Как кодируется текстовая информация в компьютере
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Вспомним некоторые известные нам факты:
Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации: N = 2 b ,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт — наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
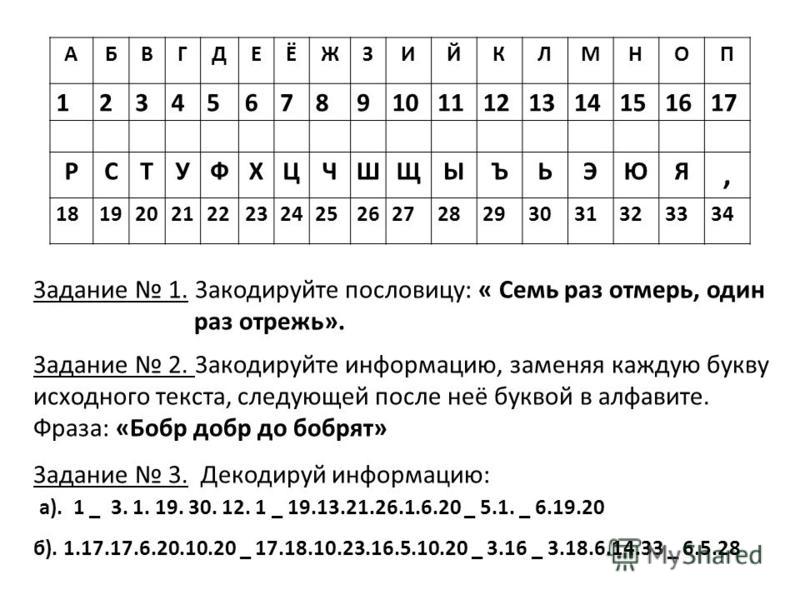
Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Порядковый номер
Символ
0 — 31
00000000 — 00011111
Символы с номерами от 0 до 31 принято называть управляющими.
Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п.
32 — 127
00100000 — 01111111
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы.
Символ 32 — пробел, т.е. пустая позиция в тексте.
Все остальные отражаются определенными знаками.
128 — 255
10000000 — 11111111
Альтернативная часть таблицы (русская).
Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер.
Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.
Первая половина таблицы кодов ASCII
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
Вторая половина таблицы кодов ASCII
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 («CP» означает «Code Page», «кодовая страница»).
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Содержание
Введение
Для того чтобы сохранить информацию, ее надо закодировать. Любая информация всегда хранится в виде кодов.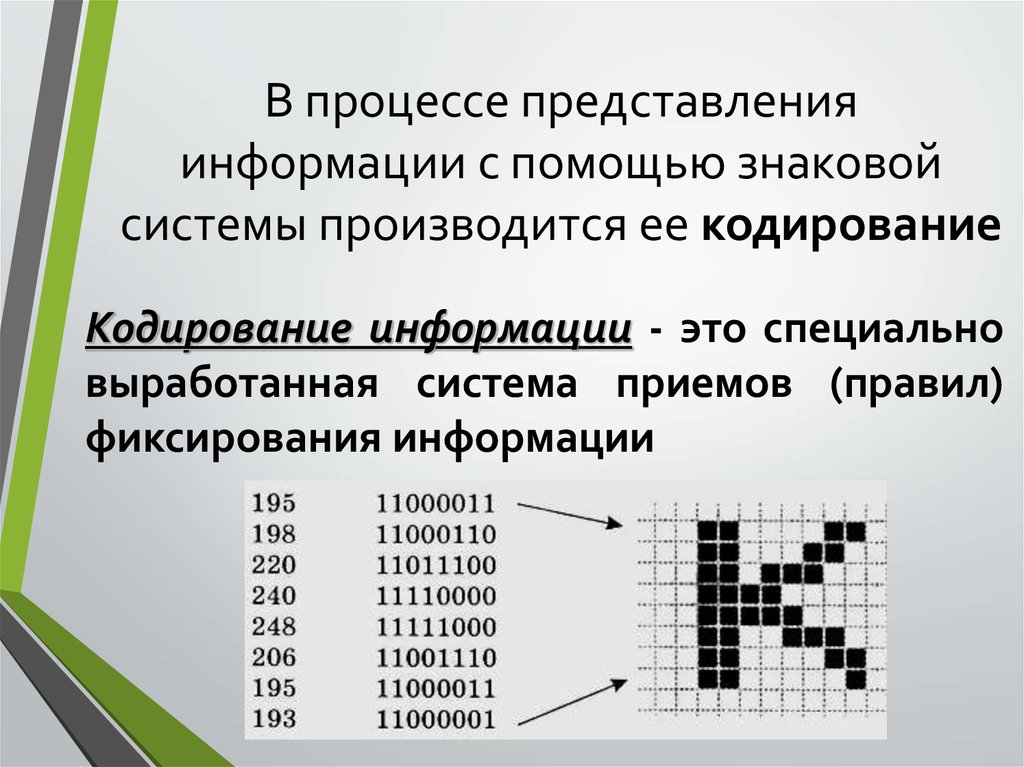
Код — набор условных обозначений для представления информации.
Кодирование — процесс представления информации в виде кода.
Для общения друг с другом мы используем код — русский язык. При разговоре этот код передается звуками, при письме — буквами.
Водитель передает сигнал с помощью гудка или миганием фар. Вы встречаетесь с кодированием информации при переходе дороги в виде сигналов светофора.
Закодировать можно и звуковую информацию: для этого существует особый метод кодирования — нотная грамота.
Та же проблема универсального средства кодирования достаточно успешно реализуется в отдельных отраслях техники, науки и культуры.
В качестве примеров можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых и многое другое.
Таким образом, кодирование сводится к использованию совокупности символов по строго определенным правилам.
Кодировать информацию можно различными способами: устно; письменно; жестами или сигналами любой другой природы.
В качестве единицы информации условились принять один бит (английский bit — binary, digit — двоичная цифра).
Бит в теории информации — количество информации, необходимое для различения двух равновероятных сообщений.
В вычислительной технике битом называют наименьшую ;порцию; памяти компьютера, необходимую для хранения одного из двух знаков ;0; и ;1;, используемых для внутри машинного представления данных и команд.
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и тому подобное).
Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
Тремя битами можно закодировать восемь различных значений:
000 001 010 011 100 101 110 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть общая формула имеет вид:
где N — количество независимых кодируемых значений; m — разрядность двоичного кодирования, принятая в данной системе.
Бит — слишком мелкая единица измерения. На практике чаще применяется более крупная единица — байт, равная восьми битам.
Именно восемь битов требуется для того, чтобы закодировать любой из 256 символов алфавита клавиатуры компьютера:
Широко используются также еще более крупные производные единицы информации:
В последнее время в связи с увеличением объемов обрабатываемой информации входят в употребление такие производные единицы, как:
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию.
Для хранения двоичного кода одного символа выделен 1 байт=8 бит.
Учитывая, что каждый бит принимает значение 0 или 1, количество их возможных сочетаний в байте равно:
Значит, с помощью 1 байта можно получить 256 разных двоичных кодовых комбинаций и отобразить с их помощью 256 различных символов.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и так далее
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111.
Таким образом, человек различает символы по их начертанию, а компьютер — по их коду.
Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице.
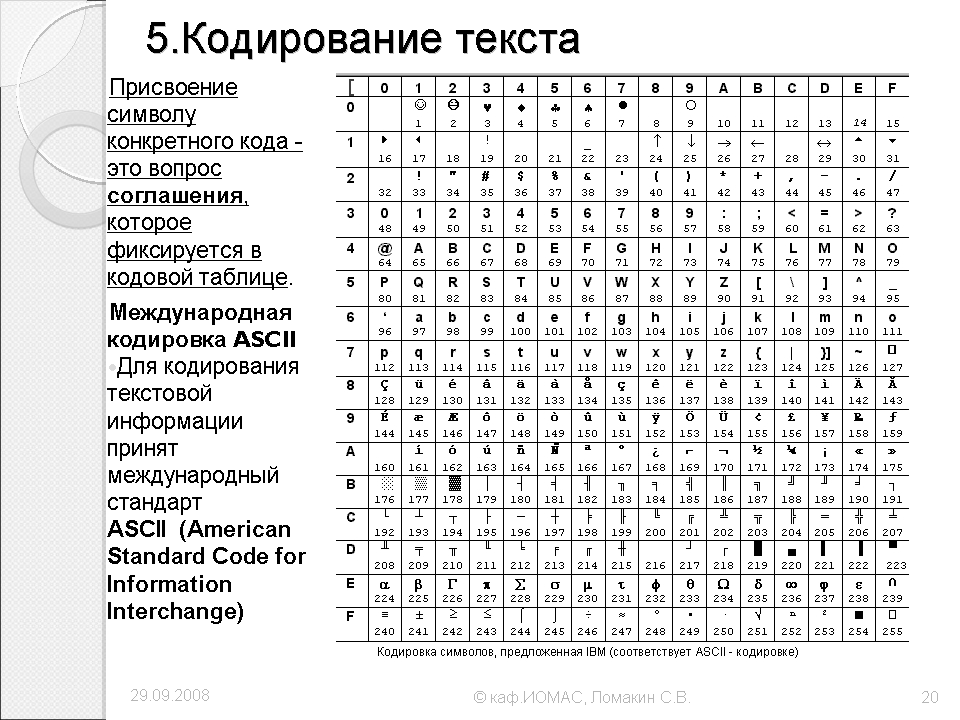
Кодирование текстовой информации с помощью байтов опирается на несколько различных стандартов, но первоосновой для всех стал стандарт ASCII (American Standart Code for Information Interchange), разработанный в США в Национальном институте ANSI (American National Standarts Institute).
В системе ASCII закреплены две таблицы кодирования — базовая и расширенная.
Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 33 кода (с 0 до 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и так далее).
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, то есть в национальных кодировках одному и тому же коду соответствуют различные символы.
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые, в свою очередь, содержат определенное количество точек (пикселей).
Каждому пикселю присвоен код, хранящий информацию о цвете пикселя.
Для получения черно-белого изображения (без полутонов) пиксель может принимать только два состояния: «белый» или «черный».
Тогда для его кодирования достаточно 1 бита: 1 — белый, 0 — черный.
Пиксель на цветном дисплее может иметь различную окраску. Поэтому 1 бита на пиксель — недостаточно.
Для кодирования 4-цветного изображения требуется два бита на пиксель, поскольку два бита могут принимать 4 различных состояния.
Может использоваться, например, такой вариант кодировки цветов:
Цветное изображение на экране монитора формируется за счет смешивания трех базовых цветов: красного, зеленого, синего.
Из трех цветов можно получить восемь комбинаций:
- Черный — 0 0 0
- Синий — 0 0 1
- Зеленый — 0 1 0
- Голубой — 0 1 1
- Красный — 1 0 0
- Розовый — 1 0 1
- Коричневый — 1 1 0
- Белый — 1 1 1
Следовательно, для кодирования 8-цветного изображения требуется три бита памяти на один пиксель.
Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности, тогда количество различных вариантов их сочетаний, дающих разные краски и оттенки, увеличивается.
Шестнадцатицветная палитра получается при использовании 4-разрядной кодировки пикселя: к трем битам базовых цветов добавляется один бит интенсивности. Этот бит управляет яркостью всех трех цветов одновременно.
Также графическая информация может быть представлена в виде векторного изображения.
Векторное изображение представляет собой графический объект, состоящий из элементарных отрезков и дуг.
Положение этих элементарных объектов определяется координатами точек и длиной радиуса.
Для каждой линии указывается ее тип (сплошная, пунктирная, штрих-пунктирная), толщина и цвет.
Информация о векторном изображении кодируется как обычная буквенно-цифровая и обрабатывается специальными программами.
Качество изображения определяется разрешающей способностью монитора, то есть количеством точек, из которых оно складывается.
Чем больше разрешающая способность, то есть чем больше количество строк растра и точек в строке, тем выше качество изображение.
Звук представляет собой звуковую волну с непрерывно меняющейся амплитудой и частотой.
Чем больше амплитуда, тем он громче для человека, чем больше частота сигнала, тем выше тон.
Программное обеспечение компьютера в настоящее время позволяет непрерывный звуковой сигнал преобразовывать в последовательность электрических импульсов, которые можно представить в двоичной форме.
Аудиоадаптер (звуковая плата) — специальное устройство, подключаемое к компьютеру, предназначенное для преобразования электрических колебаний звуковой частоты в числовой двоичный код при вводе звука и для обратного преобразования (из числового кода в электрические колебания) при воспроизведении звука.
В процессе записи звука аудиоадаптер с определенным периодом измеряет амплитуду электрического тока и заносит в регистр двоичный код полученной величины.
Затем полученный код из регистра переписывается в оперативную память компьютера.
Качество компьютерного звука определяется характеристиками аудиоадаптера: частотой дискретизации и разрядностью.
Где и как найти информацию о себе, и как удалить те данные, которые вы не хотите оставить общедоступными
Описание нескольких основных способов поиска информации на просторах Интернет для лучшего результата
Информацио о некоторых полезных сайтах, при помощи которых можно найти необходимую информацию
Статья о том, что большую часть информации о себе люди предоставляют сами, не всегда задумываясь о том, нужно ли это делать
Кодирование текстовой информации в компьютере – порой неотъемлемое условие корректной работы устройства или отображения того или иного фрагмента. Как происходит этот процесс в ходе работы компьютера с текстом и визуальной информацией, звуком – все это мы разберем в данной статье.
Вступление
Электронная вычислительная машина (которую мы в повседневной жизни называем компьютером) воспринимает текст весьма специфично. Для нее кодирование текстовой информации очень важно, поскольку она воспринимает каждый текстовый фрагмент в качестве группы обособленных друг от друга символов.
Для нее кодирование текстовой информации очень важно, поскольку она воспринимает каждый текстовый фрагмент в качестве группы обособленных друг от друга символов.
Какие бывают символы?
В роли символов для компьютера выступают не только русские, английские и другие буквы, но и еще знаки препинания, а также другие знаки. Даже пробел, которым мы разделяем слова при печатании на компьютере, устройство воспринимает как символ. Чем-то очень напоминает высшую математику, ведь там, по мнению многих профессоров, ноль имеет двойное значение: он и является числом, и одновременно ничего не обозначает. Даже для философов вопрос пробела в тексте может стать актуальной проблемой. Шутка, конечно, но, как говорится, в каждой шутке есть доля правды.
Итак, для восприятия информации компьютеру необходимо запустить процессы обработки. А какая вообще бывает информация? Темой этой статьи является кодирование текстовой информации. Мы уделим особенное внимание этой задаче, но разберемся и с другими микротемами.
Информация может быть текстовой, числовой, звуковой, графической. Компьютер должен запустить процессы, обеспечивающие кодирование текстовой информации, чтобы вывести на экран то, что мы, например, печатаем на клавиатуре. Мы будем видеть символы и буквы, это понятно. А что же видит машина? Она воспринимает абсолютно всю информацию – и речь сейчас идет не только о тексте – в качестве определенной последовательности нулей и единиц. Они составляют основу так называемого двоичного кода. Соответственно, процесс, который преобразует поступающую на устройство информацию в понятную ему, имеет название “двоичное кодирование текстовой информации”.
Краткий принцип действия двоичного кода
Почему наибольшее распространение в электронных машинах получило именно кодирование информации двоичным кодом? Текстовой основой, которая кодируется при помощи нулей и единиц, может быть абсолютно любая последовательность символов и знаков. Однако это не единственное преимущество, которое имеет двоичное текстовое кодирование информации. Все дело в том, что принцип, на котором устроен такой способ кодирования, очень прост, но в то же время достаточно функционален. Когда есть электрический импульс, его маркируют (условно, конечно) единицей. Нет импульса – маркируют нулем. То есть текстовое кодирование информации базируется на принципе построения последовательности электрических импульсов. Логическая последовательность, составленная из символов двоичного кода, называется машинным языком. В то же время кодирование и обработка текстовой информации при помощи двоичного кода позволяют осуществлять операции за достаточно краткий промежуток времени.
Все дело в том, что принцип, на котором устроен такой способ кодирования, очень прост, но в то же время достаточно функционален. Когда есть электрический импульс, его маркируют (условно, конечно) единицей. Нет импульса – маркируют нулем. То есть текстовое кодирование информации базируется на принципе построения последовательности электрических импульсов. Логическая последовательность, составленная из символов двоичного кода, называется машинным языком. В то же время кодирование и обработка текстовой информации при помощи двоичного кода позволяют осуществлять операции за достаточно краткий промежуток времени.
Биты и байты
Цифра, воспринимаемая машиной, кроет в себе некоторое количество информации. Оно равно одному биту. Это касается каждой единицы и каждого нуля, которые составляют ту или иную последовательность зашифрованной информации.
Соответственно, количество информации в любом случае можно определить, просто зная количество символов в последовательности двоичного кода. Они будут численно равны между собой. 2 цифры в коде несут в себе информацию объемом в 2 бита, 10 цифр – 10 бит и так далее. Принцип определения информационного объема, который кроется в том или ином фрагменте двоичного кода, достаточно прост, как вы видите.
Они будут численно равны между собой. 2 цифры в коде несут в себе информацию объемом в 2 бита, 10 цифр – 10 бит и так далее. Принцип определения информационного объема, который кроется в том или ином фрагменте двоичного кода, достаточно прост, как вы видите.
Вот сейчас вы читаете статью, которая состоит из последовательности, как мы считаем, букв алфавита русского языка. А компьютер, как говорилось ранее, воспринимает всю информацию (и в данном случае тоже) в качестве последовательности не букв, а нулей и единиц, обозначающих отсутствие и наличие электрического импульса.
Все дело в том, что закодировать один символ, который мы видим на экране, можно при помощи условной единицы измерения, называемой байтом. Как написано выше, у двоичного кода есть так называемая информационная нагрузка. Напомним, что численно она равняется суммарному количеству нулей и единиц в выбранном фрагменте кода. Так вот, 8 бит составляют 1 байт. Комбинации сигналов при этом могут быть самыми разными, как это легко можно заметить, нарисовав на бумаге прямоугольник, состоящий из 8 ячеек равного размера.
Выходит, что закодировать текстовую информацию можно при помощи алфавита, имеющего мощность 256 символов. В чем заключается суть? Смысл кроется в том, что каждый символ будет обладать своим двоичным кодом. Комбинации, “привязываемые” к определенным символам, начинаются от 00000000 и заканчиваются 11111111. Если переходить от двоичной к десятичной системе счисления, то кодировать информацию в такой системе можно от 0 до 255.
Не стоит забывать о том, что сейчас есть различные таблицы, которые используют кодировку букв русского алфавита. Это, например, ISO и КОИ-8, Mac и CP в двух вариациях: 1251 и 866. Легко убедиться в том, что текст, закодированный в одной из таких таблиц, не отобразится корректно в отличной от данной кодировке. Это происходит из-за того, что в разных таблицах к одному и тому же двоичному коду соответствуют различные символы.
Поначалу это было проблемой. Однако в настоящее время в программах уже встроены специальные алгоритмы, которые конвертируют текст, приводя его к корректному виду. 1997 год ознаменовался созданием кодировки под названием Unicode. В ней каждый символ имеет в своем распоряжении сразу 2 байта. Это позволяет закодировать текст, имеющий гораздо большее количество символов. 256 и 65536: есть ведь разница?
1997 год ознаменовался созданием кодировки под названием Unicode. В ней каждый символ имеет в своем распоряжении сразу 2 байта. Это позволяет закодировать текст, имеющий гораздо большее количество символов. 256 и 65536: есть ведь разница?
Кодирование графики
Кодирование текстовой и графической информации имеет некоторые схожие моменты. Как известно, для вывода графической информации используется периферийное устройство компьютера под названием “монитор”. Графика сейчас (речь идет сейчас именно о компьютерной графике) широко используется в самых разных сферах. Благо, аппаратные возможности персональных компьютеров позволяют решать достаточно сложные графические задачи.
Обрабатывать видеоинформацию стало возможным в последние годы. Но текст при этом значительно “легче” графики, что, в принципе, понятно. Из-за этого конечный размер файлов графики необходимо увеличивать. Преодолеть подобные проблемы можно, зная суть, в которой представляется графическая информация.
Давайте для начала разберемся, на какие группы подразделяется данный вид информации.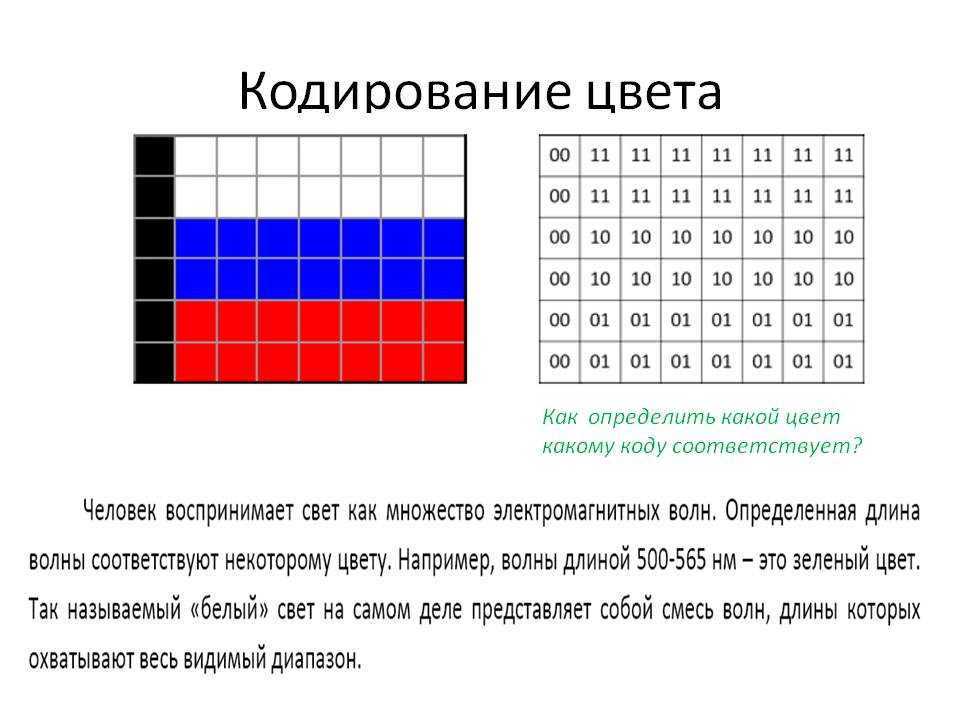 Во-первых, это растровая. Во-вторых, векторная.
Во-первых, это растровая. Во-вторых, векторная.
Растровые изображения достаточно схожи с клетчатой бумагой. Каждая клетка на такой бумаге закрашивается тем или иным цветом. Такой принцип чем-то напоминает мозаику. То есть получается, что в растровой графике изображение разбивается на отдельные элементарные части. Их именуют пикселями. В переводе на русский язык пиксели обозначают “точки”. Логично, что пиксели упорядочены относительно строк. Графическая сетка состоит как раз из определенного количества пикселей. Ее также называют растром. Принимая во внимание эти два определения, можно сказать, что растровое изображение является не чем иным, как набором пикселей, которые отображаются на сетке прямоугольного типа.
Растр монитора и размер пикселя влияют на качество изображения. Оно будет тем выше, чем больше растр у монитора. Размеры растра — это разрешение экрана, о котором наверняка слышал каждый пользователь. Одной из наиболее важных характеристик, которые имеют экраны компьютера, является разрешающая способность, а не только разрешение. Оно показывает, сколько пикселей приходится на ту или иную единицу длины. Обычно разрешающая способность монитора измеряется в пикселях на дюйм. Чем больше пикселей будет приходиться на единицу длины, тем выше будет качество, поскольку “зернистость” при этом снижается.
Оно показывает, сколько пикселей приходится на ту или иную единицу длины. Обычно разрешающая способность монитора измеряется в пикселях на дюйм. Чем больше пикселей будет приходиться на единицу длины, тем выше будет качество, поскольку “зернистость” при этом снижается.
Обработка звукового потока
Кодирование текстовой и звуковой информации, как и другие виды кодирования, имеет некоторые особенности. Речь сейчас пойдет о последнем процессе: кодировании звуковой информации.
Представление звукового потока (как и отдельного звука) может быть произведено при помощи двух способов.
При этом величина может принимать действительно огромное количество различных значений. Причем эти самые значения не остаются постоянными: они очень быстро изменяются, и этот процесс непрерывен.
Если же говорить о дискретном способе, то в этом случае величина может принимать только ограниченное количество значений. При этом изменение происходит скачкообразно. Закодировать дискретно можно не только звуковую, но и графическую информацию. Что касается и аналоговой формы, кстати.
Что касается и аналоговой формы, кстати.
Аналоговая звуковая информация хранится на виниловых пластинках, например. А вот компакт-диск уже является дискретным способом представления информации звукового характера.
В самом начале мы говорили о том, что компьютер воспринимает всю информацию на машинном языке. Для этого информация кодируется в форме последовательности электрических импульсов – нулей и единиц. Кодирование звуковой информации не является исключением из этого правила. Чтобы обработать на компьютере звук, его для начала нужно превратить в ту самую последовательность. Только после этого над потоком или единичным звуком могут совершаться операции.
Когда происходит процесс кодирования, поток подвергается временной дискретизации. Звуковая волна непрерывна, она развивается на малые участки времени. Значение амплитуды при этом устанавливается для каждого определенного интервала отдельно.
Заключение
Итак, что же мы выяснили в ходе данной статьи? Во-первых, абсолютно вся информация, которая выводится на монитор компьютера, прежде чем там появиться, подвергается кодированию. Во-вторых, это кодирование заключается в переводе информации на машинный язык. В-третьих, машинный язык представляет собой не что иное, как последовательность электрических импульсов – нулей и единиц. В-четвертых, для кодирования различных символов существуют отдельные таблицы. И, в-пятых, представить графическую и звуковую информацию можно в аналоговом и дискретном виде. Вот, пожалуй, основные моменты, которые мы разобрали. Одной из дисциплин, изучающей данную область, является информатика. Кодирование текстовой информации и его основы объясняются еще в школе, поскольку ничего сложного в этом нет.
Во-вторых, это кодирование заключается в переводе информации на машинный язык. В-третьих, машинный язык представляет собой не что иное, как последовательность электрических импульсов – нулей и единиц. В-четвертых, для кодирования различных символов существуют отдельные таблицы. И, в-пятых, представить графическую и звуковую информацию можно в аналоговом и дискретном виде. Вот, пожалуй, основные моменты, которые мы разобрали. Одной из дисциплин, изучающей данную область, является информатика. Кодирование текстовой информации и его основы объясняются еще в школе, поскольку ничего сложного в этом нет.
HTML кодирование и декодирование
Кодировщик символов в HTML коды
Выберите кодировку
UTF-8windows-1251KOI8-Rcp866ISO-8859-5ISO-8859-1
Введите строку в одно из полей и нажмите соответствующую кнопку
Строка в нормальном виде
Строка в закодированном виде
Кодирование символов, имеющих специальное назначение в html
Кодирование символов, для которых есть мнемонические имена в html
Кодирование всех символов
Исключая диапазон latin1
Побайтное представление (дамп) HEXDECIMALBINARY
кодирование в base64
Основные возможности кодировщика
-
Выбор кодировки — нажатие на кнопку GO меняет кодировку страницы, но текст внутри окон: Cтрока в нормальнов виде и Cтрока в закодированном виде может меняться непредвиденным образом (вернее везде есть своя логика, но не совсем тревиальная).

- Кодирование символов, имеющих специальное назначение в html
— опция
заменяет символы
< > & » ‘ мнемоническими ссылками html, используется для безопасной вставки фрагмента html кода в виде текста в html страницу . - Кодирование символов, для которых есть мнемонические имена — опция заменяет все символы html, для которых определены мнемонические имена, их мнемоническими html ссылками, опция помогает быстро узнать название того или иного знака.
-
Кодирование всех символов — опция кодирует любые символы с помощью html ссылок с кодом символа (unicode).
 Так как отображение символов, заданных с
помощью html ccылок одинаково, в любых кодировках, то
эта опция позволяет получить кириллический текст,
не зависящий от установок кодовой страницы браузера. Если будет нажат значок Исключая диапазон latin1, то ASCII символы кодироваться не будут (первые 127 символов диапазона UNICODE). Эта опция позволяет шифровать содержимое HTML, не нарушая разметку.
Так как отображение символов, заданных с
помощью html ccылок одинаково, в любых кодировках, то
эта опция позволяет получить кириллический текст,
не зависящий от установок кодовой страницы браузера. Если будет нажат значок Исключая диапазон latin1, то ASCII символы кодироваться не будут (первые 127 символов диапазона UNICODE). Эта опция позволяет шифровать содержимое HTML, не нарушая разметку. - Побайтное представление — опция выдает байты строк, как в шестнадцатиричном представлении, так и в десятичном. Для мультибайтовой кодировки utf-8, каждый кириллический символ кодируется двумя байтами. Эта опция может быть полезна, для анализа строк и выявления неисправностей. Она совместима с режимом кодирования для URL.
- Кодирование в base64 — опция применяется для кодирования в MIME base64.
Теоретические основы кодирования и комментарии к работе программы читайте в статье о принципах работы html кодировщика.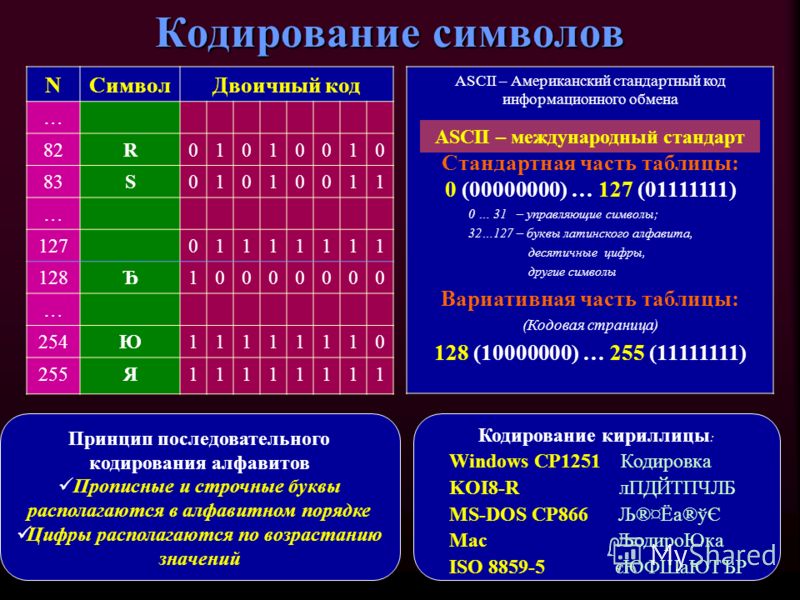 Для просмотра начального диапазона символов Unicode (первые 64К) можно воспользоваться динамической таблицей символов блоков Unicode.
Для изучения основ Unicode воспользуйтесь официальной документацией на Unicode (на английском).
Для просмотра начального диапазона символов Unicode (первые 64К) можно воспользоваться динамической таблицей символов блоков Unicode.
Для изучения основ Unicode воспользуйтесь официальной документацией на Unicode (на английском).
Что это такое и почему это важно?
Когда цифровое онлайн-содержимое переводится с одного языка на другой, могут возникнуть неприятные и распространенные побочные эффекты, когда это переведенное содержимое переносится на другой носитель.
Простые предложения, содержащие буквы с диакритическими знаками или специальное форматирование, могут выглядеть искаженными при копировании из одного файла в другой. Определенные символы и элементы пунктуации обычно отображаются как последовательность вопросительных знаков или случайных нестандартных символов.
Почему это происходит? Кодировка символов.
Что такое кодировка символов ? Кодировка символов сообщает компьютерам, как интерпретировать цифровые данные в буквы, цифры и символы. Это делается путем присвоения определенного числового значения букве, цифре или символу. Эти буквы, цифры и символы классифицируются как «символы». Символы сгруппированы в определенные «наборы символов» или «репертуары», которые связывают каждый из них с числовым значением, называемым «кодовой точкой». Затем эти символы сохраняются в виде одного или нескольких байтов.
Это делается путем присвоения определенного числового значения букве, цифре или символу. Эти буквы, цифры и символы классифицируются как «символы». Символы сгруппированы в определенные «наборы символов» или «репертуары», которые связывают каждый из них с числовым значением, называемым «кодовой точкой». Затем эти символы сохраняются в виде одного или нескольких байтов.
Когда вы вводите символы с клавиатуры или другими способами, кодировка символов сопоставляет их с соответствующими байтами в памяти компьютера. Это позволяет компьютеру правильно отображать символы. Без правильной кодировки компьютер не сможет понять символы и отобразить правильную информацию.
Для правильного отображения переведенного цифрового содержимого необходимо использовать правильную кодировку символов. Например, текст со специальными символами должен выглядеть так:
Кодировка символов 101 по Kaðlín Örvardóttir
может отображаться следующим образом:
Кодировка символов 101 по Ka▯l?n ▯rvard?ttir
, а затем несколько советов по истории наборов символов, а затем несколько советов по истории правильно использовать их для ваших проектов перевода веб-сайта. Типы кодирования символов
Типы кодирования символов До начала 1960-х годов программисты создавали специальные соглашения для внутреннего представления символов. Некоторые компьютеры различали прописные и строчные буквы, но большинство этого не делало. Этот метод работал, потому что информация обычно обрабатывалась от начала до конца на одной машине. Следовательно, не было необходимости в стандартизированной кодировке символов.
Однако, как только обмен информацией стал важным фактором, программистам понадобился стандартный код, позволяющий перемещать данные между различными моделями компьютеров. Это привело к разработке ASCII (американский стандартный код для обмена информацией).
ASCII
В 1963 году была установлена схема кодирования символов ASCII (Американский стандартный код для обмена информацией) как общий код, используемый для представления английских символов, где каждой букве присваивалось числовое значение от 0 до 127.
Большинство современных подмножеств кодировки символов основаны на схеме кодировки символов ASCII и поддерживают несколько дополнительных символов.
ANSI/Windows-1252
Когда в 1985 году появилась операционная система Windows, был быстро принят новый стандарт, известный как набор символов ANSI. Фраза «ANSI» также была известна как кодовые страницы Windows (кодовая страница 1252), хотя она не имела ничего общего с Американским национальным институтом стандартов.
Кодировка символов Windows-1252 или CP-1252 (кодовая страница 1252) стала популярной с появлением Microsoft Windows, но в конечном итоге была вытеснена, когда Unicode был реализован в Windows. Юникод, впервые выпущенный в 1991, присваивает универсальный код каждому знаку и символу для всех языков мира.
ISO-8859-1
Набор кодировок ISO-8859-1 (также известный как Latin-1) содержит все символы Windows-1252, включая расширенный набор знаков препинания и бизнес-символов. Этот стандарт можно было легко перенести на несколько текстовых процессоров и даже на недавно выпущенные версии HTML 4.
Первая редакция была опубликована в 1987 году и представляла собой прямое расширение набора символов ASCII. Хотя для своего времени поддержка была обширной, формат все еще был ограничен.
UTF-8
После дебюта ISO-8859-1 Консорциум Unicode перегруппировался для разработки более универсальных стандартов переносимого кодирования символов.
UTF-8 (8-битное преобразование Unicode) в настоящее время является наиболее широко используемым форматом кодировки символов в Интернете, поскольку он служит методом сопоставления в Unicode. UTF-8 была объявлена обязательной для содержимого веб-сайтов Рабочей группой по технологиям веб-гипертекстовых приложений, сообществом людей, заинтересованных в развитии стандарта HTML и связанных с ним технологий.
UTF-8 был разработан для полной обратной совместимости с ASCII.
Почему важна кодировка символов? Итак, ясно, что каждый набор символов использует уникальную таблицу идентификационных кодов для представления пользователю определенного символа. Если вы использовали набор символов ISO-8859-1 для редактирования документа, а затем сохранили этот документ как документ в кодировке UTF-8, не заявляя, что содержимое соответствует кодировке UTF-8, специальные символы и бизнес-символы будут отображаться нечитаемыми.
Если вы использовали набор символов ISO-8859-1 для редактирования документа, а затем сохранили этот документ как документ в кодировке UTF-8, не заявляя, что содержимое соответствует кодировке UTF-8, специальные символы и бизнес-символы будут отображаться нечитаемыми.
Большинство современных веб-браузеров поддерживают устаревшие кодировки символов, поэтому веб-сайт может содержать страницы, закодированные в ISO-8859-1, Windows-1252 или любом другом типе кодировки. Браузер должен правильно отображать эти символы на основе формата кодировки символов, о котором не сообщает сервер.
Однако, если набор символов не объявлен правильно во время рендеринга страницы, веб-сервер по умолчанию обычно отступает без какого-либо определенного формата кодировки символов (обычно ASCII).
Это заставляет ваш браузер или мобильное устройство определять правильный тип кодировки символов страницы. Согласно спецификациям WHATWG, принятым W3C, наиболее типичным резервным вариантом по умолчанию является UTF-8. Однако некоторые браузеры возвращаются к ASCII.
Однако некоторые браузеры возвращаются к ASCII.
Чтобы ваши пользователи всегда видели правильный контент на ваших производственных страницах HTML, убедитесь, что: 8
Следование этим спецификациям упростит перевод веб-сайтов на различные языки без необходимости декодирования и повторного кодирования в другие кодировки символов в многоканальных медиа, которые сегодня используются в Интернете.
Кодировка символов и локализация веб-сайта Хотя кодировка символов необходима для локализации веб-сайта, на самом деле она является частью процесса, известного как интернационализация.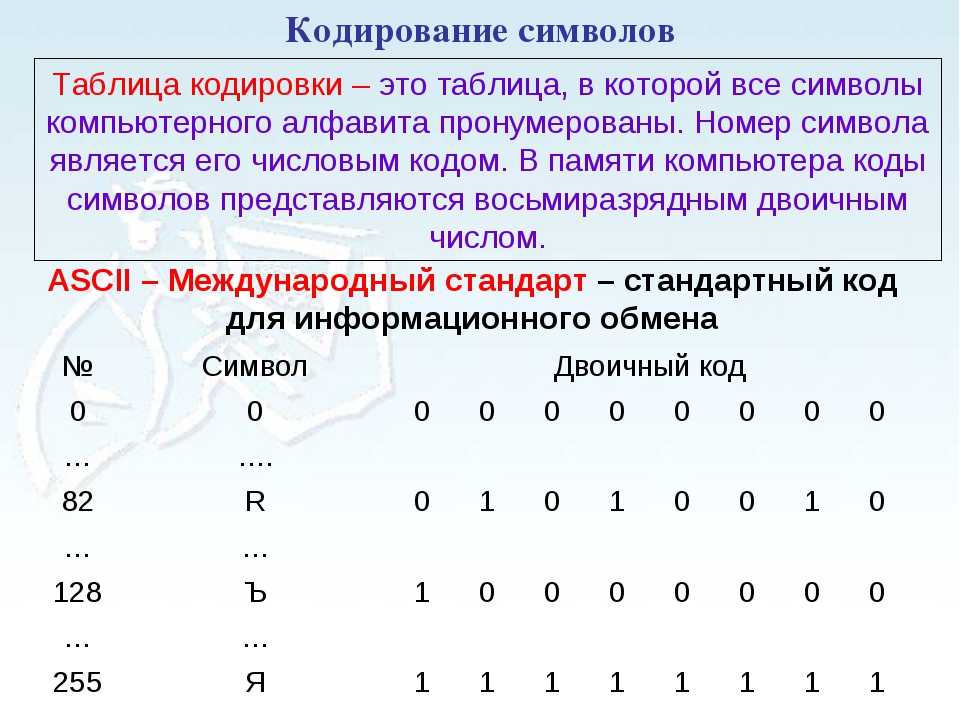 Интернационализация, часто сокращенная до i18n, позволяет приложениям вводить, обрабатывать и выводить международный текст. Для многоязычных веб-сайтов он обеспечивает успешную локализацию веб-страниц на целевые языки.
Интернационализация, часто сокращенная до i18n, позволяет приложениям вводить, обрабатывать и выводить международный текст. Для многоязычных веб-сайтов он обеспечивает успешную локализацию веб-страниц на целевые языки.
В 1990-х годах поддержка интернационализации означала, что приложение могло вводить, хранить и выводить данные в различных наборах символов и кодировках. Например, англоязычный пользователь может общаться с вами на латинице-1, а русскоязычный — на KOI8-R.
Тем не менее, эта система представляла несколько проблем, таких как невозможность представить данные из двух разных наборов пользователей на одной странице. Кроме того, каждый фрагмент данных должен быть помечен набором символов, в котором он хранится. Это означало, что HTML и все содержимое веб-страницы должны были выводиться с использованием правильного набора символов.
Последнее обновление: 13 июля 2022 г.
Кодировка символов сейчас
ASCII и UTF-8 — две современные системы кодирования текста. Оба объясняются в этом видео с участием Кейтлин Мерри.
Оба объясняются в этом видео с участием Кейтлин Мерри.
Просмотреть расшифровку
2.3
В 1963 году был принят Американский стандартный код для обмена информацией или ASCII, чтобы информацию можно было переводить между компьютерами. Он был разработан для создания международного стандарта кодирования латинского алфавита; превращая двоичные числа в текст на экране вашего компьютера. ASCII кодирует символы в семь битов двоичных данных. Поскольку каждый бит может быть либо 1, либо 0, всего получается 128 возможных комбинаций. Каждое из этих двоичных чисел можно преобразовать в десятичное число от 0 до 127. Например, 1000001 в двоичном формате равняется 65 в десятом. В ASCII каждое десятичное число соответствует символу, который мы хотим закодировать. От прописных и строчных букв до цифр, символов и компьютерных команд.
55.7
Например, 65 соответствует A в верхнем регистре. j в нижнем регистре равно 106 или 1101010 в двоичном формате. Или 0100001 равно 33, что кодирует символ восклицательного знака. Вот как hello кодируется в двоичный код с использованием ASCII. [H 1001000 E 1000101 L 1001100 L 1001100 O 1001111] Но что, если мы используем 8-битные байты? Мы просто ставим 0 перед двоичным числом. Итак, в 8-битном режиме привет выглядит так. Давайте посмотрим на все это на практике. На вашем компьютере откройте текстовый редактор Блокнот. Введите сообщение «Данные прекрасны» и сохраните его.
Вот как hello кодируется в двоичный код с использованием ASCII. [H 1001000 E 1000101 L 1001100 L 1001100 O 1001111] Но что, если мы используем 8-битные байты? Мы просто ставим 0 перед двоичным числом. Итак, в 8-битном режиме привет выглядит так. Давайте посмотрим на все это на практике. На вашем компьютере откройте текстовый редактор Блокнот. Введите сообщение «Данные прекрасны» и сохраните его.
109.1
Посмотрите на размер файла. 18 байт. Теперь добавьте еще одно слово: Дейта такая красивая. Вы добавили три новых символа S, O и пробел. Если вы еще раз посмотрите на размер файла, то увидите, что он увеличился на 3 байта. Таким образом, ASCII использует 7 бит для представления 128 символов. Но когда были разработаны 8-битные компьютеры, дополнительная цифра означала, что теперь можно было закодировать 256 символов. Проблемы возникли, когда страны начали непоследовательно использовать эти дополнительные символы. Таким образом, разные числа представляли разные символы в разных языках.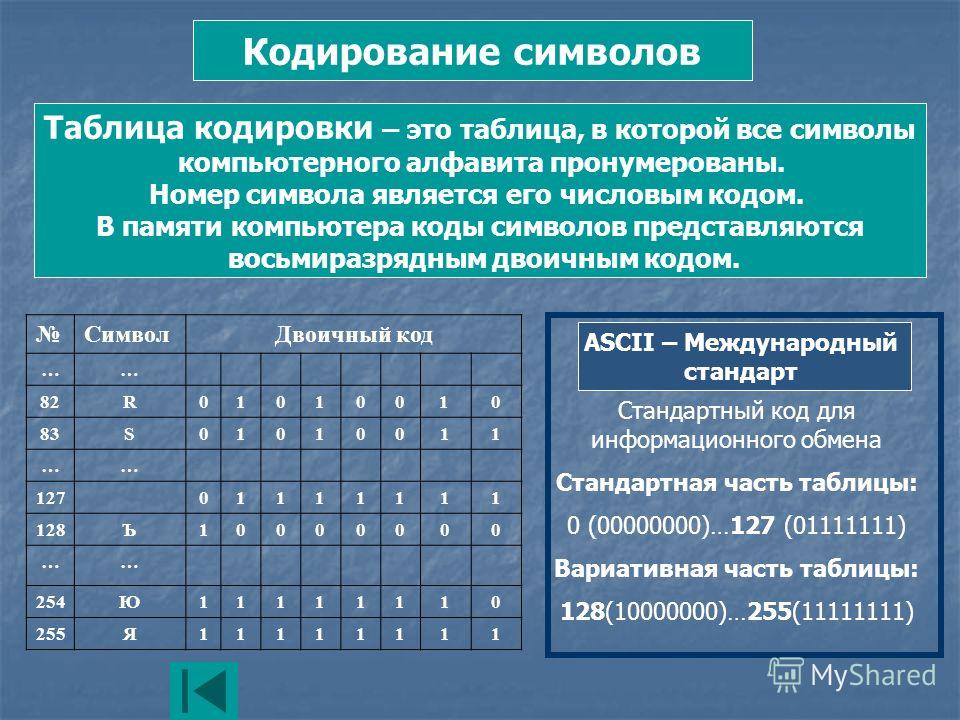 Япония создала несколько систем кодирования своего языка, которые различаются в зависимости от аппаратного обеспечения. Сообщения, отправляемые с одного японского компьютера на другой, становились искаженными и нечитаемыми, когда компьютер неправильно переводил данные.
Япония создала несколько систем кодирования своего языка, которые различаются в зависимости от аппаратного обеспечения. Сообщения, отправляемые с одного японского компьютера на другой, становились искаженными и нечитаемыми, когда компьютер неправильно переводил данные.
161
Ошибки в преобразовании японских иероглифов стали такой проблемой, что у них даже есть название для этого, моджибаке. Эта проблема стала намного хуже с изобретением всемирной паутины. Для решения проблем, связанных с отправкой документов на разных языках по всему миру, был создан консорциум для создания всемирного стандарта Unicode. Как и в ASCII, в Unicode каждому символу присваивается определенный номер. Unicode также использует старую кодировку ASCII для английского языка. Таким образом, A в верхнем регистре по-прежнему равен 65. Но Unicode кодирует гораздо больше, чем 100 000 символов в большинстве языков. Для этого он использует не 8 бит данных, а 32. Но 65, закодированные в 32 бита, выглядят так, что занимает много места.
211.5
Кроме того, многие старые компьютеры интерпретируют восемь нулей подряд как конец строки символов, также называемый нулем. Это означает, что они не будут отправлять никаких символов, которые появятся позже. Метод кодирования Unicode, UTF8, решает эти проблемы. Вплоть до номера 127 значение ASCII остается неизменным. Так что A по-прежнему 01000001. Для всего, что выше 127, UTF8 разделяет код на два байта. Он добавляет 110 к первому байту и 10 ко второму байту. Затем вы просто заполняете двоичный код для промежуточных битов. Например, число 325 равно 00101000101, которое вставляется вот так. Это работает для первых 4,096 символов. После этого добавляется еще один байт.
268,2
И еще 1 добавляется в начале первого байта, вот так. Это дает вам 16 дополнительных битов для вашего двоичного кода. На самом деле вы можете получить до 7 байтов данных, которые выглядят так. Таким образом, UTF8 позволяет избежать проблемы с 8 нулями. И он обратно совместим со старой системой ASCII. И это краткое изложение ASCII и UTF8, двух важных стандартов, которые определяют, как символы кодируются из единиц и нулей в цифровой текст, который вы просматриваете каждый день.
И это краткое изложение ASCII и UTF8, двух важных стандартов, которые определяют, как символы кодируются из единиц и нулей в цифровой текст, который вы просматриваете каждый день.
Два стандарта кодирования символов определяют, как символы расшифровываются из единиц и нулей в текст, который вы видите на экране прямо сейчас, и в различные языки, просматриваемые каждый день во всемирной паутине. Этими двумя стандартами кодирования являются ASCII и Unicode.
ASCII
Американский стандартный код для обмена информацией (ASCII) был разработан для создания международного стандарта кодирования латинского алфавита. В 1963 году был принят ASCII, чтобы информацию можно было интерпретировать между компьютерами; представляющие строчные и заглавные буквы, цифры, символы и некоторые команды. Поскольку ASCII кодируется с использованием единиц и нулей, системы счисления с основанием 2, он использует семь битов. Семь бит позволяют 2 в степени 7 = 128 возможных комбинаций цифр для кодирования символа. Таким образом,
Таким образом,
ASCII обеспечил возможность кодирования 128 важных символов:
Как работает кодировка ASCII
- Вы уже знаете, как преобразовывать десятичные числа в двоичные
- Теперь вам нужно превратить буквы в двоичные числа
- Каждому символу соответствует десятичное число (например, A → 65)
- ASCII использует 7 бит
- Мы используем первые 7 столбцов таблицы преобразования для создания 128 различных чисел (от 0 до 127)
Например, 1000001 дает нам число 65 ( 64 + 1 ), которое соответствует букве «А».
| 64 | 32 | 16 | 8 | 4 | 2 | 1 |
|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 1 |
Вот как «HELLO» закодировано в ASCII в двоичном виде:
| Латинский символ | ASCII-код |
|---|---|
| Н | 1001000 |
| Е | 1000101 |
| Л | 1001100 |
| Л | 1001100 |
| О | 1001111 |
Применим эту теорию на практике:
- Откройте Блокнот или любой другой текстовый редактор, который вы предпочитаете
- Введите сообщение и сохраните его, например.
 «данные прекрасны»
«данные прекрасны» - Посмотрите на размер файла — у меня 18 байт
- Теперь добавьте еще одно слово, например. «данные такие красивые»
- Если вы еще раз посмотрите на размер файла, то увидите, что он изменился — теперь мой файл стал на 3 байта больше (SO[SPACE]: «S», «O» и пробел)
Unicode и UTF-8
Поскольку символы ASCII кодируются 7 битами, переход на 8-битную вычислительную технологию означал использование одного дополнительного бита. С этой дополнительной цифрой Расширенный код ASCII , закодированный до 256 символов. Однако возникшая проблема заключалась в том, что страны, использующие разные языки, по-разному использовали эту дополнительную возможность кодирования. Многие страны добавили свои собственные дополнительные символы, и разные числа представляли разные символы на разных языках. Япония даже создала несколько систем кодирования японского языка в зависимости от аппаратного обеспечения, и все эти методы были несовместимы друг с другом. Таким образом, когда сообщение было отправлено с одного компьютера на другой, полученное сообщение могло стать искаженным и нечитаемым; японские системы кодирования символов были настолько сложны, что даже когда сообщение было отправлено с одного типа японского компьютера на другой, происходило нечто, называемое «модзибаке»:
Таким образом, когда сообщение было отправлено с одного компьютера на другой, полученное сообщение могло стать искаженным и нечитаемым; японские системы кодирования символов были настолько сложны, что даже когда сообщение было отправлено с одного типа японского компьютера на другой, происходило нечто, называемое «модзибаке»:
Проблема несовместимых систем кодирования стала более актуальной с изобретением Всемирной паутины, поскольку люди обменивались цифровыми документами по всему миру, используя несколько языков. Чтобы решить эту проблему, Консорциум Unicode создал универсальную систему кодирования под названием Unicode . Юникод кодирует более 100 000 символов, охватывая все символы, которые вы найдете в большинстве языков. Unicode присваивает каждому символу определенное число, а не двоичную цифру. Но были некоторые проблемы с этим, например:
- Для кодирования 100 000 символов потребуется около 32 двоичных разрядов.
 Unicode использует ASCII для английского языка, поэтому A по-прежнему равно 65. Однако при 32-битной кодировке буква A будет двоичным представлением 00000000000000000000000000000000000001000001. Это тратит впустую много ценного пространства!
Unicode использует ASCII для английского языка, поэтому A по-прежнему равно 65. Однако при 32-битной кодировке буква A будет двоичным представлением 00000000000000000000000000000000000001000001. Это тратит впустую много ценного пространства! - Многие старые компьютеры интерпретируют восемь нулей подряд (ноль) как конец строки символов. Таким образом, эти компьютеры не будут отправлять символы, следующие за восемью нулями подряд (они не будут отправлять букву A, если она представлена как 00000000000000000000000000000000000001000001).
Метод кодирования Unicode UTF-8 решает следующие проблемы:
— до символа с номером 128 используется обычное значение ASCII (например, A — 01000001)
— для любого символа после 128 кодировка UTF-8 разделяет код в два байта и добавление «110» к началу первого байта, чтобы показать, что это начальный байт, и «10» к началу второго байта, чтобы показать, что он следует за первым байтом.
Итак, для каждого символа после числа 128 у вас есть два байта:
[110xxxxx] [10xxxxxx]
И вы просто заполните двоичный код для числа между ними:
[11000101] [10000101] (это число 325 → 00101000101)
Это работает для первых 2048 символов. Для символов сверх этого добавляется еще одна «1» в начале первого байта, а также используется третий байт:
Для символов сверх этого добавляется еще одна «1» в начале первого байта, а также используется третий байт:
[1110xxxx] [10xxxxxx] [10xxxxxx]
Это дает вам 16 пробелов для двоичного кода. Таким образом, UTF-8 достигает четырех байтов:
[11110xxx] [10xxxxxx] [10xxxxxx] [10xxxxxx]
Таким образом, UTF-8 позволяет избежать проблем, упомянутых выше, а также необходимости индекса, и позволяет декодировать символы из двоичной формы в обратном порядке (т.е. имеет обратную совместимость).
Занятия в классе
Есть много занимательных занятий по обучению кодированию символов. Мы включили два упражнения ниже, чтобы вы могли попробовать их в своем классе. Какие у вас есть главные советы по обучению кодированию символов? Поделитесь ими в комментариях!
Перевод секретных сообщений : опубликовать короткое секретное сообщение в ASCII в разделе комментариев, а также перевести или ответить на ASCII-сообщения других участников
Бинарные браслеты : создавайте браслеты, используя разноцветные бусины для обозначения единиц и нулей и написания инициала или имени в ASCII.
