Способ, как найти ключевые слова в тексте онлайн
Home » Текстовые биржи » Находим ключевые слова в тексте через онлайн-сервис
Для людей, не разбирающихся в SEO-оптимизации и интернет-продвижении, непонятно, что значит выражение “ключевые слова”. Многие их путают с заголовками и подзаголовками, что еще больше усложняет взаимопонимание при заказе услуг SEO-продвижения. Найти ключевые слова в тексте онлайн понадобится любому человеку, который решил поднять свои сайт в ТОП поисковой выдачи Яндекса, Гугла или другой поисковой системы.
Содержание
- 1 Зачем нужны ключевые слова?
- 2 Как найти ключевые слова в тексте?
- 3 Сервисы и биржи, через которые можно проверить вхождения ключевых слов
- 4 Инструкция, как проверить вхождение ключевых слов в тексте
- 5 Как определить нужные ключевики для повышения ранжирования?
- 6 Заключение
- 6.
 1 Автор публикации
1 Автор публикации - 6.2 MasterCode
- 6.
Зачем нужны ключевые слова?
Что же такое ключевые слова в тексте? Это наиболее часто употребляемые слова и словесные конструкции. Именно на них опираются поисковые машины при подборе сайтов по запросу пользователя. Чем больше в тексте встречается релевантных ключевых слов, тем выше будет ранжирование сайта. У ТОП-овых сайтов самый мощный поисковый трафик, ежедневно приносящий сотни и тысячи клиентов. Причем, в отличие от контекстной рекламы, трафик будет еще идти очень долго даже после того, как вы прекратите заниматься поисковой оптимизацией.
Для того чтобы понять, по каким запросам интернет-страница будет чаще всего выдаваться пользователю, необходимо определить основную словесную конструкцию.
Как найти ключевые слова в тексте?
Можно, конечно, найти все повторяющиеся конструкции самостоятельно, но этот вариант подходит только для проверки небольших отрывков.
Сервисы и биржи, через которые можно проверить вхождения ключевых слов
Лучшие бесплатные сервисы для проверки вхождения ключевых слов в текст находятся на сайтах бирж копирайтинга. SEO-копирайтинг является одним из самых востребованных направлений на таких биржах. Для работы по этому направлению и нужны качественные сервисы анализа “ключей”.
Три лучших сервиса:
- Advego.
- Miratext.
- Программа Antiplagiarism.Net.
Пользоваться ими можно бесплатно и без регистрации. Программу можно скачать с сайта биржи Etxt либо с официального сайта, адрес которого является названием утилиты. Любой из этих вариантов полностью решит вопрос с поиском ключей, просто выберите, какой интерфейс вам удобней.
В Миратекст можно загрузить для анализа не только текст, но и сразу страницу сайта, что сильно ускорит и упростит работу с многостраничными порталами.
Инструкция, как проверить вхождение ключевых слов в тексте
Давайте убедимся, что определить частоту употребления слов и словесных конструкций можно быстро и легко. Для этого перейдем на Advego.
- Выбираем серую вкладку “Seo-анализ текста” в верхней шапке сайта.
- В открывшийся редактор вставляем нужный нам отрывок для проверки и запускаем процесс.
- Через несколько секунд получаем обширный отчет о предоставленном тексте. Нас интересует таблица “Семантическое ядро”. Показатель “Частота” показывает объем, который занимает то или иное слово от всего текста.
Как видите, провести моментальный поиск ключей онлайн может совершенно неподготовленный человек. Все что необходимо знать – адрес сервиса.
Как определить нужные ключевики для повышения ранжирования?
Чтобы лучше понять, какие ключевые фразы использовать, проанализируйте сайты ваших успешных конкурентов. Сняв “слепок” семантического ядра топовых сайтов, вы сможете использовать его как базу для наполнения своего интернет-проекта.
Сняв “слепок” семантического ядра топовых сайтов, вы сможете использовать его как базу для наполнения своего интернет-проекта.
Альтернативным вариантом будет использование сервиса Yandex.WordStat, который предоставит информацию по поисковым запросам в любом регионе и за любой период. Также он подскажет аналогичные запросы, которые могут стать дополнительными ключевыми словами.
Заключение
Ключевые слова – базовый элемент для search engine optimisation. Определить их в статье на странице сайта по силу любому человеку, при помощи специальных сервисов и программ. Высокая частотность релевантных ключей повысит страницу в ранжировании, но важно не переборщить, иначе получится переспам, а заспамленные страницы быстро вылетают из Топа Yandex и Google.
Оцените текст:
Автор публикации
Как использовать ключевые слова в тексте
Формирование поисковой выдачи зависит от определенных факторов, которые также называются факторами ранжирования.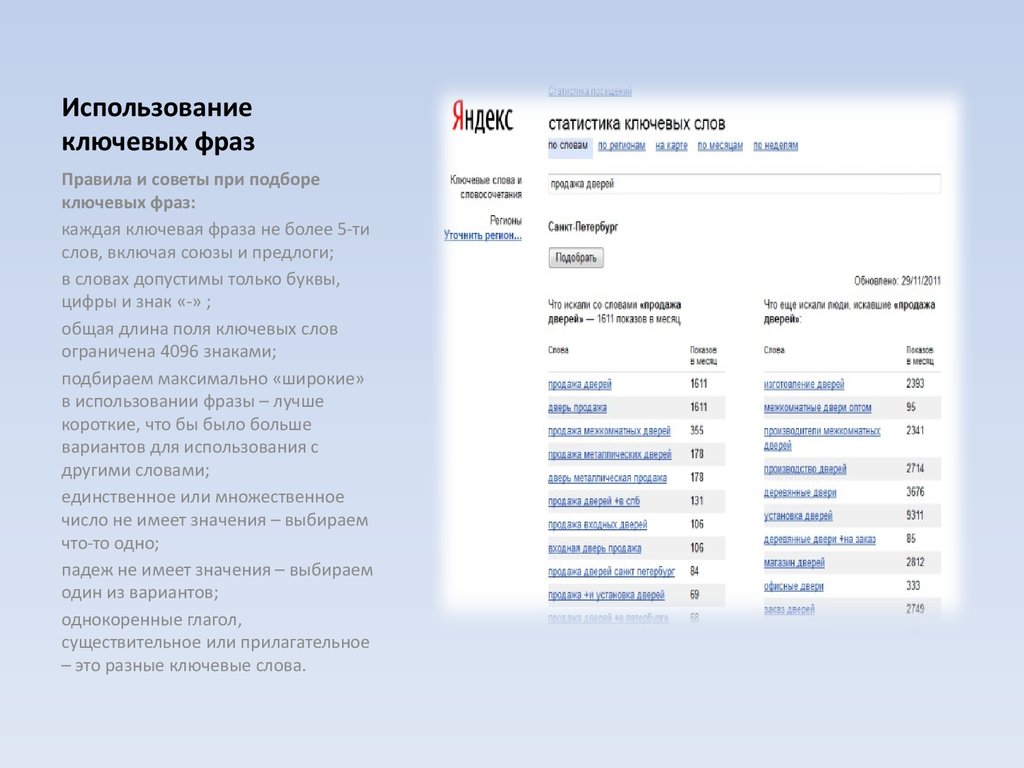 Если использовать все условия, заложенные алгоритмами поиска, то за несколько обновлений можно оказаться в топе выдачи. Одним из важнейших параметров, по которым происходит продвижение, являются специальные фразы, по ним алгоритм двигает сайты в топ. Чтобы занять лидирующие позиции, следует знать, какие ключевые слова в тексте использовать, как их подбирать, и, что самое важно, знать правильное расположение ключей.
Если использовать все условия, заложенные алгоритмами поиска, то за несколько обновлений можно оказаться в топе выдачи. Одним из важнейших параметров, по которым происходит продвижение, являются специальные фразы, по ним алгоритм двигает сайты в топ. Чтобы занять лидирующие позиции, следует знать, какие ключевые слова в тексте использовать, как их подбирать, и, что самое важно, знать правильное расположение ключей.
Что такое ключевые слова?
Ключевые слова в тексте – это фразы, которые пользователь прописывает в строку поиска для получения ответа на свой вопрос. Самые популярные поисковые системы (ПС) в РФ – Yandex и Google.
Как ключевые слова влияют на положение сайта в поисковой выдаче? Поисковики получают запрос и запускают алгоритм, который осуществляет поиск ключевых слов в тексте. Проверка происходит сразу по нескольким параметрам, слова ищутся в заголовке, в тексте, в подзаголовках и в атрибуте alt в картинках. Последнее важно, если ваши клиенты ищут по картинкам.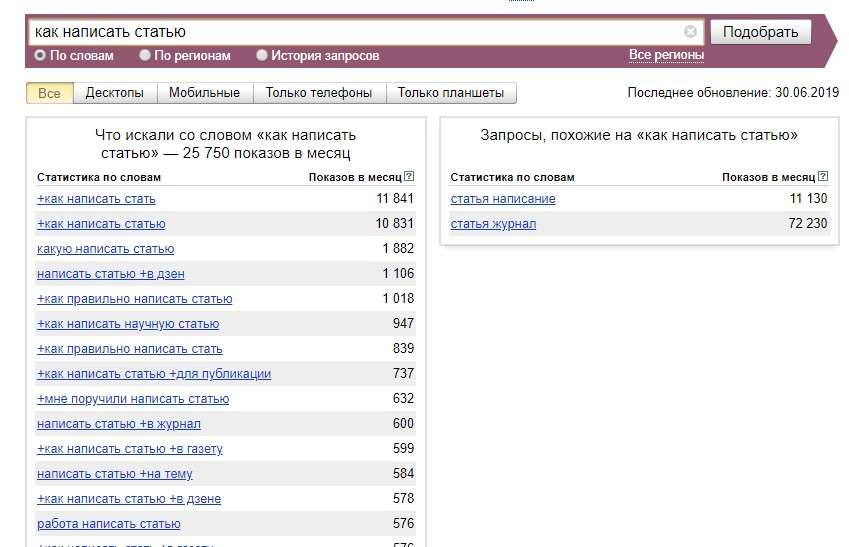
Количество слов зависит от объема текста, достаточно несколько ключевиков, чтобы страница стала продвигаться в поисковиках.
Некоторые авторы придерживаются правил и размещают один ключ на 1000 символов. Этот вариант считается оптимальным, главное не переусердствовать с размещением, иначе можно получить пессимизацию. Делайте на свое усмотрение: вы можете разместить несколько словосочетаний и попасть в топ или делать интервал в 1000 символов между ключами. При любом раскладе может произойти подъем в выдаче, так как это не единственный фактор, который следует соблюсти, чтобы оказаться на верхней позиции. Нужно еще поработать на внешнюю оптимизацию и привлекать целевую аудиторию через социальные сети.
При подборке ключей для своего сайта их следует разделить на несколько видов:
- Информационные. Обычно пользователи заходят в сеть, чтобы задать вопрос и получить на него ответ. Поэтому информационные запросы в основном содержат фразы, “как исправить”, ”что такое”, ”как сделать”, “что значит” и так далее.

- Навигационные. Клиент рассчитывает получить данные о конкретном объекте расположенном рядом или онлайн ресурсе. Например “магазин одежды в Москве”, “интернет-магазин техники”, “магазин Пятерочка”, т.е. клиент заранее настроен, на поиск бренда или сайта.
- Коммерческие. Здесь используются словосочетания, показывающие потребность в покупке или заказе товара с доставкой. Соответственно, основные ключи – это “купить”, “акция”, “распродажа”, “цена” и другие.
- Транзакционные. Они показывают, что заказчик готов совершить какое-то действие, например, “записаться в тренажерный зал”, “зарегистрироваться” и так далее. Нередко клиенты используют вопросы для получения конечного результата, например, “как проехать”, “как зарегистрироваться”, “как поступить”.
 Все они также являются транзакционными, хотя вначале используется вопрос.
Все они также являются транзакционными, хотя вначале используется вопрос.
Поисковые системы так устроены, что делают поиск ключевых слов в тексте и ищут информацию, расположенную рядом с человеком, особенно, если дело касается поиска товаров в конкретном магазине. Такой вид запроса называется “геозависимым”. Например, если прописать “магазин Пятерочка”, то появится несколько вариантов зданий, находящихся рядом, также будут указаны адреса и номера телефонов. Когда нужно проехать на определенную улицу, город в поисковой строке указывать необязательно, просто следует прописать “как проехать” и название улицы с домом, появится карта, которая автоматически построит маршрут. Это удобно, если создавать интернет-ресурс, связанный с коммерцией. В справочниках ПС можно указать адрес и номер телефона, таким образом можно помочь быстрее найти нужный объект.
Как найти ключевые слова для текста?
При индексации робот проверяет не только на наличие ключей, но правильность расположения их в тексте. Поисковые роботы давно научились обращать внимание на окончания слов, а также умеют оценивать смысловую нагрузку. Если text полностью посвящен обзору программ и вдруг в абзаце встречается купить автомобиль или квартиру, то такие статьи высокие позиции не займут.
Поисковые роботы давно научились обращать внимание на окончания слов, а также умеют оценивать смысловую нагрузку. Если text полностью посвящен обзору программ и вдруг в абзаце встречается купить автомобиль или квартиру, то такие статьи высокие позиции не займут.
Прежде чем составлять семантическое ядро, следуют сначала определиться с темой и выбрать популярную нишу, которую спрашивают больше всего. Если автор разбирается в определенной профессии и хочет про неё рассказать, но запросов мало, то в этом случае следует подыскать другую тему. Для быстрого поиска ключей нужно воспользоваться популярными сервисами “вордстат яндекс” и “планировщик гугл”. Помимо них существует еще “гугл трендс”, он способен искать запросы по регионам и странам.
Чтобы подбирать фразы для яндекса, нужно перейти на https://wordstat.yandex.ru/, задать параметры поиска и смотреть, сколько спрашивают по этому запросу. Допустим веб-сайт по компьютерам, где обучают новичков работать с программами и разбираться в железе.
В месяц спрашивают достаточно много, ниже под строкой поиска будет список, из него можно найти подходящие ключи, щелкаем мышкой, к примеру “+как сделать +на компьютере” (выше на скриншоте указано). При переходе будет новая статистика, где можно подобрать дополнительные слова. Это следует учитывать при формировании семантического ядра. Все ключи, которые удалось получить, следует сохранить в документ для этих целей подойдет excel.
Красными стрелками обозначено, что может подойти в качестве темы для новых статей.
Большинство пользователей, когда ищут информацию, то прописывают “как сделать”.
После составления списка seo можно проверить конкуренцию и произвести анализ этих сайтов. Делается это так, выбираем любое словосочетание и прописываем его в поисковике, и смотрим результат. Нередко бывает так, что первые строки позиции занимает видео с youtube, в этом случае можно попытаться продвинуться, записав видеоролик и выложив на видеохостинге.
Дополнительные темы для статей можно подобрать из списка, который появится во время поиска в разделе “люди ищут” внизу страницы поисковика. Пример на картинке.
Пример на картинке.
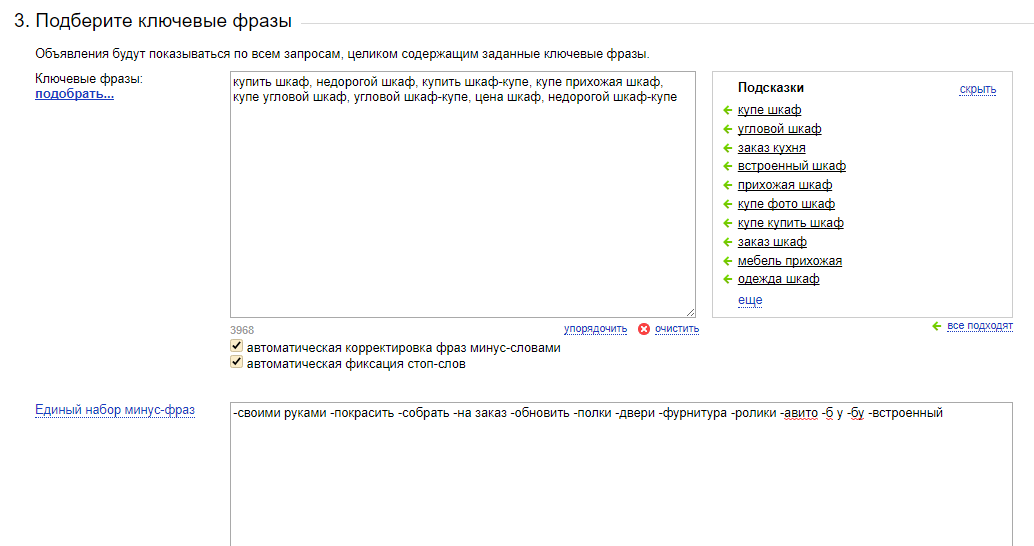
Проверяем ключевики в wordstat, те, которые пользуются популярностью, копируем и вставляем в excel документ. Таким образом, делаем подбор из десяти тем. Стоит так же проанализировать сайты конкурентов. Выполняется это с помощью специальных сервисов, которые делает парсер текстов по ключевым словам.
Бесплатным является https://www.cy-pr.com/. Здесь все просто, вводите название ресурса и нажимаете кнопку “анализ”, дальше спускаетесь почти в самый низ и там будет собрано две статистики по yandex и google копируете список ключей. Пример на картинке.
Справа в колонке показано, сколько спрашивают в месяц. Таким образом, cy-pr собирают инфу с сайтов и показывает данные.
Парсер ключевых подсказок
Как найти ключевые слова для текста? Когда вы используете вордстат для получения ответа на запрос, то помимо основной статистики у вас появляется список подсказок. С помощью специальных символов можно показать более точные результаты, вот примеры спецсимволов.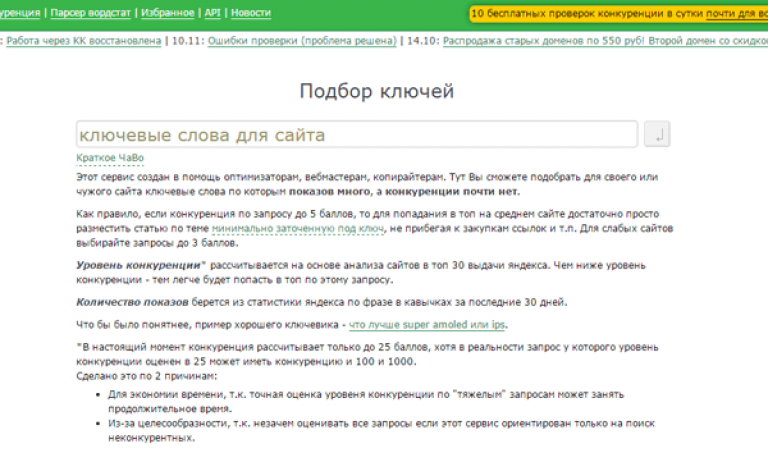
1. [] – квадратные скобки. Выводят результат только тех слов, которые спрашивали в точном порядке, так, как они обозначены в скобках. Если прописать, например, “Москва Воронеж”, то результат примерно следующий.
Если изменить местами, то в итоге мы получим другие цифры.
Из этого следует что “Москва Воронеж” считается более приоритетным запросом. Это наглядный пример для того, кто хочет запустить сайта по туристическим путевкам. Если убрать скобки, то при перестановке слов, цифра статистики останется неизменной.
2. “-” Минус позволяет заранее удалять из статистики ненужные фразы, когда вы абсолютно уверены в их частоте повторов в статье.
3. “+” Плюс включает дополнительные фразы, это могут быть предлоги, когда они обязательны для использования в тексте.
4. “|” Разделитель предназначен только для изучения частоты вариантов. Другими словами, когда требуется проанализировать, как будет смотреться один запрос с несколькими вариантами, то используется разделитель.
5. “()” – скобки предназначены для того, чтобы объединить слова в группы.
Приведем пример. Допустим, нам нужно посмотреть все возможные варианты “продвижение раскрутка” сайта и главное обозначить название поисковиков их тоже нужно сгруппировать и поставить разделить. В итоге получится вот что
“(продвижение|раскрутка) сайта + в (гугл|google|Яндекс)”. Здесь показан список информации, который пригодиться для составления контент-плана.
6. “!” – восклицательный знак ставиться перед началом каждой фразы и дает запрет на её спряжение, склонение и любую модификацию.
7. «» — показывает точное вхождение. То есть, то что задал клиент, то и получит. Чтобы узнать, что конкретно спрашивает пользователь (без изменения окончания), задайте так. Пример с компьютером на скриншоте показывает частотность ключевых слов, которые будут применяться в тексте
Какие ключевые слова в тексте документа использовать и где их правильно размещать?
Следует применять только те ключевые слова и словосочетания текста, которые являются популярными.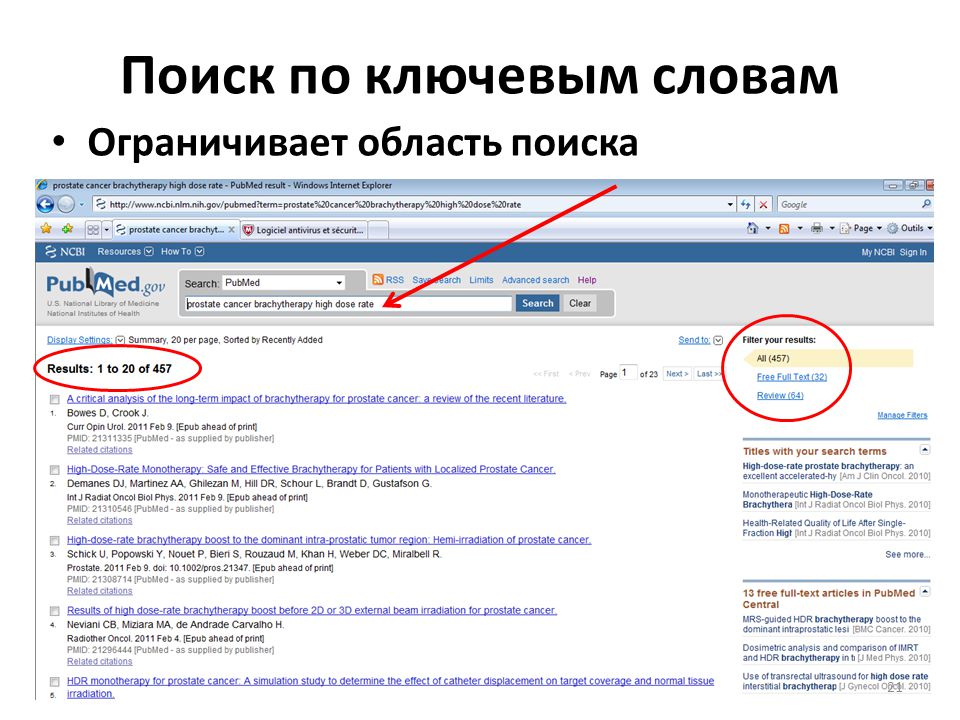 Популярность проверяется через “wordstat.yandex” и “keyword-planner”.
Популярность проверяется через “wordstat.yandex” и “keyword-planner”.
Основной вопрос заключается в том, сколько их надо применять в статье и главное где? Приведем список чек-лист.
1. Ключевые слова текста должны быть использованы в заголовке h2. Рекомендуется вставлять его только в точном вхождении, и он должен отличаться от названия материала. Большинство знают, что такое тег title, он обозначает наименование поста. Старайтесь, чтобы title и h2 различались.
2. Ключевые слова текста также следует добавлять в тег h3. Подзаголовки служат как бы разделителями, и разбивает материал на несколько фрагментов, облегчая восприятия. Есть несколько рекомендаций, как составить h3. Допустимо использовать морфологические формы главного ключа, т.е. изменять окончания. Так же при написании разрешено использовать синонимы слов из главного запроса. Если требуется, для большей читаемости можно применить разбавление, т.е. добавить между фразами предлоги.
Подзаголовки h4 и h5 используются только для того чтобы сделать содержание и поэтому не рекомендуется в них добавлять seo-ключи.
3. О правильном размещении seo-ключей по тексту. Здесь рекомендуется действовать по методу сетки. Самые весомые, которые спрашивают больше всех, следует расположить в начале и в конце “поста”. Они должны быть без изменений, в заголовке h2 также вставьте с точным вхождением. Что касается абзацев, разместите остальные короткие seo-ключи, при этом разбавив их предлогами, а также поменяв некоторые слова на синонимы.
4. Использование атрибута alt у картинки. При вставке изображения в text нужно заполнить атрибут alt словами, по которым будет продвигаться материал. Это делается, чтобы при поиске картинок в поисковике можно было найти и статью.
При написании контента, не рекомендуется начинать первый абзац с ключевого слова. Лучше добавить запрос во второе, третье предложение, но не дальше 500 символов от начала.
5. Мета тег description тоже является обязательным, однако, его влияние на продвижение стало меньше, чем несколько лет назад. Он предназначен для показа сниппета. Когда вы делаете запрос, то идет построение сайтов. Небольшое описание под оглавлением и называется сниппет.
Когда вы делаете запрос, то идет построение сайтов. Небольшое описание под оглавлением и называется сниппет.
Если забыть его указать, то snippet возьмется из абзаца ваших статей. Чтобы создать мета-тега description существует специальный тег meta. Для присвоения ему параметра нужно прописать name и в кавычках указать содержание. В content добавить описание пример на картинке.
Раньше популярным был мета-тег keywords, он создавался примерно также как и предыдущий, только в name вписывался keywords. Дальше в content, через запятую нужно было перечислить ключи, которые используются в тексте. На сегодняшний день мета-тег keywords считается устаревшим и не применяется для продвижения.
Разновидности seo-ключей, которые используются в статье
При написании статей важно правильно разместить ключевики, равномерно по всей странице. Главное не переусердствовать, иначе будет высокая заспамленность и тогда ПС понизит или вообще исключит страницу из поиска. Существует несколько разновидностей ключей.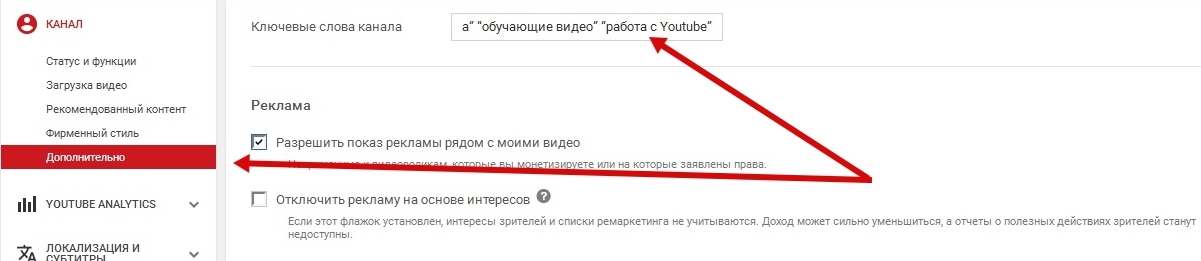
- Прямое вхождение. Считается самым распространенным и используется повсеместно на всех веб-сайтах. Большинство авторов только их и используют для продвижения. Однако трудность заключается в том, что некоторые словосочетания из SEO-ядра, проблематично добавить без склонения отдельных слов. Все зависит от мастерства копирайтера. Если допускать ошибки при вставке, то роботы при индексации заметят это и понизят такой контент в выдаче. Прямое вхождение нужно сделать в заголовке h2, а также в первом и последнем абзаце. Допустимо в некоторых случаях разбавить словосочетания знаками препинания, когда это потребуется, например запятыми. Запрещено в ключе из SEO-ядра использовать следующие знаки: вопросительные, восклицательные и точки.
- Точное вхождение предполагает вставлять ключи в том виде, в котором они указаны в техническом задании (ТЗ). Соответственно, запрещено разбавлять предлогами и даже знаками препинания. Некоторые запросы, которые являются трудночитаемыми, не рекомендуется вставлять в точном вхождении, так как это помешает восприятию.
- Разбавленные. Здесь допустимо использовать знаки препинания, предлоги и другие слова. Например “как создать сайт wordpress”, можно записать “как создать бесплатно сайт на wordress”.
- Морфологическое вхождение. Здесь предусматривает изменения слова, где применяется другое число, падеж или спряжение. К примеру, вместо “строить” записать “строим”. При морфологическом изменении слова запрещено менять первые 3-4 символа.
- Синонимическое вхождение. Под этим термином подразумевается замена некоторых слов на жаргоны, аббревиатуру или другие синонимы, которые близко похожи по смыслу, т.е. вместо автомобиля и мобильного телефона написать “машина” и “смартфон”. Этот вариант позволит убрать повторение и снизить заспамленность, при этом позиции не понизятся, а в дальнейшем это позволит увеличить охват аудитории. Если вставить аббревиатуру или сокращение, к примеру, “авто” вместо “машины”, то пользователи будут лучше воспринимать материал, что положительно скажется на поведенческом факторе (ПФ).

Внимание: существует вариант увеличить список синонимов. Если изначально он небольшой, то просто найдите синонимы, где присутствует знак “-”. Например, “оптимизация” и “seo-оптимизация”. Это два совершенно разных слова, дальше “сайт” к нему подходит “веб-сайт”, “ресурс”, “интернет-ресурс”, “площадка” и так далее, это все синонимы.
Типы ключевых слов, которые задают пользователи
При поиске стоит учитывать дополнительные человеческие факторы, которые делают посетители, когда ищут информацию в интернете. Учитывая их, можно помочь продвижению.
- Ошибки при запросе. Некоторые допускают ошибки в словах. Существуют единичные случаи, когда произошла опечатка и при наборе случайно была нажата соседняя клавиша, а бывает так, что большинство совершают одни и те же ошибки, из этого формируется трафик, которые можно направить на сайт. Например, человек написал слово “блоггер” вместо “блогер” и другие похожие варианты.
- Обратные ключи.
 Это когда клиент при поиске устанавливает последовательность слов наоборот. К примеру, автор блога написал абзац и вставил в предложение “seo оптимизация”, однако большинство посетителей задали запрос “оптимизация seo”. Для поисковых систем это не столь важно, но если требуется точно узнать насколько отличаются показатели от перестановки, то применяйте квадратные скобки []. Об этом писалось выше
Это когда клиент при поиске устанавливает последовательность слов наоборот. К примеру, автор блога написал абзац и вставил в предложение “seo оптимизация”, однако большинство посетителей задали запрос “оптимизация seo”. Для поисковых систем это не столь важно, но если требуется точно узнать насколько отличаются показатели от перестановки, то применяйте квадратные скобки []. Об этом писалось выше - С включенными аббревиатурами. Довольно часто владельцы ресурсов вместо полного название фирмы вставляют сокращения. К примеру, вместо “Интернет Магазин” пишут ИМ. Можно также некоторые англоязычные термины написать по-русски, например SEO обозначить как СЕО. Поисковики умеют анализировать страницы с двумя вариантами обозначения и использовать их для продвижения.
Данная методика позволяет снизить “тошнотность”. В результате, страница будет лучше продвигаться. Однако следует быть острожным и не применять этот способ слишком часто, так как “пост” может стать нечитаемым и ПС сделают пессимизацию или вообще исключит из индексации.
При составлении SEO-ядра следует добавить ключи с хвостами, таким образом, соберется список, у которых низкая частотность ключевых слов в тексте. Если удастся вырваться по ним в топ, и посетители будут заходить, читать и оставлять комментарии, это положительно скажется на поведенческом факторе. В итоге среднечастотные и высокочастотные запросы сами подтянутся к топу.
Раньше много лет назад было принято выделять в абзацах ключевики жирным шрифтом, используя тег “b” или “strong”. На сегодняшний день это уже не актуально. Напротив ПС могут посчитать выделенные слова заспамленными и такая статья будет хуже продвигаться.
Поисковики предпочитают тему, которая полностью раскрыта и оценивают страницу по ряду параметров: сколько времени читатели проводят на сайте, число страниц просмотренных в глубь интернет-ресурса и многое другое. Поэтому чтобы добиться высоких позиций, следует писать полностью раскрытую тему и правильно размещать ключевые слова в тексте документа.
Методы извлечения ключевых слов из документов в НЛП
Эта статья была опубликована в рамках блога по науке о данных.
Введение
Извлечение ключевых слов обычно используется для извлечения ключевой информации из ряда абзацев или документов. Извлечение ключевых слов — это автоматизированный метод извлечения наиболее релевантных слов и фраз из введенного текста. Это метод анализа текста, который включает автоматическое извлечение наиболее важных слов и выражений со страницы. Это помогает обобщить содержание текста и определить ключевые обсуждаемые вопросы — например, протокол собрания (MOM).
Источник: https://towardsdatascience.com/textrank-for-keyword-extraction-by-python-c0bae21bcec0 Предположим, вы хотите найти в Интернете большое количество оценок продуктов (возможно, сотни тысяч). Чтобы просмотреть все данные и найти термины, которые лучше всего определяют каждый обзор, можно использовать извлечение ключевых слов. Вы сможете увидеть, какие темы вызывают наибольшее обсуждение среди ваших потребителей, а автоматизация процесса сэкономит вашим сотрудникам много времени. В этом блоге я покажу вам, как извлекать ключевые слова из документов с помощью обработки естественного языка. Это те.
Это те.
- Рейк_NLTK
- Спэйси
- Текстранг
- Word облако
- KeyBert
- Яке
- API-интерфейс MonkeyLearn
- Текстразор API
Рейк_NLTK
RAKE (быстрое автоматическое извлечение ключевых слов) — это хорошо известный метод извлечения ключевых слов, который находит наиболее релевантные слова или фразы в фрагменте текста, используя набор стоп-слов и разделителей фраз. Rake nltk — это расширенная версия RAKE, поддерживаемая NLTK. Шаги для быстрого автоматического извлечения ключевых слов следующие:
- Разделить вводимое текстовое содержимое по точкам
- Создать матрицу совпадений слов
- Оценка слова — эта оценка может быть рассчитана как степень слова в матрице, как частота слова или как степень слова, деленная на его частоту
- ключевых фраз также можно создать, комбинируя ключевые слова
- Ключевое слово или ключевая фраза выбраны тогда и только тогда, когда их оценка относится к числу лучших T оценок, где T — количество ключевых слов, которые вы хотите извлечь
Реализация Python для извлечения ключевых слов с использованием алгоритма Rake
Для установки
pip3 установить rake-nltk
Для извлечения ключевых слов
Прочтите этот официальный документ, чтобы узнать больше об алгоритме RAKE.
Спэйси
Еще одна фантастическая библиотека Python NLP — spaCy. Этот пакет, более новый, чем NLTK или Scikit-Learn, направлен на то, чтобы максимально упростить глубокое обучение для анализа текстовых данных. Ниже приведены процедуры, связанные с извлечением ключевых слов из текста с использованием спайса.
- Разделить текстовое содержимое ввода по токенам
- Извлечь горячие слова из списка токенов.
- Установите горячие слова как слова с почтовым тегом « PROPN », « ADJ » или « NOUN ». (список POS-тегов настраивается)
- Найдите наиболее распространенное количество T горячих слов из списка
- Распечатать результаты
Реализация Python для извлечения ключевых слов с использованием Spacy
Для установки
pip3 установить пробел
Для извлечения ключевых слов
импортировать пространство из коллекций импорт Счетчик пунктуация импорта строки nlp = spacy.load ("en_core_web_sm") деф get_hotwords (текст): результат = [] pos_tag = ['PROPN', 'ADJ', 'СУЩЕСТВИТЕЛЬНОЕ'] документ = нлп (текст.нижний ()) для токена в документе: if(token.text в nlp.Defaults.stop_words или token.text в пунктуации): Продолжать если (токен.pos_ в pos_tag): результат.добавление(токен.текст) вернуть результат новый_текст = """ Когда дело доходит до оценки производительности экстракторов ключевых слов, вы можете использовать некоторые стандартные показатели машинного обучения: точность, достоверность, полнота и оценка F1. Однако эти показатели не отражают частичные совпадения. они учитывают только идеальное совпадение между извлеченным сегментом и правильным прогнозом для этого тега. К счастью, есть и другие метрики, способные фиксировать частичные совпадения. Примером этого является ROUGE. """ вывод = установить (get_hotwords (новый_текст)) most_common_list = Счетчик(выход).most_common(10) для элемента в most_common_list: печать (элемент [0])
Выход
точность точность способный частичный прогноз счет правильный экстракторы Спички идеально
Текстранг
Textrank — это инструмент Python, который извлекает ключевые слова и обобщает текст. Алгоритм определяет, насколько тесно связаны слова, просматривая, следуют ли они друг за другом. Затем наиболее важные термины в тексте ранжируются с использованием алгоритма PageRank. Textrank обычно совместим с конвейером Spacy. Вот основные процессы, которые Textrank выполняет при извлечении ключевых слов из документа.
Алгоритм определяет, насколько тесно связаны слова, просматривая, следуют ли они друг за другом. Затем наиболее важные термины в тексте ранжируются с использованием алгоритма PageRank. Textrank обычно совместим с конвейером Spacy. Вот основные процессы, которые Textrank выполняет при извлечении ключевых слов из документа.
Шаг – 1: Чтобы найти релевантные термины, алгоритм Textrank создает сеть слов (граф слов). Эта сеть создается путем просмотра того, какие слова связаны друг с другом. Если два слова часто встречаются в тексте рядом друг с другом, между ними устанавливается связь. Ссылка получает больший вес, если два слова чаще появляются рядом друг с другом.
Шаг – 2 :Для определения релевантности каждого слова к сформированной сети применяется алгоритм PageRank. Верхняя треть каждого из этих терминов сохраняется и считается важной. Затем, если релевантные термины появляются в тексте один за другим, создается таблица ключевых слов путем их группировки.
TextRank — это реализация Python, которая обеспечивает быстрое и точное извлечение фраз, а также резюмирование для использования в рабочих процессах spaCy. Метод графа не зависит от какого-либо конкретного естественного языка и не требует знания предметной области. Инструмент, который мы будем использовать для извлечения ключевых слов, — это PyTextRank (версия TextRank для Python в качестве плагина конвейера spaCy). Пожалуйста, ознакомьтесь с базовым документом здесь, чтобы узнать больше о Textrank.
Реализация Python для извлечения ключевых слов с использованием Textrank
Для установки
pip3 установить pytextrank
скачать spacy en_core_web_sm Для извлечения ключевых слов
импортировать пространство импортировать pytextrank # пример текста text = "Совместность систем линейных ограничений на множество натуральных чисел. Рассмотрены критерии совместности системы линейных диофантовых уравнений, строгих неравенств и нестрогих неравенств.
Выход
смешанные типы минимальные порождающие наборы системы нестрогие неравенства строгие неравенства натуральные числа линейные диофантовы уравнения решения линейные ограничения минимальный вспомогательный набор
Облако слов
Величина каждого слова представляет его частоту или релевантность в облаке слов, которое является инструментом визуализации данных для визуализации текстовых данных. Облако слов можно использовать для выделения важных текстовых данных. Данные с веб-сайтов социальных сетей часто анализируются с использованием облаков слов.
Облако слов можно использовать для выделения важных текстовых данных. Данные с веб-сайтов социальных сетей часто анализируются с использованием облаков слов.
Чем крупнее и жирнее термин появляется в облаке слов, тем больше раз он появляется в источнике текстовых данных (например, речи, записи в блоге или базе данных) (также известном как облако тегов или текстовое облако). Облако слов — это набор слов разных размеров. Чем чаще термин встречается в документе и чем он важнее, тем он крупнее и жирнее. Это отличные способы извлечения наиболее важных частей текстовых данных, таких как сообщения в блогах и базы данных.
Реализация Python для извлечения ключевых слов с использованием Wordcloud
Для установки
pip3 установить wordcloud pip3 установить matplotlib
Для извлечения ключевых слов и демонстрации их релевантности с помощью Wordcloud
импортных коллекций импортировать numpy как np импортировать панд как pd импортировать matplotlib.
Выход
Источник: Автор Источник: Автор
КейБерт
KeyBERT — это базовый и простой в использовании метод извлечения ключевых слов, который генерирует ключевые слова и фразы, наиболее похожие на данный документ, с использованием встраивания BERT. Он использует BERT-эмбеддинги и базовое косинусное сходство для поиска поддокументов в документе, которые наиболее похожи на сам документ.
BERT используется для извлечения вложений документов, чтобы получить представление на уровне документа. Затем извлекаются вложения слов для N-граммных слов/фраз. Наконец, он использует косинусное сходство, чтобы найти слова/фразы, наиболее похожие на документ. Затем наиболее сопоставимые термины могут быть идентифицированы как те, которые лучше всего описывают весь документ.
Поскольку KeyBert построен на основе BERT, он создает вложения с использованием предварительно обученных моделей на основе Huggingface Transformer. По умолчанию для встраивания используется модель all-MiniLM-L6-v2 .
Реализация Python для извлечения ключевых слов с использованием KeyBert
Для установки
pip3 установить ключ
Для извлечения ключевых слов и демонстрации их релевантности с помощью KeyBert
из импорта ключей KeyBERT
документ = """
Обучение с учителем — это задача машинного обучения по обучению функции, которая
сопоставляет ввод с выводом на основе примеров пар ввода-вывода. Это предполагает
функцию из размеченных обучающих данных, состоящих из набора обучающих примеров.
В обучении с учителем каждый пример представляет собой пару, состоящую из входного объекта
(обычно вектор) и желаемое выходное значение (также называемое контрольным сигналом).
Алгоритм обучения с учителем анализирует обучающие данные и выводит предполагаемую функцию.
которые можно использовать для отображения новых примеров. Оптимальный сценарий позволит
алгоритм для правильного определения меток класса для невидимых экземпляров. Это требует
алгоритм обучения для обобщения обучающих данных на невидимые ситуации в
«разумным» способом (см. индуктивное смещение).
kw_model = KeyBERT()
ключевые слова = kw_model.extract_keywords(doc)
печать(ключевые слова) Выход
[('под наблюдением', 0,6676), ('помеченный', 0,4896), ('обучение', 0,4813), ('обучение', 0,4134), ('метки', 0,3947)] Еще один экстрактор ключевых слов (Yake)
Для автоматического извлечения ключевых слов в Yake функции текста используются неконтролируемым образом. YAKE — это базовый неконтролируемый автоматический метод извлечения ключевых слов, который определяет наиболее релевантные ключевые слова в тексте с использованием текстовых статистических данных из отдельных текстов. Этот метод не зависит от словарей, внешних корпусов, размера текста, языка или домена и не требует обучения на определенном наборе документов. Основные характеристики алгоритма Яке следующие:
- Неконтролируемый подход
- Корпус-независимый
- Независимо от домена и языка
- Один документ
Реализация Python для извлечения ключевых слов с использованием Yake
Для установки
pip3 установить яке
Для извлечения ключевых слов и демонстрации их релевантности с помощью Yake
импортный яке
документ = """
Обучение с учителем — это задача машинного обучения по обучению функции, которая
сопоставляет ввод с выводом на основе примеров пар ввода-вывода. Это предполагает
функцию из размеченных обучающих данных, состоящих из набора обучающих примеров.
В обучении с учителем каждый пример представляет собой пару, состоящую из входного объекта
(обычно вектор) и желаемое выходное значение (также называемое контрольным сигналом).
Алгоритм обучения с учителем анализирует обучающие данные и выводит предполагаемую функцию.
которые можно использовать для отображения новых примеров. Оптимальный сценарий позволит
алгоритм для правильного определения меток класса для невидимых экземпляров. Это требует
алгоритм обучения для обобщения обучающих данных на невидимые ситуации в
«разумным» способом (см. индуктивное смещение).
kw_extractor = yake.KeywordExtractor()
ключевые слова = kw_extractor.extract_keywords(doc)
для кВт в ключевых словах:
печать (кВт) Выход
(«задача машинного обучения», 0,022703501568910843) («Обучение с учителем», 0,06742808121232775) («обучение», 0,072457069999) («данные для обучения», 0,07557730010583494) («сопоставляет ввод», 0,07860851277995791) («на основе вывода», 0,08846540097554569) («пары ввода-вывода», 0,08846540097554569) («машинное обучение», 0,09853013116161088) («учебная задача», 0,09853013116161088) («обучение», 0,10592640317285314) («функция», 0,11237403107652318) («обучающие данные, состоящие из», 0,12165867444610523) («алгоритм обучения», 0,1280547892393491) («Под наблюдением», 0.72807220248)
API-интерфейс MonkeyLearn
MonkeyLearn — это удобный инструмент для анализа текста с предварительно обученным экстрактором ключевых слов, который можно использовать для извлечения важных фраз из ваших данных с помощью API MonkeyLearn. API доступны на всех основных языках программирования, и разработчики могут извлекать ключевые слова с помощью всего нескольких строк кода и получать файл JSON с извлеченными ключевыми словами. У MonkeyLearn также есть бесплатный генератор облаков слов, который работает как простой «извлекатель ключевых слов», позволяя вам создавать облака тегов из ваших самых важных терминов. После того, как вы создадите учетную запись Monkeylearn, вам будет присвоено API-ключ и идентификатор модели для извлечения ключевых слов из текста.
Дополнительные сведения см. в официальной документации по API Monkeylearn.
Преимущества автоматизации извлечения ключевых слов
- Описания продуктов, отзывы клиентов и другие источники могут использоваться для извлечения ключевых слов.
- Определите, какие термины чаще всего используются клиентами.
- Мониторинг упоминаний брендов, продуктов и услуг в режиме реального времени
- Можно автоматизировать и ускорить извлечение и ввод данных.
Реализация Python для извлечения ключевых слов с использованием MonkeyLearn API
Для установки
pip3 установить обезьяну узнать
Для извлечения ключевых слов с помощью Monkeylearn API
от monkeylearn импортировать MonkeyLearn
мл = MonkeyLearn('your_api_key')
мой_текст = """
Когда дело доходит до оценки производительности экстракторов ключевых слов, вы можете использовать некоторые стандартные метрики машинного обучения: точность, точность, полнота и оценка F1. Однако эти показатели не отражают частичные совпадения; они учитывают только идеальное совпадение между извлеченным сегментом и правильным прогнозом для этого тега.
"""
данные = [мой_текст]
model_id = 'ваш_model_id'
результат = ml.extractors.extract (id_модели, данные)
dataDict = результат.тело
для элемента в dataDict[0]['extractions'][:10]:
печать (элемент ['parsed_value']) Выход
эффективность ключевого слова стандартная метрика счет f1 частичное совпадение правильный прогноз извлеченный сегмент машинное обучение экстрактор ключевых слов идеальное совпадение метрика
API Textrazor
Другой API для извлечения ключевых слов и других полезных элементов из неструктурированного текста — Textrazor. Доступ к Textrazor API можно получить с помощью различных компьютерных языков, включая Python, Java, PHP и другие. Вы получите ключ API для извлечения ключевых слов из текста после того, как создадите учетную запись в Textrazor. Посетите официальный сайт для получения дополнительной информации.
Textrazor — хороший выбор для разработчиков, которым нужны инструменты быстрого извлечения с широкими возможностями настройки. Это служба извлечения ключевых слов, которую можно использовать локально или в облаке. TextRazor API может использоваться для извлечения смысла из текста и может быть легко подключен к нашему необходимому языку программирования. Мы можем создавать собственные экстракторы и извлекать синонимы и отношения между объектами в дополнение к извлечению ключевых слов и объектов на 12 различных языках.
Реализация Python для извлечения ключевых слов с использованием Textrazor API
Для установки
pip3 установить textrazor
Для извлечения ключевых слов с релевантностью и доверием с веб-страницы с помощью Textrazor API
импортировать текстразор textrazor.api_key = "ваш_api_key" client = textrazor.
Выход
Документ 0,1468 2,734 Отладка 0,4502 6,739 Прикладное ПО 0,256 1,335 Высокая доступность 0,4024 5,342 Передовая практика 0,3448 1,911 Коробка 0,03577 0,9762 Прикладное ПО 0,256 1,343 Эксперимент 0,2456 4,424 Устаревание 0,1894 2,876 Объект (грамматика) 0,2584 1,039 Ложноположительные и ложноотрицательные 0,09726 2,222 Система 0,3509 1,251 Алгоритм 0,3629 17,14 Документ 0,1705 2,741 Точность и прецизионность 0,4276 2,089Конкатенация 0,4086 3,503 Твиттер 0,536 6,974 Новости 0,2727 1,43 Система 0,3509 1,251 Документ 0,1705 2,691 Клавиша интерфейса прикладного программирования 0,1133 1,795 ... ... ...
Заключение
Извлечение ключевых слов — это автоматизированный метод извлечения наиболее релевантных слов и фраз из введенного текста. Важные моменты, которые следует помнить, приведены ниже.
- Извлечение ключевых слов обычно используется, когда нам нужно извлечь ключевую информацию из пакета документов.
- В этой статье я попытался представить вам некоторые из самых популярных инструментов для задач автоматического извлечения ключевых слов в НЛП.
- Рейбл NLTK , SPACY , Textrank , Word Cloud , Keybert, и Yake — это инструменты и Monkeylearn и Textrazor , которые я упомянул здесь.
- Каждый из этих инструментов имеет свои преимущества и особенности использования.
- Это наиболее эффективные методы извлечения ключевых слов, используемые в настоящее время в области науки о данных.
Примечания
Целью извлечения ключевых слов является автоматический поиск фраз, которые лучше всего описывают содержание документа. Ключевые фразы, ключевые термины, ключевые сегменты или просто ключевые слова — это термины, используемые для определения терминов, обозначающих наиболее релевантную информацию, содержащуюся в документе. Моя страница Github содержит всю базу кода для методов извлечения ключевых слов. Если у вас возникли проблемы при использовании этих инструментов, сообщите нам об этом в разделе комментариев ниже.
Удачного кодирования🤗
Читайте последние статьи в нашем блоге.
Медиафайлы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Поиск ключевых слов в текстовом пробеле с примерами кода
Поиск ключевых слов в текстовом пространстве с примерами кода
Решение проблемы поиска ключевых слов в текстовом пробеле будет продемонстрировано на примерах в этой статье.
импортировать пространство
Мы показали, как использовать программирование для решения задачи «Поиск ключевых слов в текстовом пробеле» на множестве примеров.
Как искать ключевые слова в тексте?
Вы можете использовать экстрактор ключевых слов для извлечения отдельных слов (ключевых слов) или групп из двух или более слов, которые создают фразу (ключевые фразы). Попробуйте экстрактор ключевых слов ниже, используя свой собственный текст, чтобы извлечь отдельные слова (ключевые слова) или группы из двух или более слов, которые создают фразу (ключевые фразы).
Как извлечь ключевые слова из абзаца в Python?
Методы извлечения ключевых слов
- 11 шагов по автоматическому извлечению ключевых слов из предложений в Python — с использованием метода TF-IDF.
- Шаг 1: Импорт пакетов.
- Шаг 2. Объявление переменных.
- Шаг 3. Удалите слова, которые встречаются часто, но не имеют значения.
- Шаг 4: Подсчитайте общее количество слов во всем тексте.
Что такое ключевые слова в тексте?
Ключевое слово — это слово, фраза или другая комбинация цифр и букв, которая позволяет людям получать маркетинговые и коммуникационные SMS-сообщения.
Как извлечь ключевые слова с веб-сайта?
Как извлечь ключевые слова
- Введите URL-адрес веб-страницы, для которой вы хотите исследовать ключевые слова.
- Нажмите кнопку «Извлечь». Экстрактор автоматически выберет все наиболее часто используемые и наиболее важные слова из URL-адреса.
- Сразу после извлечения в текстовом поле появится список с ключевыми словами.
Как извлечь ключевые слова с помощью спайса?
Ниже приведены процедуры извлечения ключевых слов из текста с использованием спайса.
- Разбить вводимое текстовое содержимое на токены.
- Извлечь горячие слова из списка токенов. Установите горячие слова как слова с pos-тегом «PROPN», «ADJ» или «NOUN». (
- Найдите наиболее часто встречающееся количество T горячих слов из списка.
- Распечатать результаты.
Как вы определяете ключевые слова при чтении?
При подходе с использованием ключевых слов студенты:
- Выделите важные факты или идеи в отрывке.
- Напишите «суть» предложения, которое обобщает выделенные идеи или факты.
- Выберите «ключевое слово», которое поможет им вспомнить основную идею статьи или отрывка.
- Создайте мысленный образ, чтобы запомнить ключевое слово, а затем.
Как извлечь информацию из текста?
Давайте рассмотрим 5 распространенных методов, используемых для извлечения информации из приведенного выше текста.
- Распознавание именованных объектов. Самый простой и полезный метод в НЛП — извлечение сущностей в тексте.
- Анализ настроений.
- Обобщение текста.
- Добыча Аспекта.
- Тематическое моделирование.
Как найти ключевое слово в строке python?
Чтобы проверить, является ли строка допустимым ключевым словом, импортируйте модуль ключевых слов и используйте метод iskeyword(). При этом вы можете сразу отобразить все ключевые слова и проверить их.11 августа 2022 г.
Как искать ключевое слово в Python?
Как проверить, является ли строка ключевым словом? Python на своем языке определяет встроенный модуль «ключевое слово», который обрабатывает определенные операции, связанные с ключевыми словами.