Как бесплатно создать рекламный спецпроект в ПромоСтраницах с помощью Яндекс Форм — Маркетинг на vc.ru
Когда пишешь много разных коммерческих текстов, в какой-то момент начинает казаться, что всё это ты уже делал. Хочется попробовать что-то новое, необычное, что-то, что вызовет интерес у читателей и будет выделяться среди остального рекламного контента, при этом принесет заказчику целевой результат. Вместе с командой бренда SYNERGETIC мы много экспериментировали и в итоге такой формат нашли.
2426 просмотров
Меня зовут Даша Мощенко, я работаю редактором в ПромоСтраницах. Когда я говорю про «пишешь много текстов для заказчиков», я имею в виду действительно много. За этот год я написала и отредактировала 200 текстов для рекламодателей из TECNO, Альфа-Банка, more.tv и других.
В статье поделюсь опытом запуска рекламной кампании в ПромоСтраницах для SYNERGETIC. Получилось очень необычно, вовлекающе и красиво.
Так выглядела ПромоСтраница с тестом от SYNERGETIC
Многие рекламодатели просто не знают о возможностях Яндекс Форм и их интеграции в ПромоСтраницы.
Как интегрировать Яндекс Формы в ПромоСтраницы
1. Начинаем работу в Яндекс Формах. Для этого нужно перейти на сайт forms.yandex.ru и зарегистрироваться или авторизоваться, используя аккаунт в Яндексе.
Совет. Чтобы получить доступ к расширенным настройкам, создавайте Форму именно в редакторе Форм, а не через виджет ПромоСтраниц. В виджете функционал не полный. Кроме того, полноценный редактор в Формах просто удобнее использовать. Готовую Форму из редактора Форм можно вставить на сайт или ПромоСтраницу простым копированием и вставкой кода на страницу с помощью Ctrl + C — Ctrl + V.
2. Продумываем механику. Это самое сложное. Обычно мы прописываем все вопросы, ответы и результаты в Google Docs. Если это формат теста с результатами, нужно дополнительно прописать для каждого вопроса баллы и потом их посчитать.
Так мы прописывали и редактировали предварительный текст вопросов в Google-документе
Совет. Чтобы всё работало как надо, один из ответов в вопросе должен приносить 0 баллов, иначе весь подсчет сломается.
Так выглядит настройка баллов за ответы, чтобы всё работало правильно
Настройки вопросов, ответов и баллов находятся в редакторе формы на вкладке «Конструктор» в блоке «Тесты и квизы».
Вот так это выглядело при создании теста для SYNERGETIC.
3. Выбираем дизайн. Возможности для стилизации в редакторе почти безграничные. На вкладке «Тема» можно полностью кастомизировать форму и настроить цвета фона и текста. Можно воспользоваться стандартными темами или настроить свою: выбрать цвет и размер текста, поменять фон и кнопки.
Совет. Если вы интегрируете Форму эмбедом (вставкой кода) в ПромоСтраницу или на страницу сайта, попробуйте оставить настройки дизайна по умолчанию.
Базовая Форма по умолчанию прозрачная, и, если ничего не менять, она встраивается поверх фона страницы и принимает её цвет. Так получилось у нас с ПромоСтраницей SYNERGETIC. Не видно границ Формы, и она выглядит очень органично на странице.
Форма с тестом от SYNERGETIC на ПромоСтранице
4. Прописываем финальное сообщение и настраиваем показ результатов. На вкладке «Настройки» в разделе «Тесты и квизы» нужно настроить логику показа результатов и их внешний вид. Дополнительно к каждому результату можно загрузить фотографию. Вот как это выглядело у нас в настройках и в финальной форме.
Настройка показа результатов в редакторе Формы
Так результат в конце теста видели пользователи
Совет. Чтобы текст выглядел более аккуратным и его было удобнее читать, разметьте его html-вёрсткой: можно сделать выделение жирным или курсивом, встраивать ссылки.
Подробная инструкция по вёрстке: Как настраивать внешний вид Формы и форматировать текст.
5. Анализируем результаты. Чтобы иметь возможность отслеживать конверсии из Формы в Метрике при переходе на ваш сайт, нужно проставить utm-метки в ссылки. Не забудьте проверить, что метки есть во всех ссылках внутри теста и что у них понятные названия, по которым будет удобно проводить анализ.
Совет. Лучше использовать для оформления ссылки вёрстку, которая при клике открывает ссылку в новом окне: https://<a href=»site.ru» target=»_blank»>текст ссылки</a>?utm_source=forma&utm_content=test. Это удобнее для пользователя, а еще исключает перезагрузку страницы с Формой и сброс результата.
6. Интегрируем готовую Форму на страницу. После того как все настройки в редакторе Форм закончены, нужно скопировать код формы для вставки в вашу ПромоСтраницу. Для этого нажмите желтую кнопку «Опубликовать» вверху справа над формой (она заменится на кнопку «Поделиться»), скопируйте код и вставьте в ПромоСтраницу.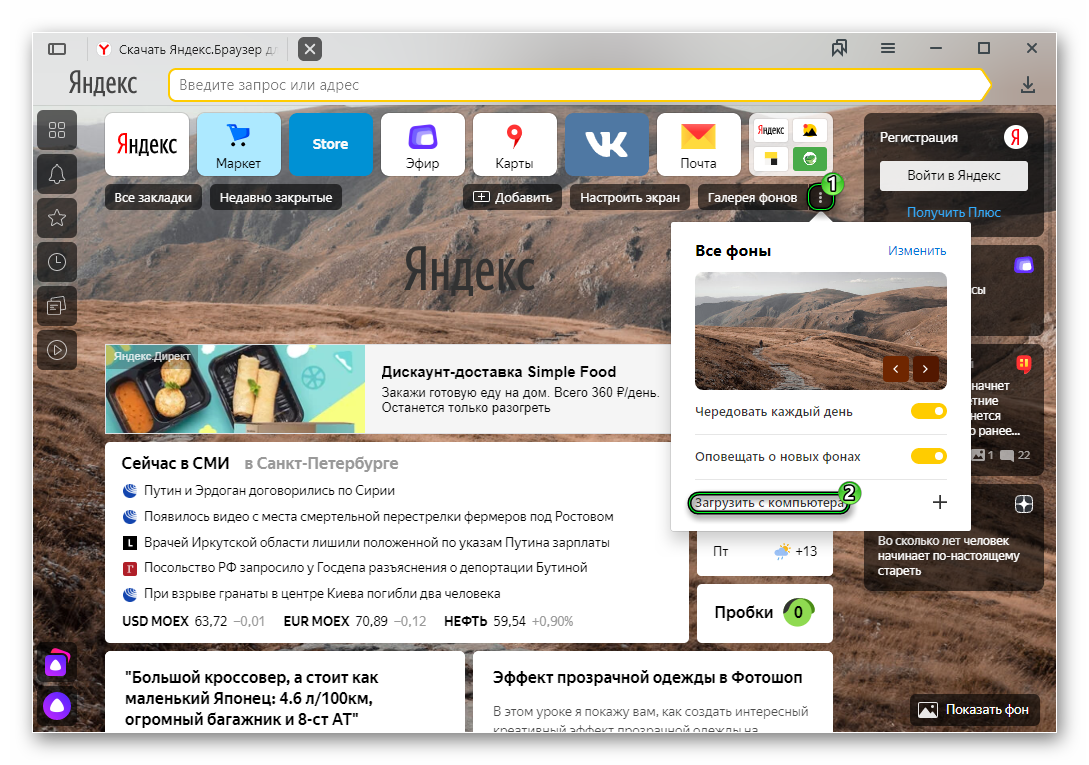
В ПромоСтраницах для этого нужно зайти в публикацию и просто вставить скопированный код
Почему стоит использовать Яндекс Формы в вашем контент-маркетинге
Формы помогают превратить обычный текст в развлекательно-охватный спецпроект в ПромоСтраницах. Такой формат может не только работать на узнаваемость, но и генерить переходы на сайт. После теста можно настроить бесшовный переход на свой сайт из ПромоСтраницы с помощью Scroll2Site и получать не только вовлеченных в тест пользователей, но и разогретый трафик.
Вот еще один очень красивый пример бренда ВкусВилл с использованием встроенной Формы в ПромоСтранице с переходом на сайт рекламодателя по Scroll2Site в конце.
Продвижение ПромоСтраниц по стратегиям «Дневной бюджет» или «Оплата за дочитывание» привлекает новую аудиторию из 70 миллионов пользователей РСЯ. Алгоритмы сами подбирают тех пользователей, которые с большей вероятностью дочитают публикацию до конца или перейдут на сайт рекламодателя через ссылки в статье.
В случае с SYNERGETIC нам удалось не только вовлечь пользователей в прохождение теста, но и сгенерить переходы на сайт. Из ПромоСтраниц мы вели пользователей сразу в интернет-магазин, где товар можно было заказать со скидкой.
Ссылки с инструкциями, которые помогут создать сложную кастомизированную Форму
Вот несколько ссылок, которые очень подробно описывают все шаги по созданию Формы:
- Подробная инструкция по созданию тестов
- Настроить условия отправки ответа, проверку капчей
- Как настроить страницу результатов
- Как настраивать внешний вид Формы и форматировать текст
- Как встраивать ссылки в результаты
- Как настроить Метрику для Формы для анализа результатов
Узнать больше о ПромоСтраницах:
- Лендинг
- Справочник
- Канал в Телеграме
Фон для Яндекс Браузера — как поменять обои
Главная » Помощь
Рубрика: Помощь
Помимо богатого функционала обозреватель предлагает пользователю сменить подложку домашней страницы Яндекс Браузера, содержащей ссылки на сайты. Для этого можно использовать встроенную галерею рисунков интернет-обозревателя, установить картинку из собственной коллекции, или найти готовые фотографии в сети интернет.
Конечно, назвать устанавливаемую фотографию полноценными обоями нельзя: пользователь видит ее только при открытии главной страницы браузера. Но тут ничего не поделаешь: обозреватель Яндекс не имеет возможностей для изменения собственной подложки открываемого сайта.
Навигация:
- Установка обоев веб-браузера
- Метод 1. Установка обоев из встроенной коллекции интернет-браузера
- Метод 2. Установка рисунка из личной коллекции на персональном компьютере
- Метод 3. Установка фото, найденного в сети интернет
- Скачать обои для Яндекс Браузер
Установка обоев веб-браузера
Ну что ж, разберем способы, с помощью которых средствами самого интернет-обозревателя можно установить фотообои в Yandex.
Метод 1. Установка обоев из встроенной коллекции интернет-браузера
Для того, чтобы поменять фон, используя собственный набор картинок веб-обозревателя, нужно сделать следующее:
- Запустить веб-браузер Yandex.
- Если по умолчанию открылся какой-либо сайт, переходим на главное табло, кликнув в строке вкладок на иконку с плюсиком («Новая вкладка»).
- Откроется начальный экран программы. Внизу, под эскизами часто открываемых ресурсов, находим надпись «Галерея» и нажимаем на нее.
- Откроется форма выбора изображений с разбивкой по категориям. Некоторые из них анимированные, они помечены значком видеокамеры в углу.
- Чтобы поставить понравившуюся заставку на главный экран, нужно кликнуть по ней левой клавишей мыши. Появится окно предварительного просмотра, в котором можно увидеть, как будет выглядеть изображение на табло интернет-обозревателя.
- Если юзера все устраивает, необходимо нажать кнопку «Применить».
Отдельно хочется отметить, что если на домашней веб-странице кликнуть мышью пиктограмму из трех точек возле надписи «Галерея», то в появившемся окне можно включить режим приостановки анимации «живого» рисунка для экономии заряда батареи ноутбука.

Метод 2. Установка рисунка из личной коллекции на персональном компьютере
Чтобы установить на головную страницу собственное изображение, нужно произвести следующие манипуляции:
- Запустить Яндекс-браузер.
- Если по умолчанию открылся интернет-сайт, перейти к главному экрану, нажав плюс в строке вкладок («Новая вкладка»).
- На головном экране нажать пиктограмму из трех точек возле надписи «Галерея фонов».
- Выбрать пункт «Загрузить с компьютера».
- В диалоговом окне найти у себя на ЭВМ нужный рисунок, выбрать его и нажать «Открыть». Фон сразу изменится, предварительный просмотр в этом случае недоступен.
Метод 3. Установка фото, найденного в сети интернет
Если при просмотре интернет-страниц юзеру понравилась определенная фотография, то ее можно легко установить в качестве основного изображения табло веб-обозревателя. Нужно просто щелкнуть по ней правой кнопкой мыши и выбрать пункт «Сделать фоном в Яндекс-Браузере».
Заключение
Как видим, изменить картинку на основной странице веб-обозревателя Yandex нетрудно, с этим справится даже начинающий пользователь персонального компьютера.
Скачать обои для Яндекс Браузер
Загрузить обои бесплатно
2
Понравилась статья? Поделиться с друзьями:
Эволюция структур данных в Яндекс.Метрике
Яндекс.Метрика — вторая по величине в мире система веб-аналитики. Метрика получает поток данных о событиях, которые произошли на сайтах или в приложениях. Наша задача состоит в том, чтобы обработать эти данные и представить их в анализируемом виде.
Обработка данных сама по себе не является проблемой. Настоящая трудность заключается в попытке определить, в какой форме следует сохранять обработанные результаты, чтобы с ними было удобно работать. В процессе разработки нам несколько раз приходилось полностью менять подход к организации хранения данных. Мы начали с таблиц MyISAM, затем использовали LSM-деревья и, в конце концов, придумали столбцовую базу данных ClickHouse. В этой статье я объясню, почему мы остановились на последнем варианте.
В этой статье я объясню, почему мы остановились на последнем варианте.
Яндекс.Метрика была запущена в 2008 году и работает уже более девяти лет. Каждый раз, когда мы меняли подход к хранению данных в прошлом, это происходило из-за того, что то или иное решение оказывалось неэффективным: либо был недостаточный запас производительности, либо решение было ненадежным, либо потребляло слишком много вычислительных ресурсов, либо просто не позволяло нам реализовать то, что нам нужно.
В старой Яндекс.Метрике для сайтов более 40 «фиксированных» типов отчетов (например, отчет по географии посетителей), несколько инструментов внутристраничной аналитики (например, карты кликов), Вебвизор (позволяет изучать действия отдельных пользователей в большая детализация), а также отдельный конструктор отчетов.
С новыми Metrica и Appmetrica вы можете настраивать каждый отчет вместо того, чтобы иметь дело с «фиксированными» типами. Вы можете добавить новые параметры (например, в отчете по поисковым запросам вы можете разбить данные по целевым страницам), сегментировать и сравнивать (скажем, между источниками трафика для всех посетителей и посетителей из Сан-Франциско), изменить свой набор метрик и т.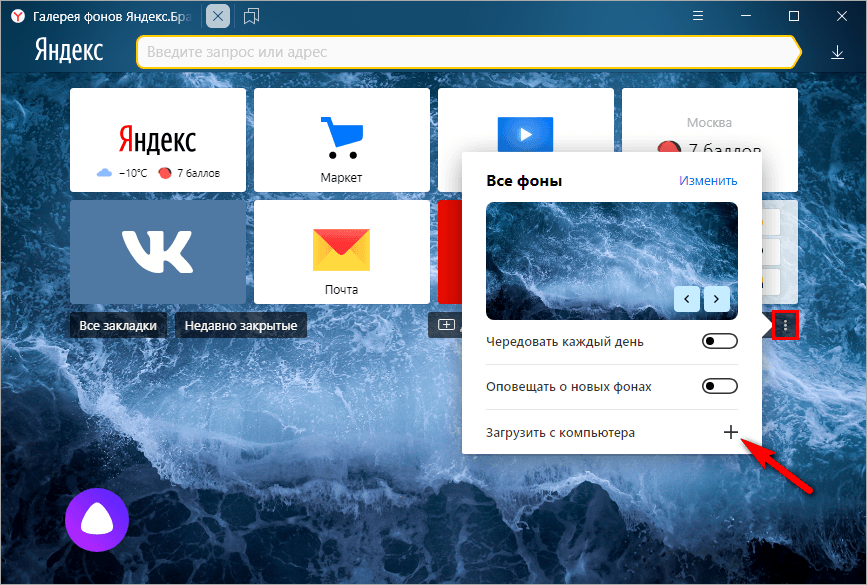 д. Таким образом, новая система требует совершенно другого подхода к хранению данных, чем тот, который мы использовали ранее.
д. Таким образом, новая система требует совершенно другого подхода к хранению данных, чем тот, который мы использовали ранее.
MyISAM
Метрика создавалась как ответвление сервиса поисковых объявлений Яндекс.Директа. Таблицы MySQL с движком MyISAM использовались в Директе для хранения статистики, с чего мы и начинали в Метрике. Мы использовали MyISAM для хранения «фиксированных» отчетов с 2008 по 2011 год.
Позвольте мне немного объяснить, какую структуру должны иметь таблицы отчетов, например, при работе с географией. Отчет формируется по конкретному сайту (точнее, по конкретному идентификатору счетчика Метрики). Это означает, что первичный ключ должен содержать CounterID. Пользователь может выбрать произвольный период отчета. Сохранение данных для каждой пары дат не имеет смысла, поэтому данные сохраняются для каждой даты, а затем суммируются по запросу для выбранного интервала. Следовательно, первичный ключ содержит дату.
Данные в отчете отображаются по регионам либо в виде списка, либо в виде дерева, состоящего из стран, регионов и городов. Таким образом, имеет смысл поместить RegionID в первичный ключ таблицы и собрать данные в дерево на стороне кода приложения, а не на стороне базы данных.
Таким образом, имеет смысл поместить RegionID в первичный ключ таблицы и собрать данные в дерево на стороне кода приложения, а не на стороне базы данных.
Допустим, мы также хотим учитывать среднюю продолжительность сеанса. Это означает, что столбцы таблицы должны содержать количество сеансов и общую продолжительность сеанса.
Таким образом, результирующая таблица будет иметь следующую структуру: CounterID, Date, RegionID -> Visits, SumVisitTime,… Теперь посмотрим, что происходит, когда мы запрашиваем отчет. Запрос SELECT выполняется с условиями, ГДЕ CounterID = AND Date BETWEEN min_date AND max_date. Другими словами, считывается диапазон первичного ключа.
Как на самом деле данные хранятся на диске?
Таблица MyISAM состоит из файла данных и индексного файла. Если из таблицы ничего не удалялось и длина строк при обновлении не менялась, то файл данных будет состоять из сериализованных строк, расположенных последовательно в том порядке, в котором они были вставлены. Индекс (включая первичный ключ) представляет собой B-дерево, листья которого содержат смещения в файле данных. Когда мы читаем данные диапазона индекса, набор смещений в файле данных извлекается из индекса. Затем файл данных считывается по этому набору смещений.
Индекс (включая первичный ключ) представляет собой B-дерево, листья которого содержат смещения в файле данных. Когда мы читаем данные диапазона индекса, набор смещений в файле данных извлекается из индекса. Затем файл данных считывается по этому набору смещений.
Рассмотрим реальную ситуацию, когда индекс находится в оперативной памяти (кэш ключей в MySQL или системный кеш страниц), но данные в нем не кэшируются. Предположим, что мы используем жесткие диски. Время, необходимое для чтения данных, зависит от объема данных, которые необходимо прочитать, и от того, сколько операций поиска необходимо выполнить. Количество операций поиска определяется расположением данных на диске.
События Метрики поступают практически в том же порядке, в котором они происходили на самом деле. В этом входящем потоке данные с разных счетчиков разбросаны совершенно хаотично. Другими словами, входящие данные являются локальными по времени, но не локальными по номеру счетчика. При записи в таблицу MyISAM данные с разных счетчиков также размещаются довольно хаотично. Это означает, что для чтения отчета с данными вам потребуется выполнить примерно столько случайных чтений, сколько строк в таблице нам нужно.
Это означает, что для чтения отчета с данными вам потребуется выполнить примерно столько случайных чтений, сколько строк в таблице нам нужно.
Типичный жесткий диск со скоростью вращения 7200 об/мин может выполнять от 100 до 200 случайных операций чтения в секунду. Массив RAID, при правильном использовании, может выполнять гораздо больше функций. Один семилетний SSD может выполнять 30 000 случайных операций чтения в секунду, но мы не можем позволить себе хранить наши данные на SSD. С этой системой, если бы нам нужно было прочитать 10 000 строк для отчета, это заняло бы более 10 секунд, что было бы совершенно неприемлемо.
InnoDB гораздо лучше подходит для чтения диапазонов первичных ключей, поскольку использует кластеризованный первичный ключ (т. е. данные хранятся упорядоченным образом в первичном ключе). Но InnoDB было невозможно использовать из-за низкой скорости записи. Если это напоминает вам о TokuDB, то читайте дальше.
Мы применили несколько трюков, чтобы MyISAM работал быстрее при выборе диапазона первичного ключа.
Таблица сортировки. Поскольку данные должны обновляться постепенно, недостаточно отсортировать таблицу один раз, но сортировать ее каждый раз невозможно. Тем не менее, это можно делать периодически для старых данных.
Разделение. Таблица делится на несколько меньших диапазонов первичных ключей. Это сделано в расчете на то, что данные из одного раздела будут храниться более-менее локально и запросы на диапазон первичного ключа будут обрабатываться быстрее. Этот метод можно отнести к ручной реализации кластеризованного первичного ключа. Это немного замедляет вставку данных. Однако при выборе количества разделов обычно удается достичь компромисса между скоростью вставки и скоростью чтения.
Разделение данных по поколениям. При одной схеме разбиения выборки могут сильно тормозить, при другой — скорость вставки. И оба тормозят при использовании промежуточного варианта. Решение этой проблемы состоит в том, чтобы разделить данные на несколько отдельных поколений. Например, первое поколение мы будем называть операционными данными; здесь разделение либо происходит по мере вставки данных (по времени), либо не происходит вообще. Мы будем называть архивные данные второго поколения; здесь происходит разбиение по мере чтения данных (по номеру счетчика). Данные передаются от поколения к поколению через скрипт, но не слишком часто (например, раз в день) и считываются сразу со всех поколений. Это помогает, но и создает массу трудностей.
Мы будем называть архивные данные второго поколения; здесь происходит разбиение по мере чтения данных (по номеру счетчика). Данные передаются от поколения к поколению через скрипт, но не слишком часто (например, раз в день) и считываются сразу со всех поколений. Это помогает, но и создает массу трудностей.
Эти (и другие) уловки некоторое время использовались в Яндекс.Метрике, чтобы все работало.
Подытожим недостатки предыдущей системы:
- очень сложно поддерживать локальность данных на диске
- таблицы заблокированы во время INSERT
- репликация медленная; реплики часто отстают
- согласованность данных после аппаратного сбоя не гарантируется
- агрегаты, такие как количество уникальных пользователей, очень сложно подсчитать и сохранить
- сжатие данных сложно использовать и работает неэффективно
- индексы занимают много места и не помещаются в ОЗУ полностью
- данные должны быть сегментированы вручную
- многие вычисления должны быть выполнены на стороне кода приложения после SELECT
- сложный в обслуживании и эксплуатации
Изображение: расположение данных на диске (художественный рендеринг)
Таким образом, пользоваться MyISAM было крайне неудобно. В дневное время серверы работали со 100% нагрузкой на дисковые массивы (постоянное движение головок). В этих условиях диски выходят из строя чаще, чем обычно. Мы использовали дисковые полки на серверах. Другими словами, нам приходилось довольно часто восстанавливать RAID-массивы. Иногда реплики так сильно отставали, что нам приходилось их удалять и создавать заново. Переключение мастера репликации действительно неудобно.
В дневное время серверы работали со 100% нагрузкой на дисковые массивы (постоянное движение головок). В этих условиях диски выходят из строя чаще, чем обычно. Мы использовали дисковые полки на серверах. Другими словами, нам приходилось довольно часто восстанавливать RAID-массивы. Иногда реплики так сильно отставали, что нам приходилось их удалять и создавать заново. Переключение мастера репликации действительно неудобно.
Несмотря на недостатки, по состоянию на 2011 год мы хранили более 580 миллиардов строк в таблицах MyISAM. Потом все было переконвертировано в Metrage, удалено и в итоге освободилось много серверов.
Metrage и OLAPServer
Мы используем Metrage для хранения фиксированных отчетов с 2010 года. Предположим, у вас следующий сценарий:
- данные постоянно записываются в базу данных небольшими партиями
- поток записи относительно велик (не менее нескольких сотен тысяч строк в секунду)
- сравнительно мало запросов на чтение (несколько тысяч запросов в секунду)
- все чтения диапазона первичного ключа (до миллионов строк на запрос)
- строки довольно короткие (около 100 байт без сжатия)
Довольно распространенная структура данных LSM Tree хорошо подходит для этого. Эта структура состоит из сравнительно небольшой группы «фрагментов» данных на диске, каждый из которых содержит данные, отсортированные по первичному ключу. Новые данные сначала помещаются в некую структуру данных ОЗУ (MemTable), а затем записываются на диск в новом отсортированном фрагменте. Периодически несколько отсортированных кусков будут уплотняться в один больший в фоновом режиме. Таким образом поддерживается относительно небольшой набор фрагментов.
Эта структура состоит из сравнительно небольшой группы «фрагментов» данных на диске, каждый из которых содержит данные, отсортированные по первичному ключу. Новые данные сначала помещаются в некую структуру данных ОЗУ (MemTable), а затем записываются на диск в новом отсортированном фрагменте. Периодически несколько отсортированных кусков будут уплотняться в один больший в фоновом режиме. Таким образом поддерживается относительно небольшой набор фрагментов.
Такие структуры данных используются в HBase и Cassandra. Среди встроенных структур данных LSM-Tree реализованы LevelDB и RocksDB. Впоследствии RocksDB используется в MyRocks, MongoRocks, TiDB, CockroachDB и многих других.
Metrage также является LSM-деревом. Произвольные структуры данных (зафиксированные во время компиляции) могут использоваться в нем как «строки». Каждая строка представляет собой пару ключ-значение. Ключ — это структура с операциями сравнения на равенство и неравенство. Значение представляет собой произвольную структуру с операциями обновления (добавления чего-либо) и слияния (агрегирования или объединения с другим значением). Короче говоря, это CRDT.
Короче говоря, это CRDT.
В качестве значений могут выступать как простые структуры (целочисленные кортежи), так и более сложные (например, хэш-таблицы для подсчета количества уникальных посетителей или структуры карты кликов). С помощью операций обновления и слияния постоянно осуществляется инкрементная агрегация данных в следующих точках:
- при вставке данных при формировании новых пакетов в ОЗУ
- во время фонового слияния
- во время запросов на чтение
Metrage также содержит необходимую нам доменную логику, которая выполняется во время запросов. Например, для региональных отчетов ключ в таблице будет содержать идентификатор самого низкого региона (города, села) и, если нам нужен отчет по стране, данные по стране будут агрегироваться на стороне сервера базы данных.
Вот основные преимущества этой структуры данных:
- Данные достаточно локально расположены на жестком диске; чтение диапазона первичного ключа происходит быстро.
- Данные сжаты в блоки. Поскольку данные хранятся упорядоченно, сжатие работает довольно хорошо при использовании алгоритмов быстрого сжатия (в 2010 году мы использовали QuickLZ, с 2011 года — LZ4).
- Хранение данных, отсортированных по первичному ключу, позволяет использовать разреженный индекс. Разреженный индекс — это массив значений первичного ключа для каждой N-й строки (порядка N тысяч). Этот индекс максимально компактен и всегда умещается в оперативной памяти.
Поскольку чтение выполняется не очень часто (даже несмотря на то, что при этом считывается много строк), увеличение задержки из-за большого количества фрагментов и распаковки блоков данных не имеет значения. Чтение дополнительных строк из-за разреженности индекса также не имеет значения.
Записанные фрагменты данных не изменяются. Это позволяет читать и писать без блокировки — для чтения делается снимок данных. Используется простой и унифицированный код, но мы можем легко реализовать всю необходимую предметно-ориентированную логику.
Нам пришлось написать Metrage вместо изменения существующего решения, потому что его на самом деле не было. В 2010 году LevelDB не существовало, а TokuDB в то время была собственностью.
Все системы, реализующие LSM-Tree, подходили для хранения неструктурированных данных и карт из BLOB в BLOB с небольшими вариациями. Но чтобы адаптировать этот тип системы для работы с произвольным CRDT, потребовалось бы гораздо больше времени, чем для разработки Metrage.
Конвертация данных из MySQL в Metrage заняла довольно много времени: если на работу программы конвертации ушло всего около недели, то на основную ее часть ушло около двух месяцев.
После передачи отчетов в Метраж мы сразу увидели увеличение скорости интерфейса Метрики. Мы используем Metrage уже пять лет, и это решение оказалось надежным. За это время было всего несколько мелких поломок. Его преимущества заключаются в простоте и эффективности, что делает его гораздо лучшим выбором для хранения данных, чем MyISAM.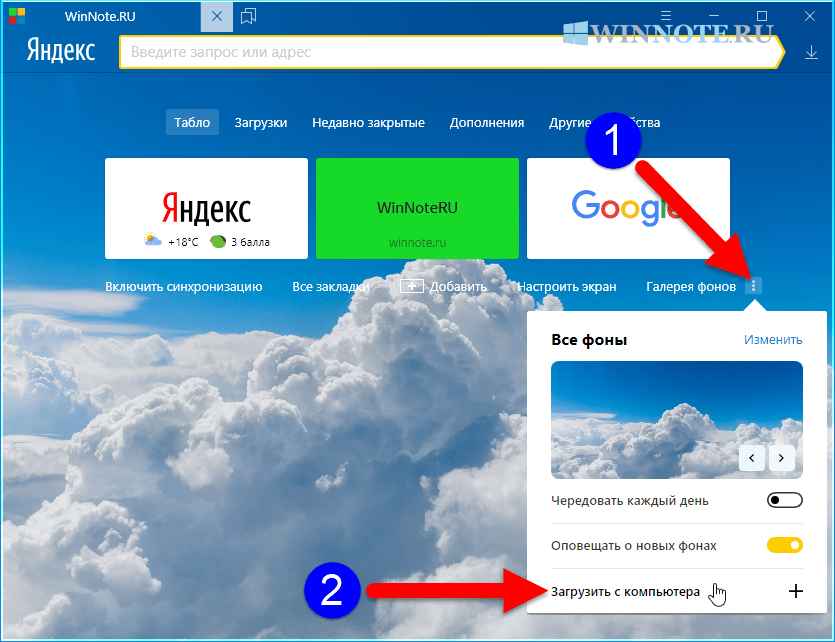
По состоянию на 2015 год мы хранили 3,37 триллиона строк в Metrage и использовали для этого 39 * 2 серверов. Потом мы отошли от хранения данных в Metrage и удалили большую часть таблиц. У системы есть свои недостатки; он действительно эффективно работает только с фиксированными отчетами. Metrage агрегирует данные и сохраняет агрегированные данные. Но для этого вы должны заранее перечислить все способы, которыми вы хотите агрегировать данные. То есть, если мы делаем это 40 разными способами, значит, Метрика будет содержать 40 типов отчетов и не более.
Чтобы смягчить это, нам пришлось какое-то время сохранять отдельное хранилище для мастера настраиваемых отчетов под названием OLAPServer. Это простая и очень ограниченная реализация столбцовой базы данных. Он поддерживает только один набор таблиц во время компиляции — таблицу сеансов. В отличие от Metrage, данные обновляются не в режиме реального времени, а несколько раз в день. Единственный поддерживаемый тип данных — это числа фиксированной длины от 1 до 8 байт, поэтому он не подходил для отчетов с другими видами данных, например URL-адресами.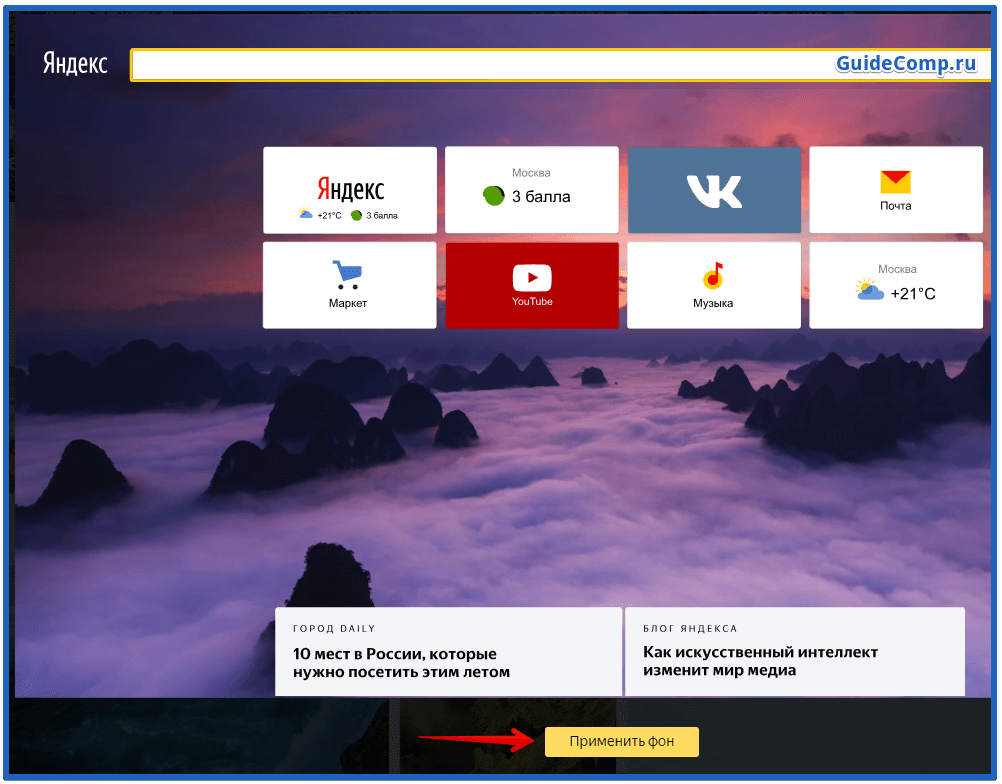
ClickHouse
С помощью OLAPServer мы поняли, насколько хорошо СУБД, ориентированные на столбцы, справляются с задачами специальной аналитики с неагрегированными данными. Если вы можете получить любой отчет из неагрегированных данных, то возникает вопрос, нужно ли данные вообще агрегировать заранее, как мы сделали с Metrage.
Изображение: обработка запросов в столбцовой базе данных
С одной стороны, предварительное агрегирование данных может уменьшить объем данных, которые используются в момент загрузки страницы отчета. С другой стороны, однако, агрегированные данные не решают всего. Вот почему:
- вам нужно заранее составить список отчетов, которые нужны вашим пользователям
- другими словами, пользователь не может составить пользовательский отчет
- при агрегации большого количества ключей объем данных не уменьшается и агрегация бесполезна
- при большом количестве отчетов слишком много вариантов агрегирования (комбинаторный взрыв)
- при агрегировании ключей высокой мощности (например, URL) количество данных уменьшается ненамного (менее чем вдвое)
- за счет этого объем данных может не уменьшаться, а фактически расти при агрегации
- пользователи не будут просматривать все отчеты, которые мы для них рассчитываем (другими словами, многие расчеты оказываются бесполезными)
- трудно поддерживать логическую согласованность при хранении большого количества различных агрегатов
Как видите, если ничего не агрегировать и работать с неагрегированными данными, то возможно объем вычислений даже сократится.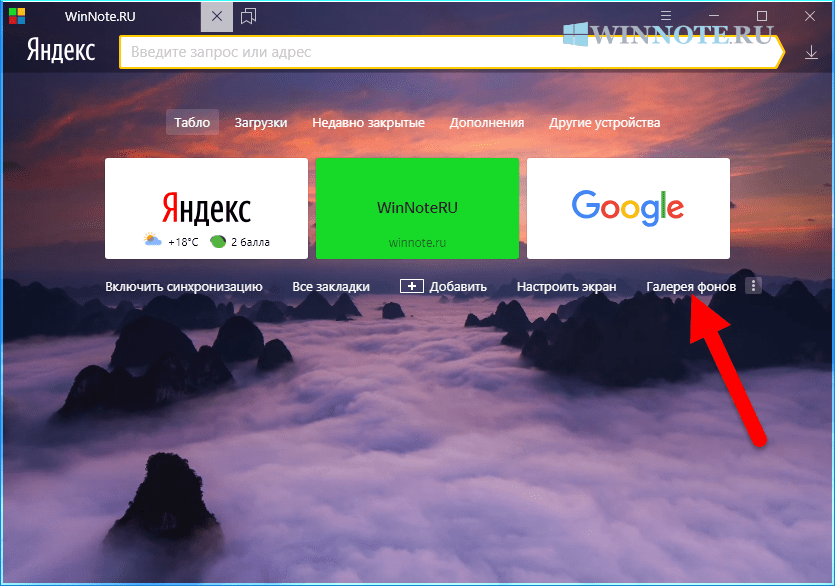 Но только работа с неагрегированными данными предъявляет очень высокие требования к эффективности системы, выполняющей запросы.
Но только работа с неагрегированными данными предъявляет очень высокие требования к эффективности системы, выполняющей запросы.
Значит, если мы агрегируем данные заранее, то делать это нужно постоянно (в реальном времени), но асинхронно по отношению к запросам пользователей. Мы действительно должны просто агрегировать данные в режиме реального времени; большая часть получаемого отчета должна состоять из подготовленных данных.
Если данные не агрегируются заранее, вся работа должна выполняться в момент запроса пользователем (т. е. в ожидании загрузки страницы отчета). Это означает, что в ответ на запрос пользователя необходимо обработать многие миллиарды строк; чем быстрее это можно сделать, тем лучше.
Для этого нужна хорошая столбцовая СУБД. На рынке не было колоночно-ориентированных СУБД, которые достаточно хорошо справлялись бы с задачами интернет-аналитики в масштабах Рунета (российского интернета) и не требовали бы запредельно дорогих лицензий.
В последнее время в качестве альтернативы коммерческим столбцовым СУБД стали появляться решения для эффективной оперативной аналитики данных в распределенных вычислительных системах: Cloudera Impala, Spark SQL, Presto и Apache Drill. Хотя такие системы могут эффективно работать с запросами для внутренних аналитических задач, их сложно представить в качестве бэкэнда для веб-интерфейса аналитической системы, доступного внешним пользователям.
Хотя такие системы могут эффективно работать с запросами для внутренних аналитических задач, их сложно представить в качестве бэкэнда для веб-интерфейса аналитической системы, доступного внешним пользователям.
В Яндексе мы разработали, а затем выложили в открытый доступ собственную колоночно-ориентированную СУБД — ClickHouse. Давайте рассмотрим основные требования, которые мы имели в виду, прежде чем приступить к разработке.
Возможность работы с большими наборами данных. В текущей Яндекс.Метрике для сайтов ClickHouse используется для хранения всех данных для отчетов. По состоянию на сентябрь 2017 года база данных состоит из 25,1 трлн строк. Он состоит из неагрегированных данных, которые используются для получения отчетов в режиме реального времени. Каждая строка в самой большой таблице содержит более 500 столбцов.
Система должна масштабироваться линейно. ClickHouse позволяет увеличивать размер кластера, добавляя новые серверы по мере необходимости. Например, основной кластер Яндекс. Метрики за три года увеличился с 60 до 426 серверов. В целях отказоустойчивости наши серверы разбросаны по разным дата-центрам. ClickHouse может использовать все аппаратные ресурсы для обработки одного запроса. Таким образом можно обрабатывать более 2 терабайт в секунду.
Метрики за три года увеличился с 60 до 426 серверов. В целях отказоустойчивости наши серверы разбросаны по разным дата-центрам. ClickHouse может использовать все аппаратные ресурсы для обработки одного запроса. Таким образом можно обрабатывать более 2 терабайт в секунду.
Высокая эффективность. Мы действительно фокусируемся на высокой производительности нашей базы данных. По результатам внутренних тестов ClickHouse обрабатывает запросы быстрее, чем любая другая система, которую мы могли бы приобрести. Например, ClickHouse работает в среднем в 2,8-3,4 раза быстрее на запросах веб-аналитики, чем одна из самых эффективных коммерческих столбцовых СУБД (назовем ее DBMS-V).
Функциональных возможностей должно быть достаточно для инструментов веб-аналитики. База данных поддерживает диалект языка SQL, подзапросы и соединения (локальные и распределенные). Существует множество расширений SQL: функции для веб-аналитики, массивы и вложенные структуры данных, функции высшего порядка, агрегатные функции для приближенных расчетов с помощью скетчинга и т.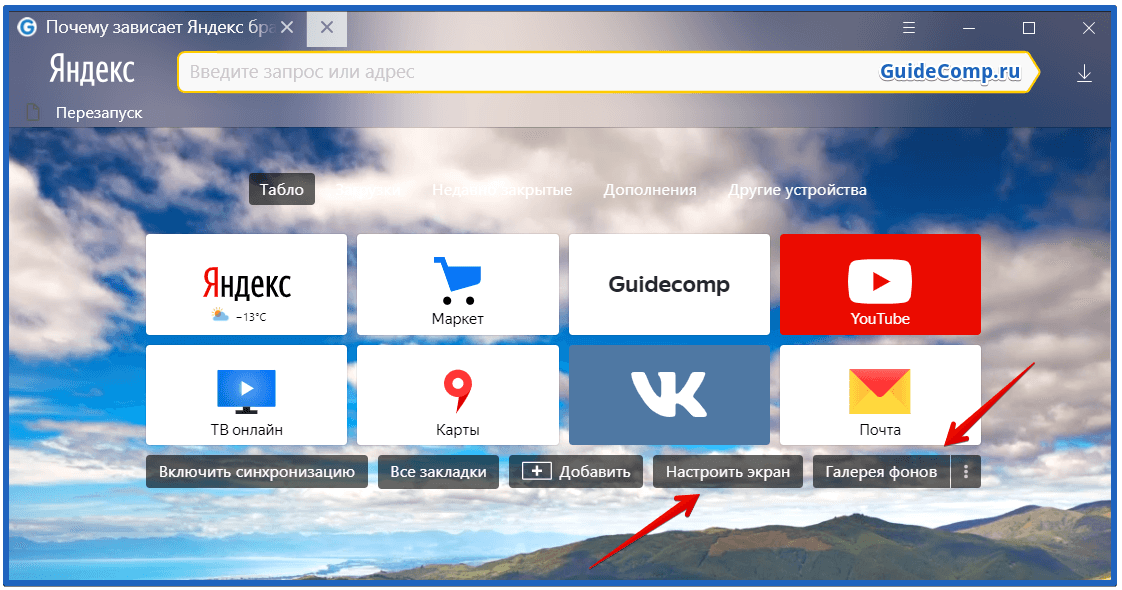 д.
д.
ClickHouse изначально разрабатывался командой Яндекс.Метрики. Кроме того, нам удалось сделать систему достаточно гибкой и расширяемой, чтобы ее можно было успешно использовать для решения различных задач. Хотя база данных может работать на больших кластерах, ее можно установить на один сервер или даже на виртуальную машину.
ClickHouse хорошо оснащен для создания всевозможных аналитических инструментов. Только подумайте: если система справится с задачами Яндекс.Метрики, можете быть уверены, что ClickHouse справится с остальными задачами с большим запасом производительности.
ClickHouse хорошо работает в качестве базы данных временных рядов; в Яндексе он обычно используется в качестве бэкенда для Graphite вместо Ceres/Whisper. Это позволяет нам работать с более чем триллионом показателей на одном сервере.
ClickHouse используется аналитикой для внутренних задач. Исходя из нашего опыта в Яндексе, ClickHouse работает примерно на три порядка выше, чем древние методы обработки данных (скрипты на MapReduce). Но это не просто количественная разница. В том-то и дело, что имея такую высокую скорость вычислений, можно позволить себе применять кардинально разные методы решения задач.
Но это не просто количественная разница. В том-то и дело, что имея такую высокую скорость вычислений, можно позволить себе применять кардинально разные методы решения задач.
Если аналитик должен составить отчет, и он компетентен в своей работе, он не будет просто строить один отчет. Скорее, они начнут с поиска десятков других отчетов, чтобы лучше понять природу данных и проверить различные гипотезы. Часто бывает полезно посмотреть на данные под разными углами, чтобы выдвинуть и проверить новые гипотезы, даже если у вас нет четкой цели.
Это возможно только в том случае, если скорость анализа данных позволяет проводить мгновенные исследования. Чем быстрее выполняются запросы, тем больше гипотез можно проверить. Работая с ClickHouse, даже возникает ощущение, что они способны думать быстрее.
Образно говоря, в традиционных системах данные подобны мертвому грузу. Манипулировать им можно, но это занимает много времени и неудобно. Однако если ваши данные находятся в ClickHouse, они гораздо более податливы: вы можете изучать их в разных срезах и детализировать до отдельных строк данных.
Спустя год с открытым исходным кодом ClickHouse теперь используется сотнями компаний по всему миру. Например, CloudFlare использует ClickHouse для аналитики DNS-трафика, ежедневно получая около 75 миллиардов событий. Другой пример — Vertamedia (платформа SSP для видео), которая ежедневно обрабатывает 200 миллиардов событий в ClickHouse со скоростью обработки около 3 миллионов строк в секунду.
Выводы
Яндекс.Метрика стала второй по величине системой веб-аналитики в мире. Объем данных, которые принимает Метрика, вырос с 200 миллионов событий в день в 2009 году до более чем 25 миллиардов в 2017 году. постоянно модифицировать наш подход к хранению данных.
Эффективное использование оборудования очень важно для нас. По нашему опыту, когда у вас есть большой объем данных, лучше не беспокоиться о том, насколько хорошо масштабируется система, а вместо этого сосредоточиться на том, насколько эффективно используется каждая аппаратная единица: каждое ядро процессора, диск и твердотельный накопитель, ОЗУ и сеть. В конце концов, если в вашей системе уже используются сотни серверов, и вам нужно работать в десять раз эффективнее, маловероятно, что вы сможете просто установить тысячи серверов, какой бы масштабируемой ни была ваша система.
В конце концов, если в вашей системе уже используются сотни серверов, и вам нужно работать в десять раз эффективнее, маловероятно, что вы сможете просто установить тысячи серверов, какой бы масштабируемой ни была ваша система.
Для достижения максимальной эффективности важно настроить решение в соответствии с потребностями конкретного типа рабочей нагрузки. Нет такой структуры данных, которая бы хорошо справлялась с совершенно разными сценариями. Например, очевидно, что базы данных типа «ключ-значение» не подходят для аналитических запросов. Чем больше нагрузка на систему, тем уже требуется специализация. Не нужно бояться использовать совершенно разные структуры данных для разных задач.
Нам удалось настроить так, чтобы оборудование Яндекс.Метрики было относительно недорогим. Это позволило нам предлагать услугу бесплатно даже очень крупным сайтам и мобильным приложениям, даже больше, чем у Яндекса, в то время как конкуренты обычно начинают просить платную подписку.
Кто-нибудь здесь использует joplin с yandex webdav или любой другой webdav на android? — Поддержка
1234 1
Привет, я пытаюсь синхронизировать заметки Джоплина с yandex webdav. Я получаю эту ошибку:
Я получаю эту ошибку:
https://ibb. co/4WKq8ZB
Нет проблем, когда я применяю те же настройки в Windows.
Возможно, я сделал некоторые настройки неправильно. Если здесь есть другие пользователи яндекса, можно сказать, как они настраивают параметры синхронизации? Я пытаюсь использовать это: ht tps://w ebdav. яндекс. ru/джоплин
Я разместил эту проблему на github. но, может быть, это не проблема, и это вызвано мной. Поэтому я публикую этот пост, чтобы узнать о конфигурациях пользователей webdav здесь и попробовать это самому.
Я использую телефон Samsung Android 8 без рута. Скачал последнюю версию с гугл плей.
Спасибо,
roman_r_m 2
Я думал, что он официально не поддерживает WebDAV. Хотя могу ошибаться
графит0 3
Как настроить Yandex WebDAV
- Зайти в свой профиль в yandex
- Перейдите в раздел Пароли и авторизация > Включить пароли приложений
- Создайте новый пароль > Файлы > Введите «Джоплин» (может быть любое имя)
- Скопируйте пароль и введите этот пароль в настройках синхронизации Joplin как
Пароль WebDAV -
URL-адрес WebDAVдолжен бытьhttps://webdav. yandex.com/ (необязательная папка joplin, в которой вы хотите хранить файлы синхронизации)/
yandex.com/ (необязательная папка joplin, в которой вы хотите хранить файлы синхронизации)/ -
Имя пользователя WebDAV: ваше имя пользователя Яндекса - «Проверить конфигурацию синхронизации», если все в порядке, перейти к синхронизации
1234 4
Яндекс и joplin официально поддерживают webdav. Я использую его на окнах без каких-либо проблем.
1234 5
Я сделал то же самое, прежде чем опубликовать это. Даже имя папки такое же. Когда я нажимаю «Проверить конфигурацию синхронизации», он говорит «ОК». Но когда я нажимаю кнопку синхронизации, я получаю сообщение об ошибке, которое я указал в сообщении.
Нет проблем в Windows 10.
graphit0 6
Если проблема связана только с мобильным устройством, убедитесь, что во время начальной синхронизации экран остается включенным, а приложение находится на переднем плане. У Джоплина нет фоновой синхронизации на мобильных устройствах.
Кроме того, это похоже на другую тему поддержки
Привет, Я использую Joplin Mobile на Android версии 2.6.8. Я синхронизирую с самостоятельным сервером Nextcloud-Server У меня довольно много заметок (около 3500), и у меня была проблема с регулярным сбоем приложения. Я (может быть, слишком поздно) потом проверил протокол и нашел там ошибки с RevisionService. Ошибки всегда были такими: «SyntaxError: Не удалось создать ревизию для примечания: … Ошибка синтаксического анализа JSON: незавершенная строка ...». В терминале я идентифицировал файл по id и узнал о продолжении…
Возможно, в заметке, на которую ссылается ошибка, есть какой-то недопустимый символ?
1234 7
графит0:
Если проблема связана только с мобильным устройством, убедитесь, что во время начальной синхронизации экран остается включенным, а приложение находится на переднем плане. У Джоплина нет фоновой синхронизации на мобильных устройствах.
Нет, проблема была не в вебдаве или заметках. Это даже не имеет прямого отношения к Джоплину.
К счастью, я нашел решение.
Я ищу ошибку в Google как «неожиданный символ 0x131 в 0 дюймах».
Я видел ссылку на github в Google. Щелкнул. Было обсуждение, в котором говорилось, что функция загрузки приложения под названием Rocket chat не работает на турецком языке.