Кодирование текстовой информации — онлайн справочник для студентов
Как кодируется текстовая информация?
Стенография
Криптография
Числовое кодирование данных в текстовом виде
Нередко тексты, написанные на естественных языках (английский, русский и так далее) подвергаются кодированию. О том, как кодируется текст, что такое стенография, какие существуют таблицы кодировки и многое другое, вы узнаете из этой статьи.
Как кодируется текстовая информация?
Есть несколько методов. Выделяют следующие способы кодирования информации:
- графический метод, при котором информация кодируется с применением специальных знаков или рисунков;
- символьный метод, при котором кодировка текста осуществляется посредством символов того же алфавита, на котором основывается исходная информация;
- числовой метод, при котором текстовые данные кодируют посредством чисел.
- если необходимо записывать текст синхронно с речью, это стоит делать посредством стенографии;
- если необходимо отправить текст адресату из другой страны, можно прибегнуть к латинице;
- если нужно представить текст в форме, понятной для грамотного человека, его стоит записывать согласно грамматическим правилам русского языка.
Чтение текста является процессом, обратным его написанию и как следствие — письменная информация становится устной речью. Чтение является ничем иным как расшифровкой письменной информации. Важно отметить тот факт, что существует различные способы кодировки одной той же информации на одном конкретном языке.
Чтение является ничем иным как расшифровкой письменной информации. Важно отметить тот факт, что существует различные способы кодировки одной той же информации на одном конкретном языке.
Поскольку мы используем русский язык, то и текст нам привычней записывать с помощью нашего алфавита — кириллицы. Однако одну и ту же информацию можно записывать с помощью латинских букв. Иногда это приходится делать, когда необходимо отправлять SMS-сообщения по мобильному телефону, в клавиатуре которого не были реализованы буквы кириллицы, или же письмо по e-mail на русском языке, если адресат не имеет локализованное программное обеспечение. Так, например, фраза «Привет, дружище!» может быть записана как: «Privet, drushishe!».
Стенография
Стенография представляет собой метод кодирования текстовых данных посредством специальных знаков. Она является достаточно быстрым способом записи речи устной формы. Стенографию далеко не каждый может освоить, а только прошедшие специальное обучение люди, известные как стенографисты.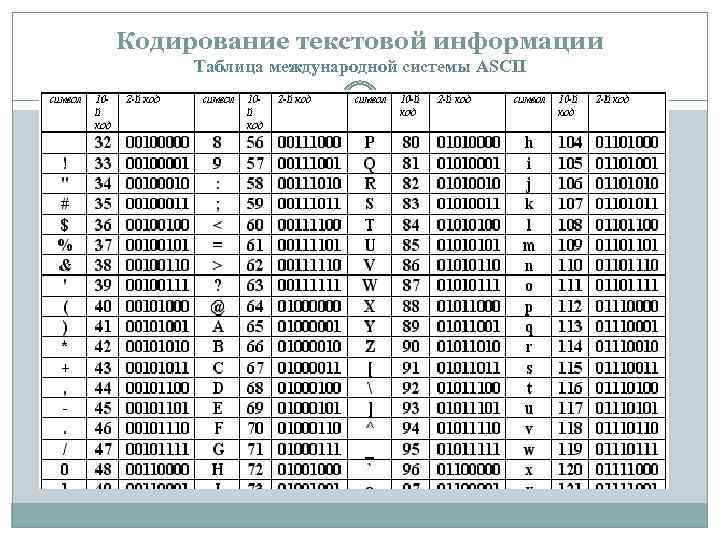
На рисунке ниже представлено то, как выглядит стенография, в которой закодирована следующая информация: «Говорить умеют все люди на свете. Даже у самых примитивных племен есть речь. Язык — это нечто всеобщее и самое человеческое, что есть на свете»: Такой метод предоставляет возможность не только производить запись, синхронную устной речи, но и сделать письменную технику более рациональной.
Кроме того, немаловажное значение имеет выбор метода кодирования данных, который, помимо прочего, может иметь связь с предполагаемым методом их обработки.
Также стоит рассмотреть пример, при котором представляются числа количественной информации. Прибегнув к буквам кириллицы, можно написать число «сорок». Если же прибегнуть к арабской десятичной системе, то число будет выглядеть как 40. Как пример, поставлена задача, вычислить какое либо числовое значение. Понятное дело, что для этой задачи мы делаем выбор в пользу наиболее удобных арабских цифр, хотя ничто не мешает прибегать к словам, однако на их написание уйдет больше времени и места.
Стоит отметить, что вышеописанные примеры написания одного и того же числа базируются на совершенно разных языках. В первом случае используются буквы русского алфавита, в то время как во втором применяется формальный математический язык, который не имеет национальной привязанности. Переход от естественного языка к формальной разновидности можно считать кодированием.
Криптография
В особых случаях возникает необходимость в засекречивании информации, содержащейся в сообщениях или документации. Это нужно для того чтобы она не была прочтена сторонними людьми. Такое кодирование текста именуется защитой данных от несанкционированного доступа, при которой секретный текст зашифровывается. В далеком прошлом пытались скрывать данные посредством тайнописи.
Под шифрованием подразумевается процесс, при котором открытый текст преобразуется в зашифрованный. Дешифрование является полностью обратным процессом преобразования, цель которого — восстановление исходного текста. Шифрование тоже является кодированием, но с использованием засекреченного метода, известного лишь источнику данных и их получателю. Есть целая наука о методах шифрования, известная как криптография.
Шифрование тоже является кодированием, но с использованием засекреченного метода, известного лишь источнику данных и их получателю. Есть целая наука о методах шифрования, известная как криптография.
Криптография — это наука, изучающая принципы и методы передачи и приема данных, зашифрованных посредством специальных ключей. Ключи — это секретные данные, применяемые при шифровке и расшифровке информации.
Числовое кодирование данных в текстовом виде
Каждый национальный язык мира обладает собственным алфавитом, состоящим из конкретного набора последовательно расположенных символов (букв). Соответственно они обладают своим порядковым номером.
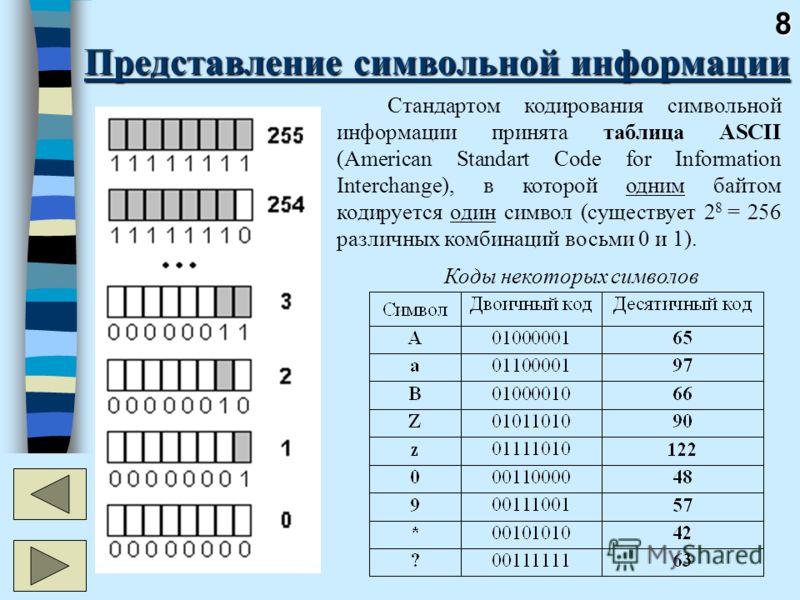
На каждую букву алфавита приходится целое положительное число — код символа, который будет храниться в памяти ПК, а при выводе на монитор или бумагу он преобразуется в тот символ, который ему соответствует. Кроме того в памяти хранятся данные о том, какая именно информация была закодирована в том или ином месте памяти. Это нужно для того, чтобы различать представленную в памяти информацию.
Это нужно для того, чтобы различать представленную в памяти информацию.
Прибегнув к соответствию алфавитных букв к числовым кодам можно формировать специальные таблицы кодирования. Если говорить более простым языком, символы того или иного алфавита обладают своими числовыми кодами, которые соответствуют конкретной таблице кодирования.
Однако, как известно, по всему миру имеется огромное количество языков и множество алфавитов, которые могут иметь множество отличий от остальных. Отсюда возникает вопрос: как можно закодировать каждый используемый алфавит на компьютере?
Еще в шестидесятых годах прошлого столетия американский институт ANSI занялся разработкой таблицы ASCII, задача которой – кодирование символов. В дальнейшем данная таблица стала применяться во всех операционных системах.
Эта таблица содержит стандарт кодирования на 7 бит, применив который компьютер окажется способен записывать любой символ в семи битную ячейку устройства для хранения информации. Важно отметить то, что в ячейке может быть сохранено вплоть до 128 состояний. В ASCII каждому из таких состояний соответствует тот или иной символ — буквы, знаки препинания и так далее.
Важно отметить то, что в ячейке может быть сохранено вплоть до 128 состояний. В ASCII каждому из таких состояний соответствует тот или иной символ — буквы, знаки препинания и так далее.
С течением времени оказалось, что из-за технического прогресса такой стандарт кодирования оказался крайне мал, поскольку в стольких состояниях одной ячейки закодировать буквы каждой письменности мира не предоставляется возможным.
Для решения данной проблемы разработчиками ПО были начаты работы по созданию восьми битных стандартов кодировки. Благодаря восьмому биту удалось увеличить диапазон кодирования в 2 раза – до 256 символов. Первая половина этих символов в таких кодировках, преимущественно, соответствуют стандарту ASCII, в то время как вторая отведена на реализацию региональных языковых особенностей.
Как известно, существует целое множество алфавитов, соответственно и таблицы ASCII-кодов имеют множество вариаций. Так в случае русского языка наиболее распространенными вариантами являются Windows-1251 и Koi8-r.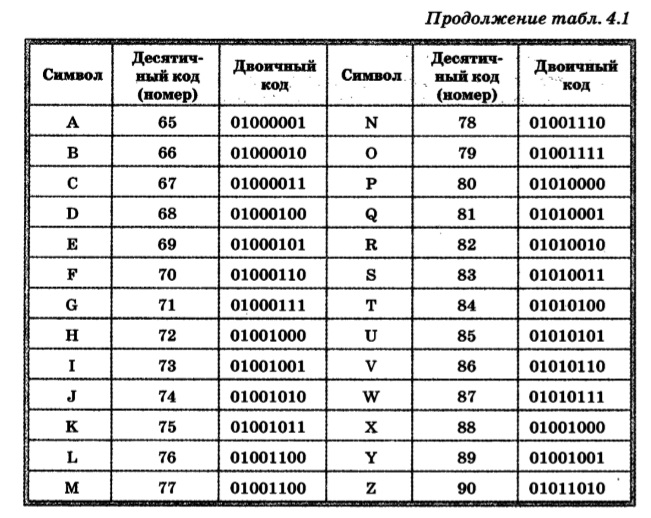
Также возникают трудности с теми языками, а алфавите содержится очень много символов, которые уместить в позиции с 128 до 255 однобайтовой кодировки невозможно.
Еще одна проблема – это когда текст содержит в себе несколько языков (допустим, русский и два любых других с латинскими буквами). В таком случае не удастся одновременно задействовать несколько таблиц.
Так было вплоть до начала девяностых годов прошлого века, пока миру не была представлена новая разработка под названием Unicode, ставшая сейчас стандартом. Она позволяла использовать в одном документе любые языки и символы.
Unicode предоставлял 31 бит, что соответствует четырем байтам без одного бита. Число вероятных комбинаций был просто огромным – свыше двух миллиардов. Это оказалось возможным благодаря тому, что стандарт описывал каждый известный алфавит, в том числе алфавиты выдуманных и давно никем не используемых языков, включая множество математических и прочих символов. Поскольку такая емкость оказалось очень большой, в основном прибегают к сокращенной версии на 16 бит со всеми современными алфавитами. Первые 128 кодов Unicode аналогичны таблице ASCII.
Смотрите также:
Кодирование и декодирование информации
Архитектура персонального компьютера
Физика
166
Реклама и PR
31
Педагогика
80
Психология
72
Социология
7
Астрономия
9
Биология
30
Культурология
86
Экология
8
Право и юриспруденция
36
Политология
13
Экономика
49
Финансы
9
История
16
Философия
8
Информатика
20
Право
35
Информационные технологии
6
Экономическая теория
7
Менеджент
719
Математика
338
Химия
20
Микро- и макроэкономика
1
Медицина
5
Государственное и муниципальное управление
2
География
542
Информационная безопасность
2
Аудит
11
Безопасность жизнедеятельности
3
Архитектура и строительство
1
Банковское дело
1
Рынок ценных бумаг
6
Менеджмент организации
2
Маркетинг
238
Кредит
3
Инвестиции
2
Журналистика
1
Конфликтология
15
Этика
9
Устройства хранения информации Устройства вывода информации Римская система счисления Что такое информация. Ее разновидности и особенности. Упрощение логических выражений
Ее разновидности и особенности. Упрощение логических выражений
Узнать цену работы
Узнай цену
своей работы
Имя
Выбрать тип работыЧасть дипломаДипломнаяКурсоваяКонтрольнаяРешение задачРефератНаучно — исследовательскаяОтчет по практикеОтветы на билетыТест/экзамен onlineМонографияЭссеДокладКомпьютерный набор текстаКомпьютерный чертежРецензияПереводРепетиторБизнес-планКонспектыПроверка качестваЭкзамен на сайтеАспирантский рефератМагистерскаяНаучная статьяНаучный трудТехническая редакция текстаЧертеж от рукиДиаграммы, таблицыПрезентация к защитеТезисный планРечь к дипломуДоработка заказа клиентаОтзыв на дипломПубликация в ВАКПубликация в ScopusДиплом MBAПовышение оригинальностиКопирайтингДругоеПринимаю Политику конфиденциальности
Подпишись на рассылку, чтобы не пропустить информацию об акциях
Кодирование информации. Стандарты кодирования текста
В информатике большое число информационных процессов проходит с использованием кодирования данных. Поэтому понимание данного процесса очень важно при постижении азов этой науки. Под кодированием информации понимают процесс преобразования символов записанных на разных естественных языках (русский язык, английский язык и т.д.) в цифровое обозначение.
Поэтому понимание данного процесса очень важно при постижении азов этой науки. Под кодированием информации понимают процесс преобразования символов записанных на разных естественных языках (русский язык, английский язык и т.д.) в цифровое обозначение.
Это означает, что при кодировании текста каждому символу присваивается определенное значение в виде нулей и единиц – байта.
Зачем кодировать информацию?
Во-первых, необходимо ответить на вопрос для чего кодировать информацию? Дело в том, что компьютер способен обрабатывать и хранить только лишь один вид представления данных – цифровой. Поэтому любую входящую в него информацию необходимо переводить в цифровой вид.
Стандарты кодирования текста
Чтобы все компьютеры могли однозначно понимать тот или иной текст, необходимо использовать общепринятые стандарты кодирования текста. В прочих случаях потребуется дополнительное перекодирование или несовместимость данных.
ASCII
Самым первым компьютерным стандартом кодирования символов стал ASCII (полное название — American Standart Code for Information Interchange). Для кодирования любого символа в нём использовали всего 7 бит. Как вы помните, что закодировать при помощи 7 бит можно лишь 27 символов или 128 символов. Этого достаточно, чтобы закодировать заглавные и прописные буквы латинского алфавита, арабские цифры, знаки препинания, а так же определенный набор специальных символов, к примеру, знак доллара — «$». Однако, чтобы закодировать символы алфавитов других народов (в том числе и символов русского алфавита) пришлось дополнять код до 8 бит (28=256 символов). При этом, для каждого языка использовалась свой отдельная кодировка.
UNICODE
Нужно было спасать положение в плане совместимости таблиц кодировки. Поэтому, со временем были разработаны новые обновлённые стандарты. В настоящее время наиболее популярной является кодировка под названием UNICODE. В ней каждый символ кодируется с помощью 2-х байт, что соответствует 216=62536 разным кодам.
В ней каждый символ кодируется с помощью 2-х байт, что соответствует 216=62536 разным кодам.
Стандарты кодирования графических данных
Чтобы закодировать изображение требуется гораздо больше байт, чем для кодирования символов. Большинство созданных и обработанных изображений, хранящихся в памяти компьютера, разделяют на две основные группы:
- изображения растровой графики;
- изображения векторной графики.
Растровая графика
В растровой графике изображение представлено набором цветных точек. Такие точки называют пикселями (pixel). При увеличении изображения такие точки превращаются в квадратики.
Для кодирования чёрно-белого изображения каждый пиксель кодируется одним битом. К примеру, чёрный цвет — 0, а белый — 1)
Наше прошлое изображение можно закодировать так:
При кодировании нецветных изображений чаще всего применяют палитру из 256 оттенков серого, начиная от белого и заканчивая чёрным. Поэтому для кодирования такой градации достаточно одного байта (28=256).
Поэтому для кодирования такой градации достаточно одного байта (28=256).
В кодирования цветных изображений применяют несколько цветовых схем.
На практике, чаще применяют цветовую модель RGB, где соответственно используется три основных цвета: красный, зелёный и синий. Остальные цветовые оттенки получаются при смешивании этих основных цветов.
Таким образом, для кодирования модели из трёх цветов в 256 тонов, получается свыше 16,5 миллионов разных цветовых оттенков. То есть для кодирования применяют 3⋅8=24 бита, что соответствует 3 байтам.
Естественно, что можно использовать минимальное количество бит для кодирования цветных изображений, но тогда может быть образовано и меньшее количество цветовых тонов, в связи, с чем качество изображения существенно понизится.
Чтобы определить размер изображения нужно умножить количество пикселей в ширину на длину количество пикселей и ещё раз умножить на размер самого пикселя в байтах.
I=a*b*i
Где
- а — количество пикселей в ширину;
- b — количество пикселей в длину;
- I – размер одного пикселя в байтах.
К примеру, цветное изображение размером 800⋅600 пикселей, занимает 60000 байт.
Векторная графика
Объекты векторной графики кодируются совершенно по-другому. Здесь изображение состоит из линий, которые могут иметь свои коэффициенты кривизны.
Стандарты кодирования звука
Звуки, которые слышит человек, представляют собой колебания воздуха. Звуковые колебания – это процесс распространения волн.
Звук имеет две основные характеристики:
- амплитуда колебаний – определяет громкость звука;
- частота колебания — определяет тональность звука.
Звук можно преобразовать в электрический сигнал, с помощью микрофона. Звук кодируется с определенным, заранее заданным интервалом времени. В этом случае измеряется размер электрического сигнала и присваивается бинарная величина. Чем чаще делают данные измерения, тем выше качество звука.
Звук кодируется с определенным, заранее заданным интервалом времени. В этом случае измеряется размер электрического сигнала и присваивается бинарная величина. Чем чаще делают данные измерения, тем выше качество звука.
Компакт-диск объемом 700 Мб, вмещает порядка 80 минут звука CD-качества.
Стандарты кодирования видео
Как вы знаете, видеоряд состоит из быстро меняющихся фрагментов. Смена кадров происходит со скоростью в интервале 24-60 кадров в секунду.
Размер видеоряда в байтах определяется размером кадра (количеством пикселей на экран по высоте и ширине), количеством используемых цветов, а также количеством кадров в секунду. Но наряду с этим может присутствовать ещё и звуковая дорожка.
Глоссарий по информатике Система счисления
Что это такое и почему это важно?
Когда цифровое онлайн-содержимое переводится с одного языка на другой, могут возникнуть неприятные и распространенные побочные эффекты, когда это переведенное содержимое переносится на другой носитель.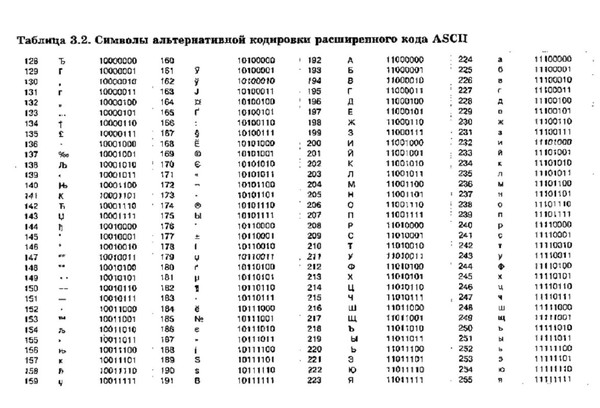
Простые предложения, содержащие буквы с диакритическими знаками или специальное форматирование, могут выглядеть искаженными при копировании из одного файла в другой. Определенные символы и элементы пунктуации обычно отображаются как последовательность вопросительных знаков или случайных нестандартных символов.
Почему это происходит? Кодировка символов.
Что такое кодировка символов ?Кодировка символов сообщает компьютерам, как интерпретировать цифровые данные в буквы, цифры и символы. Это делается путем присвоения определенного числового значения букве, цифре или символу. Эти буквы, цифры и символы классифицируются как «символы». Символы сгруппированы в определенные «наборы символов» или «репертуары», которые связывают каждый из них с числовым значением, называемым «кодовой точкой». Затем эти символы сохраняются в виде одного или нескольких байтов.
Когда вы вводите символы с клавиатуры или другими способами, кодировка символов сопоставляет их с соответствующими байтами в памяти компьютера.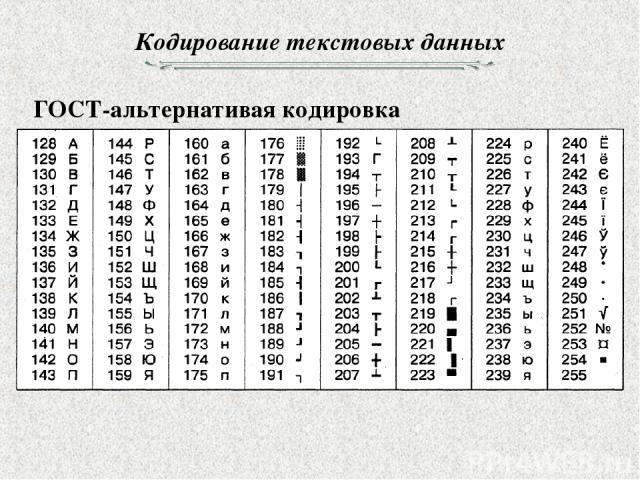 Это позволяет компьютеру правильно отображать символы. Без правильной кодировки компьютер не сможет понять символы и отобразить правильную информацию.
Это позволяет компьютеру правильно отображать символы. Без правильной кодировки компьютер не сможет понять символы и отобразить правильную информацию.
Для правильного отображения переведенного цифрового содержимого необходимо использовать правильную кодировку символов. Например, текст со специальными символами должен выглядеть так:
Кодировка символов 101 по Kaðlín Örvardóttir
может отображаться следующим образом:
Кодировка символов 101 по Ka▯l?n ▯rvard?ttir
, а затем несколько советов по истории наборов символов, а затем несколько советов по истории правильно использовать их для ваших проектов перевода веб-сайта. Типы кодирования символов До начала 1960-х годов программисты создавали специальные соглашения для внутреннего представления символов. Некоторые компьютеры различали прописные и строчные буквы, но большинство этого не делало. Этот метод работал, потому что информация обычно обрабатывалась от начала до конца на одной машине. Следовательно, не было необходимости в стандартизированной кодировке символов.
Следовательно, не было необходимости в стандартизированной кодировке символов.
Однако, как только обмен информацией стал важным фактором, программистам понадобился стандартный код, позволяющий перемещать данные между различными моделями компьютеров. Это привело к разработке ASCII (американский стандартный код для обмена информацией).
ASCII
В 1963 году была установлена схема кодирования символов ASCII (Американский стандартный код для обмена информацией) как общий код, используемый для представления английских символов, где каждой букве присваивалось числовое значение от 0 до 127.
Большинство современных подмножеств кодировки символов основаны на схеме кодировки символов ASCII и поддерживают несколько дополнительных символов.
ANSI/Windows-1252
Когда в 1985 году появилась операционная система Windows, был быстро принят новый стандарт, известный как набор символов ANSI. Фраза «ANSI» также была известна как кодовые страницы Windows (кодовая страница 1252), хотя она не имела ничего общего с Американским национальным институтом стандартов.
Кодировка символов Windows-1252 или CP-1252 (кодовая страница 1252) стала популярной с появлением Microsoft Windows, но в конечном итоге была вытеснена, когда Unicode был реализован в Windows. Юникод, впервые выпущенный в 1991, присваивает универсальный код каждому знаку и символу для всех языков мира.
ISO-8859-1
Набор кодировок ISO-8859-1 (также известный как Latin-1) содержит все символы Windows-1252, включая расширенный набор знаков препинания и бизнес-символов. Этот стандарт можно было легко перенести на несколько текстовых процессоров и даже на недавно выпущенные версии HTML 4.
Первая редакция была опубликована в 1987 году и представляла собой прямое расширение набора символов ASCII. Хотя для своего времени поддержка была обширной, формат все еще был ограничен.
UTF-8
После дебюта ISO-8859-1 Консорциум Unicode перегруппировался для разработки более универсальных стандартов переносимого кодирования символов.
UTF-8 (8-битное преобразование Unicode) в настоящее время является наиболее широко используемым форматом кодировки символов в Интернете, поскольку он служит методом сопоставления в Unicode. UTF-8 была объявлена обязательной для содержимого веб-сайтов Рабочей группой по технологиям веб-гипертекстовых приложений, сообществом людей, заинтересованных в развитии стандарта HTML и связанных с ним технологий.
UTF-8 была объявлена обязательной для содержимого веб-сайтов Рабочей группой по технологиям веб-гипертекстовых приложений, сообществом людей, заинтересованных в развитии стандарта HTML и связанных с ним технологий.
UTF-8 был разработан для полной обратной совместимости с ASCII.
Почему важна кодировка символов?Итак, ясно, что каждый набор символов использует уникальную таблицу идентификационных кодов для представления пользователю определенного символа. Если вы использовали набор символов ISO-8859-1 для редактирования документа, а затем сохранили этот документ как документ в кодировке UTF-8, не заявляя, что содержимое соответствует кодировке UTF-8, специальные символы и бизнес-символы будут отображаться нечитаемыми.
Большинство современных веб-браузеров поддерживают устаревшие кодировки символов, поэтому веб-сайт может содержать страницы, закодированные в ISO-8859-1, Windows-1252 или любом другом типе кодировки. Браузер должен правильно отображать эти символы на основе формата кодировки символов, о котором не сообщает сервер.
Однако, если набор символов не объявлен правильно во время рендеринга страницы, веб-сервер по умолчанию обычно отступает без какого-либо определенного формата кодировки символов (обычно ASCII).
Это заставляет ваш браузер или мобильное устройство определять правильный тип кодировки символов страницы. Согласно спецификациям WHATWG, принятым W3C, наиболее типичным резервным вариантом по умолчанию является UTF-8. Однако некоторые браузеры возвращаются к ASCII.
Кодировка символов Советы и рекомендацииЧтобы ваши пользователи всегда видели правильный контент на ваших производственных страницах HTML, убедитесь, что: 8
Следование этим спецификациям упростит перевод веб-сайтов на различные языки без необходимости декодирования и повторного кодирования в другие кодировки символов в многоканальных медиа, которые сегодня используются в Интернете.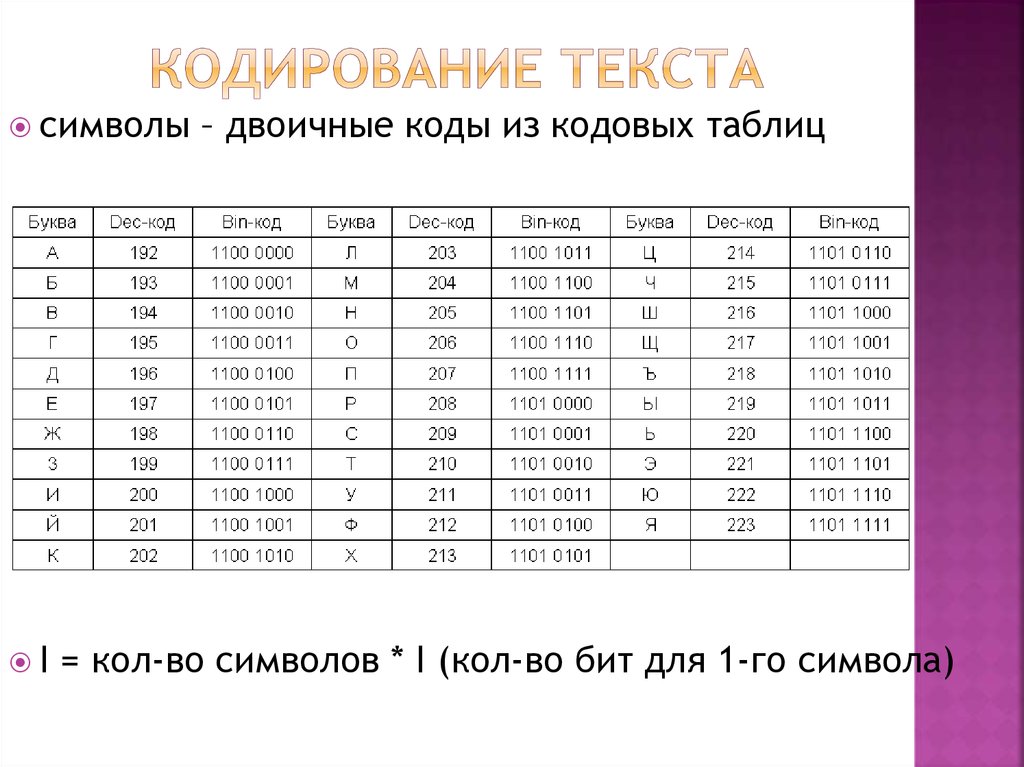
Хотя кодировка символов необходима для локализации веб-сайта, на самом деле она является частью процесса, известного как интернационализация. Интернационализация, часто сокращенная до i18n, позволяет приложениям вводить, обрабатывать и выводить международный текст. Для многоязычных веб-сайтов он обеспечивает успешную локализацию веб-страниц на целевые языки.
В 1990-х годах поддержка интернационализации означала, что приложение могло вводить, хранить и выводить данные в различных наборах символов и кодировках. Например, англоязычный пользователь может общаться с вами на латинице-1, а русскоязычный — на KOI8-R.
Тем не менее, эта система представляла несколько проблем, таких как невозможность представить данные из двух разных наборов пользователей на одной странице. Кроме того, каждый фрагмент данных должен быть помечен набором символов, в котором он хранится. Это означало, что HTML и все содержимое веб-страницы должны были выводиться с использованием правильного набора символов.
Последнее обновление: 13 июля 2022 г.
Кодировка символов сейчас
ASCII и UTF-8 — две современные системы кодирования текста. Оба объясняются в этом видео с участием Кейтлин Мерри.
Просмотреть расшифровку
2.3
В 1963 году был принят Американский стандартный код для обмена информацией или ASCII, чтобы информацию можно было переводить между компьютерами. Он был разработан для создания международного стандарта кодирования латинского алфавита; превращая двоичные числа в текст на экране вашего компьютера. ASCII кодирует символы в семь битов двоичных данных. Поскольку каждый бит может быть либо 1, либо 0, всего получается 128 возможных комбинаций. Каждое из этих двоичных чисел можно преобразовать в десятичное число от 0 до 127. Например, 1000001 в двоичном формате равняется 65 в десятом. В ASCII каждое десятичное число соответствует символу, который мы хотим закодировать. От прописных и строчных букв до цифр, символов и компьютерных команд.
От прописных и строчных букв до цифр, символов и компьютерных команд.
55.7
Например, 65 соответствует A в верхнем регистре. j в нижнем регистре равно 106 или 1101010 в двоичном формате. Или 0100001 равно 33, что кодирует символ восклицательного знака. Вот как hello кодируется в двоичный код с использованием ASCII. [H 1001000 E 1000101 L 1001100 L 1001100 O 1001111] Но что, если мы используем 8-битные байты? Мы просто ставим 0 перед двоичным числом. Итак, в 8-битном режиме привет выглядит так. Давайте посмотрим на все это на практике. На вашем компьютере откройте текстовый редактор Блокнот. Введите сообщение «Данные прекрасны» и сохраните его.
109.1
Посмотрите на размер файла. 18 байт. Теперь добавьте еще одно слово: Дейта такая красивая. Вы добавили три новых символа S, O и пробел. Если вы еще раз посмотрите на размер файла, то увидите, что он увеличился на 3 байта. Таким образом, ASCII использует 7 бит для представления 128 символов. Но когда были разработаны 8-битные компьютеры, дополнительная цифра означала, что теперь можно было закодировать 256 символов. Проблемы возникли, когда страны начали непоследовательно использовать эти дополнительные символы. Таким образом, разные числа представляли разные символы в разных языках. Япония создала несколько систем кодирования своего языка, которые различаются в зависимости от аппаратного обеспечения. Сообщения, отправляемые с одного японского компьютера на другой, становились искаженными и нечитаемыми, когда компьютер неправильно переводил данные.
Проблемы возникли, когда страны начали непоследовательно использовать эти дополнительные символы. Таким образом, разные числа представляли разные символы в разных языках. Япония создала несколько систем кодирования своего языка, которые различаются в зависимости от аппаратного обеспечения. Сообщения, отправляемые с одного японского компьютера на другой, становились искаженными и нечитаемыми, когда компьютер неправильно переводил данные.
161
Ошибки в преобразовании японских иероглифов стали такой проблемой, что у них даже есть название для этого, моджибаке. Эта проблема стала намного хуже с изобретением всемирной паутины. Для решения проблем, связанных с отправкой документов на разных языках по всему миру, был создан консорциум для создания всемирного стандарта Unicode. Как и в ASCII, в Unicode каждому символу присваивается определенный номер. Unicode также использует старую кодировку ASCII для английского языка. Таким образом, A в верхнем регистре по-прежнему равен 65. Но Unicode кодирует гораздо больше, чем 100 000 символов в большинстве языков. Для этого он использует не 8 бит данных, а 32. Но 65, закодированные в 32 бита, выглядят так, что занимает много места.
Но Unicode кодирует гораздо больше, чем 100 000 символов в большинстве языков. Для этого он использует не 8 бит данных, а 32. Но 65, закодированные в 32 бита, выглядят так, что занимает много места.
211.5
Кроме того, многие старые компьютеры интерпретируют восемь нулей подряд как конец строки символов, также называемый нулем. Это означает, что они не будут отправлять никаких символов, которые появятся позже. Метод кодирования Unicode, UTF8, решает эти проблемы. Вплоть до номера 127 значение ASCII остается неизменным. Так что A по-прежнему 01000001. Для всего, что выше 127, UTF8 разделяет код на два байта. Он добавляет 110 к первому байту и 10 ко второму байту. Затем вы просто заполняете двоичный код для промежуточных битов. Например, число 325 равно 00101000101, которое вставляется вот так. Это работает для первых 4,096 символов. После этого добавляется еще один байт.
268,2
И еще 1 добавляется в начале первого байта, вот так. Это дает вам 16 дополнительных битов для вашего двоичного кода.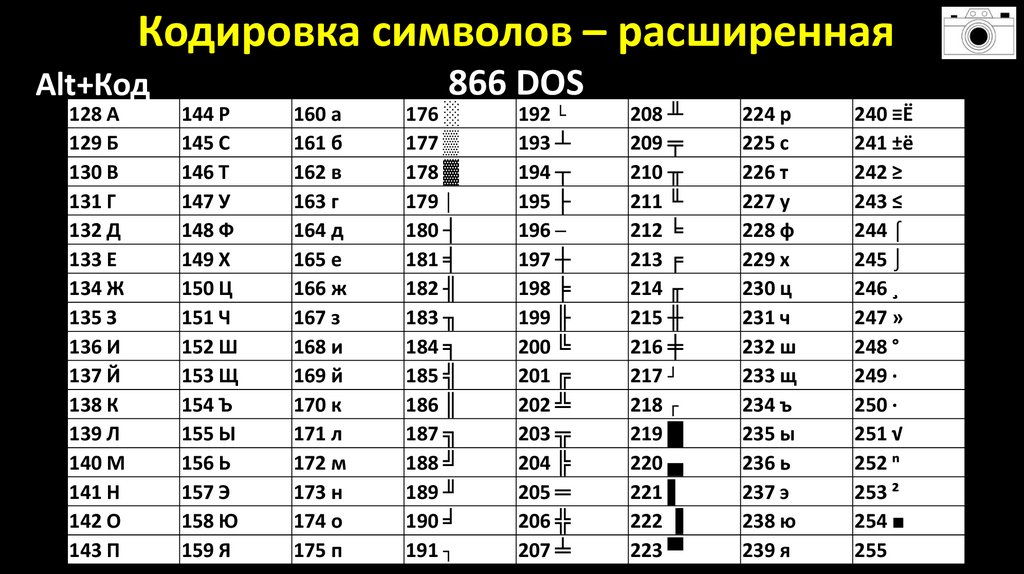 На самом деле вы можете получить до 7 байтов данных, которые выглядят так. Таким образом, UTF8 позволяет избежать проблемы с 8 нулями. И он обратно совместим со старой системой ASCII. И это краткое изложение ASCII и UTF8, двух важных стандартов, которые определяют, как символы кодируются из единиц и нулей в цифровой текст, который вы просматриваете каждый день.
На самом деле вы можете получить до 7 байтов данных, которые выглядят так. Таким образом, UTF8 позволяет избежать проблемы с 8 нулями. И он обратно совместим со старой системой ASCII. И это краткое изложение ASCII и UTF8, двух важных стандартов, которые определяют, как символы кодируются из единиц и нулей в цифровой текст, который вы просматриваете каждый день.
Два стандарта кодирования символов определяют, как символы расшифровываются из единиц и нулей в текст, который вы видите на экране прямо сейчас, и в различные языки, просматриваемые каждый день во всемирной паутине. Этими двумя стандартами кодирования являются ASCII и Unicode.
ASCII
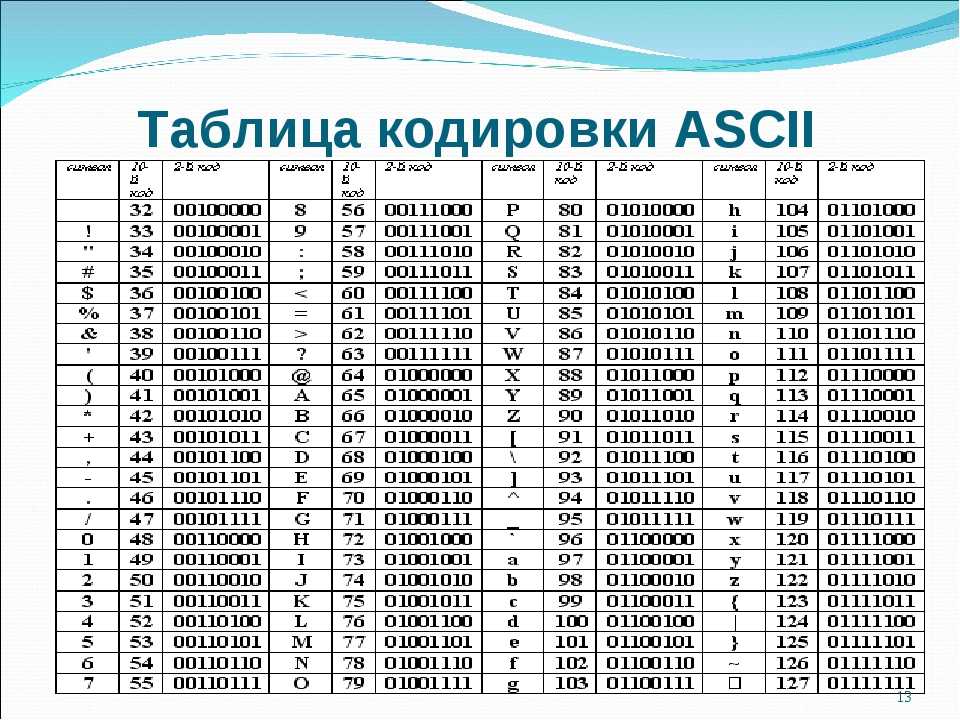
Американский стандартный код для обмена информацией (ASCII) был разработан для создания международного стандарта кодирования латинского алфавита. В 1963 году был принят ASCII, чтобы информацию можно было интерпретировать между компьютерами; представляющие строчные и заглавные буквы, цифры, символы и некоторые команды.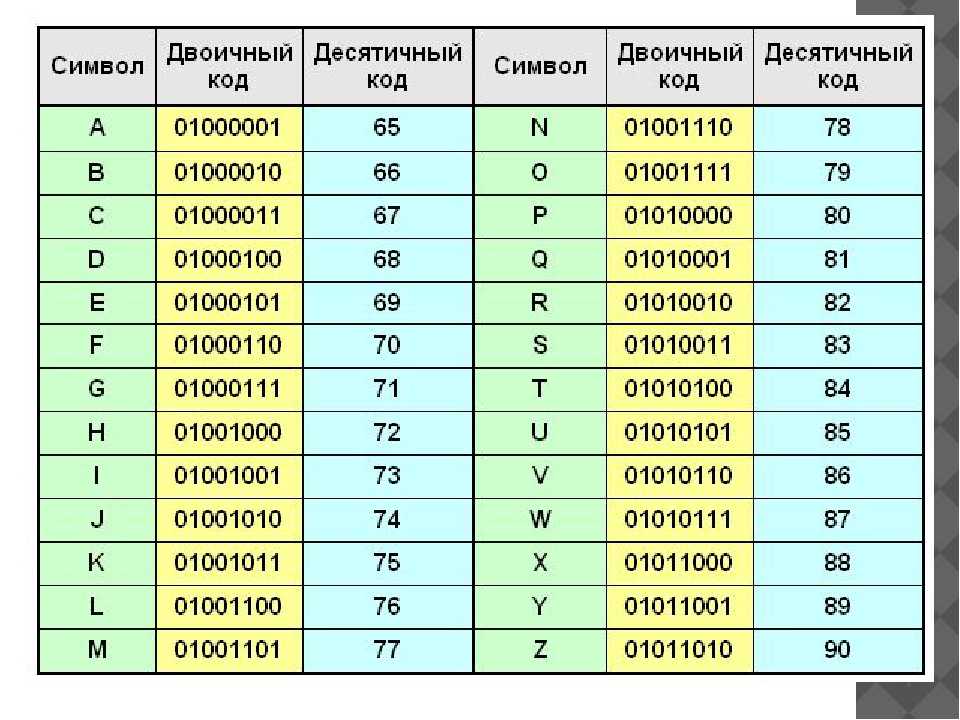 Поскольку ASCII кодируется с использованием единиц и нулей, системы счисления с основанием 2, он использует семь битов. Семь бит позволяют
Поскольку ASCII кодируется с использованием единиц и нулей, системы счисления с основанием 2, он использует семь битов. Семь бит позволяют 2 в степени 7 = 128 возможных комбинаций цифр для кодирования символа.
Таким образом,
ASCII обеспечил возможность кодирования 128 важных символов:
Как работает кодировка ASCII
- Вы уже знаете, как преобразовывать десятичные числа в двоичные
- Теперь вам нужно превратить буквы в двоичные числа
- Каждому символу соответствует десятичное число (например, A → 65)
- ASCII использует 7 бит
- Мы используем первые 7 столбцов таблицы преобразования для создания 128 различных чисел (от 0 до 127)
Например, 1000001 дает нам число 65 ( 64 + 1 ), которое соответствует букве «А».
| 64 | 32 | 16 | 8 | 4 | 2 | 1 |
|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 1 |
Вот как «HELLO» закодировано в ASCII в двоичном виде:
| Латинский символ | ASCII-код |
|---|---|
| Н | 1001000 |
| Е | 1000101 |
| Л | 1001100 |
| Л | 1001100 |
| О | 1001111 |
Применим эту теорию на практике:
- Откройте Блокнот или любой другой текстовый редактор, который вы предпочитаете
- Введите сообщение и сохраните его, например.
 «данные прекрасны»
«данные прекрасны» - Посмотрите на размер файла — у меня 18 байт
- Теперь добавьте еще одно слово, например. «данные такие красивые»
- Если вы еще раз посмотрите на размер файла, то увидите, что он изменился — теперь мой файл стал на 3 байта больше (SO[SPACE]: «S», «O» и пробел)
Unicode и UTF-8
Поскольку символы ASCII кодируются 7 битами, переход на 8-битную вычислительную технологию означал использование одного дополнительного бита. С этой дополнительной цифрой Расширенный код ASCII , закодированный до 256 символов. Однако возникшая проблема заключалась в том, что страны, использующие разные языки, по-разному использовали эту дополнительную возможность кодирования. Многие страны добавили свои собственные дополнительные символы, и разные числа представляли разные символы на разных языках. Япония даже создала несколько систем кодирования японского языка в зависимости от аппаратного обеспечения, и все эти методы были несовместимы друг с другом. Таким образом, когда сообщение было отправлено с одного компьютера на другой, полученное сообщение могло стать искаженным и нечитаемым; японские системы кодирования символов были настолько сложны, что даже когда сообщение было отправлено с одного типа японского компьютера на другой, происходило нечто, называемое «модзибаке»:
Таким образом, когда сообщение было отправлено с одного компьютера на другой, полученное сообщение могло стать искаженным и нечитаемым; японские системы кодирования символов были настолько сложны, что даже когда сообщение было отправлено с одного типа японского компьютера на другой, происходило нечто, называемое «модзибаке»:
Проблема несовместимых систем кодирования стала более актуальной с изобретением Всемирной паутины, поскольку люди обменивались цифровыми документами по всему миру, используя несколько языков. Чтобы решить эту проблему, Консорциум Unicode создал универсальную систему кодирования под названием Unicode . Юникод кодирует более 100 000 символов, охватывая все символы, которые вы найдете в большинстве языков. Unicode присваивает каждому символу определенное число, а не двоичную цифру. Но были некоторые проблемы с этим, например:
- Для кодирования 100 000 символов потребуется около 32 двоичных разрядов.
 Unicode использует ASCII для английского языка, поэтому A по-прежнему равно 65. Однако при 32-битной кодировке буква A будет двоичным представлением 00000000000000000000000000000000000001000001. Это тратит впустую много ценного пространства!
Unicode использует ASCII для английского языка, поэтому A по-прежнему равно 65. Однако при 32-битной кодировке буква A будет двоичным представлением 00000000000000000000000000000000000001000001. Это тратит впустую много ценного пространства! - Многие старые компьютеры интерпретируют восемь нулей подряд (ноль) как конец строки символов. Таким образом, эти компьютеры не будут отправлять символы, следующие за восемью нулями подряд (они не будут отправлять букву A, если она представлена как 00000000000000000000000000000000000001000001).
Метод кодирования Unicode UTF-8 решает следующие проблемы:
— до символа с номером 128 используется обычное значение ASCII (например, A — 01000001)
— для любого символа после 128 кодировка UTF-8 разделяет код в два байта и добавление «110» к началу первого байта, чтобы показать, что это начальный байт, и «10» к началу второго байта, чтобы показать, что он следует за первым байтом.
Итак, для каждого символа после числа 128 у вас есть два байта:
[110xxxxx] [10xxxxxx]
И вы просто заполните двоичный код для числа между ними:
[11000101] [10000101] (это число 325 → 00101000101)
Это работает для первых 2048 символов. Для символов сверх этого добавляется еще одна «1» в начале первого байта, а также используется третий байт:
Для символов сверх этого добавляется еще одна «1» в начале первого байта, а также используется третий байт:
[1110xxxx] [10xxxxxx] [10xxxxxx]
Это дает вам 16 пробелов для двоичного кода. Таким образом, UTF-8 достигает четырех байтов:
[11110xxx] [10xxxxxx] [10xxxxxx] [10xxxxxx]
Таким образом, UTF-8 позволяет избежать проблем, упомянутых выше, а также необходимости индекса, и позволяет декодировать символы из двоичной формы в обратном порядке (т.е. имеет обратную совместимость).
Занятия в классе
Есть много занимательных занятий по обучению кодированию символов. Мы включили два упражнения ниже, чтобы вы могли попробовать их в своем классе. Какие у вас есть главные советы по обучению кодированию символов? Поделитесь ими в комментариях!
Перевод секретных сообщений : опубликовать короткое секретное сообщение в ASCII в разделе комментариев, а также перевести или ответить на ASCII-сообщения других участников
Бинарные браслеты : создавайте браслеты, используя разноцветные бусины для обозначения единиц и нулей и написания инициала или имени в ASCII.
