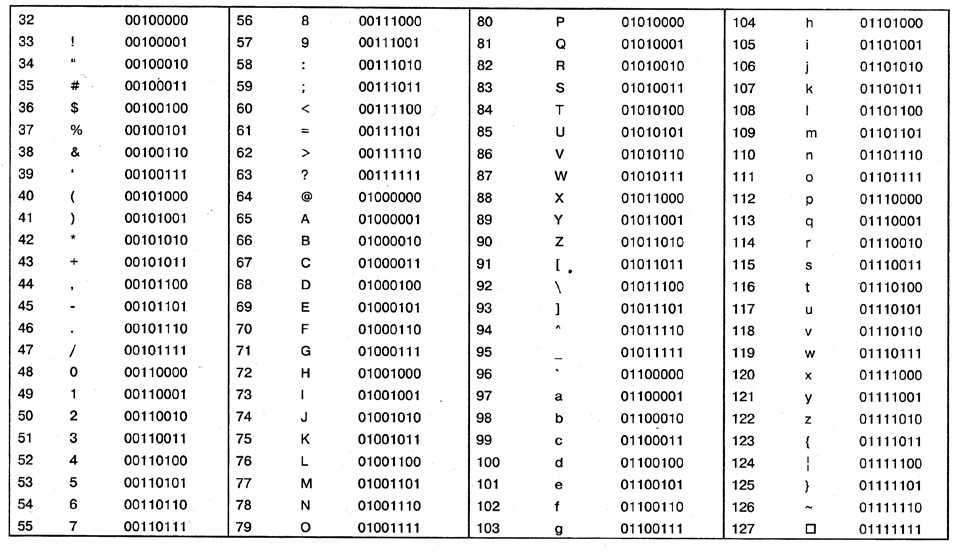
Автоопределение кодировки текста / Хабр
Введение
Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождения, название исследований, записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того, что в одном файле часть в кодировке CP1251, а часть в CP866.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять, что такое “кракозябры” или “кости”, то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Сравнение найденных решений на автоопределение кодировки
Подготовил каталог softlandia\cpd тестовые данные с файлами в разных кодировках. Содержимое файлов очень короткое и одинаковое. Одна строка “Русский в кодировке CodePageName”. Дополнил файлами со смешением кодировок и некоторыми сложными случаями и попробовал определить.
Мне кажется, получилось забавно.
| # | Кодировка | html/charset | saintfish/chardet | softlandia/cpd | enca |
|---|---|---|---|---|---|
| 1 | CP1251 | windows-1252 | CP1251 | CP1251 | CP1251 |
| 2 | CP866 | windows-1252 | windows-1252 | CP866 | CP866 |
| 3 | KOI8-R | windows-1252 | KOI8-R | KOI8-R | KOI8-R |
| 4 | ISO-8859-5 | windows-1252 | ISO-8859-5 | ISO-8859-5 | ISO-8859-5 |
| 5 | UTF-8 with BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 6 | UTF-8 without BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 7 | UTF-16LE with BOM | utf-16le | utf-16le | utf-16le | ISO-10646-UCS-2 |
| 8 | UTF-16LE without BOM | windows-1252 | ISO-8859-1 | utf-16le | unknown |
| 9 | UTF-16BE with BOM | utf-16le | utf-16be | utf-16be | ISO-10646-UCS-2 |
| 10 | UTF-16BE without BOM | windows-1252 | ISO-8859-1 | utf-16be | ISO-10646-UCS-2 |
| 11 | UTF-32LE with BOM | utf-16le | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 12 | UTF-32LE without BOM | windows-1252 | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 13 | UTF-32BE with BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 14 | UTF-32BE without BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 15 | KOI8-R (UPPER) | windows-1252 | KOI8-R | KOI8-R | CP1251 |
| 16 | CP1251 (UPPER) | windows-1252 | CP1251 | CP1251 | KOI8-R |
| 17 | CP866 & CP1251 | windows-1252 | CP1251 | CP1251 | unknown |
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно.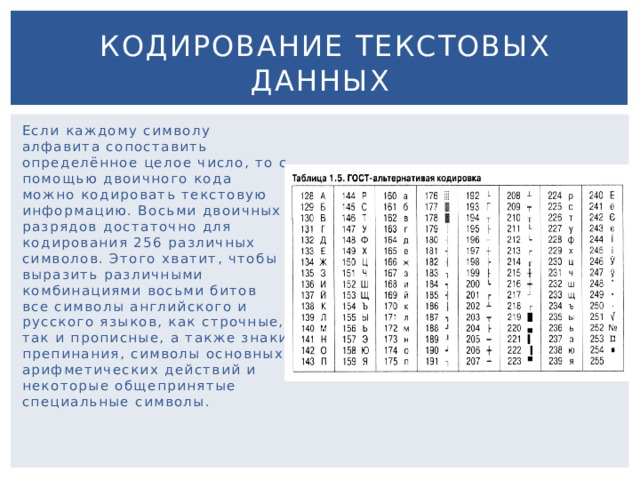 Я попробовал добавить больше текста, но результата не получил.
Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица CP 1251
Таблица KOI8-r
В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там, где у одной кодировки заглавные буквы, у другой строчные. Судя по всему enca, работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Наблюдение 3
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset. DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true.
DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true.
Собственный велосипед
Автоопределение кодировки возможно только эвристическими методами, неточно. Если мы не знаем, на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении, что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
Основные решения:
- Работу будем вести со слайсом байтов, для совместимости с charset.
 DetermineEncoding()
DetermineEncoding() - Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Критерии соответствия
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы. Для CP1251 использовал а, и, н, с, р, в, л, к, я. Для KOI8-r — о, а, и, т, с, в, л, к, м.
Для KOI8-r — о, а, и, т, с, в, л, к, м.
Второй критерий
К сожалению, для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Особенности, с которыми я столкнулся
Чуть коснусь прелестей и проблем, связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Излишне переживая и пытаясь дуть на воду, прослышав от других о страшных ожогах от молока, переборщил с проверкой входного параметра типа io. Reader. Я проверял переменную типа io.Reader с помощью рефлексии.
Reader. Я проверял переменную типа io.Reader с помощью рефлексии.
//CodePageDetect - detect code page of ascii data from reader 'r'
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
if !reflect.ValueOf(r).IsValid() {
return ASCII, fmt.Errorf("input reader is nil")
}
...Но как оказалось в моём случае достаточно проверить на nil. Теперь всё стало проще
func CodePageDetect(r io.Reader, stopStr ...string) (IDCodePage, error) {
//test input interfase
if r == nil {
return ASCII, nil
}
//make slice of byte from input reader
buf, err := bufio.NewReader(r).Peek(ReadBufSize)
if (err != nil) && (err != io.EOF) {
return ASCII, err
}
...вызов bufio.NewReader( r ).Peek(ReadBufSize) спокойно проходит следующий тест:
var data *os.File
res, err := CodePageDetect(data)В этом случае Peek() возвращает ошибку.
Разок наступил на грабли с передачей массивов по значению.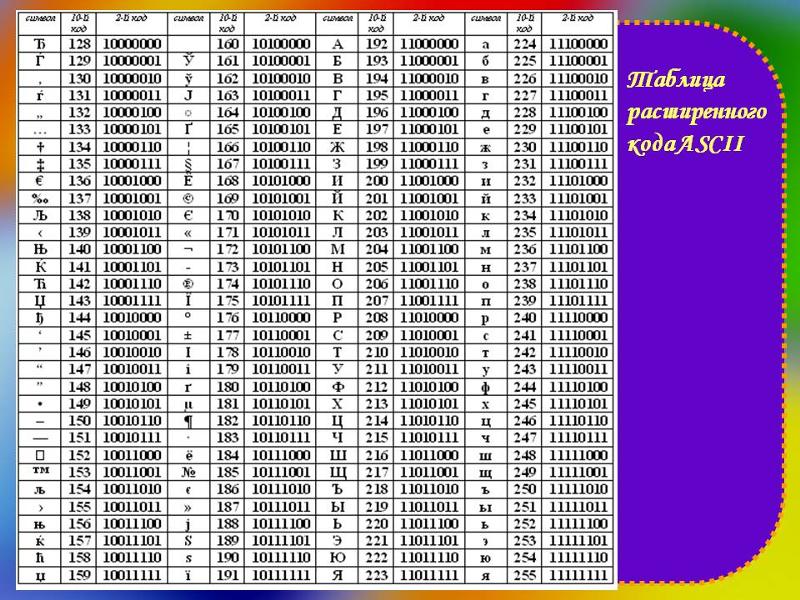 Немного тупанул на попытке изменять элементы, хранящиеся в map, пробегая по ним в range…
Немного тупанул на попытке изменять элементы, хранящиеся в map, пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно, очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные, имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно даёт результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение, когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Спасибо falconandy за конструктивные и полезные советы
Благодаря ему
- перевёл тесты на testify и они действительно стали более читабельны
- исправил в тестах пути к файлам данных для совместимости с Linux
- прошёлся линтером — таки он нашёл одну реальную ошибку (проклятущий copy/past)
Продолжаю добавлять тесты, выявился случай не определения UTF16. Обновил. Теперь UTF16 и LE и BE определяются даже в случае отсутствия русских букв
Обновил. Теперь UTF16 и LE и BE определяются даже в случае отсутствия русских букв
Декодер Лебедева, Tcode и другие онлайн дешифраторы и программы, как раскодировать, расшифровать или определить кодировку текста
Интернет Прикладное ПО Советы и рекомендации КомментироватьЗадать вопросНаписать пост
Текстовые данные, с которыми пользователь работает находясь за монитором, изначально хранятся в числовом виде. Для их преобразования применяется кодирование. В разных системах нумерации одним и тем же числовым значениям соответствуют разные последовательности букв, цифр и иных символов.
Иногда пользователь, скачавший документ или открывший веб-страницу обнаруживает, что вместо привычного текста документ заполнен непонятными символами и «кракозябрами». Это означает, что документ сохранен его автором в нерелевантной настройкам текущего пользователя кодировке.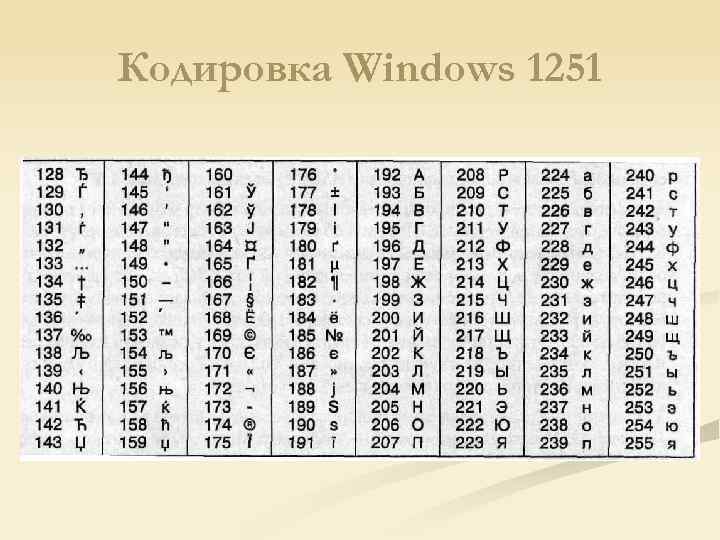 Чтобы корректно прочитать документ, потребуется декодировать его одним из методов – использовав онлайн-сервис, специальное приложение или поменяв настройки в Word.
Чтобы корректно прочитать документ, потребуется декодировать его одним из методов – использовав онлайн-сервис, специальное приложение или поменяв настройки в Word.
Стоит отметить, что стандарты в разных странах не всегда идентичны, и если российский пользователь, применяющий в Word обычную кириллическую кодировку, пытается открыть документ созданный, например, жителем Южной Америки (и сохраненный в стандартном для его страны формате), он не получит нужного отображения содержимого документа. Ряд кодировок подходит только для отображения символов определенного языка.
Лучшие сайты
Рассмотрим наиболее эффективные конвертеры символов, работающие с привычной кириллицей. Большинство из них можно использовать в режиме «по умолчанию» благодаря встроенному алгоритму расшифровки, но при надобности можно применять ручные настройки.
Универсальный декодер — конвертер кириллицы
Этот сервис наиболее популярен среди пользователей рунета. Найти можно по адресу 2cyr.com. Для работы с ним нужно скопировать подлежащий декодированию текст и вставить в предназначенное для этого поле. Нужно разместить копируемый отрывок так, чтобы уже на его первой строке встречались «кракозябры». Если пользователь хочет, чтобы сервис распознал кодировку автоматически, нужно указать это в выпадающем списке выбора. Но возможна и ручная настройка с указанием нужного типа. Закодированный фрагмент будет доступен в блоке «Результат».
Для работы с ним нужно скопировать подлежащий декодированию текст и вставить в предназначенное для этого поле. Нужно разместить копируемый отрывок так, чтобы уже на его первой строке встречались «кракозябры». Если пользователь хочет, чтобы сервис распознал кодировку автоматически, нужно указать это в выпадающем списке выбора. Но возможна и ручная настройка с указанием нужного типа. Закодированный фрагмент будет доступен в блоке «Результат».
Однако сервис, при всей своей простоте и возможности выбора, имеет и ограничения. Если поместить в поле текст объемом более 100 Кб сервис не сможет обработать его, так что длинные фрагменты придется декодировать по кусочкам.
Декодер Артемия Лебедева
Этот дешифратор работает со всеми кодировками с которыми может столкнуться пользователь, работающий с кириллицей.
Декодер Лебедева включает в себя простой и сложный (с дополнительными настройками) режимы работы. В режиме «Сложно» отображается не только исходный текст, но и преобразованный. Также можно выбрать кодировку, в которую требуется перевести текст, из выпадающего списка. Декодированный фрагмент доступен для прочтения и копирования в правом блоке.
В режиме «Сложно» отображается не только исходный текст, но и преобразованный. Также можно выбрать кодировку, в которую требуется перевести текст, из выпадающего списка. Декодированный фрагмент доступен для прочтения и копирования в правом блоке.
Fox Tools
Как и в случае с предыдущими, пользователю Fox Tools предоставляется возможность выбрать конечный результат. Сервис может работать и в режиме «по умолчанию», применяющемся в случае неизвестной желаемой кодировки, но тогда все равно придется выбирать вручную вариант результирующего текста, наиболее отвечающий его цели. Сервис имеет весьма простой и понятный дизайн интерфейса, что делает его подходящим для людей с низким уровнем компьютерной грамотности.
Translit.net
Сервис Translit, напротив, не отличается лаконичностью внешнего вида, но принцип работы с ним такой же, как и у других онлайн-декодеров. Нужно ввести текст и вручную установить желаемые настройки.
Программа Штирлиц
Это приложение предназначено для работы с русскоязычными кодировками. Текст в нее можно копировать как из буфера обмена, так и из содержимого текстового файла. Приложение реализует проверку разных схем перекодировки; если схема не обеспечивает корректного отображения всех русскоязычных слов, она отбрасывается и проверяется следующая. Также в программе Штирлиц можно создать авторскую кодовую схему и применять ее при работе с текстом, подвергшимся многократным перекодировкам.
Текст в нее можно копировать как из буфера обмена, так и из содержимого текстового файла. Приложение реализует проверку разных схем перекодировки; если схема не обеспечивает корректного отображения всех русскоязычных слов, она отбрасывается и проверяется следующая. Также в программе Штирлиц можно создать авторскую кодовую схему и применять ее при работе с текстом, подвергшимся многократным перекодировкам.
Чтобы обрабатывать сразу несколько файлов параллельно, необходимо открывать каждый из них в индивидуальном окне программы.
Декодер русских текстов TCODE
Этот программный продукт используется для восстановления русскоязычного текста, подвергшегося некоторым модификациям при передаче файла. Сюда относится и неподходящая кодировка. Решающее значение имеют первые 25 слов – они должны состоять из символов первой части ASCII. Скачать декодер можно на официальном сайте.
Как раскодировать текст в word
Поскольку этот редактор имеет огромную популярность и в нем создается большое число текстовых файлов, пользователи часто сталкиваются с некорректным отображением символов или невозможностью открыть фрагмент с неподходящей кодировкой.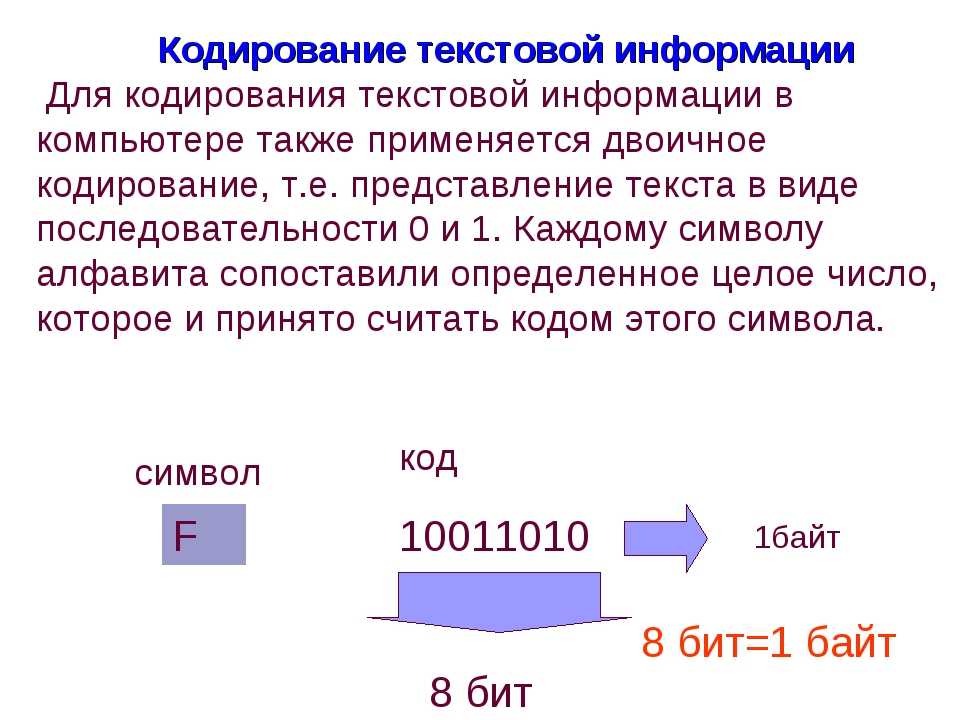
Если документ Word открылся в режиме ограниченной функциональности, нужно убрать ее. Если вместо кириллицы или латиницы по-прежнему отображаются непонятные знаки, нужно указать правильную кодировку в настройках программы. Для этого жмем кнопку «Файл» (или “Office”, в ранней версии), затем кнопку «Параметры» и выбираем «Дополнительно». Во вкладке «Общие» ставим флажок в настройке «Подтверждать преобразование формата». Подтверждаем изменения, закрываем программу, а затем опять открываем файл в ней. В окне «Преобразование» выбираем «Кодированный текст». Выбираем нужный вариант, ориентируясь на пример отображаемого теста в превью.
Как определить кодировку
Существует несколько способов определения:
- В MS Word при открытии файла: если набор отличается от СР1251, программа предложит выбрать одну из подходящих с наибольшей вероятностью кодировок. Оценить, насколько они подходят, можно по превью образца текста;
- В программе KWrite.
 В нее надо загрузить документ с расширением .txt и воспользоваться настройками в меню «Кодирование»;
В нее надо загрузить документ с расширением .txt и воспользоваться настройками в меню «Кодирование»; - Открыть файл в браузере Mozilla Firefox. При корректном отображении в меню «Вид» ищем кодировку. Искомый вариант – тот, напротив которого стоит флажок. Если содержимое отобразилось с искажениями, проверяем разные варианты в меню «Дополнительно»;
- Для работающих с Unix подойдет программа Enca.
.net — определить кодировку текстового файла?
Первый шаг — загрузить файл как массив байтов, а не как строку. Строки всегда хранятся в памяти в кодировке UTF-16, поэтому после загрузки в строку исходная кодировка теряется. Вот простой пример одного из способов загрузки файла в массив байтов:
Dim data() As Byte = File.ReadAllBytes("test.txt")
Автоматическое определение правильной кодировки для заданного массива байтов, как известно, затруднено. Иногда, чтобы быть полезным, автор данных вставляет что-то, называемое BOM (метка порядка байтов), в начало данных. Если присутствует спецификация, это делает обнаружение кодировки безболезненным, поскольку каждая кодировка использует другую спецификацию.
Если присутствует спецификация, это делает обнаружение кодировки безболезненным, поскольку каждая кодировка использует другую спецификацию.
Самый простой способ автоматически определить кодировку из спецификации — позволить StreamReader сделать это за вас. В конструкторе StreamReader вы можете передать True для аргумента detectEncodingFromByteOrderMarks . Затем вы можете получить кодировку потока, обратившись к его свойству CurrentEncoding . Однако свойство CurrentEncoding не будет работать до тех пор, пока StreamReader не прочитает спецификацию. Итак, вам сначала нужно прочитать спецификацию, прежде чем вы сможете получить кодировку, например:
Публичная функция GetFileEncoding(filePath As String) As Encoding
Использование sr в качестве нового StreamReader (filePath, True)
ср.Читать()
Вернуть sr.CurrentEncoding
Завершить использование
Конечная функция
Однако проблема с этим подходом заключается в том, что MSDN, кажется, подразумевает, что StreamReader может обнаруживать только определенные типы кодировок:
Параметр detectEncodingFromByteOrderMarks определяет кодировку, просматривая первые три байта потока.
Он автоматически распознает текст UTF-8, Unicode с прямым порядком байтов и Unicode с прямым порядком байтов, если файл начинается с соответствующих меток порядка следования байтов. Дополнительные сведения см. в методе Encoding.GetPreamble.
Кроме того, если StreamReader не может определить кодировку из спецификации или если спецификация отсутствует, по умолчанию будет использоваться кодировка UTF-8 без каких-либо указаний на сбой. Если вам нужен более детальный контроль, вы можете довольно легко прочитать спецификацию и интерпретировать ее самостоятельно. Все, что вам нужно сделать, это сравнить первые несколько байтов в массиве байтов с некоторыми известными ожидаемыми спецификациями, чтобы увидеть, совпадают ли они. Вот список некоторых общих спецификаций:
- UTF-8:
EF BB BF - Порядок байтов UTF-16 с прямым порядком байтов:
FE FF - Порядок байтов UTF-16 с прямым порядком байтов:
FF FE - Порядок байтов UTF-32 с прямым порядком байтов:
00 00 FE FF - UTF-32 порядок байтов с прямым порядком байтов:
FF FE 00 00
Итак, например, чтобы увидеть, существует ли спецификация UTF-16 (с прямым порядком байтов) в начале массива байтов, вы можете просто сделать что-то вроде этого:
Если (данные (0) = &HFF) И (данные (1) = &HFE) Тогда
' Данные начинаются с спецификации UTF-16 (с прямым порядком байтов)
Конец, если
Для удобства класс Encoding в . NET содержит метод с именем
NET содержит метод с именем GetPreamble , который возвращает спецификацию, используемую кодировкой, так что вам даже не нужно помнить, что они все собой представляют. Итак, чтобы проверить, начинается ли массив байтов со спецификацией для Unicode (UTF-16, прямой порядок следования байтов), вы можете просто сделать это:
Функция IsUtf16LittleEndian(data() as Byte) As Boolean
Dim bom() As Byte = Encoding.Unicode.GetPreamble()
Если (данные(0) = род(0)) И (данные(1) = род(1) Тогда
Вернуть истину
Еще
Вернуть ложь
Конец, если
Конечная функция
Конечно, вышеприведенная функция предполагает, что данные имеют длину не менее двух байтов, а спецификация — ровно два байта. Таким образом, хотя он и иллюстрирует, как это сделать, насколько это возможно, это не самый безопасный способ. Чтобы сделать его терпимым к разным длинам массивов, тем более что сами длины спецификаций могут варьироваться от одной кодировки к другой, было бы безопаснее сделать что-то вроде этого:
Функция IsUtf16LittleEndian(data() as Byte) As Boolean
Dim bom() As Byte = Encoding. Unicode.GetPreamble()
Возвращает data.Zip(bom, Function(x, y) x = y).All(Function(x) x)
Конечная функция
Unicode.GetPreamble()
Возвращает data.Zip(bom, Function(x, y) x = y).All(Function(x) x)
Конечная функция
Итак, возникает проблема: как получить список всех кодировок? Так уж получилось, что класс .NET Encoding также предоставляет общий (статический) метод с именем GetEncodings , который возвращает список всех поддерживаемых объектов кодирования. Следовательно, вы можете создать метод, который перебирает все объекты кодирования, получает спецификацию каждого из них и сравнивает ее с массивом байтов, пока не найдете подходящий. Например:
Открытая функция DetectEncodingFromBom(data() As Byte) As Encoding
Вернуть кодировку.GetEncodings().
Выберите (Функция (информация) info.GetEncoding()).
FirstOrDefault (Функция (enc) DataStartsWithBom (данные, enc))
Конечная функция
Частная функция DataStartsWithBom(data() As Byte, enc As Encoding) As Boolean
Dim bom() As Byte = enc.GetPreamble()
Если бом.Длина <> 0 Тогда
Возврат данных.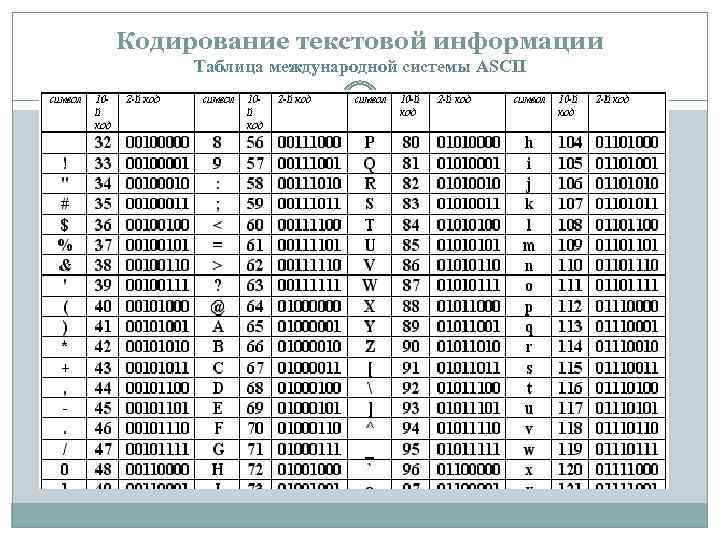 Zip(bom, Function(x, y) x = y).
Все (Функция (х) х)
Еще
Вернуть ложь
Конец, если
Конечная функция
Zip(bom, Function(x, y) x = y).
Все (Функция (х) х)
Еще
Вернуть ложь
Конец, если
Конечная функция
Как только вы сделаете такую функцию, вы сможете определить кодировку файла следующим образом:
Dim data() As Byte = File.ReadAllBytes("test.txt")
Затемнить обнаруженное кодирование как кодирование = DetectEncodingFromBom (данные)
Если обнаруженное кодирование ничего не значит, тогда
Console.WriteLine("Невозможно определить кодировку")
Еще
Console.WriteLine(detectedEncoding.EncodingName)
Конец, если
Однако остается проблема: как автоматически определить правильную кодировку при отсутствии спецификации? Технически рекомендуется не размещать спецификацию в начале ваших данных при использовании UTF-8, и ни для одной из кодовых страниц ANSI не определена спецификация. Так что вполне возможно, что текстовый файл может не иметь спецификации. Если все файлы, с которыми вы имеете дело, написаны на английском языке, вероятно, можно с уверенностью предположить, что при отсутствии спецификации будет достаточно UTF-8.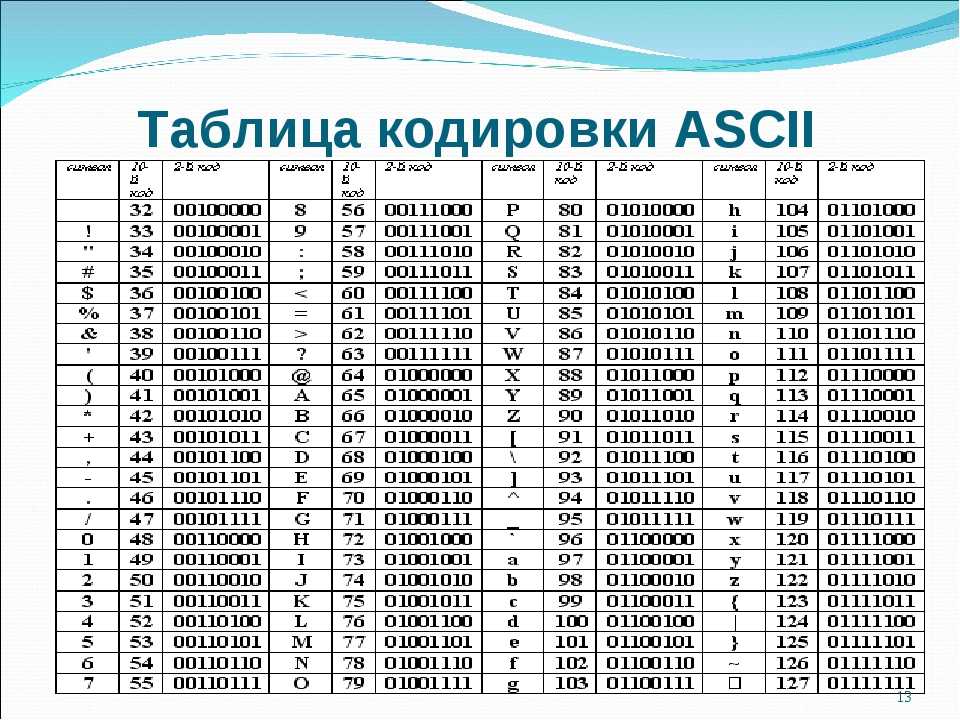 Однако, если какой-либо из файлов использует что-то другое, без спецификации, то это не сработает.
Однако, если какой-либо из файлов использует что-то другое, без спецификации, то это не сработает.
Как вы правильно заметили, есть приложения, которые автоматически определяют кодировку даже при отсутствии спецификации, но они делают это с помощью эвристики (т.е. обоснованного предположения), и иногда они не точны. В основном они загружают данные, используя каждую кодировку, а затем смотрят, «выглядят» ли данные понятными. Эта страница предлагает некоторые интересные сведения о проблемах внутри алгоритма автоматического обнаружения Блокнота. На этой странице показано, как вы можете подключиться к алгоритму автоматического обнаружения на основе COM, который использует Internet Explorer (на C#). Вот список некоторых библиотек C#, написанных людьми, которые пытаются автоматически определить кодировку массива байтов, которые могут оказаться полезными:
- TextFileEncodingDetector
- Utf8Checker
- GetTextEncoding
Несмотря на то, что этот вопрос был для C#, вы также можете найти ответы на него полезными.
Как определить кодировку символов текстового файла
· Кодирование Προγραμματισμός · кодирование κωδικοποίηση питон питон
Если вы когда-либо сталкивались с текстовым файлом с тарабарскими символами, то знаете, что во многих случаях довольно сложно определить его правильную кодировку символов.
Αν έχετε βρεθεί ποτέ αντιμέτωποι με ένα αρχείο κειμένου που περιέχει ακαταλαβίστικους χαρακτήρες, τότε γνωρίζετε ότι -πολλές φορές- είναι αρκετά δύσκολο να αναγνωρίσετε ποια είναι η σωστή κωδικοποίηση των χαρακτήρων.
Здесь есть автоматический универсальный детектор кодировок для Python 2 и 3: https://pypi. python.org/pypi/chardet.
Детектор chardet поставляется со сценарием командной строки, который сообщает о кодировках одного или нескольких файлов:
python.org/pypi/chardet.
Детектор chardet поставляется со сценарием командной строки, который сообщает о кодировках одного или нескольких файлов:
Υπάρχει ένας εργαλείο ανίχνευσης της κωδικοποίησης για Python 2 και 3 εδώ: https://pypi.python.org/pypi/chardet.chardet. Ο ανιχνευτής Chardet Διαθέτει και ένα σενάριο για τη γραμή εργαλείριο για τη γραμή εργαλείων που αναφέρει τηννήαήεναισησησηфон εγιςγιςγιςγιοναισвь εναισησγέρει τηνήεήριдобренный εοναισγέρεмас
$ chardetect какой-то текстовый файл какой-то текстовый файл: windows-1252 с уверенностью 0,5
К сожалению, chardetect не всегда находит правильную кодировку. Например, у меня был текстовый файл с кодировкой cp737, но chardetect предсказал кодировку IBM866 для этого файла (с низкой достоверностью 0,26). Для этих сложных случаев я написал инструмент, который декодирует одну строку из текстового файла, используя каждую (?) возможную кодировку символов, и сохраняет результаты в новый текстовый файл utf-8 (то же имя файла + расширение «. encodings»). Теперь мы можем визуально изучить этот файл, чтобы узнать правильную кодировку.
encodings»). Теперь мы можем визуально изучить этот файл, чтобы узнать правильную кодировку.
Δυστυχώς, όμως, το chardetect δεν βρίσκει πάντα την σωστή κωδικοποίηση. Για παράδειγμα, είχα ένα αρχείο κειμένου με κωδικοποίηση cp737 αλλά το chardetect προέβλεψε μια κωδικοποίηση IBM866 για εκείνο. Για τέτοιες δύσκολες περιπτώσεις, έγραψα ένα εργαλείο το οποίο αποκωδικοποιεί μια γραμμή από ένα αρχείο κειμένου χρησιμοποιώντας όλες (;) τις δυνατές κωδικοποίησεις και αποθηκεύει τα αποτελέσματα σε ένα νέο utf-8 αρχείο κειμένου (ίδιο όνομα αρχείου + μια κατάληξη ‘.encodings’). Τώρα, μπορούμε να εξετάσουμε οπτικά αυτό το αρχειο και να ανακαλύψουμε τη σωστί κωδικηπο.
Использование : test_encodings.py имя файла [количество строк для проверки]
Χρήση : test_encodings.py όνομα_αρχείου [αριθμός γραμμής προς έλεγχο]
$ test_encodings3. Номер технологической линии: 3 Запись успешно протестированных кодировок в sometextfile.encodings Было написано 53 из 111 протестированных кодировок. $ cat какой-то текстовый файл.кодировки
Найдя правильную кодировку, мы можем преобразовать наш текстовый файл в другую кодировку с помощью редактора (например, geany) или инструмента командной строки (например, iconv):
Έχοντας βρει τη σωστή κωδικοποίηση, μπορούμε να μετατρέψουμε το αρχείο κειμένου μας σε μια διαφορετική κωδικοποίηση χρησιμοποιώντας έναν διορθώτη κειμένου (λ.χ. τον geany) ή κάποιο εργαλείο της γραμμής εντολών (λ.χ. το iconv):
$ iconv -f cp737 -t UTF-8 входящий.txt > исходящий.txt
Вот код. Он работает как под Python 2, так и под Python 3:
Ιδού ο κώδικας. Загрузить Python 2 Загрузить Python 3:
#!/usr/bin/env python
импорт io
импорт ОС
импорт системы
из encodings.aliases импортировать псевдонимы
код = {
"ascii", "big5", "big5hkscs",
"cp037", "cp424", "cp437", "cp500", "cp720", "cp737", "cp775",
"cp850", "cp852", "cp855", "cp856", "cp857", "cp858", "cp860",
"cp861", "cp862", "cp863", "cp864", "cp865", "cp866", "cp869"",
"cp874", "cp875", "cp932", "cp949", "cp950",
"cp1006", "cp1026", "cp1140", "cp1250", "cp1251", "cp1252",
"cp1253", "cp1254", "cp1255", "cp1256", "cp1257", "cp1258",
"euc_jp", "euc_jis_2004", "euc_jisx0213", "euc_kr",
"gb2312", "gbk", "gb18030", "hz",
"iso2022_jp", "iso2022_jp_1", "iso2022_jp_2", "iso2022_jp_2004",
"iso2022_jp_3", "iso2022_jp_ext", "iso2022_kr",
"latin_1", "iso8859_2", "iso8859_3", "iso8859_4", "iso8859_5",
"iso8859_6", "iso8859_7", "iso8859_8", "iso8859_9", "iso8859_10",
"iso8859_13", "iso8859_14", "iso8859_15", "iso8859_16",
"йохаб", "koi8_r", "koi8_u",
"mac_cyrillic", "mac_greek", "mac_iceland",
"mac_latin2", "mac_roman", "mac_turkish",
"ptcp154", "shift_jis", "shift_jis_2004", "shift_jisx0213",
"utf_32", "utf_32_be", "utf_32_le",
"utf_16", "utf_16_be", "utf_16_le",
"utf_7", "utf_8", "utf_8_sig",
"idna", "mbcs", "palmos", "punycode", "rot_13",
"raw_unicode_escape", "unicode_escape", "unicode_internal",
"base64_codec", "bz2_codec", "hex_codec", "uu_codec", "zlib_codec"
}
def write_encodings (имя файла, номер_строки, окончательная_кодировка):
# Чтобы гарантировать охват как можно большего количества кодировок,
# мы берем объединение между нашим предопределенным набором кодировок и
# набор значений из encodings. aliases.aliases.
кодировки = encs.union (набор (псевдонимы. значения ()))
данные = дикт()
# прочитать строку из файла
пытаться:
с io.open(имя файла, "rb") как f:
строки = f.readlines()
строка = строки[line_number-1]
print("\nНомер строки обработки: " + str(line_number))
если длина (строка) < 3:
print("!!!Внимание!!!: Возможна пустая строка.")
Распечатать("")
кроме исключения:
_, ошибка, _ = sys.exc_info()
print("Ошибка чтения " + имя файла)
печать (ошибка)
sys.exit(1)
# Декодировать его, используя все возможные кодировки
для enc в кодировках:
пытаться:
данные[enc] = строка.decode(enc)
кроме исключения:
_, ошибка, _ = sys.exc_info()
print("Невозможно декодировать с помощью " + enc)
# печать (ошибка)
# Записываем результаты в новый текстовый файл utf-8
# Мы используем одно и то же имя файла + расширение '.
aliases.aliases.
кодировки = encs.union (набор (псевдонимы. значения ()))
данные = дикт()
# прочитать строку из файла
пытаться:
с io.open(имя файла, "rb") как f:
строки = f.readlines()
строка = строки[line_number-1]
print("\nНомер строки обработки: " + str(line_number))
если длина (строка) < 3:
print("!!!Внимание!!!: Возможна пустая строка.")
Распечатать("")
кроме исключения:
_, ошибка, _ = sys.exc_info()
print("Ошибка чтения " + имя файла)
печать (ошибка)
sys.exit(1)
# Декодировать его, используя все возможные кодировки
для enc в кодировках:
пытаться:
данные[enc] = строка.decode(enc)
кроме исключения:
_, ошибка, _ = sys.exc_info()
print("Невозможно декодировать с помощью " + enc)
# печать (ошибка)
# Записываем результаты в новый текстовый файл utf-8
# Мы используем одно и то же имя файла + расширение '. encodings'
fpath = os.path.abspath(имя файла)
новое имя_файла = fpath + '.encodings'
print("\nЗапись успешно проверенных кодировок в " + newfilename)
с открытым (новое имя файла, 'w') как выход:
с = 0
для enc в отсортированном (data.keys()):
пытаться:
out.write("%-20s" % enc)
если (sys.version_info[0] < 3):
строка = данные[enc].encode(final_encoding)
еще:
строка = данные[enc]
out.write(строка)
out.write(os.linesep)
с += 1
кроме исключения:
_, ошибка, _ = sys.exc_info()
print("Невозможно закодировать " + enc + " в " + final_encoding)
# печать (ошибка)
print("\n" + str(c) + " out of " + str(len(encodings)) +
" были написаны протестированные кодировки.\n")
если __name__ == '__main__':
nargs = длина (sys.argv)-1
если nargs < 1 или nargs > 2:
exit("Использование: test_encodings.
encodings'
fpath = os.path.abspath(имя файла)
новое имя_файла = fpath + '.encodings'
print("\nЗапись успешно проверенных кодировок в " + newfilename)
с открытым (новое имя файла, 'w') как выход:
с = 0
для enc в отсортированном (data.keys()):
пытаться:
out.write("%-20s" % enc)
если (sys.version_info[0] < 3):
строка = данные[enc].encode(final_encoding)
еще:
строка = данные[enc]
out.write(строка)
out.write(os.linesep)
с += 1
кроме исключения:
_, ошибка, _ = sys.exc_info()
print("Невозможно закодировать " + enc + " в " + final_encoding)
# печать (ошибка)
print("\n" + str(c) + " out of " + str(len(encodings)) +
" были написаны протестированные кодировки.\n")
если __name__ == '__main__':
nargs = длина (sys.argv)-1
если nargs < 1 или nargs > 2:
exit("Использование: test_encodings.