Почему не отображаются шрифты?
TILDA HELP CENTER
Проблема с отображением может возникнуть, если при редактировании блока вручную назначили другой шрифт.
Поэтому в блоке сбрасываются настройки и устанавливается шрифт по умолчанию.
Подробнее о проблеме
Например, изначально в настройках сайта (раздел «Шрифты и цвета») вы установили шрифт Roboto. Затем в блоке выделили текст и в появившемся контекстном меню вручную указали этот шрифт.
После этого в настройках сайта поменяли шрифт на Open Sans. В блоках, где шрифт не был указан вручную, текст стал отображаться новым шрифтом. Но в блоках, в которых он был задан вручную, возникает проблема. Это произошло из-за того, что предыдущий шрифт больше не подключен к сайту.
Важно: настройки, заданные вручную в контекстном меню, могут конфликтовать с другими настройками типографики
Как исправить проблему
Необходимо перейти к блоку → нажать на любое место в тексте → шрифт автоматически изменится на добавленный.
Проблемы и способы решения в зависимости от метода подключения шрифта
Шрифт подключен CSS-файлом
Шрифт подключен с помощью файла CSS, но не отображается
Подробнее
Шрифт загружен
файлами
Возможные проблемы при подключении своего шрифта через загрузку файлов
Подробнее
Шрифт добавлен из библиотеки
Возможные проблемы со стандартными шрифтами
Подробнее
Шрифт долго загружается
При открытии сайта сначала загружается системный шрифт
Подробнее
Шрифт подключен с помощью CSS-файла
Убедитесь, что вы указали корректное название шрифта в настройках сайта.
Название шрифта (font-family) должно совпадать с данными из CSS-файла: настройки сайта → раздел «Шрифты и цвета» → вкладка «Загрузить шрифт».
Важно: при подключении шрифта через CSS-файл нужно удостовериться, что сервер, с которого подключается шрифт, поддерживает Access-Control-Allow-Origin CORS для раздачи для любого домена. (Access-Control-Allow-Origin: *). Как установить эту настройку на сервере, указано в инструкции для подключения своего файла CSS
(Access-Control-Allow-Origin: *). Как установить эту настройку на сервере, указано в инструкции для подключения своего файла CSS
Шрифт подключен с помощью Google Fonts
При добавлении шрифта также важно, чтобы название шрифта в настройках сайта совпадало с названием шрифта в Google Fonts.
Помимо этого обязательно проверьте ссылку на CSS-файл Google Fonts, она должна выглядеть так:
https://fonts.googleapis.com/css2?family=Lora:wght@400;500;600;700&display=swap
Шрифт загружен файлами
В первую очередь необходимо проверить указан ли шрифт в шрифтовой паре. Важно чтобы у шрифта было прописано полное официальное название, и оно совпадало с названием, добавляемого шрифта.
Если шрифт корректно отображается на латинице, но на кириллице возникают проблемы, то в первую очередь стоит проверить, поддерживает ли он кириллические символы. Эту информацию можно проверить на стороне сервиса, в котором вы приобрели шрифт.
Также при конвертации некоторые сервисы могут портить кириллическую версию. Это можно проверить в сервисе FontDrop!. Для конвертирования рекомендуем воспользоваться WOFFer.
Это можно проверить в сервисе FontDrop!. Для конвертирования рекомендуем воспользоваться WOFFer.
Шрифт добавлен из библиотеки шрифтов
Проблема с базовыми шрифтами может наблюдаться на экспортированных проектах.
На Тильде часть шрифтов берется из библиотеки сервиса Rentafont, который предоставляет шрифты по партнерскому соглашению.
На данный момент это шрифты:
- Futura PT
- Opinion Pro
- Circe (и Circe Rounded)
- Iskra
- Orchidea Pro
- Kazimir Text
- Mediator (и Mediator Serif)
- Reforma Grotesk
Чтобы они и другие встроенные шрифты работали на экспортированном сайте, нужно обязательно указать домен, на который вы экспортируете проект в настройках сайта → «Домен». Достаточно указать название домена, подключать его не требуется.
Шрифт долго загружается
Чтобы файл шрифта загрузился, требуется время. На скорость загрузки влияет качество используемого интернет-подключения и количество контента на странице сайта.
На скорость загрузки влияет качество используемого интернет-подключения и количество контента на странице сайта.
Чтобы страница не тормозила и посетитель не ждал, сначала загружается самое важное — контент, а потом вспомогательные компоненты. Поэтому вы можете видеть системные шрифты до того, как загрузился ваш шрифт.
Воспользуйтесь блоком «Эффект загрузки страницы» (Т228, категория «Другое»). Он замедлит появление контента и текст будет отображаться с загруженными шрифтами.
Если при открытии сайта в браузере вы наблюдаете «мерцание» — сначала загружается системный шрифт, потом ваш собственный — это не ошибка, а нормальное поведение.
Настройка шрифтов для проекта
Назначаем проекту шрифты или подключаем собственные, используя Google Fonts, Adobe Fonts или внешний CSS файл
Как загрузить свой файл шрифта
Загрузка собственных файлов шрифта в форматах WOFF и WOFF2
Как подключить шрифт через Adobe Fonts
Как подключить шрифты Adobe Fonts в Тильда Паблишинг
Google Fonts / Настройка шрифтов для проекта
Как подключить шрифты Google Fonts в Тильда Паблишинг
Почему не отображаются шрифты
Возможные проблемы и способы решения
Как подключить шрифт от Rentafont
Подключение гарнитур из библиотеки сервиса аренды и покупки шрифтов
как изменять шрифты на смартфонах Xiaomi (MIUI) / Смартфоны и мобильные телефоны / iXBT Live
Многие пользователи любят операционную систему Android в первую очередь из-за возможности кастомизации оболочки под себя любимого.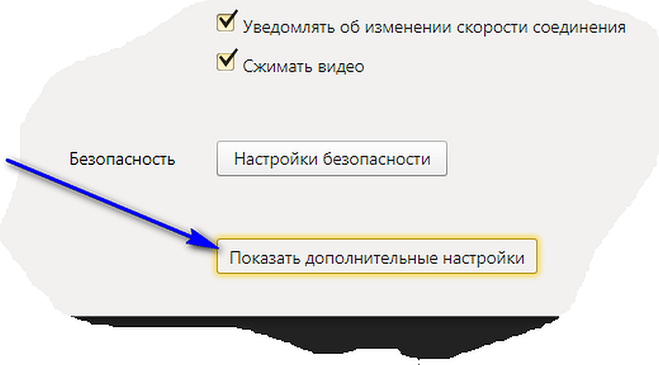 Пользователь без труда может изменять внешний вид экрана блокировки, настроить под себя рабочий стол и делать ряд других изменений функциональной и визуальной части ОС. Короче говоря, обладатель смартфона на Android может настроить оболочку под свои личные нужды для удобства использования, а также визуальную часть под свои понятия красоты.
Пользователь без труда может изменять внешний вид экрана блокировки, настроить под себя рабочий стол и делать ряд других изменений функциональной и визуальной части ОС. Короче говоря, обладатель смартфона на Android может настроить оболочку под свои личные нужды для удобства использования, а также визуальную часть под свои понятия красоты.
В данном гайде я хочу рассказать о том, как пользователь смартфона Xiaomi с оболочкой MIUI может изменять шрифты, стили текста и все остальные параметры, которые связаны с отображением текста на смартфоне. Можно использовать как системное ПО (базовые настройки, уже зашитые в оболочку), так и сторонние приложения. Для примера использую смартфон Xiaomi 11T Pro с версией MIUI 12.5.7 Global
Изменение шрифта системы MIUI
Cтандартный шрифт системы MIUI — Roboto. Он выделен жирным, читается легко и выглядит неплохо. Для изменения размера букв необходимо перейти в: Настройки — Экран — Размер текста. С помощью ползунка Вы можете изменять размер текста и видеть его будущее отображение на дисплее. Минимальный размер для наиболее «зорких» — XXS, а самый большой — XXL, подойдет пожилым людям или просто пользователям с плохим зрением.
Минимальный размер для наиболее «зорких» — XXS, а самый большой — XXL, подойдет пожилым людям или просто пользователям с плохим зрением.
Дополнительно есть возможность изменять масштабирование иконок, значков и надписей на дисплее. Тут тоже дело вкуса или остроты зрения. Переходим: Настройки — Расширенные настройки — Спец. Возможности. Далее тапаем по вкладке Зрение — Масштаб изображения на экране. Выбор: XS, S или L.
Установка несистемных шрифтов
Стиль текста, используя системные настройки, пользователь изменять не может. Самый простой вариант — воспользоваться приложением «Темы», которое является одним из предустановленных в прошивках MIUI. В Google Play можно найти множество альтернативных приложений для этих целей, однако многие из них работают нестабильно, имеют множество багов. Я опробовал несколько из них и их работа меня не устроила, шрифт изменился не везде — возможно подойдет лишь для «голого» Android.
И так, возвращаемся к приложению «Темы». Для того, чтобы появился нужный нам раздел, необходимо в настройках выставить регион «Индия». Не волнуйтесь, из-за этого для Вас ничего не изменится: ни язык, ни возможности системы. Перейдите Настройки — Расширенные настройки — Регион. Там необходимо для быстрого результата просто начать вводить название страны — Индия. Делаем ее регионом системы.
Для того, чтобы появился нужный нам раздел, необходимо в настройках выставить регион «Индия». Не волнуйтесь, из-за этого для Вас ничего не изменится: ни язык, ни возможности системы. Перейдите Настройки — Расширенные настройки — Регион. Там необходимо для быстрого результата просто начать вводить название страны — Индия. Делаем ее регионом системы.
Переходим в приложение «Темы», на нижней панели находим иконку с буквой «Т», тапаем по ней.
Выбираем любой шрифт, что пришелся по душе (свой вариант выделил), тапаем по кнопке «Бесплатно скачать», а после «Применить». Далее смартфон необходимо перезагрузить для вступления изменений в силу.
Проверяем изменения: новый шрифт появился как в настройках, так и в других приложениях. Стоит отметить, что бОльшая часть шрифтов только для латинского алфавита, кириллица при этом изменяться не будет.
Как вернуть стандартный шрифт MIUI
Для того, чтобы вернуть стандартный шрифт MIUI: запускаем приложение «Темы», переходим в личный кабинет (тапаем по иконке человечка), затем переходим в «Шрифты». Выбираем стандартный шрифт Roboto, тапаем по кнопке «Применить» и перезагружаем устройство.
Выбираем стандартный шрифт Roboto, тапаем по кнопке «Применить» и перезагружаем устройство.
Теперь Вы умеете изменять шрифты и стили их отображения на смартфонах Xiaomi/Redmi/Poco с оболочкой MIUI. Надеюсь, статья оказалась для Вас полезной!
Новости
Публикации
О закате SATA в качестве основного интерфейса накопителей я писал уже не раз. И в первую очередь заметен он по SSD – моделей-то на рынке много, но все бюджетнее и бюджетнее. И все меньше приличных…
Введение Думаю, почти каждый автомобилист при ремонте своего автомобиля, снимал пластиковые клипсы, которые в следствии демонтажа ломались. Как правило, снятую деталь нужно сразу установить…
Этим летом компания Amazfit представила рынку свой новый фитнес-браслет под названием Band 7. Его отличительная черта – повышенная автономность (до 28 дней в режиме экономии), яркий Amoled…
Вопрос об способе измерения вещей может показаться банальным и не стоящим внимания, так как все единицы измерения давно уже общеприняты и повсеместно употребляются в жизни каждого. Но тут на арену…
Но тут на арену…
Купить наушники с прямой посадкой, сегодня практически невыполнимая задача, особенно, если хочется чего-то относительно недорогого, да еще и из свежих моделей. Но, если хорошо покопаться, можно…
Всем привет, на связи Tangem! И сегодня у нас сразу два победителя получают под ёлочку по комплекту холодных мультивалютных криптокошельков. Но сперва напомним, что тут у нас вообще происходит….
Перевод прямых трансляций через Яндекс Браузер: Принципы и отличия от озвучивания видео по запросу | Сергей Дуканов | Яндекс
Мы уже рассказывали о том, как работает автоматический перевод и озвучивание видео в Яндекс Браузере. Пользователи просмотрели 81 миллион видеороликов с озвученным переводом за первые десять месяцев после релиза. Механизм работает по запросу: как только пользователь нажимает на кнопку, нейросеть получает всю звуковую дорожку, а дублированный перевод на язык пользователя появляется через несколько минут.
Но этот способ не подходит для прямых трансляций, где нужно переводить практически в реальном времени. Именно поэтому мы просто запустили отдельный, более сложный механизм трансляции прямых трансляций в Яндекс.Браузере. Анонсы устройств, спортивные соревнования, вдохновляющие космические запуски — все это и многое другое теперь можно смотреть на целевом языке в прямом эфире. Производственная версия в настоящее время поддерживает перевод только на русский язык, а английский язык появится этой осенью. Также на данный момент озвучка доступна для ограниченного набора потоков YouTube: вы можете найти полный список в конце этой статьи. В будущем мы, конечно же, откроем эту функцию для всех прямых трансляций YouTube. Нам пришлось перестраивать всю архитектуру с нуля, чтобы адаптировать механизм трансляции для потоков.
Именно поэтому мы просто запустили отдельный, более сложный механизм трансляции прямых трансляций в Яндекс.Браузере. Анонсы устройств, спортивные соревнования, вдохновляющие космические запуски — все это и многое другое теперь можно смотреть на целевом языке в прямом эфире. Производственная версия в настоящее время поддерживает перевод только на русский язык, а английский язык появится этой осенью. Также на данный момент озвучка доступна для ограниченного набора потоков YouTube: вы можете найти полный список в конце этой статьи. В будущем мы, конечно же, откроем эту функцию для всех прямых трансляций YouTube. Нам пришлось перестраивать всю архитектуру с нуля, чтобы адаптировать механизм трансляции для потоков.
С инженерной точки зрения перевод и дублирование прямых трансляций — сложная задача. Здесь сталкиваются два противоречивых требования. С одной стороны, вам нужно скормить модели как можно больше текста за раз, чтобы нейронная сеть понимала контекст каждой фразы. С другой стороны, необходимо минимизировать задержку; иначе «прямой эфир» перестанет быть таковым. Поэтому мы должны начать переводить как можно скорее: не в режиме настоящего синхронного перевода, но очень близко к нему.
Поэтому мы должны начать переводить как можно скорее: не в режиме настоящего синхронного перевода, но очень близко к нему.
Мы разработали новую услугу на основе существующих алгоритмов для быстрого и качественного перевода и дублирования прямых трансляций. Новая архитектура позволила уменьшить задержку без потери качества.
Вкратце принцип работы прямой трансляции сводится к пяти моделям машинного обучения. Одна нейросеть отвечает за распознавание речи звуковой дорожки и преобразует ее в текст. Второй движок определяет пол говорящих. Третий разбивает текст на предложения, расставляя знаки препинания и определяя, какие части текста содержат законченные мысли. Четвертая нейросеть переводит полученные куски. Наконец, пятая модель синтезирует речь на целевом языке.
На бумаге все выглядит просто, но если копнуть глубже, можно обнаружить множество подводных камней. Давайте рассмотрим этот процесс более подробно.
На начальном этапе нужно точно понимать, о чем идет речь в эфире, и определить, когда произносятся слова. Мы не просто переводим речь, но и накладываем результат обратно на видео в нужные моменты.
Мы не просто переводим речь, но и накладываем результат обратно на видео в нужные моменты.
Глубокое обучение — идеальное решение проблемы ASR (автоматического распознавания речи). Архитектура нейронной сети должна допускать сценарий использования прямой трансляции, когда необходимо обрабатывать звук по мере его поступления. Такое ограничение может повлиять на точность предсказания, но мы можем применить модель с некоторой задержкой (несколько секунд), что придает модели некоторый контекст.
Видео могут содержать посторонние шумы и музыку. Кроме того, люди могут иметь разную дикцию или говорить с разным акцентом и скоростью. Говорящих может быть много, и они могут кричать, а не говорить на умеренной громкости. И, конечно же, нужно поддерживать богатый словарный запас, ведь возможных тем видео очень много. Таким образом, сбор данных, необходимых для обучения, играет ключевую роль.
На вход алгоритм получает последовательность звуковых фрагментов, берет N из них с конца, извлекает акустические признаки (спектрограмму MEL) и подает результат на вход нейронной сети. Он, в свою очередь, выдает набор последовательностей слов (так называемых гипотез), из которых языковая модель — текстовая часть нейронной сети — выбирает наиболее правдоподобную гипотезу. Когда поступает новый фрагмент аудио, процесс повторяется.
Он, в свою очередь, выдает набор последовательностей слов (так называемых гипотез), из которых языковая модель — текстовая часть нейронной сети — выбирает наиболее правдоподобную гипотезу. Когда поступает новый фрагмент аудио, процесс повторяется.
Полученную последовательность слов необходимо перевести. Качество пострадает, если вы будете переводить слово за словом или фразу за фразой. Если вы дождетесь длинной паузы, означающей конец предложения, произойдет значительная задержка. Поэтому необходимо группировать слова в предложения, чтобы избежать потери смысла или слишком длинных предложений. Одним из способов решения этих проблем является использование модели восстановления пунктуации.
С появлением трансформеров нейронные сети стали намного лучше понимать смысл текста, отношения между словами и закономерности языковых конструкций. Вам нужен только большой объем данных. Для восстановления пунктуации достаточно взять корпус текстов, подать текст без знаков препинания на вход нейронной сети и научить сеть исправлять его обратно.
Текст поступает на вход нейросети в токенизированном виде; обычно это токены BPE. Такое разбиение не слишком мало, чтобы предотвратить удлинение последовательности, но и не слишком велико, чтобы избежать проблемы отсутствия словарного запаса, когда токен отсутствует в глоссарии. На выходе модели каждое слово имеет последующую метку, которая отмечает, какой знак препинания следует поставить.
Необходимо установить некоторый ограниченный контекст, чтобы обеспечить правильную работу в условиях прямой трансляции. Размер этого контекста должен найти компромисс между качеством и задержкой. Если мы не уверены, нужно ли разбивать предложения в данном конкретном месте, мы можем немного подождать, пока не появятся новые слова. Тогда мы либо лучше определим разбиение, либо превысим контекстный предел и будем вынуждены разбиваться там, где мы лишь немного Конечно.
Для корректного перевода и качественного озвучивания необходимо определить пол говорящего. Если вы используете классификатор пола на уровне предложения, в сценарии прямой трансляции не будет различий по сравнению со сценарием по запросу. Хранение истории голосовых линий каждого говорящего помогает нам более точно классифицировать половую принадлежность. Это снижает количество ошибок в полтора раза. Мы не только можем определить пол человека всего по одной фразе, но и рассматриваем результаты гендерной классификации по ранее сказанным фразам. Для этого нам нужно на лету определить, кому принадлежит линия, тем самым уточнив пол говорящего.
Хранение истории голосовых линий каждого говорящего помогает нам более точно классифицировать половую принадлежность. Это снижает количество ошибок в полтора раза. Мы не только можем определить пол человека всего по одной фразе, но и рассматриваем результаты гендерной классификации по ранее сказанным фразам. Для этого нам нужно на лету определить, кому принадлежит линия, тем самым уточнив пол говорящего.
С точки зрения машинного перевода ничего не изменилось по сравнению с переводом готовых видео, поэтому сейчас не будем в это углубляться. В прошлом мы рассмотрели внутреннюю работу перевода.
Базовая технология синтеза в Алисе, умном помощнике Яндекса, аналогична той, которую мы используем в видеопереводе. Разница в том, как осуществляется применение (вывод) этих нейронных сетей. Говорящий в ролике может очень быстро произнести реплику, либо перевод предложения может получиться в два раза длиннее оригинала. В этих случаях вам придется сжимать синтезированный звук, чтобы не отставать от времени. Этого можно добиться двумя способами: на уровне звуковой волны, например, с помощью PSOLA (Pitch Synchronous Overlap and Add) или внутри нейронной сети. Второй метод обеспечивает более естественное звучание речи, но требует возможности редактирования скрытых параметров.
Этого можно добиться двумя способами: на уровне звуковой волны, например, с помощью PSOLA (Pitch Synchronous Overlap and Add) или внутри нейронной сети. Второй метод обеспечивает более естественное звучание речи, но требует возможности редактирования скрытых параметров.
Важно не только доводить длительности синтезируемых фраз до нужной длины, но и разлагать их в нужные моменты. Не всегда будет идеально: придется либо ускорять запись, либо сдвигать тайминги — за это отвечает алгоритм стекирования. В прямом эфире нельзя изменить прошлое, поэтому может возникнуть ситуация, когда нужно озвучить фразу в два раза быстрее, чем она произносится в исходном видео. Для справки: ускорение более чем на 30% существенно влияет на человеческое восприятие.
Решение следующее: резервируем время заранее. Мы не торопимся складывать голосовые линии и можем дождаться новых, чтобы учесть их продолжительность. Мы также можем позволить накапливаться небольшому временному сдвигу, поскольку рано или поздно в видео будет несколько секунд тишины, и сдвиг сбрасывается до нуля.
Полученная звуковая дорожка разрезается на фрагменты и оборачивается аудиопотоком, который будет микшироваться локально в самом Браузер-клиенте.
При просмотре трансляции Браузер опрашивает стриминговый сервис (например, YouTube) на наличие новых фрагментов видео и аудио; если они есть, он загружает и воспроизводит их последовательно.
Когда пользователь нажимает на кнопку живого перевода, Яндекс.Браузер запрашивает ссылку на поток с переведенным звуком из своего бэкенда. Браузер накладывает этот трек поверх основного, соблюдая тайминги.
В отличие от готовых видео, прямая трансляция обрабатывается машинным переводом каждый момент своего существования. Stream Downloader считывает аудиопоток и отправляет его в конвейер обработки ML, компоненты которого мы разобрали выше.
Существует несколько способов организации взаимодействия между компонентами. Мы остановились на варианте с очередями сообщений, где каждый компонент оформлен как отдельный сервис:
- Запустить все модели на одной машине проблематично: они могут просто не помещаться в памяти или требовать очень специфической аппаратной конфигурации.
- Требуется для балансировки нагрузки и возможности горизонтального масштабирования. Например, сервисы машинного перевода и синтеза голоса имеют разную пропускную способность, поэтому количество фраз может отличаться.
- Службы иногда аварийно завершают работу (графическому процессору не хватает памяти, утечке памяти или отключению электроэнергии в центре обработки данных), а очереди предоставляют механизм повторных попыток.
Поток не привязан к одному экземпляру, но для обработки может потребоваться некоторый контекст (фон). Например, синтезатору необходимо хранить записи, которые еще не были помещены на окончательную звуковую дорожку. Следовательно, необходим глобальный репозиторий контекста для всех потоков. На схеме он обозначен как Global Context — по сути, это просто хранилище ключ-значение в памяти.
Наконец, полученный аудиопоток должен быть доставлен пользователю. Здесь за дело берется Stream Sender: он оборачивает аудиофрагменты в потоковый протокол, а клиент читает этот поток по ссылке.
В настоящее время мы предоставляем прямую трансляцию со средней задержкой 30–50 секунд. Иногда мы вылетаем из этого диапазона, но ненамного: стандартное отклонение около 5 секунд.
Основная трудность при переводе прямых трансляций заключается в обеспечении того, чтобы задержка не колебалась слишком сильно. Простой пример: вы открываете прямую трансляцию и через 15 секунд начинаете получать трансляцию. Если вы продолжите смотреть, рано или поздно одной из моделей понадобится больше контекста — например, если говорящий произносит длинное предложение без пауз, нейронный движок попытается получить его целиком. Тогда задержка увеличится, возможно, еще на десять секунд. Естественно, предпочтительна небольшая задержка в начале, чтобы этого не произошло.
Наша глобальная цель — сократить задержку примерно до 15 секунд. Это немного больше, чем в настоящем синхронном переводе, но достаточно для прямых трансляций, где ведущие взаимодействуют с аудиторией, например, на Twitch.
Пока полный доступ ко всем трансляциям YouTube находится в разработке, вот список каналов, где дублирование уже доступно:
— Apple
— Business Insider
— CNET Highlights
— English Speeches
— Freenvesting
— thegameawards
— Google Developers
— IGN
— NASA
— The Overlap
— SpaceX
— TechCrunch
— TED
— TEDx
Российский «Яндекс Браузер» запускает первую бета-версию Linux 10 Clone 20 Is09, No.
Вам не нужно быть русским, чтобы слышать о Яндексе, ведущей интернет-компании страны, но вам нужно будет говорить на этом языке, чтобы использовать ее фирменный веб-браузер, бета-версия которого только что запущена для Linux.Поиск Яндекса считается 4-м по популярности порталом веб-запросов после Google, Baidu и Yahoo!, но контролирует большую часть рынка русскоязычного интернет-поиска.
Но не так много, как раньше. Причина? Google Chrome, который является самым популярным веб-браузером в России и по умолчанию (естественно) использует собственную поисковую систему Google, а не Яндекс.
У них хитрое решение: взять основы с открытым исходным кодом, которые сделали Chrome таким популярным, добавить к ним немного старого вкуса Яндекса и выпустить.
И это окупается.
Основанный на Chromium «Яндекс Браузер» вырос до 6% от общего рынка браузеров в России за 2 года с момента его дебюта и с тех пор расширился, чтобы предлагать сборки для iOS и Android.
Теперь, когда вышла первая бета-версия их флагманского браузера для Linux, эта цифра может расти еще быстрее.
Яндекс.Браузер не является клоном Chrome
Страница «Новая вкладка» в Яндекс.Браузере Яндекс.Браузер работает на базе WebKit-разветвленного механизма компоновки «Blink» от Google и основана на кодовой базе Chromium с открытым исходным кодом. Быстрый практический опыт работы с браузером показывает, что он довольно ванилен в своих основах Blink и Chromium, но заметно отличается визуально и функциями, которые он предоставляет.
Интернет-компания приложила немало усилий, чтобы адаптировать браузер под своих клиентов и их потребности.
Например, имеет собственные внутренние настройки, закладки и меню; имеет инновационную страницу «новая вкладка» (которая вообще не является страницей) и поставляется с предварительно загруженным небольшим, но хорошо укомплектованным набором встроенных расширений (включая средства проверки для Яндекс.Почты и т. д.).
Яндекс.Браузер также имеет меню быстрого доступа, встроенное в рамку окна.
Хотя эта бета-версия не будет иметь большого практического значения для всех, кто находится за пределами русскоязычной страны (его можно использовать как обычный браузер, но не все строки переводятся, нерусские веб-страницы запускают функцию «перевести на русская подсказка и т. д.), он должен иметь достаточную отличительную черту, чтобы привлечь сторонников Яндекса на Ubuntu и других дистрибутивах с их текущих веб-порталов.