, вы можете получить несколько% улучшений (если вы не сделаете так, как делает большинство людей — также наивно, недоиспользуя регистры, постоянно загружая / сохраняя в памяти и фактически имея более медленную программу, чем на языке HL) ,
Однако при компиляции массивных массивов существуют довольно важные программы — как их оптимизировать? Если вы пишете код на ассемблере, вы можете получить несколько% улучшений (если вы не сделаете так, как делает большинство людей — также наивно, недоиспользуя регистры, постоянно загружая / сохраняя в памяти и фактически имея более медленную программу, чем на языке HL) ,
Однако вы можете повернуть вспять линии и волшебным образом повысить производительность (почему? Я оставляю это как «домашнее задание») — IIRC, в зависимости от различных факторов для больших матриц, может быть даже в 10 раз.
for i from 0 to N
for k from 0 to N
for j from 0 to N
A[i][j] += B[i][k] + C[k][j]
Тем не менее, есть работающие над тем, чтобы компиляторы могли это делать ( графит для gcc и Полли для всего, что использует LLVM). Они даже способны преобразовать его в (извините — я пишу блокировку по памяти):
for i from 0 to N
for K from 0 to N/n
for J from 0 to N/n
for kk from 0 to n
for jj from 0 to n
k = K*n + kk
j = J*n + jj
A[i][j] += B[i][k] + C[k][j]
Подводя итог: знание основ сборки позволяет вам копаться в различных «деталях» проектирования процессора, которые позволят вам писать более быстрые программы.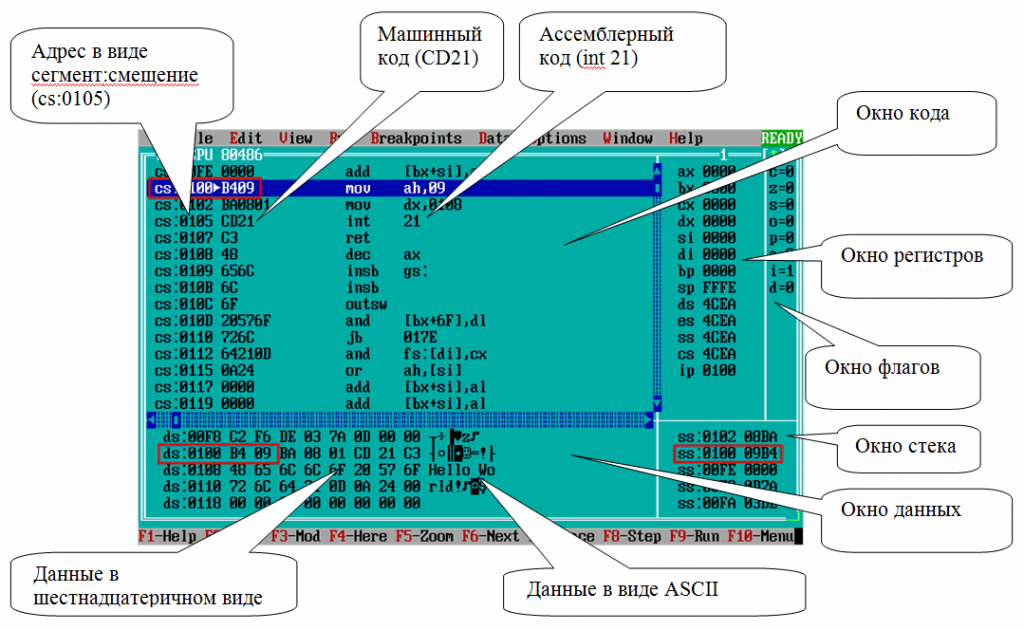 Было бы полезно узнать о различиях между архитектурами RISC / CISC или VLIW / vector Процессор / SIMD / …. Однако я бы не стал начинать с x86, поскольку они, как правило, довольно сложные (возможно, и ARM) — для начала достаточно знать, что такое регистр и т. Д.
Было бы полезно узнать о различиях между архитектурами RISC / CISC или VLIW / vector Процессор / SIMD / …. Однако я бы не стал начинать с x86, поскольку они, как правило, довольно сложные (возможно, и ARM) — для начала достаточно знать, что такое регистр и т. Д.
6 книг по Ассемблеру на русском языке
Книга поможет овладеть базовыми знаниями по языку ассемблер. Автор разобрал широкий сегмент вопросов на простом и понятном языке. Не обращай внимания на процессор – основная суть программирования под Intel не поменялась, да и понимать инфу лучше на простых вещах. Каждый кусок текста усилен кодом, так что скучно не будет. Подойдет как для опытных программистов, так и для совсем “зеленых”.
Ассемблер для процессоров Intel Pentium
Это издание – одно из лучших для новичков. Присутствует гора примеров с кодом, которые прекрасно задокументированы. После прочтения ты узнаешь, как программировать под разными ОС, как запустить пример на ассемблере, резидентные программы и многое другое. Отлично подойдет для новичков и студентов.
Assembler на примерах. Базовый курс
В книге все начинается по закону жанра – история ВТ, математика, алгоритмы, вычислительные системы и прочее (про алгоритмизацию и выч.системы почитай отдельно – пригодится). Автор книги плавно тебя подводит к изучению языка С, поэтому указатели, память и рекурсия рассматриваются довольно часто. А еще ты узнаешь об отладке и о том, как правильно тестировать свой код.
Программирование, введение в профессию. Низкоуровневое программирование
Ассемблер важен до сих пор по нескольким причинам. Первая – он незаменим в процессе познания устройства ЭВМ. Вторая – без него затруднительно писать программу управления девайсом, в котором нет нативной ОС – магнитолы, медицинские приборы, различные микроконтроллерные системы и т. д.
Материал в книге изложен понятным языком от простого к сложному – от легких примеров до написания автономных программ для «безбиосных» систем. Закрепить теорию ты сможешь заданиями в виде лабораторных работ. Подойдет для студентов и интересующихся темой.
Программирование на ассемблере
Крутая вещь, в которой краткое и лаконичное изложение материала переплетается с практикой программирования под интегральные микросхемы. Поскольку издание предназначено для прочтения студентами направления «Вычислительная техника», то представь, каким понятным языком оно написано.
Книга прекрасно подойдет для специалистов, работающих в сфере автоматизации систем, и для простого обывателя.
Основы программирования на Ассемблере
В качестве закрепления пройденной теоретической части предложены примеры-задачи, а для практической составляющей – написание кода.
Самоучитель. Ассемблер
А какую литературу по ассемблеру изучал ты?
Структура программы на ассемблере
Программирование на уровне машинных команд — это тот минимальный уровень, на котором возможно составление программ. Система машинных команд должна быть достаточной для того, чтобы реализовать требуемые действия, выдавая указания аппаратуре вычислительной машины.
Каждая машинная команда состоит из двух частей:
- операционной — определяющей, «что делать»;
- операндной — определяющей объекты обработки, «с чем делать».
Машинная команда микропроцессора, записанная на языке ассемблера, представляет собой одну строку, имеющую следующий синтаксический вид:
метка команда/директива операнд(ы) ;комментарии
При этом обязательным полем в строке является команда или директива.
Метка, команда/директива и операнды (если имеются) разделяются по крайней мере одним символом пробела или табуляции.
Если команду или директиву необходимо продолжить на следующей строке, то используется символ обратный слеш: \.
По умолчанию язык ассемблера не различает заглавные и строчные буквы в написании команд или директив.
Примеры строк кода:
Count db 1 ;Имя, директива, один операнд
mov eax,0 ;Команда, два операнда
cbw ; Команда
Метки
Метка в языке ассемблера может содержать следующие символы:
- все буквы латинского алфавита;
- цифры от 0 до 9;
- спецсимволы: _, @, $, ?.
В качестве первого символа метки может использоваться точка, но некоторые компиляторы не рекомендуют применять этот знак. В качестве меток нельзя использовать зарезервированные имена Ассемблера (директивы, операторы, имена команд).
Первым символом в метке должна быть буква или спецсимвол (но не цифра). Максимальная длина метки – 31 символ. Все метки, которые записываются в строке, не содержащей директиву ассемблера, должны заканчиваться двоеточием : .
Команды
Команда указывает транслятору, какое действие должен выполнить микропроцессор. В сегменте данных команда (или директива) определяет поле, рабочую область или константу. В сегменте кода команда определяет действие, например, пересылка (mov) или сложение (add).
Директивы
Ассемблер имеет ряд операторов, которые позволяют управлять процессом ассемблирования и формирования листинга. Эти операторы называются директивами. Они действуют только в процессе ассемблирования программы и, в отличие от команд, не генерируют машинных кодов.
Операнды
Операнд– объект, над которым выполняется машинная команда или оператор языка программирования.
Команда может иметь один или два операнда, или вообще не иметь операндов. Число операндов неявно задается кодом команды.
Примеры:
- Нет операндов ret ;Вернуться
- Один операнд inc ecx ;Увеличить ecx
- Два операнда add eax,12 ;Прибавить 12 к eax
Метка, команда (директива) и операнд не обязательно должны начинаться с какой-либо определенной позиции в строке. Однако рекомендуется записывать их в колонку для большего удобства чтения программы.
В качестве операндов могут выступать
- идентификаторы;
- цепочки символов, заключенных в одинарные или двойные кавычки;
- целые числа в двоичной, восьмеричной, десятичной или шестнадцатеричной системе счисления.
Идентификаторы
Идентификаторы – последовательности допустимых символов, использующиеся для обозначения таких объектов программы, как коды операций, имена переменных и названия меток.
Правила записи идентификаторов.
- Идентификатор может состоять из одного или нескольких символов.
- В качестве символов можно использовать буквы латинского алфавита, цифры и некоторые специальные знаки: _, ?, $, @.
- Идентификатор не может начинаться символом цифры.
- Длина идентификатора может быть до 255 символов.
- Транслятор воспринимает первые 32 символа идентификатора, а остальные игнорирует.
Комментарии
Комментарии отделяются от исполняемой строки символом ; . При этом все, что записано после символа точка с запятой и до конца строки, является комментарием. Использование комментариев в программе улучшает ее ясность, особенно там, где назначение набора команд непонятно. Комментарий может содержать любые печатные символы, включая пробел. Комментарий может занимать всю строку или следовать за командой на той же строке.
Структура программы на ассемблере
Программа, написанная на языке ассемблера, может состоять из нескольких частей, называемых модулями. В каждом модуле могут быть определены один или несколько сегментов данных, стека и кода. Любая законченная программа на ассемблере должна включать один главный, или основной, модуль, с которого начинается ее выполнение. Модуль может содержать сегменты кода, сегменты данных и стека, объявленные при помощи соответствующих директив. Перед объявлением сегментов нужно указать модель памяти при помощи директивы .MODEL.
Пример «ничего не делающей» программы на языке ассемблера:
.686P
.MODEL FLAT, STDCALL
.DATA
.CODE
START:
RET
END START
В данной программе представлена всего одна команда микропроцессора. Эта команда RET. Она обеспечивает правильное окончание работы программы. В общем случае эта команда используется для выхода из процедуры.
Остальная часть программы относится к работе транслятора.
.686P — разрешены команды защищенного режима Pentium 6 (Pentium II). Данная директива выбирает поддерживаемый набор команд ассемблера, указывая модель процессора. Буква P, указанная в конце директивы, сообщает транслятору о работе процессора в защищенном режиме.
.MODEL FLAT, stdcall — плоская модель памяти. Эта модель памяти используется в операционной системе Windows. stdcall — используемое соглашение о вызовах процедур.
.DATA — сегмент программы, содержащий данные.
.CODE — блок программы, содержащей код.
START — метка. В ассемблере метки играют большую роль, что не скажешь о современных языках высокого уровня.
END START — конец программы и сообщение транслятору, что начинать выполнение программы надо с метки START.
Каждый модуль должен содержать директиву END, отмечающую конец исходного кода программы. Все строки, которые следуют за директивой END, игнорируются. Если опустить директиву END, то генерируется ошибка.
Метка, указанная после директивы END, сообщает транслятору имя главного модуля, с которого начинается выполнение программы. Если программа содержит один модуль, метку после директивы END можно не указывать.
Назад
Назад: Язык ассемблера
Хочу всё знать: язык ассемблера | GeekBrains
Снова в тренде.
https://gbcdn.mrgcdn.ru/uploads/post/897/og_cover_image/dd191523048605359ea3596f42b8d98d
Как вы уже знаете, согласно последним мировым тенденциям, язык ассемблера снова входит в 10-ку самых популярных языков программирования. Как так получилось, что в мире, где большинство начинающих разработчиков с трудом представляет механизмы взаимодействия кода и машины, это первобытное создание вновь на виду? И главное: надо ли учить язык ассемблера? И как? Попробуем разобраться.
Краткая справка
Язык ассемблера – машинно-ориентированный код низкого уровня, первое упоминание о котором датировано 40-ми годами 20-го века в контексте взаимодействии с компьютером EDSAC. Несмотря на то, что он не всегда использует внутренние инструкции самих машин (всё-таки речь идёт об универсализации), это практически не вызывает потери в быстродействии, наоборот лишь предоставляя пользователю возможности для использования макрокоманд.
В этом и есть главная прелесть: обладая достаточно ограниченным набором команд и действий, язык ассемблера является универсальным средством, если вы хотите создать максимально быстро исполняемый код, а также пошагово отследить процессы, выполняемые машиной.
Исходя из этого выделим очевидные достоинства:
-
Быстродействие. Быстрее только использовать непосредственные инструкции процессора;
-
Безопасность. Низкоуровневость в данном случае практически исключает наличие белых пятен в коде;
-
Эффективность использования возможностей конкретной платформы. Ориентированность на используемую машину позволяет иметь серьезное преимущество по сравнению с высокоуровневыми языками;
-
Понимание исполняемого кода программистом. На таком уровне программирования код и действие имеют очевидно причинно-следственную связь.
Однако, глупо отрицать, что у столь старого языка есть явные недостатки:
-
Трудно выучить. Специализация на платформу, несколько диалектов — все это не способствует быстрому изучению и пониманию;
-
Тяжело читать. Большой листинг, простые однотипные операции;
-
Написание программ. Некоторые примитивные операции, описываемые в языках высокого уровня одной строкой, здесь могут вызывать настоящую головную боль у программиста;
-
Большинство используемых машин просто не нуждается в таком примитивном языке, как ассемблер;
-
Высокий порог входа. Представить исполняемый код в языке ассемблера сможет почти любой программист средней руки. Сделать это эффективнее компилятора — лишь малая часть;
-
Сильно ограниченное количество библиотек, сообществ, вспомогательных ресурсов по современным меркам.
Кому изучать?
Очевидно, что язык ассемблера был хорош и востребован во времена не слишком мощных компьютеров, но почему новый виток роста объявился сейчас? Всё просто: на мир огромной волной надвигается IoT. Использование многочисленных компьютеров, подчинённых одной цели, оправдывает себя только при общей максимально низкой себестоимости и высоком быстродействии, что вынуждает разработчиков обратится к старому-доброму языку ассемблера.
Таким образом, если вашей специализацией является разработка мобильных приложений, то данная тенденция вас не касается. Однако если ваш инструмент C, а на рабочем столе всегда лежит микроконтроллер, то язык ассемблера — то, что доктор прописал. В противном случае, путь в профессии будет коротким.
Книги
Zen of Assembly Language, Майкл Абраш – именно с этой книги стоит начать изучение, если уж без языка ассемблера вам не обойтись. Основная цель, которую пытается Абраш донести до читателя — это необходимость мыслить легко и широко (“иначе”) в решении сложных задач с помощью такого низкоуровневого инструмента;
Programming from the Ground Up, Джонатан Бартлетт –вторая книга по очереди для прочтения имеет более сухой язык изложения, зато изобилует полезными советами и техническими данными;
Introduction to 64 Bit Assembly Language, Programming for Linux and OS X, Рэй Сейфарт — в этой книге язык ассемблера рассматривается, как базис для всех систем и устройств. Новичку такая книга может показаться тяжелой для понимания, поэтому рекомендуется иметь за плечами хоть какие-то познания в программировании;
Assembly Language for x86 Processors, Уип Ирвинг — уже из названия вы можете понять, что это в большей степени справочная книга, рекомендуемая в учебных заведениях в качестве дополнительной литературы. Однако распространенность данных процессоров и практически неизбежность работы с ними, переносит эту книгу в раздел must-read.
Art of Assembly Language, Рэндэлл Хайд — еще одна прекрасная книга для новичков. Говорят, это одна из наиболее часто рекомендуемых книг в интернете в данной области;
PC Assembly Language, Пол Картер – обучающая языку ассемблера книга с огромным количеством примеров и конкретным их применением из реальной жизни;
Ассемблер и дизассемблирование, Пирогов Владислав – должна быть среди всего этого обучающего великолепия и книга на русском языке. Примеры кода, описание инструментов и ответы на актуальные вопросы новичков — всё прилагается;
Ассемблер? Это просто! Учимся программировать, Калашников Олег — книга второй ступени познания языка ассемблера. То лучше наложить информацию, описанную в ней, на ваши хотя бы минимальные уже полученные знания;
Ассемблер на примерах, Марек Рудольф — а вот эта книга, хоть и не российского производства (однако в оригинале вы её тоже вряд ли прочтёте), идеально подойдёт в качестве базиса. Всё доступно и понятно.
Лекция 4. Основы языка Ассемблер. Синтаксис языка Ассемблер. Ассемблерные вставки в языке C/C++.
4.1. Назначение языков ассемблера.
Ассемблер (от англ. assemble — собирать) — компилятор с языка ассемблера в команды машинного языка.
Сейчас разработка программ на ассемблере применяется в основном в программировании небольших микропроцессорных систем (микроконтроллеров), как правило, встраиваемых в какое-либо оборудование. Очень редко возникает потребность использования ассемблера в разрабатываемых программах в тех случаях, когда необходимо, например, получить наивысшую скорость выполнения определенного участка программы, выполнить операцию, которую невозможно реализовать средствами языков высокого уровня, либо уместить программу в память ограниченного объема (типичное требование для загрузчиков операционной системы).
Под каждую архитектуру процессора и под каждую ОС или семейство ОС существует свой ассемблер. Есть также так называемые кроссассемблеры, позволяющие на машинах с одной архитектурой (или в среде одной ОС) ассемблировать программы для другой целевой архитектуры или другой ОС и получать исполняемый код в формате, пригодном к исполнению на целевой архитектуре или в среде целевой ОС.
Язык ассемблера — тип языка программирования низкого уровня. Команды языка ассемблера один в один соответствуют командам процессора и представляют собой удобную символьную форму записи (мнемокод) команд и аргументов. Язык ассемблера обеспечивает связывание частей программы и данных через метки, выполняемое при ассемблировании (для каждой метки высчитывается адрес, после чего каждое вхождение метки заменяется на этот адрес).
Каждая модель процессора имеет свой набор команд и соответствующий ему язык (или диалект) ассемблера.
Обычно программы или участки кода пишутся на языке ассемблера в случаях, когда разработчику критически важно оптимизировать такие параметры, как быстродействие (например, при создании драйверов) и размер кода (загрузочные секторы, программное обеспечение для микроконтроллеров и процессоров с ограниченными ресурсами, вирусы, навесные защиты).
Связывание ассемблерного кода с другими языками. Большинство современных компиляторов позволяют комбинировать в одной программе код, написанный на разных языках программирования. Это дает возможность быстро писать сложные программы, используя высокоуровневый язык, не теряя быстродействия в критических ко времени задачах, применяя для них части, написанные на языке ассемблера. Комбинирование достигается несколькими приемами:
1. Вставка фрагментов на языке ассемблера в текст программы (специальными директивами языка) или написание процедур на языке ассемблера. Способ хороший для несложных преобразований данных, но полноценного ассемблерного кода с данными и подпрограммами, включая подпрограммы с множеством входов и выходов, не поддерживаемых высокоуровневыми языками, с помощью него сделать нельзя.
2. Модульная компиляция. Большинство современных компиляторов работают в два этапа. На первом этапе каждый файл программы компилируется в объектный модуль. А на втором объектные модули линкуются (связываются) в готовую программу. Прелесть модульной компиляции состоит в том, что каждый объектный модуль будущей программы может быть полноценно написан на своем языке программирования и скомпилирован своим компилятором (ассемблером).
Достоинства языков ассемблера.
1. Максимально оптимальное использование средств процессора, использование меньшего количества команд и обращений в память и, как следствие, большая скорость и меньший размер программы.
2. Использование расширенных наборов инструкций процессора (MMX, SSE, SSE2, SSE3).
3. Доступ к портам ввода-вывода и особым регистрам процессора (в большинстве ОС эта возможность доступна только на уровне модулей ядра и драйверов)
4. Возможность использования самомодифицирующегося (в том числе перемещаемого) кода (под многими платформами она недоступна, так как запись в страницы кода запрещена, в том числе и аппаратно, однако в большинстве общедоступных систем из-за их врожденных недостатков имеется возможность исполнения кода, содержащегося в сегменте (секции) данных, куда запись разрешена).X используется в OpenBSD , в других BSD-системах, в Linux. В Microsoft Windows (начиная с Windows XP SP2) применяется схожая технология DEP.
Недостатки языков ассемблера.
1. Большие объемы кода, большое число дополнительных мелких задач, меньшее количество доступных для использования библиотек по сравнению с языками высокого уровня.
2. Трудоемкость чтения и поиска ошибок (хотя здесь многое зависит от комментариев и стиля программирования).
3. Часто компилятор языка высокого уровня, благодаря современным алгоритмам оптимизации, даёт более эффективную программу (по соотношению качество/время разработки).
4. Непереносимость на другие платформы (кроме совместимых).
5. Ассемблер более сложен для совместных проектов.
4.2. Синтаксис ассемблера.
Синтаксис общих элементов языка. В отличие от языков программирования высокого уровня, где основным элементом языка является оператор, синтаксически программа на ассемблере состоит из последовательности строк. Строка – основная единица ассемблерной программы.
Синтаксис строки имеет следующий общий вид:
<метка:> <команда или директива> <операнды> <;комметарий>
Все эти четыре поля необязательны, в программе вполне могут присутствовать и полностью пустые строки для выделения каких либо блоков кода. Метка может быть любой комбинацией букв английского алфавита, цифр и символов _, $, @, ?, но цифра не может быть первым символом метки, а символы $ и ? иногда имеют специальные значения и обычно не рекомендуются к использованию. Большие и маленькие буквы по умолчанию не различаются, но различие можно включить, задав ту или иную опцию в командной строке ассемблера. Во втором поле, поле команды, может располагаться команда процессора, которая транслируется в исполняемый код, или директива, которая не приводит к появлению нового кода, а управляет работой самого ассемблера. В поле операндов располагаются требуемые командой или директивой операнды (то есть нельзя указать операнды и не указать команду или директиву). И наконец, в поле комментариев, начало которого отмечается символом ; (точка с запятой), можно написать все что угодно — текст от символа «;» до конца строки не анализируется ассемблером.
4.3. Ассемблерные вставки в языках высокого уровня.
Языки высокого уровня поддерживают возможность вставки ассемблерного кода. Последовательность команд Ассемблера в С-программе размещается в asm-блоке:
asm
{
команда_1 //комментарий_1
команда_2 /* комментарий_2 */
————————
команда_n ; комментарий_n
}
Книга «Программирование на ассемблере» — В. В. Одиноков, В. П. Коцубинский. Цены, рецензии, файлы, тесты, цитаты
Изучение самого «древнего» из языков программирования — ассемблера абсолютно необходимо для всех, кто желает в совершенстве овладеть искусством программирования. Почему же ассемблер столь важен? Во-первых, ни один язык программирования кроме него не дает такого ясного представления о строении аппаратуры ЭВМ. Во-вторых, язык ассемблера незаменим для разработки программ для встроенных устройств — микропроцессорных систем и микроконтроллеров, используемых в LCD телевизорах, автомагнитолах, сотовых …
Изучение самого «древнего» из языков программирования — ассемблера абсолютно необходимо для всех, кто желает в совершенстве овладеть искусством программирования. Почему же ассемблер столь важен? Во-первых, ни один язык программирования кроме него не дает такого ясного представления о строении аппаратуры ЭВМ. Во-вторых, язык ассемблера незаменим для разработки программ для встроенных устройств — микропроцессорных систем и микроконтроллеров, используемых в LCD телевизорах, автомагнитолах, сотовых телефонах, медицинской аппаратуре и других подобных разработках. Эти устройства часто не имеют операционных систем и поэтому управляющие программы должны быть автономными. Материал изложен от написания и отладки простейших программ в среде отладчика debug до практической разработки автономных программ, не использующих не только операционную систему, но и BIOS. Приведенные сведения иллюстрируются примером достаточно сложной программы — шестнадцатеричного редактора, который позволяет редактировать как содержимое оперативной памяти, так и файлы на диске. Теоретический материал в совокупности с предлагаемыми индивидуальными заданиями оформлен в виде лабораторных работ, что значительно облегчает индивидуальное восприятие предмета читателем и повышает ценность книги при использовании в учебном процессе. Для студентов технических вузов, будет полезна для широкого круга специалистов, желающих систематизировать свои познания в области программирования и устройства микропроцессорных систем. Книга «Программирование на ассемблере» авторов В. В. Одиноков, В. П. Коцубинский оценена посетителями КнигоГид, и её читательский рейтинг составил 0.00 из 10.
Для бесплатного просмотра предоставляются: аннотация, публикация, отзывы, а также файлы для скачивания.
Ассемблер — это… Что такое Ассемблер?
Эта статья — о компьютерных программах. О языке программирования см. Язык ассемблера.Ассе́мблер (от англ. assembler — сборщик) — компьютерная программа, компилятор исходного текста программы, написанной на языке ассемблера, в программу на машинном языке.
Как и сам язык (ассемблера), ассемблеры, как правило, специфичны для конкретной архитектуры, операционной системы и варианта синтаксиса языка. Вместе с тем существуют мультиплатформенные или вовсе универсальные (точнее, ограниченно-универсальные, потому что на языке низкого уровня нельзя написать аппаратно-независимые программы) ассемблеры, которые могут работать на разных платформах и операционных системах. Среди последних можно также выделить группу кросс-ассемблеров, способных собирать машинный код и исполняемые модули (файлы) для других архитектур и ОС.
Ассемблирование может быть не первым и не последним этапом на пути получения исполнимого модуля программы. Так, многие компиляторы с языков программирования высокого уровня выдают результат в виде программы на языке ассемблера, которую в дальнейшем обрабатывает ассемблер. Также результатом ассемблирования может быть не исполнимый, а объектный модуль, содержащий разрозненные блоки машинного кода и данных программы, из которого (или из нескольких объектных модулей) в дальнейшем с помощью программы-компоновщика может быть скомпонован исполнимый файл.
Архитектура x86
Ассемблеры для DOS
Наиболее известными ассемблерами для операционной системы DOS являлись Borland Turbo Assembler (TASM), Microsoft Macro Assembler (MASM) и Watcom Assembler (WASM). Также в своё время был популярен простой ассемблер A86.
Windows
При появлении операционной системы Windows появилось расширение TASM, именуемое TASM 5+ (неофициальный пакет, созданный человеком с ником !tE), позволившее создавать программы для выполнения в среде Windows. Последняя известная версия TASM — 5.3, поддерживающая инструкции MMX, на данный момент включена в Turbo C++ Explorer. Но официально развитие программы полностью остановлено.
Microsoft поддерживает свой продукт под названием Microsoft Macro Assembler. Она продолжает развиваться и по сей день, последние версии включены в наборы DDK. Но версия программы, направленная на создание программ для DOS, не развивается. Кроме того, Стивен Хатчессон создал пакет для программирования на MASM под названием «MASM32».
GNU и GNU/Linux
В состав операционной системы GNU входит пакет binutils, включающий в себя ассемблер gas (GNU Assembler), использующий AT&T-синтаксис, в отличие от большинства других популярных ассемблеров, которые используют Intel-синтаксис (поддерживается с версии 2.10).
Переносимые ассемблеры
Также существует открытый проект ассемблера, версии которого доступны под различные операционные системы, и который позволяет получать объектные файлы для этих систем. Называется этот ассемблер NASM (Netwide Assembler).
Yasm — это переписанная с нуля версия NASM под лицензией BSD (с некоторыми исключениями).
flat assembler (fasm) — молодой ассемблер под модифицированной для запрета перелицензирования (в том числе под GNU GPL) BSD-лицензией. Есть версии для KolibriOS, Linux, DOS и Windows; использует Intel-синтаксис и поддерживает инструкции x86-64.
Архитектуры RISC
MCS-51
MCS-51 (Intel 8051) — классическая архитектура микроконтроллера. Для неё существует кросс-ассемблер ASM51, выпущенный корпорацией MetaLink.
Кроме того, многие фирмы — разработчики программного обеспечения, такие как IAR или Keil, представили свои варианты ассемблеров. В ряде случаев применение этих ассемблеров оказывается более эффективным благодаря удобному набору директив и наличию среды программирования, объединяющей в себе профессиональный ассемблер и язык программирования Си, отладчик и менеджер программных проектов.
AVR
На данный момент существуют 3 компилятора производства Atmel (AVRStudio 3, AVRStudio 4, AVRStudio 5 и AVRStudio 6).
В рамках проекта AVR-GCC (он же WinAVR) существует компилятор avr-as (это портированный под AVR ассемблер GNU as из GCC).
Также существует свободный минималистический компилятор avra[1].
ARM
PIC
Пример программы на языке Assembler для микроконтроллера PIC16F628A:
LIST p=16F628A
__CONFIG 0309H
STATUS equ 0x003
TRISB equ 0x086
PORTB equ 0x006
RP0 equ 5
org 0
goto start
start:
bsf STATUS,RP0
movlw .00
movwf TRISB
bcf STATUS,RP0
led:
movlw .170
movwf PORTB
goto led
end
AVR32
MSP430
Пример программы на языке Assembler для микроконтроллера MSP430G2231 (в среде Code Composer Studio):
.cdecls C,LIST, "msp430g2231.h"
;------------------------------------------------------------------------------
.text ; Program Start
;------------------------------------------------------------------------------
RESET mov.w #0280h,SP ; Initialize stackpointer
StopWDT mov.w #WDTPW+WDTHOLD,&WDTCTL ; Stop WDT
SetupP1 bis.b #001h,&P1DIR ; P1.0 output
;
Mainloop bit.b #010h,&P1IN ; P1.4 hi/low?
jc ON ; jmp--> P1.4 is set
;
OFF bic.b #001h,&P1OUT ; P1.0 = 0 / LED OFF
jmp Mainloop ;
ON bis.b #001h,&P1OUT ; P1.0 = 1 / LED ON
jmp Mainloop ;
;
;------------------------------------------------------------------------------
; Interrupt Vectors
;------------------------------------------------------------------------------
.sect ".reset" ; MSP430 RESET Vector
.short RESET ;
.end
PowerPC
Программный пакет The PowerPC Software Development Toolset от IBM включает в себя ассемблер для PowerPC.
MIPS
Архитектуры MISC
SeaForth
Существуют:
- 8-разрядные Flash-контроллеры семейства MCS-51
- 8-разрядные RISC-контроллеры семейства AVR (ATtiny, ATmega, classic AVR). На данный момент семейство classic AVR трансформировано в ATtiny и ATmega
- 8-разрядные RISC-контроллеры семейства PIC (PIC10,PIC12,PIC16,PIC18)
- 16-разрядные RISC-контроллеры семейства PIC (PIC24HJ/FJ,dsPIC30/33)
- 32-разрядные RISC-контроллеры семейства PIC (PIC32) с архитектурой MIPS32 M4K
- 32-разрядные RISC-контроллеры семейства AVR32 (AVR32)
- 32-разрядные RISC-контроллеры семейства ARM Thumb высокой производительности (серия AT91)
Макроассемблер
Не следует путать с MASM.Макроассемблер (от греч. μάκρος — большой, обширный) — макропроцессор, базовым языком которого является язык ассемблера.[2]
Ассемблирование и компилирование
Процесс трансляции программы на языке ассемблера в объектный код принято называть ассемблированием. В отличие от компилирования, ассемблирование — более или менее однозначный и обратимый процесс. В языке ассемблера каждой мнемонике соответствует одна машинная инструкция, в то время как в языках программирования высокого уровня за каждым выражением может скрываться большое количество различных инструкций. В принципе, это деление достаточно условно, поэтому иногда трансляцию ассемблерных программ также называют компиляцией.
Примечания
См. также
Литература
- Вострикова З. П. Программирование на языке ассемблера ЕС ЭВМ. М.: Наука, 1985.
- Галисеев Г. В. Ассемблер для Win 32. Самоучитель. — М.: Диалектика, 2007. — С. 368. — ISBN 978-5-8459-1197-1
- Зубков С. В. Ассемблер для DOS, Windows и UNIX.
- Кип Ирвина. Язык ассемблера для процессоров Intel = Assembly Language for Intel-Based Computers. — М.: Вильямс, 2005. — С. 912. — ISBN 0-13-091013-9
- Калашников О. А. Ассемблер? Это просто! Учимся программировать. — БХВ-Петербург, 2011. — С. 336. — ISBN 978-5-9775-0591-8
- Магда Ю. С. Ассемблер. Разработка и оптимизация Windows-приложений. СПб.: БХВ-Петербург, 2003.
- Нортон П., Соухэ Д. Язык ассемблера для IBM PC. М.: Компьютер, 1992.
- Владислав Пирогов. Ассемблер для Windows. — СПб.: БХВ-Петербург, 2002. — 896 с. — ISBN 978-5-9775-0084-5
- Владислав Пирогов. Ассемблер и дизассемблирование. — СПб.: БХВ-Петербург, 2006. — 464 с. — ISBN 5-94157-677-3
- Сингер М. Мини-ЭВМ PDP-11: Программирование на языке ассемблера и организация машины. М.: Мир, 1984.
- Скэнлон Л. Персональные ЭВМ IBM PC и XT. Программирование на языке ассемблера. М.: Радио и связь, 1989.
- Юров В., Хорошенко С. Assembler: учебный курс. — СПб.: Питер, 2000. — С. 672. — ISBN 5-314-00047-4
- Юров В. И. Assembler: учебник для вузов / 2-е изд. СПб.: Питер, 2004.
- Юров В. И. Assembler. Практикум: учебник для вузов / 2-е изд. СПб.: Питер, 2004.
- Юров В. И. Assembler. Специальный справочник. СПб.: Питер, 2000.
Ссылки
Язык ассемблера — обзор
13.1.1 Язык ассемблера
Язык ассемблера (или Ассемблер) — это скомпилированный компьютерный язык низкого уровня. Он зависит от процессора, поскольку в основном переводит мнемонику Ассемблера непосредственно в команды, понятные конкретному процессору, на взаимно однозначной основе. Эти мнемоники ассемблера представляют собой набор инструкций для этого процессора. Кроме того, Ассемблер предоставляет команды, которые управляют процессом сборки, обрабатывают инициализацию и позволяют использовать переменные и метки, а также управлять выводом.
На ПК Ассемблер обычно используется только под MS-DOS. При работе в 32-битной операционной системе с защищенным режимом (включая Windows 95 / NT и выше) низкоуровневые программы, которые напрямую обращаются к регистрам или ячейкам памяти, вызывают нарушения защиты. Весь низкоуровневый доступ должен осуществляться через соответствующие драйверы программного обеспечения.
Для ПК с MS-DOS самым популярным языком ассемблера был Microsoft Macro Assembler или MASM. Как и большинство популярных компиляторов, MASM регулярно обновлялся.Большая часть этого обсуждения относится к версии 5.0 или более поздней, которая упростила использование определенных директив и включила поддержку инструкций, доступных только на процессорах 80286 и 80386.
Директива — это команда ассемблера, которая не преобразуется в исполняемую инструкцию, но предписывает MASM выполнить определенную задачу, облегчающую процесс сборки. Исполняемая инструкция иногда называется операционным кодом, в то время как директива ассемблера может называться псевдооперационным кодом.Директивы могут сообщать MASM много разных вещей, в том числе о том, на какой сегмент памяти делается ссылка, каково значение переменной или ячейки памяти и где начинается выполнение программы.
Одна из важных директив MASM — это .MODEL, которая определяет максимальный размер программы. Помните, что для ЦП семейства 80 × 86 память адресуется как сегменты длиной до 64 Кбайт. Если используется 16-битная адресация (для кода или данных), будет доступен только один сегмент размером 64 КБ. Модель памяти программы определяет, как различные части этой программы (код и данные) обращаются к сегментам памяти.MASM поддерживает пять моделей памяти для программ DOS: Small, Medium, Compact, Large и Huge. В модели Small все данные помещаются в один сегмент размером 64 КБ, а весь код (исполняемые инструкции) помещается в другой сегмент размером 64 КБ. В модели Medium все данные помещаются в один сегмент размером 64 КБ, но код может быть больше 64 КБ (многосегментный, требующий 32-разрядной адресации для сегмента: смещение). В модели Compact весь код помещается в один сегмент размером 64 КБ, но данные могут занимать более 64 КБ (но ни один массив не может быть больше 64 КБ).В большой модели и код, и данные могут быть больше 64 КБ (при этом ни один массив данных не может превышать 64 КБ). Наконец, в модели Huge размер кода и данных может превышать 64 КБ, а массивы данных также могут превышать 64 КБ.
Поскольку большие модели требуют больших адресов, они производят более крупные и медленные программы, чем меньшая модель. Выбирая модель для программы, постарайтесь оценить максимальный объем хранилища данных, который вам понадобится. Допустим, вы пишете программу БПФ, используя 16-битную целочисленную математику и максимальный размер выборки 2048 точек.Поскольку для каждой точки требуется два целых числа (действительное и мнимое), а каждое целое число имеет длину 2 байта, вам нужно 8096 байтов только для хранения входных (или выходных) данных. Даже если бы у вас были отдельные массивы для входных и выходных данных, это все равно было бы всего 16 192 байта. В качестве запаса прочности для временного хранилища мы удвоим это число до 32 384 байта, что составляет лишь половину сегмента размером 64 КБ. Размер кода оценить сложнее. В этом примере мы начнем с модели Small. Если бы размер кода оказался больше 64 КБ (что непросто сделать на ассемблере), мы бы перешли к модели Medium.Эти же модели памяти также применимы к компиляторам языка DOS высокого уровня от Microsoft. Если вы пишете программу MASM для работы с другим языком высокого уровня, вы должны использовать одну и ту же модель памяти для обоих.
Вот пример простой программы MASM, которая отображает на экране текстовую строку («Это простая программа MASM») с помощью функции DOS. 09h:
Здесь используются несколько директив. DOSSEG указывает MASM позаботиться о порядке различных сегментов (кода, данных, стека), но мы предпочли бы игнорировать эту деталь.Директива .DATA указывает начало сегмента данных, а .CODE указывает начало сегмента кода. Сообщение обозначается меткой text, , где директива DB (Defines Bytes) указывает, что это байтовые данные (кавычки обозначают текст ASCII). Строка должна заканчиваться символом ASCII 24h («$») для функции DOS 09h. Исполняемые инструкции помещаются в сегмент кода. Ярлык go, указывает на начало программы. Адрес текстовой строки загружается в регистры DS: DX.Затем вызывается функция DOS 09h для отображения строки. Наконец, вызывается функция DOS 4Ch для выхода из программы и возврата в DOS. Последняя директива END указывает MASM начать выполнение программы с метки (адреса) go.
MASM называется Macro Assembler, потому что он поддерживает использование макросов. Макрос — это блок программных операторов, которому дано символическое имя, которое затем можно использовать в нормальном программном коде. Макрос также может принимать параметры, когда он вызывается в программе.Когда исходный файл собирается MASM, все макросы расширяются (переводятся) в исходный текст определения. Это очень удобно, если один и тот же фрагмент кода, например функция, определяемая программистом, используется повторно. Часто предопределенные макросы могут храниться в отдельном файле вместе с другой информацией, такой как инициализация переменных. Директива INCLUDE может читать этот файл во время сборки.
Этот краткий обзор MASM едва коснулся поверхности языка ассемблера. Проверьте библиографию на другие книги по этой теме.Опять же, вам следует писать программу на языке ассемблера, только если вы работаете в DOS и язык высокого уровня не подходит для вашей задачи. Даже в этом случае обычно можно обойтись простым написанием наиболее важных разделов в MASM и их вызовом с языка высокого уровня. Далее мы рассмотрим популярный интерпретируемый язык высокого уровня: BASIC.
Определение языка ассемблера
Что такое язык ассемблера?
Ассемблер — это тип низкоуровневого языка программирования, который предназначен для непосредственного взаимодействия с аппаратным обеспечением компьютера.В отличие от машинного языка, который состоит из двоичных и шестнадцатеричных символов, языки ассемблера предназначены для чтения людьми.
Языки программирования низкого уровня, такие как язык ассемблера, являются необходимым мостом между базовым оборудованием компьютера и языками программирования более высокого уровня, такими как Python или JavaScript, на которых написаны современные программы.
Ключевые выводы
- Ассемблер — это тип языка программирования, который переводит языки высокого уровня на машинный язык.
- Это необходимый мост между программным обеспечением и лежащими в их основе аппаратными платформами.
- Сегодня языки ассемблера редко пишутся напрямую, хотя они все еще используются в некоторых нишевых приложениях, например, когда требования к производительности особенно высоки.
Как работают языки ассемблера
По сути, самые основные инструкции, выполняемые компьютером, представляют собой двоичные коды, состоящие из единиц и нулей. Эти коды напрямую переводятся в состояния «включено» и «выключено» электричества, проходящего через физические цепи компьютера.По сути, эти простые коды составляют основу «машинного языка», наиболее фундаментальной разновидности языка программирования.
Конечно, ни один человек не сможет создавать современные программы, явно запрограммировав единицы и нули. Вместо этого люди-программисты должны полагаться на различные уровни абстракции, которые могут позволить им формулировать свои команды в формате, более интуитивно понятном для людей. В частности, современные программисты выдают команды на так называемых «языках высокого уровня», которые используют интуитивно понятный синтаксис, такой как целые английские слова и предложения, а также логические операторы, такие как «И», «Или» и «Иначе», которые знакомы для повседневного использования.
Однако в конечном итоге эти высокоуровневые команды необходимо перевести на машинный язык. Вместо того, чтобы делать это вручную, программисты полагаются на языки ассемблера, целью которых является автоматический перевод между этими языками высокого и низкого уровня. Первые языки ассемблера были разработаны в 1940-х годах, и хотя современные программисты тратят очень мало времени на работу с языками ассемблера, они, тем не менее, остаются важными для общего функционирования компьютера.
Пример языка ассемблера в реальном мире
Сегодня языки ассемблера остаются предметом изучения студентов-информатиков, чтобы помочь им понять, как современное программное обеспечение соотносится с лежащими в его основе аппаратными платформами.В некоторых случаях программисты должны продолжать писать на языках ассемблера, например, когда требования к производительности особенно высоки или когда рассматриваемое оборудование несовместимо с любыми текущими языками высокого уровня.
Одним из таких примеров, имеющих отношение к финансам, являются платформы высокочастотной торговли (HFT), используемые некоторыми финансовыми фирмами. На этом рынке скорость и точность транзакций имеют первостепенное значение для того, чтобы торговые стратегии HFT оказались прибыльными.Поэтому, чтобы получить преимущество перед своими конкурентами, некоторые HFT-фирмы написали свое торговое программное обеспечение непосредственно на языках ассемблера, тем самым избавив от необходимости ждать, пока команды с языка более высокого уровня будут переведены на машинный язык.
Программированиес Linux: Дантеманн, Джефф: 8601400126363: Amazon.com: Книги
Изучите язык ассемблера, и вы выучите машину. предыдущий опыт программирования.В качестве основного языка ЦП ассемблер закладывает основу для всех других языков программирования, особенно для C, C ++ и Pascal с собственным кодом. Освоив сборку, программисты узнают, как работают компьютеры x86, вплоть до «голого кремния», на уровне детализации, с которым не может сравниться ни один другой подход.Язык ассемблера Шаг за шагом , третье издание, поможет вам:
Изучите фундаментальные концепции вычислений и программирования, включая шестнадцатеричные и двоичные системы счисления
Понять эволюцию процессоров Intel и как работают современные процессоры x86
Разберитесь в самом процессе программирования, от редактирования исходного кода до сборки, компоновки и отладки
Понимайте 32-битную адресацию памяти в защищенном режиме x86
Изучите набор инструкций x86 анализируя многочисленные полные примеры программ
Работайте с множеством бесплатных утилит программирования под Ubuntu Linux, включая редактор Kate, ассемблер NASM и набор инструментов GNU
Освойте практические детали программирования Linux, включая процедуры, макросы , шлюз вызова INT 80h и вызовы th стандартные библиотеки C
Язык ассемблера Шаг за шагом , третье издание, поможет вам:
Изучите фундаментальные концепции вычислений и программирования, включая шестнадцатеричные и двоичные системы счисления
Понять эволюцию процессоров Intel и как работают современные процессоры x86
Разберитесь в самом процессе программирования, от редактирования исходного кода до сборки, компоновки и отладки
Понимайте 32-битную адресацию памяти в защищенном режиме x86
Изучите набор инструкций x86 анализируя многочисленные полные примеры программ
Работайте с множеством бесплатных утилит программирования под Ubuntu Linux, включая редактор Kate, ассемблер NASM и набор инструментов GNU
Освойте практические детали программирования Linux, включая процедуры, макросы , шлюз вызова INT 80h и вызовы th стандартные библиотеки C
Об авторе
Джефф Дантеманн пишет о вычислениях более тридцати лет и является автором множества книг по программированию, беспроводным сетям и системному администрированию.Он был обозревателем журнала доктора Добба и редактировал известные публикации по программированию, такие как PC Techniques и Visual Developer. В нерабочее время он увлекается блогами, астрономией, радиолюбительством и сочинением научной фантастики.
Создание вашей первой простой программы на языке ассемблера MIPS — Sweetcode.io
АссемблерMIPS просто означает язык ассемблера процессора MIPS.Термин MIPS — это аббревиатура от Microprocessor without Interlocked Pipeline Stages. Это архитектура с сокращенным набором команд, разработанная организацией под названием MIPS Technologies.
Ассемблер MIPS — очень полезный язык для изучения, поскольку многие встроенные системы работают на процессоре MIPS. Знание того, как кодировать на этом языке, дает более глубокое понимание того, как эти системы работают на более низком уровне.
Перед тем, как начать кодирование на языке ассемблера MIPS
Прежде чем вы начнете штамповать код языка ассемблера MIPS, вам нужно сначала получить очень хорошую интегрированную среду разработки.Это может помочь скомпилировать и выполнить код языка ассемблера MIPS. Программное обеспечение, которое я бы порекомендовал для этой цели, — это MARS (MIPS Assembler and Runtime Simulator). Вы можете легко найти его в Google и скачать.
Введение в архитектуру MIPS
Типы данных
- Все инструкции в MIPS 32-битные.
- Байт в архитектуре MIPS соответствует 8 битам; полуслово представляет 2 байта (16 бит), а слово представляет 4 байта (32 бита).
- Для каждого символа, используемого в архитектуре MIPS, требуется 1 байт памяти. Для каждого используемого целого числа требуется 4 байта памяти.
Литералы
В архитектуре MIPS литералы представляют все числа (например, 5), символы, заключенные в одинарные кавычки (например, «g»), и строки, заключенные в двойные кавычки (например, «Дэдпул»).
Регистры
Архитектура MIPS использует 32 регистра общего назначения. Каждому регистру в этой архитектуре в инструкции на языке ассемблера предшествует символ «$».Вы можете обращаться к этим регистрам одним из двух способов. Используйте либо номер регистра (то есть от $ 0 до $ 31), либо имя регистра (например, $ t1).
Общая структура программы, созданной с использованием языка ассемблера MIPS
Типичная программа, созданная с использованием языка ассемблера MIPS, состоит из двух основных частей. Это раздел объявления данных программы и раздел кода программы.
Раздел объявления данных программы ассемблера MIPS
Раздел объявления данных программы — это часть программы, идентифицированная директивой ассемблера.данные. Это часть программы, в которой создаются и определяются все переменные, которые будут использоваться в программе. Это также часть программы, в которой память распределяется в основной памяти (RAM).
Программа на языке ассемблера MIPS объявляет переменные следующим образом:
имя: .storage_type значение (я)
«Имя» относится к имени создаваемой переменной. «Storage_type» относится к типу данных, которые переменная предназначена для хранения.«Значение (я)» относится к информации, которая должна храниться в создаваемой переменной. Следующий синтаксис языка ассемблера MIPS создает одну целочисленную переменную с начальным значением 5:
.. Данные
var1: .word 5 Раздел кода программы ассемблера MIPS
Раздел кода программы — это часть программы, в которой записаны инструкции, которые должны выполняться программой. Он помещается в раздел программы, идентифицированный директивой ассемблера.текст. Начальная точка для раздела кода программы отмечена меткой «main», а конечная точка для раздела кода программы отмечена системным вызовом выхода. Этот раздел программы на языке ассемблера MIPS обычно включает в себя манипуляции с регистрами и выполнение арифметических операций.
Манипуляции с регистрами
При манипулировании регистрами язык ассемблера MIPS использует концепции нагрузки, а также косвенную или индексированную адресацию.
В концепции адресации загрузки адрес оперативной памяти переменной в программе на языке ассемблера MIPS копируется и сохраняется во временном регистре. Например, чтобы скопировать адрес переменной с именем «var1» во временный регистр $ t0, требуется следующий синтаксис языка ассемблера MIPS:
la $ t0, var1
В концепции косвенной адресации значение, хранящееся в конкретном адресе оперативной памяти, копируется во временный регистр.Например, используйте следующий синтаксис языка ассемблера MIPS, чтобы скопировать целочисленное значение, хранящееся в адресе оперативной памяти регистра $ t0, в регистр $ t2
.лв $ t2, ($ t0)
В концепции индексированной адресации адрес регистра произвольной памяти может быть смещен на указанное значение, чтобы получить значение, хранящееся в другом адресе произвольной памяти. Например, чтобы получить значение, хранящееся в адресе памяти с произвольным доступом, который находится на четыре адреса от адреса памяти с произвольным доступом регистра $ t0, и сохранить это значение в регистре $ t2, требуется следующий синтаксис языка ассемблера MIPS :
lw $ t2, 4 ($ t0)
Выполнение арифметических операций
В языке ассемблера MIPS для большинства арифметических операций используются три операнда, и все эти операнды являются регистрами.Размер каждого операнда представляет собой слово, а общий формат выполнения арифметических операций на языке ассемблера MIPS показан следующим образом:
арифметическая_операция регистр_хранилища, первая_операция, вторая_операция
Где «arithmetic_operation» относится к выполняемой арифметической операции, «storage_register» относится к регистру, который используется для хранения результата арифметических вычислений; «First_operand» относится к регистру, который содержит первый операнд арифметической операции, а «second_operand» относится к регистру, который содержит второй операнд арифметической операции.
Наиболее распространенными арифметическими операциями, реализованными на языке ассемблера MIPS, являются сложение, вычитание, умножение и деление. В следующей таблице представлены различные перечисленные арифметические операции и их представление на языке ассемблера MIPS:
Создание простой программы на языке ассемблера MIPS
В этом посте мы создаем простую программу, которая может получать от пользователя два разных числа и выполнять арифметические операции сложения, вычитания и умножения этих двух чисел.
Первое, что нужно сделать при создании этой программы, — это определить переменные, которые будут использоваться для хранения строк, используемых в программе.
# Это простая программа, которая берет у пользователя два числа и выполняет с ними
# основные арифметические функции, такие как сложение, вычитание и умножение
# Ход программы:
# 1. Распечатайте операторы, чтобы попросить пользователя ввести два разных числа
# 2. Сохраните два числа в разных регистрах и распечатайте «меню» арифметических инструкций для пользователя
# 3.На основе выбора, сделанного пользователем, создайте структуры ветвей для выполнения команд и распечатайте результат
# 4. Выйти из программы
. Данные
prompt1: .asciiz "Введите первое число:"
prompt2: .asciiz "Введите второе число:"
menu: .asciiz "Введите число, связанное с операцией, которую вы хотите выполнить: 1 => сложить, 2 => вычесть или 3 => умножить:"
resultText: .asciiz "Ваш окончательный результат:" Второе, что нужно сделать, — это предварительно загрузить целочисленные значения, представляющие различные инструкции, которые должны выполняться программой, в соответствующие регистры для хранения.
. Текст
.globl main
главный:
# Следующий блок кода предназначен для предварительной загрузки целочисленных значений, представляющих различные инструкции, в регистры для хранения
li $ t3, 1 # Это загрузка немедленного значения 1 во временный регистр $ t3
li $ t4, 2 # Это загрузка немедленного значения 2 во временный регистр $ t4
li $ t5, 3 # Это загрузка немедленного значения 3 во временный регистр $ t5 Затем распечатайте инструкции, требующие от пользователя ввода двух чисел, над которыми он хотел бы выполнить арифметические операции.
# просит пользователя ввести первый номер
li $ v0, 4 # команда вывода строки
la $ a0, prompt1 # загрузка строки для печати в аргумент для включения печати
syscall # выполнение команды
# следующий блок кода предназначен для чтения первого числа, предоставленного пользователем
li $ v0, 5 # команда чтения целого числа
syscall # выполнение команды для чтения целого числа
move $ t0, $ v0 # перемещение числа, считанного из пользовательского ввода, во временный регистр $ t0
# просим пользователя указать второй номер
li $ v0, 4 # команда вывода строки
la $ a0, prompt2 # загрузка строки в аргумент для включения печати
syscall # выполнение команды
# чтение второго числа, которое будет предоставлено пользователю
li $ v0, 5 # команда для чтения номера, предоставленного пользователем
syscall # выполнение команды для чтения целого числа
move $ t1, $ v0 # перемещение числа, считанного из пользовательского ввода, во временный регистр $ t1 Следующим шагом является распечатка команд, которые пользователь может выполнять с двумя указанными числами.Это необходимо для того, чтобы пользователь мог выбрать курс действий.
# следующий блок кода должен распечатать все команды, которые пользователь может выполнить в отношении # двух чисел, которые он или она предоставил
li $ v0, 4 # команда вывода строки
la $ a0, меню # загрузка строки в аргумент для включения печати
syscall # выполнение команды
# следующий блок кода должен прочитать номер, предоставленный пользователем
li $ v0, 5 # команда чтения целого числа
syscall # выполнение команды
move $ t2, $ v0 # эта команда перемещает целое число во временный регистр $ t2 На этом этапе вам необходимо создать управляющие структуры, которые определяют, какие инструкции должны выполняться на основе команды, выданной пользователем.
Следующие строки кода определяют, что должно происходить в зависимости от целочисленного значения #, предоставленного пользователем
beq $ t2, $ t3, addProcess #Branch в addProcess, если $ t2 = $ t3
beq $ t2, $ t4, subtractProcess # Переход к 'subtractProcess', если $ t2 = $ t4
beq $ t2, $ t5, multiplyProcess # Перейти к 'multiplyProcess', если $ t2 = $ t5 Следующий код инструктирует сложить два предоставленных числа.
addProcess:
add $ t6, $ t0, $ t1 # это добавляет значения, хранящиеся в $ t0 и $ t1, и присваивает их временному регистру $ t6
# Следующая строка кода предназначена для печати результатов вычисления выше
li $ v0,4 # это команда для печати строки
la $ a0, resultText # это загружает строку для печати в аргумент $ a0 для печати
syscall # выполняет команду
# следующая строка кода выводит результат вычисления сложения
li $ v0,1
la $ a0, ($ t6)
системный вызов
li $ v0,10 # Это для завершения программы Это пример кода для инструкций на вычитание двух предоставленных чисел.
subtractProcess:
sub $ t6, $ t0, $ t1 # это добавляет значения, хранящиеся в $ t0 и $ t1, и присваивает их временному регистру $ t6
li $ v0,4 # это команда для печати строки
la $ a0, resultText # это загружает строку для печати в аргумент $ a0 для печати
syscall # выполняет команду
# следующая строка кода выводит результат вычисления сложения
li $ v0,1
la $ a0, ($ t6)
системный вызов
li $ v0,10 # Это для завершения программы Этот код предназначен для инструкций по умножению двух предоставленных чисел.
multiplyProcess:
mul $ t6, $ t0, $ t1 # это складывает значения, хранящиеся в $ t0 и $ t1, и присваивает их временному регистру $ t6
li $ v0,4 # это команда для печати строки
la $ a0, resultText # это загружает строку для печати в аргумент $ a0 для печати
syscall # выполняет команду
# следующая строка кода выводит результат вычисления сложения
li $ v0,1
la $ a0, ($ t6)
системный вызов
li $ v0,10 # Это для завершения программы Когда вы закончите реализацию кода, показанного выше, просто скомпилируйте свою программу и запустите ее.Поздравляю! Вы реализовали свою первую программу на языке ассемблера MIPS.
Дополнительные ссылки, чтобы узнать больше о синтаксисе языка ассемблера MIPS:
https://chortle.ccsu.edu/AssemblyTutorial/index.html
Заключение
:
Я надеюсь, что в этом руководстве вы получили все базовые навыки, необходимые для создания очень простой программы на языке ассемблера MIPS.
от Valvano
Синтаксис языка ассемблера от Valvano Разработка программного обеспечения на языке ассемблера
Синтаксис
Джонатан У.Valvano
Эта статья, в которой обсуждается программирование на языке ассемблера,
прилагается к книге Embedded Microcomputer Systems: Real Time Interfacing , опубликованной Brooks-Cole 1999. В этом документе всего четыре
части
Обзор
Синтаксис (поля, псевдооперации) (этот документ)
Локальные переменные
Примеры
Синтаксис языка ассемблера
Программы, написанные на языке ассемблера, состоят из последовательности
исходных утверждений.Каждый исходный оператор состоит из последовательности
символов ASCII, оканчивающихся символом возврата каретки. Каждое исходное заявление
может включать до четырех полей: метка, операция (инструкция
мнемоническая или ассемблерная директива), операнд и комментарий. В
ниже приведены примеры директивы сборки и обычного
машинная инструкция.
PORTAequ $ 0000; Постоянная времени сборки
ИнплдааПОРТА; Чтение данных из порта данных ввода / вывода с фиксированным адресом
Оператор на языке ассемблера содержит следующие поля.Поле метки
может использоваться для определения символа. Поле операции
определяет код операции или псевдооперацию. Поле операнда
указывает либо адрес, либо данные.
Поле комментариев позволяет программисту документировать программное обеспечение.
Иногда не все четыре поля присутствуют в ассемблере
утверждение. Строка может содержать просто комментарий. Первый токен
в этих строках должны начинаться со звездочки (*) или точки с запятой (;). Например,
; Эта строка является комментарием
* Это тоже комментарий
* Эта строка является комментарием
Команды с адресацией в собственном режиме не имеют операнда.
поле.Например,
меткаclracomment
decacomment
clicomment
incacomment
Рекомендация : Для небольших программ вы включаете автоматическую сборку цветов. В
После этого редактор раскрасит каждое поле в соответствии с его типом.
Рекомендация : Для больших программ отключите автоматическую сборку цветов, потому что система будет работать слишком медленно. Вместо этого используйте ассемблер для раскрашивания исходный код.
————————————————- ————————————-
Поле метки
Поле метки появляется как первое поле исходной выписки.
Поле метки может принимать одну из следующих трех форм:
A. Звездочка (*) или точка с запятой (;) в качестве первого символа в
поле метки указывает, что остальная часть исходной инструкции
это комментарий. Комментарии игнорируются Ассемблером и печатаются
в списке источников только для информации программиста.Примеры:
* Эта строка является комментарием
; Эта строка также является комментарием
B. Пробельный символ (пробел или табуляция) в качестве первого символа.
указывает, что поле метки пусто. У линии нет метки
и это не комментарий. На этих сборочных линиях нет этикеток:
ldaa0
rmb10
C. Символ символа в качестве первого символа указывает, что
строка имеет метку. Символы символов в верхнем или нижнем регистре.
буквы a-z, цифры 0-9 и специальные символы, точка (.),
знак доллара ($) и подчеркивание (_). Символы состоят от одного до
15 символов, первый из которых должен быть буквенным или специальным.
символы точка (.) или подчеркивание (_). Все персонажи значительны
буквы верхнего и нижнего регистра различны.
Символ может встречаться в поле метки только один раз. Если символ встречается более одного раза в поле метки, затем каждая ссылка на этот символ будет отмечен ошибкой. Исключение из этого Правило — это set псевдооперация, которая позволяет вам определять и переопределять один и тот же символ.Обычно мы используем set для определения смещения стека для локальных переменные в подпрограмме. Для получения дополнительной информации см. Примеры локальных переменных . Set позволяет двум отдельным подпрограммам повторно использовать одно и то же имя для их локальных переменных.
За исключением директив equ = andset, метке присваивается значение программного счетчика.
первого байта собираемой инструкции или данных.
Значение, присвоенное метке, является абсолютным. Этикетки могут по желанию
заканчиваться двоеточием (:).Если используется двоеточие, оно не является частью
ярлыка, но просто действует, чтобы отделить ярлык от остальных
исходной строки. Таким образом, следующие фрагменты кода эквивалентны:
здесь: deca
bnehere
heredeca
bnehere
Метка может появляться в строке сама по себе. Ассемблер интерпретирует
это как установить значение метки, равное текущему значению
счетчика программ. Метка может находиться в строке с псевдооперацией.
Таблица символов вмещает не менее 2000 символов длиной 8 символов или меньше.Допускаются дополнительные символы до 15 за счет уменьшения максимально возможного количества символов в таблице.
————————————————- ————————————-
Поле операции
Поле операции находится после метки поле и должен
предшествовать хотя бы одному символу пробела. Операция
Поле должно содержать допустимую мнемонику кода операции или директиву ассемблера.
Символы верхнего регистра в этом поле преобразуются в нижний регистр.
перед проверкой как юридическая мнемоника.Таким образом, «nop», «NOP» и
«NoP» распознаются как один и тот же мнемоник. Записи в операции
поле может быть одного из двух типов:
Код операции . Они прямо соответствуют машинным инструкциям. Код операции включает в себя любое имя регистра, связанное с инструкцией. Эти имена регистров не должны отделяться от кода операции никакими символы пробела. Таким образом, clra означает очистить аккумулятор A, но ‘clr a’ означает очищенную ячейку памяти, обозначенную меткой ‘а’.Доступные инструкции зависят от микрокомпьютера, который вы используете. используют
Директива . Это специальные коды операций, известные Ассемблеру, которые контролировать процесс сборки, а не переводить на машинные инструкции. Коды псевдоопераций, поддерживаемые этим ассемблером
| Группа A | Группа B | Группа C | означает |
| орг | org | .org | Определенный абсолютный адрес для последующего кодирования объекта |
| = | экв. | Определить постоянный символ | |
| комплект | Определить или переопределить постоянный символ | ||
| dc.b db | fcb | . Байт | Выделить байт (-ы) памяти с инициализированными значениями |
| fcc | Создать строку ASCII (без символа завершения) | ||
| постоянного тока.w dw | fdb | . Слово | Выделить слово (а) памяти с инициализированными значениями |
| dc.l dl | . Длинный | Выделить 32-битное слово (слова) в хранилище с инициализированными значениями | |
| DS DSB | юаней | .blkb | Выделить байты памяти без инициализации |
| ds.w | .blkw | Выделить байты памяти без инициализации | |
| дс.l | .blkl | Выделить 32-битные слова памяти без инициализации | |
| конец | конец | . Конец | Обозначает конец исходного кода ( TExaS игнорирует их) |
————————————————- ————————————-
Поле операнда
Интерпретация поля операнда зависит от содержимое
поля операции.Поле операнда, если требуется, должно следовать
поле операции и должно предшествовать хотя бы одному пробелу
персонаж. Поле операнда может содержать символ, выражение,
или сочетание символов и выражений, разделенных запятыми.
В поле операнда не может быть пробелов. Например
следующие две строки создают идентичный объектный код, потому что
пробела между данными и + в первой строке:
ldaadata + 1
ldaadata
Поле операнда машинных команд используется для указания режим адресации инструкции, а также операнд Инструкция.В следующей таблице приведены поля операнда. форматы.
| Операнд | Формат | 6811/6812 пример | ||
| без операнда | аккумулятор и собственный | clra | ||
| <выражение> | прямой, расширенный или относительный | ldaa 4 | ||
| # <выражение> | немедленно | ldaa # 4 | ||
| <выражение>, R | индексируется адресным регистром | ldaa 4, х | ||
| <выражение>, <выражение> | бит установлен или сброшен | bset 4, № $ 01 | ||
| <выражение>, <выражение>, <выражение> | бит тест и ветка | брсет 4, # 01 $, там | ||
| <выражение>, R, <выражение>, <выражение> | бит тест и ветка | брсет 4, х, # 01 $, там | ||
Допустимый синтаксис поля операнда зависит от микрокомпьютера. |
Каждый символ связан с 16-битным целочисленным значением, которое используется вместо символа во время вычисления выражения.Звездочка (*), используемая в выражении как символ, представляет текущее значение счетчика местоположения (первый байт многобайтовая инструкция)
Константы представляют количество данных, которые не изменяются в значение во время выполнения программы. Константы могут быть представлены ассемблеру в одном из четырех форматов: десятичном, шестнадцатеричном, двоичный или ASCII . Программист указывает формат числа ассемблеру со следующими префиксами:
0xhexadecimal, синтаксис C
% двоичный
‘c’ Код ASCII для одной буквы c
Константы без префикса интерпретируются как десятичные.Ассемблер преобразует все константы в двоичный машинный код и отображаются в листинге сборки в шестнадцатеричном формате.
Десятичная константа состоит из строки числовых цифр. В значение десятичной константы должно находиться в диапазоне 0–65535 включительно. В следующем примере показаны как допустимые, так и недопустимые десятичные константы:
| ДЕЙСТВИТЕЛЬНО | НЕДЕЙСТВИТЕЛЬНО | НЕВЕРНАЯ ПРИЧИНА |
| 12 | 123456 | более 5 цифр |
| 12345 | 12.3 | недопустимый символ |
Шестнадцатеричная константа состоит максимум из четырех символов.
из набора цифр (0-9) и заглавных букв алфавита
(A-F), и перед ним стоит знак доллара ($). Шестнадцатеричные константы
должно быть в диапазоне от $ 0000 до $ FFFF. В следующем примере показано
как действительные, так и недопустимые шестнадцатеричные константы:
| ДЕЙСТВИТЕЛЬНО | НЕДЕЙСТВИТЕЛЬНО | НЕВЕРНАЯ ПРИЧИНА |
| $ 12 | ABCD | без предшествующего «$» |
| $ ABCD | $ G2A | недопустимый символ |
| $ 001F | $ 2F018 | слишком много цифр |
Двоичная константа состоит максимум из 16 единиц или нулей, которым предшествуют
знаком процента (%).В следующем примере показаны оба действительных
и недопустимые двоичные константы:
| ДЕЙСТВИТЕЛЬНО | НЕДЕЙСТВИТЕЛЬНО | НЕВЕРНАЯ ПРИЧИНА |
| % 00101 | 1010101 | недостающих процентов |
| % 1 | % 10011000101010111 | слишком много цифр |
| % 10100 | % 210101 | неверная цифра |
Один символ ASCII может использоваться как константа в выражениях.Константы ASCII заключены в одинарные кавычки (‘). Любой персонаж,
кроме одинарной кавычки, может использоваться как символьная константа.
В следующем примере показаны допустимые и недопустимые символьные константы:
| ДЕЙСТВИТЕЛЬНО | НЕДЕЙСТВИТЕЛЬНО | НЕВЕРНАЯ ПРИЧИНА |
| ‘*’ | ДЕЙСТВИТЕЛЬНЫЙ | слишком длинный |
Для неверного случая выше ассемблер не будет указывать
ошибка.Скорее он соберет первого персонажа и проигнорирует
остаток.
————————————————- ————————————-
Поле комментария
Последнее поле исходного кода Ассемблера заявление это комментарий
поле. Это поле не является обязательным и печатается только в источнике
листинг для документации. Поле комментария отделено
из поля операнда (или из поля операции, если операнд отсутствует
требуется) хотя бы одним символом пробела.Комментарий
Поле может содержать любые печатаемые символы ASCII.
Как разработчики программного обеспечения, наша цель — создать код, который
не только решает нашу текущую проблему, но может служить основой
наших будущих проблем. Чтобы повторно использовать программное обеспечение, мы должны оставить
наш код в таком состоянии, что будущий программист (в том числе
мы сами) можем легко понять его цель, ограничения и
реализация. Документация — это не что-то прикрепленное к программному обеспечению
после того, как это сделано, а дисциплина, встроенная в него на каждом
стадия развития.Мы тщательно разрабатываем стиль программирования
предоставление соответствующих комментариев. Я чувствую комментарий, который говорит нам почему мы выполняем те или иные функции информативнее, чем комментарии
которые говорят нам, каковы функции. Примеры плохих комментариев
будет:
clrFlagFlag = 0
seiSet I = 1
ldaa $ 1003 Читать PortC
Это плохие комментарии, потому что они не содержат информации
помогите нам в будущем понять, что делает программа.
Пример хороших комментариев:
clrFlagSignify ключ не был набран
sei Следующий код не будет прерван
ldaa $ 1003Bit7 = 1, если переключатель нажат
Это хорошие комментарии, потому что они упрощают внесение изменений
программа на будущее.
Самодокументирующийся код — это программа, написанная простым и очевидным
таким образом, что его цель и функция очевидны. К
напишите такой замечательный код, сначала мы должны сформулировать проблему
Организуя его в четко определенные подзадачи. Как мы ломаемся
сложная проблема на мелкие части проходит долгий путь, делая
программное обеспечение самодокументирования. Оба понятия абстракции (представленные
в последнем разделе) и модульный код (будет представлен в
следующий раздел) обращается к этому важному вопросу организации программного обеспечения.
Сопровождение программного обеспечения — это процесс исправления ошибок, добавления
новые функции, оптимизация по скорости или объему памяти, перенос на
новое компьютерное оборудование и настройку программного обеспечения для
новые ситуации. Это НАИБОЛЕЕ ВАЖНЫЙ этап разработки программного обеспечения.
Мое личное мнение таково, что блок-схемы или руководства по программному обеспечению
не являются хорошими механизмами для документирования программ, потому что это
трудно поддерживать эти типы документации в актуальном состоянии, когда
внесены изменения.
Мы должны использовать осторожные отступы и описательные имена для
переменные, функции, метки, порты ввода / вывода.Либеральное использование equ provide
объяснение функции программного обеспечения без затрат на скорость выполнения
или требования к памяти. Дисциплинированный подход к программированию
заключается в разработке шаблонов письма, которым вы постоянно следуете.
Разработчики программного обеспечения не похожи на писателей рассказов. Это нормально
используйте один и тот же контур подпрограммы снова и снова. В следующей программе обратите внимание на следующее
вопросов стиля:
1) Начинается и заканчивается строкой из *
2) Указывает цель подпрограммы
3) Предоставляет параметры ввода / вывода, что они означают и
как они передаются
4) Различные фазы (подмодули) кода, обозначенные
строка
******************* Макс ***************************** **
* Цель: возвращает максимум два 16-битных числа
* Эта подпрограмма создает три 16-битных локальных переменных
* Входные данные: Num1 и Num2 — два 16-битных беззнаковых числа
*, переданных в стек
* Выход: RegX — это максимум X, Y
* Уничтожено: CCR
* Последовательность вызова
* ldx # 100
* pshxNum1 помещен в стек
* ldx # 200
* pshx Num2 помещен в стек
* jsrMax
* pulyBalance stack
* pulyResult
Firstset0 Первая 16-битная локальная переменная
Secondset2 Вторая 16-битная локальная переменная
Resultset4 Максимум первой, второй
Num1set12 Входной параметр1
Num2set10 Входной параметр2
Регистры MaxpshySave, которые будут изменены
* — — — — — — — — — — — — — — — — — — — — — — — — — — —
pshxAllocate Локальная переменная результата
pshxAllocate Вторая локальная переменная
pshxAllocate Первая локальная переменная
* — — — — — — — — — — — — — — — — — — — — — — — — — — — —
tsxCreate указатель кадра стека
ldyNum1, X
styFirst, XInitialize First = Num1
ldyNum2, X
stySecond, XInitialize Second = Num2
ldyFirst, X
styResult Result, X
styResult, что Result = Первый
cpySecond, X
bhsMaxOKSkip if First> = Second
ldySecond, XSince First
MaxOKldxResult, XReturn Result в RegX
* — — — — — — — — — — — — — — — — — — — — — — — — — — —
puly Удаление локальных переменных
puly
puly
* — — — — — — — — — — — — — — — — — — — — — — — — — — —
pulyRestore регистры
rts
****************** Конец макс. *************************** *
————————————————- ————————————-
Листинг ассемблера
Выходные данные ассемблера включают необязательный листинг принадлежащий
исходная программа и объектные файлы.Файл листинга создается, когда открыт файл TheList.RTF .
Каждая строка списка содержит номер ссылочной строки,
адрес и байты собраны, и исходный исходный ввод
линия. Если строка ввода вызывает вывод более 8 байтов (например,
длинная директива FCC), дополнительные байты включены в
объектный код (файл S19 или загружен в память), но не показан в
листинг. Есть три варианта сборки, каждый из которых можно переключать.
включение / выключение с помощью команды Сборка-> Параметры.
| (4) | циклов | показывает количество циклов для выполнения этой инструкции |
| [100] | всего | дает общее количество рабочих циклов с момента последней псевдооперации организации |
| {PPP} | тип | дает тип цикла |
Коды, используемые в типе цикла, различны для каждого микрокомпьютера.
Список сборки может дополнительно содержать таблицу символов.Таблица символов находится в конце списка сборок.
если включено. Таблица символов содержит название каждого символа,
вместе с его определенным значением. Поскольку установленный псевдооператор может использоваться
для переопределения символа значение в таблице символов является последним
определение.
————————————————- ————————————-
Ошибки сборки
Ошибки программирования делятся на две категории. Простой набор текста / синтаксис ошибка будет помечена ассемблером TExaS как ошибка , когда ассемблер пытается перевести исходный код в машину код.Ошибки программирования, которые сложнее найти и удалить это функциональные ошибки, которые могут быть обнаружены во время выполнения, когда программа не работает должным образом. Имеются в виду сообщения об ошибках чтобы быть понятным. Ассемблер имеет режим verbose (см. Команду Assembler-> Options), который предоставляет более подробную информацию. об ошибке и предлагает возможные решения.
Типы ошибок ассемблера
1) Неопределенный символ: программа ссылается на метку, которая не существует
Как исправить: проверьте орфографию определения и доступа
2) Неопределенный код операции или псевдооперация
Как исправить: проверьте орфографию / наличие инструкции
3) Режим адресации недоступен
Как исправить: найдите режимы адресации, доступные для
инструкция
4) Ошибка выражения
Как исправить: проверьте скобки, начните с более простого выражения
5) Ошибка фазирования возникает, когда значение символа изменяется с pass1 на pass2
Как исправить: сначала удалите все неопределенные символы, затем удалите
пересылка ссылок
6) Ошибка адреса
Как исправить: используйте псевдооперации org для сопоставления доступной памяти.
Диагностические сообщения об ошибках помещаются в файл листинга просто
после строки, содержащей ошибку. Если файл TheList.RTF отсутствует, то ошибки сборки сообщаются в файле TheLog.RTF . Если файлов TheList.RTF или TheLog.RTF нет, то ошибки сборки не выводятся.
————————————————- ————————————-
Ошибки фазировки
Ошибка фазировки во время прохода 2 ассемблера, когда
адрес метки отличается от того, когда он был ранее
рассчитано.Цель первого этапа ассемблера — создать
таблица символов. Чтобы вычислить адрес каждой сборки
строки, ассемблер должен уметь определить точное число
байтов займет каждая строка. Для большинства инструкций номер
требуемого байта фиксировано и легко вычисляется, но для других
инструкции, количество байтов может варьироваться. Возникают ошибки фазирования
когда ассемблер вычисляет размер другой инструкции
в проходе 2, чем ранее рассчитывалось на проходе 2.Иногда фазировка
ошибка часто возникает в строке программы ниже, чем
где возникает ошибка. Ошибка фазирования обычно возникает из-за
использование прямых ссылок. В этом примере 6812 символ
«index» недоступен во время сборки ldaa index, x. Ассемблер неправильно выбирает 2-х байтовую адресацию IDX.
версия режима, а не правильный 3-байтовый режим IDX1.
ldaaindex, x
indexequ 100
; …
loopldaa # 0
В листинге показана ошибка фазирования.
Copyright 1999-2000 Test EXecute And Simulate
$ 0000A6E064ldaaindex, x
$ 0064indexequ100
;…
$ 00038600loopldaa # 0
#####
Ошибка фазы
Эта строка находилась по адресу $ 0002 на проходе 1, теперь на проходе 2 это
$ 0003
*************** Таблица символов *********************
индекс $ 0064
цикл $ 0002
##### Сборка завершилась неудачно, 1 ошибка!
Когда ассемблер переходит в цикл, значения Pass 1 и Pass 2 отключаются из-за ошибки фазирования в инструкции ldaa # 0 цикла. Решение здесь — просто сначала поставить индекс, равный 100.
————————————————- ————————————-
Ассемблер псевдооператора ‘ с
Псевдооперации — это специальные команды для ассемблера, которые интерпретируются в процессе сборки. Некоторые из них создают объектный код, но большинство этого не делают. Есть два распространенных формата псевдоопераций используется при разработке языка ассемблера Motorola. Ассемблер TExaS поддерживает обе категории. Если вы планируете экспортировать ПО разработан с помощью TExaS для другого приложения, тогда вам следует ограничить использование только psuedo-op совместим с этим приложением.
Group A поддерживается Motorola MCUez, HiWare и ImageCraft.
ICC11 и ICC12
Group B поддерживается Motorola DOS уровня AS05, AS08, AS11
и AS12
Group C — некоторые альтернативные определения
| Группа A | Группа B | Группа C | означает |
| орг | org | .org | Определенный абсолютный адрес для последующего кодирования объекта |
| = | экв. | Определить постоянный символ | |
| комплект | Определить или переопределить постоянный символ | ||
| постоянного тока.б дб | fcb | . Байт | Выделить байт (-ы) памяти с инициализированными значениями |
| fcc | Создать строку ASCII (без символа завершения) | ||
| dc.w dw | fdb | . Слово | Выделить слово (а) памяти с инициализированными значениями |
| dc.l dl | . Длинный | Выделить 32-битное слово (слова) в хранилище с инициализированными значениями | |
| ds ds.b | юаней | .blkb | Выделить байты памяти без инициализации |
| ds.w | .blkw | Выделить байты памяти без инициализации | |
| DSL | .blkl | Выделить 32-битные слова памяти без инициализации | |
| конец | конец | . Конец | Обозначает конец исходного кода ( TExaS игнорирует их) |
————————————————- ————————————-
приравнивает символ к значению
<метка> equ <выражение> (<комментарий>)
<метка> = <выражение> (<комментарий>)
Директива EQU (или =) присваивает значение выражения в
поле операнда к метке.Директива equ присваивает значение
кроме программного счетчика на этикетке. Этикетка не может
быть переопределенным где-нибудь еще в программе. Выражение не может
содержать любые прямые ссылки или неопределенные символы. Приравнивается к
прямые ссылки помечаются как Ошибки фазирования phasing_error.
В следующем примере имена локальных переменных не могут быть
повторно используется в другой подпрограмме:
; MC68HC812A4
; ***** фаза привязки ***************
Iequ-4
PTequ-3
Ansequ-1
; ******* этап распределения *********
functionpshxsave old Reg X
tsxcreate указатель кадра стека
leas-4, spallocate четыре байта для I, PT, Result
; ******** Фаза доступа ************
clrI, xClear I
ldyPT, xReg Y — это копия PT
staaAns, xstore в Ans
; ******** Фаза освобождения *****
txsdeallocation
pulxrestore old X
rts
В следующем примере псевдооперация equ используется для определения
порты ввода-вывода и для доступа к различным элементам связанных
состав.
* *********** Moore.RTF *********************
* Джонатан В. Вальвано 18.07.98 10: 54:28 PM
* Контроллер конечного автомата Мура
* PC1, PC0 — двоичные входы, PB1, PB0 — двоичные выходы
PORTBequ0x01
DDRBequ0x03
PORTCequ0x04
DDRCequ0x06
TCNTequ0x84; 16-битные тактовые импульсы без знака, увеличивающиеся в каждом цикле
TSCRequ0x86; установите бит 7 = 1, чтобы включить TCNT
* Контроллер конечного автомата
* C1, C0 — это входы B1, B0 — выходы
Outequ0offset для выходного значения
* 2-битовый шаблон, сохраненный в младшей части 8-битного байта
Waitequ1offset для времени ожидания
Nextequ2offset для 4 следующих состояний
* Четыре 16-битных абсолютных адреса без знака
fdbS2, S1, S2, S3
S2fcb% 10 Выход
fcb10 Время ожидания
fdbS3, S1, S2, S3
S3fcb% 11 Выход
fcb20 Время ожидания
$ 0183 программы fdbldS1, S1, S2, S1, S1 9018 C00
movb # $ FF, TSCR enable TCNT
ldaa #% 11111111
staaDDRB B1, B0 — выходы светодиодов
ldaa #% 00000000
staaDDRC C1, C0 — входы переключателя
ldxInitState Указатель состояния выполнения
st183 * M PurposePt
stxStatePt 90:
stxStatePt * 1.Выполнить вывод для текущего состояния
* 2. Подождать заданное время
* 3. Вход от переключателей
* 4. Перейти к следующему состоянию в зависимости от входа.
* StatePt — указатель текущего состояния
FSMldxStatePt1. Вывести
ldabOut, xOutput значение для этого состояния в битах 1,0
stabPORTB
ldaaWait, x2. Ждать в этом состоянии
bsrWAIT
ldabPORTC3. Считать ввод
andb # $ 03 просто интересует бит 1,0
lslb 2 байта на 16-битный адрес
abx добавить 0,2,4,6 в зависимости от ввода
ldxNext, x4.Следующее состояние в зависимости от входа
stxStatePt
braFSM
* Reg A — время ожидания (по 256 циклов)
WAITtfra, b
clraRegD = количество циклов ожидания
adddTCNTTCNT значение в конце задержки
WloopcpdTCNTEndT-TCNT когда EndT
rts
org $ FFFE
fdbMainreset vector
————————————————- ————————————-
установить символ приравнивания к значению
<метка> set <выражение> (<комментарий>)
Директива SET присваивает значение выражения в операнде. поле к метке.Директива set присваивает значение, отличное от счетчик программы на этикетке. В отличие от псевдооперации equ, метку можно переопределить где угодно в программе. Выражение не должен содержать прямых ссылок или неопределенных символов. Использование этой псевдооперации с прямыми ссылками не допускается. отмечен ошибками фазирования.
В следующем примере имена локальных переменных можно использовать повторно.
в другой подпрограмме:
; MC68HC812A4
; ***** фаза привязки ***************
Iset-4
PTset-3
Ansset-1
; ******* этап распределения *********
functionpshxsave old Reg X
tsxcreate указатель кадра стека
leas-4, spallocate четыре байта для I, PT, Result
; ******** Фаза доступа ************
clrI, xClear I
ldyPT, xReg Y — это копия PT
staaAns, xstore в Ans
; ******** Фаза освобождения *****
txsdeallocation
pulxrestore old X
rts
———————————————— —————————————
fcb Форма постоянного байта
(<метка>) fcb
(
Директива FCB может иметь один или несколько операндов, разделенных запятыми.
Значение каждого операнда усекается до восьми бит и сохраняется.
в одном байте объектной программы. Несколько операндов
хранятся в последовательных байтах.Операнд может быть числовой константой,
символьная константа, символ или выражение. Если несколько
присутствуют операнды, один или несколько из них могут быть нулевыми (два соседних
запятые), и в этом случае будет назначен один нулевой байт
для этого операнда. Ошибка возникнет, если старшие восемь бит
из значений оцененных операндов не все единицы или все нули.
Может быть включена строка, которая хранится как последовательность
Символы ASCII. Разделители, поддерживаемые TExaS , — это «‘и \.Строка не заканчивается, поэтому программист
должен явно прекратить его. Например:
str1 fcb «Hello World», 0
В следующем конечном автомате определения fcb
используется для хранения выходных данных и времени ожидания.
Outequ0offset для выходного значения
* 2-битный шаблон, сохраненный в младшей части 8-битного байта
Waitequ1offset для времени ожидания
Nextequ2offset для 4 следующих состояний
* Четыре 16-битных абсолютных адреса без знака
fdbS2, S1, S2, S3
S2fcb% 10 Выход
fcb10 Время ожидания
fdbS3, S1, S2, S3
S3fcb% 11 Выход
fcb20 Время ожидания
fdbS1, S10005, S2, S1 9
————————————————- ————————————-
fcc Строка константных символов формы
(<метка>) FCC <разделитель> <строка> <разделитель> (<комментарий>)
Директива FCC используется для хранения строк ASCII в последовательных байтах памяти.Начинается байтовое хранилище на текущем программном счетчике. Метка присваивается первому байт в строке. В строке может содержаться любой из печатаемых символов ASCII . Строка указана между двумя одинаковыми разделителями. Первый непустой символ после директивы FCC используется в качестве разделителя. Разделители поддерживается TExaS : «‘и \.
Примеры:
LABEL1FCC’ABC ‘
LABEL2fcc «Джон Вальвано»
LABEL4fcc / Добро пожаловать в FunCity! /
Первая строка создает символов ASCII ABC в ячейке LABEL1.Будьте осторожны и не размещайте код FCC в стороне от исполняемых инструкций. Сборщик произведет
объектный код, как и для обычных инструкций, одна строка в
время. Например, следующее приведет к сбою, потому что после выполнения
инструкции LDX, 6811 будет пытаться выполнить ASCII символов «Проблема» в качестве инструкций.
ldaa100
ldx # Strg
Strgfcc «Trouble»
Обычно мы собираем все fcc, fcb, fdb вместе и помещаем их в конец нашей программы, чтобы
микрокомпьютер не пытается выполнить постоянные данные.Например,
ldaaCon8
ldyCon16
ldx # Strg
braloop
* Поскольку петля бюстгальтера безусловна,
* 6811 не выйдет за эту точку.
Strgfcc «Нет проблем»
Con8fcb100
Con16fdb1000
———————————————— —————————————
fdb Form Double Byte
(<метка>) fdb
(
Директива FDB может иметь один или несколько операндов, разделенных запятыми. 16-битное значение, соответствующее каждому операнду, сохраняется в два последовательных байта объектной программы. Хранение начинается на текущем программном счетчике. Метка присваивается первому 16-битное значение.Несколько операндов хранятся в последовательных байтах. Операнд может быть числовой константой, символьной константой, символ или выражение. Если присутствует несколько операндов, один или несколько из них могут быть нулевыми (две соседние запятые), и в этом случае для этого операнда будут назначены два байта нулей.
В следующем конечном автомате определения fdb используются для определения указателей состояния. Например, InitState и четыре указателя Next.
Outequ0offset для выходного значения
* 2-битный шаблон, сохраненный в младшей части 8-битного байта
Waitequ1offset для времени ожидания
Nextequ2offset для 4 следующих состояний
* Четыре 16-битных абсолютных адреса без знака
fdbS2, S1, S2, S3
S2fcb% 10 Выход
fcb10 Время ожидания
fdbS3, S1, S2, S3
S3fcb% 11 Выход
fcb20 Время ожидания
fdbS1, S10005, S2, S1 9
————————————————- ————————————-
постоянного тока.l Определить 32-битную константу
(<метка>) dc.l
(
Директива dl может иметь один или несколько операндов, разделенных запятыми. 32-битное значение, соответствующее каждому операнду, сохраняется в четыре последовательных байта объектной программы (big endian).В сохранение начинается с текущего программного счетчика. Метка присвоена к первому 32-битному значению. Несколько операндов хранятся в последовательном байтов. Операнд может быть числовой константой, символьной константой, символ или выражение. Если присутствует несколько операндов, один или несколько из них могут быть нулевыми (две соседние запятые), в которых case четыре байта нулей будут присвоены этому операнду.
В следующем конечном автомате определения dl используются для определения 32-битных констант.
S1dl100000, $ 12345 678
S2.long1,10,100,1000,10000,100000,1000000,10000000
S3dc.l-1,0,1
———————————————— —————————————
org Установить счетчик программ на исходную точку
org <выражение> (<комментарий>)
.org <выражение> (<комментарий>)
Директива ORG изменяет счетчик программы на указанное значение. выражением в поле операнда. Последующие заявления собираются в ячейки памяти, начиная с новой программы значение счетчика.Если в источнике не встречается директива ORG программы, счетчик программы обнуляется. Выражения не может содержать прямые ссылки или неопределенные символы.
Операторы организации в следующем скелете помещают переменные в ОЗУ.
и программы в EEPROM MC68HC812A4
* ********** <<Имя>> ********************
org $ 800 переменные идут в RAM
* << глобальные объекты, определенные с помощью rmb, идут сюда >>
org $ F000programs в EEPROM
Main: lds # $ 0C00 инициализируют стек в RAM
* << сюда идут однократные инициализации >> цикл
:
* << повторяющиеся операции перейдите сюда >>
braloop
* << подпрограммы перейдите сюда >>
org $ FFFE
fdbMainreset vector
————————————————- ————————————-
юаней Резервное несколько байтов
(<метка>) rmb <выражение> (<комментарий>)
(<метка>) ds <выражение> (<комментарий>)
(<метка>) ds.b <выражение> (<комментарий>)
(<метка>) .blkb <выражение> (<комментарий>)
Директива RMB приводит к увеличению счетчика местоположения на значение выражения в поле операнда. Эта директива резервирует блок памяти, длина которого в байтах равна к значению выражения. Зарезервированный блок памяти не инициализирован каким-либо заданным значением. Выражение не может содержать любые прямые ссылки или неопределенные символы. Эта директива обычно используется для резервирования блокнота или области стола на будущее использовать.
————————————————- ————————————-
ds.w Зарезервировать несколько слов
(<метка>) ds.w <выражение> (<комментарий>)
(<метка>) .blkw <выражение> (<комментарий>)
Директива ds.w приводит к увеличению счетчика местоположения. в 2 раза больше значения выражения в поле операнда. Этот директива резервирует блок памяти, длина которого в словах (16 бит) равно значению выражения.Блок зарезервированная память не инициализируется никаким заданным значением. Выражение не может содержать никаких прямых ссылок или неопределенных символов. Этот директива обычно используется для резервирования области блокнота или таблицы для дальнейшего использования.
————————————————- ————————————-
ds.l Зарезервировать несколько 32-битных слов
(<метка>) ds.l <выражение> (<комментарий>)
(<метка>) .blkl <выражение> (<комментарий>)
DS.Директива l заставляет счетчик местоположения быть продвинутым в 4 раза больше значения выражения в поле операнда. Этот директива резервирует блок памяти, длина которого в словах (32 бита) равно значению выражения. Блок зарезервированная память не инициализируется никаким заданным значением. Выражение не может содержать никаких прямых ссылок или неопределенных символов. Этот директива обычно используется для резервирования области блокнота или таблицы для дальнейшего использования.
———————————————— —————————————
конец Конец программы (необязательно)
конец (<комментарий>)
.конец (<комментарий>)
Директива END означает конец исходного кода. Ассемблер TExaS игнорирует эти коды псевдоопераций.
————————————————- ————————————-
Коды символов ASCII
БИТЫ от 4 до 6
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| 0 | NUL | DLE | СП | 0 | @ | P | ` | п. | |
| В | 1 | SOH | DC1 | : | 1 | A | Q | a | q |
| I | 2 | STX | DC2 | ! | 2 | B | R | б | r |
| т | 3 | ETX | DC3 | # | 3 | С | S | c | с |
| S | 4 | EOT | DC4 | $ | 4 | D | Т | d | т |
| 5 | ENQ | НАК | % | 5 | E | U | и | u | |
| 0 | 6 | ACK | SYN | и | 6 | F | В | f | v |
| 7 | BEL | ETB | ‘ | 7 | G | Вт | г | Вт | |
| т | 8 | BS | CAN | ( | 8 | H | Х | ч | х |
| O | 9 | HT | EM | ) | 9 | I | Y | и | y |
| A | LF | ПОД | * | : | Дж | Z | j | z | |
| 3 | B | VT | ESC | + | ; | К | [ | к | { |
| С | FF | ФС | , | < | л | \ | л | ; | |
| D | CR | GS | – | = | M | ] | кв.м. | } | |
| E | SO | RS | . | n | ~ | ||||
| F | S1 | США | / | ? | O | _ | o | DEL |
————————————————- ————————————-
S-19 Код объекта
S-запись выходной формат кодирует программу и объект данных
модули в формат для печати (ASCII).Это позволяет просматривать объектный файл со стандартным
инструменты и позволяет отображать модуль при переходе из
от одного компьютера к другому или во время нагрузок между хостом и целью.
Формат S-записи также включает информацию для использования в случае ошибки.
проверка для обеспечения целостности передачи данных.
S-записи — это символьные строки, состоящие из нескольких полей, которые
определить тип записи, длину записи, адрес памяти, код / данные,
и контрольная сумма. Каждый байт двоичных данных кодируется как 2-символьный
шестнадцатеричное число: первый символ, представляющий старший
4 бита, а второй — 4 младших бита байта.
5 полей, которые составляют S-запись:
1) Тип S0, S1 или S9
2) Длина записи
3) Адрес
4) Код / данные
5) Контрольная сумма
Было определено восемь типов S-записей для различных требуется кодирование, транспортировка и декодирование, но в большинстве микроконтроллеров Motorola используются только три типа . Запись S0 — это запись заголовка, содержащая имя файла в формате ASCII в поле «Код / данные». Адресное поле этот тип обычно 0000.Запись S1 — это запись данных, содержащая информацию, которая должна быть загружена последовательно. начиная с указанного адреса. Запись S9 является маркером конца файла и иногда содержит начальную адрес для начала исполнения. Во встроенной микрокомпьютерной среде, начальный адрес должен быть запрограммирован в соответствующем месте. Для большинства микроконтроллеров Motorola вектор сброса является последним. два байта ПЗУ или EEPROM.
Длина записи содержит количество пар символов в записи длины, без учета типа и длины записи.
Для типов записей S0, S1, S9 поле Address представляет собой 4-байтовое значение. Для типа записи S1 адрес указывает где поле данных должно быть загружено в память.
В поле Code / Data содержится от 0 до n байтов. Эта информация содержит исполняемый код, загружаемую память данные или описательная информация.
Поле Checksum состоит из 2 символов ASCII, используемых для проверки ошибок. В мере
значащий байт дополнения суммы значений до единицы
представлен парами символов, составляющими длину записи,
адрес и поля кода / данных.При генерации контрольной суммы
один добавляет (назовите результат суммой ) длину записи, адрес и поле кода / данных, используя 8-битный модуль
арифметика (без учета переполнения). Контрольная сумма вычисляется.
контрольная сумма = $ FF — сумма
При проверке контрольной суммы добавляется (назовем результат сумма ) длину записи, адресный код / поле данных и контрольную сумму, используя
8-битная арифметика по модулю (без учета переполнения). Сумма должна быть $ FF.
Каждая запись может заканчиваться CR / LF / NULL.
Ниже приведен типичный модуль S-записи:
S1130000285F245F2212226A0004242
237C2A
S1130010000200080008262
53812341001813
S113002041E
4E42234300182342000824A952
S107003000144ED
S107003000144ED
Модуль состоит из четырех записей кода / данных и завершения S9. записывать.
Первый код / запись данных S1 объясняется следующим образом:
S1S-запись типа S1, указывающая, что код / запись данных должна быть загружен / проверен по 2-байтовому адресу.
13 Hex 13 (19 в десятичной системе), обозначающее 19 пар символов, представляющих Далее следуют 19 байт двоичных данных.
00 Четырехсимвольное 2-байтовое поле адреса: шестнадцатеричный адрес 0000, указывает место, куда должны быть загружены следующие данные.
Следующие 16 пар символов представляют собой байты ASCII фактического программный код / данные
2A Контрольная сумма первой записи S1.
Каждая вторая и третья записи кода / данных S1 также содержат 13 долларов США. пары символов и заканчиваются контрольными суммами.Четвертый код / данные S1 запись содержит 7 пар символов.
Запись о завершении S9 объясняется следующим образом:
S9S-запись типа S9, указывающая на завершение записи.
03Hex 03, указывающий на три пары символов (3 байта) для следить.
00 Четырехсимвольное 2-байтовое поле адреса, нули 00
FCC Контрольная сумма записи S9.
Этот документ состоит из четырех общих частей
Обзор
Синтаксис (поля, псевдооперации) (этот документ)
Локальные переменные
Примеры
на языке ассемблера Arm6 на Raspberry Pi
Веб-сайт Arm рекламирует базовую архитектуру процессора как «краеугольный камень крупнейшей в мире вычислительной экосистемы», что вполне правдоподобно, учитывая количество портативных и встроенных устройств с процессорами Arm.Процессоры Arm широко используются в Интернете вещей (IoT), но они также используются в настольных компьютерах, серверах и даже в высокопроизводительных компьютерах, таких как Fugaku HPC. Но зачем смотреть на машины Arm через призму ассемблера?
Ассемблер — это символический язык, расположенный непосредственно над машинным кодом, и поэтому он предлагает особое понимание того, как работают машины и как их можно эффективно программировать. В этой статье я надеюсь проиллюстрировать этот момент с помощью архитектуры Arm6, используя мини-настольную машину Raspberry Pi 4 под управлением Debian.
Семейство процессоров Arm6 поддерживает два набора команд:
- Набор Arm с 32-битными инструкциями.
- Набор Thumb, состоящий из 16-битных и 32-битных инструкций.
В примерах в этой статье используется набор команд Arm. Ассемблерный код Arm записан строчными буквами, а псевдо-ассемблерный код — прописными.
Погрузочно-накопительные машины
Различие RISC / CISC часто наблюдается при сравнении семейства процессоров Arm и семейства процессоров Intel x86, оба из которых являются коммерческими продуктами, конкурирующими на рынке.Термины RISC (компьютер с сокращенным набором команд) и CISC (компьютер со сложным набором команд) относятся к середине 1980-х годов. Даже тогда термины вводили в заблуждение, поскольку процессоры RISC (например, MIPS) и CISC (например, Intel) содержали около 300 инструкций в своих наборах команд; сегодня количество основных инструкций в машинах Arm и Intel близко, хотя оба типа машин расширили свои наборы команд. Более четкое различие между компьютерами Arm и Intel связано не только с количеством инструкций, но и с другой архитектурной особенностью.
Архитектура набора команд (ISA) — это абстрактная модель вычислительной машины. Процессоры от Arm и Intel реализуют разные ISA: процессоры Arm реализуют ISA с загрузочным хранилищем, тогда как их аналоги Intel реализуют ISA с регистровой памятью. Разницу в ISA можно описать так:- В машине загрузки-хранения только две инструкции перемещают данные между ЦП и подсистемой памяти:
- Команда загрузки копирует биты из памяти в регистр ЦП.
- Команда сохранения копирует биты из регистра ЦП в память.
- Другие инструкции, в частности, для арифметико-логических операций, используют только регистры ЦП в качестве операндов источника и назначения. Например, вот код псевдосборки на машине загрузки-хранения для сложения двух чисел, изначально хранящихся в памяти, с сохранением их суммы обратно в память (комментарии начинаются с
##):
Задача требует четырех инструкций: две ЗАГРУЗКИ, одна ДОБАВИТЬ и одна СОХРАНИТЬ.## R0 - регистр ЦП, RAM [32] - ячейка памяти
ЗАГРУЗКА R0, RAM [32] ## R0 = RAM [32]
ЗАГРУЗКА R1, RAM [64] ## R1 = RAM [64]
ДОБАВИТЬ R2, R0, R1 ## R2 = R0 + R1
СОХРАНИТЬ R2, ОЗУ [32] ## ОЗУ [32] = R2 - Напротив, машина с регистровой памятью позволяет операндам для арифметико-логических инструкций быть регистрами или ячейками памяти, обычно в любой комбинации. Например, вот псевдо-ассемблерный код на машине с регистровой памятью для сложения двух чисел в памяти:
Задача может быть выполнена с помощью одной инструкции, хотя добавляемые биты все равно должны быть извлечены из памяти в ЦП, а затем сумма должна быть скопирована обратно в ОЗУ области памяти [32].ДОБАВИТЬ ОЗУ [32], ОЗУ [32], ОЗУ [64] ## ОЗУ [32] + = ОЗУ [64]
Любая ISA имеет компромиссы. Как показывает приведенный выше пример, ISA-сервер загрузки-хранения имеет то, что архитекторы называют «низкой плотностью инструкций»: для выполнения задачи может потребоваться относительно много инструкций. Машина с регистровой памятью имеет высокую плотность команд, что является положительным моментом. У ISA есть и положительные стороны.
Дизайн загрузки-хранилища — это попытка упростить архитектуру. Например, рассмотрим случай, когда машина с регистровой памятью имеет инструкцию со смешанными операндами:
КОПИРОВАТЬ R2, ОЗУ [64] ## R2 = ОЗУ [64]
ДОБАВИТЬ ОЗУ [32], ОЗУ [32], R2 ## ОЗУ [32] = ОЗУ [32] + R2
Выполнение инструкции ADD сложно в том смысле, что время доступа для добавляемых чисел различается — возможно, значительно, если операнд памяти находится только в основной памяти, а не в ее кэше.Машины загрузки-хранения избегают проблемы смешанного времени доступа в арифметико-логических операциях: все операнды, как регистры, имеют одинаковое время доступа.
Кроме того, архитектуры загрузки-хранения делают упор на инструкции фиксированного размера (например, 32 бита каждая), ограниченные форматы (например, одно, два или три поля на инструкцию) и относительно небольшое количество режимов адресации. Эти конструктивные ограничения означают, что блок управления процессором (CU) и арифметико-логический блок (ALU) могут быть упрощены: меньше транзисторов и проводов, меньше требуемой мощности и выделяемого тепла и т. Д.Машины для загрузки и хранения спроектированы так, чтобы быть архитектурно разреженными.
Моя цель состоит не в том, чтобы вступить в дискуссию о сравнении машин с загрузкой-хранилищем и машинами с регистровой памятью, а в том, чтобы создать пример кода в архитектуре Arm6 с загрузкой-хранилищем. Этот первый взгляд на load-store помогает объяснить следующий код. Две программы (одна на C, другая на сборке Arm6) доступны на моем сайте.
Программа hstone в C
Среди моих любимых примеров сокращенного кода — функция града, которая принимает в качестве аргумента положительное целое число.(Я использовал этот пример в предыдущей статье о WebAssembly.) Эта функция достаточно богата, чтобы выделить важные детали языка ассемблера. Функция определяется как:
3N + 1, если N нечетно
hstone (N) =
N / 2, если N четно
Например, hstone (12) оценивается как 6, тогда как hstone (11) оценивается как 34. Если N нечетно, то 3N + 1 четно; но если N четно, то N / 2 может быть либо четным (например, 4/2 = 2), либо нечетным (например, 6/2 = 3).
Функцию hstone можно использовать итеративно, передав возвращаемое значение в качестве следующего аргумента.Результатом является последовательность града , такая как эта, которая начинается с 24 в качестве исходного аргумента, возвращаемого значения 12 в качестве следующего аргумента и так далее:
24,12,6,3,10,5,16,8,4,2,1,4,2,1, ... Требуется 10 шагов, чтобы последовательность сходилась к 1, после чего последовательность 4,2,1 повторяется бесконечно: (3×1) +1 равно 4, которое делится вдвое, чтобы получить 2, которое делится вдвое, чтобы получить 1, и скоро. Для объяснения того, почему «град» кажется подходящим названием для таких последовательностей, см. «Математические загадки: последовательности града.«
Обратите внимание, что степени двойки сходятся быстро: 2 N требует всего N делений на 2, чтобы получить 1. Например, 32 = 2 5 имеет длину сходимости 5, а 512 = 2 9 имеет длину сходимости из 9. Если функция града возвращает любую степень двойки, то последовательность сходится к 1. Интерес представляет длина последовательности от начального аргумента до первого появления 1.
Гипотеза Коллатца состоит в том, что последовательность градин сходится к 1 независимо от того, каким был начальный аргумент N> 0.Ни контрпримера, ни доказательства не найдено. Гипотеза, сколь бы простая она ни была для демонстрации с помощью программы, остается чрезвычайно сложной проблемой в теории чисел.
Ниже приведен исходный код C программы hstoneC, которая вычисляет длину последовательности градин, начальное значение которой задается пользователем. Версия программы на языке ассемблера (hstoneS) предоставляется после обзора основ Arm6. Для наглядности две программы структурно похожи.
Вот исходный код на C:
#include/ * Вычислить шаги от n до 1.
- обновить нечетное n до (3 * n) + 1
- обновить четное n до (n / 2) * /
unsigned hstone (unsigned n) {
беззнаковый len = 0; / * счетчик * /
while (1) {
if (1 == n) break;
n = (0 == (n & 1))? п / 2: (3 * п) + 1;
len ++;
}
return len;
}int main () {
printf ("Целое число> 0:");
беззнаковое число;
scanf ("% u", & num);
printf ("Шаги от% u к 1:% u \ n", num, hstone (num));
возврат 0;
}
Когда программа запускается с вводом 9, вывод будет:
Шаги от 9 до 1: 19 Программа hstoneC имеет простую структуру.Основная функция предлагает пользователю ввести N (целое число> 0), а затем вызывает функцию hstone с этим вводом в качестве аргумента. Функция hstone повторяется до тех пор, пока последовательность из N не достигнет первой 1, возвращая количество необходимых шагов.
Самый сложный оператор в программе включает в себя условный оператор C, который используется для обновления N:
n = (0 == (n & 1))? п / 2: (3 * п) + 1; Это краткая форма конструкции «если-то».Тест (0 == (n & 1)) проверяет, является ли переменная C n (представляющая N) четной или нечетной в зависимости от того, равно ли нулю побитовое И для N и 1: целочисленное значение является четным только в если его младший (крайний правый) бит равен нулю. Если N четно, новым значением становится N / 2; в противном случае новым значением становится 3N + 1. Версия программы на языке ассемблера (hstoneS) также избегает явной конструкции if-else при обновлении своей реализации N.
Мини-настольный компьютер My Arm6 включает набор инструментов GNU C, который может генерировать соответствующий код на языке ассемблера.С % в качестве приглашения командной строки команда:
% gcc -S hstoneC.c ## -S флаг создает и сохраняет код сборки Это создает файл hstoneC.s, который содержит около 120 строк исходного кода на языке ассемблера, включая инструкцию nop («нет операции»). Сборка, созданная компилятором, имеет тенденцию быть трудной для чтения и может иметь неэффективность, например nop . Созданная вручную версия, такая как hstoneS.s (см. Ниже), может быть проще в использовании и даже значительно короче (например.g., hstoneS.s имеет около 50 строк кода).
Основы ассемблера
Arm6, как и большинство современных архитектур, имеет байтовую адресацию: адрес памяти является байтовым, даже если адресуемый элемент (например, 32-битная инструкция) состоит из нескольких байтов. К инструкциям обращаются с прямым порядком байтов: это адрес младшего байта. По умолчанию к элементам данных обращаются с прямым порядком байтов, но его можно изменить на прямой порядок байтов, чтобы адрес многобайтового элемента данных указывал на старший байт.По традиции младший байт изображается как крайний правый, а старший байт как крайний левый:
старший младший
/ /
+ ---- + ---- + ---- + ---- +
| b1 | b2 | b3 | b4 | ## 4 байта = 32 бита
+ ---- + ---- + ---- + ---- +
Адреса имеют размер 32 бита, а элементы данных бывают трех стандартных размеров:
- Байт имеет размер 8 бит.
- Полуслово имеет размер 16 бит.
- Слово имеет размер 32 бита.
Поддерживаются агрегаты байтов, полуслов и слов (например, массивы и структуры). Регистры ЦП имеют размер 32 бита.
Языки ассемблера, как правило, имеют три ключевые особенности с близким, а иногда и идентичным синтаксисом:
- Директивы
как в сборке Arm6, так и в сборке Intel начинаются с точки. Вот два примера Arm6, которые также работают в Intel:
Первая директива указывает, что следующий раздел содержит элементы данных, а не код.Директива
.align 4указывает, что элементы данных должны располагаться в памяти по 4-байтовым границам, что является обычным явлением в современных архитектурах. Как следует из названия, директива дает направление переводчику («ассемблеру»), когда он выполняет свою работу.Напротив, эта директива указывает код, а не раздел данных:
.textТермин «текст» является традиционным, и его значение в данном контексте — «только для чтения»: во время выполнения программы код доступен только для чтения, тогда как данные могут быть прочитаны и записаны.
- Ярлыки
как в недавней сборке Arm, так и в Intel заканчиваются двоеточием. Метка — это адрес памяти для элементов данных (например, переменных) или блоков кода (например, функций). Языки ассемблера, как правило, в значительной степени полагаются на адреса, а это означает, что манипулирование указателями — в частности, разыменование их для получения значений, на которые они указывают — занимает первое место в программировании на языке ассемблера. Вот две метки в программе hstoneS:
collatz: / * метка * /
mov r0, # 0 / * инструкция * /
loop_start: / * метка * /
...Первая метка отмечает начало функции
collatz, первая инструкция которой копирует нулевое значение (# 0) в регистрr0. (movдля кода операции «перемещение» встречается во всех языках ассемблера, но на самом деле означает «копировать».) Вторая метка,loop_start:, является адресом цикла, который вычисляет длину последовательности града. Регистрr0служит счетчиком последовательностей. Инструкции, редакторы которых, чувствительные к сборке, обычно делают отступы вместе с директивами, определяют операции, которые необходимо выполнить (например,g.,
mov) вместе с операндами (в данном случаеr0и# 0). Есть инструкции без операндов и другие с несколькими.
Приведенная выше инструкция mov не нарушает принцип загрузки-сохранения о доступе к памяти. Как правило, инструкция загрузки ( ldr в Arm6) загружает содержимое памяти в регистр. Напротив, команда mov может использоваться для копирования «немедленного значения», такого как целочисленная константа, в регистр:
mov r0, # 0 / * копирование нуля в r0 * / Команда mov также может использоваться для копирования содержимого одного регистра в другой:
mov r1, r0 / * r1 = r0 * / Код операции загрузки ldr будет неподходящим в обоих случаях, потому что ячейка памяти не используется.Примеры команд Arm6 ldr («загрузить регистр») и str («сохранить регистр») ожидаются.
Архитектура Arm6 имеет 16 первичных регистров ЦП (каждый размером 32 бита), сочетание общего и специального назначения. В таблице 1 приводится сводка, в которой перечислены специальные функции и возможности использования помимо блокнота:
Таблица 1. Регистры первичного процессора
| Регистр | Особенности |
|---|---|
| r0 | 1-й аргумент библиотечной функции, retval |
| r1 | 2-й аргумент для библиотечной функции |
| r2 | 3-й аргумент для библиотечной функции |
| r3 | 4-й аргумент библиотечной функции |
| r4 | сохраненный номер |
| r5 | сохраненный номер |
| R6 | сохраненный номер |
| r7 | сохраненных абонентов, системные вызовы |
| R8 | сохраненный номер |
| R9 | сохраненный номер |
| r10 | сохраненный номер |
| r11 | сохраненный вызываемый объект, указатель кадра |
| r12 | внутри процедуры |
| r13 | указатель стека |
| R14 | ссылка на регистр |
| r15 | счетчик программ |
В общем случае регистры ЦП служат в качестве резервной копии для стека, области основной памяти, которая обеспечивает многоразовое хранилище блокнотов для аргументов, передаваемых функциям, и локальных переменных, используемых в функциях и других блоках кода (например,г., тело петли). Учитывая, что регистры ЦП находятся на том же чипе, что и ЦП, время доступа быстрое. Доступ к стеку значительно медленнее, детали зависят от особенностей системы. Однако регистров мало. В случае Arm6 есть только 16 первичных регистров ЦП, и некоторые из них используются не только для блокнота.
Первые четыре регистра, с r0 по r3 , используются для блокнота, но также для передачи аргументов библиотечным функциям.Например, для вызова библиотечной функции, такой как printf (используемой как в программах hstoneC, так и в hstoneS), требуется, чтобы ожидаемые аргументы находились в ожидаемых регистрах. Функция printf принимает по крайней мере один аргумент (строку формата), но обычно принимает и другие (форматируемые значения). Адрес строки формата должен находиться в регистре r0 для успешного вызова. Функция, определяемая программистом, конечно, может реализовать свою собственную регистровую стратегию, но использование первых четырех регистров для аргументов функции является обычным явлением в программировании Arm6.
Регистр r0 также имеет специальное применение. Например, он обычно содержит значение, возвращаемое функцией, как в функции collatz программы hstoneS. Если программа вызывает функцию системного вызова , которая используется для вызова системных функций, таких как чтение и запись , регистр r0 содержит целочисленный идентификатор вызываемой системной функции (например, функция запись имеет 4 в качестве его идентификатора). В этом отношении регистр r0 аналогичен по назначению регистру r7 , который содержит такой идентификатор, когда функция svc («вызов супервизора») используется вместо syscall .
Регистры с r4 по r11 являются универсальными и «сохранены вызываемым» (также известные как «энергонезависимые» или «сохраненные вызовы»). Рассмотрим случай, когда функция F1 вызывает функцию F2, используя регистры для передачи аргументов в F2. Регистры с r0 по r3 являются «сохраненными вызывающими» (также известными как «изменчивые» или «закрытые по вызову») в том смысле, что, например, вызываемая функция F2 может вызывать некоторую другую функцию F3, используя те же регистры, что и F1. сделал — но с новыми значениями в нем:
27 13 191 437
\ \ \ \
r0, r1 r0, r1
F1 --------> F2 --------> F3
После того, как F1 вызывает F2, содержимое регистров r0 и r1 изменяется для вызова F2 к F3.Соответственно, F1 не должен предполагать, что его значения в r0 и r1 (27 и 13 соответственно) были сохранены; вместо этого эти значения были перезаписаны — затерты новыми значениями 191 и 437. Поскольку первые четыре регистра не «сохраняются вызываемым пользователем», вызываемая функция F2 не отвечает за сохранение и последующее восстановление значений в регистрах, установленных F1.
Регистры, сохраненные вызываемым пользователем, передают ответственность вызываемой функции. Например, если F1 использовал сохраненные вызываемым абонентом регистры r4 и r5 при вызове F2, то F2 будет отвечать за сохранение содержимого этих регистров (обычно в стеке), а затем восстановление значений перед возвратом в F1. .Тогда код F2 может начинаться и заканчиваться следующим образом:
push {r4, r5} / * сохранить значения r4 и r5 в стеке * /
... / * повторно использовать r4 и r5 для некоторых других задач * /
pop {r4, r5} / * восстановить значения r4 и r5 * /
Операция push сохраняет значения в r4 и r5 в стек. Операция сопоставления pop затем восстанавливает эти значения из стека и помещает их в r4 и r5 .
Другие регистры в таблице 1 можно использовать в качестве блокнота, но некоторые из них также имеют специальное применение. Как отмечалось ранее, регистр r7 может использоваться для выполнения системных вызовов (например, для функции write ), что подробно показано в более позднем примере. В инструкции svc целочисленный идентификатор для конкретной системной функции должен находиться в регистре r7 (например, 4 для идентификации функции записи ).
Регистр r11 имеет псевдоним fp для «указателя кадра», который указывает на начало текущего кадра вызова.Когда одна функция вызывает другую, вызываемая функция получает свою собственную область стека (кадр вызова) для использования в качестве блокнота. Указатель кадра, в отличие от указателя стека, описанного ниже, обычно остается фиксированным, пока вызываемая функция не вернется.
Регистр r12 , также известный как ip («внутрипроцедура»), используется динамическим компоновщиком. Однако между вызовами динамически подключаемых библиотечных функций программа может использовать этот регистр как блокнот.
Регистр r13 , который имеет sp («указатель стека») в качестве псевдонима, указывает на вершину стека и автоматически обновляется посредством операций push и pop .Указатель стека также можно использовать как базовый адрес со смещением; например, sp - # 4 указывает на 4 байта ниже, где sp указывает. Стек Arm6, как и его аналог Intel, растет от высоких к младшим адресам. (Некоторые авторы соответственно описывают указатель стека как указывающий на низ, а не на верх стека.)
Регистр r14 с lr в качестве псевдонима служит «регистром связи», который содержит адрес возврата для функции.Однако вызываемая функция может вызывать другую с помощью инструкции bl («переход со ссылкой») или bx («переход с обменом»), тем самым уничтожая содержимое регистра lr . Например, в программе hstoneS функция main вызывает четыре других. Соответственно, функция main сохраняет lr вызывающей стороны в стеке, а затем восстанавливает это значение. Шаблон регулярно встречается на языке ассемблера Arm6:
push {lr} / * сохранить номер звонящего * /
... / * вызываем некоторые функции * /
pop {lr} / * восстанавливаем lr вызывающего * /
Регистр r15 также является pc («счетчик программ»). В большинстве архитектур программный счетчик указывает на «следующую» команду, которая должна быть выполнена. По историческим причинам Arm6 pc указывает на на две инструкции помимо текущей. pc может управляться напрямую (например, для вызова функции), но рекомендуется использовать такие инструкции, как bl , которые управляют регистром ссылок.
Arm6 имеет обычный набор инструкций для арифметики (например, сложение, вычитание, умножение, деление), логики (например, сравнение, сдвиг), управления (например, переход, выход) и ввода / вывода (например, чтение, запись ). Результаты сравнений и других операций сохраняются в специальном регистре cpsr («регистр текущего состояния процессора»). Например, этот регистр регистрирует, вызвало ли сложение переполнение или два сравниваемых целочисленных значения равны.
Стоит повторить, что Arm6 имеет ровно две основные инструкции перемещения данных: ldr для загрузки содержимого памяти в регистр и str для сохранения содержимого регистра в памяти.Arm6 включает варианты базовых инструкций ldr и str , но шаблон загрузки-сохранения для перемещения данных между регистрами и памятью остается прежним.
Пример кода оживляет эти архитектурные детали. В следующем разделе представлена программа hailstone на ассемблере.
Программа hstone в сборке Arm6
Приведенного выше обзора сборки Arm6 достаточно, чтобы представить полный пример кода для hstoneS. Для ясности, программа на ассемблере hstoneS имеет по существу ту же структуру, что и программа на языке C hstoneC: две функции, main и collatz , и в большинстве случаев выполнение кода в каждой функции является прямым.Поведение двух программ одинаково.
Вот исходный код для hstoneS:
.data / * данные по сравнению с кодом * /Сборка
.balign 4 / * выравнивание по 4-байтовым границам * // * метки (адреса) для пользовательского ввода, средств форматирования и т. д. * /
num: .int 0 / * 4-байтовое целое * /
шагов: .int 0 / * другое для результата * / подсказка
: .asciz "Integer> 0:" / * строка ASCII с нулевым символом в конце * / формат
:.asciz "% u" / *% u для "беззнакового" * /
report: .asciz "От% u до 1 требуется% u шагов. \ n"
.text / * code: 'text' в смысле ' только для чтения '* /
.global main / * точка входа программы должна быть глобальной * /
.extern printf / * библиотечная функция * /
.extern scanf / * то же самое * /collatz: / ** collatz function ** /
mov r0, # 0 / * r0 - счетчик шагов * /
loop_start: / ** collatz loop ** /
cmp r1, # 1 / * мы закончили? (num == 1?) * /
beq collatz_end / * если да, вернуться к основному * /
и r2, r1, # 1 / * нечетно-четный тест для r1 (num) * /
cmp r2, # 0 /* даже? * /
moveq r1, r1, LSR # 1 / * четное: деление на 2 с помощью 1-битного сдвига вправо * /
addne r1, r1, r1, LSL # 1 / * odd: умножение на сложение и 1-битное влево shift * /
addne r1, # 1 / * odd: добавить 1 для (3 * num) + 1 * /add r0, r0, # 1 / * увеличить счетчик на 1 * /
b loop_start / * цикл снова * /
collatz_end:
bx lr / * возврат к вызывающему (основному) * /main:
push {lr} / * сохранение регистра ссылки в стек * // * запрос и чтение пользовательского ввода * /
ldr r0, = prompt / * форматируем адрес строки в r0 * /
bl printf / * вызываем printf с единственным аргументом r0 * /ldr r0, = format / * форматируем строку для scanf * /
ldr r1, = num / * адрес числа в r1 * /
bl scanf / * вызов scanf * /ldr r1, = num / * адрес числа в r1 * /
ldr r1, [r1] / * значение по адресу в r1 * /
bl collatz / * вызов collatz с аргументом r1 * // * демонстрация a store * /
ldr r3, = steps / * загрузка адреса памяти в r3 * /
str r0, [r3] / * сохранение шагов грады в mem [r3] * // * отчет о настройке * /
mov r2, r0 / * r0 содержит шаги града: скопировать в r2 * /
ldr r1, = num / * снова получить ввод пользователя * /
ldr r1, [r1] / * разыменовать адрес для получения значения * /
ldr r0, = report / * форматная строка для отчета в r0 * /
bl printf / * печать отчета * /pop {lr} / * возврат к вызывающему * /
Arm6 поддерживает документацию либо в стиле C (здесь используется синтаксис с косой чертой и косой чертой), либо однострочные комментарии, представленные знаком @.Программа hstoneS, как и ее аналог на C, выполняет две функции:
Точкой входа в программу является функция
main, которая обозначена меткойmain:; эта метка отмечает, где находится первая инструкция функции. В сборке Arm6 точка входа должна быть объявлена глобальной:.global mainВ языке C имя функции — это адрес блока кода, составляющего тело функции, а функция C по умолчанию —
extern(глобальная).Неудивительно, насколько C и язык ассемблера похожи друг на друга; действительно, C — переносимый язык ассемблера.Функция
collatzожидает один аргумент, который реализуется регистромr1для хранения пользовательского ввода целочисленного значения без знака (например, 9). Эта функция обновляет регистрr1до тех пор, пока он не станет равным 1, сохраняя счет шагов, связанных с регистромr0, который, таким образом, служит значением, возвращаемым функцией.
Ранний и интересный сегмент кода в main включает вызов библиотечной функции scanf , функции ввода высокого уровня, которая сканирует значение из стандартного ввода (по умолчанию с клавиатуры) и преобразует это значение в желаемый тип данных, в данном случае 4-байтовое целое число без знака. Вот полный сегмент кода:
ldr r0, = format / * адрес строки формата в r0 * /
ldr r1, = num / * адрес числа в r1 * /
bl scanf / * вызов scanf (bl = ветка со ссылкой) * /ldr r1, = num / * адрес num в r1 * /
ldr r1, [r1] / * значение по адресу в r1 * /
bl collatz / * вызываем collatz с аргументом r1 * /
Используются две метки (адреса): формат и номер , оба из которых определены в .data раздел вверху программы:
число: .int 0
формат: .asciz "% u"
Метка num: — это адрес памяти 4-байтового целочисленного значения, инициализированного нулем; формат метки : указывает на завершающуюся нулем («z» в «asciz» для нуля) строку "% u" , которая указывает, что отсканированный ввод должен быть преобразован в целое число без знака. Соответственно, первые две инструкции в сегменте кода загружают адрес строки формата ( = формат ) в регистр r0 и адрес отсканированного числа ( = число ) в регистр r1 .Обратите внимание, что каждая метка теперь начинается со знака равенства («назначить адрес») и что двоеточие удаляется в конце каждой метки. Библиотечная функция scanf может принимать произвольное количество аргументов, но первый (который scanf ожидает в регистре r0 ) должен быть «адресом» строки формата. В этом примере второй аргумент scanf — это «адрес», по которому следует сохранить отсканированное целое число.
Последние три инструкции в сегменте кода выделяют важные детали сборки.Первая инструкция ldr загружает адрес целого числа в памяти ( = число ) в регистр r1 . Однако функция collatz ожидает, что по этому адресу будет сохранено значение , а не сам адрес; следовательно, адрес разыменовывается, чтобы получить значение:
ldr r1, = num / * загрузить адрес в r1 * /
ldr r1, [r1] / * разыменование для получения значения * /
Квадратные скобки указывают память, а r1 содержит адрес памяти.Таким образом, выражение [r1] оценивается как значение , хранящееся в памяти по адресу r1 . В примере подчеркивается, что регистры могут содержать адреса и значения, хранящиеся по адресам: регистр r1 сначала содержит адрес, а затем значение, хранящееся по этому адресу.
Когда функция collatz возвращается к main , эта функция сначала выполняет операцию сохранения:
ldr r3, = steps / * steps - адрес памяти * /
str r0, [r3] / * сохранить значение r0 в памяти [r3] * /
Метка шагов: — из .Раздел данных и регистр r0 содержат шаги, вычисленные в функции collatz . Таким образом, команда str сохраняет в памяти длину последовательности градин. В команде ldr первый операнд (регистр) — это целевой для загрузки; но в операции str первый операнд (также регистр) — это источник для хранилища. В обоих случаях второй операнд — это ячейка памяти.
Некоторые дополнительные работы в основной устанавливает окончательный отчет:
mov r2, r0 / * счетчик сохранений в r2 * /
ldr r1, = num / * восстановить пользовательский ввод * /
ldr r1, [r1] / * разыменование r1 * /
ldr r0, = report / * r0 указывает на строку формата * /
bl printf / * распечатать отчет * /
В функции collatz регистр r0 отслеживает, сколько шагов необходимо для достижения 1 с ввода пользователя, но библиотечная функция printf ожидает, что ее первый аргумент (адрес строки формата) будет сохранен в регистре. р0 .Таким образом, возвращаемое значение в регистре r0 копируется в регистр r2 с помощью инструкции mov . Адрес строки формата для printf затем сохраняется в регистре r0 .
Аргументом функции collatz является отсканированный ввод, который хранится в регистре r1 ; но этот регистр обновляется в цикле collatz , если значение не равно 1 в начале. Соответственно, адрес num: снова копируется в r1 и затем разыменовывается, чтобы получить исходный ввод пользователя.Это значение становится вторым аргументом для printf , начального значения последовательности града. При такой настройке main вызывает printf с инструкцией bl («переход со ссылкой»).
В самом начале цикла collatz программа проверяет, попала ли последовательность в 1:
cmp r1, # 1
beq collatz_end
Если регистр r1 имеет значение 1, существует ответвление ( beq для «переход, если равно») до конца функции collatz , что означает возврат к вызывающему main с регистром r0 в качестве возвращаемого значения — количество шагов в последовательности градин.
Функция collatz представляет новые функции и коды операций, которые демонстрируют, насколько эффективным может быть ассемблерный код. Ассемблерный код, как и код C, проверяет четность N с регистром r1 как N:
и r2, r1, # 1 / * r2 = r1 & 1 * /
cmp r2, # 0 / * четный ли результат? * /
Результат побитовой операции И в регистре r1 и 1 сохраняется в регистре r2 . Если младший (крайний правый) бит регистра r2 равен 1, то N (регистр r1 ) является нечетным, а в противном случае — четным.Результат этого сравнения (сохраненный в специальном регистре cpsr ) автоматически используется в следующих инструкциях, таких как moveq («переместить, если равно») и addne («добавить, если не равно»).
Ассемблерный код, как и код C, теперь избегает явной конструкции if-else. Этот сегмент кода имеет тот же эффект, что и тест if-else, но код более эффективен тем, что не задействован ветвление — код выполняется в прямолинейном режиме, потому что условные тесты встроены в коды операций инструкции:
moveq r1, r1, LSR # 1 / * сдвиг вправо на 1 бит, если даже * /
addne r1, r1, r1, LSL # 1 / * сдвиг влево на 1 бит, иначе сложение * /
addne r1, # 1 / * добавляем 1 для + 1 в N = 3N + 1 * /
Инструкция moveq ( eq для «если равно») проверяет результат предыдущего теста cmp , который определяет, является ли текущее значение регистра r1 (N) четным или нечетным.Если значение в регистре r1 четное, это значение должно быть обновлено до его половины, что выполняется 1-битным сдвигом вправо ( LSR # 1 ). В общем, сдвиг вправо целого числа более эффективен, чем явное деление его на два. Например, предположим, что регистр r1 в настоящее время содержит 4, младшие четыре бита которых:
... 0100 ## 4 в двоичном формате Сдвиг вправо на 1 бит дает:
... 0010 ## 2 в двоичном формате LSR означает «логический сдвиг вправо» и контрастирует с ASR для «арифметического сдвига вправо».»Арифметический сдвиг сохраняет знак (старший бит 1 для отрицательного и 0 для неотрицательного), тогда как логический сдвиг — нет, но программы града имеют дело исключительно с беззнаковыми (следовательно, неотрицательными) значениями. При логическом сдвиге сдвинутые биты заменяются нулями.
Если регистр r1 содержит значение с нечетной четностью, возникает аналогичный прямой код:
addne r1, r1, r1, LSL # 1 / * r1 = r1 * 3 * /
addne r1, # 1 / * r1 = r1 + 1 * /
Две инструкции addne ( ne для «если не равно») выполняются только в том случае, если предыдущая проверка на четность указывает нечетное значение.Первая инструкция addne выполняет умножение посредством сдвига влево на 1 бит и сложения. В общем, сдвиг и сложение более эффективны, чем явное умножение. Второй модуль addne затем добавляет 1 к регистру r1 , так что обновление выполняется с N до 3N + 1.
Сборка программы hstoneS
Исходный код ассемблера для программы hstoneS необходимо транслировать («собирать») в двоичный объектный модуль , который затем связывается с соответствующими библиотеками, чтобы стать исполняемым.Самый простой подход — использовать компилятор GNU C так же, как он используется для компиляции программы на C, такой как hstoneC:
% gcc -o hstoneS hstoneS.s Эта команда выполняет сборку и компоновку.
Несколько более эффективный подход — использовать утилиту как , которая поставляется с набором инструментов GNU. Этот подход разделяет сборку и связывание. Вот этап сборки:
% as -o hstoneS.o hstoneS.s ## build Добавочный номер .o — традиционный для объектных модулей. Затем для связывания можно использовать системную утилиту ld , но более простой и столь же эффективный подход — вернуться к команде gcc :
% gcc -o hstoneS hstoneS.o ## ссылка Этот подход еще раз подчеркивает, что компилятор C обрабатывает любое сочетание C и сборки, будь то исходные файлы или объектные модули.
Завершение явным системным вызовом
В двух программах обработки града используются высокоуровневые функции ввода / вывода scanf и printf .Эти функции являются высокоуровневыми, поскольку имеют дело с форматированными типами (в данном случае целыми числами без знака), а не с необработанными байтами. Однако во встроенной системе эти функции могут быть недоступны; вместо этого будут использоваться функции ввода / вывода низкого уровня , чтение и , запись , которые в конечном итоге реализуют свои высокоуровневые аналоги. Эти две системные функции являются низкоуровневыми, поскольку работают с необработанными байтами.
В сборке Arm6 программа явно вызывает системную функцию, такую как write , косвенным образом — путем вызова одной из вышеупомянутых функций svc или syscall , например:
звонки звонки
программа -------> svc -------> запись
Целочисленный идентификатор для конкретной системной функции (например,g., 4 идентифицирует запись ) переходит в соответствующий регистр (регистр r7 для svc и регистр r0 для syscall ). Приведенные ниже сегменты кода иллюстрируют сначала svc , а затем syscall .
Два сегмента кода записывают традиционное приветствие на стандартный вывод, который по умолчанию является экраном. Стандартный вывод имеет файловый дескриптор , неотрицательное целое число, которое его идентифицирует.Три предопределенных дескриптора:
стандартный ввод: 0 (клавиатура по умолчанию)
стандартный вывод: 1 (экран по умолчанию)
стандартная ошибка: 2 (экран по умолчанию)
Вот сегмент кода для примера системного вызова с svc :
msg: .asciz "Hello, world! \ N" / * приветствие * /
...
mov r0, # 1 / * 1 = стандартный вывод * /
ldr r1, = msg / * адрес байтов для записи * /
mov r2, # 14 / * длина сообщения (в байтах) * /
mov r7, # 4 / * запись имеет 4 в качестве идентификатора * /
svc # 0 / * системный вызов для записи * /
Функция write принимает три аргумента, и при вызове через svc аргументы функции попадают в следующие регистры:
-
r0содержит цель для операции записи, в данном случае стандартный вывод (# 1). -
r1имеет адрес байта (ов) для записи (= msg). -
r2указывает, сколько байтов должно быть записано (# 14).
В случае инструкции svc регистр r7 определяет неотрицательным целым числом (в данном случае # 4 ), какую системную функцию вызывать. Вызов svc возвращает ноль ( # 0 ), чтобы сигнализировать об успехе, но обычно отрицательное значение указывает на ошибку.
Функции syscall и svc отличаются в деталях, но использование любой из них для вызова системной функции требует тех же двух шагов:
- Укажите системную функцию, которую нужно вызвать (в
r7дляsvc, вr0дляsyscall). - Поместите аргументы для системной функции в соответствующие регистры, которые различаются между вариантами
svcиsyscall.
Вот пример syscall вызова функции write :
сообщение:.asciz "Hello, world! \ n" / * приветствие * /
...
mov r1, # 1 / * стандартный вывод * /
ldr r2, = msg / * адрес сообщения * /
mov r3, # 14 / * количество байтов * /
mov r0, # 4 / * идентификатор для записи * /
syscall
C имеет тонкую оболочку не только для функции syscall , но и для системных функций read и write . Оболочка C для системного вызова дает общее представление:
syscall (SYS_write, / * 4 - это идентификатор для записи * /
STDOUT_FILENO, / * 1 - стандартный вывод * /
«Hello, world! \ N», / * message * /
14); / * длина байта * /
Прямой подход в C использует оболочку для системы запись функция:
запись (STDOUT_FILENO, «Привет, мир! \ N», 14); Как написать язык ассемблера: основные инструкции по сборке в наборе инструкций ARM
Изучите некоторые базовые инструкции, используемые в наборе инструкций ARM, используемом для программирования ядер ARM.
Эта статья предназначена для того, чтобы помочь вам узнать об основных инструкциях по сборке для программирования ядра ARM.
Мы воспользуемся предыдущим постом о файлах регистров ARM — пожалуйста, рассмотрите возможность просмотра этой информации, прежде чем продолжить, поскольку мы будем ссылаться на обозначения регистров и флаги регистров в приведенных ниже инструкциях.
Эта информация будет использована в следующей статье для программирования Raspberry Pi, в котором используется 32-битное ядро ARM. В этой статье мы сосредоточим наше внимание на 32-битных инструкциях ARMv7 и 32-битных регистрах.
Примечание. Более поздние версии Raspberry Pi, работающие под управлением Raspbian, используют 64-битный процессор ARMv8, но запускают его в 32-битном режиме, как и в более старых версиях v7. Мы можем рассказать об ARMv8 в следующей статье.
Дополнительная информация:
Машинный код
Команды используются процессором — давайте взглянем на машинный код, который они представляют. Поскольку большинство инструкций, которые мы рассмотрим, предназначены для операций с данными, я взял инструкцию по обработке данных из руководства ARMV7.
Рисунок 1. Инструкция обработки данных ARMНа рисунке 1 показаны 32 бита, найденные в инструкции обработки данных ARM; каждый бит имеет определенное назначение, индивидуально или как часть группы.
Поле условия имеет ширину 4 бита, так как имеется примерно пятнадцать условных кодов. Код операции имеет ширину 4 бита и находится между флагом немедленного действия, который сигнализирует, что операнд 2 содержит немедленное значение, и флагом установки условия, который мы можем использовать для обновления регистра состояния во время операции (подробнее об этом позже).Обратите внимание, что именно код операции определяет операцию — такую как сложение, вычитание или исключающее ИЛИ — которую будет выполнять процессор.
По мере того, как вы будете выполнять приведенные ниже инструкции, мы обратимся к рисунку 1 и попытаемся увидеть, как инструкция сборки кодируется в двоичном формате. И не бойтесь копаться в руководстве ARM для получения дополнительной информации.
Как читать инструкции по сборке: мнемоника и операнды
Каждая инструкция начинается с мнемоники , которая представляет операцию.После мнемоники идут операнды, над которыми будут работать. Как правило, это операнды назначения и источника, как показано ниже.
MNEMONIC DEST, SRC1, SRC2
Инструкция ADD (описанная в следующем разделе) добавляет R2 к R1 и помещает результат в регистр R0 (объяснение этих обозначений см. В предыдущей статье). Это типичный способ чтения инструкции по сборке. Добавьте R2 к R1 и поместите его (результат) в R0. Эквивалентный машинный код, который будет выполняться на процессоре, показан рядом с инструкцией ADD.
Поле «Cond» содержит «1110» для выполнения всегда. Эти биты используются при использовании условных суффиксов, добавляемых к операции ADD. Следующее поле не используется и обнулено. Поле «I» равно нулю, потому что «Op2» — это регистр, а не непосредственное значение. Поле ‘S’ равно нулю, потому что мы не добавляли S к операции ADD, т.е. мы не хотим, чтобы эта инструкция обновляла флаги регистра состояния (N, Z, C и V, обсуждаемые выше).
Если вы вернетесь к рисунку 1, обратите внимание на код операции для добавления.Это 0100b. Это говорит процессору установить путь данных для операции ADD. Последние три поля — это R1 (0001b), R0 (0000b) и R2 (… .0010b).
Cond I OpCd S Rn Rd Op2
ДОБАВИТЬ R0, R1, R2 @ 1110 | 00 | 0 | 0100 | 0 | 0001 | 0000 | 000000000010
Операнды в команде обычно являются регистрами, но они также могут быть адресами памяти или непосредственными значениями. Непосредственное значение — это точное число, которое нужно использовать.Они имеют префикс #. Например, вместо использования R2, приведенного выше, мы можем использовать непосредственное значение 42. Эта инструкция показана ниже:
Cond I OpCd S Rn Rd Op2
ДОБАВИТЬ R4, R6, # 42 @ 1110 | 00 | 1 | 0100 | 1 | 0110 | 0100 | 000000101010
Эта инструкция добавляет 42 к R6 и помещает результат в R4. На этот раз для «I» установлено значение 1, потому что мы используем непосредственное значение для операнда 2. Код операции остается тем же, поскольку мы все еще выполняем сложение.Обратите внимание, что поле «S» равно 1; поэтому мы хотим, чтобы эта операция ADD обновляла флаги нашего регистра состояния во время выполнения.
Следующая инструкция может использовать поле «Cond» для проверки флагов состояния и условного выполнения в зависимости от результата. «Rn» — это 0110b, представляющее R6, а «Rd» — это 0100b для R4. Непосредственным значением в «Op2» является 12-битное двоичное представление числа 42. Остальная часть этого раздела перечисляет подмножество самых основных инструкций ARM с кратким описанием и примером.
Инструкции по обработке данных
Следующие инструкции управляют данными.Это могут быть арифметические операции, выполняющие математические функции, операции сравнения или перемещение данных.
Дополнение (ADD)
Сложение (ADD) добавляет R2 к R1 и помещает результат в R0. Добавление с переносом (ADC) добавляет R2 к R1 вместе с флагом переноса. Это используется при работе с числами, превышающими одно 32-битное слово.
ДОБАВИТЬ R0, R1, R2
АЦП R0, R1, R2
Вычитание (SUB)
Вычитание (SUB) вычитает R2 из R1 и помещает результат в R0.Вычитание с переносом (SBC) вычитает R2 из R1 и, если флаг переноса сброшен, вычитает единицу из результата. Это эквивалентно заимствованию в арифметике и обеспечивает правильную работу вычитания нескольких слов.
SUB R0, R1, R2
SBC R0, R1, R2
Сравнить (CMP) и сравнить отрицательные (CMN)
Сравнить (CMP) и Сравнить отрицательный (CMN) сравнить два операнда. CMP вычитает R1 из R0, а CMN добавляет R2 к R1, а затем флаги состояния обновляются в соответствии с результатом сложения или вычитания.
CMP R0, R1
CMN R1, R2
Перемещение (MOV)
Операция Move (MOV) делает именно то, на что похоже. Он перемещает данные из одного места в другое. Ниже R1 копируется в R0. Вторая строка помещает непосредственное значение 8 в R0.
MOV R0, R1
MOV R0, # 8
Движение негативно (MVN)
Переместить отрицательный (MVN) выполняет аналогичную операцию, но сначала дополняет (инвертирует) данные.Это полезно при выполнении операций с отрицательными числами, в частности, с дополнением до двух. Приведенная ниже инструкция помещает НЕ 8, более известное как –9, в R0. Добавьте к этому результату единицу, и вы выполнили дополнение до двух и получили -8.
MVN R0, # 8
И выполняет побитовое И для R2 и R1 и помещает результат в R0. Вместо R2 можно использовать немедленное значение.
И R0, R1, R2
ORR и EOR
ORR и EOR выполняют побитовое OR и XOR, соответственно, для R2 и R1.
ORR R0, R1, R2
EOR R0, R1, R2
Очистить бит (BIC)
Bit Clear (BIC) выполняет побитовое И для R2 и R1, но сначала дополняет биты в R2. Эта операция часто используется с немедленными значениями, как, например, во второй строке, где непосредственное значение 0xFF инвертируется и затем объединяется оператором AND с R1. Операция AND восьми нулей с первым байтом R1 очистит эти биты, то есть установит их равными нулю, и результат будет помещен в R0.
БИК R0, R1, R2
BIC R0, R1, # 0xFF
Тестовые биты (TST) и тестовая эквивалентность (TEQ)
TeST Bits (TST) и Test Equivalence (TEQ) существуют для проверки битов, находящихся в регистрах. Эти инструкции не используют регистр назначения, а просто обновляют регистр состояния на основе результата. По сути, TST выполняет побитовое И двух операндов. Используя маску для второго операнда, мы можем проверить, установлен ли отдельный бит в R0.
В этом случае мы проверяем бит 3 (битовая маска = 1000b = 8) и устанавливаем флаг Z в зависимости от результата. TEQ выполняет ту же функцию, что и исключающее или, и отлично подходит для проверки равенства двух регистров. Это обновляет флаг N и Z, поэтому он также работает с числами со знаком; N устанавливается в единицу, если их знаки разные.
ТСТ Р0, №8
TEQ R1, R2
Умножение (MUL)
Умножение (MUL) умножает R1 на R2 и помещает результат в R0.Умножение нельзя использовать с немедленным значением.
MUL R0, R1, R2
Инструкции по переключению и повороту
Логический сдвиг влево (LSL)
Логический сдвиг влево (LSL) сдвигает биты в R1 на величину сдвига. В этом случае непосредственное значение 3 и отбрасывает самые значащие биты. Последний сдвинутый бит помещается во флаг переноса, а младшие биты заполняются нулями. Ниже R1 сдвигается влево на непосредственное значение 3 или значение от 0 до 31 в R2 и помещается в R0.Один логический сдвиг влево умножает значение на два. Это недорогой способ выполнить простое умножение.
LSL R0, R1, № 3
LSL R0, R1, R2
Логический сдвиг вправо (LSR)
Логический сдвиг вправо (LSR) работает обратным образом, как LSL, и эффективно делит значение на два. Старшие значащие биты заполняются нулями, а последний младший бит помещается во флаг переноса.
ЛСР Р0, Р1, №2
Арифметический сдвиг вправо (ASR)
Арифметический сдвиг вправо (ASR) выполняет ту же работу, что и LSR, но предназначен для чисел со знаком.Он копирует бит знака обратно в последнюю позицию слева.
ASR R0, R1, № 4
Повернуть вправо (ROR)
Повернуть вправо (ROR) вращает все биты в слове на некоторое значение. Вместо того, чтобы заполнять биты слева нулями, сдвинутые биты просто возвращаются на другой конец.
ROR R0, R1, # 5
Инструкции для операций разветвления
Одной из важных функций процессора является возможность выбора между двумя путями кода на основе набора входных данных.Именно это и делают операции ветвления. Процессор обычно выполняет одну инструкцию за другой, увеличивая R15, счетчик программ (PC), на четыре байта (то есть длину одной инструкции). При ветвлении компьютер перемещается в другое место, обозначенное меткой, которая представляет эту часть кода сборки.
Филиал (Б)
Branch (B) перемещает ПК по адресу, указанному на этикетке. Метка («цикл» в примере ниже) представляет часть кода, которую вы хотите, чтобы процессор выполнял следующим.Ярлыки — это просто текст, обычно значащее слово.
Петля В
Ответвление звена (BL)
Branch Link (BL) выполняет аналогичную операцию, но копирует адрес следующей инструкции в R14, регистр ссылок (LR). Это отлично работает при выполнении вызовов подпрограмм / процедур, потому что, как только часть кода на метке будет завершена, мы можем использовать LR, чтобы вернуться туда, где мы разветвились. Ниже мы переходим к метке «подпрограмма», а затем используем регистр ссылки, чтобы вернуться к следующей инструкции.
Подпрограмма BL
…
подпрограмма:
…
…
MOV PC, LR
Мы используем инструкцию MOV, чтобы вернуть регистр связи в счетчик программы. Это возвращает программу на место сразу после вызова нашей подпрограммы, обозначенной здесь. Обратите внимание на использование LR и ПК выше. Сборщики ARM распознают их как R14 и R15 соответственно.Это удобное напоминание программисту о выполняемой операции.
Инструкции по загрузке и сохранению
В памяти компьютера хранятся данные, необходимые процессору. Доступ к этим данным осуществляется с помощью адреса. Сначала поместив адрес в регистр, мы сможем получить доступ к данным по этому адресу. Вот почему мы используем операции загрузки и сохранения.
Регистр нагрузки (LDR)
Загрузить регистр (LDR) загружает данные, расположенные по адресу, в регистр назначения.Скобки вокруг R1 означают, что регистр содержит адрес. Используя скобки, мы помещаем данные по этому адресу в R0 вместо самого адреса. Мы также можем использовать эту нотацию для определения смещения данных от определенного адреса, как показано во второй строке. R0 будет содержать данные на расстоянии двух слов от адреса R1.
LDR R0, [R1]
LDR R0, [R1, # 8]
Мы также можем использовать метки для представления адреса, а затем соответствующие данные могут быть загружены в регистр.Первая строка ниже загружает адрес метки «info» в R0. Затем осуществляется доступ к значению, хранящемуся по этому адресу, и оно помещается в R1 во второй строке.
LDR R0, = информация
LDR R1, [R0]
Магазин(STR)
Store (STR) выполняет дополнительную операцию для загрузки. STR помещает содержимое регистра в ячейку памяти. В приведенном ниже коде данные хранятся в R1 по адресу в R0. Опять же, скобки означают, что R0 содержит адрес, и мы хотим изменить данные по этому адресу.
STR R1, [R0]
Типы загрузки и сохранения: байт (B), полуслово (H), слово (опущено), со знаком (SB), без знака (B)
И load, и store могут быть записаны с добавленным к ним типом. Этот тип указывает, будет ли инструкция манипулировать байтом (B), полусловом (H) или словом (опущено) и будут ли данные подписаны (SB) или беззнаковыми (B).
Одно из мест, где это может пригодиться, — это манипуляции со строками, поскольку символы ASCII имеют длину в один байт.Эти операции также позволяют использовать смещения при загрузке или сохранении, как показано в последней строке.
LDR R0, = текст @ загрузить 32-битный адрес в R0
STRB R1, [R0] @ сохранить байт по адресу в памяти
STRB R1, [R0, + R2] @ сохранить байт по адресу + смещение R2
Инструкции для условных операторов
Как упоминалось ранее, мнемонические символы, используемые в инструкции, могут иметь дополнительные коды условий, добавленные к ним.Это позволяет условное исполнение.
Помните, что флаги (как указано в предыдущей статье) — это Z ( z ero), C ( c arry), N ( n egative) и V (o v erflow).
Чтобы заставить инструкции обновлять регистр состояния, к большинству упомянутых до сих пор мнемоник можно добавить необязательную букву S. После обновления регистра состояния можно использовать ряд условных суффиксов, показанных ниже, для управления выполнением инструкции. Двоичные коды этих суффиксов соответствуют первым четырем битам инструкции обработки данных, показанной выше (см. Рисунок 1).
Эти суффиксы добавляются к мнемонике при написании ассемблера. В листинге ниже показаны некоторые условные суффиксы, используемые в инструкциях, упомянутых ранее.
Поскольку в следующей статье мы будем выполнять сборку с помощью ассемблера GNU, нам нужно использовать символ @ для представления комментария.
.global _start
начало:
MOV R0, # 3 @ Поместите значение 3 в R0
MOV R1, # 0 @ Поместите значение 0 в R1
цикл:
CMP R0, R1 @ Сравнить R1 с R0 (эффективно R0 минус R1)
BEQ done @ Если они равны (Z = 1), переход к метке done
ADDGT R1, # 1 @ Если R0 больше, чем R1, добавить 1 к R1
SUBLT R1, # 1 @ Если R0 меньше R1, вычтите 1 из R1
Петля B @ Ответвление и повторный запуск петли
выполнено:
@ другие дела
Надеюсь, эта статья даст вам общее представление об основных инструкциях, используемых для программирования ядра ARM.В следующей статье мы воспользуемся этими знаниями на простом примере программирования ядра с помощью Raspberry Pi.
.